
https://d2l.ai/chapter_attention-mechanisms-and-transformers/bahdanau-attention.html
11.4. The Bahdanau Attention Mechanism — Dive into Deep Learning 1.0.0-beta0 documentation
d2l.ai
11.4. The Bahdanau Attention Mechanism
The Bahdanau Attention Mechanism 이란?
The Bahdanau Attention Mechanism, also known as Additive Attention, is an attention mechanism introduced by Dzmitry Bahdanau et al. in the context of sequence-to-sequence models for machine translation. This mechanism aims to address the limitation of the basic encoder-decoder architecture, where a fixed-length context vector is used to encode the entire source sequence into a single vector. The Bahdanau Attention Mechanism enhances this architecture by allowing the decoder to focus on different parts of the source sequence as it generates each target word.
바다나우 어텐션 메커니즘, 또는 추가적인 어텐션(Additive Attention),은 Dzmitry Bahdanau 등에 의해 소개된 어텐션 메커니즘으로, 기계 번역을 위한 시퀀스-투-시퀀스 모델의 맥락에서 등장했습니다. 이 메커니즘은 기본적인 인코더-디코더 아키텍처의 한계를 해결하기 위해 개발되었습니다. 이 아키텍처에서는 고정 길이의 컨텍스트 벡터가 사용되어 전체 소스 시퀀스를 하나의 벡터로 인코딩하는 문제가 있었습니다. 바다나우 어텐션 메커니즘은 디코더가 각 타겟 단어를 생성하는 동안 소스 시퀀스의 다른 부분에 초점을 맞출 수 있도록 향상된 아키텍처를 제공합니다.
The key idea behind the Bahdanau Attention Mechanism is to compute attention scores for each source sequence position based on a weighted combination of the decoder's hidden state and the encoder's hidden states. These attention scores indicate the relevance of each source position to the current decoding step. The decoder then combines these attention-weighted encoder hidden states to obtain a context vector, which is used to generate the target word.
The steps of the Bahdanau Attention Mechanism are as follows:
바다나우 어텐션 메커니즘의 핵심 아이디어는 디코더의 현재 은닉 상태와 인코더의 은닉 상태의 가중 결합을 기반으로 각 소스 시퀀스 위치의 어텐션 스코어를 계산하는 것입니다. 이러한 어텐션 스코어는 각 소스 위치가 현재 디코딩 단계에 얼마나 관련성 있는지를 나타냅니다. 디코더는 이러한 어텐션 가중치를 사용하여 은닉 상태를 가중합하여 컨텍스트 벡터를 얻습니다. 이 컨텍스트 벡터는 타겟 단어를 생성하는 데 사용됩니다.
바다나우 어텐션 메커니즘의 단계는 다음과 같습니다:
- Compute Alignment Scores: Calculate attention scores between the decoder's current hidden state and each encoder hidden state.
어텐션 스코어 계산: 디코더의 현재 은닉 상태와 각 인코더 은닉 상태 간의 어텐션 스코어를 계산합니다. - Compute Attention Weights: Apply a softmax function to the alignment scores to get attention weights that sum up to 1. These weights represent the importance of each encoder hidden state in generating the current target word.
어텐션 가중치 계산: 어텐션 스코어에 소프트맥스 함수를 적용하여 어텐션 가중치를 얻습니다. 이 가중치는 각 인코더 은닉 상태가 현재 타겟 단어를 생성하는 데 얼마나 중요한지를 나타냅니다. - Calculate the Context Vector: Take a weighted sum of the encoder hidden states using the attention weights to obtain the context vector.
컨텍스트 벡터 계산: 어텐션 가중치를 사용하여 인코더 은닉 상태의 가중합을 계산하여 컨텍스트 벡터를 얻습니다. - Generate the Output: Combine the context vector with the decoder's current hidden state to generate the target word.
출력 생성: 컨텍스트 벡터를 디코더의 현재 은닉 상태와 결합하여 타겟 단어를 생성합니다.
The Bahdanau Attention Mechanism allows the model to selectively focus on different parts of the source sequence as it generates each target word. This helps improve the quality of generated translations and capture more complex relationships between source and target sequences. It has been a fundamental building block in many state-of-the-art sequence-to-sequence models and has contributed to significant improvements in various natural language processing tasks, including machine translation and text generation.
바다나우 어텐션 메커니즘은 모델이 각 타겟 단어를 생성하는 동안 소스 시퀀스의 다른 부분에 집중할 수 있도록 합니다. 이로써 생성된 번역의 품질을 향상시키고 소스와 타겟 시퀀스 간의 복잡한 관계를 더 잘 포착할 수 있습니다. 바다나우 어텐션 메커니즘은 많은 최신 시퀀스-투-시퀀스 모델에서 중요한 구성 요소로 사용되며 기계 번역 및 텍스트 생성과 같은 다양한 자연어 처리 작업에서 큰 향상을 이끌어냈습니다.
When we encountered machine translation in Section 10.7, we designed an encoder-decoder architecture for sequence to sequence (seq2seq) learning based on two RNNs (Sutskever et al., 2014). Specifically, the RNN encoder transforms a variable-length sequence into a fixed-shape context variable. Then, the RNN decoder generates the output (target) sequence token by token based on the generated tokens and the context variable.
섹션 10.7에서 기계 번역을 만났을 때 우리는 두 개의 RNN을 기반으로 시퀀스 대 시퀀스(seq2seq) 학습을 위한 인코더-디코더 아키텍처를 설계했습니다(Sutskever et al., 2014). 특히 RNN 인코더는 가변 길이 시퀀스를 고정된 모양의 컨텍스트 변수로 변환합니다. 그러면 RNN 디코더는 생성된 토큰과 컨텍스트 변수를 기반으로 토큰별로 출력(대상) 시퀀스 토큰을 생성합니다.
Recall Fig. 10.7.2 which we reprint below (Fig. 11.4.1) with some additional detail. Conventionally, in an RNN all relevant information about a source sequence is translated into some internal fixed-dimensional state representation by the encoder. It is this very state that is used by the decoder as the complete and exclusive source of information to generate the translated sequence. In other words, the seq2seq mechanism treats the intermediate state as a sufficient statistic of whatever string might have served as input.
그림 10.7.2는 아래에 다시 인쇄되어 있습니다(그림 11.4.1). 일반적으로 RNN에서 소스 시퀀스에 대한 모든 관련 정보는 인코더에 의해 일부 내부 fixed-dimensional state representation으로 변환됩니다. 변환된 시퀀스를 생성하기 위한 완전하고 배타적인 정보 소스로서 디코더에 의해 사용되는 바로 이 상태입니다. 즉, seq2seq 메커니즘은 중간 state 를 입력으로 제공된 문자열의 충분한 통계로 취급합니다.
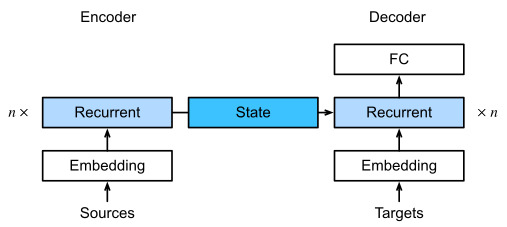
While this is quite reasonable for short sequences, it is clear that it is infeasible for long sequences, such as a book chapter or even just a very long sentence. After all, after a while there will simply not be enough “space” in the intermediate representation to store all that is important in the source sequence. Consequently the decoder will fail to translate long and complex sentences. One of the first to encounter was Graves (2013) when they tried to design an RNN to generate handwritten text. Since the source text has arbitrary length they designed a differentiable attention model to align text characters with the much longer pen trace, where the alignment moves only in one direction. This, in turn, draws on decoding algorithms in speech recognition, e.g., hidden Markov models (Rabiner and Juang, 1993).
이것은 짧은 시퀀스에 대해서는 상당히 타당하지만 책의 장이나 매우 긴 문장과 같은 긴 시퀀스에는 실행 불가능하다는 것이 분명합니다. 결국, 잠시 후 소스 시퀀스에서 중요한 모든 것을 저장할 intermediate representation에 충분한 "공간"이 없을 것입니다. 결과적으로 디코더는 길고 복잡한 문장을 번역하지 못합니다. Graves(2013)가 손으로 쓴 텍스트를 생성하기 위해 RNN을 설계하려고 시도했을 때 처음 접한 것 중 하나였습니다. 원본 텍스트의 길이는 임의적이므로 정렬이 한 방향으로만 이동하는 훨씬 더 긴 펜 추적으로 텍스트 문자를 정렬하기 위해 differentiable attention model 을 설계했습니다. 이것은 차례로 음성 인식의 디코딩 알고리즘, 예를 들어 hidden Markov models (Rabiner and Juang, 1993)을 사용합니다.
Inspired by the idea of learning to align, Bahdanau et al. (2014) proposed a differentiable attention model without the unidirectional alignment limitation. When predicting a token, if not all the input tokens are relevant, the model aligns (or attends) only to parts of the input sequence that are deemed relevant to the current prediction. This is then used to update the current state before generating the next token. While quite innocuous in its description, this Bahdanau attention mechanism has arguably turned into one of the most influential ideas of the past decade in deep learning, giving rise to Transformers (Vaswani et al., 2017) and many related new architectures.
Bahdanau et al. (2014)은 단방향 정렬 제한 없이 차별화 가능한 attention model을 제안했습니다. 토큰을 예측할 때 모든 입력 토큰이 관련되지 않은 경우 모델은 현재 예측과 관련이 있는 것으로 간주되는 입력 시퀀스의 일부에만 정렬(또는 attends)합니다. 그런 다음 다음 토큰을 생성하기 전에 현재 상태를 업데이트하는 데 사용됩니다. 이 Bahdanau attention mechanism은 description에서 큰 문제가 없어 보입니다. 그래서 이 방법은 트랜스포머(Vaswani et al., 2017) 및 많은 관련 새로운 아키텍처를 발생시키면서 딥 러닝에서 지난 10년 동안 가장 영향력 있는 아이디어 중 하나로 변모했습니다.
import torch
from torch import nn
from d2l import torch as d2l
11.4.1. Model
We follow the notation introduced by the seq2seq architecture of Section 10.7, in particular (10.7.3). The key idea is that instead of keeping the state, i.e., the context variable c summarizing the source sentence as fixed, we dynamically update it, as a function of both the original text (encoder hidden states ℎt) and the text that was already generated (decoder hidden states st′−1). This yields ct′, which is updated after any decoding time step c′. Suppose that the input sequence is of length T. In this case the context variable is the output of attention pooling:
섹션 10.7, 특히 (10.7.3)의 seq2seq architecture에 의해 도입된 표기법을 따릅니다. 핵심 아이디어는 state를 유지하는 대신, 즉 소스 문장을 고정된 것으로 요약하는 컨텍스트 변수 c를 원본 텍스트(encoder hidden states ℎt)와 이미 생성된 텍스트의 함수로 동적으로 업데이트한다는 것입니다. (decoder hidden states st'-1). 이는 임의의 decoding time step c' 후에 업데이트되는 ct'를 생성합니다. 입력 시퀀스의 길이가 T라고 가정합니다. 이 경우 컨텍스트 변수는 attention pooling의 출력입니다.

We used st′−1 as the query, and ℎt as both the key and the value. Note that ct′ is then used to generate the state st′ and to generate a new token (see (10.7.3)). In particular, the attention weight α is computed as in (11.3.3) using the additive attention scoring function defined by (11.3.7). This RNN encoder-decoder architecture using attention is depicted in Fig. 11.4.2. Note that later this model was modified such as to include the already generated tokens in the decoder as further context (i.e., the attention sum does stop at T but rather it proceeds up to t′−1). For instance, see Chan et al. (2015) for a description of this strategy, as applied to speech recognition.
우리는 쿼리로 st′-1을 사용했고 키와 값으로 ℎt를 사용했습니다. ct'는 상태 st'를 생성하고 새 토큰을 생성하는 데 사용됩니다((10.7.3) 참조). 특히 attention weight α는 (11.3.7)에 의해 정의된 additive attention scoring function를 사용하여 (11.3.3)과 같이 계산됩니다. 주의를 사용하는 이 RNN 인코더-디코더 아키텍처는 그림 11.4.2에 묘사되어 있습니다. 나중에 이 모델은 디코더에 이미 생성된 토큰을 추가 컨텍스트로 포함하도록 수정되었습니다(즉, 주의 합계는 T에서 중지하지만 오히려 t'-1까지 진행함). 예를 들어 Chan et al. (2015) 음성 인식에 적용되는 이 전략에 대한 설명입니다.

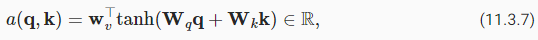
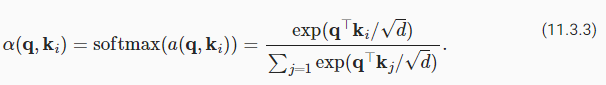
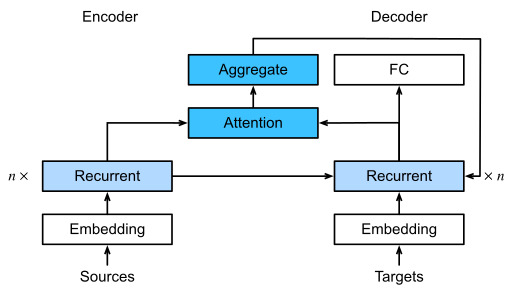
11.4.2. Defining the Decoder with Attention
To implement the RNN encoder-decoder with attention, we only need to redefine the decoder (omitting the generated symbols from the attention function simplifies the design). Let’s begin with the base interface for decoders with attention by defining the quite unsurprisingly named AttentionDecoder class.
attention이 있는 RNN 인코더-디코더를 구현하려면 디코더만 재정의하면 됩니다(attention function에서 생성된 기호를 생략하면 설계가 간소화됨). 꽤 놀랍지 않게 명명된 AttentionDecoder 클래스를 정의하여 어텐션이 있는 디코더의 기본 인터페이스부터 시작하겠습니다.
class AttentionDecoder(d2l.Decoder): #@save
"""The base attention-based decoder interface."""
def __init__(self):
super().__init__()
@property
def attention_weights(self):
raise NotImplementedError위의 코드는 어텐션 기반 디코더의 기본 인터페이스인 AttentionDecoder 클래스를 정의합니다. 이 클래스는 디코더의 기본 구조와 어텐션 메커니즘을 사용하는 인터페이스를 제공합니다.
- AttentionDecoder 클래스는 d2l.Decoder 클래스를 상속받아 구현됩니다. d2l.Decoder 클래스는 디코더 모델을 구축하기 위한 기본 클래스로 사용됩니다.
- __init__ 메서드는 클래스의 초기화를 수행합니다. 여기서 별다른 초기화 작업은 없고, 부모 클래스인 d2l.Decoder의 생성자를 호출합니다.
- @property 데코레이터는 attention_weights라는 프로퍼티를 정의합니다. 이 프로퍼티는 어텐션 가중치를 반환하는 역할을 합니다.
- attention_weights 메서드의 내용은 구현되지 않았으며, NotImplementedError를 발생시켜서 해당 메서드가 서브클래스에서 반드시 구현되어야 한다는 것을 나타냅니다. 이렇게 하여 AttentionDecoder 클래스를 상속받는 실제 어텐션 디코더 클래스는 반드시 attention_weights 메서드를 구현해야 합니다.
이렇게 AttentionDecoder 클래스는 어텐션 기반 디코더의 기본 인터페이스를 제공하며, 어텐션 가중치를 반환하는 attention_weights 메서드의 구현을 강제합니다. 이 클래스를 상속받아 실제 어텐션 메커니즘을 사용하는 디코더 클래스를 구현할 수 있습니다.
We need to implement the RNN decoder in the Seq2SeqAttentionDecoder class. The state of the decoder is initialized with (i) the hidden states of the last layer of the encoder at all time steps, used as keys and values for attention; (ii) the hidden state of the encoder at all layers at the final time step. This serves to initialize the hidden state of the decoder; and (iii) the valid length of the encoder, to exclude the padding tokens in attention pooling. At each decoding time step, the hidden state of the last layer of the decoder, obtained at the previous time step, is used as the query of the attention mechanism. Both the output of the attention mechanism and the input embedding are concatenated to serve as the input of the RNN decoder.
Seq2SeqAttentionDecoder 클래스에서 RNN 디코더를 구현해야 합니다. 디코더의 state 는 (i) attention를 위한 keys and values로 사용되는 모든 time steps에서 encoder 의 last layer의 hidden states로 초기화됩니다. (ii) 최종 시간 단계에서 모든 계층에서 인코더의 숨겨진 상태. 이는 디코더의 숨겨진 상태를 초기화하는 역할을 합니다. 및 (iii) 어텐션 풀링에서 패딩 토큰을 제외하기 위한 인코더의 유효 길이. 각 디코딩 시간 단계에서 이전 시간 단계에서 얻은 디코더의 마지막 계층의 숨겨진 상태가 어텐션 메커니즘의 쿼리로 사용됩니다. 어텐션 메커니즘의 출력과 입력 임베딩이 모두 연결되어 RNN 디코더의 입력으로 사용됩니다.
class Seq2SeqAttentionDecoder(AttentionDecoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0):
super().__init__()
self.attention = d2l.AdditiveAttention(num_hiddens, dropout)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(
embed_size + num_hiddens, num_hiddens, num_layers,
dropout=dropout)
self.dense = nn.LazyLinear(vocab_size)
self.apply(d2l.init_seq2seq)
def init_state(self, enc_outputs, enc_valid_lens):
# Shape of outputs: (num_steps, batch_size, num_hiddens).
# Shape of hidden_state: (num_layers, batch_size, num_hiddens)
outputs, hidden_state = enc_outputs
return (outputs.permute(1, 0, 2), hidden_state, enc_valid_lens)
def forward(self, X, state):
# Shape of enc_outputs: (batch_size, num_steps, num_hiddens).
# Shape of hidden_state: (num_layers, batch_size, num_hiddens)
enc_outputs, hidden_state, enc_valid_lens = state
# Shape of the output X: (num_steps, batch_size, embed_size)
X = self.embedding(X).permute(1, 0, 2)
outputs, self._attention_weights = [], []
for x in X:
# Shape of query: (batch_size, 1, num_hiddens)
query = torch.unsqueeze(hidden_state[-1], dim=1)
# Shape of context: (batch_size, 1, num_hiddens)
context = self.attention(
query, enc_outputs, enc_outputs, enc_valid_lens)
# Concatenate on the feature dimension
x = torch.cat((context, torch.unsqueeze(x, dim=1)), dim=-1)
# Reshape x as (1, batch_size, embed_size + num_hiddens)
out, hidden_state = self.rnn(x.permute(1, 0, 2), hidden_state)
outputs.append(out)
self._attention_weights.append(self.attention.attention_weights)
# After fully connected layer transformation, shape of outputs:
# (num_steps, batch_size, vocab_size)
outputs = self.dense(torch.cat(outputs, dim=0))
return outputs.permute(1, 0, 2), [enc_outputs, hidden_state,
enc_valid_lens]
@property
def attention_weights(self):
return self._attention_weights위의 코드는 어텐션 메커니즘을 사용하는 시퀀스 투 시퀀스 디코더 모델인 Seq2SeqAttentionDecoder 클래스를 정의합니다.
- Seq2SeqAttentionDecoder 클래스는 AttentionDecoder 클래스를 상속받아 구현됩니다. 이 클래스는 어텐션 메커니즘을 활용하여 시퀀스 투 시퀀스 디코더를 정의합니다.
- __init__ 메서드는 클래스의 초기화를 수행합니다. 여기서는 어텐션 메커니즘(AdditiveAttention 클래스), 임베딩 레이어(nn.Embedding 클래스), GRU 레이어(nn.GRU 클래스), 그리고 최종 출력 레이어(nn.LazyLinear 클래스) 등을 정의하고 초기화합니다. 또한 d2l.init_seq2seq 함수를 통해 가중치 초기화를 수행합니다.
- init_state 메서드는 인코더의 출력과 유효한 길이 정보를 초기 상태로 변환합니다. 이 메서드에서는 인코더의 출력을 차원을 변경하여 디코더에 맞는 형태로 변환하고, 인코더의 은닉 상태와 유효한 길이 정보도 함께 변환합니다.
- forward 메서드는 디코더의 순전파 연산을 수행합니다. 입력 데이터 X와 상태 state를 받아 디코더의 출력을 계산합니다. 이 때 어텐션 메커니즘을 활용하여 인코더의 출력과 관련 정보를 활용합니다. 순환 신경망(RNN)을 통해 디코더의 출력을 계산하며, 최종 출력을 반환합니다.
- attention_weights 메서드는 어텐션 가중치를 반환합니다. 이 메서드를 통해 디코더가 어텐션 메커니즘을 통해 어떤 부분에 주의를 기울였는지를 확인할 수 있습니다.
이렇게 Seq2SeqAttentionDecoder 클래스는 어텐션 메커니즘을 사용하여 시퀀스 투 시퀀스 디코더 모델을 구현한 클래스입니다. 입력 시퀀스와 인코더의 출력, 상태 정보를 활용하여 디코더의 출력을 생성하는 역할을 합니다.
In the following, we test the implemented decoder with attention using a minibatch of 4 sequences, each of which are 7 time steps long.
다음에서는 각각 7 time steps long인 4개 시퀀스의 미니배치를 사용하여 attention 과 함께 구현된 디코더를 테스트합니다.
vocab_size, embed_size, num_hiddens, num_layers = 10, 8, 16, 2
batch_size, num_steps = 4, 7
encoder = d2l.Seq2SeqEncoder(vocab_size, embed_size, num_hiddens, num_layers)
decoder = Seq2SeqAttentionDecoder(vocab_size, embed_size, num_hiddens,
num_layers)
X = torch.zeros((batch_size, num_steps), dtype=torch.long)
state = decoder.init_state(encoder(X), None)
output, state = decoder(X, state)
d2l.check_shape(output, (batch_size, num_steps, vocab_size))
d2l.check_shape(state[0], (batch_size, num_steps, num_hiddens))
d2l.check_shape(state[1][0], (batch_size, num_hiddens))
위의 코드는 시퀀스 투 시퀀스 모델과 어텐션 메커니즘을 사용하는 디코더 모델의 구조와 작동을 설명합니다.
- vocab_size, embed_size, num_hiddens, num_layers는 각각 어휘 크기, 임베딩 차원, 은닉 상태의 차원, RNN 계층 수를 나타냅니다.
- batch_size, num_steps는 각각 미니배치 크기와 시퀀스 길이를 나타냅니다.
- encoder 객체는 시퀀스 투 시퀀스 모델의 인코더로 d2l.Seq2SeqEncoder 클래스로부터 생성됩니다.
- decoder 객체는 어텐션 메커니즘을 사용하는 디코더로 Seq2SeqAttentionDecoder 클래스로부터 생성됩니다.
- X는 입력 데이터로, 크기는 (batch_size, num_steps)로 초기화됩니다.
- encoder(X)를 통해 인코더에 입력 데이터 X를 전달하여 인코더의 출력과 초기 상태 정보를 얻습니다.
- state = decoder.init_state(encoder(X), None)에서는 인코더의 출력과 초기 상태 정보를 활용하여 디코더의 초기 상태를 생성합니다.
- output, state = decoder(X, state)에서는 디코더에 입력 데이터 X와 초기 상태 state를 전달하여 디코더의 출력과 최종 상태를 얻습니다.
- d2l.check_shape(output, (batch_size, num_steps, vocab_size))는 디코더의 출력의 크기가 (batch_size, num_steps, vocab_size)와 일치하는지 확인합니다.
- d2l.check_shape(state[0], (batch_size, num_steps, num_hiddens))는 디코더 상태의 첫 번째 요소(출력)의 크기가 (batch_size, num_steps, num_hiddens)와 일치하는지 확인합니다.
- d2l.check_shape(state[1][0], (batch_size, num_hiddens))는 디코더 상태의 두 번째 요소(은닉 상태)의 크기가 (batch_size, num_hiddens)와 일치하는지 확인합니다.
이렇게 코드는 시퀀스 투 시퀀스 모델과 어텐션 메커니즘을 사용하는 디코더 모델의 구조를 설명하고, 입력 데이터를 통해 디코더의 출력과 상태를 확인하는 과정을 보여줍니다.
11.4.3. Training
Now that we specified the new decoder we can proceed analogously to Section 10.7.6: specify the hyperparameters, instantiate a regular encoder and a decoder with attention, and train this model for machine translation.
이제 새 디코더를 지정했으므로 섹션 10.7.6과 유사하게 진행할 수 있습니다. 하이퍼 매개변수를 지정하고 일반 인코더와 디코더를 attention과 함께 인스턴스화하고 기계 번역을 위해 이 모델을 훈련합니다.
data = d2l.MTFraEng(batch_size=128)
embed_size, num_hiddens, num_layers, dropout = 256, 256, 2, 0.2
encoder = d2l.Seq2SeqEncoder(
len(data.src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqAttentionDecoder(
len(data.tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
model = d2l.Seq2Seq(encoder, decoder, tgt_pad=data.tgt_vocab['<pad>'],
lr=0.005)
trainer = d2l.Trainer(max_epochs=30, gradient_clip_val=1, num_gpus=1)
trainer.fit(model, data)위의 코드는 Machine Translation을 위한 Seq2Seq 모델과 어텐션 메커니즘을 구현하고 학습하는 과정을 나타냅니다.
- data = d2l.MTFraEng(batch_size=128)는 데이터를 로드하고 배치 크기를 128로 설정합니다.
- embed_size, num_hiddens, num_layers, dropout는 임베딩 차원, 은닉 상태 차원, RNN 계층 수, 드롭아웃 확률을 설정합니다.
- encoder 객체는 인코더 모델로, d2l.Seq2SeqEncoder 클래스를 사용하여 생성되며, 소스 언어의 어휘 크기와 위에서 설정한 파라미터들을 입력으로 받습니다.
- decoder 객체는 어텐션 메커니즘을 사용하는 디코더 모델로, Seq2SeqAttentionDecoder 클래스를 사용하여 생성되며, 타겟 언어의 어휘 크기와 위에서 설정한 파라미터들을 입력으로 받습니다.
- model 객체는 Seq2Seq 모델로, 인코더와 디코더, 그리고 패딩 토큰의 인덱스를 입력으로 받습니다.
- trainer 객체는 학습을 관리하는 Trainer 클래스의 객체로, 최대 에포크 수, 그래디언트 클리핑 임계값, 그리고 GPU 개수를 설정합니다.
- trainer.fit(model, data)는 위에서 설정한 모델과 데이터를 이용하여 모델을 학습시키는 과정을 수행합니다.
이렇게 코드는 Machine Translation을 위한 Seq2Seq 모델과 어텐션 메커니즘을 구현하고 데이터를 활용하여 학습시키는 과정을 나타냅니다.
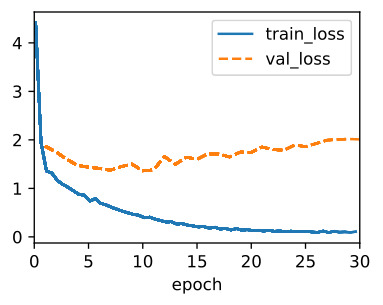
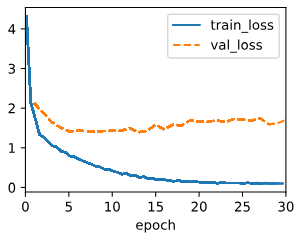
After the model is trained, we use it to translate a few English sentences into French and compute their BLEU scores.
모델이 학습된 후 이를 사용하여 영어 문장 몇 개를 프랑스어로 번역하고 BLEU 점수를 계산합니다.
engs = ['go .', 'i lost .', 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
preds, _ = model.predict_step(
data.build(engs, fras), d2l.try_gpu(), data.num_steps)
for en, fr, p in zip(engs, fras, preds):
translation = []
for token in data.tgt_vocab.to_tokens(p):
if token == '<eos>':
break
translation.append(token)
print(f'{en} => {translation}, bleu,'
f'{d2l.bleu(" ".join(translation), fr, k=2):.3f}')위의 코드는 학습된 Seq2Seq 모델을 사용하여 번역 결과를 생성하고 BLEU 스코어를 계산하여 출력하는 과정을 나타냅니다.
- engs와 fras는 영어-프랑스어 번역을 위한 예시 문장들입니다.
- preds, _ = model.predict_step(data.build(engs, fras), d2l.try_gpu(), data.num_steps)는 모델을 사용하여 입력 문장들에 대한 번역 결과를 생성합니다. data.build(engs, fras)는 입력 문장들을 데이터로 변환하는 과정을 나타냅니다. 이 결과는 예측된 토큰 시퀀스와 어텐션 가중치가 반환됩니다.
- for en, fr, p in zip(engs, fras, preds):는 각각의 예시 문장과 예측된 결과를 묶어서 순회합니다.
- 내부 루프에서 data.tgt_vocab.to_tokens(p)는 예측된 토큰 시퀀스를 단어로 변환합니다. to_tokens 함수는 모델의 출력에 대한 토큰들을 어휘 단어로 변환해주는 역할을 합니다. <eos> 토큰을 만날 때까지 변환된 토큰들을 모아 번역 결과를 생성합니다.
- d2l.bleu(" ".join(translation), fr, k=2):.3f는 생성된 번역 결과와 실제 프랑스어 문장 간의 BLEU 스코어를 계산하고 출력합니다. BLEU는 번역의 품질을 측정하는 지표로, 높을수록 번역이 원문에 가깝다는 의미입니다.
총결적으로, 이 코드는 학습된 Seq2Seq 모델을 사용하여 예시 문장에 대한 번역 결과를 생성하고, 생성된 결과와 실제 정답 문장 간의 BLEU 스코어를 계산하여 출력하는 과정을 보여줍니다.
go . => ['va', '!'], bleu,1.000
i lost . => ["j'ai", 'perdu', '.'], bleu,1.000
he's calm . => ['je', "l'ai", '.'], bleu,0.000
i'm home . => ['je', 'suis', 'chez', 'moi', '.'], bleu,1.000
BLUE score란?
The "BLEU score" stands for "Bilingual Evaluation Understudy" score. It is a metric used to evaluate the quality of machine-generated translations by comparing them to one or more reference translations (human-generated translations). BLEU is widely used in natural language processing and machine translation tasks to quantitatively measure how well a machine-generated translation aligns with one or more human references.
"BLEU 점수"는 "Bilingual Evaluation Understudy" 점수의 약자로, 기계 번역의 품질을 평가하기 위해 사용되는 지표입니다. 이 점수는 기계 생성 번역과 하나 이상의 참조 번역(인간 생성 번역)을 비교하여 평가합니다. BLEU는 자연어 처리 및 기계 번역 작업에서 기계 생성 번역이 참조 번역과 얼마나 잘 일치하는지를 정량적으로 측정하는 데 널리 사용됩니다.
BLEU computes a score between 0 and 1, where higher scores indicate better translations. The score is calculated based on the overlap of n-grams (contiguous sequences of n words) between the machine-generated translation and the reference translation(s). The basic idea is that the more n-grams are shared between the machine translation and the references, the better the translation quality.
BLEU는 0에서 1 사이의 점수를 계산하며, 높은 점수는 더 좋은 번역을 나타냅니다. 이 점수는 기계 생성 번역과 하나 이상의 인간 참조 번역 간의 n-gram(연속된 n개의 단어로 이루어진 구)의 겹치는 부분을 기반으로 계산됩니다. 기본 아이디어는 기계 번역과 참조 간에 공유되는 n-gram이 더 많을수록 번역 품질이 더 좋다는 것입니다.
In practice, BLEU score computation takes into account precision of n-grams, where precision considers how many of the n-grams in the machine translation appear in the reference, and a brevity penalty to discourage overly short translations. The BLEU score can be computed for various n-gram sizes (typically 1 to 4), and an average BLEU score is often reported.
실제로 BLEU 점수 계산은 n-gram의 정밀도(기계 번역에 나타난 n-gram 중 참조에 포함된 n-gram의 수)와, 너무 짧은 번역을 방지하기 위한 간결성 패널티를 고려합니다. BLEU 점수는 일반적으로 1에서 4까지의 다양한 n-gram 크기에 대해 계산되며, 평균 BLEU 점수가 보통 보고됩니다.
While BLEU is a useful metric, it has limitations, such as not fully capturing the nuances of human language and not being sensitive to word order. More recent evaluation metrics like METEOR, ROUGE, and CIDEr have been developed to address some of these limitations.
BLEU는 유용한 지표이지만, 인간 언어의 뉘앙스를 완전히 포착하지 못하거나 단어 순서에 민감하지 못하는 등의 한계가 있습니다. 최근에는 이러한 한계를 해결하기 위해 METEOR, ROUGE, CIDEr 등의 더 최신의 평가 지표가 개발되었습니다.
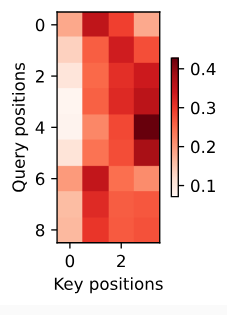
Let’s visualize the attention weights when translating the last English sentence. We see that each query assigns non-uniform weights over key-value pairs. It shows that at each decoding step, different parts of the input sequences are selectively aggregated in the attention pooling.
마지막 영어 문장을 번역하는 것에 대한 attention weights를 시각화해 봅시다. 각 쿼리가 키-값 쌍에 대해 균일하지 않은 가중치를 할당하는 것을 볼 수 있습니다. 각 디코딩 단계에서 입력 시퀀스의 다른 부분이 어텐션 풀링에서 선택적으로 집계됨을 보여줍니다.
_, dec_attention_weights = model.predict_step(
data.build([engs[-1]], [fras[-1]]), d2l.try_gpu(), data.num_steps, True)
attention_weights = torch.cat(
[step[0][0][0] for step in dec_attention_weights], 0)
attention_weights = attention_weights.reshape((1, 1, -1, data.num_steps))
# Plus one to include the end-of-sequence token
d2l.show_heatmaps(
attention_weights[:, :, :, :len(engs[-1].split()) + 1].cpu(),
xlabel='Key positions', ylabel='Query positions')위 코드는 모델의 어텐션 가중치(attention weights)를 시각화하는 과정을 나타냅니다.
- model.predict_step: 이 함수를 사용하여 모델의 예측 결과와 어텐션 가중치를 얻습니다. 입력으로는 모델이 예측할 문장의 번역 쌍(영어와 프랑스어)을 사용합니다. 또한 어텐션 가중치를 얻기 위해 세 번째 매개변수 data.num_steps와 True를 전달합니다. 이를 통해 어텐션 가중치의 시각화를 위한 준비를 합니다.
- torch.cat와 reshape: dec_attention_weights는 여러 단계에서 얻은 어텐션 가중치의 리스트입니다. 이를 모두 결합하고, 형태를 (1, 1, -1, data.num_steps)로 변경합니다. 여기서 -1은 가변적인 크기를 의미합니다.
- show_heatmaps: d2l.show_heatmaps 함수를 사용하여 어텐션 가중치를 히트맵으로 시각화합니다. 이 함수는 어텐션 가중치를 입력으로 받아 시각화된 히트맵을 생성합니다. x축과 y축에는 각각 Key 위치와 Query 위치가 표시됩니다. 이를 통해 어텐션 메커니즘이 입력 문장과 출력 문장 사이의 어디에 집중하는지 시각적으로 확인할 수 있습니다.
총평하면, 이 코드는 모델이 마지막 문장 번역에서 어떤 단어에 어떤 정도로 집중했는지를 시각화하여 확인하는 데 사용됩니다.

11.4.4. Summary
When predicting a token, if not all the input tokens are relevant, the RNN encoder-decoder with the Bahdanau attention mechanism selectively aggregates different parts of the input sequence. This is achieved by treating the state (context variable) as an output of additive attention pooling. In the RNN encoder-decoder, the Bahdanau attention mechanism treats the decoder hidden state at the previous time step as the query, and the encoder hidden states at all the time steps as both the keys and values.
토큰을 예측할 때 모든 입력 토큰이 관련되지 않은 경우 Bahdanau attention mechanism이 있는 RNN 인코더-디코더는 입력 시퀀스의 다른 부분을 선택적으로 집계합니다. 이는 state (컨텍스트 변수)를 additive attention pooling의 출력으로 처리하여 달성됩니다. RNN 인코더-디코더에서 Bahdanau attention mechanism은 이전 단계의 decoder hidden state를 쿼리로 처리하고 모든 단계의 encoder hidden states를 키와 값 모두로 처리합니다.
11.4.5. Exercises
- Replace GRU with LSTM in the experiment.
- Modify the experiment to replace the additive attention scoring function with the scaled dot-product. How does it influence the training efficiency?
'Dive into Deep Learning > D2L Attention Mechanisms and Transformer' 카테고리의 다른 글
| D2L - 11.9. Large-Scale Pretraining with Transformers (0) | 2023.08.10 |
|---|---|
| D2L - 11.8. Transformers for Vision (0) | 2023.08.10 |
| D2L - 11.7. The Transformer Architecture (0) | 2023.08.09 |
| D2L - 11.6. Self-Attention and Positional Encoding (0) | 2023.08.09 |
| D2L - 11.5. Multi-Head Attention (0) | 2023.08.08 |
| D2L - 11.3. Attention Scoring Functions (0) | 2023.08.07 |
| D2L - 11.2. Attention Pooling by Similarity (0) | 2023.08.06 |
| D2L - 11.1. Queries, Keys, and Values (0) | 2023.08.05 |
| D2L - 11. Attention Mechanisms and Transformers (0) | 2023.08.03 |