

본격적으로 AWS Deepracer를 시작했다.
첫번째 모델을 만들었다.
일단 트랙은 제일 간단한 것으로 선택 하고 Speed는 5로 선택.
직선도로니까 빠르게 달리게 만드는게 더 좋을 것 같아서.
나머지는 다 디폴트.
Reward_function도 그냥 디폴트 사용하고 시간은 30분
참고로 디폴트 함수는 아래와 같다.
def reward_function(params):
'''
Example of rewarding the agent to follow center line
'''
# Read input parameters
track_width = params['track_width']
distance_from_center = params['distance_from_center']
# Calculate 3 markers that are at varying distances away from the center line
marker_1 = 0.1 * track_width
marker_2 = 0.25 * track_width
marker_3 = 0.5 * track_width
# Give higher reward if the car is closer to center line and vice versa
if distance_from_center <= marker_1:
reward = 1.0
elif distance_from_center <= marker_2:
reward = 0.5
elif distance_from_center <= marker_3:
reward = 0.1
else:
reward = 1e-3 # likely crashed/ close to off track
return float(reward)
소스코드를 보니 트랙 중앙선 가까이 가면 점수(reward)를 더 많이 주는 간단한 로직이다.
30분 트레이닝 시키고 곧바로 Evaluate
결과는 조금 있다가…
이 첫번째 모델을 clone 해서 두번째 모델을 만들었다.
다 똑같고 reward function 함수만 내가 원하는 대로 조금 바꾸었다.
def reward_function(params):
'''
Example of rewarding the agent to follow center line
'''
reward=1e-3
# Read input parameters
track_width = params['track_width']
distance_from_center = params['distance_from_center']
steering = params['steering_angle']
speed = params['speed']
all_wheels_on_track = params['all_wheels_on_track']
if distance_from_center >=0.0 and distance_from_center <= 0.03:
reward = 1.0
if not all_wheels_on_track:
reward = -1
else:
reward = params['progress']
# Steering penality threshold, change the number based on your action space setting
ABS_STEERING_THRESHOLD = 15
# Penalize reward if the car is steering too much
if steering > ABS_STEERING_THRESHOLD:
reward *= 0.8
# add speed penalty
if speed < 2.5:
reward *=0.80
return float(reward)
이전에 썼던 디폴트 함수와는 다르게 몇가지 조건을 추가 했다.
일단 중앙선을 유지하면 좀 더 점수를 많이 주는 것은 좀 더 간단하게 만들었다.
이 부분은 이전에 훈련을 했으니까 이 정도로 해 주면 되지 않을까?
그리고 아무 바퀴라도 트랙 밖으로 나가면 -1을 하고 모두 트랙 안에 있으면 progress 만큼 reward를 주었다.
Progress는 percentage of track completed 이다.
직진해서 결승선에 더 가까이 갈 수록 점수를 더 많이 따도록 했다.
이건 차가 빠꾸하지 않고 곧장 결승점으로 직진 하도록 만들기 위해 넣었다.
그리고 갑자기 핸들을 과하게 돌리면 차가 구르거나 트랙에서 이탈할 확률이 높으니 핸들을 너무 과하게 돌리면 점수가 깎이도록 했다. (15도 이상 핸들을 꺾으면 점수가 깎인다.)
그리고 속도도 너무 천천히 가면 점수를 깎는다.
속도 세팅이 최대 5로 만들어서 그 절반인 2.5 이하고 속도를 줄이면 점수가 깎인다.
이렇게 조건들을 추가하고 Training 시작.
이건 좀 복잡하니 트레이닝 시간을 1시간 주었다.
이 두개의 모델에 대한 결과는…
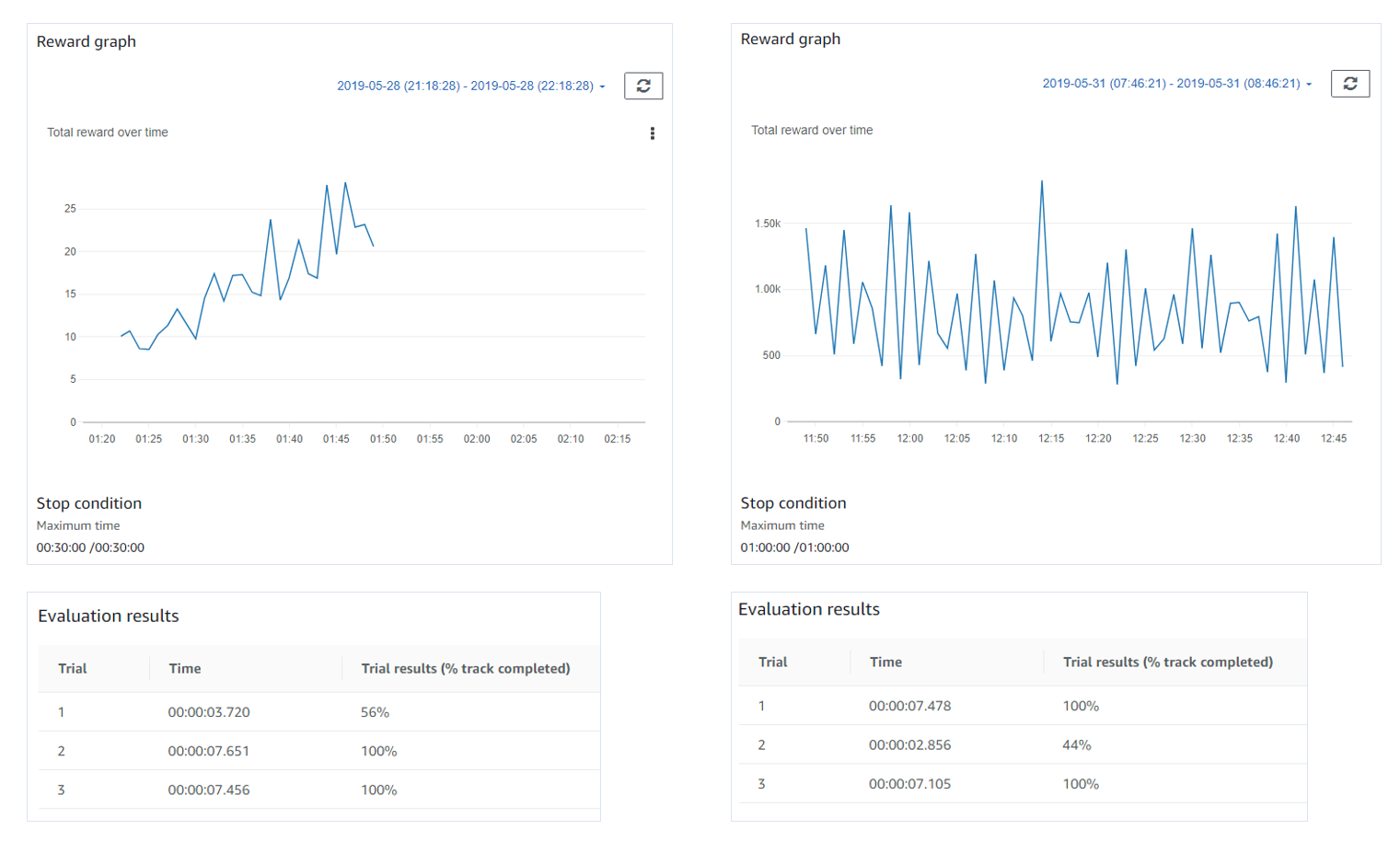
딱 보니 첫번째 디폴트 함수를 사용했을 때는 시간이 갈수록 결과가 좋게 나왔다.
그런데 두번째는 시간이 갈수록 실력이 높아지지는 않는 것 같다.
너무 조건이 여러개 들어가서 그런가?
생각해 보니 조건을 많이 넣는다고 좋은 것은 아닌것 같다.
일반적으로 코딩을 하다 보면 예외 상황을 만들지 않게 하기 위해 조건들을 아주 많이 주는 경향이 있는데 이 인공지능 쪽은 꼭 조건을 많이 줄 필요는 없을 것 같다.
앞으로 인공지능 쪽을 하다보면 일반 코딩에서의 버릇 중에 고칠 것들이 많을 것 같다.
Evaluation 결과를 보면 두개의 차이가 별로 없다.
두 모델 모두 3번중 2번 완주 했고 완주시간도 비슷한 것 같다.
조건을 쪼금 더 준 Model 2 가 좀 더 낫긴 하네. (0.2 ~0.3 초 더 빠르다.)
다음은 곡선이 있는 다른 트랙으로 훈련을 시킬 계획이다.
그런데 곡선이 있는 트랙에서는 스피드가 무조건 빠르다고 좋은 건 아닌 것 같다.
내가 스피드를 5로 주었는데 Clone을 만들어서 할 때는 이 스피드를 조절하지 못하는 것 같다.
곡선 구간에서는 reward_function을 어떻게 주어야 하지?
'IoT > AWS DeepRacer' 카테고리의 다른 글
| MEGAZONE CLOUD AWS DeepRacer League in Korea (0) | 2019.06.25 |
|---|---|
| 테슬라 주가와 2011년 넷플릭스 주가 비교 (0) | 2019.06.05 |
| AWS DeepRacer League and 2nd Virtual Race open (1) | 2019.06.04 |
| AWS Deepracer - Oval and London loop track model 훈련 결과 (0) | 2019.06.03 |
| AWS Deepracer Model 훈련 및 평가 후 볼 수 있는 정보들 (0) | 2019.06.02 |
| AWS Deepracer를 시작하면 내야 하는 요금들... (0) | 2019.05.31 |
| AWS DeepRacer - Hands-on Exercise 1 : Model Training Using AWS DeepRacer Console (0) | 2019.05.30 |
| AWS DeepRacer를 시작하기 전에 살펴볼 내용 (0) | 2019.05.17 |
| Troubleshooting (0) | 2019.01.02 |
| Drive Your Vehicle (0) | 2019.01.01 |

