
https://platform.openai.com/docs/guides/rate-limits
OpenAI API
An API for accessing new AI models developed by OpenAI
platform.openai.com

Rate limits
Overview
What are rate limits?
A rate limit is a restriction that an API imposes on the number of times a user or client can access the server within a specified period of time.
Rate limit은 API가 사용자 또는 클라이언트가 특정 시간동안 서버에 접속할 수 있는 횟수에 부과하는 제한 입니다.
Why do we have rate limits?
Rate limits are a common practice for APIs, and they're put in place for a few different reasons:
Rate limit은 API에 대한 일반적인 관행입니다. 이 제한이 있는 이유는 몇가지 이유가 있습니다.
- They help protect against abuse or misuse of the API. For example, a malicious actor could flood the API with requests in an attempt to overload it or cause disruptions in service. By setting rate limits, OpenAI can prevent this kind of activity.
- API의 남용 또는 오용을 방지하는 데 도움이 됩니다. 예를 들어 악의적인 행위자는 API에 과부하를 일으키거나 서비스를 중단시키려는 시도로 API에 요청을 플러딩할 수 있습니다. Rate Limit을 설정함으로써 OpenAI는 이러한 종류의 공격을 방지할 수 있습니다.
- Rate limits help ensure that everyone has fair access to the API. If one person or organization makes an excessive number of requests, it could bog down the API for everyone else. By throttling the number of requests that a single user can make, OpenAI ensures that the most number of people have an opportunity to use the API without experiencing slowdowns.
- Rate Limit은 모든 사람이 API에 공정하게 액세스할 수 있도록 도와줍니다. 한 개인이나 조직이 과도한 수의 요청을 하면 다른 모든 사람의 API가 중단될 수 있습니다. 단일 사용자가 만들 수 있는 요청 수를 제한함으로써 OpenAI는 대부분의 사람들이 속도 저하 없이 API를 사용할 기회를 갖도록 보장합니다.
- Rate limits can help OpenAI manage the aggregate load on its infrastructure. If requests to the API increase dramatically, it could tax the servers and cause performance issues. By setting rate limits, OpenAI can help maintain a smooth and consistent experience for all users.
- Rate limit은 OpenAI가 인프라의 총 로드를 관리하는 데 도움이 될 수 있습니다. API에 대한 요청이 급격히 증가하면 서버에 부담을 주고 성능 문제를 일으킬 수 있습니다. Rate limit을 설정함으로써 OpenAI는 모든 사용자에게 원활하고 일관된 경험을 유지하는 데 도움을 줄 수 있습니다.
What are the rate limits for our API?
We enforce rate limits at the organization level, not user level, based on the specific endpoint used as well as the type of account you have. Rate limits are measured in two ways: RPM (requests per minute) and TPM (tokens per minute). The table below highlights the default rate limits for our API but these limits can be increased depending on your use case after filling out the Rate Limit increase request form.
OpenAI는 사용된 특정 엔드포인트와 보유한 계정 유형을 기반으로 사용자 수준이 아닌 조직 수준에서 속도 제한을 적용합니다. Rate Limit은 RPM(분당 요청) 및 TPM(분당 토큰)의 두 가지 방식으로 측정됩니다. 아래 표에는 API에 대한 기본 Rate Limit이 강조되어 있지만 이러한 제한은 Rate Limit 증가 요청 양식을 작성한 후 사용 사례에 따라 증가할 수 있습니다.
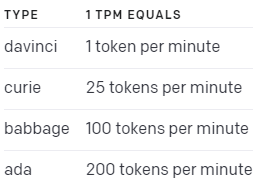
The TPM (tokens per minute) unit is different depending on the model:
TPM 은 모델에 따라 다릅니다.
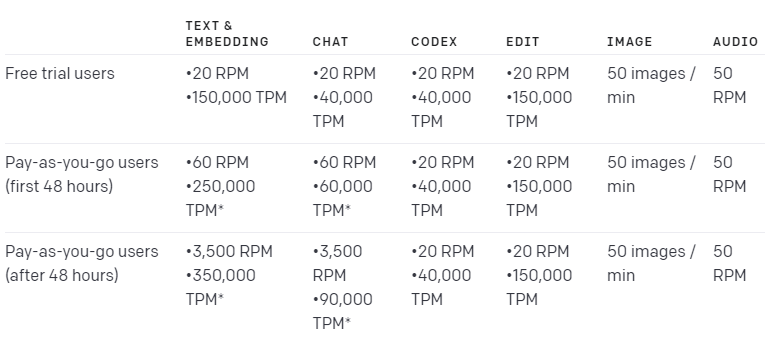
Rate limit은 먼저 발생하는 항목에 따라 두 옵션 중 하나에 의해 적중될 수 있다는 점에 유의하는 것이 중요합니다. 예를 들어 Codex 엔드포인트에 100개의 토큰만 있는 20개의 요청을 보낼 수 있으며 20개의 요청 내에서 40,000개의 토큰을 보내지 않았더라도 제한을 채울 수 있습니다.
How do rate limits work?
Rate limit이 분당 요청 60개이고 분당 150,000 davinci 토큰인 경우 requests/min 한도에 도달하거나 토큰이 부족하여 제한을 받게 됩니다. 둘 중 어느 하나에 도달하면 이러한 상황이 발생합니다. 예를 들어 분당 최대 요청 수가 60이면 초당 1개의 요청을 보낼 수 있어야 합니다. 800ms마다 1개의 요청을 보내는 경우 Rate Limit에 도달하면 프로그램을 200ms만 휴면 상태로 만들면 하나 더 요청을 보낼 수 있습니다. 그렇지 않으면 후속 요청이 실패합니다. 기본적으로 분당 3,000개의 요청을 사용하면 고객은 20ms마다 또는 0.02초마다 효과적으로 1개의 요청을 보낼 수 있습니다.
What happens if I hit a rate limit error?
Rate limit errors look like this: Rate limit 에러 메세지는 아래 처럼 나옵니다.
Rate limit reached for default-text-davinci-002 in organization org-{id} on requests per min. Limit: 20.000000 / min. Current: 24.000000 / min.
If you hit a rate limit, it means you've made too many requests in a short period of time, and the API is refusing to fulfill further requests until a specified amount of time has passed.
Rate Limit에 도달하면 짧은 시간에 너무 많은 요청을 했고 지정된 시간이 지날 때까지 API가 추가 요청 이행을 거부하고 있음을 의미합니다.
Rate limits vs max_tokens
Each model we offer has a limited number of tokens that can be passed in as input when making a request. You cannot increase the maximum number of tokens a model takes in. For example, if you are using text-ada-001, the maximum number of tokens you can send to this model is 2,048 tokens per request.
OpenAI가 제공하는 각 모델에는 request시 input으로 전달할 수 있는 토큰 수가 제한 돼 있습니다. 모델이 받을 수 있는 최대 토큰 수는 늘릴 수 없습니다. 예를 들어 text-ada-001을 사용하는 경우 이 모델에 보낼 수 있는 최대 토큰 수는 요청당 2048개의 토큰 입니다.
Error Mitigation
What are some steps I can take to mitigate this?
The OpenAI Cookbook has a python notebook that explains details on how to avoid rate limit errors.
OpenAI Cookbook에는 Rate Limit 오류를 방지하는 방법에 대한 세부 정보를 설명하는 Python 노트북이 있습니다.
아래 저의 블로그에 이에 대해 한국어로 설명하고 있습니다.
https://coronasdk.tistory.com/1273
Openai cookbook - API usage - How to handle rate limits
지난 글까지 해서 openai cookbook의 embedding 코너는 모두 마쳤습니다. OpenAI API 를 공부하면서 어떻게 하다가 CookBook 의 Embedding 부터 먼저 공부 했는데요. 이 CookBook은 원래 API usage부터 시작합니다. 오
coronasdk.tistory.com
You should also exercise caution when providing programmatic access, bulk processing features, and automated social media posting - consider only enabling these for trusted customers.
또한 프로그래밍 방식 액세스, 대량 처리 기능 및 자동화된 소셜 미디어 게시를 제공할 때 주의해야 합니다. 신뢰할 수 있는 고객에 대해서만 이러한 기능을 활성화하는 것이 좋습니다.
To protect against automated and high-volume misuse, set a usage limit for individual users within a specified time frame (daily, weekly, or monthly). Consider implementing a hard cap or a manual review process for users who exceed the limit.
자동화된 대량 오용으로부터 보호하려면 지정된 기간(일별, 주별 또는 월별) 내에서 개별 사용자에 대한 사용 제한을 설정하십시오. 한도를 초과하는 사용자에 대해 하드 캡 또는 수동 검토 프로세스를 구현하는 것을 고려하십시오.
Retrying with exponential backoff
One easy way to avoid rate limit errors is to automatically retry requests with a random exponential backoff. Retrying with exponential backoff means performing a short sleep when a rate limit error is hit, then retrying the unsuccessful request. If the request is still unsuccessful, the sleep length is increased and the process is repeated. This continues until the request is successful or until a maximum number of retries is reached. This approach has many benefits:
Rate Limit 오류를 방지하는 한 가지 쉬운 방법은 andom exponential backoff로 요청을 자동으로 재시도하는 것입니다. exponential backoff로 재시도한다는 것은 Rate Limit 오류에 도달했을 때 short sleep 모드를 수행한 다음 실패한 요청을 다시 시도하는 것을 의미합니다. 요청이 여전히 실패하면 sleep 시간이 증가하고 프로세스가 반복됩니다. 이것은 요청이 성공하거나 최대 재시도 횟수에 도달할 때까지 계속됩니다. 이 접근 방식에는 다음과 같은 많은 이점이 있습니다.
- Automatic retries means you can recover from rate limit errors without crashes or missing data
- 자동 재시도는 충돌이나 데이터 손실 없이 rate limit 오류에서 복구할 수 있음을 의미합니다.
- Exponential backoff means that your first retries can be tried quickly, while still benefiting from longer delays if your first few retries fail
- Exponential backoff 는 첫 번째 재시도를 빠르게 시도할 수 있음을 의미하며 처음 몇 번의 재시도가 실패할 경우 더 긴 지연으로부터 이점을 누릴 수 있습니다.
- Adding random jitter to the delay helps retries from all hitting at the same time.
- 지연에 andom jitter를 추가하면 동시에 모든 hitting 에서 재시도하는 데 도움이 됩니다.
Note that unsuccessful requests contribute to your per-minute limit, so continuously resending a request won’t work.
실패한 요청은 분당 한도에 영향을 미치므로 계속해서 요청을 다시 보내면 작동하지 않습니다.
Below are a few example solutions for Python that use exponential backoff.
다음은 exponential backoff를 사용하는 Python에 대한 몇 가지 예제 솔루션입니다.
Example #1: Using the Tenacity library
Tenacity is an Apache 2.0 licensed general-purpose retrying library, written in Python, to simplify the task of adding retry behavior to just about anything. To add exponential backoff to your requests, you can use the tenacity.retry decorator. The below example uses the tenacity.wait_random_exponential function to add random exponential backoff to a request.
Tenacity는 Python으로 작성된 Apache 2.0 라이센스 범용 재시도 라이브러리로 거의 모든 항목에 재시도 동작을 추가하는 작업을 단순화합니다. 요청에 exponential backoff 를 추가하려면 tenacity.retry 데코레이터를 사용할 수 있습니다. 아래 예에서는 tenacity.wait_random_exponential 함수를 사용하여 무작위 exponential backoff 를 요청에 추가합니다.
import openai
from tenacity import (
retry,
stop_after_attempt,
wait_random_exponential,
) # for exponential backoff
@retry(wait=wait_random_exponential(min=1, max=60), stop=stop_after_attempt(6))
def completion_with_backoff(**kwargs):
return openai.Completion.create(**kwargs)
completion_with_backoff(model="text-davinci-003", prompt="Once upon a time,")Note that the Tenacity library is a third-party tool, and OpenAI makes no guarantees about its reliability or security.
Tenacity 라이브러리는 타사 도구이며 OpenAI는 안정성이나 보안을 보장하지 않습니다.
Example #2: Using the backoff library
Another python library that provides function decorators for backoff and retry is backoff:
백오프 및 재시도를 위한 함수 데코레이터를 제공하는 또 다른 Python 라이브러리는 백오프입니다.
backoff
Function decoration for backoff and retry
pypi.org
import backoff
import openai
@backoff.on_exception(backoff.expo, openai.error.RateLimitError)
def completions_with_backoff(**kwargs):
return openai.Completion.create(**kwargs)
completions_with_backoff(model="text-davinci-003", prompt="Once upon a time,")Like Tenacity, the backoff library is a third-party tool, and OpenAI makes no guarantees about its reliability or security.
Tenacity와 마찬가지로 백오프 라이브러리는 타사 도구이며 OpenAI는 안정성이나 보안에 대해 보장하지 않습니다.
Example 3: Manual backoff implementation
If you don't want to use third-party libraries, you can implement your own backoff logic following this example:
타사 라이브러리를 사용하지 않으려면 다음 예제에 따라 자체 백오프 논리를 구현할 수 있습니다.
# imports
import random
import time
import openai
# define a retry decorator
def retry_with_exponential_backoff(
func,
initial_delay: float = 1,
exponential_base: float = 2,
jitter: bool = True,
max_retries: int = 10,
errors: tuple = (openai.error.RateLimitError,),
):
"""Retry a function with exponential backoff."""
def wrapper(*args, **kwargs):
# Initialize variables
num_retries = 0
delay = initial_delay
# Loop until a successful response or max_retries is hit or an exception is raised
while True:
try:
return func(*args, **kwargs)
# Retry on specific errors
except errors as e:
# Increment retries
num_retries += 1
# Check if max retries has been reached
if num_retries > max_retries:
raise Exception(
f"Maximum number of retries ({max_retries}) exceeded."
)
# Increment the delay
delay *= exponential_base * (1 + jitter * random.random())
# Sleep for the delay
time.sleep(delay)
# Raise exceptions for any errors not specified
except Exception as e:
raise e
return wrapper
@retry_with_exponential_backoff
def completions_with_backoff(**kwargs):
return openai.Completion.create(**kwargs)
다시 말하지만 OpenAI는 이 솔루션의 보안이나 효율성을 보장하지 않지만 자체 솔루션을 위한 좋은 출발점이 될 수 있습니다.
Batching requests
The OpenAI API has separate limits for requests per minute and tokens per minute.
OpenAI API에는 분당 요청 및 분당 토큰에 대한 별도의 제한이 있습니다.
If you're hitting the limit on requests per minute, but have available capacity on tokens per minute, you can increase your throughput by batching multiple tasks into each request. This will allow you to process more tokens per minute, especially with our smaller models.
분당 요청 제한에 도달했지만 분당 토큰에 사용 가능한 용량이 있는 경우 여러 작업을 각 요청에 일괄 처리하여 처리량을 늘릴 수 있습니다. 이렇게 하면 특히 더 작은 모델을 사용하여 분당 더 많은 토큰을 처리할 수 있습니다.
Sending in a batch of prompts works exactly the same as a normal API call, except you pass in a list of strings to the prompt parameter instead of a single string.
단일 문자열 대신 프롬프트 매개변수에 문자열 목록을 전달한다는 점을 제외하면 프롬프트 일괄 전송은 일반 API 호출과 정확히 동일하게 작동합니다.
Example without batching
import openai
num_stories = 10
prompt = "Once upon a time,"
# serial example, with one story completion per request
for _ in range(num_stories):
response = openai.Completion.create(
model="curie",
prompt=prompt,
max_tokens=20,
)
# print story
print(prompt + response.choices[0].text)Example with batching
import openai # for making OpenAI API requests
num_stories = 10
prompts = ["Once upon a time,"] * num_stories
# batched example, with 10 story completions per request
response = openai.Completion.create(
model="curie",
prompt=prompts,
max_tokens=20,
)
# match completions to prompts by index
stories = [""] * len(prompts)
for choice in response.choices:
stories[choice.index] = prompts[choice.index] + choice.text
# print stories
for story in stories:
print(story)
Warning: the response object may not return completions in the order of the prompts, so always remember to match responses back to prompts using the index field.
경고: 응답 개체는 프롬프트 순서대로 완료를 반환하지 않을 수 있으므로 항상 인덱스 필드를 사용하여 응답을 프롬프트에 다시 일치시켜야 합니다.
Request Increase
When should I consider applying for a rate limit increase?
Our default rate limits help us maximize stability and prevent abuse of our API. We increase limits to enable high-traffic applications, so the best time to apply for a rate limit increase is when you feel that you have the necessary traffic data to support a strong case for increasing the rate limit. Large rate limit increase requests without supporting data are not likely to be approved. If you're gearing up for a product launch, please obtain the relevant data through a phased release over 10 days.
Keep in mind that rate limit increases can sometimes take 7-10 days so it makes sense to try and plan ahead and submit early if there is data to support you will reach your rate limit given your current growth numbers.
기본 rate limit은 안정성을 극대화하고 API 남용을 방지하는 데 도움이 됩니다. 우리는 트래픽이 많은 애플리케이션을 활성화하기 위해 제한을 늘립니다. 따라서 rate limits 증가를 신청할 가장 좋은 시기는 속도 제한 증가에 대한 강력한 사례를 지원하는 데 필요한 트래픽 데이터가 있다고 생각할 때입니다. 지원 데이터가 없는 대규모 rate limits 증가 요청은 승인되지 않을 가능성이 높습니다. 제품 출시를 준비하고 있다면 10일에 걸친 단계별 릴리스를 통해 관련 데이터를 얻으십시오.
Will my rate limit increase request be rejected?
A rate limit increase request is most often rejected because it lacks the data needed to justify the increase. We have provided numerical examples below that show how to best support a rate limit increase request and try our best to approve all requests that align with our safety policy and show supporting data. We are committed to enabling developers to scale and be successful with our API.
rate limit 증가 요청은 증가를 정당화하는 데 필요한 데이터가 부족하기 때문에 거부되는 경우가 가장 많습니다. 속도 제한 증가 요청을 가장 잘 지원하는 방법을 보여주고 안전 정책에 부합하는 모든 요청을 승인하고 지원 데이터를 표시하기 위해 최선을 다하는 방법을 아래에 숫자로 나타낸 예를 제공했습니다. 우리는 개발자가 API를 사용하여 확장하고 성공할 수 있도록 최선을 다하고 있습니다.
I’ve implemented exponential backoff for my text/code APIs, but I’m still hitting this error. How do I increase my rate limit?
Currently, we don’t support increasing our free beta endpoints, such as the edit endpoint. We also don’t increase ChatGPT rate limits but you can join the waitlist for ChatGPT Professional access.
현재 edit endpoint 같은 free beta endpoints 에 대해서는 제한량 증가를 지원하지 않습니다. 또한 ChatGPT Rate Limit을 늘리지 않지만 ChatGPT Professional 액세스 대기자 명단에 가입할 수 있습니다.
We understand the frustration that limited rate limits can cause, and we would love to raise the defaults for everyone. However, due to shared capacity constraints, we can only approve rate limit increases for paid customers who have demonstrated a need through our Rate Limit Increase Request form. To help us evaluate your needs properly, we ask that you please provide statistics on your current usage or projections based on historic user activity in the 'Share evidence of need' section of the form. If this information is not available, we recommend a phased release approach. Start by releasing the service to a subset of users at your current rate limits, gather usage data for 10 business days, and then submit a formal rate limit increase request based on that data for our review and approval.
We will review your request and if it is approved, we will notify you of the approval within a period of 7-10 business days.
Here are some examples of how you might fill out this form:
limited rate limits 이 야기할 수 있는 불만을 이해하고 있으며 모든 사람을 위해 기본값을 높이고 싶습니다. 그러나 공유 용량 제약으로 인해 rate limit 증가 요청 양식을 통해 필요성을 입증한 유료 고객에 대해서만 rate limit 증가를 승인할 수 있습니다. 귀하의 필요를 적절하게 평가할 수 있도록 양식의 '필요에 대한 증거 공유' 섹션에서 이전 사용자 활동을 기반으로 현재 사용량 또는 예상에 대한 통계를 제공해 주시기 바랍니다. 이 정보를 사용할 수 없는 경우 단계적 릴리스 접근 방식을 권장합니다. 현재 rate limit으로 사용자 하위 집합에 서비스를 릴리스하고 영업일 기준 10일 동안 사용 데이터를 수집한 다음 검토 및 승인을 위해 해당 데이터를 기반으로 공식적인 rate limit 증가 요청을 제출합니다.
DALL-E API examples

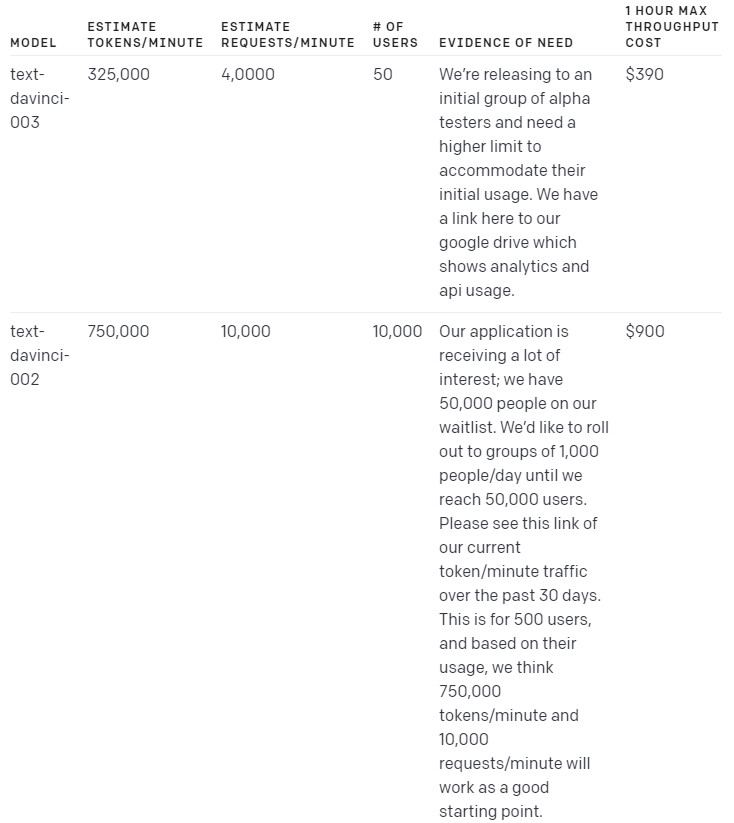
Language model examples
Code model examples
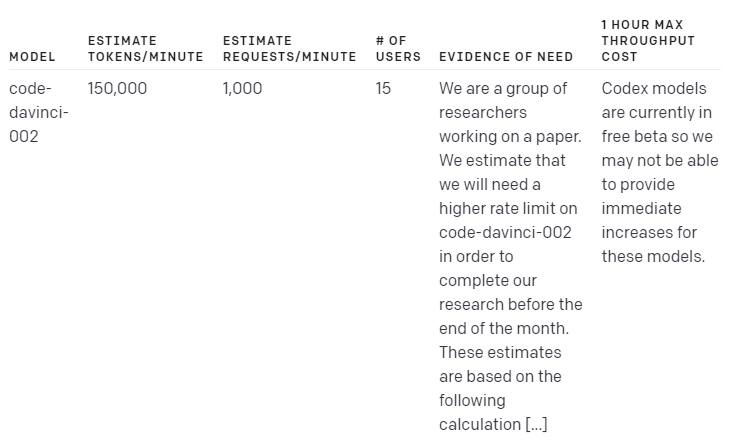
Please note that these examples are just general use case scenarios, the actual usage rate will vary depending on the specific implementation and usage.
이러한 예는 일반적인 사용 사례 시나리오일 뿐이며 실제 사용률은 특정 구현 및 사용에 따라 달라집니다.
'Open AI > GUIDES' 카테고리의 다른 글
| Guide - Error codes (0) | 2023.03.05 |
|---|---|
| Guide - Speech to text (0) | 2023.03.05 |
| Guide - Chat completion (ChatGPT API) (0) | 2023.03.05 |
| Guides - Production Best Practices (0) | 2023.01.10 |
| Guides - Safety best practices (0) | 2023.01.10 |
| Guides - Moderation (0) | 2023.01.10 |
| Guides - Embeddings (0) | 2023.01.10 |
| Guides - Fine tuning (0) | 2023.01.10 |
| Guide - Image generation (0) | 2023.01.09 |
| Guide - Code completion (0) | 2023.01.09 |

