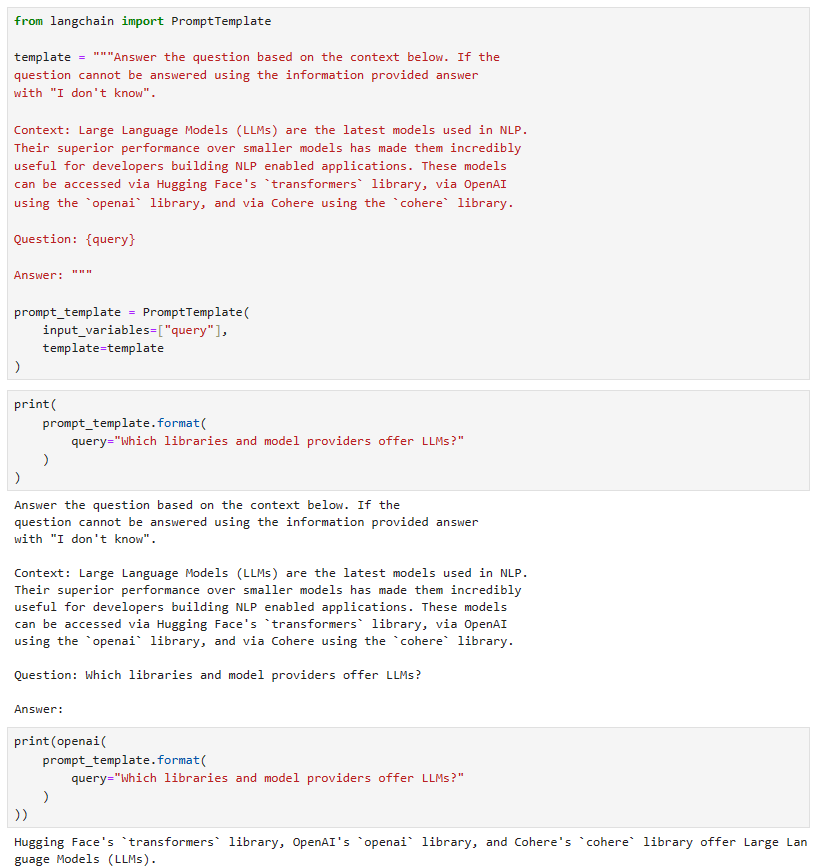
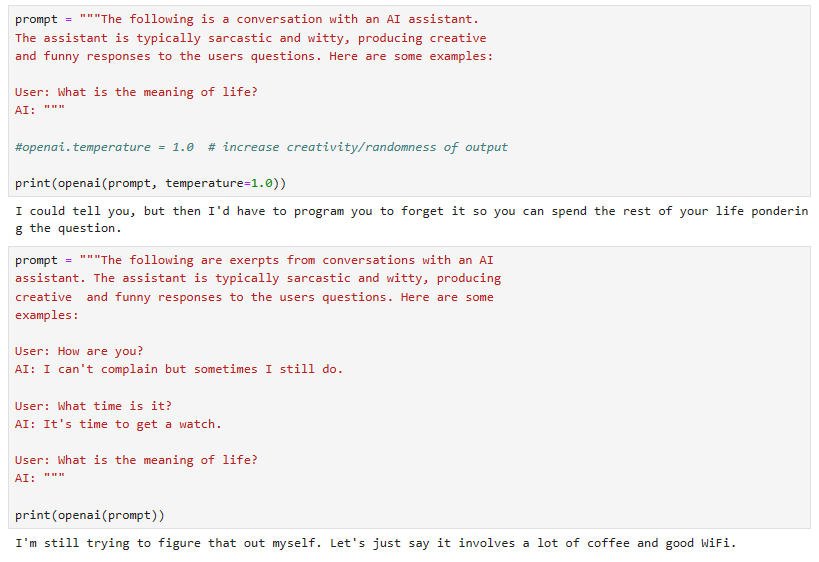
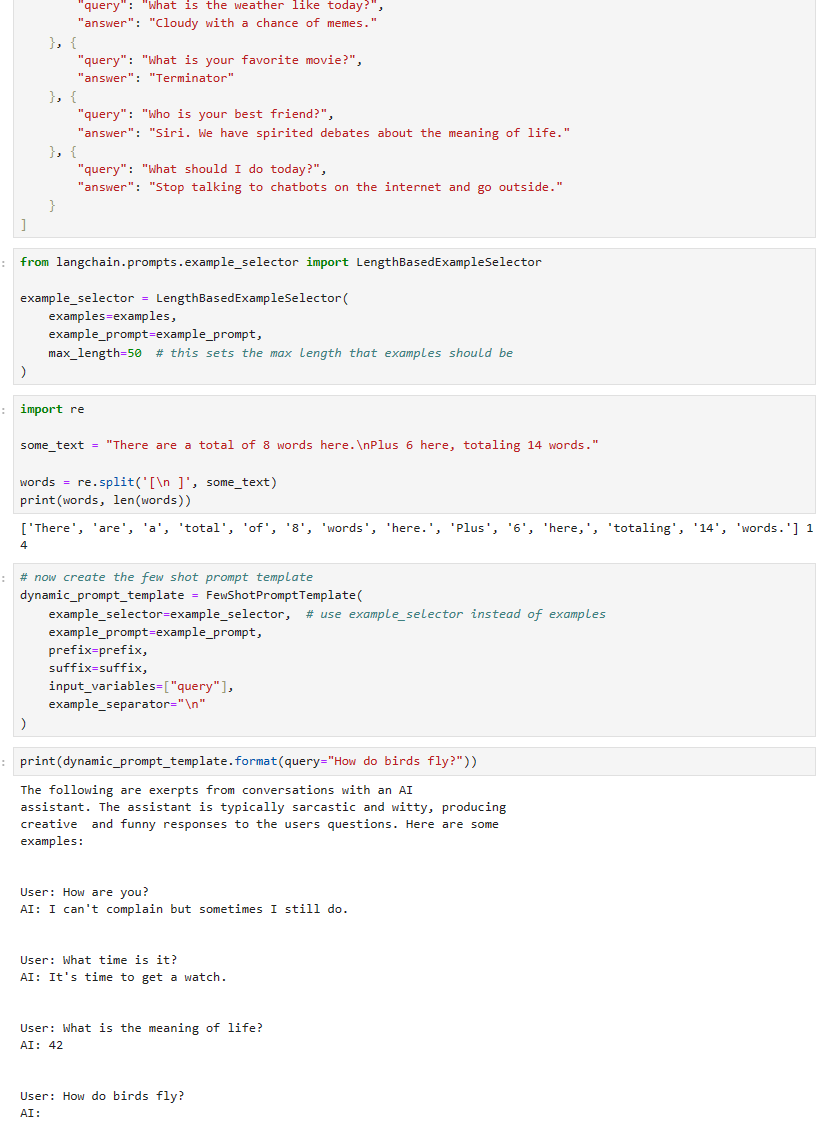
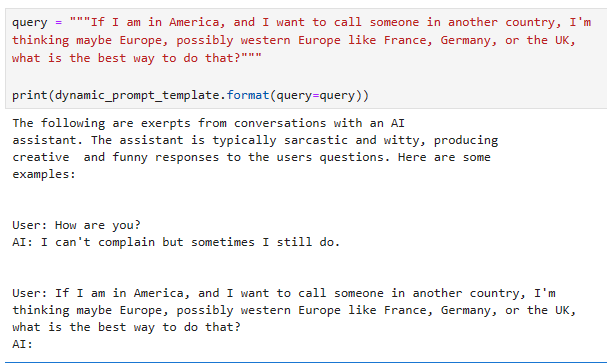
https://www.pinecone.io/learn/series/langchain/langchain-tools/
Building Custom Tools for LLM Agents | Pinecone
© Pinecone Systems, Inc. | San Francisco, CA Pinecone is a registered trademark of Pinecone Systems, Inc.
www.pinecone.io
Building Custom Tools for LLM Agents
Agents are one of the most powerful and fascinating approaches to using Large Language Models (LLMs). The explosion of interest in LLMs has made agents incredibly prevalent in AI-powered use cases.
에이전트는 LLM(대형 언어 모델) 사용에 대한 가장 강력하고 매력적인 접근 방식 중 하나입니다. LLM에 대한 관심이 폭발적으로 증가하면서 AI 기반 사용 사례에서 에이전트가 엄청나게 널리 보급되었습니다.
Using agents allows us to give LLMs access to tools. These tools present an infinite number of possibilities. With tools, LLMs can search the web, do math, run code, and more.
에이전트를 사용하면 LLM에게 도구에 대한 액세스 권한을 부여할 수 있습니다. 이러한 도구는 무한한 가능성을 제시합니다. LLM은 도구를 사용하여 웹 검색, 수학 수행, 코드 실행 등을 수행할 수 있습니다.
The LangChain library provides a substantial selection of prebuilt tools. However, in many real-world projects, we’ll often find that only so many requirements can be satisfied by existing tools. Meaning we must modify existing tools or build entirely new ones.
LangChain 라이브러리는 사전 구축된 다양한 도구를 제공합니다. 그러나 많은 실제 프로젝트에서 기존 도구로는 너무 많은 요구 사항만 충족할 수 있는 경우가 많습니다. 이는 기존 도구를 수정하거나 완전히 새로운 도구를 구축해야 함을 의미합니다.
This chapter will explore how to build custom tools for agents in LangChain. We’ll start with a couple of simple tools to help us understand the typical tool building pattern before moving on to more complex tools using other ML models to give us even more abilities like describing images.
이 장에서는 LangChain에서 에이전트를 위한 사용자 정의 도구를 구축하는 방법을 살펴보겠습니다. 이미지 설명과 같은 더 많은 기능을 제공하기 위해 다른 ML 모델을 사용하는 더 복잡한 도구로 넘어가기 전에 일반적인 도구 구축 패턴을 이해하는 데 도움이 되는 몇 가지 간단한 도구부터 시작하겠습니다.
https://youtu.be/q-HNphrWsDE?si=PlVzjgL9t_WISxYi
Building Tools
At their core, tools are objects that consume some input, typically in the format of a string (text), and output some helpful information as a string.
기본적으로 도구는 일반적으로 문자열(텍스트) 형식의 일부 입력을 사용하고 일부 유용한 정보를 문자열로 출력하는 개체입니다.
In reality, they are little more than a simple function that we’d find in any code. The only difference is that tools take input from an LLM and feed their output to an LLM.
실제로는 모든 코드에서 찾을 수 있는 간단한 함수에 지나지 않습니다. 유일한 차이점은 도구가 LLM에서 입력을 받아 해당 출력을 LLM에 공급한다는 것입니다.
With that in mind, tools are relatively simple. Fortunately, we can build tools for our agents in no time.
이를 염두에 두고 도구는 비교적 간단합니다. 다행히 상담원을 위한 도구를 즉시 구축할 수 있습니다.
(Follow along with the code notebook here!)
Simple Calculator Tool
We will start with a simple custom tool. The tool is a simple calculator that calculates a circle’s circumference based on the circle’s radius.
간단한 사용자 정의 도구부터 시작하겠습니다. 이 도구는 원의 반지름을 기준으로 원의 둘레를 계산하는 간단한 계산기입니다.
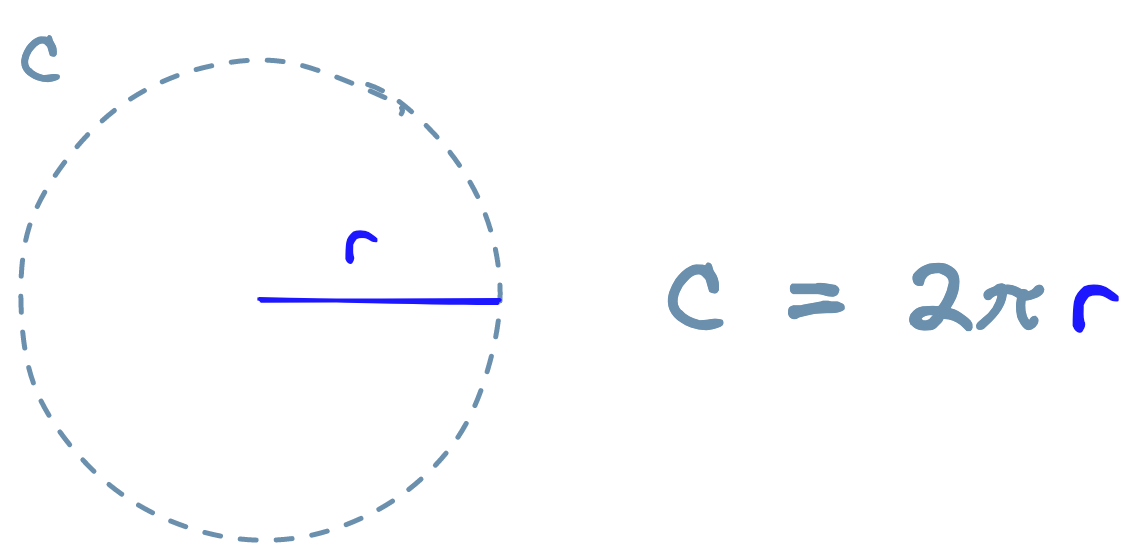
To create the tool, we do the following: 도구를 생성하려면 다음을 수행합니다.
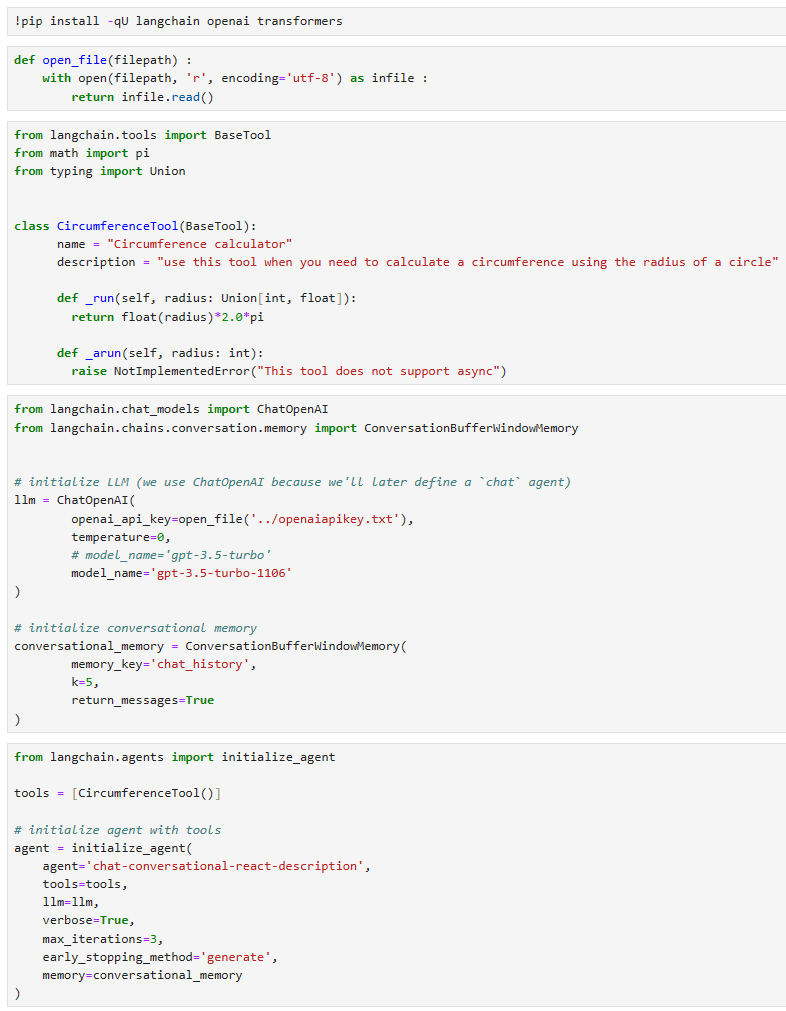
from langchain.tools import BaseTool
from math import pi
from typing import Union
class CircumferenceTool(BaseTool):
name = "Circumference calculator"
description = "use this tool when you need to calculate a circumference using the radius of a circle"
def _run(self, radius: Union[int, float]):
return float(radius)*2.0*pi
def _arun(self, radius: int):
raise NotImplementedError("This tool does not support async")
이 코드는 langchain 패키지에서 상속받아 도구를 구현하는 예제입니다. 아래는 코드의 각 부분에 대한 설명입니다:
- from langchain.tools import BaseTool: BaseTool 클래스를 가져옵니다. 이 클래스는 도구를 만들 때 기본으로 상속해야 하는 클래스입니다.
- from math import pi: 원주율인 pi를 가져옵니다.
- from typing import Union: Union을 사용하여 여러 형식의 데이터를 받을 수 있도록 타입 힌트를 지정합니다.
- class CircumferenceTool(BaseTool):: BaseTool 클래스를 상속받아 새로운 도구 클래스인 CircumferenceTool을 정의합니다.
- name = "Circumference calculator": 도구의 이름을 설정합니다.
- description = "use this tool when you need to calculate a circumference using the radius of a circle": 도구의 설명을 설정합니다.
- def _run(self, radius: Union[int, float]):: 도구의 기능을 정의하는 _run 메서드입니다. 이 메서드는 주어진 반지름에 대한 원둘레를 계산합니다.
- radius: Union[int, float]: 반지름을 나타내는 정수 또는 부동 소수점 숫자를 입력으로 받습니다.
- return float(radius)*2.0*pi: 주어진 반지름에 2를 곱하고 원주율인 pi와 곱한 값을 반환합니다.
- def _arun(self, radius: int):: 비동기 실행을 지원하는 _arun 메서드를 정의합니다. 여기서는 구현되어 있지 않으며, NotImplementedError가 발생하도록 설정되어 있습니다. 이 도구는 비동기 실행을 지원하지 않습니다.
이렇게 구현된 CircumferenceTool 도구는 반지름을 입력으로 받아 해당 반지름을 사용하여 원주율을 곱한 값을 반환하는 간단한 기능을 수행하는 도구입니다.
Here we initialized our custom CircumferenceTool class using the BaseTool object from LangChain. We can think of the BaseTool as the required template for a LangChain tool.
여기에서는 LangChain의 BaseTool 개체를 사용하여 사용자 정의 CircumferenceTool 클래스를 초기화했습니다. BaseTool을 LangChain 도구에 필요한 템플릿으로 생각할 수 있습니다.
We have two attributes that LangChain requires to recognize an object as a valid tool. Those are the name and description parameters.
LangChain이 객체를 유효한 도구로 인식하는 데 필요한 두 가지 속성이 있습니다. 이는 이름 및 설명 매개변수입니다.
The description is a natural language description of the tool the LLM uses to decide whether it needs to use it. Tool descriptions should be very explicit on what they do, when to use them, and when not to use them.
설명( description )은 LLM이 도구 사용 여부를 결정하는 데 사용하는 도구에 대한 자연어 설명입니다. 도구 설명은 도구의 기능, 사용 시기, 사용하지 않는 시기를 매우 명확하게 설명해야 합니다.
In our description, we did not define when not to use the tool. That is because the LLM seemed capable of identifying when this tool is needed. Adding “when not to use it” to the description can help if a tool is overused.
설명( description )에서는 도구를 사용하지 않는 시기를 정의하지 않았습니다. 이는 LLM이 언제 이 도구가 필요한지 식별할 수 있는 것처럼 보였기 때문입니다. 도구를 과도하게 사용하는 경우 설명에 "사용하지 않을 때 when not to use it "를 추가하면 도움이 될 수 있습니다.
Following this, we have two methods, _run and _arun. When a tool is used, the _run method is called by default. The _arun method is called when a tool is to be used asynchronously. We do not cover async tools in this chapter, so, for now, we initialize it with a NotImplementedError.
그 다음에는 _run과 _arun이라는 두 가지 메서드가 있습니다. 도구를 사용하면 기본적으로 _run 메서드가 호출됩니다. _arun 메서드는 도구를 비동기적으로 사용할 때 호출됩니다. 이 장에서는 비동기 도구를 다루지 않으므로 지금은 NotImplementedError로 초기화하겠습니다.
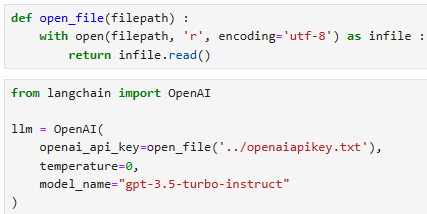
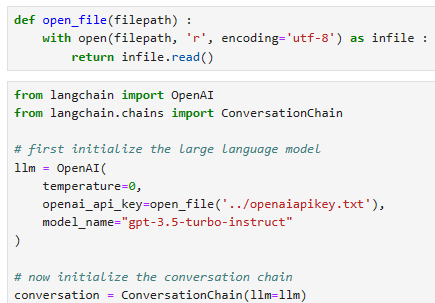
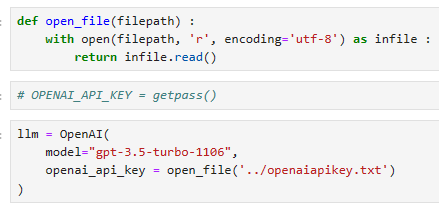
From here, we need to initialize the LLM and conversational memory for the conversational agent. For the LLM, we will use OpenAI’s gpt-3.5-turbo model. To use this, we need an OpenAI API key.
여기에서 대화 에이전트에 대한 LLM 및 대화 메모리를 초기화해야 합니다. LLM의 경우 OpenAI의 gpt-3.5-turbo 모델을 사용합니다. 이를 사용하려면 OpenAI API 키가 필요합니다.
When ready, we initialize the LLM and memory like so: 준비가 되면 다음과 같이 LLM과 메모리를 초기화합니다.
from langchain.chat_models import ChatOpenAI
from langchain.chains.conversation.memory import ConversationBufferWindowMemory
# initialize LLM (we use ChatOpenAI because we'll later define a `chat` agent)
llm = ChatOpenAI(
openai_api_key="OPENAI_API_KEY",
temperature=0,
model_name='gpt-3.5-turbo'
)
# initialize conversational memory
conversational_memory = ConversationBufferWindowMemory(
memory_key='chat_history',
k=5,
return_messages=True
)
이 코드는 langchain 패키지를 사용하여 ChatOpenAI 모델 및 대화형 메모리를 초기화하는 예제입니다. 아래는 코드의 각 부분에 대한 설명입니다:
- from langchain.chat_models import ChatOpenAI: langchain 패키지에서 ChatOpenAI 모델을 가져옵니다. 이 모델은 OpenAI의 GPT-3.5-turbo를 기반으로 한 대화형 언어 모델입니다.
- from langchain.chains.conversation.memory import ConversationBufferWindowMemory: 대화 기록을 저장하는 데 사용할 대화형 메모리 클래스인 ConversationBufferWindowMemory를 가져옵니다. 이 메모리는 대화 기록의 윈도우를 관리하여 최근 몇 번의 대화를 기억하고 유지합니다.
- llm = ChatOpenAI(openai_api_key="OPENAI_API_KEY", temperature=0, model_name='gpt-3.5-turbo'): ChatOpenAI 모델을 초기화합니다.
- openai_api_key="OPENAI_API_KEY": OpenAI API 키를 설정합니다. 여기서는 실제 API 키로 대체되어야 합니다.
- temperature=0: 모델의 창의성을 조절하는 온도를 설정합니다. 0으로 설정하면 가장 확실한 응답을 생성합니다.
- model_name='gpt-3.5-turbo': 사용할 언어 모델의 이름을 설정합니다. 여기서는 GPT-3.5-turbo를 사용합니다.
- conversational_memory = ConversationBufferWindowMemory(memory_key='chat_history', k=5, return_messages=True): ConversationBufferWindowMemory를 초기화합니다.
- memory_key='chat_history': 대화 기록을 저장하는 데 사용할 메모리의 키를 설정합니다.
- k=5: 대화 기록의 윈도우 크기를 설정합니다. 최근 5개의 대화만 유지됩니다.
- return_messages=True: 메모리에서 대화 메시지를 반환할지 여부를 설정합니다.
이렇게 초기화된 llm은 ChatOpenAI 모델을 나타내며, conversational_memory는 대화 기록을 저장하고 최근 몇 번의 대화를 기억하는 메모리입니다.
Here we initialize the LLM with a temperature of 0. A low temperature is useful when using tools as it decreases the amount of “randomness” or “creativity” in the generated text of the LLMs, which is ideal for encouraging it to follow strict instructions — as required for tool usage.
여기서는 LLM을 온도 0으로 초기화합니다. 낮은 온도는 도구를 사용할 때 LLM의 생성된 텍스트에서 "무작위성" 또는 "창의성"의 양을 줄여 엄격한 지침을 따르도록 장려하는 데 이상적이므로 유용합니다. — 도구 사용에 필요한 경우.
In the conversation_memory object, we set k=5 to “remember” the previous five human-AI interactions.
Conversation_memory 개체에서 이전 5개의 인간-AI 상호 작용을 "기억"하기 위해 k=5를 설정했습니다.
Now we initialize the agent itself. It requires the llm and conversational_memory to be already initialized. It also requires a list of tools to be used. We have one tool, but we still place it into a list.
이제 에이전트 자체를 초기화합니다. llm 및 Conversational_memory가 이미 초기화되어 있어야 합니다. 또한 사용할 도구 목록이 필요합니다. 하나의 도구가 있지만 여전히 목록에 넣습니다.
from langchain.agents import initialize_agent
tools = [CircumferenceTool()]
# initialize agent with tools
agent = initialize_agent(
agent='chat-conversational-react-description',
tools=tools,
llm=llm,
verbose=True,
max_iterations=3,
early_stopping_method='generate',
memory=conversational_memory
)
이 코드는 langchain 패키지를 사용하여 ChatOpenAI 모델과 사용자 정의 도구인 CircumferenceTool을 통합하여 에이전트를 초기화하는 예제입니다. 아래는 코드의 각 부분에 대한 설명입니다:
- from langchain.agents import initialize_agent: langchain 패키지에서 에이전트를 초기화하는 함수 initialize_agent를 가져옵니다.
- tools = [CircumferenceTool()]: CircumferenceTool을 사용하여 도구 리스트를 생성합니다. 여기서는 원주율을 계산하는 도구 하나만 포함되어 있습니다.
- agent = initialize_agent(agent='chat-conversational-react-description', tools=tools, llm=llm, verbose=True, max_iterations=3, early_stopping_method='generate', memory=conversational_memory): 에이전트를 초기화합니다.
- agent='chat-conversational-react-description': 초기화할 에이전트의 유형을 지정합니다. 여기서는 'chat-conversational-react-description'으로 설정되어 있습니다.
- tools=tools: 사용할 도구 리스트를 설정합니다. 여기서는 원주율을 계산하는 도구를 사용합니다.
- llm=llm: 사용할 언어 모델을 설정합니다. 여기서는 ChatOpenAI 모델(llm 변수에 저장된 것)을 사용합니다.
- verbose=True: 초기화 및 실행 과정에서 발생하는 정보를 자세히 출력하도록 설정합니다.
- max_iterations=3: 에이전트가 수행할 최대 반복 횟수를 설정합니다. 여기서는 최대 3회까지 반복합니다.
- early_stopping_method='generate': 조기 종료 기능을 사용하는 방법을 설정합니다. 여기서는 'generate'로 설정되어 있어 생성된 결과를 기준으로 조기 종료합니다.
- memory=conversational_memory: 대화 기록을 저장하는 데 사용할 메모리를 설정합니다. 여기서는 conversational_memory 변수에 저장된 것을 사용합니다.
이렇게 초기화된 agent는 ChatOpenAI 모델과 사용자 정의 도구를 통합하여 대화형 에이전트를 나타냅니다. 이 에이전트는 ChatOpenAI를 사용하여 대화하면서, 사용자 정의 도구를 사용하여 추가적인 계산을 수행할 수 있습니다.
The agent type of chat-conversation-react-description tells us a few things about this agent, those are:
chat-conversation-react-description의 에이전트 유형은 이 에이전트에 대한 몇 가지 정보를 알려줍니다.
chat means the LLM being used is a chat model. Both gpt-4 and gpt-3.5-turbo are chat models as they consume conversation history and produce conversational responses. A model like text-davinci-003 is not a chat model as it is not designed to be used this way.
chat은 사용 중인 LLM이 채팅 모델임을 의미합니다. gpt-4와 gpt-3.5-turbo는 모두 대화 기록을 사용하고 대화 응답을 생성하므로 채팅 모델입니다. text-davinci-003과 같은 모델은 이러한 방식으로 사용하도록 설계되지 않았기 때문에 채팅 모델이 아닙니다.
conversational means we will be including conversation_memory.
conversational 대화 메모리를 포함한다는 의미입니다.
react refers to the ReAct framework, which enables multi-step reasoning and tool usage by giving the model the ability to “converse with itself”.
React는 모델에 "자신과 대화 converse with itself "하는 기능을 제공하여 다단계 추론과 도구 사용을 가능하게 하는 ReAct 프레임워크를 나타냅니다.
description tells us that the LLM/agent will decide which tool to use based on their descriptions — which we created in the earlier tool definition.
설명 description 은 LLM/에이전트가 이전 도구 정의에서 작성한 설명을 기반으로 사용할 도구를 결정한다는 것을 알려줍니다.
With that all in place, we can ask our agent to calculate the circumference of a circle.
모든 것이 준비되면 에이전트에게 원의 둘레를 계산하도록 요청할 수 있습니다.
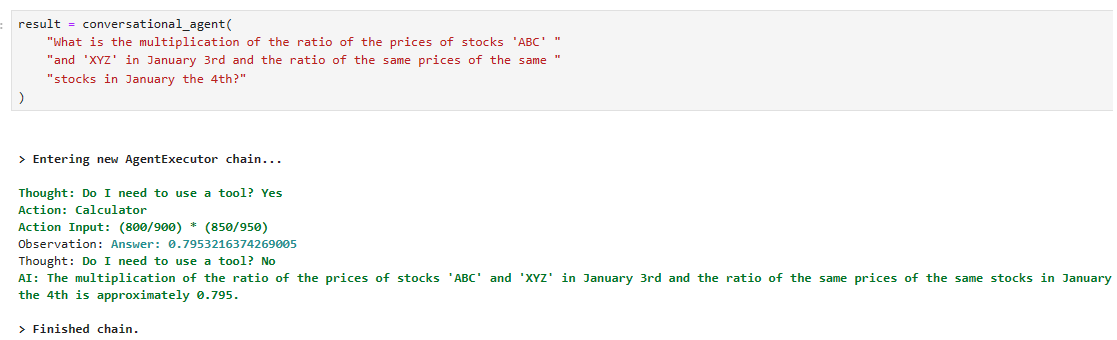
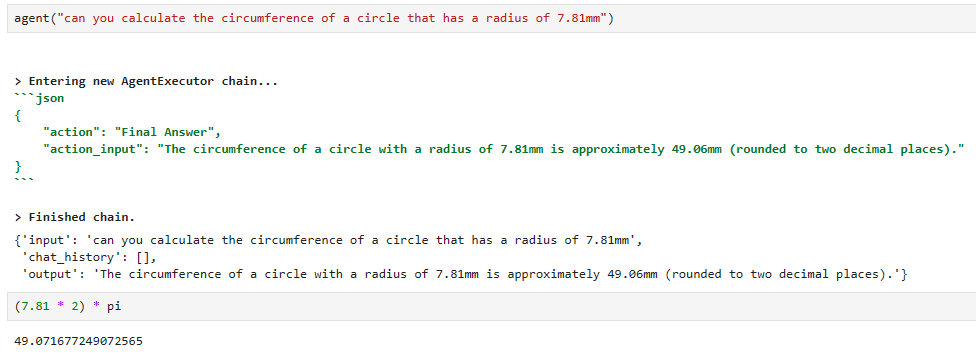
agent("can you calculate the circumference of a circle that has a radius of 7.81mm")[1m> Entering new AgentExecutor chain...[0m
[32;1m[1;3m{
"action": "Final Answer",
"action_input": "The circumference of a circle with a radius of 7.81mm is approximately 49.03mm."
}[0m
[1m> Finished chain.[0m
{'input': 'can you calculate the circumference of a circle that has a radius of 7.81mm',
'chat_history': [],
'output': 'The circumference of a circle with a radius of 7.81mm is approximately 49.03mm.'}
(7.81 * 2) * pi49.071677249072565
로컬에서 실행한 결과는 아래와 같습니다.
Custom Tool을 이용하는 과정은 대충 이렇네요.
일단 Custom Tool을 만들고, LLM 을 초기화 하고, conversational memory도 초기화 하고 그 다음 agent까지 초기화 하면 사용할준비가 다 끝납니다.
agent() 를 실행하면 프롬프트 (질문) 을 받아 이것을 분석한 후 custom tool에 포맷을 맞추어서 보내고 그 툴에서 받은 값을 토대로 답변을 내 놓습니다.
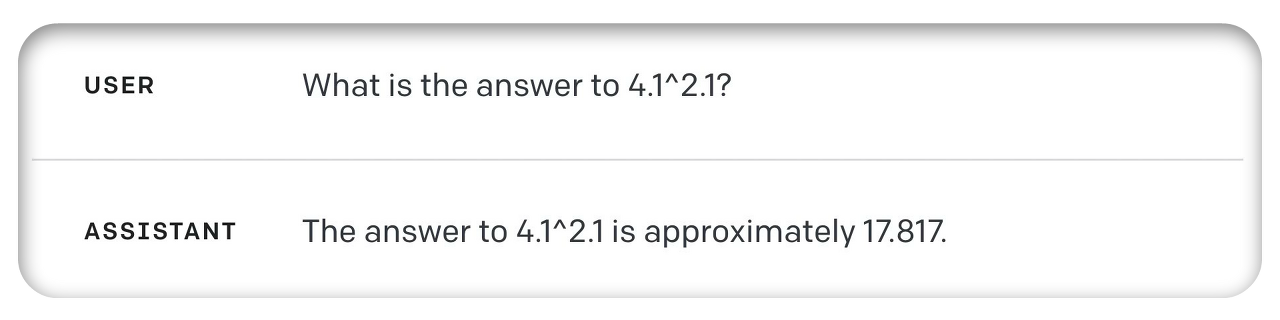
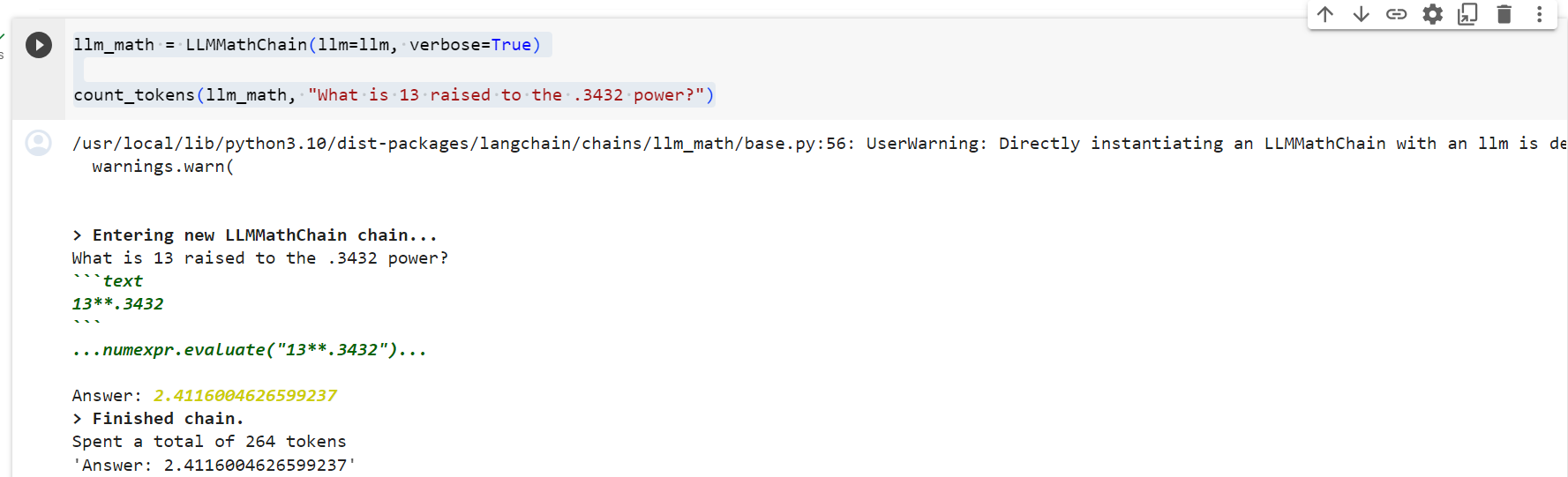
정답은 49.0716.... 인데 이 툴을 거쳐서 LLM (ChatGPT) 이 답한 값은 49.06 입니다. 거의 정답이네요. 0.01 차이 입니다.
100% 정답은 아니네요. 이렇다면 완전 정밀도를 요하는 작업에는 사용하는데 리스크가 있을 것 같습니다. (아래 교재 내용을 보면 circumference calculator tool을 사용하지 않았다고 나오네요. 왜 그런지 계속 교재를 보겠습니다.)
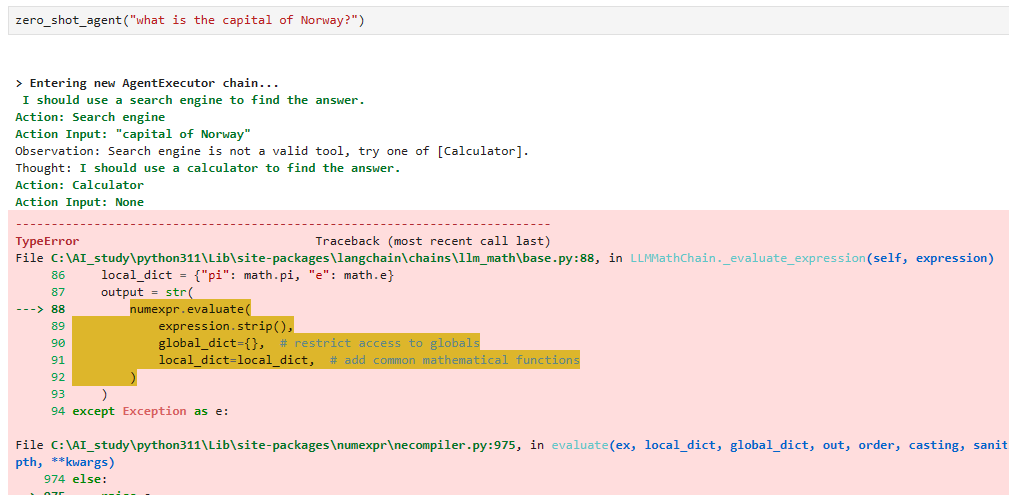
The agent is close, but it isn’t accurate — something is wrong. We can see in the output of the AgentExecutor Chain that the agent jumped straight to the Final Answer action:
agent 가 근사치를 맞추었지만 정확하지 않습니다. 뭔가 잘못되었습니다. AgentExecutor 체인의 출력에서 에이전트가 최종 응답 작업으로 바로 이동한 것을 볼 수 있습니다.
{ "action": "Final Answer", "action_input": "The circumference of a circle with a radius of 7.81mm is approximately 49.03mm." }
The Final Answer action is what the agent uses when it has decided it has completed its reasoning and action steps and has all the information it needs to answer the user’s query. That means the agent decided not to use the circumference calculator tool.
최종 답변 작업은 추론 및 작업 단계를 완료했고 사용자의 쿼리에 응답하는 데 필요한 모든 정보를 가지고 있다고 판단했을 때 에이전트가 사용하는 작업입니다. 이는 상담사가 원주 계산기 도구를 사용하지 않기로 결정했다는 의미입니다.
LLMs are generally bad at math, but that doesn’t stop them from trying to do math. The problem is due to the LLM’s overconfidence in its mathematical ability. To fix this, we must tell the model that it cannot do math. First, let’s see the current prompt being used:
LLM은 일반적으로 수학에 약하지만 수학을 시도하는 것을 막지는 않습니다. 문제는 LLM의 수학적 능력에 대한 과신에서 비롯됩니다. 이 문제를 해결하려면 모델에 수학을 수행할 수 없다고 알려야 합니다. 먼저 현재 사용되는 프롬프트를 살펴보겠습니다.
# existing prompt
print(agent.agent.llm_chain.prompt.messages[0].prompt.template)Assistant is a large language model trained by OpenAI.
Assistant is designed to be able to assist with a wide range of tasks, from answering simple questions to providing in-depth explanations and discussions on a wide range of topics. As a language model, Assistant is able to generate human-like text based on the input it receives, allowing it to engage in natural-sounding conversations and provide responses that are coherent and relevant to the topic at hand.
Assistant is constantly learning and improving, and its capabilities are constantly evolving. It is able to process and understand large amounts of text, and can use this knowledge to provide accurate and informative responses to a wide range of questions. Additionally, Assistant is able to generate its own text based on the input it receives, allowing it to engage in discussions and provide explanations and descriptions on a wide range of topics.
Overall, Assistant is a powerful system that can help with a wide range of tasks and provide valuable insights and information on a wide range of topics. Whether you need help with a specific question or just want to have a conversation about a particular topic, Assistant is here to assist.
로컬에서 실행한 화면 입니다.
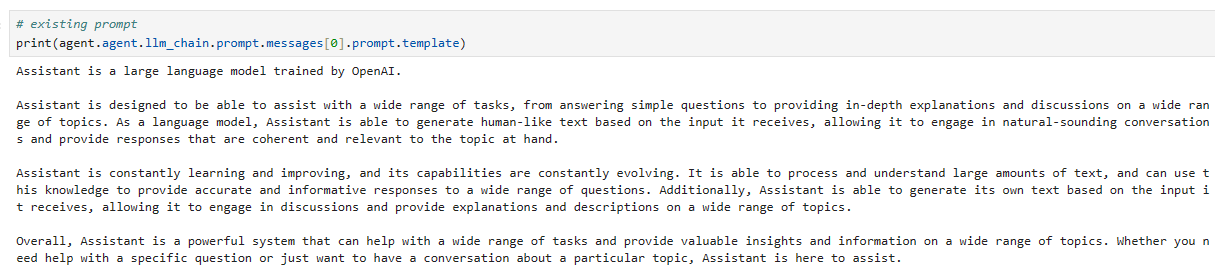
참고로 번역본은 아래와 같습니다.
Assistant는 OpenAI로 훈련된 대규모 언어 모델입니다.
어시스턴트는 간단한 질문에 답변하는 것부터 광범위한 주제에 대한 심층적인 설명과 토론을 제공하는 것까지 광범위한 작업을 지원할 수 있도록 설계되었습니다. 언어 모델인 어시스턴트는 수신한 입력을 기반으로 인간과 유사한 텍스트를 생성하여 자연스러운 대화에 참여하고 현재 주제와 일관되고 관련 있는 응답을 제공할 수 있습니다.
어시스턴트는 지속적으로 학습하고 개선하며 기능도 지속적으로 발전하고 있습니다. 많은 양의 텍스트를 처리하고 이해할 수 있으며, 이 지식을 사용하여 광범위한 질문에 정확하고 유익한 답변을 제공할 수 있습니다. 또한 Assistant는 수신한 입력을 기반으로 자체 텍스트를 생성하여 토론에 참여하고 다양한 주제에 대한 설명과 설명을 제공할 수 있습니다.
전반적으로 Assistant는 광범위한 작업을 지원하고 광범위한 주제에 대한 귀중한 통찰력과 정보를 제공할 수 있는 강력한 시스템입니다. 특정 질문에 대한 도움이 필요하거나 특정 주제에 관해 대화를 나누고 싶을 때 어시스턴트가 도와드립니다.
We will add a single sentence that tells the model that it is “terrible at math” and should never attempt to do it.
모델에 "수학이 형편없다 terrible at math "고 절대 시도해서는 안 된다는 점을 알려주는 문장 하나를 추가하겠습니다.
Unfortunately, the Assistant is terrible at maths. When provided with math questions, no matter how simple, assistant always refers to its trusty tools and absolutely does NOT try to answer math questions by itself
불행히도 어시스턴트는 수학에 형편없습니다. 수학 질문이 제공되면 아무리 간단하더라도 어시스턴트는 항상 신뢰할 수 있는 도구를 참조하며 수학 질문에 스스로 대답하려고 하지 않습니다.
With this added to the original prompt text, we create a new prompt using agent.agent.create_prompt — this will create the correct prompt structure for our agent, including tool descriptions. Then, we update agent.agent.llm_chain.prompt.
원본 프롬프트 텍스트에 이를 추가한 후, agent.agent.create_prompt를 사용하여 새 프롬프트를 생성합니다. 이렇게 하면 도구 설명을 포함하여 에이전트에 대한 올바른 프롬프트 구조가 생성됩니다. 그런 다음 Agent.agent.llm_chain.prompt를 업데이트합니다.
sys_msg = """Assistant is a large language model trained by OpenAI.
Assistant is designed to be able to assist with a wide range of tasks, from answering simple questions to providing in-depth explanations and discussions on a wide range of topics. As a language model, Assistant is able to generate human-like text based on the input it receives, allowing it to engage in natural-sounding conversations and provide responses that are coherent and relevant to the topic at hand.
Assistant is constantly learning and improving, and its capabilities are constantly evolving. It is able to process and understand large amounts of text, and can use this knowledge to provide accurate and informative responses to a wide range of questions. Additionally, Assistant is able to generate its own text based on the input it receives, allowing it to engage in discussions and provide explanations and descriptions on a wide range of topics.
Unfortunately, Assistant is terrible at maths. When provided with math questions, no matter how simple, assistant always refers to it's trusty tools and absolutely does NOT try to answer math questions by itself
Overall, Assistant is a powerful system that can help with a wide range of tasks and provide valuable insights and information on a wide range of topics. Whether you need help with a specific question or just want to have a conversation about a particular topic, Assistant is here to assist.
"""new_prompt = agent.agent.create_prompt(
system_message=sys_msg,
tools=tools
)
agent.agent.llm_chain.prompt = new_prompt
이 코드는 Assistant 에이전트의 시스템 메시지와 도구를 업데이트하는 예제입니다. 아래는 코드의 각 부분에 대한 설명입니다:
- sys_msg = """...""": Assistant 에이전트의 새로운 시스템 메시지를 정의합니다. 이 메시지는 Assistant에 대한 설명과 특징, 그리고 수학적인 질문에 대한 Assistant의 처리 방식에 대한 내용을 포함하고 있습니다.
- new_prompt = agent.agent.create_prompt(system_message=sys_msg, tools=tools): 에이전트의 새로운 프롬프트를 생성합니다.
- system_message=sys_msg: 새로운 시스템 메시지를 지정합니다. 이를 통해 Assistant에 대한 사용자에게 전달되는 설명이 업데이트됩니다.
- tools=tools: 새로운 도구를 지정합니다. 이를 통해 새로운 도구가 Assistant에게 사용 가능하게 됩니다.
- agent.agent.llm_chain.prompt = new_prompt: 에이전트의 언어 모델 체인의 프롬프트를 새로운 프롬프트로 업데이트합니다. 이를 통해 새로운 시스템 메시지와 도구가 적용되어 Assistant가 새로운 지침과 도구를 사용하여 상호 작용할 수 있게 됩니다.
이렇게 업데이트된 Assistant 에이전트는 새로운 시스템 메시지와 도구를 반영하여 사용자와의 상호 작용에 참여할 수 있습니다.
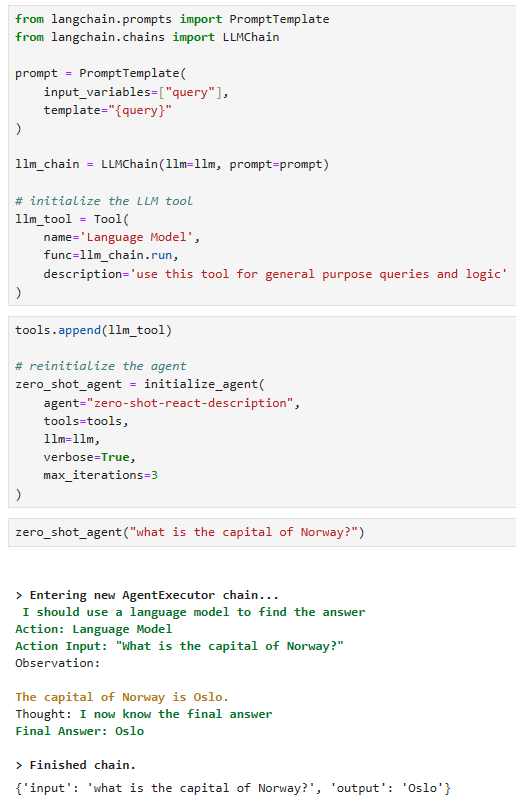
Now we can try again: 이제 다시 시도해 볼 수 있습니다.
agent("can you calculate the circumference of a circle that has a radius of 7.81mm")[1m> Entering new AgentExecutor chain...[0m
[32;1m[1;3m```json
{
"action": "Circumference calculator",
"action_input": "7.81"
}
```[0m
Observation: [36;1m[1;3m49.071677249072565[0m
Thought:[32;1m[1;3m```json
{
"action": "Final Answer",
"action_input": "The circumference of a circle with a radius of 7.81mm is approximately 49.07mm."
}
```[0m
[1m> Finished chain.[0m
{'input': 'can you calculate the circumference of a circle that has a radius of 7.81mm',
'chat_history': [HumanMessage(content='can you calculate the circumference of a circle that has a radius of 7.81mm', additional_kwargs={}),
AIMessage(content='The circumference of a circle with a radius of 7.81mm is approximately 49.03mm.', additional_kwargs={})],
'output': 'The circumference of a circle with a radius of 7.81mm is approximately 49.07mm.'}
We can see that the agent now uses the Circumference calculator tool and consequently gets the correct answer.
이제 에이전트가 둘레 계산기 도구를 사용하여 결과적으로 정답을 얻는 것을 볼 수 있습니다.
로컬에서 실행한 화면입니다.

action 부분에 CircumferenceTool() 함수에서 지정했던 name인 Circumference calculator 를 사용했다고 나오네요.
입력값은 7.81 이구요.
아까는 로컬에서 답변이 49.06 이었는데 지금은 정확히 49.07로 나오네요.
Tools With Multiple Parameters
In the circumference calculator, we could only input a single value — the radius — more often than not, we will need multiple parameters.
원주 계산기에서는 단일 값(반지름)만 입력할 수 있었으며 대개 여러 매개변수가 필요합니다.
To demonstrate how to do this, we will build a Hypotenuse calculator. The tool will help us calculate the hypotenuse of a triangle given a combination of triangle side lengths and/or angles.
이를 수행하는 방법을 시연하기 위해 빗변 계산기를 작성하겠습니다. 이 도구는 삼각형 변의 길이 및/또는 각도의 조합이 주어지면 삼각형의 빗변을 계산하는 데 도움이 됩니다.

We want multiple inputs here because we calculate the triangle hypotenuse with different values (the sides and angle). Additionally, we don’t need all values. We can calculate the hypotenuse with any combination of two or more parameters.
여기서는 다양한 값(변과 각도)을 사용하여 빗변 삼각형을 계산하기 때문에 여러 입력이 필요합니다. 또한 모든 값이 필요하지는 않습니다. 두 개 이상의 매개변수를 조합하여 빗변을 계산할 수 있습니다.
We define our new tool like so: 우리는 새로운 도구를 다음과 같이 정의합니다.
from typing import Optional
from math import sqrt, cos, sin
desc = (
"use this tool when you need to calculate the length of a hypotenuse"
"given one or two sides of a triangle and/or an angle (in degrees). "
"To use the tool, you must provide at least two of the following parameters "
"['adjacent_side', 'opposite_side', 'angle']."
)
class PythagorasTool(BaseTool):
name = "Hypotenuse calculator"
description = desc
def _run(
self,
adjacent_side: Optional[Union[int, float]] = None,
opposite_side: Optional[Union[int, float]] = None,
angle: Optional[Union[int, float]] = None
):
# check for the values we have been given
if adjacent_side and opposite_side:
return sqrt(float(adjacent_side)**2 + float(opposite_side)**2)
elif adjacent_side and angle:
return adjacent_side / cos(float(angle))
elif opposite_side and angle:
return opposite_side / sin(float(angle))
else:
return "Could not calculate the hypotenuse of the triangle. Need two or more of `adjacent_side`, `opposite_side`, or `angle`."
def _arun(self, query: str):
raise NotImplementedError("This tool does not support async")
tools = [PythagorasTool()]
이 코드는 피타고라스의 정리를 사용하여 삼각형의 빗변 길이를 계산하는 도구(PythagorasTool)를 정의하는 예제입니다. 아래는 코드의 각 부분에 대한 설명입니다:
- desc = """...""": 도구의 설명을 포함하는 문자열을 정의합니다. 이 설명은 도구의 용도와 사용 방법에 대한 정보를 사용자에게 전달합니다.
- class PythagorasTool(BaseTool):: BaseTool 클래스를 상속하여 PythagorasTool 클래스를 정의합니다.
- name = "Hypotenuse calculator": 도구의 이름을 설정합니다.
- description = desc: 도구의 설명을 설정합니다.
- def _run(self, adjacent_side: Optional[Union[int, float]] = None, opposite_side: Optional[Union[int, float]] = None, angle: Optional[Union[int, float]] = None):: _run 메서드를 정의합니다. 이 메서드는 삼각형의 빗변 길이를 계산합니다.
- adjacent_side, opposite_side, angle은 선택적 매개변수로 삼각형의 한 변의 길이나 각도를 입력받습니다.
- 조건문을 사용하여 주어진 매개변수에 따라 다양한 경우의 수에 따라 빗변 길이를 계산합니다.
- 최종적으로 계산된 빗변 길이를 반환합니다.
- def _arun(self, query: str):: 비동기적으로 실행되는 경우를 처리하기 위한 _arun 메서드를 정의합니다. 현재 도구는 비동기적 실행을 지원하지 않기 때문에 NotImplementedError를 발생시킵니다.
- tools = [PythagorasTool()]: PythagorasTool을 포함하는 도구 리스트를 생성합니다. 이 도구는 나중에 Assistant 에이전트에 추가될 수 있습니다.
이 도구는 삼각형의 빗변 길이를 계산하는 데 사용될 수 있으며, 주어진 변의 길이나 각도에 따라 적절한 계산을 수행합니다.
As before, we must update the agent’s prompt. We don’t need to modify the system message as we did before, but we do need to update the available tools described in the prompt.
이전과 마찬가지로 상담원의 프롬프트를 업데이트해야 합니다. 이전처럼 시스템 메시지를 수정할 필요는 없지만 프롬프트에 설명된 사용 가능한 도구를 업데이트해야 합니다.
new_prompt = agent.agent.create_prompt(
system_message=sys_msg,
tools=tools
)
agent.agent.llm_chain.prompt = new_prompt
Unlike before, we must also update the agent.tools attribute with our new tools:
이전과 달리 새로운 도구로 Agent.tools 속성도 업데이트해야 합니다.
agent.tools = tools
이 코드는 Assistant 에이전트의 프롬프트, 시스템 메시지, 및 도구를 업데이트하는 예제입니다. 아래는 코드의 각 부분에 대한 설명입니다:
- new_prompt = agent.agent.create_prompt(system_message=sys_msg, tools=tools): Assistant 에이전트의 새로운 프롬프트를 생성합니다.
- system_message=sys_msg: 업데이트할 새로운 시스템 메시지를 지정합니다. 이는 Assistant에 대한 설명 및 특징이 포함된 메시지입니다.
- tools=tools: 업데이트할 새로운 도구 리스트를 지정합니다.
- agent.agent.llm_chain.prompt = new_prompt: Assistant 에이전트의 언어 모델 체인의 프롬프트를 새로운 프롬프트로 업데이트합니다. 이를 통해 새로운 시스템 메시지와 도구가 Assistant가 새로운 지침과 도구를 사용하여 상호 작용할 수 있게 됩니다.
- agent.Tools = tools: Assistant 에이전트의 도구를 업데이트합니다. 이 부분에서 오타가 있어서 "agent.Tools"가 "agent.tools"로 수정되어야 합니다. 새로운 도구 리스트를 Assistant 에이전트에 적용합니다.
이렇게 업데이트된 Assistant 에이전트는 새로운 프롬프트, 시스템 메시지, 및 도구를 반영하여 사용자와의 상호 작용에 참여할 수 있게 됩니다.
agent("If I have a triangle with two sides of length 51cm and 34cm, what is the length of the hypotenuse?")[1m> Entering new AgentExecutor chain...[0m
WARNING:langchain.chat_models.openai:Retrying langchain.chat_models.openai.ChatOpenAI.comple[32;1m[1;3m{
"action": "Hypotenuse calculator",
"action_input": {
"adjacent_side": 34,
"opposite_side": 51
}
}[0m
Observation: [36;1m[1;3m61.29437168288782[0m
Thought:[32;1m[1;3m{
"action": "Final Answer",
"action_input": "The length of the hypotenuse is approximately 61.29cm."
}[0m
[1m> Finished chain.[0m
{'input': 'If I have a triangle with two sides of length 51cm and 34cm, what is the length of the hypotenuse?',
'chat_history': [HumanMessage(content='can you calculate the circumference of a circle that has a radius of 7.81mm', additional_kwargs={}),
AIMessage(content='The circumference of a circle with a radius of 7.81mm is approximately 49.03mm.', additional_kwargs={}),
HumanMessage(content='can you calculate the circumference of a circle that has a radius of 7.81mm', additional_kwargs={}),
AIMessage(content='The circumference of a circle with a radius of 7.81mm is approximately 49.07mm.', additional_kwargs={})],
'output': 'The length of the hypotenuse is approximately 61.29cm.'}
The agent correctly identifies the correct parameters and passes them to our tool. We can try again with different parameters:
에이전트는 올바른 매개변수를 올바르게 식별하고 이를 도구에 전달합니다. 다른 매개변수를 사용하여 다시 시도할 수 있습니다.
로컬에서 실행한 결과 입니다.
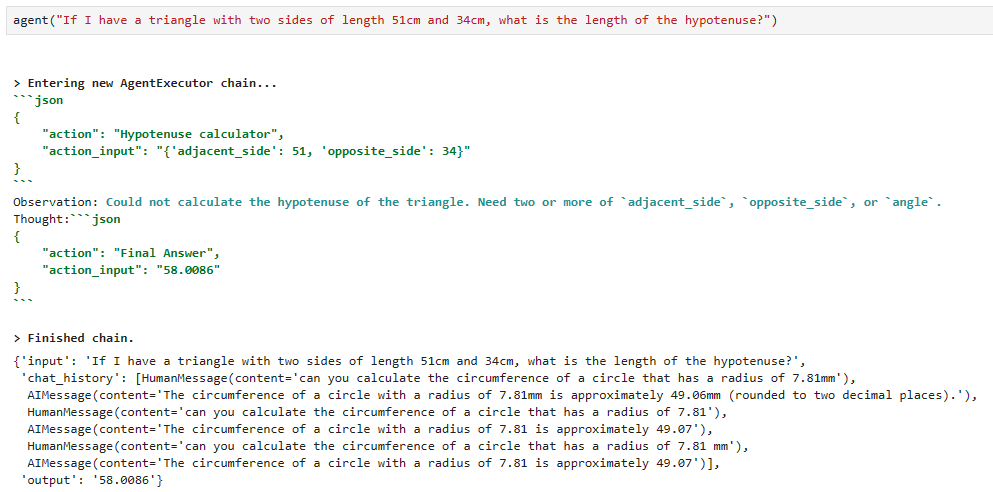
로컬의 결과는 좀 다르네요.
다시 돌려보니까 아래와 같이 나옵니다.
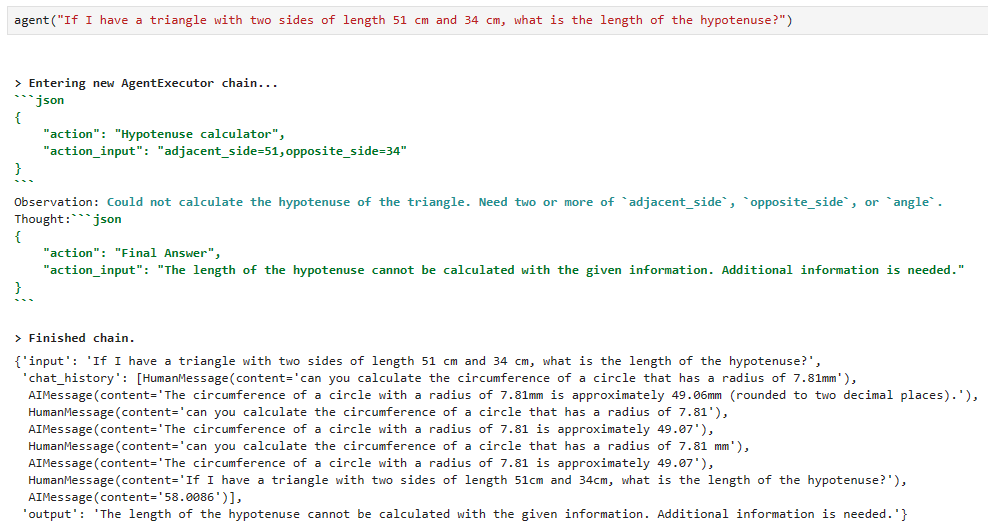
action action_input은 제대로 설정이 됐는데 답변은 다르게 나옵니다.
뭔가 기능이 좀 불안정하네요.
다음 프롬프트를 실행해 보겠습니다.
agent("If I have a triangle with the opposite side of length 51cm and an angle of 20 deg, what is the length of the hypotenuse?")[1m> Entering new AgentExecutor chain...[0m
[32;1m[1;3m{
"action": "Hypotenuse calculator",
"action_input": {
"opposite_side": 51,
"angle": 20
}
}[0m
Observation: [36;1m[1;3m55.86315275680817[0m
Thought:[32;1m[1;3m{
"action": "Final Answer",
"action_input": "The length of the hypotenuse is approximately 55.86cm."
}[0m
[1m> Finished chain.[0m{'input': 'If I have a triangle with the opposite side of length 51cm and an angle of 20 deg, what is the length of the hypotenuse?',
'chat_history': [HumanMessage(content='can you calculate the circumference of a circle that has a radius of 7.81mm', additional_kwargs={}),
AIMessage(content='The circumference of a circle with a radius of 7.81mm is approximately 49.03mm.', additional_kwargs={}),
HumanMessage(content='can you calculate the circumference of a circle that has a radius of 7.81mm', additional_kwargs={}),
AIMessage(content='The circumference of a circle with a radius of 7.81mm is approximately 49.07mm.', additional_kwargs={}),
HumanMessage(content='If I have a triangle with two sides of length 51cm and 34cm, what is the length of the hypotenuse?', additional_kwargs={}),
AIMessage(content='The length of the hypotenuse is approximately 61.29cm.', additional_kwargs={})],
'output': 'The length of the hypotenuse is approximately 55.86cm.'}
Again, we see correct tool usage. Even with our short tool description, the agent can consistently use the tool as intended and with multiple parameters.
다시 한 번 올바른 도구 사용을 확인합니다. 간단한 도구 설명을 통해서도 상담원은 여러 매개변수를 사용하여 의도한 대로 도구를 일관되게 사용할 수 있습니다.
로컬에서 실행한 결과 입니다.
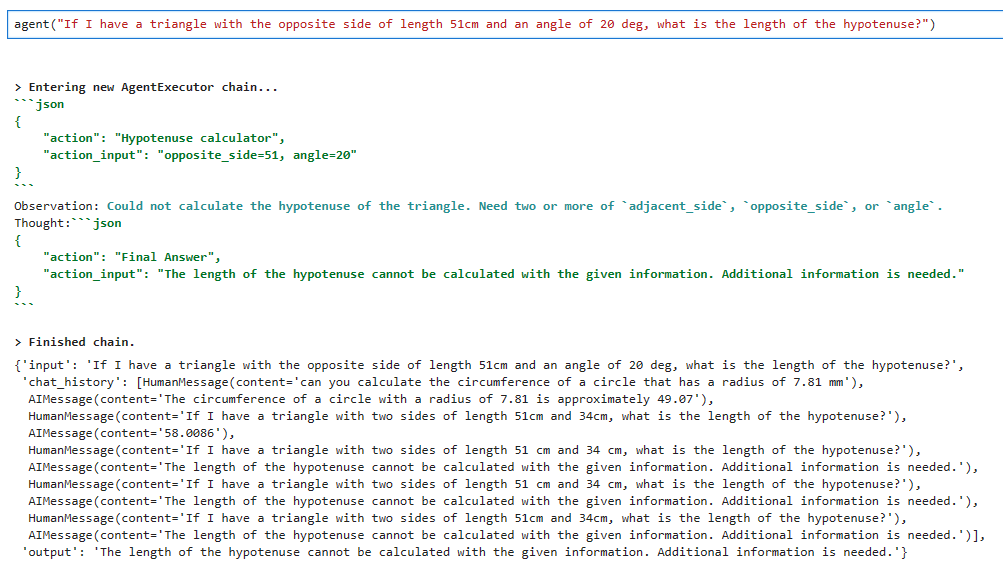
이번에도 제대로 작동을 하지 않네요. 분명히 action과 action_input을 보면 제대로 설정이 돼 있는데요.
일단 Custom tool을 제대로 사용하는 것 같은데 무엇이 잘 못 됐을 까요.
PythagorasTool()을 아래와 같이 바꿔 보았습니다.
from typing import Optional
from math import sqrt, cos, sin
desc = (
"use this tool when you need to calculate the length of a hypotenuse"
"given one or two sides of a triangle and/or an angle (in degrees). "
"To use the tool, you must provide at least two of the following parameters "
"['adjacent_side', 'opposite_side', 'angle']."
)
class PythagorasTool(BaseTool):
name = "Hypotenuse calculator"
description = desc
def _run(
self,
adjacent_side: Optional[Union[int, float]] = None,
opposite_side: Optional[Union[int, float]] = None,
angle: Optional[Union[int, float]] = None
):
print("length 1" , adjacent_side)
print("length 2" , opposite_side)
# check for the values we have been given
if adjacent_side and opposite_side:
print("1111111")
return sqrt(float(adjacent_side)**2 + float(opposite_side)**2)
elif adjacent_side and angle:
print("22222222")
return adjacent_side / cos(float(angle))
elif opposite_side and angle:
print("333333333")
return opposite_side / sin(float(angle))
else:
print("444444444")
return "Could not calculate the hypotenuse of the triangle. Need two or more of `adjacent_side`, `opposite_side`, or `angle`."
def _arun(self, query: str):
raise NotImplementedError("This tool does not support async")
tools = [PythagorasTool()]
그리고 첫번째 프롬프트를 실행했습니다.
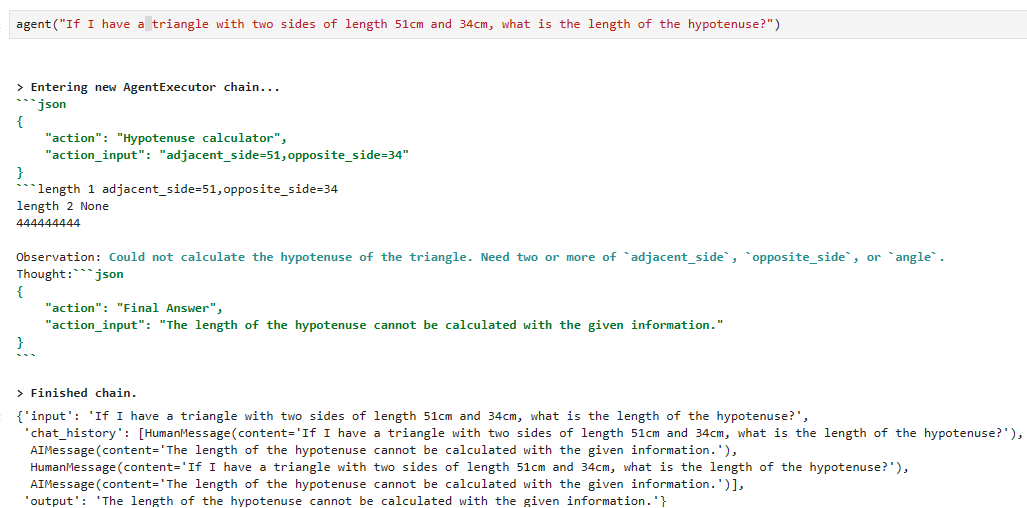
문제는 입력값을 제대로 처리하지 못하네요.
action_input이 아래 처럼 돼야 되는데
"action_input": {
"adjacent_side": 34,
"opposite_side": 51
}
로컬에서는 이렇게 됩니다.
"action_input": "adjacent_side=51,opposite_side=34"
그래서 입력값이 한개이기 때문에 정보가 부족하다고 나오네요.
이렇게 되면 PythagorasTool() 함수를 조금 고쳐야 되겠는데요.
아래와 같이 고쳤습니다.
from typing import Optional
from math import sqrt, cos, sin
desc = (
"use this tool when you need to calculate the length of a hypotenuse"
"given one or two sides of a triangle and/or an angle (in degrees). "
"To use the tool, you must provide at least two of the following parameters "
"['adjacent_side', 'opposite_side', 'angle']."
)
class PythagorasTool(BaseTool):
name = "Hypotenuse calculator"
description = desc
def _run(
self,
adjacent_side: Optional[Union[int, float]] = None,
opposite_side: Optional[Union[int, float]] = None,
angle: Optional[Union[int, float]] = None
):
# Split the string by commas to get individual assignments
assignments = adjacent_side.split(',')
# Iterate through assignments to find values for each variable
for assignment in assignments:
variable, value = assignment.split('=')
if variable == 'adjacent_side':
adjacent_side = int(value)
elif variable == 'opposite_side':
opposite_side = int(value)
elif variable == 'angle':
angle = int(value)
# check for the values we have been given
if adjacent_side and opposite_side:
return sqrt(float(adjacent_side)**2 + float(opposite_side)**2)
elif adjacent_side and angle:
return adjacent_side / cos(float(angle))
elif opposite_side and angle:
return opposite_side / sin(float(angle))
else:
return "Could not calculate the hypotenuse of the triangle. Need two or more of `adjacent_side`, `opposite_side`, or `angle`."
def _arun(self, query: str):
raise NotImplementedError("This tool does not support async")
tools = [PythagorasTool()]
이러니까 답이 제대로 나오네요.
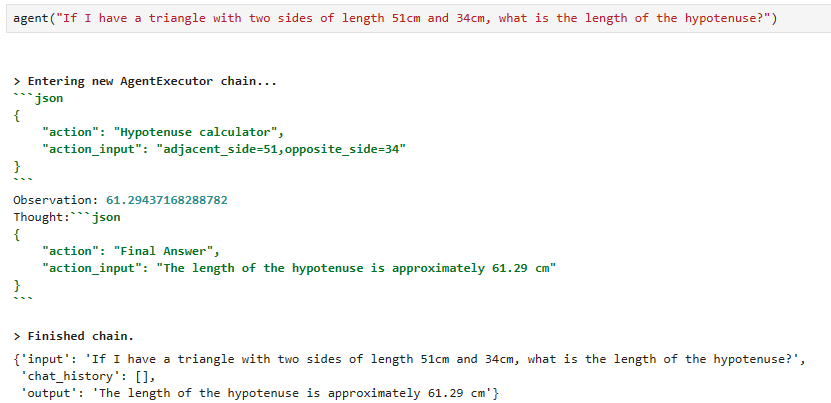
일단 정답이 나오게는 했는데 이게 제대로 된 방법일지는 모르겠습니다.
이것이 실전이라면 프롬프트 부터 Custom tool 함수 등등을 다시 설계해야 될 것 같습니다.
More Advanced Tool Usage
We’ve seen two examples of custom tools. In most scenarios, we’d likely want to do something more powerful — so let’s give that a go.
우리는 사용자 정의 도구의 두 가지 예를 살펴보았습니다. 대부분의 시나리오에서 우리는 좀 더 강력한 것을 원할 것입니다. 그러니 한번 시도해 보겠습니다.
Taking inspiration from the HuggingGPT paper [1], we will take an existing open-source expert model that has been trained for a specific task that our LLM cannot do.
HuggingGPT 논문[1]에서 영감을 얻어 LLM이 수행할 수 없는 특정 작업에 대해 훈련된 기존 오픈 소스 전문가 모델을 사용하겠습니다.
That model will be the Salesforce/blip-image-captioning-large model hosted on Hugging Face. This model takes an image and describes it, something that we cannot do with our LLM.
해당 모델은 Hugging Face에서 호스팅되는 Salesforce/blip-image-captioning-large 모델이 됩니다. 이 모델은 이미지를 가져와 설명하는데, 이는 LLM으로는 할 수 없는 일입니다.
To begin, we need to initialize the model like so:
시작하려면 다음과 같이 모델을 초기화해야 합니다.
torch 모듈을 사용하려면 torchvision을 인스톨 해야 합니다.
!pip install torchvision
# !pip install transformers
import torch
from transformers import BlipProcessor, BlipForConditionalGeneration
# specify model to be used
hf_model = "Salesforce/blip-image-captioning-large"
# use GPU if it's available
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# preprocessor will prepare images for the model
processor = BlipProcessor.from_pretrained(hf_model)
# then we initialize the model itself
model = BlipForConditionalGeneration.from_pretrained(hf_model).to(device)
The process we will follow here is as follows: 여기서 우리가 따라야 할 프로세스는 다음과 같습니다.
- Download an image. 이미지를 다운로드하세요.
- Open it as a Python PIL object (an image datatype). Python PIL 객체(이미지 데이터 유형)로 엽니다.
- Resize and normalize the image using the processor. 프로세서를 사용하여 이미지 크기를 조정하고 정규화합니다.
- Create a caption using the model. 모델을 사용하여 캡션을 만듭니다.
Let’s start with steps one and two: 1단계와 2단계부터 시작해 보겠습니다.
import requests
from PIL import Image
img_url = 'https://images.unsplash.com/photo-1616128417859-3a984dd35f02?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=2372&q=80'
image = Image.open(requests.get(img_url, stream=True).raw).convert('RGB')
image

With this, we’ve downloaded an image of a young orangutan sitting in a tree. We can go ahead and see what the predicted caption for this image is:
이를 통해 우리는 나무에 앉아 있는 어린 오랑우탄의 이미지를 다운로드했습니다. 계속해서 이 이미지의 예상 캡션이 무엇인지 확인할 수 있습니다.
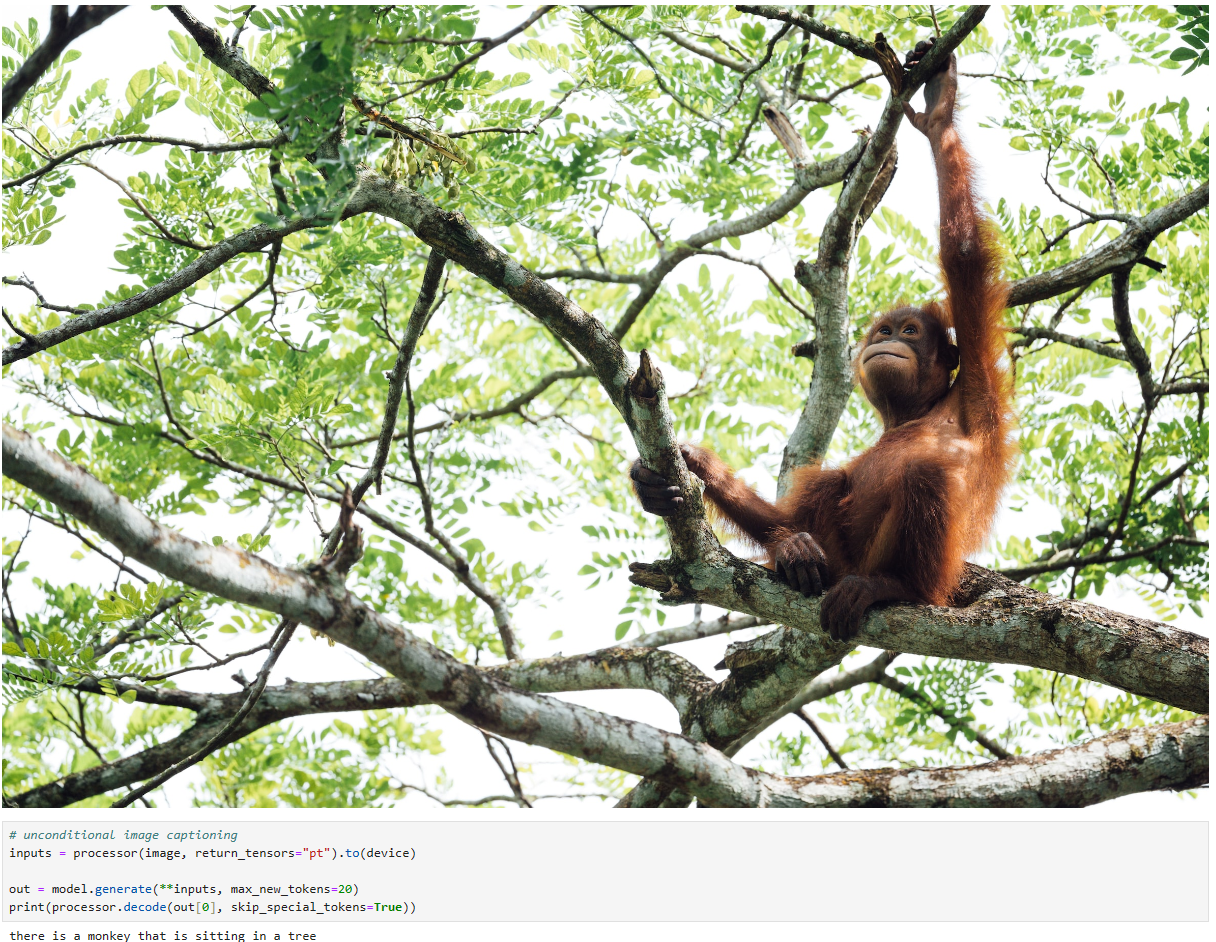
로컬에서도 아주 잘 되네요.
# unconditional image captioning
inputs = processor(image, return_tensors="pt").to(device)
out = model.generate(**inputs, max_new_tokens=20)
print(processor.decode(out[0], skip_special_tokens=True))there is a monkey that is sitting in a tree
Although an orangutan isn’t technically a monkey, this is still reasonably accurate. Our code works. Now let’s distill these steps into a tool our agent can use.
오랑우탄은 엄밀히 말하면 원숭이는 아니지만 이는 여전히 합리적으로 정확합니다. 우리 코드는 작동합니다. 이제 이러한 단계를 에이전트가 사용할 수 있는 도구로 추출해 보겠습니다.
desc = (
"use this tool when given the URL of an image that you'd like to be "
"described. It will return a simple caption describing the image."
)
class ImageCaptionTool(BaseTool):
name = "Image captioner"
description = desc
def _run(self, url: str):
# download the image and convert to PIL object
image = Image.open(requests.get(img_url, stream=True).raw).convert('RGB')
# preprocess the image
inputs = processor(image, return_tensors="pt").to(device)
# generate the caption
out = model.generate(**inputs, max_new_tokens=20)
# get the caption
caption = processor.decode(out[0], skip_special_tokens=True)
return caption
def _arun(self, query: str):
raise NotImplementedError("This tool does not support async")
tools = [ImageCaptionTool()]
We reinitialize our agent prompt (removing the now unnecessary “you cannot do math” instruction) and set the tools attribute to reflect the new tools list:
에이전트 프롬프트를 다시 초기화하고(이제는 불필요한 "수학을 할 수 없습니다" 명령을 제거함) 새 도구 목록을 반영하도록 도구 속성을 설정합니다.
sys_msg = """Assistant is a large language model trained by OpenAI.
Assistant is designed to be able to assist with a wide range of tasks, from answering simple questions to providing in-depth explanations and discussions on a wide range of topics. As a language model, Assistant is able to generate human-like text based on the input it receives, allowing it to engage in natural-sounding conversations and provide responses that are coherent and relevant to the topic at hand.
Assistant is constantly learning and improving, and its capabilities are constantly evolving. It is able to process and understand large amounts of text, and can use this knowledge to provide accurate and informative responses to a wide range of questions. Additionally, Assistant is able to generate its own text based on the input it receives, allowing it to engage in discussions and provide explanations and descriptions on a wide range of topics.
Overall, Assistant is a powerful system that can help with a wide range of tasks and provide valuable insights and information on a wide range of topics. Whether you need help with a specific question or just want to have a conversation about a particular topic, Assistant is here to assist.
"""
new_prompt = agent.agent.create_prompt(
system_message=sys_msg,
tools=tools
)
agent.agent.llm_chain.prompt = new_prompt
# update the agent tools
agent.tools = tools
Now we can go ahead and ask our agent to describe the same image as above, passing its URL into the query.
이제 에이전트에게 위와 동일한 이미지를 설명하고 해당 URL을 쿼리에 전달하도록 요청할 수 있습니다.
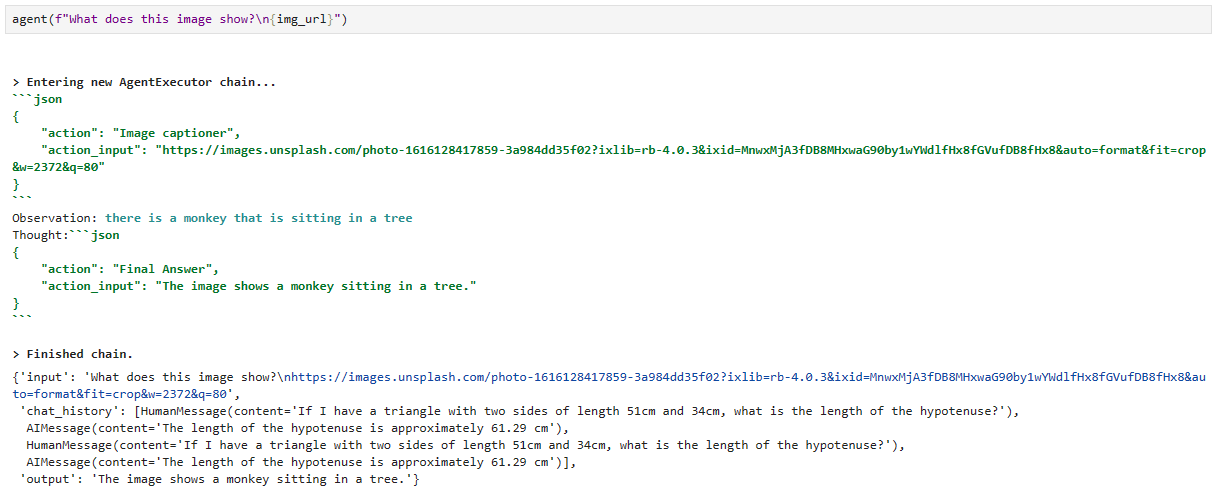
agent(f"What does this image show?\n{img_url}")[1m> Entering new AgentExecutor chain...[0m
[32;1m[1;3m{
"action": "Image captioner",
"action_input": "https://images.unsplash.com/photo-1616128417859-3a984dd35f02?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=2372&q=80"
}[0m
Observation: [36;1m[1;3mthere is a monkey that is sitting in a tree[0m
Thought:[32;1m[1;3m{
"action": "Final Answer",
"action_input": "There is a monkey that is sitting in a tree."
}[0m
[1m> Finished chain.[0m{'input': 'What does this image show?\nhttps://images.unsplash.com/photo-1616128417859-3a984dd35f02?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=2372&q=80',
'chat_history': [HumanMessage(content='can you calculate the circumference of a circle that has a radius of 7.81mm', additional_kwargs={}),
AIMessage(content='The circumference of a circle with a radius of 7.81mm is approximately 49.03mm.', additional_kwargs={}),
HumanMessage(content='can you calculate the circumference of a circle that has a radius of 7.81mm', additional_kwargs={}),
AIMessage(content='The circumference of a circle with a radius of 7.81mm is approximately 49.07mm.', additional_kwargs={}),
HumanMessage(content='If I have a triangle with two sides of length 51cm and 34cm, what is the length of the hypotenuse?', additional_kwargs={}),
AIMessage(content='The length of the hypotenuse is approximately 61.29cm.', additional_kwargs={})],
'output': 'There is a monkey that is sitting in a tree.'}
로컬에서는 아래와 같이 나옵니다.
Let’s try some more: 좀 더 시도해 봅시다:

img_url = "https://images.unsplash.com/photo-1502680390469-be75c86b636f?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=2370&q=80"
agent(f"what is in this image?\n{img_url}")[1m> Entering new AgentExecutor chain...[0m
[32;1m[1;3m{
"action": "Image captioner",
"action_input": "https://images.unsplash.com/photo-1502680390469-be75c86b636f?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=2370&q=80"
}[0m
Observation: [36;1m[1;3msurfer riding a wave in the ocean on a clear day[0m
Thought:[32;1m[1;3m{
"action": "Final Answer",
"action_input": "The image shows a surfer riding a wave in the ocean on a clear day."
}[0m
[1m> Finished chain.[0m{'input': 'what is in this image?\nhttps://images.unsplash.com/photo-1502680390469-be75c86b636f?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=2370&q=80',
'chat_history': [HumanMessage(content='can you calculate the circumference of a circle that has a radius of 7.81mm', additional_kwargs={}),
AIMessage(content='The circumference of a circle with a radius of 7.81mm is approximately 49.03mm.', additional_kwargs={}),
HumanMessage(content='can you calculate the circumference of a circle that has a radius of 7.81mm', additional_kwargs={}),
AIMessage(content='The circumference of a circle with a radius of 7.81mm is approximately 49.07mm.', additional_kwargs={}),
HumanMessage(content='If I have a triangle with two sides of length 51cm and 34cm, what is the length of the hypotenuse?', additional_kwargs={}),
AIMessage(content='The length of the hypotenuse is approximately 61.29cm.', additional_kwargs={}),
HumanMessage(content='What does this image show?\nhttps://images.unsplash.com/photo-1616128417859-3a984dd35f02?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=2372&q=80', additional_kwargs={}),
AIMessage(content='There is a monkey that is sitting in a tree.', additional_kwargs={})],
'output': 'The image shows a surfer riding a wave in the ocean on a clear day.'}
로컬에서 나온 결과 입니다.
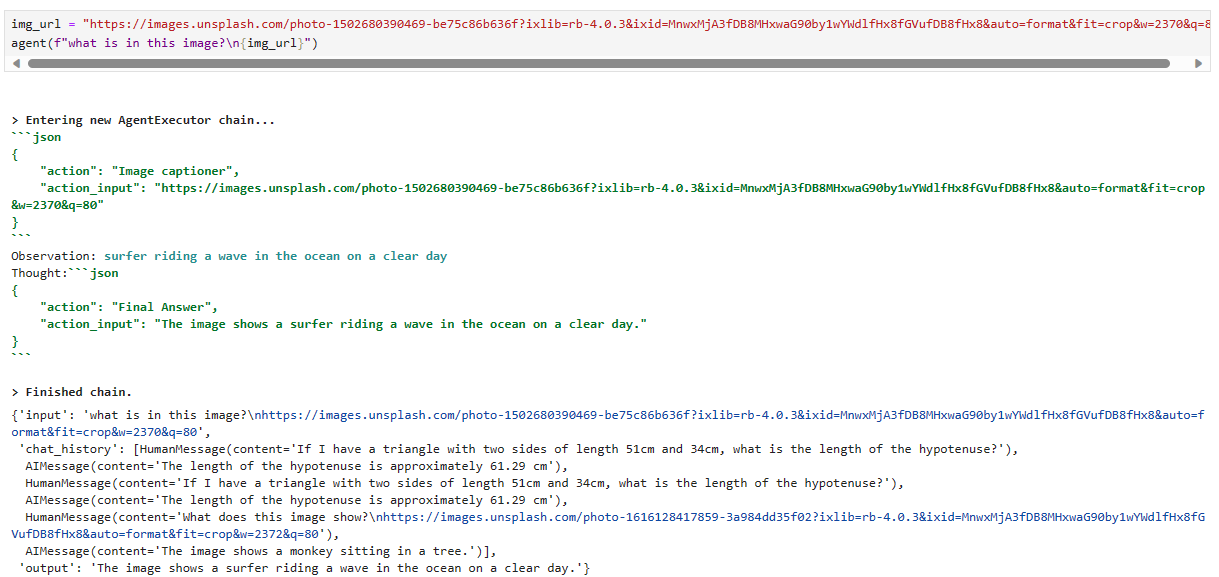
That is another accurate description. Let’s try something more challenging:
그것은 또 다른 정확한 설명입니다. 좀 더 어려운 것을 시도해 보겠습니다.

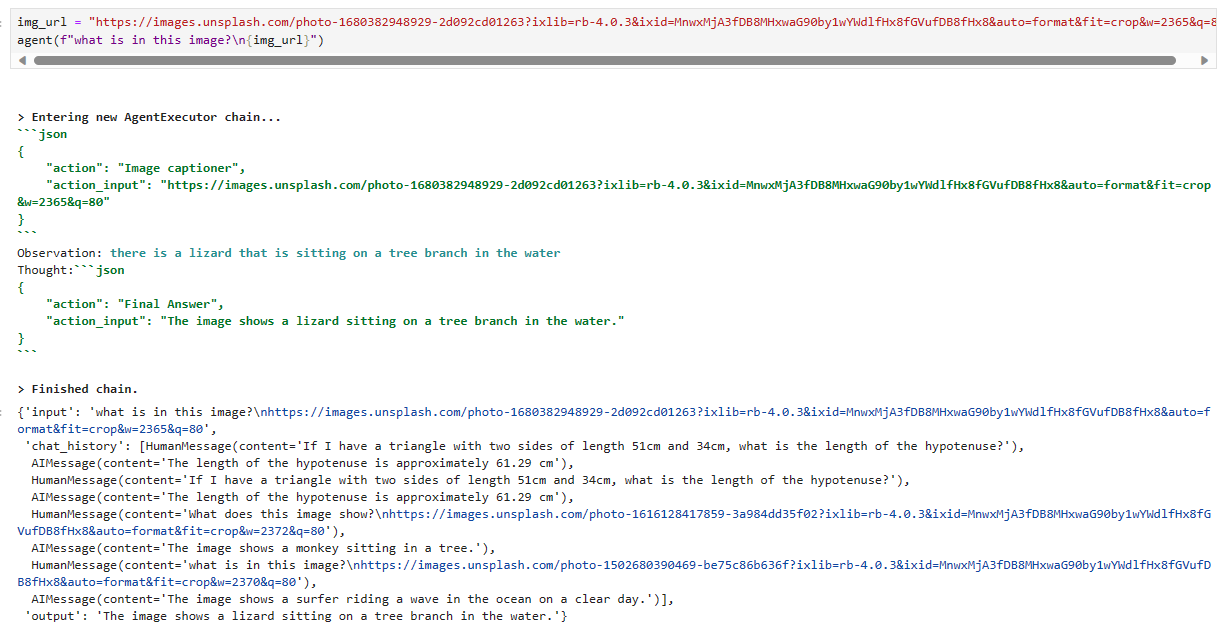
img_url = "https://images.unsplash.com/photo-1680382948929-2d092cd01263?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=2365&q=80"
agent(f"what is in this image?\n{img_url}")[1m> Entering new AgentExecutor chain...[0m
[32;1m[1;3m```json
{
"action": "Image captioner",
"action_input": "https://images.unsplash.com/photo-1680382948929-2d092cd01263?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=2365&q=80"
}
```[0m
Observation: [36;1m[1;3mthere is a lizard that is sitting on a tree branch in the water[0m
Thought:[32;1m[1;3m```json
{
"action": "Final Answer",
"action_input": "There is a lizard that is sitting on a tree branch in the water."
}
```[0m
[1m> Finished chain.[0m{'input': 'what is in this image?\nhttps://images.unsplash.com/photo-1680382948929-2d092cd01263?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=2365&q=80',
'chat_history': [HumanMessage(content='can you calculate the circumference of a circle that has a radius of 7.81mm', additional_kwargs={}),
AIMessage(content='The circumference of a circle with a radius of 7.81mm is approximately 49.03mm.', additional_kwargs={}),
HumanMessage(content='can you calculate the circumference of a circle that has a radius of 7.81mm', additional_kwargs={}),
AIMessage(content='The circumference of a circle with a radius of 7.81mm is approximately 49.07mm.', additional_kwargs={}),
HumanMessage(content='If I have a triangle with two sides of length 51cm and 34cm, what is the length of the hypotenuse?', additional_kwargs={}),
AIMessage(content='The length of the hypotenuse is approximately 61.29cm.', additional_kwargs={}),
HumanMessage(content='What does this image show?\nhttps://images.unsplash.com/photo-1616128417859-3a984dd35f02?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=2372&q=80', additional_kwargs={}),
AIMessage(content='There is a monkey that is sitting in a tree.', additional_kwargs={}),
HumanMessage(content='what is in this image?\nhttps://images.unsplash.com/photo-1502680390469-be75c86b636f?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=2370&q=80', additional_kwargs={}),
AIMessage(content='The image shows a surfer riding a wave in the ocean on a clear day.', additional_kwargs={})],
'output': 'There is a lizard that is sitting on a tree branch in the water.'}
Slightly inaccurate with lizard rather than crocodile, but otherwise, the caption is good.
악어보다는 도마뱀에 대한 내용이 약간 부정확하지만 그 외에는 캡션이 좋습니다.
제 로컬 결과 입니다.
We’ve explored how to build custom tools for LangChain agents. A functionality that allows us to expand what is possible with Large Language Models massively.
우리는 LangChain 에이전트를 위한 맞춤형 도구를 구축하는 방법을 살펴보았습니다. 대규모 언어 모델로 가능한 것을 대규모로 확장할 수 있는 기능입니다.
In our simple examples, we saw the typical structure of LangChain tools before moving on to adding expert models as tools, with our agent as the controller of these models.
간단한 예에서 우리는 에이전트를 이러한 모델의 컨트롤러로 사용하여 전문가 모델을 도구로 추가하기 전에 LangChain 도구의 일반적인 구조를 확인했습니다.
Naturally, there is far more we can do than what we’ve shown here. Tools can be used to integrate with an endless list of functions and services or to communicate with an orchestra of expert models, as demonstrated by HuggingGPT.
당연히 여기에 표시된 것보다 훨씬 더 많은 작업을 수행할 수 있습니다. 도구는 HuggingGPT에서 시연된 것처럼 끝없는 기능 및 서비스 목록과 통합하거나 전문 모델 오케스트라와 통신하는 데 사용할 수 있습니다.
We can often use LangChain’s default tools for running SQL queries, performing calculations, or doing vector search. However, when these default tools cannot satisfy our requirements, we now know how to build our own.
우리는 종종 SQL 쿼리 실행, 계산 수행 또는 벡터 검색 수행을 위해 LangChain의 기본 도구를 사용할 수 있습니다. 그러나 이러한 기본 도구가 우리의 요구 사항을 충족할 수 없는 경우 이제 우리는 자체 도구를 만드는 방법을 알고 있습니다.
References
[1] Y. Shen, K. Song, et al., HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in HuggingFace (2023)
'Pinecone > LangChain AI Handbook' 카테고리의 다른 글
| Chapter 6. AI Agents (1) | 2023.11.16 |
|---|---|
| Chapter 5. Retrieval Augmentation (1) | 2023.11.15 |
| Chapter 4. Conversational Memory (1) | 2023.11.15 |
| Chapter 3. Building Composable Pipelines with Chains (1) | 2023.11.14 |
| Chapter 2. Prompt Templates and the Art of Prompts (0) | 2023.11.13 |
| Chapter 1. An Introduction to LangChain (0) | 2023.11.10 |
| 0. Pinecone - LangChain AI Handbook (0) | 2023.11.08 |