

https://python.langchain.com/docs/expression_language/cookbook/retrieval
RAG | 🦜️🔗 Langchain
Let's look at adding in a retrieval step to a prompt and LLM, which adds up to a "retrieval-augmented generation" chain
python.langchain.com
RAG
Let's look at adding in a retrieval step to a prompt and LLM, which adds up to a "retrieval-augmented generation" chain
"검색 증강 생성 retrieval-augmented generation " 체인에 추가되는 프롬프트 및 LLM에 검색 단계를 추가하는 방법을 살펴보겠습니다.
pip install langchain openai faiss-cpu tiktoken
from operator import itemgetter
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda
from langchain.vectorstores import FAISSvectorstore = FAISS.from_texts(["harrison worked at kensho"], embedding=OpenAIEmbeddings())
retriever = vectorstore.as_retriever()
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
model = ChatOpenAI()chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)chain.invoke("where did harrison work?") 'Harrison worked at Kensho.'
이 코드는 LangChain 라이브러리와 관련 패키지를 설치한 후, LangChain을 사용하여 간단한 정보 검색 대화 체인을 설정하고 호출하는 방법을 보여줍니다. 필요한 패키지 설치:
-
- pip install langchain openai faiss-cpu tiktoken 명령어를 사용하여 LangChain 및 관련 패키지를 설치합니다.
- LangChain 라이브러리 및 관련 패키지 가져오기:
- from 문을 사용하여 필요한 라이브러리 및 패키지를 가져옵니다. 이 코드에서는 LangChain, OpenAI, FAISS, tiktoken 등을 가져옵니다.
- 정보 검색 대화 체인 설정:
- FAISS를 사용하여 특정 텍스트("harrison worked at kensho")를 포함하는 벡터 스토어를 생성합니다.
- 이 벡터 스토어를 retriever로 설정합니다.
- 대화 체인의 템플릿을 설정합니다. 이 템플릿은 "context"와 "question"을 사용하여 대화를 생성하는 데 사용됩니다.
- 대화 모델(ChatOpenAI)을 설정합니다.
- 대화 체인을 설정합니다. 이 체인은 "context"와 "question" 데이터를 받아들이고, prompt를 통해 대화를 생성하며, 이 대화를 model을 사용하여 처리하고, 마지막으로 StrOutputParser()를 사용하여 출력을 파싱합니다.
- 대화 체인 호출:
- chain.invoke("where did Harrison work?")를 통해 chain을 호출합니다. 이때 "where did Harrison work?"라는 질문이 대화 체인으로 전달되어, 해당 질문에 대한 정보 검색 대화가 생성되고 처리됩니다.
이 코드는 간단한 정보 검색 대화 체인을 설정하고 사용하는 방법을 보여주며, LangChain을 활용하여 다양한 대화 및 정보 처리 작업을 수행할 수 있습니다.
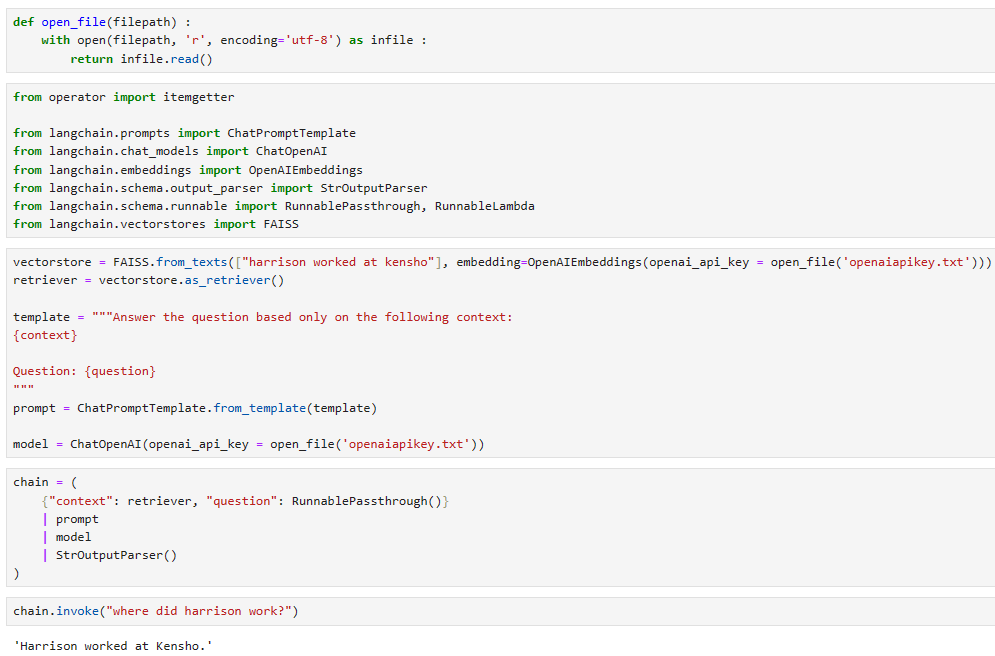
template = """Answer the question based only on the following context:
{context}
Question: {question}
Answer in the following language: {language}
"""
prompt = ChatPromptTemplate.from_template(template)
chain = {
"context": itemgetter("question") | retriever,
"question": itemgetter("question"),
"language": itemgetter("language")
} | prompt | model | StrOutputParser()chain.invoke({"question": "where did harrison work", "language": "italian"}) 'Harrison ha lavorato a Kensho.'
이 코드는 LangChain을 사용하여 정보 검색 대화 체인을 설정하고 호출하는 방법을 보여줍니다.
- 대화 체인 템플릿 설정:
- "context," "question," 그리고 "language"을 사용하여 대화 템플릿을 설정합니다.
- 이 템플릿에는 "context," "question," "language"이라는 플레이스홀더가 포함되어 있으며, 대화 체인에서 이러한 값을 사용하여 대화를 생성하고 질문에 답변합니다.
- 대화 체인 설정:
- itemgetter를 사용하여 "context," "question," 및 "language" 값을 추출합니다.
- "context" 값은 "question"을 추출한 후, retriever를 사용하여 정보 검색을 위한 컨텍스트를 가져옵니다.
- "question" 값은 "question"에서 직접 추출됩니다.
- "language" 값은 "language"에서 직접 추출됩니다.
- 이러한 추출된 값들을 사용하여 대화 체인을 설정합니다.
- 대화 체인 호출:
- chain.invoke({"question": "where did harrison work", "language": "Italian"})를 사용하여 대화 체인을 호출합니다.
- "question"과 "language" 값을 대화 체인으로 전달합니다.
- 이로 인해 "where did harrison work"라는 질문과 "Italian"이라는 언어 설정이 포함된 대화가 생성되고 처리됩니다.
이 코드를 통해 특정 질문과 언어 설정을 기반으로 대화를 생성하고 답변을 얻을 수 있습니다.


==> 한국어의 경우 Kensho에서 일했다고 대답을 하지않고 질문을 그대로 번역을 했습니다.
그래서 일본어, 중국어, 힌디, 베트남어 그리고 슬로바키아어 등 여러 언어로 시도를 해 봤는데 힌디만 한국어와 같이 대답을 하지 않고 질문을 번역했더라구요. 일본어, 중국어, 베트남어, 슬로바키아어, 이탈리아어는 다 제대로 Kensho에서 일한다는 대답을 얻어 냈습니다. 한국어와 힌디어는 아직까지 좀 부족한 부분이 많은 것 같습니다.
Conversational Retrieval Chain
We can easily add in conversation history. This primarily means adding in chat_message_history
대화 기록을 쉽게 추가할 수 있습니다. 이는 주로 chat_message_history를 추가하는 것을 의미합니다.
from langchain.schema.runnable import RunnableMap
from langchain.schema import format_document
from langchain.prompts.prompt import PromptTemplate
_template = """Given the following conversation and a follow up question, rephrase the follow up question to be a standalone question, in its original language.
Chat History:
{chat_history}
Follow Up Input: {question}
Standalone question:"""
CONDENSE_QUESTION_PROMPT = PromptTemplate.from_template(_template)
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
ANSWER_PROMPT = ChatPromptTemplate.from_template(template)
DEFAULT_DOCUMENT_PROMPT = PromptTemplate.from_template(template="{page_content}")
def _combine_documents(
docs, document_prompt=DEFAULT_DOCUMENT_PROMPT, document_separator="\n\n"
):
doc_strings = [format_document(doc, document_prompt) for doc in docs]
return document_separator.join(doc_strings)
from typing import Tuple, List
def _format_chat_history(chat_history: List[Tuple]) -> str:
buffer = ""
for dialogue_turn in chat_history:
human = "Human: " + dialogue_turn[0]
ai = "Assistant: " + dialogue_turn[1]
buffer += "\n" + "\n".join([human, ai])
return buffer
_inputs = RunnableMap(
standalone_question=RunnablePassthrough.assign(
chat_history=lambda x: _format_chat_history(x["chat_history"])
)
| CONDENSE_QUESTION_PROMPT
| ChatOpenAI(temperature=0)
| StrOutputParser(),
)
_context = {
"context": itemgetter("standalone_question") | retriever | _combine_documents,
"question": lambda x: x["standalone_question"],
}
conversational_qa_chain = _inputs | _context | ANSWER_PROMPT | ChatOpenAI()
이 코드는 LangChain에서 다양한 처리 단계를 통해 대화 기록과 연결된 질문을 독립적인 질문으로 재구성하는 과정을 보여줍니다. 아래에서 각 부분을 자세히 설명하겠습니다.
- _template 및 CONDENSE_QUESTION_PROMPT:
- _template은 텍스트 템플릿으로, 대화 기록과 관련된 질문을 독립적인 질문으로 재구성하는 과정에 사용됩니다.
- CONDENSE_QUESTION_PROMPT은 _template를 기반으로 하는 PromptTemplate 인스턴스로, 대화 기록과 관련된 템플릿 질문을 생성합니다.
- template 및 ANSWER_PROMPT:
- template은 다른 템플릿으로, 주어진 문맥과 질문을 기반으로 답변을 생성하는 과정에 사용됩니다.
- ANSWER_PROMPT은 template를 기반으로 하는 ChatPromptTemplate 인스턴스로, 답변 생성에 사용됩니다.
- DEFAULT_DOCUMENT_PROMPT:
- DEFAULT_DOCUMENT_PROMPT는 문서 형식을 생성하는 데 사용되는 템플릿입니다.
- _combine_documents 함수:
- 이 함수는 여러 문서를 결합하여 하나의 문서로 만드는 역할을 합니다. 주로 DEFAULT_DOCUMENT_PROMPT에서 사용됩니다.
- _format_chat_history 함수:
- 이 함수는 대화 기록을 정리하고 형식화하는 역할을 합니다. 대화 기록을 읽어서 사람(Human)과 AI(Assistant)의 대화 내용을 구분하고 포맷합니다.
- _inputs:
- _inputs는 RunnableMap의 인스턴스로, standalone_question 키에 대한 처리 작업을 정의합니다.
- RunnablePassthrough.assign() 함수를 사용하여 chat_history를 standalone_question에 할당하며, 이후 CONDENSE_QUESTION_PROMPT, ChatOpenAI 및 StrOutputParser를 통해 처리 작업을 수행합니다.
- _context:
- _context는 입력 및 문맥 관련 작업을 정의합니다. context 및 question 키를 정의하며, 이전 단계에서 처리된 standalone_question을 사용하여 문맥을 정리하고, 해당 문맥과 독립적인 질문을 추출합니다.
- conversational_qa_chain:
- conversational_qa_chain은 여러 단계로 구성된 LangChain 체인입니다. 이 체인은 _inputs, _context, ANSWER_PROMPT, ChatOpenAI를 순차적으로 연결하여 대화 기록 및 관련 질문을 처리하고 답변을 생성합니다.
이 코드는 LangChain에서 대화 데이터를 처리하고 관련 질문을 독립적인 질문으로 재구성하는 과정을 보여줍니다. 이를 통해 효율적으로 대화 데이터를 처리하고 답변을 생성할 수 있습니다.

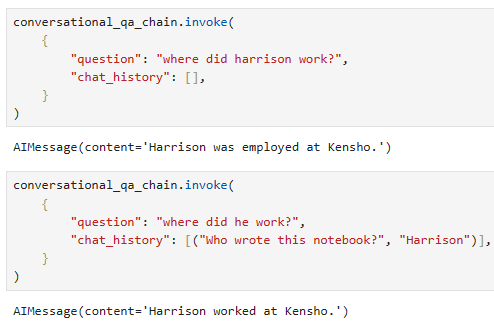
conversational_qa_chain.invoke(
{
"question": "where did harrison work?",
"chat_history": [],
}
) AIMessage(content='Harrison was employed at Kensho.', additional_kwargs={}, example=False)conversational_qa_chain.invoke(
{
"question": "where did he work?",
"chat_history": [("Who wrote this notebook?", "Harrison")],
}
)
AIMessage(content='Harrison worked at Kensho.', additional_kwargs={}, example=False)
conversational_qa_chain은 invoke 메서드를 사용하여 주어진 입력에 대한 처리를 수행하고 결과를 생성하는 것입니다. 아래는 두 가지 다른 입력에 대한 invoke 호출에 대한 설명입니다.
- 첫 번째 invoke 호출:
- "question": "where did harrison work?"와 "chat_history": []와 같이 빈 대화 기록을 가지는 입력이 주어집니다.
- 첫 번째 호출에서는 대화 기록이 비어 있으므로 독립적인 질문이 이미 주어진 질문과 동일하게 설정됩니다.
- 이때, standalone_question이 "where did harrison work?"로 설정되고, 이 질문은 모델에 전달됩니다.
- 모델은 주어진 문맥 없이 질문을 이해하고 답변을 생성합니다.
- 두 번째 invoke 호출:
- "question": "where did he work?"와 "chat_history": [("Who wrote this notebook?", "Harrison")]와 같이 대화 기록이 있는 입력이 주어집니다.
- 두 번째 호출에서는 대화 기록이 주어지며, 대화 기록의 마지막 대화는 "Harrison"로 끝나는 것을 고려합니다.
- 대화 기록에서 "Harrison"의 존재를 고려하여 새로운 독립적인 질문이 생성됩니다. 이 때 "who" 질문의 일부분인 "Harrison"을 고려하여 질문이 재구성됩니다.
- standalone_question이 "where did he work?"로 설정되고, 이 질문은 모델에 전달됩니다.
- 모델은 이 새로운 질문과 대화 기록을 고려하여 답변을 생성합니다.
이러한 방식으로 대화 기록과 관련된 질문을 재구성하고 답변을 생성합니다.
With Memory and returning source documents
This shows how to use memory with the above. For memory, we need to manage that outside at the memory. For returning the retrieved documents, we just need to pass them through all the way.
위와 같이 메모리를 사용하는 방법을 보여줍니다. 메모리의 경우 메모리 외부에서 관리해야 합니다. 검색된 문서를 반환하려면 해당 문서를 끝까지 전달하기만 하면 됩니다.
from operator import itemgetter
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(
return_messages=True, output_key="answer", input_key="question"
)
# First we add a step to load memory
# This adds a "memory" key to the input object
loaded_memory = RunnablePassthrough.assign(
chat_history=RunnableLambda(memory.load_memory_variables) | itemgetter("history"),
)
# Now we calculate the standalone question
standalone_question = {
"standalone_question": {
"question": lambda x: x["question"],
"chat_history": lambda x: _format_chat_history(x["chat_history"]),
}
| CONDENSE_QUESTION_PROMPT
| ChatOpenAI(temperature=0)
| StrOutputParser(),
}
# Now we retrieve the documents
retrieved_documents = {
"docs": itemgetter("standalone_question") | retriever,
"question": lambda x: x["standalone_question"],
}
# Now we construct the inputs for the final prompt
final_inputs = {
"context": lambda x: _combine_documents(x["docs"]),
"question": itemgetter("question"),
}
# And finally, we do the part that returns the answers
answer = {
"answer": final_inputs | ANSWER_PROMPT | ChatOpenAI(),
"docs": itemgetter("docs"),
}
# And now we put it all together!
final_chain = loaded_memory | standalone_question | retrieved_documents | answer
이 코드는 Langchain에서 대화 메모리를 사용하여 대화 기록을 기반으로 독립적인 질문을 재구성하고 답변을 생성하는 일련의 작업을 수행합니다. 다음은 주요 단계와 구성 요소의 설명입니다.
- ConversationBufferMemory 초기화:
- ConversationBufferMemory는 대화 기록을 저장하고 검색하는 메모리를 나타냅니다. 이 메모리에 저장된 대화 기록은 return_messages=True로 설정되어 메모리에서 반환될 것이고, output_key 및 input_key는 각각 출력과 입력과 관련된 키를 정의합니다.
- loaded_memory 단계:
- RunnablePassthrough.assign을 사용하여 메모리에서 대화 기록을 로드하고 chat_history로 저장합니다. 이로써 대화 기록을 메모리에서 가져올 수 있습니다.
- standalone_question 단계:
- standalone_question은 대화 기록에서 새로운 독립적인 질문을 생성하는 역할을 합니다.
- 입력으로부터 "question" 및 "chat_history"를 추출하여 CONDENSE_QUESTION_PROMPT와 ChatOpenAI를 사용하여 질문을 재구성하고, 결과를 StrOutputParser를 사용하여 텍스트로 파싱합니다.
- retrieved_documents 단계:
- retrieved_documents는 재구성된 질문을 기반으로 관련 문서를 검색합니다.
- "question"을 질문으로, "standalone_question"을 기존의 독립적인 질문으로 사용하여 검색을 수행하고 검색 결과를 "docs"로 저장합니다.
- final_inputs 단계:
- final_inputs는 독립적인 질문과 검색된 문서를 조합하여 최종 입력을 준비합니다. "context"는 검색된 문서를 나타내며 "question"은 독립적인 질문을 나타냅니다.
- answer 단계:
- answer는 최종 입력을 기반으로 답변을 생성하는 역할을 합니다.
- "answer"는 최종 질문 및 문서를 사용하여 ANSWER_PROMPT와 ChatOpenAI를 통해 답변을 생성하고 결과를 "answer"로 저장합니다.
- final_chain 단계:
- 모든 단계를 합쳐서 최종 처리 체인을 생성합니다.
- loaded_memory를 통해 대화 기록을 로드하고, standalone_question을 통해 독립적인 질문을 생성하며, retrieved_documents를 사용하여 문서를 검색하고, answer를 통해 답변을 생성합니다.
이렇게 구성된 final_chain은 주어진 입력을 처리하여 대화 기록, 독립적인 질문, 검색된 문서를 사용하여 답변을 생성합니다.

inputs = {"question": "where did harrison work?"}
result = final_chain.invoke(inputs)
result
{'answer': AIMessage(content='Harrison was employed at Kensho.', additional_kwargs={}, example=False),
'docs': [Document(page_content='harrison worked at kensho', metadata={})]}
# Note that the memory does not save automatically
# This will be improved in the future
# For now you need to save it yourself
memory.save_context(inputs, {"answer": result["answer"].content})
memory.load_memory_variables({})
{'history': [HumanMessage(content='where did harrison work?', additional_kwargs={}, example=False),
AIMessage(content='Harrison was employed at Kensho.', additional_kwargs={}, example=False)]}
이 코드는 앞서 정의한 final_chain을 사용하여 질문을 처리하고 결과를 반환하는 방법을 보여줍니다.
- inputs 딕셔너리:
- "question" 키를 사용하여 질문을 정의한 후, 이를 final_chain.invoke에 전달할 입력으로 사용합니다.
- final_chain.invoke 호출:
- final_chain을 사용하여 입력 데이터를 처리하고, 질문을 재구성하고 검색된 문서를 기반으로 답변을 생성합니다.
- result 변수에 결과가 저장되며, 결과에는 "answer" 키가 있는데 이 키를 사용하여 답변을 얻을 수 있습니다.
- 메모리 관리:
- 주석으로 설명되어 있지만, 메모리가 자동으로 저장되지 않으며 사용자가 메모리를 수동으로 저장해야 합니다.
- 따라서 memory.save_context를 사용하여 현재의 문맥과 결과를 메모리에 저장합니다.
- 이렇게 저장한 데이터는 memory.load_memory_variables를 사용하여 다시 불러올 수 있습니다.
즉, 코드는 주어진 질문에 대한 답변을 생성하고, 필요한 경우 메모리에 결과를 저장하고 불러올 수 있도록 하는 데 사용됩니다.

교재에 있는 질문 Where did harrison work? 이외에 두개의 질문 What is his name? , Does Harrison work in Kensho? 를 추가 했습니다. invoke() 를 사용하면 에러가 나서 ainvoke()를 사용했는데 HumanMessage 즉 질문은 제대로 차곡차곡 저장이 되는데 대답은 해당 질문에 맞는 대답이 나오지 않고 첫번째 대답만 계속 나오네요. 해당 질문에 대한 대답을 얻으려면 좀 다른 방법으로 해야하나 봅니다. 나중에 따로 공부를 좀 해야 겠네요.
'LangChain > LangChain Expression Language' 카테고리의 다른 글
| LC - Cookbook - Routing by semantic similarity (0) | 2023.11.07 |
|---|---|
| LC - Cookbook - Code Writing (1) | 2023.11.06 |
| LC - Cookbook - Agents (0) | 2023.11.06 |
| LC - Cookbook - Querying a SQL DB (0) | 2023.11.06 |
| LC - Cookbook - Multiple chains (0) | 2023.11.05 |
| LC - Cookbook - Prompt + LLM (1) | 2023.10.29 |
| LangChain - How to - Route between multiple Runnables (1) | 2023.10.28 |
| LangChain - How to - Use RunnableParallel/RunnableMap (1) | 2023.10.28 |
| LangChain - How to - Custom generator functions (0) | 2023.10.28 |
| LangChain - How to - Run arbitrary functions (0) | 2023.10.28 |