

15.1. Word Embedding (word2vec) — Dive into Deep Learning 1.0.3 documentation (d2l.ai)
15.1. Word Embedding (word2vec) — Dive into Deep Learning 1.0.3 documentation
d2l.ai
15.1. Word Embedding (word2vec)
Natural language is a complex system used to express meanings. In this system, words are the basic unit of the meaning. As the name implies, word vectors are vectors used to represent words, and can also be considered as feature vectors or representations of words. The technique of mapping words to real vectors is called word embedding. In recent years, word embedding has gradually become the basic knowledge of natural language processing.
자연어는 의미를 표현하는 데 사용되는 복잡한 시스템입니다. 이 시스템에서 단어는 의미의 기본 단위입니다. 이름에서 알 수 있듯이 단어 벡터는 단어를 나타내는 데 사용되는 벡터이며, 특징 벡터 또는 단어 표현으로도 간주될 수 있습니다. 단어를 실제 벡터에 매핑하는 기술을 단어 임베딩이라고 합니다. 최근 몇 년 동안 워드 임베딩은 점차 자연어 처리의 기본 지식이 되었습니다.
15.1.1. One-Hot Vectors Are a Bad Choice
We used one-hot vectors to represent words (characters are words) in Section 9.5. Suppose that the number of different words in the dictionary (the dictionary size) is N, and each word corresponds to a different integer (index) from 0 to N−1. To obtain the one-hot vector representation for any word with index i, we create a length-N vector with all 0s and set the element at position i to 1. In this way, each word is represented as a vector of length N, and it can be used directly by neural networks.
우리는 섹션 9.5에서 단어(문자는 단어)를 표현하기 위해 원-핫 벡터를 사용했습니다. 사전 dictionary 에 있는 서로 다른 단어의 수(사전 크기)가 N이고, 각 단어는 0부터 N-1까지의 서로 다른 정수(인덱스)에 해당한다고 가정합니다. 인덱스 i가 있는 단어에 대한 원-핫 벡터 표현을 얻으려면 모두 0인 길이 N 벡터를 만들고 위치 i의 요소를 1로 설정합니다. 이러한 방식으로 각 단어는 길이 N의 벡터로 표현됩니다. 신경망에서 직접 사용할 수 있습니다.
Although one-hot word vectors are easy to construct, they are usually not a good choice. A main reason is that one-hot word vectors cannot accurately express the similarity between different words, such as the cosine similarity that we often use. For vectors x,y∈ℝ**d, their cosine similarity is the cosine of the angle between them:
원-핫 단어 벡터는 구성하기 쉽지만 일반적으로 좋은 선택은 아닙니다. 주된 이유는 원-핫 단어 벡터가 우리가 자주 사용하는 코사인 유사성 cosine similarity과 같은 서로 다른 단어 간의 유사성을 정확하게 표현할 수 없기 때문입니다. 벡터 x,y∈ℝ**d의 경우 코사인 유사성 cosine similarity은 두 벡터 사이 각도의 코사인입니다.

Since the cosine similarity between one-hot vectors of any two different words is 0, one-hot vectors cannot encode similarities among words.
서로 다른 두 단어의 원-핫 벡터 간의 코사인 유사성은 0이므로 원-핫 벡터는 단어 간의 유사성을 인코딩할 수 없습니다.
코사인이란?
Cosine is a mathematical term that's used to measure the similarity between two things, like directions or vectors. Imagine you have two arrows pointing in certain directions. The cosine similarity tells you how much these arrows are aligned with each other.
코사인은 두 가지 사물, 예를 들어 방향이나 벡터 사이의 유사성을 측정하는 수학 용어입니다. 특정 방향을 가리키는 두 개의 화살표를 생각해보세요. 코사인 유사성은 이러한 화살표가 얼마나 정렬되어 있는지를 알려줍니다.
When the arrows are pointing in the exact same direction, the cosine similarity is 1. This means they are very similar. If they are perpendicular (90 degrees apart), the cosine similarity is 0, indicating they are not similar at all. And if they point in opposite directions, the cosine similarity is -1, showing that they are kind of opposite.
화살표가 정확히 같은 방향을 가리킬 때, 코사인 유사성은 1입니다. 이는 그들이 매우 유사하다는 것을 의미합니다. 만약 그들이 수직이라면 (90도 떨어져 있다면), 코사인 유사성은 0이 되어서 전혀 유사하지 않음을 나타냅니다. 그리고 만약 그들이 반대 방향을 가리키면, 코사인 유사성은 -1이 되어서 그들이 어느 정도 반대라는 것을 나타냅니다.
In simpler terms, cosine similarity helps us figure out how much two things are pointing in the same direction, like arrows or vectors. It's a way to measure how similar or different these things are based on their direction.
보다 간단한 용어로 설명하면, 코사인 유사성은 화살표나 벡터와 같이 두 가지 사물이 같은 방향을 가리키는지 얼마나 많이 가리키는지를 알려줍니다. 이것은 방향을 기반으로 이러한 사물이 얼마나 비슷하거나 다른지를 측정하는 방법입니다.
Word Embedding에서 Cosine Similarity란?
In Word Embedding within Natural Language Processing (NLP), "cosine similarity" is a measure used to quantify the similarity between two word vectors. Word embeddings are numerical representations of words in a continuous vector space. Cosine similarity is employed to assess how alike these word vectors are in terms of their direction within this space.
자연어 처리(NLP)의 단어 임베딩에서 '코사인 유사성'은 두 단어 벡터 사이의 유사성을 측정하는 데 사용되는 척도입니다. 단어 임베딩은 연속 벡터 공간에서 단어의 수치적 표현입니다. 코사인 유사성은 이 공간 내에서 이러한 단어 벡터가 방향 측면에서 얼마나 비슷한지를 평가하기 위해 사용됩니다.
Here's how it works:
작동 방식은 다음과 같습니다:
- Each word is represented as a vector in a high-dimensional space. Words with similar meanings or contexts tend to have similar vectors.
각 단어는 고차원 공간에서 벡터로 표현됩니다. 비슷한 의미나 문맥을 가진 단어는 유사한 벡터를 가집니다. - To measure the similarity between two word vectors, cosine similarity calculates the cosine of the angle between them. This angle indicates how aligned the vectors are in this high-dimensional space.
두 단어 벡터 사이의 유사성을 측정하기 위해 코사인 유사성은 그들 사이의 각도의 코사인을 계산합니다. 이 각도는 이 고차원 공간에서 벡터들이 얼마나 정렬되어 있는지를 나타냅니다. - If the angle between the vectors is very small (close to 0 degrees), the cosine of that angle is close to 1, indicating high similarity. This means the words are similar in meaning or context.
벡터 사이의 각이 매우 작은 경우(0도에 가까운 경우), 그 각의 코사인은 1에 가까워져 높은 유사성을 나타냅니다. 이는 단어들이 의미나 문맥에서 유사하다는 것을 의미합니다. - If the angle is close to 90 degrees (perpendicular vectors), the cosine of the angle is close to 0, implying low similarity. The words are dissimilar in meaning or context.
각이 90도에 가까운 경우(수직 벡터), 각의 코사인은 0에 가까워져 낮은 유사성을 나타냅니다. 단어들은 의미나 문맥에서 다르다는 것을 의미합니다. - If the angle is close to 180 degrees (opposite directions), the cosine of the angle is close to -1. This means the words have opposite meanings or contexts.
각이 180도에 가까운 경우(반대 방향), 각의 코사인은 -1에 가까워집니다. 이는 단어들이 반대의 의미나 문맥을 가진다는 것을 의미합니다.
In NLP tasks, cosine similarity is used to compare word embeddings and identify words that are contextually or semantically similar. It helps in various applications such as finding synonyms, clustering similar words, and even understanding the relationships between words in the embedding space.
NLP 작업에서 코사인 유사성은 단어 임베딩을 비교하고 문맥적으로나 의미론적으로 유사한 단어를 식별하는 데 사용됩니다. 이는 동의어를 찾거나 유사한 단어를 클러스터링하고, 심지어 임베딩 공간에서 단어 간의 관계를 이해하는 데에도 도움이 됩니다.

15.1.2. Self-Supervised word2vec
The word2vec tool was proposed to address the above issue. It maps each word to a fixed-length vector, and these vectors can better express the similarity and analogy relationship among different words. The word2vec tool contains two models, namely skip-gram (Mikolov et al., 2013) and continuous bag of words (CBOW) (Mikolov et al., 2013). For semantically meaningful representations, their training relies on conditional probabilities that can be viewed as predicting some words using some of their surrounding words in corpora. Since supervision comes from the data without labels, both skip-gram and continuous bag of words are self-supervised models.
위의 문제를 해결하기 위해 word2vec 도구가 제안되었습니다. 각 단어를 고정 길이 벡터에 매핑하며, 이러한 벡터는 서로 다른 단어 간의 유사성과 유추 관계를 더 잘 표현할 수 있습니다. word2vec 도구에는 Skip-gram(Mikolov et al., 2013)과 Continuous Bag of Words(CBOW)(Mikolov et al., 2013)라는 두 가지 모델이 포함되어 있습니다. 의미상 의미 있는 표현 semantically meaningful representations 의 경우 훈련은 말뭉치의 주변 단어 중 일부를 사용하여 일부 단어를 예측하는 것으로 볼 수 있는 조건부 확률에 의존합니다. 감독 supervision 은 레이블이 없는 데이터에서 발생하므로 스킵 그램 Skip-gram 과 연속 단어 모음 Continuous Bag of Words은 모두 자체 감독 모델 self-supervised models입니다.
word2vek 이란?
Word2Vec is a popular technique in natural language processing (NLP) that is used to generate dense vector representations (embeddings) of words. These embeddings capture semantic relationships between words and enable machines to understand the meanings and contexts of words based on their positions in the vector space.
Word2Vec은 자연어 처리(NLP)에서 널리 사용되는 기술로, 단어의 밀집 벡터 표현(임베딩)을 생성하는 데에 활용됩니다. 이러한 임베딩은 단어 간의 의미적 관계를 포착하며, 단어들의 벡터 공간 내 위치에 기반하여 기계가 단어의 의미와 문맥을 이해할 수 있도록 합니다.
The term "word2vec" refers to a family of models that are trained to learn these word embeddings from large amounts of text data. There are two main architectures within the word2vec framework:
"word2vec"이라는 용어는 대용량 텍스트 데이터로부터 이러한 단어 임베딩을 학습하는 모델 패밀리를 가리킵니다. word2vec 프레임워크 내에서 두 가지 주요 아키텍처가 있습니다:
- Skip-Gram: This architecture aims to predict context words (words nearby in a sentence) given a target word. It essentially "skips" over words to predict their context. Skip-Gram is effective for larger datasets and capturing word relationships.
Skip-Gram: 이 아키텍처는 목표 단어를 기반으로 문맥 단어(문장에서 가까운 위치에 있는 단어)를 예측하는 것을 목표로 합니다. 이는 실제로 그들의 contect를 예측하기 위해 단어를 "skips" 합니. Skip-Gram은 대규모 데이터셋과 단어 간의 관계를 잡아내는 데에 효과적입니다. - Continuous Bag of Words (CBOW): This architecture predicts a target word based on its surrounding context words. It aims to predict a "bag" of context words given the target word. CBOW is computationally efficient and works well for smaller datasets.
연속 단어 봉투 (CBOW): 이 아키텍처는 주변 문맥 단어를 기반으로 목표 단어를 예측합니다. 이는 목표 단어를 기반으로 "bag" 형태의 문맥 단어를 예측합니다. CBOW는 계산적으로 효율적이며 작은 데이터셋에 잘 작동합니다.
Here's how word2vec generally works:
- Data Preparation: A large corpus of text is collected and preprocessed.
데이터 준비: 대용량의 텍스트 말뭉치가 수집되고 전처리됩니다. - Word Tokenization: The text is divided into words or subwords, creating a vocabulary.
단어 토큰화: 텍스트가 단어나 하위 단어로 분할되어 어휘가 생성됩니다. - Embedding Learning: The chosen word2vec model architecture (Skip-Gram or CBOW) is trained on the text data. The model's parameters (word vectors) are updated during training to minimize a loss function.
임베딩 학습: 선택한 word2vec 모델 아키텍처(Skip-Gram 또는 CBOW)가 텍스트 데이터로 훈련됩니다. 모델의 매개변수(단어 벡터)는 훈련 중에 손실 함수를 최소화하기 위해 업데이트됩니다. - Semantic Relationships: After training, the learned word embeddings capture semantic relationships. Similar words have similar vectors in the embedding space.
의미적 관계: 훈련 후에 학습된 단어 임베딩은 의미적 관계를 포착합니다. 비슷한 단어는 임베딩 공간에서 비슷한 벡터를 가지게 됩니다. - Applications: These word embeddings can be used in various NLP tasks, such as machine translation, sentiment analysis, recommendation systems, and more. They enable algorithms to understand the meanings and contexts of words, even if they haven't encountered them before.
응용: 이러한 단어 임베딩은 기계 번역, 감정 분석, 추천 시스템 등 다양한 NLP 작업에 활용될 수 있습니다. 이들은 알고리즘이 의미와 문맥을 이해할 수 있도록 하며, 이전에 접하지 못한 단어라도 이해할 수 있습니다.
Word2Vec's power lies in its ability to create compact, meaningful, and dense representations of words that are suitable for use in machine learning models. These embeddings facilitate the transfer of linguistic context to numerical vectors, enabling algorithms to operate on and understand textual data more effectively.
Word2Vec의 힘은 머신 러닝 모델에서 사용하기에 적합한 간결하고 의미 있는 밀집형 단어 표현을 만들 수 있는 능력에 있습니다. 이러한 임베딩은 언어적 문맥을 수치 벡터로 전달하여 알고리즘들이 텍스트 데이터를 보다 효과적으로 처리하고 이해하는 데 도움을 줍니다.
In the following, we will introduce these two models and their training methods.
다음에서는 이 두 모델과 그 훈련 방법을 소개하겠습니다.
15.1.3. The Skip-Gram Model
The skip-gram model assumes that a word can be used to generate its surrounding words in a text sequence. Take the text sequence “the”, “man”, “loves”, “his”, “son” as an example. Let’s choose “loves” as the center word and set the context window size to 2. As shown in Fig. 15.1.1, given the center word “loves”, the skip-gram model considers the conditional probability for generating the context words: “the”, “man”, “his”, and “son”, which are no more than 2 words away from the center word:
스킵그램 모델은 단어를 사용하여 텍스트 시퀀스에서 주변 단어를 생성할 수 있다고 가정합니다. 텍스트 시퀀스 "the", "man", "loves", "his", "son"을 예로 들어 보겠습니다. “loves”를 중앙 단어 center word로 선택하고 컨텍스트 창 크기를 2로 설정해 보겠습니다. 그림 15.1.1에 표시된 대로 중앙 단어 “loves”가 주어지면 스킵-그램 모델은 컨텍스트 단어를 생성하기 위한 조건부 확률을 고려합니다. "the", "man", "his" 및 "son"은 중심 단어에서 2단어 이상 떨어져 있지 않습니다.

Assume that the context words are independently generated given the center word (i.e., conditional independence). In this case, the above conditional probability can be rewritten as
중심 단어center word가 주어지면 문맥 단어context words가 독립적으로 생성된다고 가정합니다(즉, 조건부 독립). 이 경우 위의 조건부 확률은 다음과 같이 다시 쓸 수 있습니다.


In the skip-gram model, each word has two d-dimensional-vector representations for calculating conditional probabilities. More concretely, for any word with index i in the dictionary, denote by vi∈ℝ**d and ui∈ℝ**d its two vectors when used as a center word and a context word, respectively. The conditional probability of generating any context word wo (with index o in the dictionary) given the center word wc (with index c in the dictionary) can be modeled by a softmax operation on vector dot products:
스킵 그램 모델에서 각 단어에는 조건부 확률을 계산하기 위한 두 개의 d차원 벡터 표현이 있습니다. 보다 구체적으로 사전dictionary에서 인덱스 i가 있는 단어에 대해 각각 중심 단어와 문맥 단어로 사용될 때 해당 두 벡터를 vi∈ℝ**d 및 ui∈ℝ**d로 표시합니다. 중앙 단어 wc(사전의 인덱스 c 포함)가 주어지면 임의의 컨텍스트 단어 wo(사전의 인덱스 o 포함)를 생성할 조건부 확률은 벡터 내적 vector dot products에 대한 소프트맥스 연산 softmax operation으로 모델링할 수 있습니다.

where the vocabulary index set V={0,1,…,|V|−1}. Given a text sequence of length T, where the word at time step t is denoted as w**(t). Assume that context words are independently generated given any center word. For context window size m, the likelihood function of the skip-gram model is the probability of generating all context words given any center word:
여기서 어휘 색인vocabulary index 은 V={0,1,…,|V|−1}로 설정됩니다. 길이 T의 텍스트 시퀀스가 주어지면 시간 단계 time step t의 단어는 w**(t)로 표시됩니다. 중심 단어 center word가 주어지면 문맥 단어 context words가 독립적으로 생성된다고 가정합니다. 문맥 창 크기 context window size m의 경우 스킵 그램 모델의 우도 함수 likelihood function는 중심 단어 center word가 주어지면 모든 문맥 단어 context words를 생성할 확률입니다.

where any time step that is less than 1 or greater than T can be omitted.
여기서 1보다 작거나 T보다 큰 시간 단계는 생략할 수 있습니다.
Skip gram 모델이란?
The Skip-Gram model is a type of word embedding model used in natural language processing (NLP) to learn dense vector representations of words. It's particularly effective in capturing semantic relationships between words and is a fundamental component of many NLP applications.
스킵 그램 모델은 자연어 처리(NLP)에서 사용되는 단어 임베딩 모델의 한 유형으로, 단어의 밀집 벡터 표현을 학습하는 데에 사용됩니다. 특히 이 모델은 단어 간의 의미적 관계를 포착하는 데 효과적이며, 여러 NLP 응용 프로그램의 기본 구성 요소입니다.
The main idea behind the Skip-Gram model is to predict the context words (words nearby in a sentence) given a target word. This is done by training the model on a large corpus of text data, where the goal is to maximize the probability of predicting the context words based on the target word.
스킵 그램 모델의 주요 아이디어는 목표 단어를 기반으로 문맥 단어(문장에서 가까운 위치에 있는 단어)를 예측하는 것입니다. 이를 위해 모델을 대용량의 텍스트 데이터로 훈련하며, 목표 단어를 기반으로 문맥 단어를 예측하는 확률을 최대화하는 것이 목표입니다.
Here's how the Skip-Gram model works:
스킵 그램 모델의 작동 방식은 다음과 같습니다:
- Creating Training Data: For each word in the training corpus, a window of surrounding words (context words) is selected. The target word is paired with these context words to create training examples.
훈련 데이터 생성: 훈련 말뭉치의 각 단어에 대해 주변 단어(문맥 단어)의 창이 선택됩니다. 목표 단어는 이러한 문맥 단어와 결합되어 훈련 예제가 생성됩니다. - Word Embedding Initialization: Each word is represented by two sets of vectors - one for the target word and one for the context words. These vectors are initialized randomly.
단어 임베딩 초기화: 각 단어는 두 개의 벡터 집합으로 표현됩니다 - 하나는 목표 단어를 위한 것이고, 다른 하나는 문맥 단어를 위한 것입니다. 이러한 벡터는 무작위로 초기화됩니다. - Training Objective: The model aims to maximize the probability of predicting context words given the target word. This is achieved by minimizing a loss function, which is typically a form of the negative log likelihood.
훈련 목표: 모델은 목표 단어를 기반으로 문맥 단어를 예측하는 확률을 최대화하는 것이 목표입니다. 이는 일반적으로 음의 로그 우도의 log likelihood 형태로 나타난 손실 함수를 최소화하는 것으로 달성됩니다. - Training Process: During training, the model updates the word vectors in a way that improves the prediction accuracy of context words for a given target word.
훈련 과정: 훈련 중에 모델은 단어 벡터를 업데이트하여 특정 목표 단어에 대한 문맥 단어의 예측 정확도를 개선합니다. - Semantic Relationships: The trained word vectors end up capturing semantic relationships between words. Words with similar meanings or contexts have similar vectors in the embedding space.
의미적 관계: 훈련된 단어 벡터는 단어 간의 의미적 관계를 포착합니다. 의미나 문맥이 비슷한 단어들은 임베딩 공간에서 비슷한 벡터를 가지게 됩니다. - Similarity: The cosine similarity between the learned word vectors can be used to measure the semantic similarity between words.
유사성: 학습된 단어 벡터 간의 코사인 유사도는 단어 간의 의미적 유사성을 측정하는 데 사용될 수 있습니다. - Applications: These word vectors can be used as features in various NLP tasks such as language modeling, sentiment analysis, machine translation, and more.
응용: 이러한 단어 벡터는 언어 모델링, 감정 분석, 기계 번역 등 다양한 NLP 작업에서 특성으로 사용될 수 있습니다.
Skip-Gram model's simplicity and effectiveness in capturing word relationships have made it a widely used technique in NLP. It's worth noting that the Skip-Gram model is often compared with another popular word embedding model called Continuous Bag of Words (CBOW), which predicts the target word given context words. Both models are trained using large amounts of text data and are part of the family of techniques referred to as word2vec.
스킵 그램 모델의 간결함과 단어 관계 포착 능력은 이를 NLP에서 널리 사용되는 기술로 만들었습니다. 스킵 그램 모델은 종종 Continuous Bag of Words (CBOW)라는 다른 인기있는 단어 임베딩 모델과 비교되며, CBOW는 문맥 단어를 기반으로 목표 단어를 예측합니다. 두 모델 모두 대량의 텍스트 데이터를 사용하여 훈련되며, word2vec이라는 기술 패밀리의 일부입니다.
15.1.3.1. Training
The skip-gram model parameters are the center word vector and context word vector for each word in the vocabulary. In training, we learn the model parameters by maximizing the likelihood function (i.e., maximum likelihood estimation). This is equivalent to minimizing the following loss function:
스킵그램 모델 매개변수는 어휘의 각 단어에 대한 중심 단어 벡터와 문맥 단어 벡터입니다. 훈련에서는 우도 likelihood 함수(즉, 최대 우도 likelihood 추정)를 최대화하여 모델 매개변수를 학습합니다. 이는 다음 손실 함수를 최소화하는 것과 동일합니다.

When using stochastic gradient descent to minimize the loss, in each iteration we can randomly sample a shorter subsequence to calculate the (stochastic) gradient for this subsequence to update the model parameters. To calculate this (stochastic) gradient, we need to obtain the gradients of the log conditional probability with respect to the center word vector and the context word vector. In general, according to (15.1.4) the log conditional probability involving any pair of the center word wc and the context word wo is
손실을 최소화하기 위해 확률적 경사하강법 stochastic gradient descent(SGD)을 사용할 때, 각 반복에서 더 짧은 하위 시퀀스를 무작위로 샘플링하여 이 하위 시퀀스에 대한 (확률적) 그라데이션을 계산하여 모델 매개변수를 업데이트할 수 있습니다. 이 (확률적) 기울기를 계산하려면 중앙 단어 벡터와 문맥 단어 벡터에 대한 로그 조건부 확률의 기울기를 구해야 합니다. 일반적으로 (15.1.4)에 따르면 중심 단어 wc와 문맥 단어 wo의 임의 쌍을 포함하는 로그 조건부 확률은 다음과 같습니다.

Stochastic Gradient Descent(SGD)란?
Stochastic Gradient Descent (SGD) is an optimization algorithm used in machine learning and deep learning to train models by iteratively updating the model's parameters based on the gradient of the loss function with respect to the data points.
확률적 경사 하강법(Stochastic Gradient Descent, SGD)은 머신 러닝과 딥 러닝에서 사용되는 최적화 알고리즘으로, 모델의 파라미터를 반복적으로 업데이트하여 데이터 포인트와 관련된 손실 함수의 그래디언트에 따라 모델을 학습시킵니다.
Here's what it means:
다음과 같은 의미를 가집니다:
- Gradient Descent: In machine learning, when we train a model, we often try to minimize a loss function. This loss function measures how well the model's predictions match the actual data. Gradient descent is an optimization technique that aims to find the minimum of this loss function by iteratively adjusting the model's parameters in the opposite direction of the gradient (slope) of the loss function.
경사 하강법: 머신 러닝에서 모델을 훈련할 때 종종 손실 함수를 최소화하려고 합니다. 이 손실 함수는 모델의 예측이 실제 데이터와 얼마나 잘 일치하는지를 측정합니다. 경사 하강법은 손실 함수의 최소값을 찾기 위해 모델의 파라미터를 손실 함수의 그래디언트(기울기)의 반대 방향으로 반복적으로 조정하는 최적화 기술입니다. - Stochastic: The term "stochastic" in SGD refers to randomness. Instead of computing the gradient of the loss function using the entire dataset (batch gradient descent), SGD uses a random subset of the data (mini-batch) to compute an estimate of the gradient. This introduces randomness in the optimization process.
확률적: SGD에서의 "확률적"이란 무작위성을 의미합니다. 전체 데이터셋을 사용하여 손실 함수의 그래디언트를 계산하는 대신, SGD는 무작위하게 선택된 데이터의 부분집합(미니 배치)을 사용하여 그래디언트의 추정치를 계산합니다. 이렇게 하면 최적화 과정에 무작위성이 도입됩니다. - Iterative Updates: SGD iteratively updates the model's parameters by taking small steps in the direction that reduces the loss. It processes one mini-batch of data at a time, computes the gradient for that batch, and updates the parameters accordingly.
반복적인 업데이트: SGD는 모델의 파라미터를 반복적으로 업데이트하여 손실을 줄이는 방향으로 작은 단계를 걸어갑니다. 한 번에 하나의 미니 배치 데이터를 처리하고 해당 배치에 대한 그래디언트를 계산하고 파라미터를 그에 따라 업데이트합니다. - Noise and Faster Convergence: Because SGD uses random subsets of data, it introduces a certain amount of noise into the optimization process. While this noise might seem counterintuitive, it can actually help the optimization process converge faster by escaping local minima and speeding up exploration of the loss landscape.
노이즈와 빠른 수렴: SGD는 무작위 데이터 부분집합을 사용하기 때문에 최적화 과정에 어느 정도의 노이즈가 도입됩니다. 이 노이즈는 직관적으로는 이상해보일 수 있지만, 실제로는 로컬 최소값을 벗어나고 손실 공간을 탐색을 빠르게 하여 최적화 과정을 더 빨리 수렴시킬 수 있습니다. - Learning Rate: SGD includes a parameter called the learning rate, which determines the step size for each update. A high learning rate can lead to overshooting the minimum, while a low learning rate can slow down convergence. Finding the right learning rate is important for successful training.
학습률: SGD에는 학습률이라는 매개변수가 포함되어 있으며, 각 업데이트에 대한 단계 크기를 결정합니다. 높은 학습률은 최소값을 지나칠 수 있지만 낮은 학습률은 수렴 속도를 늦출 수 있습니다. 올바른 학습률을 찾는 것은 성공적인 훈련에 중요합니다.
In summary, Stochastic Gradient Descent (SGD) is an optimization method that updates a model's parameters using randomly selected subsets of data. It iteratively adjusts the parameters to minimize the loss function and train machine learning models efficiently, often used in training neural networks and other large-scale models.
요약하면, 확률적 경사 하강법(SGD)은 무작위로 선택된 데이터 부분집합을 사용하여 모델의 파라미터를 업데이트하는 최적화 방법입니다. 이는 손실 함수를 최소화하고 머신 러닝 모델을 효율적으로 훈련시키는 데 사용되며, 주로 신경망 및 대규모 모델을 훈련시킬 때 사용됩니다.
Through differentiation, we can obtain its gradient with respect to the center word vector wc as
미분을 통해 중심 단어 벡터 wc에 대한 기울기를 다음과 같이 얻을 수 있습니다.
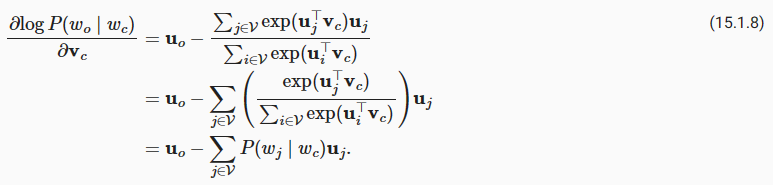
Note that the calculation in (15.1.8) requires the conditional probabilities of all words in the dictionary with wc as the center word. The gradients for the other word vectors can be obtained in the same way.
(15.1.8)의 계산에는 wc를 중심 단어로 하는 사전의 모든 단어에 대한 조건부 확률이 필요하다는 점에 유의하십시오. 다른 단어 벡터에 대한 기울기도 같은 방법으로 얻을 수 있습니다.
After training, for any word with index i in the dictionary, we obtain both word vectors vi (as the center word) and ui (as the context word). In natural language processing applications, the center word vectors of the skip-gram model are typically used as the word representations.
훈련 후 사전에 인덱스 i가 있는 단어에 대해 단어 벡터 vi(중앙 단어)와 ui(문맥 단어)를 모두 얻습니다. 자연어 처리 응용 프로그램에서는 스킵 그램 모델의 중심 단어 벡터가 일반적으로 단어 표현으로 사용됩니다.
15.1.4. The Continuous Bag of Words (CBOW) Model
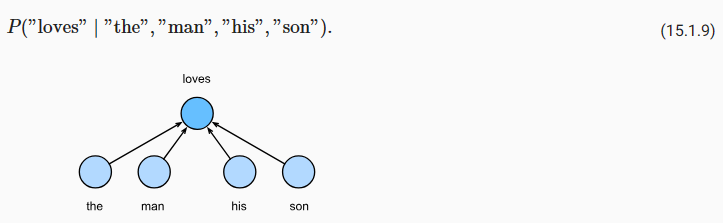
The continuous bag of words (CBOW) model is similar to the skip-gram model. The major difference from the skip-gram model is that the continuous bag of words model assumes that a center word is generated based on its surrounding context words in the text sequence. For example, in the same text sequence “the”, “man”, “loves”, “his”, and “son”, with “loves” as the center word and the context window size being 2, the continuous bag of words model considers the conditional probability of generating the center word “loves” based on the context words “the”, “man”, “his” and “son” (as shown in Fig. 15.1.2), which is
CBOW(Continuous Bag of Words) 모델은 스킵그램 모델과 유사합니다. 스킵 그램 모델과의 주요 차이점은 연속 단어 모음 모델 continuous bag of words model은 텍스트 시퀀스의 주변 문맥 단어를 기반으로 중심 단어가 생성된다고 가정한다는 것입니다. 예를 들어, 동일한 텍스트 시퀀스 "the", "man", "loves", "his" 및 "son"에서 "loves"가 중심 단어이고 컨텍스트 창 크기가 2인 연속 단어 모음 모델은 문맥 단어 "the", "man", "his" 및 "son"을 기반으로 중앙 단어 "loves"를 생성할 조건부 확률을 고려합니다(그림 15.1.2 참조).
Since there are multiple context words in the continuous bag of words model, these context word vectors are averaged in the calculation of the conditional probability. Specifically, for any word with index i in the dictionary, denote by vi∈ℝ**d and ui∈ℝ**d its two vectors when used as a context word and a center word (meanings are switched in the skip-gram model), respectively. The conditional probability of generating any center word wc (with index c in the dictionary) given its surrounding context words wo1,...,wo2m (with index o1,...,o2m in the dictionary) can be modeled by
연속 단어 모음 모델 continuous bag of words model에는 여러 개의 문맥 단어가 있으므로 이러한 문맥 단어 벡터는 조건부 확률 계산에서 평균화됩니다. 구체적으로, 사전에 인덱스 i가 있는 단어의 경우 문맥 단어와 중심 단어로 사용될 때 vi∈ℝ**d 및 ui∈ℝ**d 두 벡터로 표시됩니다(의미는 스킵-그램 모델에서 전환됨). ) 각각. 주변 문맥 단어 wo1,...,wo2m(사전에서 인덱스 o1,...,o2m 포함)이 주어지면 임의의 중심 단어 wc(사전에서 인덱스 c 포함)를 생성할 조건부 확률은 다음과 같이 모델링할 수 있습니다.

Given a text sequence of length T, where the word at time step t is denoted as w**(t). For context window size m, the likelihood function of the continuous bag of words model is the probability of generating all center words given their context words:
길이 T의 텍스트 시퀀스가 주어지면 시간 단계 t의 단어는 w**(t)로 표시됩니다. 컨텍스트 창 크기가 m인 경우 연속 단어 가방 모델 continuous bag of words model의 우도 likelihood 함수는 해당 컨텍스트 단어가 주어지면 모든 중심 단어를 생성할 확률입니다.

Continuous bag of words 모델이란?
The Continuous Bag of Words (CBOW) model is another type of word embedding model used in natural language processing (NLP) to learn dense vector representations of words. Like the Skip-Gram model, CBOW is effective in capturing semantic relationships between words and is widely used in various NLP applications.
'연속 단어 봉투' 모델(CBOW)은 자연어 처리(NLP)에서 사용되는 다른 유형의 단어 임베딩 모델로, 단어의 밀집 벡터 표현을 학습하는 데에 사용됩니다. 스킵 그램 모델과 마찬가지로 CBOW 모델도 단어 간의 의미적 관계를 잡아내는 데 효과적이며, 다양한 NLP 응용 분야에서 널리 사용됩니다.
The key concept of the CBOW model is to predict a target word given its surrounding context words. In contrast to the Skip-Gram model, which predicts context words given a target word, CBOW predicts a target word based on its context. This approach can be particularly useful for situations where you want to predict a missing word in a sentence or paragraph.
CBOW 모델의 주요 개념은 주변 문맥 단어를 기반으로 목표 단어를 예측하는 것입니다. 스킵 그램 모델과는 달리, 스킵 그램이 목표 단어를 기반으로 문맥 단어를 예측하는 것과는 반대로 CBOW는 문맥을 기반으로 목표 단어를 예측합니다. 이 접근 방식은 문장이나 단락에서 누락된 단어를 예측하려는 상황에 특히 유용할 수 있습니다.
Here's how the Continuous Bag of Words (CBOW) model works:
다음은 연속 단어 봉투(CBOW) 모델의 작동 방식입니다:
- Creating Training Data: For each word in the training corpus, a window of surrounding words (context words) is selected. The context words are used to predict the target word in the center.
훈련 데이터 생성: 훈련 말뭉치의 각 단어에 대해 주변 단어(문맥 단어)의 창이 선택됩니다. 문맥 단어는 중심에 있는 목표 단어를 예측하는 데 사용됩니다. - Word Embedding Initialization: Similar to Skip-Gram, each word is represented by two sets of vectors - one for the target word and one for the context words.
단어 임베딩 초기화: 스킵 그램과 유사하게 각 단어는 목표 단어를 위한 하나의 벡터 집합과 문맥 단어를 위한 다른 하나의 벡터 집합으로 표현됩니다. - Training Objective: The model aims to maximize the probability of predicting the target word based on the context words. This is achieved by minimizing a loss function, often a form of negative log likelihood.
훈련 목표: 모델은 문맥 단어를 기반으로 목표 단어를 예측하는 확률을 최대화하는 것이 목표입니다. 이는 일반적으로 음의 로그 우도의 형태로 나타난 손실 함수를 최소화하는 것으로 달성됩니다. - Training Process: During training, the model updates the word vectors to improve the accuracy of predicting target words from context.
훈련 과정: 훈련 중에 모델은 단어 벡터를 업데이트하여 문맥에서 목표 단어를 예측하는 정확성을 개선합니다. - Semantic Relationships: Just like Skip-Gram, the trained CBOW word vectors capture semantic relationships between words. Similar words have similar vectors in the embedding space.
의미적 관계: 스킵 그램과 마찬가지로 훈련된 CBOW 단어 벡터는 단어 간의 의미적 관계를 포착합니다. 유사한 단어는 임베딩 공간에서 유사한 벡터를 가집니다. - Applications: CBOW's word vectors can be used for various NLP tasks, including language modeling, sentiment analysis, machine translation, and more.
응용: CBOW의 단어 벡터는 언어 모델링, 감정 분석, 기계 번역 등 다양한 NLP 작업에 활용될 수 있습니다. - Efficiency: CBOW is often computationally efficient compared to Skip-Gram, making it useful for applications requiring quicker training.
효율성: CBOW는 종종 스킵 그램과 비교하여 계산적으로 효율적이며, 빠른 훈련이 필요한 응용 프로그램에 유용합니다.
In summary, the Continuous Bag of Words (CBOW) model focuses on predicting a target word from its context words, and its embeddings can be useful for understanding semantic relationships and enhancing the performance of various natural language processing tasks.
요약하면, 연속 단어 봉투(CBOW) 모델은 문맥 단어로부터 목표 단어를 예측하는 데 초점을 두며, 이러한 임베딩은 의미적 관계를 이해하고 다양한 자연어 처리 작업의 성능을 향상시키는 데에 유용합니다.
15.1.4.1. Training
Training continuous bag of words models is almost the same as training skip-gram models. The maximum likelihood estimation of the continuous bag of words model is equivalent to minimizing the following loss function:
연속 단어 모음 모델 continuous bag of words models 학습은 스킵 그램 모델 학습과 거의 동일합니다. 연속 단어 모음 모델의 최대 우도 추정은 다음 손실 함수를 최소화하는 것과 동일합니다.
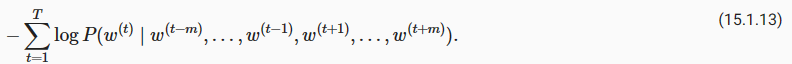
Notice that
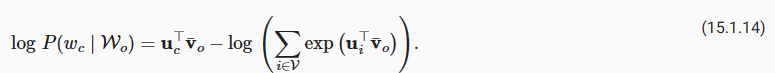
Through differentiation, we can obtain its gradient with respect to any context word vector voi(i=1,…,2m) as
미분을 통해 다음과 같이 모든 문맥 단어 벡터 voi(i=1,…,2m)에 대한 기울기를 얻을 수 있습니다.
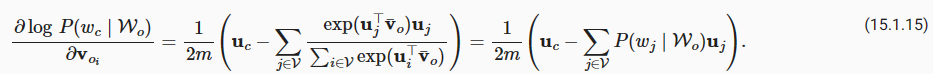
The gradients for the other word vectors can be obtained in the same way. Unlike the skip-gram model, the continuous bag of words model typically uses context word vectors as the word representations.
다른 단어 벡터에 대한 기울기도 같은 방법으로 얻을 수 있습니다. 스킵 그램 모델 skip-gram model과 달리 연속 단어 가방 모델 continuous bag of words model 은 일반적으로 문맥 단어 벡터를 단어 표현으로 사용합니다.
5.1.5. Summary
- Word vectors are vectors used to represent words, and can also be considered as feature vectors or representations of words. The technique of mapping words to real vectors is called word embedding.
단어 벡터는 단어를 표현하는 데 사용되는 벡터이며, 특징 벡터 또는 단어 표현으로도 간주될 수 있습니다. 단어를 실제 벡터에 매핑하는 기술을 단어 임베딩이라고 합니다. - The word2vec tool contains both the skip-gram and continuous bag of words models.
word2vec 도구에는 skip-gram과 continuous bag of words model이 모두 포함되어 있습니다. - The skip-gram model assumes that a word can be used to generate its surrounding words in a text sequence; while the continuous bag of words model assumes that a center word is generated based on its surrounding context words.
스킵그램 모델은 단어를 사용하여 텍스트 시퀀스에서 주변 단어를 생성할 수 있다고 가정합니다. 연속 단어 가방 모델은 중심 단어가 주변 문맥 단어를 기반으로 생성된다고 가정합니다.
15.1.6. Exercises
- What is the computational complexity for calculating each gradient? What could be the issue if the dictionary size is huge?
- Some fixed phrases in English consist of multiple words, such as “new york”. How to train their word vectors? Hint: see Section 4 in the word2vec paper (Mikolov et al., 2013).
- Let’s reflect on the word2vec design by taking the skip-gram model as an example. What is the relationship between the dot product of two word vectors in the skip-gram model and the cosine similarity? For a pair of words with similar semantics, why may the cosine similarity of their word vectors (trained by the skip-gram model) be high?
'Dive into Deep Learning > D2L Natural language Processing' 카테고리의 다른 글
| D2L - 15.10. Pretraining BERT (0) | 2023.08.30 |
|---|---|
| D2L - 15.9. The Dataset for Pretraining BERT (0) | 2023.08.30 |
| D2L - 15.8. Bidirectional Encoder Representations from Transformers (BERT) (0) | 2023.08.30 |
| D2L - 15.7. Word Similarity and Analogy (0) | 2023.08.30 |
| D2L - 15.6. Subword Embedding (0) | 2023.08.30 |
| D2L - 15.5. Word Embedding with Global Vectors (GloVe) (0) | 2023.08.29 |
| D2L - 15.4. Pretraining word2vec (0) | 2023.08.29 |
| D2L - 15.3. The Dataset for Pretraining Word Embeddings (0) | 2023.08.29 |
| D2L- 15.2. Approximate Training (1) | 2023.08.28 |
| D2L - 15. Natural Language Processing: Pretraining (0) | 2023.08.24 |