
16. Natural Language Processing: Applications — Dive into Deep Learning 1.0.3 documentation (d2l.ai)
16. Natural Language Processing: Applications — Dive into Deep Learning 1.0.3 documentation
d2l.ai
16. Natural Language Processing: Applications
We have seen how to represent tokens in text sequences and train their representations in Section 15. Such pretrained text representations can be fed to various models for different downstream natural language processing tasks.
우리는 섹션 15에서 텍스트 시퀀스에서 토큰을 표현하고 그 표현을 훈련하는 방법을 살펴보았습니다. 이러한 사전 훈련된 텍스트 표현은 다양한 다운스트림 자연어 처리 작업을 위한 다양한 모델에 공급될 수 있습니다.
In fact, earlier chapters have already discussed some natural language processing applications without pretraining, just for explaining deep learning architectures. For instance, in Section 9, we have relied on RNNs to design language models to generate novella-like text. In Section 10 and Section 11, we have also designed models based on RNNs and attention mechanisms for machine translation.
실제로 이전 장에서는 단지 딥러닝 아키텍처를 설명하기 위해 사전 훈련 없이 일부 자연어 처리 응용 프로그램을 이미 논의했습니다. 예를 들어 섹션 9에서는 RNN을 사용하여 소설 같은 텍스트를 생성하는 언어 모델을 설계했습니다. 섹션 10과 섹션 11에서는 RNN과 기계 번역을 위한 attention 메커니즘을 기반으로 모델을 설계했습니다.
However, this book does not intend to cover all such applications in a comprehensive manner. Instead, our focus is on how to apply (deep) representation learning of languages to addressing natural language processing problems. Given pretrained text representations, this chapter will explore two popular and representative downstream natural language processing tasks: sentiment analysis and natural language inference, which analyze single text and relationships of text pairs, respectively.
그러나 이 책에서는 그러한 모든 응용 프로그램을 포괄적으로 다루지는 않습니다. 대신, 우리는 자연어 처리 문제를 해결하기 위해 언어의 (심층) 표현 학습 representation learning 을 적용하는 방법에 중점을 둡니다. 미리 훈련된 텍스트 표현이 주어지면 이 장에서는 인기 있고 대표적인 두 가지 다운스트림 자연어 처리 작업, 즉 단일 텍스트와 텍스트 쌍의 관계를 각각 분석하는 감정 분석과 자연어 추론을 살펴봅니다.
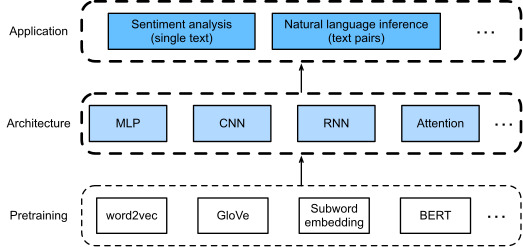
As depicted in Fig. 16.1, this chapter focuses on describing the basic ideas of designing natural language processing models using different types of deep learning architectures, such as MLPs, CNNs, RNNs, and attention. Though it is possible to combine any pretrained text representations with any architecture for either application in Fig. 16.1, we select a few representative combinations. Specifically, we will explore popular architectures based on RNNs and CNNs for sentiment analysis. For natural language inference, we choose attention and MLPs to demonstrate how to analyze text pairs. In the end, we introduce how to fine-tune a pretrained BERT model for a wide range of natural language processing applications, such as on a sequence level (single text classification and text pair classification) and a token level (text tagging and question answering). As a concrete empirical case, we will fine-tune BERT for natural language inference.
그림 16.1에 설명된 것처럼 이 장에서는 MLP, CNN, RNN 및 Attention과 같은 다양한 유형의 딥러닝 아키텍처를 사용하여 자연어 처리 모델을 설계하는 기본 아이디어를 설명하는 데 중점을 둡니다. 그림 16.1의 각 응용 프로그램에 대해 사전 훈련된 텍스트 표현을 모든 아키텍처와 결합하는 것이 가능하지만 몇 가지 대표적인 조합을 선택합니다. 특히, 감정 분석을 위해 RNN 및 CNN을 기반으로 하는 인기 있는 아키텍처를 살펴보겠습니다. 자연어 추론의 경우 어텐션과 MLP를 선택하여 텍스트 쌍을 분석하는 방법을 보여줍니다. 마지막에는 시퀀스 수준(단일 텍스트 분류 및 텍스트 쌍 분류) 및 토큰 수준(텍스트 태깅 및 질문 답변)과 같은 광범위한 자연어 처리 애플리케이션에 대해 사전 훈련된 BERT 모델을 미세 조정하는 방법을 소개합니다. ). 구체적인 실증 사례로 자연어 추론을 위해 BERT를 미세 조정해 보겠습니다.
As we have introduced in Section 15.8, BERT requires minimal architecture changes for a wide range of natural language processing applications. However, this benefit comes at the cost of fine-tuning a huge number of BERT parameters for the downstream applications. When space or time is limited, those crafted models based on MLPs, CNNs, RNNs, and attention are more feasible. In the following, we start by the sentiment analysis application and illustrate the model design based on RNNs and CNNs, respectively.
섹션 15.8에서 소개한 것처럼 BERT는 광범위한 자연어 처리 애플리케이션에 대해 최소한의 아키텍처 변경이 필요합니다. 그러나 이러한 이점은 다운스트림 애플리케이션에 대해 수많은 BERT 매개변수를 미세 조정하는 비용으로 발생합니다. 공간이나 시간이 제한되어 있는 경우 MLP, CNN, RNN 및 Attention을 기반으로 제작된 모델이 더 실현 가능합니다. 다음에서는 감정 분석 애플리케이션으로 시작하여 각각 RNN과 CNN을 기반으로 한 모델 설계를 설명합니다.
'Dive into Deep Learning > D2L Natural language Processing' 카테고리의 다른 글
| D2L - 16.5. Natural Language Inference: Using Attention (0) | 2023.09.02 |
|---|---|
| D2L - 16.4. Natural Language Inference and the Dataset (0) | 2023.09.01 |
| D2L - 16.3. Sentiment Analysis: Using Convolutional Neural Networks (0) | 2023.09.01 |
| D2L - 16.2. Sentiment Analysis: Using Recurrent Neural Networks (0) | 2023.09.01 |
| D2L - 16.1. Sentiment Analysis and the Dataset (0) | 2023.09.01 |
| D2L - 15.10. Pretraining BERT (0) | 2023.08.30 |
| D2L - 15.9. The Dataset for Pretraining BERT (0) | 2023.08.30 |
| D2L - 15.8. Bidirectional Encoder Representations from Transformers (BERT) (0) | 2023.08.30 |
| D2L - 15.7. Word Similarity and Analogy (0) | 2023.08.30 |
| D2L - 15.6. Subword Embedding (0) | 2023.08.30 |