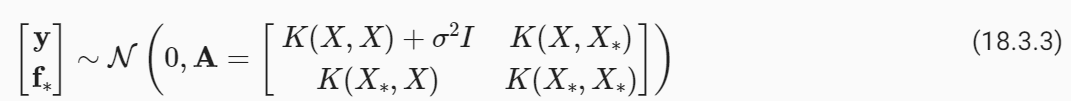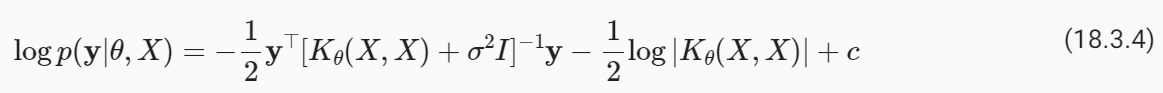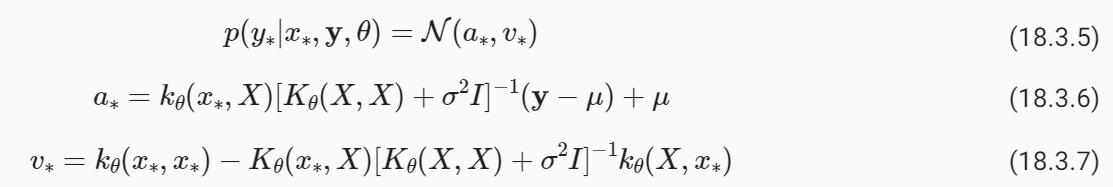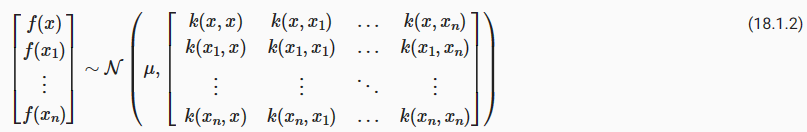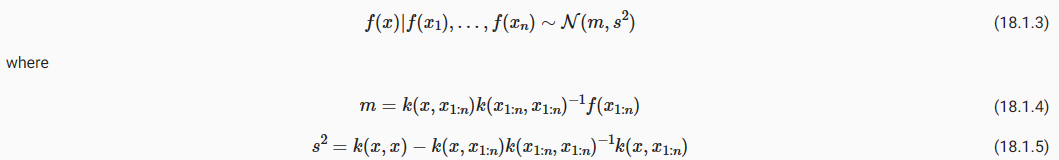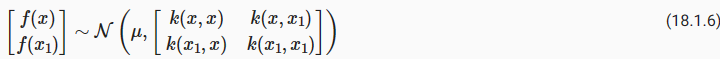https://d2l.ai/chapter_hyperparameter-optimization/hyperopt-api.html
19.2. Hyperparameter Optimization API — Dive into Deep Learning 1.0.3 documentation
d2l.ai
19.2. Hyperparameter Optimization API
Before we dive into the methodology, we will first discuss a basic code structure that allows us to efficiently implement various HPO algorithms. In general, all HPO algorithms considered here need to implement two decision making primitives, searching and scheduling. First, they need to sample new hyperparameter configurations, which often involves some kind of search over the configuration space. Second, for each configuration, an HPO algorithm needs to schedule its evaluation and decide how many resources to allocate for it. Once we start to evaluate a configuration, we will refer to it as a trial. We map these decisions to two classes, HPOSearcher and HPOScheduler. On top of that, we also provide a HPOTuner class that executes the optimization process.
방법론에 대해 알아보기 전에 먼저 다양한 HPO 알고리즘을 효율적으로 구현할 수 있는 기본 코드 구조에 대해 논의하겠습니다. 일반적으로 여기에서 고려되는 모든 HPO 알고리즘은 검색 searching 과 예약 scheduling이라는 두 가지 의사 결정 기본 요소를 구현해야 합니다. 첫째, 새로운 하이퍼파라미터 구성을 샘플링해야 하며, 여기에는 종종 구성 공간에 대한 일종의 검색이 포함됩니다. 둘째, 각 구성에 대해 HPO 알고리즘은 평가 일정을 계획하고 이에 할당할 리소스 수를 결정해야 합니다. 구성 평가를 시작하면 이를 평가판이라고 합니다. 우리는 이러한 결정을 HPOSearcher와 HPOScheduler라는 두 클래스에 매핑합니다. 또한 최적화 프로세스를 실행하는 HPOTuner 클래스도 제공합니다.
This concept of scheduler and searcher is also implemented in popular HPO libraries, such as Syne Tune (Salinas et al., 2022), Ray Tune (Liaw et al., 2018) or Optuna (Akiba et al., 2019).
이 스케줄러 및 검색기 개념은 Syne Tune(Salinas et al., 2022), Ray Tune(Liaw et al., 2018) 또는 Optuna(Akiba et al., 2019)와 같은 인기 있는 HPO 라이브러리에서도 구현됩니다.
import time
from scipy import stats
from d2l import torch as d2l위의 코드는 파이썬 모듈 및 라이브러리를 가져오는 부분입니다. 코드의 목적과 각 부분에 대한 설명은 다음과 같습니다:
- import time: 파이썬의 내장 모듈인 time 모듈을 가져옵니다. 이 모듈은 시간과 관련된 함수를 제공하며, 시간 지연(delay)을 생성하거나 시간을 측정하는 데 사용될 수 있습니다.
- from scipy import stats: SciPy 라이브러리에서 stats 모듈을 가져옵니다. SciPy는 과학 및 공학 연산을 위한 파이썬 라이브러리로, 통계, 최적화, 선형 대수, 신호 처리 등 다양한 기능을 제공합니다. 여기서는 주로 확률 분포와 통계 함수를 사용하는 stats 모듈을 가져옵니다.
- from d2l import torch as d2l: "Dive into Deep Learning" (D2L) 도서와 관련된 PyTorch 유틸리티 함수 및 도움말 기능을 제공하는 d2l 라이브러리에서 PyTorch 모듈을 가져옵니다. 이 라이브러리는 딥러닝 교육 및 예제 코드를 지원하는 데 사용됩니다. 여기서는 d2l 라이브러리에서 torch 모듈을 가져와서 d2l로 별칭을 붙입니다.
이 코드는 필요한 모듈과 라이브러리를 가져와서 이후의 작업에서 사용할 수 있도록 설정하는 부분입니다.
Hyperparameter Optimization API란 (GPT 3.5 답변)
The Hyperparameter Optimization (HPO) API refers to a programming interface or toolset that allows developers and data scientists to perform hyperparameter optimization efficiently and effectively. This API typically includes functions, classes, and methods for configuring, running, and managing the hyperparameter optimization process.
하이퍼파라미터 최적화 (HPO) API는 개발자와 데이터 과학자가 하이퍼파라미터 최적화를 효율적이고 효과적으로 수행할 수 있도록 하는 프로그래밍 인터페이스 또는 도구 세트를 가리킵니다. 이 API에는 하이퍼파라미터 최적화 프로세스를 구성하고 실행하며 관리하는 데 사용되는 함수, 클래스 및 메서드가 포함됩니다.
Here are some key components and functionalities often found in an HPO API:
다음은 일반적으로 HPO API에서 찾을 수 있는 주요 구성 요소와 기능입니다.
- Hyperparameter Configuration: The API allows users to define the hyperparameters they want to optimize and specify their respective search spaces. This involves specifying the range of values or distribution from which each hyperparameter should be sampled during optimization.
하이퍼파라미터 구성: API를 통해 사용자는 최적화하려는 하이퍼파라미터를 정의하고 해당 하이퍼파라미터의 검색 공간을 지정할 수 있습니다. 이는 각 하이퍼파라미터의 최적화 중에 샘플링해야 하는 값 또는 분포를 지정하는 것을 포함합니다. - Objective Function: Users can define the objective function (also known as the loss or evaluation function) that quantifies the performance of a machine learning model with a given set of hyperparameters. The API provides a way to evaluate the model's performance using this function.
목적 함수: 사용자는 주어진 하이퍼파라미터 세트에 대한 기계 학습 모델의 성능을 양적화하는 목적 함수(손실 또는 평가 함수로도 알려짐)를 정의할 수 있습니다. API는 이 함수를 사용하여 모델의 성능을 평가하는 방법을 제공합니다. - Optimization Algorithms: The API offers a selection of optimization algorithms such as random search, Bayesian optimization, genetic algorithms, or more advanced techniques. Users can choose the algorithm that best suits their optimization problem.
최적화 알고리즘: API는 무작위 검색, 베이지안 최적화, 유전 알고리즘 또는 더 고급 기술과 같은 최적화 알고리즘을 선택할 수 있는 옵션을 제공합니다. 사용자는 최적화 문제에 가장 적합한 알고리즘을 선택할 수 있습니다. - Concurrency and Parallelism: It provides options for running multiple hyperparameter optimization trials concurrently or in parallel. This can significantly speed up the optimization process, especially when optimizing computationally expensive models.
동시성과 병렬 처리: 일부 HPO API는 여러 하이퍼파라미터 최적화 시행을 동시에 또는 병렬로 실행하는 옵션을 제공합니다. 이렇게 하면 특히 계산 비용이 많이 드는 모델을 최적화할 때 최적화 프로세스가 크게 가속화될 수 있습니다. - Early Stopping and Resource Management: Some HPO APIs support early stopping criteria based on the performance of ongoing trials. They can also manage resources, ensuring that the optimization process respects hardware constraints.
조기 중지 및 리소스 관리: 일부 HPO API는 진행 중인 시행의 성능을 기반으로 조기 중지 기준을 지원합니다. 또한 하드웨어 제한을 존중하도록 최적화 프로세스를 관리할 수 있습니다. - Results Tracking: The API may include functions for tracking and storing the results of each optimization trial, including hyperparameters, evaluation metrics, and other relevant information.
결과 추적: API에는 각 하이퍼파라미터 최적화 시행의 결과를 추적하고 저장하는 함수가 포함될 수 있으며, 이는 하이퍼파라미터, 평가 메트릭, 기타 관련 정보를 포함합니다. - Visualization and Reporting: It often includes tools for visualizing the progress of hyperparameter optimization, such as plots or graphs showing how the objective function changes over time.
시각화 및 보고: 종종 하이퍼파라미터 최적화 진행 상황을 시각화하는 데 사용되는 도구를 포함하며, 이러한 도구는 목적 함수가 어떻게 시간에 따라 변하는지 보여주는 플롯이나 그래프를 제공합니다. - Integration with Machine Learning Frameworks: Many HPO APIs are designed to seamlessly integrate with popular machine learning libraries and frameworks like TensorFlow, PyTorch, scikit-learn, and others.
기계 학습 프레임워크 통합: 많은 HPO API는 인기 있는 기계 학습 라이브러리와 프레임워크인 TensorFlow, PyTorch, scikit-learn 및 기타 라이브러리와 원활하게 통합될 수 있도록 설계되었습니다. - Customization: Advanced users can customize the optimization process by specifying custom algorithms, resource management policies, or search strategies.
사용자 정의: 고급 사용자는 사용자 지정 알고리즘, 리소스 관리 정책 또는 검색 전략을 지정하여 최적화 프로세스를 사용자 정의할 수 있습니다. - Hyperparameter Importance Analysis: Some APIs offer functionality for analyzing the importance of different hyperparameters in the final model's performance.
하이퍼파라미터 중요도 분석: 일부 API는 최종 모델 성능에 대한 다른 하이퍼파라미터의 중요성을 분석하는 기능을 제공합니다.
Overall, the HPO API simplifies the process of hyperparameter tuning, allowing users to find optimal hyperparameter settings for their machine learning models more efficiently. It can save time and computational resources and help improve model performance. Popular examples of HPO APIs include Optuna, Hyperopt, and Ray Tune, among others.
전반적으로 HPO API는 하이퍼파라미터 튜닝 프로세스를 단순화하여 사용자가 기계 학습 모델의 최적 하이퍼파라미터 설정을 보다 효율적으로 찾을 수 있게 해줍니다. 시간과 계산 리소스를 절약하고 모델 성능을 향상시킬 수 있습니다. 인기 있는 HPO API 예제로는 Optuna, Hyperopt, Ray Tune 등이 있습니다.
19.2.1. Searcher
Below we define a base class for searchers, which provides a new candidate configuration through the sample_configuration function. A simple way to implement this function would be to sample configurations uniformly at random, as we did for random search in Section 19.1. More sophisticated algorithms, such as Bayesian optimization, will make these decisions based on the performance of previous trials. As a result, these algorithms are able to sample more promising candidates over time. We add the update function in order to update the history of previous trials, which can then be exploited to improve our sampling distribution.
아래에서는 Sample_configuration 함수를 통해 새로운 후보 구성을 제공하는 검색자를 위한 기본 클래스를 정의합니다. 이 기능을 구현하는 간단한 방법은 섹션 19.1에서 무작위 검색을 수행한 것처럼 무작위로 균일하게 구성을 샘플링하는 것입니다. 베이지안 최적화와 같은 보다 정교한 알고리즘은 이전 시도의 성능을 기반으로 이러한 결정을 내립니다. 결과적으로 이러한 알고리즘은 시간이 지남에 따라 더 유망한 후보자를 샘플링할 수 있습니다. 이전 시도의 기록을 업데이트하기 위해 업데이트 기능을 추가한 다음 샘플링 분포를 개선하는 데 활용할 수 있습니다.
class HPOSearcher(d2l.HyperParameters): #@save
def sample_configuration() -> dict:
raise NotImplementedError
def update(self, config: dict, error: float, additional_info=None):
pass위의 코드는 하이퍼파라미터(Hyperparameters) 탐색을 수행하는 클래스인 HPOSearcher를 정의하는 부분입니다. 코드의 목적과 각 부분에 대한 설명은 다음과 같습니다:
- class HPOSearcher(d2l.HyperParameters):: HPOSearcher 클래스를 정의합니다. 이 클래스는 d2l.HyperParameters 클래스를 상속합니다.
- def sample_configuration() -> dict:: 하이퍼파라미터 탐색 과정에서 하이퍼파라미터 구성(configuration)을 샘플링하는 메서드를 정의합니다. 이 메서드는 하이퍼파라미터 탐색 알고리즘이 다음으로 시도할 하이퍼파라미터 구성을 생성하고 이를 딕셔너리 형태로 반환해야 합니다. 이 메서드는 추상 메서드로 구현되지 않으며 하위 클래스에서 구현되어야 합니다.
- def update(self, config: dict, error: float, additional_info=None):: 하이퍼파라미터 탐색 알고리즘이 하이퍼파라미터 구성을 시도한 후에, 해당 구성에 대한 결과인 검증 오차와 추가 정보를 기반으로 어떤 동작을 수행해야 하는지를 정의하는 메서드입니다. 이 메서드는 하이퍼파라미터 탐색 알고리즘이 현재 시도한 하이퍼파라미터 구성(config), 해당 구성에 대한 검증 오차(error), 그리고 추가 정보(additional_info)를 인자로 받습니다. 이 메서드는 추상 메서드로 구현되지 않으며 하위 클래스에서 구현되어야 합니다.
HPOSearcher 클래스는 하이퍼파라미터 탐색 과정에서 필요한 메서드를 정의하는 기본 클래스입니다. 실제 하이퍼파라미터 탐색을 위해서는 이 클래스를 상속하고 sample_configuration과 update 메서드를 구현해야 합니다. 이 클래스를 상속한 하위 클래스에서는 하이퍼파라미터 탐색 알고리즘에 따라 구체적인 동작을 정의하게 됩니다.
The following code shows how to implement our random search optimizer from the previous section in this API. As a slight extension, we allow the user to prescribe the first configuration to be evaluated via initial_config, while subsequent ones are drawn at random.
다음 코드는 이 API의 이전 섹션에서 무작위 검색 최적화 프로그램을 구현하는 방법을 보여줍니다. 약간의 확장으로 사용자가 초기 구성을 통해 평가할 첫 번째 구성을 규정하고 후속 구성은 무작위로 그릴 수 있습니다.
class RandomSearcher(HPOSearcher): #@save
def __init__(self, config_space: dict, initial_config=None):
self.save_hyperparameters()
def sample_configuration(self) -> dict:
if self.initial_config is not None:
result = self.initial_config
self.initial_config = None
else:
result = {
name: domain.rvs()
for name, domain in self.config_space.items()
}
return result위의 코드는 랜덤 탐색(Random Search)을 수행하는 RandomSearcher 클래스를 정의하는 부분입니다. 코드의 목적과 각 부분에 대한 설명은 다음과 같습니다:
- class RandomSearcher(HPOSearcher):: RandomSearcher 클래스를 정의합니다. 이 클래스는 HPOSearcher 클래스를 상속합니다.
- def __init__(self, config_space: dict, initial_config=None):: RandomSearcher 클래스의 생성자 메서드를 정의합니다. 이 생성자 메서드는 두 개의 매개변수를 입력으로 받습니다.
- config_space: 하이퍼파라미터 탐색을 위한 하이퍼파라미터 공간을 나타내는 딕셔너리입니다. 각 하이퍼파라미터의 이름과 확률 분포가 포함되어 있어야 합니다.
- initial_config: 초기 하이퍼파라미터 구성을 나타내는 딕셔너리입니다. 기본값은 None으로 설정되어 있습니다.
- self.save_hyperparameters(): 하이퍼파라미터를 저장하는 메서드입니다. 이 메서드를 호출하여 RandomSearcher 클래스의 하이퍼파라미터를 저장합니다.
- def sample_configuration(self) -> dict:: 하이퍼파라미터 탐색 과정에서 하이퍼파라미터 구성을 랜덤하게 샘플링하는 메서드를 정의합니다. 이 메서드는 딕셔너리 형태로 하이퍼파라미터 구성을 반환해야 합니다.
- 처음에 initial_config가 설정되어 있다면, 초기 구성을 사용하고 initial_config를 None으로 설정합니다.
- 그렇지 않으면, config_space에 정의된 각 하이퍼파라미터에 대해 해당 확률 분포(domain)에서 랜덤하게 값을 샘플링하여 딕셔너리로 구성합니다.
- 최종적으로 샘플링된 하이퍼파라미터 구성을 반환합니다.
RandomSearcher 클래스는 랜덤 탐색을 수행하는 클래스로, sample_configuration 메서드에서 랜덤하게 하이퍼파라미터를 선택하여 반환합니다. 이를 통해 하이퍼파라미터 탐색을 무작위로 수행하는 간단한 탐색 전략을 구현할 수 있습니다.
19.2.2. Scheduler
Beyond sampling configurations for new trials, we also need to decide when and for how long to run a trial. In practice, all these decisions are done by the HPOScheduler, which delegates the choice of new configurations to a HPOSearcher. The suggest method is called whenever some resource for training becomes available. Apart from invoking sample_configuration of a searcher, it may also decide upon parameters like max_epochs (i.e., how long to train the model for). The update method is called whenever a trial returns a new observation.
새로운 시험을 위한 샘플링 구성 외에도 시험을 실행할 시기와 기간도 결정해야 합니다. 실제로 이러한 모든 결정은 새로운 구성 선택을 HPOSearcher에 위임하는 HPOScheduler에 의해 수행됩니다. 훈련을 위한 리소스를 사용할 수 있을 때마다 제안 메소드가 호출됩니다. 검색기의 Sample_configuration을 호출하는 것 외에도 max_epochs(즉, 모델을 훈련할 기간)와 같은 매개변수를 결정할 수도 있습니다. 업데이트 메소드는 시행에서 새로운 관찰이 반환될 때마다 호출됩니다.
class HPOScheduler(d2l.HyperParameters): #@save
def suggest(self) -> dict:
raise NotImplementedError
def update(self, config: dict, error: float, info=None):
raise NotImplementedError위의 코드는 하이퍼파라미터(Hyperparameters) 탐색을 위한 스케줄러인 HPOScheduler 클래스를 정의하는 부분입니다. 이 클래스는 하이퍼파라미터 탐색 과정에서 다양한 하이퍼파라미터 탐색 알고리즘과 스케줄링을 구현하기 위한 기반 클래스입니다. 코드의 목적과 각 부분에 대한 설명은 다음과 같습니다:
- class HPOScheduler(d2l.HyperParameters):: HPOScheduler 클래스를 정의합니다. 이 클래스는 d2l.HyperParameters 클래스를 상속합니다.
- def suggest(self) -> dict:: 하이퍼파라미터 탐색 알고리즘이 다음으로 시도할 하이퍼파라미터 구성(configuration)을 제안하는 메서드를 정의합니다. 이 메서드는 추상 메서드로 구현되지 않으며 하위 클래스에서 구현되어야 합니다. 구체적인 하이퍼파라미터 탐색 알고리즘에 따라 다음 시도할 하이퍼파라미터 구성을 반환합니다.
- def update(self, config: dict, error: float, info=None):: 하이퍼파라미터 탐색 알고리즘이 하이퍼파라미터 구성을 시도한 후에, 해당 구성에 대한 결과인 검증 오차와 추가 정보를 기반으로 어떤 동작을 수행해야 하는지를 정의하는 메서드입니다. 이 메서드는 추상 메서드로 구현되지 않으며 하위 클래스에서 구현되어야 합니다. 검증 오차와 추가 정보를 활용하여 하이퍼파라미터 탐색 알고리즘의 스케줄링 및 업데이트 동작을 정의합니다.
HPOScheduler 클래스는 다양한 하이퍼파라미터 탐색 알고리즘과 스케줄링 전략을 구현하기 위한 기반 클래스로 사용될 수 있습니다. 구체적인 하이퍼파라미터 탐색 알고리즘에 따라 suggest와 update 메서드를 하위 클래스에서 구현하여 사용할 수 있습니다.
To implement random search, but also other HPO algorithms, we only need a basic scheduler that schedules a new configuration every time new resources become available.
무작위 검색 및 기타 HPO 알고리즘을 구현하려면 새 리소스를 사용할 수 있을 때마다 새 구성을 예약하는 기본 스케줄러만 필요합니다.
class BasicScheduler(HPOScheduler): #@save
def __init__(self, searcher: HPOSearcher):
self.save_hyperparameters()
def suggest(self) -> dict:
return self.searcher.sample_configuration()
def update(self, config: dict, error: float, info=None):
self.searcher.update(config, error, additional_info=info)위의 코드는 기본적인 스케줄러인 BasicScheduler 클래스를 정의하는 부분입니다. 이 클래스는 하이퍼파라미터 탐색 과정에서 하이퍼파라미터를 제안하고 업데이트하는 역할을 합니다. 코드의 목적과 각 부분에 대한 설명은 다음과 같습니다:
- class BasicScheduler(HPOScheduler):: BasicScheduler 클래스를 정의합니다. 이 클래스는 HPOScheduler 클래스를 상속합니다.
- def __init__(self, searcher: HPOSearcher):: BasicScheduler 클래스의 생성자 메서드를 정의합니다. 이 생성자 메서드는 하이퍼파라미터 탐색을 수행하는 searcher 객체를 입력으로 받습니다.
- searcher: 하이퍼파라미터 탐색을 담당하는 HPOSearcher 클래스의 객체입니다.
- self.save_hyperparameters(): 하이퍼파라미터를 저장하는 메서드입니다. 이 메서드를 호출하여 BasicScheduler 클래스의 하이퍼파라미터를 저장합니다.
- def suggest(self) -> dict:: 하이퍼파라미터 제안 메서드를 구현합니다. 이 메서드는 searcher 객체의 sample_configuration 메서드를 호출하여 다음으로 시도할 하이퍼파라미터 구성을 제안합니다.
- self.searcher.sample_configuration(): searcher 객체의 sample_configuration 메서드를 호출하여 하이퍼파라미터 구성을 제안합니다.
- def update(self, config: dict, error: float, info=None):: 하이퍼파라미터 업데이트 메서드를 구현합니다. 이 메서드는 searcher 객체의 update 메서드를 호출하여 하이퍼파라미터 탐색 알고리즘의 업데이트 동작을 수행합니다.
- self.searcher.update(config, error, additional_info=info): searcher 객체의 update 메서드를 호출하여 하이퍼파라미터 구성(config)과 검증 오차(error)를 기반으로 업데이트 동작을 수행합니다. 추가 정보(info)도 함께 전달할 수 있습니다.
BasicScheduler 클래스는 단순한 스케줄러로, searcher 객체의 메서드를 호출하여 하이퍼파라미터를 제안하고 업데이트합니다. 구체적인 하이퍼파라미터 탐색 알고리즘과 스케줄링 전략은 searcher 객체에서 결정됩니다. 이 클래스를 사용하여 기본적인 하이퍼파라미터 탐색을 수행할 수 있습니다.
19.2.3. Tuner
Finally, we need a component that runs the scheduler/searcher and does some book-keeping of the results. The following code implements a sequential execution of the HPO trials that evaluates one training job after the next and will serve as a basic example. We will later use Syne Tune for more scalable distributed HPO cases.
마지막으로 스케줄러/검색기를 실행하고 결과를 기록하는 구성 요소가 필요합니다. 다음 코드는 다음 훈련 작업을 차례로 평가하는 HPO 시도의 순차적 실행을 구현하며 기본 예제로 사용됩니다. 나중에 더 확장 가능한 분산 HPO 사례를 위해 Syne Tune을 사용할 것입니다.
class HPOTuner(d2l.HyperParameters): #@save
def __init__(self, scheduler: HPOScheduler, objective: callable):
self.save_hyperparameters()
# Bookeeping results for plotting
self.incumbent = None
self.incumbent_error = None
self.incumbent_trajectory = []
self.cumulative_runtime = []
self.current_runtime = 0
self.records = []
def run(self, number_of_trials):
for i in range(number_of_trials):
start_time = time.time()
config = self.scheduler.suggest()
print(f"Trial {i}: config = {config}")
error = self.objective(**config)
error = float(error.cpu().detach().numpy())
self.scheduler.update(config, error)
runtime = time.time() - start_time
self.bookkeeping(config, error, runtime)
print(f" error = {error}, runtime = {runtime}")위의 코드는 하이퍼파라미터(Hyperparameters) 튜닝을 수행하는 HPOTuner 클래스를 정의하는 부분입니다. 이 클래스는 주어진 하이퍼파라미터 탐색 스케줄러(scheduler)와 목표 함수(objective)를 사용하여 하이퍼파라미터 탐색을 실행하고 결과를 기록하는 역할을 합니다. 코드의 목적과 각 부분에 대한 설명은 다음과 같습니다:
- class HPOTuner(d2l.HyperParameters):: HPOTuner 클래스를 정의합니다. 이 클래스는 d2l.HyperParameters 클래스를 상속합니다.
- def __init__(self, scheduler: HPOScheduler, objective: callable):: HPOTuner 클래스의 생성자 메서드를 정의합니다. 이 생성자 메서드는 두 개의 매개변수를 입력으로 받습니다.
- scheduler: 하이퍼파라미터 탐색 스케줄러(HPOScheduler) 객체입니다. 이 객체는 하이퍼파라미터 탐색 알고리즘과 스케줄링을 제어합니다.
- objective: 목표 함수(callable)입니다. 이 함수는 하이퍼파라미터 구성을 입력으로 받아 검증 오차를 반환하는 함수여야 합니다.
- self.save_hyperparameters(): 하이퍼파라미터를 저장하는 메서드입니다. 이 메서드를 호출하여 HPOTuner 클래스의 하이퍼파라미터를 저장합니다.
- self.incumbent, self.incumbent_error, self.incumbent_trajectory, self.cumulative_runtime, self.current_runtime, self.records: 하이퍼파라미터 탐색 결과를 저장하기 위한 인스턴스 변수들입니다. 이 변수들은 향후 결과 분석 및 시각화에 사용됩니다.
- def run(self, number_of_trials): 하이퍼파라미터 탐색을 실행하는 메서드입니다. 이 메서드는 number_of_trials 만큼의 하이퍼파라미터 탐색 시도를 수행합니다.
- 먼저 현재 시간을 측정하여 시도의 시작 시간(start_time)을 저장합니다.
- scheduler 객체를 사용하여 다음으로 시도할 하이퍼파라미터 구성(config)을 제안합니다.
- objective 함수를 사용하여 제안된 하이퍼파라미터 구성에 대한 검증 오차(error)를 계산합니다.
- 검증 오차를 float 형태로 변환하여 저장합니다.
- scheduler 객체를 사용하여 하이퍼파라미터 탐색 알고리즘을 업데이트합니다.
- 시도의 실행 시간(runtime)을 계산합니다.
- bookkeeping 메서드를 호출하여 결과를 기록합니다.
- 시도별로 제안된 하이퍼파라미터 구성, 검증 오차, 실행 시간을 출력합니다.
HPOTuner 클래스는 주어진 하이퍼파라미터 탐색 스케줄러와 목표 함수를 사용하여 하이퍼파라미터 탐색을 수행하고 결과를 기록하는 역할을 합니다. 탐색된 결과는 인스턴스 변수에 저장되어 이후 분석 및 시각화에 사용됩니다.
19.2.4. Bookkeeping the Performance of HPO Algorithms
With any HPO algorithm, we are mostly interested in the best performing configuration (called incumbent) and its validation error after a given wall-clock time. This is why we track runtime per iteration, which includes both the time to run an evaluation (call of objective) and the time to make a decision (call of scheduler.suggest). In the sequel, we will plot cumulative_runtime against incumbent_trajectory in order to visualize the any-time performance of the HPO algorithm defined in terms of scheduler (and searcher). This allows us to quantify not only how well the configuration found by an optimizer works, but also how quickly an optimizer is able to find it.
모든 HPO 알고리즘에서 우리는 가장 성능이 좋은 구성(현재라고 함)과 주어진 wall-clock time 이후의 유효성 검사 오류에 주로 관심이 있습니다. 이것이 바로 우리가 평가 실행 시간(목표 호출)과 결정을 내리는 시간(scheduler.suggest 호출)을 모두 포함하는 반복당 런타임을 추적하는 이유입니다. 후속편에서는 스케줄러(및 검색기) 측면에서 정의된 HPO 알고리즘의 언제든지 성능을 시각화하기 위해 incumbent_trajectory에 대해 cumulative_runtime을 플롯합니다. 이를 통해 우리는 옵티마이저가 찾은 구성이 얼마나 잘 작동하는지 뿐만 아니라 옵티마이저가 이를 얼마나 빨리 찾을 수 있는지를 정량화할 수 있습니다.
@d2l.add_to_class(HPOTuner) #@save
def bookkeeping(self, config: dict, error: float, runtime: float):
self.records.append({"config": config, "error": error, "runtime": runtime})
# Check if the last hyperparameter configuration performs better
# than the incumbent
if self.incumbent is None or self.incumbent_error > error:
self.incumbent = config
self.incumbent_error = error
# Add current best observed performance to the optimization trajectory
self.incumbent_trajectory.append(self.incumbent_error)
# Update runtime
self.current_runtime += runtime
self.cumulative_runtime.append(self.current_runtime)위의 코드는 HPOTuner 클래스에 새로운 메서드인 bookkeeping을 추가하는 부분입니다. bookkeeping 메서드는 하이퍼파라미터 탐색 결과를 기록하고 현재까지의 최적 하이퍼파라미터 구성 및 검증 오차를 관리합니다. 코드의 목적과 각 부분에 대한 설명은 다음과 같습니다:
- @d2l.add_to_class(HPOTuner): bookkeeping 메서드를 HPOTuner 클래스에 추가하는 데코레이터입니다. 이를 통해 bookkeeping 메서드가 HPOTuner 클래스의 일부로 추가됩니다.
- def bookkeeping(self, config: dict, error: float, runtime: float):: bookkeeping 메서드를 정의합니다. 이 메서드는 세 개의 매개변수를 입력으로 받습니다.
- config: 현재 시도한 하이퍼파라미터 구성(configuration)을 나타내는 딕셔너리입니다.
- error: 현재 시도한 하이퍼파라미터 구성에 대한 검증 오차를 나타내는 부동 소수점 숫자(float)입니다.
- runtime: 현재 시도한 하이퍼파라미터 탐색 시도의 실행 시간을 나타내는 부동 소수점 숫자(float)입니다.
- self.records.append({"config": config, "error": error, "runtime": runtime}): 시도한 하이퍼파라미터 구성(config), 검증 오차(error), 실행 시간(runtime)을 딕셔너리 형태로 묶어 records 리스트에 추가합니다. 이를 통해 각 시도의 결과가 기록됩니다.
- if self.incumbent is None or self.incumbent_error > error:: 현재까지의 최적 하이퍼파라미터 구성(incumbent)이 없거나 현재 시도한 하이퍼파라미터 구성의 검증 오차가 현재까지의 최적 검증 오차(incumbent_error)보다 작을 경우, 새로운 최적 하이퍼파라미터 구성으로 업데이트합니다.
- self.incumbent_trajectory.append(self.incumbent_error): 최적 검증 오차를 최적화 경로(incumbent_trajectory)에 추가합니다. 이를 통해 최적 검증 오차의 변화를 추적할 수 있습니다.
- self.current_runtime += runtime: 현재 시도한 하이퍼파라미터 탐색 시도의 실행 시간을 누적 실행 시간에 추가합니다.
- self.cumulative_runtime.append(self.current_runtime): 누적 실행 시간을 cumulative_runtime 리스트에 추가합니다. 이를 통해 누적 실행 시간의 변화를 추적할 수 있습니다.
bookkeeping 메서드는 하이퍼파라미터 탐색 과정에서 발생한 결과를 기록하고 최적 하이퍼파라미터 구성 및 검증 오차를 관리하는 중요한 역할을 합니다. 이를 통해 하이퍼파라미터 탐색의 진행과 결과 분석을 용이하게 할 수 있습니다.
19.2.5. Example: Optimizing the Hyperparameters of a Convolutional Neural Network
We now use our new implementation of random search to optimize the batch size and learning rate of the LeNet convolutional neural network from Section 7.6. We being by defining the objective function, which will once more be validation error.
이제 우리는 섹션 7.6의 LeNet 컨벌루션 신경망의 배치 크기와 학습 속도를 최적화하기 위해 새로운 무작위 검색 구현을 사용합니다. 우리는 다시 한 번 검증 오류가 될 목적 함수를 정의하고 있습니다.
def hpo_objective_lenet(learning_rate, batch_size, max_epochs=10): #@save
model = d2l.LeNet(lr=learning_rate, num_classes=10)
trainer = d2l.HPOTrainer(max_epochs=max_epochs, num_gpus=1)
data = d2l.FashionMNIST(batch_size=batch_size)
model.apply_init([next(iter(data.get_dataloader(True)))[0]], d2l.init_cnn)
trainer.fit(model=model, data=data)
validation_error = trainer.validation_error()
return validation_error위의 코드는 하이퍼파라미터 튜닝을 위한 목표 함수인 hpo_objective_lenet 함수를 정의하는 부분입니다. 이 함수는 LeNet 모델을 사용하여 Fashion MNIST 데이터셋에 대한 검증 오차를 반환하는 역할을 합니다. 코드의 목적과 각 부분에 대한 설명은 다음과 같습니다:
- def hpo_objective_lenet(learning_rate, batch_size, max_epochs=10):: hpo_objective_lenet 함수를 정의합니다. 이 함수는 세 개의 하이퍼파라미터와 하나의 선택적 매개변수를 입력으로 받습니다.
- learning_rate: 학습률을 나타내는 부동 소수점 숫자(float)입니다.
- batch_size: 미니배치 크기를 나타내는 정수(int)입니다.
- max_epochs: 최대 에포크 수를 나타내는 정수(int)입니다. 기본값은 10입니다.
- model = d2l.LeNet(lr=learning_rate, num_classes=10): LeNet 아키텍처를 사용하여 모델을 초기화합니다. 이때 학습률과 클래스 수를 매개변수로 설정합니다.
- trainer = d2l.HPOTrainer(max_epochs=max_epochs, num_gpus=1): 하이퍼파라미터 튜닝을 위한 트레이너 객체를 생성합니다. 최대 에포크 수와 GPU 수를 설정합니다.
- data = d2l.FashionMNIST(batch_size=batch_size): Fashion MNIST 데이터셋을 불러와서 데이터 객체를 생성합니다. 이때 미니배치 크기를 설정합니다.
- model.apply_init([next(iter(data.get_dataloader(True)))[0]], d2l.init_cnn): 모델의 가중치를 초기화합니다. 이때 데이터로부터 첫 번째 미니배치를 추출하여 초기화에 사용합니다.
- trainer.fit(model=model, data=data): 트레이너를 사용하여 모델을 학습시킵니다. 모델과 데이터를 입력으로 제공합니다.
- validation_error = trainer.validation_error(): 학습된 모델을 검증 데이터에 대해 평가하여 검증 오차를 계산합니다.
- return validation_error: 검증 오차를 반환합니다.
이 함수는 주어진 하이퍼파라미터 구성(learning_rate, batch_size, max_epochs)으로 LeNet 모델을 학습하고 검증 오차를 반환합니다. 이 함수는 하이퍼파라미터 탐색에서 목표로 하는 검증 오차를 최소화하기 위해 호출됩니다.
We also need to define the configuration space. Moreover, the first configuration to be evaluated is the default setting used in Section 7.6.
또한 구성 공간을 정의해야 합니다. 또한 평가할 첫 번째 구성은 섹션 7.6에서 사용된 기본 설정입니다.
config_space = {
"learning_rate": stats.loguniform(1e-2, 1),
"batch_size": stats.randint(32, 256),
}
initial_config = {
"learning_rate": 0.1,
"batch_size": 128,
}위의 코드는 하이퍼파라미터 탐색을 위한 하이퍼파라미터 공간(config_space)과 초기 하이퍼파라미터 구성(initial_config)을 정의하는 부분입니다. 각 부분에 대한 설명은 다음과 같습니다:
- config_space: 하이퍼파라미터 공간을 정의하는 딕셔너리입니다. 이 딕셔너리에는 탐색할 하이퍼파라미터의 이름과 각 하이퍼파라미터에 대한 확률 분포가 설정됩니다.
- "learning_rate": 학습률을 나타내는 하이퍼파라미터입니다. 이 학습률은 로그 균등 분포(stats.loguniform)를 사용하여 1e-2에서 1 사이의 값 중에서 무작위로 선택됩니다.
- "batch_size": 미니배치 크기를 나타내는 하이퍼파라미터입니다. 이 미니배치 크기는 균등 분포(stats.randint)를 사용하여 32에서 256 사이의 정수 중에서 무작위로 선택됩니다.
- initial_config: 초기 하이퍼파라미터 구성을 정의하는 딕셔너리입니다. 이 딕셔너리에는 하이퍼파라미터의 이름과 초기값이 설정됩니다.
- "learning_rate": 학습률의 초기값을 0.1로 설정합니다.
- "batch_size": 미니배치 크기의 초기값을 128로 설정합니다.
이렇게 정의된 config_space와 initial_config를 사용하여 하이퍼파라미터 탐색을 수행할 때, 하이퍼파라미터 탐색 공간은 learning_rate와 batch_size 두 가지 하이퍼파라미터를 다루며, 초기 탐색은 initial_config에서 정의한 값으로 시작합니다. 이후 하이퍼파라미터 탐색 알고리즘이 지정된 공간에서 하이퍼파라미터를 무작위로 탐색하고 목표 함수를 최적화하려고 시도합니다.
Now we can start our random search:
이제 무작위 검색을 시작할 수 있습니다.
searcher = RandomSearcher(config_space, initial_config=initial_config)
scheduler = BasicScheduler(searcher=searcher)
tuner = HPOTuner(scheduler=scheduler, objective=hpo_objective_lenet)
tuner.run(number_of_trials=5)위의 코드는 하이퍼파라미터 튜닝 프로세스를 설정하고 실행하는 부분입니다. 이 코드는 다음과 같은 주요 단계로 구성됩니다:
- searcher = RandomSearcher(config_space, initial_config=initial_config): RandomSearcher 클래스를 사용하여 하이퍼파라미터 탐색기(searcher)를 생성합니다. 이 탐색기는 정의한 하이퍼파라미터 공간(config_space)에서 무작위로 하이퍼파라미터를 샘플링하며, 초기 하이퍼파라미터 구성(initial_config)은 최초 탐색 시도에서 사용됩니다.
- scheduler = BasicScheduler(searcher=searcher): BasicScheduler 클래스를 사용하여 스케줄러(scheduler)를 생성합니다. 이 스케줄러는 하이퍼파라미터 탐색기(searcher)를 기반으로 하이퍼파라미터 탐색을 제어하며, 다음에 시도할 하이퍼파라미터 구성을 추천합니다.
- tuner = HPOTuner(scheduler=scheduler, objective=hpo_objective_lenet): HPOTuner 클래스를 사용하여 하이퍼파라미터 튜너(tuner)를 생성합니다. 이 튜너는 스케줄러와 목표 함수(objective)를 입력으로 받습니다. 목표 함수는 하이퍼파라미터 탐색 시 목표로 하는 평가 지표(여기서는 검증 오차)를 최소화하기 위해 호출됩니다.
- tuner.run(number_of_trials=5): 하이퍼파라미터 탐색을 실행합니다. number_of_trials 매개변수에 지정된 횟수(여기서는 5번)만큼 하이퍼파라미터 탐색을 반복하며, 각 시도에서 목표 함수를 호출하여 검증 오차를 최소화하는 최적의 하이퍼파라미터를 찾습니다.
이렇게 설정된 하이퍼파라미터 탐색 프로세스를 실행하면, 다양한 하이퍼파라미터 조합을 시도하여 모델의 검증 오차를 최적화하려고 노력합니다. 최적의 하이퍼파라미터 구성과 검증 오차의 기록은 tuner 객체에 저장되며, 최종적으로 가장 좋은 하이퍼파라미터 구성을 찾게 됩니다.
error = 0.9000097513198853, runtime = 62.85189199447632




==> 여러 구성으로 여러번 run 하기 때문에 시간이 많이 걸림. 아래는 CoLab에서 돌린 결과. 11분 걸

Below we plot the optimization trajectory of the incumbent to get the any-time performance of random search:
아래에서는 무작위 검색의 언제든지 성능을 얻기 위해 기존 기업의 최적화 궤적을 그립니다.
board = d2l.ProgressBoard(xlabel="time", ylabel="error")
for time_stamp, error in zip(
tuner.cumulative_runtime, tuner.incumbent_trajectory
):
board.draw(time_stamp, error, "random search", every_n=1)위의 코드는 하이퍼파라미터 탐색 과정에서 검증 오차의 변화를 시각화하는 부분입니다. 코드는 다음과 같이 동작합니다:
- board = d2l.ProgressBoard(xlabel="time", ylabel="error"): d2l.ProgressBoard 객체를 생성하여 그래프를 초기화합니다. 이 그래프는 시간(time)에 따른 검증 오차(error)의 변화를 시각화합니다. x축은 시간을 나타내고, y축은 검증 오차를 나타냅니다.
- for time_stamp, error in zip(tuner.cumulative_runtime, tuner.incumbent_trajectory):: 하이퍼파라미터 튜닝 과정에서 누적된 시간(time_stamp)과 현재까지의 최적 검증 오차(error)를 반복하면서 그래프를 그립니다.
- board.draw(time_stamp, error, "random search", every_n=1): 그래프에 데이터를 추가합니다. 시간(time_stamp)과 검증 오차(error)를 전달하고, "random search"라는 레이블을 지정합니다. every_n=1은 모든 데이터 포인트를 표시하도록 지정하는데, 이 값이 높으면 그래프에 표시되는 데이터 포인트의 수가 감소합니다.
이 코드는 하이퍼파라미터 탐색 과정 중에 검증 오차의 변화를 실시간으로 시각화하여 어떻게 하이퍼파라미터 탐색이 진행되고 있는지를 모니터링할 수 있게 합니다. 그래프는 시간에 따른 검증 오차의 추이를 보여주며, 최적의 하이퍼파라미터 구성을 찾는 과정을 시각적으로 이해하는 데 도움을 줍니다.


19.2.6. Comparing HPO Algorithms
Just as with training algorithms or model architectures, it is important to understand how to best compare different HPO algorithms. Each HPO run depends on two major sources of randomness: the random effects of the training process, such as random weight initialization or mini-batch ordering, and the intrinsic randomness of the HPO algorithm itself, such as the random sampling of random search. Hence, when comparing different algorithms, it is crucial to run each experiment several times and report statistics, such as mean or median, across a population of multiple repetitions of an algorithm based on different seeds of the random number generator.
학습 알고리즘이나 모델 아키텍처와 마찬가지로 다양한 HPO 알고리즘을 가장 잘 비교하는 방법을 이해하는 것이 중요합니다. 각 HPO 실행은 무작위성의 두 가지 주요 소스, 즉 무작위 가중치 초기화 또는 미니 배치 순서 지정과 같은 훈련 프로세스의 무작위 효과와 무작위 검색의 무작위 샘플링과 같은 HPO 알고리즘 자체의 본질적인 무작위성에 따라 달라집니다. 따라서 다양한 알고리즘을 비교할 때 각 실험을 여러 번 실행하고 난수 생성기의 다양한 시드를 기반으로 하는 알고리즘의 여러 반복 모집단에 대한 평균 또는 중앙값과 같은 통계를 보고하는 것이 중요합니다.
To illustrate this, we compare random search (see Section 19.1.2) and Bayesian optimization (Snoek et al., 2012) on tuning the hyperparameters of a feed-forward neural network. Each algorithm was evaluated 50 times with a different random seed. The solid line indicates the average performance of the incumbent across these 50 repetitions and the dashed line the standard deviation. We can see that random search and Bayesian optimization perform roughly the same up to ~1000 seconds, but Bayesian optimization can make use of the past observation to identify better configurations and thus quickly outperforms random search afterwards.
이를 설명하기 위해 피드포워드 신경망의 하이퍼파라미터 조정에 대한 무작위 검색(19.1.2절 참조)과 베이지안 최적화(Snoek et al., 2012)를 비교합니다. 각 알고리즘은 서로 다른 무작위 시드를 사용하여 50회 평가되었습니다. 실선은 50회 반복에 걸쳐 재직자의 평균 성과를 나타내고 점선은 표준 편차를 나타냅니다. 무작위 검색과 베이지안 최적화는 최대 1000초까지 거의 동일하게 수행되지만 베이지안 최적화는 과거 관찰을 활용하여 더 나은 구성을 식별할 수 있으므로 나중에 무작위 검색보다 빠르게 성능이 향상된다는 것을 알 수 있습니다.

19.2.7. Summary
This section laid out a simple, yet flexible interface to implement various HPO algorithms that we will look at in this chapter. Similar interfaces can be found in popular open-source HPO frameworks. We also looked at how we can compare HPO algorithms, and potential pitfall one needs to be aware.
이 섹션에서는 이 장에서 살펴볼 다양한 HPO 알고리즘을 구현하기 위한 간단하면서도 유연한 인터페이스를 제시했습니다. 인기 있는 오픈 소스 HPO 프레임워크에서도 유사한 인터페이스를 찾을 수 있습니다. 또한 HPO 알고리즘을 비교할 수 있는 방법과 알아야 할 잠재적인 함정도 살펴보았습니다.
19.2.8. Exercises
- The goal of this exercise is to implement the objective function for a slightly more challenging HPO problem, and to run more realistic experiments. We will use the two hidden layer MLP DropoutMLP implemented in Section 5.6.
- Code up the objective function, which should depend on all hyperparameters of the model and batch_size. Use max_epochs=50. GPUs do not help here, so num_gpus=0. Hint: Modify hpo_objective_lenet.
- Choose a sensible search space, where num_hiddens_1, num_hiddens_2 are integers in [8,1024], and dropout values lie in [0,0.95], while batch_size lies in [16,384]. Provide code for config_space, using sensible distributions from scipy.stats.
- Run random search on this example with number_of_trials=20 and plot the results. Make sure to first evaluate the default configuration of Section 5.6, which is initial_config = {'num_hiddens_1': 256, 'num_hiddens_2': 256, 'dropout_1': 0.5, 'dropout_2': 0.5, 'lr': 0.1, 'batch_size': 256}.
- In this exercise, you will implement a new searcher (subclass of HPOSearcher) which makes decisions based on past data. It depends on parameters probab_local, num_init_random. Its sample_configuration method works as follows. For the first num_init_random calls, do the same as RandomSearcher.sample_configuration. Otherwise, with probability 1 - probab_local, do the same as RandomSearcher.sample_configuration. Otherwise, pick the configuration which attained the smallest validation error so far, select one of its hyperparameters at random, and sample its value randomly like in RandomSearcher.sample_configuration, but leave all other values the same. Return this configuration, which is identical to the best configuration so far, except in this one hyperparameter.
- Code up this new LocalSearcher. Hint: Your searcher requires config_space as argument at construction. Feel free to use a member of type RandomSearcher. You will also have to implement the update method.
- Re-run the experiment from the previous exercise, but using your new searcher instead of RandomSearcher. Experiment with different values for probab_local, num_init_random. However, note that a proper comparison between different HPO methods requires repeating experiments several times, and ideally considering a number of benchmark tasks.
'Dive into Deep Learning > D2L Hyperparameter Optimization' 카테고리의 다른 글
| D2L - 19.5. Asynchronous Successive Halving (0) | 2023.09.10 |
|---|---|
| D2L - 19.4. Multi-Fidelity Hyperparameter Optimization (0) | 2023.09.10 |
| D2L - 19.3. Asynchronous Random Search (0) | 2023.09.10 |
| D2L - 19.1. What Is Hyperparameter Optimization? (0) | 2023.09.10 |
| D2L - 19. Hyperparameter Optimization (0) | 2023.09.10 |