

Stragit Track 에서 두번 훈련 시킨 모델을 Clone 해서 곡선이 있는 다른 트랙에서 훈련 시키기로 했다.
나머지 트랙 중 가장 간단한 트랙인 Oval Track에서 먼저 훈련을 시켰다.

reward_function을 약간 수정했는데....
def reward_function(params):
'''
Example of rewarding the agent to follow center line
'''
reward=1e-3
# Read input parameters
track_width = params['track_width']
distance_from_center = params['distance_from_center']
steering = params['steering_angle']
speed = params['speed']
all_wheels_on_track = params['all_wheels_on_track']
if distance_from_center >=0.0 and distance_from_center <= 0.03:
reward = 1.0
if not all_wheels_on_track:
reward = -1
else:
reward = params['progress']
# Steering penality threshold, change the number based on your action space setting
ABS_STEERING_THRESHOLD = 45
# Penalize reward if the car is steering too much
if steering > ABS_STEERING_THRESHOLD:
reward *= 0.8
# add speed penalty
if speed < 2.0:
reward *=0.80
return float(reward)
일단 여긴 곡선 구간이 있으니 핸들 꺾는 걸 조금 더 여유를 주어야 겠다고 생각했다.
이전 직선 트랙에서는 15도로 제한을 뒀는데 여기서는 45도 까지 여유를 주었다.
그 이상 핸들을 급하게 꺾으면 점수가 20% 깎이도록 했다.
그리고 곡선구간에서는 아무래도 속도를 줄여야 하니 제한을 2.0으로 고쳤다.
이전엔 2.5 였다.
이렇게 고치고 나서 100분 동안 훈련을 시켰다.

한 30분 쯤 지나면서 부터 높은 reward가 나오기 시작했다.
그리고 reward 저점도 그 이후부터는 1.50k를 넘었다.
그 이후부터는 reward의 고점이 대략 8.0k 내외이고 그런 고점이 나오는 빈도수도 크게 변화를 보이지는 않은 것 같다.
아마 위 reward_function으로 이 구간에서는 그렇게 크게 performance가 발전하기는 힘들 것 같다.
reward_function을 조금씩 고쳐가며 계속 훈련을 하고 싶지만.. 한번 그렇게 하는데 별도로 돈을 내야하기 때문에 맘 놓고 여러가지를 시도 하지 못하겠다.
일단 평가 결과는 아래와 같다.

3번 시도 중 한번만 성공했고 실패한 것도 트랙을 35%만 돌았다.
점수가 아주 저조하다.
성공했을 때의 기록은 23.797초 이다.
일단 이 트랙은 이 정도면 됐고 다음 연습 트랙은 어제 끝난 AWS Deepracer League - Viertual Circuit London Loop 에서 사용한 London Loop Track에서 훈련을 시키기로 결정 했다.

이 리그는 4/29 부터 5/31 까지 한달간 진행된 리그이다.
나는 늦게 시작해서 이 리그에는 참가를 못 했다.
6월부터 시작하는 Vertual league에 참가할 계획이다.
일단 London Loop Track에서 사용할 reward_function은 아래처럼 고쳤다.
def reward_function(params):
'''
Example of rewarding the agent to follow center line
'''
reward=1e-3
# Read input parameters
track_width = params['track_width']
distance_from_center = params['distance_from_center']
steering = params['steering_angle']
speed = params['speed']
all_wheels_on_track = params['all_wheels_on_track']
if distance_from_center >=0.0 and distance_from_center <= 0.03:
reward = 1.0
if not all_wheels_on_track:
reward = -1
else:
reward = params['progress']
# Steering penality threshold, change the number based on your action space setting
ABS_STEERING_THRESHOLD = 30
# Penalize reward if the car is steering too much
if steering > ABS_STEERING_THRESHOLD:
reward *= 0.8
# add speed penalty
if speed < 1.5:
reward *=0.80
return float(reward)
여기서도 핸들 각도와 스피드 제한 부분을 조금 수정했다.
일단 핸들 각도는 이전보다 좁은 30도를 줬다.
이 트랙이 이전 트랙보다 조금 더 급한 커브가 있지만 속도를 더 낮추는 걸로 대비하기로 했다.
스피드는 이전에 2.0 의 제한을 두던것을 1.5로 낮췄다.
훈련시간은 큰 맘 먹고 300분으로 했다.
그 결과는 아래와 같다.

여기도 보니까 30분 이후부터 조금씩 개선되는 것 같더니 1시간 이후부터 저점이 3.0K를 어느 정도 유지하는 싸이클을 보였다.
그 이후는 그게 개선되지는 않았지만 3시간 지나면서 최고점인 9.69K를 찍기 시작했다.
훈련 후 진행한 평가 결과는 아래와 같다.
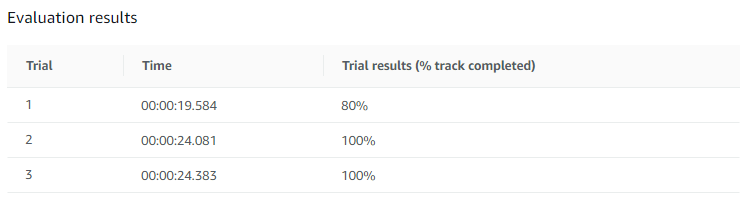
3번 중 2번 완주 했고 기록은 24초 정도 이다.
실패한 1번도 트랙을 80% 진행했다.
Oval Track과 비교해서 아주 만족스런 결과이다.
좋다.
참고로 AWS Deepracer League - Viertual Circuit London Loop 수상자들의 기록은 다음과 같다.

9초,10초, 11초.... 24초인 내가 낄 자리는 없다.
쟤네들은 어떤 reward_function을 썼고 Hyperparameter configuration은 어떤 변동을 주었는지 그리고 어떤 훈련을 얼마나 시켰는지 궁금하다.
다음주 2차 Virtual League에서 사용하는 Track 이 발표되면 그 트랙에서 집중적으로 훈련을 시킬 계획이다.
'IoT > AWS DeepRacer' 카테고리의 다른 글
| AWS Deepracer Forum Q&A (1) | 2019.07.08 |
|---|---|
| AWS Deepracer Virtual Race 최초 참가 경험 정리 (0) | 2019.07.07 |
| MEGAZONE CLOUD AWS DeepRacer League in Korea (0) | 2019.06.25 |
| 테슬라 주가와 2011년 넷플릭스 주가 비교 (0) | 2019.06.05 |
| AWS DeepRacer League and 2nd Virtual Race open (1) | 2019.06.04 |
| AWS Deepracer Model 훈련 및 평가 후 볼 수 있는 정보들 (0) | 2019.06.02 |
| AWS Deepracer 첫 모델 생성 및 결과 보기 (0) | 2019.06.02 |
| AWS Deepracer를 시작하면 내야 하는 요금들... (0) | 2019.05.31 |
| AWS DeepRacer - Hands-on Exercise 1 : Model Training Using AWS DeepRacer Console (0) | 2019.05.30 |
| AWS DeepRacer를 시작하기 전에 살펴볼 내용 (0) | 2019.05.17 |