Udemy - AWS Machine Learning, AI, SageMaker - With Python

Summary
Section 3 Linear Regression
23. Summary
Squared Loss Function is parabolic in nature. It has an important property of not only telling us the loss at a given weight, but also tells us which way to go to minimize loss
Gradient Descent optimization algorithm uses loss function to move the weights of all the features and iteratively adjusts the weights until optimal value is reached
Batch Gradient Descent predicts y value for all training examples and then adjusts the value of weights based on loss. It can converge much slower when training set is very large. Training set order does not matter as every single example in the training set is considered before making adjustments.
Stochastic Gradient Descent predicts y value for next training example and immediately adjusts the value of weights. It can converge faster when training set is very large. Training set should be random order otherwise model will not learn correctly. AWS ML uses stochastic Gradient Descent
Section 4 AWS - Linear Regression Models
27. Concept - How to evaluate regression model accuracy?
Linear Regression - Residuals
- AWS ML Console provides a Histogram that shows distribution of examples that were over estimated and underestimated and to what extent
- Available as "explore model performance" option under Evaluation -> Summary
- Ideal: Over/Under estimation should be a normal curve centered at 0.
- Structural Issue: When you observe vast majority of example falling into one side. Adding more relevant features can help remedy the situation.
31. Model Performance Summary and Conclusion
RMSE (Root Mean Square Error) is the evaluation metric for Linear Regression. Smaller the value of RMSE, better the predictive accuracy of model. Perfect model would have RMSE of 0.
To prepare data for AWS ML, it requires data to be in
1. CSV file available in S3
2. AWS Redshift Datawarehouse
3. AWS Relational Database Service (RDS) MySQL DB
Batch Prediction results are stored by AWS ML to S3 in the specified bucket
We pulled the data from S3 to local folder and plotted them
Based on the distribution of data, AWS ML suggests a recipe for processing data.
In case of numeric features, it may suggest binning the data instead of treating a raw numeric
For this example, treating x as numeric provided best results
Section 5 Adding Features To Improve Model
35. Summary
1. Underfitting occurs when model does not accurately capture relationship between features and target
2. Underfitting would cause large training errors and evaluation errors
Training RMSE: 385.1816, Evaluation RMSE: 257.8979, Baseline RMSE: 437.311
3. Evaluation Summary - Prediction overestimation and underestimation histogram provided by AWS ML console provides important clues on how the model is behaving, under-estimation and over-estimation needs to be balanced and centered around 0
4. Box plot also highlights distribution differences between predicted and actual-negatives
5. To address underfitting, add higher order polynomials or more relevant features to capture complex relationship
Training RMSE: 132.2032, Evaluation RMSE: 63.6847, Baseline RMSE: 437.311
6. When working with datasets containing 100s or even 1000s of features, it important to rely on these metrics and distribution to gain insight into model performance
Section 6 Normalization
37. Concept: Normalization to smoothen magnitude differences
Normalization Transformation (Numeric)
- When there are very large differences in magnitude of features, features that have large magnitude can dominate Model
- Example : We saw this in Quadratic Extra Features dataset
- Normalization is a process of transforming features to have a mean of 0 and variance of 1. This will ensure all features have similar scale
: Feature normalized = (feature - mean) / (sigma)
where,
mean = mean of feature x
sigma = standard deviation of feature x
: Usage : normalize (numericFeature0
- Optimization algorithm may also converge faster with normalized features compared to features that have very large scale differences
39. Summary
1. Having lot of features and complex features can help improve prediction accuracy
2. When feature ranges are orders of magnitude different, it can dominate the outcome. Normalization is a process of transforming features to have a mean of 0 and variance of 1. This will ensure all feature have similar scale.
3. Without Normalization:
Training RMSE: 83973.66, Evaluation RMSE: 158260.62, Baseline RMSE: 437.31
4. With Normalization:
Training RMSE: 72.35, Evaluation RMSE: 51.7387, Baseline RMSE: 437.31
5. Normalization can be easily enabled using AWS ML Transformation recipes
Section 7 Adding Complex Features
46. Summary
Adding polynomial features allows us fit more complex shapes
To add polynomial features that combines all input features, use sci-kit module library. Anaconda includes these modules by default
We saw good performance with degree 4 and any additional feature may bring incremental improvement, but with added complexity of managing features.
1. Model Degree 1 Training RMSE:0.5063, Evaluation RMSE:0.4308, Baseline RMSE:0.689
2. Model Degree 4 Training RMSE:0.2563, Evaluation RMSE:0.1493, Baseline RMSE:0.689
3. Model Degree 15 Training RMSE:0.2984, Evaluation RMSE:0.1222, Baseline RMSE:0.689

Section 8 Kaggle Bike Hourly Rental Prediction
50. Linear Regression Wrapup and Summary
AWS ML - Linear Regression
* Linear Model
* Gradient Descent and Stochastic Gradient Descent
* Squared Error Loss Function
* AWS ML Training, Evaluation, Interactive Prediction, Batch Prediction
* Prediction Quality
- RMSE
- Residual Histograms
* Data visualization
* Normalization
* Higher order polynomials
Section 9 - Logistic Regression Models
Image result for Linear vs. Logistic regression model
In short: Linear Regression gives continuous output. i.e. any value between a range of values. ... GLM(Generalized linear models) does not assume a linear relationship between dependent and independent variables. However, it assumes a linear relationship between link function and independent variables in logit model.
https://stackoverflow.com/questions/12146914/what-is-the-difference-between-linear-regression-and-logistic-regression
https://techdifferences.com/difference-between-linear-and-logistic-regression.html
58. Summary
Binary Classifier : Predicts positive class probability of an observation
Logistic or Sigmod function has an important property where output is between 0 and 1 for any input. This output is used by binary classifiers as a probability of positive class.
True Positive - Samples that are actual-positives correctly predicted as positive
True Negative - Samples that are actual-negatives correctly predicted as negative
False Negative - Sampleas that are actual-positives incorrectly predicted as negative
False Positive - Samples that are actual-negatives incorrectly predicted as positive
Logistic Loss Function is parabolic in nature. It has an important property of not only telling us the loss at a given weight. but also tells us which way to go to minimize loss
Gradient Descent optimization algorithm uses loss function to move the weights of all the features and iteratively adjusts the weights until optimal value is reached
Batch Gradient Descent predicts y value for all training examples and then adjusts the value of weights based on loss. It can converge much slower when training set is very large. Training set order does not matter as every single example in the training set is considered before making adjustments.
Stochastic Gradient Descent predicts y value for next training example and immediately adjusts the value of weights. It can converge faster when training set is very large. Training set should be random order otherwise model will not learn correctly. AWS ML uses stochastic Gradient Descent
Section 10
62
Classification Metrics
True Positive = count(model correctly predicted positives). Students who passed exam correctly classified as pass.
True Negative = count (model correctly predicted negatives). Students who failed exam correctly classfied as fail.
False Positive = count (model misclassified negative as positive). Students who failed exam incorrectly classified as pass.
False Negative = count (model misclassified positive as negative). Students who passes exam incorrectly classified as fail.
* True Positive Rate, Recall, Probability of detection - Fraction of positive predicted correctly. larger value indicates better predictive accuracy.
TPR = True Positive / Actual Positive
* False Positive Rate, probability of false alarm - Fraction of negative predicted as positive. Smaller value indicates better predictive accuracy
FPR = False Positive / Actual Negative
* Precision - Fraction of true positive among all predicted positive. Larger value indicates better predictive accuracy
Precision = True Positive / Predicted Positive
* Accuracy - Fraction of correct predictions. Larger value indicates better predictive accuracy
Accuracy = True Positive + True Negative / negative
where, n is the number of examples
63.
Classification Insights with AWS Histograms
Histogram - Binary Classifier
* Positive and Negative histograms
* Interactive tool to test effect of various cut-off thresholds
* Ability to save a threshold for the model
* Available under :
Model -> Evaluation Summary -> Explore Performance
https://docs.aws.amazon.com/machine-learning/latest/dg/binary-model-insights.html
64
Concept: AUC Metric
AUC - Binary Classifer
* Area Under Curve(AUC) metric - 0 to 1. Larger Value indicates better predictive accuracy
* AUC is the area of a curve formed by plotting True Positive Rate against False positive Rate at different cut-off thresholds
* AUC value of 0.5 is baseline and it is considered random-guess
* AUC closer to 1 indicates better predictive accuracy
* AUC closer to 0 indicates model has learned correct patterns, but flipping predictions (0's are predicted as 1's and vice versa).
69 Summary
For Binary Classification, Area Under Curve (AUC) is the evaluation metric to assess the quality of model
AUC is the area of a curve formed by plotting True Positive Rate against False Positive Rate at different cut-off thresholds.
* AUC metric closer to 1 indicates highly accurate prediction
* AUC metric 0.5 indicates random guess - Baseline AUC
* AUC metric closer to 0 indicates model has learned from the features, but predictions are flipped
Advanced Metrics
* Accuracy - Fraction of correct predictions. Larger value indicates better predictive accuracy
* True Positive Rate - Probability of detection. Out of all positive, how many were correctly predicted as positive. Larger value indicates better predictive accuracy
* False Positive Rate _ Probability of false alarm. Smaller value indicates better predictive accuracy. Out of all negatives, how many were incorrectly predicted as positive.
* Precision - out of all predicted as positive, how man are true positive? Larger value indicates better predictive accuracy.
Section 11
72 Concept: Evaluating Predictive Quality of Multiclass Classifiers
Multi-class metrics
* F1 Score - Harmonic mean of Recall and Precision. Larger F1 Score indicates better predictive accuracy. Binary Metic
F1 Score = 2.Precision.Recall / Precision + Recall
* Average F1 Score - For multi-class problems, average of class wise F1 score is used for accessing predictive quality
* Baseline F1 Score - Hypothentical model that predicts only most frequent class as the answer
Concept: Confusion Matrix To Evaluating Predictive Quality
Multiclass - Metrics - Confusion Matrix
* Accessible from Model -> Evaluation Summary -> Explore Model performance
* Concise table that shows percentage and count of correct classification and incorrect classifications
* Visual look at model performance
* Up to 10 classes are shown - listed from most frequent to least frequent
* For more than 10 classes, first 9 most freq. classes are shown and 10th class will collapse rest of the classes and mark as otherwise
* Option to download confusion matrix
* https://docs.aws.amazon.com/machine-learning/latest/dg/multiclass-model-insights.html
77. Summary
Multi-Class Evaluation Metric
1. F1 Score is a binary classification metic. It is harmonic mean of precision and recall
F1 Score = 2 X Precision X Recall / (Precision + Recall)
Higher F1 Score reflects better predictive accuracy
2. Multi-Class Evaluation
Average of class wise F1 Score
3. Baseline F1 Score = Hypothetical model that predicts only most frequent class as the answer
4. Visualization - Confusion Matrix - Available on AWS ML Console
Matrix. Rows = true class. Columns = predicted class
Cell color - diagonal indicates true class prediction %
Cell color - non-diagonal indicates incorrect prediction %
Last column is F1 score for that class. Last but one column is true class distribution
Last row is predicted class distribution
Upto 10 classes are shown - listed from most frequent to least frequent
For more than 10 classes, first 9 most freq. classes are shown and 10th class will collapse rest of the classes and mark as otherwise
You can download the confusion matrix thru url-Explore Performance page under Evaluations
Prediction Summary
1. Eval with default recipe settings. Average F1 score: 0.905
2. Eval with numeric recipe settings: Average F1 score: 0.827
3. Batch prediction Results (predict all 150 example outcome)
a. With default recipe settings: Average F1 Score: 0.973
b. With numeric recipe settings:Average F1 Score: 0.78
4. Classification was better with binning. Versicolor classification was impacted when numeric setting was used
5. Higher F1 Score implies better prediction accuracy
Section 12 Text Based Classification with AWS Twitter Dataset
78. AWS Twitter Feed Classification for Customer Service
https://github.com/aws-samples/machine-learning-samples/tree/master/social-media
79. Lab: Train, Evaluate Model and Assess Predictive Quality, 80. Lab: Interactive Prediction with AWS
- Practice
81. Logistic Regression Summary
AWS ML - Logistic Regression
- Linear Model
- Logistic/Sigmoid Function to produce a probability
- Stochastic Gradient Descent
- Logistic Loss function
- AWS ML Training, Evaluation, Interactive Prediction, Batch Prediction
- Prediction Quality
: TPR
: FPR
: Accuracy
:Prediction
: AUC Metrics
: F1 Score
: Average F1 Score for multi-class
- Data visualization
- Text Processing
- Normalization
- Higher order polynomials
Section 13
82. Recipe Overview
Recipe
- Recipe is a set of instructions for pre-processing data
- Recipe is a JSON like document
- Consists of three parts: Groups, Assignments, Outputs
- Groups - Groups are collection of features for which similar transformation needs to be applied
: Built-in Group : ALL_TEXT, ALL_NUMERIC, ALL_CATEGORICAL, ALL_BINARY
: Define your own groups
- Assignments - Enable creation of new features derived from existing ones
- Outputs - List features used for learning process and optionally apply transformation
Recipe is automatically applied to training data, evaluation data and to data submitted through real-time and batch prediction APIs
83. Recepe Example
84. Text Transformation
* N-gram Text Transformation
- Tokenizes input text and combines them into a slideing window of n-words, where n is specified in the recipe
- Usage: ngram(textFeature, n), where n is the size
- By default all text data is tokenized with n=1
: Example: "Customer requests urgent response" text is tokenized as {"Customer", "requests", "urgent", "response"}
- With n=2, it generates one word and two word combinations
: {"Customer requests", "requests urgent", urgent response", "Customer", "requests", "urgent", "response"}
- N-grams of size up to 10 is supported
- N-grams breaks texts at whitespace. Punctuations will be considered part of word
- You can remove punctuations using no_punct transformation
* OSB Text Transformation
- Orthogonal Spare Bigram (OSB) Transformation provides more word combinations compared to n-gram
- Usage: osb(textFeature, size)
- Puts one underscore to indicate word boundary as well as every word skipped
- For example (AWS Document provided sample).
https://docs.aws.amazon.com/ko_kr/machine-learning/latest/dg/data-transformations-reference.html
Text: "The quick brown fox jumps over the lazy dog". osb(text,4)
WINDOW,{OSB GENERATED}
"The quick brown fox", {The_quick, The__brown, The___fox}
"quick brown fox jumps", {quick_brown, quick__fox, quick___jumps}
"brown fox jumps over", {brown_fox, brown__jumps, brown___over}
"fox jumps over the", {fox_jumps, fox__over, fox___the}
"jumps over the lazy", {jumps_over, jumps__the, jumps___lazy}
"over the lazy dog", {over_the, over__lazy, over___dog}
"the lazy dog", {the_lazy, the__dog}
"lazy dog", {lazy_dog}
* Lowercase and Punctuation
- Lower Case Transformation converts text to lowercase
: Usage : lowercase(textFeature)
: Example: "The Quick Brown Fox Jumps Over the Lazy Dog" -> "the quick brown fox jumps over the lazy dog"
- Remove punctuation Transformation - removes punctuations at word boundaries
: Usage: nopunct(textFeature)
: Example: "Customer Number: 123. Ord-No: AB1235" will be by default tokenized as
{"Customer","Number:","123.","Ord-No:","AB1235"}
: With nopunct transformation -> {"Customer","Number","123","ord-No","AB1235"}
: Note: only prefix, suffix punctuations are removed. Embedded punctuations are not removed "Ord-No"
85. Numeric Transformation - Quantile Binning
* Quantile Binning Transformation (Numeric)
- Used for converting a numeric value into a categorical bin number
- Usage: quantile_bin(numericFeature, n), where n is the number of bins
- AWS ML uses this information to establish n bins of equal size based on the distribution of all values of the specified numeric feature.
- It then maps incoming numericFeature value to corresponding bin and outputs bin number as categorical value
- AWS ML Recommendation: In some cases, relationship between numeric variable and target is not linear...... binning might be usful in those scenarios
- We actually saw where binning improved predictive accuracy with Iris Dataset
86. Numeric Transformation - Normalization
Normalization Transformation (Numeric)
- When there are very large differences in magnitude of features, features that have large magnitude can dominate Model
- Example: We saw this in Quadratic Extra Features dataset
- Normalization is a process of transforming features to have a mean of 0 and variance of 1. This will enshre all features have similar scale.
: Example Feature normalized = (feature - mean)/(sigma)
where,
mean = mean of feature x
sigma = standard deviation of feature x
: Usage normalize(numericFeature)
- Optimization algorithm may also converge faster with normalized features compared to features that have very large scale differences
87. Cartesian Product Transformation - Categorical and Text
* Cartesian Product Transformation (Categorical, Text)
- Cartesian transformation generates permutations of two or more text and categorical input variables
- For example: Season and Hour combined may have stronger influence on bike rentals. Instead of treating these two as separate features, we can create a new feature Season_Hour that will combine these values.
- Usage cartesian(feature1, feature2)
- Combined features may be able to more accurately related the target attribute
Table
88. Summary
Data Transformation
Section: 14 Hyper Parameters, Model Optimization and Lifecycle
Hyper Parameters allow you to control the model building process and quality
90. Data Rearrangement, Maximum model Size, passes, Shuffle Type
Table
93. Improving Model Quality
Optimizing Model
- To improve a model following are some options
: Add more training examples
: Add more relevant features
: Model hyperparameter tuning
- Quality Metrics of Training Data and Evaluation Data can provide important clues to improve model performance
94. Model Maintenance
- Models may need to be periodically rebuilt or updated to
: Keep in-sync with new patterns
: Support new more relevant features
: Support new class - in multi - class problems
: Changes in assumptions or distribution of data that was used to train model
: Changes to cut-off threshold
Example: Home price changes month to month depending on several factors
- Have a plan to evaluate model with new data periodically. Example: Weekly, Monthly, Quartly
- Models are probabilistic in nature...
: Binary Class - Provides bestAnswer(1 or 0) and a raw prediction score. Cut-off score is configurable
: Multi Class - Provides prediction score for each class. It can be interpreted as probability of observation belonging to the class. Class with highest score is the best answer
: Regression : Provides a score that contains raw numeric prediction of the target attribute.
- When models are changed, predicted results would also change - Quality metrics like AUC, F1 Score, RMSE can be used to determine whether to go ahead with proposed model change
95. AWS Machine Learning System Limits
- AWS ML imposes certain limits to ensure robust and reliable service
- Some are soft limits and can be increased by contacting AWS Customer Service
- Size of each observation: 100KB
- Size of training data: 100GB
- Size of batch prediction input: 1TB (single file limit. can be overcome by creating more batch files)
- No. of records per batch file: 100 million
- No. of variables/features: 10,000
- Throughput per second for realtime prediction: 200 requests/second
- Max Number of classes per multi-class model: 100
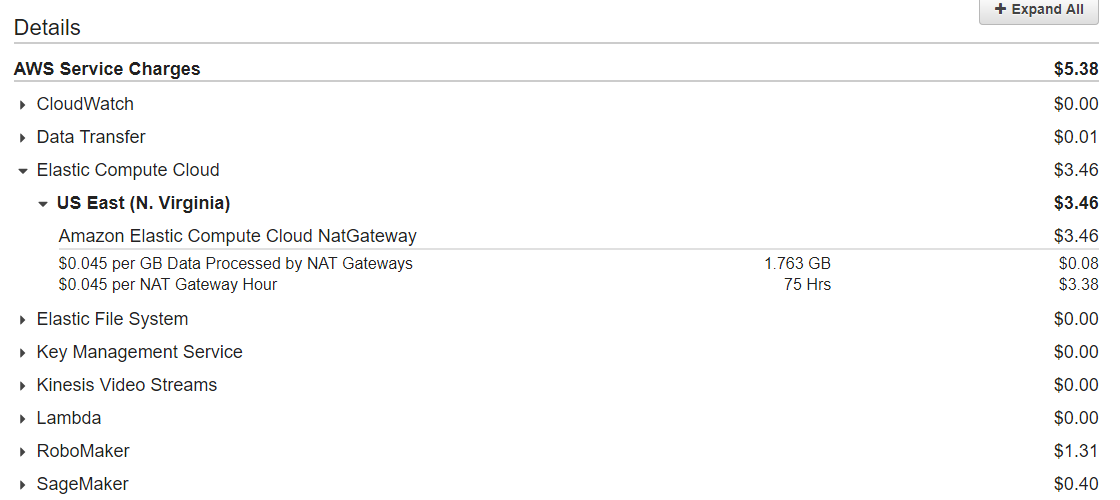
96. AWS Machine Learning Pricing
- Data Analysis and Model Building Fee - $0.42 per Hour of building time
: Number of computer hours required for data analysis, model training and evaluation
: Depends on size of input data, attributes, types of transformations applied
- Predictions Fees
: Batch predictions - $0.10/1,000 predictions founded to the nearest 1,000
: Real-time predictions - $0.0001 per prediction + Capacity reservation charge of $0.001 per hour for each 10MB provisioned for your model
Section 15 Integration of AWS Machine Learning With Your Application
98. Introduction
AWS ML Integration
- Speed!
: Turn your ideas into cool products in a matter of days
: Traditional approach would require months
- Highly scalable, secure service with redundancy built-in
: Scale automatically to train model with very large datasets
: Scale automatically to support high volume prediction needs
: Real-time prediction with capacity reservation
: Secure - Limit access to Authenticated and Authorized services and users
- Server less!
- Software Integration
: AWS Machine Learning - Complete functionality is accessible through SDK and Command Line Interfaces
: Model building and Prediction can be fully automated using SDK
: AWS SDKs in multiple lanuages - Python, Java, .NET, Javascript, Ruby, C++, ....
: Complete list languages https://aws.amazon.com/tools/
99. Integration Scenarios
Connectivity and Security Options
- You Data Center -> AWS ML Cloud Service
: Security: Key Based Authentication + IAM Policy + SSL
- AWS Hosted Application -> AWS ML Cloud Service
: Security : IAM Role + SSL
- Browser, Apps on Phone -> AWS ML Cloud Service
: Option 1: AWS Cognito Based Authentication + IAM Role + SSL
: Choice of authentication providers: Cognito, Google, Amazon, Facebook, Twitter, OpenID, Customer
: Option 2 : Key Based Authentication + IAM Policy + SSL
100. Security using IAM
Users belong to AWS root account. Cognito Users are application level users. Application belongs to AWS root account.















 GuideStandoutSkillFinal.pdf
GuideStandoutSkillFinal.pdf












































