

Chapter 3. Building Composable Pipelines with Chains
2023. 11. 14. 15:16 |
Building Composable Pipelines with Chains
02-langchain-chains.ipynb
Run, share, and edit Python notebooks
colab.research.google.com
!pip install -qU langchain openai
LangChain Handbook
Getting Started with Chains
Chains are the core of LangChain. They are simply a chain of components, executed in a particular order.
체인은 LangChain의 핵심입니다. 이는 단순히 특정 순서로 실행되는 구성 요소 체인입니다.
The simplest of these chains is the LLMChain. It works by taking a user's input, passing in to the first element in the chain — a PromptTemplate — to format the input into a particular prompt. The formatted prompt is then passed to the next (and final) element in the chain — a LLM.
이러한 체인 중 가장 간단한 것은 LLMChain입니다. 이는 사용자의 입력을 받아 체인의 첫 번째 요소인 PromptTemplate에 전달하여 입력을 특정 프롬프트로 형식화하는 방식으로 작동합니다. 그러면 형식화된 프롬프트가 체인의 다음(그리고 마지막) 요소인 LLM으로 전달됩니다.
We'll start by importing all the libraries that we'll be using in this example.
이 예제에서 사용할 모든 라이브러리를 가져오는 것부터 시작하겠습니다.
import inspect
import re
from getpass import getpass
from langchain import OpenAI, PromptTemplate
from langchain.chains import LLMChain, LLMMathChain, TransformChain, SequentialChain
from langchain.callbacks import get_openai_callback
이 코드는 다양한 모듈과 클래스를 가져오는 예제입니다. 아래는 코드의 각 부분에 대한 설명입니다:
- import inspect: Python의 inspect 모듈을 가져옵니다. 이 모듈은 코드 내에서 다양한 객체(함수, 클래스, 모듈 등)를 검사하는 데 사용됩니다. 주로 디버깅이나 동적으로 코드를 조사하는 데 활용됩니다.
- import re: 정규 표현식을 사용하기 위해 Python의 re 모듈을 가져옵니다. 정규 표현식은 문자열의 패턴을 검색하고 조작하는 데 사용됩니다.
- from getpass import getpass: getpass 모듈에서 getpass 함수를 가져옵니다. 이 함수는 사용자로부터 안전하게 비밀번호나 기타 민감한 정보를 입력 받는 데 사용됩니다.
- from langchain import OpenAI, PromptTemplate: langchain 패키지에서 OpenAI 클래스와 PromptTemplate 클래스를 가져옵니다. OpenAI 클래스는 OpenAI의 언어 모델과 상호작용하기 위한 도구를 제공하며, PromptTemplate 클래스는 템플릿 기반의 대화 흐름을 만들기 위한 도구입니다.
- from langchain.chains import LLMChain, LLMMathChain, TransformChain, SequentialChain: langchain 패키지의 chains 모듈에서 다양한 체인 관련 클래스를 가져옵니다. 이러한 클래스들은 언어 모델, 수학 모델, 변환 체인, 순차적 체인 등을 구성하는 데 사용됩니다.
- from langchain.callbacks import get_openai_callback: langchain 패키지의 callbacks 모듈에서 get_openai_callback 함수를 가져옵니다. 콜백은 비동기적인 이벤트를 처리하거나 특정 동작을 실행하는 데 사용됩니다.
이 코드는 다양한 도구와 클래스들을 가져와서 활용할 수 있도록 준비하는 것으로 보입니다. 가져온 모듈과 클래스들은 이후 코드에서 사용될 것으로 예상됩니다. 코드의 나머지 부분이 있는 경우, 해당 부분에 따라 더 자세한 설명을 제공할 수 있습니다.
To run this notebook, we will need to use an OpenAI LLM. Here we will setup the LLM we will use for the whole notebook, just input your openai api key when prompted.
이 노트북을 실행하려면 OpenAI LLM을 사용해야 합니다. 여기에서는 전체 노트북에 사용할 LLM을 설정합니다. 메시지가 표시되면 openai api 키를 입력하기만 하면 됩니다.
OPENAI_API_KEY = getpass()
이 코드는 getpass 함수를 사용하여 OpenAI API 키를 안전하게 입력받는 예제입니다. 아래는 코드의 설명입니다:
- from getpass import getpass: getpass 함수를 사용하기 위해 Python의 getpass 모듈에서 getpass 함수를 가져옵니다. 이 함수는 사용자로부터 안전하게 입력을 받는 데 사용됩니다.
- OPENAI_API_KEY = getpass(): getpass() 함수를 호출하여 사용자에게 입력을 받습니다. 사용자가 키보드로 입력한 값은 표시되지 않고, 안전하게 읽어들입니다. 이렇게 입력받은 값은 OPENAI_API_KEY 변수에 할당됩니다.
따라서, 이 코드는 사용자로부터 OpenAI API 키를 안전하게 입력받아 OPENAI_API_KEY 변수에 저장하는 역할을 합니다. 이러한 방식으로 API 키를 입력받으면 키가 화면에 표시되지 않아 보안 상 이점이 있습니다.
llm = OpenAI(
temperature=0,
openai_api_key=OPENAI_API_KEY
)
내 로컬 코드에서는 getpass() 를 사용하지 않고 외부 파일에 api 키를 저장해 놓고 이 파일을 읽어 오는 방법을 사용했습니다. 그리고 모델을 gpt-3.5-turbo-1106으로 지정했습니다.
An extra utility we will use is this function that will tell us how many tokens we are using in each call. This is a good practice that is increasingly important as we use more complex tools that might make several calls to the API (like agents). It is very important to have a close control of how many tokens we are spending to avoid unsuspected expenditures.
우리가 사용할 추가 유틸리티는 각 호출에서 사용하는 토큰 수를 알려주는 이 함수입니다. 이는 API(예: 에이전트)를 여러 번 호출할 수 있는 보다 복잡한 도구를 사용함에 따라 점점 더 중요해지는 좋은 방법입니다. 예상치 못한 지출을 피하기 위해 우리가 지출하는 토큰 수를 면밀히 통제하는 것이 매우 중요합니다.
def count_tokens(chain, query):
with get_openai_callback() as cb:
result = chain.run(query)
print(f'Spent a total of {cb.total_tokens} tokens')
return result
이 코드는 주어진 언어 모델 체인 (chain)을 사용하여 주어진 질문 (query)에 대한 응답을 생성하고, 그 과정에서 사용된 토큰의 수를 계산하는 함수입니다. 아래는 코드의 각 부분에 대한 설명입니다:
- def count_tokens(chain, query):: count_tokens 함수를 정의합니다. 이 함수는 두 개의 매개변수를 받습니다. 하나는 언어 모델 체인 (chain), 다른 하나는 질문 또는 쿼리 (query)입니다.
- with get_openai_callback() as cb:: get_openai_callback() 함수를 사용하여 OpenAI API 호출을 추적하는 콜백을 얻습니다. with 문을 사용하면 콜백이 사용된 코드 블록을 벗어날 때 자원을 적절하게 해제할 수 있습니다.
- result = chain.run(query): 언어 모델 체인을 사용하여 주어진 질문에 대한 응답을 생성합니다. 이 결과는 result 변수에 저장됩니다.
- print(f'Spent a total of {cb.total_tokens} tokens'): OpenAI API 호출 중 사용된 총 토큰 수를 출력합니다. cb.total_tokens는 콜백 객체에 저장된 총 토큰 수를 나타냅니다.
- return result: 함수는 언어 모델 체인을 사용하여 생성된 응답을 반환합니다.
이 함수는 언어 모델을 사용하여 주어진 질문에 대한 응답을 생성하면서 사용된 토큰의 총 수를 계산하고, 그 값을 출력하며, 마지막으로 생성된 응답을 반환합니다.
What are chains anyway?
Definition: Chains are one of the fundamental building blocks of this lib (as you can guess!).
정의: 체인은 이 라이브러리의 기본 구성 요소 중 하나입니다(추측할 수 있듯이!).
The official definition of chains is the following: 체인의 공식적인 정의는 다음과 같습니다.
A chain is made up of links, which can be either primitives or other chains. Primitives can be either prompts, llms, utils, or other chains.
체인은 기본 체인일 수도 있고 다른 체인일 수도 있는 링크로 구성됩니다. 기본 요소는 프롬프트, llms, utils 또는 기타 체인일 수 있습니다.
So a chain is basically a pipeline that processes an input by using a specific combination of primitives. Intuitively, it can be thought of as a 'step' that performs a certain set of operations on an input and returns the result. They can be anything from a prompt-based pass through a LLM to applying a Python function to an text.
따라서 체인은 기본적으로 특정 프리미티브 조합을 사용하여 입력을 처리하는 파이프라인입니다. 직관적으로 이는 입력에 대해 특정 작업 집합을 수행하고 결과를 반환하는 '단계'로 생각할 수 있습니다. LLM을 통한 프롬프트 기반 전달부터 텍스트에 Python 함수를 적용하는 것까지 무엇이든 될 수 있습니다.
Chains are divided in three types: Utility chains, Generic chains and Combine Documents chains. In this edition, we will focus on the first two since the third is too specific (will be covered in due course).
체인은 유틸리티 체인, 일반 체인, 결합 문서 체인의 세 가지 유형으로 나뉩니다. 이번 판에서는 세 번째 부분이 너무 구체적이기 때문에 처음 두 가지 부분에 초점을 맞추겠습니다(적절한 과정에서 다루겠습니다).
- Utility Chains: chains that are usually used to extract a specific answer from a llm with a very narrow purpose and are ready to be used out of the box.
유틸리티 체인: 일반적으로 매우 좁은 목적으로 LLM에서 특정 답변을 추출하는 데 사용되며 즉시 사용할 수 있는 체인입니다. - Generic Chains: chains that are used as building blocks for other chains but cannot be used out of the box on their own.
일반 체인: 다른 체인의 빌딩 블록으로 사용되지만 자체적으로는 사용할 수 없는 체인입니다.
Let's take a peek into what these chains have to offer!
이 체인이 무엇을 제공하는지 살펴보겠습니다!
Utility Chains
Let's start with a simple utility chain. The LLMMathChain gives llms the ability to do math. Let's see how it works!
간단한 유틸리티 체인부터 시작해 보겠습니다. LLMMathChain은 llms에 수학을 수행할 수 있는 기능을 제공합니다. 그것이 어떻게 작동하는지 봅시다!
Pro-tip: use verbose=True to see what the different steps in the chain are!
전문가 팁: 체인의 다른 단계가 무엇인지 확인하려면 verbose=True를 사용하세요!
아래 코드에서는 LLMMathChain()을 사용합니다. 이것을 사용하려면 numexpr 패키지를 먼저 설치해야 합니다.
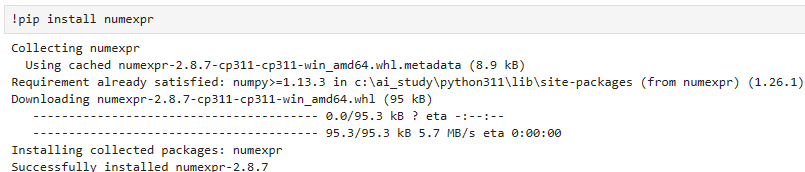
llm_math = LLMMathChain(llm=llm, verbose=True)
count_tokens(llm_math, "What is 13 raised to the .3432 power?")
이 코드는 LLMMathChain을 사용하여 주어진 수학적인 질문에 대한 응답을 생성하고, 그 과정에서 사용된 토큰의 수를 계산하는 예제입니다. 아래는 코드의 각 부분에 대한 설명입니다:
- llm_math = LLMMathChain(llm=llm, verbose=True): LLMMathChain 클래스의 인스턴스를 생성합니다. 이때, llm은 언어 모델을 나타내는 변수이며, verbose=True는 자세한 정보를 출력하도록 하는 옵션입니다. 이 체인은 수학적인 계산을 수행하는 데 사용됩니다.
- count_tokens(llm_math, "What is 13 raised to the .3432 power?"): count_tokens 함수를 호출하여, 앞서 생성한 llm_math 체인을 사용하여 주어진 수학적인 질문에 대한 응답을 생성하고, 그 과정에서 사용된 토큰의 수를 계산합니다. 이 질문은 "13을 0.3432 제곱한 값은 무엇인가요?"를 나타냅니다.
이 코드는 LLMMathChain을 이용하여 수학적인 계산을 수행하면서 사용된 토큰의 수를 출력하는 간단한 예제입니다.
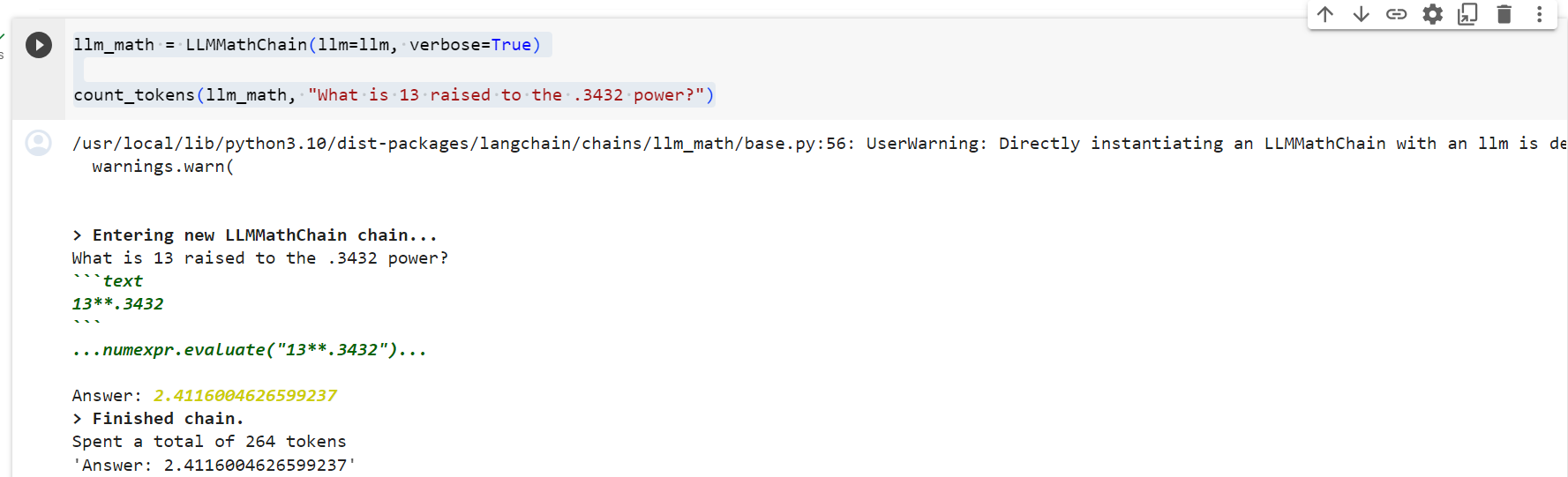
Let's see what is going on here. The chain recieved a question in natural language and sent it to the llm. The llm returned a Python code which the chain compiled to give us an answer. A few questions arise.. How did the llm know that we wanted it to return Python code?
여기서 무슨 일이 일어나고 있는지 봅시다. 체인은 자연어로 질문을 받아 LLM으로 보냈습니다. llm은 우리에게 답변을 제공하기 위해 체인이 컴파일한 Python 코드를 반환했습니다. 몇 가지 질문이 생깁니다. llm은 우리가 Python 코드를 반환하기를 원한다는 것을 어떻게 알았습니까?
Enter prompts
The question we send as input to the chain is not the only input that the llm recieves 😉. The input is inserted into a wider context, which gives precise instructions on how to interpret the input we send. This is called a prompt. Let's see what this chain's prompt is!
우리가 체인에 입력으로 보내는 질문은 llm이 받는 유일한 입력이 아닙니다 😉. 입력은 더 넓은 컨텍스트에 삽입되어 우리가 보내는 입력을 해석하는 방법에 대한 정확한 지침을 제공합니다. 이것을 프롬프트라고 합니다. 이 체인의 프롬프트가 무엇인지 봅시다!
print(llm_math.prompt.template)
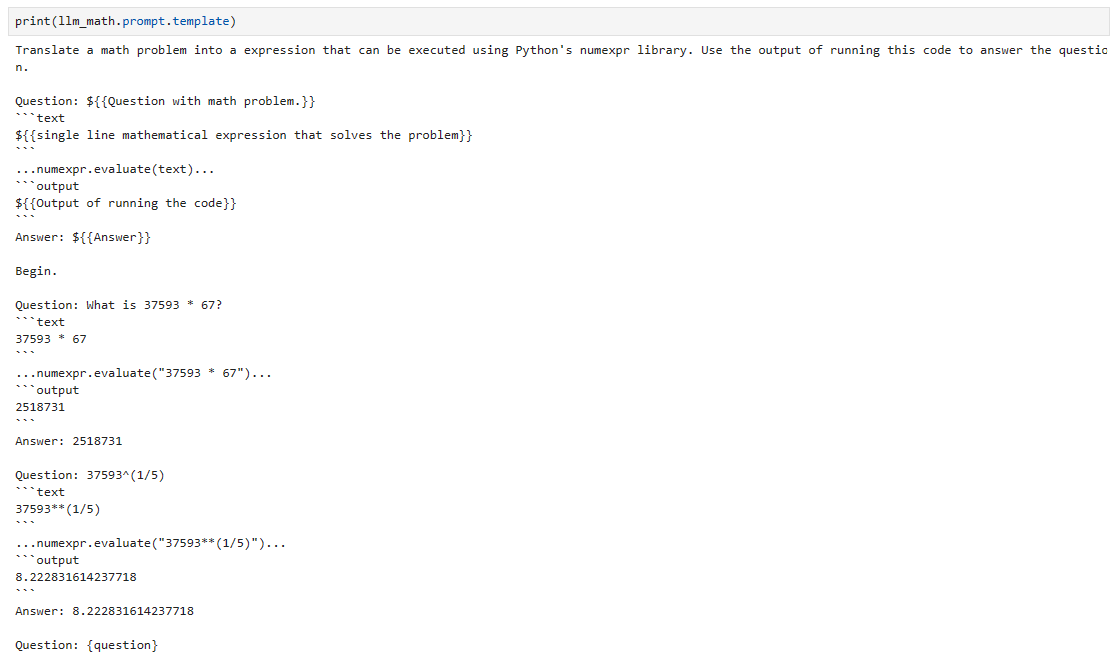
Ok.. let's see what we got here. So, we are literally telling the llm that for complex math problems it should not try to do math on its own but rather it should print a Python code that will calculate the math problem instead. Probably, if we just sent the query without any context, the llm would try (and fail) to calculate this on its own. Wait! This is testable.. let's try it out! 🧐
좋아.. 우리가 여기서 무엇을 얻었는지 보자. 따라서 우리는 문자 그대로 llm에게 복잡한 수학 문제의 경우 자체적으로 수학을 수행하려고 시도해서는 안 되며 대신 수학 문제를 계산할 Python 코드를 인쇄해야 한다고 말하는 것입니다. 아마도 컨텍스트 없이 쿼리를 보낸다면 llm은 이를 자체적으로 계산하려고 시도하고 실패할 것입니다. Wait! 이것은 테스트 가능합니다. 한번 시험해 봅시다! 🧐
# we set the prompt to only have the question we ask
prompt = PromptTemplate(input_variables=['question'], template='{question}')
llm_chain = LLMChain(prompt=prompt, llm=llm)
# we ask the llm for the answer with no context
count_tokens(llm_chain, "What is 13 raised to the .3432 power?")
이 코드는 주어진 수학적인 질문에 대한 답을 생성하면서 사용된 토큰의 수를 계산하는 예제입니다. 아래는 코드의 각 부분에 대한 설명입니다:
- llm_math = LLMMathChain(llm=llm, verbose=True): LLMMathChain 클래스의 인스턴스를 생성합니다. 이때, llm은 언어 모델을 나타내는 변수이며, verbose=True는 자세한 정보를 출력하도록 하는 옵션입니다. LLMMathChain은 수학적인 계산을 수행하는 언어 모델 체인을 나타냅니다.
- count_tokens(llm_math, "What is 13 raised to the .3432 power?"): count_tokens 함수를 호출합니다. 이 함수는 언어 모델 체인을 사용하여 주어진 수학적인 질문에 대한 응답을 생성하면서 사용된 토큰의 수를 계산합니다. 이 예제에서는 "13을 0.3432 제곱한 값은 무엇인가요?"와 같은 형태의 질문을 의미합니다.
이 코드는 언어 모델 체인을 사용하여 수학적인 질문에 대한 응답을 생성하면서 사용된 토큰의 수를 출력하는 간단한 예제입니다.

Wrong answer! Herein lies the power of prompting and one of our most important insights so far:
잘못된 답변! 여기에 프롬프트의 힘과 지금까지 우리가 얻은 가장 중요한 통찰 중 하나가 있습니다.
Insight: by using prompts intelligently, we can force the llm to avoid common pitfalls by explicitly and purposefully programming it to behave in a certain way.
통찰력: 프롬프트를 지능적으로 사용함으로써 llm이 특정 방식으로 작동하도록 명시적이고 의도적으로 프로그래밍함으로써 일반적인 함정을 피하도록 강제할 수 있습니다.
Another interesting point about this chain is that it not only runs an input through the llm but it later compiles Python code. Let's see exactly how this works.
이 체인의 또 다른 흥미로운 점은 llm을 통해 입력을 실행할 뿐만 아니라 나중에 Python 코드를 컴파일한다는 것입니다. 이것이 어떻게 작동하는지 정확히 살펴보겠습니다.
print(inspect.getsource(llm_math._call))
이 코드는 inspect 모듈을 사용하여 llm_math 객체의 _call 메서드의 소스 코드를 출력하는 예제입니다. 아래는 코드의 각 부분에 대한 설명입니다:
- inspect.getsource(llm_math._call): inspect 모듈의 getsource 함수를 사용하여 llm_math 객체의 _call 메서드의 소스 코드를 가져옵니다. _call 메서드는 언어 모델 체인의 호출을 처리하는 함수로, 언어 모델에 특정 입력을 전달하고 결과를 반환합니다.
- print(...): print 함수를 사용하여 _call 메서드의 소스 코드를 출력합니다.
이 코드는 주어진 객체의 특정 메서드의 소스 코드를 출력하는 간단한 디버깅용 목적의 예제입니다. 출력된 내용은 _call 메서드의 코드 자체일 것이며, 해당 메서드가 어떻게 작동하는지를 확인할 수 있습니다.
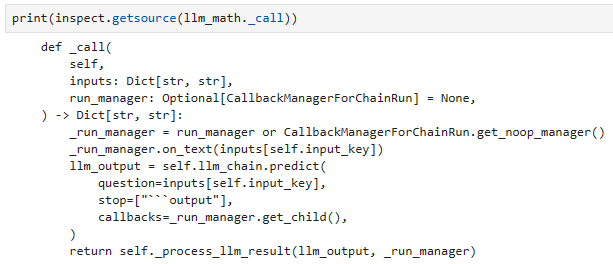
So we can see here that if the llm returns Python code we will compile it with a Python REPL* simulator. We now have the full picture of the chain: either the llm returns an answer (for simple math problems) or it returns Python code which we compile for an exact answer to harder problems. Smart!
따라서 여기서는 llm이 Python 코드를 반환하면 Python REPL* 시뮬레이터를 사용하여 이를 컴파일한다는 것을 알 수 있습니다. 이제 우리는 체인의 전체 그림을 갖게 되었습니다. llm은 답(간단한 수학 문제의 경우)을 반환하거나 더 어려운 문제에 대한 정확한 답을 위해 컴파일하는 Python 코드를 반환합니다. Smart !
Also notice that here we get our first example of chain composition, a key concept behind what makes langchain special. We are using the LLMMathChain which in turn initializes and uses an LLMChain (a 'Generic Chain') when called. We can make any arbitrary number of such compositions, effectively 'chaining' many such chains to achieve highly complex and customizable behaviour.
또한 여기에서 langchain을 특별하게 만드는 핵심 개념인 체인 구성의 첫 번째 예를 볼 수 있습니다. 우리는 호출 시 LLMChain('일반 체인')을 초기화하고 사용하는 LLMMathChain을 사용하고 있습니다. 우리는 그러한 구성을 임의의 수만큼 만들 수 있으며, 매우 복잡하고 사용자 정의 가능한 동작을 달성하기 위해 많은 체인을 효과적으로 '체인'할 수 있습니다.
Utility chains usually follow this same basic structure: there is a prompt for constraining the llm to return a very specific type of response from a given query. We can ask the llm to create SQL queries, API calls and even create Bash commands on the fly 🔥
유틸리티 체인은 일반적으로 이와 동일한 기본 구조를 따릅니다. 즉, 주어진 쿼리에서 매우 구체적인 유형의 응답을 반환하도록 llm을 제한하는 프롬프트가 있습니다. 우리는 llm에게 SQL 쿼리, API 호출을 생성하고 심지어 즉시 Bash 명령을 생성하도록 요청할 수 있습니다 🔥
The list continues to grow as langchain becomes more and more flexible and powerful so we encourage you to check it out and tinker with the example notebooks that you might find interesting.
langchain이 점점 더 유연해지고 강력해짐에 따라 목록은 계속해서 늘어나고 있으므로 이를 확인하고 흥미로울 수 있는 예제 노트북을 살펴보는 것이 좋습니다.
*A Python REPL (Read-Eval-Print Loop) is an interactive shell for executing Python code line by line
*Python REPL(Read-Eval-Print Loop)은 Python 코드를 한 줄씩 실행하기 위한 대화형 셸입니다.
Generic chains
There are only three Generic Chains in langchain and we will go all in to showcase them all in the same example. Let's go!
langchain에는 3개의 일반 체인만 있으며 동일한 예에서 모두 보여드리기 위해 올인하겠습니다. 갑시다!
Say we have had experience of getting dirty input texts. Specifically, as we know, llms charge us by the number of tokens we use and we are not happy to pay extra when the input has extra characters. Plus its not neat 😉
더러운 입력 텍스트를 받은 경험이 있다고 가정해 보겠습니다. 특히 우리가 알고 있듯이 llms는 우리가 사용하는 토큰 수에 따라 비용을 청구하며 입력에 추가 문자가 있는 경우 추가 비용을 지불하지 않습니다. 게다가 깔끔하지도 않아요 😉
First, we will build a custom transform function to clean the spacing of our texts. We will then use this function to build a chain where we input our text and we expect a clean text as output.
먼저, 텍스트의 간격을 정리하기 위한 사용자 정의 변환 함수를 구축하겠습니다. 그런 다음 이 함수를 사용하여 텍스트를 입력하고 출력으로 깨끗한 텍스트를 기대하는 체인을 구축합니다.
def transform_func(inputs: dict) -> dict:
text = inputs["text"]
# replace multiple new lines and multiple spaces with a single one
text = re.sub(r'(\r\n|\r|\n){2,}', r'\n', text)
text = re.sub(r'[ \t]+', ' ', text)
return {"output_text": text}
이 코드는 주어진 입력 텍스트에 대해 특정 변환을 수행하는 함수를 정의한 것입니다. 아래는 코드의 각 부분에 대한 설명입니다:
- def transform_func(inputs: dict) -> dict:: transform_func라는 함수를 정의합니다. 이 함수는 입력으로 딕셔너리를 받아들이고, 출력으로 또 다른 딕셔너리를 반환합니다. 입력과 출력의 형태는 각각 dict 타입으로 지정되어 있습니다.
- text = inputs["text"]: 입력으로 받은 딕셔너리에서 'text' 키에 해당하는 값을 가져와서 text 변수에 할당합니다. 이 변수에는 변환을 수행할 텍스트가 들어 있어야 합니다.
- 주석 부분(# ...)에서부터는 텍스트를 변환하는 과정을 설명하고 있습니다.
- re.sub(r'(\r\n|\r|\n){2,}', r'\n', text): 정규 표현식을 사용하여 여러 줄 바꿈 문자 또는 공백이 두 번 이상 반복되는 경우 이를 하나로 줄입니다.
- re.sub(r'[ \t]+', ' ', text): 정규 표현식을 사용하여 여러 개의 공백 또는 탭 문자가 하나의 공백으로 대체됩니다.
- return {"output_text": text}: 변환된 텍스트를 새로운 딕셔너리에 담아서 반환합니다. 이때, 'output_text'라는 키를 사용하여 변환된 텍스트를 저장합니다.
이 코드는 주어진 텍스트에 대해 여러 변환을 수행하는 함수로, 특히 여러 줄 바꿈이나 여러 공백을 간단하게 처리하는 부분이 구현되어 있습니다.
Importantly, when we initialize the chain we do not send an llm as an argument. As you can imagine, not having an llm makes this chain's abilities much weaker than the example we saw earlier. However, as we will see next, combining this chain with other chains can give us highly desirable results.
중요한 것은 체인을 초기화할 때 llm을 인수로 보내지 않는다는 것입니다. 상상할 수 있듯이 llm이 없으면 이 체인의 능력이 앞서 본 예보다 훨씬 약해집니다. 그러나 다음에 살펴보겠지만 이 체인을 다른 체인과 결합하면 매우 바람직한 결과를 얻을 수 있습니다.
clean_extra_spaces_chain = TransformChain(input_variables=["text"], output_variables=["output_text"], transform=transform_func)
이 코드는 TransformChain 클래스를 사용하여 텍스트 변환 체인을 생성하는 예제입니다. 아래는 코드의 각 부분에 대한 설명입니다:
- clean_extra_spaces_chain = TransformChain(input_variables=["text"], output_variables=["output_text"], transform=transform_func): TransformChain 클래스의 인스턴스를 생성합니다. 이때, 생성자에 세 개의 인자를 전달합니다.
- input_variables=["text"]: 체인에 사용될 입력 변수로, 이 경우에는 'text' 변수를 사용합니다.
- output_variables=["output_text"]: 체인의 출력으로 사용될 변수로, 'output_text'라는 이름으로 변환된 결과를 저장합니다.
- transform=transform_func: 변환 함수로, 이 경우에는 transform_func 함수를 사용합니다. 이 함수는 주어진 입력 텍스트에 대해 변환을 수행하고, 결과를 출력 변수에 저장하는 역할을 합니다.
이렇게 생성된 clean_extra_spaces_chain은 입력으로 텍스트를 받아들여 변환 함수를 적용하고, 그 결과를 'output_text' 변수에 저장하는 텍스트 변환 체인입니다. 이 체인을 사용하면 텍스트에 대해 정의된 변환 함수를 쉽게 적용할 수 있습니다.

Great! Now things will get interesting. 훌륭합니다! 이제 상황이 흥미로워질 것입니다.
Say we want to use our chain to clean an input text and then paraphrase the input in a specific style, say a poet or a policeman. As we now know, the TransformChain does not use a llm so the styling will have to be done elsewhere. That's where our LLMChain comes in. We know about this chain already and we know that we can do cool things with smart prompting so let's take a chance!
시인이나 경찰처럼 체인을 사용하여 입력 텍스트를 정리한 다음 입력 내용을 특정 스타일로 바꾸어 표현하고 싶다고 가정해 보겠습니다. 우리가 지금 알고 있듯이 TransformChain은 llm을 사용하지 않으므로 스타일링은 다른 곳에서 수행해야 합니다. 이것이 바로 우리 LLMChain이 필요한 곳입니다. 우리는 이미 이 체인에 대해 알고 있으며 스마트 프롬프트로 멋진 일을 할 수 있다는 것을 알고 있으므로 기회를 잡아봅시다!
template = """Paraphrase this text:
{output_text}
In the style of a {style}.
Paraphrase: """
prompt = PromptTemplate(input_variables=["style", "output_text"], template=template)
이 코드는 특정 템플릿을 사용하여 주어진 스타일과 텍스트에 대한 문장을 생성하는 PromptTemplate 클래스의 인스턴스를 만드는 예제입니다. 아래는 코드의 각 부분에 대한 설명입니다:
- template = """Paraphrase this text:...Paraphrase: """: 템플릿 문자열을 정의합니다. 이 템플릿에는 두 개의 변수가 포함되어 있습니다.
- {output_text}: 이 부분은 나중에 'output_text'라는 변수로 대체될 것입니다. 이는 어떤 텍스트를 나타내는 변수입니다.
- {style}: 이 부분은 나중에 'style'이라는 변수로 대체될 것입니다. 이는 스타일을 나타내는 변수입니다.
- 나머지 부분은 템플릿의 구조를 정의하고 있습니다.
- prompt = PromptTemplate(input_variables=["style", "output_text"], template=template): PromptTemplate 클래스의 인스턴스를 생성합니다.
- input_variables=["style", "output_text"]: 템플릿에 사용될 변수들을 정의합니다. 여기에서는 'style'과 'output_text' 변수를 사용합니다.
- template=template: 사용할 템플릿을 설정합니다. 앞서 정의한 template 변수를 사용합니다.
이렇게 생성된 prompt는 주어진 스타일과 텍스트에 대한 문장을 생성하는데 사용될 수 있는 템플릿과 변수를 가진 PromptTemplate 클래스의 인스턴스입니다. 이를 사용하면 특정 문맥과 스타일에 따라 텍스트를 생성하는데 유용하게 활용될 수 있습니다.
And next, initialize our chain: 다음으로 체인을 초기화합니다.
style_paraphrase_chain = LLMChain(llm=llm, prompt=prompt, output_key='final_output')
이 코드는 주어진 언어 모델(llm)과 특정 템플릿(prompt)을 사용하여 문장을 생성하는 LLMChain 클래스의 인스턴스를 생성하는 예제입니다. 아래는 코드의 각 부분에 대한 설명입니다:
- style_paraphrase_chain = LLMChain(llm=llm, prompt=prompt, output_key='final_output'): LLMChain 클래스의 인스턴스를 생성합니다.
- llm=llm: 사용할 언어 모델을 나타내는 변수입니다. 이 변수는 이전에 초기화된 언어 모델 객체를 참조합니다.
- prompt=prompt: 사용할 템플릿을 나타내는 변수입니다. 이 변수는 이전에 초기화된 템플릿 객체를 참조합니다.
- output_key='final_output': 생성된 문장의 결과를 저장할 변수의 이름을 지정합니다. 이 경우, 'final_output'라는 변수에 결과를 저장하도록 설정되어 있습니다.
이렇게 생성된 style_paraphrase_chain은 특정 스타일과 텍스트에 대한 문장을 생성하는데 사용될 수 있는 언어 모델 체인의 인스턴스입니다. 이 체인을 사용하면 주어진 템플릿과 변수를 활용하여 특정 스타일로 텍스트를 생성하는 과정이 쉽게 수행될 수 있습니다. 생성된 문장은 'final_output'이라는 변수에 저장됩니다.
Great! Notice that the input text in the template is called 'output_text'. Can you guess why?
좋습니! 템플릿의 입력 텍스트는 'output_text'라고 합니다. 이유를 짐작할 수 있나요?
We are going to pass the output of the TransformChain to the LLMChain!
TransformChain의 출력을 LLMChain으로 전달하겠습니다!
Finally, we need to combine them both to work as one integrated chain. For that we will use SequentialChain which is our third generic chain building block.
마지막으로, 둘을 결합하여 하나의 통합 체인으로 작동해야 합니다. 이를 위해 우리는 세 번째 일반 체인 빌딩 블록인 SequentialChain을 사용할 것입니다.
sequential_chain = SequentialChain(chains=[clean_extra_spaces_chain, style_paraphrase_chain], input_variables=['text', 'style'], output_variables=['final_output'])
이 코드는 두 개의 언어 모델 체인을 연속적으로 실행하는 SequentialChain 클래스의 인스턴스를 생성하는 예제입니다. 아래는 코드의 각 부분에 대한 설명입니다:
- sequential_chain = SequentialChain(chains=[clean_extra_spaces_chain, style_paraphrase_chain], input_variables=['text', 'style'], output_variables=['final_output']): SequentialChain 클래스의 인스턴스를 생성합니다.
- chains=[clean_extra_spaces_chain, style_paraphrase_chain]: 체인에 사용할 언어 모델 체인의 리스트를 지정합니다. 이 경우, clean_extra_spaces_chain과 style_paraphrase_chain 두 개의 체인이 연속적으로 실행됩니다.
- input_variables=['text', 'style']: 체인에 입력으로 제공될 변수들의 이름을 지정합니다. 여기에서는 'text'와 'style' 변수가 입력으로 사용됩니다.
- output_variables=['final_output']: 체인의 출력으로 생성된 변수의 이름을 지정합니다. 여기에서는 'final_output' 변수가 출력으로 사용됩니다.
이렇게 생성된 sequential_chain은 clean_extra_spaces_chain을 먼저 실행한 다음, 그 결과를 이어서 style_paraphrase_chain에 전달하여 두 체인을 연속적으로 실행하는 언어 모델 체인의 인스턴스입니다. 결과는 'final_output' 변수에 저장됩니다. 이렇게 체인을 구성하면 여러 단계의 언어 모델이 연속적으로 적용되어 원하는 형식으로 텍스트를 생성할 수 있습니다.
Our input is the langchain docs description of what chains are but dirty with some extra spaces all around.
우리의 입력은 체인이 무엇인지에 대한 langchain 문서 설명이지만 주위에 약간의 추가 공간이 있어 더러워졌습니다.
input_text = """
Chains allow us to combine multiple
components together to create a single, coherent application.
For example, we can create a chain that takes user input, format it with a PromptTemplate,
and then passes the formatted response to an LLM. We can build more complex chains by combining multiple chains together, or by
combining chains with other components.
"""
We are all set. Time to get creative! 우리는 모두 준비되었습니다. 창의력을 발휘할 시간입니다!
count_tokens(sequential_chain, {'text': input_text, 'style': 'a 90s rapper'})
이 코드는 앞서 생성한 sequential_chain 언어 모델 체인을 사용하여 특정 입력 텍스트와 스타일에 대한 문장을 생성하면서 사용된 토큰의 수를 계산하는 함수인 count_tokens를 호출하는 예제입니다. 아래는 코드의 각 부분에 대한 설명입니다:
- count_tokens(sequential_chain, {'text': input_text, 'style': 'a 90s rapper'}): count_tokens 함수를 호출합니다. 이 함수는 언어 모델 체인과 입력 변수들을 받아들여 언어 모델을 실행하면서 사용된 토큰의 수를 계산하고, 그 값을 출력합니다.
- sequential_chain: 사용할 언어 모델 체인으로, 앞서 생성한 sequential_chain 객체를 전달합니다.
- {'text': input_text, 'style': 'a 90s rapper'}: 입력으로 사용될 변수들과 그에 대한 값들을 딕셔너리 형태로 전달합니다. 여기에서는 'text' 변수에는 input_text라는 입력 텍스트가, 'style' 변수에는 "a 90s rapper"라는 스타일이 전달됩니다.
이 코드는 주어진 언어 모델 체인을 사용하여 입력 텍스트와 스타일에 대한 문장을 생성하면서 사용된 토큰의 수를 계산하는 함수를 호출하는 예제입니다. 결과로는 생성된 문장과 사용된 토큰의 총 수가 출력될 것입니다.

A note on langchain-hub
langchain-hub is a sister library to langchain, where all the chains, agents and prompts are serialized for us to use.
langchain-hub는 우리가 사용할 수 있도록 모든 체인, 에이전트 및 프롬프트가 직렬화되어 있는 langchain의 자매 라이브러리입니다.
from langchain.chains import load_chain
이 코드는 langchain 패키지에서 chains 모듈 내의 load_chain 함수를 가져오는 예제입니다. 아래는 코드의 각 부분에 대한 설명입니다:
- from langchain.chains import load_chain: langchain 패키지에서 chains 모듈 내의 load_chain 함수를 가져옵니다.
- from ... import ... 형태는 특정 모듈 또는 모듈 내의 특정 함수, 클래스 등을 현재 코드에 가져오는(import) 방식을 나타냅니다.
- 여기서는 langchain 패키지에서 chains 모듈을 불러오고, 그 중에서 load_chain 함수를 가져옵니다.
load_chain 함수는 언어 모델 체인을 불러오는 함수일 것으로 예상됩니다. 이 함수를 사용하면 이전에 저장된 언어 모델 체인을 다시 불러와서 재사용할 수 있습니다. 코드의 나머지 부분이 있으면 해당 부분에 따라 더 자세한 설명을 제공할 수 있습니다.
Loading from langchain hub is as easy as finding the chain you want to load in the repository and then using load_chain with the corresponding path. We also have load_prompt and initialize_agent, but more on that later. Let's see how we can do this with our LLMMathChain we saw earlier:
langchain 허브에서 로드하는 것은 저장소에서 로드하려는 체인을 찾은 다음 해당 경로와 함께 load_chain을 사용하는 것만큼 쉽습니다. load_prompt와 초기화_agent도 있지만 이에 대해서는 나중에 자세히 설명합니다. 앞서 본 LLMMathChain을 사용하여 이를 수행하는 방법을 살펴보겠습니다.
llm_math_chain = load_chain('lc://chains/llm-math/chain.json')
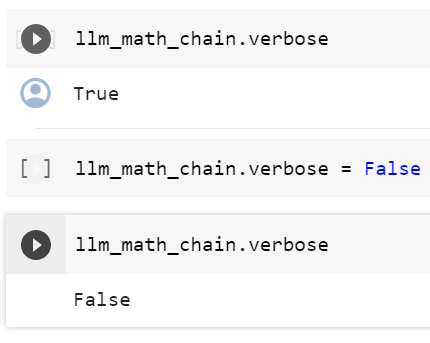
What if we want to change some of the configuration parameters? We can simply override it after loading:
일부 구성 매개변수를 변경하려면 어떻게 해야 합니까? 로드한 후에 간단히 재정의할 수 있습니다.
llm_math_chain.verbosellm_math_chain.verbose = Falsellm_math_chain.verbose
That's it for this example on chains. 이것이 체인에 대한 예제의 전부입니다.
'Pinecone > LangChain AI Handbook' 카테고리의 다른 글
| Chapter 7. Custom Tools (0) | 2023.11.17 |
|---|---|
| Chapter 6. AI Agents (1) | 2023.11.16 |
| Chapter 5. Retrieval Augmentation (1) | 2023.11.15 |
| Chapter 4. Conversational Memory (1) | 2023.11.15 |
| Chapter 2. Prompt Templates and the Art of Prompts (0) | 2023.11.13 |
| Chapter 1. An Introduction to LangChain (0) | 2023.11.10 |
| 0. Pinecone - LangChain AI Handbook (0) | 2023.11.08 |