16.3. Sentiment Analysis: Using Convolutional Neural Networks — Dive into Deep Learning 1.0.3 documentation
d2l.ai
16.3. Sentiment Analysis: Using Convolutional Neural Networks
In Section 7, we investigated mechanisms for processing two-dimensional image data with two-dimensional CNNs, which were applied to local features such as adjacent pixels. Though originally designed for computer vision, CNNs are also widely used for natural language processing. Simply put, just think of any text sequence as a one-dimensional image. In this way, one-dimensional CNNs can process local features such as n-grams in text.
섹션 7에서는 인접 픽셀과 같은 로컬 특징에 적용된 2차원 CNN을 사용하여 2차원 이미지 데이터를 처리하는 메커니즘을 조사했습니다. CNN은 원래 컴퓨터 비전용으로 설계되었지만 자연어 처리에도 널리 사용됩니다. 간단히 말해서 텍스트 시퀀스를 1차원 이미지로 생각하면 됩니다. 이러한 방식으로 1차원 CNN은 텍스트의 n-gram과 같은 로컬 기능을 처리할 수 있습니다.
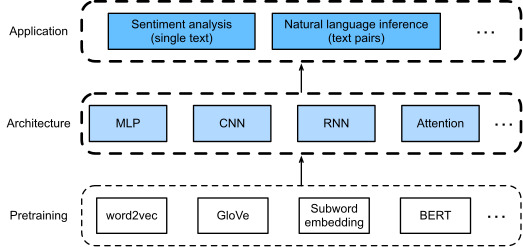
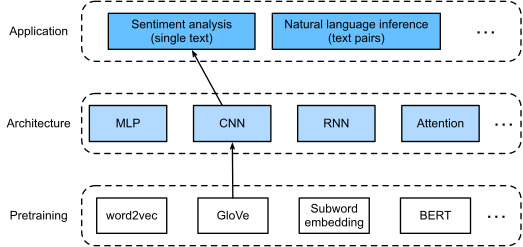
In this section, we will use the textCNN model to demonstrate how to design a CNN architecture for representing single text (Kim, 2014). Compared with Fig. 16.2.1 that uses an RNN architecture with GloVe pretraining for sentiment analysis, the only difference in Fig. 16.3.1 lies in the choice of the architecture.
이 섹션에서는 textCNN 모델을 사용하여 단일 텍스트를 표현하기 위한 CNN 아키텍처를 설계하는 방법을 보여줍니다(Kim, 2014). 감정 분석을 위해 GloVe 사전 훈련이 포함된 RNN 아키텍처를 사용하는 그림 16.2.1과 비교하면 그림 16.3.1의 유일한 차이점은 아키텍처 선택에 있습니다.
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 64
train_iter, test_iter, vocab = d2l.load_data_imdb(batch_size)
이 코드는 IMDb 감정 분석 데이터셋을 로드하고, 데이터를 미니배치로 나누어서 데이터 로더(iterator)를 생성하는 작업을 수행하는 파이토치 코드입니다. 코드의 작동 방식을 설명하겠습니다.
- 모듈 및 패키지 가져오기:
- import torch: 파이토치 라이브러리를 가져옵니다.
- from torch import nn: 파이토치의 nn 모듈에서 뉴럴 네트워크 관련 클래스와 함수를 가져옵니다.
- from d2l import torch as d2l: d2l 패키지에서 torch 모듈을 가져오되, d2l을 접두어로 사용하여 모듈을 사용할 수 있도록 합니다.
- 미니배치 크기 설정:
- batch_size = 64: 미니배치의 크기를 64로 설정합니다. 한 번에 처리하는 데이터 샘플의 개수입니다.
- 데이터 로딩:
- train_iter, test_iter, vocab = d2l.load_data_imdb(batch_size): d2l 패키지의 load_data_imdb 함수를 사용하여 IMDb 감정 분석 데이터셋을 로드하고 데이터를 미니배치로 분할하여 훈련 및 테스트 데이터 이터레이터(train_iter, test_iter)와 어휘 사전(vocab)을 반환합니다.
- train_iter: 훈련 데이터를 미니배치로 가져오는 데이터 이터레이터
- test_iter: 테스트 데이터를 미니배치로 가져오는 데이터 이터레이터
- vocab: 데이터에 사용되는 어휘 사전
즉, 이 코드는 IMDb 감정 분석 데이터셋을 로드하고 훈련 및 테스트 데이터를 미니배치로 나누어서 이후 모델 학습 및 평가에 사용할 수 있도록 데이터 로더를 생성하는 작업을 수행합니다.
16.3.1. One-Dimensional Convolutions
Before introducing the model, let’s see how a one-dimensional convolution works. Bear in mind that it is just a special case of a two-dimensional convolution based on the cross-correlation operation.
모델을 소개하기 전에 1차원 컨볼루션이 어떻게 작동하는지 살펴보겠습니다. 이는 상호 상관 연산을 기반으로 하는 2차원 컨볼루션의 특별한 경우일 뿐이라는 점을 명심하세요.

As shown in Fig. 16.3.2, in the one-dimensional case, the convolution window slides from left to right across the input tensor. During sliding, the input subtensor (e.g., 0 and 1 in Fig. 16.3.2) contained in the convolution window at a certain position and the kernel tensor (e.g., 1 and 2 in Fig. 16.3.2) are multiplied elementwise. The sum of these multiplications gives the single scalar value (e.g., 0×1+1×2=2 in Fig. 16.3.2) at the corresponding position of the output tensor.
그림 16.3.2에서 볼 수 있듯이 1차원 경우 컨볼루션 창이 입력 텐서를 가로질러 왼쪽에서 오른쪽으로 미끄러집니다. 슬라이딩하는 동안 컨볼루션 윈도우의 특정 위치에 포함된 입력 서브텐서(예: 그림 16.3.2의 0과 1)와 커널 텐서(예: 그림 16.3.2의 1과 2)가 요소별로 곱해집니다. 이러한 곱셈의 합은 출력 텐서의 해당 위치에 단일 스칼라 값(예: 그림 16.3.2의 0×1+1×2=2)을 제공합니다.
We implement one-dimensional cross-correlation in the following corr1d function. Given an input tensor X and a kernel tensor K, it returns the output tensor Y.
다음 corr1d 함수에서 1차원 상호 상관을 구현합니다. 입력 텐서 X와 커널 텐서 K가 주어지면 출력 텐서 Y를 반환합니다.
def corr1d(X, K):
w = K.shape[0]
Y = torch.zeros((X.shape[0] - w + 1))
for i in range(Y.shape[0]):
Y[i] = (X[i: i + w] * K).sum()
return Y이 코드는 1차원의 합성곱 연산을 수행하는 함수를 정의하는 파이토치 코드입니다. 코드의 작동 방식을 설명하겠습니다.
- 함수 정의:
- corr1d(X, K) 함수는 입력 시퀀스 X와 커널 K를 받아 1차원 합성곱 연산을 수행하는 역할을 합니다.
- 커널 크기 확인:
- w = K.shape[0]: 커널 K의 크기를 w로 지정합니다. 여기서 K의 크기는 커널의 길이를 의미합니다.
- 출력 텐서 초기화:
- Y = torch.zeros((X.shape[0] - w + 1)): 출력 텐서 Y를 생성합니다. X의 길이에서 커널 크기를 뺀 길이만큼의 영행렬을 생성합니다.
- 합성곱 연산 수행:
- for i in range(Y.shape[0]):: 출력 텐서의 각 원소를 계산하기 위한 루프를 수행합니다.
- (X[i: i + w] * K).sum(): 입력 시퀀스 X에서 현재 위치 i부터 i + w까지의 부분 시퀀스와 커널 K 간의 원소별 곱셈을 수행한 후 그 합을 계산합니다. 이 결과는 Y의 i 위치에 저장됩니다.
- 결과 반환:
- 계산된 출력 텐서 Y를 반환합니다. 이 텐서는 1차원 합성곱 연산 결과입니다.
즉, 이 코드는 주어진 입력 시퀀스와 커널을 사용하여 1차원 합성곱 연산을 수행하는 함수를 정의합니다. 이 함수는 시퀀스 데이터에서 패턴을 찾거나 특성을 추출하는 데 사용될 수 있습니다.
We can construct the input tensor X and the kernel tensor K from Fig. 16.3.2 to validate the output of the above one-dimensional cross-correlation implementation.
위의 1차원 상호 상관 구현의 출력을 검증하기 위해 그림 16.3.2의 입력 텐서 X와 커널 텐서 K를 구성할 수 있습니다.
X, K = torch.tensor([0, 1, 2, 3, 4, 5, 6]), torch.tensor([1, 2])
corr1d(X, K)이 코드는 주어진 입력 시퀀스와 커널을 사용하여 1차원 합성곱 연산을 수행하는 corr1d 함수를 호출하는 파이토치 코드입니다. 코드의 작동 방식을 설명하겠습니다.
- 텐서 생성:
- X는 입력 시퀀스를 나타내는 텐서로, [0, 1, 2, 3, 4, 5, 6]로 초기화됩니다.
- K는 커널을 나타내는 텐서로, [1, 2]로 초기화됩니다.
- 함수 호출:
- corr1d(X, K) 함수를 호출하여 주어진 입력 시퀀스 X와 커널 K를 사용하여 1차원 합성곱 연산을 수행합니다.
- 합성곱 연산 결과 반환:
- 함수는 주어진 입력 시퀀스 X에 대해 커널 K를 사용하여 1차원 합성곱 연산을 수행한 결과인 출력 텐서를 반환합니다.
결과적으로, 코드는 주어진 입력 시퀀스 X와 커널 K를 사용하여 1차원 합성곱 연산을 수행한 결과를 계산하고 출력합니다. 이를 통해 시퀀스 데이터에서 패턴을 추출하거나 특성을 찾는 데 사용되는 연산을 수행합니다.

tensor([ 2., 5., 8., 11., 14., 17.])
For any one-dimensional input with multiple channels, the convolution kernel needs to have the same number of input channels. Then for each channel, perform a cross-correlation operation on the one-dimensional tensor of the input and the one-dimensional tensor of the convolution kernel, summing the results over all the channels to produce the one-dimensional output tensor. Fig. 16.3.3 shows a one-dimensional cross-correlation operation with 3 input channels.
여러 채널이 있는 1차원 입력의 경우 컨볼루션 커널의 입력 채널 수가 동일해야 합니다. 그런 다음 각 채널에 대해 입력의 1차원 텐서와 컨볼루션 커널의 1차원 텐서에 대해 상호 상관 연산을 수행하고 모든 채널에 대한 결과를 합산하여 1차원 출력 텐서를 생성합니다. 그림 16.3.3은 3개의 입력 채널을 사용한 1차원 상호 상관 연산을 보여줍니다.

We can implement the one-dimensional cross-correlation operation for multiple input channels and validate the results in Fig. 16.3.3.
우리는 여러 입력 채널에 대한 1차원 상호 상관 연산을 구현하고 그림 16.3.3의 결과를 검증할 수 있습니다.
def corr1d_multi_in(X, K):
# First, iterate through the 0th dimension (channel dimension) of `X` and
# `K`. Then, add them together
return sum(corr1d(x, k) for x, k in zip(X, K))
X = torch.tensor([[0, 1, 2, 3, 4, 5, 6],
[1, 2, 3, 4, 5, 6, 7],
[2, 3, 4, 5, 6, 7, 8]])
K = torch.tensor([[1, 2], [3, 4], [-1, -3]])
corr1d_multi_in(X, K)이 코드는 다중 입력 채널을 가진 입력과 커널을 사용하여 다중 입력 채널에 대한 1차원 합성곱 연산을 수행하는 함수를 정의하고 호출하는 파이토치 코드입니다. 코드의 작동 방식을 설명하겠습니다.
- 함수 정의:
- corr1d_multi_in(X, K) 함수는 다중 입력 채널을 가진 입력 X와 커널 K를 받아 각 입력 채널에 대한 1차원 합성곱 연산을 수행한 결과를 합산하여 반환하는 역할을 합니다.
- 함수 내부에서는 zip(X, K)를 사용하여 입력 채널과 커널을 하나씩 묶어서 연산합니다.
- 입력과 커널 텐서 생성:
- X는 다중 입력 채널을 가진 입력을 나타내는 텐서입니다.
- K는 다중 커널을 나타내는 텐서입니다.
- 함수 호출:
- corr1d_multi_in(X, K) 함수를 호출하여 주어진 다중 입력 채널을 가진 입력 X와 다중 커널 K를 사용하여 다중 입력 채널에 대한 1차원 합성곱 연산을 수행합니다.
- 합성곱 연산 결과 합산:
- 함수는 zip(X, K)를 통해 각 입력 채널과 커널을 묶어서 corr1d 함수로 1차원 합성곱 연산을 수행한 결과를 합산합니다.
결과적으로, 코드는 주어진 다중 입력 채널과 커널을 사용하여 각 입력 채널에 대한 1차원 합성곱 연산을 수행한 결과를 합산하여 반환합니다. 이는 다중 채널의 입력 데이터에 대해 필터 연산을 수행하는 데 사용될 수 있습니다.
tensor([ 2., 8., 14., 20., 26., 32.])
Note that multi-input-channel one-dimensional cross-correlations are equivalent to single-input-channel two-dimensional cross-correlations. To illustrate, an equivalent form of the multi-input-channel one-dimensional cross-correlation in Fig. 16.3.3 is the single-input-channel two-dimensional cross-correlation in Fig. 16.3.4, where the height of the convolution kernel has to be the same as that of the input tensor.
다중 입력 채널 1차원 상호 상관은 단일 입력 채널 2차원 상호 상관과 동일합니다. 설명하기 위해 그림 16.3.3의 다중 입력 채널 1차원 상호 상관의 등가 형식은 그림 16.3.4의 단일 입력 채널 2차원 상호 상관입니다. 컨볼루션 커널은 입력 텐서의 커널과 동일해야 합니다.

Both the outputs in Fig. 16.3.2 and Fig. 16.3.3 have only one channel. Same as two-dimensional convolutions with multiple output channels described in Section 7.4.2, we can also specify multiple output channels for one-dimensional convolutions.
그림 16.3.2와 그림 16.3.3의 출력에는 모두 채널이 하나만 있습니다. 7.4.2절에 설명된 여러 출력 채널을 사용하는 2차원 컨볼루션과 마찬가지로 1차원 컨볼루션에 대해 여러 출력 채널을 지정할 수도 있습니다.
16.3.2. Max-Over-Time Pooling
Similarly, we can use pooling to extract the highest value from sequence representations as the most important feature across time steps. The max-over-time pooling used in textCNN works like the one-dimensional global max-pooling (Collobert et al., 2011). For a multi-channel input where each channel stores values at different time steps, the output at each channel is the maximum value for that channel. Note that the max-over-time pooling allows different numbers of time steps at different channels.
마찬가지로 풀링을 사용하여 시퀀스 표현에서 가장 높은 값을 시간 단계에 걸쳐 가장 중요한 특징으로 추출할 수 있습니다. textCNN에서 사용되는 최대 시간 풀링은 1차원 전역 최대 풀링과 유사하게 작동합니다(Collobert et al., 2011). 각 채널이 서로 다른 시간 간격으로 값을 저장하는 다중 채널 입력의 경우 각 채널의 출력은 해당 채널의 최대값입니다. 시간에 따른 최대 풀링은 서로 다른 채널에서 서로 다른 수의 시간 단계를 허용한다는 점에 유의하십시오.
Max-Over-Time Pooling 이란?
Max-over-time pooling is a type of pooling operation commonly used in natural language processing (NLP) and text analysis tasks, especially in the context of convolutional neural networks (CNNs) for text classification. The purpose of max-over-time pooling is to extract the most important information or features from a sequence of data (such as a sentence or text document) while preserving their sequential order.
맥스 오버 타임 풀링(Max-over-time pooling)은 주로 자연어 처리(NLP) 및 텍스트 분석 작업에서 사용되는 풀링 연산 중 하나로, 특히 텍스트 분류를 위한 컨볼루션 신경망(CNN)의 맥락에서 널리 사용됩니다. 맥스 오버 타임 풀링의 목적은 데이터 시퀀스(예: 문장 또는 텍스트 문서)에서 가장 중요한 정보나 특징을 추출하면서 그들의 순차적인 순서를 보존하는 것입니다.
Here's how max-over-time pooling works:
맥스 오버 타임 풀링의 작동 방식은 다음과 같습니다.
- Input: You have a sequence of data, typically represented as a matrix where each row corresponds to a token or word embedding, and the columns represent features of each token.
입력: 데이터 시퀀스를 가지고 있으며, 일반적으로 각 행이 토큰 또는 단어 임베딩에 해당하고 열은 각 토큰의 특징을 나타내는 행렬로 표현됩니다. - Pooling Operation: Max-over-time pooling takes the maximum value along a specific dimension of the input matrix. In text analysis, this dimension is often the sequence length or time steps. Essentially, for each feature (column), it selects the maximum value across all tokens in the sequence for that feature.
풀링 연산: 맥스 오버 타임 풀링은 입력 행렬의 특정 차원을 따라 최댓값을 선택합니다. 텍스트 분석에서 이 차원은 일반적으로 시퀀스 길이 또는 시간 단계입니다. 본질적으로 각 특징(열)에 대해 시퀀스 전체에서 해당 특징에 대한 모든 토큰에서 최댓값을 선택합니다. - Result: The result of max-over-time pooling is a fixed-size vector where each element represents the maximum value of a feature across the entire sequence. This vector is sometimes referred to as a "pooled feature" vector.
결과: 맥스 오버 타임 풀링의 결과는 고정 크기의 벡터입니다. 각 요소는 입력 시퀀스 전체에서 해당 특징에 대한 최댓값을 나타냅니다. 이 벡터는 종종 "풀링된 특징" 벡터로 불립니다.
The intuition behind max-over-time pooling is that it captures the most important information or the "key feature" from each feature dimension of the input sequence. In text classification tasks, this can be particularly useful because it helps identify the most relevant words or phrases in a sentence for making a classification decision.
맥스 오버 타임 풀링의 아이디어는 입력 시퀀스의 각 특징에서 가장 중요한 정보 또는 "주요 특징"을 포착하는 것입니다. 텍스트 분류 작업에서 이는 특히 유용합니다. 왜냐하면 이를 통해 분류 결정을 내리기 위해 문장 내에서 가장 관련성 높은 단어나 구를 식별할 수 있기 때문입니다.
Max-over-time pooling is often used in combination with convolutional neural networks (CNNs) for text classification tasks. After applying a series of convolutional filters to the input text, max-over-time pooling is used to select the most important features from the resulting feature maps, which are then fed into a classifier for making predictions.
맥스 오버 타임 풀링은 종종 텍스트 분류 작업을 위한 컨볼루션 신경망(CNN)과 결합하여 사용됩니다. 입력 텍스트에 일련의 컨볼루션 필터를 적용한 후, 맥스 오버 타임 풀링을 사용하여 결과 특징 맵에서 가장 중요한 특징을 선택하고, 그런 다음 예측을 위한 분류기에 공급합니다.
In summary, max-over-time pooling is a pooling technique used in NLP and text analysis to capture the most salient features from a sequence of data, such as a sentence, while preserving the sequence's order. It is particularly useful in text classification tasks to identify key information for making predictions.
요약하면, 맥스 오버 타임 풀링은 NLP 및 텍스트 분석에서 데이터 시퀀스(예: 문장)에서 가장 중요한 특징을 추출하고 순차적인 순서를 유지하는 풀링 기술 중 하나입니다. 텍스트 분류 작업에서 키 정보를 식별하는 데 유용하며, 입력 데이터 시퀀스에서 예측을 위한 핵심 정보를 파악하는 데 도움이 됩니다.
One-dimensional global max pooling 이란?
"One-dimensional global max pooling" refers to a specific type of pooling operation applied to one-dimensional data, typically used in deep learning models, particularly for tasks involving sequences such as text or time series data.
일차원 글로벌 맥스 풀링"은 주로 시퀀스와 관련된 딥러닝 모델에서 사용되는 일련의 데이터에 적용되는 풀링 작업 중 하나를 가리킵니다. 이것은 일차원 데이터에서 사용되며 주로 텍스트 또는 시계열 데이터와 같은 순차 데이터 작업에 사용됩니다.
Here's what it means:
이게 무엇을 의미하는지 살펴보겠습니다.
- One-dimensional Data: This refers to data organized in a single sequence, often represented as a vector or a sequence of values along a single dimension. Examples include a sequence of words in a sentence or a time series of sensor readings.
일차원 데이터: 이것은 하나의 시퀀스로 구성된 데이터를 나타냅니다. 일반적으로 벡터 또는 단일 차원을 따라 값의 시퀀스로 표현됩니다. 예로는 문장의 단어 시퀀스 또는 센서 데이터의 시계열이 있습니다. - Global Max Pooling: Pooling is an operation used to reduce the dimensionality of data while retaining essential information. Global max pooling, in particular, involves taking the maximum value across the entire sequence.
글로벌 맥스 풀링: 풀링은 데이터의 차원을 줄이는 연산으로, 중요한 정보를 유지하면서 데이터의 차원을 줄입니다. 특히 글로벌 맥스 풀링은 전체 시퀀스에서 최대값을 선택하는 것을 의미합니다.
In the context of one-dimensional data, one-dimensional global max pooling entails finding the maximum value from the entire sequence. Here's how it works:
일차원 데이터의 맥스 풀링은 전체 시퀀스에서 최대값을 찾는 것을 포함합니다. 작동 방식은 다음과 같습니다.
- Input: You have a one-dimensional sequence of data.
입력: 일차원 데이터 시퀀스가 있습니다. - Pooling Operation: The pooling operation scans through the entire sequence and selects the maximum value.
풀링 연산: 풀링 연산은 전체 시퀀스를 스캔하고 최대값을 선택합니다. - Output: The output of this operation is a single value, which is the maximum value found in the entire sequence.
출력: 이 작업의 결과는 전체 시퀀스에서 찾은 최대값으로, 시퀀스의 가장 중요한 특징을 나타냅니다.
One-dimensional global max pooling is commonly used in neural networks, especially in convolutional neural networks (CNNs) applied to text or time series data. It helps capture the most important or salient feature from the sequence, which can be useful for various tasks like sentiment analysis, text classification, or anomaly detection in time series data.
일차원 글로벌 맥스 풀링은 특히 텍스트 또는 시계열 데이터에 적용되는 합성곱 신경망(CNN)에서 일반적으로 사용됩니다. 이것은 시퀀스에서 가장 중요한 또는 주요한 특징을 포착하여 해당 문장이나 데이터의 대표적인 값을 얻는 데 도움이 됩니다. 이 값은 감정 분석, 텍스트 분류 또는 시계열 데이터에서 이상 탐지와 같은 다양한 작업에 유용하게 사용됩니다.
For example, in text classification, you might have a sequence of word embeddings for a sentence, and applying one-dimensional global max pooling would give you a single value representing the most important feature in that sentence, which can be used as an input for further layers in the neural network.
예를 들어 텍스트 분류에서는 문장에 대한 일련의 단어 임베딩이 있을 수 있습니다. 1차원 전역 최대 풀링을 적용하면 해당 문장에서 가장 중요한 특징을 나타내는 단일 값이 제공되며, 이는 신경망의 추가 레이어에 대한 입력으로 사용될 수 있습니다.
16.3.3. The textCNN Model
Using the one-dimensional convolution and max-over-time pooling, the textCNN model takes individual pretrained token representations as input, then obtains and transforms sequence representations for the downstream application.
1차원 컨볼루션 및 최대 시간 풀링을 사용하여 textCNN 모델은 사전 훈련된 개별 토큰 표현을 입력으로 가져온 다음 다운스트림 애플리케이션에 대한 시퀀스 표현을 얻고 변환합니다.
For a single text sequence with n tokens represented by d-dimensional vectors, the width, height, and number of channels of the input tensor are n, 1, and d, respectively. The textCNN model transforms the input into the output as follows:
d차원 벡터로 표현되는 n개의 토큰이 있는 단일 텍스트 시퀀스의 경우 입력 텐서의 너비, 높이, 채널 수는 각각 n, 1, d입니다. textCNN 모델은 다음과 같이 입력을 출력으로 변환합니다.
- Define multiple one-dimensional convolution kernels and perform convolution operations separately on the inputs. Convolution kernels with different widths may capture local features among different numbers of adjacent tokens.
여러 개의 1차원 컨볼루션 커널을 정의하고 입력에 대해 개별적으로 컨볼루션 작업을 수행합니다. 폭이 서로 다른 컨볼루션 커널은 서로 다른 수의 인접한 토큰 중에서 로컬 기능을 캡처할 수 있습니다. - Perform max-over-time pooling on all the output channels, and then concatenate all the scalar pooling outputs as a vector.
모든 출력 채널에 대해 최대 시간 풀링을 수행한 다음 모든 스칼라 풀링 출력을 벡터로 연결합니다. - Transform the concatenated vector into the output categories using the fully connected layer. Dropout can be used for reducing overfitting.
완전 연결 레이어를 사용하여 연결된 벡터를 출력 범주로 변환합니다. Dropout은 Overfitting을 줄이기 위해 사용될 수 있습니다.
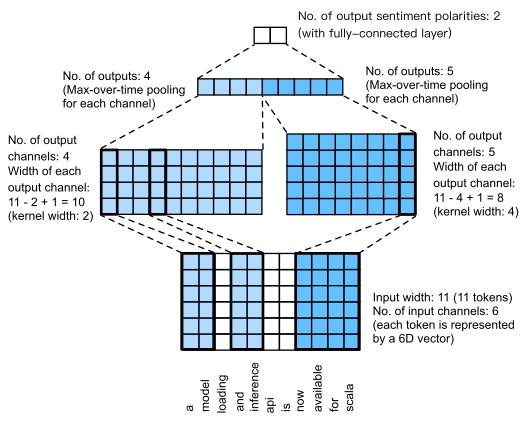
Fig. 16.3.5 illustrates the model architecture of textCNN with a concrete example. The input is a sentence with 11 tokens, where each token is represented by a 6-dimensional vectors. So we have a 6-channel input with width 11. Define two one-dimensional convolution kernels of widths 2 and 4, with 4 and 5 output channels, respectively. They produce 4 output channels with width 11−2+1=10 and 5 output channels with width 11−4+1=8. Despite different widths of these 9 channels, the max-over-time pooling gives a concatenated 9-dimensional vector, which is finally transformed into a 2-dimensional output vector for binary sentiment predictions.
그림 16.3.5는 구체적인 예를 들어 textCNN의 모델 아키텍처를 보여줍니다. 입력은 11개의 토큰이 포함된 문장이며, 각 토큰은 6차원 벡터로 표시됩니다. 따라서 너비가 11인 6채널 입력이 있습니다. 각각 4개와 5개의 출력 채널을 사용하여 너비가 2와 4인 두 개의 1차원 컨볼루션 커널을 정의합니다. 너비가 11−2+1=10인 4개의 출력 채널과 너비가 11−4+1=8인 5개의 출력 채널을 생성합니다. 이러한 9개 채널의 너비가 다름에도 불구하고 시간별 최대 풀링은 연결된 9차원 벡터를 제공하며 이는 최종적으로 이진 감정 예측을 위한 2차원 출력 벡터로 변환됩니다.
textCNN이란?
TextCNN은 텍스트 분류 및 텍스트 기반 작업을 위한 컨볼루션 신경망 (Convolutional Neural Network) 아키텍처 중 하나입니다. 주로 텍스트 문제에 적합한 모델 구조로, 텍스트 분류, 감정 분석, 스팸 탐지, 텍스트 유사성 평가 등 다양한 자연어 처리 (NLP) 작업에 사용됩니다. 아래에서 TextCNN의 주요 특징과 작동 방식을 설명하겠습니다.
주요 특징:
- 합성곱 레이어 사용: TextCNN은 합성곱 레이어를 사용하여 텍스트의 지역적인 특징을 추출합니다. 이 합성곱 레이어는 일반적으로 텍스트에서의 n-그램 (n-grams)을 감지하는 데 사용됩니다. 예를 들어, 1-gram 합성곱은 단어 수준의 특징을, 2-gram 합성곱은 이웃한 단어 쌍의 특징을 추출합니다.
- 풀링 레이어 사용: TextCNN은 풀링 레이어를 사용하여 추출된 특징을 요약합니다. 일반적으로 최대 풀링 (max-pooling)이 사용되며, 각 합성곱 필터가 생성한 특징 중에서 가장 중요한 정보만을 선택합니다. 이것은 텍스트의 중요한 부분을 강조하는 데 도움이 됩니다.
- 다중 크기의 필터: TextCNN은 서로 다른 크기의 여러 합성곱 필터를 사용합니다. 이로 인해 모델은 다양한 크기의 텍스트 구조를 캡처할 수 있으며, 단어 수준과 구문 수준의 특징을 동시에 학습할 수 있습니다.
- 단어 임베딩: 텍스트 데이터를 처리하기 위해 사전 훈련된 단어 임베딩 (Word Embedding)을 사용하는 것이 일반적입니다. 이를 통해 단어를 고정 차원의 벡터로 표현하고, 이러한 임베딩을 모델 입력으로 사용합니다.
- 전역 맥스 풀링: 마지막으로, 전역 맥스 풀링을 사용하여 합성곱 레이어의 출력을 하나의 벡터로 요약합니다. 이는 텍스트 길이와 상관없이 일정한 출력 크기를 갖게 해주며, 텍스트 분류 작업을 위해 주로 사용됩니다.
작동 방식:
- 입력 텍스트는 단어 임베딩으로 변환됩니다.
- 서로 다른 크기의 합성곱 필터가 입력 텍스트를 합성곱 연산합니다. 이것은 입력에서 서로 다른 크기의 특징을 추출합니다.
- 합성곱 결과를 최대 풀링 레이어를 통해 요약하고, 각 필터가 생성한 가장 중요한 특징만 남깁니다.
- 다양한 크기의 필터에서 얻은 특징을 하나로 연결합니다.
- 전역 맥스 풀링을 사용하여 이러한 특징을 최종적으로 하나의 벡터로 압축합니다.
- 압축된 벡터를 완전 연결 레이어를 통해 최종 예측 결과로 변환합니다.
TextCNN은 간단하면서도 강력한 텍스트 분류 모델 중 하나로, 컴퓨터 비전에서의 CNN과 유사한 구조를 텍스트 처리에 적용한 예입니다. 이 모델은 텍스트 데이터의 특징 추출과 분류를 위해 효과적이며, 자연어 처리 작업에 널리 사용됩니다.
16.3.3.1. Defining the Model
We implement the textCNN model in the following class. Compared with the bidirectional RNN model in Section 16.2, besides replacing recurrent layers with convolutional layers, we also use two embedding layers: one with trainable weights and the other with fixed weights.
다음 클래스에서 textCNN 모델을 구현합니다. 섹션 16.2의 양방향 RNN 모델과 비교하여 순환 레이어를 컨볼루셔널 레이어로 바꾸는 것 외에도 두 개의 임베딩 레이어를 사용합니다. 하나는 훈련 가능한 가중치가 있고 다른 하나는 고정 가중치가 있습니다.
class TextCNN(nn.Module):
def __init__(self, vocab_size, embed_size, kernel_sizes, num_channels,
**kwargs):
super(TextCNN, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
# The embedding layer not to be trained
self.constant_embedding = nn.Embedding(vocab_size, embed_size)
self.dropout = nn.Dropout(0.5)
self.decoder = nn.Linear(sum(num_channels), 2)
# The max-over-time pooling layer has no parameters, so this instance
# can be shared
self.pool = nn.AdaptiveAvgPool1d(1)
self.relu = nn.ReLU()
# Create multiple one-dimensional convolutional layers
self.convs = nn.ModuleList()
for c, k in zip(num_channels, kernel_sizes):
self.convs.append(nn.Conv1d(2 * embed_size, c, k))
def forward(self, inputs):
# Concatenate two embedding layer outputs with shape (batch size, no.
# of tokens, token vector dimension) along vectors
embeddings = torch.cat((
self.embedding(inputs), self.constant_embedding(inputs)), dim=2)
# Per the input format of one-dimensional convolutional layers,
# rearrange the tensor so that the second dimension stores channels
embeddings = embeddings.permute(0, 2, 1)
# For each one-dimensional convolutional layer, after max-over-time
# pooling, a tensor of shape (batch size, no. of channels, 1) is
# obtained. Remove the last dimension and concatenate along channels
encoding = torch.cat([
torch.squeeze(self.relu(self.pool(conv(embeddings))), dim=-1)
for conv in self.convs], dim=1)
outputs = self.decoder(self.dropout(encoding))
return outputs이 코드는 텍스트 분류를 위한 CNN(Convolutional Neural Network) 모델을 정의하는 파이토치 코드입니다. 코드의 작동 방식을 설명하겠습니다.
- 클래스 정의:
- TextCNN(nn.Module) 클래스는 텍스트 분류를 위한 CNN 모델을 정의합니다.
- vocab_size: 어휘 사전의 크기
- embed_size: 임베딩 차원 크기
- kernel_sizes: 커널 크기 리스트
- num_channels: 각 커널 크기에 해당하는 채널 수 리스트
- 초기화 메서드:
- __init__ 메서드에서 모델의 구조를 정의합니다.
- 임베딩 레이어, 고정된 임베딩 레이어, 드롭아웃, 디코더(FC 레이어), 풀링 레이어, 활성화 함수 레이어, 1D 컨볼루션 레이어들을 생성합니다.
- 순전파 메서드:
- forward 메서드에서 모델의 순전파 연산을 정의합니다.
- 입력 데이터에 대한 임베딩을 생성하고, 두 개의 임베딩 레이어 결과를 연결(concatenate)합니다.
- 1D 컨볼루션 레이어들을 순회하며 연산을 수행하고, 풀링과 활성화 함수를 적용한 후 연산 결과를 연결합니다.
- 최종적으로 드롭아웃과 FC 레이어를 통해 최종 출력을 계산합니다.
즉, 이 코드는 텍스트 분류를 위한 CNN 모델을 정의하는데 사용되며, 임베딩, 컨볼루션, 풀링, 드롭아웃 등의 다양한 레이어들이 조합되어 텍스트 데이터의 특성을 추출하고 분류하는 데 활용됩니다.
Let’s create a textCNN instance. It has 3 convolutional layers with kernel widths of 3, 4, and 5, all with 100 output channels.
textCNN 인스턴스를 만들어 보겠습니다. 커널 너비가 3, 4, 5이고 모두 100개의 출력 채널을 갖는 3개의 컨벌루션 레이어가 있습니다.
embed_size, kernel_sizes, nums_channels = 100, [3, 4, 5], [100, 100, 100]
devices = d2l.try_all_gpus()
net = TextCNN(len(vocab), embed_size, kernel_sizes, nums_channels)
def init_weights(module):
if type(module) in (nn.Linear, nn.Conv1d):
nn.init.xavier_uniform_(module.weight)
net.apply(init_weights);이 코드는 TextCNN 모델을 초기화하고 가중치를 초기화하는 작업을 수행하는 파이토치 코드입니다. 코드의 작동 방식을 설명하겠습니다.
- 변수 설정:
- embed_size: 임베딩 차원 크기를 100으로 설정합니다.
- kernel_sizes: 사용할 커널 크기 리스트로 [3, 4, 5]로 설정합니다.
- nums_channels: 각 커널 크기에 해당하는 채널 수 리스트로 [100, 100, 100]으로 설정합니다.
- GPU 디바이스 설정:
- devices = d2l.try_all_gpus(): 가능한 모든 GPU 디바이스를 가져옵니다.
- TextCNN 모델 생성:
- net = TextCNN(len(vocab), embed_size, kernel_sizes, nums_channels): TextCNN 클래스를 사용하여 텍스트 분류를 위한 CNN 모델을 생성합니다. 어휘 사전의 크기, 임베딩 차원 크기, 커널 크기 리스트, 채널 수 리스트를 인자로 제공합니다.
- 초기화 함수 정의:
- init_weights(module) 함수는 모듈의 가중치를 초기화하는 역할을 합니다.
- 만약 모듈이 nn.Linear 또는 nn.Conv1d 타입이라면, 해당 모듈의 가중치를 Xavier 초기화를 사용하여 초기화합니다.
- 가중치 초기화:
- net.apply(init_weights);: 모델의 가중치를 초기화하는 함수 init_weights를 적용합니다. 이를 통해 모델 내의 선형 레이어와 1D 컨볼루션 레이어의 가중치가 초기화됩니다.
결과적으로, 이 코드는 TextCNN 모델을 초기화하고 Xavier 초기화를 사용하여 모델 내의 선형 레이어와 1D 컨볼루션 레이어의 가중치를 초기화합니다. 이를 통해 모델이 효과적으로 학습될 수 있도록 준비 단계를 수행합니다.
16.3.3.2. Loading Pretrained Word Vectors
Same as Section 16.2, we load pretrained 100-dimensional GloVe embeddings as the initialized token representations. These token representations (embedding weights) will be trained in embedding and fixed in constant_embedding.
섹션 16.2와 동일하게 사전 훈련된 100차원 GloVe 임베딩을 초기화된 토큰 표현으로 로드합니다. 이러한 토큰 표현(임베딩 가중치)은 임베딩에 대해 학습되고 Constant_embedding에서 수정됩니다.
glove_embedding = d2l.TokenEmbedding('glove.6b.100d')
embeds = glove_embedding[vocab.idx_to_token]
net.embedding.weight.data.copy_(embeds)
net.constant_embedding.weight.data.copy_(embeds)
net.constant_embedding.weight.requires_grad = False이 코드는 사전 훈련된 임베딩 벡터를 사용하여 모델의 임베딩 레이어 가중치를 초기화하고, 고정된 임베딩 레이어의 학습을 방지하는 작업을 수행하는 파이토치 코드입니다. 코드의 작동 방식을 설명하겠습니다.
- 사전 훈련된 임베딩 벡터 로드:
- glove_embedding = d2l.TokenEmbedding('glove.6b.100d'): 'glove.6b.100d' 데이터셋의 사전 훈련된 임베딩 벡터를 가져옵니다. 이 벡터들은 단어에 대한 의미론적 표현을 포함하고 있습니다.
- 어휘에 해당하는 임베딩 벡터 추출:
- embeds = glove_embedding[vocab.idx_to_token]: 어휘 사전에 있는 단어들에 대응하는 임베딩 벡터를 glove_embedding에서 추출합니다. idx_to_token 메서드는 어휘 사전의 인덱스에 해당하는 단어를 반환합니다.
- 임베딩 레이어 가중치 초기화:
- net.embedding.weight.data.copy_(embeds): 모델의 임베딩 레이어의 가중치를 사전 훈련된 임베딩 벡터 embeds로 초기화합니다.
- 고정된 임베딩 레이어 가중치 초기화 및 학습 방지:
- net.constant_embedding.weight.data.copy_(embeds): 모델의 고정된 임베딩 레이어의 가중치도 사전 훈련된 임베딩 벡터 embeds로 초기화합니다.
- net.constant_embedding.weight.requires_grad = False: 고정된 임베딩 레이어의 가중치에 대한 기울기 계산을 비활성화하여 해당 가중치가 학습되지 않도록 합니다.
결과적으로, 이 코드는 모델의 임베딩 레이어와 고정된 임베딩 레이어에 대해 사전 훈련된 임베딩 벡터를 초기화하고, 고정된 임베딩 레이어의 학습을 방지하여 모델이 사전 훈련된 의미론적 정보를 활용하면서도 특정 임베딩 가중치는 업데이트되지 않도록 설정합니다.
16.3.3.3. Training and Evaluating the Model
Now we can train the textCNN model for sentiment analysis.
이제 감정 분석을 위해 textCNN 모델을 훈련할 수 있습니다.
lr, num_epochs = 0.001, 5
trainer = torch.optim.Adam(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss(reduction="none")
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs, devices)이 코드는 TextCNN 모델을 학습하는 과정을 구성하는 파이토치 코드입니다. 코드의 작동 방식을 설명하겠습니다.
- 학습률 및 에폭 설정:
- lr, num_epochs = 0.001, 5: 학습률을 0.001로 설정하고, 학습할 에폭 수를 5로 설정합니다.
- 옵티마이저 설정:
- trainer = torch.optim.Adam(net.parameters(), lr=lr): Adam 옵티마이저를 생성하고, 모델의 파라미터들을 최적화할 대상으로 지정합니다. 학습률은 위에서 설정한 값인 0.001로 설정됩니다.
- 손실 함수 설정:
- loss = nn.CrossEntropyLoss(reduction="none"): 교차 엔트로피 손실 함수를 생성하고, 각 샘플에 대한 손실 값을 개별적으로 계산하기 위해 reduction을 "none"으로 설정합니다.
- 모델 학습:
- d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs, devices): d2l 라이브러리의 train_ch13 함수를 사용하여 모델을 학습합니다. 학습 데이터인 train_iter, 검증 데이터인 test_iter, 손실 함수 loss, 옵티마이저 trainer, 에폭 수 num_epochs, GPU 디바이스 devices 등을 인자로 제공합니다.
결과적으로, 이 코드는 지정한 학습률과 에폭 수로 TextCNN 모델을 학습시키고, 손실 함수와 옵티마이저를 사용하여 모델을 최적화합니다. d2l 라이브러리의 학습 함수를 사용하여 학습 과정을 수행하며, 학습 데이터와 검증 데이터의 손실 및 성능을 모니터링하면서 모델이 훈련됩니다.
loss 0.066, train acc 0.979, test acc 0.868
4354.2 examples/sec on [device(type='cuda', index=0), device(type='cuda', index=1)]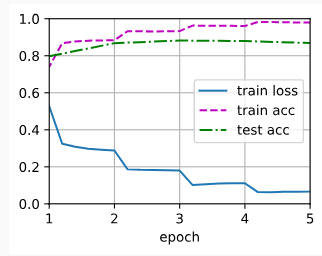
Below we use the trained model to predict the sentiment for two simple sentences.
아래에서는 훈련된 모델을 사용하여 두 개의 간단한 문장에 대한 감정을 예측합니다.
d2l.predict_sentiment(net, vocab, 'this movie is so great')이 코드는 훈련된 TextCNN 모델을 사용하여 주어진 텍스트에 대한 감성 분석 결과를 예측하는 파이토치 코드입니다. 코드의 작동 방식을 설명하겠습니다.
- 함수 호출:
- d2l.predict_sentiment(net, vocab, 'this movie is so great'): d2l 라이브러리의 predict_sentiment 함수를 호출합니다. 이 함수는 훈련된 모델 net, 어휘 사전 vocab, 그리고 예측하고자 하는 텍스트 'this movie is so great'를 인자로 제공하여 해당 텍스트의 감성을 예측합니다.
- 예측 결과 반환:
- 함수는 주어진 텍스트에 대한 감성 예측을 수행하고, 예측 결과를 반환합니다. 결과로 'positive'나 'negative'와 같은 감성 분석 결과를 출력합니다.
즉, 이 코드는 훈련된 TextCNN 모델을 사용하여 주어진 텍스트의 감성을 예측하는 작업을 수행하고 그 결과를 출력합니다. 'this movie is so great'와 같은 문장을 입력으로 주면 해당 문장의 감성 분석 결과를 예측하여 출력합니다.
'positive'
d2l.predict_sentiment(net, vocab, 'this movie is so bad')'negative'
이건 내가 바라는대로 답이 나오지 않음.

16.3.4. Summary
- One-dimensional CNNs can process local features such as n-grams in text.
1차원 CNN은 텍스트의 n-gram과 같은 로컬 기능을 처리할 수 있습니다. - Multi-input-channel one-dimensional cross-correlations are equivalent to single-input-channel two-dimensional cross-correlations.
다중 입력 채널 1차원 상호 상관은 단일 입력 채널 2차원 상호 상관과 동일합니다. - The max-over-time pooling allows different numbers of time steps at different channels.
최대 시간별 풀링은 서로 다른 채널에서 서로 다른 수의 시간 단계를 허용합니다. - The textCNN model transforms individual token representations into downstream application outputs using one-dimensional convolutional layers and max-over-time pooling layers.
textCNN 모델은 1차원 컨벌루션 레이어와 시간별 최대 풀링 레이어를 사용하여 개별 토큰 표현을 다운스트림 애플리케이션 출력으로 변환합니다.
16.3.5. Exercises
- Tune hyperparameters and compare the two architectures for sentiment analysis in Section 16.2 and in this section, such as in classification accuracy and computational efficiency.
- Can you further improve the classification accuracy of the model by using the methods introduced in the exercises of Section 16.2?
- Add positional encoding in the input representations. Does it improve the classification accuracy?
'Dive into Deep Learning > D2L Natural language Processing' 카테고리의 다른 글
| D2L - 16.7. Natural Language Inference: Fine-Tuning BERT (0) | 2023.09.02 |
|---|---|
| D2L - 16.6. Fine-Tuning BERT for Sequence-Level and Token-Level Applications (0) | 2023.09.02 |
| D2L - 16.5. Natural Language Inference: Using Attention (0) | 2023.09.02 |
| D2L - 16.4. Natural Language Inference and the Dataset (0) | 2023.09.01 |
| D2L - 16.2. Sentiment Analysis: Using Recurrent Neural Networks (0) | 2023.09.01 |
| D2L - 16.1. Sentiment Analysis and the Dataset (0) | 2023.09.01 |
| D2L - 16. Natural Language Processing: Applications (0) | 2023.09.01 |
| D2L - 15.10. Pretraining BERT (0) | 2023.08.30 |
| D2L - 15.9. The Dataset for Pretraining BERT (0) | 2023.08.30 |
| D2L - 15.8. Bidirectional Encoder Representations from Transformers (BERT) (0) | 2023.08.30 |