

20.2. Deep Convolutional Generative Adversarial Networks — Dive into Deep Learning 1.0.3 documentation
d2l.ai
20.2. Deep Convolutional Generative Adversarial Networks
In Section 20.1, we introduced the basic ideas behind how GANs work. We showed that they can draw samples from some simple, easy-to-sample distribution, like a uniform or normal distribution, and transform them into samples that appear to match the distribution of some dataset. And while our example of matching a 2D Gaussian distribution got the point across, it is not especially exciting.
섹션 20.1에서 GAN 작동 방식에 대한 기본 아이디어를 소개했습니다. 우리는 균일 분포 또는 정규 분포와 같이 간단하고 샘플링하기 쉬운 분포에서 샘플을 추출하여 일부 데이터 세트의 분포와 일치하는 것처럼 보이는 샘플로 변환할 수 있음을 보여주었습니다. 2D 가우스 분포를 일치시키는 예제는 요점을 이해했지만 특별히 흥미롭지는 않습니다.
In this section, we will demonstrate how you can use GANs to generate photorealistic images. We will be basing our models on the deep convolutional GANs (DCGAN) introduced in Radford et al. (2015). We will borrow the convolutional architecture that have proven so successful for discriminative computer vision problems and show how via GANs, they can be leveraged to generate photorealistic images.
이 섹션에서는 GAN을 사용하여 사실적인 이미지를 생성하는 방법을 보여줍니다. 우리는 Radford 등이 소개한 DCGAN(Deep Convolutional GAN)을 모델의 기반으로 삼을 것입니다. (2015). 우리는 차별적인 컴퓨터 비전 문제에 대해 매우 성공적인 것으로 입증된 컨벌루션 아키텍처를 빌려 GAN을 통해 어떻게 활용하여 사실적인 이미지를 생성할 수 있는지 보여줄 것입니다.
import warnings
import torch
import torchvision
from torch import nn
from d2l import torch as d2l- import warnings: 경고 메시지를 관리하기 위한 파이썬 내장 모듈인 warnings를 가져옵니다. 이 모듈은 경고를 표시하거나 숨기는 데 사용됩니다.
- import torch: 파이토치(PyTorch) 라이브러리를 가져옵니다. 파이토치는 딥러닝 모델을 구축하고 훈련하기 위한 인기 있는 라이브러리입니다.
- import torchvision: 파이토치와 함께 제공되는 torchvision 라이브러리를 가져옵니다. torchvision은 컴퓨터 비전 작업을 위한 데이터셋, 모델 아키텍처, 변환 등을 제공합니다.
- from torch import nn: 파이토치의 nn 모듈에서 Neural Network 모델과 관련된 클래스 및 함수를 가져옵니다. 이 모듈을 사용하여 다양한 뉴럴 네트워크 레이어를 정의하고 모델을 구성할 수 있습니다.
- from d2l import torch as d2l: D2L 라이브러리에서 파이토치 관련 기능을 가져옵니다. D2L은 Dive into Deep Learning 책의 학습 자료와 함께 제공되는 라이브러리로, 딥러닝 모델의 이해와 구현을 돕는 데 사용됩니다.
이 코드는 딥러닝 모델을 구축하고 훈련하기 위해 필요한 라이브러리와 모듈을 가져오는 부분으로, 이후의 코드에서 이러한 라이브러리와 모듈을 사용하여 모델을 구현하고 훈련할 것입니다.
20.2.1. The Pokemon Dataset
The dataset we will use is a collection of Pokemon sprites obtained from pokemondb. First download, extract and load this dataset.
우리가 사용할 데이터 세트는 pokemondb에서 얻은 포켓몬 스프라이트 모음입니다. 먼저 이 데이터세트를 다운로드하고 추출하고 로드하세요.
#@save
d2l.DATA_HUB['pokemon'] = (d2l.DATA_URL + 'pokemon.zip',
'c065c0e2593b8b161a2d7873e42418bf6a21106c')
data_dir = d2l.download_extract('pokemon')
pokemon = torchvision.datasets.ImageFolder(data_dir)- d2l.DATA_HUB['pokemon'] = (d2l.DATA_URL + 'pokemon.zip', 'c065c0e2593b8b161a2d7873e42418bf6a21106c'): 이 코드 라인은 D2L 라이브러리의 데이터 허브(DATA_HUB)에 Pokemon 데이터셋의 URL과 해당 데이터의 해시 값을 등록합니다. 이를 통해 데이터를 다운로드하고 검증할 수 있습니다.
- data_dir = d2l.download_extract('pokemon'): d2l.download_extract 함수를 사용하여 Pokemon 데이터셋을 다운로드하고 압축을 해제한 후, 압축 해제된 데이터의 디렉토리 경로를 data_dir 변수에 저장합니다.
- pokemon = torchvision.datasets.ImageFolder(data_dir): 파이토치(torchvision)의 ImageFolder 데이터셋 클래스를 사용하여 data_dir에서 이미지 데이터를 읽어옵니다. 이 클래스는 이미지 데이터를 클래스별로 정리한 폴더 구조에서 데이터를 읽어옵니다. 예를 들어, 각 폴더는 하나의 클래스(라벨)를 나타내며 해당 클래스에 속하는 이미지 파일들을 해당 폴더에 저장합니다.
이 코드를 실행하면 Pokemon 데이터셋이 다운로드되고 파이토치 데이터셋 객체인 pokemon에 로드됩니다. 이후에는 이 데이터셋을 사용하여 딥러닝 모델을 학습하고 분류 등의 작업을 수행할 수 있습니다.
Downloading ../data/pokemon.zip from http://d2l-data.s3-accelerate.amazonaws.com/pokemon.zip...
We resize each image into 64×64. The ToTensor transformation will project the pixel value into [0,1], while our generator will use the tanh function to obtain outputs in [−1,1]. Therefore we normalize the data with 0.5 mean and 0.5 standard deviation to match the value range.
각 이미지의 크기를 64×64로 조정합니다. ToTensor 변환은 픽셀 값을 [0,1]에 투영하는 반면 생성기는 tanh 함수를 사용하여 [-1,1]의 출력을 얻습니다. 따라서 값 범위와 일치하도록 평균 0.5, 표준편차 0.5로 데이터를 정규화합니다.
batch_size = 256
transformer = torchvision.transforms.Compose([
torchvision.transforms.Resize((64, 64)),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(0.5, 0.5)
])
pokemon.transform = transformer
data_iter = torch.utils.data.DataLoader(
pokemon, batch_size=batch_size,
shuffle=True, num_workers=d2l.get_dataloader_workers())- batch_size = 256: 미니배치의 크기를 설정합니다. 한 번에 처리할 데이터 샘플의 개수를 나타냅니다.
- transformer: 데이터 전처리를 위한 변환기(Transformer)를 정의합니다. 이 코드에서는 세 가지 변환을 연속적으로 적용합니다.
- torchvision.transforms.Resize((64, 64)): 이미지의 크기를 (64, 64)로 조정합니다. 모든 이미지를 동일한 크기로 조정하여 모델에 입력으로 사용합니다.
- torchvision.transforms.ToTensor(): 이미지를 파이토치 텐서로 변환합니다. 이는 이미지 데이터를 넘파이 배열에서 텐서로 변경하는 작업입니다.
- torchvision.transforms.Normalize(0.5, 0.5): 이미지의 픽셀값을 정규화(normalize)합니다. 평균과 표준편차를 0.5로 설정하여 픽셀값을 -1에서 1 사이로 스케일링합니다.
- pokemon.transform = transformer: Pokemon 데이터셋의 전체 데이터에 대해 위에서 정의한 transformer를 적용합니다. 이제 데이터셋 내의 모든 이미지는 위의 변환을 거치게 됩니다.
- data_iter = torch.utils.data.DataLoader(pokemon, batch_size=batch_size, shuffle=True, num_workers=d2l.get_dataloader_workers()): torch.utils.data.DataLoader를 사용하여 데이터셋을 미니배치로 나누고 데이터 로딩을 관리합니다.
- pokemon: 전처리된 Pokemon 데이터셋입니다.
- batch_size: 미니배치의 크기를 설정합니다.
- shuffle=True: 데이터를 에포크마다 섞습니다. 이것은 모델이 각 에포크에서 다양한 데이터를 볼 수 있도록 도와줍니다.
- num_workers=d2l.get_dataloader_workers(): 데이터 로딩을 병렬로 처리할 워커(worker) 수를 설정합니다. 이렇게 하면 데이터 로딩이 빨라지며 훈련 속도를 향상시킬 수 있습니다.
이 코드를 실행하면 Pokemon 데이터셋이 전처리되고 미니배치 단위로 모델에 공급될 수 있는 형태로 준비됩니다. 이 데이터로더를 사용하여 훈련 및 검증 과정에서 모델을 훈련하고 테스트할 수 있습니다.
Let’s visualize the first 20 images.
처음 20개의 이미지를 시각화해 보겠습니다.
warnings.filterwarnings('ignore')
d2l.set_figsize((4, 4))
for X, y in data_iter:
imgs = X[:20,:,:,:].permute(0, 2, 3, 1)/2+0.5
d2l.show_images(imgs, num_rows=4, num_cols=5)
break- warnings.filterwarnings('ignore'): 이 코드 라인은 경고 메시지를 무시하도록 설정합니다. 데이터셋을 시각화할 때 발생할 수 있는 경고 메시지를 표시하지 않도록 합니다.
- d2l.set_figsize((4, 4)): 시각화된 이미지의 크기를 설정합니다. 이 경우에는 (4, 4) 크기로 설정되었습니다.
- for X, y in data_iter:: data_iter 데이터 로더를 통해 미니배치를 순회합니다. X는 이미지 데이터를, y는 해당 이미지의 라벨을 나타냅니다.
- imgs = X[:20,:,:,:].permute(0, 2, 3, 1)/2+0.5: 첫 번째 미니배치 중에서 처음 20개의 이미지 데이터를 선택하고, 차원 순서를 변경합니다. 원래 이미지의 차원 순서는 (배치 크기, 채널 수, 높이, 너비)이지만, 여기서는 (배치 크기, 높이, 너비, 채널 수)로 변경됩니다. 또한, 이미지의 픽셀값을 0.5를 더하고 2로 나누어 스케일을 조정합니다. 이로써 이미지의 픽셀값이 [0, 1] 범위로 스케일링됩니다.
- d2l.show_images(imgs, num_rows=4, num_cols=5): d2l.show_images 함수를 사용하여 이미지를 시각화합니다. imgs는 이미지 데이터의 배치를 나타내며, num_rows와 num_cols는 행과 열의 개수를 설정합니다. 이 경우에는 4x5 격자로 이미지가 표시됩니다.
- break: 첫 번째 미니배치를 시각화하고 나서 반복문을 종료합니다. 이 코드는 시각적으로 데이터셋의 일부를 확인할 수 있도록 도와줍니다.
이 코드를 실행하면 Pokemon 데이터셋에서 선택한 이미지 샘플이 시각화되어 출력됩니다. 이를 통해 데이터셋의 내용을 확인할 수 있습니다.

20.2.2. The Generator
The generator needs to map the noise variable z∈ℝ**d, a length-d vector, to a RGB image with width and height to be 64×64 . In Section 14.11 we introduced the fully convolutional network that uses transposed convolution layer (refer to Section 14.10) to enlarge input size. The basic block of the generator contains a transposed convolution layer followed by the batch normalization and ReLU activation.
생성기는 길이 d 벡터인 노이즈 변수 z∈ℝ**d를 너비와 높이가 64×64인 RGB 이미지에 매핑해야 합니다. 섹션 14.11에서 우리는 입력 크기를 확대하기 위해 전치 컨볼루션 레이어(섹션 14.10 참조)를 사용하는 완전 컨볼루션 네트워크를 소개했습니다. 생성기의 기본 블록에는 배치 정규화 및 ReLU 활성화가 뒤따르는 전치된 컨볼루션 레이어가 포함되어 있습니다.
class G_block(nn.Module):
def __init__(self, out_channels, in_channels=3, kernel_size=4, strides=2,
padding=1, **kwargs):
super(G_block, self).__init__(**kwargs)
self.conv2d_trans = nn.ConvTranspose2d(in_channels, out_channels,
kernel_size, strides, padding, bias=False)
self.batch_norm = nn.BatchNorm2d(out_channels)
self.activation = nn.ReLU()
def forward(self, X):
return self.activation(self.batch_norm(self.conv2d_trans(X)))이 클래스는 생성자 네트워크에서 사용되는 하나의 블록을 정의합니다. 블록은 ConvTranspose2d 레이어, BatchNorm2d 레이어, 그리고 ReLU 활성화 함수로 구성됩니다.
- __init__ 메서드: 블록의 초기화를 담당합니다. 다양한 매개변수를 사용하여 ConvTranspose2d 레이어, BatchNorm2d 레이어, ReLU 활성화 함수를 생성합니다. 이 때, out_channels는 출력 채널 수, in_channels는 입력 채널 수, kernel_size는 컨볼루션 커널의 크기, strides는 스트라이드 값, padding은 패딩 값 등을 설정할 수 있습니다.
- forward 메서드: 순전파를 정의합니다. 입력 데이터 X를 ConvTranspose2d 레이어, BatchNorm2d 레이어, ReLU 활성화 함수의 순서로 전파하여 출력을 반환합니다.
이 클래스를 사용하여 생성자 네트워크를 구축할 때, GAN 모델의 생성자는 여러 개의 G_block 레이어를 쌓아서 이미지를 생성합니다. 이러한 블록을 적절하게 조합하여 원하는 이미지를 생성하는 네트워크를 만들 수 있습니다.
In default, the transposed convolution layer uses a kℎ=kw=4 kernel, a sℎ=sw=2 strides, and a Pℎ=Pw=1 padding. With a input shape of n'h×n'w=16×16, the generator block will double input’s width and height.
기본적으로 전치 컨볼루션 레이어는 kℎ=kw=4 커널, sℎ=sw=2 스트라이드 및 Pℎ=Pw=1 패딩을 사용합니다. n'h×n'w=16×16의 입력 형태를 사용하면 생성기 블록은 입력의 너비와 높이를 두 배로 늘립니다.
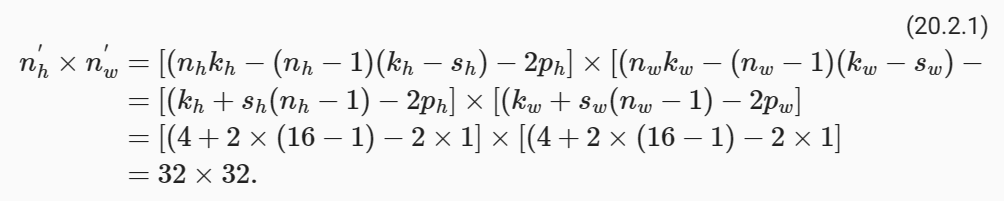
x = torch.zeros((2, 3, 16, 16))
g_blk = G_block(20)
g_blk(x).shape- x = torch.zeros((2, 3, 16, 16)): 2개의 샘플(batch size가 2), 3개의 채널(channel), 각각 16x16 크기의 이미지를 나타내는 4D 텐서를 생성합니다. 이 텐서는 가짜 이미지 생성을 위한 입력 데이터로 사용됩니다.
- g_blk = G_block(20): G_block 클래스를 사용하여 생성자 네트워크의 블록을 하나 생성합니다. 이 블록은 3D 텐서를 입력으로 받아 처리하고, 출력으로 3D 텐서를 생성합니다. 여기서 out_channels를 20으로 설정하여 출력 채널의 수를 20으로 정의합니다.
- g_blk(x).shape: 생성자 블록 g_blk에 입력 데이터 x를 전달하여 가짜 이미지를 생성합니다. 그리고 생성된 가짜 이미지의 크기(shape)를 확인합니다. 생성된 이미지의 크기를 확인하는 이유는 네트워크의 출력 크기를 이해하고 모델을 구성하기 위함입니다.
코드를 실행하면 g_blk를 사용하여 입력 데이터 x를 처리한 결과로 생성된 가짜 이미지의 크기(shape)를 확인할 수 있습니다. 이 예시에서는 출력 크기가 어떻게 결정되는지를 보여주기 위한 것이며, 실제 GAN 모델에서는 여러 개의 G_block 레이어를 조합하여 높은 해상도의 이미지를 생성하게 됩니다.
torch.Size([2, 20, 32, 32])
If changing the transposed convolution layer to a 4×4 kernel, 1×1 strides and zero padding. With a input size of 1×1, the output will have its width and height increased by 3 respectively.
전치된 컨볼루션 레이어를 4×4 커널로 변경하면 스트라이드는 1×1이고 패딩은 0입니다. 입력 크기가 1×1이면 출력의 너비와 높이가 각각 3씩 증가합니다.
x = torch.zeros((2, 3, 1, 1))
g_blk = G_block(20, strides=1, padding=0)
g_blk(x).shape코드는 생성자 네트워크의 G_block 클래스를 사용하여 가짜 이미지를 생성하는 예시를 더 자세히 설명합니다. 이번에는 스트라이드(strides)와 패딩(padding)을 다르게 설정하여 어떻게 영향을 미치는지를 보여줍니다.
- x = torch.zeros((2, 3, 1, 1)): 2개의 샘플(batch size가 2), 3개의 채널(channel), 각각 1x1 크기의 이미지를 나타내는 4D 텐서를 생성합니다. 이 텐서는 가짜 이미지 생성을 위한 입력 데이터로 사용됩니다. 이번에는 이미지 크기가 1x1로 매우 작습니다.
- g_blk = G_block(20, strides=1, padding=0): G_block 클래스를 사용하여 생성자 네트워크의 블록을 하나 생성합니다. 이 블록은 스트라이드(strides)를 1로, 패딩(padding)을 0으로 설정하여 생성됩니다. 이렇게 설정하면 출력 이미지의 크기가 입력 이미지와 동일하게 유지됩니다. 출력 채널의 수는 20으로 설정됩니다.
- g_blk(x).shape: 생성자 블록 g_blk에 입력 데이터 x를 전달하여 가짜 이미지를 생성합니다. 그리고 생성된 가짜 이미지의 크기(shape)를 확인합니다.
이번 예시에서는 스트라이드와 패딩을 1과 0으로 설정하여 출력 이미지의 크기가 입력 이미지와 동일하게 유지되었습니다. 따라서 출력 이미지의 크기는 여전히 1x1입니다. 이렇게 설정하면 이미지의 공간 해상도가 유지되면서 채널 수가 늘어나는 효과가 있습니다. 스트라이드와 패딩을 조절하여 생성자 네트워크의 출력 이미지 크기를 조절할 수 있습니다.
torch.Size([2, 20, 4, 4])The generator consists of four basic blocks that increase input’s both width and height from 1 to 32. At the same time, it first projects the latent variable into 64×8 channels, and then halve the channels each time. At last, a transposed convolution layer is used to generate the output. It further doubles the width and height to match the desired 64×64 shape, and reduces the channel size to 3. The tanh activation function is applied to project output values into the (−1,1) range.
생성기는 입력의 너비와 높이를 1에서 32로 증가시키는 4개의 기본 블록으로 구성됩니다. 동시에 잠재 변수를 먼저 64×8 채널로 투영한 다음 매번 채널을 절반으로 줄입니다. 마지막으로, 전치된 컨볼루션 레이어가 출력을 생성하는 데 사용됩니다. 원하는 64×64 모양과 일치하도록 너비와 높이를 추가로 두 배로 늘리고 채널 크기를 3으로 줄입니다. tanh 활성화 함수는 출력 값을 (-1,1) 범위로 투영하는 데 적용됩니다.
n_G = 64
net_G = nn.Sequential(
G_block(in_channels=100, out_channels=n_G*8,
strides=1, padding=0), # Output: (64 * 8, 4, 4)
G_block(in_channels=n_G*8, out_channels=n_G*4), # Output: (64 * 4, 8, 8)
G_block(in_channels=n_G*4, out_channels=n_G*2), # Output: (64 * 2, 16, 16)
G_block(in_channels=n_G*2, out_channels=n_G), # Output: (64, 32, 32)
nn.ConvTranspose2d(in_channels=n_G, out_channels=3,
kernel_size=4, stride=2, padding=1, bias=False),
nn.Tanh()) # Output: (3, 64, 64)생성자 네트워크인 net_G를 정의하는 부분으로, GAN (Generative Adversarial Network) 모델에서 사용됩니다. 이 코드는 생성자 네트워크를 구성하고 각 블록의 출력 크기를 주석으로 설명하고 있습니다.
- n_G = 64: n_G는 생성자 네트워크에서 사용할 초기 채널 수를 나타냅니다. 이 값은 64로 설정되었습니다.
- net_G = nn.Sequential(...): 생성자 네트워크를 정의하는 nn.Sequential 컨테이너를 생성합니다. 이 컨테이너는 여러 레이어를 순차적으로 쌓을 수 있도록 합니다.
- G_block(...) 블록들: 생성자 네트워크는 G_block 클래스를 사용하여 여러 개의 블록으로 구성됩니다. 각 블록은 생성자 네트워크의 한 단계를 나타내며, 입력 데이터의 차원을 높이거나 채널 수를 줄이는 역할을 합니다. 주석으로 출력 크기를 표시했습니다. 예를 들어, 첫 번째 블록은 100차원의 랜덤 노이즈 벡터를 입력으로 받고, 출력으로 (64 * 8, 4, 4) 크기의 텐서를 생성합니다.
- nn.ConvTranspose2d(...) 레이어: 마지막에는 nn.ConvTranspose2d 레이어를 사용하여 최종 출력 이미지를 생성합니다. 이 레이어는 입력 이미지의 크기를 확대하고, 출력 채널 수를 3으로 설정하여 컬러 이미지를 생성합니다.
- nn.Tanh(): 마지막으로, Tanh 활성화 함수를 사용하여 출력 이미지의 픽셀 값을 [-1, 1] 범위로 조정합니다.
이렇게 정의된 net_G는 생성자 네트워크를 나타내며, 랜덤 노이즈 벡터로부터 실제 이미지와 유사한 가짜 이미지를 생성하는 역할을 합니다.
Generate a 100 dimensional latent variable to verify the generator’s output shape.
생성기의 출력 형태를 검증하기 위해 100차원 잠재변수를 생성합니다.
x = torch.zeros((1, 100, 1, 1))
net_G(x).shape생성자 네트워크인 net_G에 랜덤 노이즈 벡터를 입력으로 주고, 이를 이용하여 가짜 이미지를 생성한 후, 생성된 이미지의 크기(shape)를 확인하는 예시를 보여줍니다.
- x = torch.zeros((1, 100, 1, 1)): 크기가 (1, 100, 1, 1)인 4D 텐서를 생성합니다. 이 텐서는 생성자 네트워크 net_G의 입력으로 사용될 랜덤 노이즈 벡터를 나타냅니다. 이 랜덤 노이즈 벡터는 100차원이며, 크기가 1x1인 가짜 이미지를 생성하기 위한 초기 입력으로 사용됩니다.
- net_G(x).shape: 생성자 네트워크 net_G에 랜덤 노이즈 벡터 x를 전달하여 가짜 이미지를 생성합니다. 그리고 생성된 가짜 이미지의 크기(shape)를 확인합니다.
코드를 실행하면 랜덤 노이즈 벡터를 입력으로 사용하여 생성자 네트워크가 가짜 이미지를 생성하고, 이 이미지의 크기(shape)를 확인합니다. 실제로 실행할 때마다 다른 랜덤한 이미지가 생성됩니다. 이것은 GAN 모델에서 생성자의 역할로 사용되며, 생성자는 학습을 통해 실제 이미지와 유사한 가짜 이미지를 생성하는 능력을 향상시킵니다.
torch.Size([1, 3, 64, 64])
20.2.3. Discriminator
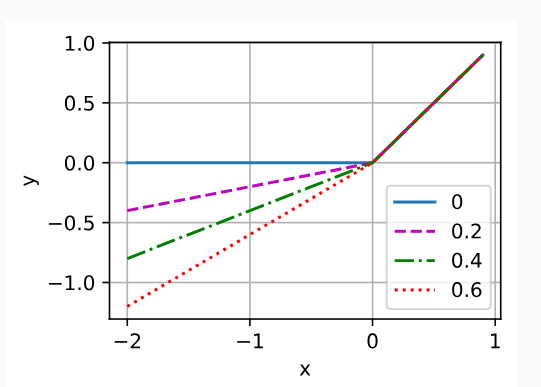
The discriminator is a normal convolutional network network except that it uses a leaky ReLU as its activation function. Given α∈[0,1], its definition is
판별자는 활성화 함수로 Leaky ReLU를 사용한다는 점을 제외하면 일반적인 컨벌루션 네트워크 네트워크입니다. α∈[0,1]이 주어지면 그 정의는 다음과 같습니다.

As it can be seen, it is normal ReLU if α=0, and an identity function if α=1. For α∈(0,1), leaky ReLU is a nonlinear function that give a non-zero output for a negative input. It aims to fix the “dying ReLU” problem that a neuron might always output a negative value and therefore cannot make any progress since the gradient of ReLU is 0.
보시다시피, α=0이면 일반 ReLU이고, α=1이면 항등함수입니다. α∈(0,1)의 경우 Leaky ReLU는 음수 입력에 대해 0이 아닌 출력을 제공하는 비선형 함수입니다. 뉴런이 항상 음수 값을 출력할 수 있고 ReLU의 기울기가 0이기 때문에 어떤 진전도 할 수 없는 "죽어가는 ReLU" 문제를 해결하는 것이 목표입니다.
alphas = [0, .2, .4, .6, .8, 1]
x = torch.arange(-2, 1, 0.1)
Y = [nn.LeakyReLU(alpha)(x).detach().numpy() for alpha in alphas]
d2l.plot(x.detach().numpy(), Y, 'x', 'y', alphas)다양한 Leaky ReLU 활성화 함수에서의 출력을 시각화하는 예시를 보여줍니다.
- alphas = [0, .2, .4, .6, .8, 1]: Leaky ReLU 활성화 함수에 사용될 alpha 값을 리스트로 정의합니다. alpha 값은 Leaky ReLU 함수에서 음수 입력에 대한 출력의 기울기를 나타냅니다. 여기서는 다양한 alpha 값을 실험해보고 시각화합니다.
- x = torch.arange(-2, 1, 0.1): -2부터 1까지 0.1 간격으로 숫자를 생성하여 x에 저장합니다. 이 범위의 숫자는 Leaky ReLU 함수에 입력으로 사용됩니다.
- Y = [nn.LeakyReLU(alpha)(x).detach().numpy() for alpha in alphas]: 각 alpha 값에 대해 Leaky ReLU 활성화 함수를 x에 적용하고 결과를 Y 리스트에 저장합니다. detach().numpy()를 사용하여 PyTorch 텐서를 넘파이 배열로 변환합니다.
- d2l.plot(x.detach().numpy(), Y, 'x', 'y', alphas): d2l.plot 함수를 사용하여 결과를 시각화합니다. x 축은 입력 x의 값, y 축은 Leaky ReLU 함수의 출력 값입니다. 각 alpha 값에 해당하는 곡선이 다른 색상으로 표시됩니다. 이를 통해 Leaky ReLU 활성화 함수의 alpha 값이 변할 때 어떻게 출력이 달라지는지를 시각적으로 확인할 수 있습니다.
코드를 실행하면 다양한 alpha 값에 대한 Leaky ReLU 함수의 출력을 시각화한 그래프가 표시됩니다. alpha 값이 커질수록 입력의 음수 부분에 대한 출력이 크게 유지되는 것을 관찰할 수 있습니다. 이를 통해 Leaky ReLU의 역할을 이해할 수 있습니다.
The basic block of the discriminator is a convolution layer followed by a batch normalization layer and a leaky ReLU activation. The hyperparameters of the convolution layer are similar to the transpose convolution layer in the generator block.
판별기의 기본 블록은 컨볼루션 계층과 그 뒤에 배치 정규화 계층 및 누출된 ReLU 활성화로 구성됩니다. 컨볼루션 레이어의 하이퍼파라미터는 생성기 블록의 전치 컨볼루션 레이어와 유사합니다.
class D_block(nn.Module):
def __init__(self, out_channels, in_channels=3, kernel_size=4, strides=2,
padding=1, alpha=0.2, **kwargs):
super(D_block, self).__init__(**kwargs)
self.conv2d = nn.Conv2d(in_channels, out_channels, kernel_size,
strides, padding, bias=False)
self.batch_norm = nn.BatchNorm2d(out_channels)
self.activation = nn.LeakyReLU(alpha, inplace=True)
def forward(self, X):
return self.activation(self.batch_norm(self.conv2d(X)))
이 코드는 GAN (Generative Adversarial Network)의 판별자 네트워크를 정의하는 클래스 D_block을 생성하는 파이토치(PyTorch) 코드입니다.
이 클래스는 판별자 네트워크의 블록을 정의합니다. 여기서 각 요소의 역할은 다음과 같습니다:
- out_channels: 이 블록에서 생성될 출력 채널의 수를 나타냅니다.
- in_channels: 입력 데이터의 채널 수를 나타냅니다. 기본값은 3으로, 이는 RGB 이미지를 가정합니다.
- kernel_size: 컨볼루션 커널의 크기를 나타냅니다. 기본값은 4로, 4x4 크기의 커널을 사용합니다.
- strides: 컨볼루션 연산에서 스트라이드를 나타냅니다. 기본값은 2로, 스트라이드 2로 컨볼루션을 수행합니다.
- padding: 컨볼루션 연산에서 패딩을 나타냅니다. 기본값은 1로, 1 픽셀의 패딩을 적용합니다.
- alpha: Leaky ReLU 활성화 함수에서 사용되는 negative slope 값을 나타냅니다. 기본값은 0.2로, 일반적으로 사용되는 값입니다.
이 클래스의 forward 메서드에서는 다음과 같은 작업을 수행합니다:
- self.conv2d(X): 입력 데이터 X에 대해 컨볼루션 연산을 수행합니다. 이 연산은 채널 수와 커널 크기에 따라 출력 텐서를 생성합니다.
- self.batch_norm(...): 컨볼루션 연산의 결과에 배치 정규화를 적용합니다. 이는 네트워크의 안정성과 학습 속도를 향상시키는 데 도움을 줍니다.
- self.activation(...): 배치 정규화를 거친 결과에 Leaky ReLU 활성화 함수를 적용합니다. Leaky ReLU는 양수 값은 그대로 두고 음수 값에 작은 기울기를 적용하는 함수로, GAN에서 주로 사용됩니다.
이 클래스를 사용하면 판별자 네트워크에서 한 블록을 구성하고, 여러 개의 이러한 블록을 조합하여 전체 판별자 네트워크를 구축할 수 있습니다. 이러한 블록을 사용하여 이미지의 특징을 추출하고 진짜와 가짜 이미지를 구분하는 역할을 수행합니다.
A basic block with default settings will halve the width and height of the inputs, as we demonstrated in Section 7.3. For example, given a input shape nℎ=nw=16, with a kernel shape kℎ=kw=4, a stride shape sℎ=sw=2, and a padding shape pℎ=pw=1, the output shape will be:
섹션 7.3에서 설명한 것처럼 기본 설정이 있는 기본 블록은 입력의 너비와 높이를 절반으로 줄입니다. 예를 들어 입력 형태 nℎ=nw=16, 커널 형태 kℎ=kw=4, 스트라이드 형태 sℎ=sw=2, 패딩 형태 pℎ=pw=1이 있는 경우 출력 형태는 다음과 같습니다.
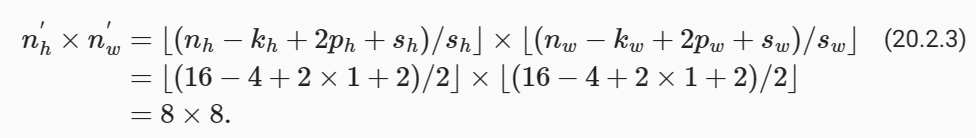
x = torch.zeros((2, 3, 16, 16))
d_blk = D_block(20)
d_blk(x).shape판별자 네트워크의 D_block 클래스를 사용하여 가짜 이미지에 대한 판별 결과를 계산하는 예시를 보여줍니다.
- x = torch.zeros((2, 3, 16, 16)): 2개의 샘플(batch size가 2), 3개의 채널(channel), 각각 16x16 크기의 이미지를 나타내는 4D 텐서를 생성합니다. 이 텐서는 판별자 네트워크 d_blk에 대한 입력 데이터로 사용됩니다.
- d_blk = D_block(20): D_block 클래스를 사용하여 판별자 네트워크의 블록을 하나 생성합니다. 이 블록은 3D 텐서를 입력으로 받아 처리하고, 출력으로 판별 결과를 나타내는 텐서를 생성합니다. 여기서 out_channels를 20으로 설정하여 출력 채널의 수를 20으로 정의합니다.
- d_blk(x).shape: 판별자 블록 d_blk에 입력 데이터 x를 전달하여 가짜 이미지에 대한 판별 결과를 계산합니다. 그리고 판별 결과의 크기(shape)를 확인합니다.
코드를 실행하면 가짜 이미지에 대한 판별 결과가 계산되고, 이 결과의 크기(shape)가 반환됩니다. 판별자 네트워크는 입력 이미지에 대한 판별 결과를 출력하며, 이를 통해 가짜 이미지와 실제 이미지를 구별합니다.
torch.Size([2, 20, 8, 8])
A basic block with default settings will halve the width and height of the inputs, as we demonstrated in Section 7.3. For example, given a input shape nℎ=nw=16, with a kernel shape kℎ=kw=4, a stride shape sℎ=sw=2, and a padding shape pℎ=pw=1, the output shape will be:
섹션 7.3에서 설명한 것처럼 기본 설정이 있는 기본 블록은 입력의 너비와 높이를 절반으로 줄입니다. 예를 들어 입력 형태 nℎ=nw=16, 커널 형태 kℎ=kw=4, 스트라이드 형태 sℎ=sw=2, 패딩 형태 pℎ=pw=1이 있는 경우 출력 형태는 다음과 같습니다.
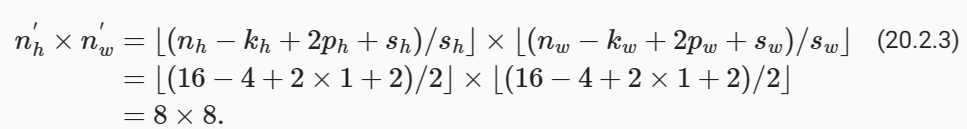
x = torch.zeros((2, 3, 16, 16))
d_blk = D_block(20)
d_blk(x).shape판별자 네트워크의 D_block 클래스를 사용하여 가짜 이미지에 대한 판별 결과를 계산하는 예시를 보여줍니다.
- x = torch.zeros((2, 3, 16, 16)): 2개의 샘플(batch size가 2), 3개의 채널(channel), 각각 16x16 크기의 이미지를 나타내는 4D 텐서를 생성합니다. 이 텐서는 판별자 네트워크 d_blk에 대한 입력 데이터로 사용됩니다.
- d_blk = D_block(20): D_block 클래스를 사용하여 판별자 네트워크의 블록을 하나 생성합니다. 이 블록은 3D 텐서를 입력으로 받아 처리하고, 출력으로 판별 결과를 나타내는 텐서를 생성합니다. 여기서 out_channels를 20으로 설정하여 출력 채널의 수를 20으로 정의합니다.
- d_blk(x).shape: 판별자 블록 d_blk에 입력 데이터 x를 전달하여 가짜 이미지에 대한 판별 결과를 계산합니다. 그리고 판별 결과의 크기(shape)를 확인합니다.
코드를 실행하면 가짜 이미지에 대한 판별 결과가 계산되고, 이 결과의 크기(shape)가 반환됩니다. 판별자 네트워크는 입력 이미지에 대한 판별 결과를 출력하며, 이를 통해 가짜 이미지와 실제 이미지를 구별합니다. 이 코드는 판별자 블록이 입력 이미지를 어떻게 처리하고 판별 결과를 출력하는지를 보여주는 예시입니다.
torch.Size([2, 20, 8, 8])
The discriminator is a mirror of the generator.
판별자는 생성자의 거울입니다.
n_D = 64
net_D = nn.Sequential(
D_block(n_D), # Output: (64, 32, 32)
D_block(in_channels=n_D, out_channels=n_D*2), # Output: (64 * 2, 16, 16)
D_block(in_channels=n_D*2, out_channels=n_D*4), # Output: (64 * 4, 8, 8)
D_block(in_channels=n_D*4, out_channels=n_D*8), # Output: (64 * 8, 4, 4)
nn.Conv2d(in_channels=n_D*8, out_channels=1,
kernel_size=4, bias=False)) # Output: (1, 1, 1)판별자 네트워크인 net_D를 정의하는 부분으로, GAN (Generative Adversarial Network) 모델에서 사용됩니다. 이 코드는 판별자 네트워크를 구성하고 각 블록의 출력 크기를 주석으로 설명하고 있습니다.
- n_D = 64: n_D는 판별자 네트워크에서 사용할 초기 채널 수를 나타냅니다. 이 값은 64로 설정되었습니다.
- net_D = nn.Sequential(...): 판별자 네트워크를 정의하는 nn.Sequential 컨테이너를 생성합니다. 이 컨테이너는 여러 레이어를 순차적으로 쌓을 수 있도록 합니다.
- D_block(...) 블록들: 판별자 네트워크는 D_block 클래스를 사용하여 여러 개의 블록으로 구성됩니다. 각 블록은 판별자 네트워크의 한 단계를 나타내며, 입력 데이터의 차원을 줄이거나 채널 수를 늘리는 역할을 합니다. 주석으로 출력 크기를 표시했습니다. 예를 들어, 첫 번째 블록은 (64, 32, 32) 크기의 텐서를 입력으로 받고, 출력으로 (64, 32, 32) 크기의 텐서를 생성합니다.
- nn.Conv2d(...) 레이어: 마지막에는 nn.Conv2d 레이어를 사용하여 최종 판별 결과를 생성합니다. 이 레이어는 입력 이미지를 판별한 결과를 출력하며, 출력 채널 수는 1로 설정되어 이진 분류 결과를 나타냅니다.
이렇게 정의된 net_D는 판별자 네트워크를 나타내며, 입력 이미지를 판별하여 이미지가 진짜인지 가짜인지를 판별하는 역할을 합니다. 판별자 네트워크는 이미지의 공간적 정보를 이용하여 판별 결과를 계산합니다.
It uses a convolution layer with output channel 1 as the last layer to obtain a single prediction value.
단일 예측 값을 얻기 위해 출력 채널 1이 있는 컨볼루션 레이어를 마지막 레이어로 사용합니다.
x = torch.zeros((1, 3, 64, 64))
net_D(x).shape판별자 네트워크인 net_D에 입력 데이터를 전달하고, 판별 결과의 크기(shape)를 확인하는 예시를 보여줍니다.
- x = torch.zeros((1, 3, 64, 64)): 크기가 (1, 3, 64, 64)인 4D 텐서를 생성합니다. 이 텐서는 판별자 네트워크 net_D에 입력 데이터로 사용됩니다. 여기서 크기 (1, 3, 64, 64)은 배치 크기가 1이고, 채널 수가 3 (RGB 이미지)이며, 이미지 크기가 64x64임을 의미합니다.
- net_D(x).shape: 생성된 입력 데이터 x를 판별자 네트워크 net_D에 전달하여 판별 결과를 계산합니다. 그리고 판별 결과의 크기(shape)를 확인합니다.
코드를 실행하면 판별자 네트워크가 입력 이미지 x를 판별하고, 판별 결과의 크기(shape)가 반환됩니다. 판별자는 입력 이미지를 받아 이미지가 진짜인지 가짜인지 판별하는 역할을 수행합니다. 이 코드는 판별자 네트워크의 출력을 확인하는 간단한 예시입니다.
torch.Size([1, 1, 1, 1])
20.2.4. Training
Compared to the basic GAN in Section 20.1, we use the same learning rate for both generator and discriminator since they are similar to each other. In addition, we change β1 in Adam (Section 12.10) from 0.9 to 0.5. It decreases the smoothness of the momentum, the exponentially weighted moving average of past gradients, to take care of the rapid changing gradients because the generator and the discriminator fight with each other. Besides, the random generated noise Z, is a 4-D tensor and we are using GPU to accelerate the computation.
20.1절의 기본 GAN과 비교하면 생성자와 판별자가 서로 유사하므로 동일한 학습률을 사용합니다. 또한 Adam(12.10절)의 β1을 0.9에서 0.5로 변경합니다. 생성자와 판별자가 서로 싸우기 때문에 빠르게 변화하는 기울기를 처리하기 위해 과거 기울기의 지수 가중 이동 평균인 운동량의 평활도를 감소시킵니다. 게다가 무작위로 생성된 노이즈 Z는 4차원 텐서이며 GPU를 사용하여 계산을 가속화합니다.
def train(net_D, net_G, data_iter, num_epochs, lr, latent_dim,
device=d2l.try_gpu()):
loss = nn.BCEWithLogitsLoss(reduction='sum')
for w in net_D.parameters():
nn.init.normal_(w, 0, 0.02)
for w in net_G.parameters():
nn.init.normal_(w, 0, 0.02)
net_D, net_G = net_D.to(device), net_G.to(device)
trainer_hp = {'lr': lr, 'betas': [0.5,0.999]}
trainer_D = torch.optim.Adam(net_D.parameters(), **trainer_hp)
trainer_G = torch.optim.Adam(net_G.parameters(), **trainer_hp)
animator = d2l.Animator(xlabel='epoch', ylabel='loss',
xlim=[1, num_epochs], nrows=2, figsize=(5, 5),
legend=['discriminator', 'generator'])
animator.fig.subplots_adjust(hspace=0.3)
for epoch in range(1, num_epochs + 1):
# Train one epoch
timer = d2l.Timer()
metric = d2l.Accumulator(3) # loss_D, loss_G, num_examples
for X, _ in data_iter:
batch_size = X.shape[0]
Z = torch.normal(0, 1, size=(batch_size, latent_dim, 1, 1))
X, Z = X.to(device), Z.to(device)
metric.add(d2l.update_D(X, Z, net_D, net_G, loss, trainer_D),
d2l.update_G(Z, net_D, net_G, loss, trainer_G),
batch_size)
# Show generated examples
Z = torch.normal(0, 1, size=(21, latent_dim, 1, 1), device=device)
# Normalize the synthetic data to N(0, 1)
fake_x = net_G(Z).permute(0, 2, 3, 1) / 2 + 0.5
imgs = torch.cat(
[torch.cat([
fake_x[i * 7 + j].cpu().detach() for j in range(7)], dim=1)
for i in range(len(fake_x)//7)], dim=0)
animator.axes[1].cla()
animator.axes[1].imshow(imgs)
# Show the losses
loss_D, loss_G = metric[0] / metric[2], metric[1] / metric[2]
animator.add(epoch, (loss_D, loss_G))
print(f'loss_D {loss_D:.3f}, loss_G {loss_G:.3f}, '
f'{metric[2] / timer.stop():.1f} examples/sec on {str(device)}')GAN (Generative Adversarial Network) 모델의 학습 함수를 정의하고 있습니다. 이 함수는 판별자와 생성자 네트워크를 학습하는 역할을 합니다.
- net_D와 net_G: 판별자 네트워크와 생성자 네트워크를 나타내는 모델 객체입니다.
- data_iter: 데이터 로더로부터 생성된 데이터 배치를 나타내는 반복자입니다.
- num_epochs: 학습할 epoch 수입니다.
- lr: 학습률 (learning rate)입니다.
- latent_dim: 생성자 네트워크의 입력 랜덤 벡터의 차원입니다.
- device: 모델을 학습할 디바이스 (CPU 또는 GPU)를 나타냅니다.
- loss = nn.BCEWithLogitsLoss(reduction='sum'): 이진 교차 엔트로피 손실 함수를 정의합니다. GAN에서는 이 손실 함수를 사용하여 판별자의 출력과 진짜/가짜 레이블 사이의 오차를 계산합니다.
- 모델 가중치 초기화: 생성자와 판별자 네트워크의 가중치를 초기화합니다.
- trainer_D와 trainer_G: 판별자와 생성자 네트워크를 각각 최적화하기 위한 Adam 옵티마이저를 생성합니다.
- animator: 학습 과정을 시각화하기 위한 d2l.Animator 객체를 생성합니다.
- 학습 루프: 지정된 epoch 수만큼 학습을 수행합니다. 각 epoch에서는 판별자와 생성자를 번갈아가며 학습하고, 학습 중간에 생성된 이미지를 시각화하여 학습 진행 상황을 확인합니다.
- 학습 속도 계산: 학습이 완료된 후, 판별자와 생성자의 손실과 학습 속도를 출력합니다.
이 함수는 GAN 모델을 학습하기 위한 핵심 학습 루프를 구현하고 있으며, 판별자와 생성자 네트워크의 학습을 번갈아가며 진행합니다. 학습이 진행됨에 따라 손실이 어떻게 변하는지 시각화하고, 학습 속도도 출력하여 모델의 학습 상태를 모니터링합니다.
We train the model with a small number of epochs just for demonstration. For better performance, the variable num_epochs can be set to a larger number.
단지 시연을 위해 적은 수의 에포크로 모델을 훈련합니다. 더 나은 성능을 위해 num_epochs 변수를 더 큰 숫자로 설정할 수 있습니다.
latent_dim, lr, num_epochs = 100, 0.005, 20
train(net_D, net_G, data_iter, num_epochs, lr, latent_dim)GAN 모델을 학습하기 위해 앞서 정의한 train 함수를 호출하는 부분입니다.
- latent_dim: 생성자 네트워크의 입력 랜덤 벡터의 차원을 나타냅니다. 여기서는 100으로 설정되었습니다.
- lr: 학습률 (learning rate)을 나타냅니다. 학습률은 0.005로 설정되었습니다.
- num_epochs: 학습할 epoch 수를 나타냅니다. 여기서는 20으로 설정되었습니다.
- train(net_D, net_G, data_iter, num_epochs, lr, latent_dim): 이전에 정의한 train 함수를 호출하여 GAN 모델을 학습합니다. 학습에 필요한 인자들을 함수에 전달합니다. 이렇게 하면 판별자와 생성자 네트워크가 데이터로부터 학습을 수행하고, 지정된 epoch 수만큼 학습이 진행됩니다.
이 코드는 GAN 모델을 실제 데이터로부터 학습시키는 부분을 실행하는 부분입니다. latent_dim, lr, num_epochs 등의 하이퍼파라미터를 설정하고, train 함수를 호출하여 학습을 시작합니다.
loss_D 0.023, loss_G 7.359, 2292.7 examples/sec on cuda:0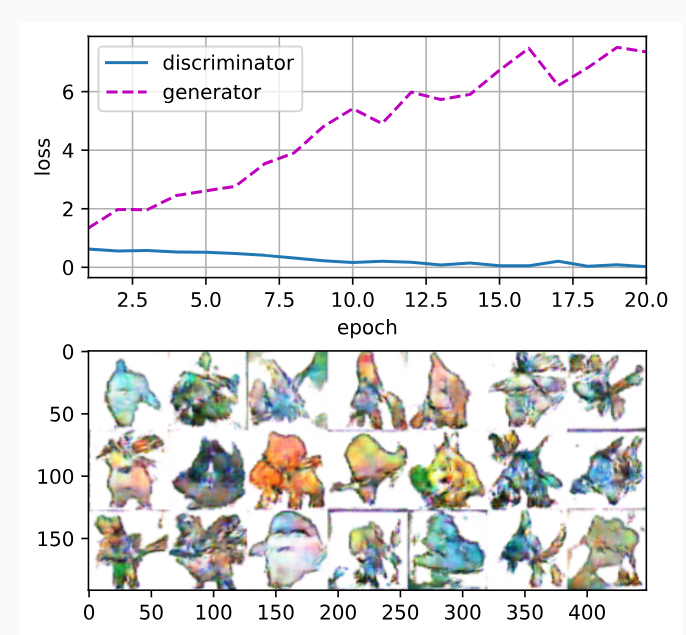
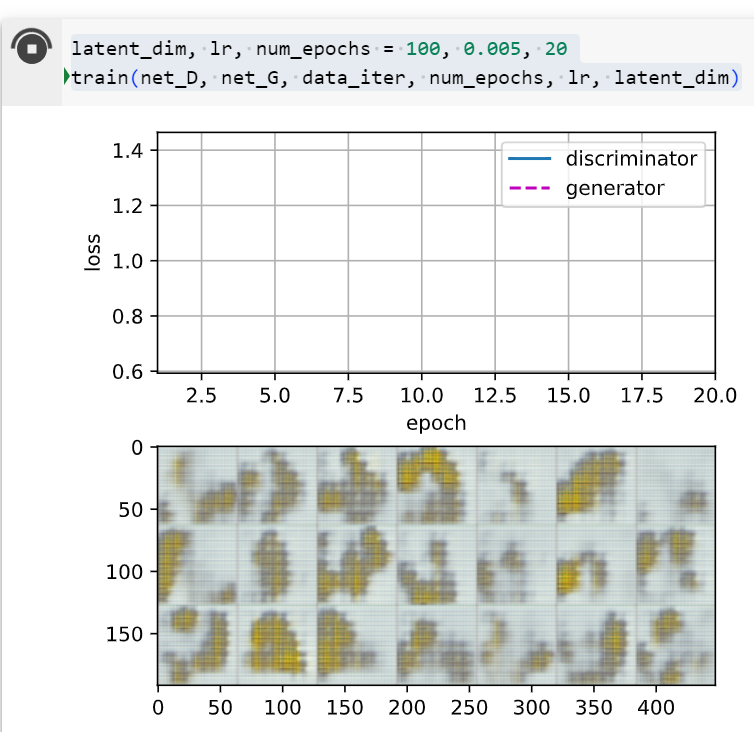
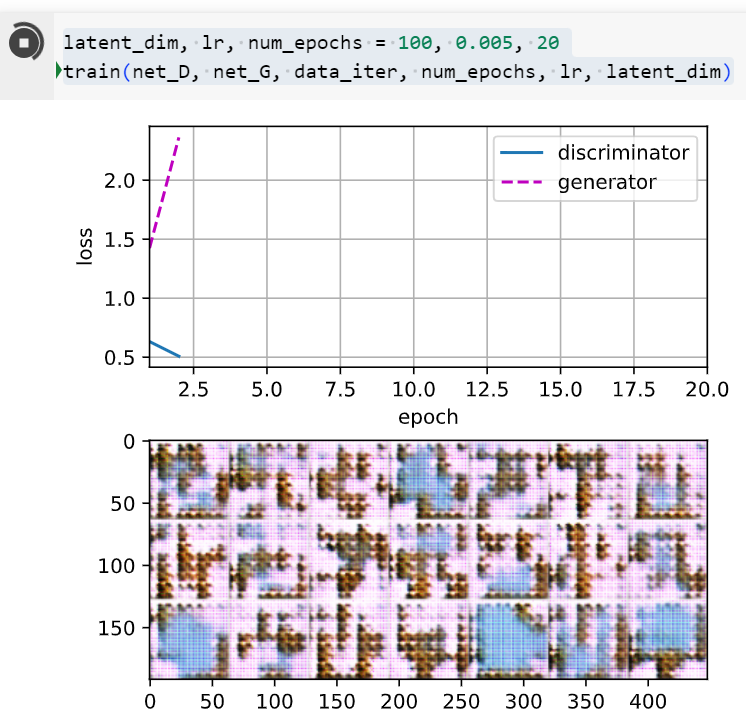
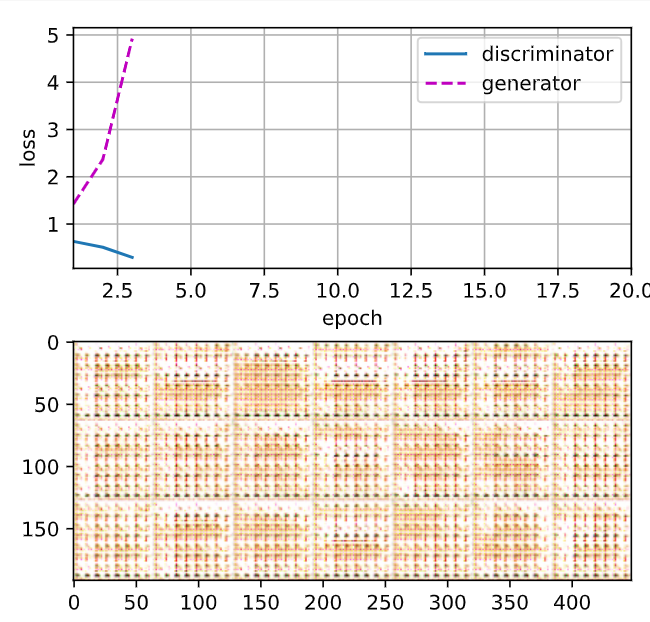
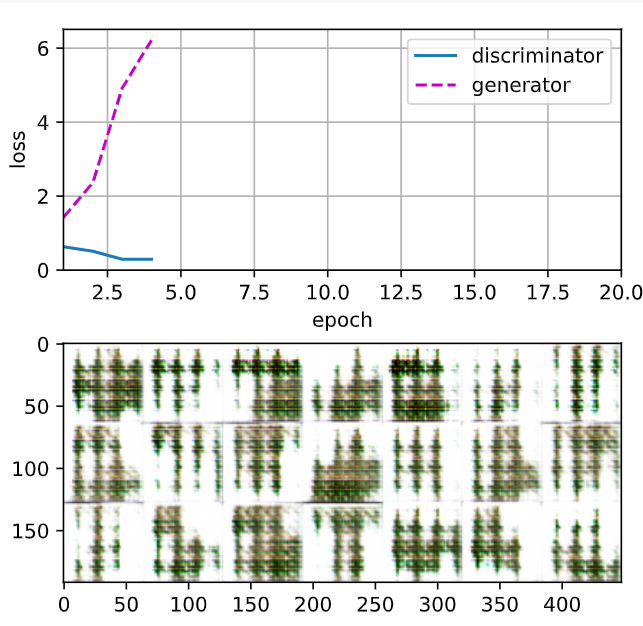
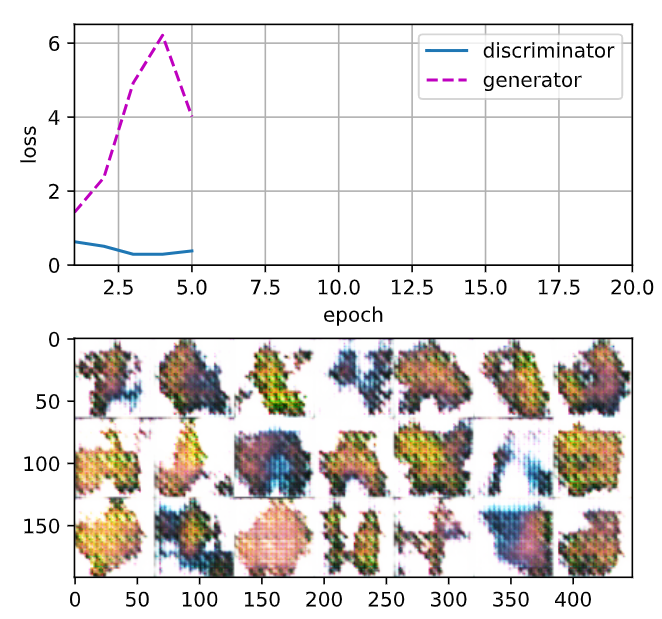
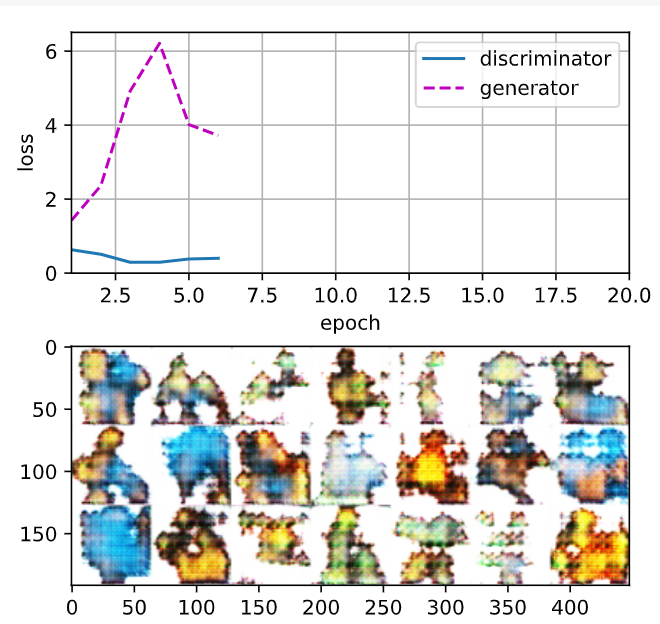
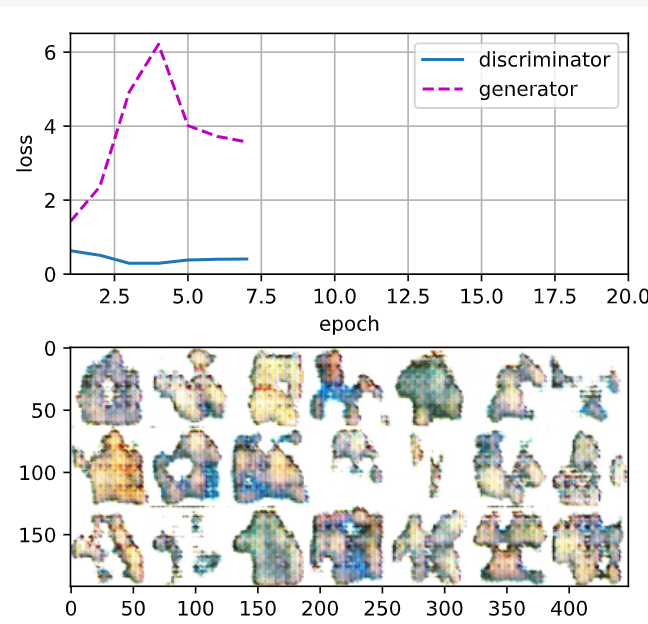
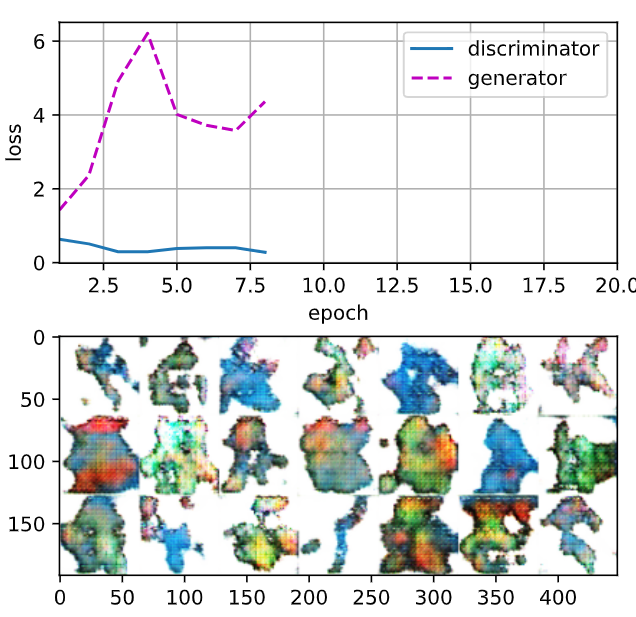
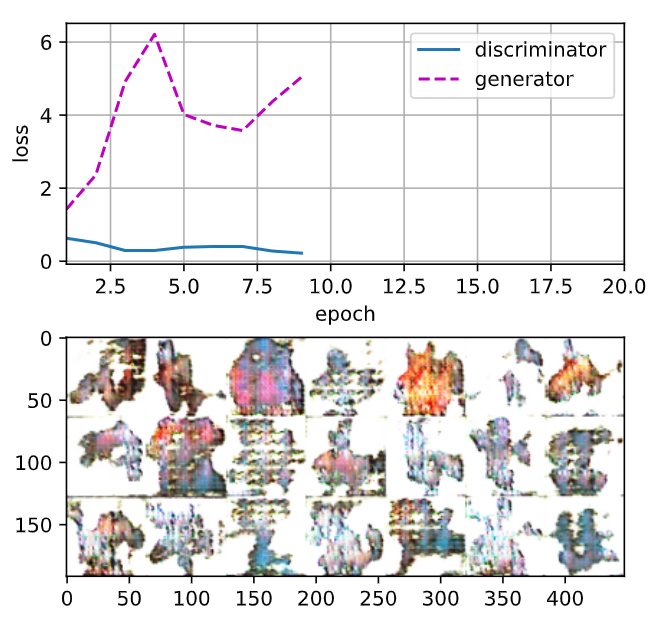
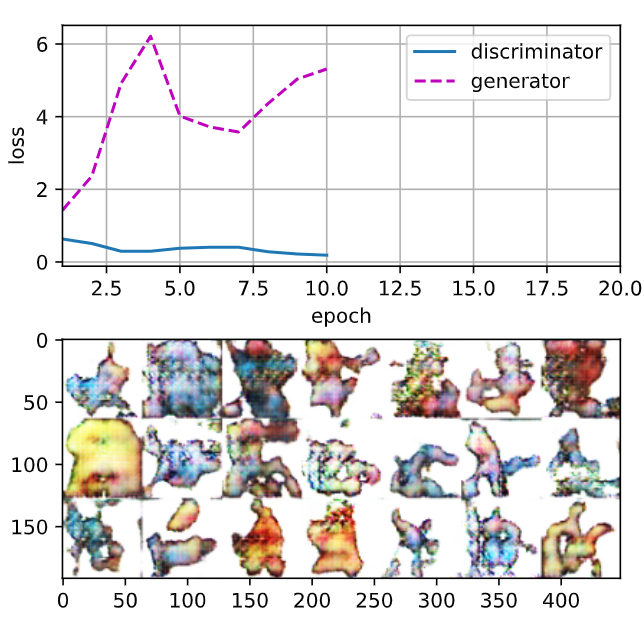
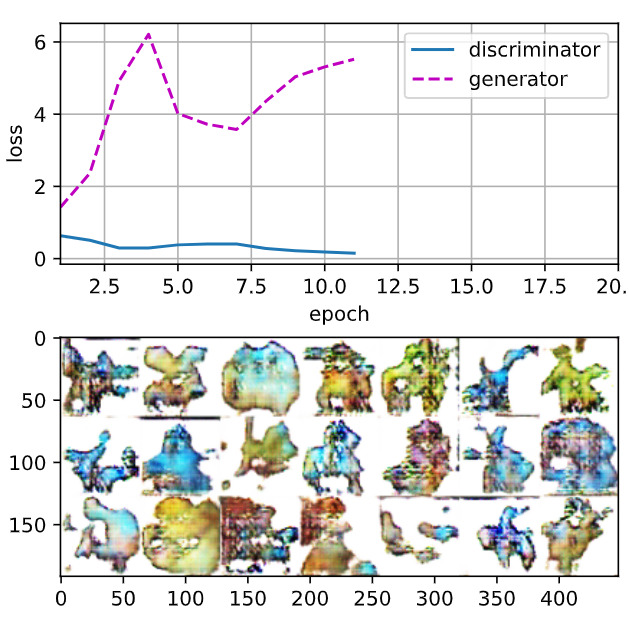
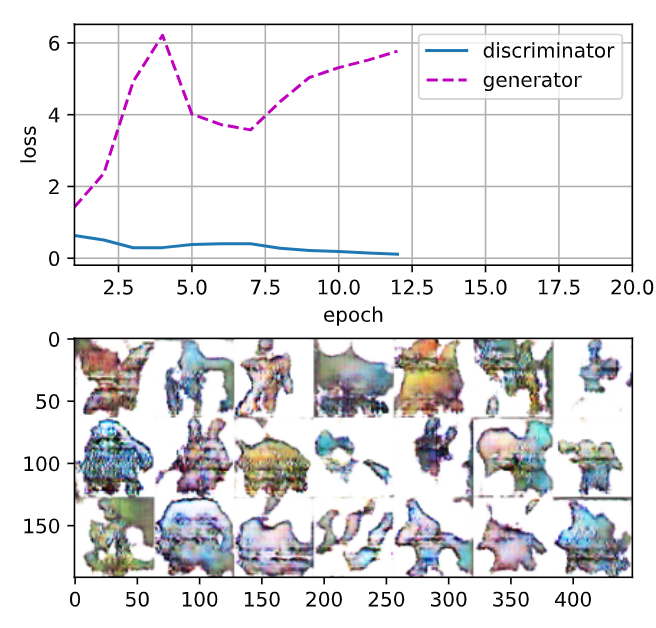
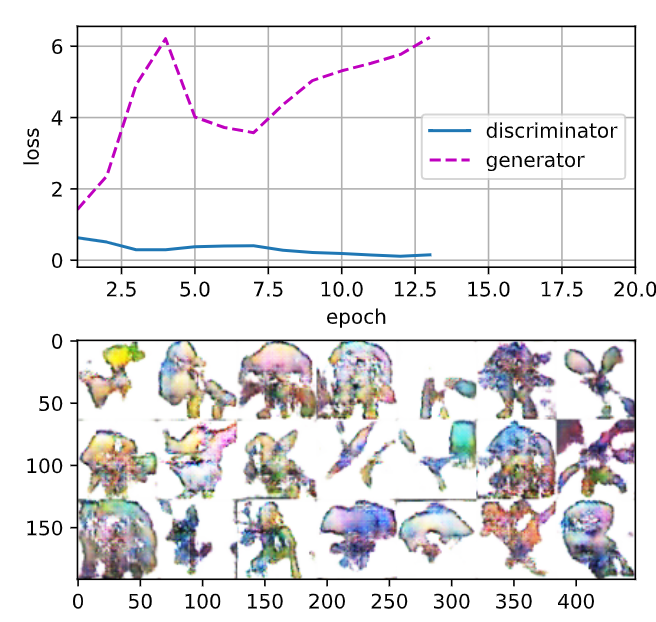
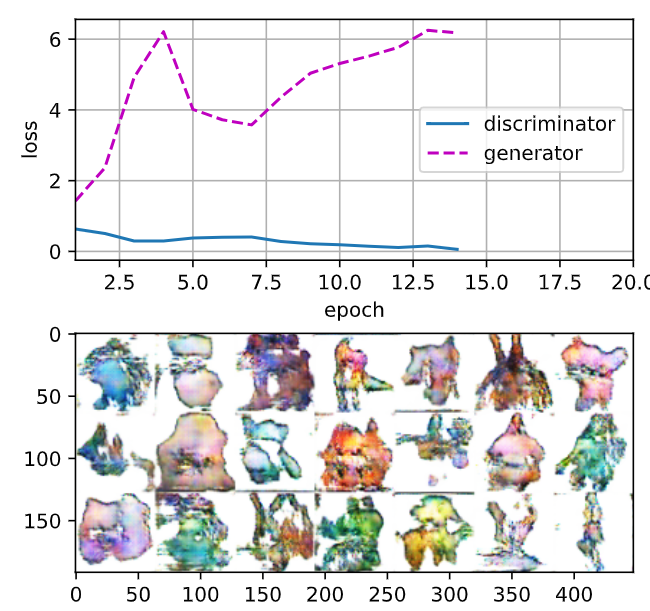
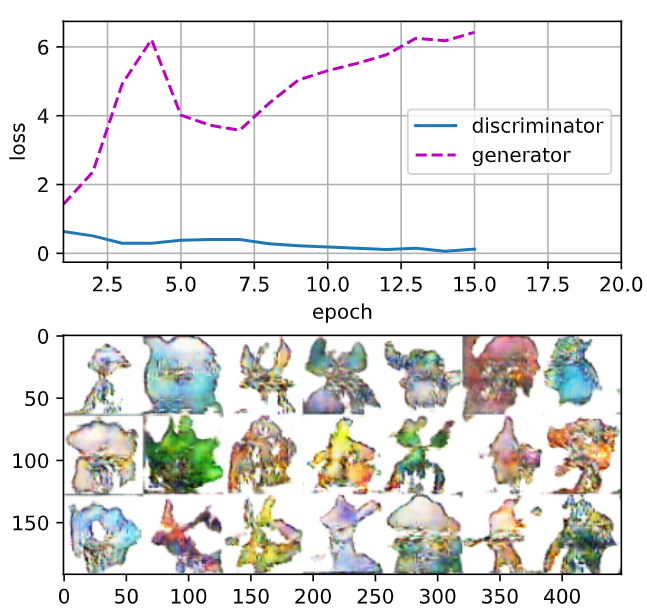
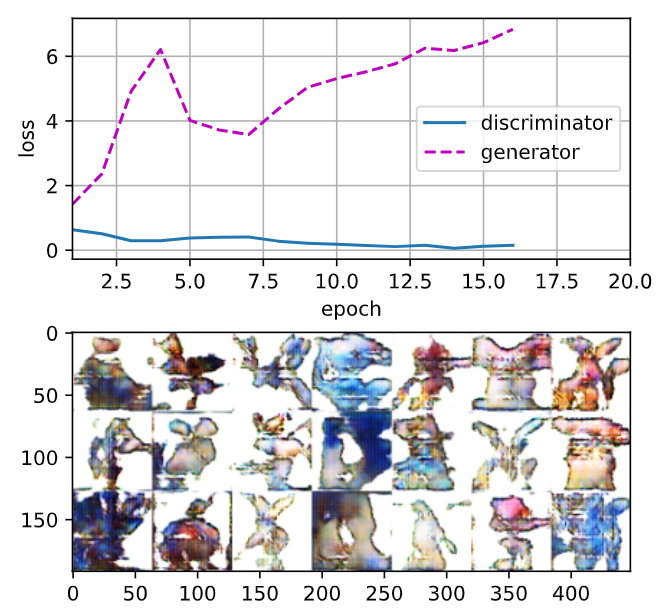

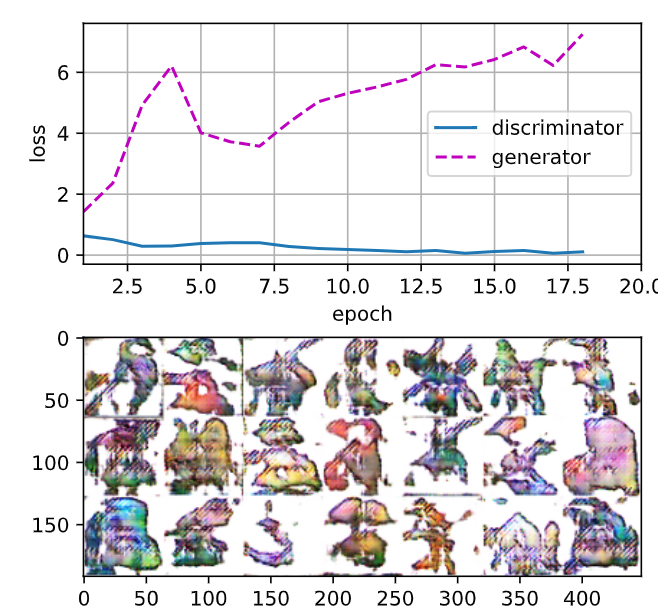

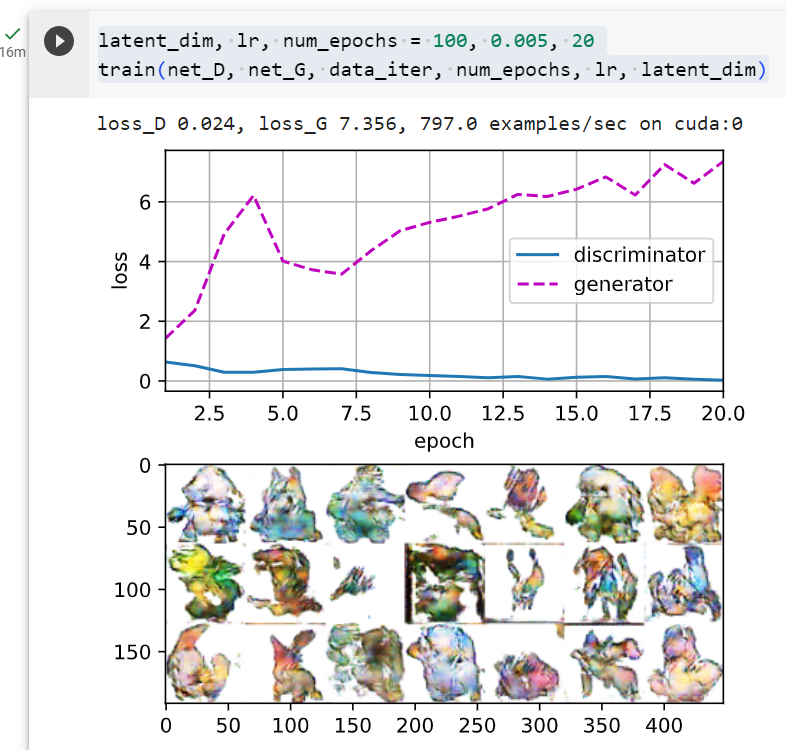
두번째 실행 결과
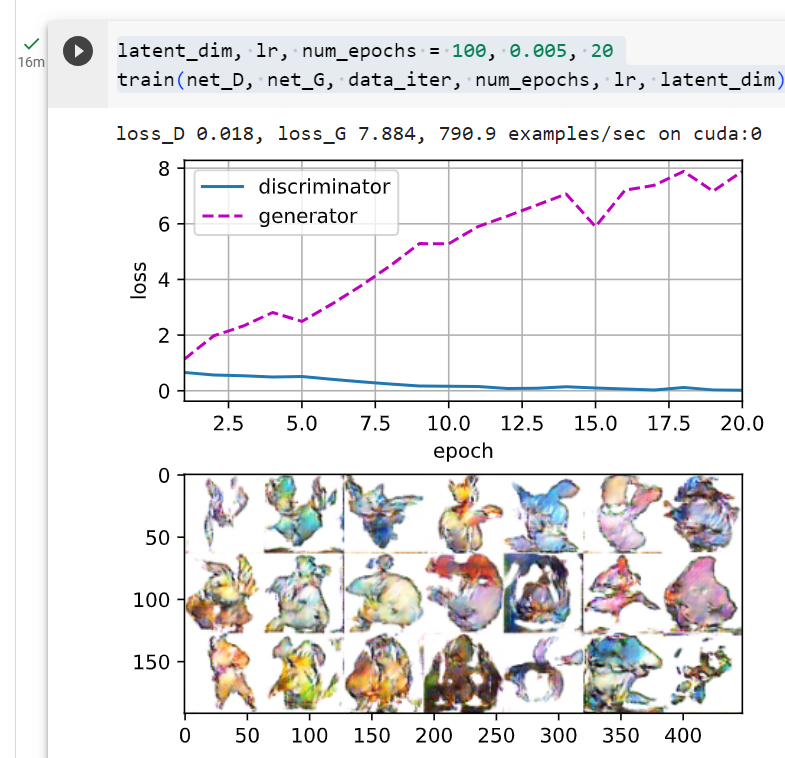
epochs를 50으로 했을 때
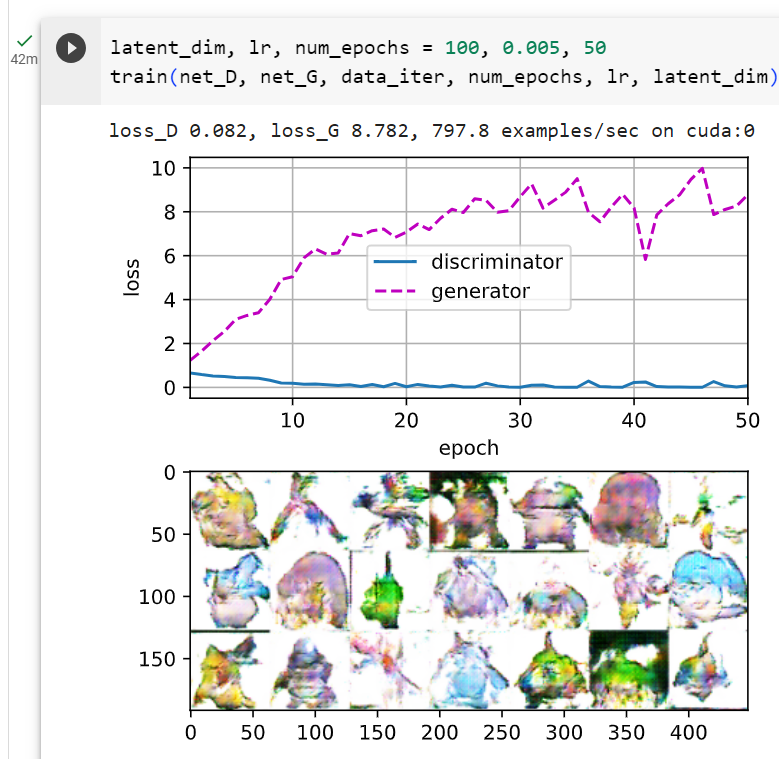
20.2.5. Summary
- DCGAN architecture has four convolutional layers for the Discriminator and four “fractionally-strided” convolutional layers for the Generator.
DCGAN 아키텍처에는 판별자(Discriminator)용 컨벌루션 레이어 4개와 생성기(Generator)용 "부분 스트라이드" 컨벌루션 레이어 4개가 있습니다. - The Discriminator is a 4-layer strided convolutions with batch normalization (except its input layer) and leaky ReLU activations.
Discriminator는 배치 정규화(입력 레이어 제외) 및 Leaky ReLU 활성화 기능을 갖춘 4레이어 스트라이드 컨볼루션입니다. - Leaky ReLU is a nonlinear function that give a non-zero output for a negative input. It aims to fix the “dying ReLU” problem and helps the gradients flow easier through the architecture.
Leaky ReLU는 음수 입력에 대해 0이 아닌 출력을 제공하는 비선형 함수입니다. 이는 "죽어가는 ReLU" 문제를 해결하는 것을 목표로 하며 아키텍처를 통해 그래디언트가 더 쉽게 흐르도록 돕습니다.
20.2.6. Exercises
- What will happen if we use standard ReLU activation rather than leaky ReLU?
- Apply DCGAN on Fashion-MNIST and see which category works well and which does not.
'Dive into Deep Learning > D2L Generative Adversarial Networks_GAN' 카테고리의 다른 글
| D2L - 20.1. Generative Adversarial Networks (0) | 2023.09.16 |
|---|