반응형
그동안 Application 개발은 프로그래밍 언어를 배운 사람들만의 전유물이었다면,
AI Application 개발은 그렇지 않은 사람들에게도 어플리케이션 개발의 기회를 줍니다.
AI 는 인간의 언어를 이해하고 인간의 언어를 통해서 작동되는 툴이라서 그렇습니다.
이 추론은 AI 로 부터 좀 더 Quality 높은 답변을 받도록 하는 기술 입니다.
이 부분이 바로 인간의 언어로 프로그래밍 할 수 있는 부분입니다.
이 기술을 배우면 굳이 AI 어플리케이션 개발 뿐만 아니라 일상 생활에서도 AI 를 좀 더 잘 활용하는데 도움이 됩니다.
이 비디오는 AI Agent Application 개발에 관심이 있는 분들을 대상으로 만들어 졌지만
IT 전문가가 아니더라도 알아두면 도움이 될 만한 추론 관련 정보를 얻으 실 수 있을 겁니다.
-------------------------------------------------------------------
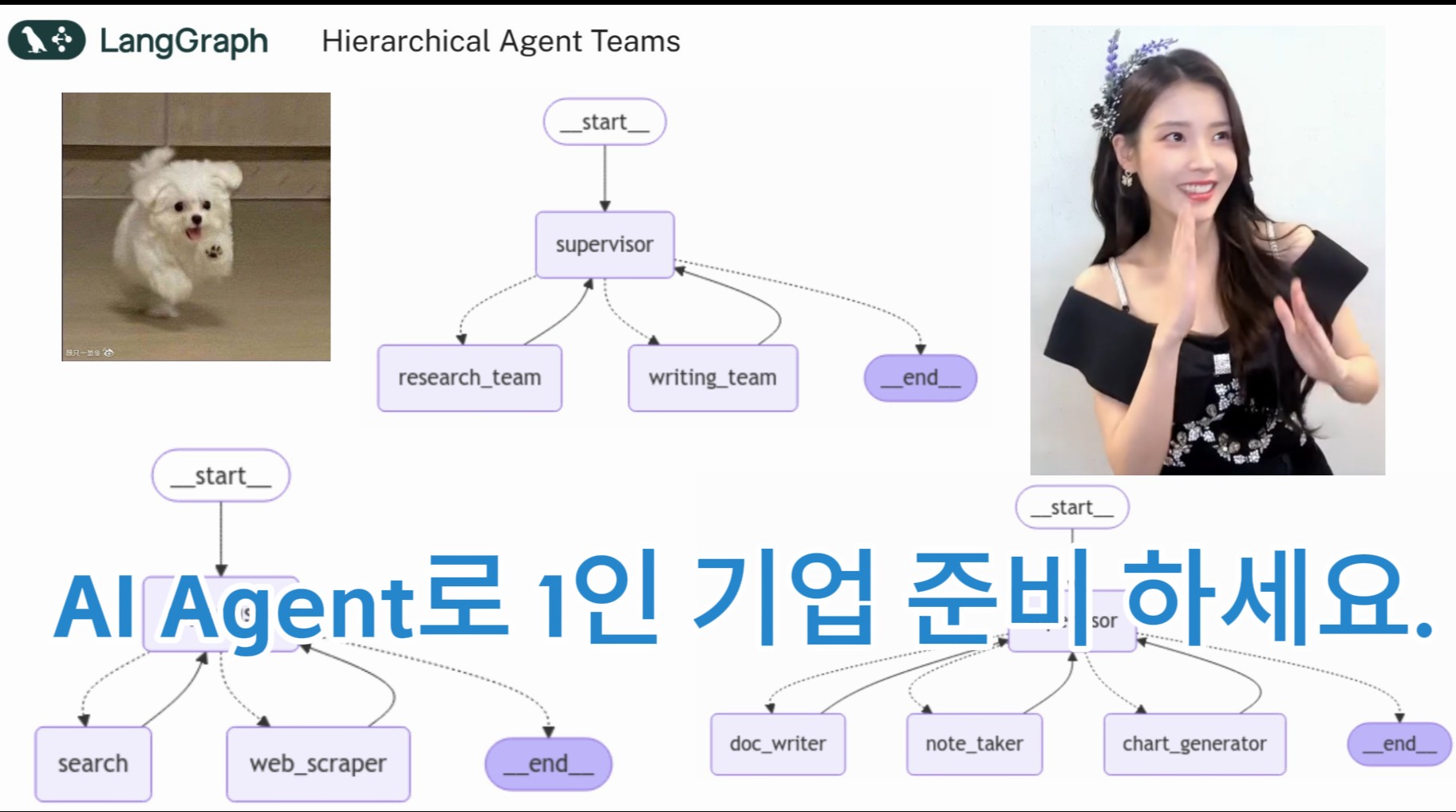
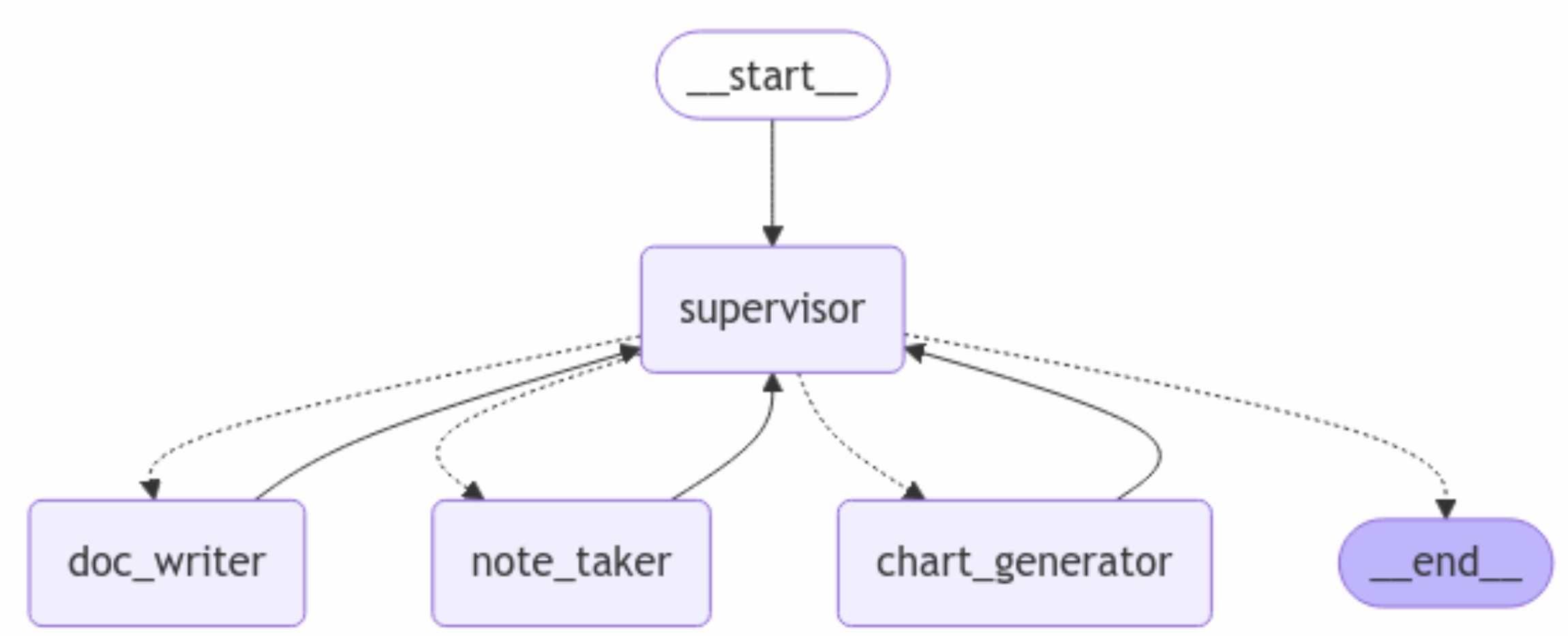
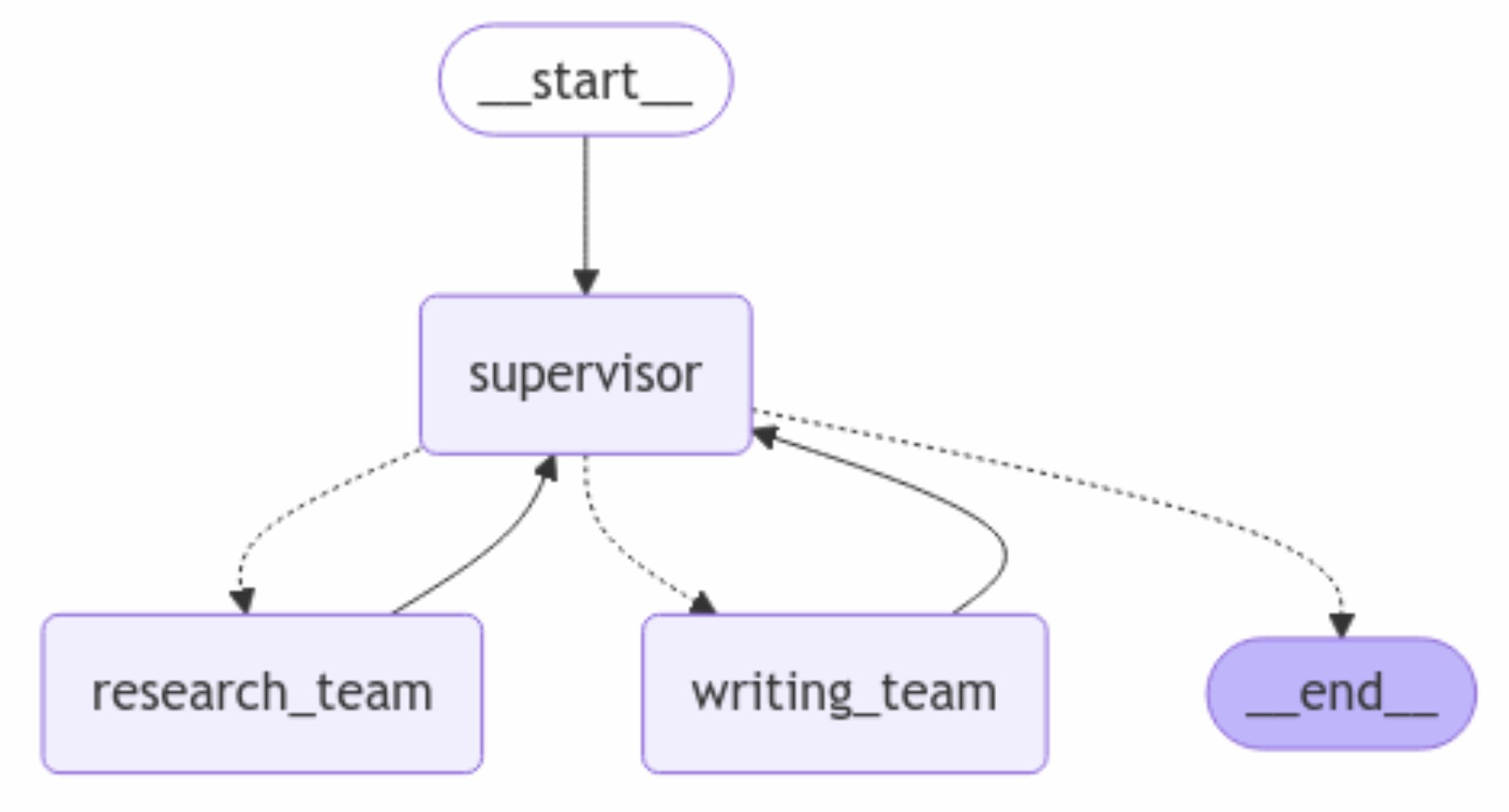
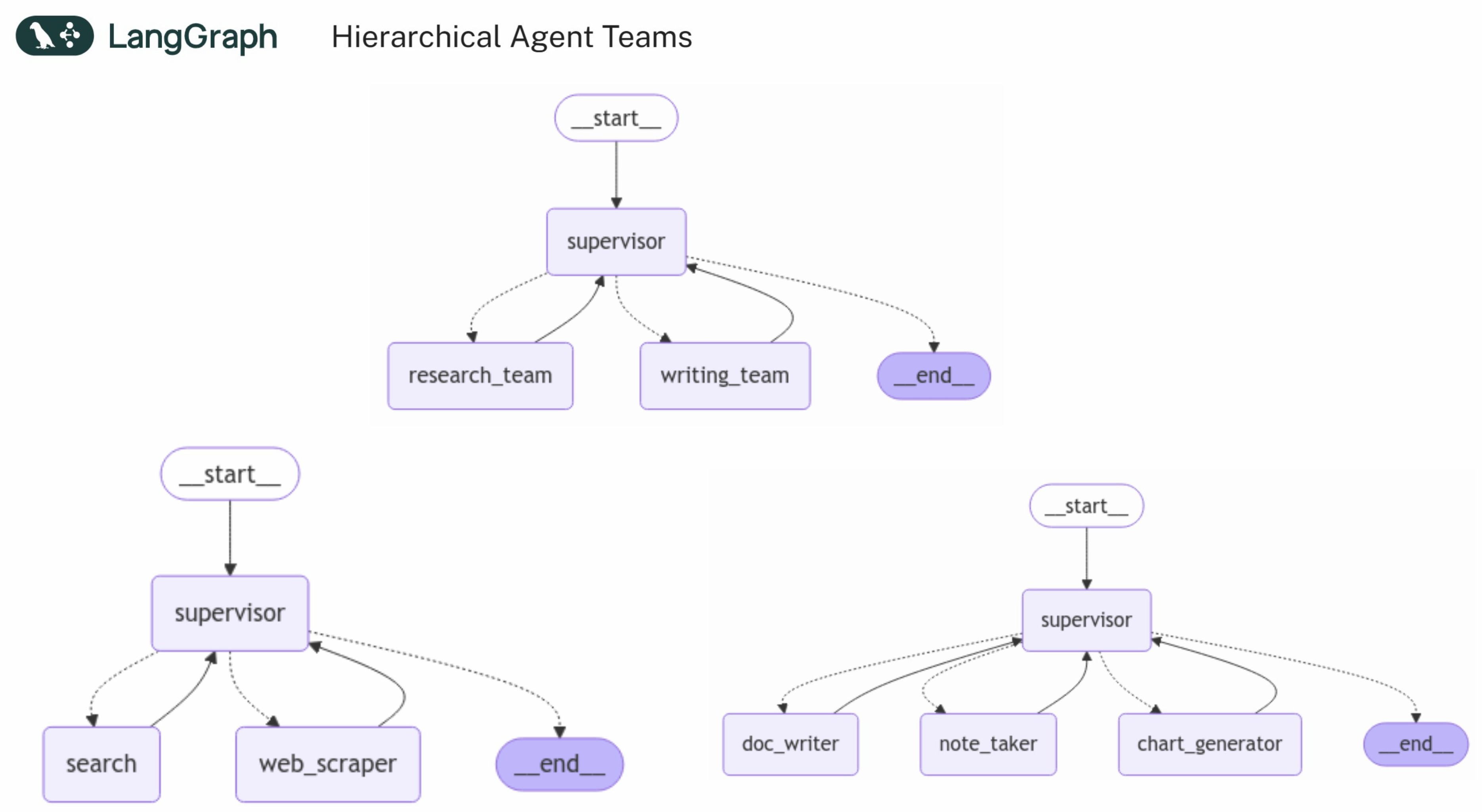
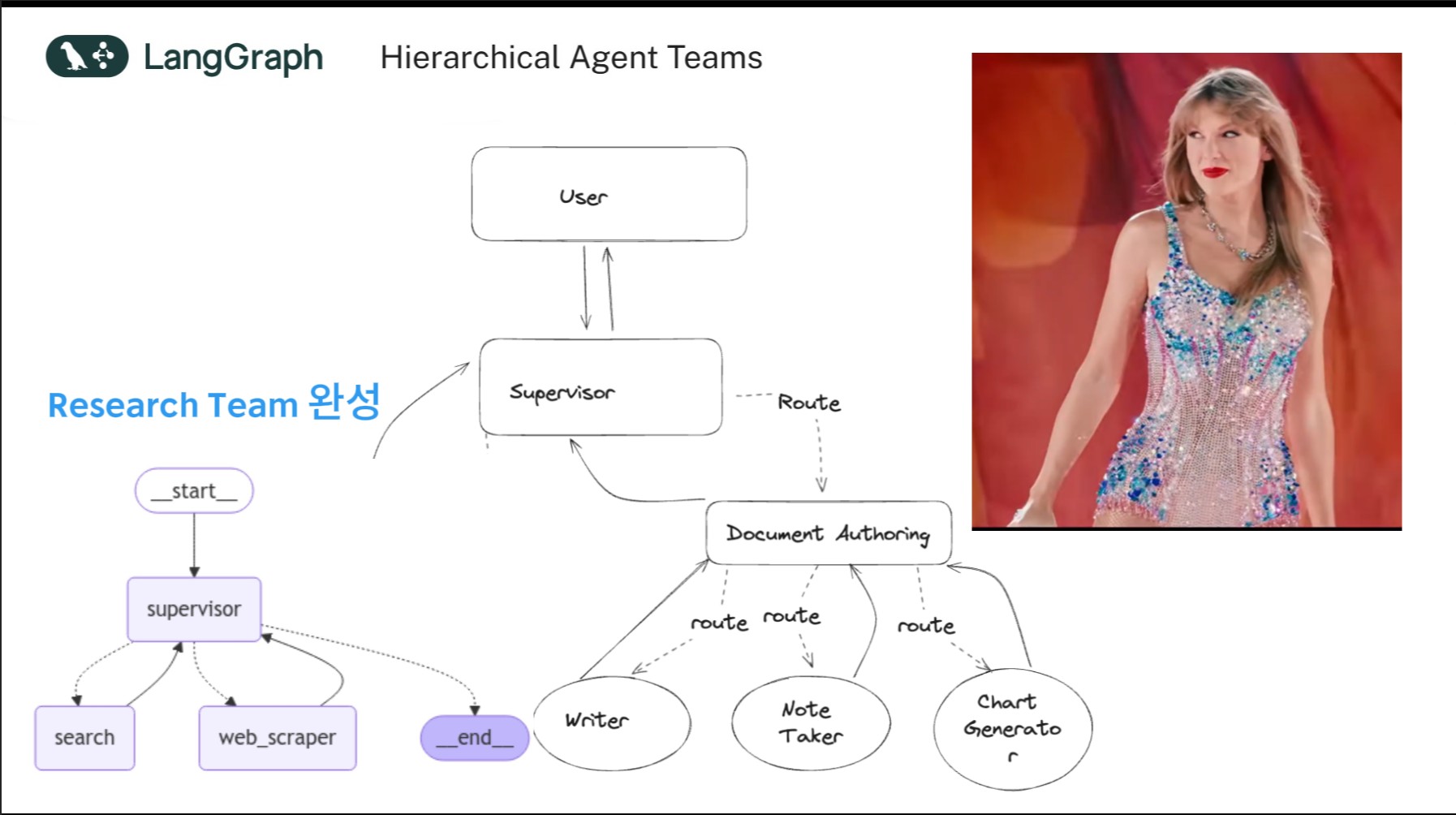
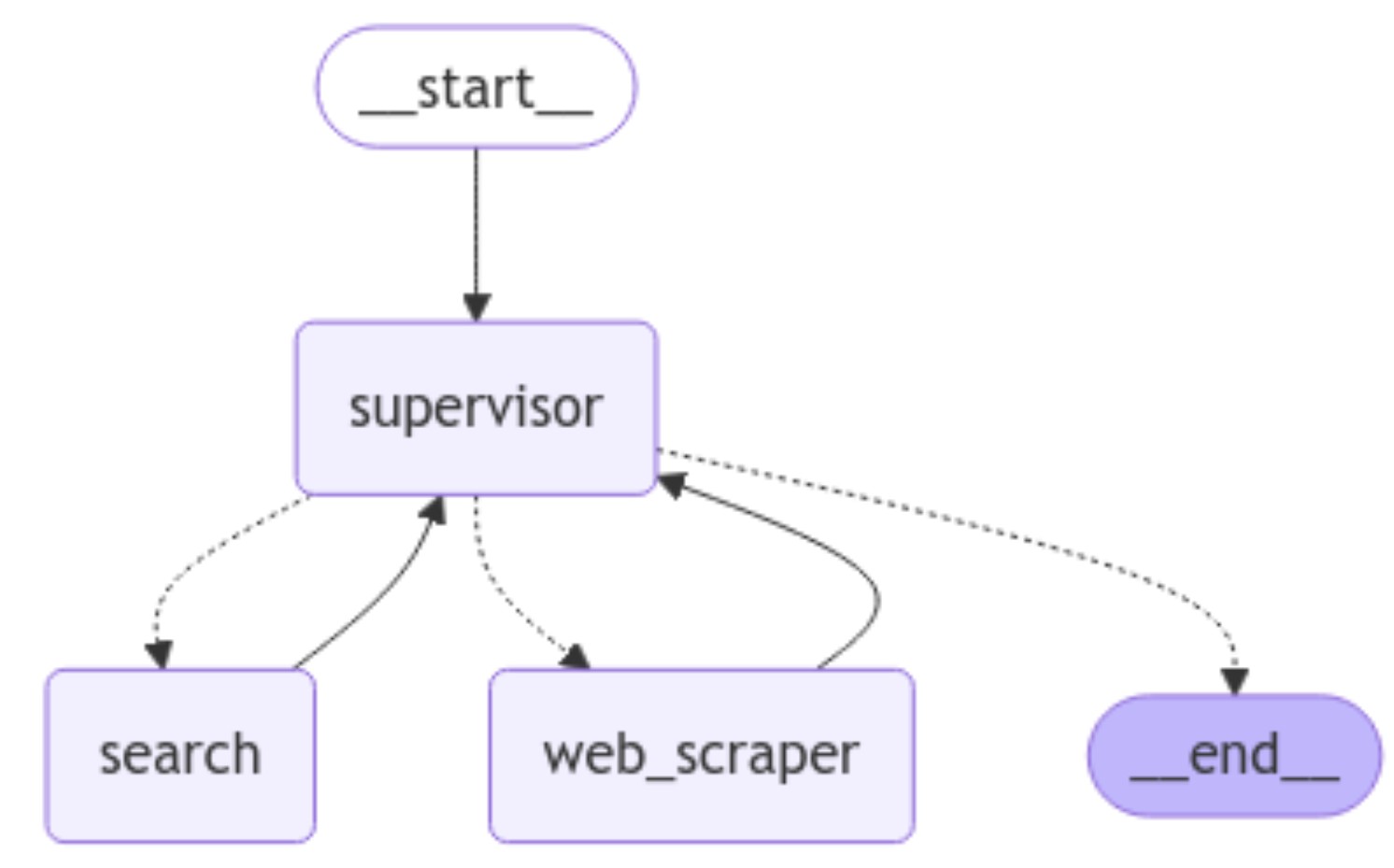
오늘은 본격적으로 REWOO 추론 방법론 LangGraph Tutorial 을 공부를 시작합니다.
AI Agent Application을 개발 하다 보면 도구 사용 관련해서 빈번하게 LLM API call 이 이뤄지게 됩니다.
이 추론 방법론은 추론과 도구사용을 분리함으로서 API call을 줄여 비용 절감을 할 수 있게 해 줍니다.
게다가 성능 향상까지 이루어 줍니다.
이 REWOO 추론 방법론이 비용절감과 성능향상을 동시에 이룰 수 있었던 비밀을 제대로 파헤쳐 보겠습니다.
https://youtu.be/qtob6xrZLwM?si=CctYX3di5F2XjoNi








반응형
'Catchup AI' 카테고리의 다른 글
| AI 시대 취업 및 사업 - 이것을 준비하세요. ReWOO 소스코드 분석 및 IT 직무 변화 전망 (0) | 2025.03.06 |
|---|---|
| 세금 보고 AI 활용 꿀팁 공유! 올해는 AI 와 함께 세금 보고 하세요. (0) | 2025.02.27 |
| 추론 방법론 비교 최종회 - 최강 AI 추론 모델들의 답변은? p.s. 일론 머스크 때문에 순위를 바꾼 사연 (0) | 2025.02.24 |
| 같은 질문에 대해 AI 들은 얼마나 다르게 답변할까? - 추론 방법론을 물어 봤습니다. - (0) | 2025.02.22 |
| AI 시대 준비는 추론에 대한 이해 부터... AI에게 질문을 잘하면 성공합니다. (0) | 2025.02.21 |
| MS AI Agent 어플리케이션 개발 환경 Azure AI Foundry 를 쉽게 설명해 주네요. (0) | 2025.02.17 |
| Microsoft Reactor 강좌 - Getting Started with Generative AI in Azure 1 (2) | 2025.02.16 |
| Plan & Execute 최종회 - 이 소스코드와 DeepSeek R1 의 응답을 비교해 보았습니다. 결과는 ... ㄷㄷㄷ (1) | 2025.02.14 |
| AI Agent, Plan & Execute : Plan 편 - 가장 유명한 K-Pop Girl Group 멤버들의 생일은? 과연 AI 의 대답은? (1) | 2025.02.12 |
| 코딩의 판이 바뀐다 - Prompt를 지배하는자, AI Agent 개발의 챔피언이 됩니다. (0) | 2025.02.08 |