
15.3. The Dataset for Pretraining Word Embeddings — Dive into Deep Learning 1.0.3 documentation
d2l.ai
15.3. The Dataset for Pretraining Word Embeddings
Now that we know the technical details of the word2vec models and approximate training methods, let’s walk through their implementations. Specifically, we will take the skip-gram model in Section 15.1 and negative sampling in Section 15.2 as an example. In this section, we begin with the dataset for pretraining the word embedding model: the original format of the data will be transformed into minibatches that can be iterated over during training.
이제 word2vec 모델의 기술적 세부 사항과 대략적인 훈련 방법을 알았으므로 구현을 살펴보겠습니다. 구체적으로, 섹션 15.1의 스킵 그램 모델과 섹션 15.2의 네거티브 샘플링을 예로 들어보겠습니다. 이 섹션에서는 단어 임베딩 모델을 사전 훈련하기 위한 데이터 세트부터 시작합니다. 데이터의 원래 형식은 훈련 중에 반복할 수 있는 미니 배치로 변환됩니다.
import collections
import math
import os
import random
import torch
from d2l import torch as d2l
이 코드는 PyTorch와 d2l(Dive into Deep Learning) 라이브러리의 일부 함수들을 사용하여 딥 러닝 모델을 구현하기 위한 환경을 설정하는 부분입니다.
- import collections:
- collections 모듈을 가져옵니다. 이 모듈은 파이썬에서 컨테이너 데이터 타입을 보다 쉽게 다룰 수 있도록 도와주는 클래스들을 제공합니다.
- import math:
- math 모듈을 가져옵니다. 이 모듈은 수학적인 연산을 수행하는 함수들을 제공합니다.
- import os:
- os 모듈을 가져옵니다. 이 모듈은 운영 체제와 관련된 기능을 제공하여 파일 경로, 디렉토리 생성 등을 다루는 데 사용됩니다.
- import random:
- random 모듈을 가져옵니다. 이 모듈은 난수 생성 및 관련된 함수를 제공합니다.
- import torch:
- PyTorch 라이브러리를 가져옵니다. PyTorch는 딥 러닝 모델을 구현하고 훈련하는 데에 사용되는 강력한 라이브러리입니다.
- from d2l import torch as d2l:
- d2l 라이브러리에서 PyTorch와 관련된 함수들을 가져와 d2l이라는 이름으로 사용하겠다는 의미입니다. 이 라이브러리는 "Dive into Deep Learning" 책의 코드와 예제를 포함하고 있는 라이브러리로, 딥 러닝 학습을 돕기 위해 만들어진 것입니다.
이 코드는 여러 모듈과 라이브러리를 가져와서 딥 러닝 모델을 구현하고 실행하기 위한 기반을 설정하는 것입니다.
15.3.1. Reading the Dataset
The dataset that we use here is Penn Tree Bank (PTB). This corpus is sampled from Wall Street Journal articles, split into training, validation, and test sets. In the original format, each line of the text file represents a sentence of words that are separated by spaces. Here we treat each word as a token.
여기서 사용하는 데이터세트는 PTB(Penn Tree Bank)입니다. 이 자료는 Wall Street Journal 기사에서 샘플링되었으며 훈련, 검증 및 테스트 세트로 구분됩니다. 원본 형식에서 텍스트 파일의 각 줄은 공백으로 구분된 단어 문장을 나타냅니다. 여기서는 각 단어를 토큰으로 처리합니다.
#@save
d2l.DATA_HUB['ptb'] = (d2l.DATA_URL + 'ptb.zip',
'319d85e578af0cdc590547f26231e4e31cdf1e42')
#@save
def read_ptb():
"""Load the PTB dataset into a list of text lines."""
data_dir = d2l.download_extract('ptb')
# Read the training set
with open(os.path.join(data_dir, 'ptb.train.txt')) as f:
raw_text = f.read()
return [line.split() for line in raw_text.split('\n')]
sentences = read_ptb()
f'# sentences: {len(sentences)}'이 코드는 PTB 데이터셋을 로드하고 텍스트로 처리하는 부분을 보여주고 있습니다.
- d2l.DATA_HUB['ptb'] = (d2l.DATA_URL + 'ptb.zip', '319d85e578af0cdc590547f26231e4e31cdf1e42'):
- d2l.DATA_HUB 딕셔너리에 'ptb'라는 키와 해당 데이터셋의 URL과 해시 값을 저장합니다. 이렇게 함으로써 데이터를 다운로드하고 압축을 해제할 때 사용할 수 있습니다.
- def read_ptb()::
- read_ptb 함수를 정의합니다. 이 함수는 PTB 데이터셋을 로드하고 텍스트를 줄 단위로 분리하여 리스트로 반환합니다.
- data_dir = d2l.download_extract('ptb'):
- d2l.download_extract 함수를 사용하여 PTB 데이터셋을 다운로드하고 압축을 해제합니다. 데이터가 저장될 디렉토리 경로를 data_dir 변수에 저장합니다.
- with open(os.path.join(data_dir, 'ptb.train.txt')) as f::
- PTB 데이터셋 내에 있는 'ptb.train.txt' 파일을 엽니다.
- raw_text = f.read():
- 파일을 읽어서 raw_text 변수에 저장합니다.
- return [line.split() for line in raw_text.split('\n')]:
- raw_text를 줄 단위로 분리한 후 각 줄을 공백으로 분리하여 단어 리스트로 만들어 반환합니다.
- sentences = read_ptb():
- read_ptb 함수를 호출하여 PTB 데이터셋의 텍스트를 처리한 결과를 sentences 변수에 저장합니다.
- f'# sentences: {len(sentences)}':
- 처리된 문장의 개수를 출력하는 문자열을 생성합니다. 이를 통해 문장의 수를 확인할 수 있습니다.

After reading the training set, we build a vocabulary for the corpus, where any word that appears less than 10 times is replaced by the “<unk>” token. Note that the original dataset also contains “<unk>” tokens that represent rare (unknown) words.
훈련 세트를 읽은 후 우리는 10번 미만으로 나타나는 모든 단어가 "<unk>" 토큰으로 대체되는 말뭉치에 대한 어휘를 구축합니다. 원본 데이터세트에는 희귀한(알 수 없는) 단어를 나타내는 “<unk>” 토큰도 포함되어 있습니다.
vocab = d2l.Vocab(sentences, min_freq=10)
f'vocab size: {len(vocab)}'이 코드는 PTB 데이터셋에서 단어 사전을 생성하는 과정을 나타내고 있습니다.
- vocab = d2l.Vocab(sentences, min_freq=10):
- d2l.Vocab 클래스를 사용하여 단어 사전(vocabulary)을 생성합니다. 이 때 sentences는 PTB 데이터셋에서 읽어온 문장들의 리스트이며, min_freq=10은 최소 빈도수가 10 이상인 단어만을 포함하도록 단어 사전을 구성하겠다는 설정입니다. 이렇게 함으로써 빈도가 낮은 희귀한 단어는 제외됩니다.
- f'vocab size: {len(vocab)}':
- 생성된 단어 사전의 크기를 출력하는 문자열을 생성합니다. len(vocab)은 단어 사전에 포함된 단어의 수를 나타냅니다. 이를 통해 단어 사전의 크기를 확인할 수 있습니다.
이 코드는 PTB 데이터셋에서 단어 사전을 생성하고 그 크기를 출력하는 과정을 보여주고 있습니다.

15.3.2. Subsampling
Text data typically have high-frequency words such as “the”, “a”, and “in”: they may even occur billions of times in very large corpora. However, these words often co-occur with many different words in context windows, providing little useful signals. For instance, consider the word “chip” in a context window: intuitively its co-occurrence with a low-frequency word “intel” is more useful in training than the co-occurrence with a high-frequency word “a”. Moreover, training with vast amounts of (high-frequency) words is slow. Thus, when training word embedding models, high-frequency words can be subsampled (Mikolov et al., 2013). Specifically, each indexed word wi in the dataset will be discarded with probability where f(wi) is the ratio of the number of words wi to the total number of words in the dataset, and the constant t is a hyperparameter (10**−4 in the experiment). We can see that only when the relative frequency f(wi)>t can the (high-frequency) word wi be discarded, and the higher the relative frequency of the word, the greater the probability of being discarded.
텍스트 데이터에는 일반적으로 "the", "a" 및 "in"과 같은 빈도가 높은 단어가 있으며 매우 큰 말뭉치에서는 수십억 번 나타날 수도 있습니다. 그러나 이러한 단어는 컨텍스트 창에서 다양한 단어와 함께 나타나는 경우가 많아 유용한 신호를 거의 제공하지 않습니다. 예를 들어, 컨텍스트 창에서 "chip"이라는 단어를 생각해 보세요. 직관적으로 낮은 빈도의 단어 "intel"과의 동시 발생은 높은 빈도의 단어 "a"와의 동시 발생보다 훈련에 더 유용합니다. 더욱이, 방대한 양의 (빈도가 높은) 단어를 사용한 훈련은 느립니다. 따라서 단어 임베딩 모델을 훈련할 때 빈도가 높은 단어를 서브샘플링할 수 있습니다(Mikolov et al., 2013). 구체적으로, 데이터세트의 각 색인 단어 wi는 확률에 따라 삭제됩니다. 여기서 f(wi)는 데이터세트의 전체 단어 수에 대한 wi 단어 수의 비율이고 상수 t는 하이퍼파라미터(실험에서는 10**− 4). 상대도수 f(wi)>t가 되어야만 (고빈도) 단어 wi가 폐기될 수 있고, 단어의 상대도수가 높을수록 폐기될 확률이 높아지는 것을 알 수 있다.
#@save
def subsample(sentences, vocab):
"""Subsample high-frequency words."""
# Exclude unknown tokens ('<unk>')
sentences = [[token for token in line if vocab[token] != vocab.unk]
for line in sentences]
counter = collections.Counter([
token for line in sentences for token in line])
num_tokens = sum(counter.values())
# Return True if `token` is kept during subsampling
def keep(token):
return(random.uniform(0, 1) <
math.sqrt(1e-4 / counter[token] * num_tokens))
return ([[token for token in line if keep(token)] for line in sentences],
counter)
subsampled, counter = subsample(sentences, vocab)이 코드는 높은 빈도 단어를 하위 샘플링하는 과정을 나타내고 있습니다.
- def subsample(sentences, vocab)::
- subsample 함수를 정의합니다. 이 함수는 입력으로 문장들의 리스트 sentences와 단어 사전 vocab을 받습니다.
- sentences = [[token for token in line if vocab[token] != vocab.unk] for line in sentences]:
- sentences 내에서 미지의 토큰('<unk>')을 제외하고 단어들을 추출하여 각 문장을 구성합니다.
- counter = collections.Counter([...]):
- 모든 문장에서 각 단어의 빈도수를 계산하여 counter에 저장합니다.
- num_tokens = sum(counter.values()):
- counter에 저장된 모든 단어의 빈도수를 합하여 총 토큰 수를 계산합니다.
- def keep(token)::
- 하위 샘플링 중에 특정 단어 token을 유지할지 여부를 결정하는 함수를 정의합니다. 이 함수는 단어의 빈도수와 총 토큰 수에 기반하여 확률적으로 결정됩니다.
- return ([[token for token in line if keep(token)] for line in sentences], counter):
- keep 함수에 따라 하위 샘플링된 문장들과 counter를 반환합니다.
- subsampled, counter = subsample(sentences, vocab):
- subsample 함수를 호출하여 높은 빈도 단어를 하위 샘플링한 결과인 subsampled와 빈도수 정보인 counter를 얻습니다.
이 코드는 높은 빈도 단어를 하위 샘플링하여 데이터셋을 줄이는 과정을 나타내고 있습니다.
SubSampling 이란?
Subsampling, in the context of natural language processing, refers to a technique used to reduce the frequency of high-frequency words in a text corpus. This technique is often applied to address the issue of words that occur very frequently and provide limited contextual information, such as common words like "the," "and," "is," etc.
서브샘플링(Subsampling)은 자연어 처리의 맥락에서 텍스트 말뭉치 내에서 높은 빈도를 가진 단어의 빈도를 줄이는 기술을 말합니다. 이 기술은 "the," "and," "is"와 같은 일반적인 단어와 같이 빈번하게 나타나지만 제한된 문맥 정보를 제공하는 단어들의 문제를 해결하기 위해 자주 활용됩니다.
The idea behind subsampling is to randomly discard some instances of high-frequency words while keeping the overall distribution of words in the text relatively unchanged. By doing so, the resulting text data can be more balanced and contain a better representation of less frequent but potentially more informative words.
서브샘플링의 아이디어는 높은 빈도 단어의 일부 인스턴스를 무작위로 제거하면서 텍스트의 단어 분포를 상대적으로 유지하는 것입니다. 이를 통해 생성된 텍스트 데이터는 보다 균형적이며 덜 빈번하지만 더 유용한 정보를 제공할 수 있는 단어의 표현을 포함하게 됩니다.
Subsampling is particularly useful in word embedding methods like Word2Vec. High-frequency words can dominate the learning process, affecting the quality of word embeddings and the models' ability to capture subtle semantic relationships. Subsampling helps mitigate this by reducing the influence of these words while retaining the essence of the data.
서브샘플링은 특히 Word2Vec과 같은 단어 임베딩 방법에서 유용하게 활용됩니다. 높은 빈도 단어는 학습 과정을 지배할 수 있으며, 단어 임베딩의 품질과 모델이 미묘한 의미적 관계를 포착하는 능력에 영향을 줄 수 있습니다. 서브샘플링은 이러한 영향을 줄이면서도 데이터의 본질을 유지함으로써 이러한 단어들의 영향을 줄이는 데 도움을 줍니다.
In subsampling, the decision of whether to keep or discard a word is often based on its frequency. Words that appear very frequently are more likely to be discarded, while less frequent words have a higher chance of being retained. The specific criteria for subsampling, such as the threshold frequency for discarding a word, may vary depending on the application and the dataset.
서브샘플링에서 어떤 단어를 유지하거나 버릴지의 결정은 주로 그 빈도에 기반합니다. 매우 빈번하게 나타나는 단어는 버려질 가능성이 높으며, 덜 빈번한 단어는 보다 높은 유지 확률을 갖습니다. 서브샘플링의 구체적인 기준(예: 단어를 버릴 빈도의 임계값)은 응용 및 데이터셋에 따라 다양할 수 있습니다.
In summary, subsampling is a technique used to reduce the influence of high-frequency words in text data, improving the quality of word embeddings and enhancing the ability of models to capture meaningful relationships between words.
요약하면, 서브샘플링은 텍스트 데이터에서 높은 빈도 단어의 영향을 줄이는 기술로, 단어 임베딩의 품질을 향상시키고 모델이 단어 간 의미적인 관계를 더 잘 포착할 수 있는 능력을 강화하는 데 사용됩니다.
The following code snippet plots the histogram of the number of tokens per sentence before and after subsampling. As expected, subsampling significantly shortens sentences by dropping high-frequency words, which will lead to training speedup.
다음 코드 조각은 서브샘플링 전후의 문장당 토큰 수에 대한 히스토그램을 표시합니다. 예상한 대로 서브샘플링은 빈도가 높은 단어를 삭제하여 문장을 크게 단축하여 훈련 속도를 향상시킵니다.
d2l.show_list_len_pair_hist(['origin', 'subsampled'], '# tokens per sentence',
'count', sentences, subsampled);이 코드는 두 개의 데이터 리스트에 대한 히스토그램을 그리는 d2l(Dive into Deep Learning) 라이브러리의 함수를 호출하는 부분입니다.
- d2l.show_list_len_pair_hist(['origin', 'subsampled'], '# tokens per sentence', 'count', sentences, subsampled);:
- show_list_len_pair_hist 함수를 호출합니다. 이 함수는 두 개의 데이터 리스트에 대한 길이(또는 개수)에 관한 히스토그램을 그립니다.
- 첫 번째 인자 ['origin', 'subsampled']는 두 개의 데이터 리스트를 나타내는 이름입니다. 'origin'은 원본 데이터 리스트를, 'subsampled'는 서브샘플링된 데이터 리스트를 나타냅니다.
- 두 번째 인자 '# tokens per sentence'는 x축의 레이블로서 "문장 당 토큰 수"를 나타냅니다.
- 세 번째 인자 'count'는 y축의 레이블로서 "개수"를 나타냅니다.
- 네 번째와 다섯 번째 인자 sentences와 subsampled는 각각 원본 데이터 리스트와 서브샘플링된 데이터 리스트를 나타냅니다.
이 코드는 원본 데이터와 서브샘플링된 데이터 간의 문장당 토큰 수에 대한 히스토그램을 그리는 기능을 수행합니다.
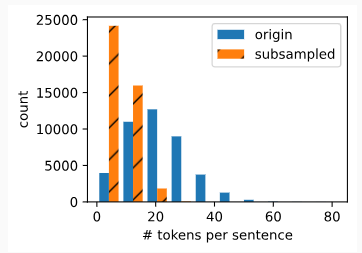
For individual tokens, the sampling rate of the high-frequency word “the” is less than 1/20.
개별 토큰의 경우 빈도가 높은 단어 “the”의 샘플링 비율은 1/20 미만입니다.
def compare_counts(token):
return (f'# of "{token}": '
f'before={sum([l.count(token) for l in sentences])}, '
f'after={sum([l.count(token) for l in subsampled])}')
compare_counts('the')
이 코드는 특정 단어의 빈도수를 비교하는 함수를 정의하고 호출하는 부분을 나타내고 있습니다.
- def compare_counts(token)::
- compare_counts 함수를 정의합니다. 이 함수는 특정 단어의 빈도수를 비교하여 문자열 형태로 반환합니다. 함수는 token이라는 인자를 받습니다.
- return (f'# of "{token}": ' ...):
- 함수의 반환값으로 사용될 문자열을 생성합니다.
- f'# of "{token}": '는 token의 이름을 포함하는 문자열을 나타냅니다.
- f'before={sum([l.count(token) for l in sentences])}, ':
- 원본 데이터 리스트 sentences에서 token의 빈도수를 계산하고 합산한 값을 나타냅니다. 이를 문자열로 생성합니다.
- f'after={sum([l.count(token) for l in subsampled])}':
- 서브샘플링된 데이터 리스트 subsampled에서 token의 빈도수를 계산하고 합산한 값을 나타냅니다. 이를 문자열로 생성합니다.
- compare_counts('the'):
- compare_counts 함수를 호출하여 'the'라는 단어의 빈도수를 비교한 결과를 얻습니다.
이 코드는 특정 단어의 원본 데이터와 서브샘플링된 데이터에서의 빈도수를 비교하는 함수를 호출하여 'the'라는 단어의 빈도수를 비교한 결과를 출력합니다.

In contrast, low-frequency words “join” are completely kept.
반면, 빈도가 낮은 단어인 "join"은 완전히 유지됩니다.
compare_counts('join')
After subsampling, we map tokens to their indices for the corpus.
서브샘플링 후 토큰을 코퍼스의 인덱스에 매핑합니다.
corpus = [vocab[line] for line in subsampled]
corpus[:3]
이 코드는 서브샘플링된 데이터 리스트를 단어 사전에 매핑하여 새로운 말뭉치(corpus)를 생성하고, 이를 확인하는 부분을 나타내고 있습니다.
- corpus = [vocab[line] for line in subsampled]:
- subsampled에 있는 각 문장(line)을 단어 사전(vocab)에 매핑하여 말뭉치(corpus)를 생성합니다. 각 문장의 단어들이 해당하는 단어 사전의 인덱스로 변환됩니다.
- corpus[:3]:
- 생성된 말뭉치 corpus에서 처음부터 3개의 원소를 슬라이싱하여 확인합니다. 이를 통해 새로운 말뭉치에서 처음 3개의 문장에 해당하는 단어 인덱스들을 확인할 수 있습니다.
이 코드는 서브샘플링된 데이터 리스트를 단어 사전에 매핑하여 말뭉치(corpus)를 생성하고, 그 말뭉치에서 처음 3개의 문장에 해당하는 단어 인덱스들을 확인하는 기능을 수행합니다.

15.3.3. Extracting Center Words and Context Words
The following get_centers_and_contexts function extracts all the center words and their context words from corpus. It uniformly samples an integer between 1 and max_window_size at random as the context window size. For any center word, those words whose distance from it does not exceed the sampled context window size are its context words.
다음 get_centers_and_contexts 함수는 말뭉치에서 모든 중심 단어와 해당 문맥 단어를 추출합니다. 1과 max_window_size 사이의 정수를 컨텍스트 창 크기로 무작위로 균일하게 샘플링합니다. 중심 단어의 경우, 그로부터의 거리가 샘플링된 컨텍스트 창 크기를 초과하지 않는 단어는 해당 단어입니다.
#@save
def get_centers_and_contexts(corpus, max_window_size):
"""Return center words and context words in skip-gram."""
centers, contexts = [], []
for line in corpus:
# To form a "center word--context word" pair, each sentence needs to
# have at least 2 words
if len(line) < 2:
continue
centers += line
for i in range(len(line)): # Context window centered at `i`
window_size = random.randint(1, max_window_size)
indices = list(range(max(0, i - window_size),
min(len(line), i + 1 + window_size)))
# Exclude the center word from the context words
indices.remove(i)
contexts.append([line[idx] for idx in indices])
return centers, contexts
이 코드는 스킵-그램(Skip-Gram) 모델에서 중심 단어와 문맥 단어를 반환하는 함수를 정의하고 있습니다.
- def get_centers_and_contexts(corpus, max_window_size)::
- get_centers_and_contexts 함수를 정의합니다. 이 함수는 말뭉치(corpus)와 최대 윈도우 크기(max_window_size)를 인자로 받습니다.
- if len(line) < 2::
- 현재 처리 중인 문장(line)의 길이가 2 미만이면 건너뜁니다. 스킵-그램 모델에서는 하나의 중심 단어와 그 주변 문맥 단어를 처리해야 하므로, 적어도 2개의 단어가 필요합니다.
- centers += line:
- 중심 단어 리스트에 현재 문장의 모든 단어를 추가합니다.
- for i in range(len(line))::
- 각 문장의 인덱스 i를 기준으로 문맥 창을 생성합니다.
- window_size = random.randint(1, max_window_size):
- 현재 중심 단어에 대한 윈도우 크기를 무작위로 선택합니다. 최대 윈도우 크기까지의 랜덤한 값으로 설정됩니다.
- indices = list(range(max(0, i - window_size), min(len(line), i + 1 + window_size))):
- 현재 문맥 창을 위한 인덱스 범위를 생성합니다. 중심 단어의 좌우로 window_size 범위 내의 인덱스를 선택합니다.
- indices.remove(i):
- 중심 단어의 인덱스 i를 문맥 단어 리스트에서 제거합니다. 중심 단어와 문맥 단어는 동일하면 안 되기 때문입니다.
- contexts.append([line[idx] for idx in indices]):
- 문맥 단어 리스트에 현재 문맥 창의 단어들을 추가합니다. 이 때 중심 단어를 제외한 인덱스들에 해당하는 단어들이 포함됩니다.
- return centers, contexts:
- 중심 단어 리스트와 문맥 단어 리스트를 반환합니다.
이 코드는 스킵-그램 모델을 위한 중심 단어와 문맥 단어를 생성하는 함수를 구현하고 있습니다.
Next, we create an artificial dataset containing two sentences of 7 and 3 words, respectively. Let the maximum context window size be 2 and print all the center words and their context words.
다음으로, 각각 7개 단어와 3개 단어로 구성된 두 문장을 포함하는 인공 데이터 세트를 만듭니다. 최대 컨텍스트 창 크기를 2로 설정하고 모든 중앙 단어와 해당 컨텍스트 단어를 인쇄합니다.
tiny_dataset = [list(range(7)), list(range(7, 10))]
print('dataset', tiny_dataset)
for center, context in zip(*get_centers_and_contexts(tiny_dataset, 2)):
print('center', center, 'has contexts', context)이 코드는 작은 데이터셋을 생성하고, 해당 데이터셋에서 중심 단어와 문맥 단어를 얻어 출력하는 부분을 보여주고 있습니다.
- tiny_dataset = [list(range(7)), list(range(7, 10))]:
- 작은 데이터셋 tiny_dataset을 생성합니다. 첫 번째 리스트는 0부터 6까지의 숫자를 포함하고, 두 번째 리스트는 7부터 9까지의 숫자를 포함합니다.
- print('dataset', tiny_dataset):
- 생성한 작은 데이터셋 tiny_dataset을 출력합니다.
- for center, context in zip(*get_centers_and_contexts(tiny_dataset, 2))::
- get_centers_and_contexts 함수를 호출하여 중심 단어와 문맥 단어를 얻습니다. 이때 윈도우 크기는 최대 2로 설정합니다.
- zip(*...)를 사용하여 중심 단어와 문맥 단어를 반복문에서 동시에 순회합니다. 각 반복에서 center는 중심 단어, context는 해당 중심 단어의 문맥 단어들을 나타냅니다.
- print('center', center, 'has contexts', context):
- 현재 중심 단어와 해당 중심 단어의 문맥 단어들을 출력합니다.
이 코드는 작은 데이터셋에서 생성된 중심 단어와 문맥 단어를 출력하는 기능을 수행합니다.

When training on the PTB dataset, we set the maximum context window size to 5. The following extracts all the center words and their context words in the dataset.
PTB 데이터 세트를 훈련할 때 최대 컨텍스트 창 크기를 5로 설정했습니다. 다음은 데이터 세트의 모든 중심 단어와 해당 컨텍스트 단어를 추출합니다.
all_centers, all_contexts = get_centers_and_contexts(corpus, 5)
f'# center-context pairs: {sum([len(contexts) for contexts in all_contexts])}'이 코드는 모든 중심 단어와 해당 중심 단어의 문맥 단어들을 생성하고, 생성된 중심-문맥 쌍의 총 개수를 출력하는 부분을 보여주고 있습니다.
- all_centers, all_contexts = get_centers_and_contexts(corpus, 5):
- get_centers_and_contexts 함수를 호출하여 모든 중심 단어와 그에 해당하는 문맥 단어들을 생성합니다. 이때 윈도우 크기는 최대 5로 설정합니다.
- all_centers에는 중심 단어 리스트가 저장되고, all_contexts에는 문맥 단어 리스트들의 리스트가 저장됩니다.
- f'# center-context pairs: {sum([len(contexts) for contexts in all_contexts])}':
- 생성된 중심-문맥 쌍의 총 개수를 문자열 형태로 출력합니다.
- sum([len(contexts) for contexts in all_contexts])는 all_contexts에 저장된 각 문맥 단어 리스트의 길이를 모두 합하여 총 중심-문맥 쌍의 개수를 계산합니다.
이 코드는 모든 중심 단어와 그에 해당하는 문맥 단어들을 생성하고, 생성된 중심-문맥 쌍의 총 개수를 출력하는 기능을 수행합니다.

15.3.4. Negative Sampling
We use negative sampling for approximate training. To sample noise words according to a predefined distribution, we define the following RandomGenerator class, where the (possibly unnormalized) sampling distribution is passed via the argument sampling_weights.
우리는 대략적인 훈련을 위해 음성 샘플링을 사용합니다. 사전 정의된 분포에 따라 노이즈 단어를 샘플링하기 위해 다음 RandomGenerator 클래스를 정의합니다. 여기서 (정규화되지 않은) 샘플링 분포는 sampling_weights 인수를 통해 전달됩니다.
#@save
class RandomGenerator:
"""Randomly draw among {1, ..., n} according to n sampling weights."""
def __init__(self, sampling_weights):
# Exclude
self.population = list(range(1, len(sampling_weights) + 1))
self.sampling_weights = sampling_weights
self.candidates = []
self.i = 0
def draw(self):
if self.i == len(self.candidates):
# Cache `k` random sampling results
self.candidates = random.choices(
self.population, self.sampling_weights, k=10000)
self.i = 0
self.i += 1
return self.candidates[self.i - 1]이 코드는 n개의 샘플링 가중치에 따라 {1, ..., n} 중에서 무작위로 추출하는 클래스를 정의하고 있습니다.
- class RandomGenerator::
- RandomGenerator 클래스를 정의합니다. 이 클래스는 n개의 샘플링 가중치에 따라 무작위로 추출하는 기능을 제공합니다.
- def __init__(self, sampling_weights)::
- RandomGenerator 클래스의 초기화 메서드입니다. 샘플링 가중치를 인자로 받습니다.
- self.population은 1부터 샘플링 가중치 개수까지의 정수 리스트입니다.
- self.sampling_weights는 입력받은 샘플링 가중치를 저장합니다.
- self.candidates는 추출한 후보 값들을 저장하는 리스트입니다.
- self.i는 추출된 후보 값들 중 현재 사용 중인 값을 나타냅니다.
- def draw(self)::
- 추출 결과를 반환하는 메서드입니다.
- self.i가 self.candidates의 길이와 같다면, 새로운 무작위 샘플링 결과를 10000번 추출하여 self.candidates에 저장합니다.
- self.i를 1 증가시키고, self.candidates[self.i - 1] 값을 반환합니다.
이 코드는 샘플링 가중치에 따라 무작위로 값을 추출하는 RandomGenerator 클래스를 정의하고 있습니다.
For example, we can draw 10 random variables X among indices 1, 2, and 3 with sampling probabilities P(X=1)=2/9,P(X=2)=3/9, and P(X=3)=4/9 as follows.
예를 들어, 샘플링 확률 P(X=1)=2/9,P(X=2)=3/9, 그리고 P(X=3)=4/9 을 사용하여 인덱스 1, 2, 3 중에서 10개의 확률 변수 X를 추출할 수 있습니다
generator = RandomGenerator([2, 3, 4])
[generator.draw() for _ in range(10)]
이 코드는 샘플링 가중치를 사용하여 무작위로 값을 추출하는 RandomGenerator 객체를 생성하고, 해당 객체를 이용해 값을 10번 추출하는 부분을 보여주고 있습니다.
- generator = RandomGenerator([2, 3, 4]):
- RandomGenerator 클래스의 인스턴스인 generator를 생성합니다. 샘플링 가중치로 [2, 3, 4]를 사용합니다. 이 가중치에 따라 1, 2, 3이 선택될 확률이 각각 1/2, 1/3, 1/4가 됩니다.
- [generator.draw() for _ in range(10)]:
- generator에서 draw 메서드를 호출하여 값을 10번 추출합니다. 추출된 값들은 리스트에 저장됩니다.
- _는 반복문에서 사용하지 않는 값에 대한 관용적인 표현입니다. 따라서 10번 반복되지만 추출된 값들은 사용되지 않습니다.
이 코드는 샘플링 가중치에 따라 RandomGenerator 객체에서 값을 10번 추출하고, 추출된 값을 리스트로 저장하는 기능을 수행합니다

For a pair of center word and context word, we randomly sample K (5 in the experiment) noise words. According to the suggestions in the word2vec paper, the sampling probability P(w) of a noise word w is set to its relative frequency in the dictionary raised to the power of 0.75 (Mikolov et al., 2013).
중심 단어와 문맥 단어 쌍에 대해 K개(실험에서는 5개)의 노이즈 단어를 무작위로 샘플링합니다. word2vec 논문의 제안에 따르면, 의미 없는 단어 w의 샘플링 확률 P(w)는 사전의 상대 빈도로 0.75승으로 설정됩니다(Mikolov et al., 2013).
#@save
def get_negatives(all_contexts, vocab, counter, K):
"""Return noise words in negative sampling."""
# Sampling weights for words with indices 1, 2, ... (index 0 is the
# excluded unknown token) in the vocabulary
sampling_weights = [counter[vocab.to_tokens(i)]**0.75
for i in range(1, len(vocab))]
all_negatives, generator = [], RandomGenerator(sampling_weights)
for contexts in all_contexts:
negatives = []
while len(negatives) < len(contexts) * K:
neg = generator.draw()
# Noise words cannot be context words
if neg not in contexts:
negatives.append(neg)
all_negatives.append(negatives)
return all_negatives
all_negatives = get_negatives(all_contexts, vocab, counter, 5)
이 코드는 부정적 샘플링에 사용할 노이즈 단어를 생성하는 함수를 정의하고 있습니다.
- def get_negatives(all_contexts, vocab, counter, K)::
- get_negatives 함수를 정의합니다. 이 함수는 부정적 샘플링에 사용할 노이즈 단어를 반환합니다. 인자로 문맥 단어들의 리스트(all_contexts), 단어 사전(vocab), 빈도수 카운터(counter), 부정적 샘플링의 개수(K)를 받습니다.
- sampling_weights = [counter[vocab.to_tokens(i)]**0.75 ...]:
- 단어 사전의 각 단어에 대한 샘플링 가중치를 계산합니다. 가중치는 해당 단어의 빈도수를 0.75 제곱한 값으로 계산됩니다.
- all_negatives, generator = [], RandomGenerator(sampling_weights):
- 부정적 샘플링에 사용할 노이즈 단어들을 저장할 리스트인 all_negatives를 생성하고, 랜덤 값을 생성하는 RandomGenerator 객체를 생성합니다. 이 객체는 위에서 계산한 샘플링 가중치를 기반으로 값을 무작위로 추출합니다.
- for contexts in all_contexts::
- 모든 문맥 단어 리스트에 대해 반복합니다.
- negatives = []:
- 현재 문맥 단어들에 대한 노이즈 단어들을 저장할 리스트인 negatives를 초기화합니다.
- while len(negatives) < len(contexts) * K::
- 노이즈 단어의 개수가 문맥 단어 개수 * K보다 작을 때까지 반복합니다.
- neg = generator.draw():
- 랜덤 생성기에서 값을 추출하여 neg에 저장합니다.
- if neg not in contexts::
- 추출한 노이즈 단어 neg가 현재 문맥 단어들에 속하지 않으면 다음을 수행합니다.
- negatives.append(neg):
- 현재 노이즈 단어를 negatives 리스트에 추가합니다.
- all_negatives.append(negatives):
- 모든 노이즈 단어 리스트를 all_negatives 리스트에 추가합니다.
- return all_negatives:
- 모든 노이즈 단어 리스트를 반환합니다.
- all_negatives = get_negatives(all_contexts, vocab, counter, 5):
- get_negatives 함수를 호출하여 모든 문맥 단어들에 대한 노이즈 단어 리스트를 생성합니다. 부정적 샘플링 개수는 5로 설정됩니다.
이 코드는 부정적 샘플링에 사용할 노이즈 단어를 생성하는 함수를 구현하고 있습니다.
15.3.5. Loading Training Examples in Minibatches
After all the center words together with their context words and sampled noise words are extracted, they will be transformed into minibatches of examples that can be iteratively loaded during training.
모든 중심 단어와 해당 문맥 단어 및 샘플링된 의미 없는 단어가 추출된 후에는 훈련 중에 반복적으로 로드할 수 있는 예제의 미니 배치로 변환됩니다.
In a minibatch, the ith example includes a center word and its ni context words and mi noise words. Due to varying context window sizes, ni+mi varies for different i. Thus, for each example we concatenate its context words and noise words in the contexts_negatives variable, and pad zeros until the concatenation length reaches maxini+mi (max_len). To exclude paddings in the calculation of the loss, we define a mask variable masks. There is a one-to-one correspondence between elements in masks and elements in contexts_negatives, where zeros (otherwise ones) in masks correspond to paddings in contexts_negatives.
미니배치에서 i번째 예제에는 중심 단어와 해당 단어의 ni 문맥 단어 및 mi 노이즈 단어가 포함됩니다. 다양한 컨텍스트 창 크기로 인해 ni+mi는 i에 따라 다릅니다. 따라서 각 예에 대해 contexts_negatives 변수에서 해당 컨텍스트 단어와 노이즈 단어를 연결하고 연결 길이가 maxini+mi(max_len)에 도달할 때까지 0을 채웁니다. 손실 계산에서 패딩을 제외하기 위해 마스크 변수 마스크를 정의합니다. 마스크의 요소와 contexts_negatives의 요소 사이에는 일대일 대응이 있습니다. 여기서 마스크의 0(그렇지 않은 경우 1)은 contexts_negatives의 패딩에 해당합니다.
To distinguish between positive and negative examples, we separate context words from noise words in contexts_negatives via a labels variable. Similar to masks, there is also a one-to-one correspondence between elements in labels and elements in contexts_negatives, where ones (otherwise zeros) in labels correspond to context words (positive examples) in contexts_negatives.
긍정적인 예와 부정적인 예를 구별하기 위해 labels 변수를 통해 contexts_negatives의 의미 없는 단어와 컨텍스트 단어를 분리합니다. 마스크와 마찬가지로 레이블의 요소와 contexts_negatives의 요소 사이에는 일대일 대응도 있습니다. 여기서 레이블의 1(그렇지 않으면 0)은 contexts_negatives의 문맥 단어(긍정적 예)에 해당합니다.
The above idea is implemented in the following batchify function. Its input data is a list with length equal to the batch size, where each element is an example consisting of the center word center, its context words context, and its noise words negative. This function returns a minibatch that can be loaded for calculations during training, such as including the mask variable.
위의 아이디어는 다음 배치화 기능으로 구현됩니다. 입력 데이터는 배치 크기와 길이가 같은 목록입니다. 여기서 각 요소는 중심 단어 center, 문맥 단어 context 및 노이즈 단어 negative로 구성된 예입니다. 이 함수는 훈련 중에 마스크 변수를 포함하는 등의 계산을 위해 로드할 수 있는 미니배치를 반환합니다.
#@save
def batchify(data):
"""Return a minibatch of examples for skip-gram with negative sampling."""
max_len = max(len(c) + len(n) for _, c, n in data)
centers, contexts_negatives, masks, labels = [], [], [], []
for center, context, negative in data:
cur_len = len(context) + len(negative)
centers += [center]
contexts_negatives += [context + negative + [0] * (max_len - cur_len)]
masks += [[1] * cur_len + [0] * (max_len - cur_len)]
labels += [[1] * len(context) + [0] * (max_len - len(context))]
return (torch.tensor(centers).reshape((-1, 1)), torch.tensor(
contexts_negatives), torch.tensor(masks), torch.tensor(labels))이 코드는 부정적 샘플링을 이용한 스킵-그램 모델을 위한 미니배치 데이터를 생성하는 함수를 정의하고 있습니다.
- def batchify(data)::
- batchify 함수를 정의합니다. 이 함수는 부정적 샘플링을 이용한 스킵-그램 모델을 위한 미니배치 데이터를 생성합니다. 인자로 데이터(data)를 받습니다.
- max_len = max(len(c) + len(n) for _, c, n in data):
- 모든 데이터에서 중심 단어, 문맥 단어, 부정적 단어를 합친 길이의 최댓값(max_len)을 계산합니다.
- centers, contexts_negatives, masks, labels = [], [], [], []:
- 중심 단어, 문맥 및 부정적 단어 조합, 마스크, 레이블을 저장할 리스트들을 초기화합니다.
- for center, context, negative in data::
- 모든 데이터에 대해 반복합니다.
- cur_len = len(context) + len(negative):
- 현재 문맥 단어와 부정적 단어 조합의 길이(cur_len)를 계산합니다.
- centers += [center], contexts_negatives += [context + negative + [0] * (max_len - cur_len)], masks += [[1] * cur_len + [0] * (max_len - cur_len)], labels += [[1] * len(context) + [0] * (max_len - len(context))]:
- 중심 단어, 문맥 및 부정적 단어 조합, 마스크, 레이블을 각각 해당 리스트에 추가합니다.
- 추가할 때에는 길이를 맞추기 위해 부족한 부분은 0으로 채워 넣습니다.
- return (torch.tensor(centers).reshape((-1, 1)), torch.tensor(contexts_negatives), torch.tensor(masks), torch.tensor(labels)):
- 생성된 데이터를 PyTorch 텐서로 변환하여 반환합니다. 중심 단어 텐서는 형태를 변환하여 열 벡터로 만듭니다. 이 때 중심 단어, 문맥 및 부정적 단어 조합, 마스크, 레이블이 순서대로 반환됩니다.
이 코드는 부정적 샘플링을 이용한 스킵-그램 모델을 위한 미니배치 데이터를 생성하는 함수를 구현하고 있습니다.
Let’s test this function using a minibatch of two examples.
두 가지 예제의 미니 배치를 사용하여 이 기능을 테스트해 보겠습니다.
x_1 = (1, [2, 2], [3, 3, 3, 3])
x_2 = (1, [2, 2, 2], [3, 3])
batch = batchify((x_1, x_2))
names = ['centers', 'contexts_negatives', 'masks', 'labels']
for name, data in zip(names, batch):
print(name, '=', data)이 코드는 두 개의 예시 데이터 (x_1, x_2)를 이용하여 스킵-그램 모델을 위한 미니배치 데이터를 생성하고, 생성된 데이터의 각 요소를 출력하는 부분을 보여주고 있습니다.
- x_1 = (1, [2, 2], [3, 3, 3, 3]), x_2 = (1, [2, 2, 2], [3, 3]):
- x_1과 x_2는 각각 중심 단어, 문맥 단어, 부정적 단어들을 튜플 형태로 저장한 예시 데이터입니다.
- batch = batchify((x_1, x_2)):
- (x_1, x_2)를 인자로하여 batchify 함수를 호출하여 미니배치 데이터를 생성합니다. 이 데이터는 batch에 저장됩니다.
- names = ['centers', 'contexts_negatives', 'masks', 'labels']:
- 생성된 미니배치 데이터의 각 요소에 대한 이름을 나타내는 리스트 names을 생성합니다.
- for name, data in zip(names, batch)::
- names 리스트와 batch의 데이터를 동시에 순회하면서 반복합니다.
- print(name, '=', data):
- 각 요소의 이름과 해당 데이터를 출력합니다.
이 코드는 스킵-그램 모델을 위한 미니배치 데이터 생성 및 출력 과정을 보여주고 있습니다.

15.3.6. Putting It All Together
Last, we define the load_data_ptb function that reads the PTB dataset and returns the data iterator and the vocabulary.
마지막으로 PTB 데이터 세트를 읽고 데이터 반복자와 어휘를 반환하는 load_data_ptb 함수를 정의합니다.
#@save
def load_data_ptb(batch_size, max_window_size, num_noise_words):
"""Download the PTB dataset and then load it into memory."""
num_workers = d2l.get_dataloader_workers()
sentences = read_ptb()
vocab = d2l.Vocab(sentences, min_freq=10)
subsampled, counter = subsample(sentences, vocab)
corpus = [vocab[line] for line in subsampled]
all_centers, all_contexts = get_centers_and_contexts(
corpus, max_window_size)
all_negatives = get_negatives(
all_contexts, vocab, counter, num_noise_words)
class PTBDataset(torch.utils.data.Dataset):
def __init__(self, centers, contexts, negatives):
assert len(centers) == len(contexts) == len(negatives)
self.centers = centers
self.contexts = contexts
self.negatives = negatives
def __getitem__(self, index):
return (self.centers[index], self.contexts[index],
self.negatives[index])
def __len__(self):
return len(self.centers)
dataset = PTBDataset(all_centers, all_contexts, all_negatives)
data_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=True,
collate_fn=batchify,
num_workers=num_workers)
return data_iter, vocab이 코드는 PTB 데이터셋을 다운로드하고 메모리로 로드하여 스킵-그램 모델을 위한 학습 데이터를 생성하는 함수를 정의하고 있습니다.
- num_workers = d2l.get_dataloader_workers():
- 데이터 로더의 워커 수를 설정합니다. 병렬 처리를 위한 워커 수입니다.
- sentences = read_ptb():
- PTB 데이터셋을 읽어와 문장들의 리스트로 저장합니다.
- vocab = d2l.Vocab(sentences, min_freq=10):
- 문장 리스트를 바탕으로 단어 사전을 생성합니다. 최소 빈도수가 10인 단어들만 단어 사전에 포함됩니다.
- subsampled, counter = subsample(sentences, vocab):
- 문장 리스트를 서브샘플링하여 새로운 문장 리스트와 빈도수 카운터를 생성합니다.
- corpus = [vocab[line] for line in subsampled]:
- 서브샘플링된 문장 리스트를 단어 사전의 인덱스로 변환하여 말뭉치(corpus)를 생성합니다.
- all_centers, all_contexts = get_centers_and_contexts(corpus, max_window_size):
- 말뭉치를 바탕으로 중심 단어와 문맥 단어를 생성합니다. 최대 윈도우 크기는 max_window_size로 설정됩니다.
- all_negatives = get_negatives(all_contexts, vocab, counter, num_noise_words):
- 문맥 단어를 기반으로 부정적 샘플링을 통해 노이즈 단어들을 생성합니다. 부정적 샘플링의 개수는 num_noise_words로 설정됩니다.
- class PTBDataset(torch.utils.data.Dataset)::
- PyTorch의 데이터셋 클래스를 상속하여 PTB 데이터셋을 위한 사용자 정의 데이터셋 클래스인 PTBDataset을 정의합니다.
- def __init__(self, centers, contexts, negatives)::
- PTBDataset 클래스의 초기화 메서드입니다. 중심 단어, 문맥 단어, 부정적 단어들을 인자로 받습니다.
- def __getitem__(self, index)::
- 해당 인덱스의 중심 단어, 문맥 단어, 부정적 단어들을 반환합니다.
- def __len__(self)::
- 데이터셋의 총 데이터 수를 반환합니다.
- dataset = PTBDataset(all_centers, all_contexts, all_negatives):
- PTBDataset 클래스의 인스턴스인 데이터셋 객체 dataset을 생성합니다.
- data_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=True, collate_fn=batchify, num_workers=num_workers):
- 생성한 데이터셋을 이용하여 데이터 로더를 생성합니다. 미니배치 크기는 batch_size로 설정되며, 데이터를 섞어서 가져오고, batchify 함수를 이용하여 미니배치 데이터를 처리합니다.
- return data_iter, vocab:
- 생성한 데이터 로더와 단어 사전을 반환합니다.
이 코드는 PTB 데이터셋을 다운로드하고 메모리로 로드하여 스킵-그램 모델을 위한 학습 데이터를 생성하는 함수를 구현하고 있습니다.
Let’s print the first minibatch of the data iterator.
데이터 반복자의 첫 번째 미니 배치를 인쇄해 보겠습니다.
data_iter, vocab = load_data_ptb(512, 5, 5)
for batch in data_iter:
for name, data in zip(names, batch):
print(name, 'shape:', data.shape)
break이 코드는 PTB 데이터셋을 미니배치 형태로 로드하여 미니배치 데이터의 형태(shape)를 출력하는 과정을 보여주고 있습니다.
- data_iter, vocab = load_data_ptb(512, 5, 5):
- load_data_ptb 함수를 호출하여 PTB 데이터셋을 미니배치 형태로 로드합니다. 미니배치 크기는 512, 최대 윈도우 크기는 5, 부정적 샘플링 개수는 5로 설정됩니다. 반환되는 data_iter는 데이터 로더, vocab은 단어 사전을 나타냅니다.
- for batch in data_iter::
- 데이터 로더를 통해 미니배치를 순회합니다.
- for name, data in zip(names, batch)::
- names 리스트와 현재 미니배치(batch)의 데이터를 동시에 순회하면서 반복합니다.
- print(name, 'shape:', data.shape):
- 각 데이터의 이름과 형태(shape)를 출력합니다.
- break:
- 첫 번째 미니배치만 확인하기 위해 break를 사용하여 반복을 종료합니다.
이 코드는 PTB 데이터셋을 미니배치 형태로 로드하여 미니배치 데이터의 형태(shape)를 출력하는 과정을 보여주고 있습니다.

15.3.7. Summary
- High-frequency words may not be so useful in training. We can subsample them for speedup in training.
- 빈도가 높은 단어는 훈련에 그다지 유용하지 않을 수 있습니다. 훈련 속도를 높이기 위해 서브샘플링을 할 수 있습니다.
- For computational efficiency, we load examples in minibatches. We can define other variables to distinguish paddings from non-paddings, and positive examples from negative ones.
- 계산 효율성을 위해 예제를 미니배치로 로드합니다. 패딩과 비패딩을 구별하고 긍정적인 예와 부정적인 예를 구별하기 위해 다른 변수를 정의할 수 있습니다.
15.3.8. Exercises¶
- How does the running time of code in this section changes if not using subsampling?
- The RandomGenerator class caches k random sampling results. Set k to other values and see how it affects the data loading speed.
- What other hyperparameters in the code of this section may affect the data loading speed?
'Dive into Deep Learning > D2L Natural language Processing' 카테고리의 다른 글
| D2L - 15.10. Pretraining BERT (0) | 2023.08.30 |
|---|---|
| D2L - 15.9. The Dataset for Pretraining BERT (0) | 2023.08.30 |
| D2L - 15.8. Bidirectional Encoder Representations from Transformers (BERT) (0) | 2023.08.30 |
| D2L - 15.7. Word Similarity and Analogy (0) | 2023.08.30 |
| D2L - 15.6. Subword Embedding (0) | 2023.08.30 |
| D2L - 15.5. Word Embedding with Global Vectors (GloVe) (0) | 2023.08.29 |
| D2L - 15.4. Pretraining word2vec (0) | 2023.08.29 |
| D2L- 15.2. Approximate Training (1) | 2023.08.28 |
| D2L- 15.1. Word Embedding (word2vec) (0) | 2023.08.25 |
| D2L - 15. Natural Language Processing: Pretraining (0) | 2023.08.24 |