반응형
https://beta.openai.com/docs/api-reference/engines
Engines
The Engines endpoints are deprecated.
엔진 엔드포인트는 더 이상 사용되지 않습니다.
These endpoints describe and provide access to the various engines available in the API.
이러한 endpoints 은 API에서 사용할 수 있는 다양한 엔진에 대한 액세스를 설명하고 제공합니다.
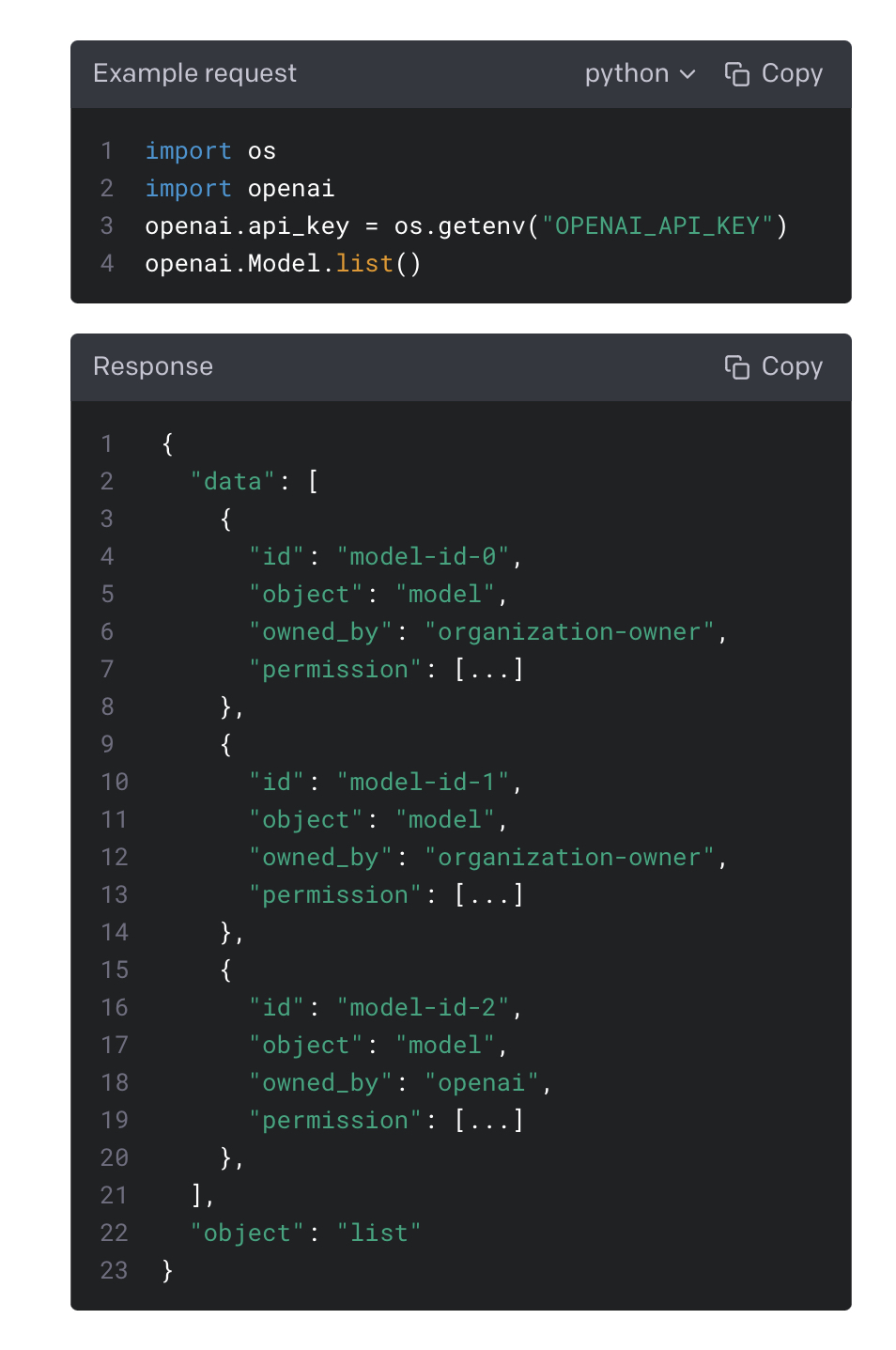
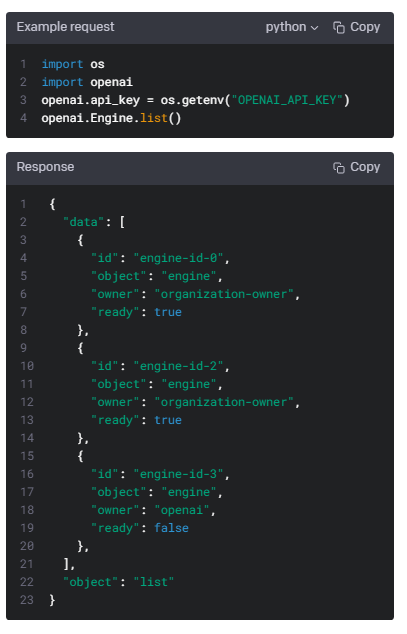
List engines
Deprecated
GET https://api.openai.com/v1/engines
Lists the currently available (non-finetuned) models, and provides basic information about each one such as the owner and availability.
현재 사용 가능한(미세 조정되지 않은) 모델을 나열하고 소유자 및 가용성과 같은 각 모델에 대한 기본 정보를 제공합니다.
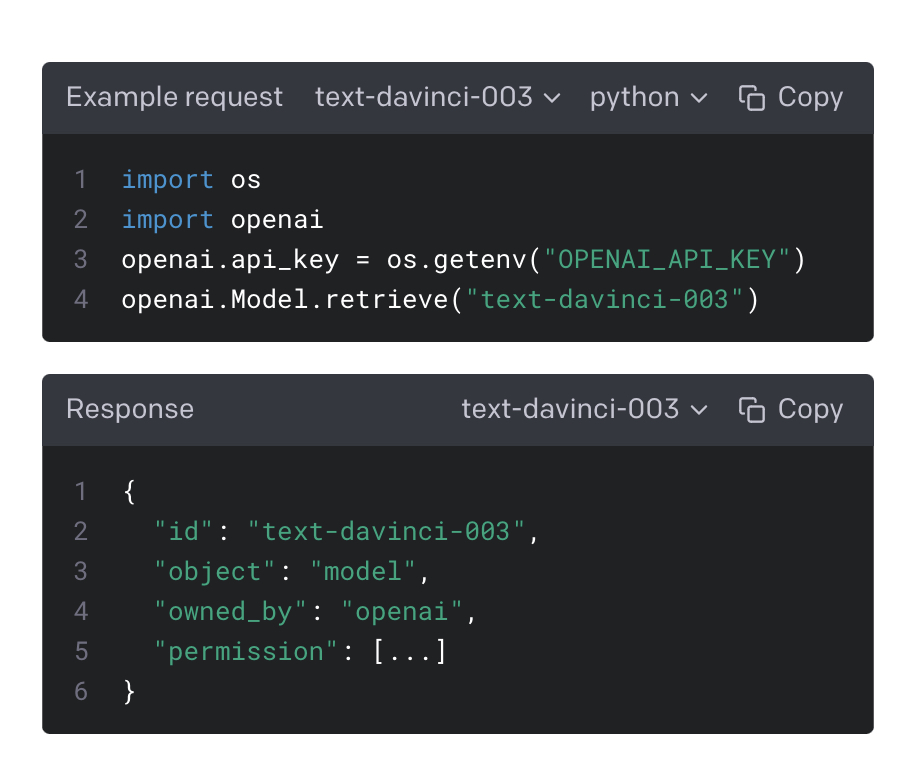
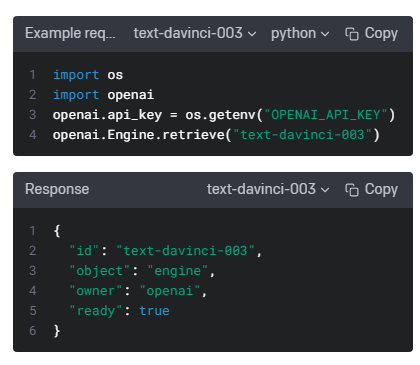
Retrieve engine
Deprecated 사용되지 않음
GET https://api.openai.com/v1/engines/{engine_id}
Retrieves a model instance, providing basic information about it such as the owner and availability.
소유자 및 가용성과 같은 기본 정보를 제공하는 모델 인스턴스를 검색합니다.
Path parameters
engine_id
string
Required
The ID of the engine to use for this request
반응형
'Open AI > API REFERENCE' 카테고리의 다른 글
| Audio - openai.Audio.transcribe(), openai.Audio.translate() (0) | 2023.03.07 |
|---|---|
| Chat - Create chat completion (ChatGPT API usage) (0) | 2023.03.06 |
| Parameter details (0) | 2023.01.17 |
| Moderations - openai.Moderation.create() (0) | 2023.01.17 |
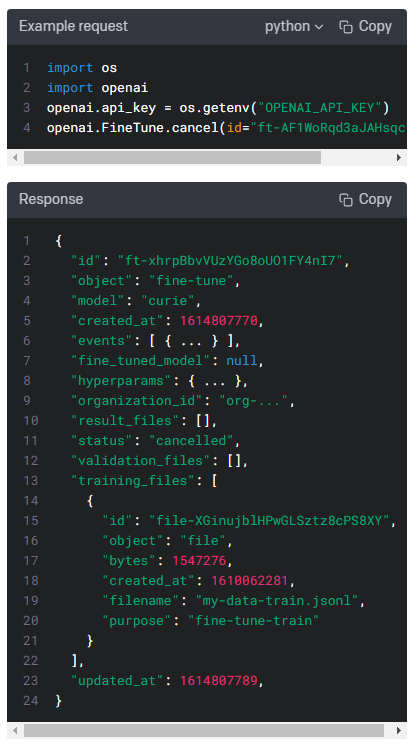
| Fine-tunes : openai.FineTune.create(), list(), retrieve(), cancel(), list_events(), delete() (0) | 2023.01.17 |
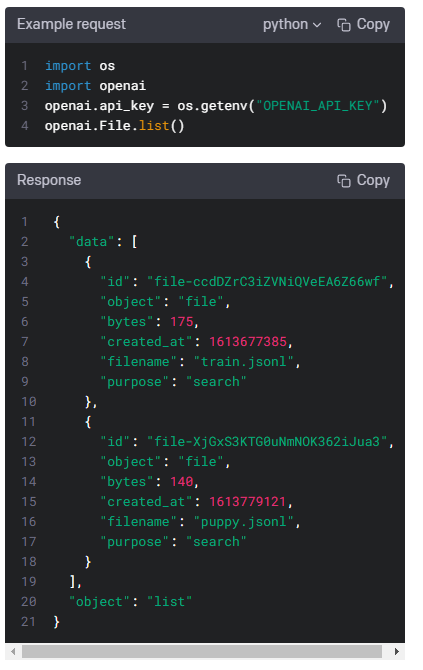
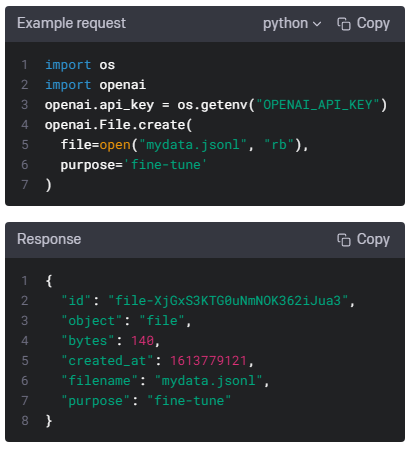
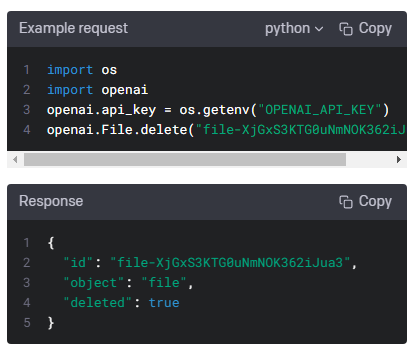
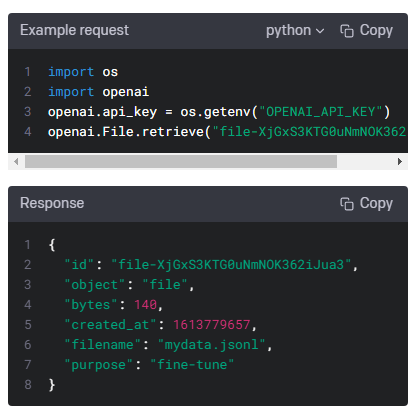
| Files - openai.File.list(), create(), delete(), retrieve(), download() (0) | 2023.01.17 |
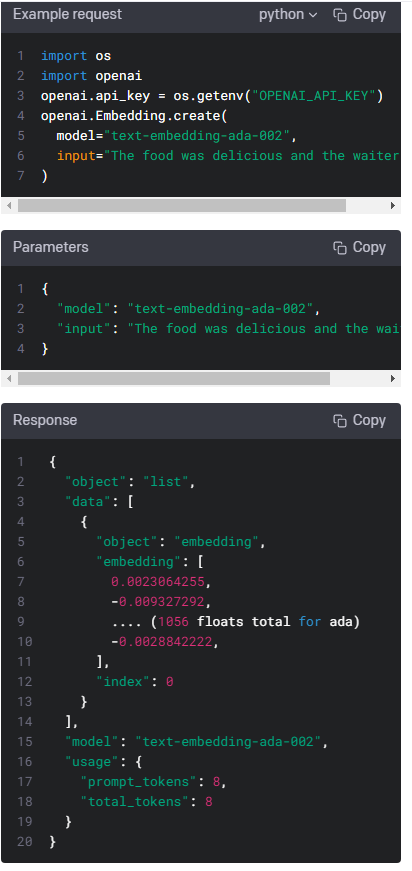
| Embeddings - openai.Embedding.create() (0) | 2023.01.17 |
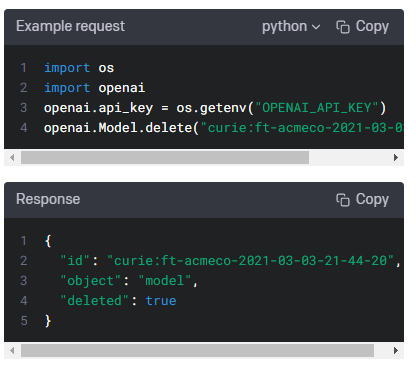
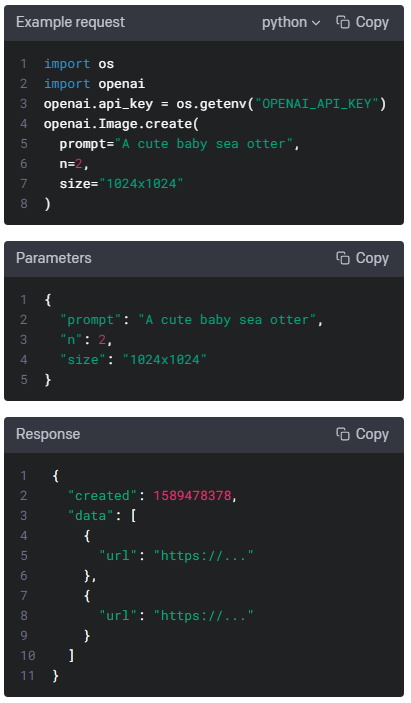
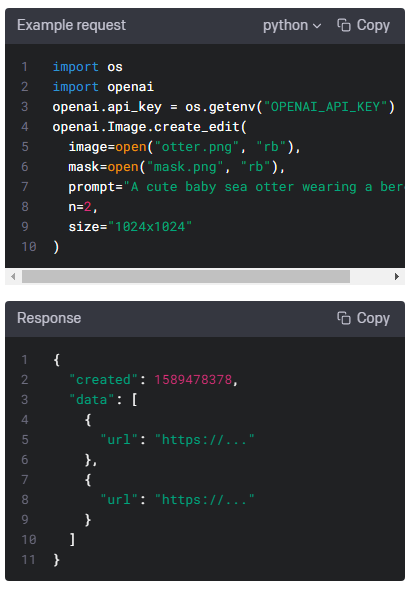
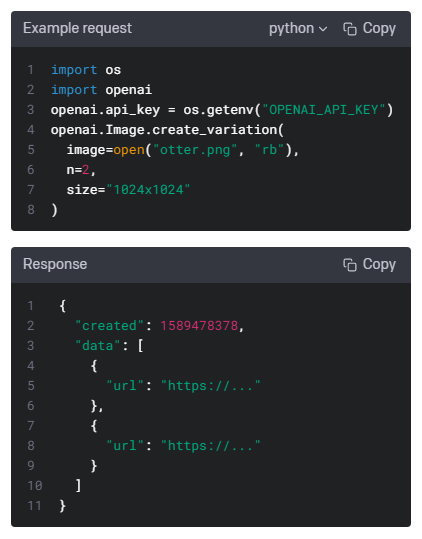
| Images - openai.Image.create(), openai.Image.create_edit(), openai.Image.create_variation() (0) | 2023.01.17 |
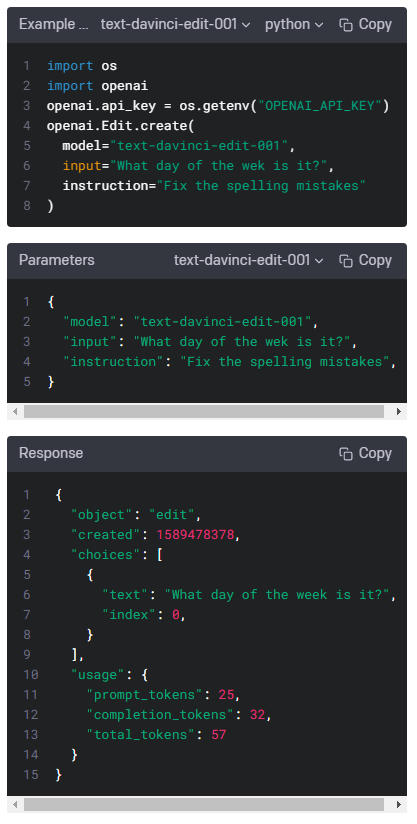
| Edits - openai.Edit.create() (0) | 2023.01.17 |
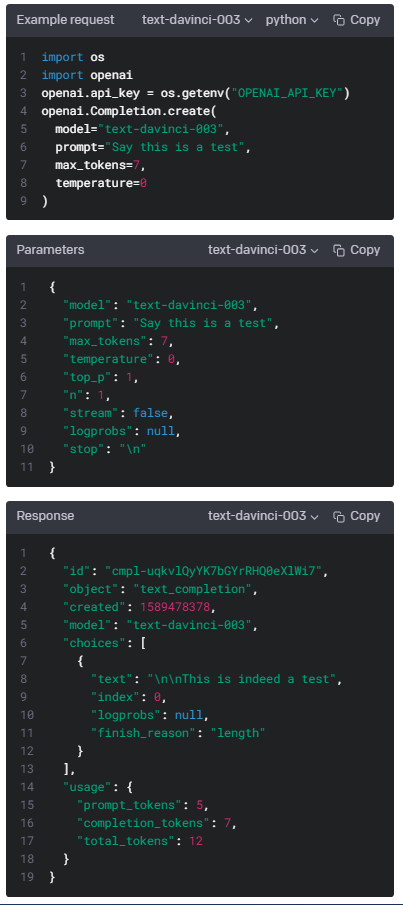
| Completions - openai.Completion.create() (0) | 2023.01.17 |