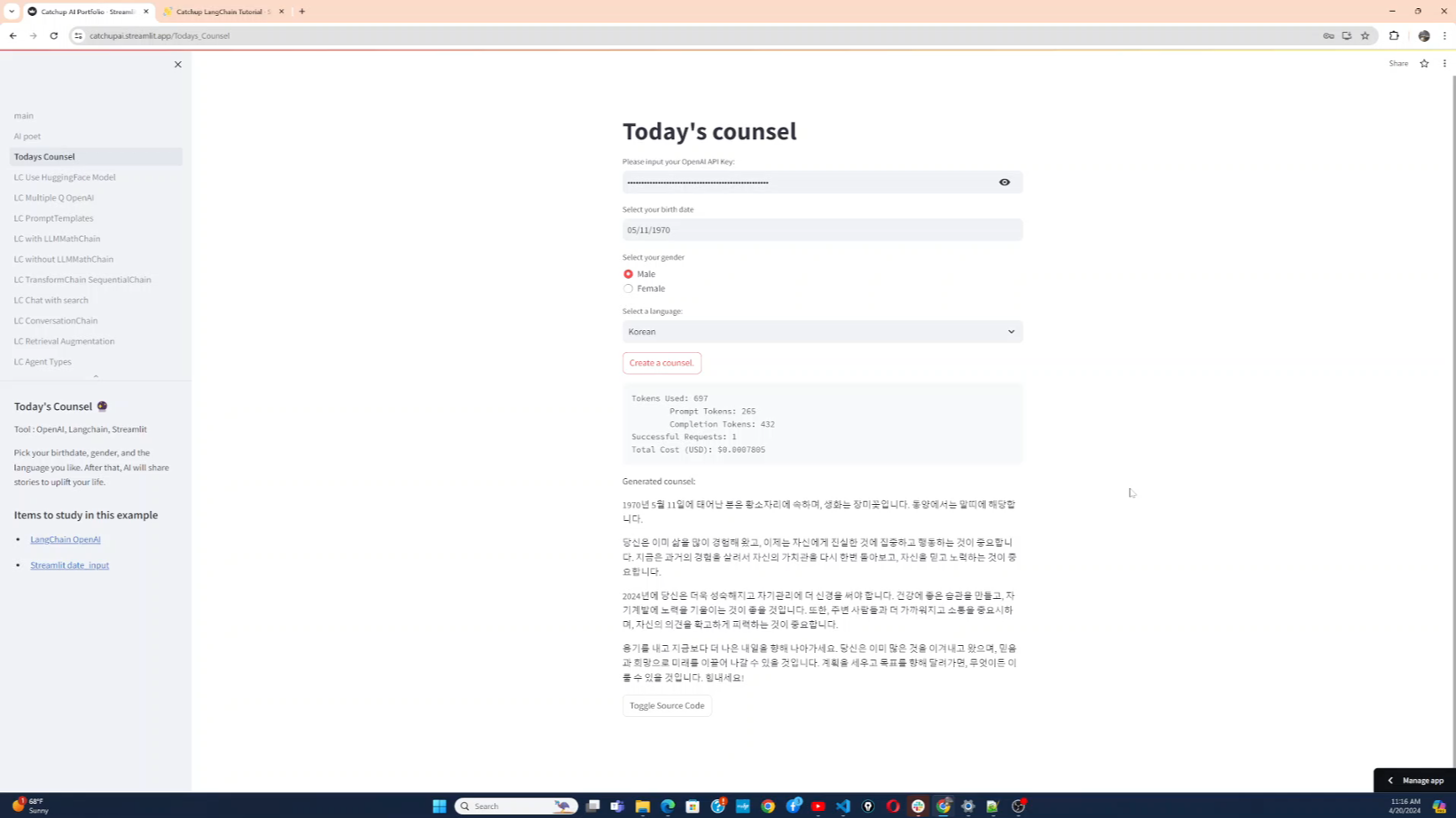
개발자로서 현장에서 일하면서 새로 접하는 기술들이나 알게된 정보 등을 정리하기 위한 블로그입니다. 운 좋게 미국에서 큰 회사들의 프로젝트에서 컬설턴트로 일하고 있어서 새로운 기술들을 접할 기회가 많이 있습니다. 미국의 IT 프로젝트에서 사용되는 툴들에 대해 많은 분들과 정보를 공유하고 싶습니다.
한국에 있을 때 Six Sigma니 잭 웰치니 하면서 GE 성장의 신화를 만들어낸 경영 기법이라면서 배워야할 모범이라고 배웠었다.
하지만 GE의 몰락을 그 안에서 직접 겪으면서 느꼈던 것은 비 인간적이고 단기 성과에 몰두하고 금융의 숫자 놀음으로 실적을 올리는 그리고 GE의 본 모습인 기술 기업을 버리고 문어발식 사업확장을 했던 잭웰치의 경영이 GE를 병들게 했고 결국은 이렇게 망하게 하는 구나 하는 생각을 하게 됐다.
아래 기사를 보면서 GE에서 일하면서 느꼈던 나의 그런 생각과 너무 일치해서 반가왔다.
비인간적이고 단기 성과에 몰두하는 경영방식이 결국은 회사를 어떻게 속으로 병들게 하고 망하게 하는지 GE를 통해서 많은 기업인들이 배워야 된다고 생각한다.