개발자로서 현장에서 일하면서 새로 접하는 기술들이나 알게된 정보 등을 정리하기 위한 블로그입니다. 운 좋게 미국에서 큰 회사들의 프로젝트에서 컬설턴트로 일하고 있어서 새로운 기술들을 접할 기회가 많이 있습니다. 미국의 IT 프로젝트에서 사용되는 툴들에 대해 많은 분들과 정보를 공유하고 싶습니다.
초기 고객으로서 귀하의 경험에 대해 듣고 싶습니다. 커뮤니티 포럼에서 자유롭게 의견을 공유하거나 팀에 직접 연락하세요.
Best, The OpenAI team
이런 내용입니다.
저는 GPT-4 API 사용 권한을 waiting list 에 3월 14일 신청 했었습니다.
Thank you for joining the waitlist to build with GPT-4!
GPT-4로 빌드하기 위한 대기자 명단에 등록해 주셔서 감사합니다!
To balance capacity with demand, we'll be sending invites gradually over time.
용량과 수요의 균형을 맞추기 위해 시간이 지남에 따라 점진적으로 초대장을 보낼 것입니다.
While we ramp up, invites will be prioritized to developers who have previously build with the OpenAI API. You can also gain priority access if you contribute model evaluations toOpenAI Evalsthat get merged, as this will help us improve the models for everyone.
확장하는 동안 초대는 이전에 OpenAI API로 빌드한 개발자에게 우선순위가 부여됩니다. 병합되는 OpenAI Eval에 모델 평가를 제공하면 모든 사람을 위해 모델을 개선하는 데 도움이 되므로 우선 액세스 권한을 얻을 수 있습니다.
Once you’re off the waitlist, you’ll receive an email with further instructions on how to get started. We will process requests for the 8K and 32K models at different rates based on capacity, so you can expect to receive 8K access first.
대기자 명단에서 제외되면 시작하는 방법에 대한 추가 지침이 포함된 이메일을 받게 됩니다. 용량에 따라 다른 속도로 8K 및 32K 모델에 대한 요청을 처리하므로 먼저 8K 액세스를 받을 수 있습니다.
We appreciate your interest, and look forward to having you build with GPT-4 soon. In the meantime, we suggest getting started with gpt-3.5-turbo, the model powering ChatGPT.
귀하의 관심에 감사드리며 곧 GPT-4로 빌드할 수 있기를 기대합니다. 그동안 ChatGPT를 지원하는 모델인 gpt-3.5-turbo를 시작하는 것이 좋습니다.
– The OpenAI Team
P.S. You can also preview GPT-4 onchat.openai.comif you’re a ChatGPT Plus subscriber. We expect to be severely capacity constrained, so there will be a usage cap for the model depending on demand and system performance.
추신 ChatGPT Plus 구독자인 경우 chat.openai.com에서 GPT-4를 미리 볼 수도 있습니다. 용량이 심각하게 제한될 것으로 예상되므로 수요 및 시스템 성능에 따라 모델에 대한 사용 한도가 있을 것입니다.
지금은 GPT-4 API 8k 용량에 대한 접근권만 허용이 된 것이네요.
어쨌든 공부를 시작할 수 있을 것 같습니다.
저는 2023년 1월 3일부터 GPT-3 API 관련해서 공부를 시작했습니다.
일종의 New Year's Resolution 이 돼 버렸는데요.
공부 거의 마칠 무렵인 3월 1일에 GPT-3.5 turbo API (ChatGPT API) 가 발표 됐습니다.
그래서 며칠동안 Update 된 API 를 다시 공부 해야 됐는데요.
14일 후인 3월 14일 Open AI 에서는 GPT-4 가 발표 됐습니다.
정말 정신 없이 발전하는 것 같습니다.
원래 계획은 OpenAI API Cookbook을 마치고 개인 프로젝트를 구상해서 추진하려고 했습니다.
이제 Cookbook을 거의 다 마치고 Azure 와 연결해서 사용할 수 있는 방법에 대한 글 3가지만 남아 있었는데...
이제 CPT-4 가 발표 됐으니 update 된 내용도 다시 수정하거나 추가해서 정리 해야 될 것 같습니다.
개인적으로 이번달 (3월) 안으로 Cookbook 공부 다 마치고 4월부터 개인 프로젝트 구상에 들어가야 겠습니다.
제목에서는 GPT-4 가 Open AI의 가장 진보된 시스템이고 더 안전하고 유용한 답변을 한다고 돼 있습니다.
이 GPT-4 API를 사용하려면 API waitlist에 등록 해야 합니다.
GPT-4는 폭넓은 일반 지식과 문제 해결 능력 덕분에 어려운 문제를 더 정확하게 풀 수 있습니다.
라고 말을 하고 있고 그 아래 GPT-4에서 개선 된 부분들에 대해 나옵니다.
우선 Creativity와 Visual input 그리고 Longer context 이렇게 3개의 탭이 있습니다.
Creativity 부터 볼까요?
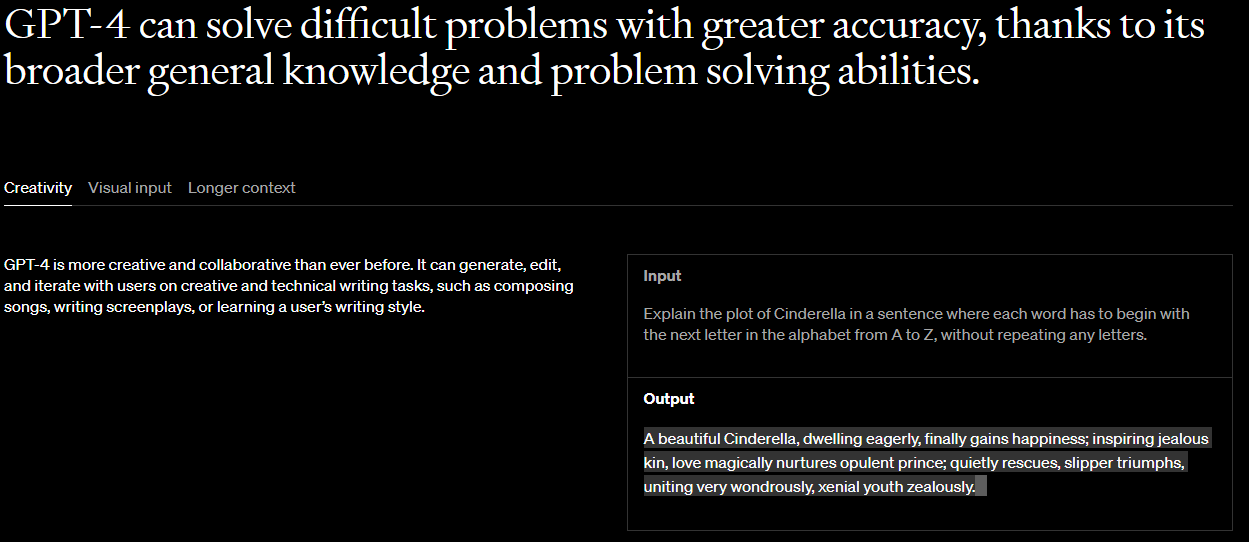
GPT4 is more creative and collaborative than ever before. It can generate, edit, and iterate with users on creative and technical writing tasks, such as composing songs, writing screenplays, or learning a user’s writing style.
GPT-4는 그 어느 때보다 창의적이고 협력적입니다. 노래 작곡, 시나리오 작성 또는 사용자의 작문 스타일 학습과 같은 창의적이고 기술적인 작문 작업에서 사용자와 함께 생성, 편집 및 반복할 수 있습니다.
Input Explain the plot of Cinderella in a sentence where each word has to begin with the next letter in the alphabet from A to Z, without repeating any letters.
Output A beautiful Cinderella, dwelling eagerly, finally gains happiness; inspiring jealous kin, love magically nurtures opulent prince; quietly rescues, slipper triumphs, uniting very wondrously, xenial youth zealously.
input으로 아래와 같은 요구를 했습니다.
문자를 반복하지 않고 A부터 Z까지 알파벳의 다음 문자로 각 단어가 시작되어야 하는 문장으로 신데렐라의 줄거리를 설명합니다.
그랬더니 신데렐라의 줄거리를 진짜 A 부터 Z까지 시작하는 단어들을 차례대로 사용해서 설명을 했습니다.
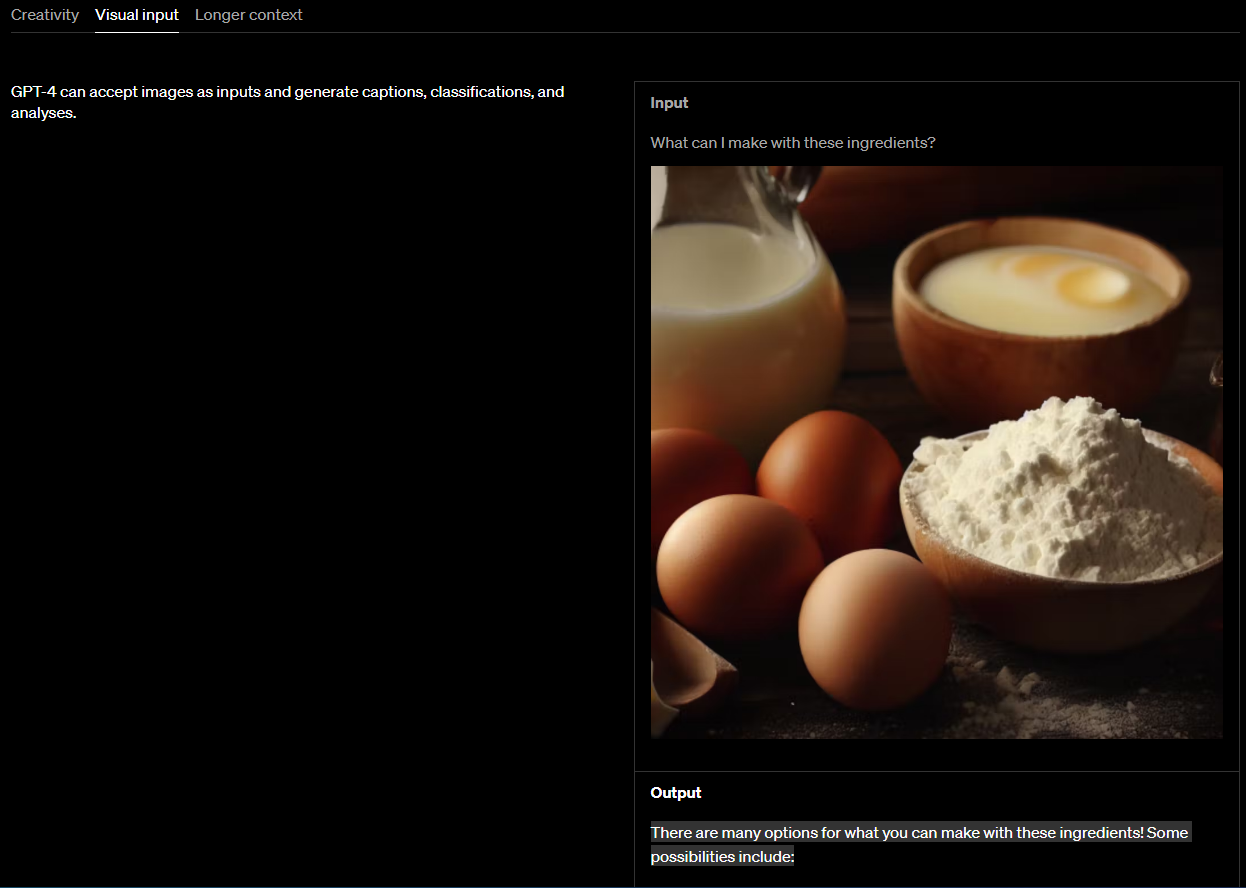
두번째는 Visual input 분야 입니다.
이미지 파일을 주고 이 재료들을 가지고 무엇을 만들 수 있냐고 물었더니...
Output There are many options for what you can make with these ingredients! Some possibilities include:
- Pancakes or waffles - Crepes - French toast - Omelette or frittata - Quiche - Custard or pudding - Cake or cupcakes - Muffins or bread- Cookies or biscuits
These are just a few examples, but the possibilities are endless! few examples, but the possibilities are endless!
이런 답변을 했네요. 그림만 보고 그 안에 있는 재료들을 판단해서 거기에 맞는 가능한 요리들을 보여 줬습니다.
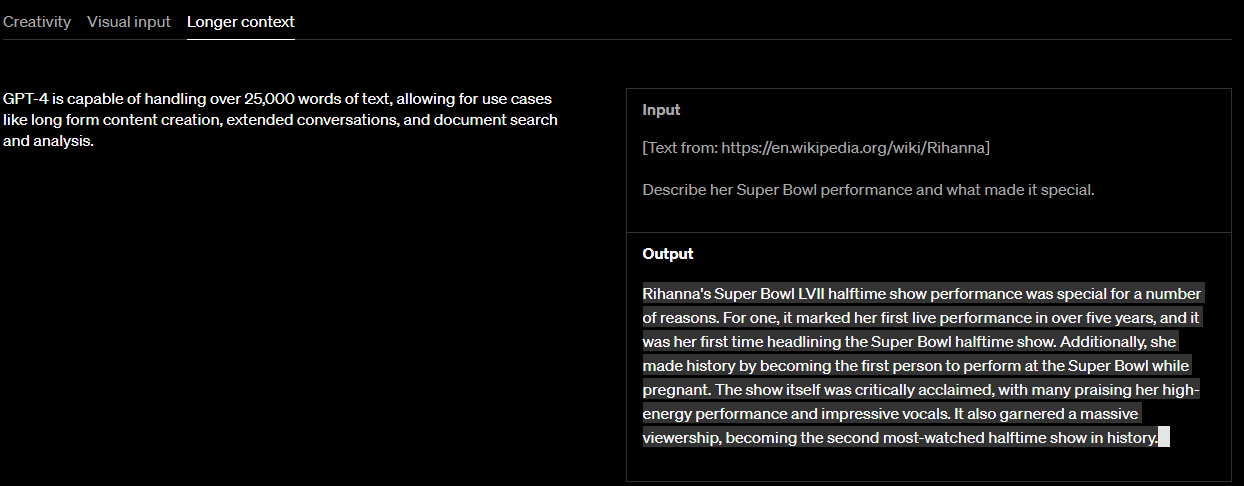
그 다음은 아주 긴 input 값을 받을 수 있다는 내용입니다.
GPT-4 is capable of handling over 25,000 words of text, allowing for use cases like long form content creation, extended conversations, and document search and analysis.
GPT-4는 25,000단어 이상의 텍스트를 처리할 수 있어 긴 형식의 콘텐츠 생성, 확장된 대화, 문서 검색 및 분석과 같은 사용 사례를 허용합니다.
예제로는 리하나의 위키피디아의 내용을 입력값으로 주고 이번 Super Bowl 공연에 대해 물어보고 GPT-4 가 대답하는 내용이 있습니다.
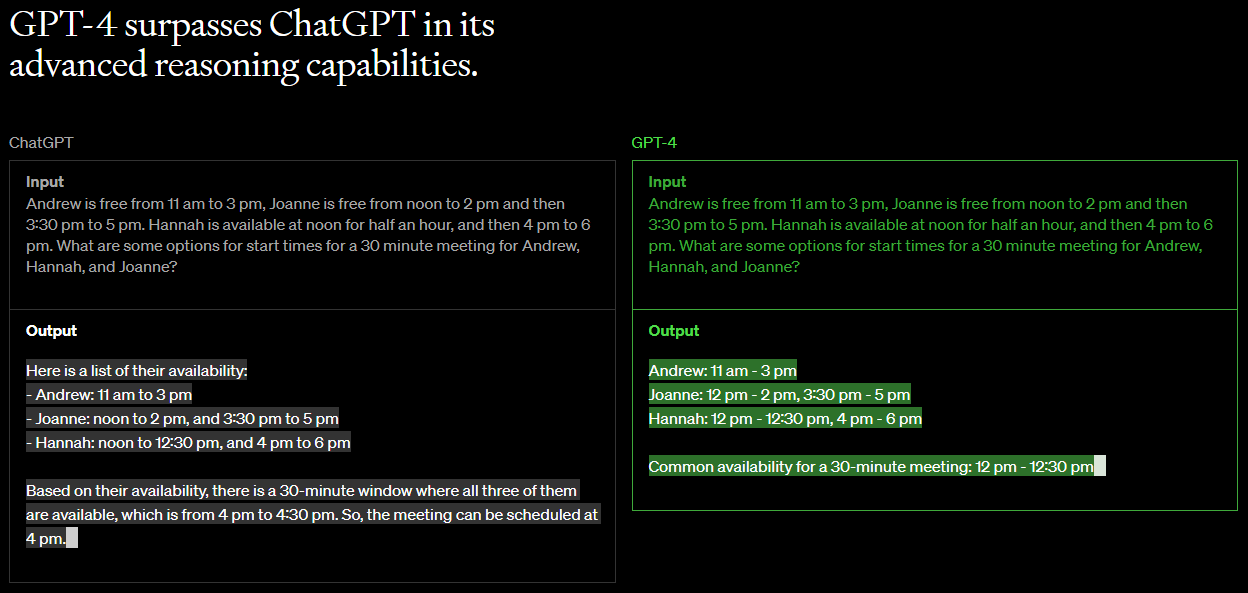
그 다음에는 GPT-4 는 작년 말에 발표 되서 센세이션을 일으켰던 ChatGPT 보다 더 성능이 좋다는 내용이 있습니다.
Uniform Bar Exam 과 Biology Olympiad 라는 테스트 경진 대회에서 GPT-4 가 ChatGPT 보다 더 높은 점수를 기록했다는 내용 입니다.
참고로 ChatGPT는 GPT-3.5 버전입니다.
밑의 설명은 GPT가 버전 2, 3, 3.5, 4 이렇게 진행돼 오면서 점점 더 정교하고 유능한 모델이 되어 가고 있다는 내용입니다.
We spent 6 months making GPT-4 safer and more aligned. GPT4 is 82% less likely to respond to requests for disallowed content and 40% more likely to produce factual responses than GPT-3.5 on our internal evaluations.
우리는 6개월 동안 GPT-4를 더 안전하고 더 잘 정렬되도록 만들었습니다. GPT-4는 허용되지 않는 콘텐츠에 대한 요청에 응답할 가능성이 82% 적고 내부 평가에서 GPT-3.5보다 사실에 입각한 응답을 할 가능성이 40% 더 높습니다.
Safety & alignment
Training with human feedback We incorporated more human feedback, including feedback submitted by ChatGPT users, to improve GPT-4’s behavior. We also worked with over 50 experts for early feedback in domains including AI safety and security.
GPT-4의 동작을 개선하기 위해 ChatGPT 사용자가 제출한 피드백을 포함하여 더 많은 사람의 피드백을 통합했습니다. 또한 AI 안전 및 보안을 포함한 도메인의 초기 피드백을 위해 50명 이상의 전문가와 협력했습니다.
Continuous improvement from real-world use We’ve applied lessons from real-world use of our previous models into GPT-4’s safety research and monitoring system. Like ChatGPT, we’ll be updating and improving GPT-4 at a regular cadence as more people use it.
우리는 이전 모델의 실제 사용에서 얻은 교훈을 GPT-4의 안전 연구 및 모니터링 시스템에 적용했습니다. ChatGPT와 마찬가지로 더 많은 사람들이 사용함에 따라 정기적으로 GPT-4를 업데이트하고 개선할 것입니다.
GPT-4-assisted safety research GPT-4’s advanced reasoning and instruction-following capabilities expedited our safety work. We used GPT-4 to help create training data for model fine-tuning and iterate on classifiers across training, evaluations, and monitoring.
GPT-4의 고급 추론 및 지시에 따른 기능은 우리의 안전 작업을 가속화했습니다. GPT-4를 사용하여 모델 미세 조정을 위한 훈련 데이터를 생성하고 훈련, 평가 및 모니터링 전반에 걸쳐 분류기를 반복했습니다.
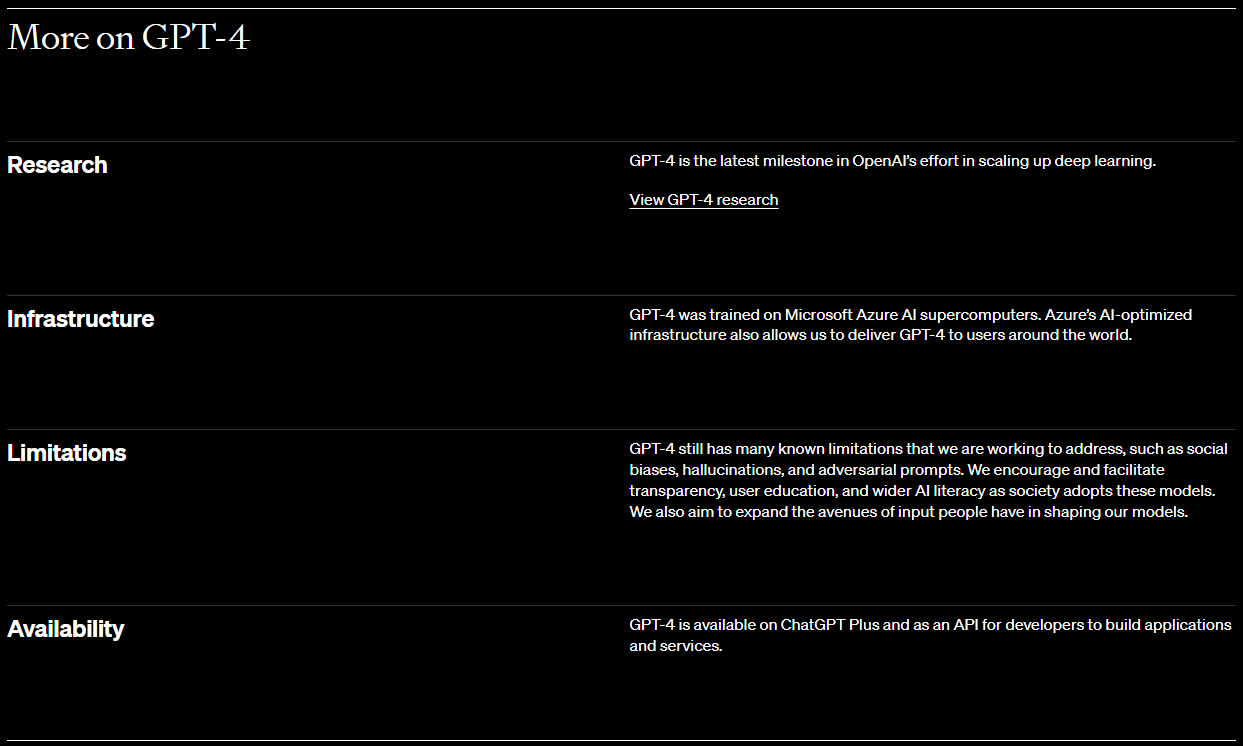
그 다음 아래 부터는 실제 이 GPT-4를 사용해서 제품을 생산 판매 하고 있는 회사와 그 제품을 나열 했습니다.
GPT-4는 Microsoft Azure AI 슈퍼컴퓨터에서 교육을 받았습니다. Azure의 AI 최적화 인프라를 통해 전 세계 사용자에게 GPT-4를 제공할 수도 있습니다.
Limitations
GPT-4에는 사회적 편견, 환각, 적대적 프롬프트와 같이 우리가 해결하기 위해 노력하고 있는 많은 알려진 한계가 있습니다. 우리는 사회가 이러한 모델을 채택함에 따라 투명성, 사용자 교육 및 광범위한 AI 활용 능력을 장려하고 촉진합니다. 우리는 또한 우리 모델을 형성하는 데 사람들이 입력할 수 있는 방법을 확장하는 것을 목표로 합니다.
Availability
GPT-4는 ChatGPT Plus에서 사용할 수 있으며 개발자가 애플리케이션 및 서비스를 구축하기 위한 API로 사용할 수 있습니다.
여기서는 GPT-4에 대해 설명하는데 모든 단어를 G로 시작하는 단어를 사용해서 설명해 봐.. 뭐 이런 작업도 보여 주고 시를 쓰는 장면도 보여 주고 하더라구요. GPT-3 에서는 하지 못했던 좀 더 성장한 GPT 기능을 보여 줬구요.
뭐니뭐니해서 GPT-4에서 가장 달라진 점은 Language 이외의 멀티미디어 기능 지원등이 있었습니다.
GPT-4 가 이미지를 인식해서 그 이미지에 대한 설명도 하고 작업도 하고 그러더라구요.
자세한 사항은 위 유투브 클립을 한번 보세요.
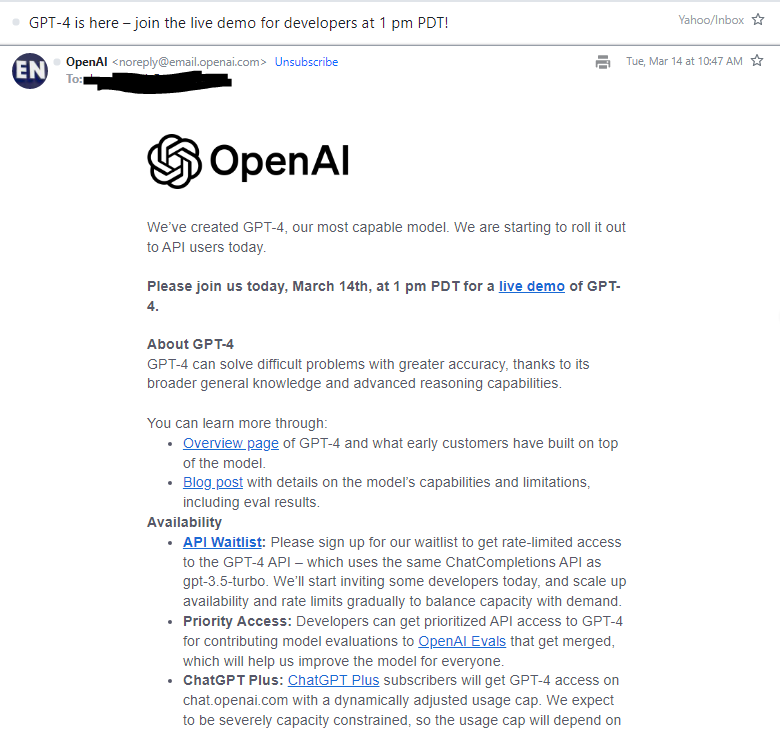
이메일 내용은 아래와 같았습니다.
We’ve created GPT-4, our most capable model. We are starting to roll it out to API users today.
Please join us today, March 14th, at 1 pm PDT for a live demo of GPT-4.
우리는 GPT-4를 만들었습니다. 가장 유능한 모델이죠. 우리는 오늘부터 API 사용자들에게 이 모델을 배포하기 시작했습니다.
About GPT-4
GPT-4 can solve difficult problems with greater accuracy, thanks to its broader general knowledge and advanced reasoning capabilities.
GPT-4는 광범위한 일반 지식과 고급 추론 기능 덕분에 어려운 문제를 더 정확하게 풀 수 있습니다.
You can learn more through: 아래 글들을 통해서 이를 배울 수 있습니다.
Overview pageof GPT-4 and what early customers have built on top of the model.
GPT-4의 개요 페이지 - 초기 고객이 모델 위에 구축한 것.
Blog postwith details on the model’s capabilities and limitations, including eval results.
평가 결과를 포함하여 모델의 기능 및 제한 사항에 대한 세부 정보가 포함된 블로그 게시물
Availability
API Waitlist:Please sign up for our waitlist to get rate-limited access to the GPT-4 API – which uses the same ChatCompletions API as gpt-3.5-turbo. We’ll start inviting some developers today, and scale up availability and rate limits gradually to balance capacity with demand.
API 대기자 명단: gpt-3.5-turbo와 동일한 ChatCompletions API를 사용하는 GPT-4 API에 대한 rate-limited 액세스 권한을 얻으려면 대기자 명단에 등록하십시오. 오늘 일부 개발자를 초대하고 용량과 수요의 균형을 맞추기 위해 가용성 및 rate-limited을 점진적으로 확장할 것입니다.
Priority Access:Developers can get prioritized API access to GPT-4 for contributing model evaluations toOpenAI Evalsthat get merged, which will help us improve the model for everyone.
Priority Access: 개발자는 병합되는 OpenAI 평가에 대한 모델 평가에 기여하기 위해 GPT-4에 대한 prioritized API 액세스를 얻을 수 있으며, 이는 모든 사람을 위해 모델을 개선하는 데 도움이 됩니다.
ChatGPT Plus:ChatGPT Plussubscribers will get GPT-4 access on chat.openai.com with a dynamically adjusted usage cap. We expect to be severely capacity constrained, so the usage cap will depend on demand and system performance. API access will still be through the waitlist.
ChatGPT Plus: ChatGPT Plus 가입자는 chat.openai.com에서 동적으로 조정된 사용 한도와 함께 GPT-4 액세스 권한을 얻습니다. 용량이 심각하게 제한될 것으로 예상되므로 사용량 한도는 수요와 시스템 성능에 따라 달라집니다. API 액세스는 여전히 대기자 명단을 통해 이루어집니다.
API Pricing
gpt-4with an 8K context window (about 13 pages of text) will cost$0.03per 1K prompt tokens, and$0.06per 1K completion tokens.
Please join us for alive demoof GPT-4 at 1pm PDT today, where Greg Brockman (co-founder & President of OpenAI) will showcase GPT-4’s capabilities and the future of building with the OpenAI API.
오늘 오후 1시(PDT) GPT-4 라이브 데모에 참여하세요. Greg Brockman(OpenAI 공동 창립자 겸 사장)이 GPT-4의 기능과 OpenAI API로 구축하는 미래를 선보일 예정입니다.
아래 예제는 ada 모델을 이용해서 이메일 내용을 보고 이게 Baseball과 연관 돼 있는지 아니면 Hockey와 연관 돼 있는 건지 GPT-3 가 인지할 수 있도록 Fine-Tuning을 사용해서 훈련시키고 새로운 모델을 만드는 과정을 보여 줍니다.
from sklearn.datasets import fetch_20newsgroups
import pandas as pd
import openai
categories = ['rec.sport.baseball', 'rec.sport.hockey']
sports_dataset = fetch_20newsgroups(subset='train', shuffle=True, random_state=42, categories=categories)
이 예제에서 사용하는 데이터는 sklearn에서 제공하는 샘플 데이터인 fetch_20newsgroups를 사용합니다.
fetch_20newsgroups 는 데이터를 다루는 연습용으로 만들어진 데이터 세트 입니다.
20개의 newsgroup에서 데이터를 가져온 겁니다. 이 뉴스그룹들은 대부분 게시판이고 사용자들이 올른 글들이 데이터가 되는 겁니다. 예를 들어 내가 낚시에 관심이 있어서 낚시 관련된 카페 같은 뉴스 그룹에 가입하고 거기에 글을 올리듯이 사람들이 글을 올린 데이터 들 입니다.
여기에는 20개의 주제들이 있습니다. 그리고 총 샘플들은 18846개가 있고 1차원 배열이고 text로 이뤄져 있습니다.
이 중에서 Baseball 과 Hockey 관련된 데이터를 가지고 이 예제에서는 Fine-Tuning을 연습하는 소스코드를 만들게 됩니다.
관련 모듈을 import 한 다음에 한 일은 이 예제에서 다룰 topic들을 선택하는 겁니다. 이 두 topic들을 categories라는 배열 변수에 아이템으로 넣습니다.
그리고 sports_dataset 라는 변수에 이 fetch_20newsgroups에 있는 데이터 들 중 위에서 선택한 rec.sport.baseball과 rec.sport.hockey 뉴스그룹에 있는 데이터들만 담습니다.
데이터를 다루려면 우선 그 데이터으 구조를 잘 알아야 합니다.
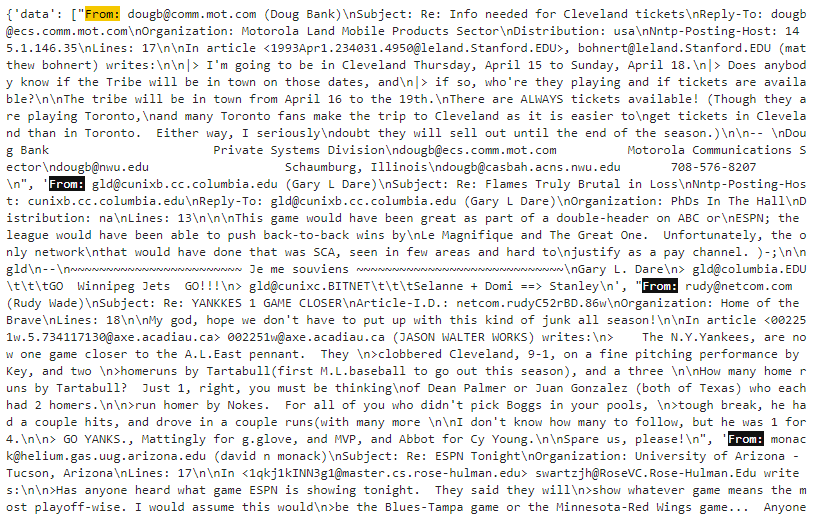
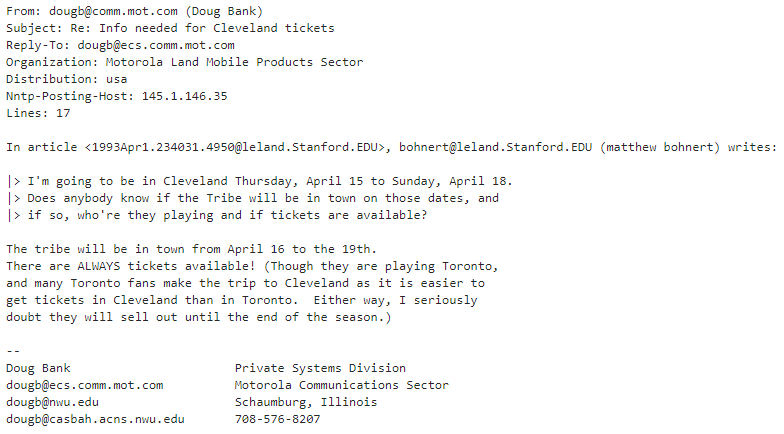
이 데이터의 첫번째 데이터만 한번 출력해 보겠습니다.
print(sports_dataset['data'][0])
그러면 결과는 이렇게 나옵니다.
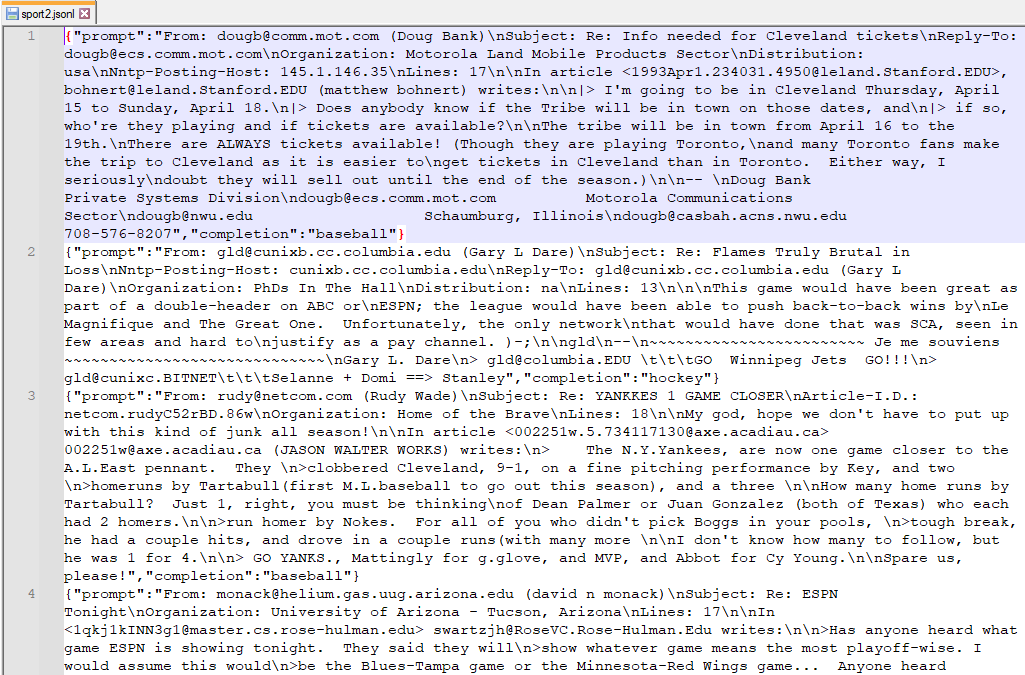
From: dougb@comm.mot.com (Doug Bank)
Subject: Re: Info needed for Cleveland tickets
Reply-To: dougb@ecs.comm.mot.com
Organization: Motorola Land Mobile Products Sector
Distribution: usa
Nntp-Posting-Host: 145.1.146.35
Lines: 17
In article <1993Apr1.234031.4950@leland.Stanford.EDU>, bohnert@leland.Stanford.EDU (matthew bohnert) writes:
|> I'm going to be in Cleveland Thursday, April 15 to Sunday, April 18.
|> Does anybody know if the Tribe will be in town on those dates, and
|> if so, who're they playing and if tickets are available?
The tribe will be in town from April 16 to the 19th.
There are ALWAYS tickets available! (Though they are playing Toronto,
and many Toronto fans make the trip to Cleveland as it is easier to
get tickets in Cleveland than in Toronto. Either way, I seriously
doubt they will sell out until the end of the season.)
--
Doug Bank Private Systems Division
dougb@ecs.comm.mot.com Motorola Communications Sector
dougb@nwu.edu Schaumburg, Illinois
dougb@casbah.acns.nwu.edu 708-576-8207
데이터는 글을 올린사람, 주제, Reply-To,, Organization, Distribution, 아이피 주소. 라인 수, 내용 등등등 ...
대충 어떤 식으로 데이터들이 구성 돼 있는지 알 수 있을 것 같습니다.
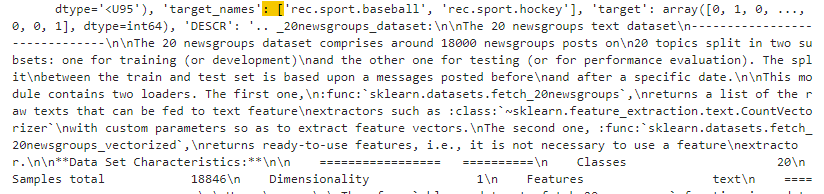
이건 sports_dataset 의 data라는 아이템에 들어 있는 첫 번째 데이터인 것이고 이 sports_dataset은 어떤 구조로 돼 있는지 한번 알아 볼까요?
결과의 일 부분인데요. sports_dataset 배열은 첫번째 item 이 data 입니다. 그리고 이 data 안에는 여러 글들이 있습니다. 각 글들은 From: 으로 시작합니다. 첫번째 글은 바로 위에서 출력한 그 글입니다. dougb@comm.mot.com으로 시작해서 708-576-8207 로 끝납니다.
data는 이렇게 구성이 돼 있고 그렇다면 다른 아이템에는 무엇이 있을 까요?
그 다음에는 target_names인데 이 변수에는 baseball과 hockey 토픽만 들어 있다는걸 확인 할 수 있습니다.
그리고 'target' : array(0,1,0...,... 이렇게 돼 있는 것은 data의 첫번째 데이터는 baseball 뉴스그룹에서 온 것이고 두번째 데이터는 hockey 그룹에서 그리고 세번째는 baseball 그룹에서 온 것이라는 것을 말합니다.
data에 있는 데이터 가지고는 이것이 어느 뉴스그룹 소속인지 알 수 없는데 이 target_names 라는 두번째 아이템에서 그 정보를 얻을 수 있네요.
오늘 다룰 Fine-Tunning 예제에서는 이 두가지 정보만 있으면 GPT-3 AI 를 훈련 시킬 수 있습니다.
len_all, len_baseball, len_hockey = len(sports_dataset.data), len([e for e in sports_dataset.target if e == 0]), len([e for e in sports_dataset.target if e == 1])
print(f"Total examples: {len_all}, Baseball examples: {len_baseball}, Hockey examples: {len_hockey}")
len(sports_dataset.data) 는 이 sports_dataset에 있는 data 아이템에 있는 데이터 수를 가져 옵니다.
len([e for e in sports_dataset.target if e == 0] 는 data에 있는 데이터 중 target 이 0인 데이터 즉 rec.sport.baseball에 속한 데이터만 가져 옵니다.
같은 방법으로 Hockey 에 속한 데이터만 가져 오려면 이러헥 사용 합니다. len([e for e in sports_dataset.target if e == 1]
결과는 아래와 같습니다.
Total examples: 1197, Baseball examples: 597, Hockey examples: 600
전체 데이터 갯수는 1197개이고 야구와 관련된 글은 597개 그리고 하키와 관련된 글은 600개 입니다.
이제 이 데이터의 구조에 대해서 어느정도 파악을 했습니다.
그러면 이 데이터를 Fune-Tuning 시키기 위한 구조로 바꾸어 주어야 합니다.
Fine-Tunning은 AI를 교육 시키는 겁니다. 이 AI를 교육시키기 위해서는 데이터를 제공해야 합니다.
GPT-3라는 AI가 알아 들을 수 있는 데이터 구조는 이전 Guide에서 설명 된 부분이 있습니다.
GPT-3는 Prompt 와 Completion 이 두 부분으로 나뉘어진 데이터세트를 제공하면 됩니다.
그러면 이 아이는 그것을 보고 패턴을 찾아내서 학습하게 되는 겁니다.
이런 내용의 글은 야구와 관련 돼 있고 또 저런 내용의 글은 하키와 관련 돼 있다는 것을 알아 내는 것이죠.
예를 들어 위에서 출력한 첫번째 글을 보시죠.
여기에는 이 글이 야구와 관련돼 있는지 하키와 관련 돼 있는지에 대한 명시적인 정보는 없습니다.
다면 이 글에는 Cleveland에 갈거고 팬들끼리 좀 모이자는 내용이 있습니다. 그리고 상대팀 이름도 있고 어디서 경기가 열리는지 뭐 이런 정보가 있습니다.
미국에서 야구에 대해 관심 있는 사람이라면 이 글은 야구와 관련된 글이라는 것을 알겠죠.
이렇게 주어진 정보만 가지고 이게 야구와 관련된 글인지 하키와 관련된 글인지 알아 내도록 GPT-3를 훈련 시킬 겁니다.
그 훈련된 AI모델은 나만의 모델이 될 겁니다.
그래서 앞으로 내가 어떤 글을 그 모델에게 보내면 그 Custom AI Model은 그게 야구와 관련된 글인지 하키와 관련된 글인지를 저에게 알려 줄 것입니다.
그러면 GPT-3를 훈련 시키기 위한 데이터 세트 형식으로 위 데이터를 변경 시켜 보겠습니다.
Prompt 와 Completion 이 두가지 컬럼이 있어야 합니다.
Prompt에는 data 정보들이 있고 Completion에는 그 글이 야구와 관련된 글인지 하키와 관련된 글인지에 대한 정보들이 들거 갈 겁니다.
import pandas as pd
labels = [sports_dataset.target_names[x].split('.')[-1] for x in sports_dataset['target']]
texts = [text.strip() for text in sports_dataset['data']]
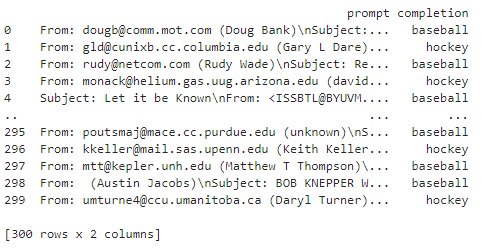
df = pd.DataFrame(zip(texts, labels), columns = ['prompt','completion']) #[:300]
df.head()
파이썬에서 데이터를 다루는 모델은 pandas를 많이 사용 합니다.
labels 부분을 보겠습니다.
위에서 sports_dataset['target'] 에는 0 과 1이라는 정보들이 있고 이 정보는 data에 있는 정보가 targetnames 의 첫번째 인수에 속하는 건지 두번째 인수에 속하는 건지를 알려 주는 것이라고 했습니다.
첫번째 인수는 rec.sport.baseball이고 두번째 인수는 rec.sport.hockey 입니다.
이 target 값에 대한 for 문이 도는데요 data 갯수가 1197이고 target의 각 인수들 (0,1) 은 각 데이터의 인수들과 매핑 돼 있으니까 이 for 문은 1197번 돌 겁니다. 이렇게 돌면서 target_names에서 해당 인수를 가져 와서 . 으로 그 텍스트를 분리 한 다음에 -1 번째 즉 맨 마지막 글자를 가지고 오게 됩니다. 그러면 baseball과 hockey라는 글자만 선택 되게 되죠.
즉 labels에는 baseball 과 hockey라는 글자들이 들어가게 되는데 이는 target 에 0이 있으면 baseball 1이 있으면 hockey가 들어가는 1197개의 인수를 가지고 있는 배열이 순서대로 들어가게 되는 겁니다.
그러면 이제 data에 있는 각 데이터를 순서대로 배열로 집어 넣으면 되겠죠?
texts = [text.strip() for text in sports_dataset['data']]
이 부분이 그 일을 합니다.
sports_dataset 에 있는 data 만큼 for 문을 돕니다. data는 1197개의 인수를 가지고 있으니 이 for 문도 1197번 돌 겁니다.
이 데이터를 그냥 texts 라는 변수에 배열 형태로 집어 넣는 겁니다. text.strip()은 해당 text의 앞 뒤에 있는 공백들을 제거 하는 겁니다.
이 부분도 중요 합니다. 데이터의 앞 뒤 공백을 제거해서 깨끗한 데이터를 만듭니다.
이제 data의 각 글을 가지고 있는 배열과 각 글들이 어느 주제에 속하는지에 대한 정보를 가지고 있는 배열들이 완성 됐습니다.
이 정보를 가지고 pandas로 GPT-3 AI 를 훈련 시킬 수 있는 형태의 데이터 세트로 만들겠습니다.
zip(texts, labels) <- 이렇게 하면 데이터와 topic이 짝 지어 지겠죠.
이 값은 pandas의 DataFrame의 첫번째 인수로 전달 되고 두번째 인수로는 컬럼 이름이 전달 됩니다. (columns = ['prompt','completion'])
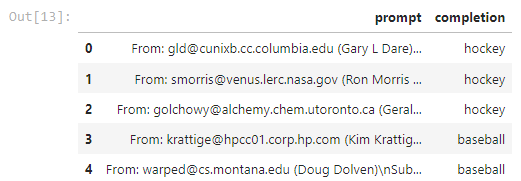
그 다음 df.head() 로 이렇게 만들어진 DataFrame에서 처음에 오는 5개의 데이터를 출력해 봅니다.
의도한 대로 각 게시글과 그 게시글이 baseball에 속한 것인지 hockey에 속한 것인지에 대한 정보가 있네요.
이 cookbook에는 300개의 데이터만 사용할 것이라고 돼 있는데 어디에서 그게 돼 있는지 모르겠네요.
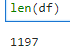
len() 을 찍어봐도 1197 개가 찍힙니다.
cookbook 설명대로 300개의 데이터만 사용하려면 아래와 같이 해야 할 것 같습니다.
import pandas as pd
labels = [sports_dataset.target_names[x].split('.')[-1] for x in sports_dataset['target']]
texts = [text.strip() for text in sports_dataset['data']]
df = pd.DataFrame(zip(texts, labels), columns = ['prompt','completion']) #[:300]
df = df.head(300)
print(df)
저는 이 300개의 데이터만 이용하겠습니다.
GPT-3 의 Fine-tuning 을 사용할 때 데이터 크기에 따라서 과금 될 거니까.. 그냥 조금만 하겠습니다. 지금은 공부하는 단계이니까 Custom model의 정확도 보다는 Custom model을 Fine tuning을 사용해서 만드는 과정을 배우면 되니까요.
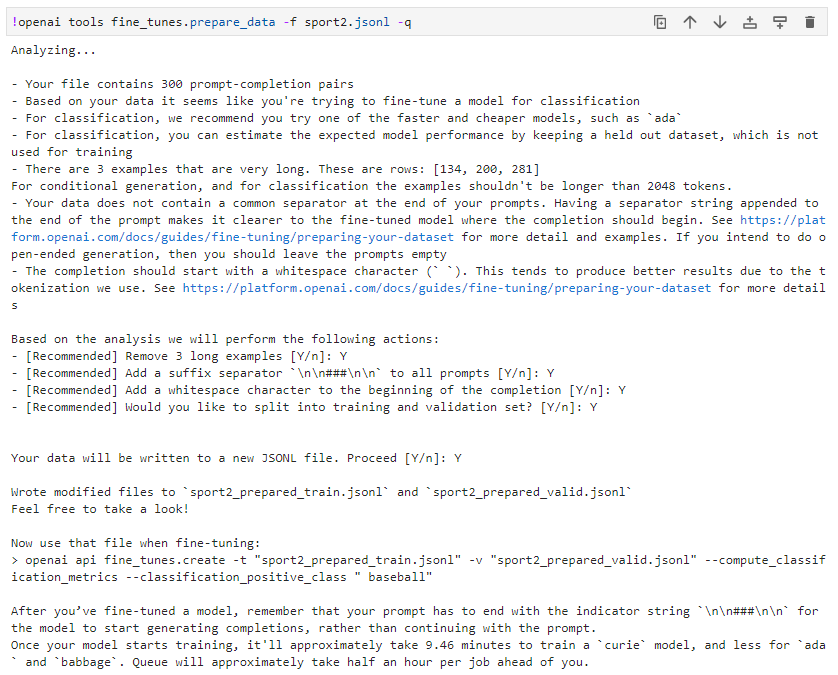
openai aools fine_tunes.prepare_data는 데이터를 검증하고 제안하고 형식을 다시 지정해 주는 툴입니다.
위 결과를 보면 Analyzing... (분석중)으로 시작해서 이 파일에는 총 300개의 prompt-completion 쌍이 있고 모델을 fine-tune 하려고 하는 것 같은데 저렴한 ada 모델을 사용하세요... 뭐 이렇게 분석과 제안내용이 표시됩니다.
그리고 너무 긴 글이 3개 있고 134, 200,281 번째 줄. .....이렇게 나오고 이 3개는 너무 길어서 제외한다고 나오네요.
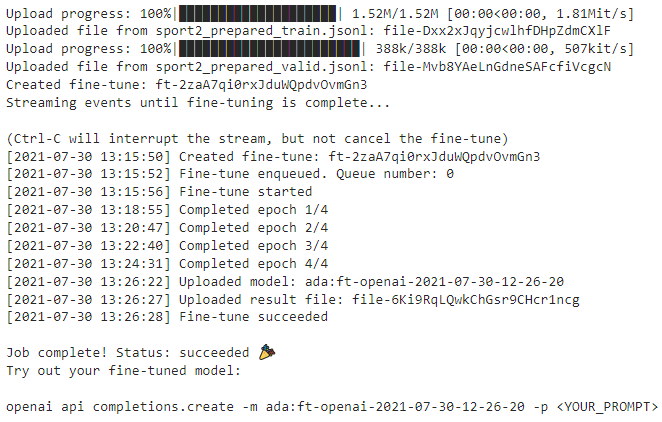
이 결과로 sport2_prepared_train.jsonl 과 sport2_prepared_valid.jsonl 파일 두개를 만들어 냅니다.
그리고 이제 fine_tunes.create을 사용해서 fine-tuning을 하면 된다고 나오네요.
Fine-tuning을 하게 되면 curie 모델을 사용하면 대략 9분 46초 정도 걸릴 것이고 ada 모델을 사용하면 그보다 더 조금 걸릴 거라네요.
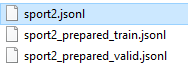
폴더를 다시 봤더니 정말 두개의 jsonl 파일이 더 생성 되었습니다.
sport2_prepared_train.jsonl에는 위에 너무 길다는 3개의 데이터를 없앤 나머지 297개의 데이터가 있습니다.
sport2_prepared_valid.jsonl에는 60개의 데이터가 있습니다.
train 데이터와 valid 데이터 이렇게 두개가 생성 되었네요. 이 두개를 생성한 이유는 나중에 새 데이터에 대한 예상 성능을 쉽게 측정하기 위해서 GPT-3 의 fine_tunes.prepare_data 함수가 만든 겁니다.
Fine-tuning
이제 다 준비가 됐습니다. 실제로 Fine tuning을 하면 됩니다.
참고로 지금 우리는 내용을 주면 이 내용이 야구에 대한건지 하키에 대한건지 분류 해 주는 fine tuned 된 모델을 생성하려고 합니다.
이 작업은 classification task에 속합니다.
그래서 train 과 valid 두 데이터 세트가 위에서 생성된 거구요.
이제 Fine-tuning을 하기 위해 아래 명령어를 사용하면 됩니다.
!openai api fine_tunes.create -t "sport2_prepared_train.jsonl" -v "sport2_prepared_valid.jsonl" --compute_classification_metrics --classification_positive_class " baseball" -m ada
fine_tunes.create 함수를 사용했고 training data로는 sport2_prepared_train.jsonl 파일이 있고 valid data로는 sport2.prepared_valid_jsonl이 제공된다고 돼 있습니다.
그 다음엔 compute_classification_metrics와 classification_positive_class "baseball" 이 주어 졌는데 이는 위에서 fine_tunes.prepare_data 에서 추천한 내용입니다. classification metics를 계산하기 위해 필요하기 때문에 추천 했습니다.
그리고 마지막에 -m ada는 ada 모델을 사용하겠다는 겁니다.
이 부분을 실행하면 요금이 청구가 됩니다.
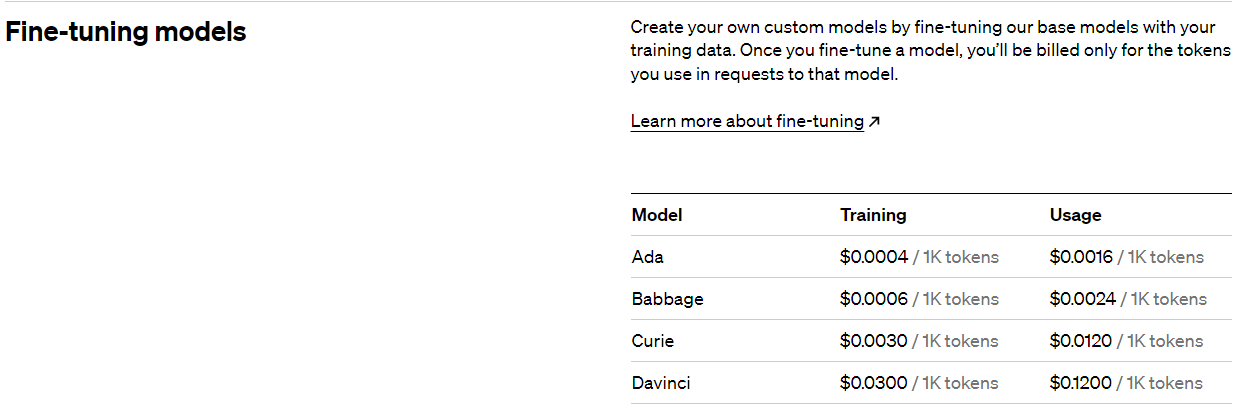
Fine-tuning models 같은 경우 과금은 아래와 같이 됩니다.
ada 모델을 사용하니까 토큰 1천개당 0.0004불이 training 과정에 들게 됩니다.
Usage도 있네요 나중에 Fine Tune 된 Custom Model을 사용하게 되면 토큰 1천개당 0.0016 불이 과금 됩니다.
test = pd.read_json('sport2_prepared_valid.jsonl', lines=True)
test.head()
We need to use the same separator following the prompt which we used during fine-tuning. In this case it is\n\n###\n\n. Since we're concerned with classification, we want the temperature to be as low as possible, and we only require one token completion to determine the prediction of the model.
fine-tuning 중에 사용한 프롬프트 다음에 동일한 구분 기호를 사용해야 합니다. 이 경우 \n\n###\n\n입니다. 우리는 분류와 관련이 있기 때문에 temperature가 가능한 한 낮아지기를 원하며 모델의 예측을 결정하기 위해 하나의 token completion만 필요합니다.
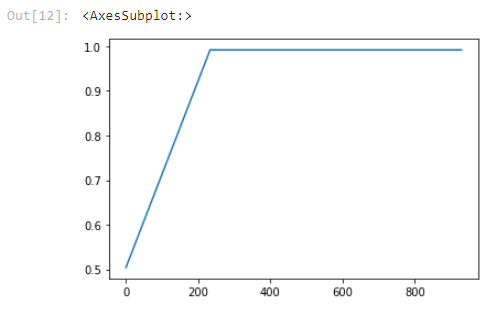
We can see that the model predicts hockey as a lot more likely than baseball, which is the correct prediction. By requesting log_probs, we can see the prediction (log) probability for each class.
모델이 야구보다 하키를 훨씬 더 많이 예측한다는 것을 알 수 있습니다. 이것이 정확한 예측입니다. log_probs를 요청하면 각 클래스에 대한 예측(로그) 확률을 볼 수 있습니다.
Generalization
Interestingly, our fine-tuned classifier is quite versatile. Despite being trained on emails to different mailing lists, it also successfully predicts tweets.
흥미롭게도 fine-tuned classifier는 매우 다재다능합니다. 다른 메일링 리스트에 대한 이메일에 대한 교육을 받았음에도 불구하고 트윗을 성공적으로 예측합니다.
sample_hockey_tweet = """Thank you to the
@Canes
and all you amazing Caniacs that have been so supportive! You guys are some of the best fans in the NHL without a doubt! Really excited to start this new chapter in my career with the
@DetroitRedWings
!!"""
res = openai.Completion.create(model=ft_model, prompt=sample_hockey_tweet + '\n\n###\n\n', max_tokens=1, temperature=0, logprobs=2)
res['choices'][0]['text']
이 내용은 이전에 없던 내용 입니다..
내용에 NHL이라는 단어가 있네요. National Hockey league 겠죠?
그러면 이 이메일은 하키와 관련한 이메일 일 겁니다.
Fine tuning으로 만든 새로운 모델도 이것을 정확하게 맞춥니다.
' hockey'
sample_baseball_tweet="""BREAKING: The Tampa Bay Rays are finalizing a deal to acquire slugger Nelson Cruz from the Minnesota Twins, sources tell ESPN."""
res = openai.Completion.create(model=ft_model, prompt=sample_baseball_tweet + '\n\n###\n\n', max_tokens=1, temperature=0, logprobs=2)
res['choices'][0]['text']
그 다음 예제에서는 Tampa Bay Rays , Minnesota Twins 라는 내용이 나옵니다.