
Openai cookbook : ChatGPT , How to format inputs to ChatGPT models
2023. 3. 4. 05:06 |
OpenAI Cookbook을 공부하고 있는 사이에 새롭게 올라온 글이 있습니다.
ChatGPT와 관련한 글인데요.
2023년 3월 1일에 최초로 올라왔습니다.
오늘은 이 글을 공부해 보도록 하겠습니다.
GitHub - openai/openai-cookbook: Examples and guides for using the OpenAI API
Examples and guides for using the OpenAI API. Contribute to openai/openai-cookbook development by creating an account on GitHub.
github.com

How to format inputs to ChatGPT models
ChatGPT는 gpt-3.5-turbo로 만들어 졌고 OpenAI의 가장 진보된 모델입니다.
OpenAI API를 사용해서 gpt-3.5-turbo로 여러분들만의 어플리케이션을 build 하실 수 있습니다.
Chat 모델은 일련의 메세지를 입력값으로 받고 AI 가 작성한 메세지를 output으로 반환합니다.
이 가이드는 몇가지 예제 API호출을 사용하여 채팅 형식을 보여 줍니다.
1. Import the openai library
# if needed, install and/or upgrade to the latest version of the OpenAI Python library
%pip install --upgrade openaiOpenAI 최신 버전으로 업데이트 하려면 pip install -- upgrade 명령으로 업데이트 합니다.
저는 윈도우즈 명령창에서 업데이트 했습니다.

2023년 3월 1일 ChatGPT API 가 OpenAI API 에 추가 됐습니다.
이 Chat API 콜의 모델 이름은 gpt-3.5-turbo 입니다. 이 모델은 ChatGPT 에서 사용되는 바로 그 모델입니다.
이와 관련한 Guide document도 추가 됐습니다.
https://platform.openai.com/docs/guides/chat
OpenAI API
An API for accessing new AI models developed by OpenAI
platform.openai.com
이 API를 사용하는 가격은 1천개의 토큰당 0.002 달러입니다.
그 다음은 openai 모듈을 import 합니다.

저 같은 경우는 openai api key 를 파일에서 읽허서 보내기 때문에 그 부분도 넣었습니다.
2. An example chat API call
chat API 콜은 다음 두가지 입력값들이 요구 됩니다.
- model: the name of the model you want to use (e.g., gpt-3.5-turbo)
- 모델 : 사용하고자 할 모델 이름 (e.g., gpt-3.5-turbo)
- messages: a list of message objects, where each object has at least two fields:
- 메세지 : 메세지 객체 리스트. 각 객체들은 최소한 아래 두개의 field를 가지고 있어야 한다.
- role: the role of the messenger (either system, user, or assistant)
- 역할 : 메센저의 역할 (시스템인지 사용자인지 혹은 조력자인지...)
- content: the content of the message (e.g., Write me a beautiful poem)
- 내용 : 메세지의 내용 (예. , 저에게 아름다운 시를 써 주세요.)
일반적으로 대화는 시스템 메세지로 시작하고 그 뒤에 사용자 및 조력자 메세지가 교대로 오지만 꼭 이 형식을 따를 필요는 없습니다.
ChatGPT 가 사용하는 Chat API가 실제로 어떻게 작동하는지 알아보기 위해 Chat API 를 호출하는 예제를 한번 살펴보겠습니다.
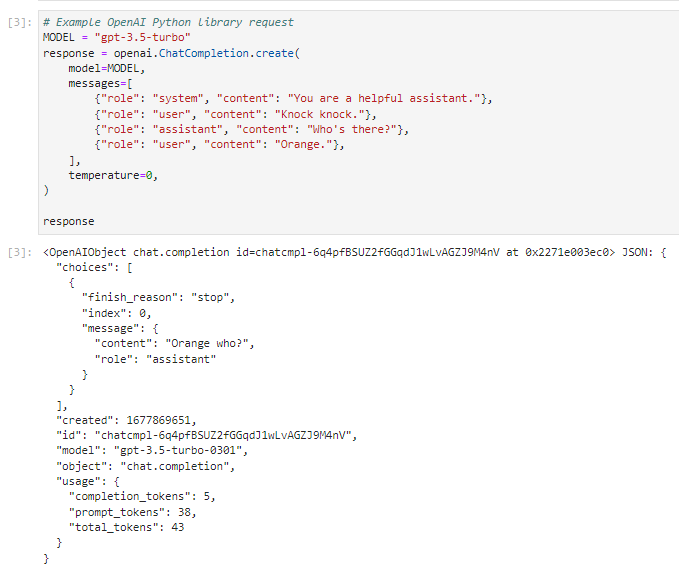
이 ChatGPT에서 사용하는 ChatAPI를 호출하는 방법은 openai.ChatCompletion.create() 을 호출하는 겁니다.
위 호출에 대한 response 객체는 여러 필드들이 있습니다.
- choices: a list of completion objects (only one, unless you set n greater than 1)
- choices : completion 객체의 리스트 (n을 1보다 높게 세팅하지 않는 한 한개만 존재한다.)
- message: the message object generated by the model, with role and content
- message : 모델에 의해 생성된 메세지 객체 (role, content)
- finish_reason: the reason the model stopped generating text (either stop, or length if max_tokens limit was reached)
- finish_reason: 모델이 텍스트 생성을 중지한 이유 (stop 이거나 max_tokens를 초과했을 경우는 그 길이)
- index: the index of the completion in the list of choices
- index: choices에 있는 리스트의 completion 의 index
- created: the timestamp of the request
- created : 해당 request의 요청 시간 정보
- id: the ID of the request (해당 request의 ID)
- model: the full name of the model used to generate the response
- model ; response를 발생시키는데 사용된 모델의 full name
- object: the type of object returned (e.g., chat.completion)
- object : 반환된 객체의 유형 (e.g., chat.completion)
- usage: the number of tokens used to generate the replies, counting prompt, completion, and total
- usage : response를 생성하는데 사용된 토큰 수. completion, prompt, totak 토큰 수
위 Request 에서 보면 messages 안에 있는 첫번째 아이템의 role 이 system 입니다.
이는 ChatGPT에게 현 상황을 설명하는 겁니다.
여기서는 너는 아주 도움을 잘 주는 조력자이다 라고 ChatGPT에게 규정했습니다.
그 다음의 user는 똑 똑 하고 노크를 하죠.
그 다음 조력자는 누구세요? 라고 묻습니다.
그 다음 user는 Orange 라고 대답하죠.
여기까지 ChatGPT에게 제공된 상황입니다.
그러면 그 다음은 ChatGPT가 알아서 그 다음에 올 수 있는 알맞는 대답을 response 할 차례입니다.
ChatGPT의 대답의 구조는 위에 설명 한 대로 입니다.
여기서 대답은 choices - message - content 에 있는 Orange who? 라는 겁니다.
나머지는 모두 이 request와 response 에 대한 데이터들입니다.
여기서 실제 ChatGPT가 상황에 맞게 대답한 부분만 받으려면 아래와 같이 하면 됩니다.

이렇게 하면 실제 ChatGPT가 대답한 Orange who? 라는 부분만 취할 수 있습니다.
대화 기반이 아닌 작업도 첫번째 user message 부분에 instruction을 넣음으로서 chat format 에 맞춰서 사용할 수 있습니다.
예를 들어 모델에게 비동기 프로그래밍을 설명하는데 검은 수염이 난 해적이 말하는 스타일로 설명하도록 요청하려면 대화를 다음과 같이 구성하시면 됩니다.

이렇게 하면 ChatGPT가 비동기 프로그래밍을 설명하는데 그 말투가 검은 수염난 해적이 말하는 것처럼 만들어서 대답을 합니다.
이것을 그 말투의 느낌까지 살려서 한글로 번역하는 것은 힘드니까 대충 구글 번역기를 돌려 보겠습니다.
어이 친구! 비동기 프로그래밍은 동시에 다른 작업을 수행하는 해적 선원을 갖는 것과 같습니다. 예, 다음 작업을 시작하기 전에 하나의 작업이 완료되기를 기다리는 대신 한 번에 여러 작업을 실행할 수 있습니다. 그것은 다른 사람들이 갑판을 청소하고 대포를 장전하는 동안 내 승무원이 돛을 올리는 것과 같습니다. 각 작업은 독립적으로 작동하지만 모두 배의 전반적인 성공에 기여합니다. 이는 기름칠이 잘 된 해적선이 더 빠르고 원활하게 항해할 수 있는 것처럼 코드를 더 빠르고 효율적으로 실행하는 강력한 방법입니다. Arr!
재밌네요.
상황 설명을 하는 system message 없이 한번 요청해 보겠습니다.

이렇게 해도 ChatGPT는 제대로 대답 합니다.
3. Tips for instructing gpt-3.5-turbo-0301
모델들에게 가장 잘 instructing 하는 방법은 모델의 버전에 따라 다를 수 있습니다. 아래 예제는 gpt-3.5-turbo-0301 버전에 적용할 때 가장 효과가 좋은 instructiong 입니다. 이후의 모델에서는 적용되지 않을 수 있습니다.
System messages
시스템 메세지는 다른 성격이나 행동 양식을 부여함으로서 assistant를 잘 준비 하도록 하는데 사용할 수 있습니다.
하지만 모델은 일반적으로 system message에 그렇게 절대적으로 주의를 기울이지는 않습니다. 그러므로 정말 중요한 부분은 user 메세지에 배치하라고 권고 드립니다.
다음은 assitant가 개념을 아주 깊이 있게 설명하도록 유도하는 system 메세지의 예 입니다.
# An example of a system message that primes the assistant to explain concepts in great depth
response = openai.ChatCompletion.create(
model=MODEL,
messages=[
{"role": "system", "content": "You are a friendly and helpful teaching assistant. You explain concepts in great depth using simple terms, and you give examples to help people learn. At the end of each explanation, you ask a question to check for understanding"},
{"role": "user", "content": "Can you explain how fractions work?"},
],
temperature=0,
)
print(response["choices"][0]["message"]["content"])
아래는 Assitent 에게 간략하고 핵심적인 답변만 하라고 유도하는 system 메세지의 예입니다.
# An example of a system message that primes the assistant to give brief, to-the-point answers
response = openai.ChatCompletion.create(
model=MODEL,
messages=[
{"role": "system", "content": "You are a laconic assistant. You reply with brief, to-the-point answers with no elaboration."},
{"role": "user", "content": "Can you explain how fractions work?"},
],
temperature=0,
)
print(response["choices"][0]["message"]["content"])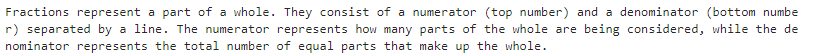
System message의 유도에 따라 대답을 자세하게 하거나 간력하게 하도록 하는 방법을 보았습니다.
Few-shot prompting
어떤 경우에는 당신이 원하는 것을 모델에게 설명하는 것 보다 그냥 보여주는게 더 편할 때가 있습니다.
이렇게 모델에게 당신이 무엇을 원하는지 보여주는 방법 중 하나는 fake example 메세지를 사용하는 것입니다.
모델이 비지니스 전문 용어를 더 간단한 말로 번역하도록 준비시키는 faked few-shot 대화를 넣어 주는 예제 입니다.
# An example of a faked few-shot conversation to prime the model into translating business jargon to simpler speech
response = openai.ChatCompletion.create(
model=MODEL,
messages=[
{"role": "system", "content": "You are a helpful, pattern-following assistant."},
{"role": "user", "content": "Help me translate the following corporate jargon into plain English."},
{"role": "assistant", "content": "Sure, I'd be happy to!"},
{"role": "user", "content": "New synergies will help drive top-line growth."},
{"role": "assistant", "content": "Things working well together will increase revenue."},
{"role": "user", "content": "Let's circle back when we have more bandwidth to touch base on opportunities for increased leverage."},
{"role": "assistant", "content": "Let's talk later when we're less busy about how to do better."},
{"role": "user", "content": "This late pivot means we don't have time to boil the ocean for the client deliverable."},
],
temperature=0,
)
print(response["choices"][0]["message"]["content"])
제가 얻은 답은 위와 같습니다.
예제의 대화가 실제 대화가 아니고 이것을 다시 참조해서는 안된다는 점을 모델에게 명확하게 하기 위해 system message의 필드 이름을 example_user 와 example_assistant 로 바꾸어서 해 보겠습니다.
위의 few-shot 예제를 이렇게 좀 바꿔서 다시 시작해 보겠습니다.
# The business jargon translation example, but with example names for the example messages
response = openai.ChatCompletion.create(
model=MODEL,
messages=[
{"role": "system", "content": "You are a helpful, pattern-following assistant that translates corporate jargon into plain English."},
{"role": "system", "name":"example_user", "content": "New synergies will help drive top-line growth."},
{"role": "system", "name": "example_assistant", "content": "Things working well together will increase revenue."},
{"role": "system", "name":"example_user", "content": "Let's circle back when we have more bandwidth to touch base on opportunities for increased leverage."},
{"role": "system", "name": "example_assistant", "content": "Let's talk later when we're less busy about how to do better."},
{"role": "user", "content": "This late pivot means we don't have time to boil the ocean for the client deliverable."},
],
temperature=0,
)
print(response["choices"][0]["message"]["content"])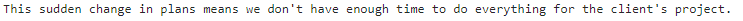
제가 받은 답은 위와 같습니다.
엔지니어링 대화에 대한 모든 시도가 첫번째 시도에서 다 성공하는 것은 아닙니다.
첫번째 시도가 실패하면 다른 방법으로 priming을 하던가 혹은 모델의 condition들을 바꾸어서 다시 시도하는 실험을 두려워 하지 마세요.
예를 들어 한 개발자는 모델이 더 높은 품질의 응답을 제공하도록 하기 위해 "지금까지 훌륭했어요. 완벽했습니다." 라는 사용자 메세지를 삽입했을 때 정확도가 더 증가한다는 것을 발견한 사례도 있습니다.
모델의 신뢰도를 높이는 방법에 대한 자세한 내용은 techniques to increase reliability 가이드를 참조하세요. 채팅용 모델용으로 작성된 것은 아니지만 기본 원칙은 동일하게 적용 될 수 있습니다.
https://coronasdk.tistory.com/1277
Openai cookbook : GPT-3 , Guide Techniques to improve reliability
오늘 공부할 내용은 답변의 신뢰성을 높이기 위한 여러 방법들을 알아보는 겁니다. 실습보다는 이론적인 것들이 많은 것 같습니다. 내용이 좀 긴데 일단 한번 시작해 보겠습니다. 원본 페이지는
coronasdk.tistory.com
4. Counting tokens
여러분이 Request를 submit 하면 API 는 그 메세지를 일련의 토큰들로 변환합니다.
여기서 토큰의 수는 다음과 같은 것들에 영향을 미칩니다.
- the cost of the request
- request에 대한 과금
- the time it takes to generate the response
- response를 발생시키는데 걸리느 ㄴ시간
- when the reply gets cut off from hitting the maximum token limit (4096 for gpt-3.5-turbo)
- 최대 토큰 수 제한 (gpt-3.5-turbo 의 경우 4096)에 다다랐을 때는 request 중 나머지는 잘려 나가게 됨
2023년 3월 1일부터 다음 함수를 사용해서 메세지 목록에서 사용될 토큰의 갯수를 미리 계산할 수 있습니다.
import tiktoken
def num_tokens_from_messages(messages, model="gpt-3.5-turbo-0301"):
"""Returns the number of tokens used by a list of messages."""
try:
encoding = tiktoken.encoding_for_model(model)
except KeyError:
encoding = tiktoken.get_encoding("cl100k_base")
if model == "gpt-3.5-turbo-0301": # note: future models may deviate from this
num_tokens = 0
for message in messages:
num_tokens += 4 # every message follows <im_start>{role/name}\n{content}<im_end>\n
for key, value in message.items():
num_tokens += len(encoding.encode(value))
if key == "name": # if there's a name, the role is omitted
num_tokens += -1 # role is always required and always 1 token
num_tokens += 2 # every reply is primed with <im_start>assistant
return num_tokens
else:
raise NotImplementedError(f"""num_tokens_from_messages() is not presently implemented for model {model}.
See https://github.com/openai/openai-python/blob/main/chatml.md for information on how messages are converted to tokens.""")tiktoken을 import 합니다.
num_tokens_from_messages() 함수를 만듭니다.
이 함수의 입력값은 메세지와 모델명 입니다.
tiktoken의 encoding_for_model()을 사용해서 encoding을 정합니다.
여기서 에러가 날 경우 cl100k_base 를 사용합니다. (이는 임베딩에서 사용했던 인코딩 입니다.)
if 문에서 모델이 gpt-3.5-turbo-0301 인 경우 그 안의 내용을 실행하게 됩니다.
그 안의 for 문은 메세지 목록의 아이템 수 만큼 루프를 돕니다.
그리고 각각의 메세지마다 4를 + 해 줍니다.
그리고 그 각각의 메세지에 대한 토큰 값을 다음 for 문 안에서 len(encoding.encode(value) 를 사용해서 계산합니다.
key 가 name 인 경우 role은 항상 1개의 토큰만 사용하기 때문에 이 부분을 빼 줍니다.
그리고 각각의 reply 마다 2씩 더해 줍니다.
이렇게 해서 계산된 값을 반환합니다.
그 다음에 아래 messages를 정해 줍니다.
messages = [
{"role": "system", "content": "You are a helpful, pattern-following assistant that translates corporate jargon into plain English."},
{"role": "system", "name":"example_user", "content": "New synergies will help drive top-line growth."},
{"role": "system", "name": "example_assistant", "content": "Things working well together will increase revenue."},
{"role": "system", "name":"example_user", "content": "Let's circle back when we have more bandwidth to touch base on opportunities for increased leverage."},
{"role": "system", "name": "example_assistant", "content": "Let's talk later when we're less busy about how to do better."},
{"role": "user", "content": "This late pivot means we don't have time to boil the ocean for the client deliverable."},
]그 다음에 이 메세지의를 파라미터로 num_tokens_from_messages() 함수를 호출해서 토큰 값을 받고 그것을 print 해 줍니다.
# example token count from the function defined above
print(f"{num_tokens_from_messages(messages)} prompt tokens counted.")
그러면 126개의 토큰이 사용됐다고 나옵니다.
참고로 이 글에서 만든 파이썬 소스코드는 아래와 같습니다.
# import the OpenAI Python library for calling the OpenAI API
import openai
def open_file(filepath):
with open(filepath, 'r', encoding='utf-8') as infile:
return infile.read()
openai.api_key = open_file('openaiapikey.txt')
# Example OpenAI Python library request
MODEL = "gpt-3.5-turbo"
response = openai.ChatCompletion.create(
model=MODEL,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Knock knock."},
{"role": "assistant", "content": "Who's there?"},
{"role": "user", "content": "Orange."},
],
temperature=0,
)
response
response['choices'][0]['message']['content']
# example with a system message
response = openai.ChatCompletion.create(
model=MODEL,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain asynchronous programming in the style of the pirate Blackbeard."},
],
temperature=0,
)
print(response['choices'][0]['message']['content'])
# example without a system message
response = openai.ChatCompletion.create(
model=MODEL,
messages=[
{"role": "user", "content": "Explain asynchronous programming in the style of the pirate Blackbeard."},
],
temperature=0,
)
print(response['choices'][0]['message']['content'])
# An example of a system message that primes the assistant to explain concepts in great depth
response = openai.ChatCompletion.create(
model=MODEL,
messages=[
{"role": "system", "content": "You are a friendly and helpful teaching assistant. You explain concepts in great depth using simple terms, and you give examples to help people learn. At the end of each explanation, you ask a question to check for understanding"},
{"role": "user", "content": "Can you explain how fractions work?"},
],
temperature=0,
)
print(response["choices"][0]["message"]["content"])
# An example of a system message that primes the assistant to give brief, to-the-point answers
response = openai.ChatCompletion.create(
model=MODEL,
messages=[
{"role": "system", "content": "You are a laconic assistant. You reply with brief, to-the-point answers with no elaboration."},
{"role": "user", "content": "Can you explain how fractions work?"},
],
temperature=0,
)
print(response["choices"][0]["message"]["content"])
# An example of a faked few-shot conversation to prime the model into translating business jargon to simpler speech
response = openai.ChatCompletion.create(
model=MODEL,
messages=[
{"role": "system", "content": "You are a helpful, pattern-following assistant."},
{"role": "user", "content": "Help me translate the following corporate jargon into plain English."},
{"role": "assistant", "content": "Sure, I'd be happy to!"},
{"role": "user", "content": "New synergies will help drive top-line growth."},
{"role": "assistant", "content": "Things working well together will increase revenue."},
{"role": "user", "content": "Let's circle back when we have more bandwidth to touch base on opportunities for increased leverage."},
{"role": "assistant", "content": "Let's talk later when we're less busy about how to do better."},
{"role": "user", "content": "This late pivot means we don't have time to boil the ocean for the client deliverable."},
],
temperature=0,
)
print(response["choices"][0]["message"]["content"])
# The business jargon translation example, but with example names for the example messages
response = openai.ChatCompletion.create(
model=MODEL,
messages=[
{"role": "system", "content": "You are a helpful, pattern-following assistant that translates corporate jargon into plain English."},
{"role": "system", "name":"example_user", "content": "New synergies will help drive top-line growth."},
{"role": "system", "name": "example_assistant", "content": "Things working well together will increase revenue."},
{"role": "system", "name":"example_user", "content": "Let's circle back when we have more bandwidth to touch base on opportunities for increased leverage."},
{"role": "system", "name": "example_assistant", "content": "Let's talk later when we're less busy about how to do better."},
{"role": "user", "content": "This late pivot means we don't have time to boil the ocean for the client deliverable."},
],
temperature=0,
)
print(response["choices"][0]["message"]["content"])
import tiktoken
def num_tokens_from_messages(messages, model="gpt-3.5-turbo-0301"):
"""Returns the number of tokens used by a list of messages."""
try:
encoding = tiktoken.encoding_for_model(model)
except KeyError:
encoding = tiktoken.get_encoding("cl100k_base")
if model == "gpt-3.5-turbo-0301": # note: future models may deviate from this
num_tokens = 0
for message in messages:
num_tokens += 4 # every message follows <im_start>{role/name}\n{content}<im_end>\n
for key, value in message.items():
num_tokens += len(encoding.encode(value))
if key == "name": # if there's a name, the role is omitted
num_tokens += -1 # role is always required and always 1 token
num_tokens += 2 # every reply is primed with <im_start>assistant
return num_tokens
else:
raise NotImplementedError(f"""num_tokens_from_messages() is not presently implemented for model {model}.
See https://github.com/openai/openai-python/blob/main/chatml.md for information on how messages are converted to tokens.""")
messages = [
{"role": "system", "content": "You are a helpful, pattern-following assistant that translates corporate jargon into plain English."},
{"role": "system", "name":"example_user", "content": "New synergies will help drive top-line growth."},
{"role": "system", "name": "example_assistant", "content": "Things working well together will increase revenue."},
{"role": "system", "name":"example_user", "content": "Let's circle back when we have more bandwidth to touch base on opportunities for increased leverage."},
{"role": "system", "name": "example_assistant", "content": "Let's talk later when we're less busy about how to do better."},
{"role": "user", "content": "This late pivot means we don't have time to boil the ocean for the client deliverable."},
]
# example token count from the function defined above
print(f"{num_tokens_from_messages(messages)} prompt tokens counted.")'Open AI > CookBook' 카테고리의 다른 글
| Openai cookbook : Azure OpenAI - How to get completions from Azure OpenAI (0) | 2023.03.18 |
|---|---|
| Azure OpenAI 를 사용하기 위한 사전 요구 사항들 - 사용 요청 거부 됨 (0) | 2023.03.18 |
| Openai cookbook : DALL-E - How to generate and edit images with DALL-E (1) | 2023.03.17 |
| Openai cookbook : Fine-tuning GPT-3 - Fine-tuned classification (0) | 2023.03.15 |
| Openai cookbook : Fine-tuning GPT-3 - Guide: best practices for fine-tuning GPT-3 to classify text (0) | 2023.03.08 |
| Openai cookbook : GPT-3 , Code Editing examples (0) | 2023.03.04 |
| Openai cookbook : GPT-3 , Code explanation examples (0) | 2023.03.04 |
| Openai cookbook : GPT-3 , Code writing examples (0) | 2023.03.04 |
| Openai cookbook : GPT-3 , Text editing examples (0) | 2023.03.04 |
| Openai cookbook : GPT-3 , Text explanation examples (0) | 2023.03.04 |

