

OpenAI 에서 제공하는 서비스에는 아래처럼 5가지로 분류할 수 있습니다.
Text completion
Code completion
Image generation
Fine-tuning
Embeddings
이 중 챗봇은 맨 처음의 Text completion 서비스를 사용했습니다.
오늘은 이 중 Embeddings에 대해 알아 보겠습니다.
좀 어려운 부분입니다.
OpenAI의 Embeddings 의 개념에 대해 알아보려면 여기를 참조하세요.
https://coronasdk.tistory.com/1222
Guides - Embeddings
https://beta.openai.com/docs/guides/embeddings/what-are-embeddings OpenAI API An API for accessing new AI models developed by OpenAI beta.openai.com Embeddings What are embeddings? OpenAI’s text embeddings measure the relatedness of text strings. Embeddi
coronasdk.tistory.com
Embeddings관련 openai API를 알아보려면 여기를 참조하세요.
https://coronasdk.tistory.com/1237
Embeddings - openai.Embedding.create()
https://beta.openai.com/docs/api-reference/embeddings Embeddings Get a vector representation of a given input that can be easily consumed by machine learning models and algorithms. 기계 학습 모델 및 알고리즘에서 쉽게 사용할 수 있는 주
coronasdk.tistory.com
그리고 이 Tensorflow.org의 자료도 참고하시면 더 깊게 이해하는데 좋습니다. (한글로도 제공됩니다.)
https://www.tensorflow.org/text/guide/word_embeddings
단어 임베딩 | Text | TensorFlow
이 페이지는 Cloud Translation API를 통해 번역되었습니다. Switch to English 단어 임베딩 컬렉션을 사용해 정리하기 내 환경설정을 기준으로 콘텐츠를 저장하고 분류하세요. 이 자습서에는 단어 임베딩
www.tensorflow.org
Embeddings는 OpenAI 의 GPT-3 가 사용자로부터 받은 파라미터가 다양한 보기에 얼마나 유사성이 있는지를 반환해 주는 서비스 입니다.
반환값은 여러개의 유사성들이 되죠. 이는 벡터 Vector 입니다.
벡터란 1 dimensional matrix를 말합니다.
embedding = vector with semantic meaning (어떤 의미가 있는 vector)
예를 들어 아래와 같은 벡터가 있습니다.
[X, Y]
여기에 의미를 부여해 보겠습니다.
X는 social power 이고 값은 max 1.0 - min -1.0 입니다.
Y는 gender이고 max 1.0 - min -1.0 입니다. 1.0 은 완전 남성이고 -1.0은 완전 여성입니다.
그러면 값이 [1.0 , 1.0] 은 황제를 나타낼 수 있겠죠. 사회적 최강자이고 남성성도 만빵인 황제요.
황제가 [1.0 , 0.5] 일 수도 있죠. 사회적 최 강자 이지만 약간 덜 남성적인 성격일 수도 있으니까요.
[-1.0, 0]인 값은 사회적 파워가 없는 사람, 자유가 박탈된 사람이 되겠죠. 감옥에 있는 사람이 되겠죠. 그리고 성별은 중성인 무엇인가가 될 것입니다.
이렇듯 제공된 벡터를 가지고 그 사람이 제공된 조건에서 어디쯤에 속할지를 가늠하는 것이 Embedding의 역할 입니다.
여기서는 2개의 dimension을 사용했습니다. 참고로 OpenAI의 모델별 output dimensions는 아래와 같습니다.

이제 기본적인 개념 정리는 여기까지 하고 OpenAI API에서 이 Embedding 기능을 사용하는 간단한 파이썬 예제를 보겠습니다.
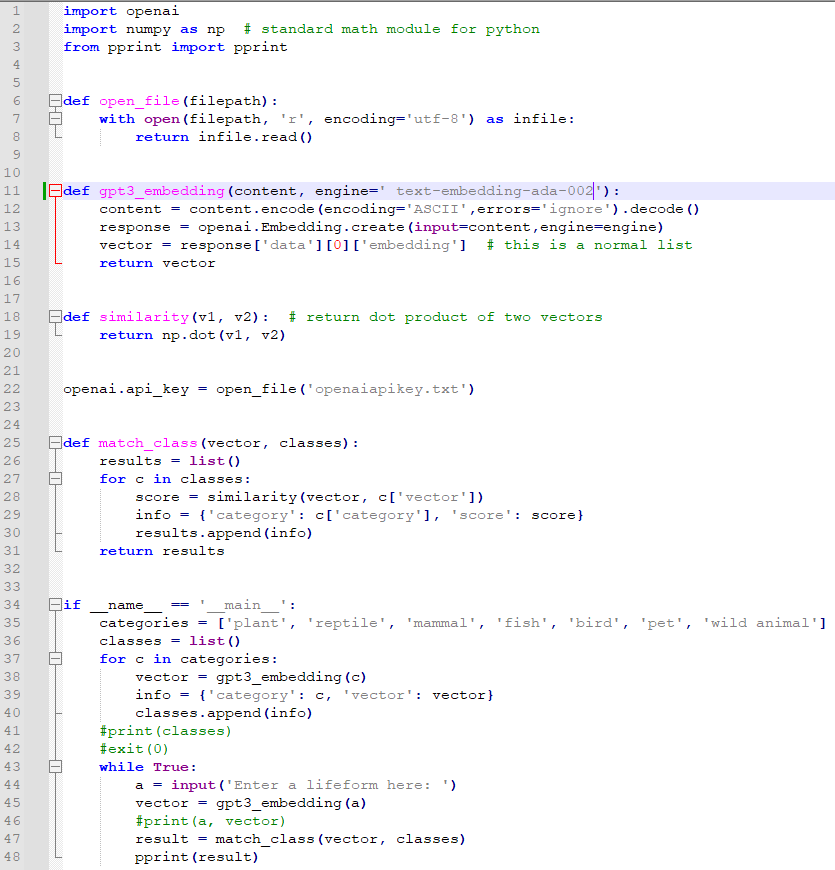
우선 2번째 줄의 numpy는 python의 기본 수학 모듈입니다. 배열을 다룰 때 많이 사용됩니다.
자세한 사항은 아래 웹사이트를 참조하세요.
NumPy
Powerful N-dimensional arrays Fast and versatile, the NumPy vectorization, indexing, and broadcasting concepts are the de-facto standards of array computing today. Numerical computing tools NumPy offers comprehensive mathematical functions, random number g
numpy.org
https://ko.wikipedia.org/wiki/NumPy
NumPy - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. NumPy("넘파이"라 읽는다)는 행렬이나 일반적으로 대규모 다차원 배열을 쉽게 처리할 수 있도록 지원하는 파이썬의 라이브러리이다. NumPy는 데이터 구조 외에도
ko.wikipedia.org
import numpy as np 는 numpy를 사용하기 위해 import 하는 것이고 이 numpy를 np 라는 이름으로 사용하겠다는 것입니다.
pprint는 pritty print의 약자로 이쁘게 프린트 해 주는 python의 메소드 입니다.
그 다음의 open_file() 함수는 반복되서 나오는 거라서 설명을 생략하겠습니다.
gpt3_embedding() 함수가 openAI의 API를 사용하기 위해 만든 함수입니다.
엔진은 text-embedding-ada-002를 사용했습니다.
2022년 12월 15일에 발표된 자료에 따르면 이 모델이 성능도 좋으며 가장 저렴한 모델이라고 소개 돼 있습니다.
https://openai.com/blog/new-and-improved-embedding-model/
New and Improved Embedding Model
We are excited to announce a new embedding model which is significantly more capable, cost effective, and simpler to use. The new model, text-embedding-ada-002, replaces five separate models for text search, text similarity, and code search, and outperform
openai.com
이 함수에서 가장 중요한 부분은 openai.Embedding.create() 입니다.
OpenAI의 embedding 기능을 사용하기 위한 API 를 호출하는 겁니다.
파라미터로는 input 과 engine 이 있습니다.
여기서 engine은 model로 사용해도 됩니다. model이 아마 최근에 바뀐 파라미터 이름인 것 같습니다.

이 함수는 content를 받아서 ASCII 형식으로 인코딩 한 값을 다시 디코드해서 content에 담습니다.
(이 부분은 따로 하지 않아도 작동 됩니다.)
이 전달받은 content를 openai.Embedding.create() 을 사용해서 OpenAI에 사용할 모델 이름과 함께 보내고 거기서 받은 값을 response 변수에 담습니다.
받은 응답 (JSON 형식) 중에 data 배열의 첫번째 항목에서 embedding 부분을 vector에 담다서 이를 리턴합니다.
그 다음 함수는 similarity인데요.
이는 두 개의 파라미터 (벡터 형식)를 받아서 numpy의 dot 메소드를 사용해서 처리한 다음에 그 값을 반환하는 겁니다.
이 메소드는 벡터의 각 element들을 곱한 값들을 더한 값을 반환합니다.
파이썬의 이 dot 메소드는 여기에서 보시면 됩니다.
https://numpy.org/doc/stable/reference/generated/numpy.dot.html
numpy.dot — NumPy v1.24 Manual
Output argument. This must have the exact kind that would be returned if it was not used. In particular, it must have the right type, must be C-contiguous, and its dtype must be the dtype that would be returned for dot(a,b). This is a performance feature.
numpy.org
그 다음 22번째 줄에서는 openai에 openaiapikey.txt 파일에 저장돼 있는 key 값을 전달하고 있습니다.
이 key 값이 valid 하면 openai api를 사용할 수 있는 권한을 가지게 됩니다.
그 다음 함수는 match_class() 함수 입니다.
이 함수는 vector와 classes라는 두 개의 파라미터를 받습니다.
아래에 보시면 알겠지만 classes 는 35번째 줄에 있는 categories 값입니다.
위에 설명했지만 openai 의 각 모델들은 수 많은 dimention을 가지고 있습니다.
이렇게 카테고리를 설정해 주지 않으면 아주 많은 리턴값이 나오게 됩니다.
그래서 이 함수를 만든건데요.
우선 반환값은 list() 로 할 겁니다.
그 다음 classes (categories) 에 있는 값들을 하나 하나 for loop를 돌면서 처리 합니다.
두 벡터값을 similarity() 함수로 보내서 np.dot 값을 받아 오는 것이죠.
그 반환된 값은 score에 저장이 되고 그 값은 아래 info 변수에서 활용 됩니다.
info에는 각 카테고리별로 similarity에서 받아온 score를 넣습니다.
그 값들을 전부 results에 넣게 되고 이 값을 반환하게 됩니다.
이제 함수에 대한 설명은 다 됐고 실제 이것이 어떻게 실행이 되는지 보겠습니다.
34번째 if 문은 여러번 설명한 파이썬 문법입니다. 이 파이썬 파일이 실행 됐을 경우 아래 내용들이 처리 됩니다.
다른 파이썬 파일에서 import 되면 아래 내용이 처리되지않을 겁니다.
categories = ['plant', 'reptile', 'mammal', 'fish', 'bird', 'pet', 'wild animal']
카테고리는 이렇게 7개를 정했습니다. 사용자가 입력한 값이 이 중 어느것에 가장 가까운지 알아 볼 겁니다.
여기에는 다른 값들을 추가해도 됩니다.
예를 들어 food 나 brand 뭐 이런것을 추가해도 될 겁니다.
그 다음은 classes라는 list()를 생성했습니다.
그리고 나서 for 루프가 나오는데요. 이 for 루프는 categories에 있는 인수들 만큼 루프를 돌립니다.
첫번째로 gpt3_embedding(c) 에 각 인수를 전달해서 그 값을 vector에 담습니다.
그 다음 info 에서는 이를 category 별로 그 vector 값이 담기게 합니다.
그리고 아까 만들었든 classes라는 리스트에 이 값을 담습니다.
이러면 categories의 각 인수들 마다 gpt 3 에서 받은 벡터값이 있게 됩니다.
이 벡터값을 이제 사용하게 됩니다.
43번째 줄을 보면 while 무한 루프를 만들었습니다.
사용자로부터 계속 입력값을 받기 위함이죠.
44번째 줄은 파이썬의 input() 메소드를 사용해서 사용자로부터 입력 받은 값을 a 라는 변수에 넣는 겁니다.
이 사용자가 입력한 값의 벡터값을 gpt3-embedding() 함수를 통해서 받습니다.
이러면 우리는 입력한 값의 벡터값과 아까 설정해 두었던 categories에 있는 각 인수들의 벡터값을 갖고 있습니다.
그러면 이제 입력한 값이 categories의 각 인수들과 얼마나 유사한지 알 수 있습니다.
47번째 줄에서는 match_class() 함수로 이 두 값을 보내서 각 카테고리별로 유사성 점수가 어떤지 정리한 값을 받습니다.
그 값은 result에 담기게 되고 pprint()를 이용해서 그 값을 이쁘게 출력을 하게 됩니다.
이걸 실행해 봤습니다.

첫번째로 frog 개구리는 새일 가능성이 가장 높고 그 다음은 물고기일 가능성이 높다고 나오네요.
그 다음 파충류일 가능성이 세번째로 높습니다.
양서류라는 보기가 없어서 그럴까요?
그 다음 sockeye는 연어의 종류인데요. 결과는 물고기일 확률이 제일 높게 나옵니다. 그 다음은 새, 그리고 음식 뭐 이런 순으로 나가네요.
그 다음은 개구리를 대문자 F를 사용해서 입력했습니다.
그러면 파충류일 가능성이 제일 높다고 나오네요.
다음 호랑이는 야생동물일 가능성이 가장 높게 나오고 그 다음은 포유류와 유사성이 높다고 나옵니다.
국수를 입력했을 때는 역시 음식이 가장 유사하고 그 다음은 물고기, 식물 뭐 이런 순으로 나옵니다.
구찌를 입력했을 때는 브랜드와 가장 유사하고 그 다음은 음식, 그 다음은 새 이렇게 나옵니다.
아까 개구리가 약간 이상하게 나와서... 보기에 양서류 (amphibians)를 추가 했습니다.
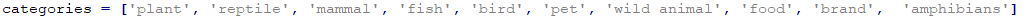

그 결과는 Frog 일 경우 양서류와 가장 유사하고 그 다음이 파충류로 나옵니다.
frog 일 경우에는 새일 가능성이 가장 높고 그 다음이 물고기 - 파충류 - 양서류 이런 순서네요.
일단 답은 100% 만족스럽지 않지만 Openai GPT 3 의 Embedding 기능에 대해서 어느 정도 감이 잡혔습니다.
참고로 이 임베딩은 아래와 같은 경우에 사용될 수 있습니다.
- Search (where results are ranked by relevance to a query string)
- Clustering (where text strings are grouped by similarity)
- Recommendations (where items with related text strings are recommended)
- Anomaly detection (where outliers with little relatedness are identified)
- Diversity measurement (where similarity distributions are analyzed)
- Classification (where text strings are classified by their most similar label)
전체 소스 코드는 아래에 있습니다.
import openai
import numpy as np # standard math module for python
from pprint import pprint
def open_file(filepath):
with open(filepath, 'r', encoding='utf-8') as infile:
return infile.read()
def gpt3_embedding(content, model='text-embedding-ada-002'):
content = content.encode(encoding='ASCII',errors='ignore').decode()
response = openai.Embedding.create(input=content,model=model)
vector = response['data'][0]['embedding'] # this is a normal list
return vector
def similarity(v1, v2): # return dot product of two vectors
return np.dot(v1, v2)
openai.api_key = open_file('openaiapikey.txt')
def match_class(vector, classes):
results = list()
for c in classes:
score = similarity(vector, c['vector'])
info = {'category': c['category'], 'score': score}
results.append(info)
return results
if __name__ == '__main__':
categories = ['plant', 'reptile', 'mammal', 'fish', 'bird', 'pet', 'wild animal', 'food', 'brand', 'amphibians']
classes = list()
for c in categories:
vector = gpt3_embedding(c)
info = {'category': c, 'vector': vector}
classes.append(info)
#print(classes)
#exit(0)
while True:
a = input('Enter a lifeform here: ')
vector = gpt3_embedding(a)
#print(a, vector)
result = match_class(vector, classes)
pprint(result)
'Open AI > Practice' 카테고리의 다른 글
| NO API key provided. error when using OpenAI command-line interface (CLI) (0) | 2023.03.12 |
|---|---|
| openai 명령어를 command 창에서 인식을 하지 못 할 때... (0) | 2023.03.11 |
| Open AI API - GPT 3 - Embedding API 예제 살펴 보기 (0) | 2023.02.11 |
| GPT3 초간단 chatbot 업그레이드 하기 (0) | 2023.02.08 |
| GPT-3 API로 초간단 Chatbot 만들기 (0) | 2023.02.08 |
| OpenAI API 첫 소스코드 분석 (초보자를 위한 해석) (0) | 2023.01.31 |
| 로컬 개발 환경 세팅하기 : Python , OpenAI Install (0) | 2023.01.27 |