
7.6. Convolutional Neural Networks (LeNet) — Dive into Deep Learning 1.0.0-beta0 documentation
d2l.ai
7.6. Convolutional Neural Networks (LeNet)
We now have all the ingredients required to assemble a fully-functional CNN. In our earlier encounter with image data, we applied a linear model with softmax regression (Section 4.4) and an MLP (Section 5.2) to pictures of clothing in the Fashion-MNIST dataset. To make such data amenable we first flattened each image from a 28×28 matrix into a fixed-length 784-dimensional vector, and thereafter processed them in fully connected layers. Now that we have a handle on convolutional layers, we can retain the spatial structure in our images. As an additional benefit of replacing fully connected layers with convolutional layers, we will enjoy more parsimonious models that require far fewer parameters.
이제 완전한 기능을 갖춘 CNN을 조립하는 데 필요한 모든 요소가 있습니다. 이전 이미지 데이터와의 만남에서 Softmax 회귀(섹션 4.4) 및 MLP(섹션 5.2)가 포함된 선형 모델을 Fashion-MNIST 데이터 세트의 의류 사진에 적용했습니다. 이러한 데이터를 사용 가능하게 만들기 위해 먼저 28×28 매트릭스의 각 이미지를 고정 길이 784차원 벡터로 평면화한 다음 완전히 연결된 레이어에서 처리했습니다. 이제 컨볼루션 레이어에 대한 핸들이 있으므로 이미지의 공간 구조를 유지할 수 있습니다. 완전 연결 레이어를 컨볼루션 레이어로 대체하는 추가 이점으로 훨씬 적은 매개변수가 필요한 더 간결한 모델을 즐길 수 있습니다.
In this section, we will introduce LeNet, among the first published CNNs to capture wide attention for its performance on computer vision tasks. The model was introduced by (and named for) Yann LeCun, then a researcher at AT&T Bell Labs, for the purpose of recognizing handwritten digits in images (LeCun et al., 1998). This work represented the culmination of a decade of research developing the technology. In 1989, LeCun’s team published the first study to successfully train CNNs via backpropagation (LeCun et al., 1989).
이 섹션에서는 컴퓨터 비전 작업에 대한 성능으로 많은 관심을 끌기 위해 처음으로 게시된 CNN 중 LeNet을 소개합니다. 이 모델은 당시 AT&T Bell Labs의 연구원이었던 Yann LeCun에 의해 이미지에서 손으로 쓴 숫자를 인식할 목적으로 도입되었습니다(LeCun et al., 1998). 이 작업은 기술 개발에 대한 10년 간의 연구의 정점을 나타냅니다. 1989년 LeCun 팀은 backpropagation 를 통해 CNN을 성공적으로 훈련시키는 첫 번째 연구를 발표했습니다(LeCun et al., 1989).
At the time LeNet achieved outstanding results matching the performance of support vector machines, then a dominant approach in supervised learning, achieving an error rate of less than 1% per digit. LeNet was eventually adapted to recognize digits for processing deposits in ATM machines. To this day, some ATMs still run the code that Yann LeCun and his colleague Leon Bottou wrote in the 1990s!
당시 LeNet은 지원 벡터 머신의 성능과 일치하는 뛰어난 결과를 달성했으며 지도 학습에서 지배적인 접근 방식으로 자릿수당 1% 미만의 오류율을 달성했습니다. LeNet은 결국 ATM 기계에서 예금을 처리하기 위해 숫자를 인식하도록 조정되었습니다. 현재까지도 일부 ATM은 Yann LeCun과 그의 동료인 Leon Bottou가 1990년대에 작성한 코드를 실행하고 있습니다!
import torch
from torch import nn
from d2l import torch as d2l
7.6.1. LeNet
At a high level, LeNet (LeNet-5) consists of two parts: (i) a convolutional encoder consisting of two convolutional layers; and (ii) a dense block consisting of three fully connected layers; The architecture is summarized in Fig. 7.6.1.
대략적으로 LeNet(LeNet-5)은 두 부분으로 구성됩니다. (i) 두 개의 컨볼루션 레이어로 구성된 컨볼루션 인코더 및 (ii) 3개의 완전히 연결된 레이어로 구성된 조밀한 블록; 아키텍처는 그림 7.6.1에 요약되어 있습니다.
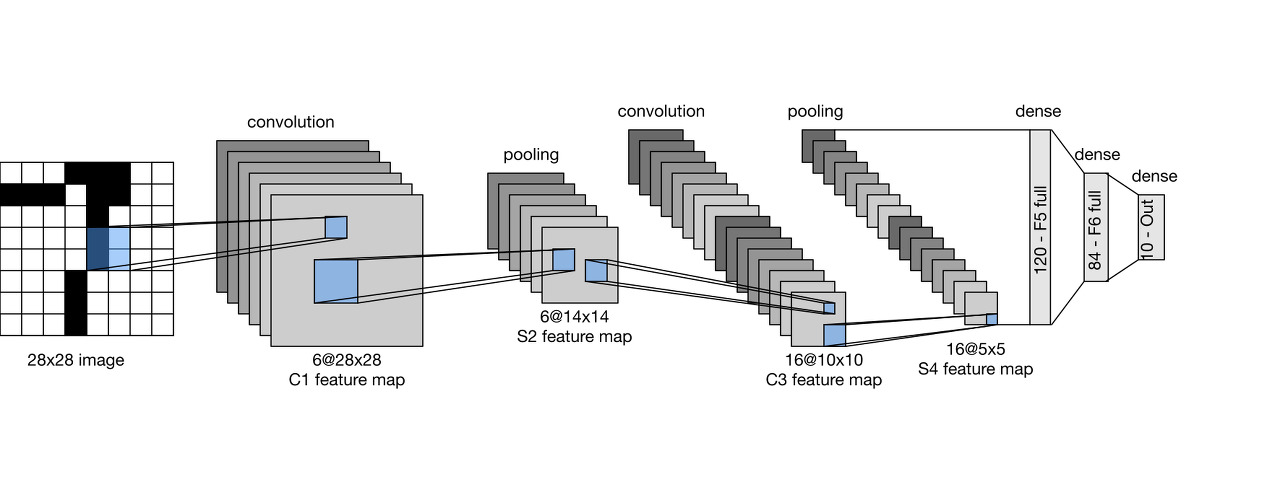
The basic units in each convolutional block are a convolutional layer, a sigmoid activation function, and a subsequent average pooling operation. Note that while ReLUs and max-pooling work better, these discoveries had not yet been made at the time. Each convolutional layer uses a 5×5 kernel and a sigmoid activation function. These layers map spatially arranged inputs to a number of two-dimensional feature maps, typically increasing the number of channels. The first convolutional layer has 6 output channels, while the second has 16. Each 2×2 pooling operation (stride 2) reduces dimensionality by a factor of 4 via spatial downsampling. The convolutional block emits an output with shape given by (batch size, number of channel, height, width).
각 컨볼루션 블록의 기본 단위는 컨볼루션 레이어, 시그모이드 활성화 함수 및 후속 평균 풀링 연산입니다. ReLU와 최대 풀링이 더 잘 작동하지만 당시에는 이러한 발견이 아직 이루어지지 않았습니다. 각 컨볼루션 레이어는 5×5 커널과 시그모이드 활성화 함수를 사용합니다. 이러한 레이어는 공간적으로 배열된 입력을 여러 2차원 기능 맵에 매핑하여 일반적으로 채널 수를 늘립니다. 첫 번째 컨볼루션 레이어에는 6개의 출력 채널이 있고 두 번째에는 16개의 출력 채널이 있습니다. 각 2×2 풀링 작업(스트라이드 2)은 공간적 다운샘플링을 통해 차원을 4배로 줄입니다. 컨벌루션 블록은 (배치 크기, 채널 수, 높이, 너비)로 지정된 형태의 출력을 내보냅니다.
In order to pass output from the convolutional block to the dense block, we must flatten each example in the minibatch. In other words, we take this four-dimensional input and transform it into the two-dimensional input expected by fully connected layers: as a reminder, the two-dimensional representation that we desire uses the first dimension to index examples in the minibatch and the second to give the flat vector representation of each example. LeNet’s dense block has three fully connected layers, with 120, 84, and 10 outputs, respectively. Because we are still performing classification, the 10-dimensional output layer corresponds to the number of possible output classes.
컨벌루션 블록의 출력을 밀집 블록으로 전달하려면 미니배치의 각 예제를 평면화해야 합니다. 다시 말해, 우리는 이 4차원 입력을 가져와 완전히 연결된 레이어에서 예상되는 2차원 입력으로 변환합니다. 다시 말해, 우리가 원하는 2차원 표현은 첫 번째 차원을 사용하여 미니배치의 예제를 인덱싱하고 두 번째로 각 예제의 플랫 벡터 표현을 제공합니다. LeNet의 고밀도 블록에는 각각 120, 84 및 10개의 출력이 있는 3개의 완전히 연결된 계층이 있습니다. 여전히 분류를 수행하고 있기 때문에 10차원 출력 계층은 가능한 출력 클래스의 수에 해당합니다.
While getting to the point where you truly understand what is going on inside LeNet may have taken a bit of work, hopefully the following code snippet will convince you that implementing such models with modern deep learning frameworks is remarkably simple. We need only to instantiate a Sequential block and chain together the appropriate layers, using Xavier initialization as introduced in Section 5.4.2.2.
LeNet 내부에서 진행되는 작업을 진정으로 이해하는 지점에 도달하는 동안 약간의 작업이 필요할 수 있지만 다음 코드 스니펫을 통해 이러한 모델을 최신 딥 러닝 프레임워크로 구현하는 것이 매우 간단하다는 것을 확신할 수 있기를 바랍니다. 섹션 5.4.2.2에서 소개한 대로 Xavier 초기화를 사용하여 Sequential 블록을 인스턴스화하고 적절한 레이어를 함께 연결하기만 하면 됩니다.
def init_cnn(module): #@save
"""Initialize weights for CNNs."""
if type(module) == nn.Linear or type(module) == nn.Conv2d:
nn.init.xavier_uniform_(module.weight)
class LeNet(d2l.Classifier): #@save
"""The LeNet-5 model."""
def __init__(self, lr=0.1, num_classes=10):
super().__init__()
self.save_hyperparameters()
self.net = nn.Sequential(
nn.LazyConv2d(6, kernel_size=5, padding=2), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.LazyConv2d(16, kernel_size=5), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.LazyLinear(120), nn.Sigmoid(),
nn.LazyLinear(84), nn.Sigmoid(),
nn.LazyLinear(num_classes))
- init_cnn(module) 함수는 CNN 모델의 가중치를 초기화하는 역할을 합니다.
- 함수 내부에서 nn.Linear 또는 nn.Conv2d 모듈의 가중치에 Xavier 초기화(Xavier initialization)를 적용합니다.
- LeNet 클래스는 d2l.Classifier 클래스를 상속받아서 정의된 LeNet-5 모델입니다.
- lr=0.1과 num_classes=10은 초기화 시 인자로 받는 학습률과 클래스 수를 나타냅니다.
- self.save_hyperparameters()는 하이퍼파라미터를 저장하는 역할을 합니다.
- self.net은 LeNet-5 모델의 구조를 정의하는 nn.Sequential 객체입니다.
- nn.Sequential 객체는 여러 개의 순차적인 레이어를 포함하는 신경망을 정의할 수 있습니다.
- 각 레이어는 nn.LazyConv2d, nn.Sigmoid, nn.AvgPool2d, nn.Flatten, nn.LazyLinear 등으로 구성됩니다.
- nn.LazyConv2d는 2D 컨볼루션 레이어를 나타내며, kernel_size와 padding 등의 인자를 설정합니다.
- nn.Sigmoid는 시그모이드 활성화 함수를 적용하는 레이어입니다.
- nn.AvgPool2d는 2D 평균 풀링 레이어를 나타내며, kernel_size와 stride 등의 인자를 설정합니다.
- nn.Flatten은 입력 데이터를 1차원으로 펼치는 레이어입니다.
- nn.LazyLinear은 선형 레이어를 나타내며, num_classes를 포함한 출력 차원을 설정합니다.
- num_classes는 분류할 클래스의 개수를 나타냅니다.
We take some liberty in the reproduction of LeNet insofar as we replace the Gaussian activation layer by a softmax layer. This greatly simplifies the implementation, not the least due to the fact that the Gaussian decoder is rarely used nowadays. Other than that, this network matches the original LeNet-5 architecture.
우리는 가우시안 활성화 레이어를 소프트맥스 레이어로 대체하는 한 LeNet의 재생산에서 약간의 자유를 얻습니다. 이것은 가우시안 디코더가 요즘 거의 사용되지 않는다는 사실 때문에 구현을 크게 단순화합니다. 그 외에는 이 네트워크가 원래 LeNet-5 아키텍처와 일치합니다.
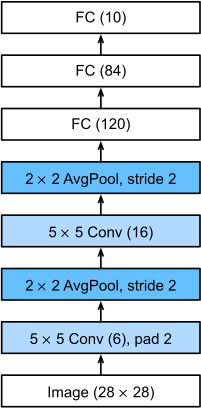
Let’s see what happens inside the network. By passing a single-channel (black and white) 28×28 image through the network and printing the output shape at each layer, we can inspect the model to make sure that its operations line up with what we expect from Fig. 7.6.2.
네트워크 내부에서 무슨 일이 일어나는지 봅시다. 네트워크를 통해 단일 채널(흑백) 28×28 이미지를 전달하고 각 레이어에서 출력 모양을 인쇄함으로써 모델을 검사하여 작업이 그림 7.6.2에서 예상한 것과 일치하는지 확인할 수 있습니다. .
@d2l.add_to_class(d2l.Classifier) #@save
def layer_summary(self, X_shape):
X = torch.randn(*X_shape)
for layer in self.net:
X = layer(X)
print(layer.__class__.__name__, 'output shape:\t', X.shape)
model = LeNet()
model.layer_summary((1, 1, 28, 28))
- layer_summary(self, X_shape) 함수는 모델의 레이어들에 대한 요약 정보를 출력하는 역할을 합니다.
- @d2l.add_to_class(d2l.Classifier)는 layer_summary 함수를 d2l.Classifier 클래스에 추가하는 데코레이터입니다.
- X_shape은 입력 데이터의 형상을 나타내는 튜플입니다.
- X는 X_shape 형상에 맞게 생성된 정규분포를 따르는 무작위 데이터입니다.
- for 루프를 통해 self.net에 포함된 각 레이어에 입력 데이터 X를 전달하고 출력 데이터의 형상을 출력합니다.
- layer.__class__.__name__은 레이어의 클래스 이름을 가져옵니다.
- X.shape는 출력 데이터의 형상을 나타냅니다.
- model = LeNet()은 LeNet 모델의 인스턴스를 생성합니다.
- model.layer_summary((1, 1, 28, 28))은 생성된 모델의 layer_summary 함수를 호출하여 입력 데이터의 형상을 전달합니다. 이를 통해 레이어별 출력 형상을 확인할 수 있습니다.

Note that the height and width of the representation at each layer throughout the convolutional block is reduced (compared with the previous layer). The first convolutional layer uses 2 pixels of padding to compensate for the reduction in height and width that would otherwise result from using a 5×5 kernel. As an aside, the image size of 28×28 pixels in the original MNIST OCR dataset is a result of trimming 2 pixel rows (and columns) from the original scans that measured 32×32 pixels. This was done primarily to save space (a 30% reduction) at a time when Megabytes mattered.
컨볼루션 블록 전체에 걸쳐 각 레이어에서 표현의 높이와 너비가 줄어듭니다(이전 레이어와 비교하여). 첫 번째 컨볼루션 레이어는 5×5 커널을 사용할 때 발생할 수 있는 높이와 너비의 감소를 보상하기 위해 2픽셀의 패딩을 사용합니다. 여담으로 원본 MNIST OCR 데이터 세트의 이미지 크기 28×28픽셀은 32×32픽셀로 측정된 원본 스캔에서 2픽셀 행(및 열)을 트리밍한 결과입니다. 이것은 주로 메가바이트가 중요할 때 공간을 절약(30% 감소)하기 위해 수행되었습니다.
In contrast, the second convolutional layer forgoes padding, and thus the height and width are both reduced by 4 pixels. As we go up the stack of layers, the number of channels increases layer-over-layer from 1 in the input to 6 after the first convolutional layer and 16 after the second convolutional layer. However, each pooling layer halves the height and width. Finally, each fully connected layer reduces dimensionality, finally emitting an output whose dimension matches the number of classes.
대조적으로 두 번째 컨볼루션 레이어는 패딩을 생략하므로 높이와 너비가 모두 4픽셀씩 줄어듭니다. 레이어 스택 위로 올라갈수록 채널 수는 입력의 1개에서 첫 번째 컨볼루션 레이어 이후 6개, 두 번째 컨볼루션 레이어 이후 16개로 레이어별로 증가합니다. 그러나 각 풀링 레이어는 높이와 너비를 절반으로 줄입니다. 마지막으로, 완전히 연결된 각 레이어는 차원을 줄이고 차원이 클래스 수와 일치하는 출력을 내보냅니다.
7.6.2. Training
Now that we have implemented the model, let’s run an experiment to see how the LeNet-5 model fares on Fashion-MNIST.
이제 모델을 구현했으므로 LeNet-5 모델이 Fashion-MNIST에서 어떻게 작동하는지 실험을 실행해 보겠습니다.
While CNNs have fewer parameters, they can still be more expensive to compute than similarly deep MLPs because each parameter participates in many more multiplications. If you have access to a GPU, this might be a good time to put it into action to speed up training. Note that the d2l.Trainer class takes care of all details. By default, it initializes the model parameters on the available devices. Just as with MLPs, our loss function is cross-entropy, and we minimize it via minibatch stochastic gradient descent.
CNN은 매개변수가 적지만 각 매개변수가 더 많은 곱셈에 참여하기 때문에 유사한 심층 MLP보다 계산 비용이 여전히 더 비쌉니다. GPU에 액세스할 수 있는 경우 훈련 속도를 높이기 위해 GPU를 실행하기에 좋은 시기일 수 있습니다. d2l.Trainer 클래스가 모든 세부 사항을 처리합니다. 기본적으로 사용 가능한 장치에서 모델 매개변수를 초기화합니다. MLP와 마찬가지로 손실 함수는 교차 엔트로피이며 미니배치 확률적 경사 하강을 통해 최소화합니다.
trainer = d2l.Trainer(max_epochs=10, num_gpus=1)
data = d2l.FashionMNIST(batch_size=128)
model = LeNet(lr=0.1)
model.apply_init([next(iter(data.get_dataloader(True)))[0]], init_cnn)
trainer.fit(model, data)- trainer = d2l.Trainer(max_epochs=10, num_gpus=1)는 훈련을 수행하기 위한 Trainer 객체를 생성합니다. 최대 에포크 수는 10이며, GPU를 1개 사용합니다.
- data = d2l.FashionMNIST(batch_size=128)는 FashionMNIST 데이터셋을 로드하는데 사용되는 FashionMNIST 객체를 생성합니다. 배치 크기는 128입니다.
- model = LeNet(lr=0.1)는 LeNet 모델의 인스턴스를 생성합니다. 학습률은 0.1로 설정됩니다.
- model.apply_init([next(iter(data.get_dataloader(True)))[0]], init_cnn)은 모델의 가중치를 초기화하는 데 사용됩니다. FashionMNIST 데이터셋에서 첫 번째 미니배치의 입력 데이터를 가져와 가중치 초기화 함수 init_cnn을 적용합니다.
- trainer.fit(model, data)는 모델을 훈련 데이터셋에 대해 학습시키는 역할을 합니다. 훈련 데이터셋은 data로 전달되고, 모델은 model로 전달됩니다.

7.6.3. Summary
In this chapter we made significant progress. We moved from the MLPs of the 1980s to the CNNs of the 1990s and early 2000s. The architectures proposed, e.g., in the form of LeNet-5 remain meaningful, even to this day. It is worth comparing the error rates on Fashion-MNIST achievable with LeNet-5 both to the very best possible with MLPs (Section 5.2) and those with significantly more advanced architectures such as ResNet (Section 8.6). LeNet is much more similar to the latter than to the former. One of the primary differences, as we shall see, is that greater amounts of computation afforded significantly more complex architectures.
이 장에서 우리는 상당한 진전을 이루었습니다. 우리는 1980년대의 MLP에서 1990년대와 2000년대 초반의 CNN으로 이동했습니다. 예를 들어 LeNet-5의 형태로 제안된 아키텍처는 오늘날까지도 의미가 있습니다. LeNet-5로 달성할 수 있는 Fashion-MNIST의 오류율을 MLP(섹션 5.2)와 ResNet(섹션 8.6)과 같은 훨씬 더 고급 아키텍처를 사용하는 오류율과 비교할 가치가 있습니다. LeNet은 전자보다 후자에 훨씬 더 유사합니다. 주요 차이점 중 하나는 훨씬 더 복잡한 아키텍처를 제공하는 더 많은 계산량입니다.
A second difference is the relative ease with which we were able to implement LeNet. What used to be an engineering challenge worth months of C++ and assembly code, engineering to improve SN, an early Lisp based deep learning tool (Bottou and Le Cun, 1988), and finally experimentation with models can now be accomplished in minutes. It is this incredible productivity boost that has democratized deep learning model development tremendously. In the next chapter we will follow down this rabbit to hole to see where it takes us.
두 번째 차이점은 우리가 LeNet을 구현할 수 있었던 상대적 용이성입니다. C++ 및 어셈블리 코드, SN 개선을 위한 엔지니어링, 초기 Lisp 기반 딥 러닝 도구(Bottou and Le Cun, 1988), 마지막으로 모델을 사용한 실험이 이제 몇 분 안에 완료될 수 있습니다. 딥 러닝 모델 개발을 엄청나게 민주화한 것은 이 놀라운 생산성 향상입니다. 다음 장에서 우리는 이 토끼가 우리를 어디로 데려가는지 알아보기 위해 구멍까지 따라갈 것입니다.
7.6.4. Exercises
- Let’s modernize LeNet. Implement and test the following changes:
- Replace the average pooling with max-pooling.
- Replace the softmax layer with ReLU.
- Try to change the size of the LeNet style network to improve its accuracy in addition to max-pooling and ReLU.
- Adjust the convolution window size.
- Adjust the number of output channels.
- Adjust the number of convolution layers.
- Adjust the number of fully connected layers.
- Adjust the learning rates and other training details (e.g., initialization and number of epochs.)
- Try out the improved network on the original MNIST dataset.
- Display the activations of the first and second layer of LeNet for different inputs (e.g., sweaters and coats).
- What happens to the activations when you feed significantly different images into the network (e.g., cats, cars, or even random noise)?
'Dive into Deep Learning > D2L Convolutional Neural Networks (CNN)' 카테고리의 다른 글
| D2L - 8.4. Multi-Branch Networks (GoogLeNet) (0) | 2023.07.18 |
|---|---|
| D2L - 8.3. Network in Network (NiN) (0) | 2023.07.11 |
| D2L - 8.2. Networks Using Blocks (VGG) (0) | 2023.07.10 |
| D2L - 8.1. Deep Convolutional Neural Networks (AlexNet) (0) | 2023.07.10 |
| D2L - 8. Modern Convolutional Neural Networks (0) | 2023.07.10 |
| D2L - 7.5. Pooling (1) | 2023.07.09 |
| D2L - 7.4. Multiple Input and Multiple Output Channels (0) | 2023.07.09 |
| D2L - 7.3. Padding and Stride (0) | 2023.07.09 |
| D2L - 7.2. Convolutions for Images (0) | 2023.07.09 |
| D2L - 7.1. From Fully Connected Layers to Convolutions (0) | 2023.07.09 |