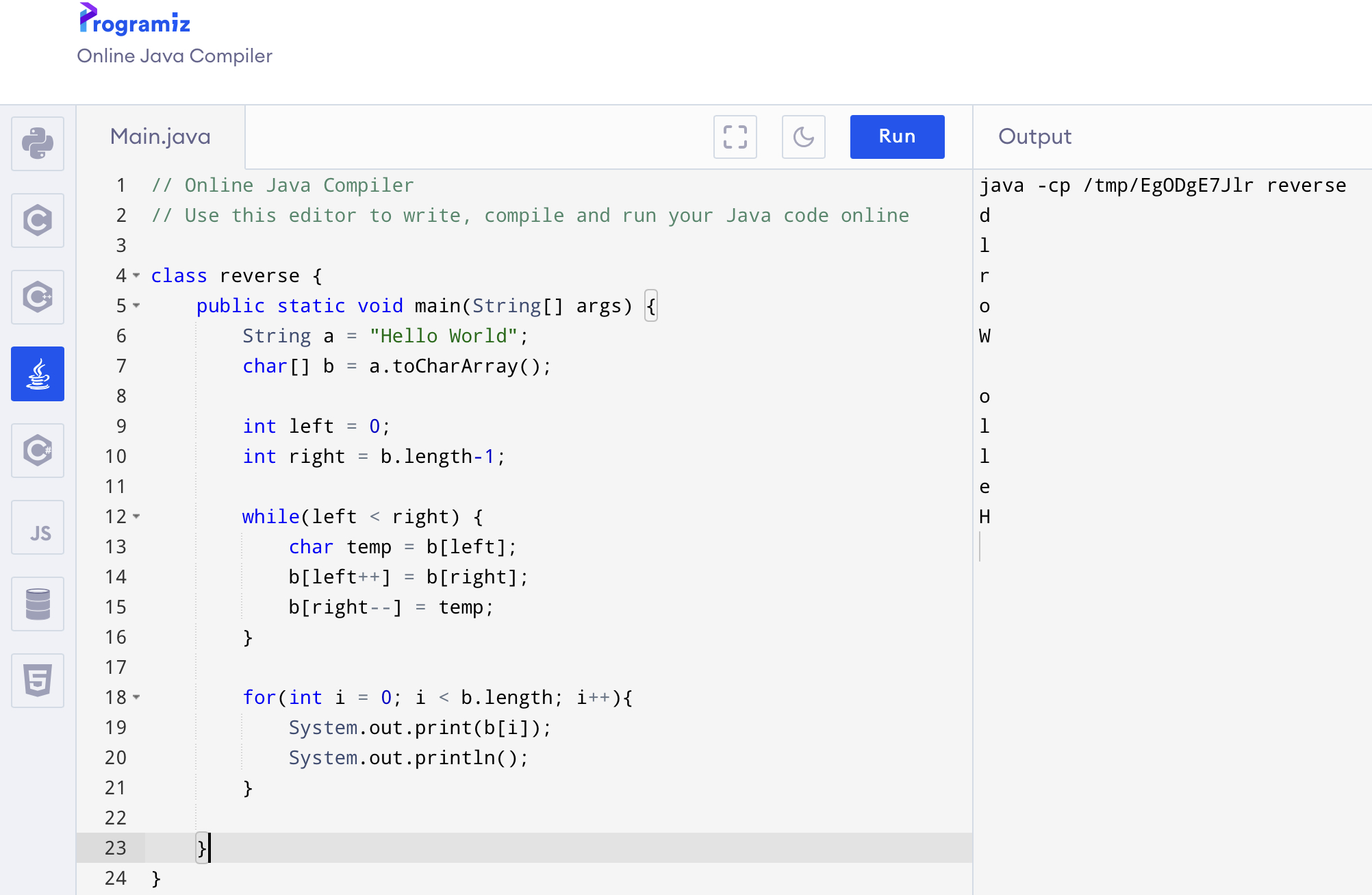
문장 안에 중복 되는 글자 찾는 코딩이다.
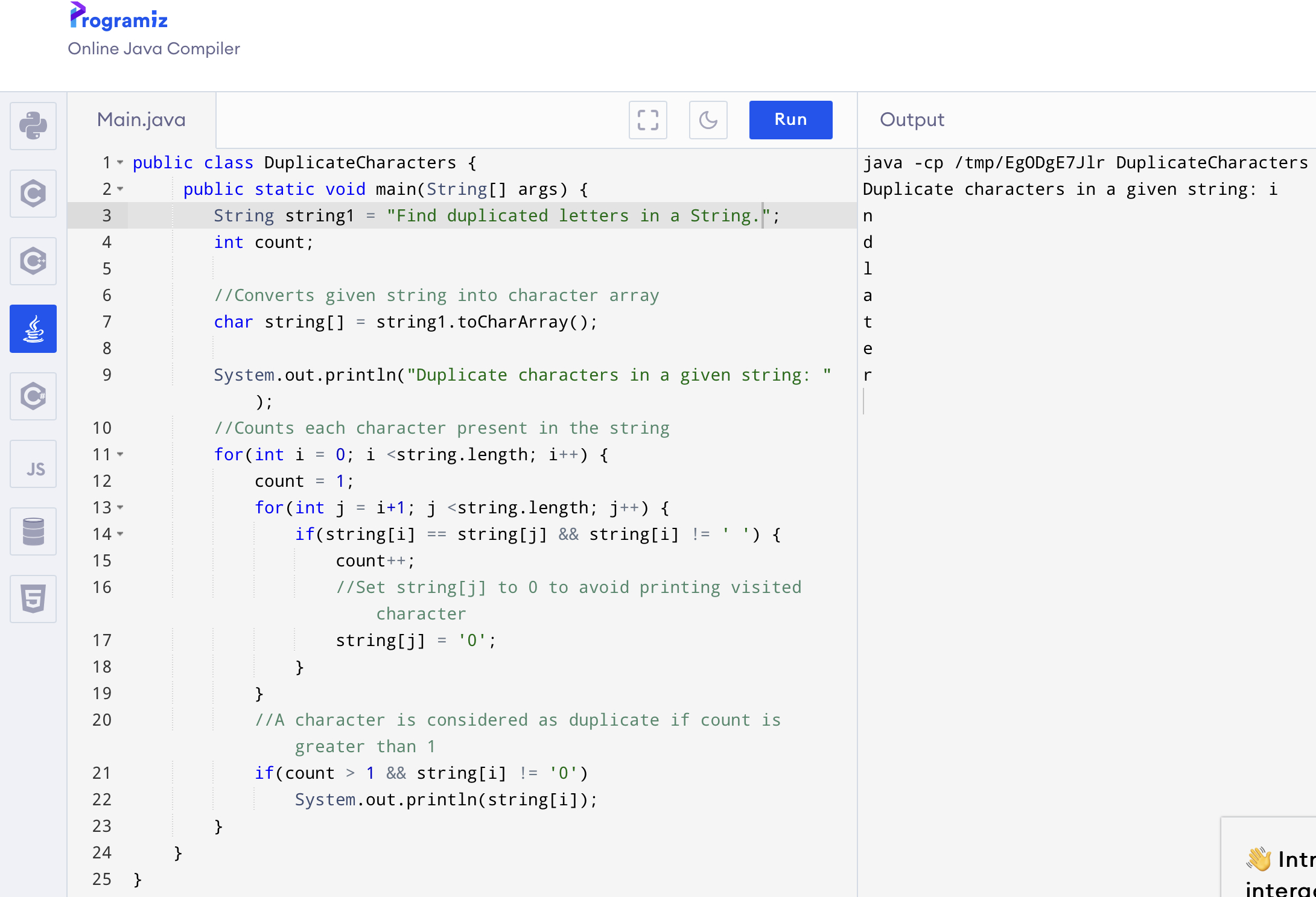
소스 코드는 아래와 같다.
public class DuplicateCharacters {
public static void main(String[] args) {
String string1 = "Find duplicated letters in a String.";
int count;
//Converts given string into character array
char string[] = string1.toCharArray();
System.out.println("Duplicate characters in a given string: ");
//Counts each character present in the string
for(int i = 0; i <string.length; i++) {
count = 1;
for(int j = i+1; j <string.length; j++) {
if(string[i] == string[j] && string[i] != ' ') {
count++;
//Set string[j] to 0 to avoid printing visited character
string[j] = '0';
}
}
//A character is considered as duplicate if count is greater than 1
if(count > 1 && string[i] != '0')
System.out.println(string[i]);
}
}
}
하나 하나 분석해 보겠다.
public class DuplicateCharacters { // 클래스 이름은 DuplicateCharacters 이다.
public static void main(String[] args) { // 실행 하기 위해 main 메소드를 사용한다.
String string1 = "Find duplicated letters in a String."; // 이게 입력 되는 스트링이다.
int count; // 중복 되는 글자가 몇개나 있는지 담을 인티저 변수이다.
//Converts given string into character array
char string[] = string1.toCharArray(); // 스트링을 어레이로 변환한다.
System.out.println("Duplicate characters in a given string: "); // 입력 값을 프린트 한다.
//Counts each character present in the string
for(int i = 0; i <string.length; i++) { // 배열내 값의 갯수 즉 스페이스를 포함한 글자의 갯수 만큼 for 문을 돌린다.
count = 1; // count를 1로 선언한다.
for(int j = i+1; j <string.length; j++) { // 배열 내 값의 갯수 보다 한개 적은 숫자 만큼 for 문을 돌린다. 이중 루프이다.
if(string[i] == string[j] && string[i] != ' ') { // 만약에 스페이스가 아닌데 같은 글자가 있으면 이 if 문을 실행한다.
count++; // 같은 글자가 있다면 count를 하나 증가 시킨다.
//Set string[j] to 0 to avoid printing visited character
string[j] = '0'; // 해당 되는 같은 글자는 0으로 바꾼다.
}
}
//A character is considered as duplicate if count is greater than 1
if(count > 1 && string[i] != '0') // count가 1보다 크고 값이 0이 아니면 if문을 출력한다.
System.out.println(string[i]); // 해당 값을 출력한다.
}
}
}
코드를 조금 바꿔 봤다.
출력 값을 리스트에 담아서 이 리스트를 출력 하도록 수정했다.
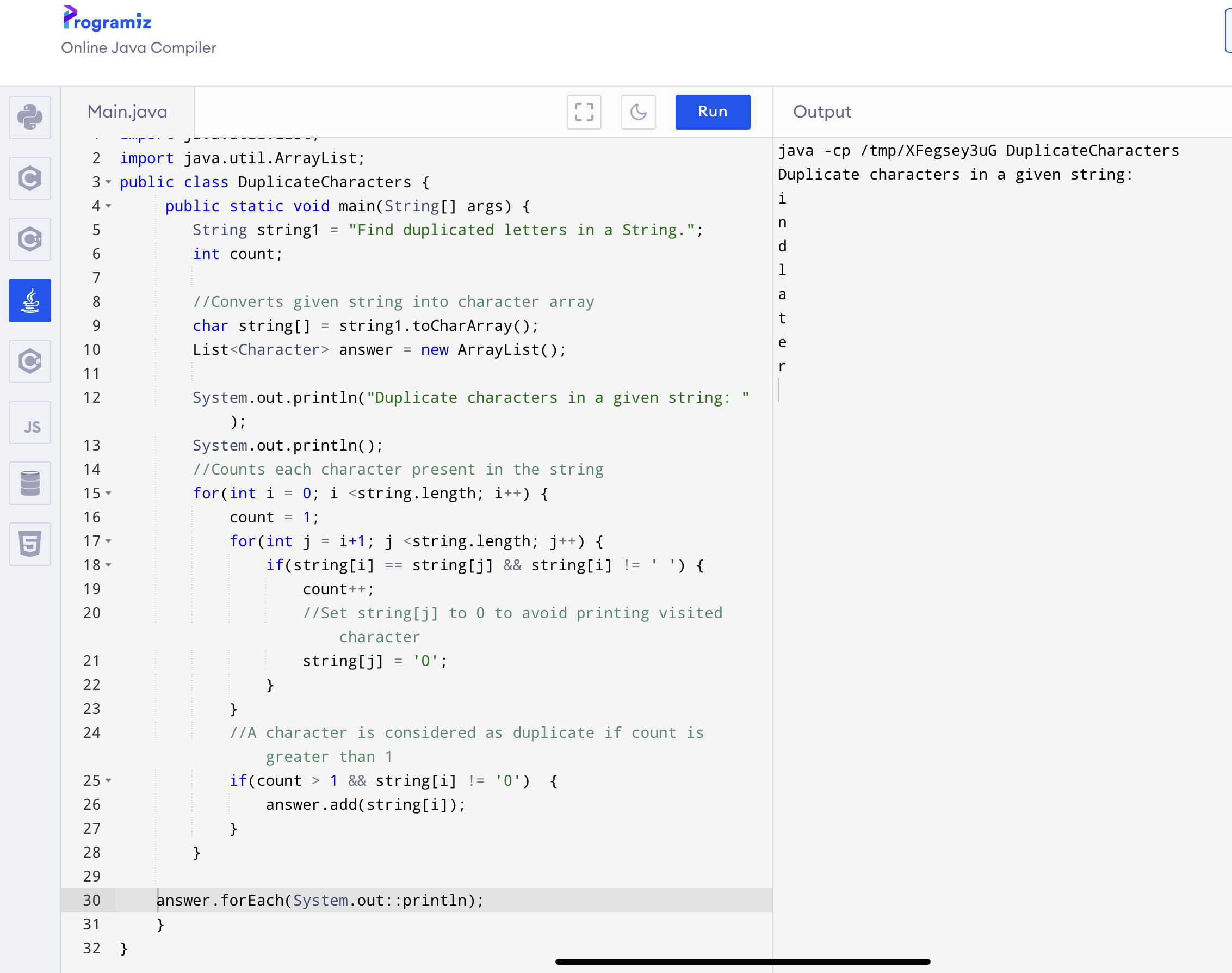
소스 코드는 아래와 같다.
수정한 부분만 주석을 달았다.
import java.util.List; // List 를 사용하기 위해 import 함
import java.util.ArrayList; // ArrayList를 사용하기 위해 import 함
public class DuplicateCharacters {
public static void main(String[] args) {
String string1 = "Find duplicated letters in a String.";
int count;
//Converts given string into character array
char string[] = string1.toCharArray();
List<Character> answer = new ArrayList(); // 출력 될 값을 담을 ArrayList를 선언 함. 이름은 answer
System.out.println("Duplicate characters in a given string: ");
System.out.println();
//Counts each character present in the string
for(int i = 0; i <string.length; i++) {
count = 1;
for(int j = i+1; j <string.length; j++) {
if(string[i] == string[j] && string[i] != ' ') {
count++;
//Set string[j] to 0 to avoid printing visited character
string[j] = '0';
}
}
//A character is considered as duplicate if count is greater than 1
if(count > 1 && string[i] != '0') {
answer.add(string[i]); // 출력 값을 answer 에 담는다.
}
}
answer.forEach(System.out::println); // forEach를 사용해 ArrayList answer의 값을 출력한다.
}
}
'etc. > Leetcode' 카테고리의 다른 글
| Leetcode - 13. Roman to Integer - Easy (0) | 2022.08.08 |
|---|---|
| Leetcode - 9. Palindrome Number - Easy (0) | 2022.08.06 |
| 미국 테크니컬 인터뷰 문제 풀이 - Reverse words in a sentence. (0) | 2022.08.03 |
| Iterator basic (0) | 2022.07.31 |
| Leetcode - 242. Valid Anagram : Easy (0) | 2022.07.31 |
| Leetcode - 442. Find All Duplicates in an Array (0) | 2022.07.26 |
| JAVA - String Revers Sample (0) | 2022.07.25 |
| Leetcode 541. Reverse String 2 - Easy (0) | 2022.07.22 |
| Leetcode 344 Reverse String - Easy (0) | 2022.07.22 |
| Leetcode 118. Pascal's Triangle (Easy) (0) | 2022.07.20 |