개발자로서 현장에서 일하면서 새로 접하는 기술들이나 알게된 정보 등을 정리하기 위한 블로그입니다. 운 좋게 미국에서 큰 회사들의 프로젝트에서 컬설턴트로 일하고 있어서 새로운 기술들을 접할 기회가 많이 있습니다. 미국의 IT 프로젝트에서 사용되는 툴들에 대해 많은 분들과 정보를 공유하고 싶습니다.
그 중에 하나가 Recursion Function 인데요. 오늘은 이 방법을 이해해 보고 그 다음 예들을 간단히 살펴 보겠습니다.
피보나치 수에 대한 정의는 아래와 같습니다.
피보나치 수(영어:Fibonacci numbers)는 첫째 및 둘째 항이 1이며 그 뒤의 모든 항은 바로 앞 두 항의 합인수열이다.
공식은 F(n) = F(n-1) + F(n-2) 입니다.
코드는 아래와 같습니다.
class Solution { public int fib(int n) { if(n<=1) return n; return fib(n-1) + fib(n-2); } }
여기서 Recursion Function이 사용 됩니다.
return fib(n-1) + fib(n-2) 는 아래와 같이 작동합니다.
자 그럼 이 Recursion Function을 이용한 코드를 보겠습니다.
class Solution { public int fib(int n) { if(n<=1) return n; return fib(n-1) + fib(n-2); } }
위 그림을 이해했다면 이 코드는 쉽게 이해 할 수 있을 겁니다.
이제 다른 방법을 알아 볼까요?
class Solution { public int fib(int N) { if (N <= 1) { return N; }
int[] cache = new int[N + 1]; cache[1] = 1; for (int i = 2; i <= N; i++) { cache[i] = cache[i - 1] + cache[i - 2]; }
return cache[N]; } }
이것은 피보나치 식을 재귀 함수를 이용하지 않고 for 루프를 이용해서 코드를 작성한 겁니다.
방법은 같습니다.
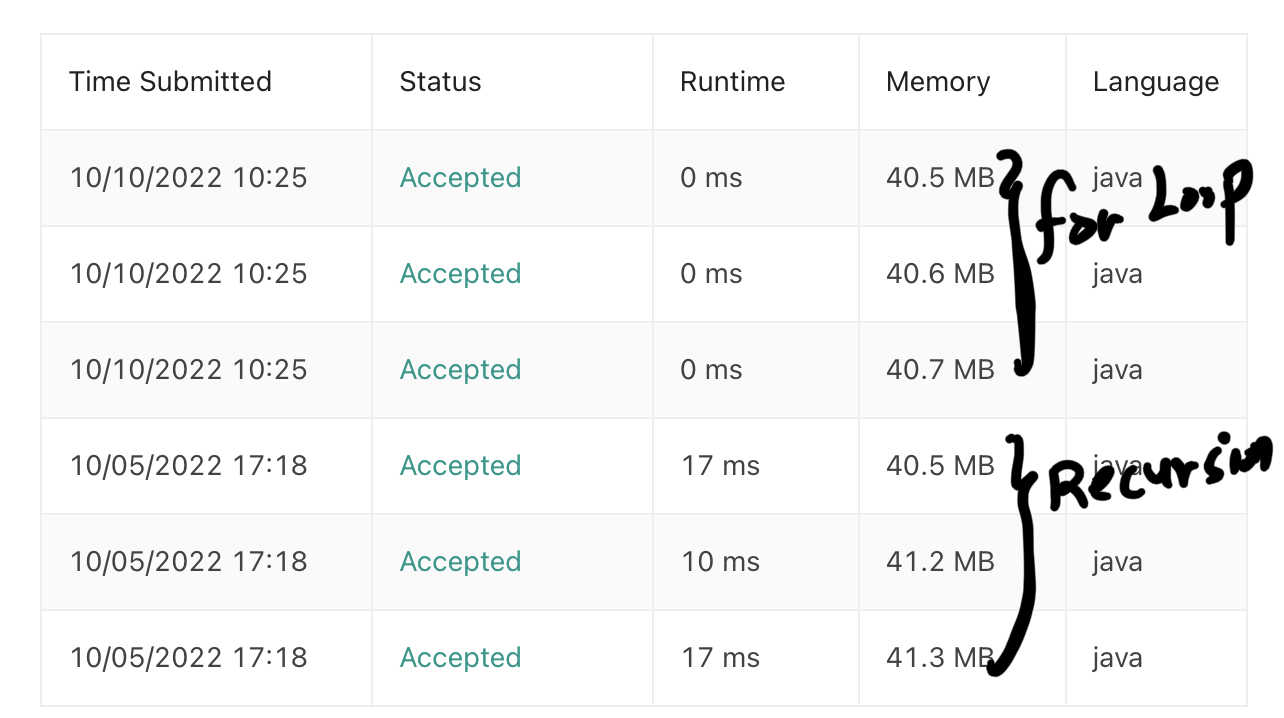
Runtime은 for loop가 조금 더 빠른 것 같습니다.
그 이외에 아래와 같은 방법들이 있습니다.
class Solution { // Creating a hash map with 0 -> 0 and 1 -> 1 pairs private Map<Integer, Integer> cache = new HashMap<>(Map.of(0, 0, 1, 1));
public int fib(int N) { if (cache.containsKey(N)) { return cache.get(N); } cache.put(N, fib(N - 1) + fib(N - 2)); return cache.get(N); } }
-----------
class Solution { public int fib(int N) { if (N <= 1) { return N; }
int current = 0; int prev1 = 1; int prev2 = 0;
for (int i = 2; i <= N; i++) { current = prev1 + prev2; prev2 = prev1; prev1 = current; } return current; } }
--------------------
class Solution { int fib(int N) { if (N <= 1) { return N; } int[][] A = new int[][]{{1, 1}, {1, 0}}; matrixPower(A, N - 1);
return A[0][0]; }
void matrixPower(int[][] A, int N) { if (N <= 1) { return; } matrixPower(A, N / 2); multiply(A, A);
int[][] B = new int[][]{{1, 1}, {1, 0}}; if (N % 2 != 0) { multiply(A, B); } }
void multiply(int[][] A, int[][] B) { int x = A[0][0] * B[0][0] + A[0][1] * B[1][0]; int y = A[0][0] * B[0][1] + A[0][1] * B[1][1]; int z = A[1][0] * B[0][0] + A[1][1] * B[1][0]; int w = A[1][0] * B[0][1] + A[1][1] * B[1][1];
public class Solution { public int climbStairs(int n) { int memo[] = new int[n + 1]; return climb_Stairs(0, n, memo); } public int climb_Stairs(int i, int n, int memo[]) { if (i > n) { return 0; } if (i == n) { return 1; } if (memo[i] > 0) { return memo[i]; } memo[i] = climb_Stairs(i + 1, n, memo) + climb_Stairs(i + 2, n, memo); return memo[i]; } }
이런 방법도 있고요.
public class Solution { public int climbStairs(int n) { if (n == 1) { return 1; } int[] dp = new int[n + 1]; dp[1] = 1; dp[2] = 2; for (int i = 3; i <= n; i++) { dp[i] = dp[i - 1] + dp[i - 2]; } return dp[n]; } }
Runtime은 모두 비슷하고 바로 위 코드가 메모리를 조금 덜 차지하는 것 같습니다.
그 다음에 제가 이해하기 힘든 코드는 아래 두가지가 있습니다.
수학 공식을 사용하던데...
public class Solution { public int climbStairs(int n) { int[][] q = {{1, 1}, {1, 0}}; int[][] res = pow(q, n); return res[0][0]; } public int[][] pow(int[][] a, int n) { int[][] ret = {{1, 0}, {0, 1}}; while (n > 0) { if ((n & 1) == 1) { ret = multiply(ret, a); } n >>= 1; a = multiply(a, a); } return ret; } public int[][] multiply(int[][] a, int[][] b) { int[][] c = new int[2][2]; for (int i = 0; i < 2; i++) { for (int j = 0; j < 2; j++) { c[i][j] = a[i][0] * b[0][j] + a[i][1] * b[1][j]; } } return c; } }
그리고
public class Solution { public int climbStairs(int n) { double sqrt5 = Math.sqrt(5); double phi = (1 + sqrt5) / 2; double psi = (1 - sqrt5) / 2; return (int) ((Math.pow(phi, n + 1) - Math.pow(psi, n + 1)) / sqrt5); }
어쩄든 제가 만든 첫번째 스크립트하고 Runtime하고 Memory 결과 값은 비슷하더라구요.
class Solution { public int singleNumber(int[] nums) { HashMap<Integer, Integer> hash_table = new HashMap<>();
for (int i : nums) { hash_table.put(i, hash_table.getOrDefault(i, 0) + 1); } for (int i : nums) { if (hash_table.get(i) == 1) { return i; } } return 0; } }
입력된 배열의 크기만큼 for문을 돌리면서 각 값들을 key 로 put 합니다.
그리고 value 부분에는 getOrDefault를 사용해서 key 값이 없으면 0+1 즉 1이 할당이 되고 있으면 그 값에 +1을 해 줍니다.
이렇게 되면 중복된 값은 value부분에 2가 될 것이고 중복되지 않은 값은 value가 1 인 채로 끝까지 남아 있을 겁니다.
여기서 HashMap의 특징을 알아야 하는데요.
해쉬맵에서 키 값의 중복은 허용되지 않습니다.
그러니까 첫번째 for문에서 기존에 key가 존재 하면 그 key에 value를 덮어 쓰게 됩니다.
그러니까 {2,1,2,1,4} 를 위 코드로 돌리면 HashMap은 이렇게 될 겁니다.
2 : 2
1 : 2
4 : 1
이런 상태에서 두번째 for 문을 돌려서 value가 1인 값을 찾으면 그 값은 4가 됩니다.
이렇게 되면 첫번째 방법보다 runtime 줄어드는 효과가 있습니다. 왜냐하면 첫번째 방법은 for문 안의 contains()에서 아이템을 모두 살펴봐야 하기 때문에 time complexity가 O(n의 제곱)인데 반해서 두번째 접근 법은 O(n)입니다.
위 3줄의 Runtime이 아래 3줄보다 훨씬 효율적인 것을 볼 수 있습니다.
세번째는 수학을 이용하는 방법 입니다.
코드는 아래와 같습니다.
class Solution { public int singleNumber(int[] nums) { int sumOfSet = 0, sumOfNums = 0; Set<Integer> set = new HashSet();
for (int num : nums) { if (!set.contains(num)) { set.add(num); sumOfSet += num; } sumOfNums += num; } return 2 * sumOfSet - sumOfNums; } }
위 수학식 중 (a+b+c)가 sumOfSet이 되고 (a+a+b+b+c) 가 sumOfNums가 됩니다.
For문 안의 첫번째 if 문에서 sumOfSet이 계산됩니다.
그리고 if문 밖에서 sumOfNums가 계산됩니다.
그 값을 이용해서 위 수학식의 계산을 그냥 return 해 주면 됩니다.
마지막 방법은 Bit Manipulation입니다.
저도 잘 모르겠는데.... 그냥 이렇게 있구나... 하고 넘어가야 할 것 같습니다.
코드는 아래와 같습니다.
class Solution { public int singleNumber(int[] nums) { int a = 0; for (int i : nums) { a ^= i; } return a; } }
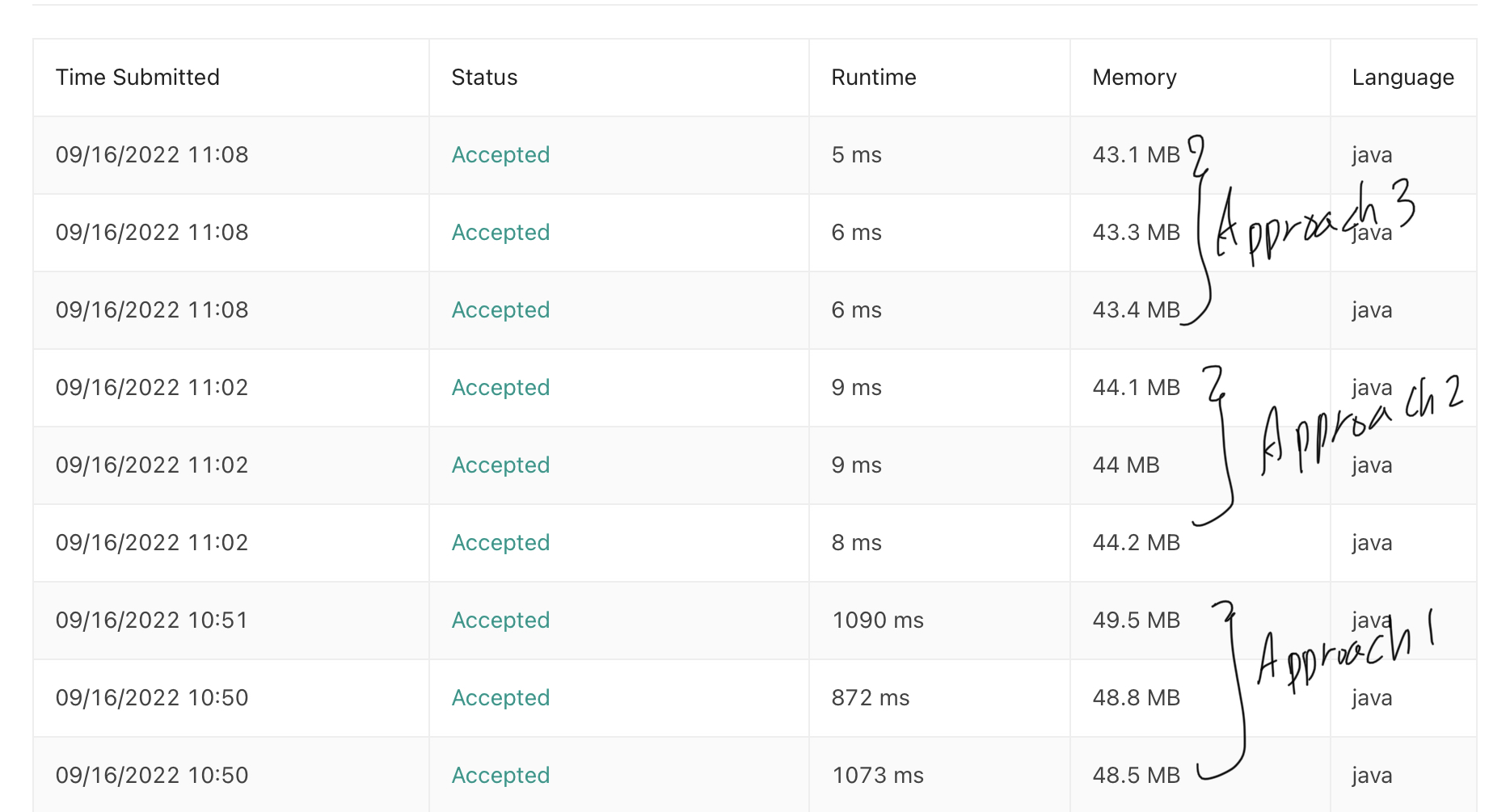
실행결과를 보면 위로 갈수록 Runtime이 줄어 드는 것을 볼 수 있습니다.
각 Approach의 파이썬 코드는 아래와 같습니다.
Python
Approach 1
class Solution(object): def singleNumber(self, nums): """ :type nums: List[int] :rtype: int """ no_duplicate_list = [] for i in nums: if i not in no_duplicate_list: no_duplicate_list.append(i) else: no_duplicate_list.remove(i) return no_duplicate_list.pop()
Approach 2
from collections import defaultdict class Solution: def singleNumber(self, nums: List[int]) -> int: hash_table = defaultdict(int) for i in nums: hash_table[i] += 1
for i in hash_table: if hash_table[i] == 1: return i
Approach 3
class Solution(object): def singleNumber(self, nums): """ :type nums: List[int] :rtype: int """ return 2 * sum(set(nums)) - sum(nums)
Approach 4
class Solution(object): def singleNumber(self, nums): """ :type nums: List[int] :rtype: int """ a = 0 for i in nums: a ^= i return a
오늘 문제는 숫자로 된 배열을 입력값으로 받고 그 숫자들이 매일 매일의 주식 가격이라고 생각하고 가장 큰 수익을 얻는 다면 그 수익은 얼마가 될까 입니다.
7,1,5,3,6,4 가 입력값이라면
7에 1에 팔면 -6이 되겠죠.
1에 사서 6에 팔면 +5가 되구요.
1에 사서 7에 팔 수는 없죠. 내일 사서 오늘 팔 수는 없으니까요.
즉 산 날은 항상 판 날보다 앞서야 됩니다.
Example 2를 보면 만약 수익을 낼 수 있는 상황이 아니면 Output은 0가 되어야 합니다.
어짜피 사고 팔면 마이너스이니까 아예 매매를 하지 않는 상황이 최선이 되는 것이죠.
매매를 하지 않으면 수익이나 손해 없이 0이 되니까요.
그렇게 어려운 문제는 아닙니다.
이중 for 문을 만들어서 계산하면 되겠죠.
우선 바깥의 for 문은 입력 된 배열의 크기만큼 돌려주세요.
안의 for 문은 각 숫자마다 그 이후의 값들 크기 만큼 돌려 줍니다. (미래에 사서 과거에 팔 수는 없으니까요)
이렇게 돌려주면 뒤의 숫자에서 앞의 숫자를 계속 빼 주고 그 중 가장 큰 값을 구하면 가장 높은 수익이 됩니다.
코드는 아래와 같습니다.
class Solution { public int maxProfit(int[] prices) { // buy on each day // find largest difference by selling on some day in buyDay's future int largestDifference = 0;
제가 만든 코드로 돌린 것 보다 Runtime이 확실히 줄어 드네요. 메모리도 약간 줄어 들고요.
이 코드를 좀 공부 해 둬야 겠습니다.
Approach 3
다음은 입력문의 첫번째와 마지막 글자부터 비교하는 것입니다.
중간에 스페이스나 부호들은 건너 뜁니다.
그러니까 그것들을 remove하는 것을 하지 않아도 됩니다.
class Solution { public boolean isPalindrome(String s) { for (int i = 0, j = s.length() - 1; i < j; i++, j--) { while (i < j && !Character.isLetterOrDigit(s.charAt(i))) { i++; } while (i < j && !Character.isLetterOrDigit(s.charAt(j))) { j--; }
if (Character.toLowerCase(s.charAt(i)) != Character.toLowerCase(s.charAt(j))) return false; }
return true; } }
마지막 방법이 훨씬 Performance가 좋네요.
내가 생각했던 쉽게 접근 하는 방법에서 조금만 더 머리를 쓴 건데 훨씬 좋은 performances 를 보이는 군요.
첫번째 배열과 첫번째 숫자의 의미는 숫자의 개수만큼 첫번째 배열의 아이템을 사용하고 나머지는 버린다 입니다.
두번째 배열과 두번째 숫자도 마찬가지 의미 입니다.
여기에 한가지 더 조건이 있습니다.
첫번째 배열의 아이템 숫자는 입력 받은 두 숫자의 합 이라는 겁니다.
이 조건 때문에 문제가 완전히 쉬워 졌습니다.
일단 첫번째 배열에서 첫번째 숫자 와 맞는 갯수 만큼만 채우고 두번째 배열에서 나머지를 그냥 채워 넣으면 되니까요.
이 조건이 있는 이유는 배열은 그 크기를 변경하는 것이 불가능 하기 때문입니다.
크기를 변경하려면 List를 사용해야 합니다. (ArrayList, LinkedList etc.)
위에 얘기한 대로 코딩을 하면 아래와 같습니다.
참 결과 값은 정렬 되어 있어야 해서 마지막에 Arrays.sort()를 사용해야 합니다.
class Solution { public void merge(int[] nums1, int m, int[] nums2, int n) { for (int i = 0; i < n; i++) { nums1[i + m] = nums2[i]; } Arrays.sort(nums1); } }
이렇게 하면 됩니다.
그런데 여기서 Arrays.sort()는 리소스를 좀 많이 차지 합니다.
좀 더 Refactoring을 하고 싶다면 아래와 같이 하면 됩니다.
class Solution { public void merge(int[] nums1, int m, int[] nums2, int n) { // Make a copy of the first m elements of nums1. int[] nums1Copy = new int[m]; for (int i = 0; i < m; i++) { nums1Copy[i] = nums1[i]; }
// Read pointers for nums1Copy and nums2 respectively. int p1 = 0; int p2 = 0;
// Compare elements from nums1Copy and nums2 and write the smallest to nums1. for (int p = 0; p < m + n; p++) { // We also need to ensure that p1 and p2 aren't over the boundaries // of their respective arrays. if (p2 >= n || (p1 < m && nums1Copy[p1] < nums2[p2])) { nums1[p] = nums1Copy[p1++]; } else { nums1[p] = nums2[p2++]; } } } }
이 방법은 첫번째 배열의 뒷자리 부터 집어 넣는 것입니다.
첫번째 배열의 맨 마지막 숫자와 두번째 배열 맨 마지막 숫자를 비교해서 큰 숫자를 마지막에 넣는 것입니다.
하나 하나 볼까요?
처음에는 nums1[]을 nums1Copy[]라는 새 배열에 카피 합니다.
그리고 인지적 p1과 p2를 생성합니다.
이제 루프를 돌릴 텐데요.
m + n 만큼 돌립니다. nums1[]의 크기가 m+n이니까 첫번째 배열의 크기만큼 돌려도 됩니다.
If 문을 보면 p2가 n보다 크거나 같거나
p1이 m보다 작고 nums1Copy[p1] 이 nums[p2] 보다 작으면 실행합니다.
실행문 은 nums1[p] 에 nums1Copy[p1] 을 넣고 p1에 1을 더합니다.
즉 첫번째 배열의 첫번째 값이 두번째 배열의 첫번째 값보다 작으면 nums1[p]에 작은 값을 넣습니다.
반대로 else를 보면 첫번째 배열의 첫번쨰 값이 크면 두번째 배열의 첫번째 값 즉 더 작은 값을 넣습니다.
그 다음은 두번째 아이템으로 가서 똑 같은 일을 반복 합니다.
이렇게 되면 두 배열에서 작은 숫자 만큼 하나하나 채워 나가게 되므로 sorting을 할 필요가 없습니다.
반대로 배열의 뒤에서 부터 집어 넣을 수도 있습니다.
class Solution { public void merge(int[] nums1, int m, int[] nums2, int n) { int r1 = m-1; int r2 = n-1;