

HF-NLP-Transformer models : Transformers, what can they do?
2023. 12. 23. 13:08 |
https://huggingface.co/learn/nlp-course/chapter1/3?fw=pt
Transformers, what can they do? - Hugging Face NLP Course
In this section, we will look at what Transformer models can do and use our first tool from the 🤗 Transformers library: the pipeline() function. 👀 See that Open in Colab button on the top right? Click on it to open a Google Colab notebook with all th
huggingface.co
Transformers, what can they do?
In this section, we will look at what Transformer models can do and use our first tool from the 🤗 Transformers library: the pipeline() function.
이 섹션에서는 Transformer 모델이 수행할 수 있는 작업을 살펴보고 🤗 Transformers 라이브러리의 첫 번째 도구인 파이프라인() 함수를 사용합니다.
If you want to run the examples locally, we recommend taking a look at the setup.
👀 오른쪽 상단에 Colab에서 열기 버튼이 보이시나요? 이 섹션의 모든 코드 샘플이 포함된 Google Colab 노트북을 열려면 클릭하세요. 이 버튼은 코드 예제가 포함된 모든 섹션에 표시됩니다.
예제를 로컬에서 실행하려면 설정을 살펴보는 것이 좋습니다.
Transformers are everywhere!
Transformer models are used to solve all kinds of NLP tasks, like the ones mentioned in the previous section. Here are some of the companies and organizations using Hugging Face and Transformer models, who also contribute back to the community by sharing their models:
Transformer 모델은 이전 섹션에서 언급한 것과 같은 모든 종류의 NLP 작업을 해결하는 데 사용됩니다. Hugging Face 및 Transformer 모델을 사용하고 모델을 공유하여 커뮤니티에 다시 기여하는 일부 회사 및 조직은 다음과 같습니다.

The 🤗 Transformers library provides the functionality to create and use those shared models. The Model Hub contains thousands of pretrained models that anyone can download and use. You can also upload your own models to the Hub!
🤗 Transformers 라이브러리는 이러한 공유 모델을 생성하고 사용할 수 있는 기능을 제공합니다. 모델 허브에는 누구나 다운로드하여 사용할 수 있는 수천 개의 사전 훈련된 모델이 포함되어 있습니다. 자신의 모델을 허브에 업로드할 수도 있습니다!
Before diving into how Transformer models work under the hood, let’s look at a few examples of how they can be used to solve some interesting NLP problems.
⚠️ Hugging Face Hub는 Transformer 모델에만 국한되지 않습니다. 누구나 원하는 모든 종류의 모델이나 데이터 세트를 공유할 수 있습니다! 사용 가능한 모든 기능을 활용하려면 Huggingface.co 계정을 만드세요!
Transformer 모델이 내부적으로 어떻게 작동하는지 알아보기 전에, 몇 가지 흥미로운 NLP 문제를 해결하는 데 어떻게 사용될 수 있는지에 대한 몇 가지 예를 살펴보겠습니다.
Working with pipelines
https://youtu.be/tiZFewofSLM?si=Es3SmFnc7IJSG0ts
The most basic object in the 🤗 Transformers library is the pipeline() function. It connects a model with its necessary preprocessing and postprocessing steps, allowing us to directly input any text and get an intelligible answer:
🤗 Transformers 라이브러리의 가장 기본적인 객체는 파이프라인() 함수입니다. 모델을 필요한 전처리 및 후처리 단계와 연결하여 텍스트를 직접 입력하고 이해하기 쉬운 답변을 얻을 수 있습니다.
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
classifier("I've been waiting for a HuggingFace course my whole life.")
[{'label': 'POSITIVE', 'score': 0.9598047137260437}]
CoLab 실행 결과
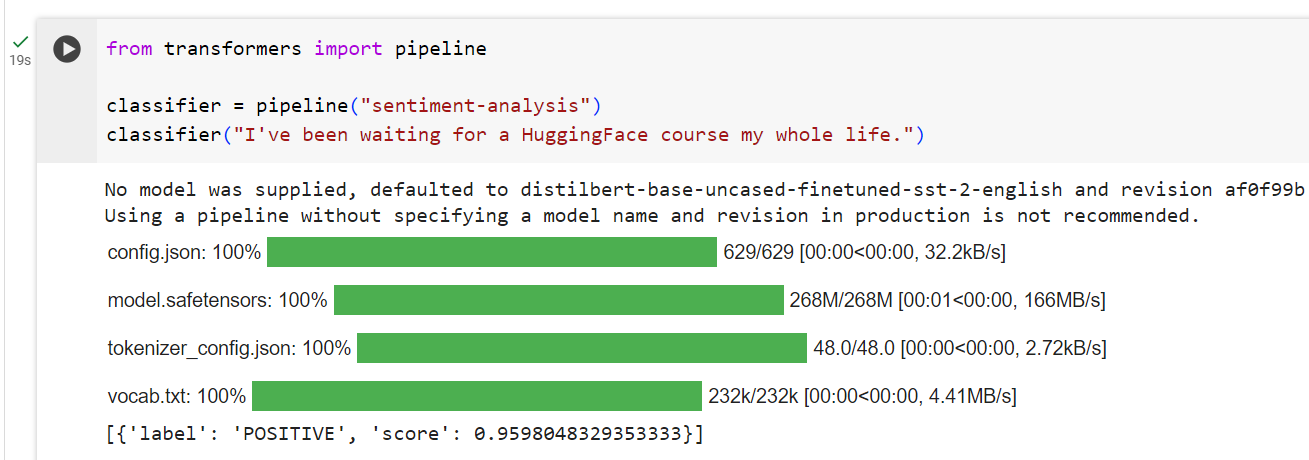
We can even pass several sentences!
여러 문장을 전달할 수도 있습니다!
classifier(
["I've been waiting for a HuggingFace course my whole life.", "I hate this so much!"]
)
[{'label': 'POSITIVE', 'score': 0.9598047137260437},
{'label': 'NEGATIVE', 'score': 0.9994558095932007}]
By default, this pipeline selects a particular pretrained model that has been fine-tuned for sentiment analysis in English. The model is downloaded and cached when you create the classifier object. If you rerun the command, the cached model will be used instead and there is no need to download the model again.
기본적으로 이 파이프라인은 영어로 된 감정 분석을 위해 미세 조정된 특정 사전 학습 모델을 선택합니다. 분류자 개체를 생성하면 모델이 다운로드되고 캐시됩니다. 명령을 다시 실행하면 캐시된 모델이 대신 사용되며 모델을 다시 다운로드할 필요가 없습니다.
There are three main steps involved when you pass some text to a pipeline:
일부 텍스트를 파이프라인에 전달할 때 관련된 세 가지 주요 단계는 다음과 같습니다.
- The text is preprocessed into a format the model can understand.
텍스트는 모델이 이해할 수 있는 형식으로 전처리됩니다. - The preprocessed inputs are passed to the model.
전처리된 입력이 모델에 전달됩니다. - The predictions of the model are post-processed, so you can make sense of them.
모델의 예측은 사후 처리되므로 이를 이해할 수 있습니다.

Some of the currently available pipelines are:
현재 사용 가능한 파이프라인 중 일부는 다음과 같습니다.
- feature-extraction (get the vector representation of a text)
- fill-mask
- ner (named entity recognition)
- question-answering
- sentiment-analysis
- summarization
- text-generation
- translation
- zero-shot-classification
Let’s have a look at a few of these!
이들 중 몇 가지를 살펴보겠습니다!
Zero-shot classification
We’ll start by tackling a more challenging task where we need to classify texts that haven’t been labelled. This is a common scenario in real-world projects because annotating text is usually time-consuming and requires domain expertise. For this use case, the zero-shot-classification pipeline is very powerful: it allows you to specify which labels to use for the classification, so you don’t have to rely on the labels of the pretrained model. You’ve already seen how the model can classify a sentence as positive or negative using those two labels — but it can also classify the text using any other set of labels you like.
라벨이 지정되지 않은 텍스트를 분류해야 하는 좀 더 어려운 작업부터 시작하겠습니다. 텍스트에 주석을 다는 것은 일반적으로 시간이 많이 걸리고 도메인 전문 지식이 필요하기 때문에 이는 실제 프로젝트에서 일반적인 시나리오입니다. 이 사용 사례의 경우 제로 샷 분류 파이프라인은 매우 강력합니다. 분류에 사용할 레이블을 지정할 수 있으므로 사전 훈련된 모델의 레이블에 의존할 필요가 없습니다. 모델이 두 레이블을 사용하여 문장을 긍정 또는 부정으로 분류하는 방법을 이미 확인했습니다. 하지만 원하는 다른 레이블 세트를 사용하여 텍스트를 분류할 수도 있습니다.
from transformers import pipeline
classifier = pipeline("zero-shot-classification")
classifier(
"This is a course about the Transformers library",
candidate_labels=["education", "politics", "business"],
)
{'sequence': 'This is a course about the Transformers library',
'labels': ['education', 'business', 'politics'],
'scores': [0.8445963859558105, 0.111976258456707, 0.043427448719739914]}
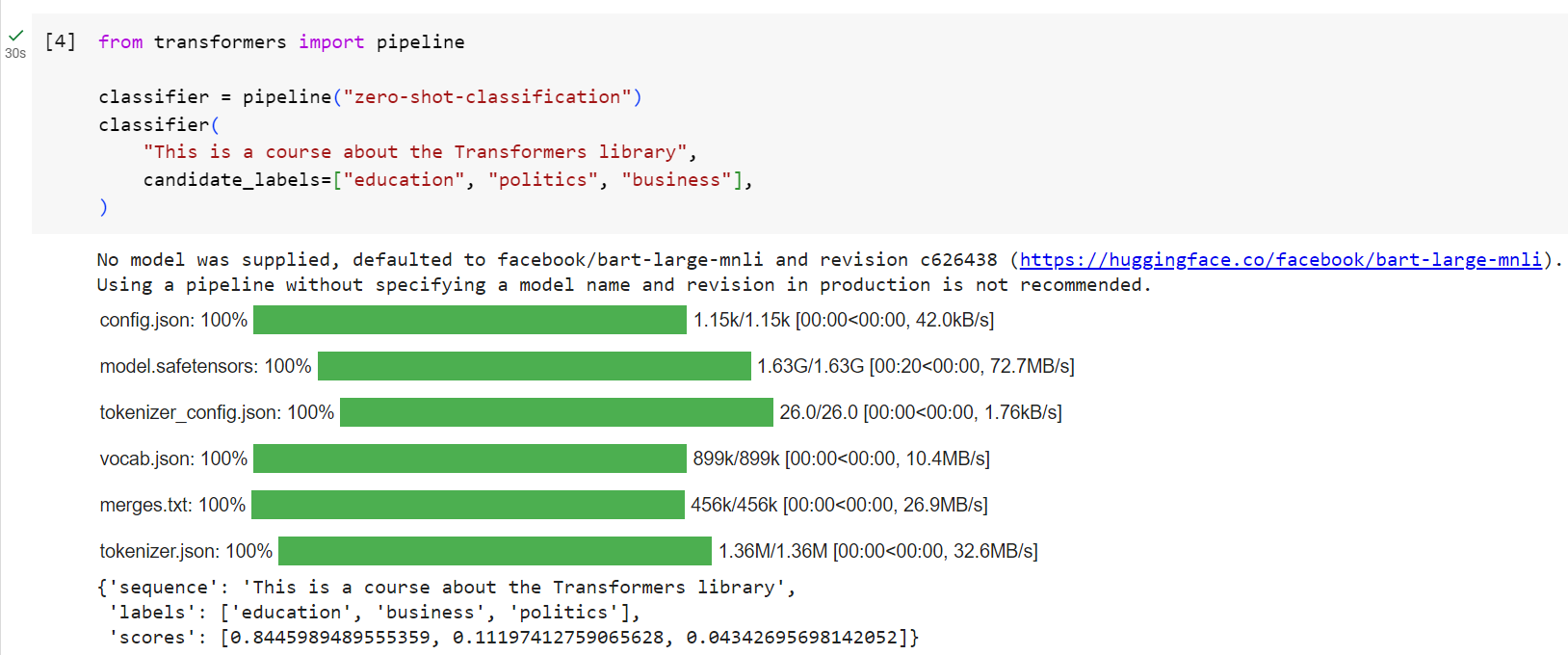
This pipeline is called zero-shot because you don’t need to fine-tune the model on your data to use it. It can directly return probability scores for any list of labels you want!
이 파이프라인을 사용하기 위해 데이터 모델을 미세 조정할 필요가 없기 때문에 제로샷이라고 합니다. 원하는 라벨 목록에 대한 확률 점수를 직접 반환할 수 있습니다!
✏️ Try it out! Play around with your own sequences and labels and see how the model behaves.
✏️ 한번 사용해 보세요! 자신만의 시퀀스와 라벨을 가지고 실험해보고 모델이 어떻게 작동하는지 확인하세요.
Text generation
Now let’s see how to use a pipeline to generate some text. The main idea here is that you provide a prompt and the model will auto-complete it by generating the remaining text. This is similar to the predictive text feature that is found on many phones. Text generation involves randomness, so it’s normal if you don’t get the same results as shown below.
이제 파이프라인을 사용하여 텍스트를 생성하는 방법을 살펴보겠습니다. 여기서 주요 아이디어는 프롬프트를 제공하면 모델이 나머지 텍스트를 생성하여 프롬프트를 자동 완성한다는 것입니다. 이는 많은 휴대폰에서 볼 수 있는 텍스트 예측 기능과 유사합니다. 텍스트 생성에는 무작위성이 포함되므로 아래와 같은 결과가 나오지 않는 것이 정상입니다.
from transformers import pipeline
generator = pipeline("text-generation")
generator("In this course, we will teach you how to")
[{'generated_text': 'In this course, we will teach you how to understand and use '
'data flow and data interchange when handling user data. We '
'will be working with one or more of the most commonly used '
'data flows — data flows of various types, as seen by the '
'HTTP'}]
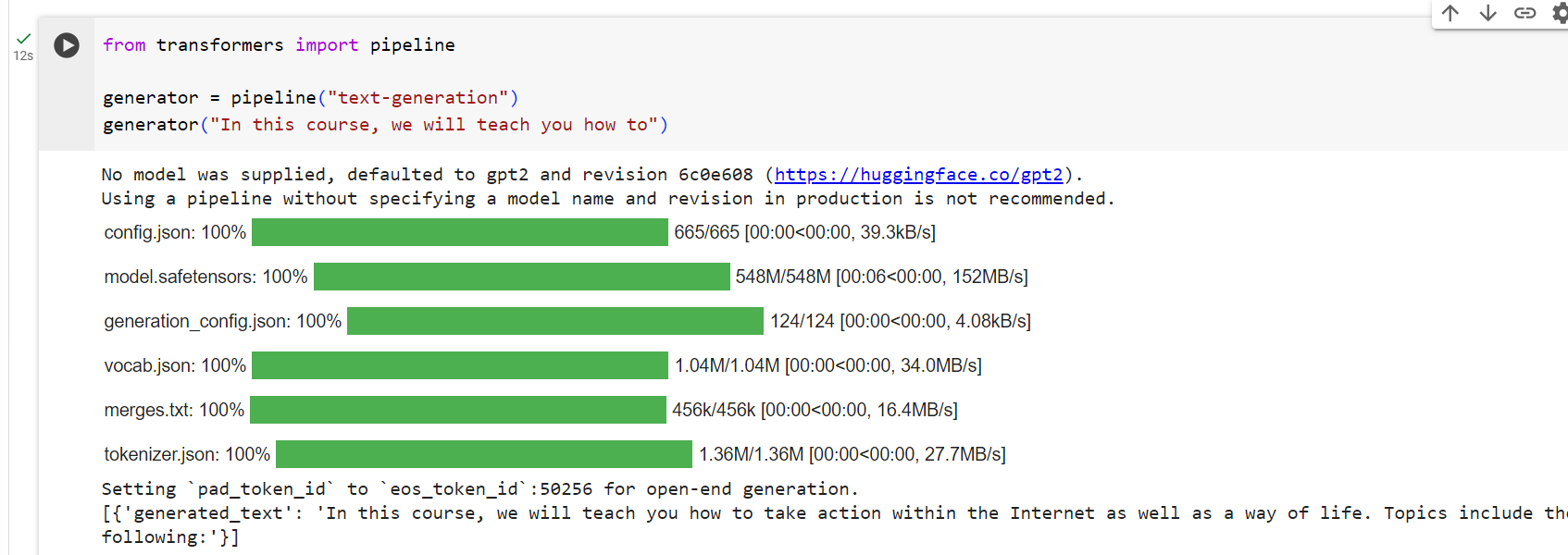
You can control how many different sequences are generated with the argument num_return_sequences and the total length of the output text with the argument max_length.
num_return_sequences 인수를 사용하여 생성되는 서로 다른 시퀀스 수와 max_length 인수를 사용하여 출력 텍스트의 전체 길이를 제어할 수 있습니다.
✏️ Try it out! Use the num_return_sequences and max_length arguments to generate two sentences of 15 words each.
✏️ 한번 사용해 보세요! num_return_sequences 및 max_length 인수를 사용하여 각각 15개 단어로 구성된 두 문장을 생성합니다.
Using any model from the Hub in a pipeline
The previous examples used the default model for the task at hand, but you can also choose a particular model from the Hub to use in a pipeline for a specific task — say, text generation. Go to the Model Hub and click on the corresponding tag on the left to display only the supported models for that task. You should get to a page like this one.
이전 예제에서는 현재 작업에 기본 모델을 사용했지만 허브에서 특정 모델을 선택하여 특정 작업(예: 텍스트 생성)을 위한 파이프라인에서 사용할 수도 있습니다. 모델 허브로 이동하여 왼쪽에서 해당 태그를 클릭하면 해당 작업에 지원되는 모델만 표시됩니다. 이와 같은 페이지로 이동해야 합니다.
Let’s try the distilgpt2 model! Here’s how to load it in the same pipeline as before:
distilgpt2 모델을 사용해 봅시다! 이전과 동일한 파이프라인에서 이를 로드하는 방법은 다음과 같습니다.
from transformers import pipeline
generator = pipeline("text-generation", model="distilgpt2")
generator(
"In this course, we will teach you how to",
max_length=30,
num_return_sequences=2,
)[{'generated_text': 'In this course, we will teach you how to manipulate the world and '
'move your mental and physical capabilities to your advantage.'},
{'generated_text': 'In this course, we will teach you how to become an expert and '
'practice realtime, and with a hands on experience on both real '
'time and real'}]
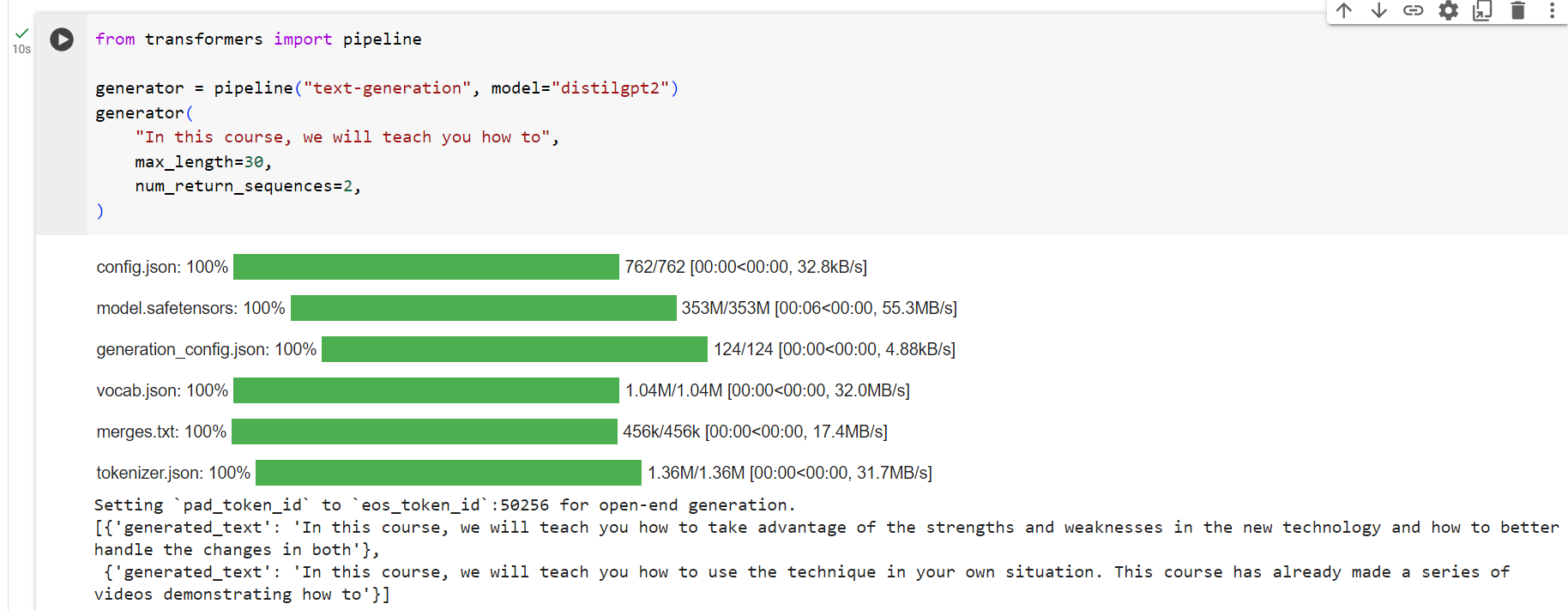
You can refine your search for a model by clicking on the language tags, and pick a model that will generate text in another language. The Model Hub even contains checkpoints for multilingual models that support several languages.
언어 태그를 클릭하여 모델 검색을 구체화하고 다른 언어로 텍스트를 생성할 모델을 선택할 수 있습니다. 모델 허브에는 여러 언어를 지원하는 다국어 모델에 대한 체크포인트도 포함되어 있습니다.
Once you select a model by clicking on it, you’ll see that there is a widget enabling you to try it directly online. This way you can quickly test the model’s capabilities before downloading it.
모델을 클릭하여 선택하면 온라인에서 직접 사용해 볼 수 있는 위젯이 표시됩니다. 이렇게 하면 모델을 다운로드하기 전에 모델의 기능을 빠르게 테스트할 수 있습니다.
✏️ Try it out! Use the filters to find a text generation model for another language. Feel free to play with the widget and use it in a pipeline!
✏️ 한번 사용해 보세요! 필터를 사용하여 다른 언어에 대한 텍스트 생성 모델을 찾으세요. 위젯을 자유롭게 가지고 파이프라인에서 사용해 보세요!
The Inference API
All the models can be tested directly through your browser using the Inference API, which is available on the Hugging Face website. You can play with the model directly on this page by inputting custom text and watching the model process the input data.
모든 모델은 Hugging Face 웹사이트에서 제공되는 Inference API를 사용하여 브라우저를 통해 직접 테스트할 수 있습니다. 이 페이지에서 사용자 정의 텍스트를 입력하고 모델이 입력 데이터를 처리하는 모습을 보면서 직접 모델을 가지고 놀 수 있습니다.
The Inference API that powers the widget is also available as a paid product, which comes in handy if you need it for your workflows. See the pricing page for more details.
위젯을 지원하는 Inference API는 유료 제품으로도 제공되므로 워크플로에 필요할 때 유용합니다. 자세한 내용은 가격 페이지를 참조하세요.
Mask filling
The next pipeline you’ll try is fill-mask. The idea of this task is to fill in the blanks in a given text:
시도할 다음 파이프라인은 채우기 마스크입니다. 이 작업의 아이디어는 주어진 텍스트의 빈칸을 채우는 것입니다.
from transformers import pipeline
unmasker = pipeline("fill-mask")
unmasker("This course will teach you all about <mask> models.", top_k=2)[{'sequence': 'This course will teach you all about mathematical models.',
'score': 0.19619831442832947,
'token': 30412,
'token_str': ' mathematical'},
{'sequence': 'This course will teach you all about computational models.',
'score': 0.04052725434303284,
'token': 38163,
'token_str': ' computational'}]
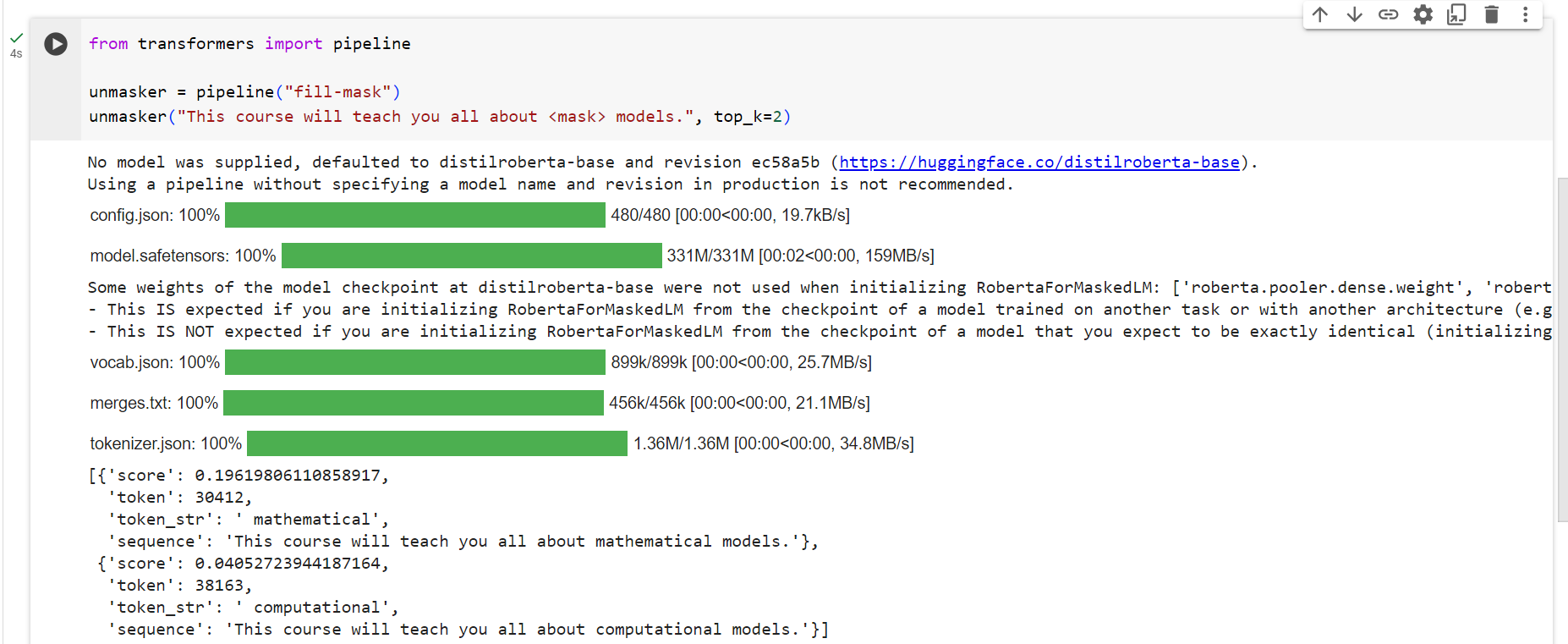
The top_k argument controls how many possibilities you want to be displayed. Note that here the model fills in the special <mask> word, which is often referred to as a mask token. Other mask-filling models might have different mask tokens, so it’s always good to verify the proper mask word when exploring other models. One way to check it is by looking at the mask word used in the widget.
top_k 인수는 표시할 가능성의 수를 제어합니다. 여기서 모델은 종종 마스크 토큰이라고 하는 특수 <mask> 단어를 채웁니다. 다른 마스크 채우기 모델에는 다른 마스크 토큰이 있을 수 있으므로 다른 모델을 탐색할 때 항상 적절한 마스크 단어를 확인하는 것이 좋습니다. 이를 확인하는 한 가지 방법은 위젯에 사용된 마스크 단어를 보는 것입니다.
✏️ Try it out! Search for the bert-base-cased model on the Hub and identify its mask word in the Inference API widget. What does this model predict for the sentence in our pipeline example above?
✏️ 한번 사용해 보세요! 허브에서 bert-base-cased 모델을 검색하고 Inference API 위젯에서 해당 마스크 단어를 식별합니다. 이 모델은 위 파이프라인 예의 문장에 대해 무엇을 예측합니까?
Named entity recognition
Named entity recognition (NER) is a task where the model has to find which parts of the input text correspond to entities such as persons, locations, or organizations. Let’s look at an example:
명명된 엔터티 인식(NER)은 모델이 입력 텍스트의 어느 부분이 사람, 위치 또는 조직과 같은 엔터티에 해당하는지 찾아야 하는 작업입니다. 예를 살펴보겠습니다:
from transformers import pipeline
ner = pipeline("ner", grouped_entities=True)
ner("My name is Sylvain and I work at Hugging Face in Brooklyn.")[{'entity_group': 'PER', 'score': 0.99816, 'word': 'Sylvain', 'start': 11, 'end': 18},
{'entity_group': 'ORG', 'score': 0.97960, 'word': 'Hugging Face', 'start': 33, 'end': 45},
{'entity_group': 'LOC', 'score': 0.99321, 'word': 'Brooklyn', 'start': 49, 'end': 57}
]
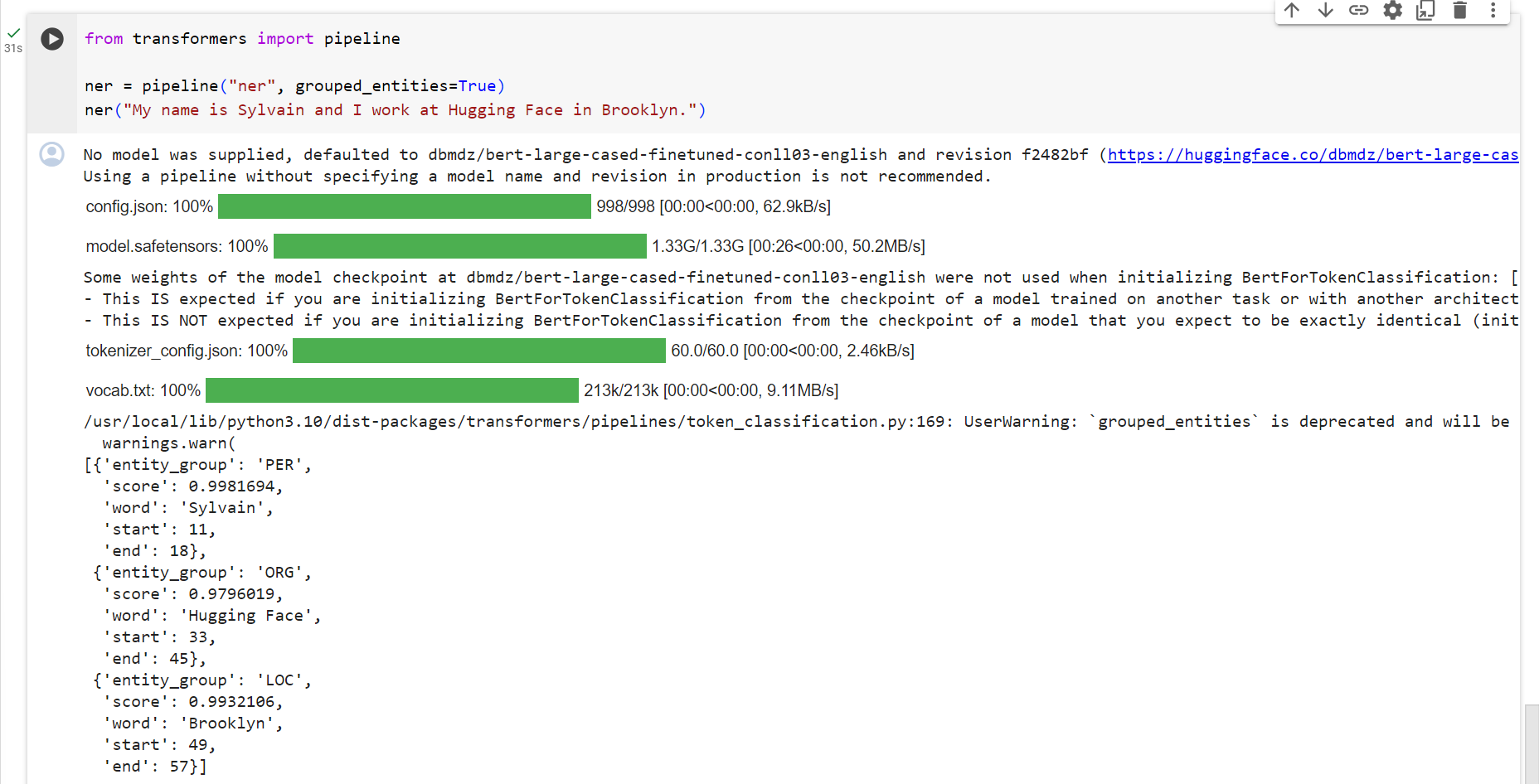
Here the model correctly identified that Sylvain is a person (PER), Hugging Face an organization (ORG), and Brooklyn a location (LOC).
여기서 모델은 Sylvain이 사람(PER), Hugging Face가 조직(ORG), Brooklyn이 위치(LOC)임을 올바르게 식별했습니다.
We pass the option grouped_entities=True in the pipeline creation function to tell the pipeline to regroup together the parts of the sentence that correspond to the same entity: here the model correctly grouped “Hugging” and “Face” as a single organization, even though the name consists of multiple words. In fact, as we will see in the next chapter, the preprocessing even splits some words into smaller parts. For instance, Sylvain is split into four pieces: S, ##yl, ##va, and ##in. In the post-processing step, the pipeline successfully regrouped those pieces.
파이프라인 생성 함수에 grouped_entities=True 옵션을 전달하여 동일한 엔터티에 해당하는 문장 부분을 함께 재그룹화하도록 파이프라인에 지시합니다. 여기서 모델은 "Hugging"과 "Face"를 단일 조직으로 올바르게 그룹화했습니다. 이름은 여러 단어로 구성됩니다. 실제로 다음 장에서 살펴보겠지만 전처리는 일부 단어를 더 작은 부분으로 분할하기도 합니다. 예를 들어 Sylvain은 S, ##yl, ##va, ##in의 네 부분으로 나뉩니다. 사후 처리 단계에서 파이프라인은 해당 조각을 성공적으로 재그룹화했습니다.
✏️ Try it out! Search the Model Hub for a model able to do part-of-speech tagging (usually abbreviated as POS) in English. What does this model predict for the sentence in the example above?
✏️ 한번 사용해 보세요! 영어로 품사 태깅(보통 POS로 약칭)을 수행할 수 있는 모델을 모델 허브에서 검색하세요. 이 모델은 위 예의 문장에 대해 무엇을 예측합니까?
Question answering
The question-answering pipeline answers questions using information from a given context:
질문 답변 파이프라인은 주어진 컨텍스트의 정보를 사용하여 질문에 답변합니다.
from transformers import pipeline
question_answerer = pipeline("question-answering")
question_answerer(
question="Where do I work?",
context="My name is Sylvain and I work at Hugging Face in Brooklyn",
){'score': 0.6385916471481323, 'start': 33, 'end': 45, 'answer': 'Hugging Face'}
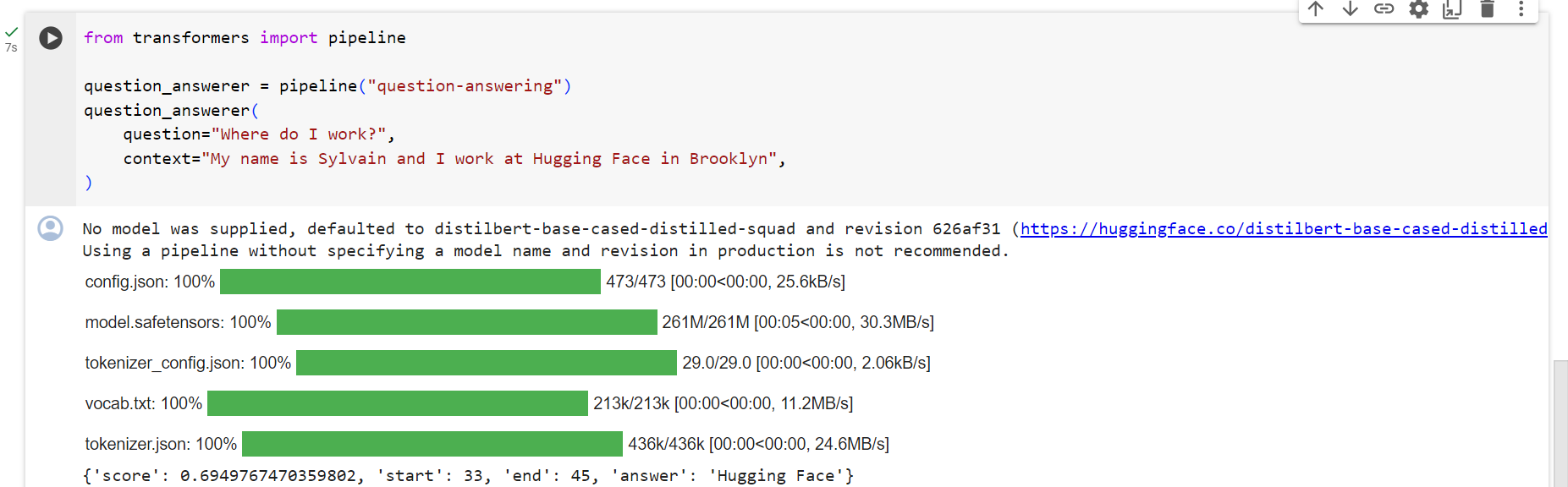
Note that this pipeline works by extracting information from the provided context; it does not generate the answer.
이 파이프라인은 제공된 컨텍스트에서 정보를 추출하여 작동합니다. 답변을 생성하지 않습니다.
Summarization
Summarization is the task of reducing a text into a shorter text while keeping all (or most) of the important aspects referenced in the text. Here’s an example:
요약은 텍스트에서 참조된 모든 중요한 측면을 유지하면서 텍스트를 더 짧은 텍스트로 줄이는 작업입니다. 예는 다음과 같습니다.
from transformers import pipeline
summarizer = pipeline("summarization")
summarizer(
"""
America has changed dramatically during recent years. Not only has the number of
graduates in traditional engineering disciplines such as mechanical, civil,
electrical, chemical, and aeronautical engineering declined, but in most of
the premier American universities engineering curricula now concentrate on
and encourage largely the study of engineering science. As a result, there
are declining offerings in engineering subjects dealing with infrastructure,
the environment, and related issues, and greater concentration on high
technology subjects, largely supporting increasingly complex scientific
developments. While the latter is important, it should not be at the expense
of more traditional engineering.
Rapidly developing economies such as China and India, as well as other
industrial countries in Europe and Asia, continue to encourage and advance
the teaching of engineering. Both China and India, respectively, graduate
six and eight times as many traditional engineers as does the United States.
Other industrial countries at minimum maintain their output, while America
suffers an increasingly serious decline in the number of engineering graduates
and a lack of well-educated engineers.
"""
)
[{'summary_text': ' America has changed dramatically during recent years . The '
'number of engineering graduates in the U.S. has declined in '
'traditional engineering disciplines such as mechanical, civil '
', electrical, chemical, and aeronautical engineering . Rapidly '
'developing economies such as China and India, as well as other '
'industrial countries in Europe and Asia, continue to encourage '
'and advance engineering .'}]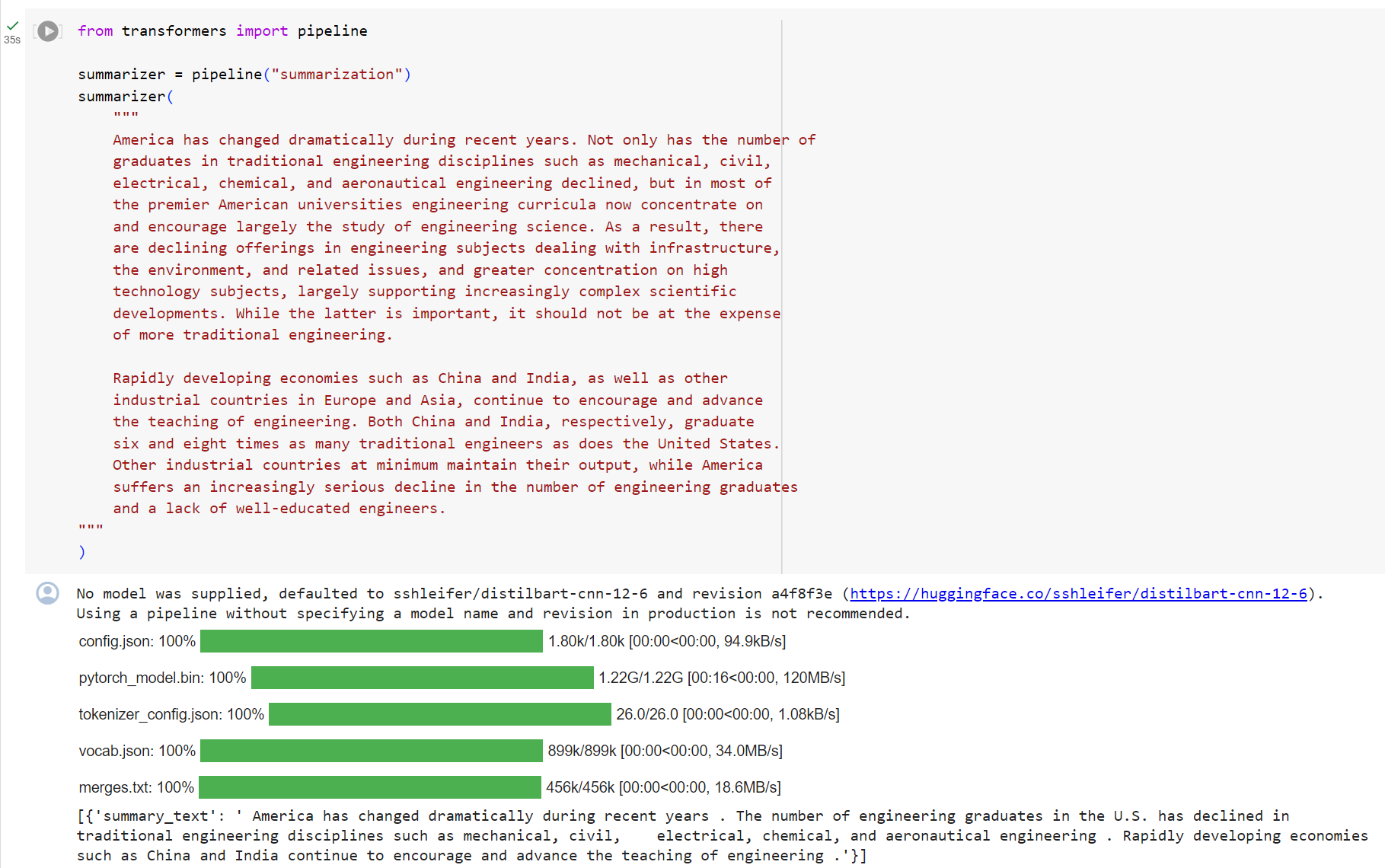
Like with text generation, you can specify a max_length or a min_length for the result.
텍스트 생성과 마찬가지로 결과에 대해 max_length 또는 min_length를 지정할 수 있습니다.
Translation
For translation, you can use a default model if you provide a language pair in the task name (such as "translation_en_to_fr"), but the easiest way is to pick the model you want to use on the Model Hub. Here we’ll try translating from French to English:
번역의 경우 작업 이름에 언어 쌍(예: "translation_en_to_fr")을 제공하면 기본 모델을 사용할 수 있지만 가장 쉬운 방법은 모델 허브에서 사용하려는 모델을 선택하는 것입니다. 여기서는 프랑스어를 영어로 번역해 보겠습니다.
from transformers import pipeline
translator = pipeline("translation", model="Helsinki-NLP/opus-mt-fr-en")
translator("Ce cours est produit par Hugging Face.")[{'translation_text': 'This course is produced by Hugging Face.'}]
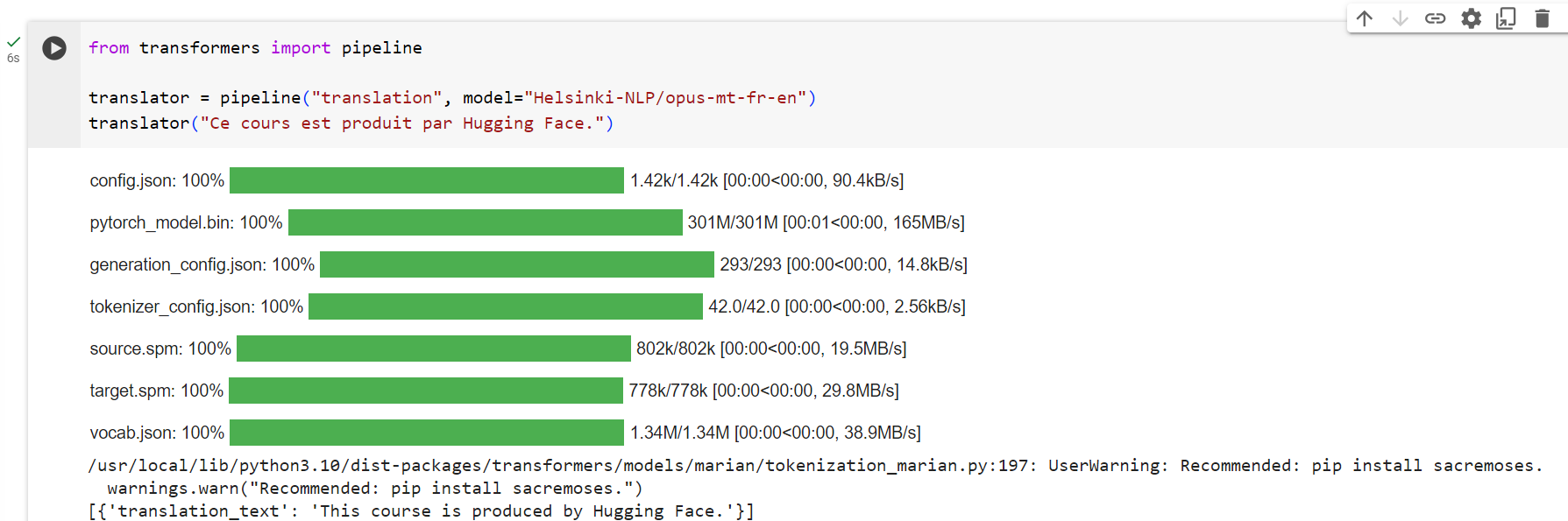
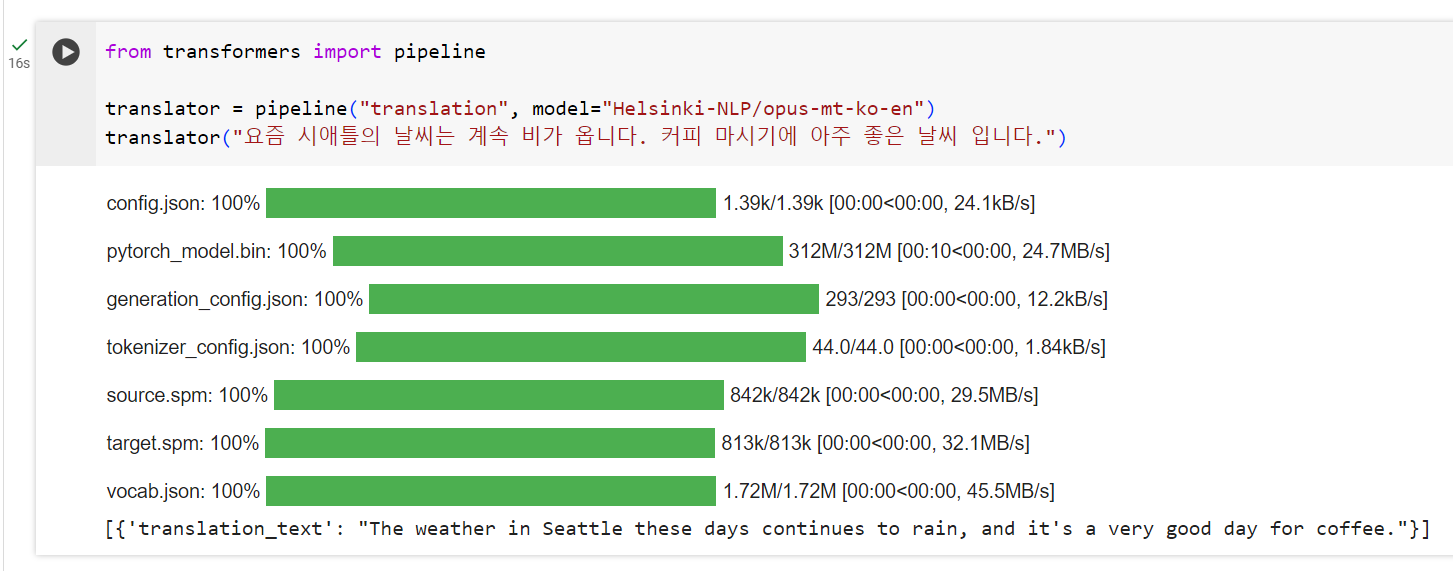
한국어를 프랑스어로 번역할 경우

한국어를 영어로 번역할 경우.
Like with text generation and summarization, you can specify a max_length or a min_length for the result.
텍스트 생성 및 요약과 마찬가지로 결과에 대해 max_length 또는 min_length를 지정할 수 있습니다.
✏️ Try it out! Search for translation models in other languages and try to translate the previous sentence into a few different languages.
✏️ 한번 사용해 보세요! 다른 언어의 번역 모델을 검색하고 이전 문장을 몇 가지 다른 언어로 번역해 보세요.
The pipelines shown so far are mostly for demonstrative purposes. They were programmed for specific tasks and cannot perform variations of them. In the next chapter, you’ll learn what’s inside a pipeline() function and how to customize its behavior.
지금까지 표시된 파이프라인은 대부분 시연 목적으로 사용되었습니다. 특정 작업을 위해 프로그래밍되었으며 다양한 작업을 수행할 수 없습니다. 다음 장에서는 파이프라인() 함수 내부의 내용과 해당 동작을 사용자 정의하는 방법을 배우게 됩니다.
https://youtu.be/xbQ0DIJA0Bc?si=GhoIMvUzzRWJMFb9
'Hugging Face > NLP Course' 카테고리의 다른 글
| HF-NLP-Transformer models : End-of-chapter quiz (1) | 2023.12.24 |
|---|---|
| HF-NLP-Transformer models : Summary (0) | 2023.12.24 |
| HF-NLP-Transformer models : Bias and limitations (1) | 2023.12.24 |
| HF-NLP-Transformer models : Sequence-to-sequence models[sequence-to-sequence-models] (1) | 2023.12.24 |
| HF-NLP-Transformer models : Decoder models (1) | 2023.12.24 |
| HF-NLP-Transformer models : Encoder models (1) | 2023.12.24 |
| HF-NLP-Transformer models : How do Transformers work? (1) | 2023.12.24 |
| HF-NLP-Transformer models : Natural Language Processing (0) | 2023.12.19 |
| HF-NLP-Transformer models : Introduction (0) | 2023.12.19 |
| HF-NLP-Setup Introduction (0) | 2023.12.19 |