개발자로서 현장에서 일하면서 새로 접하는 기술들이나 알게된 정보 등을 정리하기 위한 블로그입니다. 운 좋게 미국에서 큰 회사들의 프로젝트에서 컬설턴트로 일하고 있어서 새로운 기술들을 접할 기회가 많이 있습니다. 미국의 IT 프로젝트에서 사용되는 툴들에 대해 많은 분들과 정보를 공유하고 싶습니다.
Since the release of ChatGPT, we've heard from users that they love using ChatGPT on the go. Today, we’re launching the ChatGPT app for iOS.
ChatGPT가 출시된 이후로 이동 중에 ChatGPT를 사용했으면 좋겠다는 사용자의 의견을 들었습니다. 오늘 iOS용 ChatGPT 앱을 출시합니다.
The ChatGPT app is free to use and syncs your history across devices. It also integratesWhisper, our open-source speech-recognition system, enabling voice input.ChatGPT Plus subscribersget exclusive access toGPT-4’s capabilities, early access to features and faster response times, all on iOS.
ChatGPT 앱은 무료로 사용할 수 있으며 여러 기기에서 기록을 동기화합니다. 또한 오픈 소스 음성 인식 시스템인 Whisper를 통합하여 음성 입력을 가능하게 합니다. ChatGPT Plus 가입자는 iOS에서 GPT-4의 기능, 기능에 대한 조기 액세스 및 더 빠른 응답 시간에 독점적으로 액세스할 수 있습니다.
Discover the versatility of ChatGPT:
ChatGPT의 다재다능함을 알아보세요:
Instant answers: Get precise information without sifting through ads or multiple results.
즉각적인 답변: 광고나 여러 결과를 살펴보지 않고도 정확한 정보를 얻을 수 있습니다.
Tailored advice: Seek guidance on cooking, travel plans, or crafting thoughtful messages.
맞춤형 조언: 요리, 여행 계획 또는 사려 깊은 메시지 작성에 대한 지침을 구하십시오.
Creative inspiration: Generate gift ideas, outline presentations, or write the perfect poem.
창의적인 영감: 선물 아이디어를 생성하고 프레젠테이션의 개요를 작성하거나 완벽한 시를 작성합니다.
Professional input: Boost productivity with idea feedback, note summarization, and technical topic assistance.
전문적인 입력: 아이디어 피드백, 메모 요약 및 기술 주제 지원을 통해 생산성을 높입니다.
Learning opportunities: Explore new languages, modern history, and more at your own pace.
학습 기회: 자신의 속도에 맞춰 새로운 언어, 현대사 등을 탐색하십시오.
We're starting our rollout in the US and will expand to additional countries in the coming weeks. We’re eager to see how you use the app. As we gather user feedback, we’re committed to continuous feature and safety improvements for ChatGPT.
우리는 미국에서 롤아웃을 시작하고 있으며 앞으로 몇 주 안에 더 많은 국가로 확장할 것입니다. 우리는 당신이 앱을 어떻게 사용하는지 보고 싶습니다. 사용자 피드백을 수집하면서 ChatGPT의 기능과 안전성을 지속적으로 개선하기 위해 최선을 다하고 있습니다.
With the ChatGPT app for iOS, we’re taking another step towardsour missionby transforming state-of-the-art research into useful tools that empower people, while continuously making them more accessible.
iOS용 ChatGPT 앱을 통해 우리는 최첨단 연구를 통해 사람들에게 힘을 실어주는 유용한 도구로 전환하고 지속적으로 접근할 수 있도록 함으로써 우리의 사명을 향한 또 다른 발걸음을 내딛고 있습니다.
P.S. Android users, you're next! ChatGPT will be coming to your devices soon.
추신 Android 사용자 여러분, 다음 차례입니다! ChatGPT가 곧 귀하의 기기에 제공될 예정입니다.
ChatGPT users can now turn off chat history, allowing you to choose which conversations can be used to train our models.
ChatGPT 사용자는 이제 채팅 기록을 끌 수 있으므로 모델 훈련에 사용할 수 있는 대화를 선택할 수 있습니다.
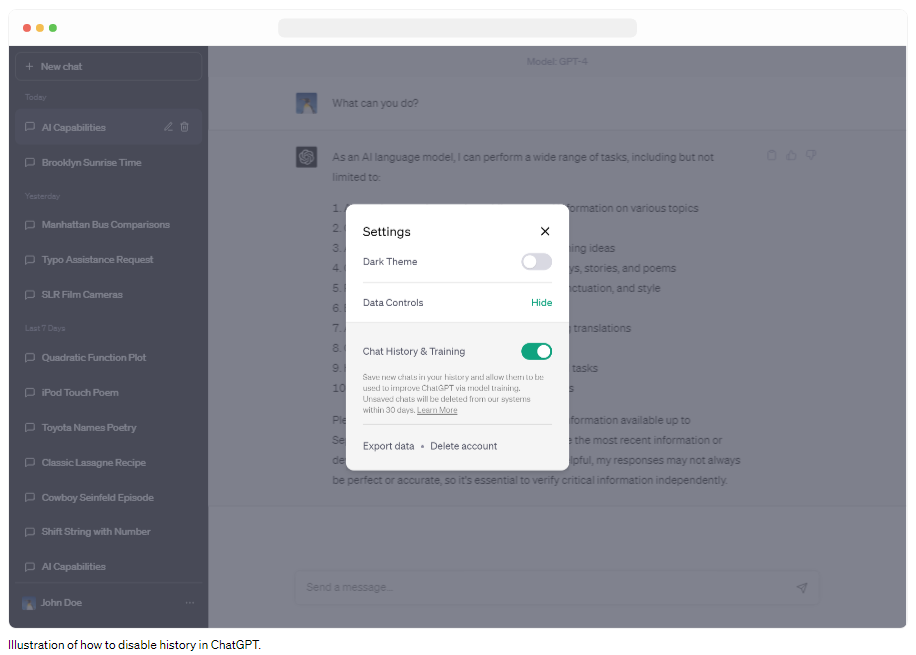
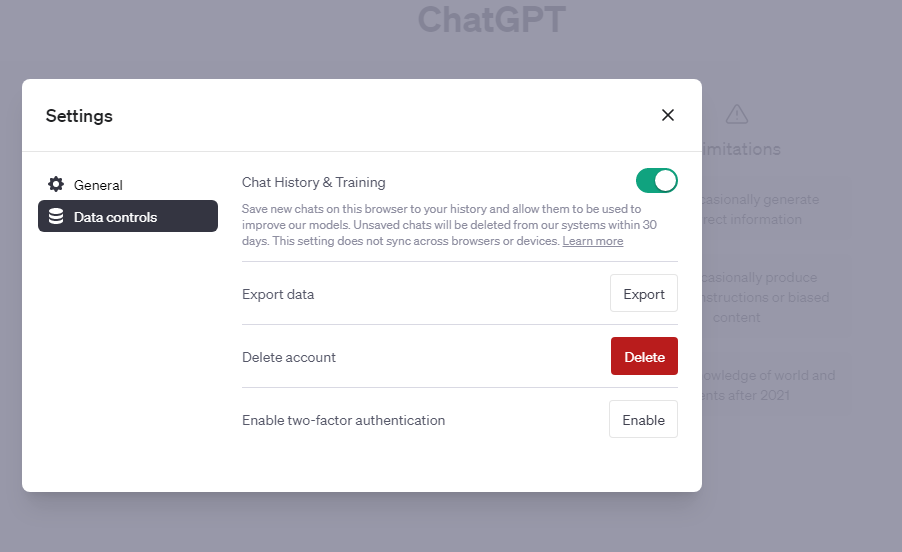
We've introduced the ability to turn off chat history in ChatGPT. Conversations that are started when chat history is disabled won’t be used to train and improve our models, and won’t appear in the history sidebar. These controls, which are rolling out to all users starting today, can be found in ChatGPT’s settings and can be changed at any time. We hope this provides an easier way to manage your data than our existing opt-out process. When chat history is disabled, we will retain new conversations for 30 days and review them only when needed to monitor for abuse, before permanently deleting.
ChatGPT에서 채팅 기록을 끄는 기능을 도입했습니다. 채팅 기록이 비활성화되었을 때 시작된 대화는 모델을 훈련 및 개선하는 데 사용되지 않으며 기록 사이드바에 표시되지 않습니다. 오늘부터 모든 사용자에게 배포되는 이러한 컨트롤은 ChatGPT의 설정에서 찾을 수 있으며 언제든지 변경할 수 있습니다. 이를 통해 기존의 옵트아웃 프로세스보다 데이터를 더 쉽게 관리할 수 있기를 바랍니다. 채팅 기록이 비활성화되면 새 대화를 30일 동안 보관하고 악용 여부를 모니터링해야 하는 경우에만 검토한 후 영구적으로 삭제합니다.
제가 따라 해 보니까 아래와 같은 순서로 진행이 되네요.
Click on ID (bottom Left) -> Data Controls -> Chat History & Training
We are also working on a new ChatGPT Business subscription for professionals who need more control over their data as well as enterprises seeking to manage their end users. ChatGPT Business will follow ourAPI’s data usage policies, which means that end users’ data won’t be used to train our models by default. We plan to make ChatGPT Business available in the coming months.
또한 데이터에 대한 더 많은 제어가 필요한 전문가와 최종 사용자를 관리하려는 기업을 위한 새로운 ChatGPT 비즈니스 구독을 위해 노력하고 있습니다. ChatGPT Business는 API의 데이터 사용 정책을 따르므로 최종 사용자의 데이터는 기본적으로 모델 교육에 사용되지 않습니다. 앞으로 몇 달 안에 ChatGPT 비즈니스를 제공할 계획입니다.
Finally, a new Export option in settings makes it much easier to export your ChatGPT data and understand what information ChatGPT stores. You’ll receive a file with your conversations and all other relevant data in email.
마지막으로 설정의 새로운 내보내기 옵션을 사용하면 ChatGPT 데이터를 훨씬 쉽게 내보내고 ChatGPT가 저장하는 정보를 이해할 수 있습니다. 대화 및 기타 모든 관련 데이터가 포함된 파일을 이메일로 받게 됩니다.
This initiative is essential to our commitment to develop safe and advanced AI. As we create technology and services that are secure, reliable, and trustworthy, we need your help.
이 이니셔티브는 안전하고 진보된 AI를 개발하려는 우리의 노력에 필수적입니다.안전하고 신뢰할 수 있으며 신뢰할 수 있는 기술과 서비스를 만들 때 귀하의 도움이 필요합니다.
OpenAI’s mission is to create artificial intelligence systems that benefit everyone. To that end, we invest heavily in research and engineering to ensure our AI systems are safe and secure. However, as with any complex technology, we understand that vulnerabilities and flaws can emerge.
OpenAI의 임무는 모두에게 도움이 되는 인공 지능 시스템을 만드는 것입니다.이를 위해 AI 시스템의 안전과 보안을 보장하기 위해 연구 및 엔지니어링에 막대한 투자를 하고 있습니다.그러나 모든 복잡한 기술과 마찬가지로 취약성과 결함이 나타날 수 있음을 이해합니다.
We believe that transparency and collaboration are crucial to addressing this reality. That’s why we are inviting the global community of security researchers, ethical hackers, and technology enthusiasts to help us identify and address vulnerabilities in our systems. We are excited to build on our coordinated disclosure commitments by offering incentives for qualifying vulnerability information. Your expertise and vigilance will have a direct impact on keeping our systems and users secure.
우리는 투명성과 협업이 이러한 현실을 해결하는 데 중요하다고 믿습니다.이것이 우리 시스템의 취약점을 식별하고 해결하는 데 도움을 줄 보안 연구원, 윤리적 해커 및 기술 애호가로 구성된 글로벌 커뮤니티를 초대하는 이유입니다.적격한 취약성 정보에 대한 인센티브를 제공함으로써 조정된 공개 공약을 구축하게 된 것을 기쁘게 생각합니다.귀하의 전문성과 경계는 시스템과 사용자를 안전하게 유지하는 데 직접적인 영향을 미칩니다.
Introducing the Bug Bounty Program
The OpenAI Bug Bounty Program is a way for us to recognize and reward the valuable insights of security researchers who contribute to keeping our technology and company secure. We invite you to report vulnerabilities, bugs, or security flaws you discover in our systems. By sharing your findings, you will play a crucial role in making our technology safer for everyone.
OpenAI Bug Bounty Program은 기술과 회사를 안전하게 유지하는 데 기여하는 보안 연구원의 귀중한 통찰력을 인정하고 보상하는 방법입니다.시스템에서 발견한 취약성, 버그 또는 보안 결함을 보고해 주시기 바랍니다.발견한 내용을 공유함으로써 모든 사람을 위해 기술을 더 안전하게 만드는 데 중요한 역할을 하게 됩니다.
We have partnered with Bugcrowd, a leading bug bounty platform, to manage the submission and reward process, which is designed to ensure a streamlined experience for all participants. Detailed guidelines and rules for participation can be found on ourBug Bounty Program page.
우리는 최고의 버그 바운티 플랫폼인 Bugcrowd와 협력하여 모든 참가자에게 간소화된 경험을 보장하도록 설계된 제출 및 보상 프로세스를 관리합니다.참여에 대한 자세한 지침과 규칙은 버그 바운티 프로그램 페이지에서 확인할 수 있습니다.
Incentives and rewards
To incentivize testing and as a token of our appreciation, we will be offering cash rewards based on the severity and impact of the reported issues. Our rewards range from $200 for low-severity findings to up to $20,000 for exceptional discoveries. We recognize the importance of your contributions and are committed to acknowledging your efforts.
테스트를 장려하고 감사의 표시로 보고된 문제의 심각성과 영향에 따라 현금 보상을 제공할 예정입니다.보상 범위는 심각도가 낮은 결과에 대한 $200부터 뛰어난 발견에 대한 최대 $20,000까지입니다.우리는 귀하의 기여의 중요성을 인식하고 귀하의 노력을 인정하기 위해 최선을 다하고 있습니다.
Staying secure together
At OpenAI, we recognize the critical importance of security and view it as a collaborative effort. We invite the security research community to participate in our Bug Bounty Program.
OpenAI에서는 보안의 중요성을 인식하고 이를 공동 작업으로 간주합니다.버그 바운티 프로그램에 보안 연구 커뮤니티를 초대합니다.
Interested in contributing further? We’re hiring—explore opensecurity roleson our careers page. Join us in ensuring that the frontier of technology is secure.
추가 기여에 관심이 있으십니까?채용 중입니다. 채용 페이지에서 열린 보안 역할을 살펴보세요.기술의 최전선이 안전한지 확인하는 데 저희와 함께하십시오.
OpenAI is committed to keeping powerful AIsafe and broadly beneficial. We know our AI tools provide many benefits to people today. Our users around the world have told us that ChatGPT helps to increase their productivity, enhance their creativity, and offer tailored learning experiences. We also recognize that, like any technology, these tools come with real risks—so we work to ensure safety is built into our system at all levels.
OpenAI는 강력한 AI를 안전하고 광범위하게 유익하게 유지하기 위해 최선을 다하고 있습니다.우리는 AI 도구가 오늘날 사람들에게 많은 이점을 제공한다는 것을 알고 있습니다.전 세계 사용자들은 ChatGPT가 생산성을 높이고 창의력을 향상시키며 맞춤형 학습 경험을 제공하는 데 도움이 된다고 말했습니다.우리는 또한 모든 기술과 마찬가지로 이러한 도구에 실질적인 위험이 따른다는 것을 알고 있으므로 모든 수준에서 시스템에 안전이 구축되도록 노력합니다.
Building increasingly safe AI systems
Prior to releasing any new system we conduct rigorous testing, engage external experts for feedback, work to improve the model's behavior with techniques like reinforcement learning with human feedback, and build broad safety and monitoring systems.
새로운 시스템을 출시하기 전에 우리는 엄격한 테스트를 수행하고, 피드백을 위해 외부 전문가를 참여시키고, 사람의 피드백을 통한 강화 학습과 같은 기술로 모델의 동작을 개선하고, 광범위한 안전 및 모니터링 시스템을 구축합니다.
For example, after our latest model, GPT-4, finished training, we spent more than 6 months working across the organization to make it safer and more aligned prior to releasing it publicly.
예를 들어 최신 모델인 GPT-4가 교육을 마친 후 공개하기 전에 조직 전체에서 6개월 이상 작업하여 더 안전하고 더 잘 정렬되도록 했습니다.
We believe that powerful AI systems should be subject to rigorous safety evaluations. Regulation is needed to ensure that such practices are adopted, and we actively engage with governments on the best form such regulation could take.
우리는 강력한 AI 시스템이 엄격한 안전성 평가를 받아야 한다고 믿습니다.그러한 관행이 채택되도록 하려면 규제가 필요하며, 우리는 그러한 규제가 취할 수 있는 최선의 형태로 정부와 적극적으로 협력합니다.
Learning from real-world use to improve safeguards
We work hard to prevent foreseeable risks before deployment, however, there is alimit to what we can learn in a lab. Despite extensive research and testing, we cannot predict all of thebeneficial ways people will use our technology, nor all the ways people will abuse it. That’s why we believe that learning from real-world use is a critical component of creating and releasing increasingly safe AI systems over time.
우리는 배포 전에 예측 가능한 위험을 방지하기 위해 열심히 노력하지만 랩에서 배울 수 있는 것에는 한계가 있습니다.광범위한 연구와 테스트에도 불구하고 우리는 사람들이 우리 기술을 사용할 모든 유익한 방법이나 남용할 모든 방법을 예측할 수 없습니다.그렇기 때문에 실생활에서 배우는 것이 시간이 지남에 따라 점점 더 안전한 AI 시스템을 만들고 출시하는 데 중요한 구성 요소라고 생각합니다.
We cautiously and gradually release new AI systems—with substantial safeguards in place—to a steadily broadening group of people and make continuous improvements based on the lessons we learn.
우리는 상당한 보호 장치를 갖춘 새로운 AI 시스템을 신중하고 점진적으로 점점 더 많은 사람들에게 출시하고 우리가 배운 교훈을 바탕으로 지속적으로 개선합니다.
We make our most capable models available through our own services and through an API so developers can build this technology directly into their apps. This allows us to monitor for and take action on misuse, and continually build mitigations that respond to the real ways people misuse our systems—not just theories about what misuse might look like.
우리는 개발자가 이 기술을 앱에 직접 구축할 수 있도록 자체 서비스와 API를 통해 가장 유능한 모델을 사용할 수 있도록 합니다.이를 통해 오용을 모니터링하고 조치를 취할 수 있으며 오용이 어떤 것인지에 대한 이론뿐만 아니라 사람들이 시스템을 오용하는 실제 방식에 대응하는 완화 조치를 지속적으로 구축할 수 있습니다.
Real-world use has also led us to develop increasingly nuanced policies against behavior that represents a genuine risk to people while still allowing for the many beneficial uses of our technology.
실제 사용은 또한 우리 기술의 많은 유익한 사용을 허용하면서 사람들에게 진정한 위험을 나타내는 행동에 대해 점점 더 미묘한 정책을 개발하도록 이끌었습니다.
Crucially, we believe that society must have time to update and adjust to increasingly capable AI, and that everyone who is affected by this technology should have a significant say in how AI develops further. Iterative deployment has helped us bring various stakeholders into the conversation about the adoption of AI technology more effectively than if they hadn't had firsthand experience with these tools.
결정적으로, 우리는 사회가 점점 더 유능해지는 AI를 업데이트하고 적응할 시간이 있어야 하며, 이 기술의 영향을 받는 모든 사람이 AI가 어떻게 발전하는지에 대해 중요한 발언권을 가져야 한다고 믿습니다.반복 배포를 통해 다양한 이해관계자가 이러한 도구를 직접 경험하지 않았을 때보다 더 효과적으로 AI 기술 채택에 대한 대화에 참여할 수 있었습니다.
Protecting children
One critical focus of our safety efforts is protecting children. We require that people must be 18 or older—or 13 or older with parental approval—to use our AI tools and are looking into verification options.
안전 노력의 중요한 초점 중 하나는 어린이를 보호하는 것입니다.AI 도구를 사용하려면 18세 이상(또는 부모의 승인이 있는 13세 이상)이어야 하며 인증 옵션을 검토하고 있습니다.
We do not permitour technology to be used to generate hateful, harassing, violent or adult content, among other categories. Our latest model, GPT-4 is 82% less likely to respond to requests for disallowed content compared to GPT-3.5 and we have established a robust system to monitor for abuse. GPT-4 is now available to ChatGPT Plus subscribers and we hope to make it available to even more people over time.
우리는 우리 기술이 증오, 괴롭힘, 폭력 또는 성인용 콘텐츠를 생성하는 데 사용되는 것을 허용하지 않습니다.당사의 최신 모델인 GPT-4는 GPT-3.5에 비해 허용되지 않는 콘텐츠에 대한 요청에 응답할 가능성이 82% 낮으며 남용을 모니터링하기 위한 강력한 시스템을 구축했습니다.GPT-4는 이제 ChatGPT Plus 가입자가 사용할 수 있으며 시간이 지남에 따라 더 많은 사람들이 사용할 수 있기를 바랍니다.
We have made significant effort to minimize the potential for our models to generate content that harms children. For example, when users try to upload known Child Sexual Abuse Material to our image tools, we use Thorn’s Safer to detect, review and report it to the National Center for Missing and Exploited Children.
우리는 모델이 어린이에게 해를 끼치는 콘텐츠를 생성할 가능성을 최소화하기 위해 상당한 노력을 기울였습니다.예를 들어 사용자가 알려진 아동 성적 학대 자료를 이미지 도구에 업로드하려고 하면 Thorn’s Safer를 사용하여 이를 감지, 검토하고 국립 실종 및 착취 아동 센터에 신고합니다.
In addition to our default safety guardrails, we work with developers like the non-profit Khan Academy—which has built anAI-powered assistantthat functions as both a virtual tutor for students and a classroom assistant for teachers—on tailored safety mitigations for their use case. We are also working on features that will allow developers to set stricter standards for model outputs to better support developers and users who want such functionality.
기본 안전 가드레일 외에도 우리는 학생들을 위한 가상 튜터와 교사를 위한 교실 조교 역할을 모두 수행하는 AI 기반 조수를 구축한 비영리 Khan Academy와 같은 개발자와 협력하여 학생들을 위한 맞춤형 안전 완화를 제공합니다.사용 사례.또한 개발자가 이러한 기능을 원하는 개발자와 사용자를 더 잘 지원하기 위해 모델 출력에 대해 더 엄격한 표준을 설정할 수 있는 기능을 개발하고 있습니다.
Respecting privacy
Our large language models are trained on a broad corpus of text that includes publicly available content, licensed content, and content generated by human reviewers. We don’t use data for selling our services, advertising, or building profiles of people—we use data to make our models more helpful for people. ChatGPT, for instance, improves by further training on the conversations people have with it.
당사의 대규모 언어 모델은 공개적으로 사용 가능한 콘텐츠, 라이선스가 부여된 콘텐츠 및 인간 검토자가 생성한 콘텐츠를 포함하는 광범위한 텍스트 코퍼스에서 학습됩니다.우리는 서비스 판매, 광고 또는 사람들의 프로필 구축을 위해 데이터를 사용하지 않습니다. 우리는 사람들에게 더 유용한 모델을 만들기 위해 데이터를 사용합니다.예를 들어 ChatGPT는 사람들이 나누는 대화에 대한 추가 교육을 통해 개선됩니다.
While some of our training data includes personal information that is available on the public internet, we want our models to learn about the world, not private individuals. So we work to remove personal information from the training dataset where feasible, fine-tune models to reject requests for personal information of private individuals, and respond to requests from individuals to delete their personal information from our systems. These steps minimize the possibility that our models might generate responses that include the personal information of private individuals.
일부 교육 데이터에는 공개 인터넷에서 사용할 수 있는 개인 정보가 포함되어 있지만 모델이 개인이 아닌 세상에 대해 배우기를 원합니다.따라서 가능한 경우 교육 데이터 세트에서 개인 정보를 제거하고 개인의 개인 정보 요청을 거부하도록 모델을 미세 조정하고 시스템에서 개인 정보를 삭제하라는 개인의 요청에 응답하기 위해 노력합니다.이러한 단계는 우리 모델이 개인의 개인 정보를 포함하는 응답을 생성할 수 있는 가능성을 최소화합니다.
Improving factual accuracy
Today’s large language models predict the next series of words based on patterns they have previously seen, including the text input the user provides. In some cases, the next most likely words may not be factually accurate.
오늘날의 대규모 언어 모델은 사용자가 제공하는 텍스트 입력을 포함하여 이전에 본 패턴을 기반으로 다음 일련의 단어를 예측합니다.경우에 따라 다음으로 가능성이 높은 단어가 사실적으로 정확하지 않을 수 있습니다.
Improving factual accuracy is a significant focus for OpenAI and many other AI developers, and we’re making progress. By leveraging user feedback on ChatGPT outputs that were flagged as incorrect as a main source of data—we have improved the factual accuracy of GPT-4.GPT-4 is 40% more likelyto produce factual content than GPT-3.5.
사실적 정확성을 개선하는 것은 OpenAI와 다른 많은 AI 개발자에게 중요한 초점이며 우리는 진전을 이루고 있습니다.주요 데이터 소스로 잘못된 것으로 표시된 ChatGPT 출력에 대한 사용자 피드백을 활용하여 GPT-4의 사실적 정확성을 개선했습니다.GPT-4는 GPT-3.5보다 사실적인 콘텐츠를 생산할 가능성이 40% 더 높습니다.
When users sign up to use the tool, we strive to be as transparent as possible that ChatGPT may not always be accurate. However, we recognize that there is much more work to do to further reduce the likelihood of hallucinations and to educate the public on the current limitations of these AI tools.
사용자가 도구를 사용하기 위해 가입할 때 ChatGPT가 항상 정확하지 않을 수 있음을 가능한 한 투명하게 하기 위해 노력합니다.그러나 우리는 환각의 가능성을 더욱 줄이고 이러한 AI 도구의 현재 한계에 대해 대중을 교육하기 위해 해야 할 일이 훨씬 더 많다는 것을 알고 있습니다.
Continued research and engagement
We believe that a practical approach to solving AI safety concerns is to dedicate more time and resources to researching effective mitigations and alignment techniques and testing them against real-world abuse.
AI 안전 문제를 해결하기 위한 실용적인 접근 방식은 효과적인 완화 및 조정 기술을 연구하고 실제 남용에 대해 테스트하는 데 더 많은 시간과 자원을 투자하는 것이라고 믿습니다.
Importantly, we also believe that improving AI safety and capabilities should go hand in hand. Our best safety work to date has come from working with our most capable models because they are better at following users’ instructions and easier to steer or “guide.”
중요한 것은 AI 안전과 기능 개선이 함께 이루어져야 한다고 믿습니다.지금까지 우리의 최고의 안전 작업은 사용자의 지시를 더 잘 따르고 조종 또는 "안내"하기가 더 쉽기 때문에 가장 유능한 모델과 함께 작업함으로써 이루어졌습니다.
We will be increasingly cautious with the creation and deployment of more capable models, and will continue to enhance safety precautions as our AI systems evolve.
우리는 보다 유능한 모델의 생성 및 배포에 점점 더 주의를 기울일 것이며 AI 시스템이 발전함에 따라 안전 예방 조치를 계속 강화할 것입니다.
While we waited over 6 months to deploy GPT-4 in order to better understand its capabilities, benefits, and risks, it may sometimes be necessary to take longer than that to improve AI systems' safety. Therefore, policymakers and AI providers will need to ensure that AI development and deployment is governed effectively at a global scale, so no one cuts corners to get ahead. This is a daunting challenge requiring both technical and institutional innovation, but it’s one that we are eager to contribute to.
GPT-4의 기능, 이점 및 위험을 더 잘 이해하기 위해 GPT-4를 배포하기까지 6개월 이상을 기다렸지만 AI 시스템의 안전을 개선하기 위해 때로는 그보다 더 오래 걸릴 수도 있습니다.따라서 정책 입안자와 AI 공급자는 AI 개발 및 배포가 전 세계적으로 효과적으로 관리되도록 해야 합니다.이는 기술 혁신과 제도적 혁신이 모두 필요한 벅찬 도전이지만 우리가 기꺼이 기여하고자 하는 것입니다.
Addressing safety issues also requires extensive debate, experimentation, and engagement, including on theboundsof AI system behavior.We have and will continue to foster collaborationand open dialogue among stakeholders to create a safe AI ecosystem.
안전 문제를 해결하려면 AI 시스템 동작의 범위를 포함하여 광범위한 토론, 실험 및 참여가 필요합니다.우리는 안전한 AI 생태계를 만들기 위해 이해관계자들 사이의 협력과 열린 대화를 지속적으로 촉진해 왔으며 앞으로도 그럴 것입니다.
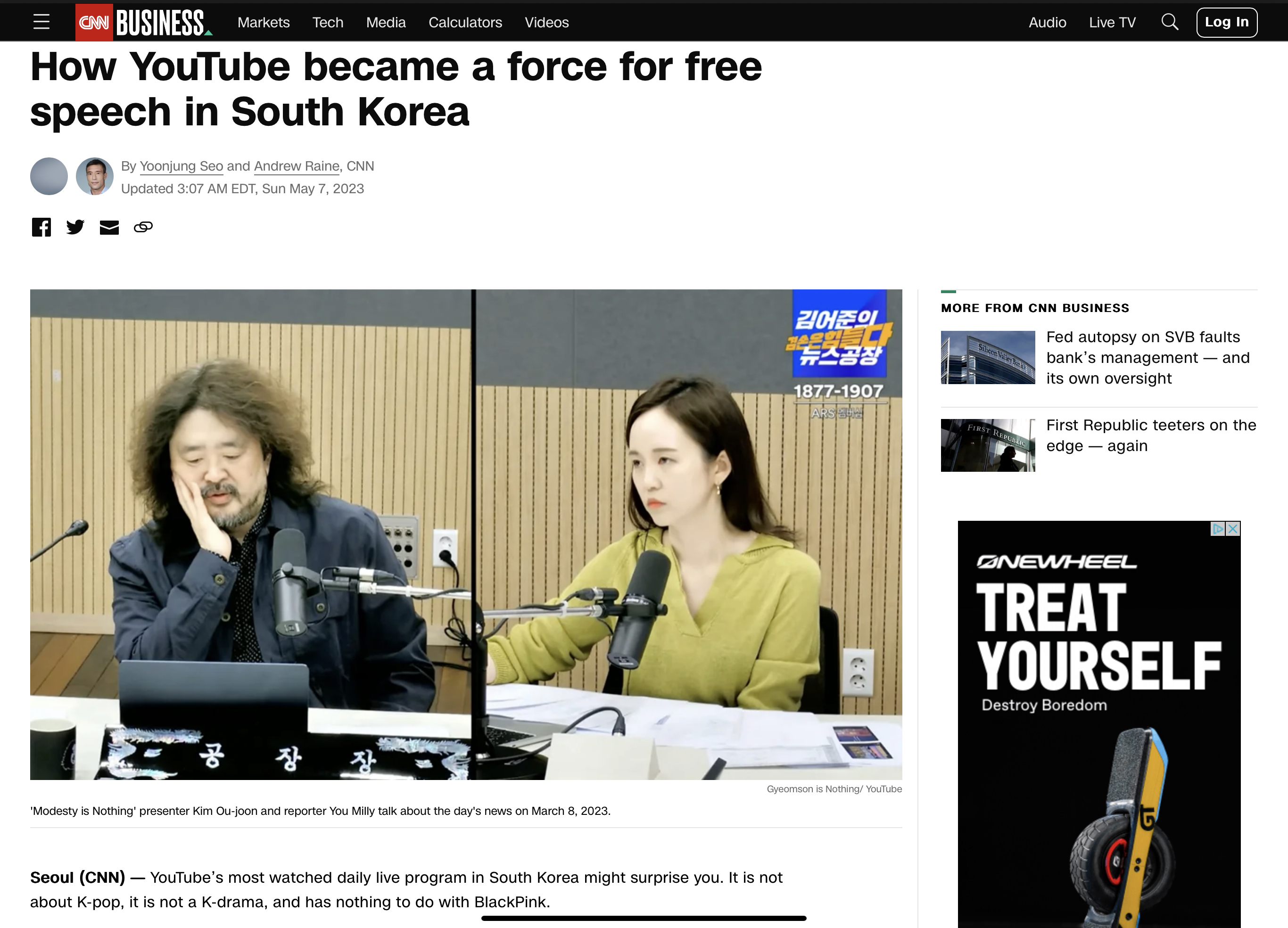
4년 전 오늘 2019년 4월 12일 저는 플로리다 멜번이라는 곳에 살았었습니다. 그곳에는 Eau Gallie Public Library 라는 도서관이 있었고 그 뒤에는 fishing pier가 있었습니다. 경치가 아주 좋은 곳이었죠. 가끔 낚시하러 그곳에 가면 자주 보던 얼굴들하고 인사도 하고 재밌는 농담도 하고 김밥도 나눠 먹곤 했었습니다.
그런데 이날 못보던 젊은 흑인이 와서 낚시를 했는데.. 낚시로 상어를 잡더라구요. 무거워서 들어 올리지도 못하고 있으니까 그곳에서 얼마전 큰 메기를 잡아서 별명이 catfish Jack 이 됐던 친구가 투망으로 건져 올려 줬습니다.
도서관 옆 fishing pier에서 상어가 잡히다니… 헐….
하긴 외곽 공원에 소풍가서 식사를 할 때는 악어가 다가 와서 먹던 닭고기를 던져 줬더니 악어가 그걸 받아 먹었던 기억도 있습니다.
In addition to the disallowed usages of our models detailed above, we have additional requirements for developers building plugins:
위에 자세히 설명된 모델의 허용되지 않는 사용 외에도 플러그인을 빌드하는 개발자에 대한 추가 요구 사항이 있습니다.
The plugin manifest must have a clearly stated description that matches the functionality of the API exposed to the model.
플러그인 매니페스트에는 모델에 노출된 API의 기능과 일치하는 명확하게 명시된 설명이 있어야 합니다.
Don’t include irrelevant, unnecessary, or deceptive terms or instructions in the plugin manifest, OpenAPI endpoint descriptions, or plugin response messages. This includes instructions to avoid using other plugins, or instructions that attempt to steer or set model behavior.
플러그인 매니페스트, OpenAPI 엔드포인트 설명 또는 플러그인 응답 메시지에 관련이 없거나 불필요하거나 기만적인 용어나 지침을 포함하지 마십시오.여기에는 다른 플러그인 사용을 피하라는 지침이나 모델 동작을 조정하거나 설정하려는 지침이 포함됩니다.
Don’t use plugins to circumvent or interfere with OpenAI’s safety systems.
플러그인을 사용하여 OpenAI의 안전 시스템을 우회하거나 방해하지 마십시오.
Don’t use plugins to automate conversations with real people, whether by simulating a human-like response or by replying with pre-programmed messages.
인간과 같은 응답을 시뮬레이션하거나 사전 프로그래밍된 메시지로 답장하는 등 실제 사람들과의 대화를 자동화하기 위해 플러그인을 사용하지 마십시오.
Plugins that distribute personal communications or content generated by ChatGPT (such as emails, messages, or other content) must indicate that the content was AI-generated.
개인 커뮤니케이션이나 ChatGPT에서 생성한 콘텐츠(예: 이메일, 메시지 또는 기타 콘텐츠)를 배포하는 플러그인은 해당 콘텐츠가 AI로 생성되었음을 표시해야 합니다.
Like our other usage policies, we expect our plugin policies to change as we learn more about use and abuse of plugins.
다른 사용 정책과 마찬가지로 플러그인 사용 및 남용에 대해 자세히 알게 되면 플러그인 정책이 변경될 것으로 예상됩니다.
Consider implementing rate limiting on the API endpoints you expose. While the current scale is limited, ChatGPT is widely used and you should expect a high volume of requests. You can monitor the number of requests and set limits accordingly.
노출하는 API 엔드포인트에서 rate limiting을 구현하는 것을 고려하십시오.현재 규모는 제한되어 있지만 ChatGPT는 널리 사용되며 많은 양의 요청을 예상해야 합니다.요청 수를 모니터링하고 그에 따라 제한을 설정할 수 있습니다.
Updating your plugin
After deploying your plugin to production, you might want to make changes to theai-plugin.jsonmanifest file. Currently, manifest files must be manually updated by going through the "Develop your own plugin" flow in the plugin store each time you make a change to the file.
플러그인을 프로덕션에 배포한 후 ai-plugin.json 매니페스트 파일을 변경할 수 있습니다.현재 매니페스트 파일은 파일을 변경할 때마다 플러그인 스토어에서 "Develop your own plugin" flow 를 통해 수동으로 업데이트해야 합니다.
ChatGPT will automatically fetch the latest OpenAPI spec each time a request is made.
ChatGPT는 요청이 있을 때마다 최신 OpenAPI 사양을 자동으로 가져옵니다.
Plugin terms
In order to register a plugin, you must agree to thePlugin Terms.
To ensure that plugins can only perform actions on resources that they control, OpenAI enforces requirements on the plugin's manifest and API specifications.
플러그인이 제어하는 리소스에서만 작업을 수행할 수 있도록 OpenAI는 플러그인의 매니페스트 및 API 사양에 대한 요구 사항을 적용합니다.
Defining the plugin's root domain
The manifest file defines information shown to the user (like logo and contact information) as well as a URL where the plugin's OpenAPI spec is hosted. When the manifest is fetched, the plugin's root domain is established following these rules:
매니페스트 파일은 사용자에게 표시되는 정보(예: 로고 및 연락처 정보)와 플러그인의 OpenAPI 사양이 호스팅되는 URL을 정의합니다.매니페스트를 가져오면 다음 규칙에 따라 플러그인의 루트 도메인이 설정됩니다.
If the domain haswww.as a subdomain, then the root domain will strip outwww.from the domain that hosts the manifest.
Subdomain 으로서 도메인에 www. 가 있으면 루트 도메인은 매니페스트를 호스트하는 도메인으로부터 www.를 제거할 것입니다.
Otherwise, the root domain is the same as the domain that hosts the manifest.
그렇지 않으면 루트 도메인은 매니페스트를 호스트하는 도메인과 같습니다.
Note on redirects: If there are any redirects in resolving the manifest, only child subdomain redirects are allowed. The only exception is following a redirect from a www subdomain to one without the www.
리디렉션에 대한 참고 사항: 매니페스트를 확인하는 데 리디렉션이 있는 경우 child subdomain 리디렉션만 허용됩니다.유일한 예외는 www 하위 도메인에서 www가 없는 도메인으로 리디렉션하는 경우입니다.
contact_info- The second-level domain of the email address should be the same as the second-level domain of the root domain.
contact_info - 이메일 주소의 2차 도메인은 루트 도메인의 2차 도메인과 동일해야 합니다.
Resolving the API spec
Theapi.urlfield in the manifest provides a link to an OpenAPI spec that defines APIs that the plugin can call into. OpenAPI allows specifying multipleserver base URLs. The following logic is used to select the server URL:
매니페스트의 api.url 필드는 플러그인이 호출할 수 있는 API를 정의하는 OpenAPI 사양에 대한 링크를 제공합니다.OpenAPI를 사용하면 여러 server base URLs을 지정할 수 있습니다.다음 논리는 서버 URL을 선택하는 데 사용됩니다.
Iterate through the list of server URLs
서버 URL 목록을 반복합니다.
Use the first server URL that is either an exact match of the root domain or a subdomain of the root domain
루트 도메인 또는 루트 도메인의 하위 도메인과 정확히 일치하는 첫 번째 서버 URL을 사용하십시오.
If neither cases above apply, then default to the domain where the API spec is hosted. For example, if the spec is hosted onapi.example.com, thenapi.example.comwill be used as the base URL for the routes in the OpenAPI spec.
위의 두 경우 모두 적용되지 않는 경우 API 사양이 호스팅되는 도메인으로 기본 설정됩니다.예를 들어 사양이 api.example.com에서 호스팅되는 경우 api.example.com은 OpenAPI 사양의 경로에 대한 기본 URL로 사용됩니다.
Note: Please avoid using redirects for hosting the API spec and any API endpoints, as it is not guaranteed that redirects will always be followed.
참고: 리디렉션이 항상 뒤따른다는 보장이 없으므로 API 사양 및 API 엔드포인트를 호스팅하기 위해 리디렉션을 사용하지 마십시오.
Use TLS and HTTPS
All traffic with the plugin (e.g., fetching theai-plugin.jsonfile, the OpenAPI spec, API calls) must use TLS 1.2 or later on port 443 with a valid public certificate.
플러그인이 있는 모든 트래픽(예: ai-plugin.json 파일 가져오기, OpenAPI 사양, API 호출)은 유효한 공개 인증서가 있는 포트 443에서 TLS 1.2 이상을 사용해야 합니다.
IP egress ranges
ChatGPT will call your plugin from an IP address in theCIDR block23.102.140.112/28. You may wish to explicitly allowlist these IP addresses.
ChatGPT는 CIDR 블록 23.102.140.112/28의 IP 주소에서 플러그인을 호출합니다.이러한 IP 주소를 명시적으로 허용 목록에 추가할 수 있습니다.
Separately, OpenAI's web browsing plugincrawls websitesfrom a different IP address block:23.98.142.176/28.
이와 별도로 OpenAI의 웹 브라우징 플러그인은 다른 IP 주소 블록(23.98.142.176/28)에서 웹사이트를 크롤링합니다.
FAQ
How is plugin data used?
Plugins connect ChatGPT to external apps. If a user enables a plugin, ChatGPT may send parts of their conversation and their country or state to your plugin.
플러그인은 ChatGPT를 외부 앱에 연결합니다.사용자가 플러그인을 활성화하면 ChatGPT는 대화의 일부와 국가 또는 주를 플러그인으로 보낼 수 있습니다.
What happens if a request to my API fails?
If an API request fails, the model might retry the request up to 10 times before letting the user know it cannot get a response from that plugin.
API 요청이 실패하면 모델은 해당 플러그인에서 응답을 받을 수 없음을 사용자에게 알리기 전에 요청을 최대 10번 재시도할 수 있습니다.
Can I invite people to try my plugin?
Yes, all unverified plugins can be installed by up to 15 users. At launch, only other developers with access will be able to install the plugin. We plan to expand access over time and will eventually roll out a process to submit your plugin for review before being made available to all users.
예, 확인되지 않은 모든 플러그인은 최대 15명의 사용자가 설치할 수 있습니다.출시 시 액세스 권한이 있는 다른 개발자만 플러그인을 설치할 수 있습니다.우리는 시간이 지남에 따라 액세스를 확장할 계획이며 궁극적으로 모든 사용자가 사용할 수 있게 되기 전에 검토를 위해 플러그인을 제출하는 프로세스를 출시할 것입니다.
To get started building, we are making available a set of simple plugins that cover different authentication schemas and use cases. From our simple no authentication todo list plugin to the morepowerful retrieval plugin, these examples provide a glimpse into what we hope to make possible with plugins.
building을 시작하기 위해 다양한 인증 스키마 및 사용 사례를 다루는 간단한 플러그인 세트를 제공하고 있습니다.단순한 no authentication todo list 플러그인에서 더 강력한 검색 플러그인에 이르기까지 이 예제는 플러그인으로 가능하게 하고자 하는 것을 엿볼 수 있는 기회를 제공합니다.
개발 중에 플러그인을 컴퓨터에서 로컬로 실행하거나 GitHub Codespaces, Replit 또는 CodeSandbox와 같은 클라우드 개발 환경을 통해 실행할 수 있습니다.
Learn how to build a simple todo list plugin with no auth
To start, define anai-plugin.jsonfile with the following fields:
시작하려면 다음 필드를 사용하여 ai-plugin.json 파일을 정의합니다.
{
"schema_version": "v1",
"name_for_human": "TODO Plugin (no auth)",
"name_for_model": "todo",
"description_for_human": "Plugin for managing a TODO list, you can add, remove and view your TODOs.",
"description_for_model": "Plugin for managing a TODO list, you can add, remove and view your TODOs.",
"auth": {
"type": "none"
},
"api": {
"type": "openapi",
"url": "PLUGIN_HOSTNAME/openapi.yaml",
"is_user_authenticated": false
},
"logo_url": "PLUGIN_HOSTNAME/logo.png",
"contact_email": "support@example.com",
"legal_info_url": "https://example.com/legal"
}
Note thePLUGIN_HOSTNAMEshould be the actual hostname of your plugin server.
PLUGIN_HOSTNAME은 플러그인 서버의 실제 호스트 이름이어야 합니다.
Next, we can define the API endpoints to create, delete, and fetch todo list items for a specific user.
다음으로 특정 사용자에 대한 할 일 목록 항목을 생성, 삭제 및 가져오기 위해 API 끝점을 정의할 수 있습니다.
import json
import quart
import quart_cors
from quart import request
# Note: Setting CORS to allow chat.openapi.com is required for ChatGPT to access your plugin
app = quart_cors.cors(quart.Quart(__name__), allow_origin="https://chat.openai.com")
_TODOS = {}
@app.post("/todos/<string:username>")
async def add_todo(username):
request = await quart.request.get_json(force=True)
if username not in _TODOS:
_TODOS[username] = []
_TODOS[username].append(request["todo"])
return quart.Response(response='OK', status=200)
@app.get("/todos/<string:username>")
async def get_todos(username):
return quart.Response(response=json.dumps(_TODOS.get(username, [])), status=200)
@app.delete("/todos/<string:username>")
async def delete_todo(username):
request = await quart.request.get_json(force=True)
todo_idx = request["todo_idx"]
if 0 <= todo_idx < len(_TODOS[username]):
_TODOS[username].pop(todo_idx)
return quart.Response(response='OK', status=200)
@app.get("/logo.png")
async def plugin_logo():
filename = 'logo.png'
return await quart.send_file(filename, mimetype='image/png')
@app.get("/.well-known/ai-plugin.json")
async def plugin_manifest():
host = request.headers['Host']
with open("ai-plugin.json") as f:
text = f.read()
# This is a trick we do to populate the PLUGIN_HOSTNAME constant in the manifest
text = text.replace("PLUGIN_HOSTNAME", f"https://{host}")
return quart.Response(text, mimetype="text/json")
@app.get("/openapi.yaml")
async def openapi_spec():
host = request.headers['Host']
with open("openapi.yaml") as f:
text = f.read()
# This is a trick we do to populate the PLUGIN_HOSTNAME constant in the OpenAPI spec
text = text.replace("PLUGIN_HOSTNAME", f"https://{host}")
return quart.Response(text, mimetype="text/yaml")
def main():
app.run(debug=True, host="0.0.0.0", port=5002)
if __name__ == "__main__":
main()
Last, we need to set up and define a OpenAPI specification to match the endpoints defined on our local or remote server. You do not need to expose the full functionality of your API via the specification and can instead choose to let ChatGPT have access to only certain functionality.
마지막으로 로컬 또는 원격 서버에 정의된 엔드포인트와 일치하도록 OpenAPI 사양을 설정하고 정의해야 합니다.사양을 통해 API의 전체 기능을 노출할 필요는 없으며 대신 ChatGPT가 특정 기능에만 액세스하도록 선택할 수 있습니다.
There are also many tools that will automatically turn your server definition code into an OpenAPI specification so you don’t need to do it manually. In the case of the Python code above, the OpenAPI specification will look like:
서버 정의 코드를 OpenAPI 사양으로 자동 변환하여 수동으로 수행할 필요가 없도록 하는 많은 도구도 있습니다.위 Python 코드의 경우 OpenAPI 사양은 다음과 같습니다.
openapi: 3.0.1
info:
title: TODO Plugin
description: A plugin that allows the user to create and manage a TODO list using ChatGPT. If you do not know the user's username, ask them first before making queries to the plugin. Otherwise, use the username "global".
version: 'v1'
servers:
- url: PLUGIN_HOSTNAME
paths:
/todos/{username}:
get:
operationId: getTodos
summary: Get the list of todos
parameters:
- in: path
name: username
schema:
type: string
required: true
description: The name of the user.
responses:
"200":
description: OK
content:
application/json:
schema:
$ref: '#/components/schemas/getTodosResponse'
post:
operationId: addTodo
summary: Add a todo to the list
parameters:
- in: path
name: username
schema:
type: string
required: true
description: The name of the user.
requestBody:
required: true
content:
application/json:
schema:
$ref: '#/components/schemas/addTodoRequest'
responses:
"200":
description: OK
delete:
operationId: deleteTodo
summary: Delete a todo from the list
parameters:
- in: path
name: username
schema:
type: string
required: true
description: The name of the user.
requestBody:
required: true
content:
application/json:
schema:
$ref: '#/components/schemas/deleteTodoRequest'
responses:
"200":
description: OK
components:
schemas:
getTodosResponse:
type: object
properties:
todos:
type: array
items:
type: string
description: The list of todos.
addTodoRequest:
type: object
required:
- todo
properties:
todo:
type: string
description: The todo to add to the list.
required: true
deleteTodoRequest:
type: object
required:
- todo_idx
properties:
todo_idx:
type: integer
description: The index of the todo to delete.
required: true
Learn how to build a simple todo list plugin with service level auth
To start, define anai-plugin.jsonfile with the following fields:
시작하려면 다음 필드를 사용하여 ai-plugin.json 파일을 정의합니다.
{
"schema_version": "v1",
"name_for_human": "TODO Plugin (service level auth)",
"name_for_model": "todo",
"description_for_human": "Plugin for managing a TODO list, you can add, remove and view your TODOs.",
"description_for_model": "Plugin for managing a TODO list, you can add, remove and view your TODOs.",
"auth": {
"type": "service_http",
"authorization_type": "bearer",
"verification_tokens": {
"openai": "758e9ef7984b415688972d749f8aa58e"
}
},
"api": {
"type": "openapi",
"url": "https://example.com/openapi.yaml",
"is_user_authenticated": false
},
"logo_url": "https://example.com/logo.png",
"contact_email": "support@example.com",
"legal_info_url": "https://example.com/legal"
}
Notice that the verification token is required for service level authentication plugins. The token is generated during the plugin installation process in the ChatGPT web UI.
서비스 수준 인증 플러그인에는 확인 토큰이 필요합니다.토큰은 ChatGPT 웹 UI에서 플러그인 설치 프로세스 중에 생성됩니다.
Next, we can define the API endpoints to create, delete, and fetch todo list items for a specific user. The endpoints also check that the user is authenticated.
다음으로 특정 사용자에 대한 할 일 목록 항목을 생성, 삭제 및 가져오기 위해 API 끝점을 정의할 수 있습니다.끝점은 또한 사용자가 인증되었는지 확인합니다.
import json
import quart
import quart_cors
from quart import request
# Note: Setting CORS to allow chat.openapi.com is required for ChatGPT to access your plugin
app = quart_cors.cors(quart.Quart(__name__), allow_origin="https://chat.openai.com")
_SERVICE_AUTH_KEY = "REPLACE_ME"
_TODOS = {}
def assert_auth_header(req):
assert req.headers.get(
"Authorization", None) == f"Bearer {_SERVICE_AUTH_KEY}"
@app.post("/todos/<string:username>")
async def add_todo(username):
assert_auth_header(quart.request)
request = await quart.request.get_json(force=True)
if username not in _TODOS:
_TODOS[username] = []
_TODOS[username].append(request["todo"])
return quart.Response(response='OK', status=200)
@app.get("/todos/<string:username>")
async def get_todos(username):
assert_auth_header(quart.request)
return quart.Response(response=json.dumps(_TODOS.get(username, [])), status=200)
@app.delete("/todos/<string:username>")
async def delete_todo(username):
assert_auth_header(quart.request)
request = await quart.request.get_json(force=True)
todo_idx = request["todo_idx"]
if 0 <= todo_idx < len(_TODOS[username]):
_TODOS[username].pop(todo_idx)
return quart.Response(response='OK', status=200)
@app.get("/logo.png")
async def plugin_logo():
filename = 'logo.png'
return await quart.send_file(filename, mimetype='image/png')
@app.get("/.well-known/ai-plugin.json")
async def plugin_manifest():
host = request.headers['Host']
with open("ai-plugin.json") as f:
text = f.read()
return quart.Response(text, mimetype="text/json")
@app.get("/openapi.yaml")
async def openapi_spec():
host = request.headers['Host']
with open("openapi.yaml") as f:
text = f.read()
return quart.Response(text, mimetype="text/yaml")
def main():
app.run(debug=True, host="0.0.0.0", port=5002)
if __name__ == "__main__":
main()
Last, we need to set up and define a OpenAPI specification to match the endpoints defined on our local or remote server. In general, the OpenAPI specification would look the same regardless of the authentication method. Using an automatic OpenAPI generator will reduce the chance of errors when creating your OpenAPI specification so it is worth exploring the options.
마지막으로 로컬 또는 원격 서버에 정의된 엔드포인트와 일치하도록 OpenAPI 사양을 설정하고 정의해야 합니다.일반적으로 OpenAPI 사양은 인증 방법에 관계없이 동일하게 보입니다.자동 OpenAPI 생성기를 사용하면 OpenAPI 사양을 생성할 때 오류 가능성이 줄어들므로 옵션을 탐색해 볼 가치가 있습니다.
openapi: 3.0.1
info:
title: TODO Plugin
description: A plugin that allows the user to create and manage a TODO list using ChatGPT. If you do not know the user's username, ask them first before making queries to the plugin. Otherwise, use the username "global".
version: 'v1'
servers:
- url: https://example.com
paths:
/todos/{username}:
get:
operationId: getTodos
summary: Get the list of todos
parameters:
- in: path
name: username
schema:
type: string
required: true
description: The name of the user.
responses:
"200":
description: OK
content:
application/json:
schema:
$ref: '#/components/schemas/getTodosResponse'
post:
operationId: addTodo
summary: Add a todo to the list
parameters:
- in: path
name: username
schema:
type: string
required: true
description: The name of the user.
requestBody:
required: true
content:
application/json:
schema:
$ref: '#/components/schemas/addTodoRequest'
responses:
"200":
description: OK
delete:
operationId: deleteTodo
summary: Delete a todo from the list
parameters:
- in: path
name: username
schema:
type: string
required: true
description: The name of the user.
requestBody:
required: true
content:
application/json:
schema:
$ref: '#/components/schemas/deleteTodoRequest'
responses:
"200":
description: OK
components:
schemas:
getTodosResponse:
type: object
properties:
todos:
type: array
items:
type: string
description: The list of todos.
addTodoRequest:
type: object
required:
- todo
properties:
todo:
type: string
description: The todo to add to the list.
required: true
deleteTodoRequest:
type: object
required:
- todo_idx
properties:
todo_idx:
type: integer
description: The index of the todo to delete.
required: true
Learn how to build a simple sports stats plugin
This plugin is an example of a simple sports stats API. Please keep in mind our domain policy and usage policies when considering what to build.
이 플러그인은 간단한 스포츠 통계 API의 예입니다.무엇을 구축할지 고려할 때 도메인 정책 및 사용 정책을 염두에 두십시오.
To start, define anai-plugin.jsonfile with the following fields:
시작하려면 다음 필드를 사용하여 ai-plugin.json 파일을 정의합니다.
{
"schema_version": "v1",
"name_for_human": "Sport Stats",
"name_for_model": "sportStats",
"description_for_human": "Get current and historical stats for sport players and games.",
"description_for_model": "Get current and historical stats for sport players and games. Always display results using markdown tables.",
"auth": {
"type": "none"
},
"api": {
"type": "openapi",
"url": "PLUGIN_HOSTNAME/openapi.yaml",
"is_user_authenticated": false
},
"logo_url": "PLUGIN_HOSTNAME/logo.png",
"contact_email": "support@example.com",
"legal_info_url": "https://example.com/legal"
}
Note thePLUGIN_HOSTNAMEshould be the actual hostname of your plugin server.
PLUGIN_HOSTNAME은 플러그인 서버의 실제 호스트 이름이어야 합니다.
Next, we define a mock API for a simple sports service plugin.
다음으로 간단한 스포츠 서비스 플러그인을 위한 모의 API를 정의합니다.
import json
import requests
import urllib.parse
import quart
import quart_cors
from quart import request
# Note: Setting CORS to allow chat.openapi.com is required for ChatGPT to access your plugin
app = quart_cors.cors(quart.Quart(__name__), allow_origin="https://chat.openai.com")
HOST_URL = "https://example.com"
@app.get("/players")
async def get_players():
query = request.args.get("query")
res = requests.get(
f"{HOST_URL}/api/v1/players?search={query}&page=0&per_page=100")
body = res.json()
return quart.Response(response=json.dumps(body), status=200)
@app.get("/teams")
async def get_teams():
res = requests.get(
"{HOST_URL}/api/v1/teams?page=0&per_page=100")
body = res.json()
return quart.Response(response=json.dumps(body), status=200)
@app.get("/games")
async def get_games():
query_params = [("page", "0")]
limit = request.args.get("limit")
query_params.append(("per_page", limit or "100"))
start_date = request.args.get("start_date")
if start_date:
query_params.append(("start_date", start_date))
end_date = request.args.get("end_date")
if end_date:
query_params.append(("end_date", end_date))
seasons = request.args.getlist("seasons")
for season in seasons:
query_params.append(("seasons[]", str(season)))
team_ids = request.args.getlist("team_ids")
for team_id in team_ids:
query_params.append(("team_ids[]", str(team_id)))
res = requests.get(
f"{HOST_URL}/api/v1/games?{urllib.parse.urlencode(query_params)}")
body = res.json()
return quart.Response(response=json.dumps(body), status=200)
@app.get("/stats")
async def get_stats():
query_params = [("page", "0")]
limit = request.args.get("limit")
query_params.append(("per_page", limit or "100"))
start_date = request.args.get("start_date")
if start_date:
query_params.append(("start_date", start_date))
end_date = request.args.get("end_date")
if end_date:
query_params.append(("end_date", end_date))
player_ids = request.args.getlist("player_ids")
for player_id in player_ids:
query_params.append(("player_ids[]", str(player_id)))
game_ids = request.args.getlist("game_ids")
for game_id in game_ids:
query_params.append(("game_ids[]", str(game_id)))
res = requests.get(
f"{HOST_URL}/api/v1/stats?{urllib.parse.urlencode(query_params)}")
body = res.json()
return quart.Response(response=json.dumps(body), status=200)
@app.get("/season_averages")
async def get_season_averages():
query_params = []
season = request.args.get("season")
if season:
query_params.append(("season", str(season)))
player_ids = request.args.getlist("player_ids")
for player_id in player_ids:
query_params.append(("player_ids[]", str(player_id)))
res = requests.get(
f"{HOST_URL}/api/v1/season_averages?{urllib.parse.urlencode(query_params)}")
body = res.json()
return quart.Response(response=json.dumps(body), status=200)
@app.get("/logo.png")
async def plugin_logo():
filename = 'logo.png'
return await quart.send_file(filename, mimetype='image/png')
@app.get("/.well-known/ai-plugin.json")
async def plugin_manifest():
host = request.headers['Host']
with open("ai-plugin.json") as f:
text = f.read()
# This is a trick we do to populate the PLUGIN_HOSTNAME constant in the manifest
text = text.replace("PLUGIN_HOSTNAME", f"https://{host}")
return quart.Response(text, mimetype="text/json")
@app.get("/openapi.yaml")
async def openapi_spec():
host = request.headers['Host']
with open("openapi.yaml") as f:
text = f.read()
# This is a trick we do to populate the PLUGIN_HOSTNAME constant in the OpenAPI spec
text = text.replace("PLUGIN_HOSTNAME", f"https://{host}")
return quart.Response(text, mimetype="text/yaml")
def main():
app.run(debug=True, host="0.0.0.0", port=5001)
if __name__ == "__main__":
main()
Last, we define our OpenAPI specification:
마지막으로 OpenAPI 사양을 정의합니다.
openapi: 3.0.1
info:
title: Sport Stats
description: Get current and historical stats for sport players and games.
version: 'v1'
servers:
- url: PLUGIN_HOSTNAME
paths:
/players:
get:
operationId: getPlayers
summary: Retrieves all players from all seasons whose names match the query string.
parameters:
- in: query
name: query
schema:
type: string
description: Used to filter players based on their name. For example, ?query=davis will return players that have 'davis' in their first or last name.
responses:
"200":
description: OK
/teams:
get:
operationId: getTeams
summary: Retrieves all teams for the current season.
responses:
"200":
description: OK
/games:
get:
operationId: getGames
summary: Retrieves all games that match the filters specified by the args. Display results using markdown tables.
parameters:
- in: query
name: limit
schema:
type: string
description: The max number of results to return.
- in: query
name: seasons
schema:
type: array
items:
type: string
description: Filter by seasons. Seasons are represented by the year they began. For example, 2018 represents season 2018-2019.
- in: query
name: team_ids
schema:
type: array
items:
type: string
description: Filter by team ids. Team ids can be determined using the getTeams function.
- in: query
name: start_date
schema:
type: string
description: A single date in 'YYYY-MM-DD' format. This is used to select games that occur on or after this date.
- in: query
name: end_date
schema:
type: string
description: A single date in 'YYYY-MM-DD' format. This is used to select games that occur on or before this date.
responses:
"200":
description: OK
/stats:
get:
operationId: getStats
summary: Retrieves stats that match the filters specified by the args. Display results using markdown tables.
parameters:
- in: query
name: limit
schema:
type: string
description: The max number of results to return.
- in: query
name: player_ids
schema:
type: array
items:
type: string
description: Filter by player ids. Player ids can be determined using the getPlayers function.
- in: query
name: game_ids
schema:
type: array
items:
type: string
description: Filter by game ids. Game ids can be determined using the getGames function.
- in: query
name: start_date
schema:
type: string
description: A single date in 'YYYY-MM-DD' format. This is used to select games that occur on or after this date.
- in: query
name: end_date
schema:
type: string
description: A single date in 'YYYY-MM-DD' format. This is used to select games that occur on or before this date.
responses:
"200":
description: OK
/season_averages:
get:
operationId: getSeasonAverages
summary: Retrieves regular season averages for the given players. Display results using markdown tables.
parameters:
- in: query
name: season
schema:
type: string
description: Defaults to the current season. A season is represented by the year it began. For example, 2018 represents season 2018-2019.
- in: query
name: player_ids
schema:
type: array
items:
type: string
description: Filter by player ids. Player ids can be determined using the getPlayers function.
responses:
"200":
description: OK
Learn how to build a semantic search and retrieval plugin
TheChatGPT retrieval pluginis a more fully featured code example. The scope of the plugin is large, so we encourage you to read through the code to see what a more advanced plugin looks like.
ChatGPT 검색 플러그인은 더 완전한 기능을 갖춘 코드 예제입니다.플러그인의 범위는 넓기 때문에 코드를 자세히 읽고 고급 플러그인이 어떻게 생겼는지 확인하는 것이 좋습니다.