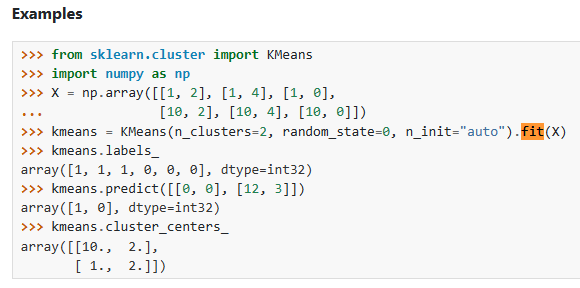
개발자로서 현장에서 일하면서 새로 접하는 기술들이나 알게된 정보 등을 정리하기 위한 블로그입니다. 운 좋게 미국에서 큰 회사들의 프로젝트에서 컬설턴트로 일하고 있어서 새로운 기술들을 접할 기회가 많이 있습니다. 미국의 IT 프로젝트에서 사용되는 툴들에 대해 많은 분들과 정보를 공유하고 싶습니다.
t-SNE decomposition (분해)를 사용해서 dimensionality를 2차원으로 줄입니다.
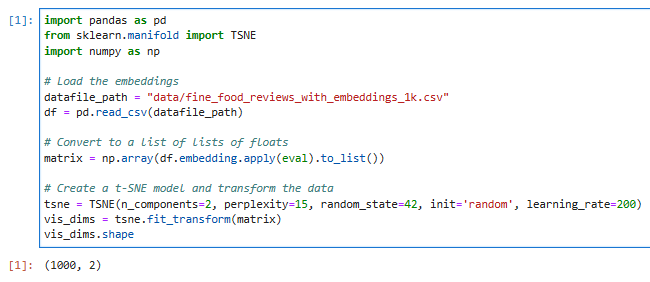
import pandas as pd
from sklearn.manifold import TSNE
import numpy as np
# Load the embeddings
datafile_path = "data/fine_food_reviews_with_embeddings_1k.csv"
df = pd.read_csv(datafile_path)
# Convert to a list of lists of floats
matrix = np.array(df.embedding.apply(eval).to_list())
# Create a t-SNE model and transform the data
tsne = TSNE(n_components=2, perplexity=15, random_state=42, init='random', learning_rate=200)
vis_dims = tsne.fit_transform(matrix)
vis_dims.shape
모듈은 pandas, numpy 그리고 sklearn.manifold의 TSNE를 사용합니다.
모두 이전 글에서 배운 모듈들 입니다.
판다스의 read_csv() 함수를 사용해서 csv 데이터 파일을 읽습니다.
그 다음 numpy 의 array()를 사용해서 csv 파일의 embedding 컬럼에 있는 값들을 리스트 형식으로 변환합니다.
이 값을 shape을 이용해서 리스트의 크기와 차원을 표시하면 위에 처럼 1000,2 라고 나옵니다.
2. Plotting the embeddings
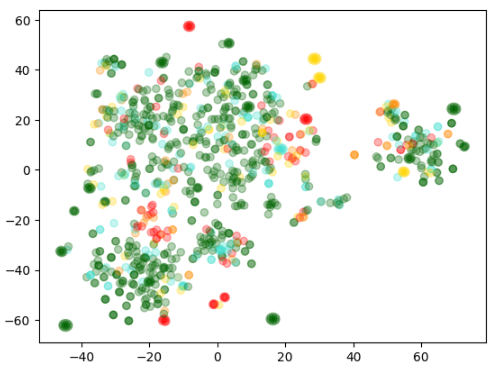
위에서 처럼 2차원으로 데이터를 정리하면 2D 산점도 분포도를 그릴 수 있다고 했습니다.
아래에서는 그것을 그리기 전에 알아보기 쉽도록 각 review에 대한 색을 지정해서 알아보기 쉽도록 합니다.
이 색은 별점 점수와 ranging 데이터를 기반으로 빨간색에서 녹색에 걸쳐 표현됩니다.
import matplotlib.pyplot as plt
import matplotlib
import numpy as np
colors = ["red", "darkorange", "gold", "turquoise", "darkgreen"]
x = [x for x,y in vis_dims]
y = [y for x,y in vis_dims]
color_indices = df.Score.values - 1
colormap = matplotlib.colors.ListedColormap(colors)
plt.scatter(x, y, c=color_indices, cmap=colormap, alpha=0.3)
for score in [0,1,2,3,4]:
avg_x = np.array(x)[df.Score-1==score].mean()
avg_y = np.array(y)[df.Score-1==score].mean()
color = colors[score]
plt.scatter(avg_x, avg_y, marker='x', color=color, s=100)
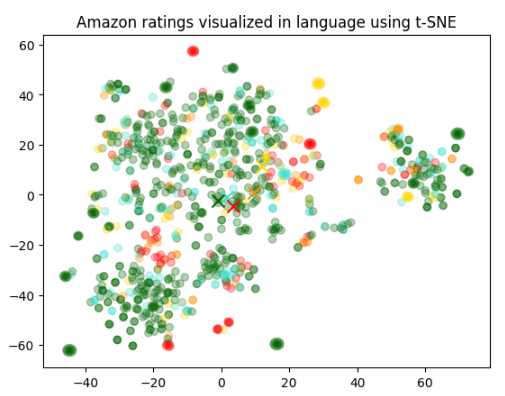
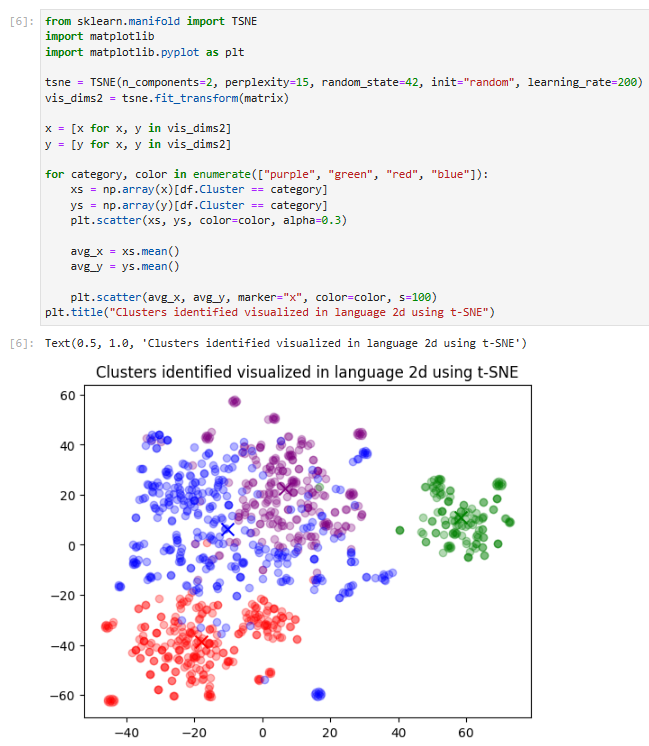
plt.title("Amazon ratings visualized in language using t-SNE")
그리고 plt.title()에서 이 표의 제목을 정해주면 결과와 같은 그림을 얻을 수 있습니다.
4개의 그룹중에 녹색 그룹은 다른 그룹들과 좀 동떨어져 있는 것을 보실 수 있습니다.
2. Text samples in the clusters & naming the clusters
지금까지는 raw data를 clustering 하는 법과 이 clustering 한 데이터를 시각화 해서 보여주는 방법을 보았습니다.
이제 openai의 api를 이용해서 각 클러스터의 랜덤 샘플들을 보여 주는 코드입니다.
openai.Completion.create() api를 사용할 것이고 모델 (engine)은 text-ada-001을 사용합니다.
prompt는 아래 질문 입니다.
What do the following customer reviews have in common?
그러면 각 클러스터 별로 review 를 분석한 값들이 response 됩니다.
우선 아래 코드를 실행 해 보겠습니다.
import openai
def open_file(filepath):
with open(filepath, 'r', encoding='utf-8') as infile:
return infile.read()
openai.api_key = open_file('openaiapikey.txt')
# Reading a review which belong to each group.
rev_per_cluster = 5
for i in range(n_clusters):
print(f"Cluster {i} Theme:", end=" ")
reviews = "\n".join(
df[df.Cluster == i]
.combined.str.replace("Title: ", "")
.str.replace("\n\nContent: ", ": ")
.sample(rev_per_cluster, random_state=42)
.values
)
response = openai.Completion.create(
engine="text-ada-001", #"text-davinci-003",
prompt=f'What do the following customer reviews have in common?\n\nCustomer reviews:\n"""\n{reviews}\n"""\n\nTheme:',
temperature=0,
max_tokens=64,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
)
print(response)
openai를 import 하고 openai api key를 제공하는 부분으로 시작합니다.
그리고 rev_per_cluster는 5로 합니다.
그 다음 for 문에서 n_clusters만큼 루프를 도는데 위에서 n_clusters는 4로 설정돼 있었습니다.
reviews에는 Title과 Content 내용을 넣는데 샘플로 5가지를 무작위로 뽑아서 넣습니다.
그리고 이 reviews 값을 prompt에 삽입해서 openai.Completion.create() api로 request 합니다.
그러면 이 prompt에 대한 response 가 response 변수에 담깁니다.
이 response 만 우선 출력해 보겠습니다.
Cluster 0 Theme: {
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"text": " Customer reviews:gluten free, healthy bars, content:\n\nThe customer reviews have in common that they save money on Amazon by ordering by themselves by looking for gluten free healthy bars. The bars are also delicious."
}
],
"created": 1677191195,
"id": "cmpl-6nEKppB6SqCz07LYTcaktEAgq06hm",
"model": "text-ada-001",
"object": "text_completion",
"usage": {
"completion_tokens": 44,
"prompt_tokens": 415,
"total_tokens": 459
}
}
Cluster 1 Theme: {
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"text": " Cat food\n\nMessy, undelicious, and possibly unhealthy."
}
],
"created": 1677191195,
"id": "cmpl-6nEKpGffRc2jyJB4gNtuCa09dG2GT",
"model": "text-ada-001",
"object": "text_completion",
"usage": {
"completion_tokens": 15,
"prompt_tokens": 529,
"total_tokens": 544
}
}
Cluster 2 Theme: {
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"text": " Coffee\n\nThe customer's reviews have in common that they are among the best in the market, Rodeo Drive, and that the customer is able to enjoy their coffee half and half because they have an Amazon account."
}
],
"created": 1677191196,
"id": "cmpl-6nEKqxza0t8vGRAiK9K5RtCy3Gwbl",
"model": "text-ada-001",
"object": "text_completion",
"usage": {
"completion_tokens": 45,
"prompt_tokens": 443,
"total_tokens": 488
}
}
Cluster 3 Theme: {
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"text": " Customer reviews of different brands of soda."
}
],
"created": 1677191196,
"id": "cmpl-6nEKqKuxe4CVJTV4GlIZ7vxe6F85o",
"model": "text-ada-001",
"object": "text_completion",
"usage": {
"completion_tokens": 8,
"prompt_tokens": 616,
"total_tokens": 624
}
}
이 respons를 보시면 각 Cluster 별로 응답을 받았습니다.
위에 for 문에서 각 클러스터별로 request를 했기 때문입니다.
이제 이 중에서 실제 질문에 대한 답변인 choices - text 부분만 뽑아 보겠습니다.
import openai
def open_file(filepath):
with open(filepath, 'r', encoding='utf-8') as infile:
return infile.read()
openai.api_key = open_file('openaiapikey.txt')
# Reading a review which belong to each group.
rev_per_cluster = 5
for i in range(n_clusters):
print(f"Cluster {i} Theme:", end=" ")
reviews = "\n".join(
df[df.Cluster == i]
.combined.str.replace("Title: ", "")
.str.replace("\n\nContent: ", ": ")
.sample(rev_per_cluster, random_state=42)
.values
)
response = openai.Completion.create(
engine="text-ada-001", #"text-davinci-003",
prompt=f'What do the following customer reviews have in common?\n\nCustomer reviews:\n"""\n{reviews}\n"""\n\nTheme:',
temperature=0,
max_tokens=64,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
)
print(response["choices"][0]["text"].replace("\n", ""))
답변은 아래와 같습니다.
Cluster 0 Theme: Customer reviews:gluten free, healthy bars, content:The customer reviews have in common that they save money on Amazon by ordering by themselves by looking for gluten free healthy bars. The bars are also delicious.
Cluster 1 Theme: Cat foodMessy, undelicious, and possibly unhealthy.
Cluster 2 Theme: CoffeeThe customer's reviews have in common that they are among the best in the market, Rodeo Drive, and that the customer is able to enjoy their coffee half and half because they have an Amazon account.
Cluster 3 Theme: Customer reviews of different brands of soda.
Cluster 0 Theme: Unnamed: 0 ProductId UserId Score \
117 400 B008JKU2CO A1XV4W7JWX341C 5
25 274 B008JKTH2A A34XBAIFT02B60 1
722 534 B0064KO16O A1K2SU61D7G41X 5
289 7 B001KP6B98 ABWCUS3HBDZRS 5
590 948 B008GG2N2S A1CLUIIJL6EHLU 5
Summary \
117 Loved these gluten free healthy bars, saved $$...
25 Should advertise coconut as an ingredient more...
722 very good!!
289 Excellent product
590 delicious
Text \
117 These Kind Bars are so good and healthy & glut...
25 First, these should be called Mac - Coconut ba...
722 just like the runts<br />great flavor, def wor...
289 After scouring every store in town for orange ...
590 Gummi Frogs have been my favourite candy that ...
combined n_tokens \
117 Title: Loved these gluten free healthy bars, s... 96
25 Title: Should advertise coconut as an ingredie... 78
722 Title: very good!!; Content: just like the run... 43
289 Title: Excellent product; Content: After scour... 100
590 Title: delicious; Content: Gummi Frogs have be... 75
embedding Cluster
117 [-0.002289338270202279, -0.01313735730946064, ... 0
25 [-0.01757248118519783, -8.266511576948687e-05,... 0
722 [-0.011768403463065624, -0.025617636740207672,... 0
289 [0.0007493243319913745, -0.017031244933605194,... 0
590 [-0.005802689120173454, 0.0007485789828933775,... 0
Cluster 1 Theme: Unnamed: 0 ProductId UserId Score \
536 731 B0029NIBE8 A3RKYD8IUC5S0N 2
332 184 B000WFRUOC A22RVTZEIVHZA 4
424 153 B0007A0AQW A15X1BO4CLBN3C 5
298 24 B003R0LKRW A1OQSU5KYXEEAE 1
960 589 B003194PBC A2FSDQY5AI6TNX 5
Summary \
536 Messy and apparently undelicious
332 The cats like it
424 cant get enough of it!!!
298 Food Caused Illness
960 My furbabies LOVE these!
Text \
536 My cat is not a huge fan. Sure, she'll lap up ...
332 My 7 cats like this food but it is a little yu...
424 Our lil shih tzu puppy cannot get enough of it...
298 I switched my cats over from the Blue Buffalo ...
960 Shake the container and they come running. Eve...
combined n_tokens \
536 Title: Messy and apparently undelicious; Conte... 181
332 Title: The cats like it; Content: My 7 cats li... 87
424 Title: cant get enough of it!!!; Content: Our ... 59
298 Title: Food Caused Illness; Content: I switche... 131
960 Title: My furbabies LOVE these!; Content: Shak... 47
embedding Cluster
536 [-0.002376032527536154, -0.0027701142244040966... 1
332 [0.02162935584783554, -0.011174295097589493, -... 1
424 [-0.007517425809055567, 0.0037251529283821583,... 1
298 [-0.0011128562036901712, -0.01970377005636692,... 1
960 [-0.009749102406203747, -0.0068712360225617886... 1
Cluster 2 Theme: Unnamed: 0 ProductId UserId Score \
135 410 B007Y59HVM A2ERWXZEUD6APD 5
439 812 B0001UK0CM A2V8WXAFG1TEOC 5
326 107 B003VXFK44 A21VWSCGW7UUAR 4
475 852 B000I6MCSY AO34Q3JGZU0JQ 5
692 922 B003TC7WN4 A3GFZIL1E0Z5V8 5
Summary \
135 Fog Chaser Coffee
439 Excellent taste
326 Good, but not Wolfgang Puck good
475 Just My Kind of Coffee
692 Rodeo Drive is Crazy Good Coffee!
Text \
135 This coffee has a full body and a rich taste. ...
439 This is to me a great coffee, once you try it ...
326 Honestly, I have to admit that I expected a li...
475 Coffee Masters Hazelnut coffee used to be carr...
692 Rodeo Drive is my absolute favorite and I'm re...
combined n_tokens \
135 Title: Fog Chaser Coffee; Content: This coffee... 42
439 Title: Excellent taste; Content: This is to me... 31
326 Title: Good, but not Wolfgang Puck good; Conte... 178
475 Title: Just My Kind of Coffee; Content: Coffee... 118
692 Title: Rodeo Drive is Crazy Good Coffee!; Cont... 59
embedding Cluster
135 [0.006498195696622133, 0.006776264403015375, 0... 2
439 [0.0039436533115804195, -0.005451332312077284,... 2
326 [-0.003140551969408989, -0.009995664469897747,... 2
475 [0.010913548991084099, -0.014923149719834328, ... 2
692 [-0.029914353042840958, -0.007755572907626629,... 2
Cluster 3 Theme: Unnamed: 0 ProductId UserId Score \
495 831 B0014X5O1C AHYRTWABDAG1H 5
978 642 B00264S63G A36AUU1UNRS48G 5
916 686 B008PYVINQ A1DRWYIO7JN1MD 2
696 926 B0062P9XPU A33KQALCZGXG8C 5
491 828 B000EIE20M A39QHSDUBR8L0T 3
Summary \
495 Wonderful alternative to soda pop
978 So convenient, for so little!
916 bot very cheesy
696 Delicious!
491 Just ok
Text \
495 This is a wonderful alternative to soda pop. ...
978 I needed two vanilla beans for the Love Goddes...
916 Got this about a month ago.first of all it sme...
696 I am not a huge beer lover. I do enjoy an occ...
491 I bought this brand because it was all they ha...
combined n_tokens \
495 Title: Wonderful alternative to soda pop; Cont... 273
978 Title: So convenient, for so little!; Content:... 121
916 Title: bot very cheesy; Content: Got this abou... 46
696 Title: Delicious!; Content: I am not a huge be... 97
491 Title: Just ok; Content: I bought this brand b... 58
embedding Cluster
495 [0.022326279431581497, -0.018449820578098297, ... 3
978 [-0.004598899278789759, -0.01737511157989502, ... 3
916 [-0.010750919580459595, -0.0193503275513649, -... 3
696 [0.009483409114181995, -0.017691848799586296, ... 3
491 [-0.0023960231337696314, -0.006881058216094971... 3
여기서 데이터를 아래와 같이 가공을 합니다.
for j in range(rev_per_cluster):
print(sample_cluster_rows.Score.values[j], end=", ")
print(sample_cluster_rows.Summary.values[j], end=": ")
print(sample_cluster_rows.Text.str[:70].values[j])
Score의 값들을 가지고 오고 끝에는 쉼표 , 를 붙입니다.
그리고 Summary의 값을 가지고 오고 끝에는 : 를 붙입니다.
그리고 Text컬럼의 string을 가지고 오는데 70자 까지만 가지고 옵니다.
전체 결과를 보겠습니다.
Cluster 0 Theme: Customer reviews:gluten free, healthy bars, content:The customer reviews have in common that they save money on Amazon by ordering by themselves by looking for gluten free healthy bars. The bars are also delicious.
5, Loved these gluten free healthy bars, saved $$ ordering on Amazon: These Kind Bars are so good and healthy & gluten free. My daughter ca
1, Should advertise coconut as an ingredient more prominently: First, these should be called Mac - Coconut bars, as Coconut is the #2
5, very good!!: just like the runts<br />great flavor, def worth getting<br />I even o
5, Excellent product: After scouring every store in town for orange peels and not finding an
5, delicious: Gummi Frogs have been my favourite candy that I have ever tried. of co
Cluster 1 Theme: Cat foodMessy, undelicious, and possibly unhealthy.
2, Messy and apparently undelicious: My cat is not a huge fan. Sure, she'll lap up the gravy, but leaves th
4, The cats like it: My 7 cats like this food but it is a little yucky for the human. Piece
5, cant get enough of it!!!: Our lil shih tzu puppy cannot get enough of it. Everytime she sees the
1, Food Caused Illness: I switched my cats over from the Blue Buffalo Wildnerness Food to this
5, My furbabies LOVE these!: Shake the container and they come running. Even my boy cat, who isn't
Cluster 2 Theme: CoffeeThe customer's reviews have in common that they are among the best in the market, Rodeo Drive, and that the customer is able to enjoy their coffee half and half because they have an Amazon account.
5, Fog Chaser Coffee: This coffee has a full body and a rich taste. The price is far below t
5, Excellent taste: This is to me a great coffee, once you try it you will enjoy it, this
4, Good, but not Wolfgang Puck good: Honestly, I have to admit that I expected a little better. That's not
5, Just My Kind of Coffee: Coffee Masters Hazelnut coffee used to be carried in a local coffee/pa
5, Rodeo Drive is Crazy Good Coffee!: Rodeo Drive is my absolute favorite and I'm ready to order more! That
Cluster 3 Theme: Customer reviews of different brands of soda.
5, Wonderful alternative to soda pop: This is a wonderful alternative to soda pop. It's carbonated for thos
5, So convenient, for so little!: I needed two vanilla beans for the Love Goddess cake that my husbands
2, bot very cheesy: Got this about a month ago.first of all it smells horrible...it tastes
5, Delicious!: I am not a huge beer lover. I do enjoy an occasional Blue Moon (all o
3, Just ok: I bought this brand because it was all they had at Ranch 99 near us. I
이제 좀 보기 좋게 됐습니다.
이번 예제는 raw 데이터를 파이썬의 여러 모듈들을 이용해서 clustering을 하고 이 cluster별로 openai.Completion.create() api를 이용해서 궁금한 답을 받는 일을 하는 예제를 배웠습니다.
큰 raw data를 카테고리화 해서 나누고 이에 대한 summary나 기타 정보를 Completion api를 통해 얻을 수 있는 방법입니다.
전체 소스코드는 아래와 같습니다.
# imports
import numpy as np
import pandas as pd
# load data
datafile_path = "./data/fine_food_reviews_with_embeddings_1k.csv"
df = pd.read_csv(datafile_path)
df["embedding"] = df.embedding.apply(eval).apply(np.array) # convert string to numpy array
matrix = np.vstack(df.embedding.values)
matrix.shape
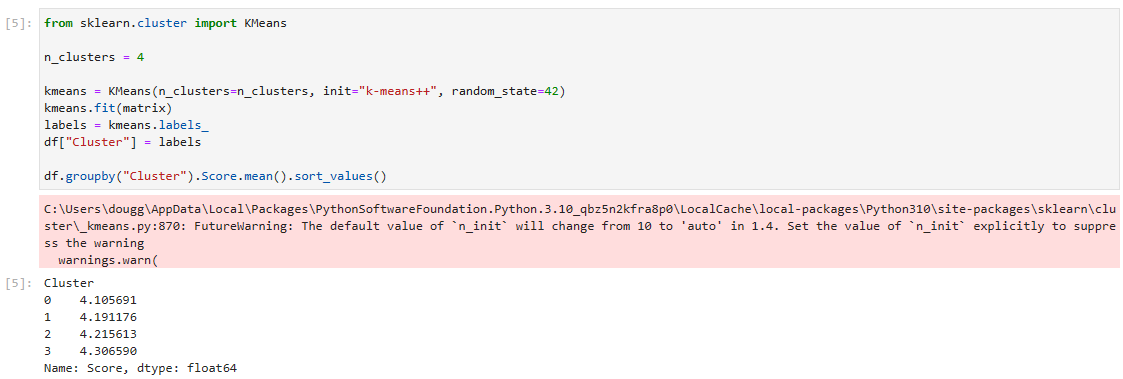
from sklearn.cluster import KMeans
n_clusters = 4
kmeans = KMeans(n_clusters=n_clusters, init="k-means++", random_state=42)
kmeans.fit(matrix)
labels = kmeans.labels_
df["Cluster"] = labels
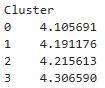
df.groupby("Cluster").Score.mean().sort_values()
from sklearn.manifold import TSNE
import matplotlib
import matplotlib.pyplot as plt
tsne = TSNE(n_components=2, perplexity=15, random_state=42, init="random", learning_rate=200)
vis_dims2 = tsne.fit_transform(matrix)
x = [x for x, y in vis_dims2]
y = [y for x, y in vis_dims2]
for category, color in enumerate(["purple", "green", "red", "blue"]):
xs = np.array(x)[df.Cluster == category]
ys = np.array(y)[df.Cluster == category]
plt.scatter(xs, ys, color=color, alpha=0.3)
avg_x = xs.mean()
avg_y = ys.mean()
plt.scatter(avg_x, avg_y, marker="x", color=color, s=100)
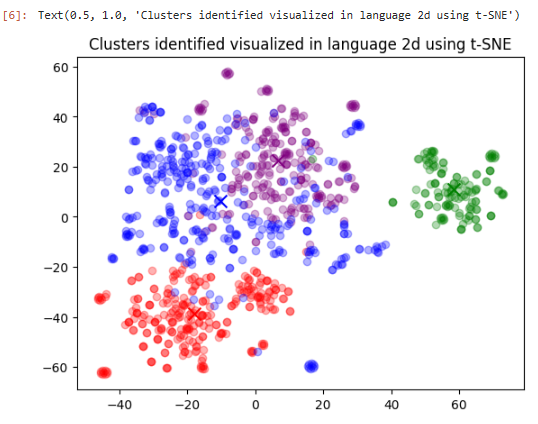
plt.title("Clusters identified visualized in language 2d using t-SNE")
import openai
def open_file(filepath):
with open(filepath, 'r', encoding='utf-8') as infile:
return infile.read()
openai.api_key = open_file('openaiapikey.txt')
# Reading a review which belong to each group.
rev_per_cluster = 5
for i in range(n_clusters):
print(f"Cluster {i} Theme:", end=" ")
reviews = "\n".join(
df[df.Cluster == i]
.combined.str.replace("Title: ", "")
.str.replace("\n\nContent: ", ": ")
.sample(rev_per_cluster, random_state=42)
.values
)
response = openai.Completion.create(
engine="text-ada-001", #"text-davinci-003",
prompt=f'What do the following customer reviews have in common?\n\nCustomer reviews:\n"""\n{reviews}\n"""\n\nTheme:',
temperature=0,
max_tokens=64,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
)
print(response["choices"][0]["text"].replace("\n", ""))
sample_cluster_rows = df[df.Cluster == i].sample(rev_per_cluster, random_state=42)
for j in range(rev_per_cluster):
print(sample_cluster_rows.Score.values[j], end=", ")
print(sample_cluster_rows.Summary.values[j], end=": ")
print(sample_cluster_rows.Text.str[:70].values[j])