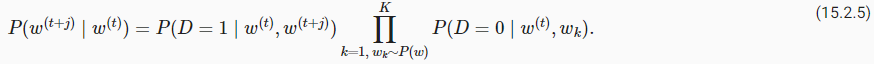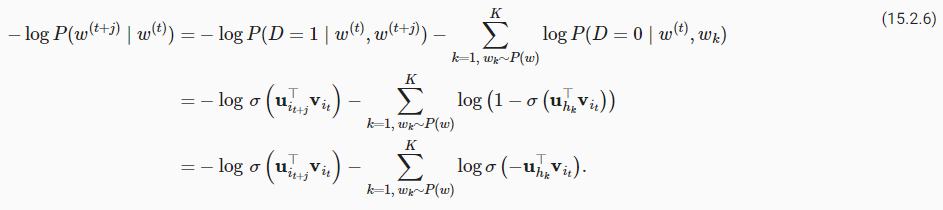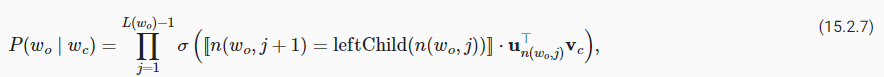15.9. The Dataset for Pretraining BERT — Dive into Deep Learning 1.0.3 documentation (d2l.ai)
15.9. The Dataset for Pretraining BERT — Dive into Deep Learning 1.0.3 documentation
d2l.ai

15.9. The Dataset for Pretraining BERT
To pretrain the BERT model as implemented in Section 15.8, we need to generate the dataset in the ideal format to facilitate the two pretraining tasks: masked language modeling and next sentence prediction. On the one hand, the original BERT model is pretrained on the concatenation of two huge corpora BookCorpus and English Wikipedia (see Section 15.8.5), making it hard to run for most readers of this book. On the other hand, the off-the-shelf pretrained BERT model may not fit for applications from specific domains like medicine. Thus, it is getting popular to pretrain BERT on a customized dataset. To facilitate the demonstration of BERT pretraining, we use a smaller corpus WikiText-2 (Merity et al., 2016).
섹션 15.8에 구현된 BERT 모델을 사전 훈련하려면 마스크된 언어 모델링과 다음 문장 예측이라는 두 가지 사전 훈련 작업을 용이하게 하기 위해 이상적인 형식으로 데이터 세트를 생성해야 합니다. 한편으로, 원래 BERT 모델은 두 개의 거대한 말뭉치인 BookCorpus와 English Wikipedia(섹션 15.8.5 참조)의 연결에 대해 사전 훈련되어 있어 이 책의 대부분의 독자가 실행하기 어렵습니다. 반면, 상용 사전 훈련된 BERT 모델은 의학과 같은 특정 영역의 애플리케이션에는 적합하지 않을 수 있습니다. 따라서 맞춤형 데이터 세트에 대해 BERT를 사전 훈련하는 것이 인기를 얻고 있습니다. BERT 사전 훈련의 시연을 용이하게 하기 위해 우리는 더 작은 말뭉치인 WikiText-2(Merity et al., 2016)를 사용합니다.
Comparing with the PTB dataset used for pretraining word2vec in Section 15.3, WikiText-2 (i) retains the original punctuation, making it suitable for next sentence prediction; (ii) retains the original case and numbers; (iii) is over twice larger.
15.3. The Dataset for Pretraining Word Embeddings — Dive into Deep Learning 1.0.3 documentation
d2l.ai
섹션 15.3의 word2vec 사전 훈련에 사용된 PTB 데이터 세트와 비교하면 WikiText-2 (i)는 원래 구두점을 유지하여 다음 문장 예측에 적합합니다. (ii) 원래 대소문자와 번호를 유지합니다. (iii) 2배 이상 크다.
import os
import random
import torch
from d2l import torch as d2lIn the WikiText-2 dataset, each line represents a paragraph where space is inserted between any punctuation and its preceding token. Paragraphs with at least two sentences are retained. To split sentences, we only use the period as the delimiter for simplicity. We leave discussions of more complex sentence splitting techniques in the exercises at the end of this section.
WikiText-2 데이터세트에서 각 줄은 구두점과 선행 토큰 사이에 공백이 삽입된 단락을 나타냅니다. 문장이 두 개 이상인 단락은 유지됩니다. 문장을 분할하려면 단순화를 위해 마침표만 구분 기호로 사용합니다. 이 섹션 끝 부분의 연습에서 더 복잡한 문장 분할 기술에 대한 논의를 남깁니다.
#@save
d2l.DATA_HUB['wikitext-2'] = (
'https://s3.amazonaws.com/research.metamind.io/wikitext/'
'wikitext-2-v1.zip', '3c914d17d80b1459be871a5039ac23e752a53cbe')
#@save
def _read_wiki(data_dir):
file_name = os.path.join(data_dir, 'wiki.train.tokens')
with open(file_name, 'r') as f:
lines = f.readlines()
# Uppercase letters are converted to lowercase ones
paragraphs = [line.strip().lower().split(' . ')
for line in lines if len(line.split(' . ')) >= 2]
random.shuffle(paragraphs)
return paragraphs위의 코드에서 이루어지는 작업은 다음과 같습니다:
- d2l.DATA_HUB['wikitext-2'] 정의: 데이터셋을 다운로드하기 위한 URL과 체크섬을 정의합니다. 이 정보는 데이터를 다운로드하고 추출하는 데 사용됩니다.
- _read_wiki 함수 정의: 이 함수는 Wikitext-2 데이터셋을 읽어와 처리하는 역할을 합니다. data_dir 매개변수는 데이터셋이 저장되어 있는 디렉토리 경로를 나타냅니다.
- 데이터 읽기 및 전처리: 함수 내부에서는 데이터 파일을 열어 각 줄을 읽어들이고 처리합니다. 각 줄을 소문자로 변환하고 ' . ' (마침표+공백)을 구분자로 사용하여 문단을 분할합니다. 문단의 길이가 2 이상인 경우에만 선택하도록 하여 문장이 적어도 두 개 이상 있는 문단들을 선택합니다.
- 데이터 섞기: 문단들을 무작위로 섞어 데이터의 랜덤성을 높입니다.
이러한 작업을 통해 _read_wiki 함수는 Wikitext-2 데이터셋을 읽어와 전처리한 후 문단들을 반환합니다. 이 데이터는 텍스트 처리 태스크에서 사용될 수 있습니다.
15.9.1. Defining Helper Functions for Pretraining Tasks
In the following, we begin by implementing helper functions for the two BERT pretraining tasks: next sentence prediction and masked language modeling. These helper functions will be invoked later when transforming the raw text corpus into the dataset of the ideal format to pretrain BERT.
다음에서는 다음 문장 예측과 마스크된 언어 모델링이라는 두 가지 BERT 사전 학습 작업에 대한 도우미 기능을 구현하는 것으로 시작합니다. 이러한 도우미 함수는 나중에 BERT를 사전 훈련하기 위해 원시 텍스트 코퍼스를 이상적인 형식의 데이터 세트로 변환할 때 호출됩니다.
15.9.1.1. Generating the Next Sentence Prediction Task
According to descriptions of Section 15.8.5.2, the _get_next_sentence function generates a training example for the binary classification task.
섹션 15.8.5.2의 설명에 따라 _get_next_sentence 함수는 이진 분류 작업에 대한 훈련 예제를 생성합니다.
#@save
def _get_next_sentence(sentence, next_sentence, paragraphs):
if random.random() < 0.5:
is_next = True
else:
# `paragraphs` is a list of lists of lists
next_sentence = random.choice(random.choice(paragraphs))
is_next = False
return sentence, next_sentence, is_next위의 코드에서 이루어지는 작업은 다음과 같습니다:
- sentence, next_sentence, paragraphs 매개변수: 함수에는 세 개의 매개변수가 전달됩니다.
- sentence: 현재 문장입니다.
- next_sentence: 다음 문장입니다.
- paragraphs: 이중 리스트 형태의 데이터셋으로, 문단들을 포함한 구조입니다.
- NSP 타겟 생성: 먼저 0.5의 확률로 is_next 라는 변수를 True로 설정합니다. 이는 현재 문장과 다음 문장이 연속된 문장인 경우를 의미합니다. 그렇지 않은 경우에는 (0.5 확률로) 다른 무작위 문단에서 문장을 선택하여 next_sentence를 업데이트하고 is_next를 False로 설정합니다. 이 경우 현재 문장과 다음 문장은 연속되지 않습니다.
- 결과 반환: 최종적으로 생성된 sentence, next_sentence, is_next를 반환합니다. 이 정보는 NSP 작업의 학습 데이터를 구성하거나 평가하는 데 사용됩니다.
NSP 작업은 BERT 모델의 학습에서 사용되며, 주어진 문장과 다음 문장이 실제로 연속되는지 여부를 판단하는 과제입니다. 이를 통해 모델은 문맥을 이해하고 문장 간의 관계를 파악할 수 있도록 학습됩니다
The following function generates training examples for next sentence prediction from the input paragraph by invoking the _get_next_sentence function. Here paragraph is a list of sentences, where each sentence is a list of tokens. The argument max_len specifies the maximum length of a BERT input sequence during pretraining.
다음 함수는 _get_next_sentence 함수를 호출하여 입력 단락에서 다음 문장 예측을 위한 훈련 예제를 생성합니다. 여기 단락은 문장 목록이며, 각 문장은 토큰 목록입니다. max_len 인수는 사전 학습 중 BERT 입력 시퀀스의 최대 길이를 지정합니다.
#@save
def _get_nsp_data_from_paragraph(paragraph, paragraphs, vocab, max_len):
nsp_data_from_paragraph = []
for i in range(len(paragraph) - 1):
tokens_a, tokens_b, is_next = _get_next_sentence(
paragraph[i], paragraph[i + 1], paragraphs)
# Consider 1 '<cls>' token and 2 '<sep>' tokens
if len(tokens_a) + len(tokens_b) + 3 > max_len:
continue
tokens, segments = d2l.get_tokens_and_segments(tokens_a, tokens_b)
nsp_data_from_paragraph.append((tokens, segments, is_next))
return nsp_data_from_paragraph위의 코드에서 이루어지는 작업은 다음과 같습니다:
- paragraph, paragraphs, vocab, max_len 매개변수: 함수에는 네 가지 매개변수가 전달됩니다.
- paragraph: 현재 문단을 나타내는 리스트입니다.
- paragraphs: 전체 데이터셋의 모든 문단들을 포함한 구조입니다.
- vocab: 어휘 사전입니다.
- max_len: 토큰의 최대 길이입니다.
- NSP 데이터 생성: 현재 문단 내에서 인접한 두 문장을 선택하여 NSP 작업에 사용되는 데이터를 생성합니다. 이를 위해 _get_next_sentence 함수를 사용하여 현재 문장과 다음 문장, 그리고 두 문장이 연속되는지 여부(is_next)를 얻어옵니다.
- 길이 조건 확인: 생성된 두 문장의 토큰들의 길이와 추가된 특수 토큰('<cls>' 및 '<sep>')을 고려하여 문장의 길이가 max_len을 초과하지 않는지 확인합니다. 만약 초과하는 경우 건너뛰고 다음 인덱스의 문장을 고려합니다.
- 토큰 및 세그먼트 생성: _get_tokens_and_segments 함수를 사용하여 두 문장의 토큰과 세그먼트를 생성합니다. 이 정보는 BERT 입력으로 사용됩니다.
- 결과 반환: 생성된 NSP 데이터인 (tokens, segments, is_next)를 리스트에 추가하여 반환합니다. 이 정보는 NSP 작업의 학습 데이터를 구성하는 데 사용됩니다.
NSP 작업은 BERT 모델의 학습에서 문장 간의 관계를 학습하는 데 사용되며, 문장이 실제로 연속되는지 여부를 판단하는 태스크입니다.
15.9.1.2. Generating the Masked Language Modeling Task
In order to generate training examples for the masked language modeling task from a BERT input sequence, we define the following _replace_mlm_tokens function. In its inputs, tokens is a list of tokens representing a BERT input sequence, candidate_pred_positions is a list of token indices of the BERT input sequence excluding those of special tokens (special tokens are not predicted in the masked language modeling task), and num_mlm_preds indicates the number of predictions (recall 15% random tokens to predict). Following the definition of the masked language modeling task in Section 15.8.5.1, at each prediction position, the input may be replaced by a special “<mask>” token or a random token, or remain unchanged. In the end, the function returns the input tokens after possible replacement, the token indices where predictions take place and labels for these predictions.
BERT 입력 시퀀스에서 마스크된 언어 모델링 작업에 대한 훈련 예제를 생성하기 위해 다음 _replace_mlm_tokens 함수를 정의합니다. 입력에서 tokens는 BERT 입력 시퀀스를 나타내는 토큰 목록이고, Candidate_pred_positions는 특수 토큰을 제외한 BERT 입력 시퀀스의 토큰 인덱스 목록이며(특수 토큰은 마스크된 언어 모델링 작업에서 예측되지 않음) num_mlm_preds는 예측 수(예측을 위해 15% 무작위 토큰을 회수) 섹션 15.8.5.1의 마스크된 언어 모델링 작업 정의에 따라 각 예측 위치에서 입력은 특수 "<mask>" 토큰 또는 무작위 토큰으로 대체되거나 변경되지 않은 상태로 유지될 수 있습니다. 결국 함수는 가능한 교체 후 입력 토큰, 예측이 발생하는 토큰 인덱스 및 이러한 예측에 대한 레이블을 반환합니다.
#@save
def _replace_mlm_tokens(tokens, candidate_pred_positions, num_mlm_preds,
vocab):
# For the input of a masked language model, make a new copy of tokens and
# replace some of them by '<mask>' or random tokens
mlm_input_tokens = [token for token in tokens]
pred_positions_and_labels = []
# Shuffle for getting 15% random tokens for prediction in the masked
# language modeling task
random.shuffle(candidate_pred_positions)
for mlm_pred_position in candidate_pred_positions:
if len(pred_positions_and_labels) >= num_mlm_preds:
break
masked_token = None
# 80% of the time: replace the word with the '<mask>' token
if random.random() < 0.8:
masked_token = '<mask>'
else:
# 10% of the time: keep the word unchanged
if random.random() < 0.5:
masked_token = tokens[mlm_pred_position]
# 10% of the time: replace the word with a random word
else:
masked_token = random.choice(vocab.idx_to_token)
mlm_input_tokens[mlm_pred_position] = masked_token
pred_positions_and_labels.append(
(mlm_pred_position, tokens[mlm_pred_position]))
return mlm_input_tokens, pred_positions_and_labels위의 코드에서 이루어지는 작업은 다음과 같습니다:
- tokens, candidate_pred_positions, num_mlm_preds, vocab 매개변수: 함수에는 네 가지 매개변수가 전달됩니다.
- tokens: 입력 문장의 토큰들을 나타내는 리스트입니다.
- candidate_pred_positions: 예측될 토큰 위치의 후보 목록입니다.
- num_mlm_preds: MLM 작업에서 예측할 토큰의 개수입니다.
- vocab: 어휘 사전입니다.
- MLM 데이터 생성: 입력 문장의 토큰들 중에서 일부를 '<mask>' 토큰이나 랜덤한 토큰으로 교체하여 MLM 작업에 사용되는 데이터를 생성합니다.
- 교체 비율 선택: 랜덤한 확률에 따라 토큰을 교체할지 여부를 결정합니다. 대부분의 경우에는 '<mask>' 토큰으로 교체하며, 일부 경우에는 토큰을 변경하지 않거나 랜덤한 토큰으로 교체합니다.
- 교체 및 레이블 생성: mlm_input_tokens 리스트에서 선택된 위치의 토큰을 교체하고, 교체된 토큰 위치와 원래 토큰 값을 pred_positions_and_labels에 저장합니다.
- 결과 반환: 교체된 토큰들을 포함한 mlm_input_tokens 리스트와 예측된 토큰 위치와 레이블을 저장한 pred_positions_and_labels 리스트를 반환합니다. 이 정보는 MLM 작업의 학습 데이터를 구성하는 데 사용됩니다.
MLM 작업은 BERT 모델의 학습에서 토큰의 일부를 가리고 해당 토큰을 예측하는 태스크로, 모델이 언어적인 패턴을 학습하고 문맥을 이해하는데 도움이 됩니다.
By invoking the aforementioned _replace_mlm_tokens function, the following function takes a BERT input sequence (tokens) as an input and returns indices of the input tokens (after possible token replacement as described in Section 15.8.5.1), the token indices where predictions take place, and label indices for these predictions.
앞서 언급한 _replace_mlm_tokens 함수를 호출함으로써 다음 함수는 BERT 입력 시퀀스(토큰)를 입력으로 사용하고 입력 토큰의 인덱스(섹션 15.8.5.1에 설명된 대로 가능한 토큰 교체 후), 예측이 발생하는 토큰 인덱스를 반환합니다. 이러한 예측에 대한 라벨 인덱스.
#@save
def _get_mlm_data_from_tokens(tokens, vocab):
candidate_pred_positions = []
# `tokens` is a list of strings
for i, token in enumerate(tokens):
# Special tokens are not predicted in the masked language modeling
# task
if token in ['<cls>', '<sep>']:
continue
candidate_pred_positions.append(i)
# 15% of random tokens are predicted in the masked language modeling task
num_mlm_preds = max(1, round(len(tokens) * 0.15))
mlm_input_tokens, pred_positions_and_labels = _replace_mlm_tokens(
tokens, candidate_pred_positions, num_mlm_preds, vocab)
pred_positions_and_labels = sorted(pred_positions_and_labels,
key=lambda x: x[0])
pred_positions = [v[0] for v in pred_positions_and_labels]
mlm_pred_labels = [v[1] for v in pred_positions_and_labels]
return vocab[mlm_input_tokens], pred_positions, vocab[mlm_pred_labels]위의 코드에서 이루어지는 작업은 다음과 같습니다:
- tokens, vocab 매개변수: 함수에는 두 가지 매개변수가 전달됩니다.
- tokens: 입력 문장의 토큰들을 나타내는 리스트입니다.
- vocab: 어휘 사전입니다.
- 후보 예측 위치 식별: 입력 문장에서 '<cls>'와 '<sep>' 토큰을 제외한 토큰들의 위치를 후보 예측 위치로 식별합니다.
- 예측할 토큰 개수 결정: 입력 문장 길이의 15%에 해당하는 토큰을 예측합니다.
- MLM 데이터 생성: _replace_mlm_tokens 함수를 사용하여 입력 문장에서 일부 토큰을 '<mask>' 토큰이나 랜덤한 토큰으로 교체하여 MLM 작업에 사용되는 데이터를 생성합니다.
- 토큰과 위치 정보 반환: MLM 작업에 필요한 토큰들과 예측 위치 정보를 반환합니다. 이 정보는 BERT 모델의 학습 데이터로 사용됩니다.
MLM 작업에서는 입력 문장의 토큰 중에서 일부를 가리고 해당 토큰을 예측하는 태스크로, 모델이 문맥을 이해하고 언어적인 패턴을 학습하는 데 도움이 됩니다.
15.9.2. Transforming Text into the Pretraining Dataset
Now we are almost ready to customize a Dataset class for pretraining BERT. Before that, we still need to define a helper function _pad_bert_inputs to append the special “<pad>” tokens to the inputs. Its argument examples contain the outputs from the helper functions _get_nsp_data_from_paragraph and _get_mlm_data_from_tokens for the two pretraining tasks.
이제 BERT 사전 훈련을 위해 Dataset 클래스를 사용자 정의할 준비가 거의 완료되었습니다. 그 전에 특수 "<pad>" 토큰을 입력에 추가하려면 도우미 함수 _pad_bert_inputs를 정의해야 합니다. 인수 예제에는 두 가지 사전 학습 작업에 대한 도우미 함수 _get_nsp_data_from_paragraph 및 _get_mlm_data_from_tokens의 출력이 포함되어 있습니다.
#@save
def _pad_bert_inputs(examples, max_len, vocab):
max_num_mlm_preds = round(max_len * 0.15)
all_token_ids, all_segments, valid_lens, = [], [], []
all_pred_positions, all_mlm_weights, all_mlm_labels = [], [], []
nsp_labels = []
for (token_ids, pred_positions, mlm_pred_label_ids, segments,
is_next) in examples:
all_token_ids.append(torch.tensor(token_ids + [vocab['<pad>']] * (
max_len - len(token_ids)), dtype=torch.long))
all_segments.append(torch.tensor(segments + [0] * (
max_len - len(segments)), dtype=torch.long))
# `valid_lens` excludes count of '<pad>' tokens
valid_lens.append(torch.tensor(len(token_ids), dtype=torch.float32))
all_pred_positions.append(torch.tensor(pred_positions + [0] * (
max_num_mlm_preds - len(pred_positions)), dtype=torch.long))
# Predictions of padded tokens will be filtered out in the loss via
# multiplication of 0 weights
all_mlm_weights.append(
torch.tensor([1.0] * len(mlm_pred_label_ids) + [0.0] * (
max_num_mlm_preds - len(pred_positions)),
dtype=torch.float32))
all_mlm_labels.append(torch.tensor(mlm_pred_label_ids + [0] * (
max_num_mlm_preds - len(mlm_pred_label_ids)), dtype=torch.long))
nsp_labels.append(torch.tensor(is_next, dtype=torch.long))
return (all_token_ids, all_segments, valid_lens, all_pred_positions,
all_mlm_weights, all_mlm_labels, nsp_labels)위의 코드에서 이루어지는 작업은 다음과 같습니다:
- examples 입력: 함수에는 입력 데이터 예시인 examples가 전달됩니다. 각 예시는 (token_ids, pred_positions, mlm_pred_label_ids, segments, is_next) 형태의 튜플로 구성되어 있습니다.
- BERT 입력 데이터 생성: 입력 데이터를 모델의 입력 형식에 맞게 생성합니다. 이 과정에서 패딩이 진행됩니다.
- 입력 데이터 반환: 모든 생성된 데이터를 리스트 형태로 반환합니다. 반환되는 데이터는 (all_token_ids, all_segments, valid_lens, all_pred_positions, all_mlm_weights, all_mlm_labels, nsp_labels) 형식입니다.
BERT 모델은 다양한 입력 데이터를 필요로 합니다. 이 함수는 이러한 입력 데이터를 정제하고 필요한 형식으로 변환하여 모델에 공급할 준비를 하는 역할을 수행합니다
Putting the helper functions for generating training examples of the two pretraining tasks, and the helper function for padding inputs together, we customize the following _WikiTextDataset class as the WikiText-2 dataset for pretraining BERT. By implementing the __getitem__function, we can arbitrarily access the pretraining (masked language modeling and next sentence prediction) examples generated from a pair of sentences from the WikiText-2 corpus.
두 가지 사전 훈련 작업의 훈련 예제를 생성하기 위한 도우미 함수와 입력 패딩을 위한 도우미 함수를 함께 배치하여 BERT 사전 훈련을 위한 WikiText-2 데이터 세트로 다음 _WikiTextDataset 클래스를 사용자 정의합니다. __getitem__function을 구현함으로써 WikiText-2 코퍼스의 문장 쌍에서 생성된 사전 훈련(마스킹된 언어 모델링 및 다음 문장 예측) 예제에 임의로 액세스할 수 있습니다.
The original BERT model uses WordPiece embeddings whose vocabulary size is 30000 (Wu et al., 2016). The tokenization method of WordPiece is a slight modification of the original byte pair encoding algorithm in Section 15.6.2. For simplicity, we use the d2l.tokenize function for tokenization. Infrequent tokens that appear less than five times are filtered out.
원래 BERT 모델은 어휘 크기가 30000인 WordPiece 임베딩을 사용합니다(Wu et al., 2016). WordPiece의 토큰화 방법은 섹션 15.6.2의 원래 바이트 쌍 인코딩 알고리즘을 약간 수정한 것입니다. 단순화를 위해 토큰화에 d2l.tokenize 함수를 사용합니다. 5회 미만으로 나타나는 빈도가 낮은 토큰은 필터링됩니다.
#@save
class _WikiTextDataset(torch.utils.data.Dataset):
def __init__(self, paragraphs, max_len):
# Input `paragraphs[i]` is a list of sentence strings representing a
# paragraph; while output `paragraphs[i]` is a list of sentences
# representing a paragraph, where each sentence is a list of tokens
paragraphs = [d2l.tokenize(
paragraph, token='word') for paragraph in paragraphs]
sentences = [sentence for paragraph in paragraphs
for sentence in paragraph]
self.vocab = d2l.Vocab(sentences, min_freq=5, reserved_tokens=[
'<pad>', '<mask>', '<cls>', '<sep>'])
# Get data for the next sentence prediction task
examples = []
for paragraph in paragraphs:
examples.extend(_get_nsp_data_from_paragraph(
paragraph, paragraphs, self.vocab, max_len))
# Get data for the masked language model task
examples = [(_get_mlm_data_from_tokens(tokens, self.vocab)
+ (segments, is_next))
for tokens, segments, is_next in examples]
# Pad inputs
(self.all_token_ids, self.all_segments, self.valid_lens,
self.all_pred_positions, self.all_mlm_weights,
self.all_mlm_labels, self.nsp_labels) = _pad_bert_inputs(
examples, max_len, self.vocab)
def __getitem__(self, idx):
return (self.all_token_ids[idx], self.all_segments[idx],
self.valid_lens[idx], self.all_pred_positions[idx],
self.all_mlm_weights[idx], self.all_mlm_labels[idx],
self.nsp_labels[idx])
def __len__(self):
return len(self.all_token_ids)위의 코드에서 이루어지는 작업은 다음과 같습니다:
- 텍스트 전처리: 입력으로 주어진 paragraphs 리스트의 각 문단을 토큰화하여 BERT 모델에 필요한 형태로 변환합니다.
- 어휘 생성: 위에서 전처리한 문단들을 바탕으로 어휘를 생성합니다. BERT 모델에서 사용할 토큰들과 토큰의 인덱스를 매핑하는 역할을 합니다.
- NSP 및 MLM 데이터 생성: 생성된 어휘와 문단 데이터를 활용하여 다음 문장 예측(NSP) 및 마스킹된 언어 모델(MLM) 학습을 위한 데이터를 생성합니다.
- 입력 데이터 패딩: 생성된 데이터를 BERT 모델의 입력 형식에 맞게 패딩합니다.
- __getitem__ 메서드: 인덱스를 입력으로 받아 해당 인덱스의 데이터를 반환합니다. BERT 모델의 입력으로 사용될 데이터를 반환합니다.
- __len__ 메서드: 데이터셋의 크기를 반환합니다.
이 클래스는 BERT 모델 학습을 위한 데이터셋을 생성하는데 필요한 모든 과정을 수행하며, 학습 데이터를 모델에 공급할 준비를 하게 됩니다
By using the _read_wiki function and the _WikiTextDataset class, we define the following load_data_wiki to download and WikiText-2 dataset and generate pretraining examples from it.
_read_wiki 함수와 _WikiTextDataset 클래스를 사용하여 다음 load_data_wiki를 정의하여 WikiText-2 데이터 세트를 다운로드하고 여기에서 사전 훈련 예제를 생성합니다.
#@save
def load_data_wiki(batch_size, max_len):
"""Load the WikiText-2 dataset."""
num_workers = d2l.get_dataloader_workers()
data_dir = d2l.download_extract('wikitext-2', 'wikitext-2')
paragraphs = _read_wiki(data_dir)
train_set = _WikiTextDataset(paragraphs, max_len)
train_iter = torch.utils.data.DataLoader(train_set, batch_size,
shuffle=True, num_workers=num_workers)
return train_iter, train_set.vocab위의 코드에서 이루어지는 작업은 다음과 같습니다:
- 데이터 디렉토리 설정: WikiText-2 데이터셋을 다운로드하고 압축을 해제한 후, 데이터 디렉토리를 가져옵니다.
- WikiText-2 데이터 읽기: _read_wiki 함수를 사용하여 WikiText-2 데이터셋을 읽어와서 전처리합니다.
- 데이터셋 생성: 전처리된 문단 데이터를 기반으로 _WikiTextDataset 클래스를 사용하여 데이터셋을 생성합니다.
- 데이터로더 생성: 생성된 데이터셋을 PyTorch의 DataLoader로 변환하여 모델 학습에 사용할 수 있는 형태로 준비합니다. 배치 사이즈와 데이터 로더의 워커 수도 설정합니다.
- 반환: 생성된 데이터로더와 어휘(vocabulary)를 반환합니다. 데이터로더는 학습에 사용되며, 어휘는 BERT 모델의 입력을 처리하기 위해 필요한 정보를 담고 있습니다.
이 함수를 호출하면 WikiText-2 데이터셋을 효율적으로 학습에 활용할 수 있는 형태로 변환하여 반환해줍니다.
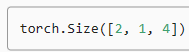
Setting the batch size to 512 and the maximum length of a BERT input sequence to be 64, we print out the shapes of a minibatch of BERT pretraining examples. Note that in each BERT input sequence, 10 (64×0.15) positions are predicted for the masked language modeling task.
배치 크기를 512로 설정하고 BERT 입력 시퀀스의 최대 길이를 64로 설정하면 BERT 사전 학습 예제의 미니 배치 모양을 인쇄합니다. 각 BERT 입력 시퀀스에서 마스크된 언어 모델링 작업에 대해 10(64×0.15) 위치가 예측됩니다.
batch_size, max_len = 512, 64
train_iter, vocab = load_data_wiki(batch_size, max_len)
for (tokens_X, segments_X, valid_lens_x, pred_positions_X, mlm_weights_X,
mlm_Y, nsp_y) in train_iter:
print(tokens_X.shape, segments_X.shape, valid_lens_x.shape,
pred_positions_X.shape, mlm_weights_X.shape, mlm_Y.shape,
nsp_y.shape)
break위의 코드에서 이루어지는 작업은 다음과 같습니다:
- batch_size와 max_len 설정: 미니 배치 크기와 최대 시퀀스 길이를 설정합니다.
- 데이터 로드 및 데이터로더 생성: load_data_wiki 함수를 호출하여 WikiText-2 데이터셋을 로드하고, 데이터로더를 생성합니다.
- 미니 배치 순회: train_iter 데이터로더에서 미니 배치를 순회합니다.
- 미니 배치 구성 요소 확인: 각 미니 배치에 포함된 요소들의 형태(shape)를 확인합니다. 이는 데이터의 구성을 이해하고 문제 없이 모델에 입력할 수 있는지 확인하기 위한 과정입니다.
위의 코드는 하나의 미니 배치만 확인하기 위해 break문을 사용하여 첫 번째 미니 배치만 순회하고 종료합니다. 출력된 형태들은 미니 배치에 포함된 다양한 요소들의 차원(shape)을 나타내며, 각각의 형태는 데이터의 차원을 나타냅니다
Downloading ../data/wikitext-2-v1.zip from https://s3.amazonaws.com/research.metamind.io/wikitext/wikitext-2-v1.zip...
torch.Size([512, 64]) torch.Size([512, 64]) torch.Size([512]) torch.Size([512, 10]) torch.Size([512, 10]) torch.Size([512, 10]) torch.Size([512])
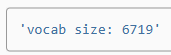
In the end, let’s take a look at the vocabulary size. Even after filtering out infrequent tokens, it is still over twice larger than that of the PTB dataset.
마지막으로 어휘량을 살펴보겠습니다. 자주 발생하지 않는 토큰을 필터링한 후에도 여전히 PTB 데이터세트보다 2배 이상 큽니다.
len(vocab)20256
15.9.3. Summary
- Comparing with the PTB dataset, the WikiText-2 dateset retains the original punctuation, case and numbers, and is over twice larger.
PTB 데이터 세트와 비교할 때 WikiText-2 날짜 세트는 원래 구두점, 대소문자 및 숫자를 유지하며 두 배 이상 더 큽니다. - We can arbitrarily access the pretraining (masked language modeling and next sentence prediction) examples generated from a pair of sentences from the WikiText-2 corpus.
WikiText-2 코퍼스의 문장 쌍에서 생성된 사전 훈련(마스크된 언어 모델링 및 다음 문장 예측) 예제에 임의로 액세스할 수 있습니다.
15.9.4. Exercises
- For simplicity, the period is used as the only delimiter for splitting sentences. Try other sentence splitting techniques, such as the spaCy and NLTK. Take NLTK as an example. You need to install NLTK first: pip install nltk. In the code, first import nltk. Then, download the Punkt sentence tokenizer: nltk.download('punkt'). To split sentences such as sentences = 'This is great ! Why not ?', invoking nltk.tokenize.sent_tokenize(sentences) will return a list of two sentence strings: ['This is great !', 'Why not ?'].
- What is the vocabulary size if we do not filter out any infrequent token?
'Dive into Deep Learning > D2L Natural language Processing' 카테고리의 다른 글
| D2L - 16.3. Sentiment Analysis: Using Convolutional Neural Networks (0) | 2023.09.01 |
|---|---|
| D2L - 16.2. Sentiment Analysis: Using Recurrent Neural Networks (0) | 2023.09.01 |
| D2L - 16.1. Sentiment Analysis and the Dataset (0) | 2023.09.01 |
| D2L - 16. Natural Language Processing: Applications (0) | 2023.09.01 |
| D2L - 15.10. Pretraining BERT (0) | 2023.08.30 |
| D2L - 15.8. Bidirectional Encoder Representations from Transformers (BERT) (0) | 2023.08.30 |
| D2L - 15.7. Word Similarity and Analogy (0) | 2023.08.30 |
| D2L - 15.6. Subword Embedding (0) | 2023.08.30 |
| D2L - 15.5. Word Embedding with Global Vectors (GloVe) (0) | 2023.08.29 |
| D2L - 15.4. Pretraining word2vec (0) | 2023.08.29 |