

AWS Cloud Practitioner Essentials (Digital) (Korean) - 01
AWS training and certification
www.aws.training
요약본 : https://github.com/yoonhok524/aws-certifications/tree/master/0.%20Cloud%20Practitioner
yoonhok524/aws-certifications
AWS 자격증 취득을 위한 관련 내용 정리. Contribute to yoonhok524/aws-certifications development by creating an account on GitHub.
github.com
정보
설명
AWS 클라우드 실무자 에센셜 과정은 특정 기술적 역할과 상관없이 AWS 클라우드 전반에 대한 이해를 원하는 사람을 위해 마련된 것입니다. 이 과정에서는 클라우드 개념, AWS 서비스, 보안, 아키텍처, 요금 및 지원의 세부 개요를 제공합니다.
과정 목표
이 과정을 이수하면 수강생은 다음을 수행할 수 있습니다.
- AWS 클라우드 개념 및 기본 글로벌 인프라를 정의
- AWS 플랫폼에서 제공되는 주요 서비스 및 일반적 사용 사례(예: 컴퓨팅, 분석 등)를 설명
- 기본 AWS 클라우드 아키텍처 원리를 설명
- AWS 플랫폼 및 공동 보안 모델의 기본 보안 및 규정 준수 측면을 설명
- 청구, 계정 관리 및 요금 모델을 정의
- 설명서 또는 기술 지원 출처를 파악(예: 백서, 지원 티켓 등)
- AWS 클라우드 가치 제안을 설명
-
AWS 클라우드에서의 배포 및 운영에 대한 기본/핵심 특징을 설명
학습 대상
본 교육 과정의 대상은 다음과 같습니다.
- 영업
- 법무
- 마케팅
- 비즈니스 분석가
- 프로젝트 관리자
- 최고 경험 책임자
- AWS 아카데미 학생
-
기타 IT 관련 전문가
사전 조건
이 과정은 입문 수준의 과정이지만 수강생이 다음을 보유하고 있다는 가정하에 진행됩니다.
- 일반 IT 기술 지식
-
일반 IT 비즈니스 지식
전달 방법
이 과정은 일련의 짧은 과정 모듈을 통해 제공됩니다.
기간
7시간
과정 개요
이 과정에서는 다음 주제를 다룹니다.
AWS 클라우드 실무자 에센셜: 소개
5분
AWS 클라우드 개념 에센셜
30분
- 클라우드 소개
-
AWS 클라우드 소개
AWS 핵심 서비스 에센셜
3시간
- 서비스 및 카테고리 개요
- AWS 글로벌 인프라 소개
- Amazon VPC 소개
- 보안 그룹 소개
- 컴퓨팅 서비스 소개
- AWS 스토리지 서비스 소개
-
AWS 데이터베이스 솔루션 소개
AWS 보안 에센셜
1시간
- AWS 보안 소개
- AWS 공동 책임 모델
- AWS 액세스 제어 및 관리
- AWS 보안 규정 준수 프로그램
-
AWS 보안 리소스
AWS 아키텍처 설계 에센셜
45분
- Well-Architected 프레임워크 소개
- 참조 아키텍처: 내결함성 및 고가용성
-
참조 아키텍처: 웹 호스팅
AWS 요금 및 지원 에센셜
45분
- 요금 기본 정보
- 요금 내역
- TCO 계산기 개요
-
AWS Support 플랜 개요
AWS 클라우드 실무자 에센셜: 추가 자료
1시간
-
AWS 클라우드 실무자 에센셜 콘텐츠 모듈에서 배운 개념을 강화하는 보충 동영상
AWS 클라우드 실무자 에센셜: 과정 요약
5분
1. 과정소개
안녕하세요, Amazon Web Services 교육 및 자격증의 Jody Soeiro de Faria입니다.
클라우드 전문가 에센셜에 참가하신 것을 환영합니다.
이 과정은 특정 기술적 역할과 상관없이 AWS 클라우드 전반에 대한 이해를 원하는 사람을 위해 마련된 것입니다.
이 과정에서는 AWS 서비스, 보안, 아키텍처, 요금 및 지원의 세부 개요를 설명합니다.
이 과정을 성공적으로 수료하면 다음과 같은 일을 할 수 있습니다.
· AWS 클라우드 개념 및 기본 글로벌 인프라를 정의· AWS 플랫폼에서 제공되는 주요 서비스 및 일반적 사용 사례를 설명
· 기본 AWS 클라우드 아키텍처 원리를 설명
· AWS 플랫폼 및 공동 보안 모델의 기본 보안 및 규정 준수 측면을 설명
· 청구, 계정 관리 및 요금 모델을 정의
· 설명서 또는 기술 지원의 소스를 식별
· AWS 클라우드 가치 제안을 설명
· AWS 클라우드에서의 배포 및 운영의 핵심적 기본 특징을 설명
이 과정은 초급 과정이지만 학습자가 전반적인 IT 기술 지식 및 IT 비즈니스 지식을 보유한 것으로 가정합니다.
이 과정은 일련의 짧은 동영상 모듈 및 지식 평가를 통해 전달됩니다.
이 과정을 이수하려면 약 6시간이 걸립니다.
클라우드 전문가 에센셜은 이 개요, 5개 콘텐츠 모듈, 보너스 자료 및 과정 요약으로 구성됩니다.
· 섹션 1에서는 AWS 클라우드 개념을 설명합니다.
이 섹션에는 클라우드에 대한 소개와 AWS 클라우드에 대한 소개가 포함됩니다.
· 섹션 2에서는 AWS 핵심 서비스를 설명합니다.
이 섹션은 서비스 및 범주의 개요, AWS 글로벌 인프라, Amazon VPC, 보안 그룹, Amazon EC2, Amazon Elastic Block Store, Amazon S3, AWS 데이터베이스 솔루션에 대한 소개로 구성됩니다.
· 섹션 3에서는 AWS 보안을 설명합니다.
이 섹션에는 AWS 보안, AWS 공동 책임 모델, AWS 액세스 제어 및 관리, AWS 보안 규정 준수 프로그램, AWS 보안 리소스에 대한 소개가 포함됩니다.
· 섹션 4에서는 AWS 아키텍처 설계를 설명합니다.
이 섹션에는 Well Architected Framework, 참조 아키텍처, 내결함성 및 고가용성, 참조 아키텍처 웹 호스팅에 대한 소개가 포함됩니다.
· 섹션 5에서는 AWS 요금 및 지원을 설명합니다.
이 섹션에는 요금 기본 사항, Amazon EC2, Amazon S3, Amazon EBS, Amazon RDS 및 Amazon CloudFront의 요금 내역, TCO Calculator 개요, AWS 지원 플랜 개요가 포함됩니다.
· 이 과정에 포함된 보너스 자료에는 이 과정을 통해 학습한 내용을 강화해 주는 여러 보충 동영상이 포함됩니다.
즐거운 학습 경험이 되기를 바랍니다.
Amazon Web Services 교육 및 자격증의 Jody Soeiro de Faria였습니다.
2. 클라우드 개념
안녕하세요, Amazon Web Services 교육 및 자격증의 Jody Soeiro de Faria입니다.
오늘은 AWS 클라우드에 대해 소개합니다.
이 과정은 클라우드 전문가가 되기 위한 과정이므로 클라우드 컴퓨팅의 정의부터 시작해 보겠습니다.
" 클라우드 컴퓨팅"이란 인터넷을 통해 IT 리소스와 애플리케이션을 온디맨드로 제공하는 서비스를 말하며 요금은 사용한 만큼만 청구됩니다.
클라우드 컴퓨팅 이전에는 이론적으로 추측한 최대 피크를 기반으로 용량을 프로비저닝해야 했습니다.
예측한 최대 피크에 미치지 않거나 이를 초과할 경우 고가에 구입한 리소스가 유휴 상태를 유지하거나 용량 부족 때문에 수요를 충족하지 못하게 될 수 있습니다.
설치 공간, 전력, 냉방 등의 간접비는 덤입니다.
하지만 AWS를 사용할 경우 서버, 데이터베이스, 스토리지, 상위 수준 애플리케이션 구성 요소를 몇 초 만에 시작할 수 있습니다.
이들을 일시적이고 처분 가능한 리소스로 취급할 수 있으므로 고정적이고 유한한 IT 인프라라는 비융통성과 제약에서 벗어날 수 있습니다.
AWS 클라우드의 장점을 활용함으로써 관리, 테스트, 안정성, 용량 계획에 보다 민첩하고 효율적으로 접근할 수 있습니다.
기업들이 클라우드로 마이그레이션하는 주된 이유 한 가지는 향상된 민첩성입니다.
민첩성에는 다음 세 가지 요소가 영향을 미칩니다.
· 속도· 실험· 혁신의 문화 어떻게 이러한 요소가 조직이 클라우드 컴퓨팅의 장점을 활용하여 민첩성을 개선할 수 있게 하는지 보다 자세히 살펴봅시다.
AWS 시설은 전 세계에 분포하고 있으므로 몇 분 만에 글로벌 확장이 가능하도록 지원할 수 있습니다.
고객이 있는 곳에 자체 데이터 센터를 두는 것은 비용 면에서 불가능할 수 있습니다.
하지만 AWS를 사용하면 막대한 투자를 할 필요 없이 이점을 활용할 수 있습니다.
클라우드 컴퓨팅에서는 새 IT 리소스를 클릭 몇 번으로 사용할 수 있습니다.
즉 개발자는 해당 리소스를 몇 주가 아니라 단 몇 분 만에 사용할 수 있으므로 조직의 민첩성이 극적으로 향상됩니다.
클라우드 컴퓨팅의 민첩성 이점 또 한 가지는 보다 자주 실험을 할 수 있다는 것입니다.
AWS를 사용할 경우 클라우드에서 코드로서의 운영이 가능하며 안전하게 실험하고, 운영 절차를 개발하고, 장애를 대비해 연습할 수 있습니다.
예를 들어 AWS를 사용하면,
· 몇 분 만에 실험을 위한 서버 시동
· 서버를 반환하거나 다른 실험을 위해 재사용
가상 리소스 및 자동화 가능한 리소스를 통해, 여러 유형의 인스턴스, 스토리지 또는 구성을 사용하여 비교 테스트를 신속하게 수행할 수 있습니다.
AWS CloudFormation을 사용하면 일관적이고 템플릿화된 샌드박스 개발, 테스트 및 프로덕션 환경을 보유하고 운영 제어 수준을 지속적으로 향상시킬 수 있습니다.
방금 언급한 대로, 클라우드 컴퓨팅에서는 낮은 비용과 위험으로 신속한 실험이 가능합니다.
이는 IT에 매우 중요합니다.
보다 빈번한 실험을 통해 새로운 구성과 혁신을 탐색할 수 있기 때문입니다.
AWS가 클라우드 컴퓨팅의 민첩성을 어떻게 활용하는지 이해하기 위해서는 컴퓨팅 리소스의 탄력성, 확장성 및 안정성을 지원하는 AWS 인프라를 살펴보아야 합니다.
AWS 클라우드 인프라는 리전 및 가용 영역("AZ")을 중심으로 구축되어 있습니다.
리전이란 전 세계에 산재한 복수의 가용 영역을 포함하는 물리적 장소입니다.
가용 영역은 하나 이상의 개별 데이터 센터로 구성되는데, 각 데이터 센터는 별도의 시설에 자리하며 예비 전력, 네트워킹 및 연결 수단을 갖추고 있습니다.
가용 영역은 프로덕션 애플리케이션 및 데이터베이스를 운영할 수 있는 기능을 제공합니다.
이러한 애플리케이션 및 데이터베이스는 단일 데이터 센터에서 가능한 것보다 더 높은 수준의 가용성, 내결함성 및 확장성을 제공합니다.
내결함성은 시스템 구성 요소에 장애가 발생하더라도 시스템이 작동 가능 상태를 유지하는 능력을 의미합니다.
이는 애플리케이션 구성 요소의 기본적인 중복성으로 볼 수 있습니다.
고가용성은 사용자가 개입할 필요 없이 시스템이 항상 작동하고 액세스 가능하며 가동 중지가 최소화되도록 해줍니다.
AWS 클라우드를 사용하면 확장 가능하고 안정적이며 안전한 글로벌 인프라의 이점을 활용하여 요구 사항을 최대한 충족할 수 있습니다.
민첩성과 관련하여 탄력성도 클라우드 컴퓨팅에서 강력한 장점입니다.
탄력성이란 간편하게 컴퓨팅 리소스의 규모를 확장 또는 축소할 수 있다는 것을 뜻하며 사용한 실제 리소스에 대해서만 지불하면 됩니다.
AWS의 탄력적 특성을 다음과 같이 활용할 수 있습니다.
· 새로운 애플리케이션을 신속하게 배포
· 워크로드가 커지면 즉시 확장
· 더는 필요하지 않은 리소스는 즉시 가동 중지
· 축소하면 인프라 비용을 지불하지 않음
필요한 가상 서버가 한 개이든 수천 개든, 컴퓨팅 리소스가 필요한 시간이 몇 시간이든 온종일이든 상관없이 AWS는 고객의 필요를 충족하기 위한 탄력적인 인프라를 제공합니다.
AWS의 주요 이점 중 한 가지는 고객이 원하는 속도로 서비스를 사용할 수 있다는 점입니다.
AWS를 사용하는 고객들은 계절적 수요 변동에 맞춰 서비스 소비를 확대, 축소 및 조정하거나 신규 서비스 또는 제품을 출시하거나 새로운 전략적 방향을 쉽게 수용할 수 있습니다.
AWS는 높은 가용성과 신뢰성을 갖춘 확장 가능한 클라우드 컴퓨팅 플랫폼을 제공하며, 이를 통해 고객들이 다양한 애플리케이션을 실행할 수 있는 도구를 제공합니다.
AWS 도구인 Auto Scaling 및 Elastic Load Balancing을 사용하여 애플리케이션의 규모를 수요에 맞춰 확장하거나 축소할 수 있습니다.
Amazon의 거대한 인프라의 힘을 빌어, 필요할 때면 언제든 컴퓨팅 및 스토리지 리소스에 액세스할 수 있습니다.
AWS를 이용하면 전 세계에 분포된 여러 리전에서 용이하게 시스템을 배포할 수 있으며, 이와 동시에 최소한의 비용으로 최종 고객에게 낮은 지연 시간과 향상된 환경을 제공할 수 있습니다.
AWS가 구현한 규모의 효율성 덕분에 고객은 여러 번의 구입 주기와 많은 비용이 소요되는 평가를 거칠 필요 없이 일관되게 혁신적인 서비스와 첨단 기술을 사용할 수 있습니다.
AWS는 거의 모든 워크로드를 지원할 수 있습니다.
이러한 혁신 수준 덕분에 고객들은 최신 기술에 지속적으로 액세스할 수 있습니다.
또한 고객이 데이터가 실제로 위치하는 리전에 대한 모든 제어권 및 소유권을 보유하여 지역별 규정 준수 및 데이터 상주 요구 사항을 용이하게 충족할 수 있다는 것도 알아둘 필요가 있습니다.
클라우드 컴퓨팅 이전에는 인프라 보안 감사가 흔히 정기적으로 실시되는 수동 방식의 프로세스였습니다.
하지만 AWS 클라우드는 고객의 IT 리소스에 대한 구성 변경 사항을 지속적으로 모니터링할 수 있는 거버넌스 기능을 제공합니다.
또한 AWS는 가장 엄격한 요건도 충족할 수 있도록 시설, 네트워크, 소프트웨어, 비즈니스 프로세스에 걸쳐 업계 최고의 기능을 제공합니다.
세계적인 수준의 강력한 보안을 자랑하는 AWS 데이터 센터는 최첨단 전자식 감시 시스템과 멀티 팩터 액세스 제어 시스템을 사용합니다.
데이터 센터에는 숙련된 보안 경비가 연중무휴 대기하며 액세스에 대한 권한은 최소한의 특권을 기준으로 엄격하게 부여됩니다.
환경 시스템은 환경 파괴가 운영에 미치는 영향을 최소화하도록 설계되었습니다.
여러 지리적 리전 및 가용 영역을 사용하면 자연재해나 시스템 장애 등 대부분 장애 모드에서도 시스템을 유지할 수 있습니다.
AWS 자산은 프로그래밍 가능한 리소스이므로, 인프라 설계 시 고객의 보안 정책을 수립하여 포함시킬 수 있습니다.
AWS 사용하면 고객이 대부분의 비즈니스 요구를 해결할 수 있는 안정적인 고성능 솔루션을 개발하도록 도울 수 있습니다.
전 세계를 대상으로 미디어 서비스를 제공하든, 널리 분산된 인력의 의료 기기를 관리하든 관계 없이 AWS는 고객에게 신속하고 저렴한 비용으로 솔루션을 구현할 수 있는 도구를 제공합니다.
AWS에서의 안정성은 시스템이 인프라 또는 서비스 장애를 복구하는 능력으로 정의됩니다.
또한 수요에 따라 컴퓨팅 리소스를 탄력적으로 확보하고 중단 사태를 완화할 수 있는 능력에 초점을 맞춥니다.
안정성을 실현하기 위해서는 아키텍처 및 시스템이 수요 변동을 처리하고 장애를 감지하여 자동으로 처리할 수 있는 잘 계획된 토대를 기반으로 해야 합니다.
AWS를 사용하는 조직들은 하드웨어 수요 예측의 불확실성을 줄여서 향상된 유연성과 용량을 달성할 수 있습니다.
뿐만 아니라, AWS는 온프레미스 솔루션이 따라오지 못할 수준 용량과 안정성을 고객에게 제공합니다.
데이터 센터 구축 사업을 하는 경우를 제외하고는 여러분은 아마 지금까지 데이터 센터 구축에 너무 많은 시간과 비용을 소비했을 것입니다.
AWS에서는 서버나 소프트웨어 라이선스 구매 또는 시설 임대를 비롯하여 고가의 인프라 구축에 소중한 리소스를 쏟아부을 필요가 없습니다.
필요한 만큼만 서비스 요금을 지불함으로써 혁신 및 발명에 집중할 수 있으므로 조달 복잡성을 줄이고 비즈니스에 완전한 탄력성을 부여할 수 있습니다.
사용한 만큼 지불하는 요금을 통해 예산을 과도하게 할당하지 않고도 변화하는 비즈니스 요구에 손쉽게 적응하고 변화에 대한 대응을 개선할 수 있습니다.
종량 과금제 모델에서는 예측치가 아닌 정확한 수요에 따라 비즈니스에 대응할 수 있으므로 위험이나 초과 프로비저닝 또는 누락되는 용량을 줄일 수 있습니다.
클라우드로 마이그레이션은 더 이상 IT 비용 절감 차원의 문제가 아니라 기업이 번창할 수 있는 환경을 구축하는 문제입니다.
디지털 혁신으로 고객을 연결하고 획기적이고 새로운 통찰력과 과학적 혁신 기술을 개발하고 혁신적이고 새로운 제품과 서비스를 제공하는 것이 그 어느 때보다 쉬워졌습니다.
Amazon Web Services는 컴퓨팅 , 스토리지 , 데이터베이스 , 분석 , 네트워킹 , 모바일 , 개발자 도구 , 관리 도구 , IoT , 보안 및 엔터프라이즈 애플리케이션을 비롯해 광범위한 글로벌 클라우드 기반 제품을 제공합니다.
이러한 서비스를 사용하면 조직이 더 빠르게 움직이고, IT 비용을 낮추며, 확장할 수 있습니다.
AWS는 세계 최대 기업 및 전 세계의 주목을 받고 있는 스타트업에서 웹 및 모바일 애플리케이션, 게임 개발 , 데이터 처리 및 웨어하우징, 스토리지, 아카이브 등을 비롯한 다양한 워크로드를 강화시키는 것으로 인정을 받았습니다.
AWS 클라우드를 사용하면 높은 비용과 장기 계약 같은 혁신의 장애물을 제거하고 AWS 서비스와 광범위한 파트너 에코시스템, 지속적인 혁신을 활용하여 비즈니스 솔루션을 추진하고 비즈니스를 성장시킬 수 있습니다.
글로벌 입지와 비즈니스 혁신을 뒷받침하는 기술을 개발할 수 있는 전문성을 갖추고 있다는 점에서 AWS를 믿고 비즈니스 성공에 도움이 되는 솔루션을 제공해 보십시오.
Amazon Web Services 교육 및 자격증의 Jody Soeiro de Faria였습니다




* 핵심 서비스
- 서비스 범주 및 소개
안녕하십니까? 저는 Amazon Web Services(AWS) 교육 및 자격증 팀의 Mike Blackmer라고 합니다.
이 모듈에서는 AWS의 서비스와 범주에 관해 다루고 AWS 설명서에 대해서도 알아볼 것입니다.
AWS는 일반적인 클라우드 아키텍처를 위한 빌딩 블록으로 활용할 수 있는 광범위한 글로벌 클라우드 기반 제품을 공급합니다.
각 제품마다 다양한 서비스를 제공합니다.
이 모듈에서 설명할 범주는 컴퓨팅, 스토리지, 데이터베이스, 네트워킹, 보안 등입니다.
그럼 이들 범주를 하나씩 살펴보겠습니다.
브라우저를 열고 aws.amazon.com에 접속합니다.
이것은 AWS 웹 사이트의 프런트 페이지입니다.
스크롤 바를 사용하여 약간 아래로 내려가면, AWS 제품 살펴보기라고 하는 섹션이 나오는데, 모든 제품 및 서비스가 여러 범주별로 배치되어 있습니다.
예를 들어 컴퓨팅을 클릭하면 목록의 처음에 Amazon EC2가 있음을 확인할 수 있는데, 다수의 다른 제품 및 서비스도 컴퓨팅 범주에 등재되어 있습니다.
Amazon EC2를 클릭하면 Amazon EC2 메인 페이지가 나타나는데, URL은 http://aws.amazon.com/EC2입니다.
메인 페이지에는 제품에 관한 소개, 상세 설명 및 몇 가지 이점이 수록되어 있습니다.
이에 더해 제품 세부 정보, 인스턴스 유형, 요금, 시작하기, FAQ 및 기타 리소스도 확인할 수 있습니다.
제품 세부 정보를 클릭하면 Amazon EC2의 기능에 관한 상세 정보가 표시됩니다.
프런트 페이지로 돌아가서 스토리지를 클릭하면 스토리지 아래에서 Amazon S3, Amazon EBS 등을 확인할 수 있습니다.
기타 스토리지 옵션도 여기에 표시됩니다.
데이터베이스에서는 Aurora, Amazon RDS, Amazon DynamoDB, Amazon Redshift 및 기타 옵션을 확인할 수 있습니다.
Amazon VPC는 컴퓨팅에 표시되는데, 컴퓨팅 리소스를 격리하기 위해 필요한 구성 요소이기 때문입니다.
네트워킹 및 콘텐츠 전송에서 확인할 수 있습니다.
보안, 자격 증명 및 규정 준수로 가면 AWS Identity & Access Management를 확인할 수 있습니다.
클릭하면 좀 더 자세한 정보가 표시됩니다.
이제 설명서에 대해 얘기하고자 합니다.
설명서 부분은 정말 잘 문서화되어 있습니다.
상단으로 스크롤 바를 이동하여 제품을 탐색하지 않고 바로 설명서 섹션으로 이동할 수 있습니다.
어떤 제품이든 최종 사용자용 설명서를 얻을 수 있습니다.
알아차리셨는지 모르겠지만, 콘솔에 로그인하지 않은 상태입니다.
따라서 Amazon EC2 퍼블릭 사용자로 액세스하겠습니다.
액세스하면 Linux용 사용 설명서, Windows용 사용 설명서, API 참조, AWS CLI 참조 등을 포함한 제반 설명서를 이용할 수 있습니다.
이곳은 정말 굉장합니다.
AWS에서 보유하고 있는 거의 모든 것을 여기에서 이용할 수 있습니다.
설명서 섹션에서 제품, 스토리지, S3 설명서를 선택하여 시작 안내서, 개발자 안내서 등을 선택할 수 있습니다.
이 프레젠테이션에서는 AWS에서 이용 가능한 제품 및 서비스의 범주를 소개하고, http://aws.amazon.com에서 더 많은 정보를 확인하는 방법을 설명했습니다.
지금까지 AWS 교육 및 자격증 팀의 Mike Blackmer였습니다.
- AWS 글로벌 인프라
안녕하세요.
저는 AWS(Amazon Web Services) 교육 및 자격증 팀에서 활동 중인 Anna Fox라고 합니다.
오늘 강의에서는 글로벌 인프라(global infrastructure)라고도 하는 AWS 호스팅에 대해 간략히 소개하겠습니다.
AWS의 글로벌 인프라는 크게 3가지 주제, 즉 리전, 가용 영역(AZ) 및 엣지 로케이션으로 구분할 수 있습니다.
먼저 리전(regions)에 대해 알아보기로 하겠습니다.
지금 보고 계신 화면은 AWS 홈페이지입니다.
여기서 화면 중앙으로 마우스를 스크롤하면 여러 가지 리전 및 엣지 로케이션으로 구성된 글로벌 네트워크 지도가 나타납니다.
이쯤에서 여러분 중 어떤 분은 리전이 정확히 무엇인지 궁금할 것입니다.
리전은 2개 이상의 가용 영역(AZ)을 호스팅하는 지리 영역을 가리킵니다.
사용자 정의 서비스 및 기능들을 구축하고 선택할 경우, 사용 중인 정보를 저장할 지리 영역을 선택할 기회가 있습니다.
해당 영역을 선택할 때는 어떤 영역이 비용을 절감하고 규제 요구 사항들을 준수하면서 지연 시간을 최적으로 조정하는 데 도움이 되는지를 고려하는 것이 중요합니다.
이번 시간에는 바로 이 점에 대해 좀 더 자세히 알아보기로 하겠습니다.
클라우드 컴퓨팅 서비스를 활용할 경우, 애플리케이션을 여러 리전에 쉽게 배포할 수 있습니다.
예를 들어, 본사에서 가장 가까운 한 리전(샌디에이고 등)에서 어떤 애플리케이션을 보유할 수 있으며, 그렇다면 미국 동부 해안 지역의 한 리전에서 배포 가능한 애플리케이션을 보유할 수도 있습니다.
이제 가장 큰 고객 기반이 미국 버지니아 주에 위치한다고 가정해 봅시다.
고객들에게 더 나은 환경을 제공하기 위해 몇 번의 마우스 클릭만으로 미국 동부의 해당 리전에 애플리케이션을 쉽게 배포할 수 있습니다.
불과 몇 분만에 최소 비용으로 지연 시간을 최소화하고 조직의 민첩성을 향상시킬 수 있습니다!리전은 서로 완전히 독립된 엔터티(entity)이며, 한 리전의 리소스는 다른 리전으로 자동 복제되지 않습니다.
이제 리전 테이블의 특정 영역에서 어떤 서비스가 제공되는지 살펴보겠습니다.
자세히 알아보기(Learn More) 링크가 보일 것입니다.
이 링크로 접근해 마우스로 클릭합니다.
이제 글로벌 인프라(Global Infrastructure) 페이지가 나타납니다.
마우스로 스크롤해 보겠습니다.
모든 AWS 로케이션에서 제공되는 서비스의 상세 정보를 나타내는 링크가 보일 것입니다.
이 링크를 클릭하면 AWS의 리전 테이블이 나타납니다.
여기서는 미주, 유럽/중동/아프리카(EMEA) 및 아시아 태평양 지역을 자세히 살펴볼 수 있습니다.
또한 이 테이블을 특정 위치로 더욱 세분화할 수 있다는 점을 확인할 수 있으며, 그곳에 어떤 서비스가 제공되는지도 알 수 있습니다.
다음은 가용 영역(AZ)에 대해 설명해 보겠습니다.
가용 영역(AZ)이란 특정 리전 내에 존재하는 데이터 센터들의 모음을 의미합니다.
가용 영역들은 서로 격리되어 있으며 다만 빠르고 지연 시간이 짧은 링크에 의해 함께 연결됩니다.
그렇다면 가용 영역을 격리하면서도 연결하는 데 따른 이점은 무엇일까요?공통의 장애 지점들이 발생할 때 이러한 장애 지점은 서로 격리되어 있는 모든 가용 영역에 대해 영향을 미치지 않습니다.
가용 영역들은 어떻게 격리되나요?각 가용 영역은 물리적으로 구분된 독립적 인프라에 속합니다.
또한 가용 영역들은 물리적, 논리적으로 분리되어 있습니다.
각 영역(AZ)은 별도의 무정전 전원 공급 장치(UPS), 현장 예비 발전기, 냉각 장비, 네트워킹 및 연결 수단을 자체적으로 갖추고 있습니다.
가용 영역들은 모두 독립적인 전력 회사의 서로 다른 전력망을 통해 전력이 공급되며, 여러 티어1 전송 서비스 공급자를 통해 연결됩니다.
AZ를 서로 격리하면 한 AZ의 장애로부터 다른 AZ를 보호할 수 있으며, 다른 AZ는 요청을 처리할 수 있습니다.
AWS의 모범 사례에 따르면 다중 AZ에 걸쳐 데이터를 프로비저닝하는 것이 좋습니다.
마지막으로 엣지 로케이션에 대해 알아보겠습니다.
AWS 엣지 로케이션은 Amazon CloudFront라고 하는 CDN(콘텐츠 전송 네트워크)을 호스팅합니다.
Cloudfront는 콘텐츠를 고객들에게 전송하는 데 사용됩니다.
콘텐츠에 대한 요청이 가장 가까운 엣지 로케이션으로 자동 라우팅되므로 콘텐츠가 더욱 빨리 최종 사용자에게 전송됩니다.
여러 엣지 로케이션과 리전으로 구성된 글로벌 네트워크를 활용하면 보다 빠른 콘텐츠 전송에 액세스할 수 있습니다.
엣지 로케이션은 대체로 리전 및 가용 영역(AZ)들과 비슷하게 인구 밀도가 높은 지역에 위치합니다.
로케이션의 전체 목록은 <http://aws.amazon.com/cloudfront/details>를 방문해 확인하시기 바랍니다.
오늘 강의에서 배운 내용을 다시 살펴보겠습니다.
이번 시간에는 리전, 가용 영역 및 엣지 로케이션으로 구성되는 AWS의 글로벌 인프라에 대해 소개했습니다.
리전은 2개 이상의 가용 영역(AZ)으로 구분된다는 점도 간략히 설명했습니다.
또한 가용 영역은 하나의 리전에 존재하는 데이터 센터들의 모음을 의미합니다.
마지막으로, 엣지 로케이션은 고객들에게 콘텐츠를 전송하기 위해 콘텐츠 전송 네트워크를 호스팅합니다.
오늘 다룬 주제들에 관한 자세한 내용은 <http://aws.amazon.com>에서 확인하시기 바랍니다.
저는 AWS(Amazon Web Services) 교육 및 자격증 팀 담당자인 Anna Fox였습니다.
- Amazon Virtual Private Cloud (VPC)
안녕하세요.
저는 이번 모듈의 강사인 Kent Rademacher입니다.
저는 현재 AWS의 수석 기술 강사로서 AWS 기반 아키텍처 설계 및 AWS 기반 시스템 운영을 가르치고 있습니다.
이 모듈에서는 Amazon VPC(Virtual Private Cloud)에 대해 배우게 됩니다.
먼저 이 서비스를 소개한 다음, Amazon VPC의 기능을 살펴보기로 하겠습니다.
그런 다음, 앞서 설명했던 기능들을 활용하여 Amazon VPC 구성 예제를 살펴 보기로 하겠습니다.
마지막으로 Amazon VPC에 대한 추가 학습을 위해 다음 단계를 간략히 요약 및 설명해보기로 하겠습니다.
AWS 클라우드는 종량 과금제 방식의 주문형 컴퓨팅 및 관리형 서비스를 제공하며, 이들 서비스는 모두 웹을 통해 액세스할 수 있습니다.
이러한 컴퓨팅 리소스 및 서비스는 친숙한 네트워크 구조로 구현된 일반 IP 프로토콜을 통해 액세스할 수 있어야 합니다.
고객은 네트워킹 모범 사례를 준수하고 규제 및 조직상의 요구 사항들도 충족해야 합니다.
Amazon VPC(Virtual Private Cloud)는 사용자의 네트워킹 요구 사항들을 충족할 네트워킹 AWS 서비스입니다.
Amazon VPC를 사용하면 온프레미스 네트워크와 동일한 여러 가지 개념 및 구성을 사용하는 AWS 클라우드 내 프라이빗 네트워크를 생성할 수 있으며, 나중에 살펴보겠지만 제어, 보안 및 유용성을 저해하지 않고도 네트워크 설정의 복잡성이 상당 부분 추상화되었습니다.
Amazon VPC는 네트워크 구성을 완벽하게 제어합니다.
고객은 IP 주소 공간, 서브넷 및 라우팅 테이블과 같은 일반 네트워킹 구성 항목들을 정의할 수 있습니다.
이를 통해 인터넷에 노출되는 항목과 Amazon VPC 내에서 격리되는 항목을 각각 제어할 수 있습니다.
Amazon VPC는 네트워크의 보안 제어를 계층화하기 위한 방편으로 배포할 수 있습니다.
이는 서브넷 격리, 액세스 제어 목록 정의 및 라우팅 규칙 사용자 지정을 포함합니다.
수신 트래픽과 송신 트래픽을 모두 허용 및 거부하도록 완벽하게 제어할 수 있습니다.
마지막으로 Amazon VPC에 배포되는 AWS 서비스는 수없이 많으며, 이들 서비스는 클라우드 네트워크에 구축된 보안을 상속하고 활용합니다.
Amazon VPC는 AWS 기초 서비스로서 수많은 AWS 서비스와 통합됩니다.
예를 들면, Amazon EC2(Elastic Cloud Compute) 인스턴스는 Amazon VPC에 배포됩니다.
마찬가지로 Amazon RDS(Relational Database Service) 데이터베이스 인스턴스는 사용 중인 VPC에 배포되는데, 여기서 데이터베이스는 온프레미스 네트워크와 똑같은 네트워크 구조를 통해 보호됩니다.
Amazon VPC를 이해하고 이를 구현하면 다른 AWS 서비스를 충분히 활용할 수 있습니다.
이제 Amazon VPC의 기능들을 살펴보기로 하겠습니다.
Amazon VPC는 리전 및 가용 영역의 AWS 글로벌 인프라를 기반으로 하며, 이 VPC를 통해 AWS 클라우드에서 제공하는 높은 가용성을 쉽게 활용할 수 있습니다.
Amazon VPC는 리전 내에 있으며 여러 가용 영역에 걸쳐 확장할 수 있습니다.
각 AWS 계정은 제반 환경을 분리하는 데 사용할 수 있는 다중 VPC를 생성할 수 있습니다.
VPC는 여러 서브넷에 의해 분할되는 하나의 IP 주소 공간을 정의합니다.
이러한 서브넷들은 가용 영역 내에 배포되기 때문에 VPC는 가용 영역을 확장합니다.
하나의 VPC에서 많은 서브넷을 생성할 수 있는 반면, 네트워크 토폴로지의 복잡성을 제한하기 위해 권장되는 서브넷들은 비교적 수가 적은 편이지만 이는 전적으로 사용자에게 달려 있습니다.
서브넷과 인터넷 사이의 트래픽을 제어하기 위해 서브넷에 대한 라우팅 테이블을 구성할 수 있습니다.
기본적으로 VPC 내 모든 서브넷은 서로 통신할 수 있습니다.
서브넷은 일반적으로 퍼블릭(public) 또는 프라이빗(private)으로 분류되는데, 퍼블릭 서브넷은 인터넷에 직접 액세스할 수 있지만 프라이빗 서브넷은 인터넷에 직접 액세스할 수 없다는 차이점이 있습니다.
서브넷을 퍼블릭으로 설정하려면 인터넷 게이트웨이를 VPC에 연결하고 퍼블릭 서브넷의 라우팅 테이블을 업데이트하여 외부로 가는 트래픽을 인터넷 게이트웨이로 전송해야 합니다.
Amazon EC2 인스턴스 역시 인터넷 게이트웨이로 라우팅하려면 퍼블릭 IP 주소가 필요합니다.
이제 컴퓨팅 리소스 및 AWS 서비스의 배포를 시작하는 데 사용할 수 있는 Amazon VPC 예제를 설계해 보겠습니다.
높은 가용성을 지원하고 여러 서브넷을 사용하는 네트워크를 생성해 보겠습니다.
먼저 VPC 또는 리전을 기반으로 하는 이상, 하나의 리전을 선택해야 합니다.
저는 오리건 리전(Oregon Region)을 선택했습니다.
그런 다음, VPC를 생성해 보겠습니다.
이제 이 VPC의 이름을 Test VPC로 정하고 이 VPC에 대한 IP 주소 공간을 정의해 보겠습니다.
10.0.0.0/16은 CIDR(Classless Inter-Domain Routing) 형식에 해당되는데, 이는 VPC에서 사용할 IP 주소가 65,000개가 넘는다는 것을 의미합니다.
그런 다음, Subnet A1이라는 이름의 서브넷을 생성합니다.
256개의 IP 주소를 포함하는 하나의 IP 주소 공간을 할당했습니다.
또한 이 서브넷이 가용 영역(AZ) A에서 실행될 것임을 지정합니다.
그런 다음, Subnet B1이라는 이름의 또 다른 서브넷을 생성했으며 하나의 IP 주소 공간을 할당합니다.
다만 이 주소 공간은 512개의 IP 주소를 포함합니다.
이제 Test IGW라는 이름의 인터넷 게이트웨이를 추가했습니다.
Subnet A1은 인터넷 게이트웨이를 통해 외부로 가는 트래픽이 라우팅되는 퍼블릭 서브넷이 됩니다.
Subnet B1은 인터넷에서 격리된 프라이빗 서브넷이 됩니다.
지금까지 수행한 실습 내용을 요약한 다음, 다음 단계를 살펴보기로 하겠습니다.
지금까지 VPC, 인터넷 게이트웨이 및 서브넷을 생성하는 방법에 대해 알아보았습니다.
다음 단계에서는 라우팅 테이블, VPC 엔드포인트 및 피어링 연결 등 그 밖의 VPC 기능들에 대해 알아보기로 하겠습니다.
또한 AWS 리소스를 VPC에 배포하는 방법에 대해서도 확인할 수 있습니다.
자세한 내용은 AWS.amazon.com/VPC를 참조하십시오.
이 과정이 약간이라도 도움이 되었기를 바라며 계속해서 다른 동영상을 학습하시기 바랍니다.
이것으로 강의를 마칩니다.
저는 AWS 교육 및 자격증 팀 담당자 Kent Rademacher였습니다.
시청해 주셔서 감사합니다.
- 보안그룹
안녕하세요.
저는 AWS(Amazon Web Services) 교육 및 자격증 팀에서 활동 중인 Anna Fox라고 합니다.
오늘 강의에서는 AWS Security Groups에 대해 간략히 소개하겠습니다.
AWS 클라우드의 보안은 AWS(Amazon Web Services)의 최우선 사항 중 하나에 속하며, 저희 AWS는 AWS Cloud에서 데이터를 보호하는 데 도움이 될 여러 가지 강력한 보안 옵션을 제공합니다.
이번 시간에 제가 이야기하고 싶은 기능 중 한 가지는 보안 그룹(security groups)입니다.
AWS에서 보안 그룹은 사용자의 가상 서버를 위한 내장 방화벽처럼 작동합니다.
이들 보안 그룹을 사용하면 인스턴스에 대한 접근성을 완벽하게 제어할 수 있습니다.
이는 가장 기초적인 수준에서 인스턴스에 대한 트래픽을 필터링하는 또 다른 방법에 불과합니다.
이러한 방법을 활용하면 어떤 트래픽을 허용 또는 거부할 것인지를 제어할 수 있습니다.
사용자의 인스턴스에 액세스할 권한이 있는 자를 결정하기 위해 보안 그룹 규칙을 구성합니다.
이 규칙들은 해당 인스턴스를 100% 프라이빗 또는 퍼블릭 상태로 유지하거나 혹은 그 중간 수준의 상태로 유지하는 등 다양하게 구성할 수 있습니다.
여기서는 전형적인 AWS 멀티티어 보안 그룹의 예를 볼 수 있습니다.
이 아키텍처에서는 이러한 멀티티어 웹 아키텍처를 수용하기 위해 다양한 보안 그룹 규칙들이 생성되었음을 알 수 있습니다.
웹 티어에서 시작할 경우, 0.0.0.0/0의 소스를 선택하면 포트 80/443에서 인터넷의 모든 사이트로부터 발신된 트래픽을 허용하는 하나의 규칙을 설정했음을 알게 됩니다.
그런 다음, 애플리케이션 티어로 이동하면 웹 티어에서 발신된 트래픽만 허용하는 하나의 보안 그룹이 있으며, 이와 마찬가지로 데이터베이스 티어는 애플리케이션 티어에서 발신된 트래픽만 허용할 수 있습니다.
마지막으로, SSH 포트 22를 통해 기업 네트워크에서 원격으로 관리를 허용할 목적으로 생성된 규칙도 있음을 알 수 있습니다.
이제 하나의 보안 그룹을 생성하는 과정을 살펴보기로 하겠습니다.
지금 저는 AWS 관리 콘솔에 로그인하고 있는데 EC2를 클릭해 보겠습니다.
탐색 창을 열면 Network & Security 아래로 Security Groups가 보입니다.
이것을 클릭해 보겠습니다.
그러면 해당 계정에 속한 일련의 보안 그룹들이 목록으로 나타납니다.
보안 그룹을 생성하려면 Create Security Group을 클릭해야 합니다.
팝업 창이 나타납니다.
이 창에서는 이름과 설명을 작성하여 이를 소스에 연결할 수 있습니다.
그런 다음, 여기서 해당 규칙으로 내려가면 모든 인바운드 트래픽은 기본적으로 DENIED(거부됨)로 설정되며 모든 아웃바운드 트래픽은 ALLOWED(허용됨)로 설정되는 것을 알 수 있습니다.
이를 편집하고 싶다면 여기서 인바운드 탭과 아웃바운드 탭을 각각 클릭해 규칙을 수정하면 됩니다.
트래픽 유형, 프로토콜, 포트 범위 및 소스별로 편집할 수 있습니다.
이때, 사용 중인 인스턴스에 필요한 트래픽이 무엇인지를 파악하고 그 트래픽만 특별히 허용하는 것이 가장 좋은 방법입니다.
잘 하셨습니다! 오늘 강의에서 배운 내용을 다시 살펴보겠습니다.
AWS는 1개 이상의 인스턴스에 대한 트래픽을 제어할 수 있는 가상 방화벽(이른바 '보안 그룹'이라고 함)을 제공합니다.
보안 그룹 규칙을 생성하면 인스턴스에 대한 접근성을 제어할 수 있습니다.
이러한 보안 그룹은 AWS 관리 콘솔에서 관리할 수 있습니다.
보안 그룹에 관한 자세한 내용은 <http://aws.amazon.com>에서 확인하시기 바랍니다.
저는 AWS(Amazon Web Services) 교육 및 자격증 팀 담당자인 Anna Fox였습니다.
- 컴퓨팅 서비스
AWS 컴퓨팅 서비스에 대한 소개를 시작하겠습니다.
저는 이곳 Amazon Web Services에서 기술 프로그램 관리자를 맡고 있는 Allen Goldberg라고 합니다.
비즈니스를 구축하고 운영하는 일은 인간 게놈의 염기서열을 분석하기 위해 모바일 앱을 구축하거나 거대한 클러스터를 실행하는지 여부에 관계없이 컴퓨팅으로 시작됩니다.
AWS는 다양한 컴퓨팅 서비스 카탈로그를 제공합니다.
단순한 애플리케이션 서비스에서부터 유연한 가상 서버는 물론, 심지어는 서버리스 컴퓨팅에 이르기까지 모든 서비스를 제공합니다.
이 동영상에서는 AWS의 컴퓨팅 서비스를 소개하고자 합니다.
여러 서버를 온프레미스로 운영할 경우, 많은 비용이 소요됩니다.
하드웨어는 실제 사용량이 아닌, 프로젝트 계획에 따라 확보해야 할 때가 많습니다.
데이터 센터는 구축, 인원 배치 및 유지 보수 시 많은 비용이 소요됩니다.
최악의 경우에는 리소스를 프로비저닝해야 합니다.
사용 중인 서버는 트래픽 급증 및 이벤트를 처리할 수 있어야 합니다.
일단 구축이 완료되면 용량이 유휴 상태가 되는 경우가 많습니다.
AWS는 유연성과 비용 효율성을 제공합니다.
AWS를 사용하면 컴퓨팅 요구를 워크로드에 맞게 조정할 수 있습니다.
확장성은 컴퓨팅 서비스에 내장되어 있기 때문에 수요가 증가하면 쉽게 확장할 수 있습니다.
수요가 감소할 경우(예를 들면, 야간 또는 주말), 애플리케이션 규모를 축소하여 비용과 리소스를 절감할 수 있습니다.
사용하지 않는 애플리케이션에 비용을 들일 필요가 없습니다.
컴퓨팅 요구는 시간이 지남에 따라 변동할 수 있는데, 예를 들면 AWS의 Amazon EC2 서비스는 단순한 웹 서버에서부터 대규모 기계 학습 클러스터에 이르기까지 모든 유형에 적합한 다양한 가상 서버 인스턴스 유형을 제공합니다.
사용자는 자신이 직접 구입한 특정 하드웨어 구성에 매이지 않고 인스턴스 유형을 쉽게 변경할 수 있습니다.
Amazon EC2를 사용하면 여러 애플리케이션을 규모에 관계없이 실행하는 완벽한 유연성을 구현할 수 있습니다.
사용 환경을 계속 완벽하게 제어할 수 있으며 온프레미스 환경과는 달리, 온디맨드(On-Demand) 가격을 적용하여 필요에 따라 리소스를 비용 효율적으로 확장 및 축소할 수 있습니다.
종종 서버를 실행할 필요가 없습니다.
서버를 실행하는 대신, 필요할 때 애플리케이션을 실행할 수 있다면 어떨까요? AWS Lambda를 사용하면 서버를 프로비저닝하거나 관리할 필요 없이 코드를 실행할 수 있습니다.
사용한 컴퓨팅 시간에 대해서만 비용을 지불하면 됩니다.
코드를 실행하지 않을 때는 비용이 발생하지 않습니다.
Lambda에서는 사실상 모든 유형의 애플리케이션 또는 백엔드 서비스(예: 모바일, 사물 인터넷(IoT), 스트리밍 서비스)에 대한 코드를 별도의 관리 없이 실행할 수 있습니다.
이를테면 업로드된 이미지를 처리하는 경우를 예로 들 수 있습니다.
이 이미지를 Amazon S3에 업로드하고 이벤트 트리거를 사용하면 유휴 서버를 굳이 대기시키지 않고도 Lambda 함수를 시작하여 이미지를 처리할 수 있습니다.
서버를 프로비저닝하고 유지 관리할 필요 없이 컴퓨팅을 실행하는 경우를 생각해 보십시오.
간단한 웹사이트 또는 전자 상거래 애플리케이션을 실행해야 할 경우, AWS는 Amazon Lightsail을 제공합니다.
Lightsail을 사용하면 하나의 가상 프라이빗 서버(virtual private server)를 단 몇 분만에 시작할 수 있으며, 간단한 웹 서버 및 애플리케이션 서버를 쉽게 관리할 수 있습니다.
Lightsail은 저렴하면서도 예측 가능한 가격으로 프로젝트를 활성화하는 데 필요한 모든 것(가상 머신, SSD 기반 스토리지, 데이터 전송, DNS 관리 및 정적 IP 주소 등)을 포함하고 있습니다.
컨테이너 서비스를 온프레미스로 사용합니까? Amazon ECS(Elastic Container Service)는 Docker 컨테이너를 지원하는 확장성과 성능이 뛰어난 컨테이너 관리 서비스이며, 이 서비스를 사용하면 Amazon EC2 인스턴스의 관리형 클러스터에서 애플리케이션을 손쉽게 실행할 수 있습니다.
Amazon ECS를 사용하면 자체적 클러스터 관리 인프라를 설치, 운영 및 확장할 필요가 없습니다.
AWS는 여러 가지 컴퓨팅 제품을 제공하며 이를 통해 애플리케이션을 가상 서버나 컨테이너 또는 코드로 배포, 실행 및 확장할 수 있습니다.
AWS는 배치 프로세싱을 자동화 및 확장하고 웹 애플리케이션을 실행 및 관리하며 가상 네트워크를 생성하기 위한 서비스를 갖추고 있습니다.
AWS 컴퓨팅 서비스에 관한 추가 정보는 AWS.Amazon.com/products/compute를 참조하시기 바랍니다.
또한 AWS는 각 서비스에 대한 세부 정보를 확인할 수 있는 일련의 서비스 수준 소개도 제공합니다.
- Amazon Elastic Compute Cloud (EC2)
안녕하세요.
저는 Mike Blackmer라고 합니다.
저는 AWS 교육 및 자격증(Training and Certification) 팀에서 교육 과정 개발 업무를 담당하고 있습니다.
Amazon EC2 개요를 발표하겠습니다.
먼저 해당 제품에 대한 몇 가지 기본적인 사실들을 제시한 다음, Amazon EC2 인스턴스를 구축 및 구성하는 방법을 보여주는 데모를 소개해 보겠습니다.
EC2란 무엇일까요? EC2는 Elastic Compute Cloud의 약어입니다.
여기서 Compute(컴퓨팅)란 제공 중인 컴퓨팅이나 서버, 리소스 등을 가리킵니다.
서버를 이용해 수행할 수 있는 일 중에는 재미있고 흥미진진한 것들이 많습니다.
또한 Cloud(클라우드)란 이러한 요소들이 클라우드에서 호스팅하는 컴퓨팅 리소스에 해당된다는 사실을 의미합니다.
첫 번째 단어인 Elastic(탄력적)은 서버를 올바르게 구성할 경우, 하나의 애플리케이션에 대한 현재의 수요에 따라 이 애플리케이션에서 필요한 서버의 수량을 자동으로 증감할 수 있다는 사실을 의미합니다.
이제 이러한 요소들을 더 이상 '서버'라 부르지 말고 그 대신에 Amazon EC2 인스턴스라는 올바른 이름을 사용해 보겠습니다.
인스턴스는 종량 과금제 방식으로 요금이 부과됩니다.
즉, 실행 중인 인스턴스 및 이러한 인스턴스를 실행 중인 시간에 한해서만 요금을 지불합니다.
여기서는 다양한 하드웨어 및 소프트웨어를 선택할 수 있으며, 인스턴스를 호스팅할 위치도 선택할 수 있습니다.
Amazon EC2는 이보다 더 많은 것을 포함하고 있습니다.
자세한 내용은 AWS.amazon.com/ec2를 참조하십시오.
이제 EC2 인스턴스를 구축 및 구성하는 방법을 시연해 보겠습니다.
또한 시연 과정에서 지금까지 다룬 주제들에 대해 좀 더 자세히 알아보기로 하겠습니다.
시연 중에는 AWS 콘솔에 로그인하여 인스턴스를 호스팅할 하나의 리전을 선택하고 EC2 마법사를 시작하며 AMI(Amazon Machine Image)를 선택하여 AWS 인스턴스에 대한 소프트웨어 플랫폼을 제공합니다.
그런 다음, 하드웨어 용량을 나타내는 인스턴스 유형을 선택합니다.
이어서 네트워크와 스토리지를 차례대로 구성하고 마지막으로 키 페어를 구성하면 해당 인스턴스를 시작한 후에 인스턴스에 연결할 수 있습니다.
저는 이미 콘솔에 로그인한 상태입니다.
먼저 EC2 인스턴스가 호스팅되는 해당 리전을 선택해 보겠습니다.
이제 리전은 인근 지역인 오리건(Oregon)으로 설정되었습니다.
드롭다운 목록을 클릭하면 다른 리전을 선택할 수도 있는데, 저는 리전을 변경하지 않고 계속 오리건으로 설정해 보겠습니다.
이제 계속 진행하여 Services를 클릭해 보겠습니다.
EC2를 클릭한 다음, Launch Instance를 클릭합니다.
첫 번째 선택 기준은 AMI(Amazon Machine Image)인데 이는 인스턴스가 시작될 때 인스턴스와 함께 발생하는 소프트웨어 로드를 가리킵니다.
Quick Start는 다양한 Linux 및 Windows 서버의 목록을 제시합니다.
또한 나만의 서버를 구축했다면 타사 이미지와 My AMIs를 포함하는 마켓플레이스도 있습니다.
여기서는 Amazon Linux AMI를 선택해 보겠습니다.
다음 화면에서는 하드웨어를 선택할 수 있는 목록이 나타납니다.
이 목록에 나열된 하드웨어들을 일컬어 인스턴스 유형이라고 하며 아래로 스크롤하면 8코어, 32GB의 메모리, 64개의 코어를 시작으로 일련의 유형들을 확인할 수 있습니다.
여기서는 매우 다양한 유형들이 존재합니다.
시연용 로우 엔드(low-end) 유형들 중 T2 Micro 인스턴스 유형을 선택해 보겠습니다.
다음은 Configure Instance Details를 선택해 보겠습니다.
동일한 하드웨어 및 소프트웨어 빌드를 공유할 수많은 이미지들을 선택적으로 생성할 수 있습니다.
생성 가능한 이미지의 개수는 10만 개로 제한되는 것 같습니다.
아시나요? 저는 지금 일자리를 유지하고 싶기 때문에 한 가지를 선택해 보겠습니다.
하나의 인스턴스를 구축해 보겠습니다.
아래로 스크롤하면 여기서는 네트워크 구성이 진행되며, 여기서는 기본값, 즉 기본 VPC(Virtual Private Cloud), 기본 서브넷 및 기본 자동 할당 설정을 계속 유지하면 DHCP 주소를 얻게 됩니다.
아래로 건너뛰면 나머지 모든 항목은 매우 양호한 것으로 나타납니다.
그런 다음, 스토리지를 추가해 보겠습니다.
이제 루트 볼륨의 크기를 12GB로 확대할 수 있습니다.
디스크의 유형을 변경할 수 있습니다.
새 볼륨을 추가할 수도 있습니다.
흥미로운 점들을 계속 살펴보기 위해 루트 볼륨의 크기를 16GB로 확대해 보겠습니다.
인스턴스를 종료하거나 삭제할 경우에는 이 볼륨을 삭제할 필요도 있습니다.
그런 다음, 태그를 추가해 보겠습니다.
EC2 인스턴스의 경우, 기본적으로 암호를 사용한 식별자 1개가 제공되기 때문에 이 식별자에 대해 친숙한 이름을 붙일 필요가 있는데 Add Tag, Name 및 Value of을 차례대로 클릭합니다.
이 식별자의 이름을 EC2 demo로 지정해 보겠습니다.
그런 다음, 보안 그룹을 구성해 보겠습니다.
보안 그룹은 일련의 방화벽 규칙을 가리킵니다.
이것은 SSH 연결을 위한 기본 규칙을 자동으로 생성합니다.
간단한 웹 연결을 허용하기 위해 또 다른 규칙을 추가할 수 있습니다.
이 규칙을 간단히 SSH GTP라는 이름으로 부르기로 하며, 이제 해당 보안 그룹이 제공하는 것이 무엇인지를 정확히 파악할 수 있습니다.
이제 Review and Launch를 클릭합니다.
선택한 항목들을 상기시키는 개요가 나타납니다.
이 개요의 모든 항목은 계획된 항목처럼 보입니다.
이제 Launch를 클릭합니다.
SSH를 사용해 시스템에 연결하려면 하나의 키 페어를 생성해야 합니다.
때문에 Create a New Key Pair를 클릭하여 해당 키 페어의 이름을 EC2 Demo로 지정한 다음, 프리이빗 키를 다운로드합니다.
이 키를 로컬에 저장합니다.
SSH를 통해 연결하려면 프라이빗 키가 꼭 필요합니다.
이제 매직 버튼을 누르면 해당 인스턴스가 시작됩니다.
인스턴스가 성공적으로 시작되었습니다.
시작 로그의 항목들은 양호한 것으로 나타납니다.
그리고 이 로그에는 암호를 사용한 식별자가 있습니다.
이 식별자를 클릭합니다.
친숙한 이름이 나타나는데 이는 해당 인스턴스 상태가 보류 중임을 의미합니다.
Refresh 버튼을 클릭하면 인스턴스가 실행됩니다.
잘 됐네요.
EC2 인스턴스 구축이 완료되었다면 이제 이 인스턴스에 액세스해 보겠습니다.
이 인스턴스를 강조 표시하면 Description 아래에서 해당 인스턴스의 퍼블릭 DNS 및 퍼블릭 IP 주소를 확인할 수 있습니다.
이제 이 DNS 및 주소를 복사하여 PuTTY를 시작하면 기본 사용자는 EC2-user로 설정됩니다.
따라서 EC2-user@를 실행합니다.
복사한 DNS를 붙여 넣은 다음, Open을 클릭해 보겠습니다.
Cache를 클릭해 로컬 키를 캐시에 저장합니다.
참! 아직 프라이빗 키를 구성하지 않았기 때문에 이 로컬 키는 작동하지 않습니다.
따라서 동일한 정보로 새 세션을 만들어 SSH 및 Auth를 선택하고 해당 프라이빗 키를 찾아봅니다.
프라이빗 키를 여기 이 폴더에 저장했는데 지금은 없습니다.
Windows 기반의 PuTTY에서는 하나의 PPK 파일이 필요하기 때문에 PuTTYgen이라 하는 또 다른 애플리케이션을 열어야 합니다.
Load를 클릭하여 오른쪽 폴더로 이동하면 PEM 파일이 있는지 확인할 수 있으며, 이 파일을 선택한 후 프라이빗 키를 저장합니다.
이렇게 하면 프라이빗 키는 PPK 파일로 저장됩니다.
이 키는 PuTTY 선택 창 아래에 있습니다.
이제 해당 연결을 열면 자동으로 로그인이 실행되며 로그인이 성공한 것으로 나타납니다.
이번 데모가 도움이 되셨기를 바랍니다.
이것으로 강의를 마칩니다.
저는 AWS 교육 및 자격증 팀 담당자 Mike Blackmer였습니다.
- AWS Lambda
안녕하세요.
저는 AWS 교육 및 자격증 팀 담당자 Ian Falconer입니다.
이번 시간에는 AWS Lambda에 대한 입문 과정을 시작하겠습니다.
AWS는 이벤트 중심의 서버리스 컴퓨팅 서비스입니다.
이번 강의에서는 AWS Lambda에 대해 논의해 보겠습니다.
AWS Lambda에 대한 간략한 소개와 서비스 혜택에 대해 살펴본 후, 몇몇 핵심 기능 및 개념들을 좀 더 자세히 다루어 보겠습니다.
그런 다음, 이 서비스의 일부 용례들을 살펴보고 마지막으로 이번 강의의 내용을 간략히 요약하는 것으로 마무리해 보겠습니다.
AWS Lambda란 무엇일까요? AWS Lambda는 서버를 프로비저닝하거나 관리할 필요 없이 코드를 실행할 수 있는 컴퓨팅 서비스입니다.
AWS Lambda는 필요할 때에만 코드를 실행하며 초당 수천 건의 요청으로 자동 확장됩니다.
이제 몇 분 동안 이 서비스의 주요 이점들을 살펴보기로 하겠습니다.
사용한 컴퓨팅에 대해서만 요금을 지불하면 됩니다.
코드가 실행되지 않는 컴퓨팅 시간에 대해서는 비용이 발생하지 않습니다.
이 때문에 AWS Lambda는 가변적이면서 단속적인 워크로드에 안성맞춤입니다.
이 서비스를 이용하면 거의 모든 애플리케이션 또는 백엔드 서비스에서 별도의 관리 없이 코드를 실행할 수 있습니다.
AWS Lambda는 고가용성 컴퓨팅 인프라에서 코드를 실행하며, 서버 및 운영 체제 유지 관리, 용량 프로비저닝, Auto Scaling, 코드 모니터링, 로깅 등 모든 관리 기능을 제공합니다.
AWS Lambda는 Node.js, Java, C Sharp 및 Python을 포함한 다양한 종류의 프로그래밍 언어들을 지원합니다.
AWS Lambda는 어떻게 사용할 수 있을까요? 이 서비스는 이벤트 중심 컴퓨팅에 사용할 수 있습니다.
Amazon S3 버킷 또는 Amazon DynamoDB 테이블의 변경을 포함한 이벤트에 대한 응답으로 코드를 실행할 수 있습니다.
Amazon API Gateway를 사용하여 HTTP 요청에 응답할 수 있습니다.
AWS SDK를 사용하여 만든 API 호출을 이용해 코드를 호출할 수 있습니다.
AWS Lambda 함수에 의해 트리거되는 서버리스 애플리케이션을 구축할 수 있으며, AWS CodePipeline AWS CodeDeploy를 사용하면 이 함수를 자동으로 배포할 수 있습니다.
AWS Lambda는 서버리스 및 마이크로 서비스 애플리케이션을 지원하기 위한 서비스입니다.
밀결합된 모놀리식 솔루션의 생성을 방지하기 위해 AWS Lambda는 다음과 같은 구성 옵션들을 활용합니다.
디스크 공간은 512MB로 제한됩니다.
메모리는 128MB에서 1,536MB까지 할당할 수 있습니다.
AWS Lambda 함수는 최대 5분까지만 실행됩니다.
사용자는 배포 패키지 크기와 파일 기술자의 최대 수에 의해 제약됩니다.
요청 및 응답 본문 페이로드는 6MB를 초과할 수 없습니다.
이벤트 요청 본문 역시 128kbit로 제한됩니다.
동시 실행 횟수는 소프트 한도에 속하며, 요청 시 증가할 수 있습니다.
AWS Lambda는 코드가 트리거되는 횟수를 기반으로 하여 실행 시간이 1msec를 경과할 때마다 구축됩니다.
Lambda 함수는 매우 간편하게 구축할 수 있습니다.
Lambda 환경을 구성한 다음, 코드를 업로드하여 코드 실행 과정을 지켜보면 됩니다.
구축 방법은 그만큼 간단합니다.
이제 빠른 데모를 진행해 봅시다.
이미지 인식 앱을 구축해 보겠습니다.
정말 짧고 가벼운 앱 하나를 구축했는데 여기서는 Amazon S3에 하나의 웹사이트를 호스팅했습니다.
하나의 이미지를 업로드하면 Lambda 함수가 트리거되는데, 이 함수는 해당 이미지를 처리하고 썸네일을 생성합니다.
Lambda 함수는 매우 쉽게 생성됩니다.
이것은 AWS Lambda의 Create Function 페이지에서 AWS 콘솔을 보여주는 화면입니다.
여기서는 이미 많은 Lambda 함수가 있음을 알 수 있습니다.
이제 Check S3 public access(S3 퍼블릭 액세스 확인) Lambda 함수를 살펴보겠습니다.
Create Function을 클릭해 Lambda 함수의 이름을 지정하면 지금 보이는 것과 같은 화면이 나타납니다.
왼쪽 상단에 Lambda 함수 이름이 지정된 것을 볼 수 있습니다.
이제 내 Lambda 함수를 구성해 보겠습니다.
런타임을 선택했습니다.
이 경우에는 Python입니다.
핸들러의 이름을 지정하고 Python 코드를 추가했습니다.
여기서는 이 Python 코드를 추가했습니다.
이 Lambda 함수는 내 S3 버킷을 검사하고 있으며 퍼블릭 액세스가 있는 모든 버킷이 나타나면 이 함수는 해당 액세스를 호출한 후 알림을 전송합니다.
내 Lambda 함수를 구성하는 동안 환경 변수들을 구성할 수 있습니다.
암호화를 적용할 경우, 태그를 적용할 수 있습니다.
하나의 실행 역할을 선택할 수 있습니다.
이 경우, 운영에 필요한 권한을 내 Lambda 함수에 부여하는 하나의 역할을 선택했습니다.
이제 내 Lambda 함수, 메모리 할당(이 경우, 128MB) 및 실행 제한 시간을 각각 구성할 수 있습니다.
제한 시간을 최대 5분으로 설정해 보겠습니다.
그런 다음, 내 트리거를 구성해 보겠습니다.
이 경우, CloudWatch 이벤트를 사용해 내 Lambda 함수를 트리거합니다.
하나의 CloudWatch 이벤트가 있음을 알 수 있습니다.
활성화된 상태의 이 이벤트는 S3 버킷 내 변경 사항들을 관찰하는 데 사용되며 이러한 특정 Lambda 함수를 트리거합니다.
이제 내 Lambda 함수에 대한 모니터링 페이지를 볼 수 있는데, 여기서는 이 Lambda 함수가 네 번 실행되었음을 invocation count(호출 횟수)에서 확인할 수 있습니다.
이 Lambda 함수가 실행될 때 알림을 전송하면 IFal public이라는 이름의 S3 버킷에 관한 정보를 여기서 볼 수 있으며, 모든 사용자에 대해 액세스할 권한을 얻게 됩니다.
이 Lambda 함수는 이러한 버킷에서 퍼블릭 액세스를 호출했으며, AWS CloudTrail도 업데이트했습니다.
AWS Lambda를 이용하면 사실상 모든 애플리케이션 또는 백엔드 서비스에 대한 코드를 실행할 수 있습니다.
AWS Lambda의 용례로는 백업 자동화, Amazon S3에 업로드된 객체의 처리, 이벤트 중심의 로그 분석, 이벤트 중심의 변환, 사물 인터넷(IoT), 서버리스 웹사이트 운영 등이 있습니다.
이제 실시간 이미지 프로세싱의 용례를 살펴보기로 하겠습니다.
고객은 S3에 하나의 이미지를 업로드하면서, 이 이미지를 즉시 처리하기 위해 Lambda 함수를 트리거합니다.
이 함수를 사용하면 동영상, 썸네일, 인덱스 파일, 프로세스 로그 및 집계 데이터를 실시간으로 트랜스코딩할 수 있습니다.
AWS의 고객사 중 한 곳인 Seattle Times는 데스크톱 컴퓨터, 태블릿, 스마트폰 등 다양한 디바이스에서 이미지를 볼 수 있도록 이미지 크기를 조정하기 위해 AWS Lambda를 사용합니다.
AWS Lambda와 Amazon Kinesis를 사용하면 애플리케이션 활동 추적, 트랜잭션 주문 처리, 클릭스트림 분석, 데이터 정리 측정치, 생성 로그 필터링, 소셜 미디어 인덱싱 분석 및 디바이스 데이터 원격 측정과 모니터링 등을 목적으로 실시간 스트리밍 데이터를 처리할 수 있습니다.
AWS의 고객들은 S3에 저장되거나 Amazon Kinesis에서 스트리밍되는 과거 데이터 및 실시간 데이터를 처리하기 위해 AWS Lambda를 사용하여 실시간으로 수십억 개의 데이터 포인트를 처리합니다.
그들은 매월 1천억 건의 이벤트를 처리할 수 있습니다.
AWS Lambda를 이용하면 추출, 변환 및 로드(ETL) 파이프라인을 구축할 수 있습니다.
또한 AWS Lambda를 이용하면 데이터 검증, 필터링, 정렬을 수행하거나 혹은 DynamoDB 테이블 내 모든 데이터 변경에 대한 그 밖의 변환들을 수행할 수 있으며, 변환된 데이터를 다른 데이터 저장소에 로드할 수도 있습니다.
Zillow는 AWS Lambda 및 Amazon Kinesis를 사용해 모바일 측정치 중 일부를 실시간으로 추적하고 있습니다.
이 업체는 비용 효율적인 솔루션을 불과 2주 만에 개발 및 배포할 수 있습니다.
AWS Lambda를 이용하면 IoT 디바이스를 위한 백엔드를 구축할 수도 있습니다.
API Gateway를 AWS Lambda와 결합하면 모바일 백엔드를 쉽게 구축할 수 있습니다.
API Gateway를 이용하면 그러한 API 요청들을 매우 간편하게 인증하고 처리할 수 있으며, AWS Lambda를 이용하면 풍부한 개인화 앱 환경을 매우 쉽게 구축하고 개발할 수 있습니다.
AWS의 고객들은 대부분 AWS Lambda, Amazon SNS 및 API Gateway를 이용한 마이크로 서비스 백엔드를 사용하여 자사의 웹사이트와 모바일 애플리케이션을 모두 실행하고 있습니다.
AWS Lambda와 그 외 AWS 서비스를 결합하면 AWS Lambda를 이용해 웹 백엔드를 구축할 수도 있습니다.
개발자들은 자동으로 확장 및 축소되는 고성능 웹 애플리케이션을 구축할 수 있습니다.
그러한 애플리케이션들은 다수의 데이터 센터에 걸쳐 고가용성의 구성 환경에서 실행되기 때문에 확장성, 백업 및 다중 데이터 센터 중복성을 구현하기 위해 관리상의 수고를 할 필요가 없습니다.
요컨대 AWS Lambda는 마이크로 서비스 아키텍처 구축에서부터 애플리케이션 실행에 이르기까지 AWS 서비스의 결합 조직인 셈입니다.
오늘 이 시간에 뭔가 조금이라도 배운 후에 나머지 강의를 계속 들으시기 바랍니다.
강의를 마칩니다.
저는 AWS 교육 및 자격증 팀의 Ian Falconer였습니다.
시청해 주셔서 감사합니다.
- AWS Elastic Beanstalk
AWS Elastic Beanstalk에 대한 소개를 시작하겠습니다.
저는 AWS(Amazon Web Services)의 EMEA(유럽, 중동 및 아프리카) 지역 담당 기술 강사인 Wilson Santana입니다.
이번 동영상에서는 AWS Elastic Beanstalk 서비스를 간략히 소개합니다.
또한 솔루션의 구성 요소에 대해서도 논의하는 한편, 해당 제품과 그 이점 및 기능들을 시연해보기로 하겠습니다.
각자 웹 서버의 개발자라고 생각하고 이번 강의 동영상을 시청하시기 바랍니다.
실제로 시스템의 전체 관리를 개발하고 실제 서버 개발의 배후에 있는 모든 것들을 관리하는 일에 대해서는 고민할 필요가 없을 것입니다.
아마도 내 애플리케이션을 클라우드로 신속하게 가져올 수 있는 방법이 궁금할 것입니다.
시스템 개발을 시작할 수 있도록 전체 환경을 신속하게 준비할 방법이 있다면 과연 무엇일까요? 이 질문에 대한 해답은 AWS Elastic Beanstalk에 있습니다.
그렇다면 AWS Elastic Beanstalk는 실제로 어떻게 작동할까요? 이 시스템의 이점과 특징으로는 무엇이 있을까요? AWS Elastic Beanstalk은 서비스로서의 플랫폼(PaaS)에 속하는데, 여기서 서비스로서의 플랫폼(PaaS)이라는 것은 사용 중인 코드를 필요에 따라 시스템에 간단히 배치할 수 있도록 전체 인프라와 전체 플랫폼이 생성되었다는 것을 의미합니다.
이것을 활용하면 사용자의 애플리케이션을 신속하게 배포할 수도 있습니다.
이전에 일부 특정 언어로 작성한 모든 코드는 사용자가 보유한 플랫폼에 간단히 배치할 수 있습니다.
또한 AWS Elastic Beanstalk은 관리상의 복잡성을 줄여줍니다.
전체 시스템을 관리하는 것에 대해서는 걱정할 필요가 없으며 다만 원한다면 전체 시스템을 완벽하게 제어할 수도 있습니다.
사용자를 위해 개발된 시스템을 제어하면 필요에 따라 인스턴스 유형을 선택하거나 데이터베이스를 선택할 수 있습니다.
또한 AWS Elastic Beanstalk을 사용하면 필요에 따라 Auto Scaling 설정값을 조정할 수 있습니다.
뿐만 아니라, 사용 중인 애플리케이션을 업데이트하고 서버 로그 파일에 액세스하며 애플리케이션의 요구에 따라 로드 밸런서에서 HTTPS를 활성화할 수도 있습니다.
또한 AWS Elastic Beanstalk은 다양한 종류의 플랫폼을 지원합니다.
이 PaaS는 패키지 빌더, 단일 컨테이너 또는 다중 컨테이너 또는 사전 구성된 도커(Preconfigured Docker)를 출처로 합니다.
이는 Go, Java with Tomcat, Java SE, Windows 기반 .NET, Node.js, PHP, Python 및 Ruby를 각각 지원합니다.
따라서 사용자의 기술과 웹 서버 개발 아이디어에 따라 코드를 작성하면 되며, Elastic Beanstalk를 사용하면 필요에 따라 사용자의 환경을 배포할 수 있습니다.
Elastic Beanstalk는 모든 애플리케이션 서비스, HTTP 서비스, 운영 체제(OS), 언어 해석기 및 호스트를 제공합니다.
여기서는 사용 중인 서비스의 요구에 따라 코드를 생성, 배포 및 준비한 후, 필요에 따라 애플리케이션을 사용하기만 하면 됩니다.
이를 통해 원하는 것을 매우 쉽게 구현하게 됩니다.
또한 사용 중인 서버는 애플리케이션 생성만을 기반으로 하여 단계별로 배포 및 업데이트할 수 있습니다.
그런 다음, 해당 버전들을 Beanstalk으로 업로드한 후 사용 중인 애플리케이션의 요구에 따라 클라우드에서 필요한 환경들을 모두 시작합니다.
그 후에는 사용자의 환경을 관리할 수 있으며 새 버전을 작성해야 할 경우, 해당 버전을 업데이트하면 됩니다.
여기서 중요한 것은 사용자가 환경을 관리할 수 있다는 점입니다.
이 사이클을 이용하면 애플리케이션을 배포하는 것만큼이나 쉽게 애플리케이션을 업데이트할 수 있게 됩니다.
이제 제품 시연으로 넘어가 Elastic Beanstalk의 특징과 이점들을 시연해보기로 하겠습니다.
실제로 여러 웹 서버를 생성했으며 가령 이 서비스를 Python으로 작성했고 모든 코드가 여기에 있는 경우를 생각해볼 수 있습니다.
애플리케이션이 올바르게 압축된 이것은 정말 간단한 코드에 속합니다.
그렇다면 이제 무엇을 해야 할까요? 전 세계의 모든 사람들에게 내 웹 서비스를 제대로 보여주려면 해당 환경을 실제로 어떻게 사용할 수 있을까요? Beanstalk을 이용하면 이런 작업을 매우 수월하게 처리할 수 있습니다.
실제로 서비스를 시작하기만 하면 되기 때문입니다.
이제 대시보드로 이동해 Elastic Beanstalk을 살펴보기로 하겠습니다.
여기서는 새 애플리케이션을 생성하기만 하면 됩니다.
애플리케이션의 이름을 입력하면 됩니다.
애플리케이션의 이름을 BeanstalkDemo로 입력해 보겠습니다.
그리고 This is a demo를 간단한 설명으로 입력합니다.
여기서는 애플리케이션을 위한 환경을 생성하는 것만 알아두면 됩니다.
그렇다면 이제 무엇을 해야 할까요? 하나의 환경을 지금 생성합니다.
이것은 웹 서버 환경에 속합니다.
작업 애플리케이션을 실행하고 장시간 실행 중인 온디맨드 워크로드를 처리하거나 여러 작업 및 일정을 처리해야 할 경우, 하나의 작업 환경으로 이동할 수 있으며 다만 이러한 상황에서는 단순한 웹 서버 환경 이외에 생성된 것이 없습니다.
여기로 이동해 Web server environment를 선택한 다음, 내 요구에 따라 몇몇 추가 데이터를 입력합니다.
수동으로 생성하려는 모든 도메인 데이터를 여기에 입력하되 자동으로 생성되는 도메인 데이터에 대해서는 입력하지 않고 빈 칸으로 두면 됩니다.
이제 This is a demo라는 설명을 입력해 보겠습니다.
여기에는 일부 옵션들이 있습니다.
그리고 이미 언급한 언어와 지원을 포함하는 사전 구성된 플랫폼들이 일부 있습니다.
이 경우에는 내 애플리케이션이 Python으로 작성되었기 때문에 Python을 선택해 보겠습니다.
또한 여기에는 샘플 애플리케이션을 실행하는 옵션도 있습니다.
따라서 Elastic Beanstalk와 연동할 애플리케이션 없이 지금 바로 계정을 사용하려는 경우, 이를 매우 간단하게 처리할 수 있습니다.
Elastic Beanstalk를 열어 샘플 애플리케이션을 실행하면 됩니다.
이 경우에는 Python으로 작성된 코드가 있습니다.
이제 코드를 업로드한 후 하나의 URL로 이동해 이를 업로드해 보겠습니다.
지금 갖고 있는 로컬 파일을 선택해 보겠습니다.
이 파일을 사용할 수 있는 경우, S3 URL을 이 파일에 업로드하기만 하면 됩니다.
내 파일은 zip 형식의 압축 파일로 되어 있는데 이 파일을 업로드하겠습니다.
기본 구성을 변경하려는 경우, Configure more options로 이동하면 됩니다.
여기 이 영역에서는 프리 티어 기본값에 해당하는 Low cost를 선택하거나 High availability 또는 Custom configuration을 선택할 수 있습니다.
본 예제에서는 이 모든 옵션을 기본값으로 계속 유지합니다.
다만 여기 이 예제에서는 기본값을 생성한 후에 이 값이 어떻게 유연하게 변동할 수 있는지를 볼 수 있습니다.
이제 환경을 생성해 보겠습니다.
이제 시스템은 전체 환경은 물론, 필요한 모든 인스턴스와 네트워킹 환경을 생성하고 있습니다.
사용 중인 애플리케이션에서 데이터베이스가 필요하거나 고가용성의 환경에서 뭔가를 추가로 배포해야 할 경우, 여기서 모든 단계가 진행 및 표시됩니다.
이러한 과정은 애플리케이션의 크기에 따라 대략 5분 내지 10분 정도 소요될 수 있으며 때로는 그보다 훨씬 더 긴 시간이 소요될 수도 있습니다.
소요 시간을 단축하기 위해 사용 가능한 코드와 똑같은 코드로 된 하나의 환경을 이미 생성했습니다.
이 환경에서는 모든 준비가 완료되는 시기를 확인하게 됩니다.
모든 준비가 완료되면 이와 같은 대시보드를 갖게 되는데 이 대시보드는 사용자가 이미 생성한 것들을 보여주며 이를 통해 새로운 버전들을 업로드하고 배포할 수 있습니다.
무엇보다 중요한 것은 이러한 URL을 갖게 된다는 점입니다.
이 URL은 누구나 어디서든지 액세스할 수 있도록 애플리케이션에 맞게 생성되었습니다.
이 URL을 클릭하면 사용자의 코드가 배포되었으며 사용자의 요구에 따라 생성되었는지 확인할 수 있습니다.
또한 여기서는 이 모든 제어를 명령줄 인터페이스(CLI) 및 스크립트를 사용해 수행할 수도 있습니다.
분명한 것은 이미 생성된 환경은 해당 코드에 따라 필요한 것을 제공한다는 점이며, 때문에 시스템의 아키텍처에 대해 미리 고민할 필요는 없습니다.
따라서 개발자들은 이처럼 매우 손쉬운 방법으로 코드를 생성하여 이를 실제 시나리오에서 사용할 수 있습니다.
본 프레젠테이션에서 뭔가 필요한 것을 익히시기 바랍니다.
저는 Wilson Santana였습니다.
시청해 주셔서 감사합니다.
- Application Load Balancer
안녕하세요, Application Load Balancer 소개에 오신 것을 환영합니다.
이 동영상에서는 Elastic Load Balancing(ELB) 서비스에 포함된 두 번째 로드 밸런서 유형인 Application Load Balancer에 대해 소개합니다.
저는 Seph Robinson입니다.
AWS에서 근무한 지는 5년이 넘었는데 현재는 Amazon Web Services(AWS)를 사용하는 고객에게 교육을 제공하는 기술 강사로 일하고 있습니다.
이 동영상에서는 먼저 Application Load Balancer의 개요를 살펴보고 이 서비스에 포함된 주요 기능을 몇 가지 소개합니다.
그런 다음 Application Load Balancer를 활용할 수 있는 몇 가지 사용 시나리오를 알아봅니다.
마지막으로 로드 밸런서 자체를 간략하게 시연합니다.
로드 밸런서란 무엇입니까? Application Load Balancer는 앞서 설명한 대로 Elastic Load Balancing 서비스의 일환으로 출시된 두 번째 유형의 로드 밸런서입니다.
이 로드 밸런서는 Classic Load Balancer가 제공하는 기능을 대부분 제공하는 이외에, 몇 가지 중요한 기능 및 개선 사항을 추가하여 독자적인 사용 사례를 구현할 수 있습니다.
간단히 살펴보면 새로 향상된 기능으로 지원되는 요청 프로토콜이 추가되었고 지표 및 액세스 로그가 개선되었으며 상태 확인 대상이 확대되었습니다.
Application Load Balancer의 추가 기능으로 경로 또는 호스트 기반 라우팅을 사용하는 요청에 대한 추가 라우팅 메커니즘, VPC에서 IPV6 기본 지원, AWS 웹 애플리케이션 통합 등이 있습니다.
Application Load Balancer를 사용할 수 있는 시나리오는 매우 다양합니다.
컨테이너를 사용하여 마이크로 서비스를 호스트하고 단일 로드 밸런서로부터 이러한 애플리케이션으로 라우팅하는 것이 한 가지 시나리오입니다.
Application Load Balancer를 사용하면 서로 다른 요청을 동일한 인스턴스로 라우팅하되 포트에 따라 다른 경로를 지정할 수 있습니다.
다양한 포트에서 수신 대기하는 여러 컨테이너가 있을 경우 라우팅 규칙을 설정하여 원하는 백엔드 애플리케이션으로만 트래픽을 분배할 수 있습니다.
Application Load Balancer에 대해 알아볼 때 배워야 할 새로운 용어가 몇 가지 있습니다.
리스너는 기본적으로 동일하지만 이제 대상을 대상 그룹으로 그룹화할 수 있습니다.
Application Load Balancer는 인스턴스 대신 대상을 등록하므로 대상 그룹이 로드 밸런서에 대상이 등록되는 방식입니다.
여기에 Application Load Balancer가 백엔드 대상을 라우팅하고 구성하는 방식을 볼 수 있습니다.
로드 밸런서에 대해 리스너를 구성할 때 로드 밸런서가 수신하는 요청이 백엔드 대상으로 라우팅되는 방식을 지정하기 위해 규칙을 생성합니다.
이러한 대상을 로드 밸런서에 등록하고 로드 밸런서가 대상에 사용하는 상태 확인을 구성하려면 대상 그룹을 생성합니다.
여기에서 보듯이 대상은 여러 대상 그룹의 멤버가 될 수 있습니다.
앞서 설명한 대로 Application Load Balancer는 향상된 기능과 추가된 기능을 모두 포함하고 있습니다.
Application Load Balancer는 HTTP/2 및 WebSockets 지원을 추가하여 지원 프로토콜을 개선했습니다.
또한 지표 차원을 추가하고 보다 세분화된 상태 확인을 수행하며 액세스 로그에서 세부 정보를 추가하여 모니터링 기능을 확장했습니다.
현재 지원되는 추가 기능에는 경로 및 호스트 기반 라우팅이 있습니다.
경로 기반 라우팅에서는 요청 내 URL을 기반으로 대상 그룹으로 라우팅하는 규칙을 생성할 수 있습니다.
호스트 기반 라우팅에서는 동일한 로드 밸런서가 여러 도메인을 지원할 수 있고 요청된 도메인을 기반으로 요청을 대상 그룹으로 라우팅할 수 있습니다.
이밖에 요청 추적을 사용하여 클라이언트에서 대상까지 요청을 추적할 수 있고 EC2 Container Service 예약 컨테이너를 사용할 때 동적 호스트 포트를 설정할 수 있습니다.
이제 Application Load Balancer 데모를 간략하게 살펴보겠습니다.
시작은 AWS Management Console입니다.
로드 밸런서를 생성하기 위해 EC2 콘솔로 이동합니다.
EC2 콘솔에 두 개의 인스턴스가 이미 실행 중인 것이 보일 것입니다.
로드 밸런서를 시연하는 동안 인스턴스가 시작할 때까지 기다릴 필요가 없도록 제가 미리 실행한 것입니다.
설정된 내용을 확인하고 테스트하기 위해 앞서 생성한 애플리케이션 ELB 테스트 인스턴스를 살펴보겠습니다.
이 인스턴스를 보면서 두 개의 컨테이너가 두 개의 포트에서 수신 대기하는지 확인하겠습니다.
이를 위해 인스턴스의 퍼블릭 IP 주소를 복사한 다음, 웹 브라우저 탭에서 데모를 위해 설정한 페이지로 이동합니다.
첫 번째 페이지는 포트 80에서 수신 대기만 하는 test.html입니다.
이 사이트로 이동하면 Container One이 작동하는 것이 보일 것입니다.
다른 포트에서 수신 대기하는지 보려면 포트 443으로 이동하고 동일한 페이지 위치로 이동합니다.
그러면 두 번째 컨테이너가 실행 중임을 알 수 있습니다.
이제 확인을 마쳤으므로 계속해서 Application Load Balancer를 생성하겠습니다.
측면 탐색 창에서 Load Balancers로 이동합니다.
생성된 로드 밸런서가 없는 것이 보일 것입니다.
Application Load Balancer를 생성하기 위해 먼저 Create Load Balancer를 클릭합니다.
여기서는 기본값 Application Load Balancer를 그대로 유지합니다.
그런 다음 Continue를 클릭합니다.
여기에서 로드 밸런서 구성을 시작합니다.
먼저 로드 밸런서 이름을 지정합니다.
여기에서 지정하는 이름이 이 로드 밸런서의 DNS 엔드포인트에 적용된다는 점을 숙지하고, 이 로드 밸런서의 이름을 Application Load Balancer의 준말인 ALB로 지정하고 테스트합니다.
이것은 인터넷 경계, 즉 공개적으로 참조할 수 있는 DNS 엔드포인트를 가지는 로드 밸런서입니다.
그래서 주소 유형을 기본값 IPV4 그대로 유지합니다.
로드 밸런서의 리스너의 경우, 기본 설정은 이미 포트 80에서 수신 대기하는 것이지만, 동일한 로드 밸런서에서 두 번째 컨테이너로 라우팅할 수 있도록 추가 리스너를 추가하겠습니다.
이것은 포트 443에 대한 간단한 HPPT 요청이 될 것입니다.
이제 로드 밸런서를 실행할 가용 영역을 선택합니다.
Application Load Balancer에서는 두 개 이상의 가용 영역을 선택해야 합니다.
그러므로 제가 이 데모를 위해 생성한 VPC를 선택하고 제가 서브넷을 생성해 놓은 가용 영역 두 개를 선택하겠습니다.
그런 다음 로드 밸런서에 태그를 지정할 수 있는 옵션이 있습니다.
로드 밸런서에 태그를 지정하려면 이 로드 밸런서를 참조할 키와 값을 지정하기만 하면 됩니다.
여기서 빌드하는 로드 밸런서는 키를 Name으로 설정하고 값을 Application Load Balancer로 설정하겠습니다.
이제 보안 설정을 구성할 수 있습니다.
이 페이지에서 SSL 리스너를 사용하는 것으로 보안 설정을 구성했을 것이지만 실제로는 그렇지 않으므로 계속해서 보안 그룹을 구성하는 다음 페이지로 이동합니다.
로드 밸런서에 대해 기본 보안 그룹을 선택 취소하고 제가 이 로드 밸런서에 대해 설정한 테스트 웹 서버 보안 그룹을 선택합니다.
이제 라우팅을 구성할 수 있습니다.
여기서 로드 밸런서의 백엔드 대상에 대한 라우팅 규칙을 구성할 수 있습니다.
미리 생성한 대상 그룹이 없기 때문에 새 대상 그룹 세트를 유지합니다.
그런 다음 대상 그룹에 이름을 지정합니다.
이 대상 그룹의 이름을 Demo One이라고 하겠습니다.
이 대상 그룹이 사용하는 프로토콜은 HTTP이고, 포트는 80입니다.
상태 확인에 대해, 트래픽은 HTTP 요청으로 유지하고 상태 확인 대상은 앞서 설정한 간단한 웹 페이지, 즉 test.html으로 지정합니다.
또한 Advanced Health Check Settings로 이동할 수도 있습니다.
여기서 상태 확인을 수행하는 방식을 조정할 수 있습니다.
조기에 대상이 정상 상태인지 확인하기 위해 상태 확인 주기를 10초로 낮출 것입니다.
하지만 시간 초과 및 정상/이상 임계값은 그대로 유지하겠습니다.
이제 대상을 등록하겠습니다.
대상을 등록하면 로드 밸런서에게 해당 포트를 적중시킬 인스턴스를 알려주므로 인스턴스를 설정하고 앞서 설정한 애플리케이션 ELB 테스트 인스턴스를 선택하겠습니다.
이 인스턴스를 선택한 다음 Add to Registered를 클릭합니다.
등록된 대상 중 하나로 나열된 것이 보일 것입니다.
계속해서 검토 페이지로 이동합니다.
Review 페이지에서 앞서 구성한 내용을 모두 확인할 수 있습니다.
로드 밸런서의 이름, 설정된 리스너 및 라우팅 규칙, Demo One으로 설정한 새로운 대상 그룹이 표시됩니다.
이제 Create를 클릭할 수 있습니다.
로드 밸런서가 성공적으로 생성되었습니다.
이제 화면을 닫으면 로드 밸런서 대시보드로 이동합니다.
이 로드 밸런서로 확인하려는 대상이 두 개이므로 두 번째 대상을 등록하려면 먼저 대상 그룹을 생성해야 합니다.
Target Group 아래에서 Create Target Group을 선택합니다.
그러면 이 새 대상 그룹이 앞서 설정한 두 번째 컨테이너로 갑니다.
이 대상 그룹은 이름이 Demo Two이고 트래픽이 HTTP 요청합니다.
하지만 요청을 포트 443으로 전달할 것입니다.
이는 VPC도 동일하고 상태 확인 대상도 동일하지만 다른 별도의 컨테이너에서 이루어지므로 test.html이 될 것입니다.
이번에도 Advanced Health Check 설정 아래에서 상태 확인을 조정할 수 있습니다.
마찬가지로 주기를 10초로 낮추겠습니다.
이제 대상 그룹을 생성할 수 있습니다.
두 번째 대상 그룹이 성공적으로 생성된 것으로 나옵니다.
이 두 번째 대상 그룹에서, 인스턴스를 대상으로 등록했는지 확인해야 합니다.
등록이 완료되었으므로 이제 로드 밸런서를 검토하고 로드 밸런서에서 수신 대기하도록 두 포트 모두 설정되었는지 확인할 수 있습니다.
하지만 로드 밸런서를 생성할 때 포트 443을 설정했기 때문에 현재 로드 밸런서가 트래픽을 Demo One으로 전달합니다.
이를 변경하려면 View and Edit Rules를 클릭하고 Then 아래에서 트래픽을 Demo One이 아니라 Demo Two로 전달하도록 앞서 생성한 규칙을 수정합니다.
그런 다음 Update와 로드 밸런서에서 포트 443에 도달하는 트래픽을 라우팅하는 규칙을 클릭합니다.
이제 로드 밸런서가 트래픽을 대상 그룹 Demo Two로 전달합니다.
이제 뒤로 돌아가 로드 밸런서를 확인할 수 있습니다.
두 번째 대상 그룹을 생성하여 로드 밸런스에 등록했으므로 테스트를 통해 트래픽이 각 컨테이너로 전송되는지 확인할 수 있습니다.
이렇게 하려면 다시 DNS 이름을 복사한 다음 첫 번째 컨테이너용의 새 탭에 DNS 이름을 붙여 넣고 이 데모를 위해 설정한 대상인 test.html으로 이동하여 Container One이 사용 가능한지 확인할 수 있습니다.
두 번째 컨테이너를 테스트하기 위해 포트 443에서 수신 대기하는 로드 밸런서가 있으므로 이를 포트 443으로 가도록 설정하겠습니다.
그러면 Container Two가 수신 대기하는 인스턴스에서 트래픽이 443으로 전달되어야 합니다.
ENTER를 누르면 이제 Container Two가 실행되는 것을 확인할 수 있습니다.
로드 밸런서의 수신 대기를 조정하려면 언제나 Listeners 탭으로 이동하여 리스너를 추가하거나 실행 중인 리스너를 수정할 수 있습니다.
요약하자면 이 데모에서는 Application Load Balancer를 시작하고, 라우팅 규칙을 구성하고, 로드 밸런서에 대상을 등록하고, Application Load Balancer의 라우팅 동작을 확인하는 절차를 시연했습니다.
이 과정이 약간이라도 도움이 되었기를 바라며 계속해서 다른 동영상을 학습하시기 바랍니다.
AWS 교육 및 자격증의 Seph Robinson이었습니다.
시청해 주셔서 감사합니다.
- 탄력적 로드발랜서
Amazon Elastic Load Balancing 소개 이 동영상에서는 탄력적 로드 밸런서의 원래 유형인 Classic Load Balancer를 소개합니다.
저는 Amazon Web Services(AWS)의 기술 강사 Seph입니다.
AWS에서 근무한지는 5년이 넘었네요.
이 동영상에서는 Classic Load Balancer에 대해 살펴볼 것입니다.
간략한 서비스 소개부터 시작하여 몇몇 주요 기능을 개략적으로 설명합니다.
그런 다음 로드 밸런서를 시작하는 절차를 간략하게 시연합니다.
Classic Load Balancer는 분산형 소프트웨어 로드 밸런싱 서비스로, 이 관리형 솔루션은 유용한 기능을 다수 포함하고 있습니다.
Elastic Load Balancing을 선택할 수 있는 다양한 시나리오는 유일하게 노출되는 액세스 포인트를 통해 웹 서버 액세스를 보호하거나, 애플리케이션 환경을 결합 해제하거나, 퍼블릭(또는 인터넷 경계) 및 내부 로드 밸런서를 함께 사용하거나, 트래픽을 여러 가용 영역으로 분산하여 고가용성 및 내결함성을 제공하거나 최소한의 오버헤드로 탄력성 및 확장성을 제고하는 것이 될 수 있습니다.
트래픽 분산의 경우, Elastic Load Balancing이 트래픽을 분산하는 능력은 어떤 유형의 요청을 분산하는가에 달려 있습니다.
TCP 요청을 분산하는 경우 Elastic Load Balancing은 이러한 요청에 대해 단순 라운드 로빈을 사용합니다.
HTTP 또는 HTTPS 요청을 처리하는 경우 Elastic Load Balancing이 백엔드 인스턴스에 대해 최소 대기 요청을 사용합니다.
또한 Elastic Load Balancing은 여러 가용 영역으로 트래픽을 분산하는 것을 돕습니다.
AWS Management Console에서 로드 밸런서를 생성할 경우 이 기능이 기본적으로 활성화됩니다.
하지만 명령줄 도구 또는 SDK를 통해 Elastic Load Balancing을 시작할 경우에는 보조 프로세스로 활성화해야 합니다.
앞서 설명한 대로, Elastic Load Balancing은 백엔드 인스턴스에 액세스하기 위한 유일하게 노출되는 액세스 포인트를 제공합니다.
이를 위한 가장 간편한 방법은 도메인의 CNAME를 Elastic Load Balancing용 엔드포인트로 가리키는 별칭(Alias) 레코드를 설정하는 것입니다.
애플리케이션에 쿠키를 사용하려는 경우 Elastic Load Balancing이 고정 세션의 기능을 제공합니다.
그러면 해당 세션 동안 사용자 세션을 바인딩할 수 있으며, 이는 기간 기반 쿠키 또는 애플리케이션 제어 고정 세션을 사용할지 여부에 따라 설정됩니다.
모니터링에 관한 한, Elastic Load Balancing은 다양한 지표를 기본적으로 제공합니다.
이러한 지표를 사용하여 HTTP 응답, 로드 밸런서 뒤의 정상/비정상 호스트 수를 확인할 수 있으며, 백엔드 인스턴스의 가용 영역을 기반으로 또는 사용 중이던 로드 밸런서를 기반으로 이러한 지표를 필터링할 수 있습니다.
상태 확인의 경우, 로드 밸런서를 사용하여 로드 밸런서 뒤의 정상/비정상 EC2 호스트의 수를 확인할 수 있습니다.
이 확인은 백엔드 EC2 인스턴스에 대한 간단한 연결 시도 또는 ping 요청을 통해 이루어집니다.
로드 밸런서는 VPC 내부의 여러 가용 영역으로 트래픽을 분산시킬 수 있는 다중 영역 로드 밸런싱을 제공하여 확장성을 높이도록 지원합니다.
또한 로드 밸런서 자체가 처리하는 트래픽 패턴에 따라 확장됩니다.
Classic Load Balancer에서는 여러 유형의 로드 밸런서를 생성할 수 있습니다.
한 유형은 인터넷 경계 또는 퍼블릭 로드 밸런서입니다.
이 유형은 여전히 교차 영역 밸런싱이 가능하며 로드 밸런서의 유일하게 노출되는 엔드포인트에서 백엔드 인스턴스로 요청을 라우팅할 수 있게 해주는 공개적으로 확인할 수 있는 DNS 이름을 제공합니다.
다른 유형의 로드 밸런서는 내부 로드 밸런서입니다.
내부 로드 밸런서는 프라이빗 노드로만 확인되어 VPC를 통해야만 액세스할 수 있는 DNS 이름을 가집니다.
이는 VPC 내부 인프라의 결합 해제를 제공하며 프론트 엔드 및 백엔드 인스턴스 모두에 대한 확장이 가능하면서도 로드 밸런서가 자체의 확장을 처리합니다.
이제 Classic Load Balancer 데모를 간략하게 살펴보겠습니다.
이 데모에서는 로드 밸런서를 시작하고 이 로드 밸런서에 인스턴스를 연결합니다.
그런 다음 트래픽이 백엔드 인스턴스로 라우팅되는지 확인할 것입니다.
제가 이 데모를 위해 이미 EC2 인스턴스를 시작했습니다.
EC2 인스턴스는 인터넷 게이트웨이가 연결된 VPC에 위치하며 퍼블릭 서브넷에 위치합니다.
그러므로 이 간단한 웹 애플리케이션이 EC2 인스턴스에서 실행되는지 확인하려면 간단히 인스턴스의 퍼블릭 IP 주소를 가져와 새 탭에 실행할 수 있습니다.
보다시피 여기에 인스턴스의 퍼블릭 IP 주소가 표시되고 이 인스턴스의 ID와 가용 영역이 표시됩니다.
이 인스턴스를 로드 밸런서 뒤에 배치하려면 EC2 콘솔의 탐색 창에서 아래로 Load Balancing까지 스크롤합니다.
여기서 Load Balancers를 클릭하면 Load Balancing 콘솔로 이동합니다.
Load Balancing 콘솔에서 Create Load Balancer를 클릭합니다.
이 데모에서는 Classic Load Balancer를 사용할 것이므로 이 로드 밸런서를 선택하고 Continue를 선택합니다.
이제 로드 밸런서 이름을 지정합니다.
로드 밸런서에 지정하는 이름이 로드 밸런서의 DNS 엔드포인트에 적용된다는 점을 기억하십시오.
이 데모의 로드 밸런서는 테스트 목적의 Classic Load Balancer이므로 clb, test로 이름을 지정합니다.
Create ELB Inside는 로드 밸런서를 생성할 환경입니다.
그러므로 EC2 Classic을 사용하는 경우, EC2 Classic에서 로드 밸런서를 생성할 수 있습니다.
이 데모에서는 제가 이미 생성한 클래식 ELB Test VPC를 사용합니다.
리스너를 구성하기 위해 먼저 로드 밸런서가 트래픽을 수신할 위치를 선택한 다음 로드 밸런서가 트래픽을 전달할 인스턴스 포트를 선택합니다.
여기 이 로드 밸런서는 포트 80에서 수신 대기하고, 또 백엔드 인스턴스의 포트 80으로 트래픽을 전달합니다.
이제 VPC에서 ELB가 작동할 서브넷을 선택합니다.
이 목적으로 제가 PrivateSubnet 1을 생성했습니다.
이것을 로드 밸런서에 추가하겠습니다.
다음으로 로드 밸런서에 보안 그룹을 할당합니다.
로드 밸런서에 사용할 보안 그룹은 제가 이미 생성해 놓은 기존 보안 그룹입니다.
이 로드 밸런서에 퍼블릭 클래식 로드 밸런싱 테스트 보안 그룹을 사용합니다.
퍼블릭 ELB이기 때문입니다.
그런 다음 보안 설정을 구성합니다.
하지만 이 로드 밸런서에 SSL이 사용되지 않으므로 보안 설정은 사용하지 않을 것입니다.
계속해서 상태 확인을 구성합니다.
상태 확인은 로드 밸런서가 요청을 전송하여 인스턴스가 실행 중인지 또는 인스턴스를 열외시켜야 하는지 여부를 확인하는 것입니다.
저는 상태 확인을 단순한 ping 요청으로 하겠습니다.
대상은 실제로 index.html이 아니라 index.php가 됩니다.
주기는 상태 확인이 전송되는 빈도이며 Response Timeout은 상태 확인을 실패로 간주할 때까지 로드 밸런서가 대기하는 시간입니다.
이 테스트에서는 주기를 10초로 줄이겠습니다.
Unhealthy threshold는 로브 밸런서가 인스턴스를 비정상으로 간주하는 데 필요한 상태 확인 요청 연속 실패 횟수이고, Healthy threshold는 로드 밸런서가 이전의 비정상 인스턴스를 정상으로 간주하는 데 필요한 테스트 연속 성공 횟수입니다.
이제 로드 밸런서에 미리 생성해 놓은 EC2 인스턴스를 추가합니다.
현재 실행 중인 인스턴스가 하나뿐이므로 이 인스턴스를 선택하여 로드 밸런서에 연결하겠습니다.
Add Tags 단계는 간편한 분류를 위해 로드 밸런서에 태그를 지정하려는 경우에 사용합니다.
이 로드 밸런서를 키 Name으로 태그 지정하고 값은 CLB test로 하겠습니다.
그런 다음 Review와 Create를 클릭합니다.
그러면 이 로드 밸런서에 대한 모든 설정을 검토할 수 있습니다.
설정을 확인했으면 Create를 클릭할 수 있습니다.
성공적으로 생성된 로드 밸런서 화면이 보이면 화면을 닫습니다.
그러면 Load Balancing 콘솔로 이동합니다.
Load Balancing 콘솔에서 로드 밸런서에 대한 세부 정보를 볼 수 있습니다.
Descriptions 탭에서 로드 밸런서의 DNS 엔드포인트, 로드 밸런서의 서브넷 및 가용 영역, 생성된 로드 밸런서의 유형 등 기본 세부 정보를 확인할 수 있습니다.
이 데모에서는 인터넷 경계 로드 밸런서를 생성했습니다.
로드 밸런서에 연결된 인스턴스를 보려면 Instances 탭을 클릭하면 됩니다.
이 화면에서 현재 로드 밸런스에 연결된 모든 인스턴스가 표시되며 수동으로 로드 밸런서에 인스턴스를 추가하거나 제거할 수 있습니다.
현재 인스턴스가 사용할 수 없는 것으로 나타납니다.
이는 인스턴스가 정상으로 간주되기 위해 필요한 횟수만큼 상태 확인을 통과하지 않았기 때문입니다.
마우스를 Information 탭으로 가져가면 인스턴스 등록이 아직 진행 중인 것으로 나옵니다.
계속해서 상태 확인 세부 정보를 확인할 수 있고 로드 밸런서에서 설정한 리스너를 확인할 수 있습니다.
이 모든 설정을 로드 밸런서가 실행 중인 상태에서 편집할 수 있습니다.
로드 밸런서의 모니터링 지표를 보려면 Monitoring 탭으로 이동할 수 있습니다.
로드 밸런서가 그리 오래 실행된 것이 아니므로 아직 지표가 보이지 않습니다.
참고로 Amazon CloudWatch 지표의 기본 주기는 5분입니다.
Instance 탭으로 돌아가면 이제 인스턴스가 사용 상태로 표시되고 있습니다.
로드 밸런서의 DNS 이름을 복사하여 새 탭에 붙여 넣은 다음 여전히 인스턴스 세부 정보가 표시되는지 확인할 수 있습니다.
이제 인스턴스에 직접 액세스한 것이 아니라 로드 밸런스를 통해 인스턴스에 액세스한 것입니다.
이 데모에서는 Classic Load Balancer를 시작했습니다.
그리고 로드 밸런서의 리스너와 상태 확인을 구성했습니다.
그런 다음 로드 밸런서에 인스턴스를 등록하고 Classic Load Balancer의 작동을 확인했습니다.
이 과정이 약간이라도 도움이 되었기를 바라며 계속해서 다른 동영상을 학습하시기 바랍니다.
AWS 교육 및 자격증의 Seph였습니다.
시청해 주셔서 감사합니다.
- Auto Scaling
안녕하십니까? 저는 AWS 교육 및 자격증 팀의 Andy Cummings라고 합니다.
Auto Scaling 소개에 오신 것을 환영합니다.
저는 AWS에 입사한지 이제 1년 반 되었고 현재는 북미 지역 AWS 고객을 대상으로 한 라이브 교육 이벤트를 담당하고 있습니다.
이 동영상에서는 Auto Scaling을 소개합니다.
서비스 개요와 가능한 사용 사례를 살펴본 다음, 서비스를 시연하면서 실제로 작동하는 모습을 살펴보도록 하겠습니다.
그러면 Auto Scaling이란 무엇입니까? Auto Scaling은 애플리케이션의 로드를 처리할 수 있는 적절한 수의 Amazon EC2 인스턴스를 유지하도록 해줍니다.
Auto Scaling을 사용하면 향후 특정 시점에서 워크로드 요구 사항을 충족하기 위해 몇 개의 EC2 인스턴스가 필요할지 추측할 필요가 없어집니다.
EC2 인스턴스에서 애플리케이션을 실행할 때 Amazon CloudWatch를 사용하여 워크로드의 성능을 모니터링하는 것이 매우 중요합니다.
하지만 CloudWatch 자체는 EC2 인스턴스를 추가하거나 제거할 수 없습니다.
여기서 Auto Scaling이 등장합니다.
예제 워크로드를 살펴봅시다.
CloudWatch를 사용하여 1주일간의 EC2 리소스 요구 사항을 측정할 것입니다.
리소스 요구 사항은 요일마다 변동하여 수요일에 가장 많은 용량이 필요하고 토요일에 가장 적은 용량이 필요합니다.
수요가 가장 많은 시기(이 경우에는 수요일)를 항상 충족하기 위해 충분 이상의 EC2 용량을 할당하는 전략을 취할 수 있습니다.
하지만 이는 일주일 중 대부분 활용되지 않는 리소스를 운영한다는 의미입니다.
이것은 하나의 선택지이지만 비용은 최적화되지 않습니다.
이와는 다르게, 더 적은 수의 EC2 인스턴스를 할당하여 비용을 줄일 수 있습니다.
이는 특정 요일에 용량 부족이 발생한다는 것을 의미합니다.
그리고 용량 문제를 해결하지 않는다면 애플리케이션 성능이 저하되거나 심지어 사용자에게 시간 초과가 발생할 수도 있습니다.
분명히 좋은 일은 아닙니다.
Auto Scaling을 사용하면 사용자가 지정하는 조건에 따라 EC2 인스턴스를 추가 또는 제거할 수 있습니다.
Auto Scaling은 성능 요구 사항이 유동적인 환경에서 특히 강력합니다.
이를 통해 성능을 유지하고 비용을 최소화할 수 있습니다.
실제로 Auto Scaling은 중요한 질문 두 가지에 답을 내놓습니다.
1) 어떻게 워크로드가 변동하는 성능 요구 사항을 충족하는 데 충분한 EC2 리소스를 확보할 수 있는가? 2) 어떻게 EC2 리소스 프로비저닝이 필요에 따라 이루어지도록 자동화할 수 있는가? Auto Scaling은 환경을 확장 가능하게 만들고 최대한 자동화한다는 두 가지의 AWS 모범 사례를 충족합니다.
서비스를 좀 더 자세히 살펴보겠습니다.
그러면 조정이란 정확히 어떤 의미입니까? 우리는 먼저 확장 및 축소의 개념을 정의해야 합니다.
Auto Scaling은 사용자가 정의하는 조건(예: CPU 사용률 80% 초과)에 따라 또는 일정에 따라 워크로드에서 실행되는 EC2 인스턴스 수를 자동으로 조정할 수 있습니다.
Auto Scaling이 인스턴스를 추가할 경우 이를 확장이라고 합니다.
Auto Scaling이 인스턴스를 종료할 경우 이를 축소하고 합니다.
사용자가 이러한 이벤트의 시작을 제어한다는 점을 기억하십시오.
그렇다면 어떻게 자동으로 조정됩니까? 자동 조정에는 세 가지 구성 요소가 필요합니다.
첫째, 시작 구성을 생성합니다.
둘째, Auto Scaling 그룹을 생성합니다.
그리고 마지막으로 Auto Scaling 정책을 하나 이상 정의합니다.
그럼 각 구성 요소의 역할을 보다 자세히 살펴보겠습니다.
시작 구성이란 무엇입니까? 이것은 Auto Scaling이 시작할 인스턴스를 정의합니다.
사용할 Amazon 머신 이미지, 인스턴스 유 형, 인스턴스에 적용할 보안 그룹 또는 역할 등 콘솔에서 EC2 인스턴스를 시작할 때 지정해야 할 모든 것을 생각하면 될 것입니다.
Auto Scaling 그룹이란 무엇입니까? 이것은 배포가 이루어지는 위치와 배포에 대한 제한을 정의하는 것입니다.
여기서 어느 VPC가 인스턴스를 배포할지, 어느 로드 밸런서에서 상호 작용할지를 정의합니다.
또한 그룹에 대한 제한도 지정합니다.
최소 개수를 2로 설정할 경우 서버가 2개 미만으로 감소할 경우 다른 인스턴스가 시작되어 이를 대체합니다.
최대 개수를 8로 설정할 경우 그룹 내 인스턴스 수가 절대로 8개를 넘지 않습니다.
희망 용량은 처음에 시작할 인스턴스 수입니다.
Auto Scaling 정책이란 무엇입니까? 이것은 언제 EC2 인스턴스를 시작 또는 종료할지를 지정하는 것입니다.
Auto Scaling을 예를 들어 매주 수요일 오후 3시 정각으로 예약하거나 인스턴스 추가 또는 제거할 임계값을 정의하는 조건을 생성할 수 있습니다.
조건 기반 정책은 Auto Scaling을 동적으로 만들어 유동적인 요구 사항을 충족할 수 있습니다.
확장 및 축소 각각 하나 이상의 Auto Scaling 정책을 생성하는 것이 모범 사례입니다.
동적 Auto Scaling은 어떻게 작용할까요? 일반적인 구성 한 가지는 EC2 인스턴스 또는 로드 밸런서로부터의 성능 정보를 기반으로 CloudWatch 경보를 생성하는 것입니다.
성능 임계값이 위반되면 CloudWatch 경보가 환경 내 EC2 인스턴스를 확장 또는 축소하는 Auto Scaling 이벤트를 트리거합니다.
CloudWatch 경보 예제를 살펴보겠습니다.
경보의 첫 번째 부분은 임계값을 포함한 조건입니다.
이 경우, CPU 사용률 80% 초과입니다.
기간을 지정할 수도 있습니다.
예를 들어 CPU 사용률이 5분 연속 80%를 상회할 경우 경보가 트리거되도록 지정할 수 있습니다.
기간은 중요합니다.
프로세서 사용률이 30초 동안 급증했다고 Auto Scaling이 새 인스턴스를 추가할 필요는 없을 테니까요.
경보의 두 번째 부분은 경보가 트리거된 후 수행할 조치입니다.
Auto Scaling에서는 조치가 인스턴스를 추가 또는 제거하는 것입니다.
그러므로 이 경우, CPU가 1회의 기간(기본적으로 5분) 동안 80%를 초과하면 Auto Scaling이 Auto Scaling 그룹에 새 인스턴스 2개를 추가합니다.
더 많은 인스턴스를 추가할수록 CPU 사용률은 감소할 것입니다.
언제 Auto Scaling 그룹에서 인스턴스를 종료할지 정의하기 위해 다른 CloudWatch 경보를 설정해야 합니다.
예를 들어 CPU 사용률이 5분 연속으로 20%를 하회할 경우 인스턴스 하나를 종료합니다.
이 모든 것의 장점은 Auto Scaling이 동적으로 워크로드를 관리하므로 사용자는 다른 문제에 집중할 수 있다는 것입니다.
이제 간략한 데모를 통해 Auto Scaling이 어떻게 작동하는지 직접 보도록 하겠습니다.
기본 시작, Auto Scaling 그룹, Auto Scaling 정책을 생성한 다음, Auto Scaling을 트리거하여 어떻게 작동하는지 보는 것으로 마무리하겠습니다.
먼저 EC2 서비스를 개설합니다.
세 가지 구성 요소를 기억하시죠? 이제 시작 구성, Auto Scaling 그룹, 하나 이상의 Auto Scaling 정책을 빌드해야 합니다.
왼쪽 창에서 Auto Scaling 섹션으로 스크롤하여 Auto Scaling Groups를 선택합니다.
Create Auto Scaling group을 클릭합니다.
그런 다음 시작 구성을 생성하도록 선택합니다.
이미 EC2 인스턴스를 시작했다면 무엇을 선택해야 할지 알 것입니다.
Amazon AMI를 선택한 다음, 대용량 인스턴스 유형인 M을 선택합니다.
이제 시작 구성에 이름을 지정합니다.
Linux M4로 명명하겠습니다.
스토리지 및 보안 그룹은 기본 설정을 그대로 사용합니다.
구성을 검토한 후 Launch, Launch Configuration을 차례로 클릭합니다.
이제 기존 키 페어를 선택하고 시작 구성을 생성합니다.
그러면 Auto Scaling 그룹의 속성으로 바로 이동합니다.
여기에 이름을 지정합니다.
Sales App으로 명명하겠습니다.
방금 빌드한 시작 구성이 사용되는 것이 보일 것입니다.
인스턴스 2개부터 시작하도록 지정한 다음 실제로 인스턴스를 배포할 VPC와 서브넷을 지정합니다.
그런 다음 2가지 조정 정책을 구성합니다.
이 그룹의 용량을 조정하는 조정 정책을 사용하도록 선택하고 인스턴스를 2개에서 8개 사이로 조정하도록 설정합니다.
여기 이것이 최대값과 최소값이 됩니다.
또한 지표의 목표 값을 설정할 수 있는 간단한 목표 추적 정책을 사용합니다.
여기서는 평균 CPU 활용률 60%를 지정하겠습니다.
그러면 목표 추적 정책이 목표 값을 충족하기 위해 자동으로 인스턴스를 시작 또는 종료합니다.
확장 및 축소를 위한 개별 정책을 생성할 수도 있지만, 목표 추적이 Auto Scaling 정책을 시작하는 가장 간단한 방법입니다.
어디에 알림과 태그를 추가할 수 있는지 검토하고 Auto Scaling 그룹을 생성하도록 선택합니다.
이제 Auto Scaling 그룹을 확인합니다.
한 번에 모두 보이도록 약간 좁히겠습니다.
최소 인스턴스 개수가 2, 최대 인스턴스 개수가 8로 설정된 것이 보일 것입니다.
Instances 탭으로 이동하면 두 개의 인스턴스가 현재 보류 상태인 것을 알 수 있습니다.
이들은 신규 인스턴스이며, 이들이 존재하는 이유는 이전에 없었기 때문입니다.
앞서 최소 개수를 2로 설정했으므로 Auto Scaling이 자동으로 두 개의 인스턴스를 여기에 시작한 것입니다.
이제 Auto Scaling을 즉시 트리거하기 위해 수동으로 최소 그룹 크기를 늘리겠습니다.
Details 탭을 클릭하고 Edit를 선택하여 최소 인스턴스 개수와 원하는 구성을 변경합니다.
이제 4를 설정하겠습니다.
이제 최소 인스턴스 개수는 2가 아니라 4가 되어야 합니다.
이미 두 개의 인스턴스가 시작되었으므로 이제 추가로 두 개가 시작되는 것이 보일 것입니다.
Instances 탭으로 돌아가 내용을 살펴보겠습니다.
보시다시피 시작 구성에 따라 자동으로 두 개의 인스턴스가 추가로 시작되었습니다.
이제 학습한 내용을 요약해 보겠습니다.
Auto Scaling을 사용하면 사용자가 지정하는 조건에 따라 EC2 인스턴스를 추가 또는 제거할 수 있습니다.
Auto Scaling은 성능 요구 사항이 유동적인 환경에서 특히 강력합니다.
이를 통해 성능을 유지하고 비용을 최소화할 수 있습니다.
무엇보다 이 프로세스는 사용자가 자고 있는 자정에 EC2 인스턴스를 축소 또는 확장할 수 있습니다.
필요한 세 가지 핵심 구성 요소는 시작 구성(무엇을 배포할 것인가), Auto Scaling 그룹(어디에 배포할 것인가), Auto Scaling 정책(언제 배포할 것인가)입니다.
여러분이 배운 모든 AWS 서비스는 또 다른 솔루션 빌드 도구임을 명심하십시오.
여러분이 활용할 수 있는 도구가 많아질수록 여러분의 역량도 강해집니다.
시청해 주셔서 감사합니다.
- Amazon Elastic Block Store (EBS)
Amazon Elastic Block Store(EBS) 소개 동영상에 오신 것을 환영합니다.
저는 AWS 교육 및 자격증 팀의 Rafael Lopes입니다.
팀의 일원으로 저는 이러한 전용 교육 콘텐츠를 개발하고 제공하는 일을 담당해 왔습니다.
이 간략한 동영상에서는 시연을 통해 Amazon EBS 서비스를 소개할 것입니다.
그럼 시작하겠습니다.
EBS 볼륨은 Amazon EC2 인스턴스의 저장 단위로 사용할 수 있습니다.
따라서 AWS에서 실행되는 인스턴스에 디스크 공간이 필요하다고 생각되면 언제나 EBS 볼륨 사용을 고려할 수 있습니다.
EBS 볼륨은 하드 디스크나 SSD 디바이스일 수 있으며 사용한 만큼 지불하면 되기 때문에, 볼륨이 더 이상 필요하지 않을 경우 삭제하여 결제를 중지할 수 있습니다.
EBS 볼륨은 내구성과 가용성을 위주로 설계됩니다.
이는 볼륨에 있는 데이터가 가용 영역(AZ)에서 실행되는 복수의 서버에 걸쳐 자동으로 복제됨을 의미합니다.
EBS 볼륨과 하드 디스크 또는 SSD와 같은 물리적 미디어 디바이스를 비교했는데, 블록 수준 복제 때문에 실제로는 EBS 볼륨의 내구성이 훨씬 더 뛰어납니다.
EBS 볼륨을 생성할 때 필요에 가장 적합한 스토리지 유형을 선택할 수 있습니다.
성능 및 비용 요건에 따라 하드 디스크와 SSD 간에 선택할 수 있습니다.
이 모든 것은 적합한 작업에 적합한 도구를 선택하는 문제에 관한 것입니다.
예를 들어 데이터베이스 인스턴스를 실행하는 경우 데이터의 이차 볼륨을 사용하도록 데이터베이스를 구성할 수 있습니다.
이 경우 운영 체제에 할당된 볼륨보다 더 빠른 성능을 발휘할 수 있습니다.
혹은 로그에 대해서는 비용이 더 저렴한 마그네틱 볼륨을 할당할 수 있습니다.
Amazon EBS를 사용하면 볼륨의 시점별 스냅샷을 생성하여 한층 더 높은 수준의 데이터 내구성을 구현할 수 있으며, AWS를 통해 어느 때고 스냅샷으로부터 새로운 볼륨을 다시 생성할 수 있습니다.
스냅샷을 공유하거나 다른 AWS 리전에 복사할 수 있으므로 재해 복구(DR) 성능이 한층 더 높아집니다.
예를 들어 스냅샷을 암호화하여 버지니아에서 도쿄까지 공유할 수 있습니다.
또한 추가 비용 없이 EBS 볼륨을 암호화할 수도 있습니다.
EC2 측에서 암호화가 이루어지기 때문에 EC2 인스턴스와 AWS 데이터 센터 내부의 EBS 볼륨 간에 이동하는 데이터가 전송 중에 암호화됩니다.
회사가 성장함에 따라 EBS에 저장되는 데이터의 양도 증가할 가능성이 높을 것입니다.
EBS 볼륨은 용량 증가와 여러 유형 간의 변환이 가능하기 때문에, 하드 디스크에서 SSD로 변경하거나 용량을 50기가바이트에서 16테라바이트로 증설할 수 있습니다.
예를 들어 인스턴스를 중단할 필요 없이 바로 운영 규모를 조정할 수 있습니다.
자, 그럼 시연을 통해 새 볼륨을 생성하여 EC2 인스턴스에 연결하는 것이 얼마나 빠르고 쉬운지 보여 드리겠습니다.
AWS Management Console의 EC2 콘솔에서 EC2 인스턴스와 EBS 볼륨을 확인할 수 있는데, Compute 탭에서 EC2의 여기를 클릭하여 찾을 수 있습니다.
인스턴스의 여기를 클릭하면 많은 인스턴스가 실행되고 있음을 확인할 수 있습니다.
볼륨은 Elastic Block Store(EBS) 볼륨 아래에 있는 Volumes의 사이드바에 위치합니다.
이들 볼륨이 나의 계정에 있는 볼륨입니다.
새 볼륨을 생성하거나 새 볼륨을 인스턴스에 연결하려면(이 경우 저는 Linux 인스턴스에 연결할 것입니다), EBS 볼륨을 인스턴스가 상주하는 곳과 동일한 가용 영역에 생성해야 합니다.
따라서 볼륨을 생성할 때 이 인스턴스가 US East One B에 있을 경우 US East One B에도 볼륨을 생성할 필요가 있습니다.
그러면 그렇게 해보겠습니다.
여기 Volumes에서 Create Volume을 클릭합니다.
여기에서 첫 번째로 지정할 것은 US East One B 가용 영역입니다.
이 EBS 볼륨을 US East One B에서 실행되는 인스턴스에 연결할 것이기 때문입니다.
이제 하드 디스크 또는 SSD와 같은 볼륨 유형을 지정할 수 있습니다.
구축하고자 하는 범용 SSD는 기가바이트 단위로만 요금이 부과됩니다.
크기가 25바이트인 볼륨을 생성하고자 하는 경우 여기에서는 25기가바이트를 지정해야 합니다.
이것이 스냅샷을 볼륨에 복원하는 방법인데, 이 경우에는 그렇게 하지 않을 것입니다.
그런 다음 Create Volume을 클릭합니다.
이는 제가 생성했던 볼륨 ID입니다.
Close를 클릭하면 이들 볼륨을 생성일, 볼륨 유형 및 크기별로 분류할 수 있는 옵션이 나타납니다.
이 볼륨이 좀 전에 생성한 볼륨이고, 25기가바이트이고, 볼륨 유형이 GP2이고, SSD라는 것을 확인할 수 있습니다.
이제 볼륨이 생성되었으니, 생성된 볼륨을 EC2 인스턴스에 연결하겠습니다.
Actions에서 여기를 클릭하여 볼륨을 연결한 다음 볼륨에 연결하고자 하는 인스턴스를 지정합니다.
이 경우는 Linux 인스턴스입니다.
그리고 디바이스입니다. /Dev/Std라고 하겠습니다. 연결합니다.
이제 인스턴스 내부를 살펴보겠습니다.
Instances에서 여기를 클릭하고, Linux를 선택하고, Connect에서 여기를 클릭하고, SSH 명령을 복사함으로써 이를 수행할 수 있습니다.
Linux 인스턴스이고 MacOS를 사용하기 때문입니다.
여기에서 내 터미널로 돌아가 SSH 명령을 실행할 수 있습니다.
그래서 SSH 명령을 복사하여 내 터미널에 붙여넣습니다.
이제 내 EC2 인스턴스에 연결되었습니다.
lsblk 명령을 실행하면 이 인스턴스에 연결한 블록 스토리지 디바이스를 확인할 수 있습니다.
여기에서 /Dev/xvdb 볼륨이 STB와 동일한 유형의 25기가바이트 디스크라는 것을 명확히 알 수 있습니다.
이제 연결된 이 EBS 볼륨으로 파일 시스템을 생성하고 /dev/xvdb 명령을 실행할 수 있습니다.
루트로서 실행되어야 합니다.
그러면 Linux 운영 체제가 이제 이 볼륨에 파일 시스템을 생성하게 됩니다.
LSBLK를 다시 실행하면 아무런 변화도 일어나지 않지만, 이제 해당 볼륨을 내 Linux 시스템에 있는 폴더에 탑재할 수 있습니다.
만약 Windows 시스템이었다면 디스크 관리자로 가서 파일 시스템을 생성한 다음에야 거기에서 탑재할 수 있을 것입니다.
Linux 시스템에서의 탑재 방법은 다음과 같습니다.
mount 명령을 실행합니다.
탑재 지점은 해당 볼륨을 탑재하고자 하는 폴더에 있는 xvdb입니다.
루트만 이를 수행할 수 있기 때문에, 루트 허가로 이를 수행합니다.
이제 볼륨이 /mnt 폴더에 탑재됩니다.
/mnt 폴더에 우리 파일 시스템이 있습니다.
따라서 파일, 디렉터리, 심볼 링크 그리고 스토리지 블록 디바이스로 가능한 모든 것을 생성할 수 있습니다.
이는 텍스트 파일입니다.
LS 명령을 실행하면 이제 그곳에서 내 파일을 확인할 수 있습니다.
디렉터리를 생성할 수 있습니다.
파일을 해당 디렉터리로 옮길 수 있습니다.
LS를 실행하면 폴더가 생성됩니다.
그 폴더에 들어가면 내 파일이 안에 있습니다.
EBS 볼륨을 생성하여 EC2 인스턴스에 연결하고 형식을 지정하는 것이 얼마나 쉬운지 알 수 있을 것입니다.
언제든지 여기로 돌아와 mount 명령을 사용하여 볼륨을 폴더에 탑재한 다음 AWS Management Console로 다시 돌아가 Volumes를 클릭한 후 내 볼륨을 선택하고 내 인스턴스에서 이 볼륨을 분리할 수 있습니다.
볼륨이 분리된 경우 가용 상태를 유지할 것입니다.
이 볼륨이 지금 사용 중인 것을 알 수 있는데, 실제로 내 인스턴스에서 사용하고 있기 때문입니다.
이 볼륨이 가용하기 때문에, 해당 볼륨을 분리하고 동일한 가용 영역에 있는 또 다른 EC2 인스턴스에 연결할 수 있습니다.
이 경우는 US East One B입니다.
이 볼륨에 태그를 지정할 수도 있습니다.
이 볼륨이 데이터베이스에 의해 사용되고 있는 경우 “database volume”이라는 태그 값을 지정하면 됩니다.
이제 이 볼륨은 데이터베이스 볼륨입니다.
AWS 리소스에 태그를 지정할 때마다 태그당 과금을 분석하여 EC2 인스턴스, EBS 스냅샷 그리고 태그를 지원하는 모든 것의 경우와 동일한 방법으로 특정 기간 내에서 해당 태그 키 이름 및 태그 값 “database volume”을 지닌 볼륨 전체의 비용이 얼마인지 확인할 수 있기 때문에 태그는 매우 중요합니다.
아주 간단합니다.
요약하자면, EBS 볼륨이 무엇인지 살펴보았고 EBS 볼륨 하나를 생성하여 Linux EC2 인스턴스에 연결하는 방법을 시연을 통해 알아보았습니다.
여러분이 조금이나마 배웠고 앞으로도 동영상 강좌를 계속 탐구하시기를 바랍니다.
AWS 교육 및 자격증 팀의 Rafael Lopes였습니다.
시청해 주셔서 감사합니다.
- Amazon Simple Storage Service (S3)
Amazon Simple Storage Service(Amazon S3) 동영상 강좌에 오신 것을 환영합니다.
저는 Heiwad Osman이라고 하며 AWS 기술 강사입니다.
Amazon S3를 소개하고, 일반 사용 사례를 다루어 보고, 시연을 통해 S3의 실제 작동 모습을 살펴볼 예정입니다.
그럼 시작하겠습니다.
Amazon S3는 데이터 저장 및 검색을 위한 간단한 API를 제공해 주는 완전관리형 스토리지 서비스입니다.
이는 S3에 저장하는 데이터는 임의의 특정 서버와 연계되어 있지 않기 때문에 고객이 직접 인프라를 관리할 필요가 없다는 의미입니다.
원하는 만큼 많은 객체를 S3에 저장할 수 있습니다.
S3는 수조 개의 객체를 저장하며 정기적으로 최대 초당 수백만 건의 요청을 처리합니다.
객체는 이미지, 동영상, 서버 로그 등 거의 모든 유형의 데이터 파일이 될 수 있습니다.
S3가 크기가 수 테라바이트인 객체까지 지원하기 때문에 데이터베이스 스냅샷도 객체처럼 저장할 수 있습니다.
또한 Amazon S3는 인터넷(HTTP 또는 HTTPS)을 통한 데이터 액세스 지연 시간이 짧기 때문에 언제 어디서든 데이터를 검색할 수 있습니다.
가상 사설 클라우드 엔드포인트를 통해 S3에 비공개적으로 액세스할 수 있습니다.
ID 및 액세스 관리 정책, S3 버킷 정책, 객체별 액세스 제어 목록을 사용하여 데이터 액세스 가능자를 정밀하게 관리할 수 있습니다.
기본적으로 데이터는 공개적으로 공유되지 않습니다.
데이터를 전송 중에 암호화하고 객체에 대한 서버 측 암호화를 활성화할 수도 있습니다.
저장하고자 하는 파일을 선택하겠습니다.
이 소개 동영상으로 해보겠습니다.
먼저 파일을 저장할 곳이 필요합니다.
S3에서는 데이터를 저장할 버킷을 생성할 수 있습니다.
이 동영상을 버킷에 객체로 저장하고자 하는 경우 나중에 객체를 검색할 때 사용할 수 있는 문자열인 키를 지정해야 합니다.
일반적으로 파일 경로와 비슷한 방식으로 이들 문자열을 설정합니다.
우리가 선택한 동영상을 해당 키를 사용하여 S3에 객체로 저장하겠습니다.
버킷을 S3에 생성할 때 특정 AWS 리전과 연계됩니다.
버킷에 데이터를 저장할 때마다 선택한 리전 내에 있는 복수의 AWS 시설에 중복 저장됩니다.
S3 서비스는 두 AWS 시설에 있는 데이터가 동시에 훼손되는 경우에도 데이터가 안전하게 저장되도록 설계되어 있습니다.
S3는 데이터가 증가하는 경우에도 여러분의 버킷을 벗어나는 스토리지까지 자동으로 관리합니다.
이러한 기능 덕분에 현재 상황에 맞춰 시작하고 애플리케이션 수요에 따라 데이터 스토리지를 증설할 수 있습니다.
또한 S3는 확장/축소가 가능하기 때문에 대용량의 볼륨 요청도 처리할 수 있습니다.
스토리지나 처리량을 직접 프로비저닝할 필요 없이 사용한 만큼만 요금을 지불하면 됩니다.
관리 콘솔, AWS CLI 또는 AWS SDK를 통해 S3에 액세스할 수 있습니다.
REST 엔드포인트를 통해 버킷에서 직접 데이터에 액세스할 수도 있습니다.
HTTP 또는 HTTPS 액세스를 지원합니다.
선택된 리전과 객체를 저장할 때 사용한 키에 대해 버킷의 S3 엔드포인트로부터 구축한 객체의 URL 예를 여기에서 확인할 수 있습니다.
이와 같은 유형의 URL 기반 액세스를 지원하기 위해서는 S3 버킷 이름이 전 세계적으로 고유해야 하며 DNS를 준수해야 합니다.
또한 객체 키가 URL에 대해 안전한 문자를 사용해야 합니다.
사실상 데이터를 무제한 저장하고 어디서든 데이터에 액세스할 수 있는 이러한 유연성 덕분에 S3 서비스는 다양한 시나리오에 적합합니다.
S3의 몇 가지 사용 사례를 살펴보겠습니다.
S3 버킷은 EC2나 전통적인 서버에 있는 애플리케이션을 포함하여 임의의 애플리케이션 인스턴스가 액세스할 수 있는 객체를 저장하기 위한 공유 장소를 임의의 애플리케이션 데이터를 위한 장소로 제공합니다.
이는 애플리케이션이 공통 위치에 저장해야 하는 사용자 생성 미디어 파일, 서버 로그 또는 기타 파일에 유용할 수 있습니다.
또한 콘텐츠를 웹을 통해 직접 가져올 수 있기 때문에 해당 콘텐츠를 애플리케이션으로부터 오프로드하고 고객이 직접 S3로부터 데이터를 가져오도록 할 수 있습니다.
정적 웹 호스팅의 경우 S3 버킷이 HTML, CSS, 자바스크립트 및 기타 파일을 포함하여 웹 사이트의 정적 콘텐츠를 제공할 수 있습니다.
높은 내구성 덕분에 S3는 데이터 백업을 저장하기에 좋은 대안입니다.
한 리전의 S3 버킷에 저장되는 데이터가 또 다른 S3 리전에 자동으로 복제될 수 있도록 리전 간 교차 복제가 가능하게 S3를 구성하여 가용성 및 재해 복구 성능을 더욱 높일 수 있습니다.
S3는 스토리지와 성능이 조정 가능하기 때문에 다양한 빅 데이터 도구를 사용하여 분석하고자 하는 데이터의 스테이징 또는 장기 저장에 적합합니다.
예를 들어 S3에 있는 데이터 스테이지를 Redshift에 로드하거나, EMR에서 처리하거나, 심지어 Amazon Athena와 같은 도구를 사용하여 그 자리에서 쿼리할 수도 있습니다.
또한 Snowball과 같은 AWS Import/Export 디바이스를 사용하여 대용량의 데이터를 S3로 가져오거나 S3에서 내보낼 수도 있습니다.
S3로 데이터를 간단하게 저장하고 액세스할 수 있기 때문에 앞으로 AWS 서비스와 함께 그리고 애플리케이션의 다른 부분에 자주 사용하게 될 것입니다.
S3의 기능과 일반 사용 사례를 살펴봤으니, 이제 AWS에 애플리케이션을 빌드할 때 S3를 효과적으로 사용하는 방법을 찾을 수 있을 것입니다.
이제 실제로 S3를 시연해 보겠습니다.
지금 우리는 AWS Management Console의 Amazon S3 섹션에 있으며, 여러 버킷의 목록을 확인할 수 있습니다.
이 섹션에서는 계속 진행하여 새 버킷을 생성한 다음 몇몇 데이터를 추가하고 추가한 데이터를 검색할 예정입니다.
그럼 계속 진행하여 Create Bucket을 클릭합니다.
여기 버킷 이름과 리전을 설정하라는 메시지가 나타납니다.
버킷 이름은 DNS를 준수해야 합니다.
이제 Amazing Bucket 1의 이름을 정한 다음 리전을 설정하겠습니다.
제 경우는 이 데이터에 액세스해야 할 애플리케이션이 EC2 인스턴스에서 실행되며 인스턴스의 EC2 세트가 Oregon 리전에 있습니다.
따라서 리전을 US West Oregon으로 설정할 것입니다.
이 시점에서 버킷 생성에 필요한 모든 결정을 한 셈입니다.
이 마법사의 다른 단계에서는 버킷의 버전을 관리하고 기본 권한을 변경하여 이 버킷에 대한 액세스 권한을 공개 인터넷 사용자나 특정 AWS 사용자에게 부여하는 작업을 해 보겠습니다.
이 경우는 기본 설정을 사용할 것이기 때문에 계속 진행하여 Create를 클릭합니다.
이제 버킷이 생성되었음을 확인할 수 있습니다.
버킷 이름.
계속하여 해당 버킷을 클릭합니다.은 Amazing Bucket 1입니다
버킷이 비어 있다는 메시지가 나타나면, 새 객체를 업로드할 수 있습니다.
이 버킷에 대한 속성과 권한이 무엇인지 알 수 있지만, 계속하여 Upload를 클릭하겠습니다.
저는 관리 콘솔에서 파일을 끌어서 놓고 파일에 대한 권한을 수정할 수 있음을 알고 있지만, AWS CLI를 사용하여 데이터를 업로드하겠습니다.
여기에서는 터미널 윈도우를 열고 이 터미널 윈도우에서 데이터를 확인할 수 있습니다.
현재 Assets라고 하는 폴더에 있으며 demo.txt라는 이름의 파일이 안에 있습니다.
이 파일을 간략하게 살펴보면 텍스트 파일임을 알 수 있습니다.
이제 나중에 내 EC2 인스턴스에서 액세스할 수 있도록 이 파일을 내 S3 버킷에 복사할 것입니다.
계속하여 S3 복사 명령을 사용하여 demo.txt를 Amazing Bucket 1에 상주하는 hello.txt 키 아래에 있는 객체에 복사할 것입니다.
이로써 데이터를 업로드했습니다.
폴더에 있는 콘텐츠를 내 로컬 시스템에 가져오고, 동기화 명령을 사용하여 동기화할 수도 있습니다.
그러면 CLI가 파일 각각을 처리하고 버킷에 존재하는지 여부를 확인하고 존재하지 않는 경우 계속하여 업로드할 것입니다.
이제 code.zip과 random.
csv도 내 버킷에 업로드했습니다.
계속하여 SSH를 EC2 인스턴스에 사용하는 경우 내 계정에 있는 임의의 S3 버킷을 읽을 수 있는 액세스 권한을 부여하는 IAM 역할과 함께 이 인스턴스가 프로비저닝되었음을 확인할 수 있습니다.
그럼 계속하여 EC2 인스턴스로부터 어떤 콘텐츠가 S3 Amazing Bucket 1에 있는지 확인합니다.
계속하여 S3 Amazing Bucket 1에서 AWS S3 ls를 수행합니다.
반복하도록 설정하여 모든 경로를 확인할 것입니다.
이러한 파일이 3개 있음을 알 수 있습니다.
앞에서와 같이 복사 명령을 사용할 수 있지만, 지금은 먼저 버킷 이름을 지정함으로써 역순으로 수행합니다.
앞서 제 버킷에서 hello.txt를 복사했습니다.
계속하여 로컬 EC2 인스턴스 스토리지에서 ls를 수행합니다.
hello.txt를 확인할 수 있습니다.
cat를 실행하면 파일을 가져올 수 있으며, 다운로드한 텍스트 파일이 많다는 것을 알 수 있습니다.
동기화 명령을 역순으로 실행할 수도 있습니다.
이제 amazing-bucket-1/files의 내용을 내 EC2 인스턴스에 있는 로컬 폴더로 동기화할 수 있습니다.
폴더가 하나 생성되었음을 확인할 수 있습니다.
폴더의 내용물은 code.zip 및 random.csv 파일 두 개입니다.
지금까지 데이터를 저장하고 다시 가져오는 내용의 S3 시작하기를 간략하게 살펴보았습니다.
다시 관리 콘솔로 돌아가서 정리해 보겠습니다.
이제 제 S3 버킷에 몇몇 파일이 있다는 것을 확인할 수 있습니다.
이 파일들은 관리 콘솔 및 AWS CLI에서 봤던 것과 동일한 파일입니다.
계속하여 hello.txt를 클릭하면 몇 가지 옵션이 나타납니다.
여기에서 객체 기준으로 속성과 권한을 변경할 수 있습니다.
이 파일의 속성 중 일부도 확인할 수 있습니다.
이제 정말로 S3 서비스 시작하기를 전부 다루어 본 것 같습니다.
이 동영상에서 S3 소개와 몇 가지 일반 사용 사례를 살펴봤습니다.
그리고 시연을 통해 버킷을 생성하고, 파일을 생성된 버킷에 복사한 다음, EC2 인스턴스로부터 이들 파일을 다운로드해 봤습니다.
시청해 주셔서 감사합니다.
- Amazon Glacier
안녕하십니까? 저는 Adam Becker입니다.
AWS에 몸담은 지 3개월째이며 기술 교육을 담당하고 있습니다.
팀의 일원으로 다수의 교육 세션에 기여했으며 강의도 많이 했습니다.
이 동영상에는 Amazon의 관리형 서비스인 Amazon Glacier를 다루어 보고, 사용 사례를 설명하고, 시연과 서비스 소개를 할 예정입니다.
그럼 동영상으로 들어가서 Amazon Glacier에 대해 배워 보겠습니다.
Amazon Glacier는 AWS에서 제공하는 스토리지 서비스 범주에 속합니다.
Amazon Glacier는 AWS의 데이터 보관 솔루션입니다.
목표는 최대한 비용 효율적이고 효과적으로 설계할 수 있도록 돕는 것이며, AWS가 그렇게 다양한 스토리지 서비스 솔루션을 제공하는 이유도 그 때문입니다.
Amazon Glacier는 AWS의 저비용 데이터 보관 솔루션입니다.
자주 액세스되지는 않지만 업무상 혹은 법적 이유로 반드시 보존해야 하는 콜드 데이터 보관용으로 설계되었습니다.
Amazon S3와 달리 Amazon Glacier는 빈번하게 액세스되는 데이터 저장용으로 설계되지 않았습니다.
대신 데이터를 저비용으로 장기간 보관할 수 있도록 설계되었습니다.
그렇기 때문에 가끔씩 액세스되는 데이터를 보관하는 데 적합합니다.
Glacier는 데이터를 복수의 시설에, 각 시설에서도 여러 디바이스에 다중 저장하기 때문에 평균적으로 연간 99.999999999%의 내구성을 발휘합니다.
이에 더해 아카이브를 저장하는 저장소에 대한 액세스 정책을 적용함으로써 Glacier에 저장되어 있는 데이터에 대한 액세스를 제어할 수 있습니다.
Amazon Glacier에는 세 가지 핵심 용어가 사용되는데, 알아 두는 편이 좋을 것입니다.
아카이브(archive)는 사진, 동영상 파일, 문서 등과 같이 Glacier에 저장하는 임의의 객체입니다.
아카이브는 Glacier에 있는 기본 스토리지 단위입니다.
각 아카이브는 자체 고유 ID와 선택하는 경우 설명도 부여할 수 있습니다.
저장소(vault)는 아카이브를 저장하는 컨테이너입니다.
저장소를 생성할 때는 저장소 이름과 저장소를 생성하고자 하는 AWS 리전을 지정합니다.
저장소 액세스 정책에서 저장소에 액세스할 수 있는 자와 할 수 없는 자, 사용자가 수행할 수 있는 작업과 수행할 수 없는 작업을 정합니다.
각 저장소에 대해 개별 저장소 액세스 정책을 수립하여 해당 저장소에 대한 액세스 권한을 관리할 수 있습니다.
또한 저장소 잠금 정책을 사용하여 저장소 변경을 방지할 수도 있습니다.
각 저장소마다 개별 액세스 정책과 그에 수반되는 저장소 잠금 정책을 가질 수 있습니다.
그렇다면 어떻게 Glacier에 데이터를 저장하고 액세스할 수 있겠습니까? AWS Management Console 내에서 Glacier에 액세스할 수 있는 반면, 저장소 생성 및 삭제나 아카이브 정책 생성 및 관리와 같은 몇 가지 작업만 이러한 방식이 가능합니다.
다른 작업의 경우 거의 모두 다른 솔루션이 필요합니다.
Glacier의 Java 또는 .NET용 REST API나 AWS SDK를 사용하여 AWS Command Line Interface(AWS CLI), 웹 또는 애플리케이션을 통해 Amazon Glacier와 상호 작용할 수 있습니다.
이 방법으로 보관하는 데이터는 Amazon S3를 포함하여 액세스할 수 있는 모든 곳에서 가져올 수 있습니다.
또한 수명 주기 정책을 사용하여 Amazon S3에서 Glacier로 데이터를 자동으로 보관할 수 있습니다.
이들 정책은 S3에서의 데이터 저장 기간, 데이터 저장 시 특정한 데이터 범위(예: 분기별 데이터 보관)과 같이 지정한 규칙을 바탕으로 Glacier에 데이터를 보관하게 됩니다.
Amazon S3의 버전 관리 기능을 활용하여 버전을 기준으로 데이터를 보관하는 수명 주기 정책을 설정할 수도 있습니다.
시간이 지남에 따라 데이터가 최종적으로 삭제되기 전에 Amazon S3로부터 Glacier로 데이터를 이전하는 수명 주기 정책의 한 예를 설명하겠습니다.
사용자가 애플리케이션에 동영상을 업로드하고 애플리케이션이 해당 동영상의 미리 보기 버전을 생성하는 상황을 가정해 보겠습니다.
이 동영상 미리 보기는 사용자가 바로 액세스할 가능성이 높기 때문에 Amazon S3 Standard에 저장됩니다.
하지만 대부분의 썸네일 미리 보기가 30일 후에는 전혀 액세스되지 않는다고 사용 데이터에 나타나는 경우 수명 주기 정책을 통해 30일 후에 해당 동영상이 S3 Standard Infrequent Access(SIA)로 자동으로 이전되도록 설정할 수 있을 것입니다.
따라서 30일이 더 경과한 후에는 미리 보기 파일도 액세스되는 일이 없을 것이므로 Amazon Glacier로 이전됩니다.
그러다가 1년에 도달하면 삭제됩니다.
극히 드문 예이기는 하지만 미리 보기가 다시 필요해진 경우에는 애플리케이션이 해당 파일이 삭제되었음을 확인하고 새 미리 보기 파일을 생성하게 됩니다.
여기에서 알아 두어야 할 중요한 점은 동영상 파일이 Amazon S3에 추가된 다음에는 수명 주기 정책이 이러한 파일 이동을 자동으로 처리하기 때문에 시간과 비용을 절약할 수 있다는 것입니다.
이제 복원에 대해 설명하겠습니다.
Glacier에 있는 데이터를 복원하고자 하는 경우에도 Amazon S3의 경우와 다르지 않습니다.
Glacier의 경우 데이터 검색은 밀리초가 아니라 분 및 시간 단위로 [측정]됩니다.
데이터 검색에는 액세스 횟수 및 비용이 각기 다른 세 가지 옵션이 있는데, 바로 대량, 표준 및 고속 검색입니다.
슬라이드에서 확인할 수 있듯이, 대량 검색은 비용이 가장 저렴한 솔루션으로 대개 5~12시간 정도 소요됩니다.
표준 검색은 대량 검색보다는 비용이 저렴하지만 고속 검색보다는 비싸며, 일반적으로 3~5시간 정도 소요됩니다.
고속 검색은 셋 중에 비용이 가장 비쌉니다.
하지만 고속 검색의 경우 일반적으로 1~5분 이내에 검색이 완료됩니다.
이를 패키지 제공 속도를 선택하는 것으로 생각하고, 워크로드에 가장 비용 효율적인 검색 속도를 정하면 됩니다.
Amazon S3와 Amazon Glacier 둘 다 데이터를 무제한 저장할 수 있는 객체 스토리지 솔루션이지만, 이 차트에서 알 수 있듯이 둘 간에는 몇 가지 중대한 차이가 존재합니다.
어떤 스토리지 솔루션이 필요에 가장 적합한지 결정할 때는 신중을 기하십시오.
사실 이 둘은 스토리지 필요에 따라 크게 다른 서비스입니다.
Amazon S3는 짧은 지연 시간으로 빈번하게 데이터에 액세스하는 용도로 설계된 반면, Glacier는 자주 액세스하지 않는 데이터를 저비용으로 장기간 보관하는 용도로 설계되어 있습니다.
S3의 최대 항목 크기는 5TB입니다.
반면에 Glacier는 최대 40TB까지 저장할 수 있습니다.
Amazon S3의 경우 데이터 액세스 속도가 빠른 만큼 기가바이트당 저장 비용은 Glacier보다 더 높습니다.
또한 S3와 Glacier 둘 다 요청당 과금 체제이지만, S3는 PUT, COPY, POST, LIST 및 GET 요청에 대해 과금하는 반면 Glacier는 업로드 및 검색 요청에 대해서만 과금합니다.
유의해야 할 또 다른 점은 Glacier의 경우 자주 액세스하지 않는 데이터를 위해 설계되어 요청 비용이 높고 검색하는 데이터에 대해 더 많은 기가바이트당 요금이 과금되기 때문에 S3에 비해 검색당 요금이 더 높습니다.
S3와 Glacier 간의 또 다른 중요한 차이점은 데이터 암호화 방식입니다.
두 솔루션 모두 HTTPS를 통해 데이터를 안전하게 저장할 수 있지만, Glacier의 경우 그곳에 있는 모든 데이터 아카이브가 기본적으로 암호화됩니다.
그에 반해 S3의 경우 애플리케이션이 서버 측 암호화를 개시해야 합니다.
기본적으로 사용자 본인만 자신의 데이터에 액세스할 수 있습니다.
그리고 AWS Identity and Access Management(IAM)를 사용하여 Amazon Glacier에 있는 데이터에 대한 액세스를 활성화하고 제어할 수 있습니다.
간단히 사용자를 지정하는 AWS IAM 정책을 설정하기만 하면 됩니다.
Amazon Glacier는 사용자를 대신하여 주요한 관리 및 보호 기능을 처리하지만, 직접 키를 관리해야 하는 경우에는 Glacier에 업로드하기 전에 데이터를 암호화할 수 있습니다.
이제 시연을 해 보겠습니다.
시연하는 동안 AWS의 UI가 어떤 모습인지 살펴보시기 바랍니다.
AWS Management Console에서 시연을 시작하겠습니다.
스토리지 영역에 집중하시기 바랍니다.
S3, Elastic File Store(Amazon EFS), Glacier 및 AWS Storage Gateway가 있을 것입니다.
이 시연에서는 Glacier를 선택할 것입니다.
그러면 스플래시 페이지가 나타납니다.
저장소를 생성하겠습니다.
Create Vault를 클릭하면 마법사가 시작됩니다.
마법사를 사용하면 아주 간단하게 옵션을 선택하고 최대한 빨리 저장소를 생성할 수 있습니다.
이 경우 제 리전을 사전에 선택했는데, 북부 버지니아입니다.
저장소 이름도 아주 간단하게 정했습니다.
저 같은 경우에는 Glacier라고 지었는데, 여러분은 최대 255자까지 임의로 정할 수 있습니다.
이름은 숫자, 문자 및 기호로 구성되는데, 공백이 있어서는 안 됩니다.
Next Step을 클릭하면 이벤트 알림 메시지를 발송할 것인지 선택할 수 있습니다.
예를 들어 백업 파일을 S3 Infrequent Access(SIA)로부터 Glacier로 이전하는 경우 작업이 완료되면 여러분에게 알림 메시지를 발송하는 기능입니다.
백업 파일을 클라우드로 이전하는 경우도 마찬가지입니다.
작업이 완료되면 저장소가 닫히고 알림 메시지가 발송됩니다.
내 정보를 검토하고 Submit을 클릭하면 내 저장소가 생성된 것입니다.
저장소로 할 수 있는 것들 중 몇 가지에 대해 알아보겠습니다.
저장소를 선택하면 이와 같이 몇 개의 탭이 나타납니다.
첫 번째는 Details입니다.
어떤 저장소인지, 언제 생성되었는지, 상주하는 리전은 어디인지에 대해 간단히 살펴볼 수 있습니다.
Notifications에서는 해당 Amazon SNS 주제로 돌아가 구독하거나 앞으로 알림을 수신할 수 있도록 설정할 수 있습니다.
아마도 가장 중요한 Permissions에서는 Glacier 저장소에 관한 정책서를 편집할 수 있습니다.
Vault Lock을 활성화할 수도 있습니다.
또한 여기에서 정책을 생성하고 편집하고 세부 정보를 열람할 수 있습니다.
이 관리 콘솔에서 설정 태그, 특히 데이터 검색 설정 태그를 생성할 수 있습니다.
내 환경에서 제한을 설정함으로써 검색 비용을 정하고 관리할 수 있습니다.
프리티어, 최대 검색 속도, 검색 무제한 중에 설정할 수 있습니다.
샌프란시스코에 소재한 Scribd는 2007년 이후 수백만 사용자가 문서를 웹에서 읽을 수 있는 형식으로 변환하고 이를 복수의 플랫폼에 걸쳐 공유할 수 있도록 지원해 오고 있습니다.
Amazon Glacier를 사용하여 데이터베이스 스냅샷을 저장하고, 이 스냅샷을 사용하여 필요할 경우 데이터베이스를 복원합니다.
로그 파일 또한 Glacier에 저장하는데, 대부분의 로그 파일은 자주 액세스하는 일이 없기 때문입니다.
Glacier를 사용하여 절감한 비용 덕분에 이제 전과 달리 보다 종합적인 백업을 구현할 수 있게 되었습니다.
스페인 바르셀로나에 소재한 Biblioteca de Catalunya 국립 도서관의 사례를 살펴보겠습니다.
이 도서관은 Glacier를 활용하여 오디오 및 비디오 파일과 같은 오래된 문서를 보관함으로써 드문드문 필요한 자료를 비용 효율적으로 저장할 수 있게 되었습니다.
누군가 그와 같은 자료를 필요로 할 경우에도 여전히 저비용으로 몇 분 혹은 몇 시간 이내에 이용할 수 있도록 할 수 있습니다.
이전에는 온프레미스 데이터 백업 솔루션을 사용했는데, Amazon Glacier로 전환하고 나서 백업 스토리지 비용을 약 75%나 절감했습니다.
핀란드에 기반을 둔 게임 개발 업체인 Supercell은 어땠을까요? 이 회사는 성공작으로 평가받는 Clash of Clans, Boom Beach, Clash Royale의 제작사입니다.
아마 여러분도 플레이해 본 적이 있을 것입니다.
이들 게임은 매일 수천만 명의 플레이어를 끌어모으며, 플레이어들은 매일 10TB가 넘는 게임 이벤트 데이터를 생성합니다.
Supercell은 Amazon Kinesis를 사용하여 이들 데이터를 실시간으로 분석하는데, 시간이 지나면 Amazon Glacier에 데이터를 저장합니다.
나중에 이벤트 데이터에 대한 보다 종합적이고 장기적인 분석이 필요해지는 경우에는 Glacier 저장소에서 데이터를 검색할 수 있습니다.
이 동영상 강의를 통해 여러분이 Amazon Glacier에 대해 조금이라도 배웠기를 바랍니다.
저는 AWS 교육 및 자격증 팀의 Adam Backer였습니다.
시청해 주셔서 감사합니다.
- Amazon Relational Database Service (RDS)
Amazon RDS라고도 하는 Amazon Relational Database Service의 소개 강의에 오신 것을 환영합니다.
안녕하십니까? 저는 AWS 교육 및 자격증 팀의 Andy Cummings라고 합니다.
AWS에서 일한 지 1년 반 정도 됐으며, 지금은 북미 지역 고객을 대상으로 라이브 교육 이벤트를 제공하는 일을 담당하고 있습니다.
이 동영상 강좌에서는 Amazon RDS에 중점을 둘 것입니다.
여러분이 Amazon RDS의 주요한 이점을 잘 이해할 수 있도록 서비스에 대한 간략한 소개로 시작한 다음 Amazon RDS 의 개요와 사용 사례를 통해 좀 더 깊이 살펴본 후에 주요 이점을 요약하여 설명하는 것으로 마무리할까 합니다.
먼저 독립 관계형 데이터베이스의 운영에 따른 문제점을 살펴보겠습니다.
자체 관계형 데이터베이스를 운영하는 경우 서버 관리, 소프트웨어 설치 및 패치, 백업, 고가용성 보장, 규모 조정, 계획, 데이터 보안, OS 설치 및 패치와 같은 수많은 관리 업무를 감당해야 합니다.
이러한 작업 모두는 여러분의 할 일 목록에 있는 다른 작업에 필요한 리소스를 소비하고 일부는 전문성 또한 요구하는 것들입니다.
AWS는 자체 관계형 데이터베이스를 운영함에 따른 문제를 해결하기 위해 지속적으로 관리할 필요 없이 관계형 데이터베이스를 구축하고 운영하고 규모를 조정해 주는 서비스를 제공합니다.
Amazon RDS는 이전에 감당했던 것과 같은 시간이 많이 소요되는 관리 업무를 자동화해 주는 동시에 비용 효율적인 규모를 조정할 수 있는 서비스(용량)를 제공합니다.
Amazon RDS를 사용하면 시간적으로 여유가 생기기 때문에 애플리케이션의 성능, 가용성, 보안 및 호환성에 보다 집중할 수 있습니다.
다시 말해 데이터 및 애플리케이션의 최적화에 중점을 둘 수 있는 것입니다.
Amazon RDS는 운영 체제 설치 및 패치, 데이터베이스 소프트웨어 설치 및 패치, 자동 백업 및 고가용성 유지를 관리합니다.
리소스 규모 조정, 전력 및 서버 관리, 유지 관리 수행 또한 AWS에서 담당합니다.
이러한 작업들을 관리형 Amazon RDS 서비스로 이전하면 운영상 워크로드와 자체 관계형 데이터베이스와 관련된 비용을 줄일 수 있습니다.
이제 서비스를 간략하게 살펴보고 몇 가지 잠재적 사용 사례를 알아보겠습니다.
Amazon RDS의 기본 빌딩 블록은 데이터베이스 인스턴스입니다.
데이터베이스 인스턴스는 사용자가 만든 여러 데이터베이스가 포함될 수 있으며, 독립 실행형 데이터베이스 인스턴스에 사용하는 것과 동일한 도구 및 애플리케이션을 사용해 액세스할 수 있는 격리된 데이터베이스 환경입니다.
데이터베이스 인스턴스에 있는 리소스는 데이터베이스 인스턴스의 등급에 의해 결정되며, 스토리지의 유형은 디스크 유형에 의해 정해집니다.
데이터베이스 인스턴스 및 스토리지는 성능 특성과 가격이 다르므로 데이터베이스 요건에 따라 성능과 비용을 조정할 수 있습니다.
데이터베이스 인스턴스를 생성하려는 경우 먼저 실행할 데이터베이스 엔진을 지정해야 합니다.
Amazon RDS는 현재 MySQL, Amazon Aurora, Microsoft Sequel Server, PostgreSQL, MariaDB, Oracle 등 6개 데이터베이스를 지원합니다.
Amazon Virtual Private Cloud 또는 VPC 서비스를 사용하여 인스턴스를 실행할 수 있습니다.
Amazon VPC를 사용하면 가상 네트워킹 환경을 제어할 수 있습니다.
자체 IP 주소 범위를 선택하고, 서브넷을 생성하고, 라우팅 및 액세스 제어 목록을 구성할 수 있습니다.
Amazon RDS의 기본 기능은 Amazon VPC에서 실행되는지 여부와 상관없이 동일합니다.
통상적으로 데이터베이스 인스턴스는 프라이빗 서브넷에 격리되며 지정된 애플리케이션 인스턴스에 대해서만 직접 액세스가 가능합니다.
Amazon VPC에 있는 서브넷은 단일 가용 영역과 연결되므로, 서브넷을 선택하면 데이터베이스 인스턴스에 대한 가용 영역 혹은 물리적 장소까지 선택하는 셈입니다.
Amazon RDS의 가장 강력한 기능 중 하나는 다중 가용영역 배포로 높은 가용성을 구현하도록 데이터베이스 인스턴스를 구성할 수 있다는 점입니다.
일단 구성하고 나면 Amazon RDS가 데이터베이스 인스턴스의 예비 복사본을 동일한 Amazon VPC 내의 또 다른 가용 영역에 자동으로 생성합니다.
데이터베이스 복사본을 생성하고 나면 트랜잭션이 예비 복사본에 동시에 복제됩니다.
복수 가용 영역으로 데이터베이스 인스턴스를 실행하면 계획된 시스템 유지 관리 중 가용성을 향상시킬 수 있으며, 데이터베이스에 데이터베이스 인스턴스 오류 및 가용 영역 중단이 일어나는 것을 방지할 수 있습니다.
마스터 데이터베이스에 장애가 발생하면 Amazon RDS가 자동으로 예비 데이터베이스 인스턴스를 새 마스터로 가동시킵니다.
동시 복제 덕분에 데이터 손실이 발생하지 않습니다.
애플리케이션이 RDS DNS 엔드포인트를 사용하여 이름을 기준으로 데이터베이스를 참조하기 때문에 애플리케이션 코드의 어떤 것도 변경하지 않고 예비 복사본을 사용하여 장애 조치를 취할 수 있습니다.
또한 Amazon RDS는 MySQL, MariaDB, PostgreSQL 및 Amazon Aurora의 읽기 전용 복제본 생성을 지원합니다.
원본 데이터베이스 인스턴스에 적용된 변경 사항은 읽기 전용 복제본 인스턴스에도 동시에 적용됩니다.
애플리케이션에서 읽기 전용 복제본으로 읽기 쿼리를 라우팅하여 원본 데이터베이스 인스턴스의 로드에 대한 부하를 줄일 수 있습니다.
읽기 전용 복제본을 사용하면 읽기 중심 데이터베이스 워크로드를 처리하기 위해 단일 데이터베이스 인스턴스의 용량 제한을 확장할 수도 있습니다.
읽기 전용 복제본을 마스터 데이터베이스 인스턴스로 승격시킬 수도 있지만, 동시 복제 때문에 수작업이 필요합니다.
읽기 전용 복제본은 마스터 데이터베이스와 다른 리전에 생성할 수 있습니다.
이 기능은 재해 복구 요건을 충족하거나 읽기를 사용자와 더 가까운 읽기 전용 복제본으로 향하게 함으로써 지연 시간을 단축하는 데 유용할 수 있습니다.
Amazon RDS는 처리량이 많고, 스토리지 확장성이 뛰어나고 가용성이 높은 데이터베이스를 필요로 하는 웹 및 모바일 애플리케이션에 적합합니다.
Amazon RDS는 라이선싱 제약이 없기 때문에 웹 및 모바일 애플리케이션의 가변적 사용량 패턴에 완벽하게 들어맞습니다.
중소 규모 전자 상거래 업체의 경우 Amazon RDS는 온라인 판매 및 소매를 위한 유연성 및 보안성이 뛰어난 저비용의 데이터베이스 솔루션을 제공합니다.
모바일 및 온라인 게임은 처리량 및 가용성이 뛰어난 데이터베이스 플랫폼을 필요로 합니다.
Amazon RDS는 데이터베이스 인프라를 관리하기 때문에 게임 개발자가 데이터베이스 서버의 프로비저닝, 규모 조정 또는 모니터링을 걱정할 필요가 없습니다.
좋습니다.
그럼 Amazon RDS 사용에 따른 몇 가지 이점을 살펴보는 것으로 이 서비스에 대해 요약해 보도록 하겠습니다.
Amazon RDS는 가장 까다로운 데이터베이스 애플리케이션까지 지원합니다.
두 가지 SSD 기반 스토리지 옵션 중에서 선택할 수 있습니다.
하나는 고성능 OLTP 애플리케이션에, 다른 하나는 비용 효율적인 범용 애플리케이션에 최적화된 것입니다.
Amazon RDS를 사용하면 가동 중지 없이 데이터베이스 컴퓨팅 및 스토리지 리소스의 규모를 조정하고 AWS Management Console, Amazon RDS 명령줄 인터페이스 또는 단순한 API 호출을 사용하여 서비스를 관리할 수 있습니다.
Amazon RDS는 다른 Amazon Web Services에서 사용하는 것과 동일하게 안정성이 높은 인프라에서 실행됩니다.
또한 제어 및 보안 성능이 뛰어난 데이터베이스 인스턴스 및 Amazon VPC를 사용할 수 있습니다.
여러분이 배운 모든 AWS 서비스는 또 다른 솔루션 빌드 도구임을 명심하십시오.
여러분이 활용할 수 있는 도구가 많아질수록 여러분의 역량도 강해집니다.
지금까지 AWS 교육 및 자격증 팀의 Andy Cummings였습니다.
시청해 주셔서 감사합니다.
- Amazon Dynamo DB
Amazon Dynamo DB 소개 과정에 오신 것을 환영합니다.
저는 Amazon Web Services(AWS)에서 솔루션스 아키텍트와 교육 및 자격증 담당 이사로 재직하고 있는 Rudy Valdez라고 합니다.
이 동영상 강좌에서는 Amazon DynamoDB 서비스를 소개하고 NoSQL 데이터 스토어를 위한 기능과 사용 사례를 살펴볼 예정입니다.
또한 Amazon DynamoDB 테이블과 새 항목을 생성하는 방법을 시연한 다음 쿼리 및 스캔 작업을 사용하여 데이터를 검색하는 방법을 알아볼 것입니다.
그럼 시작하겠습니다.
Amazon DynamoDB는 완전관리형 NoSQL 데이터베이스 서비스입니다.
Amazon은 이 서비스를 위한 모든 기반 데이터 인프라를 관리하고 내결함성 아키텍처의 일부로 미국 리전 내에 있는 여러 시설에 걸쳐 데이터를 다중 저장합니다.
Dynamo DB를 사용하여 테이블과 항목을 생성할 수 있습니다.
항목을 테이블에 추가할 수 있습니다.
표면 영역이 자동으로 데이터를 분할하고 테이블 스토리지를 갖추고 있어 워크로드 요건을 충족합니다.
테이블에 저장할 수 있는 항목의 수에 사실상 제한이 없습니다.
예를 들어 일부 고객의 경우 프로덕션 테이블에 수십억 개의 항목이 있습니다.
NoSQL 데이터베이스의 장점 중 하나는 동일한 테이블에 있는 항목의 속성이 다를 수 있다는 점입니다.
이 장점은 애플리케이션이 진화함에 따라 유연하게 속성을 추가할 수 있게 해 줍니다.
스키마 마이그레이션을 수행할 필요 없이 동일한 테이블 내에서 단계적으로 기존 형식 항목 대신 새 형식 항목을 저장할 수 있습니다.
애플리케이션이 점차 보편화되고 사용자가 지속적으로 상호 작용하다 보면 스토리지가 애플리케이션의 필요에 따라 커질 수 있습니다.
DynamoDB에 있는 모든 데이터는 SSD에 저장되며, 단순한 쿼리 언어 덕분에 지연 시간이 일관적으로 짧고 높은 쿼리 성능을 구현할 수 있습니다.
DynamoDB는 스토리지 규모를 조정할 수 있을 뿐만 아니라 테이블에 필요한 읽기 또는 쓰기 처리량을 프로비저닝할 수 있습니다.
애플리케이션 사용자 수가 증가함에 따라 DynamoDB 테이블을 확장하여 수작업 프로비저닝을 통해 증가된 읽기 및 쓰기 요청 건수를 처리할 수 있습니다.
혹은 Auto Scaling을 활성화하여 DynamoDB가 테이블에 대한 로드를 모니터링하다가 프로비저닝되는 처리량을 자동으로 늘리거나 줄이도록 할 수 있습니다.
스토리지 및 처리량 프로비저닝 측면에서 모두 테이블의 규모를 조정할 수 있는 기능 덕분에 Amazon DynamoDB는 웹, 모바일 및 사물 인터넷(IoT) 애플리케이션의 구조화 데이터에 적합합니다.
예를 들어 지속적으로 데이터를 생성하고 초당 다수의 요청을 하는 클라이언트가 많을 수 있습니다.
이러한 경우 DynamoDB의 처리량 규모 조정 기능 덕분에 클라이언트의 성능을 일관적으로 유지하는 것이 가능합니다.
DynamoDB는 지연 시간에 민감한 애플리케이션에도 사용됩니다.
대규모 테이블에서도 예측 가능한 쿼리 성능 덕분에 가변적인 지연 시간이 광고 기술이나 게이밍과 같이 사용자 경험 또는 사업 목표에 상당한 영향을 미칠 수 있는 경우에 유용합니다.
테이블 데이터는 기본 키에 의해 분할 및 색인화됩니다.
DynamoDB 테이블에서 데이터를 검색하는 방법은 두 가지입니다.
우선 쿼리 작업 시에 효과적으로 분할을 활용하고 기본 키를 사용하여 항목을 찾습니다.
두 번째 방법은 스캔을 통한 방법인데 키가 아닌 속성에 대한 조건을 대조함으로써 테이블에 있는 항목을 찾는 것입니다.
두 번째 방법을 사용하면 다른 속성으로 항목을 신축적으로 찾을 수 있습니다.
그러나 이 작업은 DynamoDB가 테이블에 있는 모든 항목을 검색하여 기준에 부합하는 것을 찾기 때문에 덜 효율적입니다.
쿼리 작업 및 Dynamo DB의 이점을 온전히 활용하려면 DynamoDB 테이블에서 항목을 고유하게 식별하는 데 사용한 키에 대해 생각해 봐야 합니다.
GUID 또는 기타 무작위 식별자와 같이 균등 분산을 통해 데이터 값의 단일 속성을 바탕으로 한 단일 기본 키를 설정할 수 있습니다.
예를 들어 제품으로 테이블을 모델링하는 경우 제품 ID와 같은 몇몇 속성을 사용할 수 있을 것입니다.
아니면 파티션 키와 이차 키로 구성되는 복합 키를 지정할 수도 있습니다.
이 예에서 책 테이블을 모델링해야 하는 경우에는 작가와 제목을 조합하여 테이블 항목을 고유하게 식별할 수 있을 것입니다.
이는 작가로 책을 검색하는 때가 많을 것이라 예상되는 경우에 유용할 수 있습니다.
그런 경우 쿼리를 사용할 수 있기 때문입니다.
이제 주제를 바꿔 새 DynamoDB 테이블 및 항목을 생성한 다음 쿼리 및 스캔 작업을 사용하여 데이터를 검색하는 시연을 해보겠습니다.
지금 저는 AWS Management Console의 Amazon DynamoDB 섹션에 있습니다.
상단을 보면 Oregon Region이 선택되어 있음을 알 수 있습니다.
이는 제가 생성하는 모든 테이블이 Oregon Region으로 배포된다는 뜻입니다.
계속하여 새 DynamoDB 테이블을 생성하겠습니다.
지정해야 할 첫 번째 파라미터는 테이블 이름입니다.
이 테이블에는 책에 관한 정보가 수록될 것이기 때문에 Books 테이블이라고 정하겠습니다.
다음으로 지정할 파라미터는 파티션 키입니다.
앞서 언급했듯이, DynamoDB는 파티션 키로 데이터를 분할하고 색인화할 것입니다.
여기에서 책 ID 같은 것을 사용할 수 있겠지만, 이 경우 작가를 기준으로 책을 검색할 일이 많을 것임을 알고 있습니다.
따라서 신속한 검색을 위해 기본 필드가 색인화되도록 하기 위해 이를 작가로 설정하고자 합니다.
하지만 실제로는 개별 작가가 제 테이블에 있는 책 중 둘 이상으로 집필했을 수 있으므로 작가는 제가 저장해야 하는 항목을 고유하게 식별하지 못할 것입니다.
저는 정렬 키를 추가함으로써 복합 키를 사용할 것입니다.
이제 작가와 제목을 조합함으로써 테이블에 있는 각각의 책을 고유하게 식별할 수 있습니다.
다음으로 정해야 할 사항은 Auto Scaling을 사용할 것인지 수동으로 처리량을 프로비저닝할 것인지 그리고 테이블에서 이차 색인을 정의해야 하는지 여부입니다.
이 시연에서는 기본 설정을 사용할 것입니다.
기본 설정을 사용하면 DynamoDB가 자동으로 테이블을 모니터링하여 그에 따라 읽기 및 쓰기 처리량을 설정합니다.
여기 신규 테이블이 있습니다.
테이블 이름은 Books이고, 기본 키는 Author, 검색 키는 Title입니다.
그럼 계속하여 상단 표시줄을 간략하게 살펴보겠습니다.
테이블에 있는 항목을 볼 수 있고, 제 지표를 확인하고 색인을 생성하고 테이블에서 다른 작업을 수행할 수도 있습니다.
계속하여 테이블에 있는 항목을 확인해 보겠습니다.
새 테이블이기 때문에 데이터가 없어 데이터 항목을 추가하겠습니다.
Create Item을 클릭하면 앞서 정한 기본 키를 바탕으로 시스템에 필요한 템플릿을 DynamoDB가 자동으로 채워 넣었음을 확인할 수 있습니다.
이 시연에서는 Author 및 Title을 사용할 수 있습니다.
이제 계속하여 H.G. Wells의 The Time Machine이라는 책을 추가할 것입니다.
다음으로 제가 할 수 있는 일은 이 항목에 추가 속성을 추가하는 것입니다.
다른 속성을 지닌 항목을 테이블에 포함할 수 있다는 유연성은 정말 유용합니다.
유연한 스키마 덕분에 개발자는 애플리케이션 요건이 변경되면 테이블 활용을 달리할 수 있습니다.
이제 오디오 또는 킨들 버전과 같이 이 책의 다양한 에디션을 추적할 수 있도록 Edition에 일단의 문자열을 추가할 것입니다.
마지막으로 이 마법사에서의 표시 형식을 트리에서 텍스트로 변경하는 것이 남았습니다.
저는 그것이 테이블에 있는 항목의 JSON 스타일 선언임을 알고 있습니다.
전체 크기가 DynamoDB 항목의 최대 크기인 400킬로바이트 이내일 때까지는 원하는 만큼 속성을 이 JSON 정의나 트리에 추가할 수 있습니다.
Save를 클릭하면 항목이 데이터 스토어에 커밋되고, 새 항목인 작가 H.G. Wells가 추가되었음을 알 수 있습니다.
제목은 The Time Machine입니다.
이 항목에 대한 에디션도 다양합니다.
잠시 동안 멈추고 좀 더 많은 데이터를 테이블에 로드하겠습니다.
됐습니다.
계속하여 테이블 새로 고침을 하면 더 많은 항목을 확인할 수 있습니다.
이제 Author, Title, Rating 및 Additions 항목이 있습니다.
참고로, 모든 항목의 속성 집합이 동일한 것은 아닙니다.
이는 DynamoDB의 유연성을 나타내는 것으로 각기 다른 속성과 각기 다른 항목을 가질 수 있게 해 줍니다.
하지만 이들 항목 중 하나는 Author와 Title이어야 하는데, 앞서 설명한 바와 같이 이들이 복합 키를 구성하기 때문입니다.
좋습니다.
테이블에서 책을 신속하게 찾으려면 쿼리 작업을 이용할 수 있습니다.
쿼리 작업을 수행할 때는 파티션 키의 값을 지정해야 합니다.
이 경우에서는 H.G. Wells가 지은 책을 찾을 것입니다.
선택적으로 키에 대한 필터 기준을 설정하고, 정렬 키 값을 기준으로 데이터를 내림차순으로 정렬할지 오름차순으로 정렬할지 선택할 수 있습니다.
Start search를 클릭하면 H.G. Wells에 대한 다수의 결과가 나타납니다.
여기에서는 네 종류의 책이 보입니다.
이 쿼리 작업에서는 제가 검색할 데이터의 파티션 키를 알고 있다는 사실을 십분 활용하고 있습니다.
데이터 대조가 아주 빠르게 이루어집니다.
반면에 제가 찾고자 하는 책의 작가를 모를 경우에는 어떻게 해야 하겠습니까? 테이블에 있는 각종 오디오 북을 모두 찾거나 키가 아닌 다른 속성에 대해 필터링하고자 한다면 어떻게 해야 합니까? 그와 같은 경우에는 스캔 작업을 활용할 수 있습니다.
예를 들어 계속 진행하여 Edition 속성에 “audible”이 포함된 책의 에디션을 찾으면 됩니다.
데이터세트에 있는 오디오 북을 모두 찾아야 합니다.
Start search를 클릭하면 여러 책이 반환됨을 확인할 수 있습니다.
혹은 추가 필터를 추가하여 점수가 3점보다 큰 항목만 표시되도록 할 수도 있습니다.
이렇게 하면 점수가 3점보다 높고 오디오 에디션인 네 가지 책이 반환됩니다.
지금까지 테이블을 생성하고, 데이터를 로드하고, 쿼리 및 스캔 작업을 둘 다 사용하여 데이터를 검색하는 기본 작업을 다루어 봤습니다.
요약하자면, Amazon DynamoDB는 확장을 통해 대량의 데이터를 저장하고 많은 요청 볼륨을 지원하고 짧은 지연 시간의 쿼리 성능을 요구하는 애플리케이션용 데이터 스토어로 활용 가능한 관리형 NoSQL 데이터베이스 서비스입니다.
지금까지 AWS 솔루션스 아키텍트와 AWS 교육 및 자격증을 담당하고 있는 Rudy Valdez였습니다.
시청해 주셔서 감사합니다.
- Amazon Redshift
안녕하십니까? Amazon Redshift에 관한 Amazon Web Services 소개 과정에 오신 것을 환영합니다.
저는 Mark Fei라고 합니다.
AWS에 입사한 지 4년이 넘었으며 지금은 AWS 교육 및 자격증 팀에서 선임 기술 강사 역할을 맡고 있습니다.
AWS 교육 과정에서는 일반 수강생 및 소프트웨어 개발자를 대상으로 DevOps, 보안, 네트워킹, 빅 데이터, 데이터 웨어하우징, 분석, 인공 지능, 기계 학습 등 광범위한 관심 분야를 다룹니다.
이 과정에서는 Amazon Redshift를 소개하고, Amazon Redshift의 내용 및 기능을 간략하게 살펴보고, Redshift의 일반 사용 사례를 설명합니다.
실제 서비스를 확인할 수 있도록 짧은 시연으로 강의를 마무리합니다.
Amazon Redshift는 속도가 빠른 완전관리형 데이터 웨어하우스로서 표준 SQL 및 기존 비즈니스 인텔리전스 도구를 사용하여 모든 데이터를 간편하고 비용 효율적으로 분석할 수 있게 해 줍니다.
Redshift를 사용하면 정교한 쿼리 최적화, 고성능 로컬 디스크에 대한 열 형식 저장, 방대한 병렬 쿼리 실행을 통해 페타바이트 규모의 구조화 데이터를 대상으로 복잡한 분석 쿼리를 실행할 수 있습니다.
대부분의 결과가 수 초 이내에서 반환됩니다.
이제 Amazon Redshift의 핵심 기능과 일부 일반 사용 사례에 대해 좀 저 상세하게 살펴보겠습니다.
Redshift는 방대한 병렬 처리 아키텍처와 더불어 열 형식 스토리지 및 자동 압축 기능을 채택하여 페타바이트 규모의 데이터 세트에 대해서도 아주 빠른 쿼리 성능을 구현합니다.
거의 모든 AWS 서비스가 그렇듯이, 사용한 만큼에 대해서는 요금을 지불하면 됩니다.
시간당 25센트에서 테라바이트당 연간 천 달러(USD) 정도의 비용으로 Redshift의 스토리지 및 처리 서비스를 신축적으로 이용할 수 있습니다.
재차 말씀드리지만, 비용이 전통적인 데이터 웨어하우스 솔루션에 비해 1/10에 불과합니다.
Redshift Spectrum을 사용하면 엑사바이트 규모의 데이터에 대해 Amazon S3에서 직접 쿼리를 실행할 수 있습니다.
Redshift 클러스터의 관리, 모니터링, 규모 조정 등 대부분의 관리 업무가 상당히 간편하게 자동화되기 때문에 데이터 및 업무에 집중할 수 있습니다.
Redshift에는 확장성이 기본적으로 제공되기 때문에 필요에 따라 콘솔에서 몇 번의 조작만으로 클러스터를 확장하거나 축소할 수 있습니다.
항상 그렇지만, Amazon Web Services의 경우 보안이 가장 중요한 고려 사항입니다.
Redshift에는 저장 및 전송 중에 데이터를 암호화하는 강력한 기능이 내장되어 있습니다.
끝으로, Amazon Redshift는 이미 알려지고 사용되고 있는 도구와 호환되고, 표준 SQL을 지원하며 고성능 JDBC 및 ODBC 커넥터를 제공하기 때문에 원하는 SQL 클라이언트 및 비즈니스 인텔리전스 도구를 사용할 수 있습니다.
그러면 일반 사용 사례로 화제를 돌려 보겠습니다.
민첩성을 확보하려는 목적으로 전통적인 엔터프라이즈 데이터 웨어하우스에서 Amazon Redshift로 마이그레이션하는 고객이 많습니다.
고객은 원하는 규모로 시작하고 IT 부서가 하드웨어 및 소프트웨어를 조달하여 프로비저닝할 필요 없이 기존의 데이터로 실험해 볼 수 있습니다.
빅 데이터 고객은 한 가지 공통점을 가지고 있는데, 기존 시스템에 흩어져 있는 방대한 양의 데이터가 한계점에 도달하고 있다는 사실입니다.
규모가 작은 고객은 일반적으로 이들 시스템을 실행할 만큼 충분한 하드웨어 및 전문 인력을 조달할 자금을 갖고 있지 않습니다.
Amazon Redshift를 사용하면 상대적으로 낮은 비용으로 데이터 웨어하우스를 시작하고 운영할 수 있습니다.
관리형 서비스인 Amazon Redshift는 데이터베이스 관리자가 필요한 경우가 많은 배포 및 지속적인 관리 업무 중 다수를 대신 수행하기 때문에 IT 부서가 쿼리 및 분석에 집중할 수 있게 해 줍니다.
Software-as-a-Service(SaaS) 고객은 Amazon Redshift가 제공하는 확장 가능하고 관리하기 쉬운 플랫폼에 매력을 느낍니다.
일부는 애플리케이션에 분석 기능을 제공하는 플랫폼을 사용합니다.
일부는 고객당 클러스터 하나를 배포하고 태깅을 사용하여 서비스 수준 계약(SLA) 및 과금 관리를 단순화하기도 합니다.
이제 얼마나 쉽게 시작하고 데이터를 로드하고 쿼리를 실행할 수 있는지 확인할 수 있도록 간단한 시연을 해 보겠습니다.
그럼 시작하겠습니다.
이 Amazon Redshift 시연을 위해 미리 AWS Management Console에 로그인하여 Redshift 대시보드에 있습니다.
Redshift 클러스터를 시작하는 게 얼마나 쉬운지 보여 드리기 위해 화면 두 개를 살펴보고자 합니다.
여기서는 클러스터 이름을 제공해야 합니다.
데이터베이스 이름과 포트 이름은 기본적으로 제공되는 것을 사용할 수 있습니다.
마스터 데이터베이스 사용자와 적절한 암호를 정해야 합니다.
그런 다음 클러스터의 크기와 유형을 지정할 수 있습니다.
선택할 노드 유형이 다양합니다.
단일 노드 클러스터를 선택할 수 있는데, 간단한 개발 및 실험에 적합합니다.
프로덕션 목적으로는 데이터 복제를 위한 노드가 두 개 이상인 다중 노드가 필요할 것입니다.
지금 보고 있는 것이 그것입니다.
그런 다음 네트워킹과 관련하여 몇 가지 선택을 합니다.
네트워킹 및 보안 그룹을 선택하고 나면, 마지막으로 Redshift 클러스터가 적절한 액세스 권한을 가지도록 서비스 역할을 선택합니다.
이 경우는 Amazon S3입니다.
Continue 버튼을 클릭하면 우리가 선택한 것을 요약해서 보여 주는 화면이 나타납니다.
시작할 준비가 되면 Launch Cluster 버튼을 클릭하면 됩니다.
일반적으로 Redshift 클러스터는 어디서든 시작하는 데 몇 분 정도 소요됩니다.
작은 클러스터의 경우에는 5분에서 6분, 큰 클러스터의 경우에는 10분에서 15분 정도 걸립니다.
여기에서는 시연을 바로 시작할 수 있도록 미리 클러스터를 시작해 놓았습니다.
보시다시피 첫 클러스터가 시작되어 가동 중입니다.
대시보드에서 클러스터를 클릭하면 이용 가능한 풍부한 정보가 표시됩니다.
제가 필요로 하는 정보의 첫 부분이 여기에 있습니다.
바로 여기 원으로 표시한 부분입니다.
이것이 제 JDBC URL입니다.
그럼 그걸 선택하여 제 클립보드로 복사하겠습니다.
제 SQL 클라이언트를 구성하여 연결할 때 곧 필요할 것입니다.
이제 SQL 워크벤치 J를 시작했습니다.
물론 임의의 SQL 클라이언트처럼 빨리 할 수도 있었습니다.
이것은 어쩌다가 제 노트북 컴퓨터에 설치한 것입니다.
좀 전에 봤던 콘솔 화면에서 복사한 해당 URL을 여기 연결 창에 미리 입력해 놓았습니다.
이렇게 하면 데이터베이스로 연결됩니다.
이제 몇 가지 SQL 명령을 실행해 보겠습니다.
웹 사이트에 있는 자가 시연에서 발췌한 명령 집합을 사용할 것입니다.
이 명령들을 실행하면 다양한 쇼와 이벤트의 티켓 판매에 관한 정보가 담긴 데이터세트에 대한 일련의 테이블 정의가 생성됩니다.
이것이 Create Table 문입니다.
계속해서 이 명령문들을 실행하면 7개 Create Table 문이 모두 성공적으로 실행됨을 확인할 수 있습니다.
다음으로 할 일은 공개적으로 이용 가능한 데이터를 Amazon S3에 상주하는 데이터세트로부터 테이블에 복사하게 될 일련의 복사 명령을 채용하는 것입니다.
제 Redshift 역할을 자격 증명으로 대체하는 간단한 작업을 수행해야 합니다.
작업을 완료하면 이제 이들 복사 명령을 실행할 수 있습니다.
Redshift에서 복사 명령은 사실상 load 명령입니다.
그렇기 때문에 복사 명령은 상당히 신속하게 실행됩니다.
15초도 안 되어 모든 데이터를 로드할 수 있음을 알 수 있습니다.
시연의 마지막 단계는 데이터세트에 대한 쿼리를 실제로 수행하는 것입니다.
그러면 쿼리 집합을 살펴보겠습니다.
첫 번째 쿼리는 PG Table Def라고 하는 시스템 테이블에 대한 쿼리로 테이블 정의를 표시합니다.
그런 다음 특정 날짜의 총 매출을 검색할 것입니다.
2008년 1월 5일입니다.
수량 기준 10대 구매자를 찾은 후에, 역대 총 매출 기준으로 99.9번째 백분위수에 해당하는 이벤트를 찾을 것입니다.
그럼 계속하여 해당 쿼리를 실행하겠습니다.
이제 여기 하단에서 결과를 확인할 수 있습니다.
결과 1은 매출 테이블에 대한 첫 번째 쿼리 정의로부터 반환된 것입니다.
결과 2인 210은 특정 날짜에 판매된 모든 티켓의 총합입니다.
결과 3은 수량 기준 10대 구매자이고, 결과 4는 역대 총 매출 기준으로 99.9번째 백분위수에 해당하는 이벤트입니다.
물론 Phantom of the Opera와 같은 인기 오페라도 있습니다.
요약하자면, Amazon Redshift는 처리 속도가 빠른 완전관리형 데이터 웨어하우스 서비스입니다.
여러분이 조금이나마 배웠고 다른 강좌도 계속 학습하시기를 바랍니다.
지금까지 AWS 교육 및 자격증 팀의 Mark Fei였습니다.
시청해 주셔서 감사합니다.
- Amazon Aurora
안녕하십니까? 저는 AWS 교육 및 자격증 팀의 Kirsten Dupart라고 합니다.
Amazon Aurora 소개 과정에 오신 것을 환영합니다.
저는 Amazon에 몸담은 지 약 일 년 반이 되었으며, 지금은 교육 및 자격증 팀에서 교과 과정 개발을 담당하고 있습니다.
Amazon Aurora와 일부 서비스, 주요 이점 및 개념에 대해 간략하게 살펴보는 것으로 강좌를 시작하겠습니다.
그런 다음 간단한 시연을 통해 AWS 콘솔에서 Amazon Aurora 데이터베이스를 설정하는 방법을 설명할 것입니다.
유명 회사의 사용 사례와 Amazon Aurora 사용에 따른 이점을 요약하여 설명할 것입니다.
Amazon Aurora는 고성능 상용 데이터베이스의 속도와 가용성에 오픈 소스 데이터베이스의 간편성과 비용 효율성을 결합한 MySQL 관계형 데이터베이스 엔진입니다.
그럼 Amazon Aurora를 간략하게 살펴본 다음 이 서비스의 핵심 개념과 기능 중 일부를 심층적으로 다루어 보겠습니다.
먼저 Amazon Aurora의 장점 중 몇 가지에 대해 알아보겠습니다.
빠릅니다.
가용성이 뛰어납니다.
MySQL보다 다섯 배 더 뛰어난 성능을 발휘하며 단지 몇 번의 마우스 클릭으로 높은 가용성을 구현합니다.
Amazon Aurora는 설정이 간단하며 여러분이 아마 이미 익숙한 SQL 쿼리를 사용합니다.
InnoDB 스토리지 엔진을 사용하기 때문에 MySQL 5.6과도 즉시 호환성을 갖추고 있습니다.
Amazon Aurora는 종량제 서비스로서 실제로 사용하는 서비스와 기능에 대해서만 요금을 지불하면 됩니다.
끝으로 Amazon Aurora는 관리형 서비스입니다.
AWS Database Migration Service 및 AWS Schema Conversion Tool과 같은 기능과 통합되어 데이터 세트를 Amazon Aurora로 원활하고 민첩하게 이전하는 데 유용합니다.
마지막 이점에 대해서는 잠시 시간을 내어 좀 더 심층적으로 다루어 보겠습니다.
방금 전에 Amazon Aurora가 관리형 서비스라고 설명했는데, 그렇다면 그것의 정확한 의미와 왜 그렇게 중요할까요? 전통적인 온프레미스 데이터베이스의 경우 데이터베이스 관리자가 앱 및 쿼리 최적화에서 하드웨어 구성, 패치, 네트워킹 설정, 전력 설정 및 HVAC까지 모든 것을 담당합니다.
하지만 Amazon EC2 인스턴스에서 가동되는 데이터베이스로 전환할 경우 기반 하드웨어를 관리하거나 데이터 센터 운영에 신경을 쓸 필요가 더 이상 없습니다.
물론 운영 체제 패치와 전반적인 소프트웨어 및 백업 운영 업무는 여전히 맡아야 할 것입니다.
데이터베이스를 Amazon Relational Database Service(Amazon RDS) 또는 Amazon Aurora에 구축할 경우 과중한 업무에서 해방될 수 있습니다.
클라우드로 전환하면 데이터베이스 규모 조정, 높은 가용성 확보, 백업 관리 및 패치 작업이 자동으로 수행되기 때문에 정말 중요한 사안인 애플리케이션 최적화에 집중할 수 있습니다.
그런데 Amazon RDS와 함께 MySQL를 사용하는 대신 Amazon Aurora를 사용하는 이유는 무엇일까요? 그와 같은 결정은 대개 Amazon이 제공하는 높은 가용성과 탄력적인 설계에서 기인합니다.
Amazon Aurora는 가용성이 뛰어나 데이터의 복사본 6개를 세 곳의 가용 영역에 걸쳐 저장하며 Amazon S3에 대한 지속적인 백업을 수행합니다.
최대 15개의 읽기 전용 복제본을 사용할 수 있어 데이터 손실 위험을 해소합니다.
게다가 Amazon Aurora는 기본 데이터베이스의 상태에 문제가 발생한 경우 즉각적인 장애 복구가 가능하도록 설계되어 있습니다.
다른 데이터베이스와 달리 Amazon Aurora는 데이터베이스 장애 발생 후에 최근 데이터베이스 체크포인트로부터 Redo 로그를 재현할 필요가 없습니다.
대신 읽기 작업 시마다 이를 수행합니다.
그렇기 때문에 대부분의 경우 데이터베이스 장애 발생 후의 데이터베이스 재시작 시간이 60초 이하로 줄어듭니다.
Amazon Aurora는 데이터베이스 프로세스에서 버퍼 캐시를 분리하여 재시작 즉시 사용할 수 있도록 합니다.
이렇게 하면 캐시가 다시 채워질 때까지는 액세스를 제한할 필요가 없어 중단이 방지됩니다.
이제 잠시 화제를 전환하여 실제 Amazon Aurora를 살펴보겠습니다.
지금 보고 있는 것은 Amazon RDS 콘솔입니다.
Aurora 인스턴스를 시작하겠습니다.
인스턴스로 가서 새 데이터베이스 인스턴스를 시작합니다.
RDS의 경우 언제나 데이터베이스 엔진을 선택할 수 있습니다.
여기서는 Amazon Aurora를 선택할 것입니다.
MySQL 또는 Postgres와의 호환성을 원하는 경우 그렇게 선택할 수 있습니다.
다음 페이지에서는 데이터베이스 인스턴스의 크기와 필요한 CPU 및 RAM의 용량을 선택해야 합니다.
지금은 기본 설정을 사용할 것입니다.
다른 가용 영역에 있는 복제본을 사용하여 배포할 수도 있습니다.
그 다음에는 기본 데이터베이스 설정입니다.
데이터베이스 이름을 정합니다.
저는 “prod”라고 하겠습니다.
그런 다음 마스터 사용자 이름과 암호를 지정합니다.
간단하게 정하겠습니다.
다음 페이지에서는 데이터베이스의 위치를 선택하고 이어서 VPC와 VPC 내의 서브넷을 정할 것입니다.
복수의 가용 영역 기능을 선택할 수 있기 때문에 서브넷 또한 복수가 가능합니다.
여기에서 공개 접근을 허용할 필요가 있는지 확인할 것입니다.
아마 아닐 것입니다.
어떤 가용 영역에 위치하는지 알고 있을 경우 지정하거나 설정하지 않고 그대로 둘 수도 있습니다.
그런 다음 신규 혹은 기존 보안 그룹(SG)을 생성하여 데이터베이스에 적용할 수 있습니다.
이렇게 하면 데이터베이스에 연결할 때 가용한 포트의 범위가 제한됩니다.
현재 보안 그룹이 없기 때문에 신규 보안 그룹을 생성할 것입니다.
원할 경우 클러스터 ID와 내 데이터베이스 서버에 있는 데이터베이스 이름을 지정할 수 있습니다.
데이터베이스 이름을 “Customers”라고 정하고 몇 가지 기본 데이터베이스 수준 설정을 수행합니다.
예를 들어 연결할 포트, 데이터베이스 설정에 적용할 파라미터를 정합니다.
이 데이터베이스에는 SSL 연결만 가능하도록 하고 싶다면 여기에서 설정할 수 있습니다.
키 관리 서비스로부터 추출된 키를 사용하여 데이터베이스를 암호화할 수 있습니다.
장애 조치, 모니터링 옵션 등에 관한 기본 설정도 지정할 수 있습니다.
Amazon RDS는 데이터베이스를 자동으로 백업합니다.
얼마나 오랫동안 백업을 유지할 것인지 선택할 수 있습니다.
백업 보존 기간은 1일에서 35일까지입니다.
저는 일주일을 선택하겠습니다.
끝으로, RDS가 새 마이너 데이터베이스 업그레이드를 자동으로 수행하도록 할 것인지 여부를 선택합니다.
자동 수행을 원하는 경우 자동 수행 시간을 지정할 수 있습니다.
저는 일요일 오전 2시를 선택할 것입니다.
아주 간단합니다.
잠시 후에 버튼을 클릭하여 데이터베이스 인스턴스를 시작하면 새 데이터베이스가 생성되어 가동을 시작할 것입니다.
Amazon RDS가 연결 문자열을 표시하게 되고 다른 데이터베이스와 마찬가지로 어디서든 연결할 수 있습니다.
이 동영상 강좌를 마무리하기 전에 한 유명 회사가 Amazon Aurora를 어떻게 활용하고 있는지를 설명하는 사용 사례를 간략하게 소개하고자 합니다.
Expedia는 이전에 전통적인 데이터베이스와 관련한 문제 때문에 고민했습니다.
수백 개의 노드로 구성되어 있으며 비용이 터무니 없이 비싸고 확장성도 없는 값비싼 대형 시스템을 사용하고 있었습니다.
Expedia는 Aurora로 전환함으로써 성능 저하 없이 데이터베이스를 확장할 수 있게 되었습니다.
물론 경제적인 운영 비용 또한 큰 장점이었습니다.
Expedia는 평균적으로 초당 약 25,000개의 인스턴스를 실행했으며 피크 시에는 70,000개에 달했습니다.
이렇게 많은 인서트를 실행하는 동안 Expedia는 쓰기 작업의 경우 30밀리초의 평균 응답 시간, 읽기 작업의 경우 17밀리초의 응답 시간을 경험할 수 있었는데, 이 모든 것이 한 달간의 데이터를 처리하면서 이루어진 것입니다.
요약하자면, Aurora는 가용성이 뛰어나고, 설정이 쉽고, 성능이 우수하며, 비용 효율적인, 관리되는 관계형 데이터베이스입니다.
여러분이 오늘 조금이나마 배웠고 이 강좌와 다른 AWS 서비스 강좌를 계속 학습하시기를 바랍니다.
지금까지 AWS 교육 및 자격증 팀의 Kirsten Dupart였습니다.
시청해 주셔서 감사합니다.
- AWS Trusted Advisor
안녕하세요.
이번 시간은 AWS Trusted Advisor에 대한 짧은 소개 동영상으로 시작하겠습니다.
저는 Tipu Qureshi이며 약 6년 동안 Amazon Web Services에서 근무했습니다.
저는 AWS Support 팀의 일원으로서 고객과 함께 협력하여 고객 경험을 향상시키는 방법을 연구하는 업무를 담당하고 있습니다.
이 동영상에는 AWS Support 팀의 일원인 Alex Buell도 등장합니다.
그는 Trusted Advisor 팀의 소프트웨어 개발 엔지니어로 일하고 있습니다.
이 동영상에서는 Trusted Advisor에 대해 살펴보고 관련 사례 연구를 검토하여 컨텍스트를 제공합니다.
그런 다음, 해당 서비스의 작동 원리에 대해 좀 더 자세히 알아보고 Alex가 시연할 빠른 데모로 마무리하고자 합니다.
또한 AWS Trusted Advisor를 사용하여 보안, 내결함성, 성능 및 비용 절감을 향상시킬 수 있는 방법을 구체적으로 살펴보겠습니다.
AWS 여정을 시작하면 리소스를 추적할 수는 있지만 그만큼 사용자의 요구가 신속하게 증가합니다.
사용자의 요구가 증가할수록 AWS 계정은 추적할 수 없을 정도로 너무 많은 리소스를 보유할 수 있습니다.
분리된 리소스, 비용 면에서 최적화되지 않고 오히려 낭비되고 있는 리소스(예: 인스턴스에 연결되지 않은 EIP), 사용되지 않고 단지 돈을 낭비하는 볼륨 또는 스냅샷 등이 존재할 수 있습니다.
또한 내결함성, 성능 또는 보안을 위해 최적화되지 않은 리소스를 가질 수도 있습니다.
이 모든 것은 중요하지만 복잡성을 추적하기는 어렵습니다.
그래서 여기에 이러한 리소스들이 증가하는 것이며 리소스가 증가할수록 이를 추적하기 위해 뭔가 필요합니다.
바로 여기에서 Trusted Advisor가 제공됩니다.
Trusted Advisor는 모범 사례를 제공하고 계정의 모든 리소스를 검사하여 각 리소스가 모범 사례에 부합하는지 확인하는 도구입니다.
Trusted Advisor는 이러한 작업을 보안, 내결함성, 성능 및 비용 최적화라는 4가지 범주로 나누어 수행합니다.
이것은 Trusted Advisor 콘솔의 대시보드에 속합니다.
(나중에 Alex가 데모를 보여줄 것입니다. ) 이는 올바른 방식으로 작업을 수행했다면 지금 당장 많은 비용을 절약할 수 있다는 것을 알기 쉽게 보여줍니다.
그리고 세 가지 범주의 검사도 진행되는데 빨간색은 즉각적인 조치가 필요함을 나타내고 노란색은 조사가 필요함을 나타내며 녹색은 여러분이 AWS를 잘 사용하고 있으며 모든 설정이 완료되었음을 나타냅니다.
현재까지 Trusted Advisor는 고객들에게 5억 달러 이상의 비용 절감 효과를 제공했으며 1,500만 건이 넘는 권장 사항을 제공했습니다.
지금까지 Trusted Advisor에 대해 좀 더 자세한 내용을 알아보았습니다.
이제 간단한 고객 사례 연구를 통해 과거에 이 서비스가 어떻게 사용되었는지를 보여주는 구체적인 한 가지 예를 살펴보기로 하겠습니다.
Hungama는 매월 23% 이상의 비용을 실제로 절감한 AWS 고객사 중 한 업체입니다.
Hungama는 여러 가지 검사를 사용했으며 특히 Underutilized EC2 인스턴스 검사(Underutilized EC2 Instance Check)를 사용했는데 이 검사에서 Hungama의 일부 개발 팀들은 인스턴스 크기 측면에서 과다 프로비저닝되었습니다.
그들은 인스턴스의 크기를 적정하게 조정하고 사용되지 않은 인스턴스로 낭비를 제거해야 했습니다.
Underutilized Amazon EC2 인스턴스 검사 외에도 Amazon EC2 예약 인스턴스 및 Underutilized Amazon EBS 볼륨 검사를 사용하여 최적의 방법으로 리소스를 사용하고 비용을 절감하고 있는지 확인했습니다.
그렇다면 Trusted Advisor는 과연 어떻게 작동할까요? Trusted Advisor는 계정 리소스를 기존 모범 사례와 비교하여 검사 형식으로 데이터를 전송합니다.
이제 Trusted Advisor는 이러한 모범 사례를 콘솔 형식으로 나타낼 뿐만 아니라 API도 갖습니다.
이외에도 특정 검사가 실패할 때 이에 대한 조치를 취할 수 있도록 해당 검사에 대한 알림을 수신할 수 있습니다.
또한 자동화를 도입할 수도 있는데 그 이유는 Trusted Advisor가 AWS Lambda와 같은 서비스를 사용할 수 있는 Amazon CloudWatch Events와 통합되어 자동 작업을 수행하고 리소스 최적화를 자동화할 수 있기 때문입니다.
이제 Alex와 함께 데모를 시연해보기로 하겠습니다.
감사합니다.
제 이름은 Alex입니다.
저는 AWS의 Trusted Advisor 팀과 3년간 함께 일했습니다.
다음은 Trusted Advisor 제품에 대한 AWS 콘솔 경험의 개요 및 프레젠테이션입니다.
기본 시작 페이지는 전체적인 대시보드입니다.
Tipu가 언급했듯이 보안, 비용 최적화 및 성능을 비롯한 다양한 유형의 검사에 대한 분석을 볼 수 있습니다.
또한 전체 검사 상태의 최근 변경 사항을 중점적으로 보여주는 섹션도 있습니다.
그리고 발표된 새로운 검사 및 변경 사항을 보다 분명하게 보여줄 공지 사항도 제공했습니다.
이제 특정 검사를 자세히 알아보기로 하겠습니다.
Service Limits 검사는 고객이 AWS에서 다양한 서비스에 대한 사용량 대 실제 사용 한도를 비교하여 볼 수 있기 때문에 많은 고객에게 매우 유용합니다.
이는 리전별로 세분되기 때문에 고객은 서비스 한도에 근접할수록 그 한도를 늘리기 위한 사전 요청을 할 수 있습니다.
이는 특정 서비스에 대한 한도에 근접할 때 알림을 전달하기 때문에 AWS 고객에게 매우 유용합니다.
이 검사를 활용하면 제품 및 고객에게 예정된 신제품 출시로 인해 서비스가 중단될 가능성을 방지할 수 있습니다.
또 다른 공통 범주로는 보안 범주가 있습니다.
이 범주는 (자주 변경 또는 교체되지 않은 이전 IAM 키에서 발생하는) IAM 관련 문제에서부터 최신 보안 문제(예: 리소스에 대한 의도하지 않은 액세스)에 이르기까지 다양한 알림을 제공합니다.
예를 들면 AWS 고객과 관련된 최근 사례에서 고객들은 귀하와 귀사가 소유한 Amazon EBS, Amazon S3 또는 Amazon RDS 인스턴스에 액세스할 수 있었습니다.
이들 인스턴스는 최근 추가된 예에 속하며 새로 고침은 주기적으로 자동 실행됩니다.
이렇게 하면 수동으로 새 업데이트를 얻기 위한 새로 고침을 굳이 시도할 필요 없이 더 많은 사전 알림을 수신할 수 있습니다.
내결함성 범주에는 서비스 팀의 지원을 받을 필요 없이 직접 조치를 취함으로써 도움을 받을 수 있는 잠재적 지원 사례와 관련된 다양한 검사가 있습니다.
서비스 중단을 피하기 위한 최근의 AWS Direct Connect 모범 사례는 물론, 보안 또는 성능 요구에 대해 권장되는 새 버전이 있을 때 업데이트를 실행하는 문제의 리소스(예: EC2 Config를 포함한 EC2 Windows)를 관리하고 구성하기 위한 그 밖의 경고 및 알림이 바로 이러한 검사의 예에 속합니다.
이메일 연락처를 설정하여 모든 검사에서 사용자의 계정 상태를 요약한 알림을 매주 수신할 수 있는 기본 설정 페이지가 있습니다.
또한 모든 검사 또는 특정 검사에 대한 보고서를 다운로드할 수 있는 기능들도 있습니다.
이들 기능은 CSV 또는 Excel 형식의 파일에 있습니다.
데이터를 저장하는 방법과 그러한 데이터를 사용해 직접 수행할 작업을 로컬에서 선택할 수 있습니다.
마지막으로 키 호출은 새로 고침(refresh) 기반의 기능에 해당됩니다.
대부분의 검사는 새 데이터를 가져와 모든 리소스의 현재 상태에 대한 업데이트를 수신할 수 있는 새로 고침 표시기가 있습니다.
바로 옆에 있는 타임라인 버튼은 전체 검사에 대한 새로 고침이 실행될 때까지의 경과 시간을 대략적으로 보여줍니다.
이것은 이 데이터의 관련성을 나타내는 지표에 속합니다.
새로 고침 버튼을 클릭하면 Trusted Advisor가 시작되며 사용 중인 계정의 모든 리소스에 대한 관련 데이터를 모두 가져와 다시 제공합니다.
준비가 되면 새로 고침 상태가 업데이트됩니다.
CloudWatch 이벤트 규칙이 새로운 기능으로 추가되었습니다.
이것은 Trusted Advisor가 실제로 새로 고침을 처리할 때마다 자동으로 수신 대기하도록 설정된 규칙의 한 예에 속합니다.
이 경우, Lambda 함수나 그 밖의 일부 활동을 설정하여 특정 검사 및 특정한 전체 상태 변경 사항과 관련해 알림을 제공하거나 조치를 취할 수 있습니다.
심지어는 특정 리소스에 대한 특정 규칙을 설정하고 이를 자신의 조직과 관련시킬 수도 있습니다.
마지막으로 고객이 보유한 리소스와 관련된 특정 태그를 입력할 수 있는 태깅 필터 기능이 있으며 해당 태그의 존재 여부와 상관없이 모든 관련 검사 결과가 필터링됩니다.
지금까지 AWS Console Trusted Advisor 경험에 대한 간략한 개요와 함께 그 특징 및 기능을 일부 살펴보았습니다.
이제 마이크를 Tipu에게 넘기겠습니다.
고마워요, Alex.
요약하자면 Trusted Advisor는 비용을 최적화하고 성능을 향상시키며 내결함성을 높이면서 보안을 구현하는 데 도움을 줄 수 있습니다.
이번 시간에 뭔가 조금이라도 배운 후에 다른 동영상을 계속 살펴보기 바랍니다.
이상 AWS Support 팀의 Tipu Qureshi와 Alex Buell의 설명을 마칩니다.
시청해 주셔서 감사합니다.

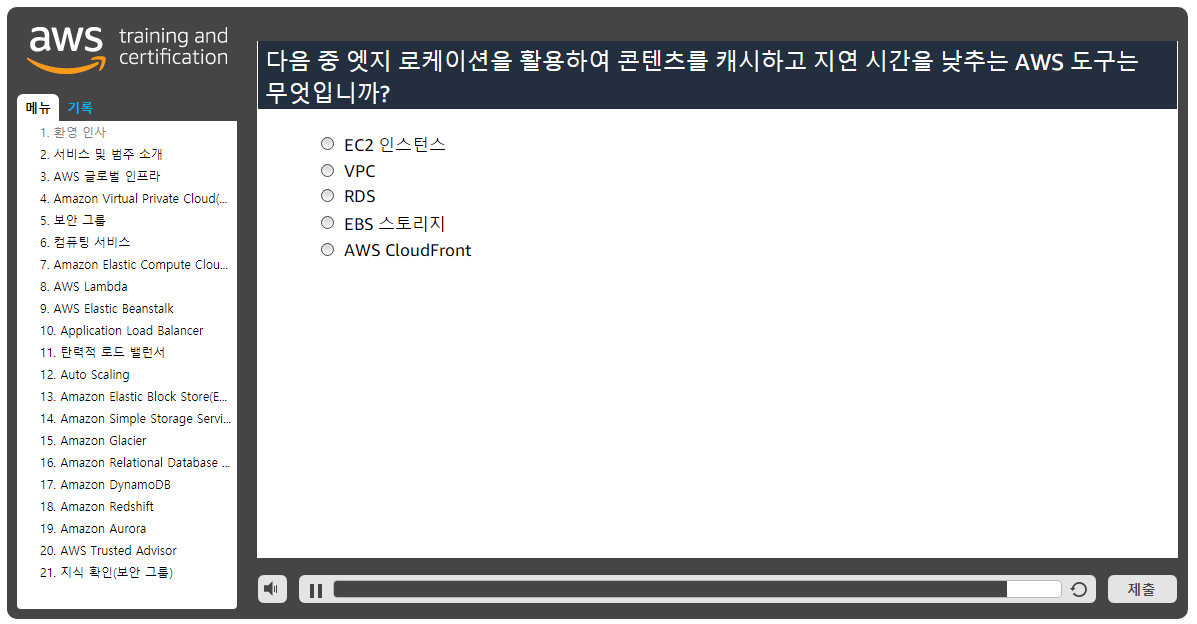


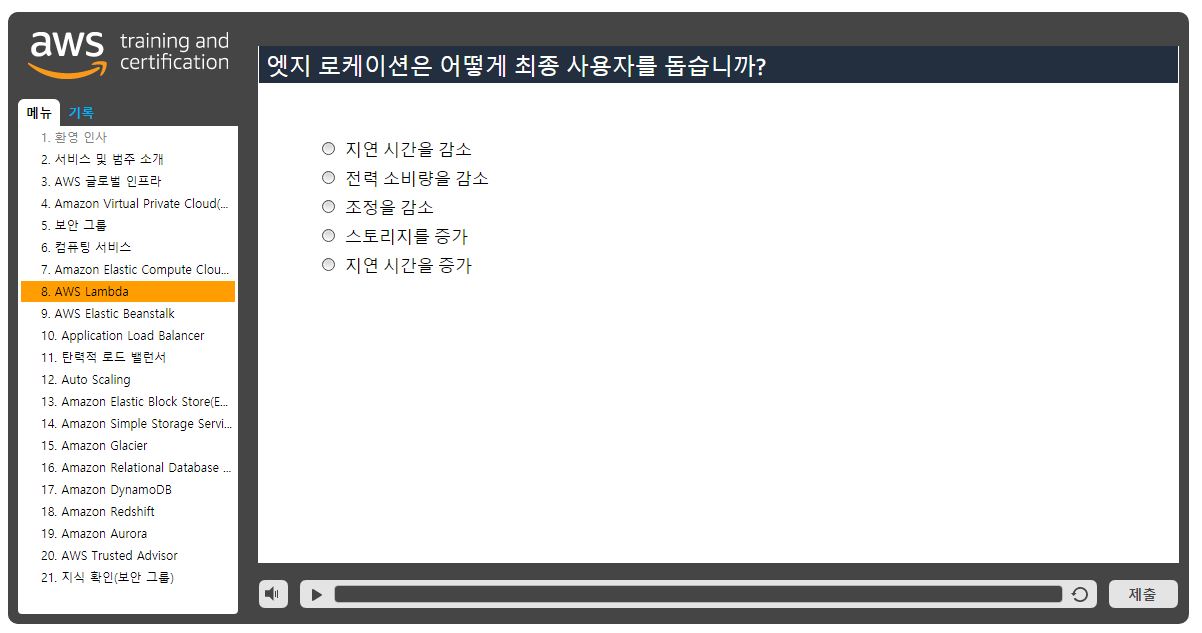
'IoT > AWS Certificate' 카테고리의 다른 글
| Udemy - Amazon Web Services (AWS) Certified - 4 Certifications! (0) | 2020.04.03 |
|---|---|
| AWS Practitioner Certificate - Free Braindumps (0) | 2020.02.18 |
| AWS Certified Cloud Practitioner - BackSpace Academy - Udemy course (0) | 2020.02.13 |
| AWS Cloud Practitioner Essentials (Digital) (Korean) - 03 (0) | 2020.01.05 |
| AWS Cloud Practitioner Essentials (Digital) (Korean) - 02 (0) | 2020.01.02 |
| AWS Certified developer associate exam samples 2 (0) | 2018.02.15 |
| AWS Certified developer associate exam samples (2) | 2018.01.26 |
| [AWS Certificate] Developer - VPC memo (1) | 2017.11.29 |
| [AWS Certificate] Developer - Route53 memo (0) | 2017.11.25 |
| [AWS Certificate] Developer - CloudFormation, Shared Responsibility Model and DNS Basic (0) | 2017.11.21 |