

https://d2l.ai/chapter_hyperparameter-optimization/sh-async.html
19.5. Asynchronous Successive Halving — Dive into Deep Learning 1.0.3 documentation
d2l.ai
19.5. Asynchronous Successive Halving
As we have seen in Section 19.3, we can accelerate HPO by distributing the evaluation of hyperparameter configurations across either multiple instances or multiples CPUs / GPUs on a single instance. However, compared to random search, it is not straightforward to run successive halving (SH) asynchronously in a distributed setting. Before we can decide which configuration to run next, we first have to collect all observations at the current rung level. This requires to synchronize workers at each rung level. For example, for the lowest rung level r min, we first have to evaluate all N=η**k configurations, before we can promote the 1/η of them to the next rung level.
섹션 19.3에서 살펴본 것처럼 하이퍼파라미터 구성 평가를 여러 인스턴스 또는 단일 인스턴스의 여러 CPU/GPU에 분산하여 HPO를 가속화할 수 있습니다. 그러나 무작위 검색에 비해 분산 설정에서 비동기적으로 연속 반감기(SH)를 실행하는 것은 간단하지 않습니다. 다음에 실행할 구성을 결정하기 전에 먼저 현재 단계 수준에서 모든 관찰을 수집해야 합니다. 이를 위해서는 각 단계 수준에서 작업자를 동기화해야 합니다. 예를 들어, 가장 낮은 단계 수준 r min의 경우 먼저 모든 N=eta**k 구성을 평가해야 그 중 1/eta를 다음 단계 수준으로 승격할 수 있습니다.
In any distributed system, synchronization typically implies idle time for workers. First, we often observe high variations in training time across hyperparameter configurations. For example, assuming the number of filters per layer is a hyperparameter, then networks with less filters finish training faster than networks with more filters, which implies idle worker time due to stragglers. Moreover, the number of slots in a rung level is not always a multiple of the number of workers, in which case some workers may even sit idle for a full batch.
모든 분산 시스템에서 동기화는 일반적으로 작업자의 유휴 시간을 의미합니다. 첫째, 우리는 하이퍼파라미터 구성 전반에 걸쳐 훈련 시간의 높은 변동을 자주 관찰합니다. 예를 들어, 레이어당 필터 수가 하이퍼파라미터라고 가정하면 필터가 적은 네트워크는 필터가 많은 네트워크보다 훈련을 더 빨리 완료합니다. 이는 낙오자로 인한 유휴 작업자 시간을 의미합니다. 또한 단계 수준의 슬롯 수가 항상 작업자 수의 배수가 되는 것은 아니며, 이 경우 일부 작업자는 전체 배치 동안 유휴 상태로 있을 수도 있습니다.
Figure Fig. 19.5.1 shows the scheduling of synchronous SH with η=2 for four different trials with two workers. We start with evaluating Trial-0 and Trial-1 for one epoch and immediately continue with the next two trials once they are finished. We first have to wait until Trial-2 finishes, which takes substantially more time than the other trials, before we can promote the best two trials, i.e., Trial-0 and Trial-3 to the next rung level. This causes idle time for Worker-1. Then, we continue with Rung 1. Also, here Trial-3 takes longer than Trial-0, which leads to an additional ideling time of Worker-0. Once, we reach Rung-2, only the best trial, Trial-0, remains which occupies only one worker. To avoid that Worker-1 idles during that time, most implementaitons of SH continue already with the next round, and start evaluating new trials (e.g Trial-4) on the first rung.
그림 그림 19.5.1은 2명의 워커를 사용한 4가지 다른 시도에 대해 θ=2인 동기식 SH의 스케줄링을 보여줍니다. 한 에포크 동안 Trial-0과 Trial-1을 평가하는 것으로 시작하고, 완료되면 다음 두 번의 시도를 즉시 계속합니다. 가장 좋은 두 가지 시도, 즉 Trial-0과 Trial-3을 다음 단계로 승격하려면 먼저 다른 시도보다 훨씬 더 많은 시간이 걸리는 Trial-2가 완료될 때까지 기다려야 합니다. 이로 인해 Worker-1의 유휴 시간이 발생합니다. 그런 다음 Rung 1을 계속 진행합니다. 또한 여기서 Trial-3은 Trial-0보다 시간이 오래 걸리므로 Worker-0의 추가 유휴 시간이 발생합니다. 일단 Rung-2에 도달하면 가장 좋은 시도인 Trial-0만 남고 작업자는 한 명만 차지합니다. 해당 시간 동안 Worker-1이 유휴 상태가 되는 것을 방지하기 위해 대부분의 SH 구현은 이미 다음 라운드에서 계속되고 첫 번째 단계에서 새로운 시도(예: Trial-4) 평가를 시작합니다.

Asynchronous successive halving (ASHA) (Li et al., 2018) adapts SH to the asynchronous parallel scenario. The main idea of ASHA is to promote configurations to the next rung level as soon as we collected at least η observations on the current rung level. This decision rule may lead to suboptimal promotions: configurations can be promoted to the next rung level, which in hindsight do not compare favourably against most others at the same rung level. On the other hand, we get rid of all synchronization points this way. In practice, such suboptimal initial promotions have only a modest impact on performance, not only because the ranking of hyperparameter configurations is often fairly consistent across rung levels, but also because rungs grow over time and reflect the distribution of metric values at this level better and better. If a worker is free, but no configuration can be promoted, we start a new configuration with r = r min, i.e the first rung level.
비동기 연속 반감기(ASHA)(Li et al., 2018)는 SH를 비동기 병렬 시나리오에 적용합니다. ASHA의 주요 아이디어는 현재 단계 수준에서 최소 eta 관측치를 수집하자마자 구성을 다음 단계 수준으로 승격시키는 것입니다. 이 결정 규칙은 최적이 아닌 승격으로 이어질 수 있습니다. 구성은 다음 단계 수준으로 승격될 수 있으며, 돌이켜보면 동일한 단계 수준의 대부분의 다른 단계와 비교했을 때 호의적이지 않습니다. 반면에 우리는 이런 방식으로 모든 동기화 지점을 제거합니다. 실제로 이러한 최적이 아닌 초기 승격은 성능에 미미한 영향만 미칠 뿐입니다. 이는 초매개변수 구성의 순위가 단계 수준 전체에서 상당히 일관되는 경우가 많을 뿐만 아니라 단계가 시간이 지남에 따라 증가하고 이 수준에서 메트릭 값의 분포를 더 잘 반영하고 더 잘 반영하기 때문입니다. 더 나은. 작업자가 무료이지만 승격할 수 있는 구성이 없으면 r = r min으로 새 구성, 즉 첫 번째 단계 수준을 시작합니다.
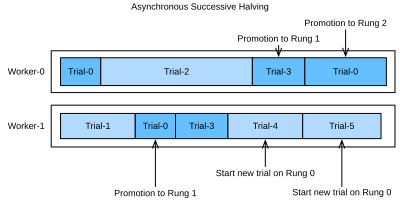
Fig. 19.5.2 shows the scheduling of the same configurations for ASHA. Once Trial-1 finishes, we collect the results of two trials (i.e Trial-0 and Trial-1) and immediately promote the better of them (Trial-0) to the next rung level. After Trial-0 finishes on rung 1, there are too few trials there in order to support a further promotion. Hence, we continue with rung 0 and evaluate Trial-3. Once Trial-3 finishes, Trial-2 is still pending. At this point we have 3 trials evaluated on rung 0 and one trial evaluated already on rung 1. Since Trial-3 performs worse than Trial-0 at rung 0, and η = 2, we cannot promote any new trial yet, and Worker-1 starts Trial-4 from scratch instead. However, once Trial-2 finishes and scores worse than Trial-3, the latter is promoted towards rung 1. Afterwards, we collected 2 evaluations on rung 1, which means we can now promote Trial-0 towards rung 2. At the same time, Worker-1 continues with evaluating new trials (i.e., Trial-5) on rung 0.
그림 19.5.2는 ASHA에 대한 동일한 구성의 스케줄링을 보여줍니다. Trial-1이 완료되면 두 가지 시도(즉, Trial-0 및 Trial-1)의 결과를 수집하고 그 중 더 나은 것(Trial-0)을 즉시 다음 단계 수준으로 승격합니다. 평가판 0이 단계 1에서 끝난 후에는 추가 승격을 지원하기에는 시도 횟수가 너무 적습니다. 따라서 우리는 단계 0을 계속 진행하고 평가판 3을 평가합니다. 평가판 3이 끝나면 평가판 2가 계속 보류됩니다. 이 시점에서 우리는 단계 0에서 평가된 3개의 시도와 단계 1에서 이미 평가된 하나의 시도를 가지고 있습니다. Trial-3은 단계 0에서 Trial-0보다 성능이 떨어지고 θ = 2이므로 아직 새로운 시도를 승격할 수 없으며 Worker- 1은 대신 Trial-4를 처음부터 시작합니다. 그러나 평가판 2가 완료되고 평가판 3보다 낮은 점수를 받으면 후자는 단계 1로 승격됩니다. 이후 단계 1에서 2개의 평가를 수집했습니다. 이는 이제 평가판 0을 단계 2로 승격할 수 있음을 의미합니다. , 작업자-1은 단계 0에서 새로운 시도(즉, 시도 5)를 계속 평가합니다.
import logging
from d2l import torch as d2l
logging.basicConfig(level=logging.INFO)
import matplotlib.pyplot as plt
from syne_tune import StoppingCriterion, Tuner
from syne_tune.backend.python_backend import PythonBackend
from syne_tune.config_space import loguniform, randint
from syne_tune.experiments import load_experiment
from syne_tune.optimizer.baselines import ASHA위의 코드는 HPO(Hyperparameter Optimization) 실험을 수행하기 위한 설정을 위한 코드입니다. 주요 라이브러리와 로깅 설정을 포함하고 있습니다.
- import logging: 로깅(logging)을 위한 파이썬 라이브러리를 가져옵니다.
- from d2l import torch as d2l: "d2l" 라이브러리에서 "torch" 모듈을 가져옵니다. 이 모듈은 PyTorch 기반의 딥 러닝 코드 작성을 지원합니다.
- logging.basicConfig(level=logging.INFO): 로깅 레벨을 INFO로 설정하고 기본 로깅 구성을 초기화합니다. 이를 통해 코드 실행 중에 로그 메시지를 출력할 수 있습니다.
- import matplotlib.pyplot as plt: Matplotlib을 사용하여 그래프를 그리기 위한 모듈을 가져옵니다.
- from syne_tune import StoppingCriterion, Tuner: SyneTune 라이브러리에서 StoppingCriterion과 Tuner 클래스를 가져옵니다. 이 클래스들은 HPO 실험을 관리하고 조정하는 데 사용됩니다.
- from syne_tune.backend.python_backend import PythonBackend: SyneTune에서 사용하는 백엔드(backend) 중 하나인 PythonBackend를 가져옵니다. 백엔드는 HPO 실험을 실행하는 방식을 지정합니다.
- from syne_tune.config_space import loguniform, randint: HPO 실험에서 사용할 하이퍼파라미터 공간을 정의하기 위해 loguniform과 randint 등의 함수를 가져옵니다. 이 함수들을 사용하여 하이퍼파라미터를 샘플링할 수 있습니다.
- from syne_tune.experiments import load_experiment: SyneTune에서 실험을 로드하고 관리하기 위한 함수를 가져옵니다.
- from syne_tune.optimizer.baselines import ASHA: ASHA(Hyperband 기반의 비동기 하이퍼파라미터 최적화 알고리즘)를 가져옵니다. ASHA는 하이퍼파라미터 최적화에 사용되는 알고리즘 중 하나입니다.
INFO:root:SageMakerBackend is not imported since dependencies are missing. You can install them with
pip install 'syne-tune[extra]'
AWS dependencies are not imported since dependencies are missing. You can install them with
pip install 'syne-tune[aws]'
or (for everything)
pip install 'syne-tune[extra]'
AWS dependencies are not imported since dependencies are missing. You can install them with
pip install 'syne-tune[aws]'
or (for everything)
pip install 'syne-tune[extra]'
INFO:root:Ray Tune schedulers and searchers are not imported since dependencies are missing. You can install them with
pip install 'syne-tune[raytune]'
or (for everything)
pip install 'syne-tune[extra]'
19.5.1. Objective Function
We will use Syne Tune with the same objective function as in Section 19.3.
섹션 19.3과 동일한 목적 함수를 사용하여 Syne Tune을 사용하겠습니다.
def hpo_objective_lenet_synetune(learning_rate, batch_size, max_epochs):
from syne_tune import Reporter
from d2l import torch as d2l
model = d2l.LeNet(lr=learning_rate, num_classes=10)
trainer = d2l.HPOTrainer(max_epochs=1, num_gpus=1)
data = d2l.FashionMNIST(batch_size=batch_size)
model.apply_init([next(iter(data.get_dataloader(True)))[0]], d2l.init_cnn)
report = Reporter()
for epoch in range(1, max_epochs + 1):
if epoch == 1:
# Initialize the state of Trainer
trainer.fit(model=model, data=data)
else:
trainer.fit_epoch()
validation_error = trainer.validation_error().cpu().detach().numpy()
report(epoch=epoch, validation_error=float(validation_error))위의 코드는 SyneTune 라이브러리를 사용하여 하이퍼파라미터 최적화를 수행하는 목적 함수(hpo_objective_lenet_synetune)를 정의한 부분입니다. 이 함수는 LeNet 아키텍처를 사용하여 이미지 분류 모델을 훈련하고, 각 하이퍼파라미터 설정에 대한 검증 오차(validation error)를 반환합니다.
주요 내용은 다음과 같습니다.
- learning_rate, batch_size, max_epochs 등의 하이퍼파라미터를 입력으로 받습니다.
- model = d2l.LeNet(lr=learning_rate, num_classes=10): 주어진 학습률(learning_rate)과 클래스 수(num_classes)를 가지고 LeNet 모델을 생성합니다.
- trainer = d2l.HPOTrainer(max_epochs=1, num_gpus=1): 하이퍼파라미터 최적화를 위한 트레이너를 생성합니다. max_epochs는 1로 설정되어 있으므로 하나의 에포크만 훈련됩니다.
- data = d2l.FashionMNIST(batch_size=batch_size): Fashion MNIST 데이터셋을 로드하고 주어진 배치 크기(batch_size)로 데이터를 미니배치 형태로 제공합니다.
- model.apply_init([next(iter(data.get_dataloader(True)))[0]], d2l.init_cnn): 초기화 함수 d2l.init_cnn을 사용하여 모델을 초기화합니다.
- report = Reporter(): 실험 결과를 기록하기 위한 Reporter 객체를 생성합니다.
- 반복문을 통해 에포크(epoch)를 1부터 max_epochs까지 증가시키면서 모델을 훈련합니다.
- 에포크가 1인 경우에는 트레이너를 초기화하고 모델을 훈련시킵니다.
- 에포크가 1보다 큰 경우에는 trainer.fit_epoch()를 호출하여 한 번의 에포크를 추가로 훈련시킵니다.
- trainer.validation_error().cpu().detach().numpy()를 통해 검증 오차(validation error)를 계산하고 반환합니다.
- report(epoch=epoch, validation_error=float(validation_error))를 사용하여 현재 에포크와 검증 오차를 Reporter에 기록합니다.
즉, 이 함수는 주어진 하이퍼파라미터 설정으로 모델을 훈련하고 검증 오차를 반환하는 역할을 합니다. SyneTune은 이 함수를 사용하여 다양한 하이퍼파라미터 설정을 시도하고 최적의 설정을 찾습니다.
We will also use the same configuration space as before:
또한 이전과 동일한 구성 공간을 사용합니다.
min_number_of_epochs = 2
max_number_of_epochs = 10
eta = 2
config_space = {
"learning_rate": loguniform(1e-2, 1),
"batch_size": randint(32, 256),
"max_epochs": max_number_of_epochs,
}
initial_config = {
"learning_rate": 0.1,
"batch_size": 128,
}위의 코드는 SyneTune 라이브러리를 사용하여 하이퍼파라미터 최적화를 수행할 때 사용되는 설정과 초기 하이퍼파라미터 값을 정의하는 부분입니다. 주요 내용은 다음과 같습니다.
- min_number_of_epochs: 실험에서 허용하는 최소 에포크 수입니다. 이 값은 2로 설정되어 있습니다.
- max_number_of_epochs: 실험에서 허용하는 최대 에포크 수입니다. 이 값은 10으로 설정되어 있습니다.
- eta: Successive Halving 알고리즘에서 사용되는 파라미터로, 곱셈 연산을 수행할 때 사용됩니다. 이 값은 2로 설정되어 있습니다.
- config_space: 하이퍼파라미터 공간을 정의하는 부분입니다. 여기서는 세 가지 하이퍼파라미터인 learning_rate, batch_size, max_epochs의 범위를 지정합니다.
- learning_rate: 로그균등 분포(loguniform distribution)를 사용하여 1e-2에서 1 사이의 값으로 설정됩니다.
- batch_size: 균등 분포(uniform distribution)를 사용하여 32에서 256 사이의 정수 값으로 설정됩니다.
- max_epochs: max_number_of_epochs로 설정된 최대 에포크 값을 가집니다.
- initial_config: 초기 하이퍼파라미터 설정을 정의하는 부분입니다. 여기서는 learning_rate를 0.1로, batch_size를 128로 초기화합니다.
이러한 설정과 초기값은 하이퍼파라미터 최적화 실험을 수행할 때 사용됩니다. SyneTune 라이브러리를 통해 하이퍼파라미터 탐색을 진행하면서 이러한 설정 범위 내에서 하이퍼파라미터 값을 조정하고 최적의 설정을 찾게 됩니다.
19.5.2. Asynchronous Scheduler
First, we define the number of workers that evaluate trials concurrently. We also need to specify how long we want to run random search, by defining an upper limit on the total wall-clock time.
먼저, 동시에 시험을 평가하는 작업자 수를 정의합니다. 또한 총 벽시계 시간의 상한을 정의하여 무작위 검색을 실행할 기간을 지정해야 합니다.
n_workers = 2 # Needs to be <= the number of available GPUs
max_wallclock_time = 12 * 60 # 12 minutes위의 코드는 하이퍼파라미터 최적화 실험을 수행할 때 사용되는 두 가지 중요한 설정을 나타냅니다.
- n_workers: 실험 도중에 병렬로 실행되는 워커(작업자)의 수를 나타냅니다. 이 수는 사용 가능한 GPU 수보다 작거나 같아야 합니다. 여기서는 2로 설정되어 있으므로 최대 2개의 GPU 또는 병렬 작업자를 사용할 수 있음을 의미합니다.
- max_wallclock_time: 하이퍼파라미터 최적화 실험의 최대 시간을 분 단위로 나타냅니다. 이 값은 12 * 60으로 설정되어 있으므로 최대 12시간(720분) 동안 실험을 진행할 수 있음을 의미합니다. 실험 시간이 이 설정 값 이내에 끝나도록 실험을 조절합니다.
The code for running ASHA is a simple variation of what we did for asynchronous random search.
ASHA를 실행하기 위한 코드는 비동기 무작위 검색을 위해 수행한 작업의 간단한 변형입니다.
mode = "min"
metric = "validation_error"
resource_attr = "epoch"
scheduler = ASHA(
config_space,
metric=metric,
mode=mode,
points_to_evaluate=[initial_config],
max_resource_attr="max_epochs",
resource_attr=resource_attr,
grace_period=min_number_of_epochs,
reduction_factor=eta,
)위의 코드는 하이퍼파라미터 최적화 실험에서 사용되는 스케줄러인 ASHA (Asynchronous Successive Halving Algorithm)를 설정하는 부분입니다.
- mode: ASHA 알고리즘에서 최적화할 메트릭의 모드를 나타냅니다. "min"으로 설정되어 있으므로 이 알고리즘은 가장 낮은 값을 찾는 데 초점을 맞추게 됩니다.
- metric: ASHA 알고리즘에서 최적화할 메트릭의 이름을 나타냅니다. 이 경우 "validation_error"로 설정되어 있으므로 검증 오차(validation error)를 최소화하려고 시도합니다.
- resource_attr: 실험에서 사용할 리소스 속성을 나타냅니다. 여기서는 "epoch"으로 설정되어 있으므로 에포크(epoch) 수를 리소스로 사용하여 하이퍼파라미터 최적화를 수행합니다.
- max_resource_attr: ASHA 알고리즘에서 사용할 최대 리소스 속성을 지정합니다. 이 경우 "max_epochs"로 설정되어 있으므로 최대 에포크 수가 사용됩니다.
- grace_period: ASHA 알고리즘에서 고려할 하이퍼파라미터를 선택하는데 필요한 최소 리소스 수를 나타냅니다. 이 값은 "min_number_of_epochs"로 설정되어 있으므로 최소 에포크 수만큼 리소스가 할당된 경우에만 하이퍼파라미터가 선택됩니다.
- reduction_factor: ASHA 알고리즘에서 에포크 수를 줄이는 비율을 나타냅니다. 이 값은 "eta"로 설정되어 있으므로 2입니다. 이것은 각 라운드에서 절반씩 에포크 수를 줄이는 것을 의미합니다.
ASHA 스케줄러는 하이퍼파라미터 최적화를 수행하는 데 사용되며, 리소스 속성을 기반으로 하이퍼파라미터 검색을 조절하는 데 도움을 줍니다.
INFO:syne_tune.optimizer.schedulers.fifo:max_resource_level = 10, as inferred from config_space
INFO:syne_tune.optimizer.schedulers.fifo:Master random_seed = 3140976097
Here, metric and resource_attr specify the key names used with the report callback, and max_resource_attr denotes which input to the objective function corresponds to r max. Moreover, grace_period provides r min, and reduction_factor is η. We can run Syne Tune as before (this will take about 12 minutes):
여기에서 metric 및 resources_attr은 보고서 콜백과 함께 사용되는 키 이름을 지정하고 max_resource_attr은 목적 함수에 대한 입력이 r max에 해당하는지 나타냅니다. 또한, Grace_기간은 r min을 제공하고, 감소_인자는 θ입니다. 이전과 같이 Syne Tune을 실행할 수 있습니다(약 12분 소요).
trial_backend = PythonBackend(
tune_function=hpo_objective_lenet_synetune,
config_space=config_space,
)
stop_criterion = StoppingCriterion(max_wallclock_time=max_wallclock_time)
tuner = Tuner(
trial_backend=trial_backend,
scheduler=scheduler,
stop_criterion=stop_criterion,
n_workers=n_workers,
print_update_interval=int(max_wallclock_time * 0.6),
)
tuner.run()위의 코드는 ASHA 스케줄러를 사용하여 하이퍼파라미터 최적화 실험을 실행하는 부분입니다.
- trial_backend: 실험을 실행하는 백엔드(Backend)를 설정합니다. 여기서는 PythonBackend를 사용하며, tune_function에는 hpo_objective_lenet_synetune 함수를, config_space에는 하이퍼파라미터 검색 공간을 설정합니다. 이 백엔드는 Python 함수를 호출하여 실험을 실행합니다.
- stop_criterion: ASHA 스케줄러를 중지시키는 기준을 설정합니다. max_wallclock_time은 실험을 실행할 최대 시간(분)을 설정하며, 이 값은 12 * 60으로 설정되어 있으므로 12분 동안 실험을 실행한 후 중지됩니다.
- tuner: Tuner 클래스를 사용하여 최적화 프로세스를 설정합니다. trial_backend에는 백엔드 설정, scheduler에는 ASHA 스케줄러, stop_criterion에는 중지 기준, n_workers에는 사용할 워커(실험 실행 프로세스) 수를 설정합니다. print_update_interval은 중간 업데이트를 출력하는 간격을 설정하며, max_wallclock_time의 60%에 해당하는 값으로 설정됩니다.
- tuner.run(): 이 명령은 하이퍼파라미터 최적화 실험을 실행합니다. ASHA 스케줄러를 사용하여 여러 하이퍼파라미터 조합을 평가하고 최적의 하이퍼파라미터를 찾습니다. 실험이 실행되는 동안 중간 업데이트가 출력됩니다.
INFO:syne_tune.tuner:results of trials will be saved on /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046
INFO:root:Detected 4 GPUs
INFO:root:running subprocess with command: /usr/bin/python /home/ci/.local/lib/python3.8/site-packages/syne_tune/backend/python_backend/python_entrypoint.py --learning_rate 0.1 --batch_size 128 --max_epochs 10 --tune_function_root /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/tune_function --tune_function_hash e03d187e043d2a17cae636d6af164015 --st_checkpoint_dir /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/0/checkpoints
INFO:syne_tune.tuner:(trial 0) - scheduled config {'learning_rate': 0.1, 'batch_size': 128, 'max_epochs': 10}
INFO:root:running subprocess with command: /usr/bin/python /home/ci/.local/lib/python3.8/site-packages/syne_tune/backend/python_backend/python_entrypoint.py --learning_rate 0.44639554136672527 --batch_size 196 --max_epochs 10 --tune_function_root /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/tune_function --tune_function_hash e03d187e043d2a17cae636d6af164015 --st_checkpoint_dir /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/1/checkpoints
INFO:syne_tune.tuner:(trial 1) - scheduled config {'learning_rate': 0.44639554136672527, 'batch_size': 196, 'max_epochs': 10}
INFO:root:running subprocess with command: /usr/bin/python /home/ci/.local/lib/python3.8/site-packages/syne_tune/backend/python_backend/python_entrypoint.py --learning_rate 0.011548051321691994 --batch_size 254 --max_epochs 10 --tune_function_root /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/tune_function --tune_function_hash e03d187e043d2a17cae636d6af164015 --st_checkpoint_dir /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/2/checkpoints
INFO:syne_tune.tuner:(trial 2) - scheduled config {'learning_rate': 0.011548051321691994, 'batch_size': 254, 'max_epochs': 10}
INFO:root:running subprocess with command: /usr/bin/python /home/ci/.local/lib/python3.8/site-packages/syne_tune/backend/python_backend/python_entrypoint.py --learning_rate 0.14942487313193167 --batch_size 132 --max_epochs 10 --tune_function_root /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/tune_function --tune_function_hash e03d187e043d2a17cae636d6af164015 --st_checkpoint_dir /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/3/checkpoints
INFO:syne_tune.tuner:(trial 3) - scheduled config {'learning_rate': 0.14942487313193167, 'batch_size': 132, 'max_epochs': 10}
INFO:syne_tune.tuner:Trial trial_id 1 completed.
INFO:root:running subprocess with command: /usr/bin/python /home/ci/.local/lib/python3.8/site-packages/syne_tune/backend/python_backend/python_entrypoint.py --learning_rate 0.06317157191455719 --batch_size 242 --max_epochs 10 --tune_function_root /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/tune_function --tune_function_hash e03d187e043d2a17cae636d6af164015 --st_checkpoint_dir /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/4/checkpoints
INFO:syne_tune.tuner:(trial 4) - scheduled config {'learning_rate': 0.06317157191455719, 'batch_size': 242, 'max_epochs': 10}
INFO:root:running subprocess with command: /usr/bin/python /home/ci/.local/lib/python3.8/site-packages/syne_tune/backend/python_backend/python_entrypoint.py --learning_rate 0.48801815412811467 --batch_size 41 --max_epochs 10 --tune_function_root /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/tune_function --tune_function_hash e03d187e043d2a17cae636d6af164015 --st_checkpoint_dir /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/5/checkpoints
INFO:syne_tune.tuner:(trial 5) - scheduled config {'learning_rate': 0.48801815412811467, 'batch_size': 41, 'max_epochs': 10}
INFO:root:running subprocess with command: /usr/bin/python /home/ci/.local/lib/python3.8/site-packages/syne_tune/backend/python_backend/python_entrypoint.py --learning_rate 0.5904067586747807 --batch_size 244 --max_epochs 10 --tune_function_root /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/tune_function --tune_function_hash e03d187e043d2a17cae636d6af164015 --st_checkpoint_dir /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/6/checkpoints
INFO:syne_tune.tuner:(trial 6) - scheduled config {'learning_rate': 0.5904067586747807, 'batch_size': 244, 'max_epochs': 10}
INFO:root:running subprocess with command: /usr/bin/python /home/ci/.local/lib/python3.8/site-packages/syne_tune/backend/python_backend/python_entrypoint.py --learning_rate 0.08812857364095393 --batch_size 148 --max_epochs 10 --tune_function_root /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/tune_function --tune_function_hash e03d187e043d2a17cae636d6af164015 --st_checkpoint_dir /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/7/checkpoints
INFO:syne_tune.tuner:(trial 7) - scheduled config {'learning_rate': 0.08812857364095393, 'batch_size': 148, 'max_epochs': 10}
INFO:root:running subprocess with command: /usr/bin/python /home/ci/.local/lib/python3.8/site-packages/syne_tune/backend/python_backend/python_entrypoint.py --learning_rate 0.012271314788363914 --batch_size 235 --max_epochs 10 --tune_function_root /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/tune_function --tune_function_hash e03d187e043d2a17cae636d6af164015 --st_checkpoint_dir /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/8/checkpoints
INFO:syne_tune.tuner:(trial 8) - scheduled config {'learning_rate': 0.012271314788363914, 'batch_size': 235, 'max_epochs': 10}
INFO:syne_tune.tuner:Trial trial_id 5 completed.
INFO:root:running subprocess with command: /usr/bin/python /home/ci/.local/lib/python3.8/site-packages/syne_tune/backend/python_backend/python_entrypoint.py --learning_rate 0.08845692598296777 --batch_size 236 --max_epochs 10 --tune_function_root /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/tune_function --tune_function_hash e03d187e043d2a17cae636d6af164015 --st_checkpoint_dir /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/9/checkpoints
INFO:syne_tune.tuner:(trial 9) - scheduled config {'learning_rate': 0.08845692598296777, 'batch_size': 236, 'max_epochs': 10}
INFO:root:running subprocess with command: /usr/bin/python /home/ci/.local/lib/python3.8/site-packages/syne_tune/backend/python_backend/python_entrypoint.py --learning_rate 0.0825770880068151 --batch_size 75 --max_epochs 10 --tune_function_root /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/tune_function --tune_function_hash e03d187e043d2a17cae636d6af164015 --st_checkpoint_dir /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/10/checkpoints
INFO:syne_tune.tuner:(trial 10) - scheduled config {'learning_rate': 0.0825770880068151, 'batch_size': 75, 'max_epochs': 10}
INFO:root:running subprocess with command: /usr/bin/python /home/ci/.local/lib/python3.8/site-packages/syne_tune/backend/python_backend/python_entrypoint.py --learning_rate 0.20235201406823256 --batch_size 65 --max_epochs 10 --tune_function_root /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/tune_function --tune_function_hash e03d187e043d2a17cae636d6af164015 --st_checkpoint_dir /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/11/checkpoints
INFO:syne_tune.tuner:(trial 11) - scheduled config {'learning_rate': 0.20235201406823256, 'batch_size': 65, 'max_epochs': 10}
INFO:root:running subprocess with command: /usr/bin/python /home/ci/.local/lib/python3.8/site-packages/syne_tune/backend/python_backend/python_entrypoint.py --learning_rate 0.3359885631737537 --batch_size 58 --max_epochs 10 --tune_function_root /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/tune_function --tune_function_hash e03d187e043d2a17cae636d6af164015 --st_checkpoint_dir /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/12/checkpoints
INFO:syne_tune.tuner:(trial 12) - scheduled config {'learning_rate': 0.3359885631737537, 'batch_size': 58, 'max_epochs': 10}
INFO:root:running subprocess with command: /usr/bin/python /home/ci/.local/lib/python3.8/site-packages/syne_tune/backend/python_backend/python_entrypoint.py --learning_rate 0.7892434579795236 --batch_size 89 --max_epochs 10 --tune_function_root /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/tune_function --tune_function_hash e03d187e043d2a17cae636d6af164015 --st_checkpoint_dir /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/13/checkpoints
INFO:syne_tune.tuner:(trial 13) - scheduled config {'learning_rate': 0.7892434579795236, 'batch_size': 89, 'max_epochs': 10}
INFO:root:running subprocess with command: /usr/bin/python /home/ci/.local/lib/python3.8/site-packages/syne_tune/backend/python_backend/python_entrypoint.py --learning_rate 0.1233786579597858 --batch_size 176 --max_epochs 10 --tune_function_root /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/tune_function --tune_function_hash e03d187e043d2a17cae636d6af164015 --st_checkpoint_dir /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/14/checkpoints
INFO:syne_tune.tuner:(trial 14) - scheduled config {'learning_rate': 0.1233786579597858, 'batch_size': 176, 'max_epochs': 10}
INFO:syne_tune.tuner:Trial trial_id 13 completed.
INFO:root:running subprocess with command: /usr/bin/python /home/ci/.local/lib/python3.8/site-packages/syne_tune/backend/python_backend/python_entrypoint.py --learning_rate 0.13707981127012328 --batch_size 141 --max_epochs 10 --tune_function_root /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/tune_function --tune_function_hash e03d187e043d2a17cae636d6af164015 --st_checkpoint_dir /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/15/checkpoints
INFO:syne_tune.tuner:(trial 15) - scheduled config {'learning_rate': 0.13707981127012328, 'batch_size': 141, 'max_epochs': 10}
INFO:root:running subprocess with command: /usr/bin/python /home/ci/.local/lib/python3.8/site-packages/syne_tune/backend/python_backend/python_entrypoint.py --learning_rate 0.02913976299993913 --batch_size 116 --max_epochs 10 --tune_function_root /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/tune_function --tune_function_hash e03d187e043d2a17cae636d6af164015 --st_checkpoint_dir /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/16/checkpoints
INFO:syne_tune.tuner:(trial 16) - scheduled config {'learning_rate': 0.02913976299993913, 'batch_size': 116, 'max_epochs': 10}
INFO:root:running subprocess with command: /usr/bin/python /home/ci/.local/lib/python3.8/site-packages/syne_tune/backend/python_backend/python_entrypoint.py --learning_rate 0.033362897489792855 --batch_size 154 --max_epochs 10 --tune_function_root /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/tune_function --tune_function_hash e03d187e043d2a17cae636d6af164015 --st_checkpoint_dir /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/17/checkpoints
INFO:syne_tune.tuner:(trial 17) - scheduled config {'learning_rate': 0.033362897489792855, 'batch_size': 154, 'max_epochs': 10}
INFO:root:running subprocess with command: /usr/bin/python /home/ci/.local/lib/python3.8/site-packages/syne_tune/backend/python_backend/python_entrypoint.py --learning_rate 0.29442952580755816 --batch_size 210 --max_epochs 10 --tune_function_root /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/tune_function --tune_function_hash e03d187e043d2a17cae636d6af164015 --st_checkpoint_dir /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/18/checkpoints
INFO:syne_tune.tuner:(trial 18) - scheduled config {'learning_rate': 0.29442952580755816, 'batch_size': 210, 'max_epochs': 10}
INFO:root:running subprocess with command: /usr/bin/python /home/ci/.local/lib/python3.8/site-packages/syne_tune/backend/python_backend/python_entrypoint.py --learning_rate 0.10214259921521483 --batch_size 239 --max_epochs 10 --tune_function_root /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/tune_function --tune_function_hash e03d187e043d2a17cae636d6af164015 --st_checkpoint_dir /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/19/checkpoints
INFO:syne_tune.tuner:(trial 19) - scheduled config {'learning_rate': 0.10214259921521483, 'batch_size': 239, 'max_epochs': 10}
INFO:syne_tune.tuner:tuning status (last metric is reported)
trial_id status iter learning_rate batch_size max_epochs epoch validation_error worker-time
0 Stopped 4 0.100000 128 10 4.0 0.430578 29.093798
1 Completed 10 0.446396 196 10 10.0 0.205652 72.747496
2 Stopped 2 0.011548 254 10 2.0 0.900570 13.729115
3 Stopped 8 0.149425 132 10 8.0 0.259171 58.980305
4 Stopped 4 0.063172 242 10 4.0 0.900579 27.773950
5 Completed 10 0.488018 41 10 10.0 0.140488 113.171314
6 Stopped 10 0.590407 244 10 10.0 0.193776 70.364757
7 Stopped 2 0.088129 148 10 2.0 0.899955 14.169738
8 Stopped 2 0.012271 235 10 2.0 0.899840 13.434274
9 Stopped 2 0.088457 236 10 2.0 0.899801 13.034437
10 Stopped 4 0.082577 75 10 4.0 0.385970 35.426524
11 Stopped 4 0.202352 65 10 4.0 0.543102 34.653495
12 Stopped 10 0.335989 58 10 10.0 0.149558 90.924182
13 Completed 10 0.789243 89 10 10.0 0.144887 77.365970
14 Stopped 2 0.123379 176 10 2.0 0.899987 12.422906
15 Stopped 2 0.137080 141 10 2.0 0.899983 13.395153
16 Stopped 4 0.029140 116 10 4.0 0.900532 27.834111
17 Stopped 2 0.033363 154 10 2.0 0.899996 13.407285
18 InProgress 1 0.294430 210 10 1.0 0.899878 6.126259
19 InProgress 0 0.102143 239 10 - - -
2 trials running, 18 finished (3 until the end), 437.07s wallclock-time
INFO:root:running subprocess with command: /usr/bin/python /home/ci/.local/lib/python3.8/site-packages/syne_tune/backend/python_backend/python_entrypoint.py --learning_rate 0.02846298236356246 --batch_size 115 --max_epochs 10 --tune_function_root /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/tune_function --tune_function_hash e03d187e043d2a17cae636d6af164015 --st_checkpoint_dir /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/20/checkpoints
INFO:syne_tune.tuner:(trial 20) - scheduled config {'learning_rate': 0.02846298236356246, 'batch_size': 115, 'max_epochs': 10}
INFO:root:running subprocess with command: /usr/bin/python /home/ci/.local/lib/python3.8/site-packages/syne_tune/backend/python_backend/python_entrypoint.py --learning_rate 0.037703019195187606 --batch_size 91 --max_epochs 10 --tune_function_root /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/tune_function --tune_function_hash e03d187e043d2a17cae636d6af164015 --st_checkpoint_dir /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/21/checkpoints
INFO:syne_tune.tuner:(trial 21) - scheduled config {'learning_rate': 0.037703019195187606, 'batch_size': 91, 'max_epochs': 10}
INFO:root:running subprocess with command: /usr/bin/python /home/ci/.local/lib/python3.8/site-packages/syne_tune/backend/python_backend/python_entrypoint.py --learning_rate 0.0741039859356903 --batch_size 192 --max_epochs 10 --tune_function_root /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/tune_function --tune_function_hash e03d187e043d2a17cae636d6af164015 --st_checkpoint_dir /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/22/checkpoints
INFO:syne_tune.tuner:(trial 22) - scheduled config {'learning_rate': 0.0741039859356903, 'batch_size': 192, 'max_epochs': 10}
INFO:root:running subprocess with command: /usr/bin/python /home/ci/.local/lib/python3.8/site-packages/syne_tune/backend/python_backend/python_entrypoint.py --learning_rate 0.3032613031191755 --batch_size 252 --max_epochs 10 --tune_function_root /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/tune_function --tune_function_hash e03d187e043d2a17cae636d6af164015 --st_checkpoint_dir /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/23/checkpoints
INFO:syne_tune.tuner:(trial 23) - scheduled config {'learning_rate': 0.3032613031191755, 'batch_size': 252, 'max_epochs': 10}
INFO:root:running subprocess with command: /usr/bin/python /home/ci/.local/lib/python3.8/site-packages/syne_tune/backend/python_backend/python_entrypoint.py --learning_rate 0.019823425532533637 --batch_size 252 --max_epochs 10 --tune_function_root /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/tune_function --tune_function_hash e03d187e043d2a17cae636d6af164015 --st_checkpoint_dir /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/24/checkpoints
INFO:syne_tune.tuner:(trial 24) - scheduled config {'learning_rate': 0.019823425532533637, 'batch_size': 252, 'max_epochs': 10}
INFO:root:running subprocess with command: /usr/bin/python /home/ci/.local/lib/python3.8/site-packages/syne_tune/backend/python_backend/python_entrypoint.py --learning_rate 0.8203370335228594 --batch_size 77 --max_epochs 10 --tune_function_root /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/tune_function --tune_function_hash e03d187e043d2a17cae636d6af164015 --st_checkpoint_dir /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/25/checkpoints
INFO:syne_tune.tuner:(trial 25) - scheduled config {'learning_rate': 0.8203370335228594, 'batch_size': 77, 'max_epochs': 10}
INFO:root:running subprocess with command: /usr/bin/python /home/ci/.local/lib/python3.8/site-packages/syne_tune/backend/python_backend/python_entrypoint.py --learning_rate 0.2960420911378594 --batch_size 104 --max_epochs 10 --tune_function_root /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/tune_function --tune_function_hash e03d187e043d2a17cae636d6af164015 --st_checkpoint_dir /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/26/checkpoints
INFO:syne_tune.tuner:(trial 26) - scheduled config {'learning_rate': 0.2960420911378594, 'batch_size': 104, 'max_epochs': 10}
INFO:root:running subprocess with command: /usr/bin/python /home/ci/.local/lib/python3.8/site-packages/syne_tune/backend/python_backend/python_entrypoint.py --learning_rate 0.2993874715754653 --batch_size 192 --max_epochs 10 --tune_function_root /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/tune_function --tune_function_hash e03d187e043d2a17cae636d6af164015 --st_checkpoint_dir /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/27/checkpoints
INFO:syne_tune.tuner:(trial 27) - scheduled config {'learning_rate': 0.2993874715754653, 'batch_size': 192, 'max_epochs': 10}
INFO:root:running subprocess with command: /usr/bin/python /home/ci/.local/lib/python3.8/site-packages/syne_tune/backend/python_backend/python_entrypoint.py --learning_rate 0.08056711961080017 --batch_size 36 --max_epochs 10 --tune_function_root /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/tune_function --tune_function_hash e03d187e043d2a17cae636d6af164015 --st_checkpoint_dir /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/28/checkpoints
INFO:syne_tune.tuner:(trial 28) - scheduled config {'learning_rate': 0.08056711961080017, 'batch_size': 36, 'max_epochs': 10}
INFO:root:running subprocess with command: /usr/bin/python /home/ci/.local/lib/python3.8/site-packages/syne_tune/backend/python_backend/python_entrypoint.py --learning_rate 0.26868380288030347 --batch_size 151 --max_epochs 10 --tune_function_root /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/tune_function --tune_function_hash e03d187e043d2a17cae636d6af164015 --st_checkpoint_dir /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/29/checkpoints
INFO:syne_tune.tuner:(trial 29) - scheduled config {'learning_rate': 0.26868380288030347, 'batch_size': 151, 'max_epochs': 10}
INFO:syne_tune.tuner:Trial trial_id 29 completed.
INFO:root:running subprocess with command: /usr/bin/python /home/ci/.local/lib/python3.8/site-packages/syne_tune/backend/python_backend/python_entrypoint.py --learning_rate 0.9197404791177789 --batch_size 66 --max_epochs 10 --tune_function_root /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/tune_function --tune_function_hash e03d187e043d2a17cae636d6af164015 --st_checkpoint_dir /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046/30/checkpoints
INFO:syne_tune.tuner:(trial 30) - scheduled config {'learning_rate': 0.9197404791177789, 'batch_size': 66, 'max_epochs': 10}
INFO:syne_tune.stopping_criterion:reaching max wallclock time (720), stopping there.
INFO:syne_tune.tuner:Stopping trials that may still be running.
INFO:syne_tune.tuner:Tuning finished, results of trials can be found on /home/ci/syne-tune/python-entrypoint-2023-08-18-20-01-52-046
--------------------
Resource summary (last result is reported):
trial_id status iter learning_rate batch_size max_epochs epoch validation_error worker-time
0 Stopped 4 0.100000 128 10 4 0.430578 29.093798
1 Completed 10 0.446396 196 10 10 0.205652 72.747496
2 Stopped 2 0.011548 254 10 2 0.900570 13.729115
3 Stopped 8 0.149425 132 10 8 0.259171 58.980305
4 Stopped 4 0.063172 242 10 4 0.900579 27.773950
5 Completed 10 0.488018 41 10 10 0.140488 113.171314
6 Stopped 10 0.590407 244 10 10 0.193776 70.364757
7 Stopped 2 0.088129 148 10 2 0.899955 14.169738
8 Stopped 2 0.012271 235 10 2 0.899840 13.434274
9 Stopped 2 0.088457 236 10 2 0.899801 13.034437
10 Stopped 4 0.082577 75 10 4 0.385970 35.426524
11 Stopped 4 0.202352 65 10 4 0.543102 34.653495
12 Stopped 10 0.335989 58 10 10 0.149558 90.924182
13 Completed 10 0.789243 89 10 10 0.144887 77.365970
14 Stopped 2 0.123379 176 10 2 0.899987 12.422906
15 Stopped 2 0.137080 141 10 2 0.899983 13.395153
16 Stopped 4 0.029140 116 10 4 0.900532 27.834111
17 Stopped 2 0.033363 154 10 2 0.899996 13.407285
18 Stopped 8 0.294430 210 10 8 0.241193 52.089688
19 Stopped 2 0.102143 239 10 2 0.900002 12.487762
20 Stopped 2 0.028463 115 10 2 0.899995 14.100359
21 Stopped 2 0.037703 91 10 2 0.900026 14.664848
22 Stopped 2 0.074104 192 10 2 0.901730 13.312770
23 Stopped 2 0.303261 252 10 2 0.900009 12.725821
24 Stopped 2 0.019823 252 10 2 0.899917 12.533380
25 Stopped 10 0.820337 77 10 10 0.196842 81.816103
26 Stopped 10 0.296042 104 10 10 0.198453 81.121330
27 Stopped 4 0.299387 192 10 4 0.336183 24.610689
28 InProgress 9 0.080567 36 10 9 0.203052 104.303746
29 Completed 10 0.268684 151 10 10 0.222814 68.217289
30 InProgress 1 0.919740 66 10 1 0.900037 10.070776
2 trials running, 29 finished (4 until the end), 723.70s wallclock-time
validation_error: best 0.1404876708984375 for trial-id 5
--------------------
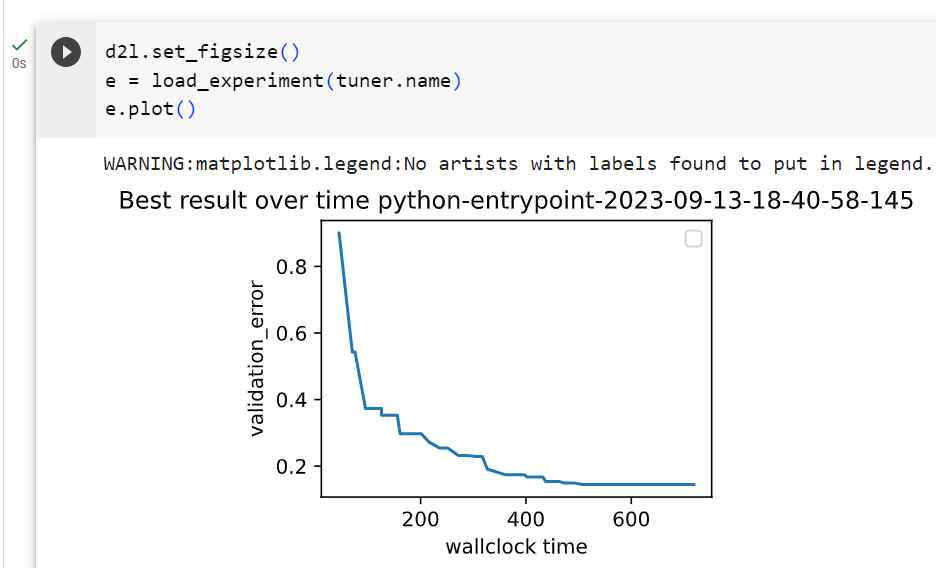
Note that we are running a variant of ASHA where underperforming trials are stopped early. This is different to our implementation in Section 19.4.1, where each training job is started with a fixed max_epochs. In the latter case, a well-performing trial which reaches the full 10 epochs, first needs to train 1, then 2, then 4, then 8 epochs, each time starting from scratch. This type of pause-and-resume scheduling can be implemented efficiently by checkpointing the training state after each epoch, but we avoid this extra complexity here. After the experiment has finished, we can retrieve and plot results.
우리는 실적이 저조한 시험을 조기에 중단하는 ASHA 변형을 실행하고 있습니다. 이는 각 훈련 작업이 고정된 max_epochs로 시작되는 섹션 19.4.1의 구현과 다릅니다. 후자의 경우 전체 10개 에포크에 도달하는 잘 수행되는 시험은 처음부터 처음부터 시작할 때마다 먼저 1개, 2개, 4개, 8개 에포크를 훈련해야 합니다. 이러한 유형의 일시 중지 및 재개 스케줄링은 각 에포크 이후 훈련 상태를 검사하여 효율적으로 구현할 수 있지만 여기서는 이러한 추가적인 복잡성을 피합니다. 실험이 완료된 후 결과를 검색하고 플롯할 수 있습니다.
d2l.set_figsize()
e = load_experiment(tuner.name)
e.plot()위의 코드는 실험 결과를 시각화하는 부분입니다.
- d2l.set_figsize(): 그래프의 크기를 설정하는 함수입니다. 이 경우 그래프의 크기를 조정합니다.
- e = load_experiment(tuner.name): load_experiment 함수를 사용하여 이전에 실행한 실험 결과를 로드합니다. tuner.name은 이전에 실행한 튜너의 이름을 나타냅니다.
- e.plot(): 로드한 실험 결과를 시각화합니다. 이로써 실험 결과 그래프가 표시됩니다. 실험 결과에는 하이퍼파라미터 값에 대한 메트릭(metric)의 변화 추이와 관련된 정보가 포함됩니다.
WARNING:matplotlib.legend:No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
19.5.3. Visualize the Optimization Process
Once more, we visualize the learning curves of every trial (each color in the plot represents a trial). Compare this to asynchronous random search in Section 19.3. As we have seen for successive halving in Section 19.4, most of the trials are stopped at 1 or 2 epochs (r min or η ∗ r min). However, trials do not stop at the same point, because they require different amount of time per epoch. If we ran standard successive halving instead of ASHA, we would need to synchronize our workers, before we can promote configurations to the next rung level.
다시 한 번 모든 시행의 학습 곡선을 시각화합니다(플롯의 각 색상은 시행을 나타냄). 이것을 섹션 19.3의 비동기 무작위 검색과 비교하십시오. 섹션 19.4에서 연속적인 반감기에 대해 살펴본 것처럼 대부분의 시행은 1 또는 2 에포크(r min 또는 θ * r min)에서 중단됩니다. 그러나 시도는 에포크마다 필요한 시간이 다르기 때문에 동일한 지점에서 멈추지 않습니다. ASHA 대신 표준 연속 절반을 실행한 경우 구성을 다음 단계 수준으로 승격하려면 먼저 작업자를 동기화해야 합니다.
d2l.set_figsize([6, 2.5])
results = e.results
for trial_id in results.trial_id.unique():
df = results[results["trial_id"] == trial_id]
d2l.plt.plot(
df["st_tuner_time"],
df["validation_error"],
marker="o"
)
d2l.plt.xlabel("wall-clock time")
d2l.plt.ylabel("objective function")위의 코드는 실험 결과를 시각화하는 부분입니다.
- d2l.set_figsize([6, 2.5]): 그래프의 크기를 설정하는 함수입니다. 이 경우 그래프의 가로 폭을 6로, 세로 높이를 2.5로 설정합니다.
- results = e.results: 로드한 실험 결과에서 실제 결과 데이터를 가져옵니다.
- for trial_id in results.trial_id.unique():: 실험 결과 중에서 고유한(trial_id가 다른) 각 실험에 대해서 반복합니다.
- df = results[results["trial_id"] == trial_id]: 현재 반복 중인 trial_id에 해당하는 실험 결과 데이터를 선택합니다.
- d2l.plt.plot(...): 선택한 실험 결과 데이터를 그래프로 표시합니다. x 축은 wall-clock time(실행 시간)을, y 축은 objective function(목적 함수) 값을 나타냅니다. marker="o"는 데이터 포인트를 원 형태로 표시하라는 옵션입니다.
- d2l.plt.xlabel("wall-clock time"): x 축에 "wall-clock time" 레이블을 추가합니다.
- d2l.plt.ylabel("objective function"): y 축에 "objective function" 레이블을 추가합니다.
이 코드는 실험 중 각 trial의 wall-clock time에 따른 objective function 값의 변화를 그래프로 표시하여 실험 결과를 시각적으로 확인할 수 있도록 합니다.
Text(0, 0.5, 'objective function')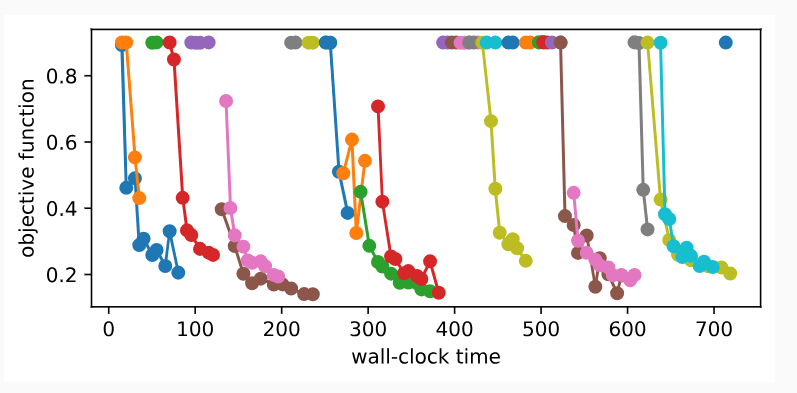

19.5.4. Summary
Compared to random search, successive halving is not quite as trivial to run in an asynchronous distributed setting. To avoid synchronisation points, we promote configurations as quickly as possible to the next rung level, even if this means promoting some wrong ones. In practice, this usually does not hurt much, and the gains of asynchronous versus synchronous scheduling are usually much higher than the loss of the suboptimal decision making.
무작위 검색과 비교할 때, 연속적인 반감기는 비동기 분산 설정에서 실행하는 것이 그리 간단하지 않습니다. 동기화 지점을 피하기 위해 우리는 구성을 가능한 한 빨리 다음 단계 수준으로 승격합니다. 이는 잘못된 구성의 승격을 의미하더라도 마찬가지입니다. 실제로 이것은 일반적으로 큰 해를 끼치지 않으며 비동기식 스케줄링과 동기식 스케줄링의 이점은 일반적으로 차선책 의사 결정의 손실보다 훨씬 높습니다.
Asynchronous Successive Halving에 대해서 (GPT 3.5. 의 설명)
**비동기식 연속 하프링(Asynchronous Successive Halving)**은 하이퍼파라미터 최적화를 위한 고급 알고리즘 중 하나입니다. 이 방법은 Successive Halving 기술을 기반으로 하지만 병렬 처리와 비동기적 실행을 허용하여 계산 리소스를 효율적으로 활용합니다.
연속 하프링(Continuous Successive Halving) 또는 ASHA로도 알려진 이 방법은 다음과 같은 주요 아이디어를 포함합니다:
- 파라미터 세트는 다양한 하이퍼파라미터 구성을 나타냅니다. 초기에는 여러 구성이 생성됩니다.
- 리소스 할당: 초기에는 모든 파라미터 세트가 작은 리소스를 할당받아 빠르게 평가됩니다. 그런 다음 상위 성능을 보이는 세트가 더 많은 리소스를 할당받게 됩니다.
- 제거 및 확장: 하위 퍼포먼스를 보이는 파라미터 세트는 제거되고, 상위 퍼포먼스를 보이는 세트는 추가 리소스를 받아 성능을 더욱 정확하게 평가합니다. 이 과정을 반복하여 가장 우수한 하이퍼파라미터 세트를 찾습니다.
- 병렬 처리: ASHA는 파라미터 세트를 병렬로 처리하여 리소스 효율성을 극대화합니다. 이것은 다수의 하이퍼파라미터 구성을 동시에 평가하는 데 사용되며, 여러 프로세스 또는 워커(worker)가 동시에 실행됩니다.
비동기식 연속 하프링은 병렬 처리를 통해 하이퍼파라미터 최적화의 속도를 크게 높이며, 최적의 하이퍼파라미터 설정을 더욱 효율적으로 찾을 수 있도록 돕습니다. 이것은 계산 리소스를 최대한 활용하면서도 최상의 결과를 달성하기 위한 강력한 도구 중 하나입니다.
'Dive into Deep Learning > D2L Hyperparameter Optimization' 카테고리의 다른 글
| D2L - 19.4. Multi-Fidelity Hyperparameter Optimization (0) | 2023.09.10 |
|---|---|
| D2L - 19.3. Asynchronous Random Search (0) | 2023.09.10 |
| D2L - 19.2. Hyperparameter Optimization API (0) | 2023.09.10 |
| D2L - 19.1. What Is Hyperparameter Optimization? (0) | 2023.09.10 |
| D2L - 19. Hyperparameter Optimization (0) | 2023.09.10 |