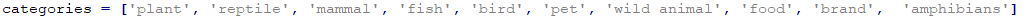개발자로서 현장에서 일하면서 새로 접하는 기술들이나 알게된 정보 등을 정리하기 위한 블로그입니다. 운 좋게 미국에서 큰 회사들의 프로젝트에서 컬설턴트로 일하고 있어서 새로운 기술들을 접할 기회가 많이 있습니다. 미국의 IT 프로젝트에서 사용되는 툴들에 대해 많은 분들과 정보를 공유하고 싶습니다.
Error: No API key provided. You can set your API key in code using 'openai.api_key = <API-KEY>', or you can set the environment variable OPENAI_API_KEY=<API-KEY>). If your API key is stored in a file, you can point the openai module at it with 'openai.api_key_path = <PATH>'. You can generate API keys in the OpenAI web interface. See https://onboard.openai.com for details, or email support@openai.com if you have any questions.
오류: API 키가 제공되지 않았습니다. 'openai.api_key = <API-KEY>'를 사용하여 코드에서 API 키를 설정하거나 환경 변수 OPENAI_API_KEY=<API-KEY>)를 설정할 수 있습니다. API 키가 파일에 저장되어 있는 경우 'openai.api_key_path = <PATH>'로 openai 모듈을 가리킬 수 있습니다. OpenAI 웹 인터페이스에서 API 키를 생성할 수 있습니다. 자세한 내용은 https://onboard.openai.com을 참조하거나 질문이 있는 경우 support@openai.com으로 이메일을 보내십시오.
해결 방법이 몇가지 나오는데 저 같은 경우는 환경변수를 세팅 해서 해결 했습니다.
System Properties에서 Environment Variables 버튼을 클릭합니다.
그 다음 밑에 있는 패널인 System variables에서 New 버튼을 클릭합니다.
이렇게 환경 변수에 OPENAI_API_KEY 를 세팅 한 후 모두 OK 버튼을 눌러서 닫습니다.
이렇게 하면 OpenAI CLI 를 사용할 수 있게 됩니다.
사용하기 전에 기존에 실행중이던 JupyterNotebook 이나 JupyterLab local server 는 shutdown 하시고 윈도우즈 Command Prompt 창도 닫습니다.
그리고 새로운 윈도우즈 명령창 (Command Prompt) 에서 Jupyter 를 실행하신 다음에 사용하시면 됩니다.
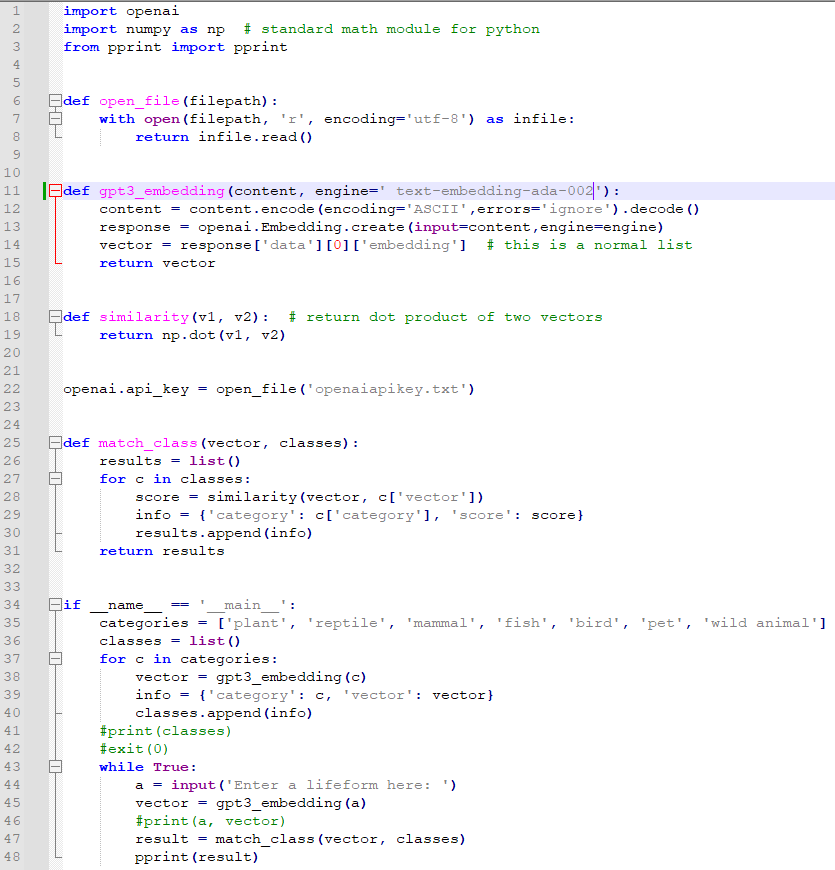
카테고리는 이렇게 7개를 정했습니다. 사용자가 입력한 값이 이 중 어느것에 가장 가까운지 알아 볼 겁니다.
여기에는 다른 값들을 추가해도 됩니다.
예를 들어 food 나 brand 뭐 이런것을 추가해도 될 겁니다.
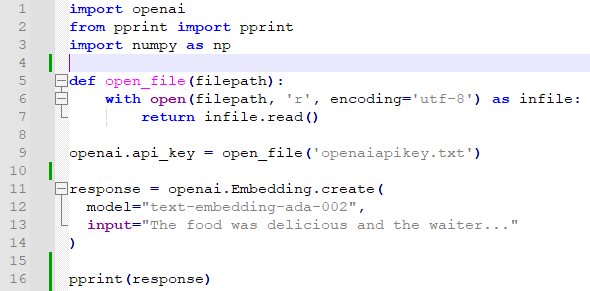
그 다음은 classes라는 list()를 생성했습니다.
그리고 나서 for 루프가 나오는데요. 이 for 루프는 categories에 있는 인수들 만큼 루프를 돌립니다.
첫번째로 gpt3_embedding(c) 에 각 인수를 전달해서 그 값을 vector에 담습니다.
그 다음 info 에서는 이를 category 별로 그 vector 값이 담기게 합니다.
그리고 아까 만들었든 classes라는 리스트에 이 값을 담습니다.
이러면 categories의 각 인수들 마다 gpt 3 에서 받은 벡터값이 있게 됩니다.
이 벡터값을 이제 사용하게 됩니다.
43번째 줄을 보면 while 무한 루프를 만들었습니다.
사용자로부터 계속 입력값을 받기 위함이죠.
44번째 줄은 파이썬의 input() 메소드를 사용해서 사용자로부터 입력 받은 값을 a 라는 변수에 넣는 겁니다.
이 사용자가 입력한 값의 벡터값을 gpt3-embedding() 함수를 통해서 받습니다.
이러면 우리는 입력한 값의 벡터값과 아까 설정해 두었던 categories에 있는 각 인수들의 벡터값을 갖고 있습니다.
그러면 이제 입력한 값이 categories의 각 인수들과 얼마나 유사한지 알 수 있습니다.
47번째 줄에서는 match_class() 함수로 이 두 값을 보내서 각 카테고리별로 유사성 점수가 어떤지 정리한 값을 받습니다.
그 값은 result에 담기게 되고 pprint()를 이용해서 그 값을 이쁘게 출력을 하게 됩니다.
이걸 실행해 봤습니다.
첫번째로 frog 개구리는 새일 가능성이 가장 높고 그 다음은 물고기일 가능성이 높다고 나오네요.
그 다음 파충류일 가능성이 세번째로 높습니다.
양서류라는 보기가 없어서 그럴까요?
그 다음 sockeye는 연어의 종류인데요. 결과는 물고기일 확률이 제일 높게 나옵니다. 그 다음은 새, 그리고 음식 뭐 이런 순으로 나가네요.
그 다음은 개구리를 대문자 F를 사용해서 입력했습니다.
그러면 파충류일 가능성이 제일 높다고 나오네요.
다음 호랑이는 야생동물일 가능성이 가장 높게 나오고 그 다음은 포유류와 유사성이 높다고 나옵니다.
국수를 입력했을 때는 역시 음식이 가장 유사하고 그 다음은 물고기, 식물 뭐 이런 순으로 나옵니다.
구찌를 입력했을 때는 브랜드와 가장 유사하고 그 다음은 음식, 그 다음은 새 이렇게 나옵니다.
아까 개구리가 약간 이상하게 나와서... 보기에 양서류 (amphibians)를 추가 했습니다.
그 결과는 Frog 일 경우 양서류와 가장 유사하고 그 다음이 파충류로 나옵니다.
frog 일 경우에는 새일 가능성이 가장 높고 그 다음이 물고기 - 파충류 - 양서류 이런 순서네요.
일단 답은 100% 만족스럽지 않지만 Openai GPT 3 의 Embedding 기능에 대해서 어느 정도 감이 잡혔습니다.
참고로 이 임베딩은 아래와 같은 경우에 사용될 수 있습니다.
Search(where results are ranked by relevance to a query string)
Clustering(where text strings are grouped by similarity)
Recommendations(where items with related text strings are recommended)
Anomaly detection(where outliers with little relatedness are identified)
Diversity measurement(where similarity distributions are analyzed)
Classification(where text strings are classified by their most similar label)
전체 소스 코드는 아래에 있습니다.
import openai import numpy as np # standard math module for python from pprint import pprint
def open_file(filepath): with open(filepath, 'r', encoding='utf-8') as infile: return infile.read()
def gpt3_embedding(content, model='text-embedding-ada-002'): content = content.encode(encoding='ASCII',errors='ignore').decode() response = openai.Embedding.create(input=content,model=model) vector = response['data'][0]['embedding'] # this is a normal list return vector
def similarity(v1, v2): # return dot product of two vectors return np.dot(v1, v2)
openai.api_key = open_file('openaiapikey.txt')
def match_class(vector, classes): results = list() for c in classes: score = similarity(vector, c['vector']) info = {'category': c['category'], 'score': score} results.append(info) return results
if __name__ == '__main__': categories = ['plant', 'reptile', 'mammal', 'fish', 'bird', 'pet', 'wild animal', 'food', 'brand', 'amphibians'] classes = list() for c in categories: vector = gpt3_embedding(c) info = {'category': c, 'vector': vector} classes.append(info) #print(classes) #exit(0) while True: a = input('Enter a lifeform here: ') vector = gpt3_embedding(a) #print(a, vector) result = match_class(vector, classes) pprint(result)
OpenAI를 사용하기 위해서는 내가 Open AI로 부터 받은 API KEY를 제공해서 인증을 받아야 합니다. 일정의 비밀번호이죠.
Open AI API는 유료입니다.
지난 글에서 간단한 질문 하나 하는데 1원정도가 청구 되는 걸 보았습니다.
유료이기 때문에 나의 API KEY를 사용해서 인증을 받고 그 다음에 사용하는 만큼 금액이 청구 됩니다.
당연히 이 API KEY를 보내지 않으면 OpenAI API를 사용할 수 없습니다.
이 API KEY를 보내는 방법은 8번째 줄에 있습니다.
openai.api_key = "My API KEY"
그런데 여기에 키를 하드 코딩 하면 보안상 문제가 될 수 있고 또한 이 키가 변경이 되었을 때 일일이 모든 파일에 있는 키 정보를 업데이트 해야 합니다. 관리상의 문제가 있죠.
그래서 보통 이런 경우는 별도의 파일을 만들어서 관리를 하고 파이썬 파일 안에서는 이 파일을 열고 그 내용을 읽어서 사용합니다.
이렇게 파일을 열고 그 내용을 읽는 부분을 함수로 만든 부분이 3~5째 줄에 있는 내용입니다.
def open_file(filepath) : with open(filepath, 'r', encoding='utf-8') as infile : return infile.read()
파이썬에서 함수를 만들려면 def 로 시작하면 됩니다. 그 다음은 함수 이름이 오고 그 다음 괄호 안에 파라미터들을 넣습니다.파라미터가 여러개 있는 경우 쉼표 , 로 구분합니다. 그리고 마지막엔 : 로 끝납니다.
그 다음 줄은 함수의 내용입니다.
파이썬에서 파일을 열고 읽는 방법은 아래와 같습니다.open("파일 이름", r,)두번째 파라미터인 r은 이 파일을 읽겠다는 겁니다. w 는 파일에 내용을 쓸 때 사용하고 a는 파일 내용 마지막에 새로운 내용을 추가할 때 사용할 수 있습니다.일반적으로 프로그래밍에서는 파일을 열었으면 마지막에 더 이상 사용하지 않을 때 이 파일을 close()해주어야 합니다. file_data = open("file.txt")print(file_data.readline(), end="")file_data.close()
이렇게 해야 되는데요. with를 사용해면 이 close() 부분을 자동으로 해 줍니다.아래 두 줄은 위의 세 줄과 똑 같은 겁니다.
with open("file.txt) as file_data:print(file_data.readline(), end="")
Close()는 with 문을 나올 때 이루어 집니다.
참고로 파이썬에서는 들여쓰기로 영역을 지정합니다.자바에서는 함수 (메소드)를 선언 할 때 {}로 지정하는 것과 차이가 있습니다.
그러므로 파이썬에서는 들여쓰기를 할 때 주의 해야 합니다.If, for, class, def 등을 사용할 때 그 줄 끝에 : 가 나오게 되는데 그 다음줄은 반드시 들여쓰기를 해야 합니다.그리고 블럭 내의 들여쓰기 칸 수는 같습니다.
위반시에는 indentationError: unexpected indent 라는 에러를 출력합니다.
이제 위의 코드를 해석할 수 있는 사전 지식은 다 갖추었습니다.
open_file()이라는 함수를 만든다는 것이 첫째줄에서 이야기 하는 겁니다. 파라미터는 filepath 입니다.
다음에 칸을 들여써서 with open() 을 사용해서 파일을 엽니다.
열 파일은 filepath입니다. 나중에 이 함수를 호출 할 때 제공해 주어야 합니다.
r은 이 파일을 읽겠다는 의미이고 세번째 파라미터는 그 파일의 인코딩 형식입니다. Txt 파일은 Ute-8이라고 선언해 주면 됩니다.
세번째 파라미터는 생략해도 작동을 할 겁니다. 보다 정확하게 하기 위해 선언 해 주셔도 됩니다.
as infile 은 변수 이름이 infile 이라는 겁니다.
파일을 열었으니까 그 내용이 infile에 저장 돼 있는 겁니다.
그 다음은 infile의 내용을 read()를 사용해서 가져오고 그 내용을 return 하는 겁니다.
이로서 open_file() 함수는 다 이해 했습니다.
이 함수를 사용하는 부분이 바로 8번째 줄입니다.
openai.api_key=open_file('openaiapikey.txt')
openai.api_key 는 OpenAI에서 정한 규칙입니다. API 키를 제공하기 위해서는 이 변수에 API 키 정보를 담으면 됩니다.
= 이후에 내용이 아까 만들었던 함수를 호출하는 부분입니다.
파라미터는 openaiapikey.txt 입니다. 따로 폴더 정보가 없으면 현재 폴더에서 해당 파일을 찾아서 열게 됩니다.이 텍스트 파일은 미리 만들어서 그 안에 API 키 정보를 넣어 두어야 합니다.
자 이러면 OpenAI 에 내 API 키를 제공했고 이 키가 유효하다면 지금부터 OpenAI API 를 사용할 수 있습니다.
10번째 줄은 또 다른 함수를 선언 한 것입니다.
gpt3_completion() 이란 함수를 선언했고 파라미터는 8개나 되네요.이 파라미터들은 함수 안에서 사용하게 될 겁니다.
이 줄은 :로 끝났고 그 아래서 부터는 들여쓰기를 해서 이 함수의 영역을 나타냅니다.
이 함수는 OpenAI 의 Completion.create() API 를 사용하기 위해 만드는 겁니다.
우선 Completion.create()에 대해 알아야 합니다.
이것은 제 블로그의 Open AI > API REFERENCE > Completions - openai.Completion.create() 를 보시면 자세한 사항을 볼 수 있습니다.