오늘은 모델을 생성하고 Training 시키고 Evaluation까지 시키고 난 후 볼 수 있는 여러 정보들을 살펴 봤다.

우선 Reward Graph를 보면 Refresh 버튼 밑에 메뉴항목이 있다.
View in metrics와 View logs가 있는데..
일단 View in metrics로 가 보자.
그러면 Cloud Watch의 Total reward over time 페이지로 이동한다.
AWS Cloud Watch는 AWS 클라우드 서비스들에 대한 모니터링 정보를 제공하는 서비스이다.
Amazon CloudWatch is a monitoring service for AWS cloud resources and the applications you run on AWS. You can use Amazon CloudWatch to collect and track metrics, collect and monitor log files, set alarms, and automatically react to changes in your AWS resources.
이 Total Reward over time 페이지는 아래와 같다.

Reward Graph가 좀 더 자세하게 나오고 그 아래에는 뭔지 모를 4개의 탭이 있고 더 뭔지 모를 여러 정보들이 있다.
뭐 별로 눈길을 끄는게 없어서 다음으로 패스.
View logs를 클릭 해 봤다.
역시 AWS Cloudwatch 서비스 페이지로 넘어갔다.
여기에는 로그 정보들이 있다.
매일 코딩을 하다보면 어쩔 수 없이 뚫어져라 볼 수 밖에 없는 게 로그 정보들이라서 이건 좀 친숙하다.

우선 첫번째 링크는 Lamda로그인 것 같은데 여기엔 별 정보가 없었다.

두 번째 로그는 시뮬레이션 관련 로그인 것 같다.
이 정보들을 활용하는 법을 알면 유용한 정보일 수 있을 것 같다.
아직은 잘 몰라서 그냥 이런게 있다는 것만 알고 넘어간다.
마지막 세번째 링크가 Training 관련 로그이다.

여기엔 좀 뭔가 알아 먹을 것 같은 로그 정보들이 있다.
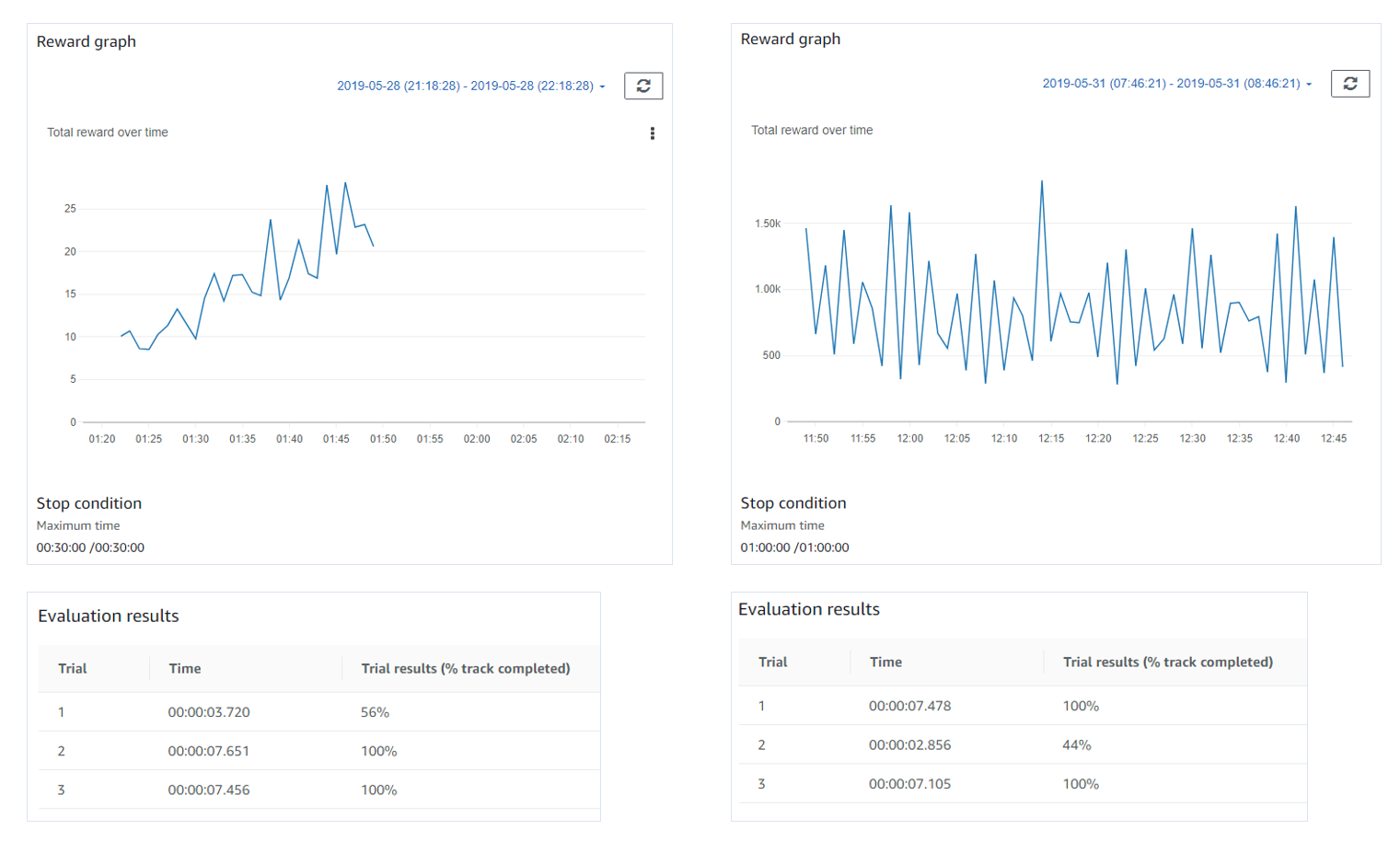
이건 직선 트랙에 디폴트 reward_function 을 사용한 트레이닝 로그인데 여기에 에피소드와 이터레이션 정보가 있다.
30분간 트레이닝을 시켰는데 마지막 에피소드는 372 이다.
아마 372번 훈련을 한 것이다.
1개의 iteration에는 20개의 에피소드가 있다.
그래서 총 18개의 iteration이 있다.
각 에피소드 별로 Total Reward와 Steps 정보가 있다.
이 로그에는 대충 이런 정보들이 있다.

그 외에 이 로그 시작 부분에 각 종 환경 변수나 파라미터 정보들이 있다.

그 다음 Evaluation section에는 평가 결과 정보가 있다.
평가는 3번 하는 것 같다.
평가 작업은 계속 할 수 있는데 이 서비스는 별도의 요금을 내는 것 같아서 여러번 시도하지는 않았다.

그 다음 Training Configuration section에는 여러 config 정보를 볼 수 있다.
Reward function의 Show 버튼을 누르면 이 모델에서 사용한 Reward function을 볼 수 있다.
그리고 그 밑에 Action space 정보를 볼 수 있는 버튼이 있다.
Framewark 은 Tensorflow를 사용했고 Reinforcement learning algorithm은 PPO를 사용했다는 정보가 있다.
그리고 마지막은 Hyperparameter 정보들이 있다.
지금까지 직선 트랙에서 두 번 훈련 시켰다.
다음은 곡선이 들어간 트랙에서 훈련을 시켜보기로 했다.
'IoT > AWS DeepRacer' 카테고리의 다른 글
| AWS Deepracer Virtual Race 최초 참가 경험 정리 (0) | 2019.07.07 |
|---|---|
| MEGAZONE CLOUD AWS DeepRacer League in Korea (0) | 2019.06.25 |
| 테슬라 주가와 2011년 넷플릭스 주가 비교 (0) | 2019.06.05 |
| AWS DeepRacer League and 2nd Virtual Race open (1) | 2019.06.04 |
| AWS Deepracer - Oval and London loop track model 훈련 결과 (0) | 2019.06.03 |
| AWS Deepracer 첫 모델 생성 및 결과 보기 (0) | 2019.06.02 |
| AWS Deepracer를 시작하면 내야 하는 요금들... (0) | 2019.05.31 |
| AWS DeepRacer - Hands-on Exercise 1 : Model Training Using AWS DeepRacer Console (0) | 2019.05.30 |
| AWS DeepRacer를 시작하기 전에 살펴볼 내용 (0) | 2019.05.17 |
| Troubleshooting (0) | 2019.01.02 |