https://beta.openai.com/docs/api-reference/completions
Completions
Given a prompt, the model will return one or more predicted completions, and can also return the probabilities of alternative tokens at each position.
프롬프트가 주어지면 모델은 하나 이상의 예상 완료(Completion)를 반환하고 각 위치에서 대체 토큰의 확률을 반환할 수도 있습니다.
Create completion
POST https://api.openai.com/v1/completions
Creates a completion for the provided prompt and parameters
제공된 프롬프트 및 매개변수에 대한 완성(completion)을 생성합니다.
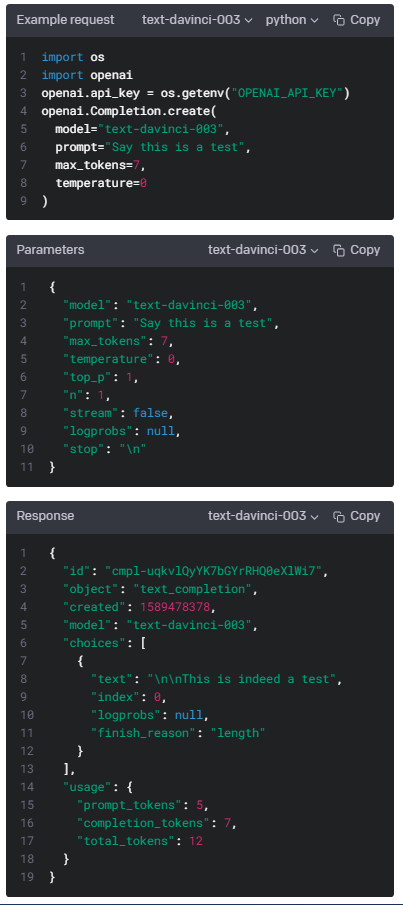
Request body
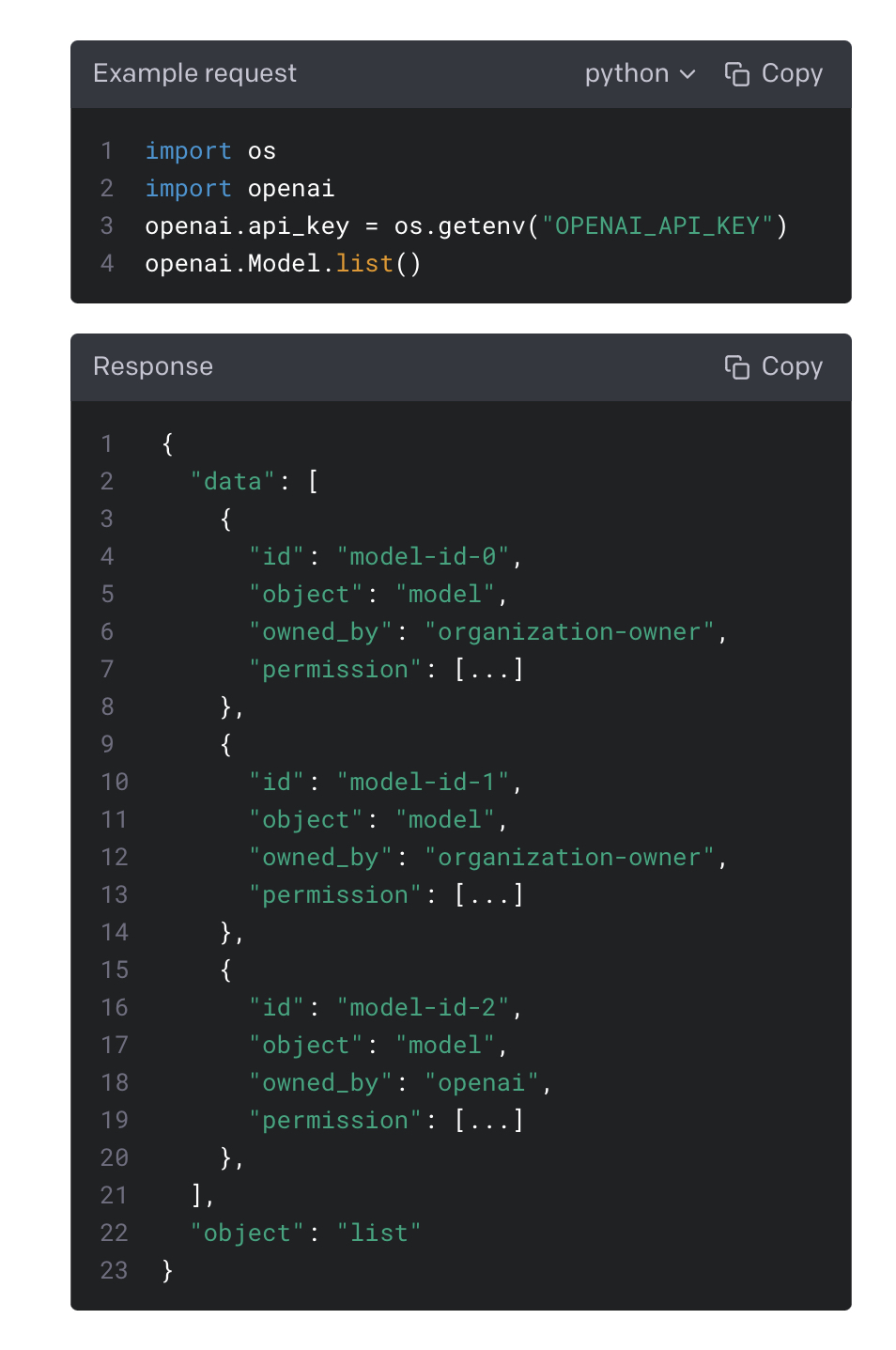
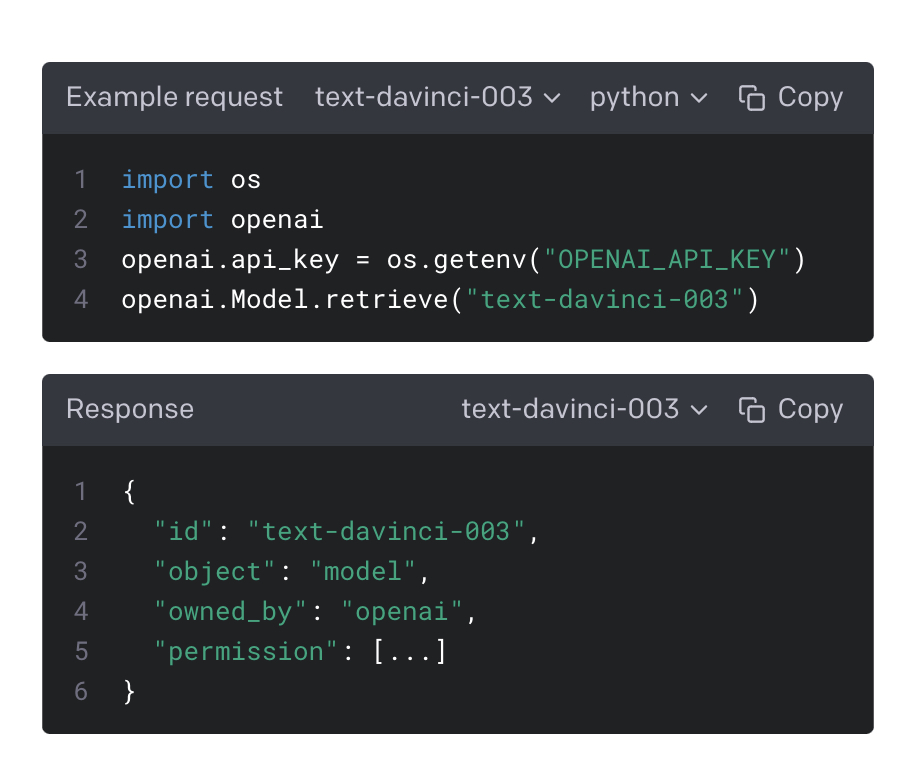
ID of the model to use. You can use the List models API to see all of your available models, or see our Model overview for descriptions of them.
사용할 모델의 ID입니다. 모델 목록 API를 사용하여 사용 가능한 모든 모델을 보거나 모델 개요에서 설명을 볼 수 있습니다.
The prompt(s) to generate completions for, encoded as a string, array of strings, array of tokens, or array of token arrays.
문자열, 문자열 배열, 토큰 배열 또는 토큰 배열 배열로 인코딩된 완성(completions )을 생성하는 프롬프트입니다.
Note that <|endoftext|> is the document separator that the model sees during training, so if a prompt is not specified the model will generate as if from the beginning of a new document.
<|endoftext|>는 훈련 중에 모델이 보는 문서 구분 기호이므로 프롬프트가 지정되지 않으면 모델이 새 문서의 시작 부분에서 생성되는 것처럼 생성됩니다.
The suffix that comes after a completion of inserted text.
삽입된 텍스트가 완료된 뒤에 오는 접미사.
The maximum number of tokens to generate in the completion.
completion 에서 생성할 수 있는 최대 토큰 수입니다.
The token count of your prompt plus max_tokens cannot exceed the model's context length. Most models have a context length of 2048 tokens (except for the newest models, which support 4096).
프롬프트의 토큰 수에 max_tokens를 더한 값은 모델의 컨텍스트 길이를 초과할 수 없습니다. 대부분의 모델은 컨텍스트 길이가 2048 토큰입니다(4096을 지원하는 최신 모델 제외).
What sampling temperature to use. Higher values means the model will take more risks. Try 0.9 for more creative applications, and 0 (argmax sampling) for ones with a well-defined answer.
사용할 샘플링 온도. 값이 높을수록 모델이 더 많은 위험을 감수하게 됩니다. 더 창의적인 응용 프로그램에는 0.9를, 잘 정의된 답이 있는 응용 프로그램에는 0(argmax 샘플링)을 사용해 보십시오.
We generally recommend altering this or top_p but not both.
일반적으로 temperature나 top_p를 변경하는 것이 좋지만 둘 다 변경하는 것은 권장하지 않습니다.
An alternative to sampling with temperature, called nucleus sampling, where the model considers the results of the tokens with top_p probability mass. So 0.1 means only the tokens comprising the top 10% probability mass are considered.
모델이 top_p 확률 질량으로 토큰의 결과를 고려하는 핵 샘플링이라고 하는 온도(temperature)를 사용한 샘플링의 대안입니다. 따라서 0.1은 상위 10% 확률 질량을 구성하는 토큰만 고려됨을 의미합니다.
We generally recommend altering this or temperature but not both.
일반적으로 top_p 또는 온도 (temperature) 를 변경하는 것이 좋지만 둘 다 변경하는 것은 권장하지 않습니다.
How many completions to generate for each prompt.
각 프롬프트에 대해 생성할 완료 수입니다.
Note: Because this parameter generates many completions, it can quickly consume your token quota. Use carefully and ensure that you have reasonable settings for max_tokens and stop.
참고: 이 매개변수는 많은 완료를 생성하기 때문에 토큰 할당량을 빠르게 소비할 수 있습니다. 신중하게 사용하고 max_tokens 및 중지에 대한 합리적인 설정이 있는지 확인하십시오.
Whether to stream back partial progress. If set, tokens will be sent as data-only server-sent events as they become available, with the stream terminated by a data: [DONE] message.
부분 진행 상황을 스트리밍할지 여부입니다. 설정되면 토큰이 사용 가능해지면 데이터 전용 서버 전송 이벤트로 전송되며, 스트림은 data: [DONE] 메시지로 종료됩니다.
Include the log probabilities on the logprobs most likely tokens, as well the chosen tokens. For example, if logprobs is 5, the API will return a list of the 5 most likely tokens. The API will always return the logprob of the sampled token, so there may be up to logprobs+1 elements in the response.
logprobs 가장 가능성이 높은 토큰과 선택한 토큰에 대한 로그 확률을 포함합니다. 예를 들어 logprobs가 5이면 API는 가능성이 가장 높은 5개의 토큰 목록을 반환합니다. API는 항상 샘플링된 토큰의 logprob를 반환하므로 응답에 최대 logprobs+1 요소가 있을 수 있습니다.
The maximum value for logprobs is 5. If you need more than this, please contact us through our Help center and describe your use case.
logprobs의 최대 값은 5입니다. 이보다 더 필요한 경우 고객 센터를 통해 문의하여 사용 사례를 설명하십시오.
Echo back the prompt in addition to the completion
완료(completion)에 더해서 프롬프트를 반환합니다.
Up to 4 sequences where the API will stop generating further tokens. The returned text will not contain the stop sequence.
API가 추가 토큰 생성을 중지하는 최대 4개의 시퀀스. 반환된 텍스트에는 중지 시퀀스가 포함되지 않습니다.
Number between -2.0 and 2.0. Positive values penalize new tokens based on whether they appear in the text so far, increasing the model's likelihood to talk about new topics.
-2.0에서 2.0 사이의 숫자입니다. 양수 값은 지금까지 텍스트에 나타나는지 여부에 따라 새 토큰에 페널티를 주어 모델이 새 주제에 대해 이야기할 가능성을 높입니다.
See more information about frequency and presence penalties.
Number between -2.0 and 2.0. Positive values penalize new tokens based on their existing frequency in the text so far, decreasing the model's likelihood to repeat the same line verbatim.
-2.0에서 2.0 사이의 숫자입니다. 양수 값은 지금까지 텍스트의 기존 빈도를 기반으로 새 토큰에 페널티를 주어 모델이 동일한 줄을 그대로 반복할 가능성을 줄입니다.
See more information about frequency and presence penalties.
Generates best_of completions server-side and returns the "best" (the one with the highest log probability per token). Results cannot be streamed.
서버측에서 best_of 완료를 생성하고 "최고"(토큰당 로그 확률이 가장 높은 항목)를 반환합니다. 결과를 스트리밍할 수 없습니다.
When used with n, best_of controls the number of candidate completions and n specifies how many to return – best_of must be greater than n.
n과 함께 사용하는 경우 best_of는 후보 완료 수를 제어하고 n은 반환할 수를 지정합니다. best_of는 n보다 커야 합니다.
Note: Because this parameter generates many completions, it can quickly consume your token quota. Use carefully and ensure that you have reasonable settings for max_tokens and stop.
참고: 이 매개변수는 많은 완료를 생성하기 때문에 토큰 할당량을 빠르게 소비할 수 있습니다. 신중하게 사용하고 max_tokens 및 중지에 대한 합리적인 설정이 있는지 확인하십시오.
Modify the likelihood of specified tokens appearing in the completion.
완료(completion)에 지정된 토큰이 나타날 가능성을 수정합니다.
Accepts a json object that maps tokens (specified by their token ID in the GPT tokenizer) to an associated bias value from -100 to 100. You can use this tokenizer tool (which works for both GPT-2 and GPT-3) to convert text to token IDs. Mathematically, the bias is added to the logits generated by the model prior to sampling. The exact effect will vary per model, but values between -1 and 1 should decrease or increase likelihood of selection; values like -100 or 100 should result in a ban or exclusive selection of the relevant token.
토큰(GPT 토크나이저의 토큰 ID로 지정됨)을 -100에서 100 사이의 관련 바이어스 값으로 매핑하는 json 개체를 허용합니다. 이 토크나이저 도구(GPT-2 및 GPT-3 모두에서 작동)를 사용하여 변환할 수 있습니다. 토큰 ID에 대한 텍스트. 수학적으로 바이어스는 샘플링 전에 모델에 의해 생성된 로짓에 추가됩니다. 정확한 효과는 모델마다 다르지만 -1과 1 사이의 값은 선택 가능성을 낮추거나 높여야 합니다. -100 또는 100과 같은 값은 관련 토큰을 금지하거나 배타적으로 선택해야 합니다.
As an example, you can pass {"50256": -100} to prevent the <|endoftext|> token from being generated.
예를 들어 {"50256": -100}을 전달하여 <|endoftext|> 토큰이 생성되지 않도록 할 수 있습니다.
A unique identifier representing your end-user, which can help OpenAI to monitor and detect abuse. Learn more.
OpenAI가 남용을 모니터링하고 탐지하는 데 도움이 될 수 있는 최종 사용자를 나타내는 고유 식별자입니다.
'Open AI > API REFERENCE' 카테고리의 다른 글
| Moderations - openai.Moderation.create() (0) | 2023.01.17 |
|---|---|
| Fine-tunes : openai.FineTune.create(), list(), retrieve(), cancel(), list_events(), delete() (0) | 2023.01.17 |
| Files - openai.File.list(), create(), delete(), retrieve(), download() (0) | 2023.01.17 |
| Embeddings - openai.Embedding.create() (0) | 2023.01.17 |
| Images - openai.Image.create(), openai.Image.create_edit(), openai.Image.create_variation() (0) | 2023.01.17 |
| Edits - openai.Edit.create() (0) | 2023.01.17 |
| Models - openai.Model.list(), openai.Model.retrieve() (0) | 2023.01.16 |
| Making Request - Open AI API 에 요청 하기 : curl (0) | 2023.01.16 |
| Authentication - Open AI API 사용을 위한 인증 받기 : openai.api_key = os.getenv("OPENAI_API_KEY) (0) | 2023.01.16 |
| Introduction - pip install openai , npm install openai (0) | 2023.01.16 |