
20.1. Generative Adversarial Networks — Dive into Deep Learning 1.0.3 documentation (d2l.ai)
20.1. Generative Adversarial Networks — Dive into Deep Learning 1.0.3 documentation
d2l.ai
20.1. Generative Adversarial Networks
Throughout most of this book, we have talked about how to make predictions. In some form or another, we used deep neural networks to learn mappings from data examples to labels. This kind of learning is called discriminative learning, as in, we’d like to be able to discriminate between photos of cats and photos of dogs. Classifiers and regressors are both examples of discriminative learning. And neural networks trained by backpropagation have upended everything we thought we knew about discriminative learning on large complicated datasets. Classification accuracies on high-res images have gone from useless to human-level (with some caveats) in just 5-6 years. We will spare you another spiel about all the other discriminative tasks where deep neural networks do astoundingly well.
이 책의 대부분에서 우리는 예측하는 방법에 대해 이야기했습니다. 어떤 형태로든 우리는 심층 신경망을 사용하여 데이터 예제에서 레이블까지의 매핑을 학습했습니다. 이런 종류의 학습을 차별적 학습 discriminative learning 이라고 합니다. 고양이 사진과 개 사진을 구별할 수 있기를 원하기 때문입니다. 분류기 Classifiers 와 회귀자 regressors 는 모두 차별 학습 discriminative learning 의 예입니다. 그리고 역전파로 훈련된 신경망은 크고 복잡한 데이터 세트에 대한 차별적 학습에 대해 우리가 알고 있다고 생각했던 모든 것을 뒤집어 놓았습니다. 고해상도 이미지의 분류 정확도는 단 5~6년 만에 쓸모없는 수준에서 인간 수준(몇 가지 주의 사항 있음)으로 바뀌었습니다. 심층 신경망이 놀라울 정도로 잘 수행되는 다른 모든 식별 작업에 대해 더 이상 이야기하지 않겠습니다.
But there is more to machine learning than just solving discriminative tasks. For example, given a large dataset, without any labels, we might want to learn a model that concisely captures the characteristics of this data. Given such a model, we could sample synthetic data examples that resemble the distribution of the training data. For example, given a large corpus of photographs of faces, we might want to be able to generate a new photorealistic image that looks like it might plausibly have come from the same dataset. This kind of learning is called generative modeling.
그러나 머신러닝에는 단지 차별적 discriminative 인 작업을 해결하는 것보다 더 많은 것이 있습니다. 예를 들어, 라벨이 없는 대규모 데이터 세트가 있으면 이 데이터의 특성을 간결하게 포착하는 모델을 학습하고 싶을 수 있습니다. 이러한 모델이 주어지면 훈련 데이터의 분포와 유사한 합성 데이터 예제를 샘플링할 수 있습니다. 예를 들어, 얼굴 사진으로 구성된 대규모 코퍼스가 있으면 동일한 데이터세트에서 나온 것처럼 보이는 새로운 사실적인 이미지를 생성할 수 있기를 원할 수 있습니다. 이러한 종류의 학습을 생성 모델링이라고 합니다.
Until recently, we had no method that could synthesize novel photorealistic images. But the success of deep neural networks for discriminative learning opened up new possibilities. One big trend over the last three years has been the application of discriminative deep nets to overcome challenges in problems that we do not generally think of as supervised learning problems. The recurrent neural network language models are one example of using a discriminative network (trained to predict the next character) that once trained can act as a generative model.
최근까지 우리는 새로운 사실적 이미지를 합성할 수 있는 방법이 없었습니다. 그러나 차별적 학습을 위한 심층 신경망의 성공은 새로운 가능성을 열어주었습니다. 지난 3년 동안의 큰 추세 중 하나는 일반적으로 지도 학습 문제로 생각하지 않는 문제를 극복하기 위해 차별적인 딥 넷을 적용한 것입니다. 순환 신경망 언어 모델은 일단 훈련되면 생성 모델 역할을 할 수 있는 식별 네트워크(다음 문자를 예측하도록 훈련됨)를 사용하는 한 가지 예입니다.
In 2014, a breakthrough paper introduced Generative adversarial networks (GANs) (Goodfellow et al., 2014), a clever new way to leverage the power of discriminative models to get good generative models. At their heart, GANs rely on the idea that a data generator is good if we cannot tell fake data apart from real data. In statistics, this is called a two-sample test - a test to answer the question whether datasets X={x1,…,xn} and X′={x1′,…,x'n} were drawn from the same distribution. The main difference between most statistics papers and GANs is that the latter use this idea in a constructive way. In other words, rather than just training a model to say “hey, these two datasets do not look like they came from the same distribution”, they use the two-sample test to provide training signals to a generative model. This allows us to improve the data generator until it generates something that resembles the real data. At the very least, it needs to fool the classifier even if our classifier is a state of the art deep neural network.
2014년 획기적인 논문에서는 판별 모델의 힘을 활용하여 좋은 생성 모델을 얻는 영리하고 새로운 방법인 생성적 적대 네트워크(GAN)(Goodfellow et al., 2014)를 소개했습니다. GAN의 핵심은 실제 데이터와 가짜 데이터를 구별할 수 없다면 데이터 생성기가 좋다는 생각에 의존합니다. 통계에서는 이를 2-표본 검정이라고 합니다. 즉, 데이터 세트 X={x1,…,xn} 및 X′={x1′,…,x'n}이 동일한 분포에서 추출되었는지 여부에 대한 질문에 대답하는 테스트입니다. 대부분의 통계 논문과 GAN의 주요 차이점은 후자가 이 아이디어를 건설적인 방식으로 사용한다는 것입니다. 즉, 단순히 "이 두 데이터 세트는 동일한 분포에서 나온 것처럼 보이지 않습니다"라고 말하도록 모델을 훈련시키는 대신 2-샘플 테스트를 사용하여 생성 모델에 훈련 신호를 제공합니다. 이를 통해 실제 데이터와 유사한 것을 생성할 때까지 데이터 생성기를 개선할 수 있습니다. 최소한 분류기가 최첨단 심층 신경망이라 하더라도 분류기를 속일 필요는 있습니다.
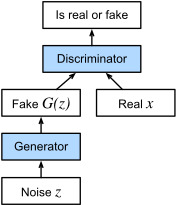
The GAN architecture is illustrated in Fig. 20.1.1. As you can see, there are two pieces in GAN architecture - first off, we need a device (say, a deep network but it really could be anything, such as a game rendering engine) that might potentially be able to generate data that looks just like the real thing. If we are dealing with images, this needs to generate images. If we are dealing with speech, it needs to generate audio sequences, and so on. We call this the generator network. The second component is the discriminator network. It attempts to distinguish fake and real data from each other. Both networks are in competition with each other. The generator network attempts to fool the discriminator network. At that point, the discriminator network adapts to the new fake data. This information, in turn is used to improve the generator network, and so on.
GAN 아키텍처는 그림 20.1.1에 설명되어 있습니다. 보시다시피, GAN 아키텍처에는 두 가지 부분이 있습니다. 먼저, 잠재적으로 보이는 데이터를 생성할 수 있는 장치(예: 심층 네트워크이지만 실제로는 게임 렌더링 엔진과 같은 모든 것이 될 수 있음)가 필요합니다. 진짜처럼. 이미지를 다루는 경우 이미지를 생성해야 합니다. 음성을 다루는 경우 오디오 시퀀스 등을 생성해야 합니다. 우리는 이것을 Generator 네트워크라고 부릅니다. 두 번째 구성 요소는 discriminator 네트워크입니다. 가짜 데이터와 실제 데이터를 구별하려고 시도합니다. 두 네트워크는 서로 경쟁하고 있습니다. 생성자 네트워크는 판별자 discriminator 네트워크를 속이려고 시도합니다. 이 시점에서 판별기 네트워크는 새로운 가짜 데이터에 적응합니다. 이 정보는 generator network 등을 개선하는 데 사용됩니다.
The discriminator is a binary classifier to distinguish if the input x is real (from real data) or fake (from the generator). Typically, the discriminator outputs a scalar prediction o∈ℝ for input x, such as using a fully connected layer with hidden size 1, and then applies sigmoid function to obtain the predicted probability D(x)=1/(1+e**−o). Assume the label y for the true data is 1 and 0 for the fake data. We train the discriminator to minimize the cross-entropy loss, i.e.,
판별자는 입력 x가 실제(실제 데이터에서)인지 가짜(생성기에서)인지 구별하는 이진 분류기입니다. 일반적으로 판별기는 은닉 크기가 1인 완전 연결 레이어를 사용하는 것과 같이 입력 x에 대해 스칼라 예측 o∈ℝ을 출력합니다. 그런 다음 시그모이드 함수를 적용하여 예측 확률 'D(x)=1/(1+e**−o)'를 얻습니다. 실제 데이터의 레이블 y는 1이고 가짜 데이터의 레이블은 0이라고 가정합니다. 교차 엔트로피 손실을 최소화하기 위해 판별자를 훈련합니다. 즉,
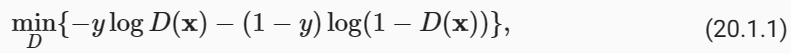
For the generator, it first draws some parameter z∈ℝ**d from a source of randomness, e.g., a normal distribution z∼N(0,1). We often call z as the latent variable. It then applies a function to generate x′=G(z). The goal of the generator is to fool the discriminator to classify x′=G(z) as true data, i.e., we want D(G(z))≈1. In other words, for a given discriminator D, we update the parameters of the generator G to maximize the cross-entropy loss when y=0, i.e.,
생성기의 경우 먼저 임의성의 소스(예: 정규 분포 z∼N(0,1))에서 일부 매개변수 z∈ℝ**d를 그립니다. 우리는 종종 z를 잠재 변수라고 부릅니다. 그런 다음 x′=G(z)를 생성하는 함수를 적용합니다. 생성기의 목표는 판별기를 속여 x′=G(z)를 실제 데이터로 분류하는 것입니다. 즉, D(G(z))≒1을 원합니다. 즉, 주어진 판별기 D에 대해 생성기 G의 매개변수를 업데이트하여 y=0일 때 교차 엔트로피 손실을 최대화합니다. 즉,
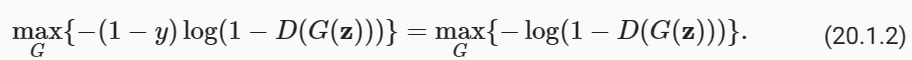
If the generator does a perfect job, then D(x′)≈1, so the above loss is near 0, which results in the gradients that are too small to make good progress for the discriminator. So commonly, we minimize the following loss:
생성기가 완벽한 작업을 수행하면 D(x′) ≒1이므로 위의 손실은 0에 가까워서 판별기가 제대로 진행하기에는 기울기가 너무 작아집니다. 따라서 일반적으로 다음 손실을 최소화합니다.
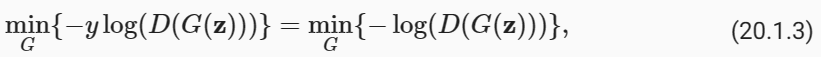
which is just feeding x′=G(z) into the discriminator but giving label y=1.
x′=G(z)를 판별자에 입력하지만 라벨 y=1을 제공합니다.
To sum up, D and G are playing a “minimax” game with the comprehensive objective function:
요약하자면, D와 G는 포괄적인 목적 함수를 사용하여 "미니맥스" 게임을 하고 있습니다.
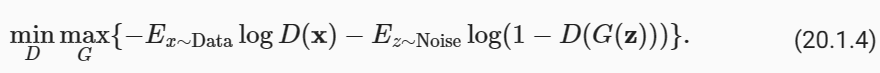
Many of the GANs applications are in the context of images. As a demonstration purpose, we are going to content ourselves with fitting a much simpler distribution first. We will illustrate what happens if we use GANs to build the world’s most inefficient estimator of parameters for a Gaussian. Let’s get started.
GAN 애플리케이션의 대부분은 이미지와 관련되어 있습니다. 데모 목적으로 먼저 훨씬 간단한 배포판을 맞추는 것으로 만족하겠습니다. GAN을 사용하여 세계에서 가장 비효율적인 가우스 매개변수 추정기를 구축하면 어떤 일이 발생하는지 설명하겠습니다. 시작하자.
%matplotlib inline
import torch
from torch import nn
from d2l import torch as d2l- %matplotlib inline: 이 코드 라인은 주피터 노트북 환경에서 그래프를 인라인으로 표시하도록 지정하는 명령입니다. 즉, 그래프가 노트북 안에서 바로 표시됩니다.
- import torch: 파이토치 라이브러리를 임포트합니다. 파이토치는 딥 러닝 모델을 구축하고 학습하는 데 사용되는 라이브러리입니다.
- from torch import nn: 파이토치의 nn 모듈에서 필요한 부분을 가져옵니다. nn 모듈은 신경망을 정의하고 학습하는 데 사용되는 다양한 도구와 클래스를 포함하고 있습니다.
- from d2l import torch as d2l: "Dive into Deep Learning" 라이브러리에서 torch 모듈을 가져옵니다. 이 라이브러리는 교재와 관련된 유틸리티 함수와 도우미 함수를 제공합니다.
이 코드의 주요 목적은 파이토치와 "Dive into Deep Learning" 라이브러리를 설정하고 사용 가능한 도구와 기능을 가져오는 것입니다. 이러한 도구와 기능은 GAN을 구현하고 실험하는 데 사용될 것입니다.
20.1.1. Generate Some “Real” Data
Since this is going to be the world’s lamest example, we simply generate data drawn from a Gaussian.
이것은 세계에서 가장 형편없는 예가 될 것이기 때문에 우리는 단순히 가우스에서 가져온 데이터를 생성합니다.
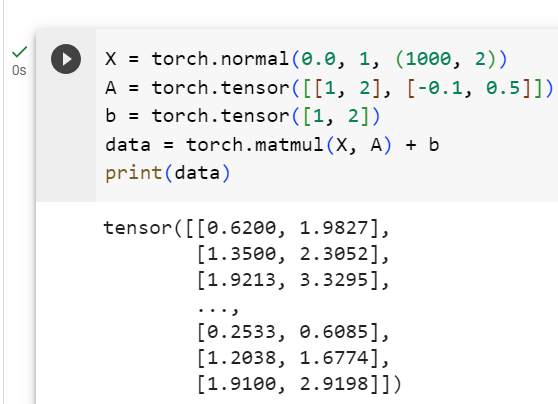
X = torch.normal(0.0, 1, (1000, 2))
A = torch.tensor([[1, 2], [-0.1, 0.5]])
b = torch.tensor([1, 2])
data = torch.matmul(X, A) + b- X = torch.normal(0.0, 1, (1000, 2)): X는 평균이 0이고 표준 편차가 1인 정규 분포 (표준 정규 분포)에서 무작위로 샘플링된 값을 가지는 1000x2 크기의 텐서입니다. 이는 평균이 0이고 표준 편차가 1인 가우시안 분포에서 무작위로 데이터를 생성하는 것을 나타냅니다.
- A = torch.tensor([[1, 2], [-0.1, 0.5]]): A는 2x2 크기의 텐서로, 행렬입니다. 이 행렬은 데이터에 곱해져서 변환을 수행하는 데 사용될 것입니다. 첫 번째 행은 [1, 2]이고 두 번째 행은 [-0.1, 0.5]입니다.
- b = torch.tensor([1, 2]): b는 1x2 크기의 텐서로, 벡터입니다. 이 벡터는 데이터에 더해질 것이며, 각 차원에 대한 평행 이동을 나타냅니다. 첫 번째 요소는 1이고 두 번째 요소는 2입니다.
- data = torch.matmul(X, A) + b: data는 행렬 X를 행렬 A로 변환하고 벡터 b를 더한 결과입니다. 이것은 선형 변환과 평행 이동을 나타내며, 데이터셋 data에 저장됩니다. 즉, X의 각 데이터 포인트에 대해 선형 변환과 평행 이동이 수행되어 최종 데이터셋이 생성됩니다.
이 코드는 데이터를 생성하는 과정을 보여주며, 이 데이터는 GAN 또는 다른 딥 러닝 모델을 학습하고 실험하는 데 사용될 수 있습니다.
Let’s see what we got. This should be a Gaussian shifted in some rather arbitrary way with mean b and covariance matrix A**T A.
우리가 무엇을 얻었는지 봅시다. 이는 평균 b 및 공분산 행렬 A**T A를 사용하여 다소 임의적인 방식으로 이동된 가우스여야 합니다.
d2l.set_figsize()
d2l.plt.scatter(data[:100, (0)].detach().numpy(), data[:100, (1)].detach().numpy());
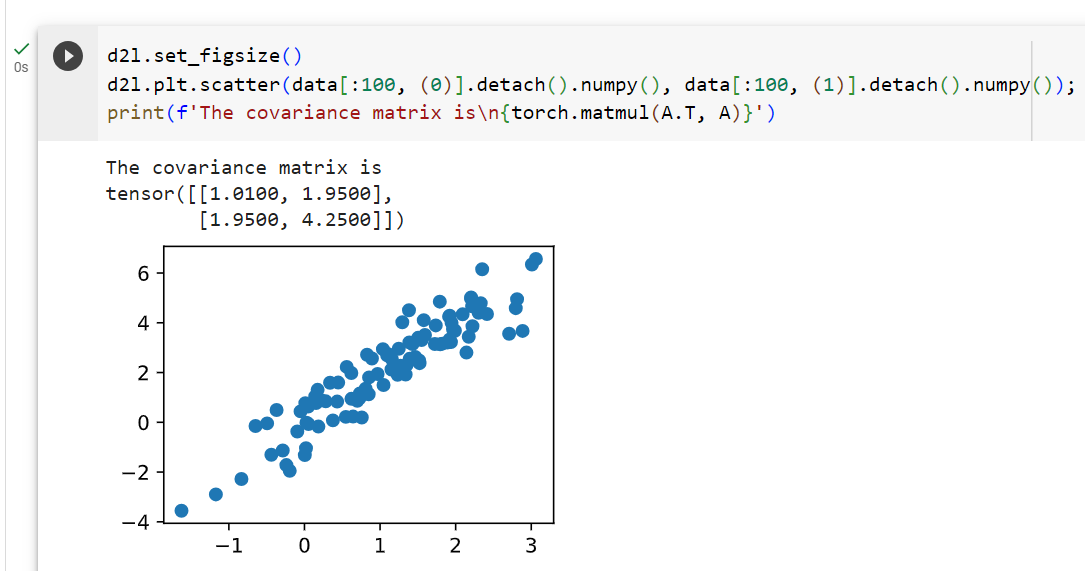
print(f'The covariance matrix is\n{torch.matmul(A.T, A)}')- d2l.set_figsize(): 이 함수는 "Dive into Deep Learning" 라이브러리인 d2l을 사용하여 그림의 크기를 설정합니다. 이 코드에서는 그림 크기를 미리 설정하여 플롯을 만들 때 적절한 크기로 설정합니다.
- d2l.plt.scatter(data[:100, (0)].detach().numpy(), data[:100, (1)].detach().numpy()): 이 코드는 데이터를 산점도로 표시합니다. data에서 처음 100개의 데이터 포인트에 대해 두 번째 차원과 세 번째 차원의 값을 가져와서 산점도를 그립니다. detach().numpy()는 텐서를 넘파이 배열로 변환하는 작업입니다.
- print(f'The covariance matrix is\n{torch.matmul(A.T, A)}'): 이 코드는 주어진 행렬 A의 전치 행렬과 A 자체를 곱한 결과를 출력합니다. 이것은 데이터의 공분산 행렬을 나타내며, 출력 메시지에 포함됩니다.
이 코드는 데이터의 분포를 시각화하고 해당 데이터의 공분산을 계산하여 출력하는 역할을 합니다. 이를 통해 데이터의 특성과 분포를 파악할 수 있습니다.
The covariance matrix is
tensor([[1.0100, 1.9500],
[1.9500, 4.2500]])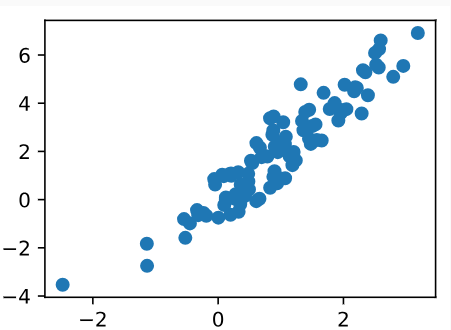
batch_size = 8
data_iter = d2l.load_array((data,), batch_size)- batch_size = 8: 이 코드 라인은 미니배치의 크기를 8로 설정합니다. 미니배치는 한 번에 모델에 입력되는 데이터의 일부분을 나타냅니다. 여기서는 8개의 데이터 포인트로 구성된 미니배치를 사용하겠다는 것을 의미합니다.
- data_iter = d2l.load_array((data,), batch_size): 이 코드 라인은 d2l 라이브러리의 load_array 함수를 사용하여 데이터를 미니배치로 나누는 데이터 반복자를 생성합니다. load_array 함수는 데이터를 가져와서 지정한 배치 크기로 나누고, 각 미니배치를 생성하는데 사용됩니다. 이 데이터 반복자(data_iter)를 사용하면 모델을 학습할 때 미니배치 단위로 데이터를 처리할 수 있습니다.
즉, 이 코드는 데이터를 작은 배치로 분할하고, 각 미니배치에 대한 반복자(data_iter)를 생성하는 과정을 나타냅니다. 이것은 모델 학습 및 평가에서 사용되는 일반적인 데이터 처리 방법 중 하나입니다.
20.1.2. Generator
Our generator network will be the simplest network possible - a single layer linear model. This is since we will be driving that linear network with a Gaussian data generator. Hence, it literally only needs to learn the parameters to fake things perfectly.
우리의 생성기 네트워크는 가능한 가장 간단한 네트워크, 즉 단일 레이어 선형 모델이 될 것입니다. 이는 가우스 데이터 생성기를 사용하여 선형 네트워크를 구동할 것이기 때문입니다. 따라서 말 그대로 완벽하게 가짜를 만들기 위한 매개변수만 학습하면 됩니다.
net_G = nn.Sequential(nn.Linear(2, 2))- nn.Sequential: 파이토치의 nn.Sequential은 뉴럴 네트워크의 일련의 연속적인 레이어를 정의하는 컨테이너입니다. 이 컨테이너를 사용하면 각 레이어를 순차적으로 쌓을 수 있습니다.
- nn.Linear(2, 2): 이 부분은 nn.Sequential 내부에 추가될 첫 번째 레이어입니다. nn.Linear는 선형 변환을 수행하는 레이어로, 입력 차원과 출력 차원을 지정합니다. 여기서는 입력 차원이 2이고 출력 차원이 2인 선형 레이어를 정의합니다. 즉, 이 생성자 신경망은 2차원의 입력을 받아 2차원의 출력을 생성합니다.
이 코드는 간단한 생성자 신경망을 정의하는데 사용됩니다. GAN(Generative Adversarial Network)에서 생성자는 무작위 노이즈를 입력으로 받아 원하는 형태의 데이터를 생성하는 역할을 합니다. 이 코드에서는 입력 차원과 출력 차원이 모두 2로 설정되었으므로, 이 생성자는 2차원의 데이터를 생성하는 데 사용될 것입니다.
20.1.3. Discriminator
For the discriminator we will be a bit more discriminating: we will use an MLP with 3 layers to make things a bit more interesting.
판별자의 경우 좀 더 판별할 것입니다. 3개 레이어가 있는 MLP를 사용하여 좀 더 흥미롭게 만들 것입니다.
net_D = nn.Sequential(
nn.Linear(2, 5), nn.Tanh(),
nn.Linear(5, 3), nn.Tanh(),
nn.Linear(3, 1))- nn.Sequential: 파이토치의 nn.Sequential은 뉴럴 네트워크의 일련의 연속적인 레이어를 정의하는 컨테이너입니다. 이 컨테이너를 사용하면 각 레이어를 순차적으로 쌓을 수 있습니다.
- nn.Linear(2, 5): 이 부분은 nn.Sequential 내부에 추가될 첫 번째 레이어입니다. nn.Linear는 선형 변환을 수행하는 레이어로, 입력 차원과 출력 차원을 지정합니다. 여기서는 입력 차원이 2이고 출력 차원이 5인 선형 레이어를 정의합니다. 이 레이어는 입력 데이터를 5차원 공간으로 변환합니다.
- nn.Tanh(): 이는 하이퍼볼릭 탄젠트 활성화 함수를 나타냅니다. 이 활성화 함수는 레이어의 출력을 -1과 1 사이로 변환합니다.
- 이어지는 nn.Linear, nn.Tanh() 레이어들은 비슷한 방식으로 연결됩니다. 두 번째 레이어는 5차원을 3차원으로, 세 번째 레이어는 3차원을 1차원으로 변환합니다.
이 코드는 간단한 판별자 신경망을 정의하는데 사용됩니다. GAN(Generative Adversarial Network)에서 판별자는 생성된 데이터와 실제 데이터를 구분하는 역할을 합니다. 이 판별자는 2차원의 입력을 받아 하이퍼볼릭 탄젠트를 사용하여 비선형 변환을 수행하고, 여러 레이어를 통해 데이터를 1차원 출력으로 분류합니다.
20.1.4. Training
First we define a function to update the discriminator.
먼저 판별자를 업데이트하는 함수를 정의합니다.
#@save
def update_D(X, Z, net_D, net_G, loss, trainer_D):
"""Update discriminator."""
batch_size = X.shape[0]
ones = torch.ones((batch_size,), device=X.device)
zeros = torch.zeros((batch_size,), device=X.device)
trainer_D.zero_grad()
real_Y = net_D(X)
fake_X = net_G(Z)
# Do not need to compute gradient for `net_G`, detach it from
# computing gradients.
fake_Y = net_D(fake_X.detach())
loss_D = (loss(real_Y, ones.reshape(real_Y.shape)) +
loss(fake_Y, zeros.reshape(fake_Y.shape))) / 2
loss_D.backward()
trainer_D.step()
return loss_D
- def update_D(X, Z, net_D, net_G, loss, trainer_D): 이 함수는 판별자 네트워크를 업데이트하는 역할을 합니다. 이 함수는 다음 매개변수들을 입력으로 받습니다.
- X: 실제 데이터 샘플 배치
- Z: 생성자 네트워크에 의해 생성된 가짜 데이터 샘플 배치
- net_D: 판별자 네트워크
- net_G: 생성자 네트워크
- loss: 손실 함수
- trainer_D: 판별자 네트워크를 최적화하기 위한 옵티마이저
- batch_size = X.shape[0]: 배치 크기를 구합니다. 이는 입력 데이터 X의 첫 번째 차원인 배치 차원의 크기입니다.
- ones = torch.ones((batch_size,), device=X.device): 길이가 batch_size인 1로 채워진 텐서를 생성합니다. 이 텐서는 실제 데이터에 대한 레이블로 사용됩니다. device 매개변수는 텐서를 어느 장치 (예: CPU 또는 GPU)에서 계산할 것인지를 지정합니다.
- zeros = torch.zeros((batch_size,), device=X.device): 길이가 batch_size인 0으로 채워진 텐서를 생성합니다. 이 텐서는 가짜 데이터에 대한 레이블로 사용됩니다.
- trainer_D.zero_grad(): 판별자 네트워크의 그래디언트를 초기화합니다. 이는 새로운 그래디언트를 계산하기 전에 이전 그래디언트를 제거하는데 사용됩니다.
- real_Y = net_D(X): 실제 데이터 X를 판별자 네트워크에 전달하여 실제 데이터의 판별 결과를 계산합니다.
- fake_X = net_G(Z): 생성자 네트워크에 의해 생성된 가짜 데이터 Z를 판별자 네트워크에 전달하여 가짜 데이터의 판별 결과를 계산합니다.
- fake_Y = net_D(fake_X.detach()): 생성자 네트워크에 의해 생성된 가짜 데이터 fake_X를 판별자 네트워크에 전달합니다. .detach()를 사용하여 생성자 네트워크의 그래디언트를 계산하지 않도록 설정합니다.
- loss_D = (loss(real_Y, ones.reshape(real_Y.shape)) + loss(fake_Y, zeros.reshape(fake_Y.shape))) / 2: 실제 데이터와 가짜 데이터에 대한 판별자의 손실을 계산합니다. 이 손실은 실제 데이터의 판별 결과와 1 사이의 손실, 그리고 가짜 데이터의 판별 결과와 0 사이의 손실을 평균화한 것입니다.
- loss_D.backward(): 판별자 네트워크의 손실에 대한 그래디언트를 계산합니다.
- trainer_D.step(): 판별자 네트워크의 매개변수를 업데이트합니다. 최적화된 그래디언트를 사용하여 신경망의 매개변수를 조정합니다.
- return loss_D: 계산된 판별자의 손실을 반환합니다.
이 함수는 GAN의 판별자 네트워크를 학습하기 위해 사용되며, 생성자와 판별자 사이의 경쟁을 통해 모델을 훈련시키는 데 필요합니다.
The generator is updated similarly. Here we reuse the cross-entropy loss but change the label of the fake data from 0 to 1.
생성기도 비슷하게 업데이트됩니다. 여기서는 교차 엔트로피 손실을 재사용하지만 가짜 데이터의 레이블을 0에서 1로 변경합니다.
#@save
def update_G(Z, net_D, net_G, loss, trainer_G):
"""Update generator."""
batch_size = Z.shape[0]
ones = torch.ones((batch_size,), device=Z.device)
trainer_G.zero_grad()
# We could reuse `fake_X` from `update_D` to save computation
fake_X = net_G(Z)
# Recomputing `fake_Y` is needed since `net_D` is changed
fake_Y = net_D(fake_X)
loss_G = loss(fake_Y, ones.reshape(fake_Y.shape))
loss_G.backward()
trainer_G.step()
return loss_G- def update_G(Z, net_D, net_G, loss, trainer_G): 이 함수는 생성자 네트워크를 업데이트하는 역할을 합니다. 이 함수는 다음 매개변수들을 입력으로 받습니다.
- Z: 생성자 네트워크의 입력으로 사용될 무작위 노이즈 벡터 배치
- net_D: 판별자 네트워크
- net_G: 생성자 네트워크
- loss: 손실 함수
- trainer_G: 생성자 네트워크를 최적화하기 위한 옵티마이저
- batch_size = Z.shape[0]: 배치 크기를 구합니다. 이는 입력 데이터 Z의 첫 번째 차원인 배치 차원의 크기입니다.
- ones = torch.ones((batch_size,), device=Z.device): 길이가 batch_size인 1로 채워진 텐서를 생성합니다. 이 텐서는 생성자가 생성한 데이터에 대한 레이블로 사용됩니다. device 매개변수는 텐서를 어느 장치 (예: CPU 또는 GPU)에서 계산할 것인지를 지정합니다.
- trainer_G.zero_grad(): 생성자 네트워크의 그래디언트를 초기화합니다. 이는 새로운 그래디언트를 계산하기 전에 이전 그래디언트를 제거하는데 사용됩니다.
- fake_X = net_G(Z): 생성자 네트워크에 무작위 노이즈 Z를 전달하여 가짜 데이터를 생성합니다.
- fake_Y = net_D(fake_X): 생성된 가짜 데이터 fake_X를 판별자 네트워크에 전달하여 가짜 데이터의 판별 결과를 계산합니다. 이 부분은 판별자를 통해 가짜 데이터를 판별한 결과입니다.
- loss_G = loss(fake_Y, ones.reshape(fake_Y.shape)): 생성자의 손실을 계산합니다. 이 손실은 생성자가 생성한 가짜 데이터에 대한 판별자의 출력과 1 사이의 손실을 나타냅니다. 생성자는 판별자를 속이려고 노력하며, 따라서 이 손실을 최소화하려고 합니다.
- loss_G.backward(): 생성자 네트워크의 손실에 대한 그래디언트를 계산합니다.
- trainer_G.step(): 생성자 네트워크의 매개변수를 업데이트합니다. 최적화된 그래디언트를 사용하여 신경망의 매개변수를 조정합니다.
- return loss_G: 계산된 생성자의 손실을 반환합니다.
이 함수는 GAN의 생성자 네트워크를 학습하기 위해 사용됩니다. 생성자는 판별자를 속이려고 하며, 이를 통해 실제와 유사한 데이터를 생성하도록 훈련됩니다.
Both the discriminator and the generator performs a binary logistic regression with the cross-entropy loss. We use Adam to smooth the training process. In each iteration, we first update the discriminator and then the generator. We visualize both losses and generated examples.
판별자와 생성자 모두 교차 엔트로피 손실을 사용하여 이진 로지스틱 회귀를 수행합니다. 우리는 훈련 과정을 원활하게 하기 위해 Adam을 사용합니다. 각 반복에서 먼저 판별자를 업데이트한 다음 생성자를 업데이트합니다. 손실과 생성된 사례를 모두 시각화합니다.
def train(net_D, net_G, data_iter, num_epochs, lr_D, lr_G, latent_dim, data):
loss = nn.BCEWithLogitsLoss(reduction='sum')
for w in net_D.parameters():
nn.init.normal_(w, 0, 0.02)
for w in net_G.parameters():
nn.init.normal_(w, 0, 0.02)
trainer_D = torch.optim.Adam(net_D.parameters(), lr=lr_D)
trainer_G = torch.optim.Adam(net_G.parameters(), lr=lr_G)
animator = d2l.Animator(xlabel='epoch', ylabel='loss',
xlim=[1, num_epochs], nrows=2, figsize=(5, 5),
legend=['discriminator', 'generator'])
animator.fig.subplots_adjust(hspace=0.3)
for epoch in range(num_epochs):
# Train one epoch
timer = d2l.Timer()
metric = d2l.Accumulator(3) # loss_D, loss_G, num_examples
for (X,) in data_iter:
batch_size = X.shape[0]
Z = torch.normal(0, 1, size=(batch_size, latent_dim))
metric.add(update_D(X, Z, net_D, net_G, loss, trainer_D),
update_G(Z, net_D, net_G, loss, trainer_G),
batch_size)
# Visualize generated examples
Z = torch.normal(0, 1, size=(100, latent_dim))
fake_X = net_G(Z).detach().numpy()
animator.axes[1].cla()
animator.axes[1].scatter(data[:, 0], data[:, 1])
animator.axes[1].scatter(fake_X[:, 0], fake_X[:, 1])
animator.axes[1].legend(['real', 'generated'])
# Show the losses
loss_D, loss_G = metric[0]/metric[2], metric[1]/metric[2]
animator.add(epoch + 1, (loss_D, loss_G))
print(f'loss_D {loss_D:.3f}, loss_G {loss_G:.3f}, '
f'{metric[2] / timer.stop():.1f} examples/sec')이 함수는 GAN 모델을 훈련하는 주요 루프를 포함하고 있습니다. 주요 단계는 다음과 같습니다.
- BCEWithLogitsLoss를 사용하여 손실 함수를 설정합니다. 이 손실 함수는 이진 분류 손실 함수로 사용됩니다.
- 판별자와 생성자 네트워크의 가중치를 초기화합니다. 일반적으로 작은 랜덤값으로 초기화합니다.
- Adam 옵티마이저를 설정하여 판별자와 생성자 네트워크의 매개변수를 최적화합니다.
- 애니메이터를 설정하여 훈련 중에 손실과 생성된 데이터를 시각화합니다.
- 주어진 에포크 수(num_epochs) 동안 훈련 루프를 실행합니다. 각 에포크에서는 판별자와 생성자 네트워크를 업데이트하고 손실을 누적합니다.
- 생성된 예제를 시각화하여 실제 데이터와 비교합니다.
- 각 에포크의 손실을 기록하고 애니메이터를 통해 시각화합니다.
- 훈련이 끝난 후 최종 손실과 훈련 속도를 출력합니다.
이 함수를 호출하여 GAN 모델을 훈련하고 결과를 시각화할 수 있습니다.
Now we specify the hyperparameters to fit the Gaussian distribution.
이제 가우스 분포에 맞게 하이퍼파라미터를 지정합니다.
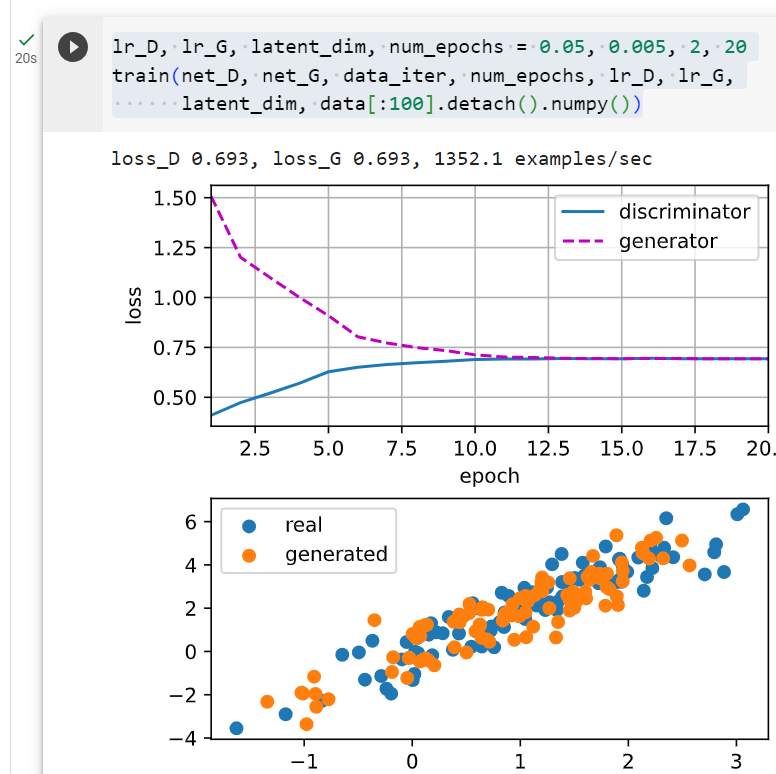
lr_D, lr_G, latent_dim, num_epochs = 0.05, 0.005, 2, 20
train(net_D, net_G, data_iter, num_epochs, lr_D, lr_G,
latent_dim, data[:100].detach().numpy())- lr_D, lr_G, latent_dim, num_epochs: 이 코드 라인에서는 GAN 모델을 훈련하는데 사용되는 하이퍼파라미터를 설정합니다.
- lr_D: 판별자 네트워크를 최적화하는 데 사용되는 학습률입니다.
- lr_G: 생성자 네트워크를 최적화하는 데 사용되는 학습률입니다.
- latent_dim: 생성자의 입력 노이즈 벡터의 차원입니다.
- num_epochs: 훈련하는 데 사용할 에포크(훈련 주기) 수입니다.
- train(net_D, net_G, data_iter, num_epochs, lr_D, lr_G, latent_dim, data[:100].detach().numpy()): 이 코드 라인에서는 train 함수를 호출하여 GAN 모델을 실제로 훈련합니다.
- net_D: 판별자 네트워크
- net_G: 생성자 네트워크
- data_iter: 데이터 반복자
- num_epochs: 설정한 에포크 수
- lr_D, lr_G: 판별자와 생성자의 학습률
- latent_dim: 생성자의 입력 노이즈 벡터의 차원
- data[:100].detach().numpy(): 사용할 데이터 중에서 처음 100개의 데이터를 선택하고 넘파이 배열로 변환한 것입니다. GAN 모델을 훈련할 때는 실제 데이터의 일부만 사용하여 훈련합니다.
이 코드를 실행하면 GAN 모델이 주어진 데이터에 대해 훈련되고, 훈련 과정 중에 손실이 감소하면서 생성된 가짜 데이터가 실제 데이터와 유사해지는 것을 관찰할 수 있습니다.
loss_D 0.693, loss_G 0.693, 1020.0 examples/sec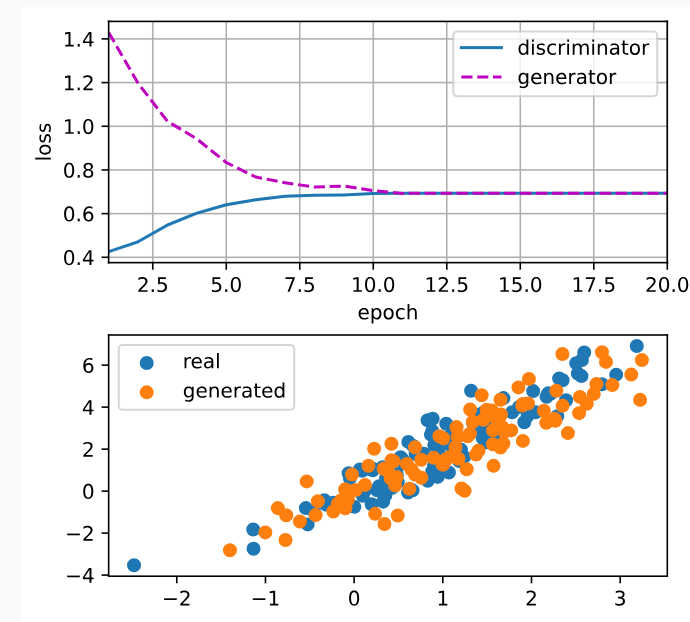
20.1.5. Summary
- Generative adversarial networks (GANs) composes of two deep networks, the generator and the discriminator.
- GAN(Generative Adversarial Network)은 생성자와 판별자라는 두 개의 심층 네트워크로 구성됩니다.
- The generator generates the image as much closer to the true image as possible to fool the discriminator, via maximizing the cross-entropy loss, i.e., maxlog(D(x′)).
- 생성기는 교차 엔트로피 손실(예: maxlog(D(x′)))을 최대화하여 판별기를 속이기 위해 가능한 한 실제 이미지에 더 가까운 이미지를 생성합니다.
- The discriminator tries to distinguish the generated images from the true images, via minimizing the cross-entropy loss, i.e., min−y logD(x)−(1−y)log(1−D(x)).
- 판별자는 교차 엔트로피 손실, 즉 min−y logD(x)−(1−y)log(1−D(x))를 최소화하여 생성된 이미지를 실제 이미지와 구별하려고 시도합니다.
20.1.6. Exercises
- Does an equilibrium exist where the generator wins, i.e. the discriminator ends up unable to distinguish the two distributions on finite samples?
- 생성자가 승리하는 평형이 존재합니까? 즉, 판별자가 유한 샘플에서 두 분포를 구별할 수 없게 됩니까?
https://youtu.be/odpjk7_tGY0?si=VdPZUy_pliDQuy9s
https://youtu.be/AVvlDmhHgC4?si=NdxDspK0LVNwpV8H
'Dive into Deep Learning > D2L Generative Adversarial Networks_GAN' 카테고리의 다른 글
| D2L - 20.2. Deep Convolutional Generative Adversarial Networks (0) | 2023.09.16 |
|---|