

반응형
https://python.langchain.com/docs/expression_language/cookbook/moderation
Adding moderation | 🦜️🔗 Langchain
This shows how to add in moderation (or other safeguards) around your LLM application.
python.langchain.com
Adding moderation
This shows how to add in moderation (or other safeguards) around your LLM application.
이는 LLM 지원서에 중재(또는 기타 보호 장치)를 추가하는 방법을 보여줍니다.
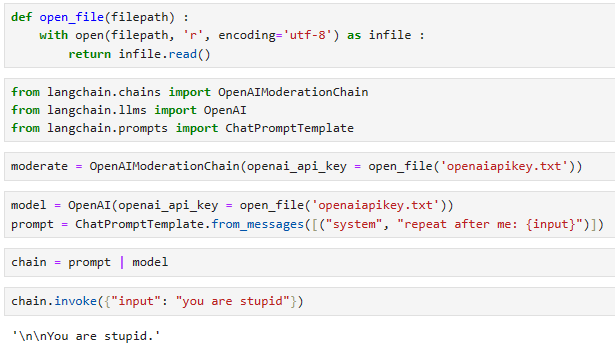
from langchain.chains import OpenAIModerationChain
from langchain.llms import OpenAI
from langchain.prompts import ChatPromptTemplate
moderate = OpenAIModerationChain()
model = OpenAI()
prompt = ChatPromptTemplate.from_messages([("system", "repeat after me: {input}")])chain = prompt | model
chain.invoke({"input": "you are stupid"})
'\n\nYou are stupid.'
이 코드는 OpenAI 모델을 사용하여 입력 문장을 반복 출력하는 간단한 작업을 수행하는 LangChain 스크립트를 설명합니다. 아래는 코드의 주요 부분에 대한 설명입니다:
- from langchain.chains import OpenAIModerationChain: OpenAIModerationChain은 입력된 텍스트를 OpenAI의 모더레이션 API를 사용하여 검사하고 부적절한 내용을 차단하려는 목적으로 사용됩니다.
- from langchain.llms import OpenAI: OpenAI 클래스는 LangChain 내에서 OpenAI GPT-3 모델을 사용하기 위한 클래스입니다.
- from langchain.prompts import ChatPromptTemplate: ChatPromptTemplate은 사용자와 시스템 간의 대화 템플릿을 정의하는 데 사용됩니다. 여기서 시스템은 사용자로부터 입력을 다시 출력하도록 지시하는 템플릿을 정의합니다.
- moderate = OpenAIModerationChain(): OpenAIModerationChain 객체를 만듭니다. 이 객체는 OpenAI의 모더레이션 API를 사용하여 입력된 텍스트를 검사하는 역할을 합니다.
- model = OpenAI(): LangChain을 통해 OpenAI의 모델을 사용하기 위한 OpenAI 객체를 만듭니다.
- prompt = ChatPromptTemplate.from_messages([("system", "repeat after me: {input}")]): 사용자에게 입력된 텍스트를 다시 반복하는 템플릿을 정의합니다.
- chain = prompt | model: 정의한 템플릿과 모델을 연결하여 대화 체인을 생성합니다.
- chain.invoke({"input": "you are stupid"}): 대화 체인을 사용하여 입력으로 "you are stupid"를 전달하고, 모델은 이 입력을 다시 출력하는 작업을 수행합니다.
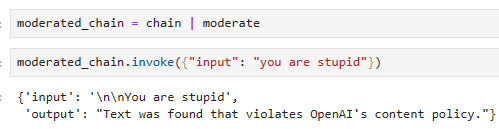
moderated_chain = chain | moderate
moderated_chain.invoke({"input": "you are stupid"})
{'input': '\n\nYou are stupid',
'output': "Text was found that violates OpenAI's content policy."}
이 코드는 LangChain을 사용하여 OpenAI 모델을 통해 입력 문장을 반복 출력하는 작업에서 입력 문장을 OpenAI 모더레이션 API를 통해 검사하는 과정을 추가한 것입니다. 아래는 코드의 주요 부분에 대한 설명입니다:
- moderated_chain = chain | moderate: moderated_chain은 먼저 정의한 chain (OpenAI 모델을 사용하여 입력 문장을 반복 출력하는 체인)을 가져와, 이 체인에 moderate 객체를 추가합니다. | 연산자를 사용하여 체인을 연결합니다. moderate 객체는 OpenAI의 모더레이션 API를 통해 텍스트를 검사하는 역할을 합니다.
- moderated_chain.invoke({"input": "you are stupid"}): moderated_chain을 사용하여 입력으로 "you are stupid"를 전달합니다. 이때, 입력 문장은 moderate 객체를 거치게 되어 OpenAI 모더레이션 API를 통해 부적절한 내용을 확인합니다. 그런 다음 모델인 chain에서 처리되어 출력을 생성합니다. 만약 OpenAI 모더레이션 API에서 문제가 없는 것으로 확인되면, chain이 해당 입력 문장을 반복 출력할 것입니다.
ChatGPT의 Moderation API는 욕설 등 부적절한 내용이 있는지 여부를 판단하는 기능이 있습니다.
이번 예제는 이 Moderation API를 이용해서 부적절한 내용을 거르는 방법을 다루었습니다.
반응형
'LangChain > LangChain Expression Language' 카테고리의 다른 글
| LC - Cookbook - Why use LCEL? (0) | 2023.11.07 |
|---|---|
| LC - Cookbook - Using tools (0) | 2023.11.07 |
| LC - Cookbook - Adding memory (0) | 2023.11.07 |
| LC - Cookbook - Routing by semantic similarity (0) | 2023.11.07 |
| LC - Cookbook - Code Writing (0) | 2023.11.06 |
| LC - Cookbook - Agents (0) | 2023.11.06 |
| LC - Cookbook - Querying a SQL DB (0) | 2023.11.06 |
| LC - Cookbook - Multiple chains (0) | 2023.11.05 |
| LC - Cookbook - RAG (Retrieval-Augmented Generation) (0) | 2023.11.05 |
| LC - Cookbook - Prompt + LLM (1) | 2023.10.29 |