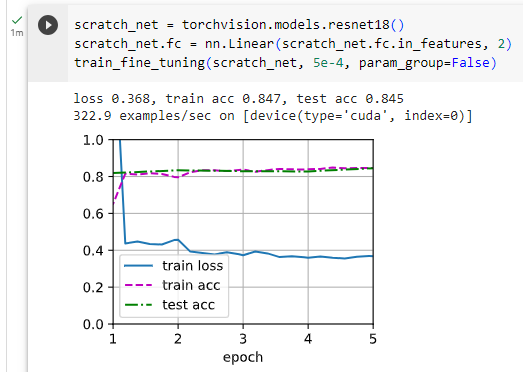
개발자로서 현장에서 일하면서 새로 접하는 기술들이나 알게된 정보 등을 정리하기 위한 블로그입니다. 운 좋게 미국에서 큰 회사들의 프로젝트에서 컬설턴트로 일하고 있어서 새로운 기술들을 접할 기회가 많이 있습니다. 미국의 IT 프로젝트에서 사용되는 툴들에 대해 많은 분들과 정보를 공유하고 싶습니다.
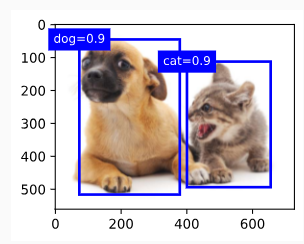
When discussing object detection tasks inSection 14.3–Section 14.8, rectangular bounding boxes are used to label and predict objects in images. This section will discuss the problem ofsemantic segmentation, which focuses on how to divide an image into regions belonging to different semantic classes. Different from object detection, semantic segmentation recognizes and understands what are in images in pixel level: its labeling and prediction of semantic regions are in pixel level.Fig. 14.9.1shows the labels of the dog, cat, and background of the image in semantic segmentation. Compared with in object detection, the pixel-level borders labeled in semantic segmentation are obviously more fine-grained.
섹션 14.3–섹션 14.8에서 개체 감지 작업을 논의할 때 사각형 경계 상자는 이미지의 개체에 레이블을 지정하고 예측하는 데 사용됩니다. 이 섹션에서는 이미지를 다른 의미semantic 클래스에 속하는 영역으로 나누는 방법에 중점을 둔 의미 분할 semantic segmentation 문제에 대해 설명합니다. 객체 감지와 달리 semantic segmentation은 픽셀 수준에서 이미지에 있는 것을 인식하고 이해합니다. 의미 영역 semantic regions 의 라벨링 및 예측은 픽셀 수준에서 이루어집니다. 그림 14.9.1은 시맨틱 세그멘테이션에서 이미지의 개, 고양이, 배경의 라벨을 보여준다. 개체 감지와 비교할 때 시맨틱 분할semantic segmentation에서 레이블이 지정된 픽셀 수준 경계는 분명히 더 세분화됩니다.
Fig. 14.9.1 Labels of the dog, cat, and background of the image in semantic segmentation.
14.9.1.Image Segmentation and Instance Segmentation
There are also two important tasks in the field of computer vision that are similar to semantic segmentation, namely image segmentation and instance segmentation. We will briefly distinguish them from semantic segmentation as follows.
컴퓨터 비전 분야에는 시맨틱 분할semantic segmentation과 유사한 두 가지 중요한 작업, 즉 이미지 분할image segmentation과 인스턴스 분할instance segmentation이 있습니다. 다음과 같이 시맨틱 분할과 간략하게 구분합니다.
Image segmentationdivides an image into several constituent regions. The methods for this type of problem usually make use of the correlation between pixels in the image. It does not need label information about image pixels during training, and it cannot guarantee that the segmented regions will have the semantics that we hope to obtain during prediction. Taking the image inFig. 14.9.1as input, image segmentation may divide the dog into two regions: one covers the mouth and eyes which are mainly black, and the other covers the rest of the body which is mainly yellow.
이미지 분할은 이미지를 여러 구성 영역으로 나눕니다. 이러한 유형의 문제에 대한 방법은 일반적으로 이미지의 픽셀 간의 상관 관계를 사용합니다. 훈련하는 동안 이미지 픽셀에 대한 레이블 정보가 필요하지 않으며 분할된 영역이 예측 중에 얻고자 하는 의미 체계를 가질 것이라고 보장할 수 없습니다. 그림 14.9.1의 이미지를 입력으로 사용하면 이미지 분할은 개를 두 영역으로 나눌 수 있습니다. 하나는 주로 검은색인 입과 눈을 덮고 다른 하나는 주로 노란색인 몸의 나머지 부분을 덮습니다.
Instance segmentationis also calledsimultaneous detection and segmentation. It studies how to recognize the pixel-level regions of each object instance in an image. Different from semantic segmentation, instance segmentation needs to distinguish not only semantics, but also different object instances. For example, if there are two dogs in the image, instance segmentation needs to distinguish which of the two dogs a pixel belongs to.
인스턴스 분할은 동시 감지 및 분할이라고도 합니다. 이미지에서 각 개체 인스턴스의 픽셀 수준 영역을 인식하는 방법을 연구합니다. 시맨틱 분할과 달리 인스턴스 분할은 시맨틱뿐만 아니라 다른 객체 인스턴스도 구분해야 합니다. 예를 들어, 이미지에 두 마리의 개가 있는 경우 인스턴스 분할은 픽셀이 속한 두 개 중 어느 것을 구별해야 합니다.
d2l.DATA_HUB['voc2012']: d2l.DATA_HUB 딕셔너리에 'voc2012'라는 키를 가진 항목을 추가합니다. 이 항목은 데이터 다운로드를 위한 URL 및 체크섬 정보를 포함하는 튜플입니다.
d2l.DATA_URL + 'VOCtrainval_11-May-2012.tar': d2l.DATA_URL과 문자열을 합쳐서 VOC2012 데이터의 URL을 생성합니다.
'4e443f8a2eca6b1dac8a6c57641b67dd40621a49': 다운로드한 파일의 체크섬(해시 값)입니다.
voc_dir = d2l.download_extract('voc2012', 'VOCdevkit/VOC2012'): 'voc2012' 데이터를 다운로드하고 압축을 해제하여 voc_dir 변수에 저장합니다. download_extract 함수는 주어진 키에 해당하는 데이터를 다운로드하고 압축을 해제합니다. 여기서 'voc2012' 데이터는 VOC2012 데이터셋을 의미하며, VOCdevkit/VOC2012 경로에 압축을 해제합니다.
이 코드는 'voc2012' 데이터를 다운로드하고 압축을 해제하여 데이터가 저장될 디렉토리 경로인 voc_dir을 설정하는 내용을 나타냅니다. VOC2012 데이터셋은 객체 검출과 이미지 분류 등 다양한 컴퓨터 비전 작업에 사용되는 데이터셋입니다.
Downloading ../data/VOCtrainval_11-May-2012.tar from http://d2l-data.s3-accelerate.amazonaws.com/VOCtrainval_11-May-2012.tar...
After entering the path../data/VOCdevkit/VOC2012, we can see the different components of the dataset. TheImageSets/Segmentationpath contains text files that specify training and test samples, while theJPEGImagesandSegmentationClasspaths store the input image and label for each example, respectively. The label here is also in the image format, with the same size as its labeled input image. Besides, pixels with the same color in any label image belong to the same semantic class. The following defines theread_voc_imagesfunction to read all the input images and labels into the memory.
../data/VOCdevkit/VOC2012 경로를 입력하면 데이터 세트의 다양한 구성 요소를 볼 수 있습니다. ImageSets/Segmentation 경로에는 교육 및 테스트 샘플을 지정하는 텍스트 파일이 포함되어 있으며 JPEGImages 및 SegmentationClass 경로는 각각 각 예제에 대한 입력 이미지와 레이블을 저장합니다. 여기의 레이블도 레이블이 지정된 입력 이미지와 크기가 같은 이미지 형식입니다. 게다가 어떤 레이블 이미지에서 같은 색상을 가진 픽셀은 같은 의미 클래스에 속합니다. 다음은 모든 입력 이미지와 레이블을 메모리로 읽어들이는 read_voc_images 함수를 정의합니다.
#@save
def read_voc_images(voc_dir, is_train=True):
"""Read all VOC feature and label images."""
txt_fname = os.path.join(voc_dir, 'ImageSets', 'Segmentation',
'train.txt' if is_train else 'val.txt')
mode = torchvision.io.image.ImageReadMode.RGB
with open(txt_fname, 'r') as f:
images = f.read().split()
features, labels = [], []
for i, fname in enumerate(images):
features.append(torchvision.io.read_image(os.path.join(
voc_dir, 'JPEGImages', f'{fname}.jpg')))
labels.append(torchvision.io.read_image(os.path.join(
voc_dir, 'SegmentationClass' ,f'{fname}.png'), mode))
return features, labels
train_features, train_labels = read_voc_images(voc_dir, True)
#@save: 주석으로, 코드 조각을 문서로 저장할 때 사용되는 주석입니다.
def read_voc_images(voc_dir, is_train=True):: read_voc_images라는 함수를 정의합니다. 이 함수는 VOC 데이터셋의 특징 이미지와 라벨 이미지를 읽어오는 역할을 합니다.
voc_dir: VOC 데이터셋이 저장된 디렉토리 경로입니다.
is_train=True: 훈련 데이터인지 여부를 나타내는 변수입니다.
txt_fname = os.path.join(voc_dir, 'ImageSets', 'Segmentation', 'train.txt' if is_train else 'val.txt'): 훈련 데이터 또는 검증 데이터 이미지 파일 이름이 나열된 텍스트 파일의 경로를 생성합니다.
mode = torchvision.io.image.ImageReadMode.RGB: 읽어온 이미지를 RGB 형식으로 읽어오도록 설정합니다.
with open(txt_fname, 'r') as f:: 텍스트 파일을 열고 f라는 이름으로 사용합니다.
images = f.read().split(): 파일에서 읽은 이미지 파일 이름들을 공백으로 분리하여 리스트로 저장합니다.
features, labels = [], []: 특징 이미지와 라벨 이미지를 저장할 빈 리스트 features와 labels를 생성합니다.
for i, fname in enumerate(images):: 이미지 파일 이름들을 반복하면서 처리합니다.
features.append(torchvision.io.read_image(os.path.join(voc_dir, 'JPEGImages', f'{fname}.jpg'))): 이미지 파일을 읽어와 특징 이미지 리스트에 추가합니다.
labels.append(torchvision.io.read_image(os.path.join(voc_dir, 'SegmentationClass' ,f'{fname}.png'), mode)): 라벨 이미지 파일을 읽어와 라벨 이미지 리스트에 추가합니다.
return features, labels: 읽어온 특징 이미지와 라벨 이미지 리스트를 반환합니다.
train_features, train_labels = read_voc_images(voc_dir, True): VOC 데이터셋에서 훈련 데이터의 특징 이미지와 라벨 이미지를 읽어와 각각 train_features와 train_labels 변수에 할당합니다.
이 코드는 VOC 데이터셋에서 훈련 데이터의 특징 이미지와 라벨 이미지를 읽어오는 함수 read_voc_images를 정의하고 이를 호출하여 train_features와 train_labels를 생성하는 내용을 나타냅니다.
We draw the first five input images and their labels. In the label images, white and black represent borders and background, respectively, while the other colors correspond to different classes.
처음 5개의 입력 이미지와 레이블을 그립니다. 레이블 이미지에서 흰색과 검은색은 각각 테두리와 배경을 나타내고 나머지 색상은 다른 클래스에 해당합니다.
n = 5
imgs = train_features[:n] + train_labels[:n]
imgs = [img.permute(1,2,0) for img in imgs]
d2l.show_images(imgs, 2, n);
n = 5: 변수 n에 5를 할당합니다. 이는 표시할 이미지의 개수를 의미합니다.
imgs = train_features[:n] + train_labels[:n]: train_features 리스트에서 처음부터 n개의 이미지와 train_labels 리스트에서 처음부터 n개의 이미지를 선택하여 리스트 imgs에 결합합니다. 이렇게 하면 특징 이미지와 해당하는 라벨 이미지가 번갈아가며 포함된 리스트가 생성됩니다.
imgs = [img.permute(1,2,0) for img in imgs]: imgs 리스트 내의 이미지들의 차원을 변경합니다. 각 이미지의 차원을 (채널, 높이, 너비)에서 (높이, 너비, 채널)로 변경하면 이미지가 보다 일반적인 형태로 표현됩니다.
d2l.show_images(imgs, 2, n);: imgs 리스트에 포함된 이미지들을 2개의 열로 나누어서 n개씩 그립니다. d2l.show_images 함수는 이미지를 그리는 함수로서 여러 이미지를 그룹으로 나누어서 표시합니다.
이 코드는 훈련 데이터셋에서 특징 이미지와 라벨 이미지를 일정 개수만큼 선택하고, 차원을 변경한 후에 이를 그룹으로 나누어서 표시하는 내용을 나타냅니다.
Next, we enumerate the RGB color values and class names for all the labels in this dataset.
다음으로 이 데이터 세트의 모든 레이블에 대한 RGB 색상 값과 클래스 이름을 열거합니다.
VOC_COLORMAP: VOC 데이터셋에서 클래스 인덱스에 따라 색상을 부여하는 컬러맵을 정의한 변수입니다. 각 클래스에 대해 RGB 값으로 색상을 지정하여 클래스를 시각화할 때 사용됩니다.
VOC_CLASSES: VOC 데이터셋에서 정의된 클래스 이름들을 나열한 변수입니다. 이 변수에는 배경과 다양한 객체 클래스들의 이름이 포함되어 있습니다.
이 코드는 VOC 데이터셋에서 클래스들의 컬러맵과 클래스 이름들을 정의하는 내용을 나타냅니다. VOC 데이터셋은 객체 검출, 분할 등의 작업에 사용되는 데이터셋으로, 이러한 정보들은 시각화 및 레이블 관련 작업에서 사용됩니다.
With the two constants defined above, we can conveniently find the class index for each pixel in a label. We define thevoc_colormap2labelfunction to build the mapping from the above RGB color values to class indices, and thevoc_label_indicesfunction to map any RGB values to their class indices in this Pascal VOC2012 dataset.
위에서 정의한 두 상수를 사용하면 레이블의 각 픽셀에 대한 클래스 인덱스를 편리하게 찾을 수 있습니다. 우리는 voc_colormap2label 함수를 정의하여 위의 RGB 색상 값에서 클래스 인덱스로의 매핑을 구축하고 voc_label_indices 함수를 정의하여 RGB 값을 이 Pascal VOC2012 데이터 세트의 클래스 인덱스로 매핑합니다.
#@save
def voc_colormap2label():
"""Build the mapping from RGB to class indices for VOC labels."""
colormap2label = torch.zeros(256 ** 3, dtype=torch.long)
for i, colormap in enumerate(VOC_COLORMAP):
colormap2label[
(colormap[0] * 256 + colormap[1]) * 256 + colormap[2]] = i
return colormap2label
#@save
def voc_label_indices(colormap, colormap2label):
"""Map any RGB values in VOC labels to their class indices."""
colormap = colormap.permute(1, 2, 0).numpy().astype('int32')
idx = ((colormap[:, :, 0] * 256 + colormap[:, :, 1]) * 256
+ colormap[:, :, 2])
return colormap2label[idx]
#@save: 주석으로, 코드 조각을 문서로 저장할 때 사용되는 주석입니다.
voc_colormap2label(): VOC 데이터셋의 클래스 컬러맵을 이용하여 RGB 값에서 클래스 인덱스로 매핑하는 함수입니다. VOC 데이터셋의 클래스 컬러맵을 이용하여 RGB 값의 조합을 클래스 인덱스로 변환하는 매핑을 생성하고 반환합니다.
colormap2label = torch.zeros(256 ** 3, dtype=torch.long): 256^3 크기의 모든 조합에 대한 클래스 인덱스를 담는 텐서를 생성합니다.
for i, colormap in enumerate(VOC_COLORMAP):: VOC 컬러맵의 각 색상에 대해 반복합니다.
(colormap[0] * 256 + colormap[1]) * 256 + colormap[2]: RGB 값을 클래스 인덱스로 변환하여 텐서의 해당 위치에 클래스 인덱스를 저장합니다.
voc_label_indices(colormap, colormap2label): 주어진 VOC 라벨 컬러맵을 이용하여 RGB 값을 클래스 인덱스로 변환하는 함수입니다.
colormap.permute(1, 2, 0).numpy().astype('int32'): 라벨 컬러맵을 높이-너비-채널 형태에서 너비-채널-높이 형태로 변경하고, 넘파이 배열로 변환하며 데이터 타입을 'int32'로 변환합니다.
((colormap[:, :, 0] * 256 + colormap[:, :, 1]) * 256 + colormap[:, :, 2]): RGB 값을 클래스 인덱스로 변환하는 계산을 수행하여 클래스 인덱스 텐서 idx를 생성합니다.
return colormap2label[idx]: 생성한 클래스 인덱스 텐서 idx를 이용하여 RGB 값의 클래스 인덱스로 변환한 결과를 반환합니다.
이 코드는 VOC 데이터셋의 라벨 컬러맵과 RGB 값들을 클래스 인덱스로 변환하기 위한 함수들을 정의하는 내용을 나타냅니다. 이러한 함수들은 데이터셋 시각화 및 레이블 처리 작업에서 사용됩니다.
For example, in the first example image, the class index for the front part of the airplane is 1, while the background index is 0.
예를 들어, 첫 번째 예제 이미지에서 비행기 앞부분의 클래스 인덱스는 1이고 배경 인덱스는 0입니다.
y = voc_label_indices(train_labels[0], voc_colormap2label())
y[105:115, 130:140], VOC_CLASSES[1]
y = voc_label_indices(train_labels[0], voc_colormap2label()): train_labels 리스트에서 첫 번째 라벨 이미지를 이용하여 voc_colormap2label() 함수를 통해 라벨 컬러맵을 클래스 인덱스로 변환한 결과를 변수 y에 할당합니다.
y[105:115, 130:140], VOC_CLASSES[1]: y 변수의 특정 범위를 선택하여 그 값을 출력하고, VOC_CLASSES 리스트의 두 번째 클래스 이름을 출력합니다.
이 코드는 VOC 데이터셋의 첫 번째 라벨 이미지에 대해 라벨 컬러맵을 클래스 인덱스로 변환한 결과를 변수 y에 저장하고, 이 변수에서 특정 영역의 값을 선택하여 출력하는 내용을 나타냅니다. 또한, VOC_CLASSES 리스트에서 두 번째 클래스의 이름을 출력합니다. 이를 통해 라벨 이미지의 레이블 정보를 확인할 수 있습니다.
In previous experiments such as inSection 8.1–Section 8.4, images are rescaled to fit the model’s required input shape. However, in semantic segmentation, doing so requires rescaling the predicted pixel classes back to the original shape of the input image. Such rescaling may be inaccurate, especially for segmented regions with different classes. To avoid this issue, we crop the image to afixedshape instead of rescaling. Specifically, using random cropping from image augmentation, we crop the same area of the input image and the label.
섹션 8.1–섹션 8.4와 같은 이전 실험에서 이미지는 모델의 필수 입력 모양에 맞게 크기가 조정됩니다. 그러나 의미론적 분할에서 그렇게 하려면 예측된 픽셀 클래스를 입력 이미지의 원래 모양으로 다시 스케일링해야 합니다. 이러한 크기 조정은 특히 클래스가 다른 분할 영역의 경우 부정확할 수 있습니다. 이 문제를 방지하기 위해 크기를 다시 조정하는 대신 이미지를 고정된 모양으로 자릅니다. 특히, 이미지 확대에서 임의 자르기를 사용하여 입력 이미지와 레이블의 동일한 영역을 자릅니다.
#@save
def voc_rand_crop(feature, label, height, width):
"""Randomly crop both feature and label images."""
rect = torchvision.transforms.RandomCrop.get_params(
feature, (height, width))
feature = torchvision.transforms.functional.crop(feature, *rect)
label = torchvision.transforms.functional.crop(label, *rect)
return feature, label
imgs = []
for _ in range(n):
imgs += voc_rand_crop(train_features[0], train_labels[0], 200, 300)
imgs = [img.permute(1, 2, 0) for img in imgs]
d2l.show_images(imgs[::2] + imgs[1::2], 2, n);
#@save: 주석으로, 코드 조각을 문서로 저장할 때 사용되는 주석입니다.
voc_rand_crop(feature, label, height, width): 특징 이미지와 라벨 이미지를 주어진 높이와 너비에 맞춰 무작위로 잘라내는 함수입니다.
rect = torchvision.transforms.RandomCrop.get_params(feature, (height, width)): 무작위로 자르기 위한 좌표 정보를 얻습니다. 이 때, get_params 함수는 무작위 자르기를 위해 필요한 좌표 정보를 반환합니다.
feature = torchvision.transforms.functional.crop(feature, *rect): 주어진 좌표 정보를 이용하여 특징 이미지를 무작위로 잘라냅니다.
label = torchvision.transforms.functional.crop(label, *rect): 주어진 좌표 정보를 이용하여 라벨 이미지도 무작위로 잘라냅니다.
imgs = []: 빈 리스트 imgs를 생성합니다.
for _ in range(n):: n번 반복하는 루프를 실행합니다.
imgs += voc_rand_crop(train_features[0], train_labels[0], 200, 300): voc_rand_crop 함수를 사용하여 특징 이미지와 라벨 이미지를 200x300 크기로 무작위로 자르고, imgs 리스트에 추가합니다.
imgs = [img.permute(1, 2, 0) for img in imgs]: imgs 리스트 내의 이미지들의 차원을 변경합니다. 각 이미지의 차원을 (채널, 높이, 너비)에서 (높이, 너비, 채널)로 변경하면 이미지가 보다 일반적인 형태로 표현됩니다.
d2l.show_images(imgs[::2] + imgs[1::2], 2, n);: imgs 리스트에 포함된 이미지들을 두 개의 열로 나누어서 그룹으로 나눈 뒤에 표시합니다. 이 때, 첫 번째 그룹은 imgs의 짝수 인덱스 이미지들로, 두 번째 그룹은 홀수 인덱스 이미지들로 구성됩니다.
이 코드는 VOC 데이터셋의 첫 번째 특징 이미지와 라벨 이미지를 무작위로 자르고, 이를 시각화하여 표시하는 내용을 나타냅니다. 이를 통해 데이터 증강과 이미지 처리 과정을 이해할 수 있습니다.
14.9.2.2.Custom Semantic Segmentation Dataset Class
We define a custom semantic segmentation dataset classVOCSegDatasetby inheriting theDatasetclass provided by high-level APIs. By implementing the__getitem__function, we can arbitrarily access the input image indexed asidxin the dataset and the class index of each pixel in this image. Since some images in the dataset have a smaller size than the output size of random cropping, these examples are filtered out by a customfilterfunction. In addition, we also define thenormalize_imagefunction to standardize the values of the three RGB channels of input images.
상위 수준 API에서 제공하는 Dataset 클래스를 상속하여 사용자 지정 시맨틱 세분화 데이터 세트 클래스 VOCSegDataset을 정의합니다. __getitem__ 함수를 구현하면 데이터셋에서 idx로 인덱싱된 입력 이미지와 이 이미지의 각 픽셀의 클래스 인덱스에 임의로 액세스할 수 있습니다. 데이터 세트의 일부 이미지는 임의 자르기의 출력 크기보다 크기가 작기 때문에 이러한 예는 사용자 정의 필터 기능으로 필터링됩니다. 또한 normalize_image 함수를 정의하여 입력 이미지의 세 RGB 채널 값을 표준화합니다.
class VOCSegDataset(torch.utils.data.Dataset):: torch.utils.data.Dataset 클래스를 상속하여 커스텀 데이터셋 클래스 VOCSegDataset을 정의합니다. 이 클래스는 VOC 데이터셋을 불러오고 처리하기 위한 기능을 제공합니다.
self.transform: VOC 데이터셋의 이미지를 정규화하는 변환을 수행하는 객체를 생성합니다.
self.crop_size: 임의로 자를 크기를 저장하는 변수입니다.
features, labels = read_voc_images(voc_dir, is_train=is_train): read_voc_images 함수를 이용하여 특징 이미지와 라벨 이미지를 불러옵니다.
self.features = [self.normalize_image(feature) for feature in self.filter(features)]: 특징 이미지들을 필터링하고 정규화합니다.
self.colormap2label = voc_colormap2label(): 라벨 컬러맵을 클래스 인덱스로 매핑하는 매핑을 생성합니다.
def normalize_image(self, img):: 이미지를 정규화하는 함수입니다.
def filter(self, imgs):: 이미지들을 필터링하는 함수입니다.
def __getitem__(self, idx):: 데이터셋에서 특정 인덱스의 아이템을 가져오는 메서드입니다.
def __len__(self):: 데이터셋의 길이를 반환하는 메서드입니다.
이 코드는 VOC 데이터셋을 커스텀 데이터셋 클래스로 정의하는 내용을 나타냅니다. 이 클래스는 데이터셋을 불러오고 처리하는 기능을 제공하여 모델 학습 등에 활용될 수 있습니다.
14.9.2.3.Reading the Dataset
We use the customVOCSegDataset class to create instances of the training set and test set, respectively. Suppose that we specify that the output shape of randomly cropped images is320×480. Below we can view the number of examples that are retained in the training set and test set.
맞춤형 VOCSegDataset 클래스를 사용하여 훈련 세트와 테스트 세트의 인스턴스를 각각 생성합니다. 임의로 자른 이미지의 출력 모양이 320×480이라고 지정한다고 가정합니다. 아래에서 훈련 세트와 테스트 세트에 보관된 예의 수를 볼 수 있습니다.
crop_size = (320, 480): 임의로 자를 크기를 (320, 480)로 지정합니다.
voc_train = VOCSegDataset(True, crop_size, voc_dir): VOCSegDataset 클래스를 이용하여 VOC 데이터셋의 학습용 데이터셋 voc_train을 생성합니다. True는 학습 데이터셋을 의미하며, crop_size와 voc_dir은 해당 클래스의 생성자에 필요한 인자입니다.
voc_test = VOCSegDataset(False, crop_size, voc_dir): VOCSegDataset 클래스를 이용하여 VOC 데이터셋의 테스트용 데이터셋 voc_test를 생성합니다. False는 테스트 데이터셋을 의미하며, crop_size와 voc_dir은 해당 클래스의 생성자에 필요한 인자입니다.
이 코드는 학습용과 테스트용 VOC 데이터셋을 생성하는 내용을 나타냅니다. 이를 통해 데이터셋을 생성하여 모델 학습 및 평가에 활용할 수 있습니다.
read 1114 examples
read 1078 examples
Setting the batch size to 64, we define the data iterator for the training set. Let’s print the shape of the first minibatch. Different from in image classification or object detection, labels here are three-dimensional tensors.
배치 크기를 64로 설정하고 훈련 세트에 대한 데이터 반복자를 정의합니다. 첫 번째 미니 배치의 모양을 인쇄해 봅시다. 이미지 분류 또는 객체 감지와 달리 여기서 레이블은 3차원 텐서입니다.
batch_size = 64
train_iter = torch.utils.data.DataLoader(voc_train, batch_size, shuffle=True,
drop_last=True,
num_workers=d2l.get_dataloader_workers())
for X, Y in train_iter:
print(X.shape)
print(Y.shape)
break
batch_size = 64: 배치 크기를 64로 지정합니다.
train_iter = torch.utils.data.DataLoader(voc_train, batch_size, shuffle=True, drop_last=True, num_workers=d2l.get_dataloader_workers()): torch.utils.data.DataLoader 클래스를 사용하여 학습용 데이터셋 voc_train을 불러오는 데이터 로더 train_iter를 생성합니다. 이 데이터 로더는 배치 크기를 batch_size로 설정하고, 데이터를 섞어서 가져오며(shuffle=True), 마지막 배치를 무시합니다(drop_last=True), 병렬로 데이터를 로딩할 때 사용할 워커의 수를 d2l.get_dataloader_workers()로 설정합니다.
for X, Y in train_iter:: train_iter에서 배치 단위로 데이터를 가져옵니다.
print(X.shape): 현재 배치의 특징 이미지 X의 모양을 출력합니다.
print(Y.shape): 현재 배치의 라벨 이미지 Y의 모양을 출력합니다.
break: 첫 번째 배치만 확인하고 반복을 종료합니다.
이 코드는 데이터 로더를 사용하여 학습용 데이터셋을 배치 단위로 불러와서 모양을 확인하는 내용을 나타냅니다. 이를 통해 데이터 로딩 및 배치 처리 과정을 이해할 수 있습니다.
Finally, we define the followingload_data_vocfunction to download and read the Pascal VOC2012 semantic segmentation dataset. It returns data iterators for both the training and test datasets.
마지막으로 Pascal VOC2012 시맨틱 분할 데이터 세트를 다운로드하고 읽기 위해 다음 load_data_voc 함수를 정의합니다. 교육 및 테스트 데이터 세트 모두에 대한 데이터 반복자를 반환합니다.
num_workers = d2l.get_dataloader_workers(): 데이터 로더가 사용할 워커의 수를 가져옵니다.
train_iter = torch.utils.data.DataLoader(VOCSegDataset(True, crop_size, voc_dir), batch_size, shuffle=True, drop_last=True, num_workers=num_workers): 학습 데이터셋을 위한 데이터 로더 train_iter를 생성합니다. True는 학습 데이터셋을 의미하며, VOCSegDataset 클래스를 사용하여 데이터셋을 불러옵니다.
test_iter = torch.utils.data.DataLoader(VOCSegDataset(False, crop_size, voc_dir), batch_size, drop_last=True, num_workers=num_workers): 테스트 데이터셋을 위한 데이터 로더 test_iter를 생성합니다. False는 테스트 데이터셋을 의미하며, VOCSegDataset 클래스를 사용하여 데이터셋을 불러옵니다.
return train_iter, test_iter: 학습 데이터셋과 테스트 데이터셋의 데이터 로더를 반환합니다.
이 코드는 VOC 시맨틱 세그멘테이션 데이터셋을 불러오기 위한 함수를 정의한 내용을 나타냅니다. 이 함수를 통해 모델 학습 및 평가에 활용할 수 있는 데이터 로더를 얻을 수 있습니다.
14.9.3.Summary
Semantic segmentation recognizes and understands what are in an image in pixel level by dividing the image into regions belonging to different semantic classes.
시맨틱 분할은 이미지를 서로 다른 시맨틱 클래스에 속하는 영역으로 나누어 이미지에 있는 것을 픽셀 수준으로 인식하고 이해합니다.
One of the most important semantic segmentation dataset is Pascal VOC2012.
가장 중요한 시맨틱 분할 데이터 세트 중 하나는 Pascal VOC2012입니다.
In semantic segmentation, since the input image and label correspond one-to-one on the pixel, the input image is randomly cropped to a fixed shape rather than rescaled.
시맨틱 분할에서 입력 이미지와 레이블은 픽셀에서 일대일로 대응하므로 입력 이미지는 크기를 다시 조정하지 않고 고정된 모양으로 무작위로 자릅니다.
14.9.4.Exercises
How can semantic segmentation be applied in autonomous vehicles and medical image diagnostics? Can you think of other applications?
Recall the descriptions of data augmentation inSection 14.1. Which of the image augmentation methods used in image classification would be infeasible to be applied in semantic segmentation?
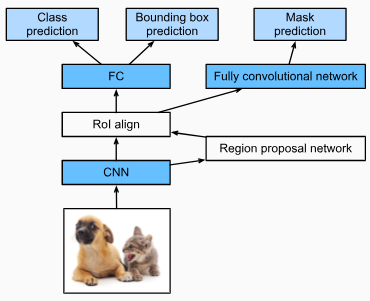
Besides single shot multibox detection described inSection 14.7, region-based CNNs or regions with CNN features (R-CNNs) are also among many pioneering approaches of applying deep learning to object detection(Girshicket al., 2014). In this section, we will introduce the R-CNN and its series of improvements: the fast R-CNN(Girshick, 2015), the faster R-CNN(Renet al., 2015), and the mask R-CNN(Heet al., 2017). Due to limited space, we will only focus on the design of these models.
섹션 14.7에서 설명한 단일 샷 멀티박스 감지 외에도 지역 기반 CNN 또는 CNN 기능이 있는 지역(R-CNN)도 객체 감지에 딥 러닝을 적용하는 많은 선구적인 접근 방식 중 하나입니다(Girshick et al., 2014). 이 섹션에서는 R-CNN과 일련의 개선 사항인 fast R-CNN(Girshick, 2015), faster R-CNN(Ren et al., 2015) 및 mask R-CNN(He 외, 2017). 제한된 공간으로 인해 이러한 모델의 디자인에만 집중할 것입니다.
14.8.1.R-CNNs
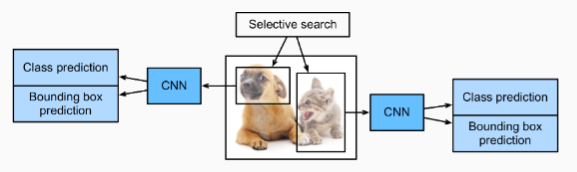
TheR-CNNfirst extracts many (e.g., 2000)region proposalsfrom the input image (e.g., anchor boxes can also be considered as region proposals), labeling their classes and bounding boxes (e.g., offsets). (Girshicket al., 2014)
R-CNN은 먼저 입력 이미지에서 많은(예: 2000개) region proposals을 추출하고(예: 앵커 상자도 region proposals으로 간주할 수 있음) 해당 클래스 및 경계 상자(예: 오프셋)에 레이블을 지정합니다.
Then a CNN is used to perform forward propagation on each region proposal to extract its features. Next, features of each region proposal are used for predicting the class and bounding box of this region proposal.
그런 다음 CNN을 사용하여 각 region proposal에 대한 순방향 전파를 수행하여 해당 features을 추출합니다. 다음으로, 각 region proposal의 features은 이 region proposal의 클래스와 경계 상자를 예측하는 데 사용됩니다.
Fig. 14.8.1 The R-CNN model.
Fig. 14.8.1shows the R-CNN model. More concretely, the R-CNN consists of the following four steps:
그림 14.8.1은 R-CNN 모델을 보여준다. 보다 구체적으로 R-CNN은 다음 네 단계로 구성됩니다.
Performselective searchto extract multiple high-quality region proposals on the input image(Uijlingset al., 2013). These proposed regions are usually selected at multiple scales with different shapes and sizes. Each region proposal will be labeled with a class and a ground-truth bounding box.
입력 이미지에서 여러 고품질 region proposals을 추출하기 위해 선택적 검색을 수행합니다(Uijlings et al., 2013). 이러한 제안된 영역은 일반적으로 모양과 크기가 다른 여러 척도에서 선택됩니다. 각 region proposals은 클래스와 ground-truth 경계 상자로 레이블이 지정됩니다.
Choose a pretrained CNN and truncate it before the output layer. Resize each region proposal to the input size required by the network, and output the extracted features for the region proposal through forward propagation.
사전 훈련된 CNN을 선택하고 출력 계층 앞에서 자릅니다. 각 region proposal의 크기를 네트워크에서 요구하는 입력 크기로 조정하고 순방향 전파를 통해 추출된 region proposal의 -features- 특징을 출력합니다.
Take the extracted features and labeled class of each region proposal as an example. Train multiple support vector machines to classify objects, where each support vector machine individually determines whether the example contains a specific class.
각 지역 제안region proposal의 추출된 기능 features과 레이블이 지정된 클래스를 예로 들어 보겠습니다. 여러 서포트 벡터 머신을 훈련시켜 개체를 분류합니다. 여기서 각 서포트 벡터 머신은 예제에 특정 클래스가 포함되어 있는지 여부를 개별적으로 결정합니다.
Take the extracted features and labeled bounding box of each region proposal as an example. Train a linear regression model to predict the ground-truth bounding box.
각 지역 제안 region proposal의 추출된 특징과 레이블이 지정된 경계 상자를 예로 들어 보겠습니다. ground-truth 경계 상자를 예측하도록 선형 회귀 모델을 훈련합니다.
Although the R-CNN model uses pretrained CNNs to effectively extract image features, it is slow. Imagine that we select thousands of region proposals from a single input image: this requires thousands of CNN forward propagations to perform object detection. This massive computing load makes it infeasible to widely use R-CNNs in real-world applications.
R-CNN 모델은 사전 훈련된 CNN을 사용하여 이미지 특징을 효과적으로 추출하지만 속도가 느립니다. 단일 입력 이미지에서 수천 개의 지역 제안 region proposals을 선택한다고 상상해보십시오. 개체 감지를 수행하려면 수천 개의 CNN 정방향 전파가 필요합니다. 이 막대한 컴퓨팅 부하로 인해 실제 응용 프로그램에서 R-CNN을 널리 사용하는 것이 불가능합니다.
Region Proposal 이란?
A "Region Proposal" refers to a process in object detection tasks where potential regions or bounding boxes containing objects of interest are proposed within an image. In object detection, the goal is to identify and localize objects within an image, often by drawing bounding boxes around them. However, directly applying object detection algorithms to all possible image regions can be computationally expensive and inefficient.
"Region Proposal(영역 제안)"은 객체 검출 작업에서 이미지 내에 관심 대상 객체가 포함될 가능성이 있는 영역 또는 경계 상자를 제안하는 과정을 의미합니다. 객체 검출에서의 목표는 이미지 내에서 객체를 식별하고 위치를 파악하는 것인데, 모든 가능한 이미지 영역에 대해 직접 객체 검출 알고리즘을 적용하는 것은 계산적으로 부담스럽고 비효율적일 수 있습니다.
To address this, region proposal methods are used to narrow down the search space for object detection. These methods aim to generate a relatively small set of potential regions or bounding boxes that are likely to contain objects. These proposals serve as the input to the subsequent object detection algorithm, significantly reducing the computational burden.
이러한 문제를 해결하기 위해 영역 제안 방법을 사용하여 객체 검출을 위한 검색 공간을 좁힙니다. 이러한 방법은 객체가 포함될 가능성이 높은 상대적으로 작은 영역이나 경계 상자 세트를 생성하는 것을 목표로 합니다. 이러한 제안은 후속 객체 검출 알고리즘의 입력으로 사용되며, 계산 부담을 크게 줄여줍니다.
There are various techniques for generating region proposals. Some common methods include:
영역 제안을 생성하는 다양한 기법이 있습니다. 일반적인 방법은 다음과 같습니다:
Sliding Window Approach: A small window of fixed size is moved across the image at different scales and positions. Bounding boxes are generated for each window location. This approach can be computationally intensive due to the need to slide the window over the entire image.
슬라이딩 윈도우 접근법: 고정 크기의 작은 창을 이미지 상에서 다양한 스케일과 위치로 이동시키면서 각 창 위치에 대한 경계 상자를 생성합니다. 이 접근법은 전체 이미지에 대해 창을 이동시켜야 하기 때문에 계산적으로 비싼 경우가 있을 수 있습니다.
Selective Search: This method generates region proposals by grouping pixels based on their similarity in color, texture, and intensity. The algorithm combines regions of varying sizes and shapes to create a diverse set of proposals.
Selective Search(선택적 검색): 이 방법은 색상, 질감, 강도의 유사성을 기반으로 픽셀을 그룹화하여 영역 제안을 생성합니다. 알고리즘은 다양한 크기와 모양의 영역을 결합하여 다양한 제안 세트를 만듭니다.
EdgeBoxes: EdgeBoxes uses the edges in an image to generate object proposals. It identifies object-like regions by examining the number of bounding box edges that overlap with the object's edge.
EdgeBoxes: EdgeBoxes는 이미지 내의 가장자리를 활용하여 객체 제안을 생성합니다. 객체의 가장자리와 겹치는 경계 상자 가장자리의 수를 조사하여 객체와 유사한 영역을 식별합니다.
Region Proposal Networks (RPNs): RPNs are part of modern object detection frameworks like Faster R-CNN. They use convolutional neural networks to generate region proposals directly from the input image. RPNs learn to propose regions that are likely to contain objects.
Region Proposal Networks (RPNs): RPN은 Faster R-CNN과 같은 현대적인 객체 검출 프레임워크의 일부입니다. RPN은 컨볼루션 신경망을 사용하여 입력 이미지로부터 직접적으로 영역 제안을 생성합니다. RPN은 객체가 포함될 가능성이 높은 영역을 제안하도록 학습됩니다.
After generating region proposals, these proposals are typically ranked or scored based on their likelihood of containing objects. High-scoring proposals are then passed to the subsequent object classification and localization steps of the object detection pipeline.
영역 제안을 생성한 후, 이러한 제안은 일반적으로 객체 포함 가능성에 따라 순위 또는 점수를 매깁니다. 높은 점수를 받은 제안은 후속 객체 분류 및 위치 파악 단계로 전달됩니다.
In summary, "Region Proposal" refers to the process of generating potential bounding boxes or regions in an image that are likely to contain objects. This process helps reduce the search space for object detection tasks and improves the efficiency of object detection algorithms.
요약하면, "Region Proposal(영역 제안)"은 이미지 내에 있는 객체가 포함될 가능성이 높은 경계 상자나 영역을 생성하는 과정을 의미합니다. 이 과정을 통해 객체 검출 작업의 검색 공간이 축소되며, 객체 검출 알고리즘의 효율성이 향상됩니다.
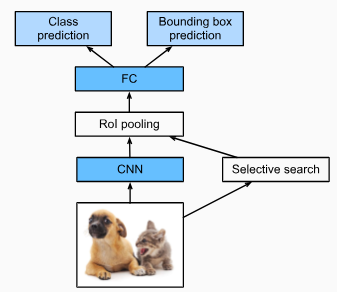
14.8.2.Fast R-CNN
The main performance bottleneck of an R-CNN lies in the independent CNN forward propagation for each region proposal, without sharing computation. Since these regions usually have overlaps, independent feature extractions lead to much repeated computation. One of the major improvements of thefast R-CNNfrom the R-CNN is that the CNN forward propagation is only performed on the entire image(Girshick, 2015).
R-CNN의 주요 성능 병목 현상은 계산을 공유하지 않고 각 region proposal에 대한 독립적인 CNN 순방향 전파에 있습니다. 이러한 영역은 일반적으로 겹치기 때문에 독립적인 특징 추출은 많은 반복 계산으로 이어집니다. R-CNN에서 빠른 R-CNN의 주요 개선 사항 중 하나는 CNN 순방향 전파가 전체 이미지에서만 수행된다는 것입니다(Girshick, 2015).
Fig. 14.8.2 The fast R-CNN model.
Fig. 14.8.2describes the fast R-CNN model. Its major computations are as follows:
그림 14.8.2는 빠른 R-CNN 모델을 설명합니다. 주요 계산은 다음과 같습니다.
Compared with the R-CNN, in the fast R-CNN the input of the CNN for feature extraction is the entire image, rather than individual region proposals. Moreover, this CNN is trainable. Given an input image, let the shape of the CNN output be1×c×ℎ1×w1.
R-CNN과 비교할 때 빠른 R-CNN에서 특징 feature 추출을 위한 CNN의 입력은 개별 영역 제안region proposals 이 아닌 전체 이미지입니다. 게다가, 이 CNN은 학습이 가능합니다. 입력 이미지가 주어지면 CNN 출력의 모양을 1×c×ℎ1×w1이라고 합니다.
Suppose that selective search generatesnregion proposals. These region proposals (of different shapes) mark regions of interest (of different shapes) on the CNN output. Then these regions of interest further extract features of the same shape (say heightℎ2and widthw2are specified) in order to be easily concatenated. To achieve this, the fast R-CNN introduces theregion of interest (RoI) poolinglayer: the CNN output and region proposals are input into this layer, outputting concatenated features of shapen×c×ℎ2×w2that are further extracted for all the region proposals.
선택적 검색이 n개의 지역 제안 region proposals을 생성한다고 가정합니다. 이러한 영역 제안 region proposals(다른 모양)은 CNN 출력에서 관심 영역 regions of interest (다른 모양)을 표시합니다. 그런 다음 이러한 관심 영역은 쉽게 연결하기 위해 동일한 모양(높이 ℎ2 및 너비 w2가 지정됨)의 특징을 추가로 추출합니다. 이를 달성하기 위해 빠른 R-CNN은 관심 영역(regions of interest -RoI) 풀링 레이어를 도입합니다. CNN 출력 및 영역 제안 region proposa 이 이 레이어에 입력됩니다. 모든 영역 제안 region proposa에 대해 추가로 추출되는 shape n×c×ℎ2×w2의 연결된 특징 features을 출력합니다.
Using a fully connected layer, transform the concatenated features into an output of shapen×d, whereddepends on the model design.
완전 연결 레이어를 사용하여 연결된 피처를 모양 shape n×d의 출력으로 변환합니다. 여기서 d는 모델 디자인에 따라 다릅니다.
Predict the class and bounding box for each of thenregion proposals. More concretely, in class and bounding box prediction, transform the fully connected layer output into an output of shapen×q(qis the number of classes) and an output of shapen×4, respectively. The class prediction uses softmax regression.
n개의 영역 제안 region proposals 각각에 대한 클래스 및 경계 상자를 예측합니다. 보다 구체적으로 클래스 및 경계 상자 예측에서 완전 연결 계층 출력을 각각 모양 n×q(q는 클래스 수) 및 모양 n×4의 출력으로 변환합니다. 클래스 예측은 softmax 회귀를 사용합니다.
The region of interest pooling layer proposed in the fast R-CNN is different from the pooling layer introduced inSection 7.5. In the pooling layer, we indirectly control the output shape by specifying sizes of the pooling window, padding, and stride. In contrast, we can directly specify the output shape in the region of interest pooling layer.
fast R-CNN에서 제안하는 region of interest pooling layer은 섹션 7.5에서 소개한 풀링 계층과 다릅니다. 풀링 레이어에서 풀링 창, 패딩 및 보폭의 크기를 지정하여 출력 모양을 간접적으로 제어합니다. 반대로 관심 영역 풀링 레이어에서 출력 모양을 직접 지정할 수 있습니다.
Region of Interest Pooling Layer (RoI Layer) 란?
The Region of Interest (RoI) pooling layer is a component commonly used in convolutional neural networks (CNNs) for object detection and instance segmentation tasks. Its primary purpose is to extract fixed-size feature representations from variable-sized regions of an input feature map. The RoI pooling layer plays a critical role in handling objects of different sizes and positions within an image and is crucial for enabling CNNs to perform accurate object localization and recognition.
관심 영역 풀링 레이어(Region of Interest pooling layer)는 객체 탐지 및 인스턴스 분할 작업에 널리 사용되는 컨볼루션 신경망(CNN) 구성 요소입니다. 주요 목적은 입력 특성 맵의 가변 크기 영역에서 고정 크기의 특성 표현을 추출하는 것입니다. 관심 영역 풀링 레이어는 이미지 내 다양한 크기와 위치의 객체를 처리하는 중요한 역할을 하며, 정확한 객체 지역화와 인식을 위한 CNN의 핵심 역할을 합니다.
In object detection tasks, a CNN generates a set of candidate bounding box predictions for potential objects within an image. These bounding boxes can vary in size and aspect ratio based on the object's location and scale. The RoI pooling layer is applied to these predicted bounding boxes to obtain a consistent spatial resolution of feature representations, which can then be fed into subsequent layers for classification and regression.
객체 탐지 작업에서 CNN은 이미지 내 잠재적인 객체에 대한 후보 바운딩 박스 예측 집합을 생성합니다. 이러한 바운딩 박스는 객체의 위치와 크기에 따라 크기와 종횡비가 다를 수 있습니다. 관심 영역 풀링 레이어는 이러한 예측된 바운딩 박스에 적용되어 고정된 공간 해상도(예: 7x7)의 특성 표현을 얻습니다. 이로써 후속 레이어로 분류 및 회귀 작업에 입력될 수 있습니다.
The RoI pooling layer operates as follows:
관심 영역 풀링 레이어는 다음과 같이 작동합니다:
Input: The input consists of a feature map generated by the preceding layers of the CNN and a set of predicted bounding boxes (RoIs).
입력: 입력은 CNN의 이전 레이어에서 생성된 특성 맵과 예측된 바운딩 박스(RoIs) 집합으로 구성됩니다.
Bounding Box Adaptation: Each RoI is adapted and aligned to a fixed spatial resolution (e.g., 7x7) using RoI pooling. This involves dividing the RoI into a grid of equal cells and selecting the maximum value from each cell. This pooling operation ensures that each RoI is transformed into a consistent feature map with the same spatial dimensions.
바운딩 박스 적: 각 RoI는 관심 영역 풀링을 사용하여 고정된 공간 해상도(예: 7x7)에 맞게 조정됩니다. 이는 RoI를 동일한 크기의 셀 그리드로 나누고 각 셀에서 최대 값을 선택하는 것을 포함합니다. 이 풀링 연산을 통해 각 RoI가 동일한 공간 차원을 가진 일관된 특성 맵으로 변환됩니다.
Feature Extraction: The RoI pooling operation generates fixed-size feature maps for each RoI. These feature maps can be directly fed into fully connected layers for classification or regression tasks.
특성 추출: 관심 영역 풀링 작업은 각 RoI에 대해 고정된 크기의 특성 맵을 생성합니다. 이러한 특성 맵은 분류나 회귀 작업을 위해 직접 완전 연결 레이어에 입력될 수 있습니다.
By using the RoI pooling layer, CNNs can effectively handle objects of different sizes, enabling the network to focus on relevant object details and reducing the impact of variations in object scale and position. This layer is a key component in modern object detection architectures like Faster R-CNN and Mask R-CNN.
관심 영역 풀링 레이어를 사용함으로써 CNN은 다양한 크기의 객체를 효과적(효율)으로 처리할 수 있으며, 네트워크는 관련성 있는 객체 세부 정보에 집중하고 객체 크기와 위치의 변동을 줄일 수 있습니다. 이 레이어는 Faster R-CNN 및 Mask R-CNN과 같은 현대적인 객체 탐지 아키텍처에서 핵심 구성 요소입니다.
Overall, the RoI pooling layer plays a pivotal role in enabling CNNs to process variable-sized regions of an input feature map, thereby facilitating accurate object detection, localization, and segmentation in complex scenes.
전반적으로, 관심 영역 풀링 레이어는 입력 특성 맵의 가변 크기 영역을 처리하는 데 중요한 역할을하여 복잡한 장면에서 정확한 객체 탐지, 지역화 및 분할을 용이하게 하는 데 중요한 역할을 합니다.
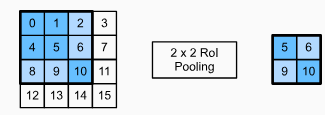
For example, let’s specify the output height and width for each region asℎ2andw2, respectively. For any region of interest window of shapeℎ×w, this window is divided into aℎ2×w2grid of subwindows, where the shape of each subwindow is approximately(ℎ/ℎ2)×(w/w2). In practice, the height and width of any subwindow shall be rounded up, and the largest element shall be used as output of the subwindow. Therefore, the region of interest pooling layer can extract features of the same shape even when regions of interest have different shapes.
예를 들어 각 영역의 출력 높이와 너비를 각각 ℎ2와 w2로 지정해 보겠습니다. ℎ×w 모양의 관심 영역 창에 대해 이 창은 ℎ2×w2 그리드의 하위 창으로 나뉘며 각 하위 창의 모양은 대략 (ℎ/ℎ2)×(w/w2)입니다. 실제로 모든 하위 창의 높이와 너비는 반올림되고 가장 큰 요소가 하위 창의 출력으로 사용됩니다. 따라서 관심 영역 풀링 계층은 관심 영역의 모양이 다른 경우에도 동일한 모양의 특징을 추출할 수 있습니다.
As an illustrative example, inFig. 14.8.3, the upper-left3×3region of interest is selected on a4×4input. For this region of interest, we use a2×2region of interest pooling layer to obtain a2×2output. Note that each of the four divided subwindows contains elements 0, 1, 4, and 5 (5 is the maximum); 2 and 6 (6 is the maximum); 8 and 9 (9 is the maximum); and 10.
예를 들어, 그림 14.8.3에서 왼쪽 상단의 3×3 관심 영역이 4×4 입력에서 선택됩니다. 이 관심 영역에 대해 2×2 관심 영역 풀링 계층을 사용하여 2×2 출력을 얻습니다. 4개의 분할된 하위 창 각각에는 요소 0, 1, 4 및 5(5가 최대값)가 포함되어 있습니다. 2 및 6(6이 최대값); 8 및 9(9가 최대); 및 10.
Fig. 14.8.3 A 2×2 region of interest pooling layer.
Below we demonstrate the computation of the region of interest pooling layer. Suppose that the height and width of the CNN-extracted featuresXare both 4, and there is only a single channel.
아래에서는 관심 영역 풀링 계층의 계산을 보여줍니다. CNN에서 추출한 특징 X의 높이와 너비가 모두 4이고 채널이 하나만 있다고 가정합니다.
import torch
import torchvision
X = torch.arange(16.).reshape(1, 1, 4, 4)
X
import torch: 파이토치 라이브러리를 가져옵니다.
import torchvision: 파이토치 비전 라이브러리를 가져옵니다. 이미지 관련 작업을 위한 함수와 모델을 포함하고 있습니다.
X = torch.arange(16.).reshape(1, 1, 4, 4): 0부터 15까지의 숫자로 이루어진 배열을 생성합니다. .reshape(1, 1, 4, 4)를 사용하여 배열을 4x4 크기의 4차원 텐서로 변환합니다. 이렇게 변환하면 (batch_size, channels, height, width) 형태로 텐서를 표현하게 됩니다. 여기서 batch_size와 channels는 1로 설정되었습니다.
X: 생성된 텐서 X를 출력합니다.
이 코드는 4x4 크기의 1채널 이미지를 표현하는 4차원 텐서 X를 생성하고 출력하는 내용을 나타냅니다.
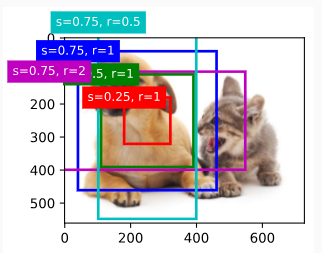
Let’s further suppose that the height and width of the input image are both 40 pixels and that selective search generates two region proposals on this image. Each region proposal is expressed as five elements: its object class followed by the(x,y)-coordinates of its upper-left and lower-right corners.
또한 입력 이미지의 높이와 너비가 모두 40픽셀이고 선택적 검색이 이 이미지에 대해 두 개의 영역 제안region proposals을 생성한다고 가정해 보겠습니다. 각 영역 제안은 5개의 요소로 표현됩니다. 개체 클래스와 왼쪽 상단 및 오른쪽 하단 모서리의 (x,y) 좌표가 뒤따릅니다.
torch.Tensor: 파이토치에서 텐서를 생성하는 클래스입니다. 행렬이나 다차원 배열과 유사한 데이터 구조를 나타냅니다.
[[0, 0, 0, 20, 20], [0, 0, 10, 30, 30]]: 2개의 리스트를 가진 리스트로 이루어진 텐서를 생성합니다. 각 리스트는 5개의 숫자로 이루어져 있으며, 각각의 리스트는 ROI(Region of Interest) 정보를 나타냅니다. 각 ROI 정보는 [batch index, class index, x1, y1, x2, y2] 형태로 표현됩니다. 여기서 batch index는 배치 내에서 몇 번째 이미지인지, class index는 객체 클래스를 의미하며, (x1, y1)은 좌상단 좌표, (x2, y2)는 우하단 좌표를 나타냅니다. ==> 요소가 5개인데 설명은 6개로 돼 있음. 교재 내용을 보면 object class,x1,y1,x2,y2 가 맞는 것 같
이 코드는 두 개의 ROI 정보를 담은 텐서 rois를 생성하는 내용을 나타냅니다.
Because the height and width ofXare1/10of the height and width of the input image, the coordinates of the two region proposals are multiplied by 0.1 according to the specifiedspatial_scaleargument. Then the two regions of interest are marked onXasX[:,:,0:3,0:3]andX[:,:,1:4,0:4], respectively. Finally in the2×2region of interest pooling, each region of interest is divided into a grid of sub-windows to further extract features of the same shape2×2.
X의 높이와 너비는 입력 이미지의 높이와 너비의 1/10이기 때문에 두 영역 제안의 좌표는 지정된 spatial_scale 인수에 따라 0.1이 곱해집니다. 그런 다음 두 개의 관심 영역이 X에 각각 X[:, :, 0:3, 0:3] 및 X[:, :, 1:4, 0:4]로 표시됩니다. 마지막으로 2×2 관심 영역 풀링에서는 각 관심 영역을 하위 창의 그리드로 나누어 동일한 모양의 2×2 특징을 더 추출합니다.
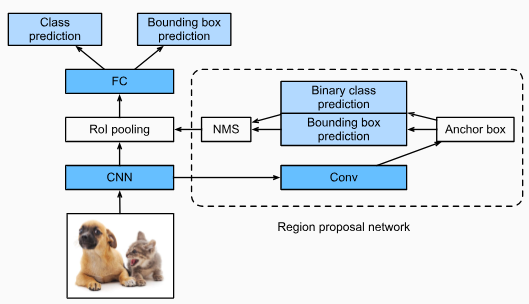
To be more accurate in object detection, the fast R-CNN model usually has to generate a lot of region proposals in selective search. To reduce region proposals without loss of accuracy, thefaster R-CNNproposes to replace selective search with aregion proposal network(Renet al., 2015).
개체 감지에서 보다 정확하려면 fast R-CNN 모델은 일반적으로 선택적 검색에서 많은 영역 제안을 생성해야 합니다. 정확도 손실 없이 지역 제안 region proposals을 줄이기 위해 Faster R-CNN은 선택적 검색을 지역 제안 region proposals 네트워크로 대체할 것을 제안합니다(Ren et al., 2015).
Fig. 14.8.4 The faster R-CNN model.
Fig. 14.8.4shows the faster R-CNN model. Compared with the fast R-CNN, the faster R-CNN only changes the region proposal method from selective search to a region proposal network. The rest of the model remain unchanged. The region proposal network works in the following steps:
그림 14.8.4는 더 빠른 R-CNN 모델을 보여줍니다. 빠른 R-CNN과 비교할 때 더 빠른 R-CNN은 지역 제안 region proposal 방법만 선택적 검색에서 지역 제안 region proposal 네트워크로 변경합니다. 나머지 모델은 변경되지 않습니다. 지역 제안 네트워크는 다음 단계로 작동합니다.
Use a3×3convolutional layer with padding of 1 to transform the CNN output to a new output withcchannels. In this way, each unit along the spatial dimensions of the CNN-extracted feature maps gets a new feature vector of lengthc.
패딩이 1인 3×3 컨벌루션 레이어를 사용하여 CNN 출력을 c 채널이 있는 새 출력으로 변환합니다. 이러한 방식으로 CNN 추출 기능 맵의 공간 차원을 따라 각 단위는 길이가 c인 새로운 기능 벡터를 얻습니다.
Centered on each pixel of the feature maps, generate multiple anchor boxes of different scales and aspect ratios and label them.
기능 맵의 각 픽셀을 중심으로 다양한 크기와 가로 세로 비율의 여러 앵커 상자를 생성하고 레이블을 지정합니다.
Using the length-cfeature vector at the center of each anchor box, predict the binary class (background or objects) and bounding box for this anchor box.
각 앵커 상자의 중심에 있는 길이-c 특징 벡터를 사용하여 이 앵커 상자의 이진 클래스(배경 또는 객체) 및 경계 상자를 예측합니다.
Consider those predicted bounding boxes whose predicted classes are objects. Remove overlapped results using non-maximum suppression. The remaining predicted bounding boxes for objects are the region proposals required by the region of interest pooling layer.
예측 클래스가 객체인 예측된 경계 상자를 고려하십시오. 최대가 아닌 억제를 사용하여 중첩된 결과를 제거합니다. 개체에 대한 나머지 예측 경계 상자는 관심 영역 풀링 레이어에 필요한 영역 제안입니다.
It is worth noting that, as part of the faster R-CNN model, the region proposal network is jointly trained with the rest of the model. In other words, the objective function of the faster R-CNN includes not only the class and bounding box prediction in object detection, but also the binary class and bounding box prediction of anchor boxes in the region proposal network. As a result of the end-to-end training, the region proposal network learns how to generate high-quality region proposals, so as to stay accurate in object detection with a reduced number of region proposals that are learned from data.
더 빠른 R-CNN 모델의 일부로 영역 제안 region proposal 네트워크가 모델의 나머지 부분과 공동으로 훈련된다는 점은 주목할 가치가 있습니다. 즉, 더 빠른 R-CNN의 목적 함수는 객체 감지에서 클래스 및 경계 상자 예측뿐만 아니라 영역 제안 region proposal 네트워크에서 앵커 상자의 이진 클래스 및 경계 상자 예측을 포함합니다. 종단 간 교육의 결과, 지역 제안 region proposal 네트워크는 고품질 지역 제안 region proposal을 생성하는 방법을 학습하여 데이터에서 학습된 지역 제안 region proposal의 수를 줄임과 동시 객체 감지에서 정확성을 유지합니다.
14.8.4.Mask R-CNN
In the training dataset, if pixel-level positions of object are also labeled on images, themask R-CNNcan effectively leverage such detailed labels to further improve the accuracy of object detection(Heet al., 2017).
학습 데이터 세트에서 개체의 픽셀 수준 위치도 이미지에 레이블이 지정된 경우 마스크 R-CNN은 이러한 세부 레이블을 효과적으로 활용하여 개체 감지의 정확도를 더욱 향상시킬 수 있습니다(He et al., 2017).
Fig. 14.8.5 The mask R-CNN model.
As shown inFig. 14.8.5, the mask R-CNN is modified based on the faster R-CNN. Specifically, the mask R-CNN replaces the region of interest pooling layer with theregion of interest (RoI) alignmentlayer. This region of interest alignment layer uses bilinear interpolation to preserve the spatial information on the feature maps, which is more suitable for pixel-level prediction. The output of this layer contains feature maps of the same shape for all the regions of interest. They are used to predict not only the class and bounding box for each region of interest, but also the pixel-level position of the object through an additional fully convolutional network. More details on using a fully convolutional network to predict pixel-level semantics of an image will be provided in subsequent sections of this chapter.
그림 14.8.5와 같이 더 빠른 R-CNN을 기반으로 마스크 R-CNN이 수정되었습니다. 특히, 마스크 R-CNN은 관심 영역 풀링 레이어를 관심 영역(RoI) 정렬 레이어로 대체합니다. 이 관심 영역 정렬 레이어는 쌍선형 보간을 사용하여 픽셀 수준 예측에 더 적합한 기능 맵의 공간 정보를 보존합니다. 이 레이어의 출력에는 모든 관심 영역에 대해 동일한 모양의 기능 맵이 포함됩니다. 각 관심 영역에 대한 클래스 및 경계 상자뿐만 아니라 추가적인 완전 컨벌루션 네트워크를 통해 개체의 픽셀 수준 위치를 예측하는 데 사용됩니다. 이미지의 픽셀 수준 의미론을 예측하기 위해 완전 컨벌루션 네트워크를 사용하는 방법에 대한 자세한 내용은 이 장의 다음 섹션에서 제공됩니다.
14.8.5.Summary
The R-CNN extracts many region proposals from the input image, uses a CNN to perform forward propagation on each region proposal to extract its features, then uses these features to predict the class and bounding box of this region proposal.
R-CNN은 입력 이미지에서 많은 영역 제안region proposals을 추출하고, CNN을 사용하여 각 영역 제안에 대해 정방향 전파를 수행하여 해당 기능을 추출한 다음 이러한 기능을 사용하여 이 영역 제안의 클래스 및 경계 상자를 예측합니다.
One of the major improvements of the fast R-CNN from the R-CNN is that the CNN forward propagation is only performed on the entire image. It also introduces the region of interest pooling layer, so that features of the same shape can be further extracted for regions of interest that have different shapes.
R-CNN에서 빠른 R-CNN의 주요 개선 사항 중 하나는 CNN 순방향 전파가 전체 이미지에서만 수행된다는 것입니다. 또한 관심 영역 풀링 레이어를 도입하여 모양이 다른 관심 영역에 대해 동일한 모양의 특징을 추가로 추출할 수 있습니다.
The faster R-CNN replaces the selective search used in the fast R-CNN with a jointly trained region proposal network, so that the former can stay accurate in object detection with a reduced number of region proposals.
더 빠른 R-CNN은 빠른 R-CNN에서 사용되는 선택적 검색을 공동으로 훈련된 영역 제안 네트워크로 대체하므로 전자는 감소된 수의 영역 제안으로 객체 감지에서 정확성을 유지할 수 있습니다.
Based on the faster R-CNN, the mask R-CNN additionally introduces a fully convolutional network, so as to leverage pixel-level labels to further improve the accuracy of object detection.
더 빠른 R-CNN을 기반으로 하는 마스크 R-CNN은 픽셀 수준 레이블을 활용하여 개체 감지의 정확도를 더욱 향상시키기 위해 완전히 컨벌루션 네트워크를 추가로 도입합니다.
14.8.6.Exercises
Can we frame object detection as a single regression problem, such as predicting bounding boxes and class probabilities? You may refer to the design of the YOLO model(Redmonet al., 2016).
Compare single shot multibox detection with the methods introduced in this section. What are their major differences? You may refer to Figure 2 ofZhaoet al.(2019).
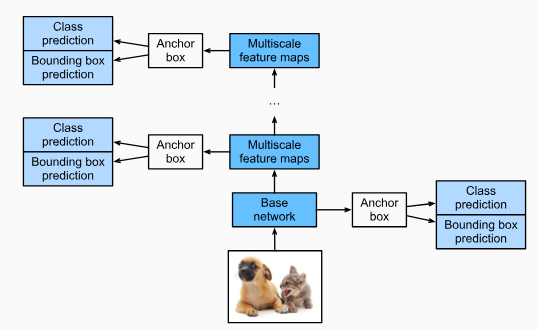
InSection 14.3–Section 14.6, we introduced bounding boxes, anchor boxes, multiscale object detection, and the dataset for object detection. Now we are ready to use such background knowledge to design an object detection model: single shot multibox detection (SSD)(Liuet al., 2016). This model is simple, fast, and widely used. Although this is just one of vast amounts of object detection models, some of the design principles and implementation details in this section are also applicable to other models.
섹션 14.3–섹션 14.6에서 경계 상자, 앵커 상자, 멀티스케일 객체 감지 및 객체 감지를 위한 데이터 세트를 소개했습니다. 이제 이러한 배경 지식을 사용하여 객체 감지 모델인 단일 샷 멀티박스 감지(SSD)를 설계할 준비가 되었습니다(Liu et al., 2016). 이 모델은 간단하고 빠르며 널리 사용됩니다. 이것은 방대한 양의 객체 감지 모델 중 하나일 뿐이지만 이 섹션의 일부 설계 원칙 및 구현 세부 정보는 다른 모델에도 적용할 수 있습니다.
Single Shot Multibox Detection (SSD) 란?
Single Shot Multibox Detection (SSD) is a popular object detection algorithm in computer vision. It is designed to efficiently detect and localize objects in images. The "Single Shot" in its name indicates that it performs both object localization and classification in a single forward pass through a neural network, making it a faster and more efficient approach compared to some other object detection methods that involve multiple stages.
'Single Shot Multibox Detection' (SSD)은 컴퓨터 비전에서 널리 사용되는 객체 검출 알고리즘입니다. 이 알고리즘은 이미지 내의 객체를 효율적으로 검출하고 위치를 지정하는 데 사용됩니다. 그 이름에 있는 "Single Shot"은 이 알고리즘이 객체의 위치 지정 및 분류를 하나의 순방향 전파로 처리한다는 것을 의미하며, 다른 객체 검출 방법과 비교하여 더 빠르고 효율적인 방법을 나타냅니다.
Here's a brief overview of how SSD works:
다음은 SSD의 작동 방식에 대한 간략한 설명입니다:
Anchor Boxes: SSD uses a predefined set of anchor boxes of different sizes and aspect ratios that serve as reference bounding boxes. These anchor boxes are centered at various positions across the image.
앵커 박스: SSD는 다양한 크기와 종횡비를 가진 미리 정의된 앵커 박스 세트를 사용합니다. 이 앵커 박스는 이미지 내 다양한 위치에 중심이 맞춰져 있습니다.
Convolutional Backbone: The input image is passed through a convolutional neural network (CNN) backbone. This backbone extracts features from the image, capturing different levels of information.
합성곱 기반: 입력 이미지는 합성곱 신경망(CNN) 백본을 통과합니다. 이 백본은 이미지에서 특징을 추출하여 다양한 정보 수준을 포착합니다.
Multi-scale Feature Maps: SSD uses feature maps from different layers of the CNN to detect objects at various scales. These feature maps capture objects of different sizes due to the different receptive fields of the convolutional layers.
다중 스케일 특징 맵: SSD는 CNN의 다른 레이어에서 특징 맵을 사용하여 다양한 크기의 객체를 검출합니다. 이러한 특징 맵은 합성곱 레이어의 다른 수용 영역으로 인해 다양한 크기의 객체를 포착합니다.
Localization and Classification: For each position in the feature maps, SSD predicts the offsets to adjust the anchor boxes, aiming to match the true object bounding boxes. Additionally, SSD predicts the probability scores for different object classes.
위치 지정 및 분류: 특징 맵 내 각 위치에 대해 SSD는 앵커 박스를 조정하기 위한 오프셋을 예측하여 실제 객체의 경계 상자에 맞추려고 합니다. 또한 SSD는 다른 객체 클래스에 대한 확률 점수를 예측합니다.
Non-Maximum Suppression (NMS): To remove duplicate detections and improve precision, SSD uses non-maximum suppression. This step selects the most confident detection for each object and discards overlapping detections.
비최대 억제 (NMS): 중복 검출을 제거하고 정확도를 향상시키기 위해 SSD는 비최대 억제를 사용합니다. 이 단계에서는 각 객체에 대해 가장 자신있는 검출을 선택하고 겹치는 검출을 제거합니다.
The main advantages of SSD include its real-time performance, as it directly predicts object classes and bounding box coordinates in a single pass, without relying on region proposals. This makes it suitable for applications where speed is crucial, such as real-time object detection in videos or robotics.
SSD의 주요 장점은 객체의 클래스와 경계 상자 좌표를 단일 전파로 직접 예측하기 때문에 실시간 성능을 발휘한다는 점입니다. 이로써 영상이나 로보틱스와 같이 속도가 중요한 응용 분야에 적합합니다.
However, one limitation of SSD is that it might struggle with detecting small objects in high-resolution images, as the predefined anchor boxes might not match well with those objects. Despite this limitation, SSD remains a widely used and effective approach for object detection tasks.
하지만 SSD의 단점 중 하나는 고해상도 이미지에서 작은 객체를 검출하는 데 어려움을 겪을 수 있다는 점입니다. 미리 정의된 앵커 박스가 이러한 객체와 잘 일치하지 않을 수 있기 때문입니다. 이런 한계에도 불구하고 SSD는 여전히 객체 검출 작업에 널리 사용되는 효과적인 방법입니다.
14.7.1.Model
Fig. 14.7.1provides an overview of the design of single-shot multibox detection. This model mainly consists of a base network followed by several multiscale feature map blocks. The base network is for extracting features from the input image, so it can use a deep CNN. For example, the original single-shot multibox detection paper adopts a VGG network truncated before the classification layer(Liuet al., 2016), while ResNet has also been commonly used. Through our design we can make the base network output larger feature maps so as to generate more anchor boxes for detecting smaller objects. Subsequently, each multiscale feature map block reduces (e.g., by half) the height and width of the feature maps from the previous block, and enables each unit of the feature maps to increase its receptive field on the input image.
그림 14.7.1은 단일 샷 멀티박스 감지 설계의 개요를 제공합니다. 이 모델은 주로 기본 네트워크와 여러 다중 스케일 기능 맵 블록으로 구성됩니다. 기본 네트워크는 입력 이미지에서 특징을 추출하기 위한 것이므로 심층 CNN을 사용할 수 있습니다. 예를 들어 원래의 단일 샷 멀티박스 감지 용지는 분류 계층 앞에서 잘린 VGG 네트워크를 채택하고(Liu et al., 2016), ResNet도 일반적으로 사용되었습니다. 우리의 설계를 통해 우리는 더 작은 물체를 감지하기 위해 더 많은 앵커 박스를 생성하기 위해 기본 네트워크 출력을 더 큰 기능 맵으로 만들 수 있습니다. 그 후, 각 멀티스케일 특징 맵 블록은 이전 블록에서 특징 맵의 높이와 너비를 줄이고(예: 절반) 특징 맵의 각 단위가 입력 이미지에서 수용 필드를 증가시킬 수 있도록 합니다.
Recall the design of multiscale object detection through layerwise representations of images by deep neural networks inSection 14.5. Since multiscale feature maps closer to the top ofFig. 14.7.1are smaller but have larger receptive fields, they are suitable for detecting fewer but larger objects.
섹션 14.5에서 심층 신경망에 의한 이미지의 계층적 표현을 통한 다중 스케일 객체 감지 설계를 상기하십시오. 그림 14.7.1의 상단에 가까운 멀티스케일 특징 맵은 더 작지만 수용 필드가 더 크기 때문에 더 적지만 더 큰 물체를 감지하는 데 적합합니다.
In a nutshell, via its base network and several multiscale feature map blocks, single-shot multibox detection generates a varying number of anchor boxes with different sizes, and detects varying-size objects by predicting classes and offsets of these anchor boxes (thus the bounding boxes); thus, this is a multiscale object detection model.
간단히 말해서, 기본 네트워크와 여러 멀티스케일 기능 맵 블록을 통해 단일 샷 멀티박스 감지는 다양한 크기의 다양한 앵커 박스를 생성하고 이러한 앵커 박스의 클래스와 오프셋을 예측하여 다양한 크기의 객체를 감지합니다(따라서 경계 상자); 따라서 이것은 다중 스케일 객체 감지 모델입니다.
Fig. 14.7.1 As a multiscale object detection model, single-shot multibox detection mainly consists of a base network followed by several multiscale feature map blocks.
In the following, we will describe the implementation details of different blocks inFig. 14.7.1. To begin with, we discuss how to implement the class and bounding box prediction.
다음에서는 그림 14.7.1의 여러 블록에 대한 구현 세부 사항을 설명합니다. 먼저 클래스 및 경계 상자 예측을 구현하는 방법에 대해 설명합니다.
14.7.1.1.Class Prediction Layer
Let the number of object classes beq. Then anchor boxes haveq+1classes, where class 0 is background. At some scale, suppose that the height and width of feature maps areℎandw, respectively. Whenαanchor boxes are generated with each spatial position of these feature maps as their center, a total ofℎwαanchor boxes need to be classified. This often makes classification with fully connected layers infeasible due to likely heavy parametrization costs. Recall how we used channels of convolutional layers to predict classes inSection 8.3. Single-shot multibox detection uses the same technique to reduce model complexity.
객체 클래스의 수를 q라 하자. 그런 다음 앵커 상자에는 q+1 클래스가 있으며 여기서 클래스 0은 배경입니다. 어떤 축척에서 특징 맵의 높이와 너비가 각각 ℎ와 w라고 가정합니다. 이러한 특징 맵의 각 공간 위치를 중심으로 α 앵커 박스를 생성하면 총 ℎwα 앵커 박스를 분류해야 한다. 이로 인해 매개변수화 비용이 높을 가능성이 높기 때문에 완전히 연결된 계층으로 분류하는 것이 불가능한 경우가 많습니다. 섹션 8.3에서 클래스를 예측하기 위해 컨벌루션 레이어의 채널을 어떻게 사용했는지 기억하십시오. 단일 샷 멀티박스 감지는 동일한 기술을 사용하여 모델 복잡성을 줄입니다.
Specifically, the class prediction layer uses a convolutional layer without altering width or height of feature maps. In this way, there can be a one-to-one correspondence between outputs and inputs at the same spatial dimensions (width and height) of feature maps. More concretely, channels of the output feature maps at any spatial position (x,y) represent class predictions for all the anchor boxes centered on (x,y) of the input feature maps. To produce valid predictions, there must beα(q+1)output channels, where for the same spatial position the output channel with indexi(q+1)+jrepresents the prediction of the classj(0≤j≤q) for the anchor boxi(0≤i<a).
특히 클래스 예측 레이어는 피처 맵의 너비나 높이를 변경하지 않고 컨볼루션 레이어를 사용합니다. 이러한 방식으로 기능 맵의 동일한 공간 차원(너비 및 높이)에서 출력과 입력 간에 일대일 대응이 있을 수 있습니다. 보다 구체적으로, 임의의 공간 위치(x, y)에 있는 출력 기능 맵의 채널은 입력 기능 맵의 (x, y) 중심에 있는 모든 앵커 박스에 대한 클래스 예측을 나타냅니다. 유효한 예측을 생성하려면 α(q+1) 출력 채널이 있어야 합니다. 여기서 동일한 공간 위치에 대해 인덱스 i(q+1)+j가 있는 출력 채널은 클래스 j(0≤j≤q)의 예측을 나타냅니다. 앵커 박스 i의 경우(0≤i<a).
Below we define such a class prediction layer, specifyingαandqvia argumentsnum_anchorsandnum_classes, respectively. This layer uses a3×3convolutional layer with a padding of 1. The width and height of the input and output of this convolutional layer remain unchanged.
아래에서 우리는 각각 num_anchors 및 num_classes 인수를 통해 α 및 q를 지정하여 이러한 클래스 예측 계층을 정의합니다. 이 레이어는 패딩이 1인 3×3 컨볼루션 레이어를 사용합니다. 이 컨볼루션 레이어의 입력 및 출력의 너비와 높이는 변경되지 않습니다.
%matplotlib inline
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
def cls_predictor(num_inputs, num_anchors, num_classes):
return nn.Conv2d(num_inputs, num_anchors * (num_classes + 1),
kernel_size=3, padding=1)
%matplotlib inline: 이 줄은 Jupyter Notebook 등에서 맷플롯립 그래프를 인라인으로 표시하도록 설정하는 매직 커맨드입니다. 그래프를 노트북 셀 안에서 바로 볼 수 있게 합니다.
import torch: 파이토치 라이브러리를 임포트합니다. 딥러닝 모델을 구성하고 학습시키는 데 사용됩니다.
import torchvision: 파이토치 비전(Vision) 관련 라이브러리를 임포트합니다. 이미지 데이터를 다루고 변환하는 등의 기능을 제공합니다.
from torch import nn: 파이토치의 nn 모듈로부터 필요한 클래스와 함수를 가져옵니다. 신경망 모델을 구성하는 데 사용됩니다.
from torch.nn import functional as F: 파이토치의 functional 모듈로부터 함수를 가져와 F로 별칭을 붙입니다. 신경망 구성 중 함수들을 사용하기 위해 가져옵니다.
from d2l import torch as d2l: 'Dive into Deep Learning' 도서의 코드 라이브러리(d2l)로부터 파이토치 관련 모듈을 가져옵니다.
def cls_predictor(num_inputs, num_anchors, num_classes): 이 함수는 분류(classification) 작업을 위한 예측기 모듈을 생성합니다. num_inputs는 입력 특성 맵의 채널 수를 나타내고, num_anchors는 각 위치에서 예측할 앵커(anchor)의 수를 나타냅니다. num_classes는 분류하려는 클래스의 수입니다.
return nn.Conv2d(num_inputs, num_anchors * (num_classes + 1), kernel_size=3, padding=1): 이 함수는 2D 합성곱(Convolution) 레이어를 생성하여 예측기 모듈을 반환합니다. 합성곱 레이어는 입력 특성 맵과 필터를 사용하여 특성을 추출하는 데 사용됩니다. num_inputs는 입력 채널 수, num_anchors * (num_classes + 1)는 출력 채널 수를 나타냅니다. 여기서 (num_classes + 1)은 각 클래스와 배경(class 0)을 분류하기 위한 채널 수입니다. kernel_size=3은 필터의 크기를 3x3으로 설정하고, padding=1은 입력 주변에 0 패딩을 추가하여 입력과 출력의 크기를 동일하게 유지합니다.
이 코드는 파이토치를 사용하여 클래스 예측을 위한 합성곱 레이어를 생성하는 함수를 정의하는 것입니다. 이러한 레이어는 주로 객체 검출과 분류 작업에 사용됩니다.
14.7.1.2.Bounding Box Prediction Layer
The design of the bounding box prediction layer is similar to that of the class prediction layer. The only difference lies in the number of outputs for each anchor box: here we need to predict four offsets rather thanq+1classes.
경계 상자 예측 계층의 설계는 클래스 예측 계층의 설계와 유사합니다. 유일한 차이점은 각 앵커 박스의 출력 수에 있습니다. 여기서 우리는 q+1 클래스가 아닌 4개의 오프셋을 예측해야 합니다.
def bbox_predictor(num_inputs, num_anchors):: 이 함수는 바운딩 박스(prediction box) 예측기 모듈을 생성하는 역할을 합니다. num_inputs는 입력 특성 맵의 채널 수를 나타내며, num_anchors는 각 위치에서 예측할 앵커(anchor)의 수를 나타냅니다.
return nn.Conv2d(num_inputs, num_anchors * 4, kernel_size=3, padding=1): 이 함수는 2D 합성곱(Convolution) 레이어를 생성하여 바운딩 박스 예측기 모듈을 반환합니다. 합성곱 레이어는 입력 특성 맵과 필터를 사용하여 특성을 추출하는 데 사용됩니다. num_inputs는 입력 채널 수, num_anchors * 4는 출력 채널 수를 나타냅니다. 여기서 num_anchors * 4는 각 앵커에 대한 바운딩 박스의 좌표를 예측하기 위한 채널 수입니다. 바운딩 박스의 좌표는 일반적으로 (x_min, y_min, x_max, y_max) 형식으로 표현되며, 이 경우 각 앵커마다 4개의 좌표를 예측해야 하므로 num_anchors * 4 채널이 필요합니다. kernel_size=3은 필터의 크기를 3x3으로 설정하고, padding=1은 입력 주변에 0 패딩을 추가하여 입력과 출력의 크기를 동일하게 유지합니다.
이 코드는 파이토치를 사용하여 바운딩 박스 예측을 위한 합성곱 레이어를 생성하는 함수를 정의하는 것입니다. 이러한 레이어는 객체 검출 작업에서 앵커와 관련된 바운딩 박스의 좌표를 예측하기 위해 사용됩니다.
14.7.1.3.Concatenating Predictions for Multiple Scales
As we mentioned, single-shot multibox detection uses multiscale feature maps to generate anchor boxes and predict their classes and offsets. At different scales, the shapes of feature maps or the numbers of anchor boxes centered on the same unit may vary. Therefore, shapes of the prediction outputs at different scales may vary.
앞에서 언급했듯이 단일 샷 멀티박스 감지는 멀티스케일 기능 맵을 사용하여 앵커 박스를 생성하고 해당 클래스와 오프셋을 예측합니다. 서로 다른 축척에서 피쳐 맵의 모양이나 같은 단위를 중심으로 하는 앵커 박스의 수가 다를 수 있습니다. 따라서 서로 다른 스케일에서 예측 출력의 모양이 다를 수 있습니다.
In the following example, we construct feature maps at two different scales,Y1andY2, for the same minibatch, where the height and width ofY2are half of those ofY1. Let’s take class prediction as an example. Suppose that 5 and 3 anchor boxes are generated for every unit inY1andY2, respectively. Suppose further that the number of object classes is 10. For feature mapsY1andY2the numbers of channels in the class prediction outputs are5×(10+1)=55and3×(10+1)=33, respectively, where either output shape is (batch size, number of channels, height, width).
다음 예제에서는 동일한 미니배치에 대해 Y1과 Y2의 두 가지 다른 축척으로 피처 맵을 구성합니다. 여기서 Y2의 높이와 너비는 Y1의 절반입니다. 클래스 예측을 예로 들어 보겠습니다. Y1과 Y2의 모든 유닛에 대해 각각 5개와 3개의 앵커 박스가 생성된다고 가정합니다. 개체 클래스의 수가 10이라고 가정합니다. 특징 맵 Y1 및 Y2의 경우 클래스 예측 출력의 채널 수는 각각 5×(10+1)=55 및 3×(10+1)=33입니다. 여기서 출력 형태는 (배치 크기, 채널 수, 높이, 너비)입니다.
def forward(x, block):: 이 함수는 주어진 입력 x와 블록(block)을 사용하여 순전파(forward pass)를 수행하는 역할을 합니다. 입력 x를 block에 적용하고 결과를 반환합니다.
return block(x): 이 줄은 주어진 블록 block을 입력 x에 적용하여 결과를 반환합니다. 이는 신경망의 순전파 단계에서 레이어를 통과시키는 역할을 합니다.
Y1 = forward(torch.zeros((2, 8, 20, 20)), cls_predictor(8, 5, 10)): torch.zeros((2, 8, 20, 20))는 크기가 2x8x20x20인 입력 데이터를 생성합니다. 이 입력 데이터를 cls_predictor(8, 5, 10) 함수에 적용하여 예측기를 생성합니다. 그리고 forward 함수를 이용하여 입력 데이터를 예측기에 통과시켜 Y1 결과를 얻습니다.
Y2 = forward(torch.zeros((2, 16, 10, 10)), cls_predictor(16, 3, 10)): torch.zeros((2, 16, 10, 10))는 크기가 2x16x10x10인 입력 데이터를 생성합니다. 이 입력 데이터를 cls_predictor(16, 3, 10) 함수에 적용하여 예측기를 생성합니다. 그리고 forward 함수를 이용하여 입력 데이터를 예측기에 통과시켜 Y2 결과를 얻습니다.
Y1.shape, Y2.shape: 이 줄은 Y1과 Y2의 형태(shape)를 확인합니다. .shape는 배열의 크기를 나타내는 속성(attribute)입니다. 이 코드에서는 Y1과 Y2의 출력 크기를 확인하여 결과를 반환합니다.
이 코드는 주어진 입력 데이터를 예측기에 통과시켜 각각 Y1과 Y2 출력을 얻고, 이들 출력의 크기를 확인하는 역할을 합니다. 이는 딥러닝 모델의 순전파 작업을 보여주는 간단한 예시입니다.
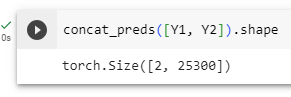
As we can see, except for the batch size dimension, the other three dimensions all have different sizes. To concatenate these two prediction outputs for more efficient computation, we will transform these tensors into a more consistent format.
보시다시피 배치 크기 차원을 제외하고 다른 세 차원은 모두 크기가 다릅니다. 보다 효율적인 계산을 위해 이 두 예측 출력을 연결하기 위해 이 텐서를 보다 일관된 형식으로 변환합니다.
Note that the channel dimension holds the predictions for anchor boxes with the same center. We first move this dimension to the innermost. Since the batch size remains the same for different scales, we can transform the prediction output into a two-dimensional tensor with shape (batch size, height×width×number of channels). Then we can concatenate such outputs at different scales along dimension 1.
채널 차원은 중심이 같은 앵커 박스에 대한 예측을 보유합니다. 먼저 이 차원을 가장 안쪽으로 이동합니다. 다른 스케일에 대해 배치 크기가 동일하게 유지되므로 예측 출력을 모양(배치 크기, 높이 × 너비 × 채널 수)이 있는 2차원 텐서로 변환할 수 있습니다. 그런 다음 차원 1을 따라 다른 스케일에서 이러한 출력을 연결할 수 있습니다.
def flatten_pred(pred):
return torch.flatten(pred.permute(0, 2, 3, 1), start_dim=1)
def concat_preds(preds):
return torch.cat([flatten_pred(p) for p in preds], dim=1)
def flatten_pred(pred):: 이 함수는 예측 결과 텐서(pred)를 2D로 평탄화(flatten)하는 역할을 합니다.
pred.permute(0, 2, 3, 1): pred의 차원을 변경하여 이미지 각 위치의 예측 값을 마지막 차원으로 가져옵니다. 즉, 이미지 각 위치에 대한 예측 값들이 모두 한 차원으로 모이게 됩니다.
torch.flatten(...): 위에서 변경한 예측 텐서를 2D로 평탄화합니다. start_dim=1은 평탄화 작업을 시작할 차원을 나타냅니다. 여기서는 첫 번째 차원(배치 차원)을 제외하고 평탄화를 수행합니다.
def concat_preds(preds):: 이 함수는 여러 예측 결과 텐서들(preds)을 연결(concatenate)하여 하나의 큰 2D 텐서로 만드는 역할을 합니다.
torch.cat(...): 여러 개의 텐서를 지정된 차원(dim)을 기준으로 연결합니다. 여기서는 flatten_pred(p) for p in preds를 통해 preds 안의 각 예측 텐서를 2D로 평탄화하고, 이들을 차원 dim=1을 기준으로 연결하여 하나의 큰 텐서로 만듭니다.
이러한 코드는 주어진 예측 텐서들을 평탄화하거나 연결하여 전처리하는 함수들을 정의합니다. 주로 신경망 출력을 처리하고 객체 검출 작업을 수행할 때 사용될 수 있습니다.
In this way, even thoughY1andY2have different sizes in channels, heights, and widths, we can still concatenate these two prediction outputs at two different scales for the same minibatch.
이러한 방식으로 Y1과 Y2가 채널, 높이 및 너비에서 다른 크기를 가지더라도 동일한 미니배치에 대해 두 가지 다른 스케일에서 이 두 예측 출력을 연결할 수 있습니다.
concat_preds([Y1, Y2]).shape
concat_preds([Y1, Y2]): 이 부분은 concat_preds 함수를 사용하여 Y1과 Y2 두 개의 출력을 연결(concatenate)한 결과를 생성합니다. 이 함수는 주어진 출력들을 하나의 큰 2D 텐서로 만들어줍니다.
.shape: 이 코드는 연결한 결과 텐서의 크기(shape)를 확인하는 역할을 합니다. .shape는 텐서의 차원 크기를 나타내는 속성(attribute)입니다.
결과적으로, 이 코드는 Y1과 Y2 두 개의 출력을 연결한 텐서의 크기(shape)를 확인합니다. 이는 객체 검출 모델에서 다양한 예측 결과를 하나의 큰 텐서로 합치는 작업을 수행할 때 사용될 수 있습니다.
14.7.1.4.Downsampling Block
In order to detect objects at multiple scales, we define the following downsampling blockdown_sample_blkthat halves the height and width of input feature maps. In fact, this block applies the design of VGG blocks inSection 8.2.1. More concretely, each downsampling block consists of two3×3convolutional layers with padding of 1 followed by a2×2max-pooling layer with stride of 2. As we know,3×3convolutional layers with padding of 1 do not change the shape of feature maps. However, the subsequent2×2max-pooling reduces the height and width of input feature maps by half. For both input and output feature maps of this downsampling block, because1×2+(3−1)+(3−1)=6, each unit in the output has a6×6receptive field on the input. Therefore, the downsampling block enlarges the receptive field of each unit in its output feature maps.
여러 스케일에서 객체를 감지하기 위해 입력 기능 맵의 높이와 너비를 절반으로 줄이는 다음과 같은 다운샘플링 블록 down_sample_blk를 정의합니다. 실제로 이 블록은 섹션 8.2.1의 VGG 블록 설계를 적용합니다. 보다 구체적으로 각 다운샘플링 블록은 패딩이 1인 두 개의 3×3 컨볼루션 레이어와 보폭이 2인 2×2 최대 풀링 레이어로 구성됩니다. 아시다시피 패딩이 1인 3×3 컨볼루션 레이어는 피쳐 맵의 모양. 그러나 후속 2×2 최대 풀링은 입력 기능 맵의 높이와 너비를 절반으로 줄입니다. 이 다운샘플링 블록의 입력 및 출력 기능 맵 모두에 대해 1×2+(3−1)+(3−1)=6이므로 출력의 각 단위는 입력에 6×6 수용 필드를 가집니다. 따라서 다운샘플링 블록은 출력 기능 맵에서 각 유닛의 수용 필드를 확대합니다.
def down_sample_blk(in_channels, out_channels):: 이 함수는 다운샘플링(down-sampling) 블록을 생성하는 역할을 합니다. 다운샘플링 블록은 입력의 공간 해상도를 줄이는 데 사용되며, 주로 컨볼루션 신경망(Convolutional Neural Network, CNN) 아키텍처에서 활용됩니다. in_channels는 입력 채널 수를, out_channels는 출력 채널 수를 나타냅니다.
blk = []: 빈 리스트 blk를 생성합니다. 이 리스트는 블록 내의 연속적인 레이어를 저장할 역할을 합니다.
for _ in range(2):: 2번 반복하는 루프를 생성합니다. 루프 안에서는 두 개의 컨볼루션 레이어를 생성하고, 이후 레이어들을 순차적으로 추가하게 됩니다.
blk.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)): 컨볼루션 레이어를 생성하여 blk 리스트에 추가합니다. 이 레이어는 입력 채널 수 in_channels에서 출력 채널 수 out_channels로 변환합니다. kernel_size=3은 커널(필터) 크기를 3x3으로 설정하고, padding=1은 입력 주변에 0 패딩을 추가하여 입력과 출력의 크기를 동일하게 유지합니다.
blk.append(nn.BatchNorm2d(out_channels)): 배치 정규화(Batch Normalization) 레이어를 추가합니다. 이는 신경망 내부에서 입력 데이터의 평균과 분산을 조정하여 학습 안정성을 향상시키는 역할을 합니다.
blk.append(nn.ReLU()): ReLU(Rectified Linear Unit) 활성화 함수 레이어를 추가합니다. ReLU는 비선형성을 도입하여 네트워크가 복잡한 함수를 학습할 수 있게 합니다.
in_channels = out_channels: 다음 레이어에서의 입력 채널 수를 현재 출력 채널 수로 업데이트합니다.
blk.append(nn.MaxPool2d(2)): 최대 풀링(Max Pooling) 레이어를 추가합니다. 최대 풀링은 입력의 공간 해상도를 줄이는 데 사용되며, 특성 맵에서 가장 큰 값을 선택하여 다운샘플링합니다. 2는 풀링 영역의 크기를 2x2로 설정하는 것을 의미합니다.
return nn.Sequential(*blk): 생성한 레이어들을 순차적으로 실행하는 nn.Sequential 컨테이너를 생성하고 반환합니다. *blk는 리스트 내의 레이어들을 펼쳐서 순차적으로 컨테이너에 추가하라는 의미입니다.
이 함수는 입력 채널 수와 출력 채널 수를 입력으로 받아 다운샘플링 블록을 생성하는 역할을 합니다. 이 블록은 CNN에서 특성 추출을 위해 사용되며, 컨볼루션, 배치 정규화, 활성화 함수, 풀링 등의 레이어로 구성됩니다.
In the following example, our constructed downsampling block changes the number of input channels and halves the height and width of the input feature maps.
다음 예에서 구성된 다운샘플링 블록은 입력 채널 수를 변경하고 입력 기능 맵의 높이와 너비를 절반으로 줄입니다.
forward(torch.zeros((2, 3, 20, 20)), down_sample_blk(3, 10)): 이 부분은 forward 함수를 사용하여 입력 데이터와 다운샘플링 블록(down_sample_blk(3, 10))을 통과시킨 결과를 생성합니다. torch.zeros((2, 3, 20, 20))는 크기가 2x3x20x20인 입력 데이터를 생성합니다. down_sample_blk(3, 10)는 입력 채널 수가 3이고 출력 채널 수가 10인 다운샘플링 블록을 생성합니다. 이 입력 데이터를 다운샘플링 블록에 통과시켜 결과를 얻습니다.
.shape: 이 코드는 결과 텐서의 크기(shape)를 확인하는 역할을 합니다. .shape는 텐서의 차원 크기를 나타내는 속성(attribute)입니다.
결과적으로, 이 코드는 입력 데이터를 다운샘플링 블록을 통과시켜 얻은 결과 텐서의 크기(shape)를 확인합니다. 다운샘플링은 풀링과 컨볼루션 레이어 등을 통해 입력 데이터의 공간 해상도를 줄이는 과정을 말하며, 결과적으로 텐서의 크기가 변할 수 있습니다.
14.7.1.5.Base Network Block
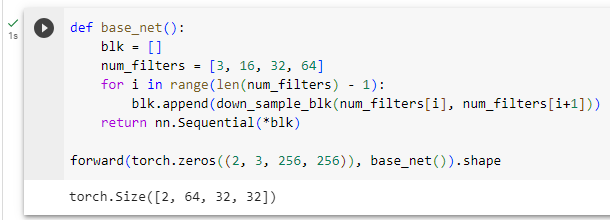
The base network block is used to extract features from input images. For simplicity, we construct a small base network consisting of three downsampling blocks that double the number of channels at each block. Given a256×256input image, this base network block outputs32×32feature maps (256/2**3=32).
기본 네트워크 블록은 입력 이미지에서 특징을 추출하는 데 사용됩니다. 단순화를 위해 각 블록에서 채널 수를 두 배로 늘리는 3개의 다운샘플링 블록으로 구성된 작은 기본 네트워크를 구성합니다. 256×256 입력 이미지가 주어지면 이 기본 네트워크 블록은 32×32 기능 맵(256/2**3=32)을 출력합니다.
def base_net():
blk = []
num_filters = [3, 16, 32, 64]
for i in range(len(num_filters) - 1):
blk.append(down_sample_blk(num_filters[i], num_filters[i+1]))
return nn.Sequential(*blk)
forward(torch.zeros((2, 3, 256, 256)), base_net()).shape
def base_net():: 이 함수는 기본 신경망(Base Network)을 생성하는 역할을 합니다. 기본 신경망은 객체 검출 네트워크의 초기 부분으로 사용됩니다.
blk = []: 빈 리스트 blk를 생성합니다. 이 리스트는 신경망 내의 연속된 레이어를 저장할 역할을 합니다.
num_filters = [3, 16, 32, 64]: num_filters는 입력 채널 수와 각 블록에서 사용할 출력 채널 수를 나타내는 리스트입니다. 여기서 [3, 16, 32, 64]는 입력 채널 수가 3이고, 첫 번째 블록의 출력 채널 수가 16, 두 번째 블록의 출력 채널 수가 32, 세 번째 블록의 출력 채널 수가 64임을 나타냅니다.
for i in range(len(num_filters) - 1):: num_filters 리스트의 길이보다 하나 적은 횟수만큼 반복하는 루프를 생성합니다. 이 루프는 각 블록에 대한 다운샘플링 블록을 생성하여 blk 리스트에 추가합니다.
blk.append(down_sample_blk(num_filters[i], num_filters[i+1])): down_sample_blk 함수를 사용하여 다운샘플링 블록을 생성하고 blk 리스트에 추가합니다. 현재 인덱스 i에 해당하는 출력 채널 수와 그 다음 인덱스 i+1에 해당하는 출력 채널 수를 이용하여 다운샘플링 블록을 생성합니다.
return nn.Sequential(*blk): 생성한 블록들을 순차적으로 실행하는 nn.Sequential 컨테이너를 생성하고 반환합니다. *blk는 리스트 내의 블록들을 펼쳐서 순차적으로 컨테이너에 추가하라는 의미입니다.
forward(torch.zeros((2, 3, 256, 256)), base_net()).shape: 이 코드는 입력 데이터를 기본 신경망에 통과시킨 결과 텐서의 크기(shape)를 확인합니다. torch.zeros((2, 3, 256, 256))는 크기가 2x3x256x256인 입력 데이터를 생성합니다. 이 입력 데이터를 기본 신경망에 통과시켜 결과 텐서를 얻습니다. 결과적으로, 이 코드는 입력 데이터를 기본 신경망에 넣고 얻은 출력 텐서의 크기를 확인합니다.
이 코드는 객체 검출 네트워크의 기본 부분인 기본 신경망을 정의하고, 입력 데이터를 이 신경망에 통과시킨 결과의 크기를 확인하는 역할을 합니다. 기본 신경망은 다양한 다운샘플링 블록을 사용하여 입력 데이터의 공간 해상도를 줄이는 역할을 수행합니다.
14.7.1.6.The Complete Model
The complete single shot multibox detection model consists of five blocks. The feature maps produced by each block are used for both (i) generating anchor boxes and (ii) predicting classes and offsets of these anchor boxes. Among these five blocks, the first one is the base network block, the second to the fourth are downsampling blocks, and the last block uses global max-pooling to reduce both the height and width to 1. Technically, the second to the fifth blocks are all those multiscale feature map blocks inFig. 14.7.1.
완전한 단일 샷 멀티박스 감지 모델은 5개의 블록으로 구성됩니다. 각 블록에서 생성된 기능 맵은 (i) 앵커 상자 생성 및 (ii) 이러한 앵커 상자의 클래스 및 오프셋 예측에 모두 사용됩니다. 이 5개의 블록 중 첫 번째는 기본 네트워크 블록이고 두 번째에서 네 번째는 다운샘플링 블록이며 마지막 블록은 글로벌 최대 풀링을 사용하여 높이와 너비를 모두 1로 줄입니다. 기술적으로 두 번째에서 다섯 번째 블록은 그림 14.7.1의 모든 멀티스케일 특징 맵 블록입니다.
def get_blk(i):
if i == 0:
blk = base_net()
elif i == 1:
blk = down_sample_blk(64, 128)
elif i == 4:
blk = nn.AdaptiveMaxPool2d((1,1))
else:
blk = down_sample_blk(128, 128)
return blk
def get_blk(i):: 이 함수는 블록(block)을 반환하는 역할을 합니다. 블록은 객체 검출 네트워크의 다양한 구성 요소 중 하나입니다. 함수는 입력으로 정수 i를 받습니다.
if i == 0:: 만약 i가 0이라면 아래 코드를 실행합니다. 이 부분은 i가 0일 때의 블록을 정의하는 부분입니다.
blk = base_net(): base_net() 함수를 호출하여 기본 신경망 블록을 생성하고 blk 변수에 할당합니다.
elif i == 1:: 만약 i가 1이라면 아래 코드를 실행합니다. 이 부분은 i가 1일 때의 블록을 정의하는 부분입니다.
blk = down_sample_blk(64, 128): down_sample_blk 함수를 호출하여 입력 채널 수가 64이고 출력 채널 수가 128인 다운샘플링 블록을 생성하고 blk 변수에 할당합니다.
elif i == 4:: 만약 i가 4라면 아래 코드를 실행합니다. 이 부분은 i가 4일 때의 블록을 정의하는 부분입니다.
blk = nn.AdaptiveMaxPool2d((1,1)): nn.AdaptiveMaxPool2d((1,1))를 사용하여 2D 적응형 최대 풀링 블록을 생성하고 blk 변수에 할당합니다. 이 블록은 입력 데이터의 크기에 상관없이 고정된 크기의 풀링을 수행합니다.
else:: 만약 i가 위의 조건들에 해당하지 않는 경우, 즉 0, 1, 4가 아닌 경우 아래 코드를 실행합니다. 이 부분은 위의 조건들에 해당하지 않는 경우의 블록을 정의하는 부분입니다.
blk = down_sample_blk(128, 128): down_sample_blk 함수를 호출하여 입력 채널 수와 출력 채널 수가 모두 128인 다운샘플링 블록을 생성하고 blk 변수에 할당합니다.
return blk: 생성한 블록을 반환합니다.
이 함수는 입력 정수 i에 따라 다양한 유형의 블록을 생성하여 반환하는 역할을 합니다. 이러한 블록들은 객체 검출 네트워크의 다양한 구성을 나타내며, 입력 i에 따라 다운샘플링 블록, 적응형 풀링 블록 등을 생성할 수 있습니다.
Now we define the forward propagation for each block. Different from in image classification tasks, outputs here include (i) CNN feature mapsY, (ii) anchor boxes generated usingYat the current scale, and (iii) classes and offsets predicted (based onY) for these anchor boxes.
이제 각 블록에 대한 순방향 전파를 정의합니다. 이미지 분류 작업과 달리 여기서 출력에는 (i) CNN 기능 맵 Y, (ii) 현재 스케일에서 Y를 사용하여 생성된 앵커 상자, (iii) 이러한 앵커 상자에 대해 예측된 클래스 및 오프셋(Y 기반)이 포함됩니다.
def blk_forward(X, blk, size, ratio, cls_predictor, bbox_predictor):: 이 함수는 입력 데이터 X와 여러 가지 요소들을 활용하여 객체 검출 네트워크의 순전파 과정을 수행하는 역할을 합니다. 함수는 다양한 인자들을 입력으로 받습니다.
Y = blk(X): 입력 데이터 X를 블록 blk에 통과시켜 특성 맵 Y를 생성합니다. blk는 객체 검출 네트워크에서 사용되는 블록을 나타내며, 입력 데이터를 변환하고 특성을 추출하는 역할을 합니다.
anchors = d2l.multibox_prior(Y, sizes=size, ratios=ratio): d2l.multibox_prior 함수를 사용하여 특성 맵 Y에 대한 앵커(anchor) 박스들을 생성합니다. 앵커는 객체 검출에서 다양한 크기와 종횡비를 가지는 사각형 박스를 의미하며, 객체의 위치와 크기를 추론하는 데 사용됩니다. sizes는 앵커 박스의 크기 리스트를, ratios는 앵커 박스의 종횡비 리스트를 나타냅니다.
cls_preds = cls_predictor(Y): 특성 맵 Y를 입력으로 받아 클래스 예측기(cls_predictor)를 통과시켜 객체 클래스에 대한 예측값 cls_preds를 생성합니다. 이 예측값은 각 앵커 박스에 대한 객체 클래스 확률을 의미합니다.
bbox_preds = bbox_predictor(Y): 특성 맵 Y를 입력으로 받아 바운딩 박스 예측기(bbox_predictor)를 통과시켜 바운딩 박스 예측값 bbox_preds를 생성합니다. 이 예측값은 각 앵커 박스에 대한 바운딩 박스의 좌표를 의미합니다.
return (Y, anchors, cls_preds, bbox_preds): 이 코드는 생성한 여러 결과를 튜플로 묶어서 반환합니다. 반환되는 결과에는 특성 맵 Y, 앵커 박스들, 클래스 예측값, 바운딩 박스 예측값이 포함됩니다. 이러한 결과들은 객체 검출 네트워크의 순전파 결과로 활용됩니다.
이 함수는 객체 검출 네트워크에서 입력 데이터를 블록에 통과시켜 특성을 추출하고, 앵커 박스, 클래스 예측값, 바운딩 박스 예측값을 생성하는 과정을 수행하는 역할을 합니다. 이러한 정보들은 객체 검출 작업에서 중요한 역할을 하며, 네트워크가 위치와 클래스 정보를 예측하는 데 사용됩니다.
Recall that inFig. 14.7.1a multiscale feature map block that is closer to the top is for detecting larger objects; thus, it needs to generate larger anchor boxes. In the above forward propagation, at each multiscale feature map block we pass in a list of two scale values via thesizesargument of the invokedmultibox_priorfunction (described inSection 14.4). In the following, the interval between 0.2 and 1.05 is split evenly into five sections to determine the smaller scale values at the five blocks: 0.2, 0.37, 0.54, 0.71, and 0.88. Then their larger scale values are given by√0.2×0.37=0.272,√0.37×0.54=0.447, and so on.
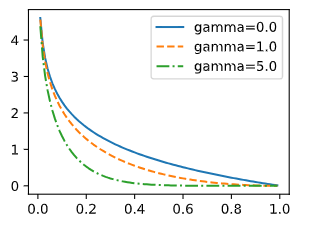
그림 14.7.1에서 상단에 가까운 멀티스케일 특징 맵 블록은 더 큰 물체를 감지하기 위한 것임을 상기하십시오. 따라서 더 큰 앵커 박스를 생성해야 합니다. 위의 순방향 전파에서 각 멀티스케일 기능 맵 블록에서 호출된 multibox_prior 함수의 크기 인수를 통해 두 개의 스케일 값 목록을 전달합니다(섹션 14.4에서 설명). 다음에서는 0.2와 1.05 사이의 간격을 5개 섹션으로 균일하게 분할하여 5개 블록(0.2, 0.37, 0.54, 0.71 및 0.88)에서 더 작은 척도 값을 결정합니다. 그런 다음 더 큰 척도 값은 √0.2×0.37=0.272, √0.37×0.54=0.447 등으로 지정됩니다.
sizes: 이 부분은 앵커 박스(anchor box)의 크기를 나타내는 리스트입니다. 앵커 박스는 객체 검출에서 다양한 크기와 종횡비를 가진 사각형 박스를 의미합니다. 각 리스트 요소는 [w, h] 형태로, [0.2, 0.272], [0.37, 0.447] 등과 같이 사각형의 너비와 높이를 나타냅니다.
ratios: 이 부분은 앵커 박스의 종횡비(ratio)를 나타내는 리스트입니다. 종횡비는 박스의 너비와 높이 비율을 의미합니다. [1, 2, 0.5]와 같이 리스트 안에 종횡비를 나타내는 숫자들을 나열합니다. 이때 * 5는 리스트를 5번 복사하여 크기를 늘린 것을 의미합니다.
num_anchors: 이 부분은 총 앵커 박스의 개수를 계산하는 변수입니다. 앵커 박스의 개수는 크기와 종횡비에 따라 달라지며, 이 변수는 이를 계산하는데 사용됩니다. len(sizes[0])는 첫 번째 크기 리스트에 있는 요소의 개수를 나타내며, len(ratios[0])는 첫 번째 종횡비 리스트에 있는 요소의 개수를 나타냅니다. 마지막으로 - 1을 하여 중복으로 세어진 1개의 종횡비를 제외합니다.
이 코드는 객체 검출 작업에서 사용되는 앵커 박스의 크기와 종횡비를 정의하고, 총 앵커 박스의 개수를 계산하는 역할을 합니다. 이러한 앵커 박스는 네트워크가 객체의 위치와 크기를 예측하는 데 사용되는 중요한 개념입니다.
Now we can define the complete modelTinySSDas follows.
self.num_classes = num_classes: 클래스 변수 num_classes를 설정하여 클래스의 개수를 저장합니다.
idx_to_in_channels = [64, 128, 128, 128, 128]: 입력 채널 수에 대한 리스트입니다. 각 블록에 대한 입력 채널 수를 나타냅니다.
루프를 통해 각 블록에 대한 동작을 설정합니다.
setattr(self, f'blk_{i}', get_blk(i)): get_blk 함수를 사용하여 i번째 블록을 생성하고 해당 블록을 self에 속성으로 추가합니다.
setattr(self, f'cls_{i}', cls_predictor(...)): cls_predictor 함수를 사용하여 클래스 예측기를 생성하고 해당 예측기를 self에 속성으로 추가합니다.
setattr(self, f'bbox_{i}', bbox_predictor(...)): bbox_predictor 함수를 사용하여 바운딩 박스 예측기를 생성하고 해당 예측기를 self에 속성으로 추가합니다.
def forward(self, X):: 순전파 메서드입니다. 네트워크의 입력을 받아서 순전파 연산을 수행합니다.
빈 리스트들을 생성하여 앵커, 클래스 예측값, 바운딩 박스 예측값을 저장할 공간을 할당합니다.
루프를 통해 각 블록에 대한 동작을 수행합니다.
X, anchors[i], cls_preds[i], bbox_preds[i] = blk_forward(...): blk_forward 함수를 사용하여 블록 i에 입력 X를 통과시키고 앵커, 클래스 예측값, 바운딩 박스 예측값을 얻습니다.
anchors = torch.cat(anchors, dim=1): 앵커들을 텐서로 변환하고 차원 1을 기준으로 연결합니다.
cls_preds = concat_preds(cls_preds): 클래스 예측값들을 연결(concatenate)하여 하나의 큰 텐서로 만듭니다.
cls_preds = cls_preds.reshape(...): 클래스 예측값의 차원을 변환하여 클래스 개수에 맞게 재구성합니다.
bbox_preds = concat_preds(bbox_preds): 바운딩 박스 예측값들을 연결하여 하나의 큰 텐서로 만듭니다.
최종적으로, 앵커, 클래스 예측값, 바운딩 박스 예측값을 반환합니다.
이 클래스는 작은 SSD 객체 검출 모델을 정의하고, 입력 데이터를 순전파하여 앵커, 클래스 예측값, 바운딩 박스 예측값을 생성하는 역할을 합니다. 클래스 예측과 바운딩 박스 예측을 통해 객체 검출을 수행하는 네트워크 구조를 나타냅니다.
We create a model instance and use it to perform forward propagation on a minibatch of256×256imagesX.
모델 인스턴스를 생성하고 이를 사용하여 256×256 이미지 X의 미니배치에서 정방향 전파를 수행합니다.
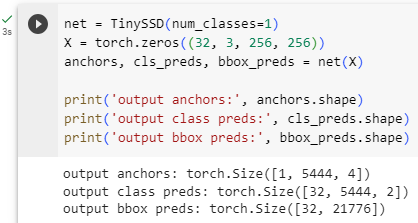
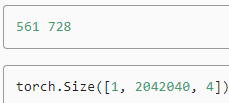
As shown earlier in this section, the first block outputs32×32feature maps. Recall that the second to fourth downsampling blocks halve the height and width and the fifth block uses global pooling. Since 4 anchor boxes are generated for each unit along spatial dimensions of feature maps, at all the five scales a total of(322+162+82+42+1)×4=5444anchor boxes are generated for each image.
이 섹션의 앞부분에 표시된 것처럼 첫 번째 블록은 32×32 기능 맵을 출력합니다. 두 번째에서 네 번째 다운샘플링 블록은 높이와 너비를 절반으로 줄이고 다섯 번째 블록은 전역 풀링을 사용한다는 점을 기억하세요. 특징 맵의 공간 차원을 따라 각 단위에 대해 4개의 앵커 상자가 생성되므로 모든 5개 축척에서 각 이미지에 대해 총 (322+162+82+42+1)×4=5444개의 앵커 상자가 생성됩니다.
net = TinySSD(num_classes=1)
X = torch.zeros((32, 3, 256, 256))
anchors, cls_preds, bbox_preds = net(X)
print('output anchors:', anchors.shape)
print('output class preds:', cls_preds.shape)
print('output bbox preds:', bbox_preds.shape)
net = TinySSD(num_classes=1): TinySSD 클래스를 사용하여 객체 검출을 위한 작은 SSD 모델 net을 생성합니다. num_classes=1은 검출하려는 클래스의 개수를 1로 설정한다는 의미입니다.
X = torch.zeros((32, 3, 256, 256)): 크기가 32x3x256x256인 입력 데이터 X를 생성합니다. 이 입력 데이터는 배치 크기가 32이고 채널 수가 3인 이미지로 구성되며, 이미지의 가로 및 세로 크기는 각각 256입니다.
anchors, cls_preds, bbox_preds = net(X): 생성한 모델 net에 입력 데이터 X를 통과시켜 앵커, 클래스 예측값, 바운딩 박스 예측값을 얻습니다. anchors, cls_preds, bbox_preds 변수에 각각의 결과가 할당됩니다.
print('output anchors:', anchors.shape): anchors의 크기를 출력합니다. 이 부분은 네트워크의 순전파 결과로 생성된 앵커의 크기를 확인하는 역할을 합니다.
print('output class preds:', cls_preds.shape): cls_preds의 크기를 출력합니다. 이 부분은 네트워크의 순전파 결과로 생성된 클래스 예측값의 크기를 확인하는 역할을 합니다.
print('output bbox preds:', bbox_preds.shape): bbox_preds의 크기를 출력합니다. 이 부분은 네트워크의 순전파 결과로 생성된 바운딩 박스 예측값의 크기를 확인하는 역할을 합니다.
이 코드는 작은 SSD 모델에 입력 데이터를 통과시켜 앵커, 클래스 예측값, 바운딩 박스 예측값을 생성하고, 각 결과의 크기를 확인하는 역할을 수행합니다.
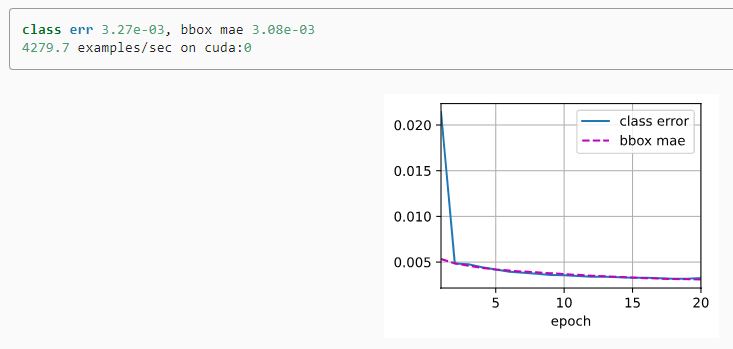
14.7.2.Training
Now we will explain how to train the single shot multibox detection model for object detection.
이제 객체 감지를 위해 단일 샷 멀티박스 감지 모델을 훈련하는 방법을 설명합니다.
14.7.2.1.Reading the Dataset and Initializing the Model
To begin with, let’s read the banana detection dataset described inSection 14.6.
batch_size = 32: 배치 크기를 32로 설정합니다. 배치 크기는 한 번의 학습 단계에서 처리되는 데이터의 개수를 나타냅니다. 여기서는 32개의 데이터가 하나의 배치로 묶여 처리될 것입니다.
train_iter, _ = d2l.load_data_bananas(batch_size): d2l.load_data_bananas(batch_size) 함수를 호출하여 바나나 객체 검출 데이터셋을 로드합니다. 이 함수는 학습 데이터를 미니배치로 나누어 제공하는 데이터 로더를 생성합니다. 여기서 반환되는 train_iter는 학습 데이터셋의 미니배치를 순회하는 반복자(iterator)입니다. 코드에서 _는 두 번째 반환값을 무시하는 변수입니다. 이렇게 생성된 데이터 로더를 사용하여 모델을 학습하게 될 것입니다.
이 코드는 배치 크기를 설정하고 바나나 객체 검출 데이터셋을 미니배치로 나누어 학습용 데이터 로더를 생성하는 역할을 합니다.
There is only one class in the banana detection dataset. After defining the model, we need to initialize its parameters and define the optimization algorithm.
바나나 감지 데이터 세트에는 하나의 클래스만 있습니다. 모델을 정의한 후 매개변수를 초기화하고 최적화 알고리즘을 정의해야 합니다.
device, net = d2l.try_gpu(), TinySSD(num_classes=1)
trainer = torch.optim.SGD(net.parameters(), lr=0.2, weight_decay=5e-4)
device, net = d2l.try_gpu(), TinySSD(num_classes=1): d2l.try_gpu() 함수를 사용하여 GPU 디바이스를 시도하고, 그 결과를 device 변수에 저장합니다. 그 다음, TinySSD 클래스를 사용하여 객체 검출을 위한 작은 SSD 모델 net을 생성합니다. num_classes=1은 검출하려는 클래스의 개수를 1로 설정한다는 의미입니다.
trainer = torch.optim.SGD(net.parameters(), lr=0.2, weight_decay=5e-4): torch.optim.SGD를 사용하여 확률적 경사 하강법(Stochastic Gradient Descent) 옵티마이저 trainer를 생성합니다. net.parameters()는 모델의 학습 가능한 매개변수들을 가져옵니다. lr=0.2는 학습률(learning rate)을 0.2로 설정한다는 의미이며, weight_decay=5e-4는 L2 정규화를 위한 가중치 감쇠(weight decay)를 설정합니다. 이 옵티마이저는 모델을 학습할 때 매개변수 업데이트를 수행하는데 사용됩니다.
이 코드는 GPU 디바이스를 시도하고 작은 SSD 모델을 생성한 후, 확률적 경사 하강법 옵티마이저를 설정하는 역할을 합니다. 이러한 설정을 통해 모델을 GPU로 이동하고, 옵티마이저를 사용하여 모델의 학습 과정을 설정합니다.
14.7.2.2.Defining Loss and Evaluation Functions
Object detection has two types of losses. The first loss concerns classes of anchor boxes: its computation can simply reuse the cross-entropy loss function that we used for image classification. The second loss concerns offsets of positive (non-background) anchor boxes: this is a regression problem. For this regression problem, however, here we do not use the squared loss described inSection 3.1.3. Instead, we use theℓ1norm loss, the absolute value of the difference between the prediction and the ground-truth. The mask variablebbox_masksfilters out negative anchor boxes and illegal (padded) anchor boxes in the loss calculation. In the end, we sum up the anchor box class loss and the anchor box offset loss to obtain the loss function for the model.
객체 감지에는 두 가지 유형의 손실이 있습니다. 첫 번째 손실은 앵커 박스의 클래스와 관련이 있습니다. 해당 계산은 이미지 분류에 사용한 교차 엔트로피 손실 함수를 단순히 재사용할 수 있습니다. 두 번째 손실은 포지티브(배경이 아닌) 앵커 상자의 오프셋과 관련됩니다. 이것은 회귀 문제입니다. 그러나이 회귀 문제의 경우 여기에서는 섹션 3.1.3에서 설명한 제곱 손실을 사용하지 않습니다. 대신, 우리는 예측과 ground-truth 사이의 차이의 절대값인 ℓ1 놈 손실을 사용합니다. 마스크 변수 bbox_masks는 손실 계산에서 음의 앵커 상자와 불법(패딩된) 앵커 상자를 필터링합니다. 마지막으로 앵커 박스 클래스 손실과 앵커 박스 오프셋 손실을 합산하여 모델에 대한 손실 함수를 얻습니다.
cls_loss = nn.CrossEntropyLoss(reduction='none'): nn.CrossEntropyLoss 함수를 사용하여 클래스 예측값과 클래스 실제값 사이의 손실(loss)를 계산하는데 사용될 cls_loss를 정의합니다. reduction='none'은 손실을 각 샘플에 대해 개별적으로 계산하겠다는 의미입니다.
bbox_loss = nn.L1Loss(reduction='none'): nn.L1Loss 함수를 사용하여 바운딩 박스 예측값과 실제 바운딩 박스 사이의 L1 손실(loss)를 계산하는데 사용될 bbox_loss를 정의합니다. reduction='none'은 손실을 각 샘플에 대해 개별적으로 계산하겠다는 의미입니다.
def calc_loss(cls_preds, cls_labels, bbox_preds, bbox_labels, bbox_masks):: 손실을 계산하는 함수를 정의합니다. 이 함수는 클래스 예측값, 클래스 실제값, 바운딩 박스 예측값, 바운딩 박스 실제값, 바운딩 박스 마스크를 입력으로 받습니다.
batch_size, num_classes = cls_preds.shape[0], cls_preds.shape[2]: 배치 크기와 클래스 개수를 가져옵니다.
cls_loss(cls_preds.reshape(-1, num_classes), cls_labels.reshape(-1)): 클래스 예측값과 실제값을 모양을 변형하여 크로스 엔트로피 손실을 계산합니다. reshape(-1, num_classes)는 데이터를 배치 크기와 클래스 개수에 맞게 재구성하여 계산합니다.
.reshape(batch_size, -1).mean(dim=1): 계산된 클래스 손실을 다시 배치 크기에 맞게 재구성하고, 각 배치의 평균을 계산합니다.
bbox_loss(bbox_preds * bbox_masks, bbox_labels * bbox_masks).mean(dim=1): 바운딩 박스 예측값과 실제값에 바운딩 박스 마스크를 적용하여 L1 손실을 계산하고, 각 배치의 평균을 계산합니다.
return cls + bbox: 클래스 손실과 바운딩 박스 손실을 더하여 최종 손실을 반환합니다.
이 함수는 클래스 예측과 바운딩 박스 예측 간의 손실을 계산하는데 사용되며, 클래스 손실과 바운딩 박스 손실을 더하여 최종적인 학습 손실을 계산하는 역할을 합니다.
We can use accuracy to evaluate the classification results. Due to the usedℓ1norm loss for the offsets, we use themean absolute errorto evaluate the predicted bounding boxes. These prediction results are obtained from the generated anchor boxes and the predicted offsets for them.
정확도를 사용하여 분류 결과를 평가할 수 있습니다. 오프셋에 사용된 ℓ1 노름 손실로 인해 예측된 경계 상자를 평가하기 위해 평균 절대 오차를 사용합니다. 이러한 예측 결과는 생성된 앵커 박스와 그에 대한 예측된 오프셋에서 얻습니다.
def cls_eval(cls_preds, cls_labels):
# Because the class prediction results are on the final dimension,
# `argmax` needs to specify this dimension
return float((cls_preds.argmax(dim=-1).type(
cls_labels.dtype) == cls_labels).sum())
def bbox_eval(bbox_preds, bbox_labels, bbox_masks):
return float((torch.abs((bbox_labels - bbox_preds) * bbox_masks)).sum())
def cls_eval(cls_preds, cls_labels):: 클래스 예측값과 실제 클래스 레이블 사이의 일치 여부를 평가하는 함수를 정의합니다. 이 함수는 클래스 예측값, 실제 클래스 레이블을 입력으로 받습니다.
cls_preds.argmax(dim=-1): 클래스 예측값에서 가장 높은 값의 인덱스를 찾습니다. 여기서 dim=-1은 마지막 차원을 기준으로 최대값을 찾는다는 의미입니다.
.type(cls_labels.dtype) == cls_labels: 클래스 예측값의 최대 인덱스와 실제 클래스 레이블이 같은지를 비교합니다. 이 결과는 불리언 값으로 반환됩니다.
.sum(): 불리언 값을 모두 합산하여 일치하는 클래스 개수를 구합니다.
return float(...): 일치하는 클래스 개수를 부동소수점 형태로 반환합니다.
def bbox_eval(bbox_preds, bbox_labels, bbox_masks):: 바운딩 박스 예측값과 실제 바운딩 박스 레이블 사이의 차이를 평가하는 함수를 정의합니다. 이 함수는 바운딩 박스 예측값, 실제 바운딩 박스 레이블, 바운딩 박스 마스크를 입력으로 받습니다.
torch.abs((bbox_labels - bbox_preds) * bbox_masks): 실제 바운딩 박스 레이블과 예측 바운딩 박스 값 사이의 차이를 계산하고, 이를 바운딩 박스 마스크와 곱하여 차이를 마스크된 영역에만 적용합니다. 이렇게 계산된 결과는 절댓값을 취합니다.
.sum(): 절댓값 차이를 모두 합산하여 바운딩 박스 예측과 실제 값 사이의 차이를 구합니다.
return float(...): 바운딩 박스 값의 차이를 부동소수점 형태로 반환합니다.
이러한 함수들은 클래스 예측과 바운딩 박스 예측의 정확도와 일치도를 평가하는 데 사용됩니다. cls_eval 함수는 클래스 예측 정확도를 평가하고, bbox_eval 함수는 바운딩 박스 예측과 실제 값 사이의 차이를 평가합니다.
14.7.2.3.Training the Model
When training the model, we need to generate multiscale anchor boxes (anchors) and predict their classes (cls_preds) and offsets (bbox_preds) in the forward propagation. Then we label the classes (cls_labels) and offsets (bbox_labels) of such generated anchor boxes based on the label informationY. Finally, we calculate the loss function using the predicted and labeled values of the classes and offsets. For concise implementations, evaluation of the test dataset is omitted here.
모델을 교육할 때 다중 스케일 앵커 상자(앵커)를 생성하고 순방향 전파에서 해당 클래스(cls_preds) 및 오프셋(bbox_preds)을 예측해야 합니다. 그런 다음 레이블 정보 Y를 기반으로 이렇게 생성된 앵커 박스의 클래스(cls_labels)와 오프셋(bbox_labels)에 레이블을 지정합니다. 마지막으로 클래스와 오프셋의 예측 및 레이블 값을 사용하여 손실 함수를 계산합니다. 간결한 구현을 위해 테스트 데이터 세트의 평가는 여기에서 생략됩니다.
num_epochs, timer = 20, d2l.Timer()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['class error', 'bbox mae'])
net = net.to(device)
for epoch in range(num_epochs):
# Sum of training accuracy, no. of examples in sum of training accuracy,
# Sum of absolute error, no. of examples in sum of absolute error
metric = d2l.Accumulator(4)
net.train()
for features, target in train_iter:
timer.start()
trainer.zero_grad()
X, Y = features.to(device), target.to(device)
# Generate multiscale anchor boxes and predict their classes and
# offsets
anchors, cls_preds, bbox_preds = net(X)
# Label the classes and offsets of these anchor boxes
bbox_labels, bbox_masks, cls_labels = d2l.multibox_target(anchors, Y)
# Calculate the loss function using the predicted and labeled values
# of the classes and offsets
l = calc_loss(cls_preds, cls_labels, bbox_preds, bbox_labels,
bbox_masks)
l.mean().backward()
trainer.step()
metric.add(cls_eval(cls_preds, cls_labels), cls_labels.numel(),
bbox_eval(bbox_preds, bbox_labels, bbox_masks),
bbox_labels.numel())
cls_err, bbox_mae = 1 - metric[0] / metric[1], metric[2] / metric[3]
animator.add(epoch + 1, (cls_err, bbox_mae))
print(f'class err {cls_err:.2e}, bbox mae {bbox_mae:.2e}')
print(f'{len(train_iter.dataset) / timer.stop():.1f} examples/sec on '
f'{str(device)}')
num_epochs, timer = 20, d2l.Timer(): 학습 에포크 수를 20으로 설정하고, 시간 측정을 위한 d2l.Timer() 객체를 생성합니다.
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], legend=['class error', 'bbox mae']): 그래프를 그리기 위한 d2l.Animator() 객체를 생성합니다. 이 그래프는 에포크별 클래스 오류와 바운딩 박스 평균 절대 오차(MAE)를 나타낼 것입니다.
net = net.to(device): 모델 net을 GPU 디바이스로 이동시킵니다.
for epoch in range(num_epochs):: 에포크 수만큼 반복합니다.
metric = d2l.Accumulator(4): 훈련 중에 모니터링할 메트릭 값을 저장할 d2l.Accumulator() 객체를 생성합니다. 이 메트릭은 훈련 정확도, 훈련 정확도의 샘플 개수, 절댓값 오차, 절댓값 오차의 샘플 개수를 나타냅니다.
net.train(): 모델을 훈련 모드로 설정합니다.
for features, target in train_iter:: 훈련 데이터 로더에서 미니배치를 가져옵니다.
timer.start(): 시간 측정을 시작합니다.
trainer.zero_grad(): 옵티마이저의 그라디언트를 초기화합니다.
X, Y = features.to(device), target.to(device): 입력 데이터와 레이블을 GPU 디바이스로 이동시킵니다.
anchors, cls_preds, bbox_preds = net(X): 입력 데이터를 모델에 통과시켜 앵커, 클래스 예측값, 바운딩 박스 예측값을 얻습니다.
bbox_labels, bbox_masks, cls_labels = d2l.multibox_target(anchors, Y): 앵커와 레이블을 이용하여 바운딩 박스 레이블, 바운딩 박스 마스크, 클래스 레이블을 생성합니다.
l = calc_loss(...): 계산된 레이블과 예측값을 사용하여 손실 함수를 계산합니다.
l.mean().backward(): 손실의 평균을 구하고, 역전파를 수행합니다.
trainer.step(): 옵티마이저를 사용하여 모델의 매개변수를 업데이트합니다.
metric.add(...): 훈련 중에 계산된 메트릭 값을 누적합니다. 클래스 정확도와 바운딩 박스 MAE를 계산하여 누적합니다.
cls_err, bbox_mae = ...: 에포크별 클래스 오류와 바운딩 박스 평균 절대 오차를 계산합니다.
animator.add(...): 그래프를 그리기 위해 그래프 데이터를 추가합니다. 에포크와 클래스 오류, 바운딩 박스 MAE를 그래프에 추가합니다.
print(f'class err {cls_err:.2e}, bbox mae {bbox_mae:.2e}'): 학습 종료 후, 최종 클래스 오류와 바운딩 박스 MAE를 출력합니다.
print(f'{len(train_iter.dataset) / timer.stop():.1f} examples/sec on ' f'{str(device)}'): 학습 속도를 출력합니다. 데이터셋에 대한 처리 속도와 사용한 디바이스(GPU) 정보도 함께 출력합니다.
이 코드는 작은 SSD 모델을 학습하는 주요 학습 루프를 나타내며, 각 에포크마다 클래스 오류와 바운딩 박스 MAE를 계산하여 모니터링합니다.
14.7.3.Prediction
During prediction, the goal is to detect all the objects of interest on the image. Below we read and resize a test image, converting it to a four-dimensional tensor that is required by convolutional layers.
예측하는 동안 목표는 이미지에서 관심 대상을 모두 감지하는 것입니다. 아래에서는 테스트 이미지를 읽고 크기를 조정하여 컨볼루션 레이어에 필요한 4차원 텐서로 변환합니다.
X = torchvision.io.read_image('../img/banana.jpg').unsqueeze(0).float()
img = X.squeeze(0).permute(1, 2, 0).long()
Using themultibox_detectionfunction below, the predicted bounding boxes are obtained from the anchor boxes and their predicted offsets. Then non-maximum suppression is used to remove similar predicted bounding boxes.
아래의 multibox_detection 함수를 사용하여 앵커 박스와 예측된 오프셋에서 예측된 경계 상자를 얻습니다. 그런 다음 유사한 예측 경계 상자를 제거하기 위해 최대가 아닌 억제가 사용됩니다.
def predict(X):
net.eval()
anchors, cls_preds, bbox_preds = net(X.to(device))
cls_probs = F.softmax(cls_preds, dim=2).permute(0, 2, 1)
output = d2l.multibox_detection(cls_probs, bbox_preds, anchors)
idx = [i for i, row in enumerate(output[0]) if row[0] != -1]
return output[0, idx]
output = predict(X)
def predict(X):: 입력 이미지 X에 대한 객체 검출 예측을 수행하는 함수를 정의합니다.
net.eval(): 모델을 평가 모드로 설정합니다. 평가 모드에서는 드롭아웃이나 배치 정규화와 같은 레이어의 동작이 변경되어 평가에 적합하게 동작합니다.
anchors, cls_preds, bbox_preds = net(X.to(device)): 입력 이미지를 모델에 통과시켜 앵커, 클래스 예측값, 바운딩 박스 예측값을 얻습니다. X를 GPU 디바이스로 이동시켜 계산합니다.
cls_probs = F.softmax(cls_preds, dim=2).permute(0, 2, 1): 클래스 예측값에 소프트맥스 함수를 적용하여 클래스 확률을 계산합니다. dim=2는 클래스 차원을 기준으로 소프트맥스를 계산한다는 의미이며, .permute(0, 2, 1)은 클래스 차원을 뒤로 옮깁니다.
output = d2l.multibox_detection(cls_probs, bbox_preds, anchors): 클래스 확률과 바운딩 박스 예측값, 앵커 정보를 이용하여 객체 검출을 수행합니다. 이 함수는 객체 검출 결과를 반환합니다.
idx = [i for i, row in enumerate(output[0]) if row[0] != -1]: 검출 결과 중에서 신뢰도가 -1이 아닌 객체 인덱스를 찾습니다.
return output[0, idx]: 신뢰도가 -1이 아닌 객체에 대한 검출 결과를 반환합니다.
output = predict(X): 입력 이미지 X에 대한 객체 검출을 수행하여 결과를 output에 저장합니다.
이 코드는 학습된 모델을 사용하여 입력 이미지에 대한 객체 검출을 수행하고, 결과를 반환하는 함수를 정의하며, 실제로 객체 검출을 수행하여 결과를 output에 저장하는 과정을 나타냅니다.
Finally, we display all the predicted bounding boxes with confidence 0.9 or above as output.
bbox = [row[2:6] * torch.tensor((w, h, w, h), device=row.device)]: 객체 검출 결과에서 바운딩 박스 정보를 가져온 후, 바운딩 박스 좌표를 이미지 크기에 맞게 스케일 조정합니다.
d2l.show_bboxes(fig.axes, bbox, '%.2f' % score, 'w'): 스케일 조정된 바운딩 박스와 신뢰도 값을 사용하여 Matplotlib의 축에 바운딩 박스와 레이블을 표시합니다.
display(img, output.cpu(), threshold=0.9): 입력 이미지 img와 객체 검출 결과 output를 시각화합니다. 여기서 output의 텐서를 CPU로 이동시켜야 Matplotlib과 호환됩니다. 신뢰도 임계값은 0.9로 설정되어 0.9보다 높은 신뢰도를 가진 객체만 표시됩니다.
이 코드는 객체 검출 결과를 시각화하여 신뢰도 임계값을 넘는 객체들을 표시하는 함수를 정의하고, 실제 이미지와 객체 검출 결과를 사용하여 시각화하는 과정을 나타냅니다.
14.7.4.Summary
Single shot multibox detection is a multiscale object detection model. Via its base network and several multiscale feature map blocks, single-shot multibox detection generates a varying number of anchor boxes with different sizes, and detects varying-size objects by predicting classes and offsets of these anchor boxes (thus the bounding boxes).
단일 샷 멀티박스 감지는 다중 스케일 객체 감지 모델입니다. 기본 네트워크와 여러 멀티스케일 기능 맵 블록을 통해 단일 샷 멀티박스 감지는 다양한 크기의 다양한 앵커 박스를 생성하고 이러한 앵커 박스(따라서 경계 박스)의 클래스와 오프셋을 예측하여 다양한 크기의 객체를 감지합니다.
When training the single-shot multibox detection model, the loss function is calculated based on the predicted and labeled values of the anchor box classes and offsets.
단일 샷 멀티박스 감지 모델을 훈련할 때 손실 함수는 앵커 박스 클래스 및 오프셋의 예측 및 레이블 값을 기반으로 계산됩니다.
14.7.5.Exercises
Can you improve the single-shot multibox detection by improving the loss function? For example, replaceℓ1norm loss with smoothℓ1norm loss for the predicted offsets. This loss function uses a square function around zero for smoothness, which is controlled by the hyperparameterσ:
Whenσis very large, this loss is similar to theℓ1norm loss. When its value is smaller, the loss function is smoother.
def smooth_l1(data, scalar):
out = []
for i in data:
if abs(i) < 1 / (scalar ** 2):
out.append(((scalar * i) ** 2) / 2)
else:
out.append(abs(i) - 0.5 / (scalar ** 2))
return torch.tensor(out)
sigmas = [10, 1, 0.5]
lines = ['-', '--', '-.']
x = torch.arange(-2, 2, 0.1)
d2l.set_figsize()
for l, s in zip(lines, sigmas):
y = smooth_l1(x, scalar=s)
d2l.plt.plot(x, y, l, label='sigma=%.1f' % s)
d2l.plt.legend();
def smooth_l1(data, scalar):: 입력 데이터 data와 스칼라 값 scalar를 받아서 smooth L1 손실 함수 값을 계산하는 함수를 정의합니다.
out = []: 결과 값을 저장할 빈 리스트를 생성합니다.
for i in data:: 입력 데이터의 각 원소에 대해서 반복합니다.
if abs(i) < 1 / (scalar ** 2):: 만약 입력 데이터의 절댓값이 1 / (scalar ** 2)보다 작으면,
out.append(((scalar * i) ** 2) / 2): 출력 리스트에 (scalar * i)^2 / 2 값을 추가합니다.
else:: 그렇지 않으면,
out.append(abs(i) - 0.5 / (scalar ** 2)): 출력 리스트에 abs(i) - 0.5 / (scalar ** 2) 값을 추가합니다.
return torch.tensor(out): 계산된 결과를 텐서 형태로 반환합니다.
sigmas = [10, 1, 0.5]: 다양한 시그마 값 리스트를 정의합니다.
lines = ['-', '--', '-.']: 그래프에서 사용할 라인 스타일을 정의합니다.
x = torch.arange(-2, 2, 0.1): -2부터 2까지 0.1 간격으로 숫자들을 생성하여 x를 정의합니다.
d2l.set_figsize(): 그래프 크기를 설정합니다.
for l, s in zip(lines, sigmas):: 라인 스타일과 시그마 값을 하나씩 가져오면서 반복합니다.
y = smooth_l1(x, scalar=s): smooth_l1 함수를 사용하여 x 값에 대한 smooth L1 손실 함수 값을 계산하여 y에 저장합니다.
d2l.plt.plot(x, y, l, label='sigma=%.1f' % s): 계산된 x와 y 값을 사용하여 그래프를 그리고, 라벨에 시그마 값을 표시합니다.
d2l.plt.legend(): 그래프에 범례를 표시합니다.
이 코드는 다양한 시그마 값을 사용하여 smooth L1 손실 함수를 그래프로 표현하는 작업을 수행합니다.
def focal_loss(gamma, x):
return -(1 - x) ** gamma * torch.log(x)
x = torch.arange(0.01, 1, 0.01)
for l, gamma in zip(lines, [0, 1, 5]):
y = d2l.plt.plot(x, focal_loss(gamma, x), l, label='gamma=%.1f' % gamma)
d2l.plt.legend();
def focal_loss(gamma, x):: 파라미터 gamma와 입력 x를 받아 focal loss 값을 계산하는 함수를 정의합니다.
x = torch.arange(0.01, 1, 0.01): 0.01부터 1까지 0.01 간격으로 숫자들을 생성하여 x를 정의합니다.
for l, gamma in zip(lines, [0, 1, 5]):: 라인 스타일과 감마 값을 하나씩 가져오면서 반복합니다.
y = d2l.plt.plot(x, focal_loss(gamma, x), l, label='gamma=%.1f' % gamma): x 값에 대해 해당 감마 값을 사용하여 focal loss를 계산하고, 그래프를 그립니다. 라벨에 감마 값을 표시합니다.
d2l.plt.legend(): 그래프에 범례를 표시합니다.
이 코드는 다양한 감마 값과 입력에 대한 focal loss 함수를 그래프로 표현하는 작업을 수행합니다.
Due to space limitations, we have omitted some implementation details of the single shot multibox detection model in this section. Can you further improve the model in the following aspects:
When an object is much smaller compared with the image, the model could resize the input image bigger.
There are typically a vast number of negative anchor boxes. To make the class distribution more balanced, we could downsample negative anchor boxes.
In the loss function, assign different weight hyperparameters to the class loss and the offset loss.
Use other methods to evaluate the object detection model, such as those in the single shot multibox detection paper(Liuet al., 2016).
There is no small dataset such as MNIST and Fashion-MNIST in the field of object detection. In order to quickly demonstrate object detection models, we collected and labeled a small dataset. First, we took photos of free bananas from our office and generated 1000 banana images with different rotations and sizes. Then we placed each banana image at a random position on some background image. In the end, we labeled bounding boxes for those bananas on the images.
객체 감지 분야에는 MNIST, Fashion-MNIST와 같은 작은 데이터셋이 없습니다. 객체 감지 모델을 신속하게 시연하기 위해 작은 데이터 세트를 수집하고 레이블을 지정했습니다. 먼저 사무실에서 무료로 제공되는 바나나 사진을 찍어 회전과 크기가 다른 1000개의 바나나 이미지를 생성했습니다. 그런 다음 일부 배경 이미지의 임의 위치에 각 바나나 이미지를 배치했습니다. 결국 이미지의 바나나에 대한 경계 상자에 레이블을 지정했습니다.
14.6.1.Downloading the Dataset
The banana detection dataset with all the image and csv label files can be downloaded directly from the Internet.
모든 이미지 및 csv 레이블 파일이 포함된 바나나 감지 데이터 세트는 인터넷에서 직접 다운로드할 수 있습니다.
%matplotlib inline
import os
import pandas as pd
import torch
import torchvision
from d2l import torch as d2l
#@save
d2l.DATA_HUB['banana-detection'] = (
d2l.DATA_URL + 'banana-detection.zip',
'5de26c8fce5ccdea9f91267273464dc968d20d72')
위 코드는 데이터셋을 다운로드하기 위한 설정과 관련된 내용을 포함하고 있습니다. 코드를 한 줄씩 살펴보겠습니다.
%matplotlib inline: 이는 Jupyter Notebook 환경에서 Matplotlib 그래프를 인라인으로 표시하도록 설정하는 명령입니다. Matplotlib 그래프가 노트북 내에서 바로 표시되도록 해줍니다.
import os: 파이썬 내장 라이브러리인 os 모듈을 불러옵니다. 파일 및 디렉토리 경로 관련 기능을 사용할 수 있도록 해줍니다.
import pandas as pd: 데이터 분석과 조작을 위한 판다스 라이브러리를 불러옵니다. 관례상 판다스는 pd로 축약하여 사용됩니다.
import torch: 파이토치 라이브러리를 불러옵니다. 딥러닝 모델을 구축하고 훈련하기 위한 도구를 제공합니다.
import torchvision: 파이토치에서 제공하는 컴퓨터 비전 관련 라이브러리입니다. 이미지 데이터셋 및 전처리 기능을 포함하고 있습니다.
from d2l import torch as d2l: "Dive into Deep Learning" 교재의 파이토치 관련 도우미 함수들을 가져옵니다. d2l은 이러한 도우미 함수들을 사용하기 위한 이름 공간입니다.
d2l.DATA_HUB['banana-detection']: 데이터셋을 다운로드하기 위한 정보를 딕셔너리로 정의합니다. 해당 정보에는 데이터셋의 다운로드 URL과 데이터셋의 해시값이 포함됩니다. 데이터셋의 해시값은 데이터의 무결성을 검증하기 위해 사용됩니다.
'banana-detection.zip': 데이터셋의 압축 파일 이름입니다.
'5de26c8fce5ccdea9f91267273464dc968d20d72': 데이터셋 파일의 해시값입니다. 이 값은 데이터 파일의 무결성을 확인하기 위해 사용됩니다. 데이터가 변조되지 않았는지 확인하는 용도로 사용됩니다.
14.6.2.Reading the Dataset
We are going to read the banana detection dataset in theread_data_bananasfunction below. The dataset includes a csv file for object class labels and ground-truth bounding box coordinates at the upper-left and lower-right corners.
아래의 read_data_bananas 함수에서 바나나 감지 데이터 세트를 읽을 것입니다. 데이터 세트에는 개체 클래스 레이블에 대한 csv 파일과 왼쪽 상단 및 오른쪽 하단 모서리의 실측 경계 상자 좌표가 포함되어 있습니다.
#@save
def read_data_bananas(is_train=True):
"""Read the banana detection dataset images and labels."""
data_dir = d2l.download_extract('banana-detection')
csv_fname = os.path.join(data_dir, 'bananas_train' if is_train
else 'bananas_val', 'label.csv')
csv_data = pd.read_csv(csv_fname)
csv_data = csv_data.set_index('img_name')
images, targets = [], []
for img_name, target in csv_data.iterrows():
images.append(torchvision.io.read_image(
os.path.join(data_dir, 'bananas_train' if is_train else
'bananas_val', 'images', f'{img_name}')))
# Here `target` contains (class, upper-left x, upper-left y,
# lower-right x, lower-right y), where all the images have the same
# banana class (index 0)
targets.append(list(target))
return images, torch.tensor(targets).unsqueeze(1) / 256
위 코드는 바나나 검출 데이터셋의 이미지와 레이블을 읽어오는 함수를 정의하고 있습니다. 코드를 한 줄씩 살펴보겠습니다.
def read_data_bananas(is_train=True):: 이 함수는 바나나 검출 데이터셋의 이미지와 레이블을 읽어오는 기능을 수행합니다. is_train 매개변수는 데이터셋이 훈련용인지 검증용인지를 나타내며, 기본값은 True입니다.
data_dir = d2l.download_extract('banana-detection'): 데이터셋을 다운로드하고 압축을 해제하여 저장할 디렉토리를 지정합니다. download_extract 함수를 사용하여 데이터셋을 다운로드하고 압축을 해제합니다.
csv_fname = os.path.join(data_dir, 'bananas_train' if is_train else 'bananas_val', 'label.csv'): 데이터셋의 레이블 정보가 담긴 CSV 파일의 경로를 지정합니다. is_train이 True인 경우 훈련용 데이터셋의 레이블 파일 경로를, 그렇지 않은 경우 검증용 데이터셋의 레이블 파일 경로를 지정합니다.
csv_data = pd.read_csv(csv_fname): Pandas를 사용하여 CSV 파일을 읽어 데이터를 데이터프레임 형태로 가져옵니다.
csv_data = csv_data.set_index('img_name'): 데이터프레임에서 'img_name' 열을 인덱스로 설정합니다. 각 이미지 파일의 이름을 인덱스로 사용하여 이미지와 레이블을 연결할 수 있도록 합니다.
images, targets = [], []: 이미지와 레이블을 저장하기 위한 빈 리스트를 생성합니다.
for img_name, target in csv_data.iterrows():: 데이터프레임을 순회하면서 이미지 이름과 레이블 정보를 하나씩 가져옵니다.
images.append(torchvision.io.read_image(...)): 이미지 파일을 읽어와서 리스트에 추가합니다. torchvision.io.read_image 함수를 사용하여 이미지 파일을 읽습니다.
targets.append(list(target)): 레이블 정보를 리스트에 추가합니다. 레이블은 클래스와 바운딩 박스의 좌표로 구성되어 있습니다.
By using theread_data_bananasfunction to read images and labels, the followingBananasDatasetclass will allow us to create a customizedDatasetinstance for loading the banana detection dataset.
read_data_bananas 함수를 사용하여 이미지와 레이블을 읽으면 다음 BananasDataset 클래스를 통해 바나나 감지 데이터 세트를 로드하기 위한 사용자 지정 Dataset 인스턴스를 만들 수 있습니다.
#@save
class BananasDataset(torch.utils.data.Dataset):
"""A customized dataset to load the banana detection dataset."""
def __init__(self, is_train):
self.features, self.labels = read_data_bananas(is_train)
print('read ' + str(len(self.features)) + (f' training examples' if
is_train else f' validation examples'))
def __getitem__(self, idx):
return (self.features[idx].float(), self.labels[idx])
def __len__(self):
return len(self.features)
위 코드는 PyTorch의 Dataset 클래스를 상속받아 바나나 검출 데이터셋을 사용하기 위한 사용자 정의 데이터셋 클래스를 정의하고 있습니다. 코드를 한 줄씩 살펴보겠습니다.
class BananasDataset(torch.utils.data.Dataset):: BananasDataset은 torch.utils.data.Dataset 클래스를 상속받아 사용자 정의 데이터셋 클래스를 정의하고 있습니다.
def __init__(self, is_train):: 클래스의 생성자 메서드입니다. 데이터셋의 초기화 작업을 수행합니다. is_train 매개변수는 데이터셋이 훈련용인지 검증용인지를 나타내며, 해당 데이터셋을 읽어와서 self.features와 self.labels에 저장합니다. 또한 읽어온 예제의 개수를 출력합니다.
def __getitem__(self, idx):: 데이터셋의 특정 인덱스 idx에 해당하는 샘플을 반환합니다. 해당 샘플의 이미지 데이터와 레이블을 튜플로 반환합니다. 이미지 데이터는 float 타입으로 변환되어 반환됩니다.
def __len__(self):: 데이터셋의 전체 샘플 개수를 반환합니다. 데이터셋의 길이를 알려주는 역할을 합니다.
이렇게 정의된 BananasDataset 클래스를 사용하면 데이터로더를 생성하여 모델 학습에 활용할 수 있습니다. 이 클래스는 데이터셋을 효율적으로 관리하고 모델 학습에 필요한 샘플과 레이블을 제공하는데 도움을 줍니다.
Finally, we define theload_data_bananasfunction to return two data iterator instances for both the training and test sets. For the test dataset, there is no need to read it in random order.
마지막으로 훈련 세트와 테스트 세트 모두에 대해 두 개의 데이터 반복자 인스턴스를 반환하도록 load_data_bananas 함수를 정의합니다. 테스트 데이터 세트의 경우 무작위 순서로 읽을 필요가 없습니다.
위의 코드는 '바나나 감지 데이터셋'을 로드하는 함수인 load_data_bananas를 정의하는 코드입니다. 아래에 코드를 한국어로 설명해보겠습니다.
load_data_bananas(batch_size): 이 함수는 바나나 감지 데이터셋을 로드하는 역할을 합니다. batch_size라는 매개변수를 입력으로 받습니다.
"""바나나 감지 데이터셋을 로드합니다.""": 이 줄은 함수의 설명을 나타내는 주석입니다. 함수가 어떤 역할을 하는지 간단하게 설명하고 있습니다.
train_iter = torch.utils.data.DataLoader(BananasDataset(is_train=True), batch_size, shuffle=True): train_iter라는 변수에는 훈련용 데이터를 로드하기 위한 DataLoader 객체가 저장됩니다. BananasDataset(is_train=True)는 훈련 데이터용 바나나 감지 데이터셋을 나타냅니다. batch_size는 한 번에 처리할 데이터의 개수를 나타내며, shuffle=True는 데이터를 섞어서 순서를 랜덤하게 만듭니다.
val_iter = torch.utils.data.DataLoader(BananasDataset(is_train=False), batch_size): val_iter라는 변수에는 검증용 데이터를 로드하기 위한 DataLoader 객체가 저장됩니다. BananasDataset(is_train=False)는 검증 데이터용 바나나 감지 데이터셋을 나타냅니다. batch_size는 한 번에 처리할 데이터의 개수를 나타냅니다.
return train_iter, val_iter: 이 함수는 train_iter와 val_iter 두 가지 값을 반환합니다. 이 두 변수는 각각 훈련용 데이터와 검증용 데이터를 로드하는 DataLoader 객체입니다.
이 함수는 주어진 batch_size에 따라 훈련용과 검증용 바나나 감지 데이터를 DataLoader를 통해 로드하고, 이를 반환하는 역할을 합니다.
Let’s read a minibatch and print the shapes of both images and labels in this minibatch. The shape of the image minibatch, (batch size, number of channels, height, width), looks familiar: it is the same as in our earlier image classification tasks. The shape of the label minibatch is (batch size,m, 5), wheremis the largest possible number of bounding boxes that any image has in the dataset.
미니배치를 읽고 이 미니배치에서 이미지와 레이블의 모양을 모두 인쇄해 보겠습니다. 이미지 미니배치의 모양(배치 크기, 채널 수, 높이, 너비)은 친숙해 보입니다. 이전 이미지 분류 작업과 동일합니다. 레이블 미니배치의 모양은 (배치 크기, m, 5)입니다. 여기서 m은 이미지가 데이터세트에 포함할 수 있는 최대 경계 상자 수입니다.
Although computation in minibatches is more efficient, it requires that all the image examples contain the same number of bounding boxes to form a minibatch via concatenation. In general, images may have a varying number of bounding boxes; thus, images with fewer thanmbounding boxes will be padded with illegal bounding boxes untilmis reached. Then the label of each bounding box is represented by an array of length 5. The first element in the array is the class of the object in the bounding box, where -1 indicates an illegal bounding box for padding. The remaining four elements of the array are the (x,y)-coordinate values of the upper-left corner and the lower-right corner of the bounding box (the range is between 0 and 1). For the banana dataset, since there is only one bounding box on each image, we havem=1.
미니 배치의 계산이 더 효율적이지만 연결을 통해 미니 배치를 형성하려면 모든 이미지 예제에 동일한 수의 경계 상자가 포함되어야 합니다. 일반적으로 이미지에는 다양한 수의 경계 상자가 있을 수 있습니다. 따라서 m 미만의 경계 상자가 있는 이미지는 m에 도달할 때까지 잘못된 경계 상자로 채워집니다. 그런 다음 각 경계 상자의 레이블은 길이가 5인 배열로 표시됩니다. 배열의 첫 번째 요소는 경계 상자에 있는 개체의 클래스이며 여기서 -1은 패딩에 대한 잘못된 경계 상자를 나타냅니다. 배열의 나머지 4개 요소는 경계 상자의 왼쪽 위 모서리와 오른쪽 아래 모서리의 (x, y) 좌표 값입니다(범위는 0과 1 사이). 바나나 데이터셋의 경우 각 이미지에 경계 상자가 하나만 있으므로 m=1입니다.
batch_size, edge_size = 32, 256: 이 줄은 batch_size와 edge_size라는 두 개의 변수에 각각 32와 256 값을 할당합니다. batch_size는 한 번에 처리할 데이터의 개수이고, edge_size는 가로 또는 세로 방향의 이미지 크기를 나타냅니다.
train_iter, _ = load_data_bananas(batch_size): 이 줄은 load_data_bananas 함수를 이용하여 바나나 감지 훈련 데이터를 로드합니다. batch_size 매개변수를 통해 한 번에 처리할 데이터의 개수를 설정합니다. 반환되는 값 중에서 첫 번째 값인 train_iter는 훈련 데이터를 로드하는 DataLoader 객체를 나타냅니다. 두 번째 값인 _는 반환되는 두 번째 객체를 무시하는 역할을 합니다.
batch = next(iter(train_iter)): 이 줄은 훈련 데이터의 첫 번째 배치를 가져와서 batch 변수에 저장합니다. train_iter는 DataLoader 객체이므로, iter(train_iter)를 통해 이를 반복 가능한(iterable) 객체로 변환하고, next() 함수를 통해 첫 번째 배치를 가져옵니다.
batch[0].shape, batch[1].shape: 이 줄은 현재 로드된 배치의 첫 번째 요소와 두 번째 요소의 크기(shape)를 확인합니다. batch[0]은 이미지 데이터를 나타내며, batch[1]은 해당 이미지에 대한 레이블을 나타냅니다. .shape는 배열의 크기를 확인하는 메서드입니다.
이 코드는 주어진 batch_size와 edge_size를 사용하여 바나나 감지 훈련 데이터를 로드하고, 첫 번째 배치의 이미지 데이터와 레이블의 크기를 확인하는 역할을 합니다.
14.6.3.Demonstration
Let’s demonstrate ten images with their labeled ground-truth bounding boxes. We can see that the rotations, sizes, and positions of bananas vary across all these images. Of course, this is just a simple artificial dataset. In practice, real-world datasets are usually much more complicated.
레이블이 지정된 ground-truth 경계 상자가 있는 10개의 이미지를 시연해 보겠습니다. 바나나의 회전, 크기 및 위치가 이 모든 이미지에서 다르다는 것을 알 수 있습니다. 물론 이것은 단순한 인공 데이터 세트일 뿐입니다. 실제로 실제 데이터 세트는 일반적으로 훨씬 더 복잡합니다.
imgs = (batch[0][:10].permute(0, 2, 3, 1)) / 255: 이 줄은 batch 변수에서 첫 번째 10개의 이미지 데이터를 선택하고, 차원 순서를 변경하며 픽셀 값 범위를 0에서 1 사이로 스케일링하여 imgs 변수에 저장합니다. 이미지의 픽셀 값은 원래 0에서 255 범위이지만, 여기서는 0에서 1 범위로 스케일을 조정합니다. permute(0, 2, 3, 1)는 차원을 순서대로 변경하는데, [0, 2, 3, 1] 순서로 변경함으로써 이미지의 차원 순서를 변경합니다.
axes = d2l.show_images(imgs, 2, 5, scale=2): imgs에 저장된 이미지 데이터를 2행 5열의 그리드 형태로 시각화하고, 각 이미지의 크기를 2배로 확대하여 axes 변수에 저장합니다. d2l.show_images 함수는 이미지들을 그리드로 나타내주는 도우미 함수입니다.
for ax, label in zip(axes, batch[1][:10]):: axes와 batch[1][:10]를 순회하면서 각 이미지와 해당 이미지의 레이블을 처리합니다.
d2l.show_bboxes(ax, [label[0][1:5] * edge_size], colors=['w']): d2l.show_bboxes 함수를 사용하여 이미지 위에 레이블에 해당하는 바운딩 박스를 그립니다. ax는 이미지를 나타내는 축(axes) 객체입니다. label[0][1:5] * edge_size는 레이블에서 바운딩 박스의 좌표를 추출하고 edge_size를 곱하여 실제 이미지 크기에 맞게 스케일링합니다. colors=['w']는 바운딩 박스의 색상을 흰색으로 설정합니다.
이 코드는 훈련 데이터의 첫 번째 10개 이미지를 시각화하고, 각 이미지에 해당하는 바운딩 박스를 그려서 바나나를 감지하는 레이블을 시각적으로 확인합니다.
14.6.4.Summary
The banana detection dataset we collected can be used to demonstrate object detection models.
우리가 수집한 바나나 감지 데이터 세트는 객체 감지 모델을 시연하는 데 사용할 수 있습니다.
The data loading for object detection is similar to that for image classification. However, in object detection the labels also contain information of ground-truth bounding boxes, which is missing in image classification.
객체 감지를 위한 데이터 로딩은 이미지 분류와 유사합니다. 그러나 객체 감지에서 레이블에는 이미지 분류에서 누락된 ground-truth 경계 상자의 정보도 포함됩니다.
14.6.5.Exercises
Demonstrate other images with ground-truth bounding boxes in the banana detection dataset. How do they differ with respect to bounding boxes and objects?
Say that we want to apply data augmentation, such as random cropping, to object detection. How can it be different from that in image classification? Hint: what if a cropped image only contains a small portion of an object?
InSection 14.4, we generated multiple anchor boxes centered on each pixel of an input image. Essentially these anchor boxes represent samples of different regions of the image. However, we may end up with too many anchor boxes to compute if they are generated foreverypixel. Think of a561×728input image. If five anchor boxes with varying shapes are generated for each pixel as their center, over two million anchor boxes (561×728×5) need to be labeled and predicted on the image.
섹션 14.4에서 입력 이미지의 각 픽셀을 중심으로 여러 앵커 상자를 생성했습니다. 기본적으로 이러한 앵커 상자는 이미지의 다른 영역 샘플을 나타냅니다. 그러나 앵커 상자가 모든 픽셀에 대해 생성되는 경우 계산하기에는 앵커 상자가 너무 많아질 수 있습니다. 561×728 입력 이미지를 생각해 보십시오. 각 픽셀마다 다양한 모양의 앵커 박스 5개를 중심으로 생성하면 200만 개가 넘는 앵커 박스(561×728×5)를 이미지에 라벨링하고 예측해야 합니다.
14.5.1.Multiscale Anchor Boxes
You may realize that it is not difficult to reduce anchor boxes on an image. For instance, we can just uniformly sample a small portion of pixels from the input image to generate anchor boxes centered on them. In addition, at different scales we can generate different numbers of anchor boxes of different sizes. Intuitively, smaller objects are more likely to appear on an image than larger ones. As an example,1×1,1×2, and2×2objects can appear on a2×2image in 4, 2, and 1 possible ways, respectively. Therefore, when using smaller anchor boxes to detect smaller objects, we can sample more regions, while for larger objects we can sample fewer regions.
이미지에서 앵커 박스를 줄이는 것이 어렵지 않다는 것을 알 수 있습니다. 예를 들어 입력 이미지에서 픽셀의 작은 부분을 균일하게 샘플링하여 중앙에 앵커 상자를 생성할 수 있습니다. 또한 크기가 다르면 크기가 다른 다양한 수의 앵커 박스를 생성할 수 있습니다. 직관적으로 작은 물체가 큰 물체보다 이미지에 나타날 가능성이 더 큽니다. 예를 들어, 1×1, 1×2, 2×2 객체는 각각 4, 2, 1가지 가능한 방식으로 2×2 이미지에 나타날 수 있습니다. 따라서 더 작은 앵커 상자를 사용하여 더 작은 객체를 감지할 때 더 많은 영역을 샘플링할 수 있는 반면 더 큰 객체의 경우 더 적은 영역을 샘플링할 수 있습니다.
To demonstrate how to generate anchor boxes at multiple scales, let’s read an image. Its height and width are 561 and 728 pixels, respectively.
여러 척도에서 앵커 상자를 생성하는 방법을 시연하기 위해 이미지를 읽어 보겠습니다. 높이와 너비는 각각 561픽셀과 728픽셀입니다.
%matplotlib inline
import torch
from d2l import torch as d2l
img = d2l.plt.imread('../img/catdog.jpg')
h, w = img.shape[:2]
h, w
(561, 728)
위 코드는 이미지 파일을 로드하고 해당 이미지의 높이와 너비를 계산하는 부분입니다.
%matplotlib inline: 이 코드는 Jupyter Notebook 등에서 Matplotlib 그림을 인라인으로 표시하도록 설정하는 명령입니다. Matplotlib을 사용하여 그래프나 이미지를 출력할 때 주피터 노트북 내에서 바로 볼 수 있게 합니다.
import torch: 파이토치 라이브러리를 임포트합니다. 딥러닝과 텐서 연산을 위해 사용됩니다.
from d2l import torch as d2l: d2l (Dive into Deep Learning) 라이브러리에서 파이토치에 대한 별칭을 d2l로 설정합니다. 이를 통해 d2l 라이브러리의 함수와 클래스를 이 코드에서 사용할 수 있게 됩니다.
img = d2l.plt.imread('../img/catdog.jpg'): 이미지 파일을 읽어와 img 변수에 저장합니다. 이미지 파일의 경로는 ../img/catdog.jpg로 설정되어 있습니다. 해당 경로에 이미지 파일이 있어야 합니다.
h, w = img.shape[:2]: 읽어온 이미지의 높이와 너비를 h와 w 변수에 저장합니다. .shape 속성을 사용하여 이미지의 형태를 확인하고, [:2] 슬라이싱을 통해 높이와 너비 정보만 추출합니다. 이렇게 함으로써 이미지의 높이와 너비를 h와 w 변수에 각각 할당합니다.
따라서 이 코드는 이미지 파일을 로드하고 해당 이미지의 높이와 너비를 확인하는 부분입니다.
Recall that inSection 7.2we call a two-dimensional array output of a convolutional layer a feature map. By defining the feature map shape, we can determine centers of uniformly sampled anchor boxes on any image.
섹션 7.2에서 우리는 컨볼루션 레이어의 2차원 배열 출력을 피처 맵이라고 부릅니다. feature 맵 모양을 정의하여 모든 이미지에서 균일하게 샘플링된 앵커 박스의 중심을 결정할 수 있습니다.
Thedisplay_anchorsfunction is defined below. We generate anchor boxes (anchors) on the feature map (fmap) with each unit (pixel) as the anchor box center. Since the(x,y)-axis coordinate values in the anchor boxes (anchors) have been divided by the width and height of the feature map (fmap), these values are between 0 and 1, which indicate the relative positions of anchor boxes in the feature map.
display_anchors 함수는 아래에 정의되어 있습니다. 각 단위(픽셀)를 앵커 상자 중심으로 하여 feature 맵(fmap)에 앵커 상자(앵커)를 생성합니다. 앵커 박스(anchor)의 (x,y)축 좌표 값을 특징 맵(fmap)의 너비와 높이로 나누었으므로 이 값은 0과 1 사이이며, 이것은 feature 맵에서 앵커 상자의 상대적 위치를 나타냅니다.
Since centers of the anchor boxes (anchors) are spread over all units on the feature map (fmap), these centers must beuniformlydistributed on any input image in terms of their relative spatial positions. More concretely, given the width and height of the feature mapfmap_wandfmap_h, respectively, the following function willuniformlysample pixels infmap_hrows andfmap_wcolumns on any input image. Centered on these uniformly sampled pixels, anchor boxes of scales(assuming the length of the listsis 1) and different aspect ratios (ratios) will be generated.
앵커 상자(앵커)의 중심은 기능 맵(fmap)의 모든 단위에 분산되어 있으므로 이러한 중심은 상대적인 공간 위치 측면에서 모든 입력 이미지에 균일하게 분포되어야 합니다. 보다 구체적으로, 기능 맵 fmap_w 및 fmap_h의 너비와 높이가 각각 주어지면 다음 함수는 모든 입력 이미지에서 fmap_h 행과 fmap_w 열의 픽셀을 균일하게 샘플링합니다. 이렇게 균일하게 샘플링된 픽셀을 중심으로 축척 s(목록 s의 길이가 1이라고 가정) 및 다른 종횡비(비율)의 앵커 상자가 생성됩니다.
def display_anchors(fmap_w, fmap_h, s):
d2l.set_figsize()
# Values on the first two dimensions do not affect the output
fmap = torch.zeros((1, 10, fmap_h, fmap_w))
anchors = d2l.multibox_prior(fmap, sizes=s, ratios=[1, 2, 0.5])
bbox_scale = torch.tensor((w, h, w, h))
d2l.show_bboxes(d2l.plt.imshow(img).axes,
anchors[0] * bbox_scale)
위 코드는 앵커 박스를 생성하고 시각적으로 표시하는 함수를 정의하는 부분입니다.
def display_anchors(fmap_w, fmap_h, s):: display_anchors라는 함수를 정의합니다. 이 함수는 세 개의 인자를 받습니다: fmap_w, fmap_h, s.
d2l.set_figsize(): 그래프의 크기를 설정하는 함수입니다. 이를 통해 플롯된 그림이 더 크게 표시될 수 있도록 설정합니다.
fmap = torch.zeros((1, 10, fmap_h, fmap_w)): fmap은 4D 텐서로, 형태는 (1, 10, fmap_h, fmap_w)입니다. 첫 번째 차원은 배치 크기, 두 번째 차원은 채널 수, 세 번째와 네 번째 차원은 특징 맵의 높이와 너비입니다. 여기서 특징 맵의 값을 0으로 초기화합니다.
anchors = d2l.multibox_prior(fmap, sizes=s, ratios=[1, 2, 0.5]): d2l.multibox_prior 함수를 사용하여 앵커 박스를 생성합니다. 이 함수는 입력으로 특징 맵, 앵커 박스의 크기(sizes), 앵커 박스의 종횡비(ratios)를 받습니다. fmap은 앞서 생성한 4D 텐서이며, sizes는 앵커 박스의 크기를 의미합니다. ratios는 앵커 박스의 종횡비를 나타냅니다.
bbox_scale = torch.tensor((w, h, w, h)): bbox_scale은 이미지의 높이와 너비를 포함하는 1D 텐서입니다. 이미지의 너비와 높이를 통해 크기 조절에 사용됩니다.
d2l.show_bboxes(d2l.plt.imshow(img).axes, anchors[0] * bbox_scale): d2l.show_bboxes 함수를 호출하여 앵커 박스를 이미지 위에 시각적으로 표시합니다. 이 함수는 두 개의 인자를 받습니다. 첫 번째 인자는 이미지가 그려질 축(axes)을 나타내며, 두 번째 인자는 앵커 박스의 좌표를 나타냅니다. 이 좌표를 bbox_scale로 크기를 조절한 뒤 앵커 박스를 시각적으로 표시합니다.
이 함수는 입력으로 주어진 특징 맵 크기와 앵커 박스의 크기, 종횡비를 활용하여 앵커 박스를 생성하고 시각적으로 표시하는 역할을 합니다.
First, let’s consider detection of small objects. In order to make it easier to distinguish when displayed, the anchor boxes with different centers here do not overlap: the anchor box scale is set to 0.15 and the height and width of the feature map are set to 4. We can see that the centers of the anchor boxes in 4 rows and 4 columns on the image are uniformly distributed.
먼저 작은 물체 감지에 대해 살펴보겠습니다. 표시할 때 쉽게 구별할 수 있도록 여기에서 중심이 다른 앵커 상자는 겹치지 않습니다. 앵커 상자 크기는 0.15로 설정되고 기능 맵의 높이와 너비는 4로 설정됩니다. 중심이 서로 다른 것을 볼 수 있습니다. 이미지에서 4행 4열의 앵커 상자가 균일하게 분포되어 있습니다.
display_anchors(fmap_w=4, fmap_h=4, s=[0.15])
위 코드는 display_anchors 함수를 호출하여 특정한 파라미터로 앵커 박스를 생성하고 시각화하는 과정을 보여줍니다.
display_anchors(fmap_w=4, fmap_h=4, s=[0.15]): display_anchors 함수를 호출하는 부분입니다. 함수에 세 개의 인자를 전달합니다. fmap_w는 특징 맵의 너비를, fmap_h는 특징 맵의 높이를, s는 앵커 박스의 크기를 의미하는 리스트를 전달합니다.
fmap_w=4, fmap_h=4: 특징 맵의 너비와 높이를 각각 4로 설정합니다.
s=[0.15]: 앵커 박스의 크기를 0.15로 설정합니다.
이렇게 설정된 파라미터로 display_anchors 함수가 호출되면, 해당 특징 맵과 앵커 박스의 크기를 활용하여 앵커 박스를 생성하고 이미지 위에 시각적으로 표시합니다. 이를 통해 특정 크기의 앵커 박스가 특정 위치에 어떻게 배치되는지를 확인할 수 있습니다.
We move on to reduce the height and width of the feature map by half and use larger anchor boxes to detect larger objects. When the scale is set to 0.4, some anchor boxes will overlap with each other.
계속해서 기능 맵의 높이와 너비를 절반으로 줄이고 더 큰 앵커 상자를 사용하여 더 큰 개체를 감지합니다. 배율을 0.4로 설정하면 일부 앵커 상자가 서로 겹칩니다.
display_anchors(fmap_w=2, fmap_h=2, s=[0.4])
Finally, we further reduce the height and width of the feature map by half and increase the anchor box scale to 0.8. Now the center of the anchor box is the center of the image.
마지막으로 기능 맵의 높이와 너비를 절반으로 줄이고 앵커 상자 크기를 0.8로 늘립니다. 이제 앵커 상자의 중심이 이미지의 중심이 됩니다.
display_anchors(fmap_w=1, fmap_h=1, s=[0.8])
14.5.2.Multiscale Detection
Since we have generated multiscale anchor boxes, we will use them to detect objects of various sizes at different scales. In the following we introduce a CNN-based multiscale object detection method that we will implement inSection 14.7.
멀티스케일 앵커 박스를 생성했으므로 이를 사용하여 다양한 스케일에서 다양한 크기의 객체를 감지할 것입니다. 다음에서는 14.7절에서 구현할 CNN 기반 멀티스케일 객체 감지 방법을 소개합니다.
At some scale, say that we have cfeature maps of shapeℎ×w. Using the method inSection 14.5.1, we generateℎwsets of anchor boxes, where each set hasαanchor boxes with the same center. For example, at the first scale in the experiments inSection 14.5.1, given ten (number of channels)4×4feature maps, we generated 16 sets of anchor boxes, where each set contains 3 anchor boxes with the same center. Next, each anchor box is labeled with the class and offset based on ground-truth bounding boxes. At the current scale, the object detection model needs to predict the classes and offsets ofℎwsets of anchor boxes on the input image, where different sets have different centers.
어떤 규모에서 모양 ℎ×w의 특징 맵이 c개 있다고 가정해 보겠습니다. 섹션 14.5.1의 방법을 사용하여 ℎw 앵커 상자 세트를 생성합니다. 여기서 각 세트에는 동일한 중심을 가진 α 앵커 상자가 있습니다. 예를 들어 섹션 14.5.1 실험의 첫 번째 스케일에서 10개(채널 수)의 4×4 기능 맵이 주어졌을 때 우리는 16개의 앵커 상자 세트를 생성했으며 각 세트에는 동일한 중심을 가진 3개의 앵커 상자가 포함되어 있습니다. 다음으로, 각 앵커 상자는 실측 경계 상자를 기반으로 클래스 및 오프셋으로 레이블이 지정됩니다. 현재 규모에서 물체 감지 모델은 입력 이미지에서 앵커 상자의 ℎw 세트의 클래스와 오프셋을 예측해야 합니다. 여기서 세트마다 중심이 다릅니다.
Assume that thecfeature maps here are the intermediate outputs obtained by the CNN forward propagation based on the input image. Since there areℎwdifferent spatial positions on each feature map, the same spatial position can be thought of as havingcunits. According to the definition of receptive field inSection 7.2, thesecunits at the same spatial position of the feature maps have the same receptive field on the input image: they represent the input image information in the same receptive field. Therefore, we can transform thecunits of the feature maps at the same spatial position into the classes and offsets of theαanchor boxes generated using this spatial position. In essence, we use the information of the input image in a certain receptive field to predict the classes and offsets of the anchor boxes that are close to that receptive field on the input image.
여기서 c 특성 맵은 입력 이미지를 기반으로 CNN 정방향 전파에 의해 얻은 중간 출력이라고 가정합니다. 각 특징 맵에는 ℎw개의 서로 다른 공간 위치가 있으므로 동일한 공간 위치는 c 단위를 갖는 것으로 생각할 수 있습니다. 7.2 절의 수용 필드의 정의에 따르면, 특징 맵의 동일한 공간 위치에 있는 이러한 c 단위는 입력 이미지에서 동일한 수용 필드를 갖습니다. 즉, 동일한 수용 필드에서 입력 이미지 정보를 나타냅니다. 따라서 동일한 공간 위치에 있는 피처 맵의 c 단위를 이 공간 위치를 사용하여 생성된 α 앵커 상자의 클래스 및 오프셋으로 변환할 수 있습니다. 본질적으로 우리는 입력 이미지의 수용 필드에 가까운 앵커 박스의 클래스와 오프셋을 예측하기 위해 특정 수용 필드의 입력 이미지 정보를 사용합니다.
When the feature maps at different layers have varying-size receptive fields on the input image, they can be used to detect objects of different sizes. For example, we can design a neural network where units of feature maps that are closer to the output layer have wider receptive fields, so they can detect larger objects from the input image.
다른 레이어의 기능 맵이 입력 이미지에 다양한 크기의 수용 필드를 가지고 있는 경우 다양한 크기의 객체를 감지하는 데 사용할 수 있습니다. 예를 들어 출력 레이어에 더 가까운 기능 맵 단위가 더 넓은 수용 필드를 갖는 신경망을 설계하여 입력 이미지에서 더 큰 객체를 감지할 수 있습니다.
In a nutshell, we can leverage layerwise representations of images at multiple levels by deep neural networks for multiscale object detection. We will show how this works through a concrete example inSection 14.7.
간단히 말해서, 우리는 다중 규모 객체 감지를 위해 심층 신경망에 의해 여러 수준에서 이미지의 계층적 표현을 활용할 수 있습니다. 섹션 14.7에서 구체적인 예를 통해 이것이 어떻게 작동하는지 보여줄 것입니다.
14.5.3.Summary
At multiple scales, we can generate anchor boxes with different sizes to detect objects with different sizes.
다양한 규모에서 다양한 크기의 앵커 박스를 생성하여 다양한 크기의 물체를 감지할 수 있습니다.
By defining the shape of feature maps, we can determine centers of uniformly sampled anchor boxes on any image.
특징 맵의 모양을 정의함으로써 모든 이미지에서 균일하게 샘플링된 앵커 박스의 중심을 결정할 수 있습니다.
We use the information of the input image in a certain receptive field to predict the classes and offsets of the anchor boxes that are close to that receptive field on the input image.
특정 수용 필드의 입력 이미지 정보를 사용하여 입력 이미지의 해당 수용 필드에 가까운 앵커 박스의 클래스와 오프셋을 예측합니다.
Through deep learning, we can leverage its layerwise representations of images at multiple levels for multiscale object detection.
딥 러닝을 통해 멀티스케일 객체 감지를 위해 여러 수준에서 이미지의 레이어별 표현을 활용할 수 있습니다.
14.5.4.Exercises
According to our discussions inSection 8.1, deep neural networks learn hierarchical features with increasing levels of abstraction for images. In multiscale object detection, do feature maps at different scales correspond to different levels of abstraction? Why or why not?
At the first scale (fmap_w=4,fmap_h=4) in the experiments inSection 14.5.1, generate uniformly distributed anchor boxes that may overlap.
Given a feature map variable with shape1×c×ℎ×w, wherec,ℎ, andware the number of channels, height, and width of the feature maps, respectively. How can you transform this variable into the classes and offsets of anchor boxes? What is the shape of the output?
Object detection algorithms usually sample a large number of regions in the input image, determine whether these regions contain objects of interest, and adjust the boundaries of the regions so as to predict theground-truth bounding boxesof the objects more accurately. Different models may adopt different region sampling schemes. Here we introduce one of such methods: it generates multiple bounding boxes with varying scales and aspect ratios centered on each pixel. These bounding boxes are calledanchor boxes. We will design an object detection model based on anchor boxes inSection 14.7.
객체 감지 알고리즘은 일반적으로 입력 이미지에서 많은 수의 영역을 샘플링하고 이러한 영역에 관심 객체가 포함되어 있는지 확인하고 영역의 경계를 조정하여 객체의 실측 경계 상자를 더 정확하게 예측합니다. 다른 모델은 다른 지역 샘플링 방식을 채택할 수 있습니다. 여기서는 이러한 방법 중 하나를 소개합니다. 각 픽셀을 중심으로 다양한 크기와 종횡비로 여러 경계 상자를 생성합니다. 이러한 경계 상자를 앵커 상자라고 합니다. 섹션 14.7에서 앵커 박스를 기반으로 객체 감지 모델을 설계할 것입니다.
First, let’s modify the printing accuracy just for more concise outputs.
먼저 보다 간결한 출력을 위해 인쇄 정확도를 수정해 보겠습니다.
%matplotlib inline
import torch
from d2l import torch as d2l
torch.set_printoptions(2) # Simplify printing accuracy
from d2l import torch as d2l: 'd2l'이라는 이름으로 PyTorch의 기능을 사용할 수 있도록 임포트합니다.
torch.set_printoptions(2): 출력 정밀도를 소수점 둘째 자리까지 설정합니다. 이렇게 하면 텐서의 값을 간소화된 형식으로 출력할 수 있습니다.
즉, 코드는 PyTorch 텐서의 출력 정밀도를 조정하여 더 간소하고 읽기 쉬운 형식으로 값을 표시하는 예시를 보여줍니다.
Anchor box란?
"Anchor Box"는 객체 탐지(Object Detection) 및 객체 위치 예측 작업에서 사용되는 개념입니다. 객체 탐지 모델에서 객체의 위치와 클래스를 예측할 때, 이미지 내에서 다양한 크기와 종횡비를 가진 객체에 대해 예측을 수행해야 합니다. 이때 Anchor Box는 이러한 다양한 객체의 크기와 종횡비에 대응하는 사전 정의된 사각형 형태의 박스입니다.
Anchor Box는 주로 합성곱 신경망(Convolutional Neural Network, CNN) 기반의 객체 탐지 모델에서 사용됩니다. 모델은 이미지를 입력으로 받아 여러 스케일의 특징 맵을 추출합니다. Anchor Box는 이러한 특징 맵의 각 위치에서 객체를 예측하기 위한 후보 영역을 제시하는 역할을 합니다.
Anchor Box는 크게 두 가지 파라미터로 정의됩니다:
크기(Sizes): 다양한 객체 크기에 대응하기 위해 정의되는 박스의 가로와 세로 크기입니다. 예를 들어, 작은 객체에 대응하는 작은 크기의 박스와 큰 객체에 대응하는 큰 크기의 박스를 정의할 수 있습니다.
종횡비(Ratios): 객체의 종횡비에 대응하기 위해 정의되는 박스의 가로와 세로의 비율입니다. 종횡비는 주로 1:1, 1:2, 2:1과 같은 비율로 정의되며, 다양한 객체 모양에 대응하기 위해 사용됩니다.
객체 탐지 모델은 특징 맵의 각 위치에서 여러 개의 Anchor Box를 생성하고, 이를 기반으로 객체의 위치와 클래스를 예측합니다. 이후 예측된 정보와 실제 객체 위치를 비교하여 모델을 훈련하게 됩니다. Anchor Box를 이용하면 다양한 크기와 모양의 객체에 대한 예측을 효과적으로 수행할 수 있습니다.
14.4.1.Generating Multiple Anchor Boxes
Suppose that the input image has a height ofℎand width ofw. We generate anchor boxes with different shapes centered on each pixel of the image. Let thescalebes∈(0,1]and theaspect ratio(ratio of width to height) isr>0. Then the width and height of the anchor box arews√randℎs/√r, respectively. Note that when the center position is given, an anchor box with known width and height is determined.
입력 이미지의 높이가 ℎ이고 너비가 w라고 가정합니다. 이미지의 각 픽셀을 중심으로 다양한 모양의 앵커 박스를 생성합니다. 스케일을 s∈(0,1]로 하고 종횡비(너비와 높이의 비율)를 r>0이라고 하면 앵커 박스의 너비와 높이는 각각 ws√r과 ℎs/√r입니다. 중심 위치가 주어지면 너비와 높이가 알려진 앵커 박스가 결정됩니다.
To generate multiple anchor boxes with different shapes, let’s set a series of scaless1,…,snand a series of aspect ratiosr1,…,rm. When using all the combinations of these scales and aspect ratios with each pixel as the center, the input image will have a total ofwℎnmanchor boxes. Although these anchor boxes may cover all the ground-truth bounding boxes, the computational complexity is easily too high. In practice, we can only consider those combinations containings1or r1:
모양이 다른 여러 앵커 박스를 생성하기 위해 일련의 축척 s1,…,sn과 일련의 종횡비 r1,…,rm을 설정해 보겠습니다. 각 픽셀을 중심으로 이러한 배율과 종횡비의 모든 조합을 사용할 때 입력 이미지는 총 wℎnm 앵커 상자를 갖게 됩니다. 이러한 앵커 상자가 실측 경계 상자를 모두 덮을 수 있지만 계산 복잡도가 너무 높습니다. 실제로는 s1 또는 r1을 포함하는 조합만 고려할 수 있습니다.
That is to say, the number of anchor boxes centered on the same pixel isn+m−1. For the entire input image, we will generate a total ofwℎ(n+m−1)anchor boxes.
즉, 동일한 픽셀을 중심으로 하는 앵커 박스의 수는 n+m-1입니다. 전체 입력 이미지에 대해 총 wℎ(n+m−1)개의 앵커 상자를 생성합니다.
The above method of generating anchor boxes is implemented in the followingmultibox_priorfunction. We specify the input image, a list of scales, and a list of aspect ratios, then this function will return all the anchor boxes.
앵커 박스를 생성하는 위의 방법은 다음 multibox_prior 함수에서 구현됩니다. 입력 이미지, 축척 목록 및 종횡비 목록을 지정하면 이 함수는 모든 앵커 상자를 반환합니다.
#@save
def multibox_prior(data, sizes, ratios):
"""Generate anchor boxes with different shapes centered on each pixel."""
in_height, in_width = data.shape[-2:]
device, num_sizes, num_ratios = data.device, len(sizes), len(ratios)
boxes_per_pixel = (num_sizes + num_ratios - 1)
size_tensor = torch.tensor(sizes, device=device)
ratio_tensor = torch.tensor(ratios, device=device)
# Offsets are required to move the anchor to the center of a pixel. Since
# a pixel has height=1 and width=1, we choose to offset our centers by 0.5
offset_h, offset_w = 0.5, 0.5
steps_h = 1.0 / in_height # Scaled steps in y axis
steps_w = 1.0 / in_width # Scaled steps in x axis
# Generate all center points for the anchor boxes
center_h = (torch.arange(in_height, device=device) + offset_h) * steps_h
center_w = (torch.arange(in_width, device=device) + offset_w) * steps_w
shift_y, shift_x = torch.meshgrid(center_h, center_w, indexing='ij')
shift_y, shift_x = shift_y.reshape(-1), shift_x.reshape(-1)
# Generate `boxes_per_pixel` number of heights and widths that are later
# used to create anchor box corner coordinates (xmin, xmax, ymin, ymax)
w = torch.cat((size_tensor * torch.sqrt(ratio_tensor[0]),
sizes[0] * torch.sqrt(ratio_tensor[1:])))\
* in_height / in_width # Handle rectangular inputs
h = torch.cat((size_tensor / torch.sqrt(ratio_tensor[0]),
sizes[0] / torch.sqrt(ratio_tensor[1:])))
# Divide by 2 to get half height and half width
anchor_manipulations = torch.stack((-w, -h, w, h)).T.repeat(
in_height * in_width, 1) / 2
# Each center point will have `boxes_per_pixel` number of anchor boxes, so
# generate a grid of all anchor box centers with `boxes_per_pixel` repeats
out_grid = torch.stack([shift_x, shift_y, shift_x, shift_y],
dim=1).repeat_interleave(boxes_per_pixel, dim=0)
output = out_grid + anchor_manipulations
return output.unsqueeze(0)
위 코드는 'multibox_prior'라는 함수로, 다양한 크기와 비율의 앵커 박스를 이미지 내의 각 픽셀 중심에 생성하는 기능을 수행합니다.
multibox_prior(data, sizes, ratios): 이 함수는 입력 데이터 텐서 data, 앵커 박스의 크기 목록 sizes, 그리고 앵커 박스의 비율 목록 ratios를 받습니다. 이 함수는 이미지 내의 각 픽셀 중심을 기준으로 다양한 크기와 비율의 앵커 박스를 생성하여 반환합니다.
함수 내부에서 다음 단계가 수행됩니다:
입력 데이터의 높이와 너비를 가져옵니다.
크기와 비율 텐서를 생성하고 디바이스를 설정합니다.
픽셀 중심의 이동을 위한 오프셋을 계산합니다.
y축과 x축에 대한 스케일된 스텝 값을 계산합니다.
중심 포인트를 생성하여 앵커 박스의 중심을 지정합니다.
다양한 크기와 비율을 활용하여 각 픽셀 중심에서 앵커 박스의 크기를 조정합니다.
생성된 앵커 박스를 반환합니다.
이렇게 생성된 앵커 박스는 객체 감지 작업에서 사용되며, 여러 크기와 비율의 박스를 이미지의 각 픽셀에 적용함으로써 객체를 탐지하는데 사용됩니다.
각 라인별로 분석해 보겠습니다.
#@save
def multibox_prior(data, sizes, ratios):
"""Generate anchor boxes with different shapes centered on each pixel."""
함수 정의가 시작됩니다. 함수 이름은 multibox_prior이며, 입력으로 data, sizes, ratios를 받습니다. 함수 내용은 "Generate anchor boxes with different shapes centered on each pixel.(각 픽셀을 중심으로 다른 모양의 앵커 상자 생성)"라는 주석으로 설명되어 있습니다.
입력 데이터인 data의 높이와 너비를 가져와 in_height와 in_width로 할당합니다. 또한 data의 디바이스 정보를 가져와 device에 할당하고, sizes와 ratios의 길이를 이용하여 앵커 박스의 크기와 비율 개수를 각각 num_sizes와 num_ratios에 할당합니다. boxes_per_pixel은 앵커 박스 개수를 의미합니다.
생성된 앵커 박스들의 형상을 출력합니다. 이는 (앵커 박스 개수, 4)의 형태로 출력됩니다. 4는 앵커 박스의 좌표 정보를 의미하며, (x, y, width, height) 형식으로 구성됩니다.
After changing the shape of the anchor box variableYto (image height, image width, number of anchor boxes centered on the same pixel, 4), we can obtain all the anchor boxes centered on a specified pixel position. In the following, we access the first anchor box centered on (250, 250). It has four elements: the(x,y)-axis coordinates at the upper-left corner and the(x,y)-axis coordinates at the lower-right corner of the anchor box. The coordinate values of both axes are divided by the width and height of the image, respectively.
앵커 박스 변수 Y의 모양을 (이미지 높이, 이미지 너비, 같은 픽셀을 중심으로 하는 앵커 박스 수, 4)로 변경하면 지정된 픽셀 위치를 중심으로 하는 모든 앵커 박스를 얻을 수 있습니다. 다음에서는 (250, 250)을 중심으로 하는 첫 번째 앵커 상자에 액세스합니다. 앵커 상자의 왼쪽 위 모서리에 있는 (x,y)축 좌표와 오른쪽 아래 모서리에 있는 (x,y)축 좌표의 네 가지 요소가 있습니다. 두 축의 좌표 값은 각각 이미지의 너비와 높이로 나뉩니다.
bbox를 이용하여 Matplotlib의 Rectangle 객체를 생성하고, 해당 객체를 축에 추가합니다.
만약 labels가 존재하고, 현재 인덱스가 레이블 개수보다 작으면, 해당 레이블 정보를 바운딩 박스 중심에 출력합니다. 이때 텍스트 색상과 배경 색상이 조정되어 텍스트가 더 잘 보이도록 설정됩니다.
As we just saw, the coordinate values of thexandyaxes in the variableboxeshave been divided by the width and height of the image, respectively. When drawing anchor boxes, we need to restore their original coordinate values; thus, we define variablebbox_scalebelow. Now, we can draw all the anchor boxes centered on (250, 250) in the image. As you can see, the blue anchor box with a scale of 0.75 and an aspect ratio of 1 well surrounds the dog in the image.
방금 본 것처럼 변수 상자의 x 및 y축 좌표 값은 각각 이미지의 너비와 높이로 나뉩니다. 앵커 상자를 그릴 때 원래 좌표 값을 복원해야 합니다. 따라서 아래에 변수 bbox_scale을 정의합니다. 이제 이미지에서 (250, 250)을 중심으로 모든 앵커 상자를 그릴 수 있습니다. 보시다시피 스케일 0.75, 종횡비 1 well인 파란색 앵커 상자가 이미지에서 강아지를 잘 둘러싸고 있습니다.
그래프의 크기를 설정하는 함수입니다. d2l은 딥러닝 모델 관련 기능을 제공하는 패키지입니다.
bbox_scale은 바운딩 박스의 크기를 조정하기 위한 스케일을 나타냅니다. 이미지의 폭과 높이 값을 담고 있습니다.
img를 Matplotlib의 imshow 함수를 이용하여 이미지로 표시합니다. 그림을 그릴 축(axes) 객체를 fig에 저장합니다.
show_bboxes 함수를 호출하여 바운딩 박스를 이미지 위에 그립니다. boxes[250, 250, :, :] * bbox_scale는 선택한 픽셀 위치에서 생성된 여러 바운딩 박스의 좌표를 의미합니다.
각 바운딩 박스에 대한 레이블도 함께 지정하여 출력합니다. 이를 통해 바운딩 박스의 크기와 종횡비에 대한 정보를 확인할 수 있습니다.
14.4.2.Intersection over Union (IoU)
We just mentioned that an anchor box “well” surrounds the dog in the image. If the ground-truth bounding box of the object is known, how can “well” here be quantified? Intuitively, we can measure the similarity between the anchor box and the ground-truth bounding box. We know that theJaccard indexcan measure the similarity between two sets. Given setsAandB, their Jaccard index is the size of their intersection divided by the size of their union:
우리는 방금 이미지에서 개를 둘러싼 앵커 박스 "well"을 언급했습니다. 객체의 실측 경계 상자가 알려진 경우 여기에서 "well"을 어떻게 정량화할 수 있습니까? 직관적으로 앵커 상자와 실측 경계 상자 사이의 유사성을 측정할 수 있습니다. 우리는 Jaccard 지수가 두 세트 간의 유사성을 측정할 수 있다는 것을 알고 있습니다. 집합 A와 B가 주어지면 Jaccard 지수는 교집합의 크기를 합집합의 크기로 나눈 값입니다.
Jaccard Index란?
The "Jaccard index," also known as the "Intersection over Union (IoU)," is a statistical measure used to evaluate the similarity or overlap between two sets. It is commonly used in the field of image segmentation, object detection, and binary classification tasks to measure the accuracy of predicted regions or bounding boxes compared to the ground truth.
"Jaccard 지수," 또는 "교집합 비율 (IoU, Intersection over Union),"은 두 집합 간의 유사성 또는 중첩을 평가하는 통계적 지표입니다. 이미지 분할, 객체 탐지 및 이진 분류 작업 분야에서 예측된 영역이나 바운딩 박스와 실제값 간의 정확성을 측정하는 데 주로 사용됩니다.
In the context of object detection or image segmentation, the Jaccard index calculates the ratio of the area of overlap between the predicted region and the ground truth region to the total area encompassed by both regions. Mathematically, the Jaccard index is defined as:
객체 탐지나 이미지 분할의 맥락에서 Jaccard 지수는 예측된 영역과 실제값 영역 사이의 중첩 영역의 면적을 전체 영역으로 나눈 비율을 계산합니다. 수학적으로 Jaccard 지수는 다음과 같이 정의됩니다.
J(A,B)=∣A∩B∣/∣A∪B∣
Where:
A represents the set of pixels or elements in the predicted region.
A는 예측된 영역의 픽셀 또는 요소의 집합을 나타냅니다.
B represents the set of pixels or elements in the ground truth region.
B는 실제값 영역의 픽셀 또는 요소의 집합을 나타냅니다.
∣A∩B∣ denotes the size of the intersection between sets A and B.
∣A∩B∣는 집합 A와 B 사이의 교집합의 크기를 나타냅니다.
∣A∪B∣ denotes the size of the union of sets A and B.
∣A∪B∣는 집합 A와 B의 합집합의 크기를 나타냅니다.
The Jaccard index ranges from 0 to 1, where 0 indicates no overlap between the sets (no agreement), and 1 indicates complete overlap (perfect agreement). In the context of object detection, a higher Jaccard index implies a better alignment between the predicted bounding box and the ground truth bounding box.
Jaccard 지수는 0부터 1까지의 범위를 가지며, 0은 집합 간에 중첩이 없음을 나타내며 (일치하지 않음), 1은 완전한 중첩을 나타냅니다 (완전히 일치). 객체 탐지의 맥락에서 높은 Jaccard 지수는 예측된 바운딩 박스와 실제값 바운딩 박스 간의 좋은 정렬을 나타냅니다.
The Jaccard index is a valuable metric for evaluating the accuracy of algorithms in tasks that involve identifying regions of interest or bounding boxes, as it provides insight into the quality of predictions by measuring their spatial agreement with the actual ground truth.
Jaccard 지수는 관심 영역이나 바운딩 박스를 식별하는 작업에서 알고리즘의 정확성을 평가하는 데 유용한 지표로, 예측의 공간적인 일치를 측정하여 실제값과의 품질을 평가합니다.
In fact, we can consider the pixel area of any bounding box as a set of pixels. In this way, we can measure the similarity of the two bounding boxes by the Jaccard index of their pixel sets. For two bounding boxes, we usually refer their Jaccard index asintersection over union(IoU), which is the ratio of their intersection area to their union area, as shown inFig. 14.4.1. The range of an IoU is between 0 and 1: 0 means that two bounding boxes do not overlap at all, while 1 indicates that the two bounding boxes are equal.
사실 경계 상자의 픽셀 영역을 픽셀 집합으로 간주할 수 있습니다. 이러한 방식으로 픽셀 집합의 Jaccard 인덱스로 두 경계 상자의 유사성을 측정할 수 있습니다. 두 개의 경계 상자에 대해 우리는 일반적으로 그림 14.4.1과 같이 교차 영역과 결합 영역의 비율인 Jaccard 인덱스를 IoU(교차점 오버 유니온)라고 합니다. IoU의 범위는 0에서 1 사이입니다. 0은 두 경계 상자가 전혀 겹치지 않음을 의미하고 1은 두 경계 상자가 동일함을 나타냅니다.
Fig. 14.4.1 IoU is the ratio of the intersection area to the union area of two bounding boxes.
For the remainder of this section, we will use IoU to measure the similarity between anchor boxes and ground-truth bounding boxes, and between different anchor boxes. Given two lists of anchor or bounding boxes, the followingbox_ioucomputes their pairwise IoU across these two lists.
이 섹션의 나머지 부분에서는 IoU를 사용하여 앵커 상자와 ground-truth 경계 상자, 서로 다른 앵커 상자 간의 유사성을 측정합니다. 두 개의 앵커 또는 경계 상자 목록이 주어지면 다음 box_iou는 이 두 목록에서 쌍별 IoU를 계산합니다.
#@save
def box_iou(boxes1, boxes2):
"""Compute pairwise IoU across two lists of anchor or bounding boxes."""
box_area = lambda boxes: ((boxes[:, 2] - boxes[:, 0]) *
(boxes[:, 3] - boxes[:, 1]))
# Shape of `boxes1`, `boxes2`, `areas1`, `areas2`: (no. of boxes1, 4),
# (no. of boxes2, 4), (no. of boxes1,), (no. of boxes2,)
areas1 = box_area(boxes1)
areas2 = box_area(boxes2)
# Shape of `inter_upperlefts`, `inter_lowerrights`, `inters`: (no. of
# boxes1, no. of boxes2, 2)
inter_upperlefts = torch.max(boxes1[:, None, :2], boxes2[:, :2])
inter_lowerrights = torch.min(boxes1[:, None, 2:], boxes2[:, 2:])
inters = (inter_lowerrights - inter_upperlefts).clamp(min=0)
# Shape of `inter_areas` and `union_areas`: (no. of boxes1, no. of boxes2)
inter_areas = inters[:, :, 0] * inters[:, :, 1]
union_areas = areas1[:, None] + areas2 - inter_areas
return inter_areas / union_areas
위 코드는 두 개의 바운딩 박스 리스트 간에 서로 겹치는 면적의 비율인 IoU (Intersection over Union)를 계산하는 함수를 정의하는 코드입니다. 코드를 한 줄씩 설명하겠습니다.
box_iou 함수는 두 개의 바운딩 박스 리스트 간의 IoU를 계산하는 함수입니다. 이 함수는 앵커 박스(anchor box) 또는 바운딩 박스(bounding box) 리스트를 입력으로 받습니다.
box_area는 입력으로 들어온 바운딩 박스들의 면적을 계산하는 람다(lambda) 함수입니다. 바운딩 박스의 너비와 높이를 이용하여 면적을 계산합니다.
boxes1 리스트와 boxes2 리스트의 각각의 바운딩 박스에 대한 면적을 계산하여 areas1과 areas2에 저장합니다.
겹치는 영역의 좌상단 점과 우하단 점을 계산하여 inter_upperlefts와 inter_lowerrights에 저장합니다. inters는 겹치는 영역의 너비와 높이입니다. clamp(min=0) 함수를 이용하여 음수 값을 0으로 만듭니다.
겹치는 영역의 너비와 높이를 이용하여 겹치는 영역의 면적과 합집합의 면적을 계산합니다.
계산된 겹치는 영역의 면적과 합집합의 면적을 이용하여 IoU를 계산하고 반환합니다. 이를 통해 두 개의 바운딩 박스 리스트 간의 IoU를 계산할 수 있습니다.
14.4.3.Labeling Anchor Boxes in Training Data
In a training dataset, we consider each anchor box as a training example. In order to train an object detection model, we needclassandoffsetlabels for each anchor box, where the former is the class of the object relevant to the anchor box and the latter is the offset of the ground-truth bounding box relative to the anchor box. During the prediction, for each image we generate multiple anchor boxes, predict classes and offsets for all the anchor boxes, adjust their positions according to the predicted offsets to obtain the predicted bounding boxes, and finally only output those predicted bounding boxes that satisfy certain criteria.
교육 데이터 세트에서 각 앵커 상자를 교육 예제로 간주합니다. 개체 감지 모델을 훈련하려면 각 앵커 상자에 대한 클래스 및 오프셋 레이블이 필요합니다. 여기서 전자는 앵커 상자와 관련된 개체의 클래스입니다. 후자는 앵커 상자에 대한 실측 경계 상자의 오프셋입니다. 예측하는 동안 각 이미지에 대해 여러 개의 앵커 상자를 생성하고 모든 앵커 상자에 대한 클래스와 오프셋을 예측하고 예측된 경계 상자를 얻기 위해 예측된 오프셋에 따라 위치를 조정하고 마지막으로 특정 기준을 충족하는 예측된 경계 상자만 출력합니다. .
As we know, an object detection training set comes with labels for locations ofground-truth bounding boxesand classes of their surrounded objects. To label any generatedanchor box, we refer to the labeled location and class of itsassignedground-truth bounding box that is closest to the anchor box. In the following, we describe an algorithm for assigning closest ground-truth bounding boxes to anchor boxes.
아시다시피 객체 감지 훈련 세트에는 ground-truth 경계 상자의 위치와 둘러싸인 객체의 클래스에 대한 레이블이 함께 제공됩니다. 생성된 앵커 상자에 레이블을 지정하려면 앵커 상자에 가장 가까운 할당된 ground-truth 경계 상자의 레이블이 지정된 위치와 클래스를 참조합니다. 다음에서는 가장 가까운 ground-truth 경계 상자를 앵커 상자에 할당하는 알고리즘을 설명합니다.
14.4.3.1.Assigning Ground-Truth Bounding Boxes to Anchor Boxes
Given an image, suppose that the anchor boxes areA1,A2,…,Anaand the ground-truth bounding boxes areB1,B2,…,Bnb, wherena≥nb. Let’s define a matrixX∈ℝ**na×nb, whose elementxijin theithrow andjthcolumn is the IoU of the anchor boxAiand the ground-truth bounding boxBj. The algorithm consists of the following steps:
주어진 이미지에서 앵커 상자가 A1,A2,…,Ana이고 ground-truth 경계 상자가 B1,B2,…,Bnb라고 가정합니다. 행렬 X∈ℝ**na×nb를 정의해 보겠습니다. 여기서 i번째 행과 j번째 열의 요소 xij는 앵커 상자 Ai와 ground-truth 경계 상자 Bj의 IoU입니다. 알고리즘은 다음 단계로 구성됩니다.
Find the largest element in matrixXand denote its row and column indices asi1andj1, respectively. Then the ground-truth bounding boxBj1is assigned to the anchor boxAi1. This is quite intuitive becauseAi1andBj1are the closest among all the pairs of anchor boxes and ground-truth bounding boxes. After the first assignment, discard all the elements in thei1throw and the j1thcolumn in matrixX.
행렬 X에서 가장 큰 요소를 찾고 해당 행 및 열 인덱스를 각각 i1 및 j1로 나타냅니다. 그런 다음 ground-truth 경계 상자 Bj1이 앵커 상자 Ai1에 할당됩니다. 이것은 Ai1과 Bj1이 모든 앵커 박스와 ground-truth bounding box 쌍 중에서 가장 가깝기 때문에 매우 직관적입니다. 첫 번째 할당 후 행렬 X의 i1번째 행과 j1번째 열의 모든 요소를 버립니다.
Find the largest of the remaining elements in matrix X and denote its row and column indices asi2andj2, respectively. We assign ground-truth bounding boxBj2to anchor boxAi2and discard all the elements in thei2throw and thej2thcolumn in matrixX.
행렬 X에서 나머지 요소 중 가장 큰 요소를 찾고 해당 행 및 열 인덱스를 각각 i2 및 j2로 나타냅니다. ground-truth 경계 상자 Bj2를 앵커 상자 Ai2에 할당하고 행렬 X의 i2번째 행과 j2번째 열에 있는 모든 요소를 버립니다.
At this point, elements in two rows and two columns in matrixXhave been discarded. We proceed until all elements innbcolumns in matrixXare discarded. At this time, we have assigned a ground-truth bounding box to each ofnbanchor boxes.
이 시점에서 행렬 X의 두 행과 두 열의 요소는 버려졌습니다. 행렬 X의 nb 열에 있는 모든 요소가 버려질 때까지 진행합니다. 이때 각 nb 앵커 박스에 ground-truth 경계 상자를 할당했습니다.
Only traverse through the remainingna−nbanchor boxes. For example, given any anchor boxAi, find the ground-truth bounding boxBjwith the largest IoU withAithroughout theithrow of matrixX, and assignBjtoAionly if this IoU is greater than a predefined threshold.
나머지 na-nb 앵커 박스를 통해서만 트래버스하십시오. 예를 들어 앵커 상자 Ai가 주어지면 행렬 X의 i번째 행 전체에서 Ai와 함께 가장 큰 IoU가 있는 실측 경계 상자 Bj를 찾고 이 IoU가 미리 정의된 임계값보다 큰 경우에만 Bj를 Ai에 할당합니다.
Let’s illustrate the above algorithm using a concrete example. As shown inFig. 14.4.2(left), assuming that the maximum value in matrixXisx23, we assign the ground-truth bounding boxB3to the anchor boxA2. Then, we discard all the elements in row 2 and column 3 of the matrix, find the largestx71in the remaining elements (shaded area), and assign the ground-truth bounding boxB1to the anchor boxA7. Next, as shown inFig. 14.4.2(middle), discard all the elements in row 7 and column 1 of the matrix, find the largestx54in the remaining elements (shaded area), and assign the ground-truth bounding boxB4to the anchor boxA5. Finally, as shown inFig. 14.4.2(right), discard all the elements in row 5 and column 4 of the matrix, find the largestx92in the remaining elements (shaded area), and assign the ground-truth bounding boxB2to the anchor boxA9. After that, we only need to traverse through the remaining anchor boxesA1,A3,A4,A6,A8and determine whether to assign them ground-truth bounding boxes according to the threshold.
구체적인 예를 사용하여 위의 알고리즘을 설명하겠습니다. 그림 14.4.2(왼쪽)에 표시된 대로 행렬 X의 최대값이 x23이라고 가정하고 앵커 상자 A2에 ground-truth 경계 상자 B3을 할당합니다. 그런 다음 행렬의 2행과 3열의 모든 요소를 버리고 나머지 요소(음영 영역)에서 가장 큰 x71을 찾고 ground-truth 경계 상자 B1을 앵커 상자 A7에 할당합니다. 다음으로 그림 14.4.2(가운데)와 같이 행렬의 7행 1열의 원소를 모두 버리고 나머지 원소(음영 영역)에서 가장 큰 x54를 찾아 ground-truth bounding box B4를 할당한다. 앵커 박스 A5에. 마지막으로 그림 14.4.2(오른쪽)과 같이 행렬의 5행 4열의 원소를 모두 버리고 나머지 원소(음영 영역)에서 가장 큰 x92를 찾아,실측 경계 상자 B2를 앵커 상자 A9에 할당합니다. 그런 다음 나머지 앵커 상자 A1,A3,A4,A6,A8을 통과하고 임계값에 따라 실측 경계 상자를 할당할지 여부만 결정하면 됩니다.
Fig. 14.4.2 Assigning ground-truth bounding boxes to anchor boxes.
This algorithm is implemented in the followingassign_anchor_to_bboxfunction.
이 알고리즘은 다음 assign_anchor_to_bbox 함수에서 구현됩니다.
#@save
def assign_anchor_to_bbox(ground_truth, anchors, device, iou_threshold=0.5):
"""Assign closest ground-truth bounding boxes to anchor boxes."""
num_anchors, num_gt_boxes = anchors.shape[0], ground_truth.shape[0]
# Element x_ij in the i-th row and j-th column is the IoU of the anchor
# box i and the ground-truth bounding box j
jaccard = box_iou(anchors, ground_truth)
# Initialize the tensor to hold the assigned ground-truth bounding box for
# each anchor
anchors_bbox_map = torch.full((num_anchors,), -1, dtype=torch.long,
device=device)
# Assign ground-truth bounding boxes according to the threshold
max_ious, indices = torch.max(jaccard, dim=1)
anc_i = torch.nonzero(max_ious >= iou_threshold).reshape(-1)
box_j = indices[max_ious >= iou_threshold]
anchors_bbox_map[anc_i] = box_j
col_discard = torch.full((num_anchors,), -1)
row_discard = torch.full((num_gt_boxes,), -1)
for _ in range(num_gt_boxes):
max_idx = torch.argmax(jaccard) # Find the largest IoU
box_idx = (max_idx % num_gt_boxes).long()
anc_idx = (max_idx / num_gt_boxes).long()
anchors_bbox_map[anc_idx] = box_idx
jaccard[:, box_idx] = col_discard
jaccard[anc_idx, :] = row_discard
return anchors_bbox_map
위 코드는 앵커 박스(Anchor Boxes)에 대해 가장 가까운 실제 바운딩 박스(Ground-Truth Bounding Boxes)를 할당하는 함수를 정의하는 코드입니다. 코드를 한 줄씩 설명하겠습니다.
max_ious는 각 앵커 박스에 대한 가장 큰 IoU 값을, indices는 해당 IoU 값을 가지는 실제 바운딩 박스의 인덱스를 나타냅니다. iou_threshold 이상의 IoU 값을 가지는 앵커 박스들에 대해 가장 가까운 실제 바운딩 박스의 인덱스를 anchors_bbox_map에 할당합니다.
할당된 바운딩 박스와 IoU 값을 표시하기 위해 사용할 보조 텐서인 col_discard와 row_discard를 생성합니다.
for _ in range(num_gt_boxes):
max_idx = torch.argmax(jaccard) # Find the largest IoU
box_idx = (max_idx % num_gt_boxes).long()
anc_idx = (max_idx / num_gt_boxes).long()
anchors_bbox_map[anc_idx] = box_idx
jaccard[:, box_idx] = col_discard
jaccard[anc_idx, :] = row_discard
각 실제 바운딩 박스에 대해 가장 큰 IoU 값을 가지는 앵커 박스를 찾아 해당 앵커 박스의 인덱스와 실제 바운딩 박스의 인덱스를 anchors_bbox_map에 할당합니다. 할당한 후 해당 앵커 박스와 실제 바운딩 박스에 대한 IoU 값을 무효화하기 위해 jaccard의 해당 열과 행을 col_discard와 row_discard로 설정합니다.
return anchors_bbox_map
앵커 박스와 실제 바운딩 박스 간의 할당 결과를 반환합니다.
14.4.3.2.Labeling Classes and Offsets
Now we can label the class and offset for each anchor box. Suppose that an anchor boxAis assigned a ground-truth bounding boxB. On the one hand, the class of the anchor boxAwill be labeled as that ofB. On the other hand, the offset of the anchor boxAwill be labeled according to the relative position between the central coordinates ofBandAtogether with the relative size between these two boxes. Given varying positions and sizes of different boxes in the dataset, we can apply transformations to those relative positions and sizes that may lead to more uniformly distributed offsets that are easier to fit. Here we describe a common transformation. Given the central coordinates ofAandBas(xa,ya)and(xb,yb), their widths aswaand wb and their heights asℎaandℎb, respectively. We may label the offset ofAas
이제 각 앵커 상자의 클래스와 오프셋에 레이블을 지정할 수 있습니다. 앵커 상자 A에 실측 경계 상자 B가 할당되었다고 가정합니다. 한편으로 앵커 상자 A의 클래스는 B의 클래스로 레이블이 지정됩니다. 다른 한편으로 앵커 상자 A의 오프셋은 다음과 같습니다. 이 두 상자 사이의 상대 크기와 함께 B와 A의 중심 좌표 사이의 상대 위치에 따라 레이블이 지정됩니다. 데이터 세트에 있는 다양한 상자의 다양한 위치와 크기가 주어지면 더 쉽게 맞출 수 있는 보다 균일하게 분포된 오프셋으로 이어질 수 있는 상대적인 위치와 크기에 변환을 적용할 수 있습니다. 여기서는 일반적인 변환에 대해 설명합니다. A와 B의 중심 좌표가 (xa,ya)와 (xb,yb)로 주어지면 너비는 wa와 wb, 높이는 각각 ℎa와 ℎb입니다. A의 오프셋을 다음과 같이 표시할 수 있습니다.
위 코드는 앵커 박스와 해당 앵커 박스에 할당된 실제 바운딩 박스 사이의 변환을 계산하는 함수를 정의하는 코드입니다. 코드를 한 줄씩 설명하겠습니다.
offset_boxes 함수는 앵커 박스와 해당 앵커 박스에 할당된 실제 바운딩 박스 사이의 변환을 계산하는 함수입니다.
d2l.box_corner_to_center 함수를 이용하여 앵커 박스와 할당된 바운딩 박스를 모두 상단 왼쪽 모서리에서 중심 좌표와 너비, 높이 형태로 변환합니다.
offset_xy는 중심 좌표의 변화를 나타내는 텐서로, (할당된 바운딩 박스 중심 좌표 - 앵커 박스 중심 좌표) / 앵커 박스 너비 및 높이로 계산됩니다. offset_wh는 너비와 높이의 변화를 나타내는 텐서로, 5 * log(1e-6 + 할당된 바운딩 박스 높이 / 앵커 박스 높이)로 계산됩니다. 이때 eps는 로그 계산에서 0으로 나누기를 방지하는 작은 값입니다.
offset_xy와 offset_wh를 수평 방향으로 연결하여 하나의 텐서인 offset을 생성합니다.
계산된 변환을 반환합니다. 이 변환은 앵커 박스를 기준으로 해당 앵커 박스에 할당된 실제 바운딩 박스의 변화량을 나타내게 됩니다.
If an anchor box is not assigned a ground-truth bounding box, we just label the class of the anchor box as “background”. Anchor boxes whose classes are background are often referred to asnegativeanchor boxes, and the rest are calledpositiveanchor boxes. We implement the followingmultibox_targetfunction to label classes and offsets for anchor boxes (theanchorsargument) using ground-truth bounding boxes (thelabelsargument). This function sets the background class to zero and increments the integer index of a new class by one.
앵커 상자에 실측 경계 상자가 할당되지 않은 경우 앵커 상자의 클래스를 "배경"으로 레이블을 지정합니다. 클래스가 배경인 앵커 박스는 종종 네거티브 앵커 박스라고 하고 나머지는 포지티브 앵커 박스라고 합니다. 다음 multibox_target 함수를 구현하여 ground-truth 경계 상자(label 인수)를 사용하여 앵커 상자(anchors 인수)의 클래스 및 오프셋에 레이블을 지정합니다. 이 함수는 백그라운드 클래스를 0으로 설정하고 새 클래스의 정수 인덱스를 1씩 증가시킵니다.
#@save
def multibox_target(anchors, labels):
"""Label anchor boxes using ground-truth bounding boxes."""
batch_size, anchors = labels.shape[0], anchors.squeeze(0)
batch_offset, batch_mask, batch_class_labels = [], [], []
device, num_anchors = anchors.device, anchors.shape[0]
for i in range(batch_size):
label = labels[i, :, :]
anchors_bbox_map = assign_anchor_to_bbox(
label[:, 1:], anchors, device)
bbox_mask = ((anchors_bbox_map >= 0).float().unsqueeze(-1)).repeat(
1, 4)
# Initialize class labels and assigned bounding box coordinates with
# zeros
class_labels = torch.zeros(num_anchors, dtype=torch.long,
device=device)
assigned_bb = torch.zeros((num_anchors, 4), dtype=torch.float32,
device=device)
# Label classes of anchor boxes using their assigned ground-truth
# bounding boxes. If an anchor box is not assigned any, we label its
# class as background (the value remains zero)
indices_true = torch.nonzero(anchors_bbox_map >= 0)
bb_idx = anchors_bbox_map[indices_true]
class_labels[indices_true] = label[bb_idx, 0].long() + 1
assigned_bb[indices_true] = label[bb_idx, 1:]
# Offset transformation
offset = offset_boxes(anchors, assigned_bb) * bbox_mask
batch_offset.append(offset.reshape(-1))
batch_mask.append(bbox_mask.reshape(-1))
batch_class_labels.append(class_labels)
bbox_offset = torch.stack(batch_offset)
bbox_mask = torch.stack(batch_mask)
class_labels = torch.stack(batch_class_labels)
return (bbox_offset, bbox_mask, class_labels)
위 코드는 앵커 박스와 실제 바운딩 박스에 기반하여 앵커 박스에 라벨을 지정하는 함수인 multibox_target를 정의하는 코드입니다. 코드를 한 줄씩 설명하겠습니다.
multibox_target 함수는 앵커 박스와 실제 바운딩 박스를 기반으로 앵커 박스에 라벨을 지정하는 함수입니다.
batch_size는 배치 내의 데이터 수를 나타냅니다. labels 텐서의 크기에서 배치 차원을 제거한 뒤, 앵커 박스 텐서를 할당합니다.
계산 결과를 저장하기 위한 빈 리스트인 batch_offset, batch_mask, batch_class_labels를 생성합니다.
for i in range(batch_size):
label = labels[i, :, :]
anchors_bbox_map = assign_anchor_to_bbox(label[:, 1:], anchors, device)
각 배치 데이터에 대하여 반복하면서 실제 바운딩 박스 정보를 가져오고, 해당 실제 바운딩 박스와 앵커 박스 간의 IoU를 계산하여 할당을 수행합니다.
할당된 바운딩 박스를 기준으로 앵커 박스와 실제 바운딩 박스 사이의 변환을 계산합니다. 이 변환을 offset으로 저장하고, batch_offset 리스트에 추가합니다. 마찬가지로 바운딩 박스 마스크와 클래스 라벨 정보도 batch_mask와 batch_class_labels 리스트에 추가합니다.
batch_offset, batch_mask, batch_class_labels를 스택하여 최종적으로 배치 단위의 변환 정보, 마스크 정보, 클래스 라벨 정보를 생성합니다.
return (bbox_offset, bbox_mask, class_labels)
계산된 변환 정보, 마스크 정보, 클래스 라벨 정보를 반환합니다. 이 정보는 학습할 때 앵커 박스의 위치와 클래스에 대한 정보를 지원하기 위해 사용됩니다.
14.4.3.3.An Example
Let’s illustrate anchor box labeling via a concrete example. We define ground-truth bounding boxes for the dog and cat in the loaded image, where the first element is the class (0 for dog and 1 for cat) and the remaining four elements are the(x,y)-axis coordinates at the upper-left corner and the lower-right corner (range is between 0 and 1). We also construct five anchor boxes to be labeled using the coordinates of the upper-left corner and the lower-right corner:A0,…,A4(the index starts from 0). Then we plot these ground-truth bounding boxes and anchor boxes in the image.
구체적인 예를 통해 앵커 박스 라벨링을 설명하겠습니다. 로드된 이미지에서 개와 고양이에 대한 ground-truth 경계 상자를 정의합니다. 여기서 첫 번째 요소는 클래스(개는 0, 고양이는 1)이고 나머지 4개 요소는 (x,y)축 좌표입니다. 왼쪽 위 모서리와 오른쪽 아래 모서리(범위는 0과 1 사이)입니다. 또한 왼쪽 위 모서리와 오른쪽 아래 모서리의 좌표인 A0,…,A4(인덱스는 0부터 시작)를 사용하여 레이블을 지정할 5개의 앵커 상자를 구성합니다. 그런 다음 이러한 실측 경계 상자와 앵커 상자를 이미지에 플로팅합니다.
Using themultibox_targetfunction defined above, we can label classes and offsets of these anchor boxes based on the ground-truth bounding boxes for the dog and cat. In this example, indices of the background, dog, and cat classes are 0, 1, and 2, respectively. Below we add an dimension for examples of anchor boxes and ground-truth bounding boxes.
위에서 정의한 multibox_target 함수를 사용하여 개와 고양이에 대한 ground-truth 경계 상자를 기반으로 이러한 앵커 상자의 클래스와 오프셋에 레이블을 지정할 수 있습니다. 이 예제에서 background, dog, cat 클래스의 인덱스는 각각 0, 1, 2입니다. 아래에서 앵커 박스와 ground-truth 경계 상자의 예에 대한 차원을 추가합니다.
위 코드는 multibox_target 함수를 사용하여 앵커 박스에 라벨을 할당하는 과정을 설명합니다.
anchors.unsqueeze(dim=0)는 anchors 텐서에 차원을 하나 추가하여 배치 차원을 생성합니다. anchors 텐서는 앵커 박스의 좌표 정보를 가지고 있는 텐서입니다. 이것은 실제 데이터와의 계산을 위해 배치 차원을 맞추기 위한 과정입니다.
ground_truth.unsqueeze(dim=0)도 마찬가지로 실제 바운딩 박스의 정보를 가지고 있는 텐서에 배치 차원을 추가합니다. 이 과정 역시 실제 데이터와의 계산을 위해 배치 차원을 맞추기 위한 것입니다.
이렇게 앵커 박스와 실제 바운딩 박스의 정보를 하나의 배치로 변환한 뒤, multibox_target 함수를 호출하여 해당 배치에 대한 라벨링을 수행합니다. 이때, multibox_target 함수는 앵커 박스에 대한 라벨 정보를 계산하고 반환합니다.
There are three items in the returned result, all of which are in the tensor format. The third item contains the labeled classes of the input anchor boxes.
반환된 결과에는 3개의 항목이 있으며 모두 텐서 형식입니다. 세 번째 항목에는 입력 앵커 상자의 레이블이 지정된 클래스가 포함되어 있습니다.
Let’s analyze the returned class labels below based on anchor box and ground-truth bounding box positions in the image. First, among all the pairs of anchor boxes and ground-truth bounding boxes, the IoU of the anchor boxA4and the ground-truth bounding box of the cat is the largest. Thus, the class ofA4is labeled as the cat. Taking out pairs containingA4or the ground-truth bounding box of the cat, among the rest the pair of the anchor boxA1and the ground-truth bounding box of the dog has the largest IoU. So the class ofA1is labeled as the dog. Next, we need to traverse through the remaining three unlabeled anchor boxes:A0,A2, andA3. ForA0, the class of the ground-truth bounding box with the largest IoU is the dog, but the IoU is below the predefined threshold (0.5), so the class is labeled as background; forA2, the class of the ground-truth bounding box with the largest IoU is the cat and the IoU exceeds the threshold, so the class is labeled as the cat; forA3, the class of the ground-truth bounding box with the largest IoU is the cat, but the value is below the threshold, so the class is labeled as background.
이미지의 앵커 상자 및 ground-truth 경계 상자 위치를 기반으로 아래 반환된 클래스 레이블을 분석해 보겠습니다. 먼저, 앵커 박스와 ground-truth bounding box의 모든 쌍 중에서 앵커 박스 A4와 cat의 ground-truth bounding box의 IoU가 가장 크다. 따라서 A4의 클래스는 고양이로 표시됩니다. A4 또는 고양이의 ground-truth bounding box를 포함하는 쌍을 꺼내고 나머지 중에서 앵커 상자 A1과 dog의 ground-truth bounding box의 쌍이 가장 큰 IoU를 갖습니다. 따라서 A1의 class 개로 분류됩니다. 다음으로 레이블이 지정되지 않은 나머지 3개의 앵커 상자(A0, A2 및 A3)를 통과해야 합니다. A0의 경우 IoU가 가장 큰 ground-truth 경계 상자의 클래스는 개이지만 IoU는 사전 정의된 임계값(0.5) 미만이므로 클래스는 배경으로 레이블이 지정됩니다. A2의 경우 IoU가 가장 큰 ground-truth 경계 상자의 클래스는 고양이이고 IoU는 임계값을 초과하므로 클래스는 고양이로 레이블이 지정됩니다. A3의 경우 IoU가 가장 큰 ground-truth bounding box의 클래스는 cat이지만 값이 임계값 미만이므로 클래스를 background로 레이블링합니다.
labels[2]
위 코드는 labels 텐서에서 인덱스 2에 해당하는 데이터를 추출하는 작업을 수행합니다.
labels 텐서는 multibox_target 함수의 결과로 생성된 텐서입니다. 이 텐서는 앵커 박스에 할당된 라벨 정보를 담고 있습니다.
[2]는 텐서의 인덱스 연산자로, 해당 인덱스에 해당하는 데이터를 추출합니다. 인덱스 2는 배치 내에서 세 번째 데이터를 의미합니다.
따라서 labels[2]는 세 번째 배치에 해당하는 앵커 박스의 라벨 정보를 반환합니다. 이 정보에는 각 앵커 박스에 할당된 클래스 라벨과 바운딩 박스의 오프셋 정보가 포함될 수 있습니다.
tensor([[0, 1, 2, 0, 2]])
The second returned item is a mask variable of the shape (batch size, four times the number of anchor boxes). Every four elements in the mask variable correspond to the four offset values of each anchor box. Since we do not care about background detection, offsets of this negative class should not affect the objective function. Through elementwise multiplications, zeros in the mask variable will filter out negative class offsets before calculating the objective function.
두 번째 반환된 항목은 모양(배치 크기, 앵커 상자 수의 4배)의 마스크 변수입니다. 마스크 변수의 모든 4개 요소는 각 앵커 상자의 4개 오프셋 값에 해당합니다. 우리는 배경 감지에 관심이 없기 때문에 이 네거티브 클래스의 오프셋은 목적 함수에 영향을 미치지 않아야 합니다. 요소별 곱셈을 통해 마스크 변수의 0은 목적 함수를 계산하기 전에 음수 클래스 오프셋을 필터링합니다.
labels[1]
위 코드는 labels 텐서에서 인덱스 1에 해당하는 데이터를 추출하는 작업을 수행합니다.
labels 텐서는 multibox_target 함수의 결과로 생성된 텐서입니다. 이 텐서는 앵커 박스에 할당된 라벨 정보를 담고 있습니다.
[1]는 텐서의 인덱스 연산자로, 해당 인덱스에 해당하는 데이터를 추출합니다. 인덱스 1은 두 번째 차원 내의 데이터를 의미합니다.
따라서 labels[1]은 앵커 박스에 할당된 바운딩 박스의 오프셋 정보를 반환합니다. 이 정보는 각 앵커 박스마다 정답 바운딩 박스와의 오프셋 변환을 나타내는 값들로 구성되어 있습니다.
The first returned item contains the four offset values labeled for each anchor box. Note that the offsets of negative-class anchor boxes are labeled as zeros.
첫 번째로 반환된 항목에는 각 앵커 상자에 대해 레이블이 지정된 4개의 오프셋 값이 포함되어 있습니다. 네거티브 클래스 앵커 상자의 오프셋은 0으로 레이블이 지정됩니다.
labels[0]
위 코드는 labels 텐서에서 인덱스 0에 해당하는 데이터를 추출하는 작업을 수행합니다.
labels 텐서는 multibox_target 함수의 결과로 생성된 텐서입니다. 이 텐서는 앵커 박스에 할당된 라벨 정보를 담고 있습니다.
[0]는 텐서의 인덱스 연산자로, 해당 인덱스에 해당하는 데이터를 추출합니다. 인덱스 0은 첫 번째 차원 내의 데이터를 의미합니다.
따라서 labels[0]은 각 앵커 박스에 대한 바운딩 박스의 오프셋 변환 값들을 가지고 있는 텐서를 반환합니다. 이 값들은 해당 앵커 박스의 위치와 크기를 바탕으로 실제 정답 바운딩 박스와의 오프셋을 나타내는 값들입니다.
14.4.4.Predicting Bounding Boxes with Non-Maximum Suppression
During prediction, we generate multiple anchor boxes for the image and predict classes and offsets for each of them. Apredicted bounding boxis thus obtained according to an anchor box with its predicted offset. Below we implement theoffset_inversefunction that takes in anchors and offset predictions as inputs and applies inverse offset transformations to return the predicted bounding box coordinates.
예측하는 동안 이미지에 대한 여러 앵커 상자를 생성하고 각각에 대한 클래스와 오프셋을 예측합니다. 예측된 오프셋을 갖는 앵커 박스에 따라 예측된 바운딩 박스가 얻어진다. 아래에서는 앵커 및 오프셋 예측을 입력으로 받아들이고 역 오프셋 변환을 적용하여 예측된 경계 상자 좌표를 반환하는 offset_inverse 함수를 구현합니다.
위 코드는 앵커 박스와 예측된 오프셋을 사용하여 예측된 바운딩 박스를 계산하는 함수인 offset_inverse를 정의합니다.
anchors: 앵커 박스의 좌표와 크기 정보를 가지고 있는 텐서입니다.
offset_preds: 앵커 박스의 예측된 오프셋 정보를 가지고 있는 텐서입니다.
위 함수는 다음과 같은 단계로 동작합니다:
d2l.box_corner_to_center(anchors): 입력으로 들어온 앵커 박스의 좌상단, 우하단 좌표를 중심 좌표와 폭/높이로 변환합니다.
offset_preds[:, :2] * anc[:, 2:] / 10 + anc[:, :2]: 예측된 오프셋의 x, y 값을 앵커 박스의 크기로 스케일링한 후 중심 좌표를 더하여 예측된 바운딩 박스의 중심 좌표를 계산합니다.
torch.exp(offset_preds[:, 2:] / 5) * anc[:, 2:]: 예측된 오프셋의 폭, 높이 값을 지수함수로 변환한 후 앵커 박스의 크기로 스케일링하여 예측된 바운딩 박스의 폭과 높이를 계산합니다.
torch.cat((pred_bbox_xy, pred_bbox_wh), axis=1): 중심 좌표와 폭/높이 값을 합쳐서 예측된 바운딩 박스의 정보를 생성합니다.
d2l.box_center_to_corner(pred_bbox): 예측된 바운딩 박스의 중심 좌표와 폭/높이 정보를 좌상단, 우하단 좌표로 변환하여 예측된 바운딩 박스를 생성합니다.
이렇게 생성된 predicted_bbox는 앵커 박스와 예측된 오프셋을 이용하여 예측된 바운딩 박스의 좌상단, 우하단 좌표 정보를 가지고 있는 텐서입니다.
When there are many anchor boxes, many similar (with significant overlap) predicted bounding boxes can be potentially output for surrounding the same object. To simplify the output, we can merge similar predicted bounding boxes that belong to the same object by usingnon-maximum suppression(NMS).
앵커 박스가 많으면 동일한 객체를 둘러싸는 유사한(상당한 중첩이 있는) 예측 경계 상자가 많이 출력될 수 있습니다. 출력을 단순화하기 위해 NMS(Non-Maximum Suppression)를 사용하여 동일한 객체에 속하는 유사한 예측 경계 상자를 병합할 수 있습니다.
Here is how non-maximum suppression works. For a predicted bounding box B, the object detection model calculates the predicted likelihood for each class. Denoting by pthe largest predicted likelihood, the class corresponding to this probability is the predicted class for B. Specifically, we refer topas theconfidence(score) of the predicted bounding boxB. On the same image, all the predicted non-background bounding boxes are sorted by confidence in descending order to generate a listL. Then we manipulate the sorted listLin the following steps:
non-maximumsuppression이 작동하는 방식은 다음과 같습니다. 예측된 경계 상자 B의 경우 객체 감지 모델은 각 클래스에 대한 예측 가능성을 계산합니다. 가장 큰 예측 가능도를 p로 표시하면 이 확률에 해당하는 클래스가 B에 대한 예측 클래스입니다. 구체적으로 p는 예측된 경계 상자 B의 신뢰도(점수)입니다. 배경 경계 상자는 목록 L을 생성하기 위해 내림차순으로 신뢰도로 정렬됩니다. 그런 다음 다음 단계에서 정렬된 목록 L을 조작합니다.
Select the predicted bounding box B1with the highest confidence fromLas a basis and remove all non-basis predicted bounding boxes whose IoU withB1exceeds a predefined thresholdϵfromL. At this point,Lkeeps the predicted bounding box with the highest confidence but drops others that are too similar to it. In a nutshell, those withnon-maximumconfidence scores aresuppressed.
L에서 신뢰도가 가장 높은 예측 경계 상자 B1을 기준으로 선택하고 B1과의 IoU가 L에서 미리 정의된 임계값 ϵ를 초과하는 비기준 예측 경계 상자를 모두 제거합니다. 이 시점에서 L은 예측 경계 상자를 가장 높은 신뢰도로 유지합니다. 그러나 너무 유사한 다른 항목은 삭제합니다. 간단히 말해서 최대 신뢰도 점수가 아닌 항목은 표시되지 않습니다.
Select the predicted bounding boxB2with the second highest confidence fromLas another basis and remove all non-basis predicted bounding boxes whose IoU withB2exceedsϵfromL.
L에서 두 번째로 신뢰도가 높은 예측 경계 상자 B2를 다른 기준으로 선택하고 B2의 IoU가 L에서 ϵ를 초과하는 비기준 예측 경계 상자를 모두 제거합니다.
Repeat the above process until all the predicted bounding boxes inLhave been used as a basis. At this time, the IoU of any pair of predicted bounding boxes inLis below the thresholdϵ; thus, no pair is too similar with each other.
L의 모든 예측된 경계 상자가 기준으로 사용될 때까지 위의 프로세스를 반복합니다. 이때 L에 있는 예측된 경계 상자 쌍의 IoU는 임계값 ϵ 미만입니다. 따라서 어떤 쌍도 서로 너무 유사하지 않습니다.
Output all the predicted bounding boxes in the listL.
목록 L의 모든 예측 경계 상자를 출력합니다.
The followingnmsfunction sorts confidence scores in descending order and returns their indices.
다음 nms 함수는 신뢰도 점수를 내림차순으로 정렬하고 해당 인덱스를 반환합니다.
#@save
def nms(boxes, scores, iou_threshold):
"""Sort confidence scores of predicted bounding boxes."""
B = torch.argsort(scores, dim=-1, descending=True)
keep = [] # Indices of predicted bounding boxes that will be kept
while B.numel() > 0:
i = B[0]
keep.append(i)
if B.numel() == 1: break
iou = box_iou(boxes[i, :].reshape(-1, 4),
boxes[B[1:], :].reshape(-1, 4)).reshape(-1)
inds = torch.nonzero(iou <= iou_threshold).reshape(-1)
B = B[inds + 1]
return torch.tensor(keep, device=boxes.device)
위 코드는 비최대 억제(NMS, Non-Maximum Suppression) 알고리즘을 사용하여 중복된 예측된 바운딩 박스를 제거하는 함수인 nms를 정의합니다.
boxes: 예측된 바운딩 박스의 좌표 정보를 가지고 있는 텐서입니다.
scores: 예측된 바운딩 박스의 신뢰도 점수를 가지고 있는 텐서입니다.
iou_threshold: IoU 임계값으로, 이 값을 넘는 예측된 바운딩 박스들은 중복으로 간주됩니다.
iou = box_iou(boxes[i, :].reshape(-1, 4), boxes[B[1:], :].reshape(-1, 4)).reshape(-1): 선택된 바운딩 박스와 다른 모든 바운딩 박스 간의 IoU를 계산합니다.
inds = torch.nonzero(iou <= iou_threshold).reshape(-1): IoU 값이 임계값보다 작거나 같은 바운딩 박스들의 인덱스를 찾습니다.
B = B[inds + 1]: 중복으로 간주되지 않은 바운딩 박스들의 인덱스를 업데이트합니다.
위 과정을 반복하면서 중복으로 간주되지 않은 바운딩 박스들의 인덱스를 keep 리스트에 추가합니다.
return torch.tensor(keep, device=boxes.device): 최종적으로 선택된 바운딩 박스들의 인덱스를 텐서로 반환합니다.
이렇게 선택된 바운딩 박스들은 중복된 예측된 바운딩 박스들을 제거하는 데 사용됩니다.
We define the followingmultibox_detectionto apply non-maximum suppression to predicting bounding boxes. Do not worry if you find the implementation a bit complicated: we will show how it works with a concrete example right after the implementation.
예측 경계 상자에 최대가 아닌 억제를 적용하기 위해 다음 multibox_detection을 정의합니다. 구현이 약간 복잡하다고 생각되더라도 걱정하지 마십시오. 구현 직후 구체적인 예를 통해 어떻게 작동하는지 보여드리겠습니다.
#@save
def multibox_detection(cls_probs, offset_preds, anchors, nms_threshold=0.5,
pos_threshold=0.009999999):
"""Predict bounding boxes using non-maximum suppression."""
device, batch_size = cls_probs.device, cls_probs.shape[0]
anchors = anchors.squeeze(0)
num_classes, num_anchors = cls_probs.shape[1], cls_probs.shape[2]
out = []
for i in range(batch_size):
cls_prob, offset_pred = cls_probs[i], offset_preds[i].reshape(-1, 4)
conf, class_id = torch.max(cls_prob[1:], 0)
predicted_bb = offset_inverse(anchors, offset_pred)
keep = nms(predicted_bb, conf, nms_threshold)
# Find all non-`keep` indices and set the class to background
all_idx = torch.arange(num_anchors, dtype=torch.long, device=device)
combined = torch.cat((keep, all_idx))
uniques, counts = combined.unique(return_counts=True)
non_keep = uniques[counts == 1]
all_id_sorted = torch.cat((keep, non_keep))
class_id[non_keep] = -1
class_id = class_id[all_id_sorted]
conf, predicted_bb = conf[all_id_sorted], predicted_bb[all_id_sorted]
# Here `pos_threshold` is a threshold for positive (non-background)
# predictions
below_min_idx = (conf < pos_threshold)
class_id[below_min_idx] = -1
conf[below_min_idx] = 1 - conf[below_min_idx]
pred_info = torch.cat((class_id.unsqueeze(1),
conf.unsqueeze(1),
predicted_bb), dim=1)
out.append(pred_info)
return torch.stack(out)
위 코드는 Non-Maximum Suppression(NMS) 알고리즘을 사용하여 예측된 바운딩 박스에 대한 최종 예측 결과를 생성하는 함수인 multibox_detection을 정의합니다.
이 함수는 다음과 같은 단계로 동작합니다:
device, batch_size = cls_probs.device, cls_probs.shape[0]: 디바이스와 배치 크기 정보를 가져옵니다.
anchors = anchors.squeeze(0): 앵커 박스의 차원을 조정합니다.
cls_probs[i], offset_preds[i].reshape(-1, 4): i번째 배치의 클래스 확률과 예측된 오프셋 값을 가져옵니다.
conf, class_id = torch.max(cls_prob[1:], 0): 클래스 확률 중 가장 높은 값을 선택하고 그 인덱스와 값을 가져옵니다.
offset_inverse(anchors, offset_pred): 예측된 오프셋 값을 사용하여 예측된 바운딩 박스를 계산합니다.
중복되지 않은 바운딩 박스 인덱스와 모든 인덱스를 합쳐서 유니크한 값과 빈도수를 계산합니다.
중복되지 않은 인덱스들을 찾아 배경 클래스(-1)로 설정하고, 클래스 및 신뢰도 값을 갱신합니다.
pos_threshold 값보다 작은 신뢰도 값을 가진 인덱스를 찾아 배경 클래스로 설정하고, 신뢰도 값을 업데이트합니다.
최종 예측 정보를 생성하여 반환합니다.
즉, 이 함수는 NMS를 사용하여 중복된 예측된 바운딩 박스를 제거하고, 최종 예측된 클래스와 신뢰도, 바운딩 박스 정보를 생성합니다.
Now let’s apply the above implementations to a concrete example with four anchor boxes. For simplicity, we assume that the predicted offsets are all zeros. This means that the predicted bounding boxes are anchor boxes. For each class among the background, dog, and cat, we also define its predicted likelihood.
이제 위의 구현을 4개의 앵커 상자가 있는 구체적인 예에 적용해 보겠습니다. 단순화를 위해 예측된 오프셋이 모두 0이라고 가정합니다. 이는 예측된 경계 상자가 앵커 상자임을 의미합니다. 배경, 개, 고양이 중 각 클래스에 대해 예측 가능성도 정의합니다.
위 코드는 예시 데이터를 사용하여 multibox_detection 함수를 호출하는 부분입니다. 여기서 주어진 anchors, offset_preds, cls_probs 데이터는 예측된 바운딩 박스의 위치, 오프셋, 클래스 확률을 나타내는 정보입니다.
anchors: 예측된 바운딩 박스의 앵커 정보입니다. 여기서 각 행은 각 바운딩 박스의 좌상단과 우하단 좌표를 나타냅니다.
offset_preds: 예측된 바운딩 박스의 오프셋 정보입니다. 여기서는 모든 값이 0으로 초기화되어 있습니다.
cls_probs: 예측된 바운딩 박스의 클래스 확률 정보입니다. 각 행은 각 바운딩 박스에 대한 클래스 확률을 나타냅니다. 첫 번째 행은 배경 클래스(클래스 0)에 대한 확률을 나타내고, 나머지 두 행은 각각 개(dog)와 고양이(cat) 클래스에 대한 확률을 나타냅니다.
이렇게 예측된 앵커, 오프셋, 클래스 확률 정보를 가지고 multibox_detection 함수를 호출하면, 예측된 바운딩 박스들을 NMS를 통해 최적화하여 최종 예측 결과를 생성합니다.
We can plot these predicted bounding boxes with their confidence on the image.
위 코드는 이미지 위에 예측된 앵커 박스와 해당 클래스에 대한 확률 정보를 표시하는 부분입니다.
fig = d2l.plt.imshow(img): 입력 이미지를 시각화하는 부분입니다. d2l.plt.imshow() 함수는 이미지를 화면에 표시합니다.
show_bboxes(fig.axes, anchors * bbox_scale, ['dog=0.9', 'dog=0.8', 'dog=0.7', 'cat=0.9']): show_bboxes 함수를 호출하여 앵커 박스와 해당 클래스에 대한 확률 정보를 시각화합니다. 이 함수는 이미지 위에 각 앵커 박스를 사각형으로 그리고, 사각형 안에 해당 클래스와 확률을 표시합니다. anchors는 예측된 앵커 박스들을 나타내는 텐서입니다. bbox_scale은 이미지 크기를 앵커 박스 크기에 맞게 조정하기 위한 스케일링 인자입니다. 마지막으로, 사각형 안에 나타나는 문자열은 해당 클래스와 확률을 나타냅니다.
Now we can invoke themultibox_detectionfunction to perform non-maximum suppression, where the threshold is set to 0.5. Note that we add a dimension for examples in the tensor input.
이제 multibox_detection 함수를 호출하여 임계값이 0.5로 설정된 비최대 억제를 수행할 수 있습니다. 텐서 입력에 예제에 대한 차원을 추가합니다.
We can see that the shape of the returned result is (batch size, number of anchor boxes, 6). The six elements in the innermost dimension gives the output information for the same predicted bounding box. The first element is the predicted class index, which starts from 0 (0 is dog and 1 is cat). The value -1 indicates background or removal in non-maximum suppression. The second element is the confidence of the predicted bounding box. The remaining four elements are the(x,y)-axis coordinates of the upper-left corner and the lower-right corner of the predicted bounding box, respectively (range is between 0 and 1).
반환된 결과의 모양이 (배치 크기, 앵커 상자 수, 6)임을 알 수 있습니다. 가장 안쪽 차원의 6개 요소는 동일한 예측 경계 상자에 대한 출력 정보를 제공합니다. 첫 번째 요소는 0부터 시작하는 예측 클래스 인덱스입니다(0은 개, 1은 고양이). 값 -1은 최대가 아닌 억제에서 백그라운드 또는 제거를 나타냅니다. 두 번째 요소는 예측된 경계 상자의 신뢰도입니다. 나머지 4개의 요소는 각각 예측된 경계 상자의 왼쪽 위 모서리와 오른쪽 아래 모서리의 (x,y)축 좌표입니다(범위는 0과 1 사이).
After removing those predicted bounding boxes of class -1, we can output the final predicted bounding box kept by non-maximum suppression.
클래스 -1의 예측 경계 상자를 제거한 후 비최대 억제로 유지되는 최종 예측 경계 상자를 출력할 수 있습니다.
fig = d2l.plt.imshow(img)
for i in output[0].detach().numpy():
if i[0] == -1:
continue
label = ('dog=', 'cat=')[int(i[0])] + str(i[1])
show_bboxes(fig.axes, [torch.tensor(i[2:]) * bbox_scale], label)
위 코드는 다중 객체 탐지 모델의 결과를 시각화하는 부분입니다.
fig = d2l.plt.imshow(img): 입력 이미지를 시각화합니다.
for i in output[0].detach().numpy():: 다중 객체 탐지 모델의 결과를 하나씩 반복하면서 처리합니다. output 텐서의 첫 번째 배치의 결과를 사용합니다.
if i[0] == -1:: 만약 객체의 클래스 ID가 -1이면 (배경인 경우) 건너뜁니다.
label = ('dog=', 'cat=')[int(i[0])] + str(i[1]): 클래스 ID에 따라 객체의 레이블을 생성합니다. 클래스 ID 0은 'dog=', 클래스 ID 1은 'cat='을 갖습니다. 그리고 해당 클래스의 확률 값을 문자열로 추가합니다.
show_bboxes(fig.axes, [torch.tensor(i[2:]) * bbox_scale], label): show_bboxes 함수를 사용하여 이미지에 예측된 박스를 그려줍니다. i[2:]는 박스의 좌표 정보를 나타내며, bbox_scale을 곱하여 실제 이미지 크기에 맞게 스케일 조정한 값으로 설정됩니다. 그리고 label을 표시하여 어떤 클래스의 객체인지와 확률을 함께 나타냅니다.
이 코드는 모델의 출력을 바탕으로 예측된 객체의 박스를 시각화하고, 각 박스 위에 해당하는 레이블과 확률 값을 표시하는 부분입니다.
In practice, we can remove predicted bounding boxes with lower confidence even before performing non-maximum suppression, thereby reducing computation in this algorithm. We may also post-process the output of non-maximum suppression, for example, by only keeping results with higher confidence in the final output.
실제로 non-maximum suppression를 수행하기 전에도 낮은 신뢰도로 예측된 경계 상자를 제거할 수 있으므로 이 알고리즘의 계산을 줄일 수 있습니다. 예를 들어 최종 출력에서 신뢰도가 더 높은 결과만 유지하여 최대가 아닌 억제의 출력을 사후 처리할 수도 있습니다.
NMS (Non-Maximum Suppression)이란?
Non-Maximum Suppression (NMS) is a post-processing technique commonly used in object detection tasks to reduce duplicate or overlapping bounding box predictions and retain only the most relevant and accurate ones. NMS helps refine the output of object detection algorithms by selecting the most appropriate bounding boxes for detected objects while eliminating redundant and overlapping detections.
비최대 억제(NMS, Non-Maximum Suppression)는 객체 탐지 작업에서 널리 사용되는 후 처리 기법으로, 중복되거나 겹치는 바운딩 박스 예측을 줄이고 가장 관련성 높고 정확한 예측만 보존하는 데 사용됩니다. NMS는 객체 탐지 알고리즘의 출력을 개선하기 위해 감지된 객체에 가장 적절한 바운딩 박스를 선택하고 중복 및 겹침을 없애는 역할을 합니다.
The primary goal of NMS is to eliminate multiple bounding box predictions that cover the same object. This is often the case when object detection models generate multiple bounding boxes for the same object due to different scales, positions, or overlapping receptive fields. NMS considers the confidence scores associated with each bounding box prediction to determine the most likely accurate ones.
NMS의 주요 목표는 동일한 객체를 포함하는 여러 바운딩 박스 예측을 제거하는 것입니다. 이는 객체 탐지 모델이 서로 다른 크기, 위치 또는 겹치는 수용 영역 때문에 동일한 객체에 대해 여러 개의 바운딩 박스를 생성하는 경우가 많기 때문입니다. NMS는 각 바운딩 박스 예측과 연관된 신뢰도 점수를 고려하여 가장 정확한 것을 판별합니다.
Here's how the Non-Maximum Suppression algorithm works:
다음은 비최대 억제 알고리즘의 작동 방식입니다.
Input: The algorithm takes a set of bounding box predictions along with their associated confidence scores.
입력: 알고리즘은 바운딩 박스 예측 세트와 연관된 신뢰도 점수를 가져옵니다.
Sorting: The bounding box predictions are first sorted based on their confidence scores in descending order. This ensures that the bounding box with the highest confidence score is considered first.
정렬: 바운딩 박스 예측은 먼저 신뢰도 점수를 내림차순으로 정렬됩니다. 이렇게 하면 가장 높은 신뢰도 점수를 가진 바운딩 박스가 먼저 고려됩니다.
Suppression: Starting from the bounding box with the highest confidence score, NMS compares it with the remaining bounding boxes. If the Intersection over Union (IoU) between the two bounding boxes exceeds a certain threshold (often defined by the user), the bounding box with the lower confidence score is suppressed or discarded.
억제: 가장 높은 신뢰도 점수를 가진 바운딩 박스부터 시작하여 NMS는 나머지 바운딩 박스와 비교합니다. 두 바운딩 박스 사이의 교집합 비율 (IoU)이 일정한 임계값을 초과하면 낮은 신뢰도 점수를 가진 바운딩 박스가 억제되거나 삭제됩니다.
Iteration: The process is repeated for the remaining bounding boxes, excluding those that have been suppressed. 반복: 남은 바운딩 박스에 대해 프로세스가 반복됩니다. 억제된 바운딩 박스를 제외하고 수행됩니다.
Output: The result is a reduced set of non-overlapping and accurate bounding box predictions, each associated with its corresponding confidence score.
출력: 결과는 겹치지 않는 정확한 바운딩 박스 예측의 줄어든 세트이며, 각각 해당하는 신뢰도 점수가 포함됩니다.
The threshold used in NMS plays a critical role in controlling the level of overlap allowed between bounding boxes. If the threshold is set too high, it may remove valid bounding boxes. Conversely, if it is set too low, redundant bounding boxes might still be present.
NMS에서 사용되는 임계값은 바운딩 박스 간에 허용되는 겹침 수준을 조절하는 데 중요한 역할을 합니다. 임계값이 너무 높게 설정되면 유효한 바운딩 박스가 제거될 수 있습니다. 반대로 너무 낮게 설정하면 중복 바운딩 박스가 여전히 존재할 수 있습니다.
NMS is an effective technique to refine object detection results, improving the precision of the algorithm and reducing the likelihood of multiple detections for the same object. It is a crucial step in achieving accurate and reliable object localization and classification in tasks like object detection and instance segmentation.
NMS는 객체 탐지 결과를 개선하는 효과적인 기술로, 알고리즘의 정밀도를 향상시키고 동일한 객체에 대한 다중 감지 가능성을 줄이는 데 중요한 역할을 합니다. 객체 탐지 및 인스턴스 분할과 같은 작업에서 정확하고 신뢰할 수 있는 객체 위치 및 분류를 달성하는 중요한 단계입니다.
14.4.5.Summary
We generate anchor boxes with different shapes centered on each pixel of the image.
이미지의 각 픽셀을 중심으로 다양한 모양의 앵커 박스를 생성합니다.
Intersection over union (IoU), also known as Jaccard index, measures the similarity of two bounding boxes. It is the ratio of their intersection area to their union area.
Jaccard 인덱스라고도 하는 IoU(Intersection over Union)는 두 경계 상자의 유사성을 측정합니다. 교차 영역과 결합 영역의 비율입니다.
In a training set, we need two types of labels for each anchor box. One is the class of the object relevant to the anchor box and the other is the offset of the ground-truth bounding box relative to the anchor box.
트레이닝 세트에서는 각 앵커 박스에 대해 두 가지 유형의 레이블이 필요합니다. 하나는 앵커 상자와 관련된 객체의 클래스이고 다른 하나는 앵커 상자에 대한 실측 경계 상자의 오프셋입니다.
During prediction, we can use non-maximum suppression (NMS) to remove similar predicted bounding boxes, thereby simplifying the output.
예측 중에 비최대 억제(NMS)를 사용하여 유사한 예측된 경계 상자를 제거하여 출력을 단순화할 수 있습니다.
14.4.6.Exercises
Change values ofsizesandratiosin themultibox_priorfunction. What are the changes to the generated anchor boxes?
Construct and visualize two bounding boxes with an IoU of 0.5. How do they overlap with each other?
Non-maximum suppression is a greedy algorithm that suppresses predicted bounding boxes byremovingthem. Is it possible that some of these removed ones are actually useful? How can this algorithm be modified to suppresssoftly? You may refer to Soft-NMS(Bodlaet al., 2017).
Rather than being hand-crafted, can non-maximum suppression be learned?
In earlier sections (e.g.,Section 8.1–Section 8.4), we introduced various models for image classification. In image classification tasks, we assume that there is onlyonemajor object in the image and we only focus on how to recognize its category. However, there are oftenmultipleobjects in the image of interest. We not only want to know their categories, but also their specific positions in the image. In computer vision, we refer to such tasks asobject detection(orobject recognition).
이전 섹션(예: 섹션 8.1–섹션 8.4)에서 이미지 분류를 위한 다양한 모델을 소개했습니다. 이미지 분류 작업에서는 이미지에 주요 객체가 하나만 있다고 가정하고 해당 범주를 인식하는 방법에만 집중합니다. 그러나 관심 있는 이미지에는 여러 개체가 있는 경우가 많습니다. 우리는 그들의 범주뿐만 아니라 이미지에서의 특정 위치도 알고 싶어합니다. 컴퓨터 비전에서는 객체 감지(또는 객체 인식)와 같은 작업을 참조합니다.
Object detection has been widely applied in many fields. For example, self-driving needs to plan traveling routes by detecting the positions of vehicles, pedestrians, roads, and obstacles in the captured video images. Besides, robots may use this technique to detect and localize objects of interest throughout its navigation of an environment. Moreover, security systems may need to detect abnormal objects, such as intruders or bombs.
객체 감지는 많은 분야에서 광범위하게 적용되었습니다. 예를 들어 자율주행차는 촬영한 영상에서 차량, 보행자, 도로, 장애물 등의 위치를 감지해 주행 경로를 계획해야 한다. 게다가 로봇은 이 기술을 사용하여 환경을 탐색하는 동안 관심 대상을 감지하고 위치를 파악할 수 있습니다. 또한 보안 시스템은 침입자나 폭탄과 같은 비정상적인 물체를 감지해야 할 수도 있습니다.
In the next few sections, we will introduce several deep learning methods for object detection. We will begin with an introduction topositions(orlocations) of objects.
다음 몇 섹션에서는 객체 감지를 위한 몇 가지 딥 러닝 방법을 소개합니다. 객체의 위치(또는 위치)에 대한 소개부터 시작하겠습니다.
%matplotlib inline
import torch
from d2l import torch as d2l
위 코드는 Matplotlib을 사용하여 이미지와 그래프를 Jupyter Notebook에서 표시하는 설정을 수행하는 것입니다.
%matplotlib inline: 이 코드는 Jupyter Notebook에서 Matplotlib의 그림을 노트북 셀 안에 직접 표시하도록 설정하는 명령입니다. 그래프나 이미지를 출력하면 노트북 안에서 바로 확인할 수 있게 됩니다.
import torch: PyTorch 라이브러리를 가져오는 코드입니다.
from d2l import torch as d2l: d2l (Dive into Deep Learning) 라이브러리에서 torch 모듈을 가져오는데, 이렇게 함으로써 d2l 라이브러리의 torch 모듈을 d2l이라는 이름으로 사용할 수 있게 됩니다. 이 라이브러리는 딥러닝과 관련된 여러 유용한 함수와 도구들을 제공합니다.
We will load the sample image to be used in this section. We can see that there is a dog on the left side of the image and a cat on the right. They are the two major objects in this image.
이 섹션에서 사용할 샘플 이미지를 로드합니다. 이미지의 왼쪽에는 개가 있고 오른쪽에는 고양이가 있는 것을 볼 수 있습니다. 이 이미지에서 두 개의 주요 객체입니다.
d2l.set_figsize(): Matplotlib 그래프의 크기를 설정하는 함수입니다. d2l 라이브러리의 set_figsize() 함수를 호출하여 그래프의 크기를 미리 정의된 기본 크기로 설정합니다.
img = d2l.plt.imread('../img/catdog.jpg'): 이미지 파일을 읽어와 변수 img에 저장합니다. 이미지 파일은 ../img/catdog.jpg 경로에서 읽어옵니다. d2l.plt.imread() 함수는 이미지 파일을 NumPy 배열로 변환하여 반환합니다.
d2l.plt.imshow(img): Matplotlib의 imshow() 함수를 사용하여 이미지를 표시합니다. img에 저장된 NumPy 배열 이미지를 그래프 상에 표시합니다. 이 때, 이미지는 해당 경로의 파일을 읽어온 것이므로 이 코드는 경로에 해당하는 이미지를 출력합니다.
14.3.1.Bounding Boxes
In object detection, we usually use abounding boxto describe the spatial location of an object. The bounding box is rectangular, which is determined by thexandycoordinates of the upper-left corner of the rectangle and the such coordinates of the lower-right corner. Another commonly used bounding box representation is the(x,y)-axis coordinates of the bounding box center, and the width and height of the box.
객체 감지에서 우리는 일반적으로 bounding box를 사용하여 객체의 공간적 위치(spatial location)를 설명합니다. 경계 상자 bounding box는 직사각형이며 직사각형의 왼쪽 위 모서리의 x 및 y 좌표와 오른쪽 아래 모서리의 이러한 좌표에 의해 결정됩니다. 일반적으로 사용되는 또 다른 경계 상자 bounding box 표현은 경계 상자 bounding box 중심의 (x,y)축 좌표와 상자의 너비 및 높이입니다.
Here we define functions to convert between these two representations:box_corner_to_centerconverts from the two-corner representation to the center-width-height presentation, andbox_center_to_cornervice versa. The input argumentboxesshould be a two-dimensional tensor of shape (n, 4), wherenis the number of bounding boxes.
여기서 우리는 이 두 가지 표현 사이를 변환하는 함수를 정의합니다. box_corner_to_center는 두 모서리 표현에서 중앙 너비 표현으로 변환하고 box_center_to_corner는 그 반대로 변환합니다. 입력 인수 상자는 모양이 (n, 4)인 2차원 텐서여야 합니다. 여기서 n은 경계 상자의 수입니다.
box_corner_to_center(boxes): 이 함수는 주어진 바운딩 박스의 좌표를 (상단 왼쪽, 하단 오른쪽) 형식에서 (중심, 너비, 높이) 형식으로 변환하는 역할을 합니다.
입력: boxes는 바운딩 박스의 좌표를 나타내는 텐서입니다. 각 행은 (상단 왼쪽 x, 상단 왼쪽 y, 하단 오른쪽 x, 하단 오른쪽 y) 형식으로 된 좌표를 가지고 있습니다.
출력: 변환된 바운딩 박스의 좌표를 나타내는 텐서입니다. 각 행은 (중심 x, 중심 y, 너비, 높이) 형식으로 된 좌표를 가지고 있습니다.
box_center_to_corner(boxes): 이 함수는 주어진 바운딩 박스의 좌표를 (중심, 너비, 높이) 형식에서 (상단 왼쪽, 하단 오른쪽) 형식으로 변환하는 역할을 합니다.
입력: boxes는 바운딩 박스의 좌표를 나타내는 텐서입니다. 각 행은 (중심 x, 중심 y, 너비, 높이) 형식으로 된 좌표를 가지고 있습니다.
출력: 변환된 바운딩 박스의 좌표를 나타내는 텐서입니다. 각 행은 (상단 왼쪽 x, 상단 왼쪽 y, 하단 오른쪽 x, 하단 오른쪽 y) 형식으로 된 좌표를 가지고 있습니다.
We will define the bounding boxes of the dog and the cat in the image based on the coordinate information. The origin of the coordinates in the image is the upper-left corner of the image, and to the right and down are the positive directions of thexandyaxes, respectively.
좌표 정보를 기반으로 이미지에서 강아지와 고양이의 경계 상자를 정의합니다. 이미지에서 좌표의 원점은 이미지의 왼쪽 위 모서리이고 오른쪽과 아래는 각각 x축과 y축의 양의 방향입니다.
# Here `bbox` is the abbreviation for bounding box
dog_bbox, cat_bbox = [60.0, 45.0, 378.0, 516.0], [400.0, 112.0, 655.0, 493.0]
위 코드에서는 개와 고양이의 바운딩 박스 좌표를 리스트로 정의하고 있습니다.
dog_bbox: 개의 바운딩 박스 좌표입니다. 각 값은 순서대로 (상단 왼쪽 x, 상단 왼쪽 y, 하단 오른쪽 x, 하단 오른쪽 y) 형식으로 바운딩 박스의 좌표를 나타냅니다.
cat_bbox: 고양이의 바운딩 박스 좌표입니다. 각 값은 순서대로 (상단 왼쪽 x, 상단 왼쪽 y, 하단 오른쪽 x, 하단 오른쪽 y) 형식으로 바운딩 박스의 좌표를 나타냅니다.
이렇게 정의된 바운딩 박스 좌표는 이미지에서 개와 고양이 객체의 위치를 나타내기 위해 사용될 수 있습니다.
We can verify the correctness of the two bounding box conversion functions by converting twice.
위 코드는 바운딩 박스 좌표 변환 함수를 사용하여 변환 전과 변환 후의 좌표가 동일한지 확인하는 작업을 수행합니다.
boxes 텐서를 정의합니다. 이는 개와 고양이의 바운딩 박스 좌표가 포함되어 있습니다.
box_corner_to_center 함수를 사용하여 바운딩 박스 좌표를 (상자의 중심, 너비, 높이) 형식으로 변환합니다.
변환된 좌표를 box_center_to_corner 함수를 사용하여 다시 (상단 왼쪽 x, 상단 왼쪽 y, 하단 오른쪽 x, 하단 오른쪽 y) 형식으로 변환합니다.
마지막으로 변환된 좌표와 원래 좌표 boxes가 동일한지 비교합니다.
즉, 이 코드는 바운딩 박스 좌표 변환 함수들이 서로 상호 호환되는지 검증하는 과정을 나타냅니다. 만약 변환 함수들이 정확하게 작동하고 서로 호환된다면, 변환 전과 후의 좌표는 동일해야 합니다.
Let’s draw the bounding boxes in the image to check if they are accurate. Before drawing, we will define a helper functionbbox_to_rect. It represents the bounding box in the bounding box format of thematplotlibpackage.
정확한지 확인하기 위해 이미지에 경계 상자를 그려 봅시다. 그리기 전에 도우미 함수 bbox_to_rect를 정의합니다. matplotlib 패키지의 경계 상자 형식으로 경계 상자를 나타냅니다.
#@save
def bbox_to_rect(bbox, color):
"""Convert bounding box to matplotlib format."""
# Convert the bounding box (upper-left x, upper-left y, lower-right x,
# lower-right y) format to the matplotlib format: ((upper-left x,
# upper-left y), width, height)
return d2l.plt.Rectangle(
xy=(bbox[0], bbox[1]), width=bbox[2]-bbox[0], height=bbox[3]-bbox[1],
fill=False, edgecolor=color, linewidth=2)
위 코드는 바운딩 박스 좌표를 Matplotlib의 형식으로 변환하는 함수인 bbox_to_rect를 정의합니다.
bbox: 변환할 바운딩 박스 좌표입니다.
color: Matplotlib에서 사용할 선의 색상입니다.
이 함수는 바운딩 박스의 좌표를 (상단 왼쪽 x, 상단 왼쪽 y, 하단 오른쪽 x, 하단 오른쪽 y) 형식에서 Matplotlib 형식인 ((상단 왼쪽 x, 상단 왼쪽 y), width, height) 형식으로 변환합니다. 변환된 정보를 바탕으로 plt.Rectangle을 생성하여 반환합니다. 이 때 선의 색상과 선의 굵기 등을 설정하여 시각적인 효과를 부여합니다. 반환된 객체는 그래프에 추가하여 바운딩 박스를 시각적으로 나타낼 수 있습니다.
After adding the bounding boxes on the image, we can see that the main outline of the two objects are basically inside the two boxes.
이미지에 테두리 상자를 추가한 후 두 개체의 주요 윤곽선이 기본적으로 두 상자 안에 있음을 알 수 있습니다.
fig.axes.add_patch(bbox_to_rect(dog_bbox, 'blue')): 강아지 바운딩 박스를 파란색 선으로 그립니다.
fig.axes.add_patch(bbox_to_rect(cat_bbox, 'red')): 고양이 바운딩 박스를 빨간색 선으로 그립니다.
이렇게 하면 bbox_to_rect 함수를 사용하여 바운딩 박스를 Matplotlib의 Rectangle로 변환하고, 해당 Rectangle 객체를 이미지 위에 추가하여 바운딩 박스를 시각적으로 표시할 수 있습니다.
14.3.2.Summary
Object detection not only recognizes all the objects of interest in the image, but also their positions. The position is generally represented by a rectangular bounding box. 개체 감지는 이미지에서 관심 있는 모든 개체뿐만 아니라 해당 개체의 위치도 인식합니다. 위치는 일반적으로 직사각형 경계 상자로 표시됩니다.
We can convert between two commonly used bounding box representations. 일반적으로 사용되는 두 가지 경계 상자 표현 간에 변환할 수 있습니다.
14.3.3.Exercises
Find another image and try to label a bounding box that contains the object. Compare labeling bounding boxes and categories: which usually takes longer?
Why is the innermost dimension of the input argumentboxesofbox_corner_to_centerandbox_center_to_corneralways 4?
In earlier chapters, we discussed how to train models on the Fashion-MNIST training dataset with only 60000 images. We also described ImageNet, the most widely used large-scale image dataset in academia, which has more than 10 million images and 1000 objects. However, the size of the dataset that we usually encounter is between those of the two datasets.
이전 장에서 60000개의 이미지만으로 Fashion-MNIST 교육 데이터 세트에서 모델을 교육하는 방법에 대해 논의했습니다. 또한 학계에서 가장 널리 사용되는 대규모 이미지 데이터 세트인 ImageNet에 대해서도 설명했습니다. 이 데이터 세트에는 천만 개 이상의 이미지와 1000개 개체가 있습니다. 그러나 우리가 일반적으로 접하는 데이터 세트의 크기는 두 데이터 세트의 중간 크기입니다.
Suppose that we want to recognize different types of chairs from images, and then recommend purchase links to users. One possible method is to first identify 100 common chairs, take 1000 images of different angles for each chair, and then train a classification model on the collected image dataset. Although this chair dataset may be larger than the Fashion-MNIST dataset, the number of examples is still less than one-tenth of that in ImageNet. This may lead to overfitting of complicated models that are suitable for ImageNet on this chair dataset. Besides, due to the limited amount of training examples, the accuracy of the trained model may not meet practical requirements.
이미지에서 다양한 유형의 의자를 인식하고 사용자에게 구매 링크를 추천하고 싶다고 가정합니다. 한 가지 가능한 방법은 먼저 100개의 일반적인 의자를 식별하고 각 의자에 대해 서로 다른 각도의 이미지 1000개를 가져온 다음 수집된 이미지 데이터 세트에서 분류 모델을 훈련하는 것입니다. 이 의자 데이터셋은 Fashion-MNIST 데이터셋보다 클 수 있지만 예제의 수는 여전히 ImageNet의 1/10 미만입니다. 이로 인해 이 의자 데이터 세트에서 ImageNet에 적합한 복잡한 모델이 과대적합될 수 있습니다. 게다가 제한된 양의 학습 예제로 인해 학습된 모델의 정확도가 실제 요구 사항을 충족하지 못할 수 있습니다.
In order to address the above problems, an obvious solution is to collect more data. However, collecting and labeling data can take a lot of time and money. For example, in order to collect the ImageNet dataset, researchers have spent millions of dollars from research funding. Although the current data collection cost has been significantly reduced, this cost still cannot be ignored.
위의 문제를 해결하기 위한 확실한 해결책은 더 많은 데이터를 수집하는 것입니다. 그러나 데이터를 수집하고 레이블을 지정하는 데는 많은 시간과 비용이 소요될 수 있습니다. 예를 들어 ImageNet 데이터 세트를 수집하기 위해 연구자들은 연구 자금에서 수백만 달러를 지출했습니다. 현재 데이터 수집 비용이 크게 줄었지만 이 비용은 여전히 무시할 수 없습니다.
Another solution is to applytransfer learningto transfer the knowledge learned from thesource datasetto thetarget dataset. For example, although most of the images in the ImageNet dataset have nothing to do with chairs, the model trained on this dataset may extract more general image features, which can help identify edges, textures, shapes, and object composition. These similar features may also be effective for recognizing chairs.
또 다른 해결책은 전이 학습(transfer learning)을 적용하여 원본 데이터 세트에서 학습한 지식을 대상 데이터 세트로 이전하는 것입니다. 예를 들어 ImageNet 데이터세트의 대부분의 이미지는 의자와 관련이 없지만 이 데이터세트에서 훈련된 모델은 가장자리, 질감, 모양 및 개체 구성을 식별하는 데 도움이 될 수 있는 보다 일반적인 이미지 기능을 추출할 수 있습니다. 이러한 유사한 기능은 의자를 인식하는 데에도 효과적일 수 있습니다.
Transfer Learning (전이 학습) 이란?
'transfer learning(전이 학습)'은 하나의 작업에서 학습한 모델의 지식을 다른 관련 작업으로 전달하여 학습하는 기술을 말합니다. 기존에 학습된 모델의 일부 또는 전체 네트워크 구조와 가중치를 새로운 작업에 재사용하는 것을 의미합니다. 이를 통해 새로운 작업에 대한 학습 데이터가 부족한 경우에도 모델의 성능을 향상시킬 수 있습니다.
전이 학습은 다음과 같은 장점을 가지고 있습니다:
데이터 부족 문제 해결: 새로운 작업에 충분한 양의 학습 데이터가 없을 때, 기존 작업에서 학습한 모델을 전이하여 성능을 향상시킬 수 있습니다.
학습 시간 단축: 기존에 학습된 모델의 가중치를 초기화로 사용하면 초기 모델의 성능은 높아지며, 새로운 작업에 대한 학습 시간을 단축할 수 있습니다.
일반화 능력 향상: 기존 작업에서 학습한 모델은 이미 다양한 특징을 학습했으므로 이를 활용하여 새로운 작업에서의 성능을 향상시킬 수 있습니다.
전이 학습은 이미지 분류, 객체 검출, 자연어 처리 등 다양한 분야에서 활용되며, 사전 학습된 모델을 가져와서 적절한 수정 및 조정을 통해 새로운 작업에 맞게 재사용하는 것이 일반적인 접근 방식입니다.
14.2.1.Steps
In this section, we will introduce a common technique in transfer learning:fine-tuning. As shown inFig. 14.2.1, fine-tuning consists of the following four steps:
이 섹션에서는 전이 학습의 일반적인 기술인 미세 조정을 소개합니다. 그림 14.2.1과 같이 미세 조정은 다음 네 단계로 구성됩니다.
Fig. 14.2.1 Fine tuning.
When target datasets are much smaller than source datasets, fine-tuning helps to improve models’ generalization ability.
대상 데이터 세트가 소스 데이터 세트보다 훨씬 작을 때 미세 조정하면 모델의 일반화 능력을 향상시키는 데 도움이 됩니다.
14.2.2.Hot Dog Recognition
Let’s demonstrate fine-tuning via a concrete case: hot dog recognition. We will fine-tune a ResNet model on a small dataset, which was pretrained on the ImageNet dataset. This small dataset consists of thousands of images with and without hot dogs. We will use the fine-tuned model to recognize hot dogs from images.
핫도그 인식이라는 구체적인 사례를 통해 미세 조정을 시연해 보겠습니다. ImageNet 데이터 세트에서 사전 훈련된 작은 데이터 세트에서 ResNet 모델을 미세 조정합니다. 이 작은 데이터 세트는 핫도그가 있거나 없는 수천 개의 이미지로 구성됩니다. 미세 조정된 모델을 사용하여 이미지에서 핫도그를 인식합니다.
%matplotlib inline
import os
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
이 코드는 딥러닝 모델을 구축하고 학습하기 위해 필요한 라이브러리와 설정을 불러오는 부분입니다. 각 줄의 역할을 살펴보겠습니다:
%matplotlib inline: 이 코드는 주피터 노트북 상에서 그래프를 인라인으로 표시하도록 설정하는 매직 명령어입니다. 따라서 그래프를 그릴 때 별도의 창이 아니라 노트북 셀 내에서 바로 보여집니다.
import os: os 모듈은 운영체제와 상호 작용하는 함수를 제공하는 파이썬 내장 모듈입니다. 파일 경로 조작, 환경 변수 설정 등에 사용될 수 있습니다.
import torch: PyTorch 라이브러리를 불러옵니다. 딥러닝 모델을 구축하고 학습하기 위한 핵심 라이브러리입니다.
import torchvision: PyTorch에서 이미지 및 비디오 데이터셋, 변환 등을 처리하기 위한 도구를 제공하는 라이브러리입니다.
from torch import nn: PyTorch의 nn 모듈을 불러옵니다. 이 모듈은 신경망 계층을 정의하고 관리하는 데 사용됩니다.
from d2l import torch as d2l: d2l 모듈에서 torch 모듈을 가져와 d2l이라는 이름으로 사용합니다. 이것은 Dive into Deep Learning (D2L) 프로젝트의 파이썬 유틸리티 모듈로, 딥러닝 학습을 위한 함수 및 도우미 기능을 제공합니다.
이 코드 블록은 딥러닝 모델을 구축하고 학습하는 데 필요한 주요 라이브러리와 설정을 불러오는 역할을 합니다. 해당 코드 이후에 딥러닝 모델을 정의하고 데이터를 불러와 학습하는 등의 작업을 진행할 수 있습니다.
14.2.2.1.Reading the Dataset
The hot dog dataset we use was taken from online images. This dataset consists of 1400 positive-class images containing hot dogs, and as many negative-class images containing other foods. 1000 images of both classes are used for training and the rest are for testing.
우리가 사용하는 핫도그 데이터 세트는 온라인 이미지에서 가져왔습니다. 이 데이터 세트는 핫도그를 포함하는 1400개의 포지티브 클래스 이미지와 다른 음식을 포함하는 많은 네거티브 클래스 이미지로 구성됩니다. 두 클래스의 1000개 이미지는 훈련에 사용되고 나머지는 테스트에 사용됩니다.
After unzipping the downloaded dataset, we obtain two foldershotdog/trainandhotdog/test. Both folders havehotdogandnot-hotdogsubfolders, either of which contains images of the corresponding class.
다운로드한 데이터 세트의 압축을 푼 후 hotdog/train 및 hotdog/test 폴더 두 개를 얻습니다. 두 폴더 모두 핫도그 하위 폴더와 핫도그가 아닌 하위 폴더가 있으며 둘 중 하나에는 해당 클래스의 이미지가 포함되어 있습니다.
이 코드는 D2L (Dive into Deep Learning) 라이브러리의 데이터 허브에 새로운 데이터셋을 등록하고 데이터셋을 다운로드하고 압축을 해제하는 역할을 합니다. 각 줄의 역할을 살펴보겠습니다:
#@save: 이 주석은 코드 블록이 문서화를 위한 주석임을 나타냅니다. D2L에서는 이러한 주석을 사용하여 문서를 생성하는 데 활용합니다.
d2l.DATA_HUB['hotdog'] = (d2l.DATA_URL + 'hotdog.zip', 'fba480ffa8aa7e0febbb511d181409f899b9baa5'): 이 줄은 데이터 허브에 'hotdog'라는 이름으로 새로운 데이터셋을 등록하는 역할을 합니다. 등록된 데이터셋에 대한 정보 (URL과 해시)를 제공합니다. 이 정보를 통해 데이터셋을 다운로드하고 검증할 수 있습니다.
data_dir = d2l.download_extract('hotdog'): 이 코드는 등록한 'hotdog' 데이터셋을 다운로드하고 압축을 해제하여 로컬 디렉토리에 저장하는 역할을 합니다. 데이터셋의 다운로드 URL과 해시를 사용하여 데이터셋을 검증합니다. data_dir 변수에는 데이터셋이 저장된 로컬 디렉토리 경로가 저장됩니다.
이 코드 블록은 D2L 라이브러리의 데이터 허브에 새로운 데이터셋을 등록하고 해당 데이터셋을 다운로드하고 압축을 해제하여 사용할 수 있도록 준비하는 역할을 합니다.
Print number of images in the data_dir.
# Display the first 5 images
for i in range(5):
img = mpimg.imread(image_files[i])
plt.imshow(img)
plt.axis('off') # Turn off axis labels
plt.show()
Number of images: 2800
We create two instances to read all the image files in the training and testing datasets, respectively.
교육 및 테스트 데이터 세트의 모든 이미지 파일을 읽기 위해 각각 두 개의 인스턴스를 만듭니다.
이 코드는 'hotdog' 데이터셋의 학습 및 테스트 이미지들을 로드하는 역할을 합니다. 이해하기 쉽게 코드를 분석해보겠습니다:
#@save: 이 주석은 코드 블록이 문서화를 위한 주석임을 나타냅니다.
train_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train')): 이 줄은 학습 이미지들이 포함된 디렉토리에서 이미지를 로드하여 train_imgs에 저장합니다. ImageFolder는 디렉토리 구조를 기반으로 이미지 데이터셋을 생성합니다. 학습 이미지들은 'train' 서브디렉토리에 저장되어 있습니다.
test_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test')): 이 줄은 테스트 이미지들을 로드하여 test_imgs에 저장합니다. 테스트 이미지들은 'test' 서브디렉토리에 저장되어 있습니다.
이렇게 코드를 실행하면 'hotdog' 데이터셋의 학습 이미지와 테스트 이미지를 train_imgs와 test_imgs에 로드하게 됩니다. 'ImageFolder' 클래스는 데이터셋을 쉽게 관리하고 처리할 수 있도록 도와주는 유용한 도구입니다.
The first 8 positive examples and the last 8 negative images are shown below. As you can see, the images vary in size and aspect ratio.
처음 8개의 긍정적인 예와 마지막 8개의 부정적인 이미지가 아래에 나와 있습니다. 보시다시피 이미지의 크기와 종횡비가 다릅니다.
hotdogs = [train_imgs[i][0] for i in range(8)]
not_hotdogs = [train_imgs[-i - 1][0] for i in range(8)]
d2l.show_images(hotdogs + not_hotdogs, 2, 8, scale=1.4);
이 코드는 d2l (Dive into Deep Learning) 라이브러리의 d2l.show_images 함수를 사용하여 이미지 그리드를 표시하는 코드입니다. 이 함수는 이미지 목록을 격자 레이아웃으로 표시하는 데 사용됩니다.
코드의 각 부분이 하는 일은 다음과 같습니다.
hotdogs = [train_imgs[i][0] for i in range(8)]: 이 줄은 train_imgs 데이터셋에서 처음 8개의 이미지를 담은 hotdogs 리스트를 생성합니다. hotdogs의 각 요소는 이미지를 나타내는 텐서입니다.
not_hotdogs = [train_imgs[-i - 1][0] for i in range(8)]: 이 줄은 train_imgs 데이터셋에서 마지막 8개의 이미지를 담은 not_hotdogs 리스트를 생성합니다. 마찬가지로, not_hotdogs의 각 요소는 이미지를 나타내는 텐서입니다.
d2l.show_images(hotdogs + not_hotdogs, 2, 8, scale=1.4);: 이 줄은 d2l.show_images 함수를 사용하여 이미지 그리드를 표시합니다. 표시할 이미지로 hotdogs와 not_hotdogs 리스트를 연결합니다. 2와 8 인자는 격자가 2행 8열을 가지도록 지정합니다. scale=1.4 인자는 표시되는 이미지의 크기를 조정하여 더 나은 가시성을 확보합니다.
요약하면, 이 코드는 d2l.show_images 함수를 사용하여 그리드 형태로 16개의 이미지를 표시합니다. 처음 8개 이미지는 핫도그이고, 마지막 8개 이미지는 핫도그가 아닌 이미지입니다.
During training, we first crop a random area of random size and random aspect ratio from the image, and then scale this area to a224×224input image. During testing, we scale both the height and width of an image to 256 pixels, and then crop a central224×224area as input. In addition, for the three RGB (red, green, and blue) color channels westandardizetheir values channel by channel. Concretely, the mean value of a channel is subtracted from each value of that channel and then the result is divided by the standard deviation of that channel.
학습하는 동안 먼저 이미지에서 임의의 크기와 가로 세로 비율의 임의 영역을 자른 다음 이 영역을 224×224 입력 이미지로 조정합니다. 테스트하는 동안 이미지의 높이와 너비를 모두 256픽셀로 조정한 다음 중앙 224×224 영역을 입력으로 자릅니다. 또한 3개의 RGB(빨간색, 녹색 및 파란색) 색상 채널의 경우 해당 값을 채널별로 표준화합니다. 구체적으로, 채널의 평균값을 해당 채널의 각 값에서 뺀 다음 결과를 해당 채널의 표준 편차로 나눕니다.
# Specify the means and standard deviations of the three RGB channels to
# standardize each channel
normalize = torchvision.transforms.Normalize(
[0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
train_augs = torchvision.transforms.Compose([
torchvision.transforms.RandomResizedCrop(224),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
normalize])
test_augs = torchvision.transforms.Compose([
torchvision.transforms.Resize([256, 256]),
torchvision.transforms.CenterCrop(224),
torchvision.transforms.ToTensor(),
normalize])
이 코드는 이미지 데이터 전처리를 위한 변환들을 정의하는 부분입니다. 데이터셋을 학습 및 테스트용으로 나눈 후에, 각 데이터셋의 이미지에 대해 수행할 전처리 작업을 설정하는데 사용됩니다. 코드의 각 줄이 하는 역할을 살펴보겠습니다.
normalize = torchvision.transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]): 이 줄은 이미지 정규화를 위한 변환을 정의합니다. 정규화는 각 채널의 평균과 표준 편차를 사용하여 RGB 이미지를 정규화합니다. 이러한 정규화는 모델의 학습 안정성과 성능을 향상시키는 데 도움이 됩니다.
train_augs = torchvision.transforms.Compose([...]): 이 줄은 학습 데이터에 적용할 전처리 과정을 정의합니다. torchvision.transforms.Compose 함수는 여러 개의 전처리 함수를 하나로 연결하여 적용할 수 있게 해줍니다. 학습 데이터에 적용되는 변환은 다음과 같습니다:
RandomResizedCrop(224): 이미지를 임의의 크기로 자르고 224x224 크기로 크롭합니다.
RandomHorizontalFlip(): 이미지를 수평으로 무작위로 뒤집습니다.
ToTensor(): 이미지를 텐서 형식으로 변환합니다.
normalize: 앞서 정의한 정규화를 적용합니다.
test_augs = torchvision.transforms.Compose([...]): 이 줄은 테스트 데이터에 적용할 전처리 과정을 정의합니다. 테스트 데이터에 적용되는 변환은 다음과 같습니다:
Resize([256, 256]): 이미지 크기를 256x256으로 조정합니다.
CenterCrop(224): 이미지를 중앙을 기준으로 224x224 크기로 크롭합니다.
ToTensor(): 이미지를 텐서 형식으로 변환합니다.
normalize: 정규화를 적용합니다.
이렇게 정의된 train_augs와 test_augs는 학습 및 테스트 데이터셋에서 이미지에 적용될 전처리 변환들을 구성합니다.
14.2.2.2.Defining and Initializing the Model
We use ResNet-18, which was pretrained on the ImageNet dataset, as the source model. Here, we specifypretrained=Trueto automatically download the pretrained model parameters. If this model is used for the first time, Internet connection is required for download.
ImageNet 데이터 세트에서 사전 훈련된 ResNet-18을 소스 모델로 사용합니다. 여기에서 pretrained=True를 지정하여 사전 훈련된 모델 매개변수를 자동으로 다운로드합니다. 이 모델을 처음 사용하는 경우 다운로드를 위해 인터넷 연결이 필요합니다.
이 코드는 torchvision 라이브러리의 resnet18 모델을 미리 학습된 가중치와 함께 불러오는 부분입니다.
torchvision.models.resnet18(pretrained=True)은 ResNet-18 아키텍처를 가져와서 미리 학습된 가중치를 사용하여 초기화한 모델을 생성합니다. ResNet-18은 18개의 층으로 구성된 딥 컨볼루션 신경망 아키텍처로, 이미지 분류와 같은 컴퓨터 비전 작업에서 널리 사용됩니다.
pretrained=True 매개변수는 미리 학습된 가중치를 사용하겠다는 의미입니다. 이렇게 하면 모델이 ImageNet 데이터셋에서 사전 학습된 가중치를 가져옵니다. ImageNet은 대규모 이미지 데이터셋으로, 다양한 카테고리에 속하는 이미지로 구성되어 있습니다. 이러한 사전 학습된 가중치는 초기화 단계에서 모델의 성능을 향상시키는 데 도움이 됩니다.
따라서 pretrained_net은 미리 학습된 ResNet-18 모델을 나타냅니다. 이 모델은 이미지 분류 작업에 사용될 수 있으며, 이미지 데이터를 입력으로 받아 각 클래스에 대한 확률 분포를 출력하는 역할을 할 수 있습니다.
사전 훈련된 소스 모델 인스턴스에는 여러 피처 레이어와 출력 레이어 fc가 포함되어 있습니다. 이 분할의 주요 목적은 출력 레이어를 제외한 모든 레이어의 모델 매개변수를 미세 조정하는 것입니다. 소스 모델의 멤버 변수 fc는 다음과 같습니다.
pretrained_net.fc
pretrained_net.fc는 미리 학습된 ResNet-18 모델의 마지막 fully connected (FC) 레이어를 나타냅니다.
ResNet-18 아키텍처의 마지막에는 fully connected 레이어가 존재하며, 이 레이어는 모델이 ImageNet 데이터셋과 같은 대규모 이미지 분류 작업에서 사용될 때 출력 클래스 수에 해당하는 뉴런을 가지고 있습니다. 이 fully connected 레이어는 이미지 특성을 활용하여 각 클래스에 대한 확률 분포를 생성합니다.
pretrained_net.fc를 호출하면 ResNet-18 모델의 마지막 fully connected 레이어가 반환됩니다. 이 레이어는 모델의 출력 역할을 하며, 이 레이어를 통과한 출력은 클래스 확률 분포를 나타냅니다. 이 fully connected 레이어를 변경하거나 새로운 데이터셋에 맞게 fine-tuning하는 등의 작업을 수행할 수 있습니다.
As a fully connected layer, it transforms ResNet’s final global average pooling outputs into 1000 class outputs of the ImageNet dataset. We then construct a new neural network as the target model. It is defined in the same way as the pretrained source model except that its number of outputs in the final layer is set to the number of classes in the target dataset (rather than 1000).
완전히 연결된 계층으로서 ResNet의 최종 글로벌 평균 풀링 출력을 ImageNet 데이터 세트의 1000개 클래스 출력으로 변환합니다. 그런 다음 대상 모델로 새로운 신경망을 구성합니다. 최종 계층의 출력 수가 대상 데이터 세트의 클래스 수(1000이 아닌)로 설정된다는 점을 제외하면 사전 훈련된 소스 모델과 동일한 방식으로 정의됩니다.
In the code below, the model parameters before the output layer of the target model instancefinetune_netare initialized to model parameters of the corresponding layers from the source model. Since these model parameters were obtained via pretraining on ImageNet, they are effective. Therefore, we can only use a small learning rate tofine-tunesuch pretrained parameters. In contrast, model parameters in the output layer are randomly initialized and generally require a larger learning rate to be learned from scratch. Letting the base learning rate beη, a learning rate of10ηwill be used to iterate the model parameters in the output layer.
η - eta
아래 코드에서 대상 모델 인스턴스 finetune_net의 출력 레이어 앞의 모델 매개변수는 소스 모델에서 해당 레이어의 모델 매개변수로 초기화됩니다. 이러한 모델 매개변수는 ImageNet에서 사전 학습을 통해 얻었기 때문에 효과적입니다. 따라서 사전 훈련된 매개변수를 미세 조정하기 위해 작은 학습 속도만 사용할 수 있습니다. 반대로 출력 계층의 모델 매개변수는 무작위로 초기화되며 일반적으로 처음부터 학습하려면 더 큰 학습률이 필요합니다. 기본 학습 속도를 η로 하면 출력 레이어에서 모델 매개변수를 반복하는 데 10η의 학습 속도가 사용됩니다.
위 코드는 미리 학습된 ResNet-18 아키텍처를 가져와서, 해당 아키텍처의 마지막 fully connected 레이어를 새로운 레이어로 교체하는 과정을 나타냅니다.
finetune_net = torchvision.models.resnet18(pretrained=True): 미리 학습된 ResNet-18 모델을 가져옵니다. 이 모델은 ImageNet 데이터셋에서 학습되어 다양한 이미지 분류 작업에 사용할 수 있는 기본 아키텍처와 가중치를 가지고 있습니다.
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2): 기존의 마지막 fully connected 레이어를 새로운 선형 레이어로 교체합니다. 이 때, finetune_net.fc.in_features는 기존 fully connected 레이어의 입력 feature 수를 나타냅니다. 여기서는 이를 유지한 채로 출력 클래스 수를 2로 설정하여 이진 분류 작업에 적합하도록 모델을 수정합니다.
nn.init.xavier_uniform_(finetune_net.fc.weight): 새로운 fully connected 레이어의 가중치를 Xavier 초기화 방법을 사용하여 초기화합니다. 이 초기화 방법은 신경망 가중치 초기화에 일반적으로 사용되는 방법 중 하나로, 초기 가중치를 효과적으로 설정해 네트워크의 학습을 원활하게 만듭니다.
이러한 수정 작업을 통해 ResNet-18 모델을 기존 분류 작업에서 새로운 이진 분류 작업에 맞게 fine-tuning할 수 있습니다. 새로운 fully connected 레이어는 2개의 클래스에 대한 확률 분포를 출력하도록 설정되어 이진 분류 작업을 수행할 수 있게 됩니다.
14.2.2.3.Fine-Tuning the Model
First, we define a training functiontrain_fine_tuningthat uses fine-tuning so it can be called multiple times.
먼저 여러 번 호출할 수 있도록 미세 조정을 사용하는 훈련 함수 train_fine_tuning을 정의합니다.
# If `param_group=True`, the model parameters in the output layer will be
# updated using a learning rate ten times greater
def train_fine_tuning(net, learning_rate, batch_size=128, num_epochs=5,
param_group=True):
train_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train'), transform=train_augs),
batch_size=batch_size, shuffle=True)
test_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'test'), transform=test_augs),
batch_size=batch_size)
devices = d2l.try_all_gpus()
loss = nn.CrossEntropyLoss(reduction="none")
if param_group:
params_1x = [param for name, param in net.named_parameters()
if name not in ["fc.weight", "fc.bias"]]
trainer = torch.optim.SGD([{'params': params_1x},
{'params': net.fc.parameters(),
'lr': learning_rate * 10}],
lr=learning_rate, weight_decay=0.001)
else:
trainer = torch.optim.SGD(net.parameters(), lr=learning_rate,
weight_decay=0.001)
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,
devices)
위 코드는 fine-tuning을 통해 사전 훈련된 신경망 모델을 새로운 작업에 맞게 학습시키는 과정을 정의한 함수를 나타냅니다.
train_fine_tuning(net, learning_rate, batch_size=128, num_epochs=5, param_group=True): fine-tuning을 수행하기 위한 함수를 정의합니다. net은 모델, learning_rate는 학습률, batch_size는 배치 크기, num_epochs는 학습 에포크 수를 나타냅니다. param_group는 파라미터 그룹화 여부를 결정하는 매개변수로, True로 설정하면 출력 레이어의 가중치에 더 높은 학습률을 적용하는 방식을 사용합니다.
train_iter와 test_iter: 학습 및 테스트 데이터를 DataLoader로 불러오는 과정을 나타냅니다. ImageFolder를 사용하여 데이터셋을 생성하고, transform을 통해 이미지 변환 작업을 수행합니다.
devices = d2l.try_all_gpus(): 사용 가능한 GPU 디바이스를 모두 가져오는 과정입니다.
loss = nn.CrossEntropyLoss(reduction="none"): 손실 함수를 교차 엔트로피 손실로 정의합니다. reduction을 "none"으로 설정하면 배치 내 각 샘플에 대한 손실 값을 구할 수 있습니다.
if param_group:: param_group가 True인 경우, 모델 파라미터를 그룹화하여 학습률을 설정하는 방식을 사용합니다. 이 때, params_1x는 출력 레이어를 제외한 모든 파라미터를 가져오는 리스트입니다. 출력 레이어의 파라미터는 학습률을 10배로 높여서 적용합니다.
trainer = torch.optim.SGD(...): SGD (stochastic gradient descent, 확률적 경사 하강법) 최적화 알고리즘을 사용하여 학습을 수행하는 옵티마이저를 정의합니다. params_1x와 출력 레이어의 파라미터에 서로 다른 학습률을 적용하도록 설정합니다.
d2l.train_ch13(...): 정의한 학습 함수를 호출하여 fine-tuning 학습을 수행합니다. 학습과 테스트 데이터셋, 손실 함수, 옵티마이저 등을 인자로 전달하여 모델을 학습시킵니다.
We set the base learning rate to a small value in order tofine-tunethe model parameters obtained via pretraining. Based on the previous settings, we will train the output layer parameters of the target model from scratch using a learning rate ten times greater.
사전 학습을 통해 얻은 모델 매개 변수를 미세 조정하기 위해 기본 학습 속도를 작은 값으로 설정했습니다. 이전 설정을 기반으로 10배 더 큰 학습률을 사용하여 대상 모델의 출력 계층 매개변수를 처음부터 훈련합니다.
train_fine_tuning(finetune_net, 5e-5)
위 코드는 fine-tuning을 통해 사전 훈련된 ResNet 모델인 finetune_net을 학습하는 과정을 나타냅니다.
train_fine_tuning(finetune_net, 5e-5): train_fine_tuning 함수를 호출하여 finetune_net 모델을 학습합니다. 5e-5는 학습률을 나타내며, 여기서는 상대적으로 작은 학습률로 설정되어 있습니다. 따라서 finetune_net 모델을 학습하면서 학습률을 조절하여 새로운 작업에 맞게 가중치를 조정하게 됩니다.
For comparison, we define an identical model, but initialize all of its model parameters to random values. Since the entire model needs to be trained from scratch, we can use a larger learning rate.
비교를 위해 동일한 모델을 정의하지만 모든 모델 매개변수를 임의의 값으로 초기화합니다. 전체 모델을 처음부터 훈련해야 하므로 더 큰 학습률을 사용할 수 있습니다.
위 코드는 "from scratch"로 새로운 ResNet 모델을 생성하고 학습하는 과정을 나타냅니다.
scratch_net = torchvision.models.resnet18(): 새로운 ResNet 모델을 생성합니다. 이 모델은 사전 훈련된 가중치 없이 초기화된 상태입니다.
scratch_net.fc = nn.Linear(scratch_net.fc.in_features, 2): 생성한 새로운 ResNet 모델의 Fully Connected (FC) 레이어를 수정합니다. 입력 특성 개수에 따라 출력 특성 개수가 2인 FC 레이어로 변경됩니다. 이것은 분류 문제에서 두 개의 클래스를 구분하는 데 사용됩니다.
train_fine_tuning(scratch_net, 5e-4, param_group=False): train_fine_tuning 함수를 호출하여 생성한 새로운 ResNet 모델 scratch_net을 학습합니다. 5e-4는 학습률을 나타내며, param_group=False로 설정되어 FC 레이어에 해당하는 가중치만 학습되며, 사전 훈련된 모델의 가중치는 고정됩니다. 이렇게 하면 새로운 작업에 맞게 FC 레이어만 학습됩니다.
As we can see, the fine-tuned model tends to perform better for the same epoch because its initial parameter values are more effective.
보시다시피 미세 조정된 모델은 초기 매개변수 값이 더 효과적이기 때문에 동일한 에포크에 대해 더 나은 성능을 보이는 경향이 있습니다.
14.2.3.Summary
Transfer learning transfers knowledge learned from the source dataset to the target dataset. Fine-tuning is a common technique for transfer learning. 전이 학습은 원본 데이터 세트에서 학습한 지식을 대상 데이터 세트로 이전합니다. 미세 조정은 전이 학습을 위한 일반적인 기술입니다.
The target model copies all model designs with their parameters from the source model except the output layer, and fine-tunes these parameters based on the target dataset. In contrast, the output layer of the target model needs to be trained from scratch. 대상 모델은 출력 레이어를 제외한 소스 모델의 매개변수가 있는 모든 모델 디자인을 복사하고 대상 데이터 세트를 기반으로 이러한 매개변수를 미세 조정합니다. 반대로 대상 모델의 출력 계층은 처음부터 학습해야 합니다.
Generally, fine-tuning parameters uses a smaller learning rate, while training the output layer from scratch can use a larger learning rate. 일반적으로 미세 조정 매개변수는 더 작은 학습률을 사용하는 반면 출력 계층을 처음부터 훈련하면 더 큰 학습률을 사용할 수 있습니다.
14.2.4.Exercises
Keep increasing the learning rate offinetune_net. How does the accuracy of the model change?
Further adjust hyperparameters offinetune_netandscratch_netin the comparative experiment. Do they still differ in accuracy?
Set the parameters before the output layer offinetune_netto those of the source model and donotupdate them during training. How does the accuracy of the model change? You can use the following code.
for param in finetune_net.parameters():
param.requires_grad = False
4. In fact, there is a “hotdog” class in theImageNetdataset. Its corresponding weight parameter in the output layer can be obtained via the following code. How can we leverage this weight parameter?
InSection 8.1, we mentioned that large datasets are a prerequisitefor the success of deep neural networks in various applications.Image augmentationgenerates similar but distinct training examples after a series of random changes to the training images, thereby expanding the size of the training set. Alternatively, image augmentation can be motivated by the fact that random tweaks of training examples allow models to rely less on certain attributes, thereby improving their generalization ability. For example, we can crop an image in different ways to make the object of interest appear in different positions, thereby reducing the dependence of a model on the position of the object. We can also adjust factors such as brightness and color to reduce a model’s sensitivity to color. It is probably true that image augmentation was indispensable for the success of AlexNet at that time. In this section we will discuss this widely used technique in computer vision.
섹션 8.1에서 대규모 데이터 세트가 다양한 애플리케이션에서 심층 신경망의 성공을 위한 전제 조건이라고 언급했습니다. 이미지 확대는 트레이닝 이미지에 대한 일련의 무작위 변경 후에 유사하지만 별개의 트레이닝 예제를 생성하여 트레이닝 세트의 크기를 확장합니다. 또는 훈련 예제를 임의로 조정하면 모델이 특정 속성에 덜 의존하게 되므로 일반화 능력이 향상된다는 사실에 의해 이미지 확대가 동기가 될 수 있습니다. 예를 들어 관심 대상이 다른 위치에 나타나도록 다양한 방법으로 이미지를 잘라 대상 위치에 대한 모델의 의존성을 줄일 수 있습니다. 밝기 및 색상과 같은 요소를 조정하여 색상에 대한 모델의 민감도를 줄일 수도 있습니다. 당시 AlexNet의 성공을 위해 이미지 확대가 필수 불가결한 것은 아마도 사실일 것입니다. 이 섹션에서는 컴퓨터 비전에서 널리 사용되는 이 기술에 대해 설명합니다.
Image Augmentation이란?
Image augmentation refers to the process of applying various transformations to images in order to create new variations of the original images. This technique is commonly used in machine learning and computer vision tasks, especially in training deep learning models for image recognition, object detection, and other tasks. The goal of image augmentation is to increase the diversity and variability of the training dataset, which can lead to improved model generalization and performance on unseen data.
이미지 증강은 원본 이미지에 다양한 변환을 적용하여 새로운 변형된 이미지를 생성하는 과정을 말합니다. 이 기술은 주로 기계 학습과 컴퓨터 비전 작업에서 사용되며, 특히 이미지 인식, 물체 감지 및 기타 작업에 대한 딥 러닝 모델을 훈련할 때 많이 활용됩니다. 이미지 증강의 목표는 훈련 데이터셋의 다양성과 가변성을 증가시켜 모델의 일반화 성능과 새로운 데이터에서의 성능을 향상시키는 것입니다.
Image augmentation techniques involve making small, controlled changes to the images while preserving their semantic content. Some common image augmentation techniques include:
이미지 증강 기법은 이미지의 시맨틱 콘텐츠를 보존하면서 작은 제어된 변화를 가하는 것을 포함합니다. 일반적인 이미지 증강 기술로는 다음과 같은 것들이 있습니다:
Horizontal and Vertical Flips: Mirroring the image horizontally or vertically to create variations. 수평 및 수직 뒤집기: 이미지를 수평 또는 수직으로 뒤집어서 변형을 만듭니다.
Rotation: Rotating the image by a certain degree. 회전: 이미지를 일정한 각도로 회전합니다.
Zoom: Enlarging or shrinking the image slightly. 확대 및 축소: 이미지를 약간 확대하거나 축소합니다.
Brightness and Contrast Adjustment: Changing the brightness and contrast levels of the image. 밝기 및 대비 조절: 이미지의 밝기와 대비 수준을 조정합니다.
Color Jittering: Applying small color changes to the image. 색상 조절: 이미지에 작은 색상 변화를 적용합니다.
Noise Addition: Adding small amounts of noise to the image. 노이즈 추가: 이미지에 작은 양의 노이즈를 추가합니다.
Random Cropping: Cropping a random portion of the image. 임의의 자르기: 이미지의 임의 부분을 자릅니다.
Elastic Transformations: Applying elastic deformations to the image. 탄성 변형: 이미지에 탄성 변형을 적용합니다.
These transformations help the model learn to be invariant to small changes in the input data, making it more robust and accurate when applied to real-world data.
이러한 변환은 모델이 입력 데이터의 작은 변화에 불변하게 학습하도록 도와줍니다. 이로써 모델은 실제 세계 데이터에 적용할 때 더 견고하고 정확하게 작동할 수 있게 됩니다.
In the context of deep learning and neural networks, image augmentation is often used during the training process to prevent overfitting, improve model generalization, and enhance the model's ability to handle various conditions and scenarios.
딥 러닝과 신경망의 맥락에서 이미지 증강image augmentation은 종종 훈련 과정 중에 사용되어 과적합을 방지하고 모델의 일반화 성능을 개선하며 다양한 조건과 시나리오를 처리할 수 있는 능력을 향상시킵니다.
%matplotlib inline
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
14.1.1.Common Image Augmentation Methods
In our investigation of common image augmentation methods, we will use the following400×500image an example.
위 코드는 주피터 노트북에서 사용되는 코드로, 주어진 이미지 파일을 열어서 화면에 보여주는 예제입니다. 코드를 한 줄씩 살펴보겠습니다:
%matplotlib inline: 이 라인은 주피터 노트북에서 그래프나 이미지 등을 인라인으로 표시하기 위한 명령입니다. 이를 통해 그래프나 이미지를 코드 셀 아래에 바로 표시할 수 있습니다.
import torch: 파이토치 라이브러리를 가져옵니다.
import torchvision: 파이토치의 torchvision 패키지를 가져옵니다. torchvision은 이미지 데이터셋 및 변환을 다루는 라이브러리입니다.
from torch import nn: 파이토치의 nn 모듈에서 nn을 가져옵니다. nn은 신경망 모델을 구축하는 데 사용되는 모듈들을 포함하고 있습니다.
from d2l import torch as d2l: d2l 라이브러리에서 torch 모듈을 가져와 d2l이라는 이름으로 사용합니다.
d2l.set_figsize(): 그래프의 크기를 설정하는 d2l 라이브러리의 함수를 호출합니다.
img = d2l.Image.open('../img/cat1.jpg'): d2l 라이브러리의 Image 모듈을 사용하여 '../img/cat1.jpg' 경로에 있는 이미지 파일을 엽니다. img 변수에 이미지 객체가 저장됩니다.
d2l.plt.imshow(img): d2l 라이브러리의 plt 모듈을 사용하여 이미지를 표시합니다. imshow 함수를 호출하여 img를 표시하고, ;를 사용하여 출력 결과를 숨깁니다.
위 코드는 이미지 파일 '../img/cat1.jpg'를 열어서 주피터 노트북에서 화면에 표시하는 예제입니다. 이를 실행하면 해당 경로의 이미지가 출력되게 됩니다.
Most image augmentation methods have a certain degree of randomness. To make it easier for us to observe the effect of image augmentation, next we define an auxiliary functionapply. This function runs the image augmentation methodaugmultiple times on the input imageimgand shows all the results.
대부분의 이미지 확대 image augmentation 방법에는 어느 정도의 무작위성이 있습니다. 이미지 확대 image augmentation 효과를 더 쉽게 관찰할 수 있도록 다음으로 보조 함수 적용을 정의합니다. 이 함수는 입력 이미지 img에서 이미지 확대 image augmentation 방법 aug를 여러 번 실행하고 모든 결과를 표시합니다.
def apply(img, aug, num_rows=2, num_cols=4, scale=1.5):
Y = [aug(img) for _ in range(num_rows * num_cols)]
d2l.show_images(Y, num_rows, num_cols, scale=scale)
위 코드는 이미지 변환 (Augmentation) 함수를 적용하여 변환된 이미지들을 그리드 형태로 표시하는 함수를 정의한 것입니다. 코드를 한 줄씩 살펴보겠습니다:
def apply(img, aug, num_rows=2, num_cols=4, scale=1.5):: apply라는 함수를 정의합니다. 이 함수는 세 개의 인자를 받습니다. 첫 번째 인자 img는 입력 이미지입니다. 두 번째 인자 aug는 이미지 변환 함수를 나타냅니다. num_rows와 num_cols는 그리드에 표시할 행과 열의 개수를 지정하며, scale은 이미지의 크기를 조절하는 인자입니다.
Y = [aug(img) for _ in range(num_rows * num_cols)]: aug 함수를 num_rows * num_cols번 반복하여 변환된 이미지들을 리스트 Y에 저장합니다. 각 반복마다 aug(img)를 호출하여 이미지를 변환합니다.
d2l.show_images(Y, num_rows, num_cols, scale=scale): 변환된 이미지 리스트 Y를 num_rows 행과 num_cols 열로 나타내는 그리드 형태로 표시합니다. 이미지의 크기는 scale 인자를 사용하여 조절합니다.
즉, 위 함수 apply는 입력 이미지를 주어진 변환 함수로 여러 번 변환하여 그리드 형태로 출력하는 역할을 수행합니다. 이를 통해 이미지 변환의 효과를 시각적으로 확인할 수 있습니다.
14.1.1.1.Flipping and Cropping
Flipping the image left and right usually does not change the category of the object. This is one of the earliest and most widely used methods of image augmentation. Next, we use thetransformsmodule to create theRandomHorizontalFlipinstance, which flips an image left and right with a 50% chance.
이미지를 좌우로 뒤집는 것은 일반적으로 개체의 범주를 변경하지 않습니다. 이것은 이미지 확대의 가장 초기이자 가장 널리 사용되는 방법 중 하나입니다. 다음으로 변환transforms 모듈을 사용하여 이미지를 50%의 확률로 좌우로 뒤집는 RandomHorizontalFlip 인스턴스를 만듭니다.
위 코드는 이미지 변환 함수를 적용하여 입력 이미지를 수평으로 뒤집은 후 변환된 이미지들을 그리드 형태로 표시하는 작업을 수행합니다. 코드를 한 줄씩 살펴보겠습니다:
apply(img, torchvision.transforms.RandomHorizontalFlip()): apply 함수를 호출하여 입력 이미지 img에 torchvision.transforms.RandomHorizontalFlip() 변환 함수를 적용합니다. 이 변환 함수는 입력 이미지를 무작위로 수평으로 뒤집습니다. 즉, 이미지의 왼쪽과 오른쪽이 뒤바뀝니다.
위 코드는 apply 함수를 사용하여 입력 이미지를 수평으로 뒤집은 후 변환된 이미지들을 그리드 형태로 표시하는 작업을 수행합니다. 이를 통해 이미지 뒤집기 변환의 효과를 시각적으로 확인할 수 있습니다.
Flipping up and down is not as common as flipping left and right. But at least for this example image, flipping up and down does not hinder recognition. Next, we create aRandomVerticalFlipinstance to flip an image up and down with a 50% chance.
위아래로 뒤집는 것은 좌우로 뒤집는 것만큼 일반적이지 않습니다. 그러나 적어도 이 예제 이미지의 경우 위아래로 뒤집는 것이 인식을 방해하지 않습니다. 다음으로 RandomVerticalFlip 인스턴스를 생성하여 50% 확률로 이미지를 위아래로 뒤집습니다.
위 코드는 입력 이미지에 수직으로 무작위로 뒤집기 변환을 적용하고, 이를 그리드 형태로 시각화하는 작업을 수행합니다. 코드를 단계별로 설명하겠습니다:
apply(img, torchvision.transforms.RandomVerticalFlip()): apply 함수를 호출하여 입력 이미지 img에 torchvision.transforms.RandomVerticalFlip() 변환 함수를 적용합니다. 이 변환 함수는 입력 이미지를 무작위로 수직으로 뒤집습니다. 즉, 이미지의 위쪽과 아래쪽이 뒤바뀝니다.
이 코드는 입력 이미지를 수직으로 뒤집은 후 변환된 이미지들을 그리드 형태로 표시합니다. 이를 통해 이미지 뒤집기 변환의 효과를 시각적으로 확인할 수 있습니다.
In the example image we used, the cat is in the middle of the image, but this may not be the case in general. InSection 7.5, we explained that the pooling layer can reduce the sensitivity of a convolutional layer to the target position. In addition, we can also randomly crop the image to make objects appear in different positions in the image at different scales, which can also reduce the sensitivity of a model to the target position.
우리가 사용한 예제 이미지에서 고양이는 이미지 중앙에 있지만 일반적으로 그렇지 않을 수 있습니다. 7.5절에서 풀링 레이어가 목표 위치에 대한 컨볼루션 레이어의 민감도를 감소시킬 수 있다고 설명했습니다. 또한 이미지를 무작위로 잘라 개체가 이미지의 다른 위치에 다른 배율로 나타나도록 할 수도 있습니다. 이렇게 하면 대상 위치에 대한 모델의 민감도를 줄일 수도 있습니다.
In the code below, we randomly crop an area with an area of10%∼100%of the original area each time, and the ratio of width to height of this area is randomly selected from0.5∼2. Then, the width and height of the region are both scaled to 200 pixels. Unless otherwise specified, the random number betweenaandbin this section refers to a continuous value obtained by random and uniform sampling from the interval[a,b].
아래 코드에서는 매번 원래 영역의 10%~100% 영역을 무작위로 자르고 이 영역의 너비와 높이의 비율을 0.5~2 중에서 무작위로 선택합니다. 그런 다음 영역의 너비와 높이가 모두 200픽셀로 조정됩니다. 달리 명시하지 않는 한, 이 섹션에서 a와 b 사이의 난수는 간격 [a,b]에서 무작위로 균일하게 샘플링하여 얻은 연속 값을 나타냅니다.
위 코드는 입력 이미지에 무작위 크기와 종횡비로 자르기(resize crop) 변환을 적용하고, 이를 그리드 형태로 시각화하는 작업을 수행합니다. 코드를 단계별로 설명하겠습니다:
shape_aug = torchvision.transforms.RandomResizedCrop((200, 200), scale=(0.1, 1), ratio=(0.5, 2)): torchvision.transforms.RandomResizedCrop() 변환 함수를 사용하여 shape_aug라는 변수에 무작위 크기로 자르기 변환을 생성합니다. 이 함수는 입력 이미지를 주어진 크기로 자르고, 무작위로 크기와 종횡비를 변화시킵니다. 여기서 (200, 200)은 자르고자 하는 크기를 의미하며, scale=(0.1, 1)은 무작위로 선택할 크기의 범위를 나타내고, ratio=(0.5, 2)는 무작위로 선택할 종횡비의 범위를 나타냅니다.
apply(img, shape_aug): apply 함수를 호출하여 입력 이미지 img에 shape_aug로 정의된 변환 함수를 적용합니다. 이를 통해 입력 이미지에 무작위 크기와 종횡비로 자르기 변환을 적용한 이미지들을 그리드 형태로 표시합니다.
이 코드는 이미지를 무작위 크기와 종횡비로 자르는 변환을 적용하여 이미지의 다양한 부분을 추출하고 시각화하는 역할을 합니다.
14.1.1.2.Changing Colors
Another augmentation method is changing colors. We can change four aspects of the image color: brightness, contrast, saturation, and hue. In the example below, we randomly change the brightness of the image to a value between 50% (1−0.5) and 150% (1+0.5) of the original image.
또 다른 증강 방법은 색상을 변경하는 것입니다. 이미지 색상의 네 가지 측면인 밝기, 대비, 채도 및 색조를 변경할 수 있습니다. 아래 예에서는 이미지의 밝기를 원본 이미지의 50%(1−0.5)와 150%(1+0.5) 사이의 값으로 무작위로 변경합니다.
위 코드는 입력 이미지에 색상 조정 변환을 적용하고, 이를 시각화하는 작업을 수행합니다. 코드를 단계별로 설명하겠습니다:
torchvision.transforms.ColorJitter(brightness=0.5, contrast=0, saturation=0, hue=0): torchvision.transforms.ColorJitter() 변환 함수를 사용하여 색상 조정 변환을 생성합니다. 이 함수는 입력 이미지의 색상을 조정하여 다양한 효과를 줄 수 있습니다. 여기서 brightness, contrast, saturation, hue 매개변수를 조정하여 각각 밝기, 대비, 채도, 색조를 조정할 수 있습니다. 각 매개변수의 값이 0보다 크면 변환이 적용됩니다.
apply(img, torchvision.transforms.ColorJitter(brightness=0.5, contrast=0, saturation=0, hue=0)): apply 함수를 호출하여 입력 이미지 img에 색상 조정 변환 함수를 적용합니다. 이를 통해 입력 이미지에 다양한 색상 조정 효과를 적용한 이미지들을 그리드 형태로 표시합니다.
이 코드는 이미지의 색상을 다양하게 변화시켜 시각화하는 역할을 합니다. 여기서는 밝기를 조정하고 대비, 채도, 색조는 조정하지 않습니다.
Similarly, we can randomly change the hue of the image.
위 코드는 입력 이미지에 대한 torchvision.transforms.ColorJitter() 변환을 사용하여 색상 조정 변환을 적용하고, 이를 시각화하는 작업을 수행합니다. 코드를 단계별로 설명하겠습니다:
torchvision.transforms.ColorJitter(brightness=0, contrast=0, saturation=0, hue=0.5): torchvision.transforms.ColorJitter() 변환 함수를 사용하여 색상 조정 변환을 생성합니다. 여기서 brightness, contrast, saturation 매개변수를 0으로 설정하고, hue 매개변수를 0.5로 설정하여 색조에 대한 조정만 적용될 수 있도록 합니다. hue 값이 0.5이므로 이미지의 색조가 최대 ±0.5만큼 변경됩니다.
apply(img, torchvision.transforms.ColorJitter(brightness=0, contrast=0, saturation=0, hue=0.5)): apply 함수를 호출하여 입력 이미지 img에 색상 조정 변환 함수를 적용합니다. 이를 통해 입력 이미지에 다양한 색조 조정 효과를 적용한 이미지들을 그리드 형태로 표시합니다.
이 코드는 이미지의 색조를 다양하게 변화시켜 시각화하는 역할을 합니다.
We can also create aRandomColorJitterinstance and set how to randomly change thebrightness,contrast,saturation, andhueof the image at the same time.
또한 RandomColorJitter 인스턴스를 생성하고 동시에 이미지의 밝기, 대비, 채도 및 색조를 무작위로 변경하는 방법을 설정할 수 있습니다.
위 코드는 torchvision.transforms.ColorJitter() 변환을 사용하여 입력 이미지에 다양한 색상 조정을 적용하고, 이를 시각화하는 작업을 수행합니다. 코드를 단계별로 설명하겠습니다:
torchvision.transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5): torchvision.transforms.ColorJitter() 변환 함수를 사용하여 색상 조정 변환을 생성합니다. 여기서 brightness, contrast, saturation 매개변수를 0.5로 설정하고, hue 매개변수를 0.5로 설정하여 밝기, 대비, 채도, 색조에 대한 조정을 적용할 수 있도록 합니다. 이렇게 설정하면 입력 이미지의 색상이 다양하게 변화됩니다.
apply(img, color_aug): apply 함수를 호출하여 입력 이미지 img에 색상 조정 변환 함수 color_aug를 적용합니다. 이를 통해 입력 이미지에 다양한 색상 조정 효과를 적용한 이미지들을 그리드 형태로 표시합니다.
이 코드는 입력 이미지의 밝기, 대비, 채도, 색조를 다양하게 변화시켜 시각화하는 역할을 합니다.
In practice, we will combine multiple image augmentation methods. For example, we can combine the different image augmentation methods defined above and apply them to each image via aComposeinstance.
실제로는 여러 이미지 확대 방법을 결합합니다. 예를 들어 위에서 정의한 다양한 이미지 확대 방법을 결합하고 Compose 인스턴스를 통해 각 이미지에 적용할 수 있습니다.
all_images = torchvision.datasets.CIFAR10(train=True, root="../data",
download=True)
d2l.show_images([all_images[i][0] for i in range(32)], 4, 8, scale=0.8);
위 코드는 CIFAR-10 데이터셋에서 이미지를 가져와 시각화하는 작업을 수행합니다. 코드를 단계별로 설명하겠습니다:
torchvision.datasets.CIFAR10(train=True, root="../data", download=True): CIFAR-10 데이터셋을 로드합니다. train 매개변수를 True로 설정하여 학습 데이터셋을 로드하며, root 매개변수에 데이터의 저장 경로를 지정합니다. download 매개변수를 True로 설정하면 데이터셋을 다운로드합니다.
[all_images[i][0] for i in range(32)]: CIFAR-10 데이터셋에서 처음부터 32개의 이미지를 가져와 리스트로 만듭니다. 각 이미지 데이터는 (이미지, 레이블) 형태로 저장되어 있으며, 여기서는 이미지 데이터만을 선택합니다.
d2l.show_images([...], 4, 8, scale=0.8): d2l.show_images() 함수를 사용하여 이미지 리스트를 그리드 형태로 시각화합니다. 4는 그리드의 행 수, 8은 그리드의 열 수를 나타냅니다. scale 매개변수는 이미지 크기의 스케일을 조절하는 역할을 합니다.
이 코드는 CIFAR-10 데이터셋에서 가져온 처음 32개의 이미지를 4x8 그리드로 시각화하여 보여줍니다.
In order to obtain definitive results during prediction, we usually only apply image augmentation to training examples, and do not use image augmentation with random operations during prediction. Here we only use the simplest random left-right flipping method. In addition, we use aToTensorinstance to convert a minibatch of images into the format required by the deep learning framework, i.e., 32-bit floating point numbers between 0 and 1 with the shape of (batch size, number of channels, height, width).
예측 중에 결정적인 결과를 얻기 위해 일반적으로 훈련 예제에만 이미지 확대를 적용하고 예측 중에 임의 작업으로 이미지 확대를 사용하지 않습니다. 여기서는 가장 간단한 임의의 좌우 뒤집기 방법만 사용합니다. 또한 ToTensor 인스턴스를 사용하여 이미지의 미니 배치를 딥 러닝 프레임워크에 필요한 형식, 즉 (배치 크기, 채널 수, 높이, 너비).
위 코드는 데이터 증강을 위한 데이터 변환 함수들을 정의하는 작업을 수행합니다. 코드를 단계별로 설명하겠습니다:
train_augs: 학습 데이터에 적용할 데이터 증강 변환 함수들을 조합한 객체를 생성합니다. torchvision.transforms.Compose() 함수를 사용하여 여러 변환 함수들을 순차적으로 적용할 수 있습니다.
torchvision.transforms.RandomHorizontalFlip(): 무작위로 이미지를 수평으로 뒤집는 데이터 증강을 수행합니다. 이는 이미지를 좌우로 반전시키는 효과를 줍니다.
torchvision.transforms.ToTensor(): 이미지를 텐서 형태로 변환합니다. 이 작업은 이미지 데이터를 신경망에 입력하기 위해 필요한 전처리 단계 중 하나입니다.
test_augs: 테스트 데이터에 적용할 데이터 변환 함수들을 조합한 객체를 생성합니다. 여기서는 테스트 데이터에는 이미지 뒤집기 등의 변환을 적용하지 않고, 단순히 이미지를 텐서로 변환하는 ToTensor() 변환만 적용합니다.
이렇게 정의된 train_augs와 test_augs 객체는 학습 및 테스트 데이터에 데이터 증강 및 전처리를 적용할 때 사용됩니다. 학습 데이터에는 수평 뒤집기와 이미지를 텐서로 변환하는 작업이 수행되며, 테스트 데이터에는 이미지를 텐서로 변환하는 작업만 수행됩니다.
Next, we define an auxiliary function to facilitate reading the image and applying image augmentation. Thetransformargument provided by PyTorch’s dataset applies augmentation to transform the images. For a detailed introduction toDataLoader, please refer toSection 4.2.
다음으로 이미지 읽기 및 이미지 확대 적용을 용이하게 하는 보조 기능을 정의합니다. PyTorch의 데이터 세트에서 제공하는 변환 인수는 증강을 적용하여 이미지를 변환합니다. DataLoader에 대한 자세한 소개는 섹션 4.2를 참조하십시오.
위 코드는 CIFAR-10 데이터셋을 로드하는 함수인 load_cifar10를 정의하는 부분입니다. 코드를 단계별로 설명하겠습니다:
is_train: 학습 데이터인지 테스트 데이터인지를 나타내는 인자입니다. True이면 학습 데이터를, False이면 테스트 데이터를 로드합니다.
augs: 데이터 증강 및 전처리를 적용하기 위한 데이터 변환 함수를 받는 인자입니다. 앞서 정의한 train_augs 또는 test_augs와 같은 변환 함수 객체를 여기에 전달합니다.
batch_size: 배치 크기를 나타내는 인자입니다. 데이터를 미니배치로 나눠서 로드할 때 한 번에 로드되는 데이터 샘플의 개수입니다.
torchvision.datasets.CIFAR10(): CIFAR-10 데이터셋을 로드하는 함수입니다. 해당 데이터셋은 지정된 경로에서 이미 다운로드된 경우 로드하며, 그렇지 않은 경우 다운로드합니다. 데이터셋은 CIFAR-10의 학습 데이터 또는 테스트 데이터 중 하나를 선택하여 로드합니다.
transform: 데이터 변환 함수 객체를 전달합니다. 이를 통해 데이터 증강 및 전처리 작업을 수행합니다.
torch.utils.data.DataLoader(): 데이터셋을 미니배치 형태로 로드하기 위한 데이터 로더 객체를 생성합니다. 배치 크기와 데이터 순서를 지정하여 데이터를 로드하며, 필요한 경우 데이터 로드를 병렬화합니다.
d2l.get_dataloader_workers(): 데이터 로더를 병렬화할 때 사용할 워커의 수를 반환하는 함수입니다. 데이터 로드 성능을 향상시키기 위해 병렬 처리에 사용됩니다.
반환값: 로드된 데이터셋을 배치 단위로 로드하는 데이터 로더 객체를 반환합니다. 이를 통해 학습 또는 테스트 데이터를 미니배치 형태로 반복해서 사용할 수 있습니다.
14.1.2.1.Multi-GPU Training
#@save
def train_batch_ch13(net, X, y, loss, trainer, devices):
"""Train for a minibatch with multiple GPUs (defined in Chapter 13)."""
if isinstance(X, list):
# Required for BERT fine-tuning (to be covered later)
X = [x.to(devices[0]) for x in X]
else:
X = X.to(devices[0])
y = y.to(devices[0])
net.train()
trainer.zero_grad()
pred = net(X)
l = loss(pred, y)
l.sum().backward()
trainer.step()
train_loss_sum = l.sum()
train_acc_sum = d2l.accuracy(pred, y)
return train_loss_sum, train_acc_sum
#@save
def train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,
devices=d2l.try_all_gpus()):
"""Train a model with multiple GPUs (defined in Chapter 13)."""
timer, num_batches = d2l.Timer(), len(train_iter)
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1],
legend=['train loss', 'train acc', 'test acc'])
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
for epoch in range(num_epochs):
# Sum of training loss, sum of training accuracy, no. of examples,
# no. of predictions
metric = d2l.Accumulator(4)
for i, (features, labels) in enumerate(train_iter):
timer.start()
l, acc = train_batch_ch13(
net, features, labels, loss, trainer, devices)
metric.add(l, acc, labels.shape[0], labels.numel())
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(metric[0] / metric[2], metric[1] / metric[3],
None))
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {metric[0] / metric[2]:.3f}, train acc '
f'{metric[1] / metric[3]:.3f}, test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on '
f'{str(devices)}')
위 코드는 다중 GPU를 활용하여 모델을 학습하는 함수인 train_ch13와 해당 함수 내에서 호출되는 train_batch_ch13 함수를 정의하는 부분입니다. 코드를 단계별로 설명하겠습니다:
train_batch_ch13(net, X, y, loss, trainer, devices): 다중 GPU로 미니배치 학습을 수행하는 함수입니다. 인자로는 모델 net, 입력 데이터 X, 레이블 데이터 y, 손실 함수 loss, 옵티마이저 trainer, 그리고 사용할 GPU 디바이스들의 리스트 devices가 전달됩니다. 이 함수는 미니배치를 처리하고, 손실 계산, 역전파, 가중치 갱신 등의 학습 과정을 수행합니다.
train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs, devices=d2l.try_all_gpus()): 다중 GPU로 모델을 학습하는 함수입니다. 인자로는 모델 net, 학습 데이터 로더 train_iter, 테스트 데이터 로더 test_iter, 손실 함수 loss, 옵티마이저 trainer, 학습 에포크 수 num_epochs, 그리고 사용할 GPU 디바이스들의 리스트 devices가 전달됩니다. 이 함수는 각 에포크마다 학습과 평가 과정을 반복하여 모델을 학습하고 성능을 평가합니다.
nn.DataParallel(net, device_ids=devices).to(devices[0]): DataParallel을 사용하여 모델 net을 여러 GPU에 병렬화하여 할당하는 과정입니다. 병렬화된 모델은 devices[0]에 할당됩니다.
d2l.Accumulator(4): 성능 메트릭을 누적하기 위한 Accumulator 객체를 생성합니다. 누적할 값은 손실, 정확도, 데이터 샘플 수, 예측 수로 총 4개입니다.
timer.start() 및 timer.stop(): 각 미니배치 학습 시간을 측정하기 위한 타이머를 시작하고 중지합니다.
d2l.evaluate_accuracy_gpu(net, test_iter): 테스트 데이터에 대한 정확도를 GPU를 이용하여 평가하는 함수입니다.
animator.add(...): 학습 과정 및 성능 변화를 시각화하는 Animator 객체에 정보를 추가합니다.
마지막에는 각 에포크마다 학습 및 평가 결과를 출력하고, 처리한 예제 수에 대한 처리 속도도 출력합니다.
이러한 함수를 사용하면 다중 GPU를 활용하여 모델을 학습하고 성능을 평가할 수 있습니다.
Now we can define thetrain_with_data_augfunction to train the model with image augmentation. This function gets all available GPUs, uses Adam as the optimization algorithm, applies image augmentation to the training dataset, and finally calls thetrain_ch13function just defined to train and evaluate the model.
이제 train_with_data_aug 함수를 정의하여 이미지 확대image augmentation로 모델을 훈련할 수 있습니다. 이 함수는 사용 가능한 모든 GPU를 가져오고 Adam을 최적화 알고리즘으로 사용하며 훈련 데이터 세트에 이미지 증대를 적용하고 마지막으로 방금 정의한 train_ch13 함수를 호출하여 모델을 훈련하고 평가합니다.
위 코드는 데이터 증강을 적용하여 ResNet-18 모델을 학습하는 과정을 정의하는 부분입니다. 코드를 단계별로 설명하겠습니다:
batch_size, devices, net: 미니배치 크기 batch_size, 사용 가능한 GPU 디바이스 리스트 devices, 그리고 d2l.resnet18 함수를 사용하여 클래스 수 10개, 입력 채널 3개인 ResNet-18 모델 net을 생성합니다.
net.apply(d2l.init_cnn): 모델의 가중치 초기화를 위해 d2l.init_cnn 함수를 적용합니다. 이 함수는 모델 내부의 합성곱 레이어의 가중치를 초기화합니다.
train_with_data_aug(train_augs, test_augs, net, lr=0.001): 데이터 증강을 적용하여 모델을 학습하는 함수입니다. 인자로는 학습 데이터 증강 변환 train_augs, 테스트 데이터 증강 변환 test_augs, 모델 net, 학습률 lr이 전달됩니다. 이 함수는 데이터 로더를 생성하고, 손실 함수, 옵티마이저 등을 설정하여 모델을 학습합니다.
train_iter = load_cifar10(True, train_augs, batch_size): 학습 데이터 로더를 생성합니다. load_cifar10 함수를 사용하여 CIFAR-10 학습 데이터에 데이터 증강을 적용한 후 미니배치 크기 batch_size로 분할합니다.
test_iter = load_cifar10(False, test_augs, batch_size): 테스트 데이터 로더를 생성합니다. 학습 데이터와 마찬가지로 테스트 데이터에 데이터 증강을 적용하고 미니배치 크기 batch_size로 분할합니다.
loss = nn.CrossEntropyLoss(reduction="none"): 손실 함수로 교차 엔트로피 손실 함수를 사용하며, reduction 인자를 "none"으로 설정하여 각 샘플에 대한 손실 값을 반환합니다.
trainer = torch.optim.Adam(net.parameters(), lr=lr): Adam 옵티마이저를 생성하고, 모델의 파라미터를 최적화 대상으로 설정합니다. 학습률은 lr로 설정됩니다.
net(next(iter(train_iter))[0]): 모델의 가중치를 초기화하고, 모델의 출력을 계산하여 GPU 메모리에 모델을 적재합니다.
train_ch13(net, train_iter, test_iter, loss, trainer, 10, devices): 다중 GPU를 활용하여 모델을 학습하는 train_ch13 함수를 호출하여 모델을 학습하고 성능을 평가합니다. 학습과 평가는 각각 10 에포크 동안 수행됩니다.
이러한 과정을 통해 데이터 증강을 적용하고, ResNet-18 모델을 학습하며 성능을 평가하는 과정이 구현되어 있습니다.
Let’s train the model using image augmentation based on random left-right flipping.
무작위 좌우 반전을 기반으로 한 이미지 확대를 사용하여 모델을 훈련시켜 봅시다.
train_with_data_aug(train_augs, test_augs, net)
14.1.3.Summary
Image augmentation generates random images based on existing training data to improve the generalization ability of models.
이미지 증대는 모델의 일반화 능력을 향상시키기 위해 기존 학습 데이터를 기반으로 임의의 이미지를 생성합니다.
In order to obtain definitive results during prediction, we usually only apply image augmentation to training examples, and do not use image augmentation with random operations during prediction.
예측 중에 결정적인 결과를 얻기 위해 일반적으로 훈련 예제에만 이미지 확대를 적용하고 예측 중에 임의 작업으로 이미지 확대를 사용하지 않습니다.
Deep learning frameworks provide many different image augmentation methods, which can be applied simultaneously.
딥 러닝 프레임워크는 동시에 적용할 수 있는 다양한 이미지 확대 image augmentation 방법을 제공합니다.
14.1.4.Exercises
Train the model without using image augmentation:train_with_data_aug(test_augs,test_augs). Compare training and testing accuracy when using and not using image augmentation. Can this comparative experiment support the argument that image augmentation can mitigate overfitting? Why?
Combine multiple different image augmentation methods in model training on the CIFAR-10 dataset. Does it improve test accuracy?
Refer to the online documentation of the deep learning framework. What other image augmentation methods does it also provide?
Whether it is medical diagnosis, self-driving vehicles, camera monitoring, or smart filters, many applications in the field of computer vision are closely related to our current and future lives. In recent years, deep learning has been the transformative power for advancing the performance of computer vision systems. It can be said that the most advanced computer vision applications are almost inseparable from deep learning. In view of this, this chapter will focus on the field of computer vision, and investigate methods and applications that have recently been influential in academia and industry.
의료 진단, 자율 주행 차량, 카메라 모니터링 또는 스마트 필터 등 컴퓨터 비전 분야의 많은 응용 프로그램은 현재와 미래의 삶과 밀접한 관련이 있습니다. 최근 몇 년 동안 딥 러닝은 컴퓨터 비전 시스템의 성능을 향상시키는 변혁적인 힘이었습니다. 가장 진보된 컴퓨터 비전 응용 프로그램은 딥 러닝과 거의 분리할 수 없다고 말할 수 있습니다. 이를 고려하여 이 장에서는 컴퓨터 비전 분야에 초점을 맞추고 최근 학계와 산업계에 영향을 미치고 있는 방법과 응용을 조사합니다.
InSection 7andSection 8, we studied various convolutional neural networks that are commonly used in computer vision, and applied them to simple image classification tasks. At the beginning of this chapter, we will describe two methods that may improve model generalization, namelyimage augmentationandfine-tuning, and apply them to image classification. Since deep neural networks can effectively represent images in multiple levels, such layerwise representations have been successfully used in various computer vision tasks such asobject detection,semantic segmentation, andstyle transfer. Following the key idea of leveraging layerwise representations in computer vision, we will begin with major components and techniques for object detection. Next, we will show how to usefully convolutional networksfor semantic segmentation of images. Then we will explain how to use style transfer techniques to generate images like the cover of this book. In the end, we conclude this chapter by applying the materials of this chapter and several previous chapters on two popular computer vision benchmark datasets.
7절과 8절에서는 컴퓨터 비전에서 흔히 사용되는 다양한 컨볼루션 신경망을 연구하고 이를 간단한 이미지 분류 작업에 적용하였다. 이 장의 시작 부분에서 모델 일반화를 개선할 수 있는 두 가지 방법, 즉 이미지 확대 및 미세 조정을 설명하고 이미지 분류에 적용할 것입니다. 심층 신경망은 여러 수준에서 이미지를 효과적으로 표현할 수 있기 때문에 이러한 레이어별 표현은 개체 감지, 의미론적 분할 및 스타일 전송과 같은 다양한 컴퓨터 비전 작업에서 성공적으로 사용되었습니다. 컴퓨터 비전에서 계층별 표현을 활용하는 핵심 아이디어에 따라 물체 감지를 위한 주요 구성 요소와 기술부터 시작하겠습니다. 다음으로 이미지의 시맨틱 분할을 위해 완전 컨벌루션 네트워크를 사용하는 방법을 보여줍니다. 그런 다음 스타일 변환 기술을 사용하여 이 책의 표지와 같은 이미지를 생성하는 방법을 설명합니다. 마지막으로 이 장의 자료와 두 가지 인기 있는 컴퓨터 비전 벤치마크 데이터 세트에 대한 이전 장의 여러 장을 적용하여 이 장을 마무리합니다.