
15.8. Bidirectional Encoder Representations from Transformers (BERT) — Dive into Deep Learning 1.0.3 documentation
d2l.ai
15.8. Bidirectional Encoder Representations from Transformers (BERT)
BERT 란?
BERT (Bidirectional Encoder Representations from Transformers)는 자연어 처리(NLP) 분야에서 가장 혁신적인 모델 중 하나로, 2018년에 고안되었습니다. BERT는 사전 훈련된 언어 모델로, 언어의 다양한 태스크에 대한 성능을 크게 향상시켰습니다. 이 모델은 Transformers 아키텍처를 기반으로 하며, 양방향 언어 모델링을 통해 문맥을 고려한 텍스트 임베딩을 생성합니다.
BERT의 주요 특징과 개념을 설명해보겠습니다:
- 사전 훈련과 미세 조정: BERT는 "사전 훈련(pre-training)"과 "미세 조정(fine-tuning)" 두 단계로 모델을 구축합니다. 사전 훈련 단계에서는 대량의 텍스트 데이터로 모델을 미리 학습시킵니다. 그리고 이후 미세 조정 단계에서는 특정 NLP 태스크에 대해 작은 양의 태스크 관련 데이터로 모델을 미세 조정하여 해당 태스크에 적합한 정보를 학습합니다.
- 양방향 언어 모델링: BERT는 양방향 언어 모델링을 수행합니다. 이는 문장 내 모든 단어를 좌우 방향으로 모두 고려하여 임베딩을 생성하는 것을 의미합니다. 이는 기존의 단방향 모델보다 훨씬 풍부한 문맥 정보를 반영할 수 있도록 도와줍니다.
- 사전 훈련 태스크: BERT는 사전 훈련을 위해 "마스크드 언어 모델링"과 "다음 문장 예측"이라는 두 가지 태스크를 활용합니다. "마스크드 언어 모델링"에서는 문장 내에서 임의의 단어를 가리고 그 단어를 모델이 추론하도록 합니다. "다음 문장 예측"에서는 두 문장의 관계를 판단하여 한 문장이 다른 문장의 뒤에 올 확률을 예측합니다.
- Transfer Learning: BERT는 사전 훈련을 통해 언어의 일반적인 특징을 학습하고, 이를 다양한 NLP 태스크에 전이 학습(transfer learning)하여 활용합니다. BERT를 미세 조정하여 특정 태스크에 맞게 튜닝하면, 해당 태스크에서 높은 성능을 달성할 수 있습니다.
- Transformer 아키텍처: BERT는 Transformer 아키텍처의 여러 레이어를 쌓아 만들어진 모델입니다. Self-Attention 메커니즘을 활용하여 문장 내 단어 간의 상관 관계를 모델링하며, 여러 개의 인코더 레이어로 구성되어 문맥을 잘 파악하는 텍스트 임베딩을 생성합니다.
BERT는 자연어 처리에서 다양한 태스크에 적용할 수 있는 범용적인 임베딩을 제공하며, 전통적인 NLP 모델보다 훨씬 뛰어난 성능을 보입니다. 그 결과, BERT는 자연어 이해와 생성 과제에서 혁신적인 역할을 하였고, 이후로도 다양한 NLP 모델의 기반이 되는 중요한 아키텍처 중 하나로 자리 잡았습니다.
We have introduced several word embedding models for natural language understanding. After pretraining, the output can be thought of as a matrix where each row is a vector that represents a word of a predefined vocabulary. In fact, these word embedding models are all context-independent. Let’s begin by illustrating this property.
우리는 자연어 이해를 위한 여러 단어 임베딩 모델을 도입했습니다. 사전 훈련 후 출력은 각 행이 사전 정의된 어휘의 단어를 나타내는 벡터인 행렬로 간주될 수 있습니다. 실제로 이러한 단어 임베딩 모델은 모두 상황에 독립적입니다. 이 속성을 설명하는 것부터 시작하겠습니다.
15.8.1. From Context-Independent to Context-Sensitive
Recall the experiments in Section 15.4 and Section 15.7. For instance, word2vec and GloVe both assign the same pretrained vector to the same word regardless of the context of the word (if any). Formally, a context-independent representation of any token x is a function f(x) that only takes x as its input. Given the abundance of polysemy and complex semantics in natural languages, context-independent representations have obvious limitations. For instance, the word “crane” in contexts “a crane is flying” and “a crane driver came” has completely different meanings; thus, the same word may be assigned different representations depending on contexts.
15.4절과 15.7절의 실험을 떠올려 보세요. 예를 들어, word2vec과 GloVe는 모두 단어의 컨텍스트(있는 경우)에 관계없이 동일한 사전 훈련된 벡터를 동일한 단어에 할당합니다. 공식적으로 토큰 x의 컨텍스트 독립적 표현은 x만 입력으로 사용하는 함수 f(x)입니다. 자연어의 풍부한 다의어와 복잡한 의미를 고려할 때 문맥 독립적 표현에는 분명한 한계가 있습니다. 예를 들어, "a crane is flying"와 "a crane driver came"라는 맥락에서 "crane"이라는 단어는 완전히 다른 의미를 갖습니다. 따라서 동일한 단어에도 상황에 따라 다른 표현이 할당될 수 있습니다.
This motivates the development of context-sensitive word representations, where representations of words depend on their contexts. Hence, a context-sensitive representation of token x is a function f(x,c(x)) depending on both x and its context c(x). Popular context-sensitive representations include TagLM (language-model-augmented sequence tagger) (Peters et al., 2017), CoVe (Context Vectors) (McCann et al., 2017), and ELMo (Embeddings from Language Models) (Peters et al., 2018).
이는 단어 표현이 문맥에 따라 달라지는 문맥 인식 단어 표현의 개발에 동기를 부여합니다. 따라서 토큰 x의 상황에 맞는 표현은 x와 해당 상황 c(x)에 모두 의존하는 함수 f(x,c(x))입니다. 널리 사용되는 상황 인식 표현에는 TagLM(언어 모델 증강 시퀀스 태거)(Peters et al., 2017), CoVe(컨텍스트 벡터)(McCann et al., 2017) 및 ELMo(Embeddings from Language Models)(Peters et al. al., 2018) 등이 있습니.
For example, by taking the entire sequence as input, ELMo is a function that assigns a representation to each word from the input sequence. Specifically, ELMo combines all the intermediate layer representations from pretrained bidirectional LSTM as the output representation. Then the ELMo representation will be added to a downstream task’s existing supervised model as additional features, such as by concatenating ELMo representation and the original representation (e.g., GloVe) of tokens in the existing model. On the one hand, all the weights in the pretrained bidirectional LSTM model are frozen after ELMo representations are added. On the other hand, the existing supervised model is specifically customized for a given task. Leveraging different best models for different tasks at that time, adding ELMo improved the state of the art across six natural language processing tasks: sentiment analysis, natural language inference, semantic role labeling, coreference resolution, named entity recognition, and question answering.
예를 들어 ELMo는 전체 시퀀스를 입력으로 사용하여 입력 시퀀스의 각 단어에 표현을 할당하는 함수입니다. 특히 ELMo는 사전 훈련된 양방향 LSTM의 모든 중간 계층 표현을 출력 표현으로 결합합니다. 그런 다음 ELMo 표현은 ELMo 표현과 기존 모델의 토큰 원래 표현(예: GloVe)을 연결하는 등의 추가 기능으로 다운스트림 작업의 기존 감독 모델에 추가됩니다. 한편, 사전 훈련된 양방향 LSTM 모델의 모든 가중치는 ELMo 표현이 추가된 후에 고정됩니다. 반면, 기존 지도 모델은 특정 작업에 맞게 특별히 맞춤화되었습니다. 당시 다양한 작업에 대해 다양한 최상의 모델을 활용하고 ELMo를 추가하여 감정 분석, 자연어 추론, 의미론적 역할 레이블 지정, 상호 참조 해결, 명명된 엔터티 인식 및 질문 응답 등 6가지 자연어 처리 작업 전반에 걸쳐 최신 기술을 향상시켰습니다.
ELMo란?
ELMo (Embeddings from Language Models)는 사전 훈련된 언어 모델을 활용하여 단어 임베딩을 생성하는 기술입니다. ELMo는 2018년에 제안된 자연어 처리 기법 중 하나로, 언어 모델을 사용하여 단어의 의미를 잘 포착하고 문맥을 고려한 풍부한 단어 임베딩을 만들어냅니다.
ELMo는 다음과 같은 특징을 가지고 있습니다:
- 사전 훈련된 언어 모델 사용: ELMo는 언어 모델을 사전 훈련하여 단어의 의미와 문맥 정보를 학습합니다. 이 때, 양방향 LSTM (Bidirectional Long Short-Term Memory)을 사용하여 단어의 좌우 문맥을 모두 고려합니다.
- 문맥 정보 반영: ELMo는 단어의 임베딩을 생성할 때 해당 단어가 나타나는 문맥 정보를 모두 고려합니다. 이렇게 함으로써 단어의 다의성을 해소하고 문맥을 풍부하게 반영한 임베딩을 얻을 수 있습니다.
- 계층적 특성 추출: ELMo는 다양한 언어적 특징을 반영하기 위해 여러 계층의 언어 모델을 사용하여 임베딩을 생성합니다. 이는 각 계층의 모델이 단어의 다양한 언어적 특성을 포착하도록 도와줍니다.
- 사전 훈련 및 파인 튜닝: ELMo는 먼저 대규모 텍스트 데이터로 사전 훈련된 언어 모델을 생성한 다음, 특정 자연어 처리 작업에 맞게 파인 튜닝하여 사용합니다. 이로써 작업에 특화된 품질 높은 임베딩을 얻을 수 있습니다.
ELMo는 문맥을 고려한 임베딩을 통해 다양한 자연어 처리 작업에서 성능 향상을 이룰 수 있습니다. 특히 ELMo 임베딩은 감정 분석, 질문 응답, 기계 번역, 개체명 인식 등 다양한 자연어 처리 작업에 활용되며, 사전 훈련된 모델의 높은 품질과 다양한 언어 특징을 반영하는 장점을 가지고 있습니다.
15.8.2. From Task-Specific to Task-Agnostic
Although ELMo has significantly improved solutions to a diverse set of natural language processing tasks, each solution still hinges on a task-specific architecture. However, it is practically non-trivial to craft a specific architecture for every natural language processing task. The GPT (Generative Pre-Training) model represents an effort in designing a general task-agnostic model for context-sensitive representations (Radford et al., 2018). Built on a Transformer decoder, GPT pretrains a language model that will be used to represent text sequences. When applying GPT to a downstream task, the output of the language model will be fed into an added linear output layer to predict the label of the task. In sharp contrast to ELMo that freezes parameters of the pretrained model, GPT fine-tunes all the parameters in the pretrained Transformer decoder during supervised learning of the downstream task. GPT was evaluated on twelve tasks of natural language inference, question answering, sentence similarity, and classification, and improved the state of the art in nine of them with minimal changes to the model architecture.
ELMo는 다양한 자연어 처리 작업에 대한 솔루션을 크게 개선했지만 각 솔루션은 여전히 작업별 아키텍처에 달려 있습니다. 그러나 모든 자연어 처리 작업에 대해 특정 아키텍처를 제작하는 것은 사실상 쉽지 않습니다. GPT(Generative Pre-Training) 모델은 상황에 맞는 표현을 위한 일반적인 작업 독립적 모델을 설계하려는 노력을 나타냅니다(Radford et al., 2018). Transformer 디코더를 기반으로 구축된 GPT는 텍스트 시퀀스를 나타내는 데 사용될 언어 모델을 사전 학습합니다. 다운스트림 작업에 GPT를 적용하면 언어 모델의 출력이 추가된 선형 출력 레이어에 공급되어 작업의 레이블을 예측합니다. 사전 학습된 모델의 매개변수를 고정하는 ELMo와는 대조적으로 GPT는 다운스트림 작업의 지도 학습 중에 사전 학습된 Transformer 디코더의 모든 매개변수를 미세 조정합니다. GPT는 자연어 추론, 질의 응답, 문장 유사성, 분류 등 12가지 과제에 대해 평가했으며, 모델 아키텍처를 최소한으로 변경하면서 9가지 항목을 최신 수준으로 개선했습니다.
However, due to the autoregressive nature of language models, GPT only looks forward (left-to-right). In contexts “i went to the bank to deposit cash” and “i went to the bank to sit down”, as “bank” is sensitive to the context to its left, GPT will return the same representation for “bank”, though it has different meanings.
그러나 언어 모델의 자동 회귀 특성으로 인해 GPT는 앞(왼쪽에서 오른쪽)만 봅니다. "i went to the bank to deposit cash" 및 "i went to the bank to sit down"라는 맥락에서 "bank"은 왼쪽의 상황에 민감하므로 GPT는 '은행'에 대해 동일한 표현을 반환하지만 의미는 다릅니다.
15.8.3. BERT: Combining the Best of Both Worlds
As we have seen, ELMo encodes context bidirectionally but uses task-specific architectures; while GPT is task-agnostic but encodes context left-to-right. Combining the best of both worlds, BERT (Bidirectional Encoder Representations from Transformers) encodes context bidirectionally and requires minimal architecture changes for a wide range of natural language processing tasks (Devlin et al., 2018). Using a pretrained Transformer encoder, BERT is able to represent any token based on its bidirectional context. During supervised learning of downstream tasks, BERT is similar to GPT in two aspects. First, BERT representations will be fed into an added output layer, with minimal changes to the model architecture depending on nature of tasks, such as predicting for every token vs. predicting for the entire sequence. Second, all the parameters of the pretrained Transformer encoder are fine-tuned, while the additional output layer will be trained from scratch. Fig. 15.8.1 depicts the differences among ELMo, GPT, and BERT.
앞서 살펴본 것처럼 ELMo는 컨텍스트를 양방향으로 인코딩하지만 작업별 아키텍처를 사용합니다. GPT는 작업에 구애받지 않지만 컨텍스트를 왼쪽에서 오른쪽으로 인코딩합니다. 두 가지 장점을 결합한 BERT(BiDirectional Encoder Representations from Transformers)는 컨텍스트를 양방향으로 인코딩하고 광범위한 자연어 처리 작업에 대해 최소한의 아키텍처 변경이 필요합니다(Devlin et al., 2018). 사전 훈련된 Transformer 인코더를 사용하여 BERT는 양방향 컨텍스트를 기반으로 모든 토큰을 나타낼 수 있습니다. 다운스트림 작업에 대한 지도 학습 중에 BERT는 두 가지 측면에서 GPT와 유사합니다. 첫째, BERT 표현은 모든 토큰에 대한 예측과 전체 시퀀스에 대한 예측과 같은 작업의 성격에 따라 모델 아키텍처를 최소한으로 변경하여 추가된 출력 레이어에 공급됩니다. 둘째, 사전 훈련된 Transformer 인코더의 모든 매개변수가 미세 조정되는 반면, 추가 출력 레이어는 처음부터 훈련됩니다. 그림 15.8.1은 ELMo, GPT, BERT의 차이점을 보여줍니다.
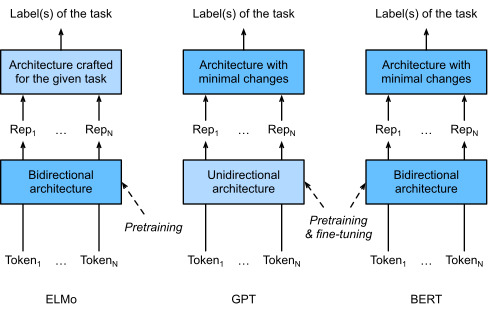
BERT further improved the state of the art on eleven natural language processing tasks under broad categories of (i) single text classification (e.g., sentiment analysis), (ii) text pair classification (e.g., natural language inference), (iii) question answering, (iv) text tagging (e.g., named entity recognition). All proposed in 2018, from context-sensitive ELMo to task-agnostic GPT and BERT, conceptually simple yet empirically powerful pretraining of deep representations for natural languages have revolutionized solutions to various natural language processing tasks.
BERT는 (i) 단일 텍스트 분류(예: 감정 분석), (ii) 텍스트 쌍 분류(예: 자연어 추론), (iii) 질문 응답의 광범위한 범주에서 11가지 자연어 처리 작업에 대한 최신 기술을 더욱 개선했습니다. , (iv) 텍스트 태깅(예: 명명된 개체 인식). context-sensitive ELMo부터 task-agnostic GPT 및 BERT에 이르기까지 2018년에 제안된 모든 것, 개념적으로 단순하지만 경험적으로 강력한 자연어에 대한 심층 표현 사전 학습은 다양한 자연어 처리 작업에 대한 솔루션에 혁명을 일으켰습니다.
In the rest of this chapter, we will dive into the pretraining of BERT. When natural language processing applications are explained in Section 16, we will illustrate fine-tuning of BERT for downstream applications.
이 장의 나머지 부분에서는 BERT의 사전 훈련에 대해 살펴보겠습니다. 섹션 16에서 자연어 처리 애플리케이션을 설명할 때 다운스트림 애플리케이션을 위한 BERT의 미세 조정을 설명합니다.
import torch
from torch import nn
from d2l import torch as d2l
15.8.4. Input Representation
In natural language processing, some tasks (e.g., sentiment analysis) take single text as input, while in some other tasks (e.g., natural language inference), the input is a pair of text sequences. The BERT input sequence unambiguously represents both single text and text pairs. In the former, the BERT input sequence is the concatenation of the special classification token “<cls>”, tokens of a text sequence, and the special separation token “<sep>”. In the latter, the BERT input sequence is the concatenation of “<cls>”, tokens of the first text sequence, “<sep>”, tokens of the second text sequence, and “<sep>”. We will consistently distinguish the terminology “BERT input sequence” from other types of “sequences”. For instance, one BERT input sequence may include either one text sequence or two text sequences.
자연어 처리에서 일부 작업(예: 감정 분석)은 단일 텍스트를 입력으로 사용하는 반면, 일부 다른 작업(예: 자연어 추론)에서는 입력이 텍스트 시퀀스 쌍입니다. BERT 입력 시퀀스는 단일 텍스트와 텍스트 쌍을 모두 명확하게 나타냅니다. 전자의 경우 BERT 입력 시퀀스는 특수 분류 토큰 “<cls>”, 텍스트 시퀀스 토큰 및 특수 분리 토큰 “<sep>”의 연결입니다. 후자의 경우, BERT 입력 시퀀스는 첫 번째 텍스트 시퀀스의 토큰인 "<cls>", 두 번째 텍스트 시퀀스의 토큰인 "<sep>" 및 "<sep>"의 연결입니다. 우리는 "BERT 입력 시퀀스"라는 용어를 다른 유형의 "시퀀스"와 일관되게 구별할 것입니다. 예를 들어, 하나의 BERT 입력 시퀀스에는 하나의 텍스트 시퀀스 또는 두 개의 텍스트 시퀀스가 포함될 수 있습니다.
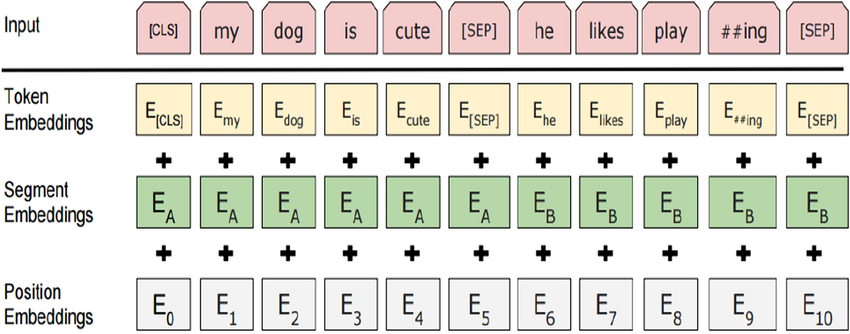
To distinguish text pairs, the learned segment embeddings eA and eB are added to the token embeddings of the first sequence and the second sequence, respectively. For single text inputs, only eA is used.
텍스트 쌍을 구별하기 위해 학습된 세그먼트 임베딩 eA 및 eB가 각각 첫 번째 시퀀스와 두 번째 시퀀스의 토큰 임베딩에 추가됩니다. 단일 텍스트 입력의 경우 eA만 사용됩니다.
The following get_tokens_and_segments takes either one sentence or two sentences as input, then returns tokens of the BERT input sequence and their corresponding segment IDs.
다음 get_tokens_and_segments는 한 문장 또는 두 문장을 입력으로 사용한 다음 BERT 입력 시퀀스의 토큰과 해당 세그먼트 ID를 반환합니다.
#@save
def get_tokens_and_segments(tokens_a, tokens_b=None):
"""Get tokens of the BERT input sequence and their segment IDs."""
tokens = ['<cls>'] + tokens_a + ['<sep>']
# 0 and 1 are marking segment A and B, respectively
segments = [0] * (len(tokens_a) + 2)
if tokens_b is not None:
tokens += tokens_b + ['<sep>']
segments += [1] * (len(tokens_b) + 1)
return tokens, segments이 함수는 BERT 모델의 입력으로 사용되는 토큰과 세그먼트 ID를 생성하는 과정을 수행합니다. BERT의 입력 형식은 [CLS] - 토큰 A - [SEP] - 토큰 B - [SEP]으로 구성되며, 이때 세그먼트 A는 토큰 A에 대한 세그먼트 ID(0), 세그먼트 B는 토큰 B에 대한 세그먼트 ID(1)를 나타냅니다.
- tokens_a: 첫 번째 시퀀스의 토큰 리스트입니다.
- tokens_b: 두 번째 시퀀스의 토큰 리스트(선택 사항)입니다.
함수 내용:
- tokens: BERT 입력 시퀀스에 해당하는 토큰 리스트를 구성합니다. 시퀀스의 처음은 [CLS] 토큰으로 시작하고, 첫 번째 시퀀스의 토큰들을 이어붙인 후 [SEP] 토큰을 추가합니다. 두 번째 시퀀스가 제공되면 해당 시퀀스의 토큰들을 이어붙이고 다시 [SEP] 토큰을 추가합니다.
- segments: 각 토큰의 세그먼트 ID를 나타내는 리스트를 구성합니다. 세그먼트 A는 토큰 A에 대한 것이므로 길이는 tokens_a의 길이 + 2입니다. 만약 두 번째 시퀀스가 제공되면 해당 시퀀스에 대한 세그먼트 ID를 추가합니다.
이 함수를 통해 토큰과 세그먼트 ID를 생성하여 BERT 입력 형식에 맞게 구성할 수 있습니다.
BERT chooses the Transformer encoder as its bidirectional architecture. Common in the Transformer encoder, positional embeddings are added at every position of the BERT input sequence. However, different from the original Transformer encoder, BERT uses learnable positional embeddings. To sum up, Fig. 15.8.2 shows that the embeddings of the BERT input sequence are the sum of the token embeddings, segment embeddings, and positional embeddings.
15.8. Bidirectional Encoder Representations from Transformers (BERT) — Dive into Deep Learning 1.0.3 documentation
d2l.ai
BERT는 양방향 아키텍처로 Transformer 인코더를 선택합니다. Transformer 인코더에서 일반적으로 위치 임베딩은 BERT 입력 시퀀스의 모든 위치에 추가됩니다. 그러나 원래 Transformer 인코더와 달리 BERT는 학습 가능한 위치 임베딩을 사용합니다. 요약하면 그림 15.8.2는 BERT 입력 시퀀스의 임베딩이 토큰 임베딩, 세그먼트 임베딩 및 위치 임베딩의 합임을 보여줍니다.

The following BERTEncoder class is similar to the TransformerEncoder class as implemented in Section 11.7. Different from TransformerEncoder, BERTEncoder uses segment embeddings and learnable positional embeddings.
다음 BERTEncoder 클래스는 섹션 11.7에 구현된 TransformerEncoder 클래스와 유사합니다. TransformerEncoder와 달리 BERTEncoder는 세그먼트 임베딩과 학습 가능한 위치 임베딩을 사용합니다.
#@save
class BERTEncoder(nn.Module):
"""BERT encoder."""
def __init__(self, vocab_size, num_hiddens, ffn_num_hiddens, num_heads,
num_blks, dropout, max_len=1000, **kwargs):
super(BERTEncoder, self).__init__(**kwargs)
self.token_embedding = nn.Embedding(vocab_size, num_hiddens)
self.segment_embedding = nn.Embedding(2, num_hiddens)
self.blks = nn.Sequential()
for i in range(num_blks):
self.blks.add_module(f"{i}", d2l.TransformerEncoderBlock(
num_hiddens, ffn_num_hiddens, num_heads, dropout, True))
# In BERT, positional embeddings are learnable, thus we create a
# parameter of positional embeddings that are long enough
self.pos_embedding = nn.Parameter(torch.randn(1, max_len,
num_hiddens))
def forward(self, tokens, segments, valid_lens):
# Shape of `X` remains unchanged in the following code snippet:
# (batch size, max sequence length, `num_hiddens`)
X = self.token_embedding(tokens) + self.segment_embedding(segments)
X = X + self.pos_embedding[:, :X.shape[1], :]
for blk in self.blks:
X = blk(X, valid_lens)
return X이 클래스는 BERT 모델의 인코더 부분을 정의합니다. BERT 모델은 토큰 임베딩, 세그먼트 임베딩, 여러 개의 변환기 블록 및 위치 임베딩을 포함하고 있습니다.
- vocab_size: 토큰의 종류 수입니다.
- num_hiddens: 임베딩 차원 및 히든 레이어의 차원입니다.
- ffn_num_hiddens: Feed-Forward 신경망의 히든 레이어 차원입니다.
- num_heads: Multi-Head Attention의 헤드 수입니다.
- num_blks: 변환기 블록의 개수입니다.
- dropout: 드롭아웃 비율입니다.
- max_len: 최대 시퀀스 길이입니다.
- kwargs: 추가 매개변수입니다.
이 클래스는 다음과 같은 요소들로 구성됩니다:
- token_embedding: 토큰 임베딩 레이어입니다. 입력 토큰을 임베딩 벡터로 변환합니다.
- segment_embedding: 세그먼트 임베딩 레이어입니다. 입력 세그먼트 정보를 임베딩 벡터로 변환합니다.
- blks: 여러 개의 변환기 블록을 포함하는 순차적인 레이어입니다.
- pos_embedding: 위치 임베딩 매개변수로서, BERT에서 위치 임베딩은 학습 가능합니다.
forward 메서드에서는 다음과 같은 작업을 수행합니다:
- token_embedding과 segment_embedding을 사용하여 토큰과 세그먼트 임베딩을 생성합니다.
- 위치 임베딩을 추가합니다.
- blks에 있는 각 변환기 블록을 차례로 통과시킵니다.
- 최종 인코딩 결과를 반환합니다.
이를 통해 BERTEncoder 클래스는 BERT의 인코더 부분을 구현하며, 입력 토큰과 세그먼트를 받아서 인코딩된 벡터를 반환합니다.
Suppose that the vocabulary size is 10000. To demonstrate forward inference of BERTEncoder, let’s create an instance of it and initialize its parameters.
어휘 크기가 10000이라고 가정합니다. BERTEncoder의 순방향 추론을 시연하기 위해 인스턴스를 만들고 해당 매개변수를 초기화하겠습니다.
vocab_size, num_hiddens, ffn_num_hiddens, num_heads = 10000, 768, 1024, 4
ffn_num_input, num_blks, dropout = 768, 2, 0.2
encoder = BERTEncoder(vocab_size, num_hiddens, ffn_num_hiddens, num_heads,
num_blks, dropout)위의 코드에서 다음과 같은 변수들을 설정하고 있습니다:
- vocab_size: 어휘 크기로, 모델에서 다루는 토큰의 종류 수입니다.
- num_hiddens: 임베딩 차원 및 각 변환기 블록의 출력 차원입니다.
- ffn_num_hiddens: Feed-Forward 신경망의 히든 레이어 차원입니다.
- num_heads: Multi-Head Attention의 헤드 수입니다.
- ffn_num_input: Feed-Forward 신경망의 입력 차원으로, 일반적으로 num_hiddens와 동일합니다.
- num_blks: 변환기 블록의 개수입니다.
- dropout: 드롭아웃 비율입니다.
그리고 BERTEncoder 클래스의 인스턴스인 encoder를 생성합니다. 이를 통해 BERT 인코더 모델을 정의하고 인코딩 작업을 수행할 수 있게 됩니다. encoder 객체는 위에서 설정한 매개변수들을 바탕으로 BERT 인코더를 생성한 것입니다.
We define tokens to be 2 BERT input sequences of length 8, where each token is an index of the vocabulary. The forward inference of BERTEncoder with the input tokens returns the encoded result where each token is represented by a vector whose length is predefined by the hyperparameter num_hiddens. This hyperparameter is usually referred to as the hidden size (number of hidden units) of the Transformer encoder.
우리는 토큰을 길이 8의 2개의 BERT 입력 시퀀스로 정의합니다. 여기서 각 토큰은 어휘의 인덱스입니다. 입력 토큰을 사용한 BERTEncoder의 순방향 추론은 각 토큰이 하이퍼파라미터 num_hiddens에 의해 길이가 미리 정의된 벡터로 표현되는 인코딩된 결과를 반환합니다. 이 하이퍼파라미터는 일반적으로 Transformer 인코더의 숨겨진 크기(숨겨진 단위 수)라고 합니다.
tokens = torch.randint(0, vocab_size, (2, 8))
segments = torch.tensor([[0, 0, 0, 0, 1, 1, 1, 1], [0, 0, 0, 1, 1, 1, 1, 1]])
encoded_X = encoder(tokens, segments, None)
encoded_X.shape위 코드에서 다음과 같은 작업을 수행하고 있습니다:
- tokens와 segments 생성: 임의의 정수로 구성된 tokens와 세그먼트 정보를 생성합니다. tokens는 (2, 8) 모양의 텐서로, 2개의 시퀀스 각각에 8개의 토큰이 포함되어 있습니다. segments는 (2, 8) 모양의 텐서로, 세그먼트 정보를 나타내는데 0은 첫 번째 세그먼트를, 1은 두 번째 세그먼트를 나타냅니다.
- 인코딩: encoder 객체를 사용하여 tokens와 segments를 인코딩한 결과를 계산합니다. 이를 encoded_X에 저장합니다. 이 과정은 BERT 인코더의 forward 연산과정을 의미합니다. 입력 토큰과 세그먼트 정보를 통해 인코딩된 특성 행렬을 얻게 됩니다.
- 결과 확인: encoded_X의 형태(shape)를 출력하여 인코딩된 결과의 텐서 모양을 확인합니다. 출력된 형태는 인코딩된 특성 행렬의 모양을 나타냅니다.
결과적으로 encoded_X는 인코딩된 특성 행렬로, 첫 번째 차원은 시퀀스의 개수, 두 번째 차원은 시퀀스의 길이, 세 번째 차원은 임베딩 차원(num_hiddens)으로 구성됩니다. 따라서 encoded_X.shape의 결과는 (2, 8, 768)이 됩니다.
torch.Size([2, 8, 768])
15.8.5. Pretraining Tasks
The forward inference of BERTEncoder gives the BERT representation of each token of the input text and the inserted special tokens “<cls>” and “<seq>”. Next, we will use these representations to compute the loss function for pretraining BERT. The pretraining is composed of the following two tasks: masked language modeling and next sentence prediction.
BERTEncoder의 순방향 추론은 입력 텍스트의 각 토큰과 삽입된 특수 토큰 "<cls>" 및 "<seq>"에 대한 BERT representation을 제공합니다. 다음으로 이러한 representations을 사용하여 BERT 사전 학습을 위한 손실 함수를 계산합니다. 사전 훈련은 마스크된 언어 모델링과 다음 문장 예측이라는 두 가지 작업으로 구성됩니다.
15.8.5.1. Masked Language Modeling
As illustrated in Section 9.3, a language model predicts a token using the context on its left. To encode context bidirectionally for representing each token, BERT randomly masks tokens and uses tokens from the bidirectional context to predict the masked tokens in a self-supervised fashion. This task is referred to as a masked language model.
섹션 9.3에 설명된 대로 언어 모델은 왼쪽의 컨텍스트를 사용하여 토큰을 예측합니다. 각 토큰을 표현하기 위해 컨텍스트를 양방향으로 인코딩하기 위해 BERT는 토큰을 무작위로 마스킹하고 양방향 컨텍스트의 토큰을 사용하여 자체 감독 방식으로 마스킹된 토큰을 예측합니다. 이 작업을 마스크된 언어 모델이라고 합니다.
In this pretraining task, 15% of tokens will be selected at random as the masked tokens for prediction. To predict a masked token without cheating by using the label, one straightforward approach is to always replace it with a special “<mask>” token in the BERT input sequence. However, the artificial special token “<mask>” will never appear in fine-tuning. To avoid such a mismatch between pretraining and fine-tuning, if a token is masked for prediction (e.g., “great” is selected to be masked and predicted in “this movie is great”), in the input it will be replaced with:
이 사전 훈련 작업에서는 토큰의 15%가 예측을 위한 마스크된 토큰으로 무작위로 선택됩니다. 레이블을 사용하여 부정 행위 없이 마스킹된 토큰을 예측하기 위한 한 가지 간단한 접근 방식은 항상 BERT 입력 시퀀스에서 특수 "<mask>" 토큰으로 바꾸는 것입니다. 그러나 인공 특수 토큰 “<mask>”는 미세 조정에서는 절대 나타나지 않습니다. 사전 훈련과 미세 조정 사이의 불일치를 피하기 위해 토큰이 예측을 위해 마스크된 경우(예: "이 영화는 훌륭합니다"에서 "훌륭함"이 마스크되고 예측되도록 선택됨) 입력에서 다음으로 대체됩니다.
- a special “<mask>” token for 80% of the time (e.g., “this movie is great” becomes “this movie is <mask>”);
80%의 시간 동안 특수 "<마스크>" 토큰(예: "이 영화는 훌륭합니다"는 "이 영화는 <마스크>입니다"가 됨) - a random token for 10% of the time (e.g., “this movie is great” becomes “this movie is drink”);
10%의 시간에 대한 무작위 토큰(예: "이 영화는 훌륭해요"는 "이 영화는 술입니다"가 됩니다) - the unchanged label token for 10% of the time (e.g., “this movie is great” becomes “this movie is great”).
10%의 시간 동안 변경되지 않은 레이블 토큰(예: "이 영화는 훌륭합니다"는 "이 영화는 훌륭합니다"가 됨)
Note that for 10% of 15% time a random token is inserted. This occasional noise encourages BERT to be less biased towards the masked token (especially when the label token remains unchanged) in its bidirectional context encoding.
15% 시간 중 10% 동안 무작위 토큰이 삽입된다는 점에 유의하세요. 이러한 간헐적인 노이즈는 BERT가 양방향 컨텍스트 인코딩에서 마스크된 토큰(특히 레이블 토큰이 변경되지 않은 상태로 유지되는 경우)에 덜 편향되도록 장려합니다.
We implement the following MaskLM class to predict masked tokens in the masked language model task of BERT pretraining. The prediction uses a one-hidden-layer MLP (self.mlp). In forward inference, it takes two inputs: the encoded result of BERTEncoder and the token positions for prediction. The output is the prediction results at these positions.
BERT 사전 학습의 마스크된 언어 모델 작업에서 마스크된 토큰을 예측하기 위해 다음 MaskLM 클래스를 구현합니다. 예측은 단일 숨겨진 레이어 MLP(self.mlp)를 사용합니다. 순방향 추론에서는 BERTEncoder의 인코딩된 결과와 예측을 위한 토큰 위치라는 두 가지 입력을 사용합니다. 출력은 이러한 위치에서의 예측 결과입니다.
#@save
class MaskLM(nn.Module):
"""The masked language model task of BERT."""
def __init__(self, vocab_size, num_hiddens, **kwargs):
super(MaskLM, self).__init__(**kwargs)
self.mlp = nn.Sequential(nn.LazyLinear(num_hiddens),
nn.ReLU(),
nn.LayerNorm(num_hiddens),
nn.LazyLinear(vocab_size))
def forward(self, X, pred_positions):
num_pred_positions = pred_positions.shape[1]
pred_positions = pred_positions.reshape(-1)
batch_size = X.shape[0]
batch_idx = torch.arange(0, batch_size)
# Suppose that `batch_size` = 2, `num_pred_positions` = 3, then
# `batch_idx` is `torch.tensor([0, 0, 0, 1, 1, 1])`
batch_idx = torch.repeat_interleave(batch_idx, num_pred_positions)
masked_X = X[batch_idx, pred_positions]
masked_X = masked_X.reshape((batch_size, num_pred_positions, -1))
mlm_Y_hat = self.mlp(masked_X)
return mlm_Y_hat위의 코드에서 수행되는 작업은 다음과 같습니다:
- 초기화 메서드(__init__): MaskLM 클래스의 초기화 메서드에서는 MLM 작업을 위한 신경망 구조를 정의합니다. num_hiddens는 은닉 유닛의 수, vocab_size는 어휘 크기를 나타냅니다.
- Forward 메서드(forward): 이 메서드는 BERT의 마스킹된 언어 모델 작업을 수행합니다. 입력으로 주어진 X는 BERT 인코더의 출력입니다. pred_positions는 마스킹된 위치를 나타내는 텐서로, 예측해야 할 위치에 대한 정보를 가지고 있습니다.
- pred_positions의 형태(shape)를 조정하여 마스크된 위치 정보를 준비합니다.
- 마스크된 위치에 해당하는 특성만 추출하여 masked_X를 생성합니다.
- masked_X를 MLP 모델(self.mlp)에 통과시켜 마스킹된 언어 모델의 예측값을 계산합니다.
즉, 이 모듈은 인코더의 출력을 받아서 마스크된 위치의 특성을 추출하고, 이를 통해 마스킹된 언어 모델 작업을 수행하여 단어 예측을 수행합니다.
To demonstrate the forward inference of MaskLM, we create its instance mlm and initialize it. Recall that encoded_X from the forward inference of BERTEncoder represents 2 BERT input sequences. We define mlm_positions as the 3 indices to predict in either BERT input sequence of encoded_X. The forward inference of mlm returns prediction results mlm_Y_hat at all the masked positions mlm_positions of encoded_X. For each prediction, the size of the result is equal to the vocabulary size.
MaskLM의 순방향 추론을 보여주기 위해 인스턴스 mlm을 생성하고 초기화합니다. BERTEncoder의 순방향 추론에서 나온 Encoded_X는 2개의 BERT 입력 시퀀스를 나타냅니다. 우리는 mlm_positions를 Encoded_X의 BERT 입력 시퀀스에서 예측할 3개의 인덱스로 정의합니다. mlm의 순방향 추론은 Encoded_X의 모든 마스크 위치 mlm_positions에서 예측 결과 mlm_Y_hat를 반환합니다. 각 예측에 대해 결과의 크기는 어휘 크기와 같습니다.
mlm = MaskLM(vocab_size, num_hiddens)
mlm_positions = torch.tensor([[1, 5, 2], [6, 1, 5]])
mlm_Y_hat = mlm(encoded_X, mlm_positions)
mlm_Y_hat.shape위의 코드에서 수행되는 작업은 다음과 같습니다:
- MaskLM 모델 생성: MaskLM 클래스로부터 MLM 모델을 생성합니다. vocab_size는 어휘 크기, num_hiddens는 은닉 유닛의 수입니다.
- 마스크된 위치 정보 생성: mlm_positions 텐서는 마스킹된 위치 정보를 나타내며, 이 정보를 통해 모델은 어떤 위치의 단어를 예측할지 결정합니다.
- MLM 모델 적용: 생성한 mlm 모델에 인코딩된 입력 encoded_X와 마스크된 위치 정보 mlm_positions를 전달하여 마스킹된 언어 모델 작업을 수행합니다. 모델은 이 위치에서 어떤 단어가 들어갈지 예측한 결과를 반환합니다.
- 결과 확인: mlm_Y_hat은 마스킹된 언어 모델의 예측 결과입니다. 이 결과의 형태(shape)를 확인하면 마스크된 위치의 단어 예측에 대한 확률값 분포를 확인할 수 있습니다.
즉, 위의 코드는 MaskLM 모델을 사용하여 BERT의 마스킹된 언어 모델 작업을 수행하고, 예측 결과의 형태(shape)를 출력하는 예제입니다
torch.Size([6])
15.8.5.2. Next Sentence Prediction
Although masked language modeling is able to encode bidirectional context for representing words, it does not explicitly model the logical relationship between text pairs. To help understand the relationship between two text sequences, BERT considers a binary classification task, next sentence prediction, in its pretraining. When generating sentence pairs for pretraining, for half of the time they are indeed consecutive sentences with the label “True”; while for the other half of the time the second sentence is randomly sampled from the corpus with the label “False”.
마스킹된 언어 모델링은 단어를 표현하기 위해 양방향 컨텍스트를 인코딩할 수 있지만 텍스트 쌍 간의 논리적 관계를 명시적으로 모델링하지는 않습니다. 두 텍스트 시퀀스 간의 관계를 이해하는 데 도움을 주기 위해 BERT는 사전 학습에서 이진 분류 작업, 다음 문장 예측을 고려합니다. 사전 학습을 위해 문장 쌍을 생성할 때 절반의 시간 동안 실제로는 "True"라는 레이블이 붙은 연속 문장입니다. 나머지 절반 동안은 "False"라는 라벨이 붙은 코퍼스에서 두 번째 문장이 무작위로 샘플링됩니다.
The following NextSentencePred class uses a one-hidden-layer MLP to predict whether the second sentence is the next sentence of the first in the BERT input sequence. Due to self-attention in the Transformer encoder, the BERT representation of the special token “<cls>” encodes both the two sentences from the input. Hence, the output layer (self.output) of the MLP classifier takes X as input, where X is the output of the MLP hidden layer whose input is the encoded “<cls>” token.
다음 NextSentencePred 클래스는 단일 숨겨진 레이어 MLP를 사용하여 두 번째 문장이 BERT 입력 시퀀스에서 첫 번째 문장의 다음 문장인지 예측합니다. Transformer 인코더의 self-attention으로 인해 특수 토큰 “<cls>”의 BERT 표현은 입력의 두 문장을 모두 인코딩합니다. 따라서 MLP 분류기의 출력 계층(self.output)은 X를 입력으로 사용합니다. 여기서 X는 입력이 인코딩된 "<cls>" 토큰인 MLP 숨겨진 계층의 출력입니다.
#@save
class NextSentencePred(nn.Module):
"""The next sentence prediction task of BERT."""
def __init__(self, **kwargs):
super(NextSentencePred, self).__init__(**kwargs)
self.output = nn.LazyLinear(2)
def forward(self, X):
# `X` shape: (batch size, `num_hiddens`)
return self.output(X)위의 코드에서 수행되는 작업은 다음과 같습니다:
- NextSentencePred 모듈 생성: NextSentencePred 클래스로부터 다음 문장 예측 작업을 수행하는 모듈을 생성합니다.
- 모듈 구성: 모듈 내부에는 출력을 생성하는 레이어인 nn.LazyLinear이 정의되어 있습니다. nn.LazyLinear(2)는 출력 레이어를 생성하며, 이 레이어는 2개의 출력 유닛을 가집니다. 이것은 다음 문장이 관련성이 있을지 없을지에 대한 이진 예측을 수행하기 위한 레이어입니다.
- Forward 연산: forward 함수는 주어진 입력 X를 받아 출력을 계산합니다. X의 형태는 (배치 크기, num_hiddens)입니다. 입력 X를 출력 레이어에 전달하여 다음 문장 예측 작업을 수행하고 결과를 반환합니다.
위의 코드는 BERT의 다음 문장 예측 작업을 위한 모듈인 NextSentencePred를 정의하는 예제입니다.
We can see that the forward inference of an NextSentencePred instance returns binary predictions for each BERT input sequence.
NextSentencePred 인스턴스의 순방향 추론이 각 BERT 입력 시퀀스에 대해 이진 예측을 반환하는 것을 볼 수 있습니다.
# PyTorch by default will not flatten the tensor as seen in mxnet where, if
# flatten=True, all but the first axis of input data are collapsed together
encoded_X = torch.flatten(encoded_X, start_dim=1)
# input_shape for NSP: (batch size, `num_hiddens`)
nsp = NextSentencePred()
nsp_Y_hat = nsp(encoded_X)
nsp_Y_hat.shape위의 코드에서 수행되는 작업은 다음과 같습니다:
- encoded_X 펼치기: torch.flatten 함수를 사용하여 encoded_X 텐서를 펼치는 작업을 수행합니다. encoded_X는 이전 단계에서 인코딩된 BERT 출력 텐서로, 차원을 펼쳐서 2차원으로 만듭니다. start_dim=1 인자는 펼치는 시작 차원을 지정합니다.
- NextSentencePred 모듈 생성: 다음 문장 예측 작업을 위한 NextSentencePred 모듈을 생성합니다.
- Forward 연산: 생성된 NextSentencePred 모듈에 펼쳐진 encoded_X를 입력으로 전달하여 다음 문장 예측 작업을 수행하고, 결과 nsp_Y_hat을 얻습니다.
- 결과 확인: nsp_Y_hat의 형태(shape)를 확인하여 다음 문장 예측 작업의 결과를 파악합니다. 결과 형태는 (batch size, 2)입니다. 두 개의 출력 유닛은 각각 두 가지 다른 클래스(다음 문장이 관련성이 있을 경우 1, 없을 경우 0)에 대한 확률 예측을 나타냅니다.
위의 코드는 BERT의 다음 문장 예측 작업을 수행하는 예제로, 인코딩된 텍스트 데이터를 입력으로 하여 다음 문장이 관련성이 있을지 없을지를 예측하는 모듈을 생성하고 결과를 확인하는 과정을 보여줍니다
torch.Size([2, 2])The cross-entropy loss of the 2 binary classifications can also be computed.
2개의 이진 분류의 교차 엔트로피 손실도 계산할 수 있습니다.
nsp_y = torch.tensor([0, 1])
nsp_l = loss(nsp_Y_hat, nsp_y)
nsp_l.shape위의 코드에서 수행되는 작업은 다음과 같습니다:
- nsp_y 정의: 다음 문장 예측 작업에서 실제 정답 레이블을 나타내는 텐서 nsp_y를 정의합니다. 이 예제에서는 두 개의 미니배치 샘플에 대한 정답 레이블을 나타냅니다. 첫 번째 샘플은 관련성이 없는 경우(0), 두 번째 샘플은 관련성이 있는 경우(1)를 나타냅니다.
- 손실 계산: 앞서 정의한 nsp_Y_hat 텐서와 nsp_y 정답 레이블을 사용하여 다음 문장 예측 작업의 손실을 계산합니다. 이를 위해 사용하는 손실 함수인 loss는 코드에는 나타나지 않았지만, BERT의 다음 문장 예측 작업에서는 일반적으로 교차 엔트로피(Cross Entropy) 손실이 사용됩니다.
- 손실 형태 확인: nsp_l의 형태(shape)를 확인하여 계산된 손실의 형태를 파악합니다. 이 경우 nsp_l은 스칼라값입니다. 미니배치 내 각 샘플에 대한 손실을 합한 결과를 나타냅니다.
위의 코드는 BERT의 다음 문장 예측 작업에서 손실을 계산하는 과정을 보여주는 예제입니다.
torch.Size([2])
It is noteworthy that all the labels in both the aforementioned pretraining tasks can be trivially obtained from the pretraining corpus without manual labeling effort. The original BERT has been pretrained on the concatenation of BookCorpus (Zhu et al., 2015) and English Wikipedia. These two text corpora are huge: they have 800 million words and 2.5 billion words, respectively.
앞서 언급한 사전 훈련 작업의 모든 레이블은 수동 레이블 지정 작업 없이 사전 훈련 코퍼스에서 쉽게 얻을 수 있다는 점은 주목할 만합니다. 원래 BERT는 BookCorpus(Zhu et al., 2015)와 English Wikipedia의 연결을 통해 사전 학습되었습니다. 이 두 개의 텍스트 말뭉치에는 각각 8억 단어와 25억 단어가 있습니다.
15.8.6. Putting It All Together
When pretraining BERT, the final loss function is a linear combination of both the loss functions for masked language modeling and next sentence prediction. Now we can define the BERTModel class by instantiating the three classes BERTEncoder, MaskLM, and NextSentencePred. The forward inference returns the encoded BERT representations encoded_X, predictions of masked language modeling mlm_Y_hat, and next sentence predictions nsp_Y_hat.
BERT를 사전 훈련할 때 최종 손실 함수는 마스크된 언어 모델링과 다음 문장 예측을 위한 손실 함수의 선형 조합입니다. 이제 BERTEncoder, MaskLM 및 NextSentencePred 세 클래스를 인스턴스화하여 BERTModel 클래스를 정의할 수 있습니다. 순방향 추론은 인코딩된 BERT 표현 encode_X, 마스크된 언어 모델링 mlm_Y_hat의 예측 및 다음 문장 예측 nsp_Y_hat을 반환합니다.
#@save
class BERTModel(nn.Module):
"""The BERT model."""
def __init__(self, vocab_size, num_hiddens, ffn_num_hiddens,
num_heads, num_blks, dropout, max_len=1000):
super(BERTModel, self).__init__()
self.encoder = BERTEncoder(vocab_size, num_hiddens, ffn_num_hiddens,
num_heads, num_blks, dropout,
max_len=max_len)
self.hidden = nn.Sequential(nn.LazyLinear(num_hiddens),
nn.Tanh())
self.mlm = MaskLM(vocab_size, num_hiddens)
self.nsp = NextSentencePred()
def forward(self, tokens, segments, valid_lens=None, pred_positions=None):
encoded_X = self.encoder(tokens, segments, valid_lens)
if pred_positions is not None:
mlm_Y_hat = self.mlm(encoded_X, pred_positions)
else:
mlm_Y_hat = None
# The hidden layer of the MLP classifier for next sentence prediction.
# 0 is the index of the '<cls>' token
nsp_Y_hat = self.nsp(self.hidden(encoded_X[:, 0, :]))
return encoded_X, mlm_Y_hat, nsp_Y_hat위의 코드에서 수행되는 작업은 다음과 같습니다:
- nsp_y 정의: 다음 문장 예측 작업에서 실제 정답 레이블을 나타내는 텐서 nsp_y를 정의합니다. 이 예제에서는 두 개의 미니배치 샘플에 대한 정답 레이블을 나타냅니다. 첫 번째 샘플은 관련성이 없는 경우(0), 두 번째 샘플은 관련성이 있는 경우(1)를 나타냅니다.
- 손실 계산: 앞서 정의한 nsp_Y_hat 텐서와 nsp_y 정답 레이블을 사용하여 다음 문장 예측 작업의 손실을 계산합니다. 이를 위해 사용하는 손실 함수인 loss는 코드에는 나타나지 않았지만, BERT의 다음 문장 예측 작업에서는 일반적으로 교차 엔트로피(Cross Entropy) 손실이 사용됩니다.
- 손실 형태 확인: nsp_l의 형태(shape)를 확인하여 계산된 손실의 형태를 파악합니다. 이 경우 nsp_l은 스칼라값입니다. 미니배치 내 각 샘플에 대한 손실을 합한 결과를 나타냅니다.
위의 코드는 BERT의 다음 문장 예측 작업에서 손실을 계산하는 과정을 보여주는 예제입니다.
15.8.7. Summary
- Word embedding models such as word2vec and GloVe are context-independent. They assign the same pretrained vector to the same word regardless of the context of the word (if any). It is hard for them to handle well polysemy or complex semantics in natural languages.
word2vec 및 GloVe와 같은 단어 임베딩 모델은 상황에 독립적입니다. 단어의 맥락(있는 경우)에 관계없이 동일한 사전 훈련된 벡터를 동일한 단어에 할당합니다. 자연어에서는 다의어나 복잡한 의미를 잘 다루기가 어렵습니다. - For context-sensitive word representations such as ELMo and GPT, representations of words depend on their contexts.
ELMo 및 GPT와 같은 상황에 맞는 단어 표현의 경우 단어 표현은 해당 상황에 따라 달라집니다. - ELMo encodes context bidirectionally but uses task-specific architectures (however, it is practically non-trivial to craft a specific architecture for every natural language processing task); while GPT is task-agnostic but encodes context left-to-right.
ELMo는 컨텍스트를 양방향으로 인코딩하지만 작업별 아키텍처를 사용합니다(그러나 모든 자연어 처리 작업에 대해 특정 아키텍처를 만드는 것은 사실상 쉽지 않습니다). GPT는 작업에 구애받지 않지만 컨텍스트를 왼쪽에서 오른쪽으로 인코딩합니다. - BERT combines the best of both worlds: it encodes context bidirectionally and requires minimal architecture changes for a wide range of natural language processing tasks.
BERT는 두 가지 장점을 결합합니다. 즉, 컨텍스트를 양방향으로 인코딩하고 광범위한 자연어 처리 작업에 대해 최소한의 아키텍처 변경이 필요합니다. - The embeddings of the BERT input sequence are the sum of the token embeddings, segment embeddings, and positional embeddings.
BERT 입력 시퀀스의 임베딩은 토큰 임베딩, 세그먼트 임베딩 및 위치 임베딩의 합계입니다. - Pretraining BERT is composed of two tasks: masked language modeling and next sentence prediction. The former is able to encode bidirectional context for representing words, while the latter explicitly models the logical relationship between text pairs.
사전 훈련 BERT는 마스크된 언어 모델링과 다음 문장 예측이라는 두 가지 작업으로 구성됩니다. 전자는 단어를 표현하기 위해 양방향 컨텍스트를 인코딩할 수 있는 반면, 후자는 텍스트 쌍 간의 논리적 관계를 명시적으로 모델링합니다.
https://www.youtube.com/live/QCOT5D7Pa7s?si=BfY_2QMLWpFqvm9T
15.8.8. Exercises
- All other things being equal, will a masked language model require more or fewer pretraining steps to converge than a left-to-right language model? Why?
- In the original implementation of BERT, the positionwise feed-forward network in BERTEncoder (via d2l.TransformerEncoderBlock) and the fully connected layer in MaskLM both use the Gaussian error linear unit (GELU) (Hendrycks and Gimpel, 2016) as the activation function. Research into the difference between GELU and ReLU.
'Dive into Deep Learning > D2L Natural language Processing' 카테고리의 다른 글
| D2L - 16.2. Sentiment Analysis: Using Recurrent Neural Networks (0) | 2023.09.01 |
|---|---|
| D2L - 16.1. Sentiment Analysis and the Dataset (0) | 2023.09.01 |
| D2L - 16. Natural Language Processing: Applications (0) | 2023.09.01 |
| D2L - 15.10. Pretraining BERT (0) | 2023.08.30 |
| D2L - 15.9. The Dataset for Pretraining BERT (0) | 2023.08.30 |
| D2L - 15.7. Word Similarity and Analogy (0) | 2023.08.30 |
| D2L - 15.6. Subword Embedding (0) | 2023.08.30 |
| D2L - 15.5. Word Embedding with Global Vectors (GloVe) (0) | 2023.08.29 |
| D2L - 15.4. Pretraining word2vec (0) | 2023.08.29 |
| D2L - 15.3. The Dataset for Pretraining Word Embeddings (0) | 2023.08.29 |