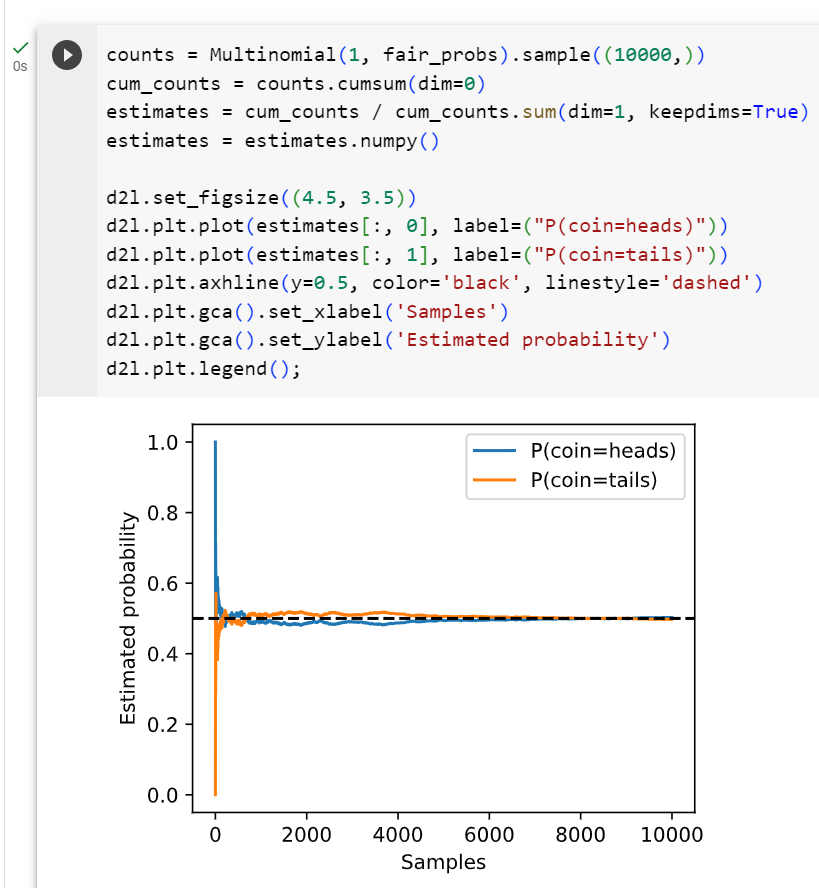
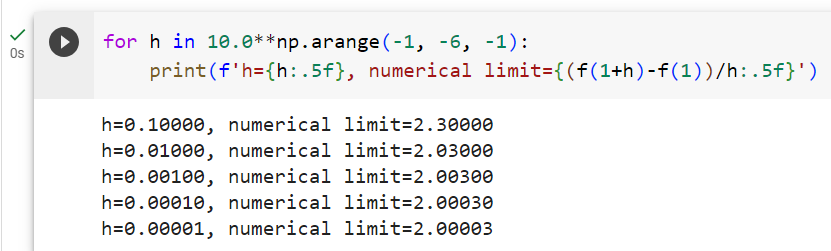
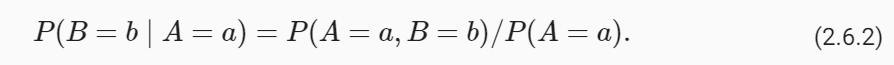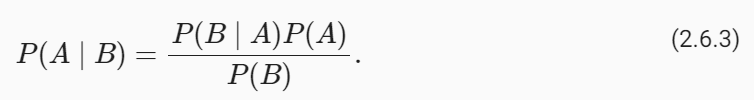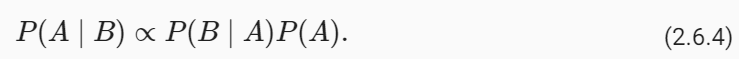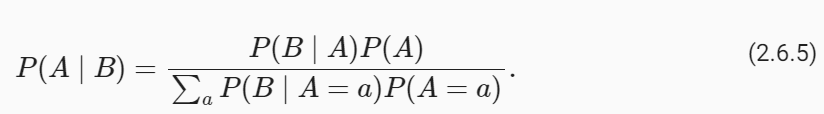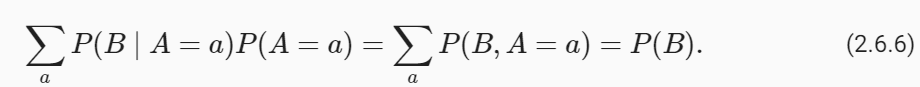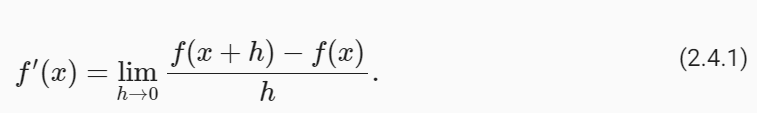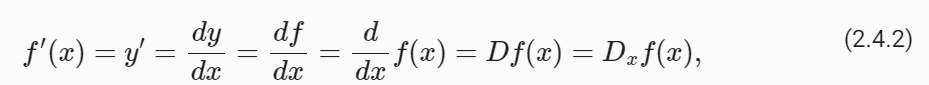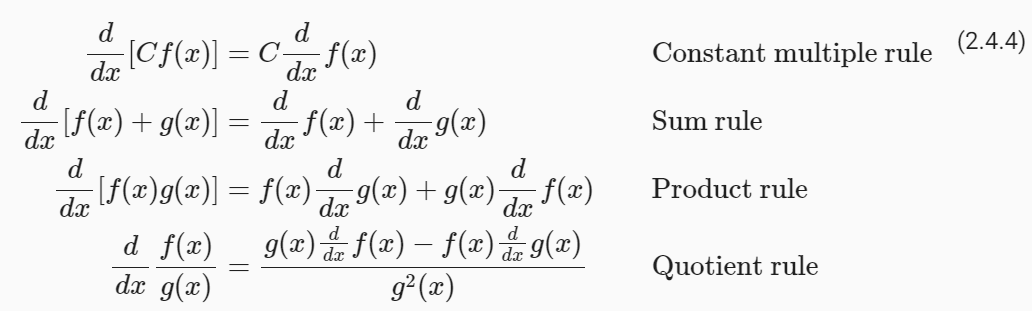https://python.langchain.com/docs/expression_language/interface
Interface | 🦜️🔗 Langchain
To make it as easy as possible to create custom chains, we've implemented a "Runnable" protocol. The Runnable protocol is implemented for most components.
python.langchain.com
In an effort to make it as easy as possible to create custom chains, we've implemented a "Runnable" protocol that most components implement. This is a standard interface with a few different methods, which makes it easy to define custom chains as well as making it possible to invoke them in a standard way. The standard interface exposed includes:
사용자 정의 체인을 최대한 쉽게 생성하기 위한 노력의 일환으로 우리는 대부분의 구성 요소가 구현하는 "실행 가능" 프로토콜을 구현했습니다. 이는 몇 가지 다른 메소드가 포함된 표준 인터페이스로, 사용자 정의 체인을 쉽게 정의할 수 있을 뿐만 아니라 표준 방식으로 호출할 수도 있습니다. 노출된 표준 인터페이스에는 다음이 포함됩니다.
- stream: stream back chunks of the response 응답의 청크를 다시 스트리밍합니다.
- invoke: call the chain on an input 입력에서 체인을 호출합니다.
- batch: call the chain on a list of inputs 입력 목록에서 체인을 호출합니다.
These also have corresponding async methods: 여기에는 해당하는 비동기 메서드도 있습니다.
- astream: stream back chunks of the response async 응답 비동기 청크를 다시 스트리밍합니다.
- ainvoke: call the chain on an input async 입력 비동기에서 체인 호출
- abatch: call the chain on a list of inputs async 비동기 입력 목록에서 체인을 호출합니다.
- astream_log: stream back intermediate steps as they happen, in addition to the final response
최종 응답 외에도 중간 단계가 발생하면 다시 스트리밍합니다.
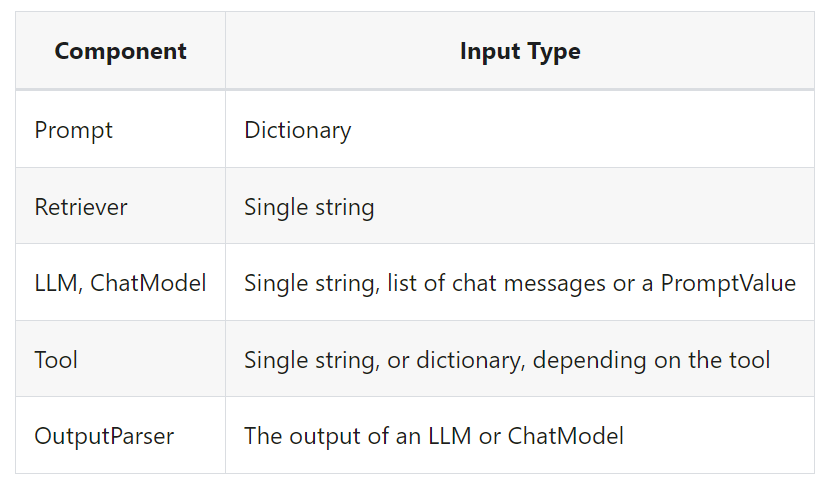
The type of the input varies by component:
입력 유형은 구성 요소에 따라 다릅니다.
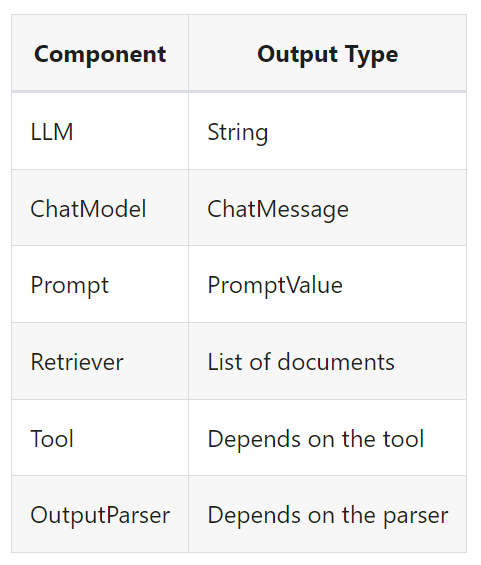
The output type also varies by component:
출력 유형도 구성요소에 따라 다릅니다.
All runnables expose properties to inspect the input and output types:
모든 실행 가능 항목은 입력 및 출력 유형을 검사하기 위한 속성을 노출합니다.
- input_schema: an input Pydantic model auto-generated from the structure of the Runnable
- input_schema: Runnable의 구조에서 자동 생성된 입력 Pydantic 모델
- output_schema: an output Pydantic model auto-generated from the structure of the Runnable
- output_schema: Runnable의 구조에서 자동 생성된 출력 Pydantic 모델
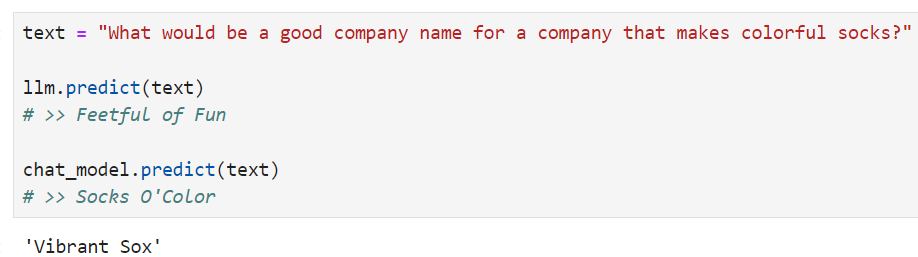
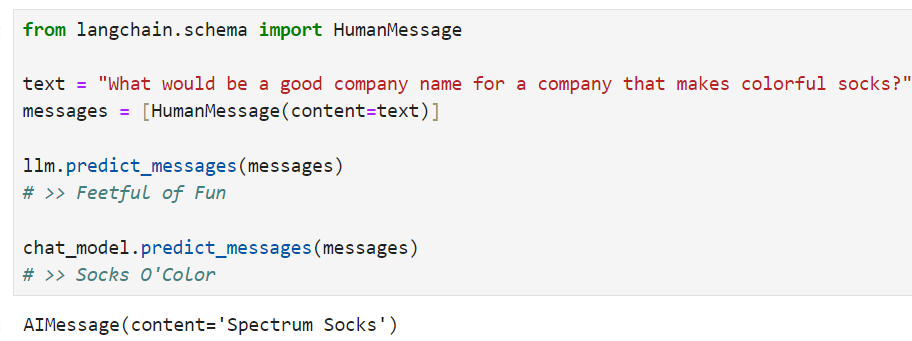
Let's take a look at these methods! To do so, we'll create a super simple PromptTemplate + ChatModel chain.
이러한 방법들을 살펴보겠습니다! 이를 위해 매우 간단한 PromptTemplate + ChatModel 체인을 생성하겠습니다.
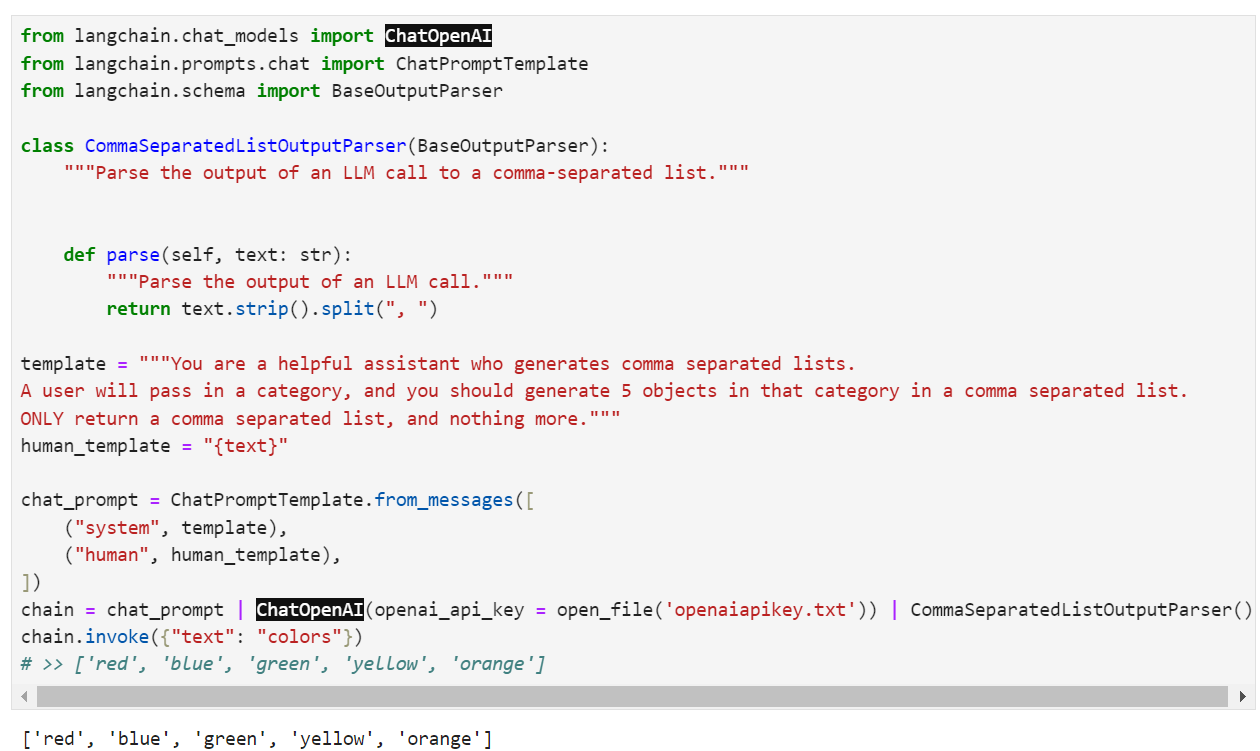
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
model = ChatOpenAI()
prompt = ChatPromptTemplate.from_template("tell me a joke about {topic}")
chain = prompt | model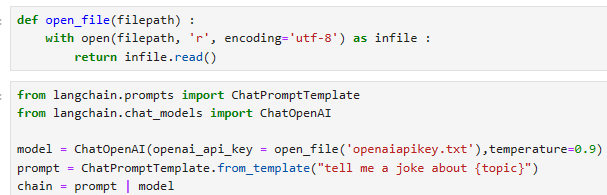
이 코드는 "langchain" 라이브러리를 사용하여 OpenAI의 언어 모델을 활용하는 예시를 제공합니다.
- from langchain.prompts import ChatPromptTemplate:
- "langchain" 라이브러리에서 ChatPromptTemplate 클래스를 가져오는 명령입니다.
- ChatPromptTemplate 클래스는 대화 생성에 사용되는 템플릿을 만들고 활용하는 데 도움을 주는 클래스입니다.
- from langchain.chat_models import ChatOpenAI:
- "langchain" 라이브러리에서 ChatOpenAI 클래스를 가져오는 명령입니다.
- ChatOpenAI 클래스는 OpenAI의 언어 모델을 활용하는 데 사용되는 클래스입니다.
- model = ChatOpenAI(openai_api_key = open_file('openaiapikey.txt'), temperature=0.9):
- ChatOpenAI 클래스의 인스턴스를 생성합니다.
- openai_api_key 매개변수에 OpenAI API 키를 파일로부터 읽어온 값을 전달합니다.
- temperature 매개변수는 모델의 창의성을 조절하는 요소로, 0.9로 설정되어 있으며 높을수록 더 다양한 출력이 생성됩니다.
- prompt = ChatPromptTemplate.from_template("tell me a joke about {topic}"):
- ChatPromptTemplate 클래스의 from_template 메서드를 사용하여 템플릿을 생성합니다.
- 템플릿 문자열 "tell me a joke about {topic}"은 {topic} 부분이 나중에 대체될 변수를 나타냅니다.
- chain = prompt | model:
- prompt와 model을 결합하여 대화 체인을 생성합니다.
- 이러한 체인을 사용하면 템플릿을 모델과 함께 사용하여 모델에게 대화 형식으로 질문을 하고 응답을 받을 수 있습니다.
이 코드는 주어진 주제에 대한 재미있는 농담을 생성하기 위해 OpenAI 모델을 사용하는 예시를 나타내고 있습니다. 모델은 주어진 API 키 및 설정과 함께 템플릿을 사용하여 대화를 생성하고 대화의 연장으로 대화를 계속할 수 있습니다.
Input Schema
A description of the inputs accepted by a Runnable. This is a Pydantic model dynamically generated from the structure of any Runnable. You can call .schema() on it to obtain a JSONSchema representation.
Runnable이 허용하는 입력에 대한 설명입니다. 이는 Runnable의 구조에서 동적으로 생성된 Pydantic 모델입니다. .schema()를 호출하여 JSONSchema 표현을 얻을 수 있습니다.
# The input schema of the chain is the input schema of its first part, the prompt.
chain.input_schema.schema()이 코드는 "chain"이라는 객체의 입력 스키마(input schema)를 설명하고 있습니다. "chain"은 여러 부분으로 구성된 대화 체인이며, 이 코드는 체인의 입력 스키마를 확인하는 부분에 대한 설명입니다.
# 체인의 입력 스키마는 체인의 첫 번째 부분인 prompt의 입력 스키마와 동일합니다.
chain.input_schema.schema()- "chain"은 여러 부분으로 이루어진 대화 체인을 나타내는 객체입니다. 이 대화 체인은 대화를 구성하고 관리하는 데 사용됩니다.
- chain.input_schema.schema()은 체인의 입력 스키마를 확인하는 코드입니다. 입력 스키마는 데이터나 정보의 구조와 형식을 정의하는데 사용됩니다.
- 주석(#)은 코드에 설명을 추가하는 데 사용되며, 이 경우에는 주석으로 코드의 목적을 설명하고 있습니다.
- 이 코드에서 "chain"의 입력 스키마는 "prompt"라는 첫 번째 부분의 입력 스키마와 동일하다고 설명하고 있습니다. 즉, 체인의 입력 스키마는 체인의 첫 번째 부분인 "prompt"에서 정의한 입력 스키마와 일치합니다.
- 입력 스키마의 역할은 데이터의 형식, 구조, 및 유효성 검사에 관련됩니다. 이 코드는 입력 스키마를 확인하는 용도로 사용되며, 체인의 구조와 입력 데이터에 대한 정보를 얻을 수 있습니다.
이 코드는 체인의 입력 스키마를 확인하고 첫 번째 부분 "prompt"의 입력 스키마와 일치한다는 점을 강조하는 목적으로 사용됩니다.

prompt.input_schema.schema()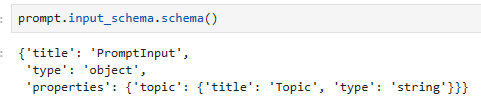
model.input_schema.schema()return 값
{'title': 'ChatOpenAIInput',
'anyOf': [{'type': 'string'},
{'$ref': '#/definitions/StringPromptValue'},
{'$ref': '#/definitions/ChatPromptValueConcrete'},
{'type': 'array',
'items': {'anyOf': [{'$ref': '#/definitions/AIMessage'},
{'$ref': '#/definitions/HumanMessage'},
{'$ref': '#/definitions/ChatMessage'},
{'$ref': '#/definitions/SystemMessage'},
{'$ref': '#/definitions/FunctionMessage'}]}}],
'definitions': {'StringPromptValue': {'title': 'StringPromptValue',
'description': 'String prompt value.',
'type': 'object',
'properties': {'text': {'title': 'Text', 'type': 'string'},
'type': {'title': 'Type',
'default': 'StringPromptValue',
'enum': ['StringPromptValue'],
'type': 'string'}},
'required': ['text']},
'AIMessage': {'title': 'AIMessage',
'description': 'A Message from an AI.',
'type': 'object',
'properties': {'content': {'title': 'Content', 'type': 'string'},
'additional_kwargs': {'title': 'Additional Kwargs', 'type': 'object'},
'type': {'title': 'Type',
'default': 'ai',
'enum': ['ai'],
'type': 'string'},
'example': {'title': 'Example', 'default': False, 'type': 'boolean'}},
'required': ['content']},
'HumanMessage': {'title': 'HumanMessage',
'description': 'A Message from a human.',
'type': 'object',
'properties': {'content': {'title': 'Content', 'type': 'string'},
'additional_kwargs': {'title': 'Additional Kwargs', 'type': 'object'},
'type': {'title': 'Type',
'default': 'human',
'enum': ['human'],
'type': 'string'},
'example': {'title': 'Example', 'default': False, 'type': 'boolean'}},
'required': ['content']},
'ChatMessage': {'title': 'ChatMessage',
'description': 'A Message that can be assigned an arbitrary speaker (i.e. role).',
'type': 'object',
'properties': {'content': {'title': 'Content', 'type': 'string'},
'additional_kwargs': {'title': 'Additional Kwargs', 'type': 'object'},
'type': {'title': 'Type',
'default': 'chat',
'enum': ['chat'],
'type': 'string'},
'role': {'title': 'Role', 'type': 'string'}},
'required': ['content', 'role']},
'SystemMessage': {'title': 'SystemMessage',
'description': 'A Message for priming AI behavior, usually passed in as the first of a sequence\nof input messages.',
'type': 'object',
'properties': {'content': {'title': 'Content', 'type': 'string'},
'additional_kwargs': {'title': 'Additional Kwargs', 'type': 'object'},
'type': {'title': 'Type',
'default': 'system',
'enum': ['system'],
'type': 'string'}},
'required': ['content']},
'FunctionMessage': {'title': 'FunctionMessage',
'description': 'A Message for passing the result of executing a function back to a model.',
'type': 'object',
'properties': {'content': {'title': 'Content', 'type': 'string'},
'additional_kwargs': {'title': 'Additional Kwargs', 'type': 'object'},
'type': {'title': 'Type',
'default': 'function',
'enum': ['function'],
'type': 'string'},
'name': {'title': 'Name', 'type': 'string'}},
'required': ['content', 'name']},
'ChatPromptValueConcrete': {'title': 'ChatPromptValueConcrete',
'description': 'Chat prompt value which explicitly lists out the message types it accepts.\nFor use in external schemas.',
'type': 'object',
'properties': {'messages': {'title': 'Messages',
'type': 'array',
'items': {'anyOf': [{'$ref': '#/definitions/AIMessage'},
{'$ref': '#/definitions/HumanMessage'},
{'$ref': '#/definitions/ChatMessage'},
{'$ref': '#/definitions/SystemMessage'},
{'$ref': '#/definitions/FunctionMessage'}]}},
'type': {'title': 'Type',
'default': 'ChatPromptValueConcrete',
'enum': ['ChatPromptValueConcrete'],
'type': 'string'}},
'required': ['messages']}}}
Output Schema
A description of the outputs produced by a Runnable. This is a Pydantic model dynamically generated from the structure of any Runnable. You can call .schema() on it to obtain a JSONSchema representation.
Runnable이 생성한 출력에 대한 설명입니다. 이는 Runnable의 구조에서 동적으로 생성된 Pydantic 모델입니다. .schema()를 호출하여 JSONSchema 표현을 얻을 수 있습니다.
# The output schema of the chain is the output schema of its last part, in this case a ChatModel, which outputs a ChatMessage
chain.output_schema.schema()
이 코드는 "chain" 객체의 출력 스키마를 설명하고 있습니다. "chain"은 여러 부분으로 구성된 대화 체인이며, 이 코드는 체인의 출력 스키마를 확인하는 부분에 대한 설명입니다.
# 체인의 출력 스키마는 마지막 부분인 ChatModel의 출력 스키마와 동일합니다. 이 경우에는 ChatMessage가 출력됩니다.
chain.output_schema.schema()- "chain"은 여러 부분으로 이루어진 대화 체인을 나타내는 객체입니다. 이 대화 체인은 대화의 구조와 출력을 관리하는 데 사용됩니다.
- chain.output_schema.schema()은 체인의 출력 스키마를 확인하는 코드입니다. 출력 스키마는 데이터나 정보의 구조와 형식을 정의하는데 사용됩니다.
- 주석(#)은 코드에 설명을 추가하는 데 사용되며, 이 경우에는 주석으로 코드의 목적을 설명하고 있습니다.
- 이 코드에서 "chain"의 출력 스키마는 이 체인의 마지막 부분인 "ChatModel"에서 정의한 출력 스키마와 일치한다고 설명하고 있습니다. 마지막 부분인 "ChatModel"이 "ChatMessage"를 출력하므로, 체인의 출력 스키마도 "ChatMessage"와 일치합니다.
- 출력 스키마의 역할은 데이터의 형식, 구조, 및 유효성 검사에 관련됩니다. 이 코드는 출력 스키마를 확인하는 용도로 사용되며, 체인의 구조와 출력 데이터에 대한 정보를 얻을 수 있습니다.
이 코드는 체인의 출력 스키마를 확인하고 마지막 부분 "ChatModel"의 출력 스키마와 일치한다는 점을 강조하는 목적으로 사용됩니다.
return 값
{'title': 'ChatOpenAIOutput',
'anyOf': [{'$ref': '#/definitions/AIMessage'},
{'$ref': '#/definitions/HumanMessage'},
{'$ref': '#/definitions/ChatMessage'},
{'$ref': '#/definitions/SystemMessage'},
{'$ref': '#/definitions/FunctionMessage'}],
'definitions': {'AIMessage': {'title': 'AIMessage',
'description': 'A Message from an AI.',
'type': 'object',
'properties': {'content': {'title': 'Content', 'type': 'string'},
'additional_kwargs': {'title': 'Additional Kwargs', 'type': 'object'},
'type': {'title': 'Type',
'default': 'ai',
'enum': ['ai'],
'type': 'string'},
'example': {'title': 'Example', 'default': False, 'type': 'boolean'}},
'required': ['content']},
'HumanMessage': {'title': 'HumanMessage',
'description': 'A Message from a human.',
'type': 'object',
'properties': {'content': {'title': 'Content', 'type': 'string'},
'additional_kwargs': {'title': 'Additional Kwargs', 'type': 'object'},
'type': {'title': 'Type',
'default': 'human',
'enum': ['human'],
'type': 'string'},
'example': {'title': 'Example', 'default': False, 'type': 'boolean'}},
'required': ['content']},
'ChatMessage': {'title': 'ChatMessage',
'description': 'A Message that can be assigned an arbitrary speaker (i.e. role).',
'type': 'object',
'properties': {'content': {'title': 'Content', 'type': 'string'},
'additional_kwargs': {'title': 'Additional Kwargs', 'type': 'object'},
'type': {'title': 'Type',
'default': 'chat',
'enum': ['chat'],
'type': 'string'},
'role': {'title': 'Role', 'type': 'string'}},
'required': ['content', 'role']},
'SystemMessage': {'title': 'SystemMessage',
'description': 'A Message for priming AI behavior, usually passed in as the first of a sequence\nof input messages.',
'type': 'object',
'properties': {'content': {'title': 'Content', 'type': 'string'},
'additional_kwargs': {'title': 'Additional Kwargs', 'type': 'object'},
'type': {'title': 'Type',
'default': 'system',
'enum': ['system'],
'type': 'string'}},
'required': ['content']},
'FunctionMessage': {'title': 'FunctionMessage',
'description': 'A Message for passing the result of executing a function back to a model.',
'type': 'object',
'properties': {'content': {'title': 'Content', 'type': 'string'},
'additional_kwargs': {'title': 'Additional Kwargs', 'type': 'object'},
'type': {'title': 'Type',
'default': 'function',
'enum': ['function'],
'type': 'string'},
'name': {'title': 'Name', 'type': 'string'}},
'required': ['content', 'name']}}}
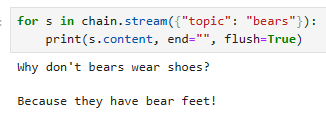
Stream
for s in chain.stream({"topic": "bears"}):
print(s.content, end="", flush=True)이 코드는 "chain" 객체를 사용하여 대화를 생성하고 출력하는 부분을 설명하고 있습니다.
- for s in chain.stream({"topic": "bears"})::
- 이 부분은 "chain" 객체를 사용하여 대화를 생성하는 반복문입니다.
- "chain.stream({"topic": "bears"})"은 주어진 입력 매개변수인 {"topic": "bears"}를 사용하여 대화를 시작하고 그 결과를 반복적으로 처리합니다.
- print(s.content, end="", flush=True):
- "s"는 반복문에서 가져온 대화의 한 부분을 나타냅니다.
- "s.content"는 대화의 내용을 나타내며, 이 부분은 출력됩니다.
- "end=""`"는 "print" 함수가 줄 바꿈 문자를 출력하지 않도록 합니다. 따라서 출력이 연이어 나타납니다.
- "flush=True"는 출력을 즉시 표시하도록 하는 옵션으로, 출력이 즉시 화면에 나타납니다.
이 코드는 "chain"을 사용하여 주제가 "bears"인 대화를 생성하고 해당 대화를 반복적으로 처리하여 출력합니다. 출력은 줄 바꿈 없이 연이어 표시되며, flush=True 옵션을 사용하여 즉시 표시됩니다.
Invoke
chain.invoke({"topic": "bears"})이 코드는 "chain" 객체를 사용하여 대화를 생성하고 실행하는 부분을 설명하고 있습니다.
- chain.invoke({"topic": "bears"}):
- 이 부분은 "chain" 객체를 사용하여 대화를 생성하고 실행하는 명령입니다.
- {"topic": "bears"}는 입력 매개변수로 주어진 딕셔너리를 나타냅니다. 여기서 "topic"은 대화 주제를 설정하는데 사용되는 키이며, "bears"는 주제로 설정됩니다.
이 코드는 "chain"을 사용하여 주제가 "bears"인 대화를 생성하고 실행합니다. 이로써 대화 모델은 "bears" 주제에 관한 대화를 생성하고 결과를 반환합니다.

Batch
chain.batch([{"topic": "bears"}, {"topic": "cats"}])이 코드는 "chain" 객체를 사용하여 여러 대화를 일괄 처리하는 방법을 보여주고 있습니다.
- chain.batch([{"topic": "bears"}, {"topic": "cats"}]):
- 이 부분은 "chain" 객체를 사용하여 여러 대화를 일괄 처리하는 명령입니다.
- {"topic": "bears"}와 {"topic": "cats"}는 입력 매개변수로 주어진 딕셔너리의 목록을 나타냅니다. 각 딕셔너리에는 "topic" 키와 대화 주제를 설정하는 값이 포함되어 있습니다.
이 코드는 "chain"을 사용하여 "bears" 주제와 "cats" 주제에 관한 여러 대화를 생성하고 처리합니다. 이로써 대화 모델은 주어진 주제에 따라 대화를 생성하고 결과를 반환합니다.

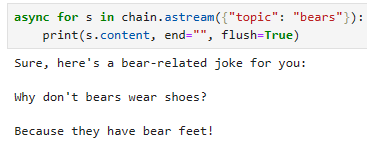
Async Stream
async for s in chain.astream({"topic": "bears"}):
print(s.content, end="", flush=True)이 코드는 비동기로 "chain" 객체를 사용하여 대화를 생성하고 출력하는 부분을 설명하고 있습니다.
- async for s in chain.astream({"topic": "bears"})::
- 이 부분은 비동기 반복문으로, "chain" 객체를 사용하여 대화를 생성하고 결과를 처리합니다.
- chain.astream({"topic": "bears"})은 주어진 입력 매개변수인 {"topic": "bears"}를 사용하여 대화를 시작하고 비동기 스트림을 통해 결과를 받아옵니다.
- print(s.content, end="", flush=True):
- "s"는 스트림에서 가져온 대화의 한 부분을 나타냅니다.
- "s.content"는 대화의 내용을 나타내며, 이 부분은 출력됩니다.
- "end=""`"는 "print" 함수가 줄 바꿈 문자를 출력하지 않도록 합니다. 따라서 출력이 연이어 나타납니다.
- "flush=True"는 출력을 즉시 표시하도록 하는 옵션으로, 출력이 즉시 화면에 나타납니다.
이 코드는 "chain"을 사용하여 주제가 "bears"인 대화를 생성하고 비동기 스트림을 통해 결과를 받아오며, 결과를 출력합니다. 출력은 줄 바꿈 없이 연이어 표시되며, flush=True 옵션을 사용하여 즉시 표시됩니다.
Async Invoke
await chain.ainvoke({"topic": "bears"})이 코드는 "chain" 객체를 사용하여 대화를 생성하고 실행하는 비동기 방식을 설명하고 있습니다.
- await chain.ainvoke({"topic": "bears"}):
- 이 부분은 "chain" 객체를 사용하여 비동기로 대화를 생성하고 실행하는 명령입니다.
- {"topic": "bears"}는 입력 매개변수로 주어진 딕셔너리를 나타냅니다. 여기서 "topic"은 대화 주제를 설정하는데 사용되는 키이며, "bears"는 주제로 설정됩니다.
이 코드는 "chain"을 사용하여 "bears" 주제에 관한 대화를 생성하고 실행합니다. await 키워드는 비동기 작업이 완료될 때까지 대기하도록 하며, 대화의 실행이 완료되면 결과를 반환합니다.

Async Batch
await chain.abatch([{"topic": "bears"}])이 코드는 "chain" 객체를 사용하여 대화를 생성하고 실행하는 비동기 일괄 처리 방법을 설명하고 있습니다.
- await chain.abatch([{"topic": "bears"}]):
- 이 부분은 "chain" 객체를 사용하여 비동기로 대화를 생성하고 실행하는 명령입니다.
- {"topic": "bears"}는 입력 매개변수로 주어진 딕셔너리의 목록을 나타냅니다. 각 딕셔너리에는 "topic" 키와 대화 주제를 설정하는 값이 포함되어 있습니다.
이 코드는 "chain"을 사용하여 "bears" 주제에 관한 대화를 생성하고 실행합니다. await 키워드는 비동기 작업이 완료될 때까지 대기하도록 하며, 대화의 실행이 완료되면 결과를 반환합니다.

Async Stream Intermediate Steps
All runnables also have a method .astream_log() which is used to stream (as they happen) all or part of the intermediate steps of your chain/sequence.
모든 runnables 는 체인/시퀀스의 중간 단계 전체 또는 일부를 스트리밍하는 데 사용되는 .astream_log() 메서드도 있습니다.
This is useful to show progress to the user, to use intermediate results, or to debug your chain.
이는 사용자에게 진행 상황을 표시하거나, 중간 결과를 사용하거나, 체인을 디버깅하는 데 유용합니다.
You can stream all steps (default) or include/exclude steps by name, tags or metadata.
모든 단계를 스트리밍(기본값)하거나 이름, 태그 또는 메타데이터별로 단계를 포함/제외할 수 있습니다.
This method yields JSONPatch ops that when applied in the same order as received build up the RunState.
이 메서드는 수신된 순서와 동일한 순서로 적용될 때 RunState를 구축하는 JSONPatch 작업을 생성합니다.
class LogEntry(TypedDict):
id: str
"""ID of the sub-run."""
name: str
"""Name of the object being run."""
type: str
"""Type of the object being run, eg. prompt, chain, llm, etc."""
tags: List[str]
"""List of tags for the run."""
metadata: Dict[str, Any]
"""Key-value pairs of metadata for the run."""
start_time: str
"""ISO-8601 timestamp of when the run started."""
streamed_output_str: List[str]
"""List of LLM tokens streamed by this run, if applicable."""
final_output: Optional[Any]
"""Final output of this run.
Only available after the run has finished successfully."""
end_time: Optional[str]
"""ISO-8601 timestamp of when the run ended.
Only available after the run has finished."""
class RunState(TypedDict):
id: str
"""ID of the run."""
streamed_output: List[Any]
"""List of output chunks streamed by Runnable.stream()"""
final_output: Optional[Any]
"""Final output of the run, usually the result of aggregating (`+`) streamed_output.
Only available after the run has finished successfully."""
logs: Dict[str, LogEntry]
"""Map of run names to sub-runs. If filters were supplied, this list will
contain only the runs that matched the filters."""
위의 코드는 Python 3.8 이상에서 사용 가능한 TypedDict를 사용하여 두 개의 타입 딕셔너리(LogEntry 및 RunState)를 정의하고 있습니다. 이 타입 딕셔너리는 특정 키와 그에 상응하는 데이터 형식을 명시적으로 정의함으로써 딕셔너리의 구조를 제한하고 코드의 가독성과 안정성을 향상시킵니다.
- LogEntry 타입 딕셔너리:
- id: str: 서브런의 ID를 나타내는 문자열.
- name: str: 실행 중인 객체의 이름을 나타내는 문자열.
- type: str: 실행 중인 객체의 유형(예: 프롬프트, 체인, llm 등)을 나타내는 문자열.
- tags: List[str]: 실행에 대한 태그 목록을 나타내는 문자열 리스트.
- metadata: Dict[str, Any]: 실행에 대한 메타데이터를 나타내는 키-값 쌍의 딕셔너리.
- start_time: str: 실행이 시작된 ISO-8601 타임스탬프를 나타내는 문자열.
- streamed_output_str: List[str]: 이 실행에 의해 스트리밍된 LLM 토큰의 목록(적용 가능한 경우).
- final_output: Optional[Any]: 이 실행의 최종 출력. 실행이 성공적으로 완료된 후에만 사용 가능한 옵셔널 타입 데이터.
- end_time: Optional[str]: 실행이 종료된 ISO-8601 타임스탬프. 실행이 성공적으로 완료된 후에만 사용 가능한 옵셔널 타입 데이터.
- RunState 타입 딕셔너리:
- id: str: 실행의 ID를 나타내는 문자열.
- streamed_output: List[Any]: Runnable.stream()에 의해 스트리밍된 출력 청크 목록을 나타내는 리스트.
- final_output: Optional[Any]: 실행의 최종 출력. 일반적으로 streamed_output을 집계한 결과입니다. 실행이 성공적으로 완료된 후에만 사용 가능한 옵셔널 타입 데이터.
- logs: Dict[str, LogEntry]: 실행의 이름과 서브런(로그 엔트리) 간의 매핑. 필터가 제공된 경우 해당 필터와 일치하는 실행만 포함합니다.
이러한 타입 딕셔너리는 데이터 구조와 형식을 명확히 정의하며, 이러한 정보를 사용하는 코드에서 유용한 형식 검증과 가독성을 제공합니다.
Streaming JSONPatch chunks
This is useful eg. to stream the JSONPatch in an HTTP server, and then apply the ops on the client to rebuild the run state there. See LangServe for tooling to make it easier to build a webserver from any Runnable.
이는 유용합니다. HTTP 서버에서 JSONPatch를 스트리밍한 다음 클라이언트에 작업을 적용하여 실행 상태를 다시 빌드합니다. Runnable에서 웹 서버를 더 쉽게 구축할 수 있는 도구는 LangServe를 참조하세요.
from langchain.embeddings import OpenAIEmbeddings
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough
from langchain.vectorstores import FAISS
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
vectorstore = FAISS.from_texts(["harrison worked at kensho"], embedding=OpenAIEmbeddings())
retriever = vectorstore.as_retriever()
retrieval_chain = (
{"context": retriever.with_config(run_name='Docs'), "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
async for chunk in retrieval_chain.astream_log("where did harrison work?", include_names=['Docs']):
print("-"*40)
print(chunk)이 코드는 "langchain" 라이브러리를 사용하여 OpenAI 모델을 활용하여 질문 응답 시스템을 구축하는 예시를 제공합니다.
- 모듈 및 클래스 가져오기:
- langchain.embeddings 모듈에서 OpenAIEmbeddings 클래스를 가져옵니다. 이 클래스는 OpenAI의 임베딩을 사용하기 위한 도구를 제공합니다.
- langchain.schema.output_parser 모듈에서 StrOutputParser 클래스를 가져옵니다. 이 클래스는 출력을 파싱하는 데 사용됩니다.
- langchain.schema.runnable 모듈에서 RunnablePassthrough 클래스를 가져옵니다. 이 클래스는 실행 가능한 객체를 나타내는 클래스입니다.
- langchain.vectorstores 모듈에서 FAISS 클래스를 가져옵니다. 이 클래스는 FAISS 벡터 저장소를 만들고 관리하는 도구를 제공합니다.
- 템플릿 정의:
- "template" 변수에는 질문에 대한 컨텍스트와 질문 자체를 템플릿으로 정의합니다.
- 질문 응답 시스템 구성:
- "prompt" 변수에는 "ChatPromptTemplate.from_template(template)"을 사용하여 템플릿을 기반으로한 대화 템플릿을 생성합니다.
- "vectorstore" 변수에는 "FAISS.from_texts"를 사용하여 벡터 저장소를 생성합니다. 이 벡터 저장소는 "harrison worked at kensho"와 같은 텍스트로 초기화되며, OpenAI 임베딩을 사용하여 벡터를 생성합니다.
- "retriever" 변수에는 "vectorstore.as_retriever()"를 사용하여 정보 검색(retrieval)을 위한 객체를 생성합니다.
- 실행 체인 설정:
- "retrieval_chain" 변수에는 실행 체인을 설정합니다. 이 체인은 다음과 같이 구성됩니다:
- "context"와 "question" 매개변수를 사용하여 "retriever.with_config(run_name='Docs')"와 "RunnablePassthrough()"를 결합합니다.
- "prompt" 템플릿을 추가합니다.
- 모델(model)을 추가합니다.
- 출력 파서(StrOutputParser)를 추가합니다.
- "retrieval_chain" 변수에는 실행 체인을 설정합니다. 이 체인은 다음과 같이 구성됩니다:
- 결과 검색 및 출력:
- 비동기 반복문(async for)을 사용하여 질문을 실행하고 결과를 검색합니다.
- retrieval_chain.astream_log("where did harrison work?", include_names=['Docs'])를 사용하여 "where did harrison work?"라는 질문을 실행하고, 실행 결과를 가져옵니다.
- 실행 결과를 출력합니다.
이 코드는 OpenAI 모델을 사용하여 컨텍스트와 질문을 기반으로 질문 응답 시스템을 구현하고, 결과를 출력하는 과정을 나타냅니다.
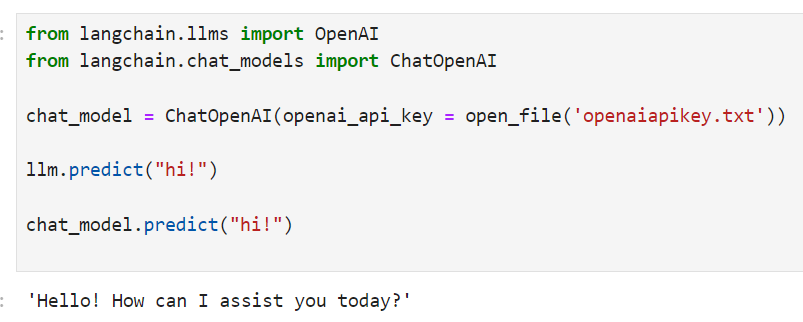
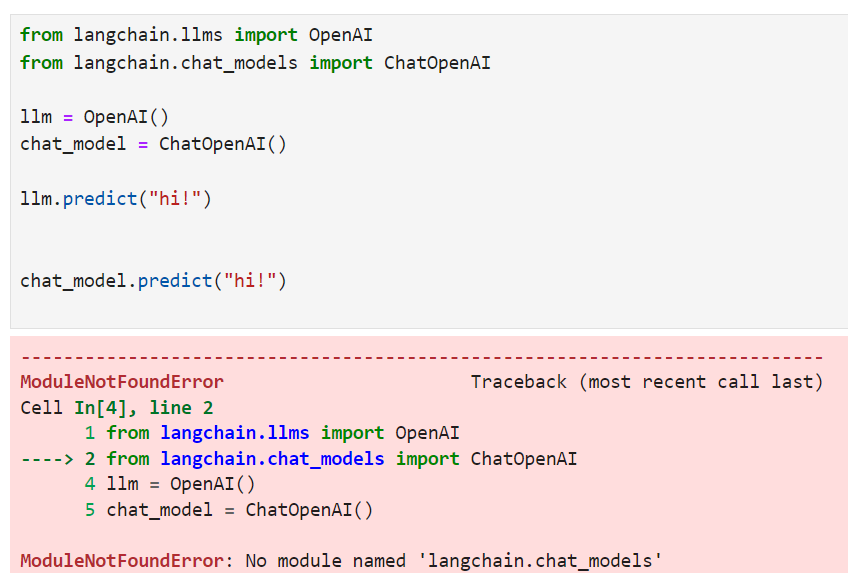
나는 OpenAI key를 외부 파일에서 읽어 오도록 아래와 같이 코딩 했음
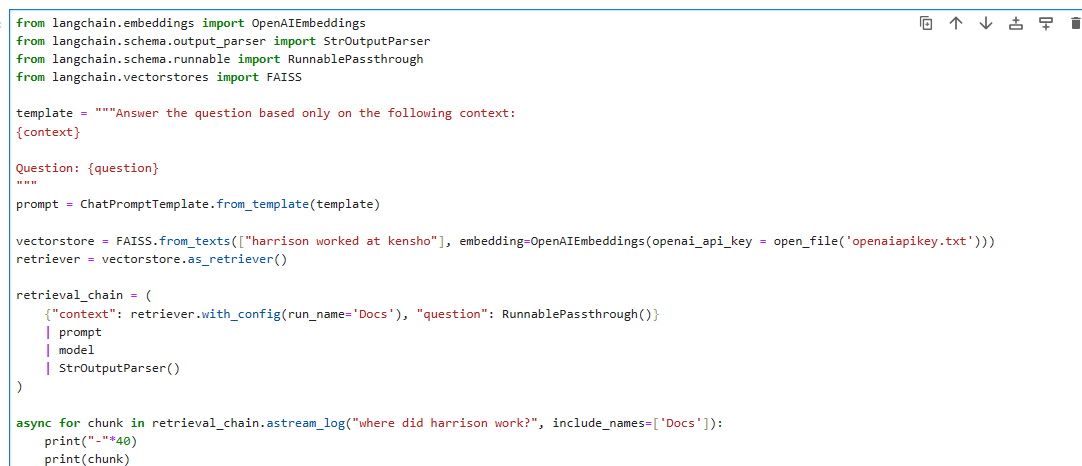
return 값

Streaming the incremental RunState
You can simply pass diff=False to get incremental values of RunState. You get more verbose output with more repetitive parts.
간단히 diff=False를 전달하여 RunState의 증분 값을 얻을 수 있습니다. 반복되는 부분이 많아지면 더 자세한 출력을 얻을 수 있습니다.
async for chunk in retrieval_chain.astream_log("where did harrison work?", include_names=['Docs'], diff=False):
print("-"*70)
print(chunk)
이 코드는 질문 응답 시스템을 통해 질문을 실행하고 결과를 비동기적으로 가져오는 부분을 설명하고 있습니다.
- async for chunk in retrieval_chain.astream_log("where did harrison work?", include_names=['Docs'], diff=False)::
- 이 부분은 비동기 반복문으로, "retrieval_chain" 객체를 사용하여 질문을 실행하고 결과를 비동기적으로 처리합니다.
- retrieval_chain.astream_log("where did harrison work?", include_names=['Docs'], diff=False)는 "where did harrison work?"라는 질문을 실행하고 결과를 가져오는 코드입니다.
- include_names=['Docs']는 결과에 대한 필터로, "Docs"라는 이름을 가진 실행에 대한 결과만 포함합니다.
- diff=False는 결과를 비교(diff)하지 않도록 설정합니다.
- print("-"*70):
- 이 부분은 구분선을 출력합니다. 출력 결과를 시각적으로 구분하기 위해 사용됩니다.
- print(chunk):
- "chunk"는 질문 실행의 결과를 나타냅니다.
- 이 부분은 실행 결과를 출력합니다.
이 코드는 "retrieval_chain"을 사용하여 "where did harrison work?"라는 질문을 실행하고 결과를 가져오며, 결과를 출력합니다. 결과는 "Docs"라는 이름을 가진 실행에 대한 것만 포함되며, diff를 비활성화하고 결과를 출력합니다.
return 값
----------------------------------------------------------------------
RunLog({'final_output': None,
'id': 'd16fad8f-018a-4dcd-9bce-bab37e9c19d7',
'logs': {},
'streamed_output': []})
----------------------------------------------------------------------
RunLog({'final_output': None,
'id': 'd16fad8f-018a-4dcd-9bce-bab37e9c19d7',
'logs': {'Docs': {'end_time': None,
'final_output': None,
'id': '91e795ef-5cf9-4580-bf94-b4a2464cf5ab',
'metadata': {},
'name': 'Docs',
'start_time': '2023-10-26T16:54:45.839',
'streamed_output_str': [],
'tags': ['map:key:context', 'FAISS', 'OpenAIEmbeddings'],
'type': 'retriever'}},
'streamed_output': []})
----------------------------------------------------------------------
RunLog({'final_output': None,
'id': 'd16fad8f-018a-4dcd-9bce-bab37e9c19d7',
'logs': {'Docs': {'end_time': '2023-10-26T16:54:46.135',
'final_output': {'documents': [Document(page_content='harrison worked at kensho')]},
'id': '91e795ef-5cf9-4580-bf94-b4a2464cf5ab',
'metadata': {},
'name': 'Docs',
'start_time': '2023-10-26T16:54:45.839',
'streamed_output_str': [],
'tags': ['map:key:context', 'FAISS', 'OpenAIEmbeddings'],
'type': 'retriever'}},
'streamed_output': []})
----------------------------------------------------------------------
RunLog({'final_output': None,
'id': 'd16fad8f-018a-4dcd-9bce-bab37e9c19d7',
'logs': {'Docs': {'end_time': '2023-10-26T16:54:46.135',
'final_output': {'documents': [Document(page_content='harrison worked at kensho')]},
'id': '91e795ef-5cf9-4580-bf94-b4a2464cf5ab',
'metadata': {},
'name': 'Docs',
'start_time': '2023-10-26T16:54:45.839',
'streamed_output_str': [],
'tags': ['map:key:context', 'FAISS', 'OpenAIEmbeddings'],
'type': 'retriever'}},
'streamed_output': ['']})
----------------------------------------------------------------------
RunLog({'final_output': None,
'id': 'd16fad8f-018a-4dcd-9bce-bab37e9c19d7',
'logs': {'Docs': {'end_time': '2023-10-26T16:54:46.135',
'final_output': {'documents': [Document(page_content='harrison worked at kensho')]},
'id': '91e795ef-5cf9-4580-bf94-b4a2464cf5ab',
'metadata': {},
'name': 'Docs',
'start_time': '2023-10-26T16:54:45.839',
'streamed_output_str': [],
'tags': ['map:key:context', 'FAISS', 'OpenAIEmbeddings'],
'type': 'retriever'}},
'streamed_output': ['', 'H']})
----------------------------------------------------------------------
RunLog({'final_output': None,
'id': 'd16fad8f-018a-4dcd-9bce-bab37e9c19d7',
'logs': {'Docs': {'end_time': '2023-10-26T16:54:46.135',
'final_output': {'documents': [Document(page_content='harrison worked at kensho')]},
'id': '91e795ef-5cf9-4580-bf94-b4a2464cf5ab',
'metadata': {},
'name': 'Docs',
'start_time': '2023-10-26T16:54:45.839',
'streamed_output_str': [],
'tags': ['map:key:context', 'FAISS', 'OpenAIEmbeddings'],
'type': 'retriever'}},
'streamed_output': ['', 'H', 'arrison']})
----------------------------------------------------------------------
RunLog({'final_output': None,
'id': 'd16fad8f-018a-4dcd-9bce-bab37e9c19d7',
'logs': {'Docs': {'end_time': '2023-10-26T16:54:46.135',
'final_output': {'documents': [Document(page_content='harrison worked at kensho')]},
'id': '91e795ef-5cf9-4580-bf94-b4a2464cf5ab',
'metadata': {},
'name': 'Docs',
'start_time': '2023-10-26T16:54:45.839',
'streamed_output_str': [],
'tags': ['map:key:context', 'FAISS', 'OpenAIEmbeddings'],
'type': 'retriever'}},
'streamed_output': ['', 'H', 'arrison', ' worked']})
----------------------------------------------------------------------
RunLog({'final_output': None,
'id': 'd16fad8f-018a-4dcd-9bce-bab37e9c19d7',
'logs': {'Docs': {'end_time': '2023-10-26T16:54:46.135',
'final_output': {'documents': [Document(page_content='harrison worked at kensho')]},
'id': '91e795ef-5cf9-4580-bf94-b4a2464cf5ab',
'metadata': {},
'name': 'Docs',
'start_time': '2023-10-26T16:54:45.839',
'streamed_output_str': [],
'tags': ['map:key:context', 'FAISS', 'OpenAIEmbeddings'],
'type': 'retriever'}},
'streamed_output': ['', 'H', 'arrison', ' worked', ' at']})
----------------------------------------------------------------------
RunLog({'final_output': None,
'id': 'd16fad8f-018a-4dcd-9bce-bab37e9c19d7',
'logs': {'Docs': {'end_time': '2023-10-26T16:54:46.135',
'final_output': {'documents': [Document(page_content='harrison worked at kensho')]},
'id': '91e795ef-5cf9-4580-bf94-b4a2464cf5ab',
'metadata': {},
'name': 'Docs',
'start_time': '2023-10-26T16:54:45.839',
'streamed_output_str': [],
'tags': ['map:key:context', 'FAISS', 'OpenAIEmbeddings'],
'type': 'retriever'}},
'streamed_output': ['', 'H', 'arrison', ' worked', ' at', ' Kens']})
----------------------------------------------------------------------
RunLog({'final_output': None,
'id': 'd16fad8f-018a-4dcd-9bce-bab37e9c19d7',
'logs': {'Docs': {'end_time': '2023-10-26T16:54:46.135',
'final_output': {'documents': [Document(page_content='harrison worked at kensho')]},
'id': '91e795ef-5cf9-4580-bf94-b4a2464cf5ab',
'metadata': {},
'name': 'Docs',
'start_time': '2023-10-26T16:54:45.839',
'streamed_output_str': [],
'tags': ['map:key:context', 'FAISS', 'OpenAIEmbeddings'],
'type': 'retriever'}},
'streamed_output': ['', 'H', 'arrison', ' worked', ' at', ' Kens', 'ho']})
----------------------------------------------------------------------
RunLog({'final_output': None,
'id': 'd16fad8f-018a-4dcd-9bce-bab37e9c19d7',
'logs': {'Docs': {'end_time': '2023-10-26T16:54:46.135',
'final_output': {'documents': [Document(page_content='harrison worked at kensho')]},
'id': '91e795ef-5cf9-4580-bf94-b4a2464cf5ab',
'metadata': {},
'name': 'Docs',
'start_time': '2023-10-26T16:54:45.839',
'streamed_output_str': [],
'tags': ['map:key:context', 'FAISS', 'OpenAIEmbeddings'],
'type': 'retriever'}},
'streamed_output': ['', 'H', 'arrison', ' worked', ' at', ' Kens', 'ho', '.']})
----------------------------------------------------------------------
RunLog({'final_output': None,
'id': 'd16fad8f-018a-4dcd-9bce-bab37e9c19d7',
'logs': {'Docs': {'end_time': '2023-10-26T16:54:46.135',
'final_output': {'documents': [Document(page_content='harrison worked at kensho')]},
'id': '91e795ef-5cf9-4580-bf94-b4a2464cf5ab',
'metadata': {},
'name': 'Docs',
'start_time': '2023-10-26T16:54:45.839',
'streamed_output_str': [],
'tags': ['map:key:context', 'FAISS', 'OpenAIEmbeddings'],
'type': 'retriever'}},
'streamed_output': ['',
'H',
'arrison',
' worked',
' at',
' Kens',
'ho',
'.',
'']})
----------------------------------------------------------------------
RunLog({'final_output': {'output': 'Harrison worked at Kensho.'},
'id': 'd16fad8f-018a-4dcd-9bce-bab37e9c19d7',
'logs': {'Docs': {'end_time': '2023-10-26T16:54:46.135',
'final_output': {'documents': [Document(page_content='harrison worked at kensho')]},
'id': '91e795ef-5cf9-4580-bf94-b4a2464cf5ab',
'metadata': {},
'name': 'Docs',
'start_time': '2023-10-26T16:54:45.839',
'streamed_output_str': [],
'tags': ['map:key:context', 'FAISS', 'OpenAIEmbeddings'],
'type': 'retriever'}},
'streamed_output': ['',
'H',
'arrison',
' worked',
' at',
' Kens',
'ho',
'.',
'']})
Parallelism
Let's take a look at how LangChain Expression Language supports parallel requests. For example, when using a RunnableParallel (often written as a dictionary) it executes each element in parallel.
LangChain Expression Language가 어떻게 병렬 요청을 지원하는지 살펴보겠습니다. 예를 들어 RunnableParallel(종종 사전으로 작성됨)을 사용하면 각 요소가 병렬로 실행됩니다.
from langchain.schema.runnable import RunnableParallel
chain1 = ChatPromptTemplate.from_template("tell me a joke about {topic}") | model
chain2 = ChatPromptTemplate.from_template("write a short (2 line) poem about {topic}") | model
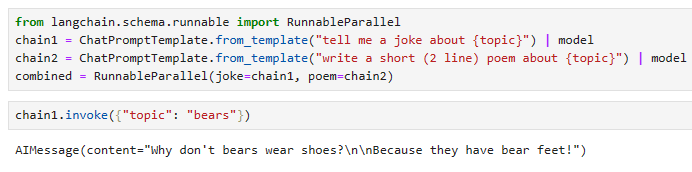
combined = RunnableParallel(joke=chain1, poem=chain2)chain1.invoke({"topic": "bears"})이 코드는 "langchain" 라이브러리를 사용하여 두 개의 병렬 실행 체인을 생성하고, 이 두 체인을 조합하여 단일 실행 객체를 만들고, 그 중 하나인 "chain1"을 사용하여 특정 주제에 대한 실행을 시작하는 예시를 보여줍니다
- 모듈 및 클래스 가져오기:
- langchain.schema.runnable 모듈에서 RunnableParallel 클래스를 가져옵니다. 이 클래스는 병렬 실행을 관리하고 조합하는 데 사용됩니다.
- 실행 체인 생성:
- "chain1"은 "ChatPromptTemplate.from_template("tell me a joke about {topic}") | model"를 사용하여 생성됩니다. 이 체인은 주어진 주제에 관한 농담을 생성하기 위해 대화 템플릿과 모델을 조합합니다.
- "chain2"는 "ChatPromptTemplate.from_template("write a short (2 line) poem about {topic}") | model"를 사용하여 생성됩니다. 이 체인은 주어진 주제에 관한 짧은 시를 생성하기 위해 대화 템플릿과 모델을 조합합니다.
- 병렬 실행 조합:
- "combined"는 "RunnableParallel(joke=chain1, poem=chain2)"를 사용하여 생성됩니다. 이 객체는 "joke" 및 "poem"이라는 이름으로 "chain1"과 "chain2"를 조합한 것입니다. 이를 통해 "joke" 및 "poem" 실행을 병렬로 시작하고 결과를 처리할 수 있습니다.
- 실행 시작:
- "chain1.invoke({"topic": "bears"})"을 사용하여 "chain1"을 실행합니다. 이 부분은 "bears" 주제에 관한 농담을 생성하는 실행을 시작합니다.
이 코드는 두 개의 병렬 실행 체인을 생성하고 실행하기 위한 방법을 보여주며, "chain1"을 사용하여 "bears" 주제에 관한 실행을 시작합니다.
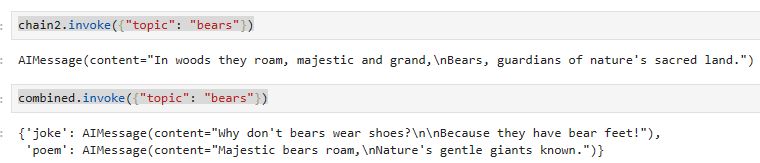
chain2.invoke({"topic": "bears"})combined.invoke({"topic": "bears"})이 코드는 "chain2"와 "combined" 두 실행 체인을 사용하여 "bears" 주제에 관한 실행을 시작하는 부분을 설명하고 있습니다.
- "chain2.invoke({"topic": "bears"})":
- 이 부분은 "chain2"를 사용하여 "bears" 주제에 관한 실행을 시작합니다. "chain2"는 주어진 주제에 관한 짧은 시를 생성하기 위한 실행을 나타냅니다.
- "combined.invoke({"topic": "bears"})":
- 이 부분은 "combined"를 사용하여 "bears" 주제에 관한 실행을 시작합니다. "combined"는 "joke" 및 "poem"이라는 이름으로 두 개의 실행 체인을 병렬로 조합한 것입니다.
이 코드는 "chain2"와 "combined" 두 실행 체인을 사용하여 "bears" 주제에 관한 실행을 시작하며, 각 실행은 주어진 주제에 따라 농담 또는 시를 생성하는 목적을 갖고 있습니다.
Parallelism on batches
Parallelism can be combined with other runnables. Let's try to use parallelism with batches.
병렬성은 다른 실행 가능 항목과 결합될 수 있습니다. 배치에 병렬성을 사용해 보겠습니다.
chain1.batch([{"topic": "bears"}, {"topic": "cats"}])이 코드는 "chain1" 실행 체인을 사용하여 여러 개의 실행을 일괄 처리하는 방법을 설명하고 있습니다.
- chain1.batch([{"topic": "bears"}, {"topic": "cats"}]):
- 이 부분은 "chain1"을 사용하여 "bears" 주제와 "cats" 주제에 관한 여러 실행을 일괄 처리하는 명령입니다.
- [{"topic": "bears"}, {"topic": "cats"}]는 실행의 입력 매개변수로 사용되는 딕셔너리 목록을 나타냅니다. 각 딕셔너리에는 "topic" 키와 실행할 주제에 해당하는 값이 포함되어 있습니다.
이 코드는 "chain1"을 사용하여 "bears" 주제와 "cats" 주제에 대한 여러 실행을 생성하고 처리합니다. 각 실행은 주어진 주제에 따라 농담을 생성하는 목적을 갖고 있습니다.

chain2.batch([{"topic": "bears"}, {"topic": "cats"}])
combined.batch([{"topic": "bears"}, {"topic": "cats"}])
'LangChain > LangChain Expression Language' 카테고리의 다른 글
| LC - Cookbook - RAG (Retrieval-Augmented Generation) (0) | 2023.11.05 |
|---|---|
| LC - Cookbook - Prompt + LLM (1) | 2023.10.29 |
| LangChain - How to - Route between multiple Runnables (1) | 2023.10.28 |
| LangChain - How to - Use RunnableParallel/RunnableMap (1) | 2023.10.28 |
| LangChain - How to - Custom generator functions (0) | 2023.10.28 |
| LangChain - How to - Run arbitrary functions (0) | 2023.10.28 |
| LangChain - How to - Add fallbacks (1) | 2023.10.28 |
| LangChain - How to - Configuration (0) | 2023.10.27 |
| LangChain - How to - Bind runtime args (0) | 2023.10.27 |
| LangChain - LangChain Expression Language (LCEL) (0) | 2023.10.20 |