

https://beta.openai.com/docs/api-reference/fine-tunes
Fine-tunes
Manage fine-tuning jobs to tailor a model to your specific training data.
미세 조정 작업을 관리하여 특정 학습 데이터에 맞게 모델을 맞춤화합니다.
Related guide: Fine-tune models
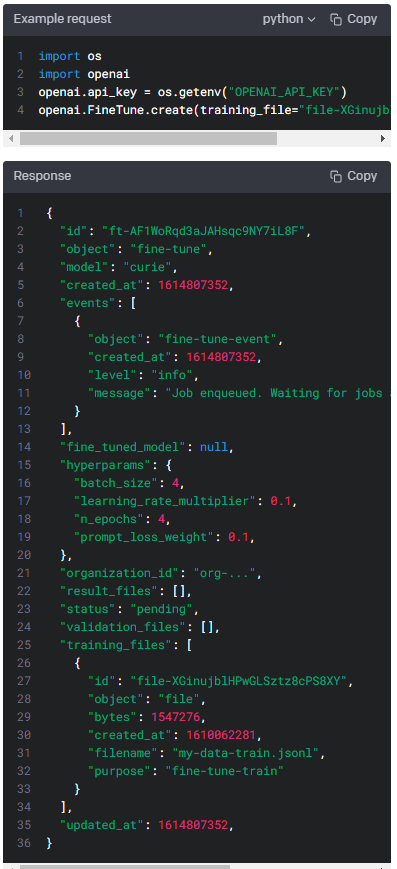
Create fine-tune
POST https://api.openai.com/v1/fine-tunes
Creates a job that fine-tunes a specified model from a given dataset.
지정된 데이터 세트에서 지정된 모델을 미세 조정하는 작업을 만듭니다.
Response includes details of the enqueued job including job status and the name of the fine-tuned models once complete.
응답에는 완료되면 작업 상태 및 미세 조정된 모델의 이름을 포함하여 대기열에 추가된 작업의 세부 정보가 포함됩니다.
Request body
The ID of an uploaded file that contains training data.
교육 데이터가 포함된 업로드된 파일의 ID입니다.
See upload file for how to upload a file.
파일 업로드 방법은 파일 업로드를 참조하세요.
Your dataset must be formatted as a JSONL file, where each training example is a JSON object with the keys "prompt" and "completion". Additionally, you must upload your file with the purpose fine-tune.
데이터 세트는 JSONL 파일로 형식화되어야 합니다. 여기서 각 교육 예제는 "prompt" 및 "completion" 키가 있는 JSON 개체입니다. 또한 미세 조정 목적으로 파일을 업로드해야 합니다.
See the fine-tuning guide for more details.
자세한 내용은 미세 조정 가이드를 참조하세요.
The ID of an uploaded file that contains validation data.
유효성 검사 데이터가 포함된 업로드된 파일의 ID입니다.
If you provide this file, the data is used to generate validation metrics periodically during fine-tuning. These metrics can be viewed in the fine-tuning results file. Your train and validation data should be mutually exclusive.
이 파일을 제공하면 미세 조정 중에 정기적으로 유효성 검사 지표를 생성하는 데 데이터가 사용됩니다. 이러한 메트릭은 미세 조정 결과 파일에서 볼 수 있습니다. 학습 및 검증 데이터는 상호 배타적이어야 합니다.
Your dataset must be formatted as a JSONL file, where each validation example is a JSON object with the keys "prompt" and "completion". Additionally, you must upload your file with the purpose fine-tune.
데이터 세트는 JSONL 파일로 형식화되어야 합니다. 여기서 각 검증 예제는 "prompt" 및 "completion" 키가 있는 JSON 개체입니다. 또한 미세 조정 목적으로 파일을 업로드해야 합니다.
See the fine-tuning guide for more details.
자세한 내용은 미세 조정 가이드를 참조하세요.
The name of the base model to fine-tune. You can select one of "ada", "babbage", "curie", "davinci", or a fine-tuned model created after 2022-04-21. To learn more about these models, see the Models documentation.
미세 조정할 기본 모델의 이름입니다. "ada", "babbage", "curie", "davinci" 또는 2022-04-21 이후 생성된 미세 조정된 모델 중 하나를 선택할 수 있습니다. 이러한 모델에 대한 자세한 내용은 모델 설명서를 참조하십시오.
The number of epochs to train the model for. An epoch refers to one full cycle through the training dataset.
모델을 훈련할 에포크 수입니다. 에포크는 교육 데이터 세트를 통한 하나의 전체 주기를 나타냅니다.
The batch size to use for training. The batch size is the number of training examples used to train a single forward and backward pass.
교육에 사용할 배치 크기입니다. 배치 크기는 단일 정방향 및 역방향 패스를 훈련하는 데 사용되는 훈련 예제의 수입니다.
By default, the batch size will be dynamically configured to be ~0.2% of the number of examples in the training set, capped at 256 - in general, we've found that larger batch sizes tend to work better for larger datasets.
기본적으로 배치 크기는 훈련 세트에 있는 예제 수의 ~0.2%로 동적으로 구성되며 최대 256개로 제한됩니다. 일반적으로 배치 크기가 클수록 데이터 세트가 더 잘 작동하는 경향이 있습니다.
The learning rate multiplier to use for training. The fine-tuning learning rate is the original learning rate used for pretraining multiplied by this value.
훈련에 사용할 학습률 승수입니다. 미세 조정 학습률은 사전 훈련에 사용된 원래 학습률에 이 값을 곱한 것입니다.
By default, the learning rate multiplier is the 0.05, 0.1, or 0.2 depending on final batch_size (larger learning rates tend to perform better with larger batch sizes). We recommend experimenting with values in the range 0.02 to 0.2 to see what produces the best results.
기본적으로 학습률 승수는 최종 batch_size에 따라 0.05, 0.1 또는 0.2입니다(배치 크기가 클수록 학습률이 높을수록 더 잘 수행되는 경향이 있음). 0.02에서 0.2 범위의 값으로 실험하여 최상의 결과를 생성하는 것이 무엇인지 확인하는 것이 좋습니다.
The weight to use for loss on the prompt tokens. This controls how much the model tries to learn to generate the prompt (as compared to the completion which always has a weight of 1.0), and can add a stabilizing effect to training when completions are short.
프롬프트 토큰에서 손실에 사용할 가중치입니다. 이것은 모델이 프롬프트를 생성하기 위해 학습을 시도하는 정도를 제어하고(항상 가중치가 1.0인 완료와 비교하여) 완료가 짧을 때 훈련에 안정화 효과를 추가할 수 있습니다.
If prompts are extremely long (relative to completions), it may make sense to reduce this weight so as to avoid over-prioritizing learning the prompt.
프롬프트가 매우 긴 경우(완료에 비해) 프롬프트 학습에 과도한 우선순위를 두지 않도록 이 가중치를 줄이는 것이 좋습니다.
If set, we calculate classification-specific metrics such as accuracy and F-1 score using the validation set at the end of every epoch. These metrics can be viewed in the results file.
설정된 경우 매 에포크가 끝날 때마다 검증 세트를 사용하여 정확도 및 F-1 점수와 같은 분류별 메트릭을 계산합니다. 이러한 메트릭은 결과 파일에서 볼 수 있습니다.
In order to compute classification metrics, you must provide a validation_file. Additionally, you must specify classification_n_classes for multiclass classification or classification_positive_class for binary classification.
분류 메트릭을 계산하려면 validation_file을 제공해야 합니다. 또한 다중 클래스 분류의 경우 classification_n_classes를 지정하고 이진 분류의 경우 classification_positive_class를 지정해야 합니다.
The number of classes in a classification task.
분류 작업의 클래스 수입니다.
This parameter is required for multiclass classification.
이 매개변수는 다중 클래스 분류에 필요합니다.
The positive class in binary classification.
이진 분류의 포지티브 클래스입니다.
This parameter is needed to generate precision, recall, and F1 metrics when doing binary classification.
이 매개변수는 이진 분류를 수행할 때 정밀도, 재현율 및 F1 메트릭을 생성하는 데 필요합니다.
If this is provided, we calculate F-beta scores at the specified beta values. The F-beta score is a generalization of F-1 score. This is only used for binary classification.
이것이 제공되면 지정된 베타 값에서 F-베타 점수를 계산합니다. F-베타 점수는 F-1 점수를 일반화한 것입니다. 이진 분류에만 사용됩니다.
With a beta of 1 (i.e. the F-1 score), precision and recall are given the same weight. A larger beta score puts more weight on recall and less on precision. A smaller beta score puts more weight on precision and less on recall.
베타 1(즉, F-1 점수)에서는 정밀도와 재현율에 동일한 가중치가 부여됩니다. 베타 점수가 클수록 재현율에 더 많은 가중치를 부여하고 정밀도에는 덜 적용합니다. 베타 점수가 작을수록 정밀도에 더 많은 가중치를 부여하고 재현율에 더 적은 가중치를 둡니다.
A string of up to 40 characters that will be added to your fine-tuned model name.
미세 조정된 모델 이름에 추가될 최대 40자의 문자열입니다.
For example, a suffix of "custom-model-name" would produce a model name like ada:ft-your-org:custom-model-name-2022-02-15-04-21-04.
예를 들어 "custom-model-name" 접미사는 ada:ft-your-org:custom-model-name-2022-02-15-04-21-04와 같은 모델 이름을 생성합니다.
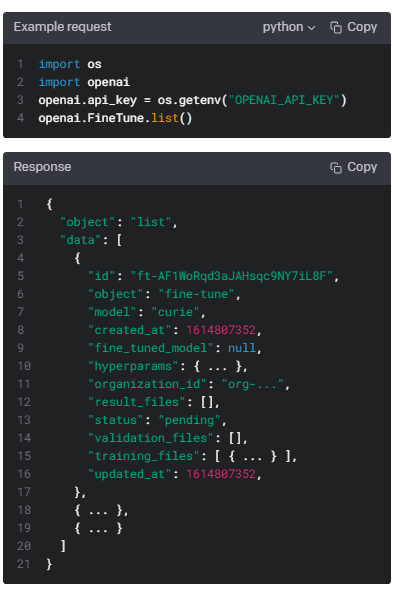
List fine-tunes
GET https://api.openai.com/v1/fine-tunes
List your organization's fine-tuning jobs
여러분 조직의 미세 조정 작업들의 리스트를 보여 줍니다.
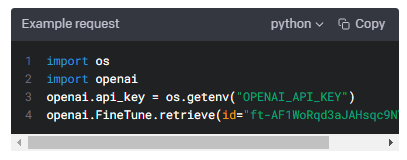
Retrieve fine-tune
GET https://api.openai.com/v1/fine-tunes/{fine_tune_id}
Gets info about the fine-tune job.
미세 조정 작업에 대한 정보를 얻습니다.
Response
{
"id": "ft-AF1WoRqd3aJAHsqc9NY7iL8F",
"object": "fine-tune",
"model": "curie",
"created_at": 1614807352,
"events": [
{
"object": "fine-tune-event",
"created_at": 1614807352,
"level": "info",
"message": "Job enqueued. Waiting for jobs ahead to complete. Queue number: 0."
},
{
"object": "fine-tune-event",
"created_at": 1614807356,
"level": "info",
"message": "Job started."
},
{
"object": "fine-tune-event",
"created_at": 1614807861,
"level": "info",
"message": "Uploaded snapshot: curie:ft-acmeco-2021-03-03-21-44-20."
},
{
"object": "fine-tune-event",
"created_at": 1614807864,
"level": "info",
"message": "Uploaded result files: file-QQm6ZpqdNwAaVC3aSz5sWwLT."
},
{
"object": "fine-tune-event",
"created_at": 1614807864,
"level": "info",
"message": "Job succeeded."
}
],
"fine_tuned_model": "curie:ft-acmeco-2021-03-03-21-44-20",
"hyperparams": {
"batch_size": 4,
"learning_rate_multiplier": 0.1,
"n_epochs": 4,
"prompt_loss_weight": 0.1,
},
"organization_id": "org-...",
"result_files": [
{
"id": "file-QQm6ZpqdNwAaVC3aSz5sWwLT",
"object": "file",
"bytes": 81509,
"created_at": 1614807863,
"filename": "compiled_results.csv",
"purpose": "fine-tune-results"
}
],
"status": "succeeded",
"validation_files": [],
"training_files": [
{
"id": "file-XGinujblHPwGLSztz8cPS8XY",
"object": "file",
"bytes": 1547276,
"created_at": 1610062281,
"filename": "my-data-train.jsonl",
"purpose": "fine-tune-train"
}
],
"updated_at": 1614807865,
}
Path parameters
The ID of the fine-tune job
미세 조정 작업의 아이디 입니다.
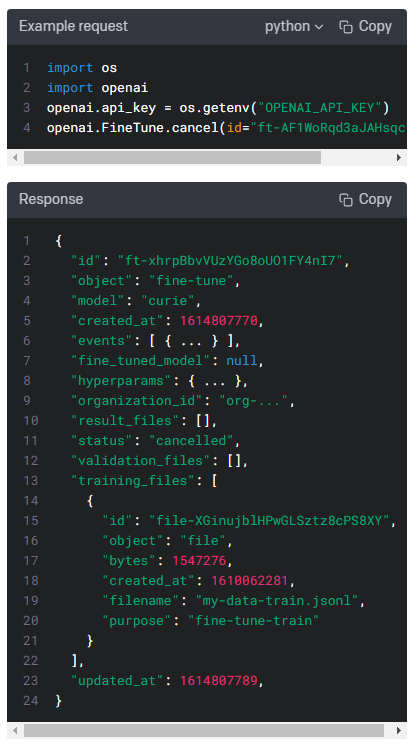
Cancel fine-tune
POST https://api.openai.com/v1/fine-tunes/{fine_tune_id}/cancel
Immediately cancel a fine-tune job.
미세 조정 작업을 즉각적으로 취소합니다.
Path parameters
The ID of the fine-tune job to cancel
취소하기 위한 미세조정 작업의 아이디 입니다.
List fine-tune events
GET https://api.openai.com/v1/fine-tunes/{fine_tune_id}/events
Get fine-grained status updates for a fine-tune job.
미세 조정 작업을 위해 세분화된 상태 업데이트를 받습니다.

Path parameters
The ID of the fine-tune job to get events for.
이벤트를 가져올 미세 조정 작업의 ID입니다.
Query parameters
Whether to stream events for the fine-tune job. If set to true, events will be sent as data-only server-sent events as they become available. The stream will terminate with a data: [DONE] message when the job is finished (succeeded, cancelled, or failed).
미세 조정 작업에 대한 이벤트를 스트리밍할지 여부입니다. true로 설정하면 이벤트가 사용 가능해지면 데이터 전용 서버 전송 이벤트로 전송됩니다. 스트림은 작업이 완료되면(성공, 취소 또는 실패) data: [DONE] 메시지와 함께 종료됩니다.
If set to false, only events generated so far will be returned.
false로 설정하면 지금까지 생성된 이벤트만 반환됩니다.
Delete fine-tune model
DELETE https://api.openai.com/v1/models/{model}
Delete a fine-tuned model. You must have the Owner role in your organization.
미세 조정 모델을 삭제 합니다. 해당 조직의 Owner 롤을 가지고 있어야 합니다.
Path parameters
The model to delete
삭제 될 모델
'Open AI > API REFERENCE' 카테고리의 다른 글
| Audio - openai.Audio.transcribe(), openai.Audio.translate() (0) | 2023.03.07 |
|---|---|
| Chat - Create chat completion (ChatGPT API usage) (0) | 2023.03.06 |
| Parameter details (0) | 2023.01.17 |
| Engines - openai.Engine.list(), (0) | 2023.01.17 |
| Moderations - openai.Moderation.create() (0) | 2023.01.17 |
| Files - openai.File.list(), create(), delete(), retrieve(), download() (0) | 2023.01.17 |
| Embeddings - openai.Embedding.create() (0) | 2023.01.17 |
| Images - openai.Image.create(), openai.Image.create_edit(), openai.Image.create_variation() (0) | 2023.01.17 |
| Edits - openai.Edit.create() (0) | 2023.01.17 |
| Completions - openai.Completion.create() (0) | 2023.01.17 |

