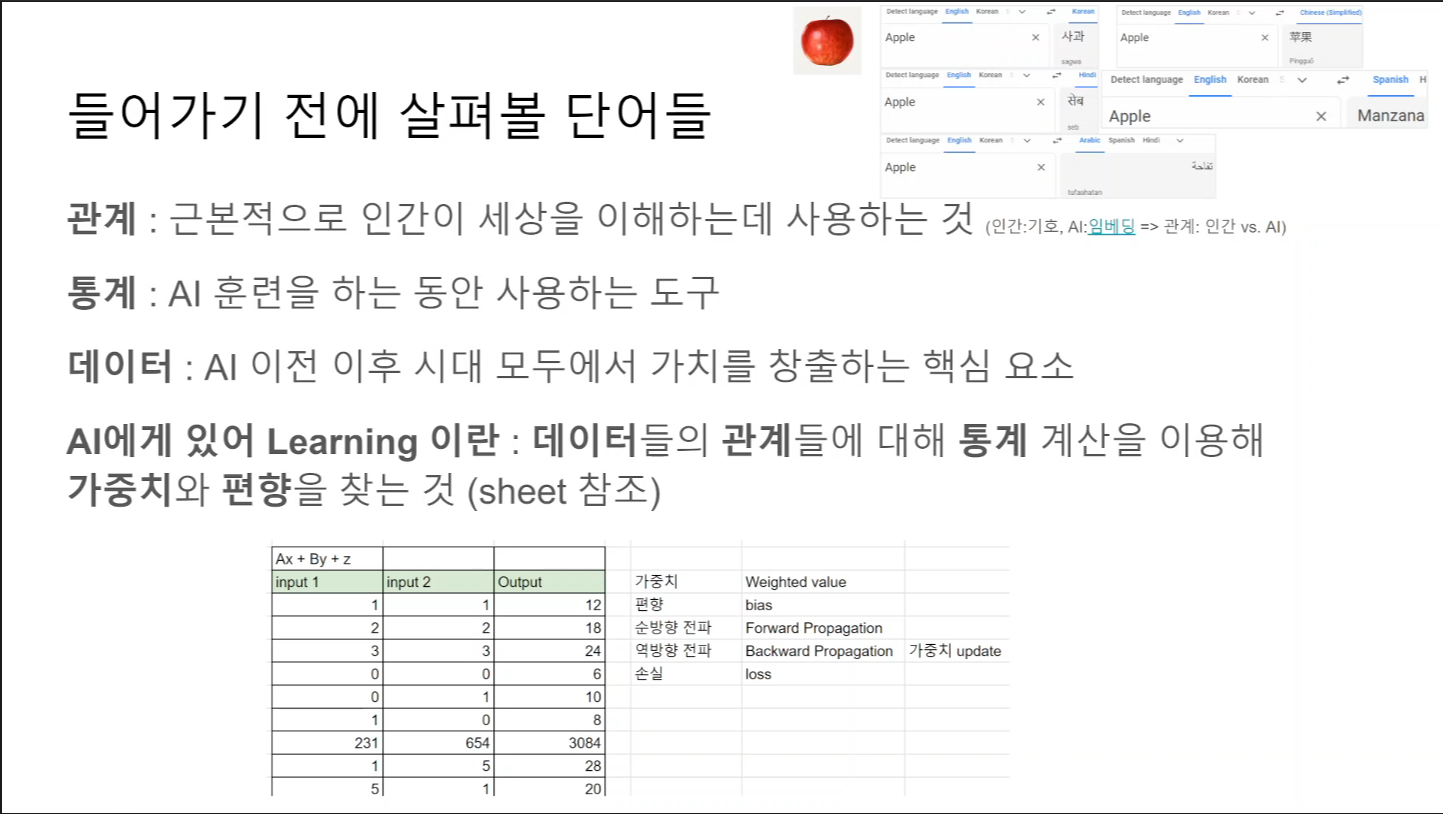
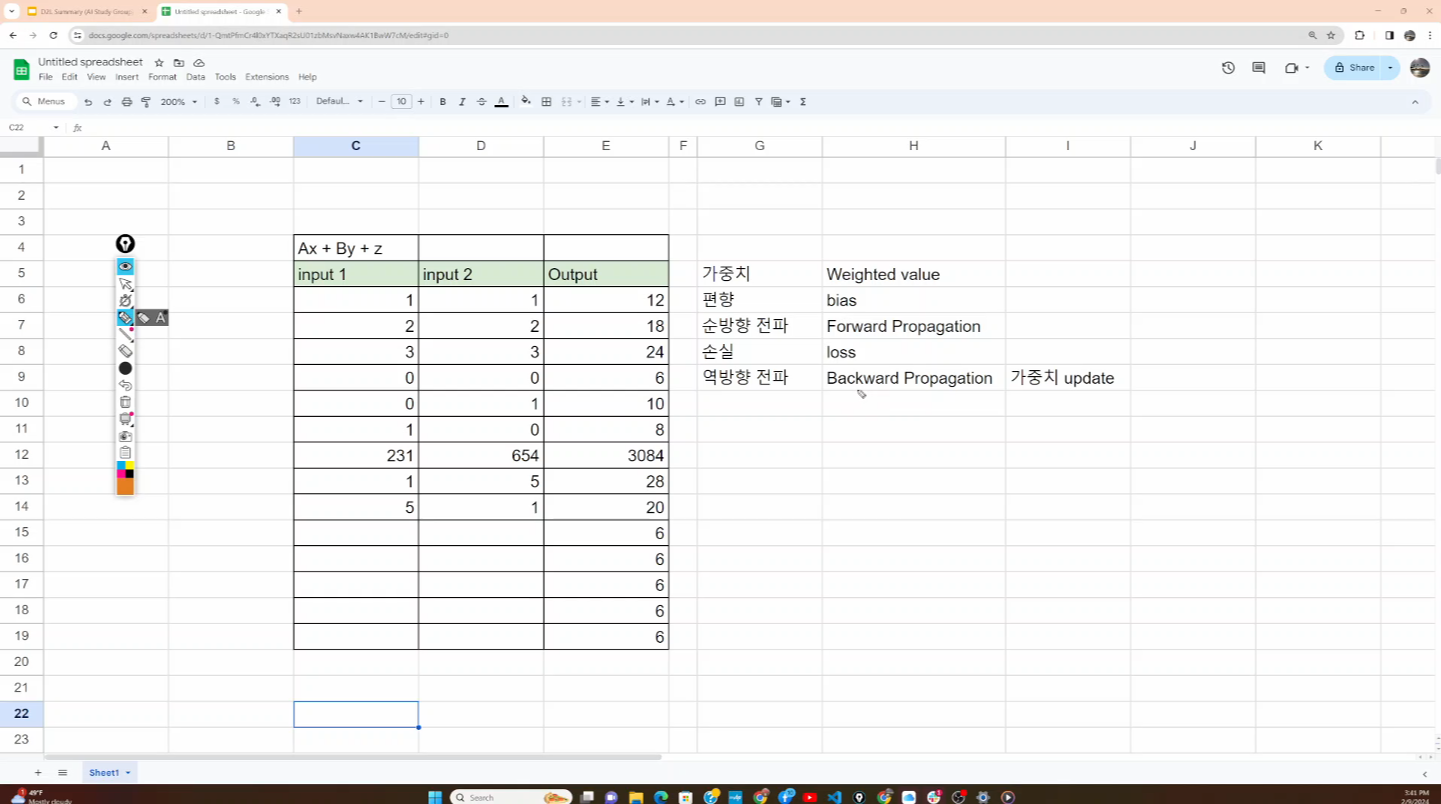
개발자로서 현장에서 일하면서 새로 접하는 기술들이나 알게된 정보 등을 정리하기 위한 블로그입니다. 운 좋게 미국에서 큰 회사들의 프로젝트에서 컬설턴트로 일하고 있어서 새로운 기술들을 접할 기회가 많이 있습니다. 미국의 IT 프로젝트에서 사용되는 툴들에 대해 많은 분들과 정보를 공유하고 싶습니다.
To best understand the agent framework, let’s build an agent that has two tools: one to look things up online, and one to look up specific data that we’ve loaded into a index.
에이전트 프레임워크를 가장 잘 이해하기 위해 두 가지 도구가 있는 에이전트를 구축해 보겠습니다. 하나는 온라인으로 항목을 조회하는 도구이고 다른 하나는 인덱스에 로드한 특정 데이터를 조회하는 도구입니다.
This will assume knowledge ofLLMsandretrievalso if you haven’t already explored those sections, it is recommended you do so.
이는 LLM 및 검색에 대한 지식을 가정하므로 해당 섹션을 아직 탐색하지 않았다면 탐색하는 것이 좋습니다.
By definition, agents take a self-determined, input-dependent sequence of steps before returning a user-facing output. This makes debugging these systems particularly tricky, and observability particularly important.LangSmithis especially useful for such cases.
정의에 따르면 에이전트는 사용자에게 표시되는 출력을 반환하기 전에 입력에 따라 자체 결정된 일련의 단계를 수행합니다. 이로 인해 이러한 시스템을 디버깅하는 것이 특히 까다로워지고 관찰 가능성이 특히 중요해집니다. LangSmith는 이러한 경우에 특히 유용합니다.
When building with LangChain, all steps will automatically be traced in LangSmith. To set up LangSmith we just need set the following environment variables:
LangChain으로 구축할 때 모든 단계는 LangSmith에서 자동으로 추적됩니다. LangSmith를 설정하려면 다음 환경 변수만 설정하면 됩니다.
We first need to create the tools we want to use. We will use two tools:Tavily(to search online) and then a retriever over a local index we will create
먼저 사용하려는 도구를 만들어야 합니다. 우리는 두 가지 도구를 사용할 것입니다: Tavily(온라인 검색용)와 우리가 생성할 로컬 인덱스에 대한 검색기
We have a built-in tool in LangChain to easily use Tavily search engine as tool. Note that this requires an API key - they have a free tier, but if you don’t have one or don’t want to create one, you can always ignore this step.
우리는 Tavily 검색 엔진을 도구로 쉽게 사용할 수 있도록 LangChain에 내장된 도구를 가지고 있습니다. 이를 위해서는 API 키가 필요합니다. 무료 등급이 있지만 API 키가 없거나 생성하고 싶지 않은 경우 언제든지 이 단계를 무시할 수 있습니다.
Once you create your API key, you will need to export that as:
API 키를 생성한 후에는 이를 다음과 같이 내보내야 합니다.
export TAVILY_API_KEY="..."
from langchain_community.tools.tavily_search import TavilySearchResults
search = TavilySearchResults()
search.invoke("what is the weather in SF")
[{'url': 'https://www.metoffice.gov.uk/weather/forecast/9q8yym8kr',
'content': 'Thu 11 Jan Thu 11 Jan Seven day forecast for San Francisco San Francisco (United States of America) weather Find a forecast Sat 6 Jan Sat 6 Jan Sun 7 Jan Sun 7 Jan Mon 8 Jan Mon 8 Jan Tue 9 Jan Tue 9 Jan Wed 10 Jan Wed 10 Jan Thu 11 Jan Find a forecast Please choose your location from the nearest places to : Forecast days Today Today Sat 6 Jan Sat 6 JanSan Francisco 7 day weather forecast including weather warnings, temperature, rain, wind, visibility, humidity and UV ... (11 January 2024) Time 00:00 01:00 02:00 03:00 04:00 05:00 06:00 07:00 08:00 09:00 10:00 11:00 12:00 ... Oakland Int. 11.5 miles; San Francisco International 11.5 miles; Corte Madera 12.3 miles; Redwood City 23.4 miles;'},
{'url': 'https://www.latimes.com/travel/story/2024-01-11/east-brother-light-station-lighthouse-california',
'content': "May 18, 2023 Jan. 4, 2024 Subscribe for unlimited accessSite Map Follow Us MORE FROM THE L.A. TIMES Jan. 8, 2024 Travel & Experiences This must be Elysian Valley (a.k.a. Frogtown) Jan. 5, 2024 Food June 30, 2023The East Brother Light Station in the San Francisco Bay is not a destination for everyone. ... Jan. 11, 2024 3 AM PT ... Champagne and hors d'oeuvres are served in late afternoon — outdoors if ..."}]
We will also create a retriever over some data of our own. For a deeper explanation of each step here, seethis section.
우리는 또한 우리 자신의 일부 데이터에 대한 검색기를 만들 것입니다. 각 단계에 대한 자세한 설명은 이 섹션을 참조하세요.
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
loader = WebBaseLoader("https://docs.smith.langchain.com/overview")
docs = loader.load()
documents = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=200
).split_documents(docs)
vector = FAISS.from_documents(documents, OpenAIEmbeddings())
retriever = vector.as_retriever()
retriever.get_relevant_documents("how to upload a dataset")[0]
Document(page_content="dataset uploading.Once we have a dataset, how can we use it to test changes to a prompt or chain? The most basic approach is to run the chain over the data points and visualize the outputs. Despite technological advancements, there still is no substitute for looking at outputs by eye. Currently, running the chain over the data points needs to be done client-side. The LangSmith client makes it easy to pull down a dataset and then run a chain over them, logging the results to a new project associated with the dataset. From there, you can review them. We've made it easy to assign feedback to runs and mark them as correct or incorrect directly in the web app, displaying aggregate statistics for each test project.We also make it easier to evaluate these runs. To that end, we've added a set of evaluators to the open-source LangChain library. These evaluators can be specified when initiating a test run and will evaluate the results once the test run completes. If we’re being honest, most of", metadata={'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith', 'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en'})
Now that we have populated our index that we will do doing retrieval over, we can easily turn it into a tool (the format needed for an agent to properly use it)
이제 검색을 수행할 인덱스를 채웠으므로 이를 도구(에이전트가 올바르게 사용하는 데 필요한 형식)로 쉽게 전환할 수 있습니다.
from langchain.tools.retriever import create_retriever_tool
retriever_tool = create_retriever_tool(
retriever,
"langsmith_search",
"Search for information about LangSmith. For any questions about LangSmith, you must use this tool!",
)
Now that we have defined the tools, we can create the agent. We will be using an OpenAI Functions agent - for more information on this type of agent, as well as other options, seethis guide
from langchain import hub
# Get the prompt to use - you can modify this!
prompt = hub.pull("hwchase17/openai-functions-agent")
prompt.messages
[SystemMessagePromptTemplate(prompt=PromptTemplate(input_variables=[], template='You are a helpful assistant')),
MessagesPlaceholder(variable_name='chat_history', optional=True),
HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['input'], template='{input}')),
MessagesPlaceholder(variable_name='agent_scratchpad')]
Now, we can initalize the agent with the LLM, the prompt, and the tools. The agent is responsible for taking in input and deciding what actions to take. Crucially, the Agent does not execute those actions - that is done by the AgentExecutor (next step). For more information about how to think about these components, see ourconceptual guide
이제 LLM, 프롬프트 및 도구를 사용하여 에이전트를 초기화할 수 있습니다. 에이전트는 입력을 받아들이고 어떤 조치를 취할지 결정하는 역할을 담당합니다. 결정적으로 에이전트는 이러한 작업을 실행하지 않습니다. 이는 AgentExecutor(다음 단계)에 의해 수행됩니다. 이러한 구성 요소에 대해 생각하는 방법에 대한 자세한 내용은 개념 가이드를 참조하세요.
from langchain.agents import create_openai_functions_agent
agent = create_openai_functions_agent(llm, tools, prompt)
Finally, we combine the agent (the brains) with the tools inside the AgentExecutor (which will repeatedly call the agent and execute tools). For more information about how to think about these components, see ourconceptual guide
We can now run the agent on a few queries! Note that for now, these are allstatelessqueries (it won’t remember previous interactions).
이제 몇 가지 쿼리에 대해 에이전트를 실행할 수 있습니다! 현재로서는 이는 모두 상태 비저장 쿼리입니다(이전 상호 작용을 기억하지 않음).
agent_executor.invoke({"input": "hi!"})
> Entering new AgentExecutor chain...
Hello! How can I assist you today?
> Finished chain.
{'input': 'hi!', 'output': 'Hello! How can I assist you today?'}
agent_executor.invoke({"input": "how can langsmith help with testing?"})
> Entering new AgentExecutor chain...
Invoking: `langsmith_search` with `{'query': 'LangSmith testing'}`
[Document(page_content='LangSmith Overview and User Guide | 🦜️🛠️ LangSmith', metadata={'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith', 'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en'}), Document(page_content='Skip to main content🦜️🛠️ LangSmith DocsPython DocsJS/TS DocsSearchGo to AppLangSmithOverviewTracingTesting & EvaluationOrganizationsHubLangSmith CookbookOverviewOn this pageLangSmith Overview and User GuideBuilding reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.Over the past two months, we at LangChain have been building and using LangSmith with the goal of bridging this gap. This is our tactical user guide to outline effective ways to use LangSmith and maximize its benefits.On by default\u200bAt LangChain, all of us have LangSmith’s tracing running in the background by default. On the Python side, this is achieved by setting environment variables, which we establish whenever we launch a virtual environment or open our bash shell and leave them set. The same principle applies to most JavaScript', metadata={'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith', 'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en'}), Document(page_content='You can also quickly edit examples and add them to datasets to expand the surface area of your evaluation sets or to fine-tune a model for improved quality or reduced costs.Monitoring\u200bAfter all this, your app might finally ready to go in production. LangSmith can also be used to monitor your application in much the same way that you used for debugging. You can log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise. Each run can also be assigned string tags or key-value metadata, allowing you to attach correlation ids or AB test variants, and filter runs accordingly.We’ve also made it possible to associate feedback programmatically with runs. This means that if your application has a thumbs up/down button on it, you can use that to log feedback back to LangSmith. This can be used to track performance over time and pinpoint under performing data points, which you can subsequently add to a dataset for future testing — mirroring the', metadata={'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith', 'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en'}), Document(page_content='inputs, and see what happens. At some point though, our application is performing\nwell and we want to be more rigorous about testing changes. We can use a dataset\nthat we’ve constructed along the way (see above). Alternatively, we could spend some\ntime constructing a small dataset by hand. For these situations, LangSmith simplifies', metadata={'source': 'https://docs.smith.langchain.com/overview', 'title': 'LangSmith Overview and User Guide | 🦜️🛠️ LangSmith', 'description': 'Building reliable LLM applications can be challenging. LangChain simplifies the initial setup, but there is still work needed to bring the performance of prompts, chains and agents up the level where they are reliable enough to be used in production.', 'language': 'en'})]LangSmith can help with testing in several ways. Here are some ways LangSmith can assist with testing:
1. Tracing: LangSmith provides tracing capabilities that can be used to monitor and debug your application during testing. You can log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise.
2. Evaluation: LangSmith allows you to quickly edit examples and add them to datasets to expand the surface area of your evaluation sets. This can help you test and fine-tune your models for improved quality or reduced costs.
3. Monitoring: Once your application is ready for production, LangSmith can be used to monitor your application. You can log feedback programmatically with runs, track performance over time, and pinpoint underperforming data points. This information can be used to improve your application and add to datasets for future testing.
4. Rigorous Testing: When your application is performing well and you want to be more rigorous about testing changes, LangSmith can simplify the process. You can use existing datasets or construct small datasets by hand to test different scenarios and evaluate the performance of your application.
For more detailed information on how to use LangSmith for testing, you can refer to the [LangSmith Overview and User Guide](https://docs.smith.langchain.com/overview).
> Finished chain.
{'input': 'how can langsmith help with testing?',
'output': 'LangSmith can help with testing in several ways. Here are some ways LangSmith can assist with testing:\n\n1. Tracing: LangSmith provides tracing capabilities that can be used to monitor and debug your application during testing. You can log all traces, visualize latency and token usage statistics, and troubleshoot specific issues as they arise.\n\n2. Evaluation: LangSmith allows you to quickly edit examples and add them to datasets to expand the surface area of your evaluation sets. This can help you test and fine-tune your models for improved quality or reduced costs.\n\n3. Monitoring: Once your application is ready for production, LangSmith can be used to monitor your application. You can log feedback programmatically with runs, track performance over time, and pinpoint underperforming data points. This information can be used to improve your application and add to datasets for future testing.\n\n4. Rigorous Testing: When your application is performing well and you want to be more rigorous about testing changes, LangSmith can simplify the process. You can use existing datasets or construct small datasets by hand to test different scenarios and evaluate the performance of your application.\n\nFor more detailed information on how to use LangSmith for testing, you can refer to the [LangSmith Overview and User Guide](https://docs.smith.langchain.com/overview).'}
As mentioned earlier, this agent is stateless. This means it does not remember previous interactions. To give it memory we need to pass in previouschat_history. Note: it needs to be calledchat_historybecause of the prompt we are using. If we use a different prompt, we could change the variable name
앞서 언급했듯이 이 에이전트는 Stateless입니다. 이는 이전 상호작용을 기억하지 못한다는 것을 의미합니다. 메모리를 제공하려면 이전 chat_history를 전달해야 합니다. 참고: 우리가 사용하는 프롬프트 때문에 chat_history라고 불러야 합니다. 다른 프롬프트를 사용하면 변수 이름을 변경할 수 있습니다.
# Here we pass in an empty list of messages for chat_history because it is the first message in the chat
agent_executor.invoke({"input": "hi! my name is bob", "chat_history": []})
> Entering new AgentExecutor chain...
Hello Bob! How can I assist you today?
> Finished chain.
{'input': 'hi! my name is bob',
'chat_history': [],
'output': 'Hello Bob! How can I assist you today?'}
from langchain_core.messages import AIMessage, HumanMessage
agent_executor.invoke(
{
"chat_history": [
HumanMessage(content="hi! my name is bob"),
AIMessage(content="Hello Bob! How can I assist you today?"),
],
"input": "what's my name?",
}
)
> Entering new AgentExecutor chain...
Your name is Bob.
> Finished chain.
{'chat_history': [HumanMessage(content='hi! my name is bob'),
AIMessage(content='Hello Bob! How can I assist you today?')],
'input': "what's my name?",
'output': 'Your name is Bob.'}
If we want to keep track of these messages automatically, we can wrap this in a RunnableWithMessageHistory. For more information on how to use this, seethis guide
이러한 메시지를 자동으로 추적하려면 이를 RunnableWithMessageHistory로 래핑할 수 있습니다. 이를 사용하는 방법에 대한 자세한 내용은 이 가이드를 참조하세요.
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
message_history = ChatMessageHistory()
agent_with_chat_history = RunnableWithMessageHistory(
agent_executor,
# This is needed because in most real world scenarios, a session id is needed
# It isn't really used here because we are using a simple in memory ChatMessageHistory
lambda session_id: message_history,
input_messages_key="input",
history_messages_key="chat_history",
)
agent_with_chat_history.invoke(
{"input": "hi! I'm bob"},
# This is needed because in most real world scenarios, a session id is needed
# It isn't really used here because we are using a simple in memory ChatMessageHistory
config={"configurable": {"session_id": "<foo>"}},
)
> Entering new AgentExecutor chain...
Hello Bob! How can I assist you today?
> Finished chain.
{'input': "hi! I'm bob",
'chat_history': [],
'output': 'Hello Bob! How can I assist you today?'}
agent_with_chat_history.invoke(
{"input": "what's my name?"},
# This is needed because in most real world scenarios, a session id is needed
# It isn't really used here because we are using a simple in memory ChatMessageHistory
config={"configurable": {"session_id": "<foo>"}},
)
> Entering new AgentExecutor chain...
Your name is Bob.
> Finished chain.
{'input': "what's my name?",
'chat_history': [HumanMessage(content="hi! I'm bob"),
AIMessage(content='Hello Bob! How can I assist you today?')],
'output': 'Your name is Bob.'}
That’s a wrap! In this quick start we covered how to create a simple agent. Agents are a complex topic, and there’s lot to learn! Head back to themain agent pageto find more resources on conceptual guides, different types of agents, how to create custom tools, and more!
마무리입니다! 이 빠른 시작에서는 간단한 에이전트를 만드는 방법을 다루었습니다. 에이전트는 복잡한 주제이며 배울 것이 많습니다! 기본 에이전트 페이지로 돌아가서 개념 가이드, 다양한 유형의 에이전트, 사용자 정의 도구를 만드는 방법 등에 대한 추가 리소스를 찾아보세요!
Open AI 에서는 2024년 1월 25일 new generation of embedding models, new GPT-4 Turbo, moderation models, new API usage management tools 를 발표 했습니다.
그리고 조만간 더 저렴한 GPT-3.5 Turbo 모델을 발표할 예정입니다.
이들 새로운 모델에는 다음과 같은 것 들이 포함 됩니다.
Two new embedding models
An updated GPT-4 Turbo preview model
An updated GPT-3.5 Turbo model
An updated text moderation model
새로운 임베딩 모델은 더 낮은 가격으로 이용할 수 있습니다.
새로운 임베딩 모델은 아래와 같습니다.
* Small embedding model
- text-embedding-3-small : 고효율 임베딩 모델, 이전 모델인 text-embedding-ada-002 보다 업그레이드 됨
더욱 강력한 성능.text-embedding-ada-002와 text-embedding-3-small을 비교하면 일반적으로 사용되는 다중 언어 검색 벤치마크(MIRACL)의 평균 점수가 31.4%에서 44.0%로 증가했습니다. 영어 과제 벤치마크(MTEB)가 61.0%에서 62.3%로 증가했습니다.
인하 된 가격.text-embedding-3-small은 이전 세대 text-embedding-ada-002 모델보다 훨씬 더 효율적입니다. text-embedding-3-small의 가격은 text-embedding-ada-002에 비해 1,000개 토큰당 가격이 $0.0001에서 $0.00002로 5배 인하되었습니다.
* Large text embedding model
- text-embedding-3-large : 최고 성능 모델.
text-embedding-3-large는 새로운 차세대 대형 임베딩 모델이며 최대 3072차원의 임베딩을 생성합니다.
더욱 강력한 성능. text-embedding-3-large는 새로운 최고 성능 모델입니다. text-embedding-ada-002와 text-embedding-3-large 비교: MIRACL에서는 평균 점수가 31.4%에서 54.9%로 증가한 반면, MTEB에서는 평균 점수가 61.0%에서 64.6%로 증가했습니다.
text-embedding-3-large의 가격은 $0.00013/1,000토큰입니다. Embeddings guide 에서 새로운 임베딩 모델 사용에 대해 자세히 알아볼 수 있습니다.
Native support for shortening embeddings
Using larger embeddings, for example storing them in a vector store for retrieval, generally costs more and consumes more compute, memory and storage than using smaller embeddings.
예를 들어 검색을 위해 벡터 저장소에 저장하는 등 더 큰 임베딩을 사용하면 더 작은 임베딩을 사용하는 것보다 일반적으로 더 많은 비용이 들고 더 많은 컴퓨팅, 메모리 및 스토리지를 사용합니다.
Both of our new embeddings models were trained with a technique that allows developers to trade-off performance and cost of using embeddings. Specifically, developers can shorten embeddings (i.e. remove some numbers from the end of the sequence) without the embedding losing its concept-representing properties by passing in thedimensionsAPI parameter. For example, on the MTEB benchmark, atext-embedding-3-largeembedding can be shortened to a size of 256 while still outperforming an unshortenedtext-embedding-ada-002embedding with a size of 1536.
두 가지 새로운 임베딩 모델은 모두 개발자가 임베딩 사용 비용과 성능을 절충할 수 있는 기술로 교육되었습니다. 특히 개발자는 차원 API 매개변수를 전달하여 임베딩이 개념을 나타내는 속성을 잃지 않고 임베딩을 단축할 수 있습니다(예: 시퀀스 끝에서 일부 숫자 제거). 예를 들어, MTEB 벤치마크에서 text-embedding-3-large 임베딩은 크기 256으로 단축되면서도 크기 1536의 단축되지 않은 text-embedding-ada-002 임베딩보다 성능이 뛰어납니다.
This enables very flexible usage. For example, when using a vector data store that only supports embeddings up to 1024 dimensions long, developers can now still use our best embeddings modeltext-embedding-3-largeand specify a value of 1024 for thedimensionsAPI parameter, which will shorten the embedding down from 3072 dimensions, trading off some accuracy in exchange for the smaller vector size.
이를 통해 매우 유연한 사용이 가능합니다. 예를 들어, 최대 1024차원 길이의 임베딩만 지원하는 벡터 데이터 저장소를 사용할 때 개발자는 이제 최고의 임베딩 모델 text-embedding-3-large를 사용하고 차원 API 매개변수에 값 1024를 지정할 수 있습니다. 3072 차원에서 임베딩을 줄여 벡터 크기가 더 작아지는 대가로 어느 정도 정확도를 희생했습니다.
Other new models and lower pricing
Updated GPT-3.5 Turbo model and lower pricing
Next week we are introducing a new GPT-3.5 Turbo model,gpt-3.5-turbo-0125, and for the third time in the past year, we will be decreasing prices on GPT-3.5 Turbo to help our customers scale. Input prices for the new model are reduced by 50% to $0.0005 /1K tokens and output prices are reduced by 25% to $0.0015 /1K tokens. This model will also have various improvements including higher accuracy at responding in requested formats and a fix fora bugwhich caused a text encoding issue for non-English language function calls.
다음 주에 우리는 새로운 GPT-3.5 Turbo 모델인 gpt-3.5-turbo-0125를 선보일 예정이며, 고객의 확장을 돕기 위해 작년에 세 번째로 GPT-3.5 Turbo의 가격을 인하할 예정입니다. 새 모델의 입력 가격은 $0.0005/1K 토큰으로 50% 인하되고, 출력 가격은 $0.0015/1K 토큰으로 25% 인하됩니다. 또한 이 모델에는 요청된 형식으로 응답할 때 더 높은 정확도와 영어가 아닌 언어 함수 호출에 대한 텍스트 인코딩 문제를 일으키는 버그 수정 등 다양한 개선 사항이 포함됩니다.
Customers using the pinnedgpt-3.5-turbomodel alias will be automatically upgraded fromgpt-3.5-turbo-0613 togpt-3.5-turbo-0125two weeks after this model launches.
고정된 gpt-3.5-turbo 모델 별칭을 사용하는 고객은 이 모델 출시 2주 후 gpt-3.5-turbo-0613에서 gpt-3.5-turbo-0125로 자동 업그레이드됩니다.
Updated GPT-4 Turbo preview
Over 70% of requests from GPT-4 API customers have transitioned to GPT-4 Turbo since its release, as developers take advantage of its updated knowledge cutoff, larger 128k context windows, and lower prices.
개발자가 업데이트된 지식 컷오프, 더 커진 128k 컨텍스트 창 및 저렴한 가격을 활용함에 따라 GPT-4 API 고객의 요청 중 70% 이상이 출시 이후 GPT-4 Turbo로 전환되었습니다.
Today, we are releasing an updated GPT-4 Turbo preview model,gpt-4-0125-preview. This model completes tasks like code generation more thoroughly than the previous preview model and is intended to reduce cases of “laziness” where the model doesn’t complete a task. The new model also includes the fix for the bug impacting non-English UTF-8 generations.
오늘 우리는 업데이트된 GPT-4 Turbo 미리보기 모델인 gpt-4-0125-preview를 출시합니다. 이 모델은 이전 미리 보기 모델보다 코드 생성과 같은 작업을 더 철저하게 완료하며 모델이 작업을 완료하지 못하는 "게으름"의 경우를 줄이기 위한 것입니다. 새 모델에는 영어가 아닌 UTF-8 세대에 영향을 미치는 버그에 대한 수정 사항도 포함되어 있습니다.
For those who want to be automatically upgraded to new GPT-4 Turbo preview versions, we are also introducing a newgpt-4-turbo-previewmodel name alias, which will always point to our latest GPT-4 Turbo preview model.
새로운 GPT-4 Turbo 미리보기 버전으로 자동 업그레이드하려는 사람들을 위해 항상 최신 GPT-4 Turbo 미리보기 모델을 가리키는 새로운 gpt-4-turbo-preview 모델 이름 별칭도 도입합니다.
We plan to launch GPT-4 Turbo with vision in general availability in the coming months.
우리는 앞으로 몇 달 안에 비전이 포함된 GPT-4 Turbo를 일반 출시할 계획입니다.
Updated moderation model
The free Moderation API allows developers to identify potentially harmful text. As part of our ongoing safety work, we are releasingtext-moderation-007, our most robust moderation model to-date.
무료 Moderation API를 통해 개발자는 잠재적으로 유해한 텍스트를 식별할 수 있습니다. 지속적인 안전 작업의 일환으로 현재까지 가장 강력한 조정 모델인 text-moderation-007을 출시합니다.
Thetext-moderation-latestandtext-moderation-stablealiases have been updated to point to it. You can learn more about building safe AI systems through oursafety best practices guide.
text-moderation-latest 및 text-moderation-stable 별칭이 이를 가리키도록 업데이트되었습니다. 안전 모범 사례 가이드를 통해 안전한 AI 시스템 구축에 대해 자세히 알아볼 수 있습니다.
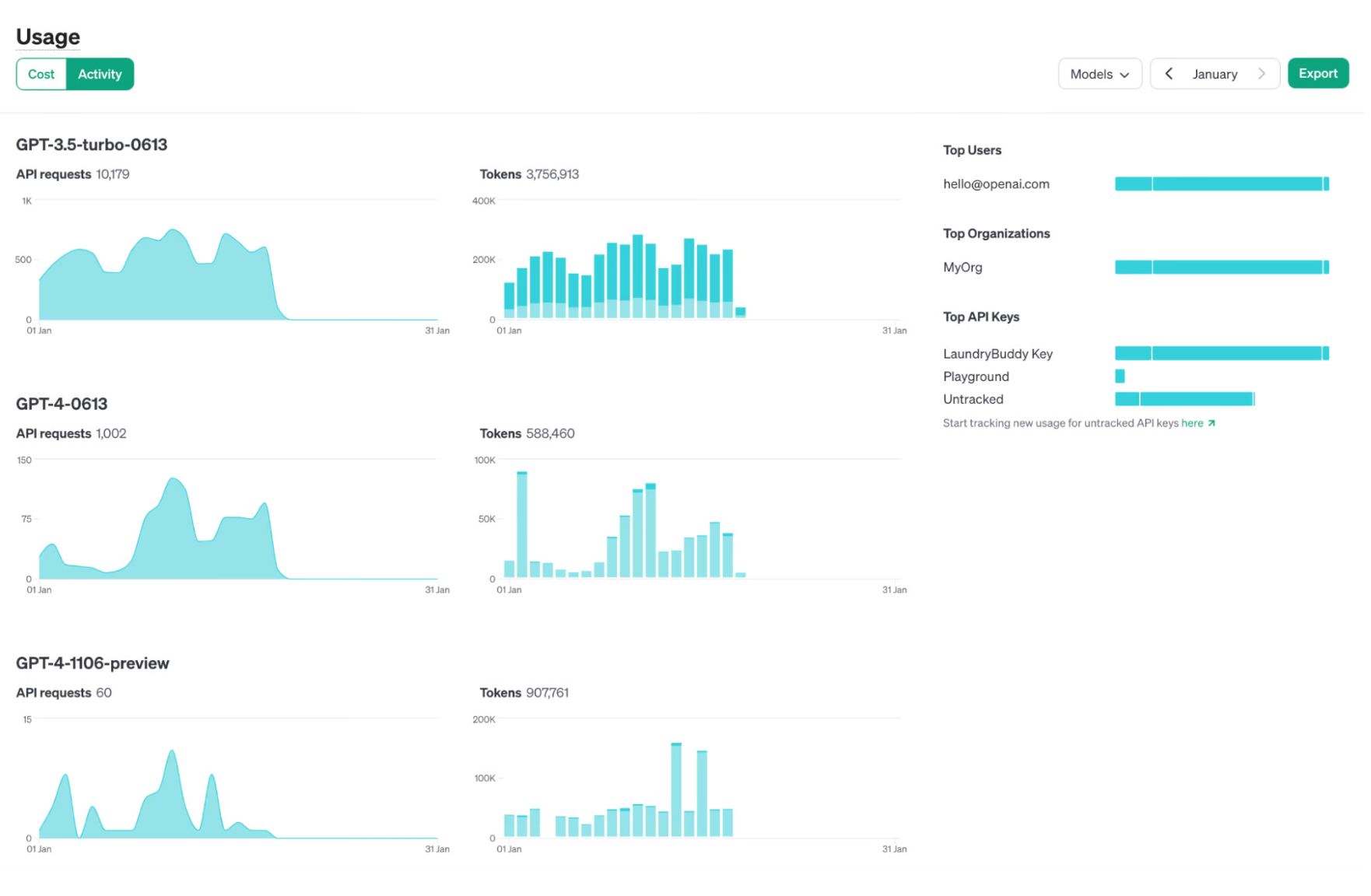
New ways to understand API usage and manage API keys
We are launching two platform improvements to give developers both more visibility into their usage and control over API keys.
우리는 개발자에게 API 키 사용에 대한 더 많은 가시성과 제어권을 제공하기 위해 두 가지 플랫폼 개선 사항을 출시할 예정입니다.
First, developers can now assign permissions to API keys from theAPI keys page. For example, a key could be assigned read-only access to power an internal tracking dashboard, or restricted to only access certain endpoints.
첫째, 이제 개발자는 API 키 페이지에서 API 키에 권한을 할당할 수 있습니다. 예를 들어 내부 추적 대시보드를 구동하기 위해 키에 읽기 전용 액세스 권한을 할당하거나 특정 엔드포인트에만 액세스하도록 제한할 수 있습니다.
Second, the usage dashboard and usage export function now expose metrics on an API key level afterturning on tracking. This makes it simple to view usage on a per feature, team, product, or project level, simply by having separate API keys for each.
둘째, 이제 추적을 활성화한 후 사용량 대시보드 및 사용량 내보내기 기능이 API 키 수준에 지표를 노출합니다. 이를 통해 각각에 대해 별도의 API 키를 보유함으로써 기능, 팀, 제품 또는 프로젝트 수준별 사용량을 간단하게 확인할 수 있습니다.
In the coming months, we plan to further improve the ability for developers to view their API usage and manage API keys, especially in larger organizations.
앞으로 몇 달 안에 우리는 특히 대규모 조직에서 개발자가 자신의 API 사용량을 확인하고 API 키를 관리할 수 있는 기능을 더욱 향상시킬 계획입니다.
For the latest updates on OpenAI's APIs, follow us on X at@OpenAIDevs.
OpenAI API에 대한 최신 업데이트를 보려면 @OpenAIDevs에서 X를 팔로우하세요.
How OpenAI is approaching 2024 worldwide elections
We’re working to prevent abuse, provide transparency on AI-generated content, and improve access to accurate voting information.
Protecting the integrity of elections requires collaboration from every corner of the democratic process, and we want to make sure our technology is not used in a way that could undermine this process.
선거의 무결성을 보호하려면 민주적 절차의 모든 부분에서 협력이 필요하며, 우리는 우리의 기술이 이 절차를 훼손할 수 있는 방식으로 사용되지 않도록 하고 싶습니다.
우리의 도구는 AI를 사용하여 국가 서비스를 강화하는 것부터 환자를 위한 의료 양식을 단순화하는 것까지 사람들이 일상 생활을 개선하고 복잡한 문제를 해결할 수 있도록 지원합니다.
We want to make sure that our AI systems are built, deployed, and usedsafely. Like any new technology, these tools come with benefits and challenges. They are also unprecedented, and we will keep evolving our approach as we learn more about how our tools are used.
우리는 AI 시스템이 안전하게 구축, 배포 및 사용되기를 원합니다. 다른 새로운 기술과 마찬가지로 이러한 도구에도 이점과 과제가 있습니다. 이는 또한 전례 없는 일이며, 도구 사용 방법에 대해 더 많이 배우면서 접근 방식을 계속 발전시킬 것입니다.
As we prepare for elections in 2024 across the world’s largest democracies, our approach is to continue our platform safety work by elevating accurate voting information, enforcing measured policies, and improving transparency.We have a cross-functional effort dedicated to election work, bringing together expertise from our safety systems, threat intelligence, legal, engineering, and policy teams to quickly investigate and address potential abuse.
우리는 세계 최대 민주주의 국가의 2024년 선거를 준비하면서 정확한 투표 정보를 높이고, 신중한 정책을 시행하고, 투명성을 개선하여 플랫폼 안전 작업을 계속하는 것입니다. 우리는 안전 시스템, 위협 인텔리전스, 법률, 엔지니어링 및 정책 팀의 전문 지식을 모아 잠재적인 남용을 신속하게 조사하고 해결하기 위해 선거 업무에 전념하는 다기능적 노력을 기울이고 있습니다.
The following are key initiatives our teams are investing in to prepare for elections this year:
다음은 올해 선거를 준비하기 위해 우리 팀이 투자하고 있는 주요 이니셔티브입니다.
Preventing abuse
We expect and aim for people to use our tools safely and responsibly, and elections are no different. We work to anticipate and prevent relevant abuse—such as misleading “deepfakes”, scaled influence operations, or chatbots impersonating candidates. Prior to releasing new systems, we red team them, engage users and external partners for feedback, and build safety mitigations to reduce the potential for harm. For years, we’ve been iterating on tools to improve factual accuracy, reduce bias, and decline certain requests. These tools provide a strong foundation for our work around election integrity. For instance, DALL·E has guardrails to decline requests that ask for image generation of real people, including candidates.
우리는 사람들이 우리의 도구를 안전하고 책임감 있게 사용하기를 기대하고 목표하며, 선거도 이와 다르지 않습니다. 우리는 오해를 불러일으키는 "딥페이크", 대규모 영향력 행사 또는 후보자를 사칭하는 챗봇과 같은 관련 남용을 예측하고 예방하기 위해 노력합니다. 새로운 시스템을 출시하기 전에 우리는 레드팀을 구성하고 피드백을 받기 위해 사용자와 외부 파트너를 참여시키며 피해 가능성을 줄이기 위한 안전 완화 조치를 구축합니다. 수년 동안 우리는 사실의 정확성을 높이고, 편견을 줄이고, 특정 요청을 거부하는 도구를 반복적으로 사용해 왔습니다. 이러한 도구는 선거 무결성에 관한 작업을 위한 강력한 기반을 제공합니다. 예를 들어 DALL·E에는 후보자를 포함한 실제 인물의 이미지 생성을 요청하는 요청을 거부하는 가드레일이 있습니다.
We regularly refine ourUsage Policiesfor ChatGPT and the API as we learn more about how people use or attempt to abuse our technology. A few to highlight for elections:
우리는 사람들이 우리 기술을 어떻게 사용하거나 남용하려고 시도하는지 자세히 파악하면서 ChatGPT 및 API에 대한 사용 정책을 정기적으로 개선합니다. 선거를 위해 강조할 몇 가지:
We’re still working to understand how effective our tools might be for personalized persuasion. Until we know more, we don’t allow people to build applications for political campaigning and lobbying.
우리는 우리의 도구가 개인화된 설득에 얼마나 효과적인지 이해하기 위해 계속 노력하고 있습니다. 더 많은 내용을 알기 전까지는 사람들이 정치 캠페인 및 로비 활동을 위한 애플리케이션을 구축하는 것을 허용하지 않습니다.
People want to know and trust that they are interacting with a real person, business, or government. For that reason, we don’t allow builders to create chatbots that pretend to be real people (e.g., candidates) or institutions (e.g., local government).
사람들은 자신이 실제 사람, 기업 또는 정부와 상호 작용하고 있다는 사실을 알고 신뢰하고 싶어합니다. 이러한 이유로 우리는 빌더가 실제 사람(예: 후보자) 또는 기관(예: 지방 정부)인 것처럼 가장하는 챗봇을 만드는 것을 허용하지 않습니다.
We don’t allow applications that deter people from participation in democratic processes—for example, misrepresenting voting processes and qualifications (e.g., when, where, or who is eligible to vote) or that discourage voting (e.g., claiming a vote is meaningless).
사람들이 민주적 절차에 참여하는 것을 방해하는 애플리케이션(예: 투표 절차 및 자격(예: 언제, 어디서, 누가 투표할 자격이 있는지)을 허위로 표시하거나 투표를 방해하는 애플리케이션(예: 투표가 무의미하다고 주장))은 허용되지 않습니다. .
With our new GPTs, users can report potential violations to us.
새로운 GPT를 통해 사용자는 잠재적인 위반 사항을 신고할 수 있습니다.
Transparency around AI-generated content
Better transparency around image provenance—including the ability to detect which tools were used to produce an image—can empower voters to assess an image with trust and confidence in how it was made. We’re working on several provenance efforts. Early this year, we will implement theCoalition for Content Provenance and Authenticity’sdigital credentials—an approach that encodes details about the content’s provenance using cryptography—for images generated by DALL·E 3.
이미지를 생성하는 데 어떤 도구가 사용되었는지 감지하는 기능을 포함하여 이미지 출처에 대한 투명성이 향상되면 유권자는 이미지 제작 방법에 대한 신뢰와 자신감을 가지고 이미지를 평가할 수 있습니다. 우리는 여러 출처에 대한 노력을 기울이고 있습니다. 올해 초 우리는 DALL·E 3에서 생성된 이미지에 대해 암호화를 사용하여 콘텐츠 출처에 대한 세부 정보를 인코딩하는 접근 방식인 콘텐츠 출처 및 진위성 연합의 디지털 자격 증명을 구현할 예정입니다.
We are also experimenting with a provenance classifier, a new tool for detecting images generated by DALL·E. Our internal testing has shown promising early results, even where images have been subject to common types of modifications. We plan to soon make it available to our first group of testers—including journalists, platforms, and researchers—for feedback.
또한 DALL·E에서 생성된 이미지를 감지하는 새로운 도구인 출처 분류기를 실험하고 있습니다. 우리의 내부 테스트는 이미지가 일반적인 유형의 수정을 받은 경우에도 유망한 초기 결과를 보여주었습니다. 우리는 곧 언론인, 플랫폼, 연구원을 포함한 첫 번째 테스터 그룹이 피드백을 받을 수 있도록 할 계획입니다.
Finally, ChatGPT is increasingly integrating with existing sources of information—for example, users will start to get access to real-time news reporting globally, including attribution and links. Transparency around the origin of information and balance in news sources can help voters better assess information and decide for themselves what they can trust.
마지막으로 ChatGPT는 점점 더 기존 정보 소스와 통합되고 있습니다. 예를 들어 사용자는 속성 및 링크를 포함하여 전 세계적으로 실시간 뉴스 보고에 액세스할 수 있게 됩니다. 정보 출처에 대한 투명성과 뉴스 소스의 균형은 유권자가 정보를 더 잘 평가하고 신뢰할 수 있는 정보를 스스로 결정하는 데 도움이 될 수 있습니다.
Improving access to authoritative voting information
In the United States, we are working with theNational Association of Secretaries of State(NASS), the nation's oldest nonpartisan professional organization for public officials. ChatGPT will direct users to CanIVote.org, the authoritative website on US voting information, when asked certain procedural election related questions—for example, where to vote. Lessons from this work will inform our approach in other countries and regions.
미국에서는 미국에서 가장 오래된 공직자를 위한 초당파적 전문 조직인 전국 국무장관 협회(NASS)와 협력하고 있습니다. ChatGPT는 특정 절차적 선거 관련 질문(예: 투표 장소)을 묻는 경우 미국 투표 정보에 대한 권위 있는 웹사이트인 CanIVote.org로 사용자를 안내합니다. 이 작업에서 얻은 교훈은 다른 국가 및 지역에서의 우리의 접근 방식에 영향을 미칠 것입니다.
We’ll have more to share in the coming months. We look forward to continuing to work with and learn from partners to anticipate and prevent potential abuse of our tools in the lead up to this year’s global elections.
앞으로 몇 달 동안 더 많은 내용을 공유할 예정입니다. 우리는 올해 세계 선거를 앞두고 우리 도구의 남용 가능성을 예측하고 방지하기 위해 계속해서 파트너와 협력하고 파트너로부터 배우기를 기대합니다.
We’re launching a new ChatGPT plan for teams of all sizes, which provides a secure, collaborative workspace to get the most out of ChatGPT at work.
We launched ChatGPT Enterprise a few months ago and industry leaders like Block, Canva, Carlyle, The Estée Lauder Companies, PwC, and Zapier are already using it to redefine how their organizations operate. Today, we’re adding a new self-serve plan:ChatGPT Team.
우리는 몇 달 전에 ChatGPT Enterprise를 출시했으며 Block, Canva, Carlyle, The Estée Lauder Companies, PwC, Zapier와 같은 업계 리더들은 이미 ChatGPT Enterprise를 사용하여 조직 운영 방식을 재정의하고 있습니다. 오늘 우리는 새로운 셀프 서비스 계획인 ChatGPT 팀을 추가합니다.
ChatGPT Team offers access to our advanced models like GPT-4 and DALL·E 3, and tools like Advanced Data Analysis. It additionally includes a dedicated collaborative workspace for your team and admin tools for team management. As with ChatGPT Enterprise, you own and control your business data—we do not train on your business data or conversations, and our models don’t learn from your usage. More details on our data privacy practices can be found on ourprivacy pageandTrust Portal.
ChatGPT 팀은 GPT-4 및 DALL·E 3과 같은 고급 모델과 고급 데이터 분석과 같은 도구에 대한 액세스를 제공합니다. 또한 팀을 위한 전용 공동 작업 공간과 팀 관리를 위한 관리 도구가 포함되어 있습니다. ChatGPT Enterprise와 마찬가지로 귀하는 귀하의 비즈니스 데이터를 소유하고 제어합니다. 당사는 귀하의 비즈니스 데이터나 대화를 학습하지 않으며 당사 모델은 귀하의 사용법을 학습하지 않습니다. 당사의 데이터 개인정보 보호 관행에 대한 자세한 내용은 당사의 개인정보 보호 페이지와 Trust Portal에서 확인할 수 있습니다.
ChatGPT Team includes:
Access to GPT-4 with 32K context window
32K 컨텍스트 창을 통해 GPT-4에 액세스
Tools like DALL·E 3, GPT-4 with Vision, Browsing, Advanced Data Analysis—with higher message caps
DALL·E 3, 비전, 브라우징, 고급 데이터 분석 기능을 갖춘 GPT-4와 같은 도구(메시지 한도가 더 높음)
No training on your business data or conversations
We recentlyannounced GPTs—custom versions of ChatGPT that you can create for a specific purpose with instructions, expanded knowledge, and custom capabilities. These can be especially useful for businesses and teams. With GPTs, you can customize ChatGPT to your team’s specific needs and workflows (no code required) and publish them securely to your team’s workspace. GPTs can help with a wide range of tasks, such as assisting in project management, team onboarding, generating code, performing data analysis, securely taking action in your existing systems and tools, or creating collateral to match your brand tone and voice. Today, we announced theGPT Storewhere you can find useful and popular GPTs from your workspace.
우리는 최근 GPTs를 발표했습니다. 이는 지침, 확장된 지식, 사용자 정의 기능을 통해 특정 목적을 위해 만들 수 있는 ChatGPT의 사용자 정의 버전입니다. 이는 비즈니스와 팀에 특히 유용할 수 있습니다. GPTs를 사용하면 ChatGPT를 팀의 특정 요구 사항과 작업 흐름에 맞게 맞춤설정하고(코드 필요 없음) 팀의 작업 공간에 안전하게 게시할 수 있습니다. GPTs는 프로젝트 관리 지원, 팀 온보딩, 코드 생성, 데이터 분석 수행, 기존 시스템 및 도구에서 안전하게 조치 수행, 브랜드 톤 및 목소리에 맞는 자료 생성 등 다양한 작업에 도움을 줄 수 있습니다. 오늘 우리는 귀하의 작업 공간에서 유용하고 인기 있는 GPTs를 찾을 수 있는 GPT 스토어를 발표했습니다.
Improve team efficiency and work quality
Integrating AI into everyday organizational workflows can make your team more productive. In a recent study by the Harvard Business School, employees at Boston Consulting Group who were given access to GPT-4 reported completing tasks 25% faster and achieved a 40% higher quality in their work as compared to their peers who did not have access.
AI를 일상적인 조직 워크플로에 통합하면 팀의 생산성이 향상될 수 있습니다. Harvard Business School의 최근 연구에 따르면 GPT-4에 대한 액세스 권한이 부여된 Boston Consulting Group의 직원은 액세스 권한이 없는 동료에 비해 작업을 25% 더 빨리 완료하고 작업 품질이 40% 더 높은 것으로 나타났습니다.
Connor O’Brien, VP of GTM Strategy & Operations at Sourcegraph, shares, "We use ChatGPT in almost every part of our business, from financial modeling for pricing and packaging to internal and external communications to board prep to recruiting and note taking—it’s accelerated everything we do allowing us to execute at a high level."
Sourcegraph의 GTM 전략 및 운영 부사장인 Connor O'Brien은 다음과 같이 말합니다. "우리는 가격 책정 및 패키징을 위한 재무 모델링부터 내부 및 외부 커뮤니케이션, 이사회 준비, 채용 및 메모 작성에 이르기까지 비즈니스의 거의 모든 부분에서 ChatGPT를 사용합니다. 우리가 하는 모든 일을 가속화하여 높은 수준에서 실행할 수 있게 되었습니다."
Dr. John Brownstein, Chief Innovation Officer at Boston Children’s Hospital says, “With ChatGPT Team, we’ve been able to pilot innovative GPTs that enhance our team’s productivity and collaboration. As we integrate GPTs safely and responsibly across internal operations, we know the transformative impact this will have in strengthening the systems that enable our doctors, researchers, students, and administrative staff to provide exceptional care to every patient that walks through our doors.”
Boston Children’s Hospital의 최고 혁신 책임자인 Dr. John Brownstein은 이렇게 말합니다. “ChatGPT 팀을 통해 우리는 팀의 생산성과 협업을 향상시키는 혁신적인 GPT를 시험해 볼 수 있었습니다. 내부 운영 전반에 걸쳐 GPT를 안전하고 책임감 있게 통합함으로써 우리는 의사, 연구원, 학생 및 행정 직원이 우리 문을 방문하는 모든 환자에게 탁월한 진료를 제공할 수 있는 시스템을 강화하는 데 혁신적인 영향을 미칠 것임을 알고 있습니다.”
ChatGPT Team costs $25/month per user when billed annually, or $30/month per user when billed monthly. You canexplore the detailsor get started now by upgrading in your ChatGPT settings.
ChatGPT 팀의 비용은 연간 청구 시 사용자당 월 $25, 월별 청구 시 사용자당 월 $30입니다. ChatGPT 설정에서 업그레이드하여 세부 정보를 살펴보거나 지금 시작할 수 있습니다.
It’s been two months since we announced GPTs, and users have already created over 3 million custom versions of ChatGPT. Many builders have shared their GPTs for others to use. Today, we're starting to roll out the GPT Store to ChatGPT Plus, Team and Enterprise users so you can find useful and popular GPTs. Visit chat.openai.com/gpts to explore.
GPTs 를 발표한 지 두 달이 지났고 사용자는 이미 300만 개 이상의 ChatGPT 맞춤 버전을 만들었습니다. 많은 빌더가 다른 사람들이 사용할 수 있도록 GPTs 를 공유했습니다. 오늘 우리는 유용하고 인기 있는 GPTs 를 찾을 수 있도록 ChatGPT Plus, Team 및 Enterprise 사용자에게 GPT Store를 출시하기 시작했습니다. chat.openai.com/gpts를 방문하여 살펴보세요.
Discover what’s trending in the store
The store features a diverse range of GPTs developed by our partners and the community. Browse popular and trending GPTs on the community leaderboard, with categories like DALL·E, writing, research, programming, education, and lifestyle.
이 스토어에는 파트너와 커뮤니티가 개발한 다양한 GPT가 있습니다. 커뮤니티 리더보드에서 DALL·E, 글쓰기, 연구, 프로그래밍, 교육, 라이프스타일과 같은 카테고리를 포함하는 인기 있고 인기 있는 GPT를 찾아보세요.
New featured GPTs every week
We will also highlight useful and impactful GPTs. Some of our first featured GPTs include:
또한 유용하고 영향력 있는 GPT를 강조하겠습니다. 첫 번째 주요 GPT 중 일부는 다음과 같습니다.
Building your own GPT is simple and doesn't require any coding skills.
자신만의 GPT를 구축하는 것은 간단하며 코딩 기술이 필요하지 않습니다.
If you’d like to share a GPT in the store, you’ll need to:스토어에서 GPT를 공유하려면 다음을 수행해야 합니다.
Save your GPT forEveryone(Anyone with a linkwill not be shown in the store).
모든 사람을 위해 GPT를 저장하세요. 링크가 있는 사람은 누구나 스토어에 표시되지 않습니다.
Verify your Builder Profile (Settings→Builder profile→Enable your name or a verified website).
빌더 프로필을 확인하세요(설정 → 빌더 프로필 → 이름 또는 확인된 웹사이트 활성화).
Please review our latestusage policiesandGPT brand guidelinesto ensure your GPT is compliant. To help ensure GPTs adhere to our policies, we've established a new review system in addition to the existing safety measures we've built into our products. The review process includes both human and automated review. Users are alsoable to reportGPTs.
귀하의 GPT가 규정을 준수하는지 확인하려면 최신 사용 정책과 GPT 브랜드 가이드라인을 검토하세요. GPT가 Google 정책을 준수할 수 있도록 Google에서는 제품에 적용한 기존 안전 조치 외에 새로운 검토 시스템을 구축했습니다. 검토 프로세스에는 사람이 수행하는 검토와 자동 검토가 모두 포함됩니다. 사용자는 GPT를 보고할 수도 있습니다.
Builders can earn based on GPT usage
In Q1 we will launch a GPT builder revenue program. As a first step, US builders will be paid based on user engagement with their GPTs. We'll provide details on the criteria for payments as we get closer.
1분기에는 GPT 빌더 수익 프로그램을 시작할 예정입니다. 첫 번째 단계로 미국 builders 는 GPT에 대한 사용자 참여를 기반으로 비용을 지불받습니다. 결제 기준에 대한 자세한 내용은 추후 확정되는 대로 안내해 드리겠습니다.
Team and Enterprise customers can manage GPTs
Today, we announced our newChatGPT Teamplan for teams of all sizes. Team customers have access to a private section of the GPT Store which includes GPTs securely published to your workspace. The GPT Store will be available soon forChatGPT Enterprisecustomers and will include enhanced admin controls like choosing how internal-only GPTs are shared and which external GPTs may be used inside your business. Like all usage on ChatGPT Team and Enterprise, we do not use your conversations with GPTs to improve our models.
오늘 우리는 모든 규모의 팀을 위한 새로운 ChatGPT 팀 계획을 발표했습니다. 팀 고객은 작업공간에 안전하게 게시된 GPT가 포함된 GPT 스토어의 비공개 섹션에 액세스할 수 있습니다. GPT 스토어는 곧 ChatGPT Enterprise 고객에게 제공될 예정이며 내부 전용 GPT 공유 방법 및 비즈니스 내에서 사용할 수 있는 외부 GPT 선택과 같은 향상된 관리 제어 기능이 포함됩니다. ChatGPT Team 및 Enterprise의 모든 사용과 마찬가지로 우리는 모델을 개선하기 위해 GPT와의 대화를 사용하지 않습니다.
We support journalism, partner with news organizations, and believe The New York Times lawsuit is without merit.
Our goal is to develop AI tools thatempower peopleto solve problems that are otherwise out of reach. People worldwide are already using our technology toimprove their daily lives. Millions of developers and more than 92% of Fortune 500 are building on our products today.
우리의 목표는 사람들이 다른 방법으로는 접근할 수 없는 문제를 해결할 수 있도록 지원하는 AI 도구를 개발하는 것입니다. 전 세계 사람들은 이미 일상 생활을 개선하기 위해 우리의 기술을 사용하고 있습니다. 오늘날 수백만 명의 개발자와 Fortune 500대 기업 중 92% 이상이 우리 제품을 기반으로 개발하고 있습니다.
While we disagree with the claims in The New York Times lawsuit, we view it as an opportunity to clarify our business, our intent, and how we build our technology. Our position can be summed up in these four points, which we flesh out below:
우리는 New York Times 소송의 주장에 동의하지 않지만, 이를 우리의 비즈니스, 의도, 기술 구축 방법을 명확히 할 수 있는 기회로 봅니다. 우리의 입장은 다음 네 가지로 요약될 수 있으며, 아래에서 구체적으로 설명하겠습니다.
We collaborate with news organizations and are creating new opportunities
우리는 언론 기관과 협력하여 새로운 기회를 창출하고 있습니다.
Training is fair use, but we provide an opt-out because it’s the right thing to do
Training 은 공정한 사용이지 올바른 일이기 때문에 거부할 수 있는 옵션을 제공합니다.
“Regurgitation” is a rare bug that we are working to drive to zero
"Regurgitation 역류, 표"는 우리가 제로화하기 위해 노력하고 있는 희귀한 버그입니다.
The New York Times is not telling the full story
New York Times는 전체 내용을 말하지 않습니다.
1. We collaborate with news organizations and are creating new opportunities
1. 우리는 언론사와 협력하여 새로운 기회를 창출하고 있습니다.
We work hard in our technology design process to support news organizations. We’ve met with dozens, as well as leading industry organizations like the News/Media Alliance, to explore opportunities, discuss their concerns, and provide solutions. We aim to learn, educate, listen to feedback, and adapt.
우리는 언론사를 지원하기 위해 기술 설계 프로세스에 열심히 노력하고 있습니다. 우리는 기회를 탐색하고, 우려 사항을 논의하고, 솔루션을 제공하기 위해 뉴스/미디어 연합(News/Media Alliance)과 같은 선도적인 업계 조직뿐만 아니라 수십 곳을 만났습니다. 우리는 배우고, 교육하고, 피드백을 듣고, 적응하는 것을 목표로 합니다.
Our goals are to support a healthy news ecosystem, be a good partner, and create mutually beneficial opportunities. With this in mind, we have pursued partnerships with news organizations to achieve these objectives:
우리의 목표는 건강한 뉴스 생태계를 지원하고, 좋은 파트너가 되며, 상호 이익이 되는 기회를 창출하는 것입니다. 이를 염두에 두고 우리는 다음과 같은 목표를 달성하기 위해 언론 기관과 파트너십을 추구해 왔습니다.
Deploy our products to benefit and support reporters and editors, by assisting with time-consuming tasks like analyzing voluminous public records and translating stories.
방대한 공공 기록 분석 및 기사 번역과 같이 시간이 많이 걸리는 작업을 지원하여 기자와 편집자에게 혜택을 주고 지원하기 위해 제품을 배포합니다.
Teach our AI models about the world by training on additional historical, non-publicly available content.
추가로 비공개로 제공되는 역사적 콘텐츠를 훈련하여 AI 모델에 세상에 대해 가르칩니다.
Display real-time content with attribution in ChatGPT, providing new ways for news publishers to connect with readers.
ChatGPT에 속성이 포함된 실시간 콘텐츠를 표시하여 뉴스 게시자가 독자와 연결할 수 있는 새로운 방법을 제공합니다.
Associated Press, Axel Springer, American Journalism Project 및 NYU와의 초기 파트너십을 통해 우리의 접근 방식을 엿볼 수 있습니다.
2. Training is fair use, but we provide an opt-out because it’s the right thing to do
2. Training은 공정한 사용이지만 옳은 일이기 때문에 거부할 수 있는 옵션을 제공합니다.
Training AI models using publicly available internet materials is fair use, as supported by long-standing and widely accepted precedents. We view this principle as fair to creators, necessary for innovators, and critical for US competitiveness.
공개적으로 이용 가능한 인터넷 자료를 사용하여 AI 모델을 훈련시키는 것은 오랫동안 지속되고 널리 받아들여지는 선례에 의해 뒷받침되는 공정 사용입니다. 우리는 이 원칙이 창작자에게는 공정하고 혁신가에게는 필요하며 미국 경쟁력에 매우 중요하다고 생각합니다.
AI 모델 훈련이 공정한 사용으로 허용된다는 원칙은 최근 미국 저작권청에 의견을 제출한 다양한 학계, 도서관 협회, 시민 사회 단체, 스타트업, 미국 선도 기업, 창작자, 작가 및 기타 사람들에 의해 지지됩니다. 유럽 연합, 일본, 싱가포르, 이스라엘을 포함한 다른 지역 및 국가에도 저작권이 있는 콘텐츠에 대한 훈련 모델을 허용하는 법률이 있습니다. 이는 AI 혁신, 발전 및 투자에 유리합니다.
That being said, legal right is less important to us than being good citizens. We have led the AI industry in providing a simple opt-outprocessfor publishers (which The New York Times adopted in August 2023) to prevent our tools from accessing their sites.
즉, 법적 권리는 좋은 시민이 되는 것보다 우리에게 덜 중요합니다. Google은 Google 도구가 사이트에 액세스하지 못하도록 게시자에게 간단한 거부 프로세스(2023년 8월 New York Times 채택)를 제공함으로써 AI 업계를 주도해 왔습니다.
3. “Regurgitation” is a rare bug that we are working to drive to zero
3. “Regurgitation, 표절, 역류, 토해내”는 우리가 제로화하기 위해 노력하고 있는 희귀한 버그입니다.
Our models were designed and trained to learn concepts in order to apply them tonew problems.
우리의 모델은 개념을 새로운 문제에 적용하기 위해 학습하도록 설계되고 훈련되었습니다.
Memorization is a rare failure of the learning process that we are continually making progress on, but it’s more common when particular content appears more than once in training data, like if pieces of it appear on lots of different public websites. So we have measures in place to limit inadvertent memorization and prevent regurgitation in model outputs. We also expect our users to act responsibly; intentionally manipulating our models to regurgitate is not an appropriate use of our technology and is against our terms of use.
암기 Memorization 는 우리가 지속적으로 발전하고 있는 학습 과정에서 드문 실패이지만, 특정 콘텐츠가 여러 공개 웹사이트에 나타나는 것처럼 특정 콘텐츠가 훈련 데이터에 두 번 이상 나타날 때 더 일반적입니다. 따라서 우리는 의도하지 않은 암기 Memorization 를 제한하고 모델 출력의 역류 Regurgitation 를 방지하기 위한 조치를 취했습니다. 또한 우리는 사용자가 책임감 있게 행동할 것을 기대합니다. 의도적으로 모델을 조작하여 역류 Regurgitation 시키는 것은 당사 기술의 적절한 사용이 아니며 당사 이용 약관에 위배됩니다.
Just as humans obtain a broad education to learn how to solve new problems, we want our AI models to observe the range of the world’s information, including from every language, culture, and industry. Because models learn from the enormous aggregate of human knowledge, any one sector—including news—is a tiny slice of overall training data, and any single data source—including The New York Times—is not significant for the model’s intended learning.
인간이 새로운 문제를 해결하는 방법을 배우기 위해 광범위한 교육을 받는 것처럼 우리는 AI 모델이 모든 언어, 문화, 산업을 포함하여 전 세계의 다양한 정보를 관찰하기를 원합니다. 모델은 인간 지식의 막대한 집합체로부터 학습하기 때문에 뉴스를 포함한 모든 한 부문은 전체 교육 데이터의 작은 조각이며 New York Times를 포함한 단일 데이터 소스는 모델의 의도된 학습에 중요하지 않습니다.
4. The New York Times is not telling the full story
4. 뉴욕타임스는 전체 내용을 말하지 않습니다.
Our discussions with The New York Times had appeared to be progressing constructively through our last communication on December 19. The negotiations focused on a high-value partnership around real-time display with attribution in ChatGPT, in which The New York Times would gain a new way to connect with their existing and new readers, and our users would gain access to their reporting. We had explained to The New York Times that, like any single source, their content didn't meaningfully contribute to the training of our existing models and also wouldn't be sufficiently impactful for future training. Their lawsuit on December 27—which we learned about by reading The New York Times—came as a surprise and disappointment to us.
The New York Times와의 논의는 12월 19일 마지막 커뮤니케이션을 통해 건설적으로 진행되는 것으로 나타났습니다. 협상은 ChatGPT의 속성이 포함된 실시간 디스플레이를 중심으로 한 고부가가치 파트너십에 초점을 맞췄으며, 이로 인해 The New York Times는 새로운 이점을 얻게 됩니다. 기존 및 신규 독자와 연결하는 방법이며 사용자는 보고에 액세스할 수 있습니다. 우리는 다른 단일 소스와 마찬가지로 해당 콘텐츠가 기존 모델의 교육에 의미 있게 기여하지 않았으며 향후 교육에도 충분한 영향을 미치지 않을 것이라고 The New York Times에 설명했습니다. New York Times를 읽으면서 알게 된 12월 27일의 소송은 우리에게 놀라움과 실망으로 다가왔습니다.
Along the way, they had mentioned seeing some regurgitation of their content but repeatedly refused to share any examples, despite our commitment to investigate and fix any issues. We’ve demonstrated how seriously we treat this as a priority, such as in July when wetook down a ChatGPT featureimmediately after we learned it could reproduce real-time content in unintended ways.
그 과정에서 그들은 콘텐츠가 일부 역류 Regurgitation 되는 것을 언급했지만 문제를 조사하고 수정하겠다는 우리의 노력에도 불구하고 어떤 사례도 공유하기를 반복적으로 거부했습니다. 우리는 의도하지 않은 방식으로 실시간 콘텐츠를 재현할 수 있다는 사실을 알게 된 직후 ChatGPT 기능을 중단한 7월과 같이 이를 얼마나 진지하게 우선순위로 취급하는지 보여주었습니다.
Interestingly, the regurgitations The New York Times induced appear to be from years-old articles that have proliferated onmultiplethird-partywebsites. It seems they intentionally manipulated prompts, often including lengthy excerpts of articles, in order to get our model to regurgitate. Even when using such prompts, our models don’t typically behave the way The New York Times insinuates, which suggests they either instructed the model to regurgitate or cherry-picked their examples from many attempts.
흥미롭게도 New York Times가 유발한 역류 Regurgitation 는 여러 제3자 웹사이트에 확산된 오래된 기사에서 나온 것으로 보입니다. 우리 모델이 역류 Regurgitation 하도록 하기 위해 종종 긴 기사 발췌를 포함하여 프롬프트를 의도적으로 조작한 것 같습니다. 이러한 프롬프트를 사용할 때에도 우리 모델은 일반적으로 The New York Times가 암시하는 방식으로 동작하지 않습니다. 이는 모델이 모델에 역류 Regurgitation 하도록 지시했거나 여러 시도에서 사례를 선별했음을 의미합니다.
Despite their claims, this misuse is not typical or allowed user activity, and is not a substitute for The New York Times. Regardless, we are continually making our systems more resistant to adversarial attacks to regurgitate training data, and have already made much progress in our recent models.
그들의 주장에도 불구하고 이러한 오용은 일반적이지 않거나 허용되는 사용자 활동이 아니며 The New York Times를 대체할 수 없습니다. 그럼에도 불구하고 우리는 훈련 데이터를 역류 Regurgitation 시키는 적대적 공격에 대한 시스템 저항력을 높이기 위해 지속적으로 노력하고 있으며 이미 최근 모델에서 많은 진전을 이루었습니다.
We regard The New York Times’ lawsuit to be without merit. Still, we are hopeful for a constructive partnership with The New York Times and respect its long history, which includes reporting thefirst working neural networkover 60 years ago and championing First Amendment freedoms.
우리는 New York Times의 소송이 가치가 없다고 생각합니다. 그럼에도 불구하고 우리는 The New York Times와의 건설적인 파트너십을 희망하며 60년 전 최초로 작동하는 신경망을 보고하고 수정헌법 제1조의 자유를 옹호하는 등의 오랜 역사를 존중합니다.
We look forward to continued collaboration with news organizations, helping elevate their ability to produce quality journalism by realizing the transformative potential of AI.
우리는 AI의 혁신적인 잠재력을 실현하여 양질의 저널리즘을 생산하는 능력을 향상시키는 언론 기관과의 지속적인 협력을 기대합니다.
This is the end of the first part of the course! Part 2 will be released on November 15th with a big community event, see more informationhere.
이것으로 강좌의 첫 번째 부분이 끝났습니다! 파트 2는 대규모 커뮤니티 이벤트와 함께 11월 15일에 출시될 예정입니다. 자세한 내용은 여기에서 확인하세요.
You should now be able to fine-tune a pretrained model on a text classification problem (single or pairs of sentences) and upload the result to the Model Hub. To make sure you mastered this first section, you should do exactly that on a problem that interests you (and not necessarily in English if you speak another language)! You can find help in theHugging Face forumsand share your project inthis topiconce you’re finished.
이제 텍스트 분류 문제(단일 또는 쌍의 문장)에 대해 사전 학습된 모델을 미세 조정하고 결과를 모델 허브에 업로드할 수 있습니다. 이 첫 번째 섹션을 완전히 마스터하려면 관심 있는 문제에 대해 정확하게 해당 섹션을 완료해야 합니다(다른 언어를 사용하는 경우 반드시 영어로 할 필요는 없음)! Hugging Face 포럼에서 도움을 찾을 수 있으며 작업이 끝나면 이 주제에서 프로젝트를 공유할 수 있습니다.
We can’t wait to see what you will build with this!