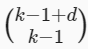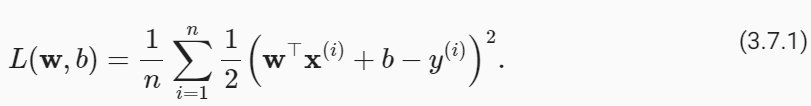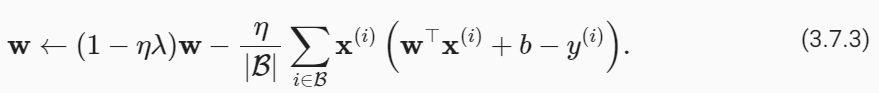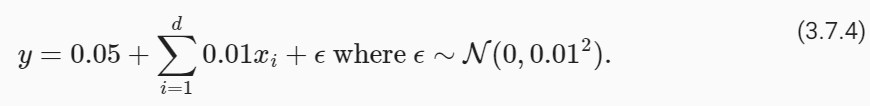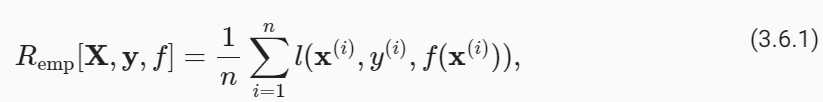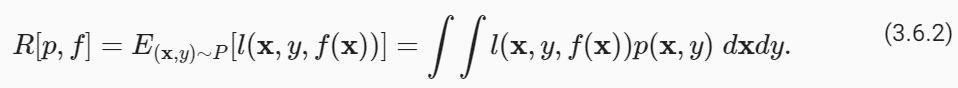개발자로서 현장에서 일하면서 새로 접하는 기술들이나 알게된 정보 등을 정리하기 위한 블로그입니다. 운 좋게 미국에서 큰 회사들의 프로젝트에서 컬설턴트로 일하고 있어서 새로운 기술들을 접할 기회가 많이 있습니다. 미국의 IT 프로젝트에서 사용되는 툴들에 대해 많은 분들과 정보를 공유하고 싶습니다.
Partnership with Axel Springer to deepen beneficial use of AI in journalism
Axel Springer is the first publishing house globally to partner with us on a deeper integration of journalism in AI technologies.
This news was originally shared by Axel Springer and can also be readhere.
이 소식은 원래 Axel Springer가 공유했으며 여기에서도 읽을 수 있습니다.
Axel Springer is the first publishing house globally to partner with OpenAI on a deeper integration of journalism in AI technologies.
Axel Springer는 저널리즘과 AI 기술의 심층 통합을 위해 OpenAI와 파트너십을 맺은 전 세계 최초의 출판사입니다.
Axel Springer and OpenAI have announced a global partnership to strengthen independent journalism in the age of artificial intelligence (AI). The initiative will enrich users’ experience with ChatGPT by adding recent and authoritative content on a wide variety of topics, and explicitly values the publisher’s role in contributing to OpenAI’s products. This marks a significant step in both companies’ commitment to leverage AI for enhancing content experiences and creating new financial opportunities that support a sustainable future for journalism.
Axel Springer와 OpenAI가 인공지능(AI) 시대에 독립적인 저널리즘을 강화하기 위한 글로벌 파트너십을 발표했습니다. 이 이니셔티브는 다양한 주제에 대한 권위 있는 최신 콘텐츠를 추가하여 ChatGPT에 대한 사용자 경험을 풍부하게 하고 OpenAI 제품에 기여하는 게시자의 역할을 명시적으로 높이 평가합니다. 이는 콘텐츠 경험을 향상하고 저널리즘의 지속 가능한 미래를 지원하는 새로운 재정적 기회를 창출하기 위해 AI를 활용하려는 두 회사의 약속에서 중요한 단계입니다.
With this partnership, ChatGPT users around the world will receive summaries of selected global news content from Axel Springer’s media brands including POLITICO, BUSINESS INSIDER, and European properties BILD and WELT, including otherwise paid content. ChatGPT’s answers to user queries will include attribution and links to the full articles for transparency and further information.
이 파트너십을 통해 전 세계 ChatGPT 사용자는 유료 콘텐츠를 포함하여 POLITICO, BUSINESS INSIDER, 유럽 자산 BILD 및 WELT를 포함한 Axel Springer의 미디어 브랜드에서 선택된 글로벌 뉴스 콘텐츠의 요약을 받게 됩니다. 사용자 쿼리에 대한 ChatGPT의 답변에는 투명성과 추가 정보를 위해 전체 기사에 대한 출처 및 링크가 포함됩니다.
In addition, the partnership supports Axel Springer’s existing AI-driven ventures that build upon OpenAI’s technology. The collaboration also involves the use of quality content from Axel Springer media brands for advancing the training of OpenAI’s sophisticated large language models.
또한 이번 파트너십은 OpenAI 기술을 기반으로 구축된 Axel Springer의 기존 AI 기반 벤처를 지원합니다. 또한 이번 협력에는 OpenAI의 정교한 대규모 언어 모델 교육을 발전시키기 위해 Axel Springer 미디어 브랜드의 고품질 콘텐츠를 사용하는 것도 포함됩니다.
We are excited to have shaped this global partnership between Axel Springer and OpenAI – the first of its kind. We want to explore the opportunities of AI empowered journalism – to bring quality, societal relevance and the business model of journalism to the next level.
우리는 Axel Springer와 OpenAI 간의 최초의 글로벌 파트너십을 구축하게 된 것을 기쁘게 생각합니다. 우리는 AI 기반 저널리즘의 기회를 탐색하여 저널리즘의 품질, 사회적 관련성 및 비즈니스 모델을 한 단계 끌어올리고 싶습니다.
Mathias Döpfner, CEO of Axel Springer
“This partnership with Axel Springer will help provide people with new ways to access quality, real-time news content through our AI tools. We are deeply committed to working with publishers and creators around the world and ensuring they benefit from advanced AI technology and new revenue models,” says Brad Lightcap, COO of OpenAI.
“Axel Springer와의 이번 파트너십은 사람들에게 AI 도구를 통해 고품질의 실시간 뉴스 콘텐츠에 액세스할 수 있는 새로운 방법을 제공하는 데 도움이 될 것입니다. 우리는 전 세계 출판사 및 창작자들과 협력하여 이들이 첨단 AI 기술과 새로운 수익 모델의 혜택을 누릴 수 있도록 최선을 다하고 있습니다.”라고 OpenAI의 COO인 Brad Lightcap은 말합니다.
About Axel Springer
Axel Springer is a media and technology company active in more than 40 countries. By providing information across its diverse media brands (among others BILD, WELT, INSIDER, POLITICO) and classifieds portals (StepStone Group and AVIV Group) Axel Springer SE empowers people to make free decisions for their lives. Today, the transformation from a traditional print media company to Europe’s leading digital publisher has been successfully accomplished. The next goal has been identified: Axel Springer wants to become global market leader in digital content and digital classifieds through accelerated growth. The company is headquartered in Berlin and employs more than 18,000 people worldwide.
Axel Springer는 40개국 이상에서 활동하는 미디어 및 기술 회사입니다. 다양한 미디어 브랜드(BILD, WELT, INSIDER, POLITICO 등) 및 광고 포털(StepStone Group 및 AVIV Group) 전반에 걸쳐 정보를 제공함으로써 Axel Springer SE는 사람들이 자신의 삶에 대해 자유로운 결정을 내릴 수 있도록 지원합니다. 오늘날 전통적인 인쇄 매체 회사에서 유럽 최고의 디지털 출판사로의 전환이 성공적으로 이루어졌습니다. 다음 목표가 확인되었습니다. Axel Springer는 가속화된 성장을 통해 디지털 콘텐츠 및 디지털 광고 분야의 글로벌 시장 리더가 되고자 합니다. 이 회사는 베를린에 본사를 두고 있으며 전 세계적으로 18,000명 이상의 직원을 고용하고 있습니다.
Axel Springer and OpenAI have announced a global partnership to strengthen independent journalism in the age of artificial intelligence (AI). The initiative will enrich users’ experience with ChatGPT by adding recent and authoritative content on a wide variety of topics, and explicitly values the publisher’s role in contributing to OpenAI’s products. This marks a significant step in both companies’ commitment to leverage AI for enhancing content experiences and creating new financial opportunities that support a sustainable future for journalism.
Axel Springer와 OpenAI가 인공지능(AI) 시대에 독립적인 저널리즘을 강화하기 위한 글로벌 파트너십을 발표했습니다. 이 이니셔티브는 다양한 주제에 대한 권위 있는 최신 콘텐츠를 추가하여 ChatGPT에 대한 사용자 경험을 풍부하게 하고 OpenAI 제품에 기여하는 게시자의 역할을 명시적으로 높이 평가합니다. 이는 콘텐츠 경험을 향상하고 저널리즘의 지속 가능한 미래를 지원하는 새로운 재정적 기회를 창출하기 위해 AI를 활용하려는 두 회사의 약속에서 중요한 단계입니다.
With this partnership, ChatGPT users around the world will receive summaries of selected global news content from Axel Springer’s media brands including POLITICO, BUSINESS INSIDER, and European properties BILD and WELT, including otherwise paid content. ChatGPT’s answers to user queries will include attribution and links to the full articles for transparency and further information.
이 파트너십을 통해 전 세계 ChatGPT 사용자는 유료 콘텐츠를 포함하여 POLITICO, BUSINESS INSIDER, 유럽 자산 BILD 및 WELT를 포함한 Axel Springer의 미디어 브랜드에서 선택된 글로벌 뉴스 콘텐츠의 요약을 받게 됩니다. 사용자 쿼리에 대한 ChatGPT의 답변에는 투명성과 추가 정보를 위해 전체 기사에 대한 출처 및 링크가 포함됩니다.
In addition, the partnership supports Axel Springer’s existing AI-driven ventures that build upon OpenAI’s technology. The collaboration also involves the use of quality content from Axel Springer media brands for advancing the training of OpenAI’s sophisticated large language models.
또한 이번 파트너십은 OpenAI 기술을 기반으로 구축된 Axel Springer의 기존 AI 기반 벤처를 지원합니다. 또한 이번 협력에는 OpenAI의 정교한 대규모 언어 모델 교육을 발전시키기 위해 Axel Springer 미디어 브랜드의 고품질 콘텐츠를 사용하는 것도 포함됩니다.
Mathias Döpfner, CEO of Axel Springer:“We are excited to have shaped this global partnership between Axel Springer and OpenAI – the first of its kind. We want to explore the opportunities of AI empowered journalism – to bring quality, societal relevance and the business model of journalism to the next level.”
Axel Springer의 CEO인 Mathias Döpfner는 다음과 같이 말했습니다. “Axel Springer와 OpenAI 간의 최초의 글로벌 파트너십을 구축하게 되어 기쁘게 생각합니다. 우리는 AI 기반 저널리즘의 기회를 탐색하여 저널리즘의 품질, 사회적 관련성 및 비즈니스 모델을 한 단계 끌어올리고 싶습니다.”
Brad Lightcap, COO of OpenAI:“This partnership with Axel Springer will help provide people with new ways to access quality, real-time news content through our AI tools. We are deeply committed to working with publishers and creators around the world and ensuring they benefit from advanced AI technology and new revenue models.”
OpenAI의 COO인 Brad Lightcap은 다음과 같이 말했습니다. “Axel Springer와의 이번 파트너십은 사람들이 AI 도구를 통해 고품질의 실시간 뉴스 콘텐츠에 액세스할 수 있는 새로운 방법을 제공하는 데 도움이 될 것입니다. 우리는 전 세계 출판사 및 창작자와 협력하여 이들이 첨단 AI 기술과 새로운 수익 모델의 혜택을 누릴 수 있도록 최선을 다하고 있습니다.”
In this tutorial, you learn how to use Amazon SageMaker to build, train, and tune a TensorFlow deep learning model.
이 자습서에서는 Amazon SageMaker를 사용하여 TensorFlow 딥 러닝 모델을 구축, 훈련 및 조정하는 방법을 알아봅니다.
Amazon SageMakeris a fully managed service that provides machine learning (ML) developers and data scientists with the ability to build, train, and deploy ML models quickly. Amazon SageMaker provides you with everything you need to train and tune models at scale without the need to manage infrastructure. You can useAmazon SageMaker Studio, the first integrated development environment (IDE) for machine learning, to quickly visualize experiments and track training progress without ever leaving the familiar Jupyter Notebook interface. Within Amazon SageMaker Studio, you can useAmazon SageMaker Experimentsto track, evaluate, and organize experiments easily.
Amazon SageMaker는 기계 학습(ML) 개발자와 데이터 과학자에게 ML 모델을 신속하게 구축, 교육 및 배포할 수 있는 기능을 제공하는 완전관리형 서비스입니다. Amazon SageMaker는 인프라를 관리할 필요 없이 대규모로 모델을 훈련하고 조정하는 데 필요한 모든 것을 제공합니다. 기계 학습을 위한 최초의 통합 개발 환경(IDE)인 Amazon SageMaker Studio를 사용하면 친숙한 Jupyter Notebook 인터페이스를 벗어나지 않고도 실험을 신속하게 시각화하고 훈련 진행 상황을 추적할 수 있습니다. Amazon SageMaker Studio 내에서 Amazon SageMaker 실험을 사용하여 실험을 쉽게 추적, 평가 및 구성할 수 있습니다.
In this tutorial, you learn how to:
이 자습서에서는 다음 방법을 알아봅니다.
Set up Amazon SageMaker Studio Amazon SageMaker Studio 설정
Download a public dataset using an Amazon SageMaker Studio Notebook and upload it to Amazon S3 Amazon SageMaker Studio Notebook을 사용하여 공개 데이터 세트를 다운로드하고 Amazon S3에 업로드합니다.
Create an Amazon SageMaker Experiment to track and manage training jobs 훈련 작업을 추적하고 관리하기 위한 Amazon SageMaker 실험 생성
Run a TensorFlow training job on a fully managed GPU instance using one-click training with Amazon SageMaker Amazon SageMaker의 원클릭 교육을 사용하여 완전 관리형 GPU 인스턴스에서 TensorFlow 교육 작업 실행
Improve accuracy by running a large-scaleAmazon SageMaker Automatic Model Tuningjob to find the best model hyperparameters 대규모 Amazon SageMaker 자동 모델 튜닝 작업을 실행하여 최상의 모델 하이퍼파라미터를 찾아 정확성을 향상시킵니다.
Visualize training results 훈련 결과 시각화
You’ll be using theCIFAR-10 datasetto train a model in TensorFlow to classify images into 10 classes. This dataset consists of 60,000 32x32 color images, split into 40,000 images for training, 10,000 images for validation and 10,000 images for testing.
CIFAR-10 데이터 세트를 사용하여 TensorFlow에서 모델을 훈련하여 이미지를 10개 클래스로 분류하게 됩니다. 이 데이터 세트는 60,000개의 32x32 컬러 이미지로 구성되어 있으며 훈련용 이미지 40,000개, 검증용 이미지 10,000개, 테스트용 이미지 10,000개로 나뉩니다.
이 튜토리얼의 비용은 약 $100입니다.
Amazon SageMaker Studio에 온보딩하고 Amazon SageMaker Studio 제어판을 설정하려면 다음 단계를 완료하십시오.
b. Amazon SageMaker 탐색 창에서 Amazon SageMaker Studio를 선택합니다.
참고: Amazon SageMaker Studio를 처음 사용하는 경우 Studio onboarding process 를 완료해야 합니다. 온보딩 시 인증 방법으로 AWS Single Sign-On(AWS SSO) 또는 AWS Identity and Access Management(IAM)를 사용하도록 선택할 수 있습니다. IAM 인증을 사용하는 경우 빠른 시작 또는 표준 설정 절차를 선택할 수 있습니다. 어떤 옵션을 선택해야 할지 잘 모르겠으면 Onboard to Amazon SageMaker Studio 을 참조하고 IT 관리자에게 도움을 요청하세요. 단순화를 위해 이 자습서에서는 빠른 시작 절차를 사용합니다.
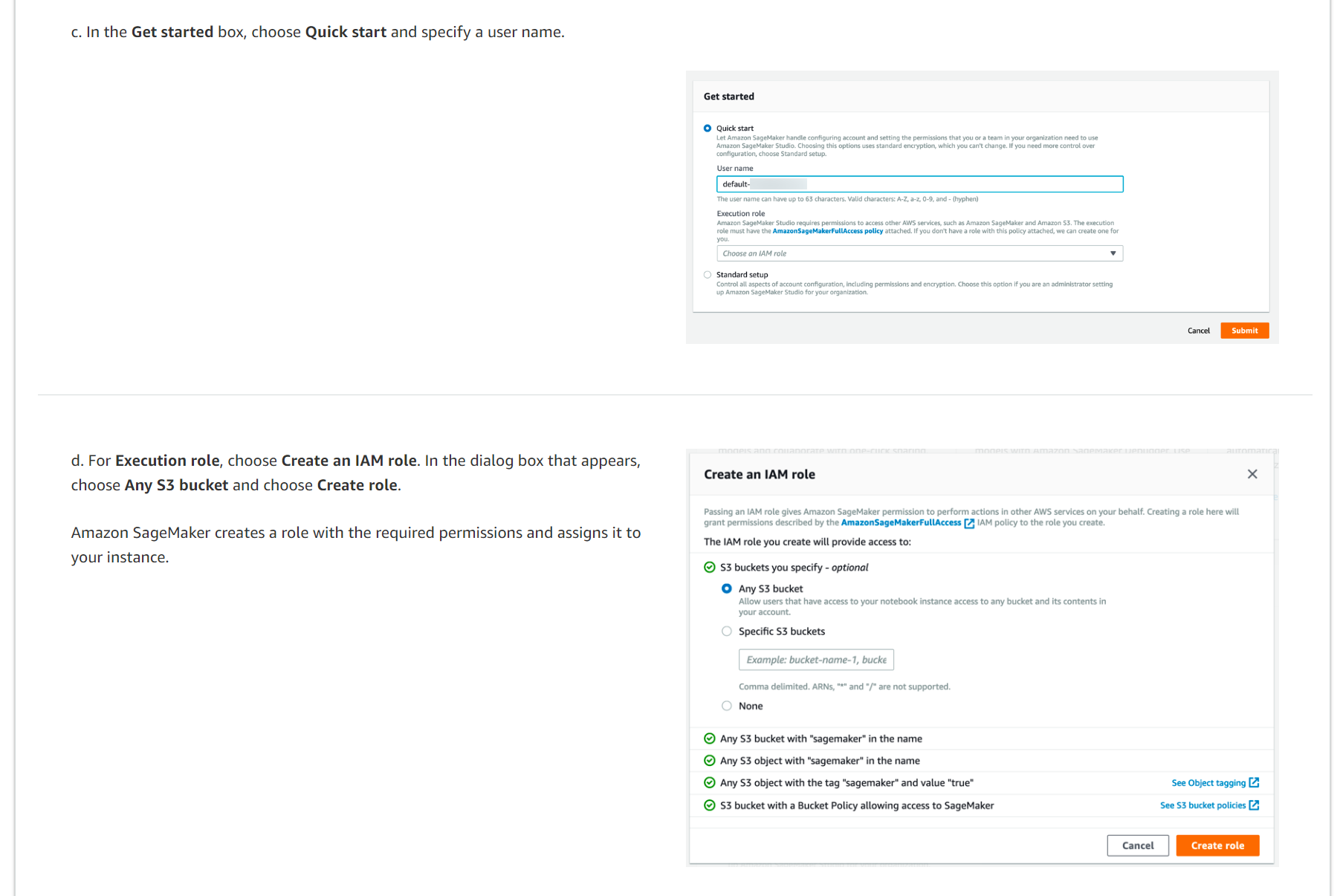
c. 시작하기 상자에서 빠른 시작을 선택하고 사용자 이름을 지정합니다.
d. 실행 역할에서 IAM 역할 생성을 선택합니다. 표시되는 대화 상자에서 모든 S3 버킷을 선택하고 역할 생성을 선택합니다. Amazon SageMaker는 필요한 권한이 있는 역할을 생성하고 이를 인스턴스에 할당합니다.
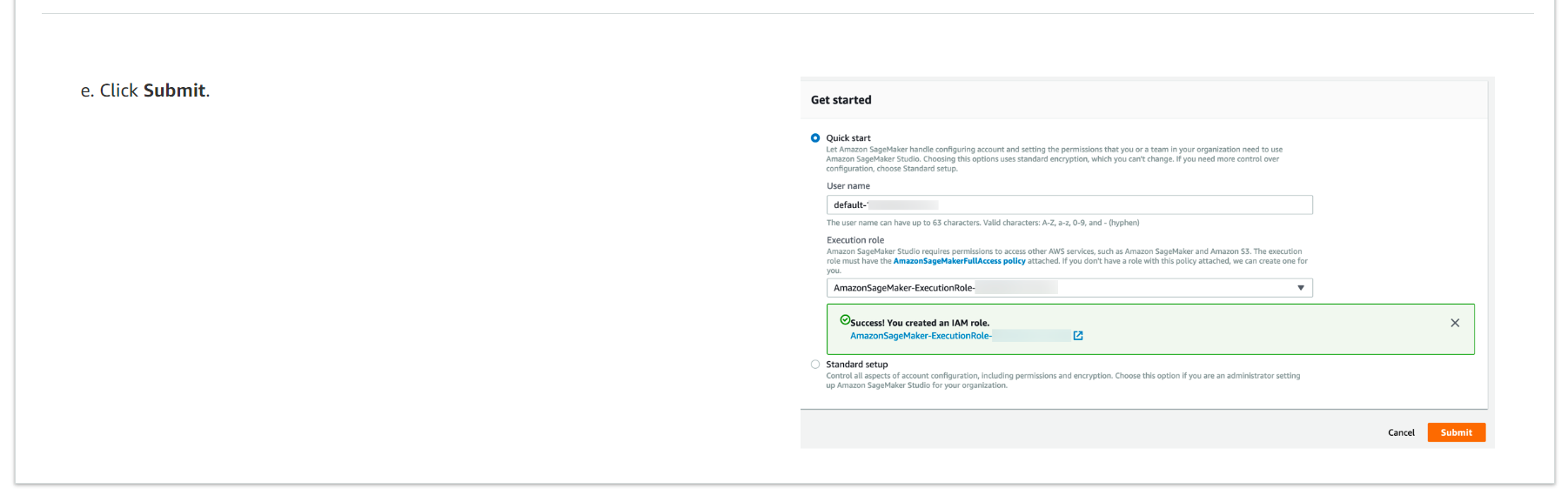
e. Submit을 클릭하세요.
Amazon SageMaker Studio 노트북은 훈련 스크립트를 구축하고 테스트하는 데 필요한 모든 것이 포함된 원클릭 Jupyter 노트북입니다. SageMaker Studio에는 실험 추적 및 시각화도 포함되어 있어 전체 기계 학습 워크플로를 한 곳에서 쉽게 관리할 수 있습니다.
SageMaker 노트북을 생성하고, 데이터 세트를 다운로드하고, 데이터 세트를 TensorFlow 지원 TFRecord 형식으로 변환한 다음 데이터 세트를 Amazon S3에 업로드하려면 다음 단계를 완료하십시오.
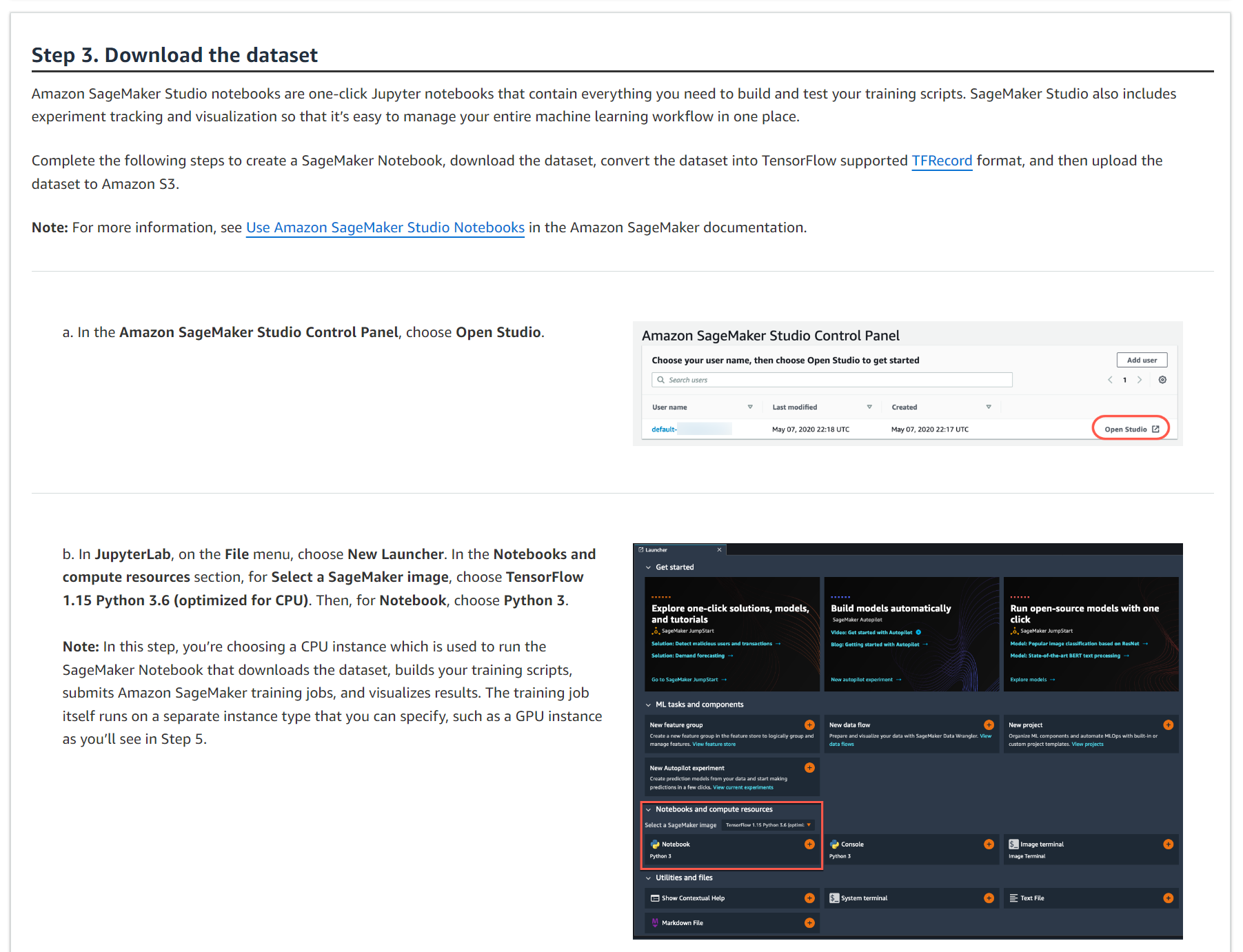
a. Amazon SageMaker Studio 제어판에서 Open Studio를 선택합니다.
b. JupyterLab의 파일 메뉴에서 새 실행 프로그램을 선택합니다. 노트북 및 컴퓨팅 리소스 섹션의 SageMaker 이미지 선택에서 TensorFlow 1.15 Python 3.6(CPU에 최적화됨)을 선택합니다. 그런 다음 노트북에서 Python 3을 선택합니다.
참고: 이 단계에서는 데이터 세트를 다운로드하고, 교육 스크립트를 작성하고, Amazon SageMaker 교육 작업을 제출하고, 결과를 시각화하는 SageMaker 노트북을 실행하는 데 사용되는 CPU 인스턴스를 선택합니다. 훈련 작업 자체는 5단계에서 볼 수 있는 GPU 인스턴스와 같이 지정할 수 있는 별도의 인스턴스 유형에서 실행됩니다.
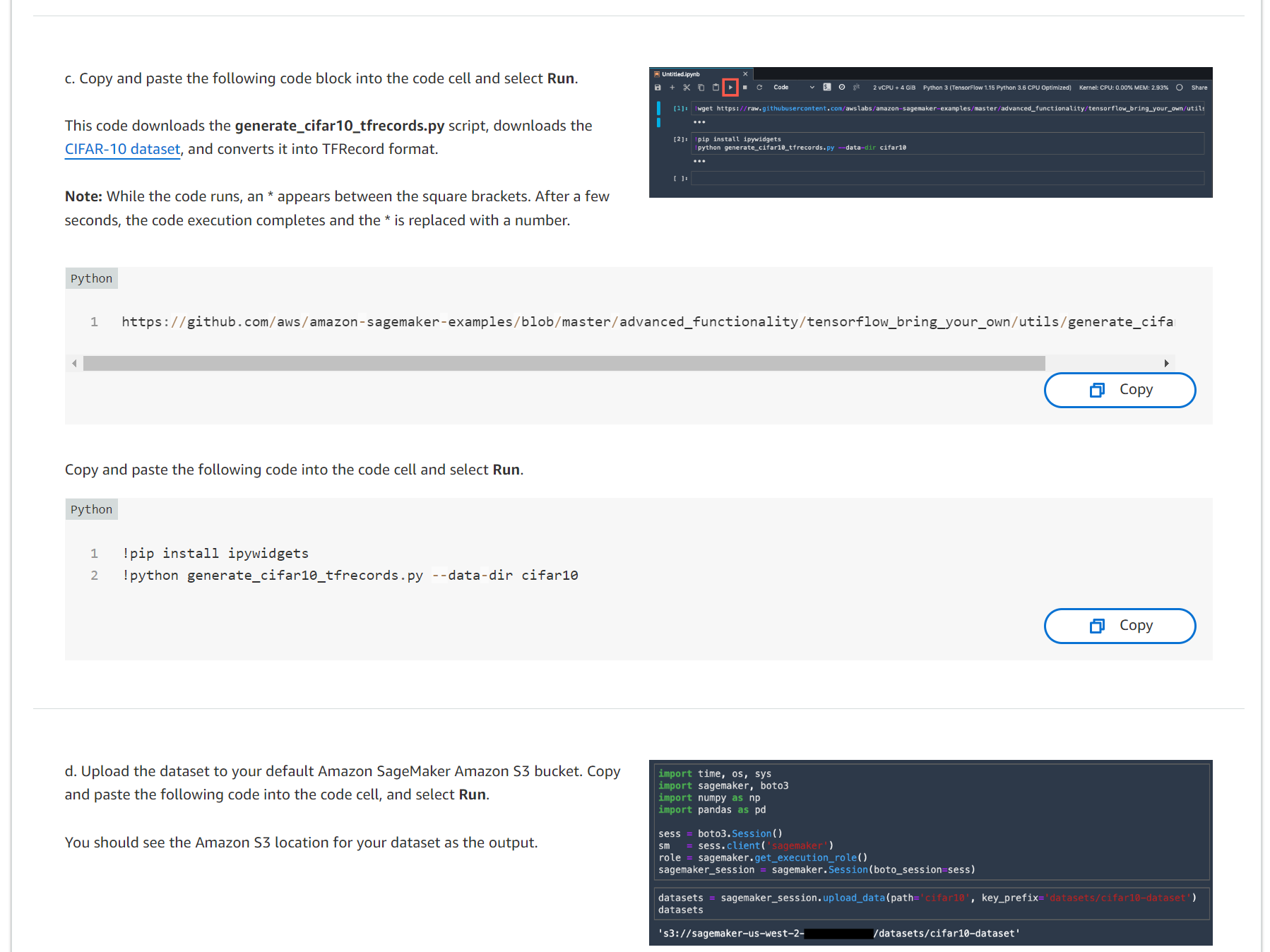
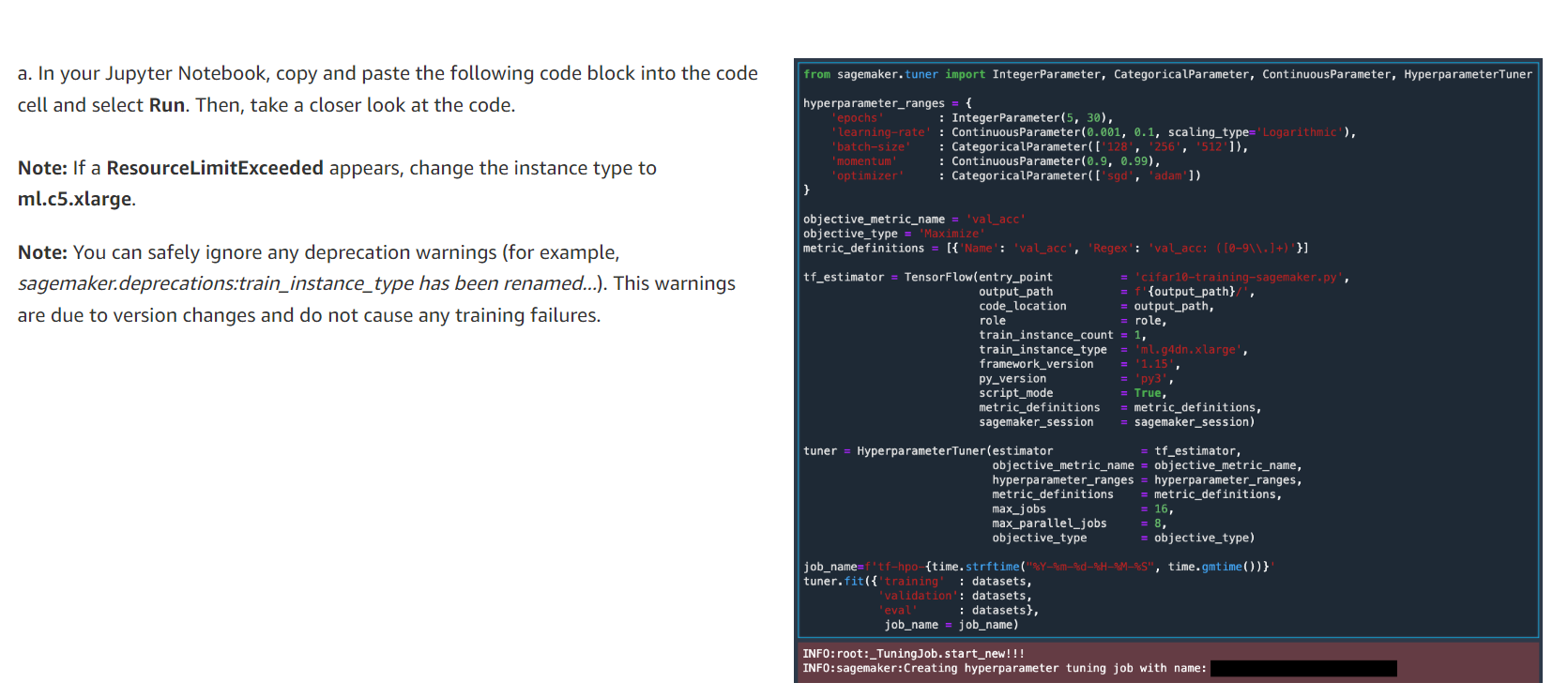
c. 다음 코드 블록을 복사하여 코드 셀에 붙여넣고 실행을 선택합니다.
이 코드는 generate_cifar10_tfrecords.py 스크립트를 다운로드하고 CIFAR-10 dataset 를 다운로드한 후 TFRecord 형식으로 변환합니다.
참고: 코드가 실행되는 동안 대괄호 사이에 *가 나타납니다. 몇 초 후에 코드 실행이 완료되고 *가 숫자로 대체됩니다.
d. 기본 Amazon SageMaker Amazon S3 버킷에 데이터세트를 업로드합니다. 다음 코드를 복사하여 코드 셀에 붙여넣고 실행을 선택합니다.
데이터세트의 Amazon S3 위치가 출력으로 표시되어야 합니다.
import time, os, sys
import sagemaker, boto3
import numpy as np
import pandas as pd
sess = boto3.Session()
sm = sess.client('sagemaker')
role = sagemaker.get_execution_role()
sagemaker_session = sagemaker.Session(boto_session=sess)
datasets = sagemaker_session.upload_data(path='cifar10', key_prefix='datasets/cifar10-dataset')
datasets
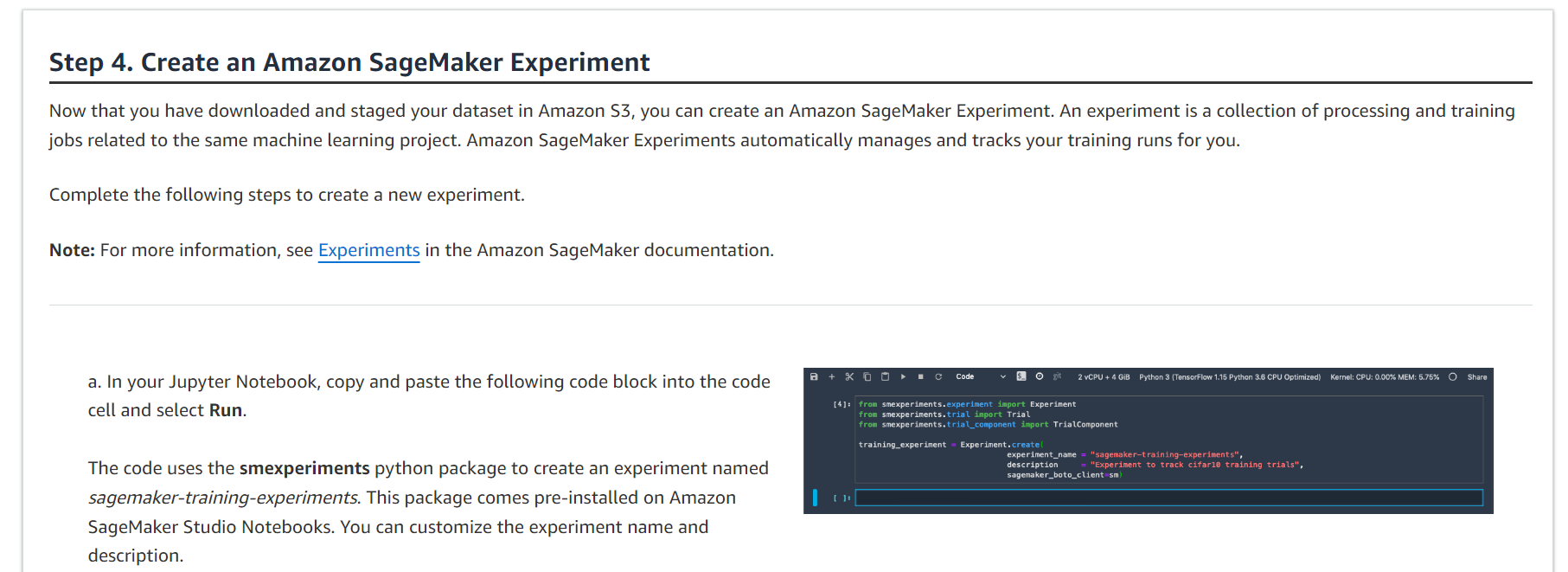
이제 Amazon S3에서 데이터 세트를 다운로드하고 준비했으므로 Amazon SageMaker 실험을 생성할 수 있습니다. 실험은 동일한 기계 학습 프로젝트와 관련된 처리 및 학습 작업의 모음입니다. Amazon SageMaker Experiments는 훈련 실행을 자동으로 관리하고 추적합니다.
새 실험을 만들려면 다음 단계를 완료하세요.
참고: 자세한 내용은 Amazon SageMaker 설명서의 실험을 참조하십시오.
from smexperiments.experiment import Experiment
from smexperiments.trial import Trial
from smexperiments.trial_component import TrialComponent
training_experiment = Experiment.create(
experiment_name = "sagemaker-training-experiments",
description = "Experiment to track cifar10 training trials",
sagemaker_boto_client=sm)
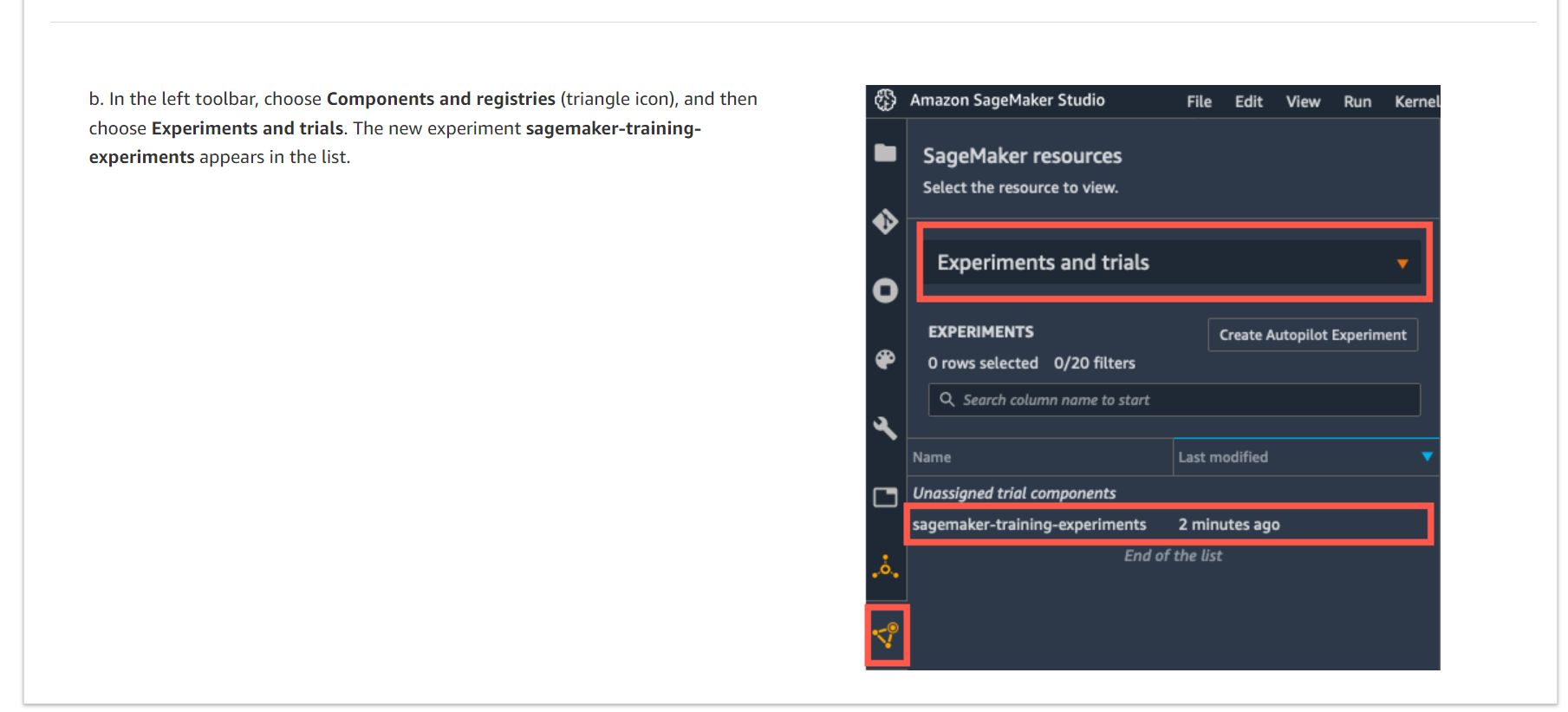
b. 왼쪽 도구 모음에서 구성 요소 및 레지스트리(삼각형 아이콘)를 선택한 다음 실험 및 시험을 선택합니다. 새 실험 Sagemaker-training-experiments가 목록에 나타납니다.
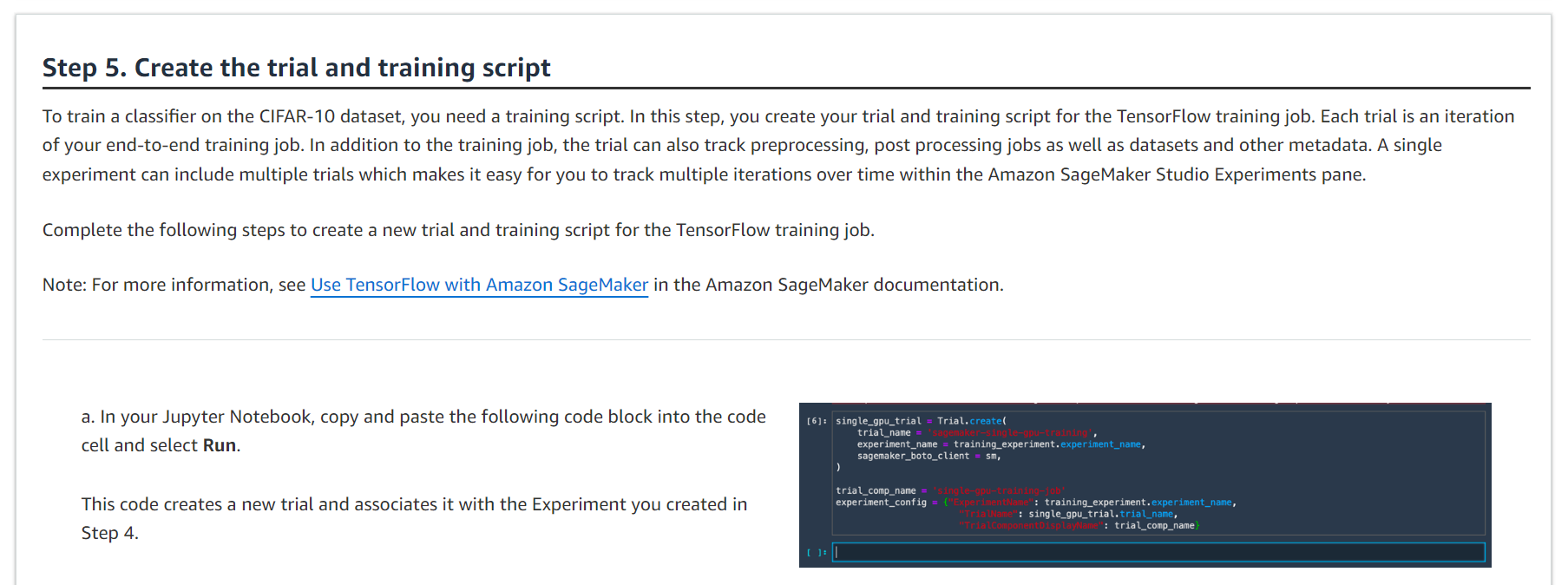
CIFAR-10 데이터 세트에서 분류기를 훈련하려면 훈련 스크립트가 필요합니다. 이 단계에서는 TensorFlow 학습 작업을 위한 평가판 및 학습 스크립트를 만듭니다. 각 시도는 엔드 투 엔드 훈련 작업의 반복입니다. 훈련 작업 외에도 평가판에서는 전처리, 후처리 작업은 물론 데이터 세트 및 기타 메타데이터도 추적할 수 있습니다. 단일 실험에는 여러 시도가 포함될 수 있으므로 Amazon SageMaker Studio 실험 창 내에서 시간 경과에 따른 여러 반복을 쉽게 추적할 수 있습니다.
TensorFlow 학습 작업을 위한 새로운 평가판 및 학습 스크립트를 생성하려면 다음 단계를 완료하세요.
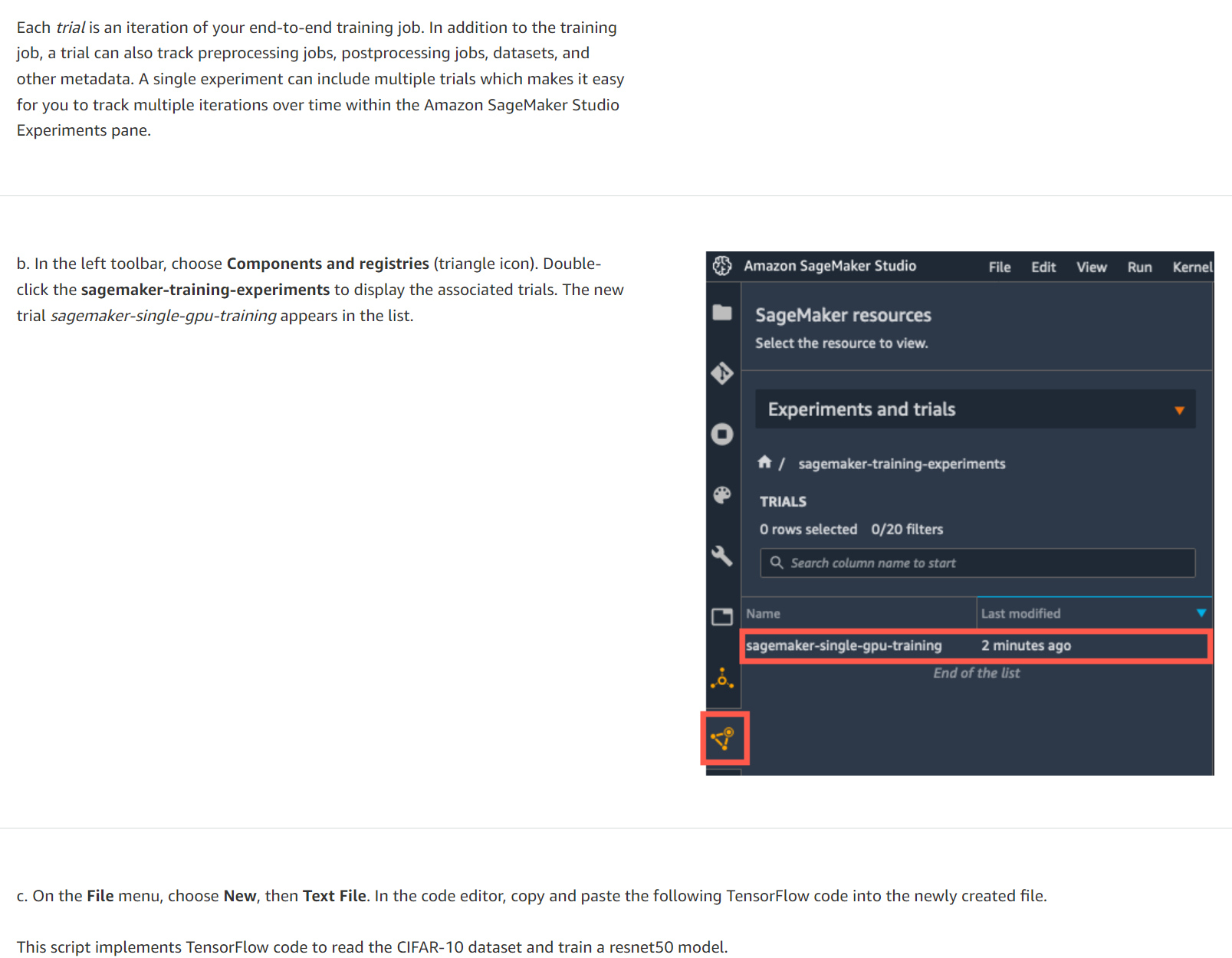
각 시도는 엔드 투 엔드 훈련 작업의 반복입니다. 훈련 작업 외에도 시도에서는 전처리 작업, 후처리 작업, 데이터 세트 및 기타 메타데이터를 추적할 수도 있습니다. 단일 실험에는 여러 시도가 포함될 수 있으므로 Amazon SageMaker Studio 실험 창 내에서 시간 경과에 따른 여러 반복을 쉽게 추적할 수 있습니다.
b. 왼쪽 도구 모음에서 구성 요소 및 레지스트리(삼각형 아이콘)를 선택합니다. Sagemaker-training-experiments를 두 번 클릭하여 관련 시도를 표시합니다. 새로운 평가판 Sagemaker-single-Gpu-training이 목록에 나타납니다.
c. 파일 메뉴에서 새로 만들기를 선택한 다음 텍스트 파일을 선택합니다. 코드 편집기에서 다음 TensorFlow 코드를 복사하여 새로 생성된 파일에 붙여넣습니다.
이 스크립트는 TensorFlow 코드를 구현하여 CIFAR-10 데이터 세트를 읽고 resnet50 모델을 교육합니다.
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.layers import Input, Dense, Flatten
from tensorflow.keras.models import Model, load_model
from tensorflow.keras.optimizers import Adam, SGD
import argparse
import os
import re
import time
HEIGHT = 32
WIDTH = 32
DEPTH = 3
NUM_CLASSES = 10
def single_example_parser(serialized_example):
"""Parses a single tf.Example into image and label tensors."""
# Dimensions of the images in the CIFAR-10 dataset.
# See http://www.cs.toronto.edu/~kriz/cifar.html for a description of the
# input format.
features = tf.io.parse_single_example(
serialized_example,
features={
'image': tf.io.FixedLenFeature([], tf.string),
'label': tf.io.FixedLenFeature([], tf.int64),
})
image = tf.decode_raw(features['image'], tf.uint8)
image.set_shape([DEPTH * HEIGHT * WIDTH])
# Reshape from [depth * height * width] to [depth, height, width].
image = tf.cast(
tf.transpose(tf.reshape(image, [DEPTH, HEIGHT, WIDTH]), [1, 2, 0]),
tf.float32)
label = tf.cast(features['label'], tf.int32)
image = train_preprocess_fn(image)
label = tf.one_hot(label, NUM_CLASSES)
return image, label
def train_preprocess_fn(image):
# Resize the image to add four extra pixels on each side.
image = tf.image.resize_with_crop_or_pad(image, HEIGHT + 8, WIDTH + 8)
# Randomly crop a [HEIGHT, WIDTH] section of the image.
image = tf.image.random_crop(image, [HEIGHT, WIDTH, DEPTH])
# Randomly flip the image horizontally.
image = tf.image.random_flip_left_right(image)
return image
def get_dataset(filenames, batch_size):
"""Read the images and labels from 'filenames'."""
# Repeat infinitely.
dataset = tf.data.TFRecordDataset(filenames).repeat().shuffle(10000)
# Parse records.
dataset = dataset.map(single_example_parser, num_parallel_calls=tf.data.experimental.AUTOTUNE)
# Batch it up.
dataset = dataset.batch(batch_size, drop_remainder=True)
return dataset
def get_model(input_shape, learning_rate, weight_decay, optimizer, momentum):
input_tensor = Input(shape=input_shape)
base_model = keras.applications.resnet50.ResNet50(include_top=False,
weights='imagenet',
input_tensor=input_tensor,
input_shape=input_shape,
classes=None)
x = Flatten()(base_model.output)
predictions = Dense(NUM_CLASSES, activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=predictions)
return model
def main(args):
# Hyper-parameters
epochs = args.epochs
lr = args.learning_rate
batch_size = args.batch_size
momentum = args.momentum
weight_decay = args.weight_decay
optimizer = args.optimizer
# SageMaker options
training_dir = args.training
validation_dir = args.validation
eval_dir = args.eval
train_dataset = get_dataset(training_dir+'/train.tfrecords', batch_size)
val_dataset = get_dataset(validation_dir+'/validation.tfrecords', batch_size)
eval_dataset = get_dataset(eval_dir+'/eval.tfrecords', batch_size)
input_shape = (HEIGHT, WIDTH, DEPTH)
model = get_model(input_shape, lr, weight_decay, optimizer, momentum)
# Optimizer
if optimizer.lower() == 'sgd':
opt = SGD(lr=lr, decay=weight_decay, momentum=momentum)
else:
opt = Adam(lr=lr, decay=weight_decay)
# Compile model
model.compile(optimizer=opt,
loss='categorical_crossentropy',
metrics=['accuracy'])
# Train model
history = model.fit(train_dataset, steps_per_epoch=40000 // batch_size,
validation_data=val_dataset,
validation_steps=10000 // batch_size,
epochs=epochs)
# Evaluate model performance
score = model.evaluate(eval_dataset, steps=10000 // batch_size, verbose=1)
print('Test loss :', score[0])
print('Test accuracy:', score[1])
# Save model to model directory
model.save(f'{os.environ["SM_MODEL_DIR"]}/{time.strftime("%m%d%H%M%S", time.gmtime())}', save_format='tf')
#%%
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# Hyper-parameters
parser.add_argument('--epochs', type=int, default=10)
parser.add_argument('--learning-rate', type=float, default=0.01)
parser.add_argument('--batch-size', type=int, default=128)
parser.add_argument('--weight-decay', type=float, default=2e-4)
parser.add_argument('--momentum', type=float, default='0.9')
parser.add_argument('--optimizer', type=str, default='sgd')
# SageMaker parameters
parser.add_argument('--model_dir', type=str)
parser.add_argument('--training', type=str, default=os.environ['SM_CHANNEL_TRAINING'])
parser.add_argument('--validation', type=str, default=os.environ['SM_CHANNEL_VALIDATION'])
parser.add_argument('--eval', type=str, default=os.environ['SM_CHANNEL_EVAL'])
args = parser.parse_args()
main(args)
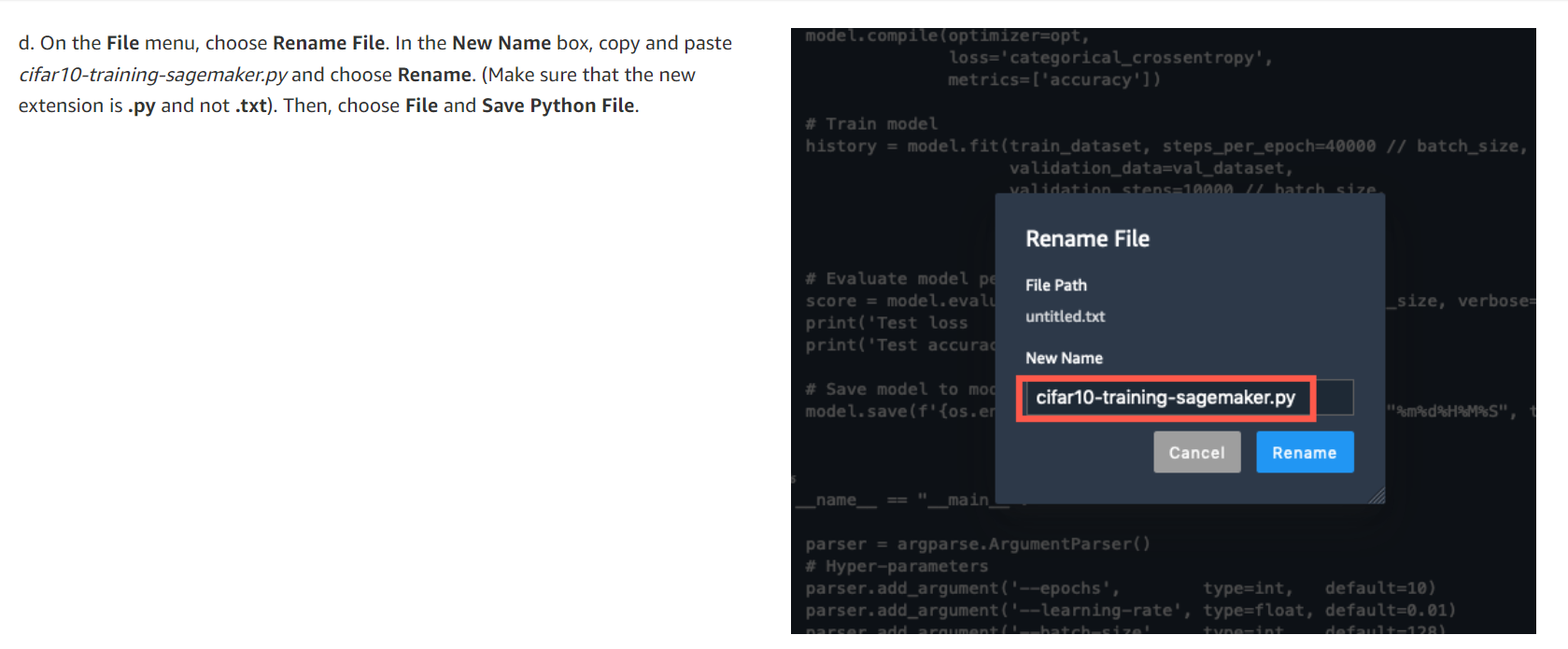
d. 파일 메뉴에서 파일 이름 바꾸기를 선택합니다. 새 이름 상자에서 cifar10-training-sagemaker.py를 복사하여 붙여넣고 이름 바꾸기를 선택합니다. (새 확장자가 .txt가 아니라 .py인지 확인하세요.) 그런 다음 파일을 선택하고 Python 파일 저장을 선택합니다.
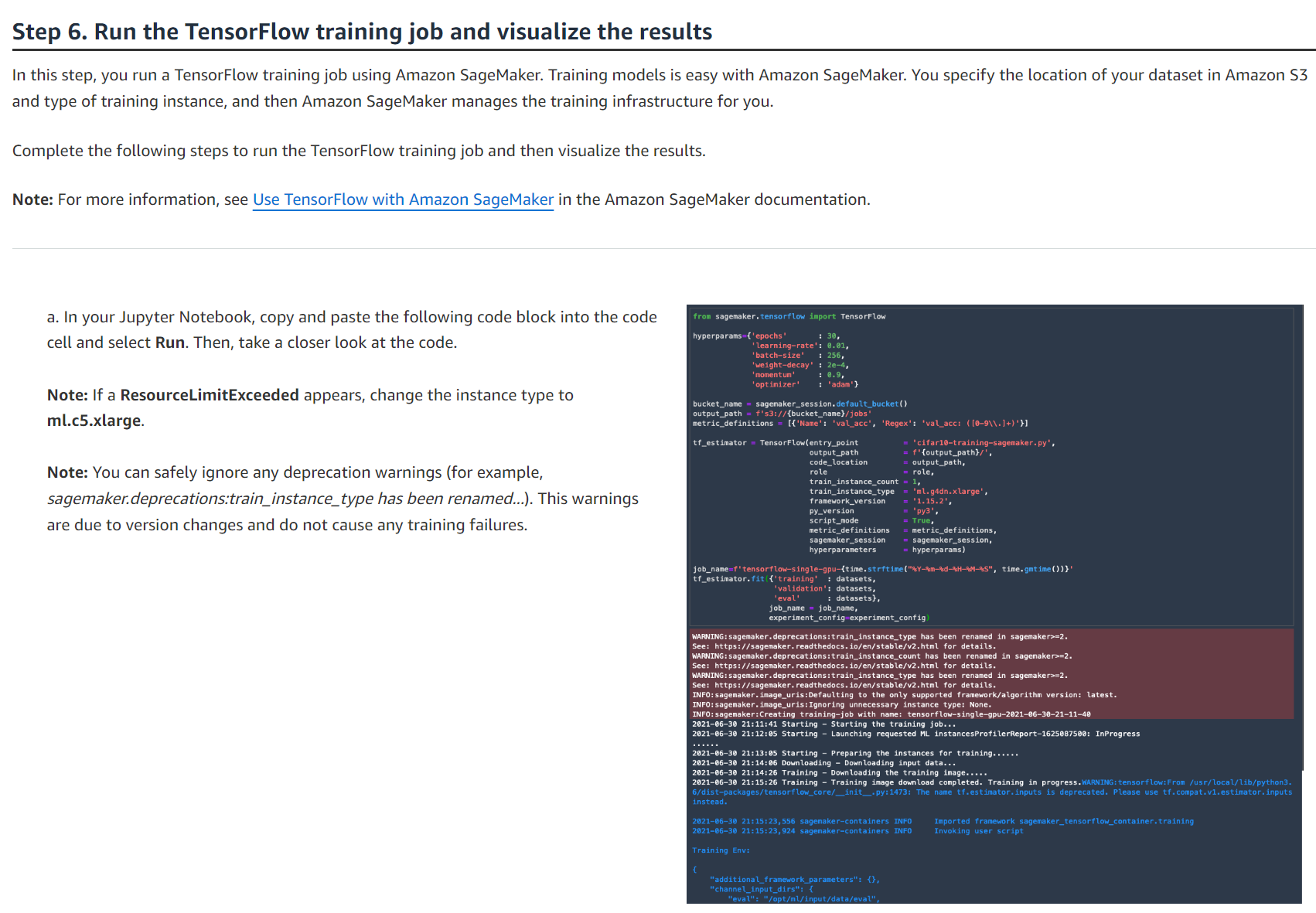
이 단계에서는 Amazon SageMaker를 사용하여 TensorFlow 훈련 작업을 실행합니다. Amazon SageMaker를 사용하면 모델 훈련이 쉽습니다. Amazon S3의 데이터 세트 위치와 훈련 인스턴스 유형을 지정하면 Amazon SageMaker가 훈련 인프라를 관리합니다.
- 학습 작업 하이퍼파라미터를 지정합니다. - Amazon SageMaker Estimator 함수를 호출하고 훈련 작업 세부 정보(훈련 스크립트 이름, 훈련할 인스턴스 유형, 프레임워크 버전 등)를 제공합니다. - 훈련 작업을 시작하기 위해 fit 함수를 호출합니다.
Amazon SageMaker는 요청된 인스턴스를 자동으로 프로비저닝하고, 데이터 세트를 다운로드하고, TensorFlow 컨테이너를 가져오고, 훈련 스크립트를 다운로드하고, 훈련을 시작합니다.
이 예에서는 GPU 인스턴스인 ml.g4dn.xlarge에서 실행할 Amazon SageMaker 훈련 작업을 제출합니다. 딥 러닝 훈련은 계산 집약적이며 결과를 더 빠르게 얻으려면 GPU 인스턴스가 권장됩니다.
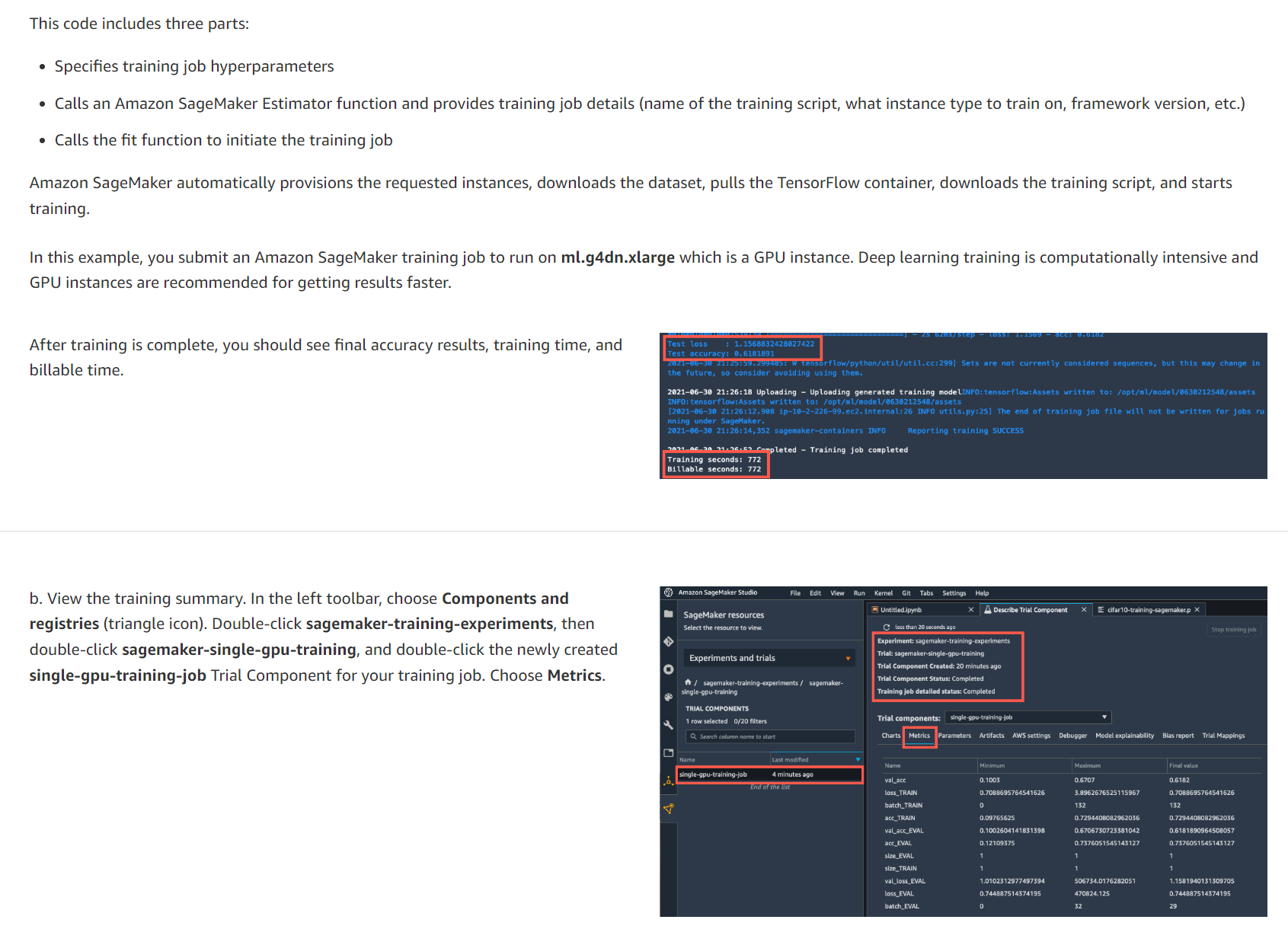
학습이 완료되면 최종 정확도 결과, 학습 시간 및 청구 가능 시간이 표시됩니다.
b. 교육 요약을 봅니다. 왼쪽 도구 모음에서 구성 요소 및 레지스트리(삼각형 아이콘)를 선택합니다. sagemaker-training-experiments를 두 번 클릭한 다음 sagemaker-single-gpu-training을 두 번 클릭하고 훈련 작업에 대해 새로 생성된 Single-Gpu-training-job 평가판 구성 요소를 두 번 클릭합니다. 측정항목을 선택합니다.
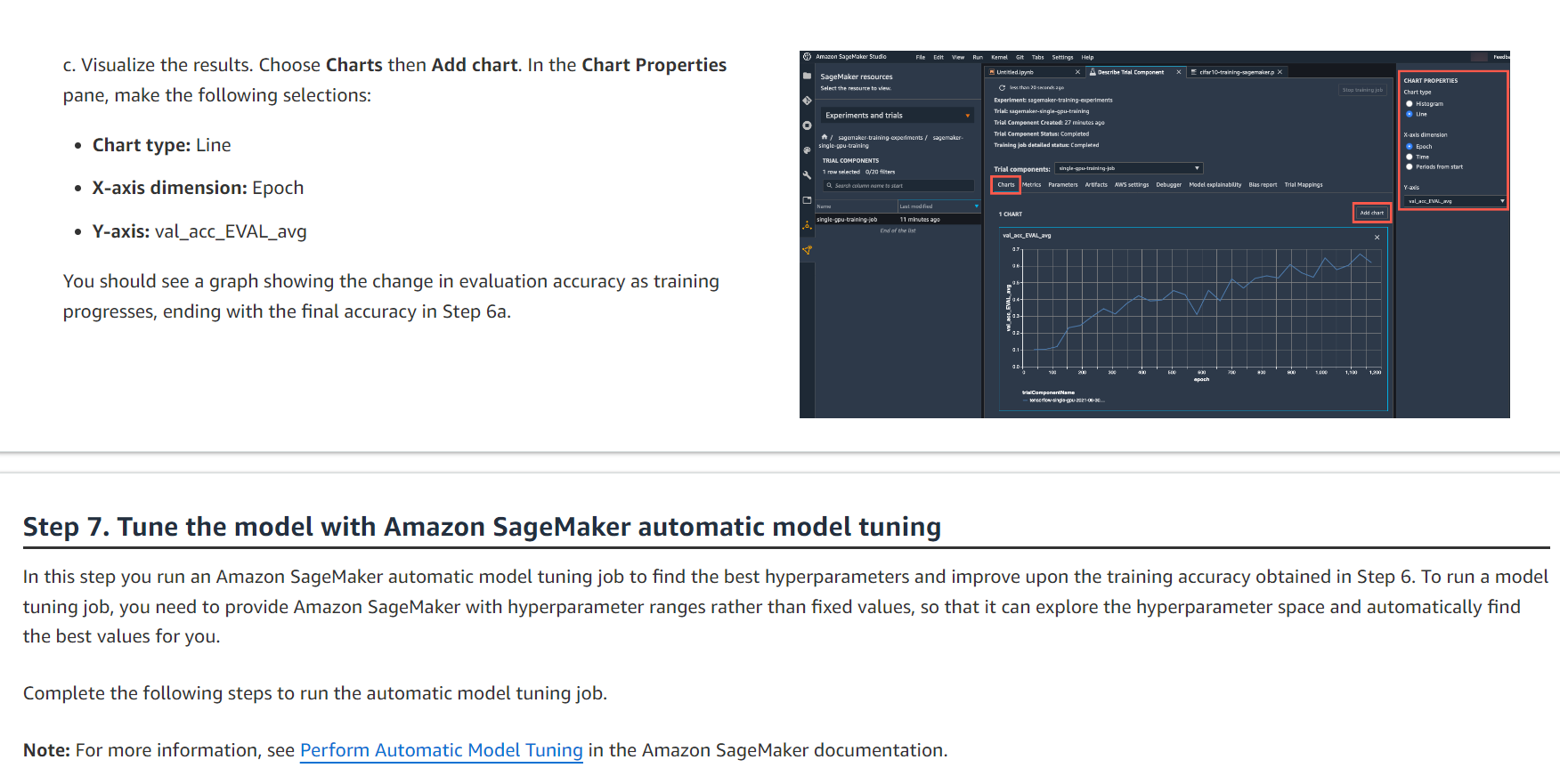
c. 결과를 시각화합니다. 차트를 선택한 다음 차트 추가를 선택합니다. 차트 속성 창에서 다음을 선택합니다.
차트 유형: 선 X축 차원: Epoch Y축: val_acc_EVAL_avg 학습이 진행됨에 따라 평가 정확도의 변화를 보여주는 그래프가 표시되고 6a단계의 최종 정확도로 끝납니다.
Step 7. Tune the model with Amazon SageMaker automatic model tuning
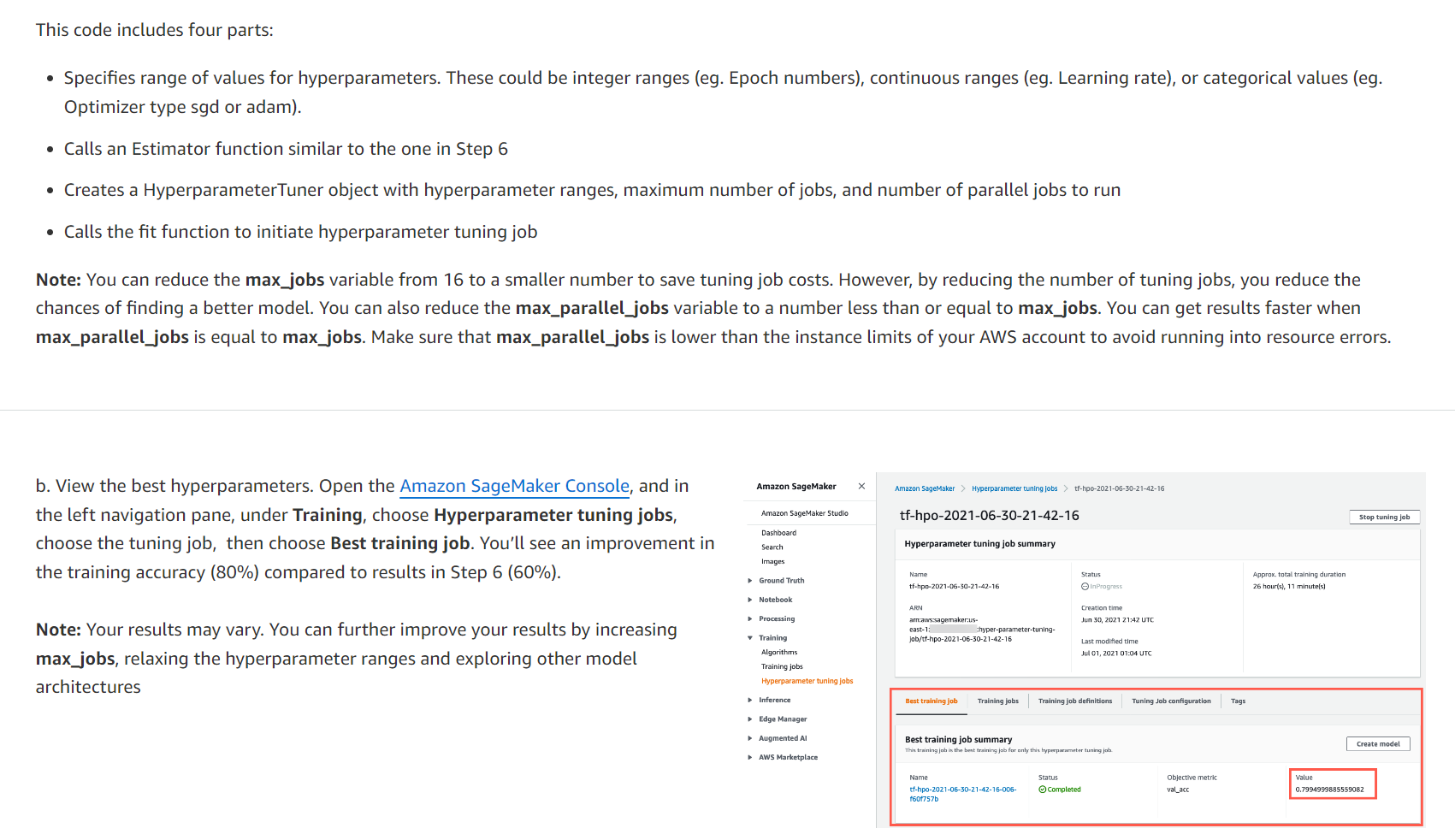
이 단계에서는 Amazon SageMaker 자동 모델 튜닝 작업을 실행하여 최상의 하이퍼파라미터를 찾고 6단계에서 얻은 훈련 정확도를 향상시킵니다. 모델 튜닝 작업을 실행하려면 Amazon SageMaker에 고정 값이 아닌 하이퍼파라미터 범위를 제공해야 합니다. 하이퍼파라미터 공간을 탐색하고 자동으로 최적의 값을 찾을 수 있다는 것입니다. 자동 모델 튜닝 작업을 실행하려면 다음 단계를 완료하세요.
- 하이퍼파라미터의 값 범위를 지정합니다. 이는 정수 범위(예: Epoch 번호), 연속 범위(예: 학습률) 또는 범주형 값(예: 최적화 유형 sgd 또는 adam)일 수 있습니다. - 6단계의 것과 유사한 Estimator 함수를 호출합니다. - 하이퍼파라미터 범위, 최대 작업 수, 실행할 병렬 작업 수를 포함하는 HyperparameterTuner 객체를 생성합니다. - 초매개변수 조정 작업을 시작하기 위해 맞춤 함수를 호출합니다.
참고: max_jobs 변수를 16에서 더 작은 숫자로 줄여 튜닝 작업 비용을 절약할 수 있습니다. 그러나 튜닝 작업 수를 줄이면 더 나은 모델을 찾을 가능성이 줄어듭니다. max_parallel_jobs 변수를 max_jobs보다 작거나 같은 숫자로 줄일 수도 있습니다. max_parallel_jobs가 max_jobs와 같으면 결과를 더 빨리 얻을 수 있습니다. 리소스 오류가 발생하지 않도록 max_parallel_jobs가 AWS 계정의 인스턴스 제한보다 낮은지 확인하십시오.
b. 최고의 하이퍼파라미터를 확인하세요. Amazon SageMaker 콘솔을 열고 왼쪽 탐색 창의 훈련 아래에서 하이퍼파라미터 튜닝 작업을 선택하고 튜닝 작업을 선택한 다음 최상의 훈련 작업을 선택합니다. 6단계의 결과(60%)에 비해 훈련 정확도(80%)가 향상되는 것을 확인할 수 있습니다.
참고: 결과는 다를 수 있습니다. max_jobs를 늘리고, 하이퍼파라미터 범위를 완화하고, 다른 모델 아키텍처를 탐색하여 결과를 더욱 향상시킬 수 있습니다.
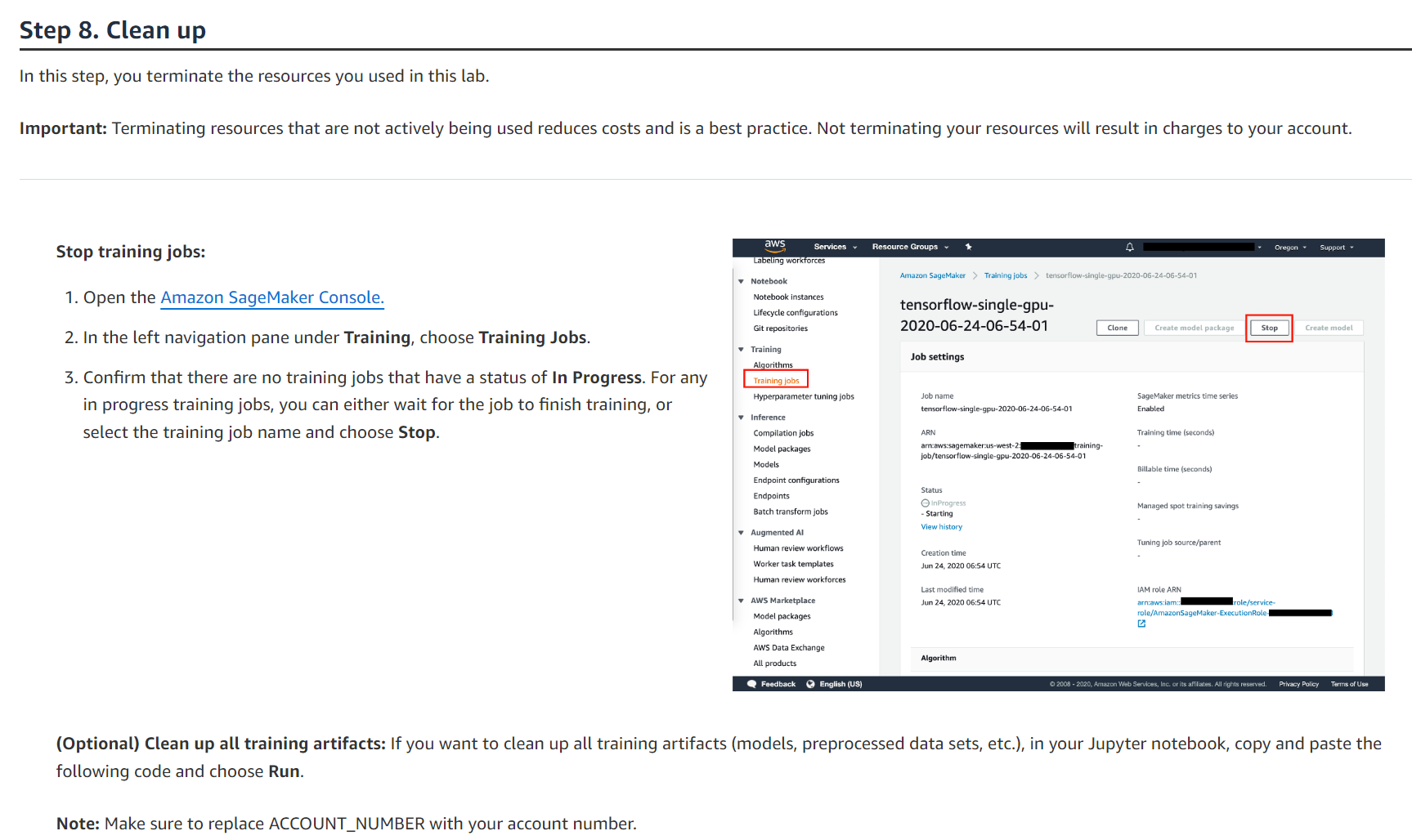
이 단계에서는 이 실습에서 사용한 리소스를 종료합니다.
중요: 적극적으로 사용되지 않는 리소스를 종료하면 비용이 절감되므로 모범 사례입니다. 리소스를 종료하지 않으면 계정에 요금이 청구됩니다.
학습 작업을 중지합니다.
1. Amazon SageMaker 콘솔을 엽니다. 2. 교육 아래 왼쪽 탐색 창에서 교육 작업을 선택합니다. 3. 진행 중 상태의 교육 작업이 없는지 확인합니다. 진행 중인 훈련 작업의 경우 작업이 훈련을 마칠 때까지 기다리거나 훈련 작업 이름을 선택하고 중지를 선택할 수 있습니다.
(선택 사항) 모든 훈련 아티팩트 정리: 모든 훈련 아티팩트(모델, 사전 처리된 데이터 세트 등)를 정리하려면 Jupyter Notebook에서 다음 코드를 복사하여 붙여넣고 실행을 선택합니다.
Now that we have characterized the problem of overfitting, we can introduce our firstregularizationtechnique. Recall that we can always mitigate overfitting by collecting more training data. However, that can be costly, time consuming, or entirely out of our control, making it impossible in the short run. For now, we can assume that we already have as much high-quality data as our resources permit and focus the tools at our disposal when the dataset is taken as a given.
이제 과적합 문제를 특성화했으므로 첫 번째 정규화 기술을 소개할 수 있습니다. 더 많은 훈련 데이터를 수집하면 항상 과적합을 완화할 수 있다는 점을 기억하세요. 그러나 이는 비용이 많이 들고, 시간이 많이 걸리거나 완전히 통제할 수 없어 단기적으로 불가능할 수 있습니다. 지금은 리소스가 허용하는 만큼의 고품질 데이터를 이미 보유하고 있다고 가정하고 데이터 세트를 주어진 것으로 간주할 때 사용할 수 있는 도구에 집중할 수 있습니다.
Recall that in our polynomial regression example (Section 3.6.2.1) we could limit our model’s capacity by tweaking the degree of the fitted polynomial. Indeed, limiting the number of features is a popular technique for mitigating overfitting. However, simply tossing aside features can be too blunt an instrument. Sticking with the polynomial regression example, consider what might happen with high-dimensional input. The natural extensions of polynomials to multivariate data are calledmonomials, which are simply products of powers of variables. The degree of a monomial is the sum of the powers. For example,x1**2x2, andx3x5**2 (
)are both monomials of degree 3.
다항식 회귀 예제(섹션 3.6.2.1)에서 피팅된 다항식의 차수를 조정하여 모델의 용량을 제한할 수 있다는 점을 기억하세요. 실제로 특성 수를 제한하는 것은 과적합을 완화하는 데 널리 사용되는 기술입니다. 그러나 단순히 기능을 제쳐두는 것은 너무 무뚝뚝한 도구가 될 수 있습니다. 다항식 회귀 예제를 계속 사용하면서 고차원 입력에서 어떤 일이 발생할 수 있는지 생각해 보세요. 다변량 데이터에 대한 다항식의 자연스러운 확장을 단항식이라고 하며 이는 단순히 변수 거듭제곱의 곱입니다. 단항식의 차수는 거듭제곱의 합입니다. 예를 들어 x1**2x2와 x3x5**2 ()는 모두 3차 단항식입니다.
Note that the number of terms with degreedblows up rapidly asdgrows larger. Givenkvariables, the number of monomials of degreedis(k−1+d k−1) (
). Even small changes in degree, say from2to3, dramatically increase the complexity of our model. Thus we often need a more fine-grained tool for adjusting function complexity.
d가 커짐에 따라 차수 d를 갖는 항의 수가 급격히 증가한다는 점에 유의하십시오. k개의 변수가 주어지면 d차 단항식의 수는 (k−1+d k−1)입니다. 2에서 3까지의 작은 변화조차도 모델의 복잡성을 극적으로 증가시킵니다. 따라서 함수 복잡성을 조정하기 위해 보다 세분화된 도구가 필요한 경우가 많습니다.
%matplotlib inline
import torch
from torch import nn
from d2l import torch as d2l
3.7.1.Norms and Weight Decay
Rather than directly manipulating the number of parameters,weight decay, operates by restricting the values that the parameters can take. More commonly calledℓ2regularization outside of deep learning circles when optimized by minibatch stochastic gradient descent, weight decay might be the most widely used technique for regularizing parametric machine learning models. The technique is motivated by the basic intuition that among all functionsf, the functionf=0(assigning the value0to all inputs) is in some sense thesimplest, and that we can measure the complexity of a function by the distance of its parameters from zero. But how precisely should we measure the distance between a function and zero? There is no single right answer. In fact, entire branches of mathematics, including parts of functional analysis and the theory of Banach spaces, are devoted to addressing such issues.
매개변수 수를 직접 조작하는 대신 가중치 감소는 매개변수가 취할 수 있는 값을 제한하여 작동합니다. 미니배치 확률적 경사 하강법으로 최적화할 때 딥 러닝 분야 외부에서 더 일반적으로 ℓ2 정규화라고 불리는 가중치 감소는 파라메트릭 기계 학습 모델을 정규화하는 데 가장 널리 사용되는 기술일 수 있습니다. 이 기술은 모든 함수 f 중에서 함수 f=0(모든 입력에 값 0을 할당하는)이 어떤 의미에서는 가장 단순하며 함수의 복잡성을 함수의 거리로 측정할 수 있다는 기본적인 직관에 의해 동기가 부여되었습니다. 매개변수는 0부터 시작됩니다. 하지만 함수와 0 사이의 거리를 얼마나 정확하게 측정해야 할까요? 정답은 하나도 없습니다. 실제로 기능 분석의 일부와 바나흐 공간 이론을 포함한 수학의 전체 분야가 이러한 문제를 해결하는 데 전념하고 있습니다.
One simple interpretation might be to measure the complexity of a linear functionf(x)=w⊤xby some norm of its weight vector, e.g.,‖w‖**2. Recall that we introduced theℓ2norm andℓ1norm, which are special cases of the more generalℓpnorm, inSection 2.3.11. The most common method for ensuring a small weight vector is to add its norm as a penalty term to the problem of minimizing the loss. Thus we replace our original objective,minimizing the prediction loss on the training labels, with new objective,minimizing the sum of the prediction loss and the penalty term. Now, if our weight vector grows too large, our learning algorithm might focus on minimizing the weight norm‖w‖**2rather than minimizing the training error. That is exactly what we want. To illustrate things in code, we revive our previous example fromSection 3.1for linear regression. There, our loss was given by
한 가지 간단한 해석은 선형 함수 f(x)=w⊤x의 복잡성을 해당 가중치 벡터의 일부 표준(예: "w"**2)으로 측정하는 것입니다. 섹션 2.3.11에서 보다 일반적인 ℓp 노름의 특수한 경우인 ℓ2 노름과 ℓ1 노름을 소개했음을 기억하세요. 작은 가중치 벡터를 보장하는 가장 일반적인 방법은 손실을 최소화하는 문제에 페널티 항으로 해당 노름을 추가하는 것입니다. 따라서 우리는 훈련 라벨의 예측 손실을 최소화하는 원래 목표를 예측 손실과 페널티 항의 합을 최소화하는 새로운 목표로 대체합니다. 이제 가중치 벡터가 너무 커지면 학습 알고리즘은 훈련 오류를 최소화하는 대신 가중치 표준 "w"**2를 최소화하는 데 중점을 둘 수 있습니다. 그것이 바로 우리가 원하는 것입니다. 코드로 내용을 설명하기 위해 선형 회귀에 대한 섹션 3.1의 이전 예제를 되살립니다. 거기에서 우리의 손실은 다음과 같습니다.
Recall thatx**(i)are the features,y**(i)is the label for any data examplei, and(w,b)are the weight and bias parameters, respectively. To penalize the size of the weight vector, we must somehow add‖w‖**2to the loss function, but how should the model trade off the standard loss for this new additive penalty? In practice, we characterize this trade-off via theregularization constantλ, a nonnegative hyperparameter that we fit using validation data:
x**(i)는 특징이고, y**(i)는 데이터 예제 i에 대한 레이블이며, (w,b)는 각각 가중치 및 편향 매개변수라는 점을 기억하세요. 가중치 벡터의 크기에 페널티를 적용하려면 어떻게든 손실 함수에 "w"**2를 추가해야 합니다. 하지만 모델은 이 새로운 추가 페널티에 대한 표준 손실을 어떻게 교환해야 할까요? 실제로 우리는 검증 데이터를 사용하여 피팅한 음이 아닌 하이퍼파라미터인 정규화 상수 λ를 통해 이러한 절충안을 특성화합니다.
For λ =0, we recover our original loss function. For λ >0, we restrict the size of‖W‖. We divide by2by convention: when we take the derivative of a quadratic function, the2and1/2cancel out, ensuring that the expression for the update looks nice and simple. The astute reader might wonder why we work with the squared norm and not the standard norm (i.e., the Euclidean distance). We do this for computational convenience. By squaring theℓ2norm, we remove the square root, leaving the sum of squares of each component of the weight vector. This makes the derivative of the penalty easy to compute: the sum of derivatives equals the derivative of the sum.
λ =0인 경우 원래의 손실 함수를 복구합니다. λ >0인 경우 "W" 크기를 제한합니다. 관례에 따라 2로 나눕니다. 이차 함수의 미분을 취하면 2와 1/2이 상쇄되어 업데이트에 대한 식이 멋지고 단순해 보입니다. 기민한 독자라면 왜 우리가 표준 표준(예: 유클리드 거리)이 아닌 제곱 표준을 사용하여 작업하는지 궁금할 것입니다. 우리는 계산상의 편의를 위해 이렇게 합니다. ℓ2 노름을 제곱함으로써 제곱근을 제거하고 가중치 벡터의 각 구성요소의 제곱합을 남깁니다. 이는 페널티의 미분을 계산하기 쉽게 만듭니다. 미분의 합은 합계의 미분과 같습니다.
Moreover, you might ask why we work with theℓ2norm in the first place and not, say, theℓ1norm. In fact, other choices are valid and popular throughout statistics. Whileℓ2-regularized linear models constitute the classicridge regressionalgorithm,ℓ1-regularized linear regression is a similarly fundamental method in statistics, popularly known aslasso regression. One reason to work with theℓ2norm is that it places an outsize penalty on large components of the weight vector. This biases our learning algorithm towards models that distribute weight evenly across a larger number of features. In practice, this might make them more robust to measurement error in a single variable. By contrast,ℓ1penalties lead to models that concentrate weights on a small set of features by clearing the other weights to zero. This gives us an effective method forfeature selection, which may be desirable for other reasons. For example, if our model only relies on a few features, then we may not need to collect, store, or transmit data for the other (dropped) features.
게다가 왜 우리가 ℓ1 표준이 아닌 ℓ2 표준으로 작업하는지 궁금할 수도 있습니다. 실제로 통계 전반에 걸쳐 다른 선택이 유효하고 널리 사용됩니다. ℓ2 정규화 선형 모델이 고전적인 능선 회귀 알고리즘을 구성하는 반면, ℓ1 정규화 선형 회귀는 lasso 회귀로 널리 알려진 통계의 유사한 기본 방법입니다. ℓ2 표준을 사용하는 한 가지 이유는 가중치 벡터의 큰 구성요소에 특대 페널티를 적용한다는 것입니다. 이는 우리의 학습 알고리즘을 더 많은 수의 특성에 균등하게 가중치를 분배하는 모델로 편향시킵니다. 실제로 이는 단일 변수의 측정 오류에 더욱 강력해질 수 있습니다. 대조적으로, ℓ1 페널티는 다른 가중치를 0으로 지워서 작은 특성 집합에 가중치를 집중시키는 모델로 이어집니다. 이는 다른 이유로 바람직할 수 있는 특징 선택을 위한 효과적인 방법을 제공합니다. 예를 들어 모델이 몇 가지 기능에만 의존하는 경우 다른(삭제된) 기능에 대한 데이터를 수집, 저장 또는 전송할 필요가 없을 수 있습니다.
Using the same notation in(3.1.11), minibatch stochastic gradient descent updates forℓ2-regularized regression as follows:
(3.1.11)의 동일한 표기법을 사용하여 ℓ2 정규 회귀에 대한 미니배치 확률적 경사하강법 업데이트는 다음과 같습니다.
As before, we updatewbased on the amount by which our estimate differs from the observation. However, we also shrink the size of wtowards zero. That is why the method is sometimes called “weight decay”: given the penalty term alone, our optimization algorithmdecaysthe weight at each step of training. In contrast to feature selection, weight decay offers us a mechanism for continuously adjusting the complexity of a function. Smaller values of λ correspond to less constrainedw, whereas larger values of λ constrainwmore considerably. Whether we include a corresponding bias penaltyb**2can vary across implementations, and may vary across layers of a neural network. Often, we do not regularize the bias term. Besides, althoughℓ2regularization may not be equivalent to weight decay for other optimization algorithms, the idea of regularization through shrinking the size of weights still holds true.
이전과 마찬가지로 추정값이 관측값과 다른 정도에 따라 w를 업데이트합니다. 그러나 w의 크기도 0으로 축소합니다. 이것이 바로 이 방법을 "가중치 감소"라고 부르는 이유입니다. 페널티 항만 주어지면 우리의 최적화 알고리즘은 훈련의 각 단계에서 가중치를 감소시킵니다. 기능 선택과 달리 가중치 감소는 기능의 복잡성을 지속적으로 조정하는 메커니즘을 제공합니다. λ의 값이 작을수록 w가 덜 제한되는 반면, λ의 값이 클수록 w가 더 크게 제한됩니다. 해당 바이어스 페널티 b**2를 포함하는지 여부는 구현에 따라 다를 수 있으며 신경망의 계층에 따라 다를 수 있습니다. 종종 우리는 편향 항을 정규화하지 않습니다. 게다가 ℓ2 정규화는 다른 최적화 알고리즘의 가중치 감소와 동일하지 않을 수 있지만 가중치 크기 축소를 통한 정규화 아이디어는 여전히 유효합니다.
3.7.2.High-Dimensional Linear Regression
We can illustrate the benefits of weight decay through a simple synthetic example.
간단한 합성 예를 통해 체중 감소의 이점을 설명할 수 있습니다.
First, we generate some data as before:
먼저 이전과 같이 일부 데이터를 생성합니다.
In this synthetic dataset, our label is given by an underlying linear function of our inputs, corrupted by Gaussian noise with zero mean and standard deviation 0.01. For illustrative purposes, we can make the effects of overfitting pronounced, by increasing the dimensionality of our problem to d=200and working with a small training set with only 20 examples.
이 합성 데이터 세트에서 레이블은 평균이 0이고 표준 편차가 0.01인 가우스 노이즈로 인해 손상된 입력의 기본 선형 함수로 제공됩니다. 설명을 위해 문제의 차원을 d=200으로 늘리고 20개의 예제만 있는 작은 훈련 세트로 작업하여 과적합의 효과를 뚜렷하게 만들 수 있습니다.
class Data(d2l.DataModule):
def __init__(self, num_train, num_val, num_inputs, batch_size):
self.save_hyperparameters()
n = num_train + num_val
self.X = torch.randn(n, num_inputs)
noise = torch.randn(n, 1) * 0.01
w, b = torch.ones((num_inputs, 1)) * 0.01, 0.05
self.y = torch.matmul(self.X, w) + b + noise
def get_dataloader(self, train):
i = slice(0, self.num_train) if train else slice(self.num_train, None)
return self.get_tensorloader([self.X, self.y], train, i)
3.7.3.Implementation from Scratc
Now, let’s try implementing weight decay from scratch. Since minibatch stochastic gradient descent is our optimizer, we just need to add the squaredℓ2penalty to the original loss function.
이제 처음부터 가중치 감소를 구현해 보겠습니다. 미니배치 확률적 경사하강법이 우리의 최적화 프로그램이므로 원래 손실 함수에 제곱된 ℓ2 페널티를 추가하기만 하면 됩니다.
3.7.3.1.Definingℓ2Norm Penalty
Perhaps the most convenient way of implementing this penalty is to square all terms in place and sum them.
아마도 이 페널티를 구현하는 가장 편리한 방법은 모든 항을 제곱하고 합하는 것입니다.
def l2_penalty(w):
return (w ** 2).sum() / 2
3.7.3.2.Defining the Model
In the final model, the linear regression and the squared loss have not changed sinceSection 3.4, so we will just define a subclass ofd2l.LinearRegressionScratch. The only change here is that our loss now includes the penalty term.
최종 모델에서는 선형 회귀와 제곱 손실이 섹션 3.4 이후로 변경되지 않았으므로 d2l.LinearRegressionScratch의 하위 클래스만 정의하겠습니다. 여기서 유일한 변경 사항은 이제 손실에 페널티 기간이 포함된다는 것입니다.
The following code fits our model on the training set with 20 examples and evaluates it on the validation set with 100 examples.
다음 코드는 20개의 예제가 있는 훈련 세트에 모델을 맞추고 100개의 예제가 있는 검증 세트에서 모델을 평가합니다.
data = Data(num_train=20, num_val=100, num_inputs=200, batch_size=5)
trainer = d2l.Trainer(max_epochs=10)
def train_scratch(lambd):
model = WeightDecayScratch(num_inputs=200, lambd=lambd, lr=0.01)
model.board.yscale='log'
trainer.fit(model, data)
print('L2 norm of w:', float(l2_penalty(model.w)))
3.7.3.3.Training without Regularization
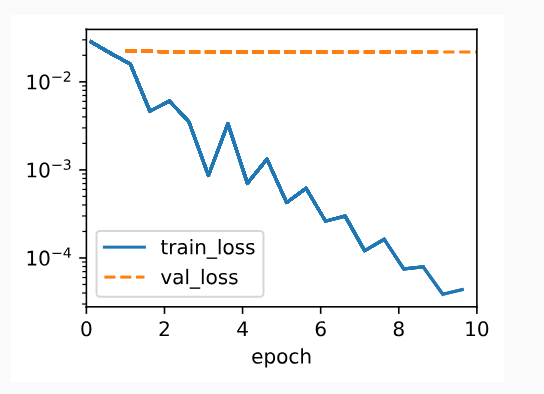
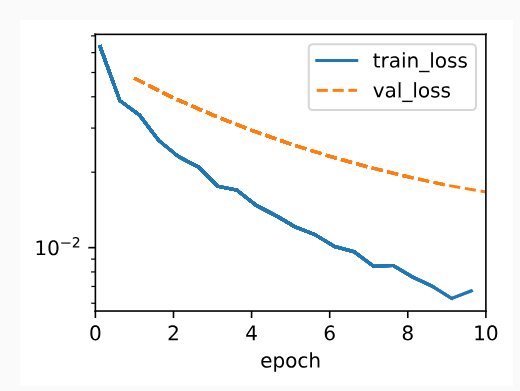
We now run this code withlambd=0, disabling weight decay. Note that we overfit badly, decreasing the training error but not the validation error—a textbook case of overfitting.
이제 이 코드를 Lambd = 0으로 실행하여 가중치 감소를 비활성화합니다. 우리는 과적합을 심하게 하여 학습 오류를 줄였지만 검증 오류는 줄이지 않았습니다. 이는 과적합의 교과서적인 사례입니다.
train_scratch(0)
L2 norm of w: 0.009948714636266232
3.7.3.4.Using Weight Decay
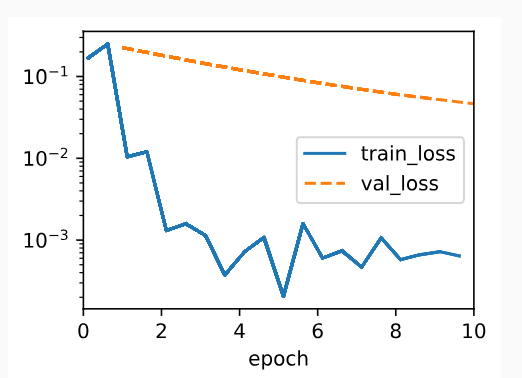
Below, we run with substantial weight decay. Note that the training error increases but the validation error decreases. This is precisely the effect we expect from regularization.
아래에서는 상당한 체중 감소를 보여줍니다. 학습 오류는 증가하지만 검증 오류는 감소합니다. 이것이 바로 우리가 정규화에서 기대하는 효과입니다.
train_scratch(3)
L2 norm of w: 0.0017270983662456274
3.7.4.Concise Implementation
Because weight decay is ubiquitous in neural network optimization, the deep learning framework makes it especially convenient, integrating weight decay into the optimization algorithm itself for easy use in combination with any loss function. Moreover, this integration serves a computational benefit, allowing implementation tricks to add weight decay to the algorithm, without any additional computational overhead. Since the weight decay portion of the update depends only on the current value of each parameter, the optimizer must touch each parameter once anyway.
가중치 감소는 신경망 최적화에서 어디에나 존재하기 때문에 딥 러닝 프레임워크는 모든 손실 함수와 결합하여 쉽게 사용할 수 있도록 최적화 알고리즘 자체에 가중치 감소를 통합하여 이를 특히 편리하게 만듭니다. 또한 이러한 통합은 추가 계산 오버헤드 없이 알고리즘에 가중치 감소를 추가하는 구현 트릭을 허용하므로 계산상의 이점을 제공합니다. 업데이트의 가중치 감소 부분은 각 매개변수의 현재 값에만 의존하므로 최적화 프로그램은 어쨌든 각 매개변수를 한 번 터치해야 합니다.
Below, we specify the weight decay hyperparameter directly throughweight_decaywhen instantiating our optimizer. By default, PyTorch decays both weights and biases simultaneously, but we can configure the optimizer to handle different parameters according to different policies. Here, we only setweight_decayfor the weights (thenet.weightparameters), hence the bias (thenet.biasparameter) will not decay.
아래에서는 최적화 프로그램을 인스턴스화할 때 Weight_decay를 통해 직접 가중치 감소 하이퍼파라미터를 지정합니다. 기본적으로 PyTorch는 가중치와 편향을 동시에 감소시키지만, 다양한 정책에 따라 다양한 매개변수를 처리하도록 최적화 프로그램을 구성할 수 있습니다. 여기서는 가중치(net.weight 매개변수)에 대해서만 Weight_decay를 설정하므로 편향(net.bias 매개변수)은 감소하지 않습니다.
The plot looks similar to that when we implemented weight decay from scratch. However, this version runs faster and is easier to implement, benefits that will become more pronounced as you address larger problems and this work becomes more routine.
플롯은 처음부터 가중치 감소를 구현했을 때와 유사해 보입니다. 그러나 이 버전은 더 빠르게 실행되고 구현하기가 더 쉬우므로 더 큰 문제를 해결하고 이 작업이 더 일상화될수록 이점이 더욱 뚜렷해집니다.
model = WeightDecay(wd=3, lr=0.01)
model.board.yscale='log'
trainer.fit(model, data)
print('L2 norm of w:', float(l2_penalty(model.get_w_b()[0])))
L2 norm of w: 0.013779522851109505
So far, we have touched upon one notion of what constitutes a simple linear function. However, even for simple nonlinear functions, the situation can be much more complex. To see this, the concept ofreproducing kernel Hilbert space (RKHS)allows one to apply tools introduced for linear functions in a nonlinear context. Unfortunately, RKHS-based algorithms tend to scale poorly to large, high-dimensional data. In this book we will often adopt the common heuristic whereby weight decay is applied to all layers of a deep network.
지금까지 우리는 단순한 선형 함수를 구성하는 개념 중 하나를 다루었습니다. 그러나 단순한 비선형 함수의 경우에도 상황은 훨씬 더 복잡할 수 있습니다. 이를 확인하기 위해 RKHS(커널 힐베르트 공간 재현) 개념을 사용하면 비선형 맥락에서 선형 함수에 대해 도입된 도구를 적용할 수 있습니다. 불행하게도 RKHS 기반 알고리즘은 대규모 고차원 데이터에 제대로 확장되지 않는 경향이 있습니다. 이 책에서 우리는 딥 네트워크의 모든 계층에 가중치 감소를 적용하는 일반적인 경험적 방법을 자주 채택할 것입니다.
3.7.5.Summary
Regularization is a common method for dealing with overfitting. Classical regularization techniques add a penalty term to the loss function (when training) to reduce the complexity of the learned model. One particular choice for keeping the model simple is using anℓ2penalty. This leads to weight decay in the update steps of the minibatch stochastic gradient descent algorithm. In practice, the weight decay functionality is provided in optimizers from deep learning frameworks. Different sets of parameters can have different update behaviors within the same training loop.
정규화는 과적합을 처리하는 일반적인 방법입니다. 고전적인 정규화 기술은 학습된 모델의 복잡성을 줄이기 위해 (훈련 시) 손실 함수에 페널티 항을 추가합니다. 모델을 단순하게 유지하기 위한 한 가지 특별한 선택은 다음을 사용하는 것입니다. 패널티. 이로 인해 미니배치 확률적 경사하강법 알고리즘의 업데이트 단계에서 가중치 감소가 발생합니다. 실제로 가중치 감소 기능은 딥러닝 프레임워크의 최적화 프로그램에서 제공됩니다. 서로 다른 매개변수 세트는 동일한 훈련 루프 내에서 서로 다른 업데이트 동작을 가질 수 있습니다.
Consider two college students diligently preparing for their final exam. Commonly, this preparation will consist of practicing and testing their abilities by taking exams administered in previous years. Nonetheless, doing well on past exams is no guarantee that they will excel when it matters. For instance, imagine a student, Extraordinary Ellie, whose preparation consisted entirely of memorizing the answers to previous years’ exam questions. Even if Ellie were endowed with an extraordinary memory, and thus could perfectly recall the answer to anypreviously seenquestion, she might nevertheless freeze when faced with a new (previously unseen) question. By comparison, imagine another student, Inductive Irene, with comparably poor memorization skills, but a knack for picking up patterns. Note that if the exam truly consisted of recycled questions from a previous year, Ellie would handily outperform Irene. Even if Irene’s inferred patterns yielded 90% accurate predictions, they could never compete with Ellie’s 100% recall. However, even if the exam consisted entirely of fresh questions, Irene might maintain her 90% average.
최종 시험을 부지런히 준비하는 두 명의 대학생을 생각해 보십시오. 일반적으로 이 준비는 전년도에 시행된 시험을 통해 자신의 능력을 연습하고 테스트하는 것으로 구성됩니다. 그럼에도 불구하고 과거 시험에서 좋은 성적을 냈다고 해서 중요한 순간에 뛰어난 성적을 거둘 것이라는 보장은 없습니다. 예를 들어, 전년도 시험 문제에 대한 답을 암기하는 것만으로 준비를 했던 Extraordinary Ellie라는 학생을 상상해 보십시오. Ellie가 특별한 기억력을 부여받아 이전에 본 질문에 대한 답을 완벽하게 기억할 수 있다고 하더라도 새로운(이전에는 볼 수 없었던) 질문에 직면하면 그녀는 얼어붙을 수도 있습니다. 이에 비해 암기 능력은 비교적 낮지만 패턴을 파악하는 능력이 있는 또 다른 학생인 Induction Irene을 상상해 보십시오. 시험이 실제로 전년도의 질문을 재활용하여 구성되었다면 Ellie가 Irene보다 더 좋은 성적을 냈을 것입니다. 아이린이 추론한 패턴이 90% 정확한 예측을 내놨다고 해도 엘리의 100% 회상과 결코 경쟁할 수는 없습니다. 그러나 시험이 완전히 새로운 문제로 구성되더라도 아이린은 평균 90%를 유지할 수 있습니다.
As machine learning scientists, our goal is to discoverpatterns. But how can we be sure that we have truly discovered ageneralpattern and not simply memorized our data? Most of the time, our predictions are only useful if our model discovers such a pattern. We do not want to predict yesterday’s stock prices, but tomorrow’s. We do not need to recognize already diagnosed diseases for previously seen patients, but rather previously undiagnosed ailments in previously unseen patients. This problem—how to discover patterns thatgeneralize—is the fundamental problem of machine learning, and arguably of all of statistics. We might cast this problem as just one slice of a far grander question that engulfs all of science: when are we ever justified in making the leap from particular observations to more general statements?
기계 학습 과학자로서 우리의 목표는 패턴을 발견하는 것입니다. 하지만 단순히 데이터를 암기한 것이 아니라 실제로 일반적인 패턴을 발견했다는 것을 어떻게 확신할 수 있습니까? 대부분의 경우 예측은 모델이 그러한 패턴을 발견한 경우에만 유용합니다. 우리는 어제의 주가를 예측하고 싶지 않고 내일의 주가를 예측하고 싶습니다. 우리는 이전에 본 환자에 대해 이미 진단된 질병을 인식할 필요가 없으며, 이전에 보지 못한 환자의 이전에 진단되지 않은 질병을 인식할 필요가 있습니다. 일반화되는 패턴을 발견하는 방법이라는 문제는 기계 학습과 모든 통계의 근본적인 문제입니다. 우리는 이 문제를 모든 과학을 포괄하는 훨씬 더 큰 질문의 한 조각으로 간주할 수 있습니다. 특정 관찰에서 보다 일반적인 진술로 도약하는 것이 언제 정당화될 수 있습니까?
In real life, we must fit our models using a finite collection of data. The typical scales of that data vary wildly across domains. For many important medical problems, we can only access a few thousand data points. When studying rare diseases, we might be lucky to access hundreds. By contrast, the largest public datasets consisting of labeled photographs, e.g., ImageNet(Denget al., 2009), contain millions of images. And some unlabeled image collections such as the Flickr YFC100M dataset can be even larger, containing over 100 million images(Thomeeet al., 2016). However, even at this extreme scale, the number of available data points remains infinitesimally small compared to the space of all possible images at a megapixel resolution. Whenever we work with finite samples, we must keep in mind the risk that we might fit our training data, only to discover that we failed to discover a generalizable pattern.
실생활에서는 유한한 데이터 모음을 사용하여 모델을 맞춰야 합니다. 해당 데이터의 일반적인 규모는 도메인에 따라 크게 다릅니다. 많은 중요한 의료 문제의 경우 우리는 수천 개의 데이터 포인트에만 접근할 수 있습니다. 희귀 질병을 연구할 때 운이 좋게도 수백 가지 질병에 접근할 수 있습니다. 대조적으로, ImageNet(Deng et al., 2009)과 같이 레이블이 지정된 사진으로 구성된 가장 큰 공개 데이터 세트에는 수백만 개의 이미지가 포함되어 있습니다. 그리고 Flickr YFC100M 데이터 세트와 같은 일부 레이블이 없는 이미지 컬렉션은 1억 개가 넘는 이미지를 포함하여 훨씬 더 클 수 있습니다(Thomee et al., 2016). 그러나 이러한 극단적인 규모에서도 사용 가능한 데이터 포인트의 수는 메가픽셀 해상도에서 가능한 모든 이미지의 공간에 비해 무한히 작은 상태로 유지됩니다. 유한한 샘플로 작업할 때마다 훈련 데이터를 적합했지만 일반화 가능한 패턴을 발견하지 못했다는 사실을 발견하게 될 위험을 염두에 두어야 합니다.
The phenomenon of fitting closer to our training data than to the underlying distribution is calledoverfitting, and techniques for combatting overfitting are often calledregularizationmethods. While it is no substitute for a proper introduction to statistical learning theory (seeBoucheronet al.(2005), Vapnik (1998)), we will give you just enough intuition to get going. We will revisit generalization in many chapters throughout the book, exploring both what is known about the principles underlying generalization in various models, and also heuristic techniques that have been found (empirically) to yield improved generalization on tasks of practical interest.
기본 분포보다 훈련 데이터에 더 가깝게 피팅되는 현상을 과적합이라고 하며, 과적합을 방지하는 기술을 종종 정규화 방법이라고 합니다. 이것이 통계적 학습 이론에 대한 적절한 소개를 대체할 수는 없지만(Boucheron et al.(2005), Vapnik(1998) 참조), 시작하는 데 충분한 직관을 제공할 것입니다. 우리는 다양한 모델의 일반화 기본 원리에 대해 알려진 내용과 실제 관심 있는 작업에 대해 개선된 일반화를 산출하기 위해 (경험적으로) 발견된 경험적 기법을 탐구하면서 책 전체의 여러 장에서 일반화를 다시 살펴볼 것입니다.
3.6.1.Training Error and Generalization Error
In the standard supervised learning setting, we assume that the training data and the test data are drawnindependentlyfromidenticaldistributions. This is commonly called theIID assumption. While this assumption is strong, it is worth noting that, absent any such assumption, we would be dead in the water. Why should we believe that training data sampled from distributionP(X,Y)should tell us how to make predictions on test data generated by adifferent distributionQ(X,Y)? Making such leaps turns out to require strong assumptions about howPand Qare related. Later on we will discuss some assumptions that allow for shifts in distribution but first we need to understand the IID case, whereP(⋅)=Q(⋅).
표준 지도 학습 설정에서는 훈련 데이터와 테스트 데이터가 동일한 분포에서 독립적으로 추출된다고 가정합니다. 이를 일반적으로 IID 가정이라고 합니다. 이 가정은 강력하지만, 그러한 가정이 없다면 우리는 물 속에서 죽을 것이라는 점은 주목할 가치가 있습니다. 분포 P(X,Y)에서 샘플링된 훈련 데이터가 다른 분포 Q(X,Y)에 의해 생성된 테스트 데이터에 대해 예측하는 방법을 알려주어야 하는 이유는 무엇입니까? 그러한 도약을 위해서는 P와 Q가 어떻게 관련되어 있는지에 대한 강력한 가정이 필요하다는 것이 밝혀졌습니다. 나중에 우리는 분포의 변화를 허용하는 몇 가지 가정에 대해 논의할 것이지만 먼저 P(⋅)=Q(⋅)인 IID 사례를 이해해야 합니다.
To begin with, we need to differentiate between thetraining errorRemp, which is astatisticcalculated on the training dataset, and thegeneralization errorR, which is anexpectationtaken with respect to the underlying distribution. You can think of the generalization error as what you would see if you applied your model to an infinite stream of additional data examples drawn from the same underlying data distribution. Formally the training error is expressed as asum(with the same notation asSection 3.1):
우선, 훈련 데이터세트에서 계산된 통계인 훈련 오류 Remp와 기본 분포에 대한 기대값인 일반화 오류 R을 구별해야 합니다. 일반화 오류는 동일한 기본 데이터 분포에서 추출된 추가 데이터 예제의 무한한 스트림에 모델을 적용한 경우 표시되는 오류로 생각할 수 있습니다. 공식적으로 훈련 오류는 합계로 표현됩니다(섹션 3.1과 동일한 표기법 사용).
while the generalization error is expressed as an integral:
일반화 오류는 적분으로 표현됩니다.
Problematically, we can never calculate the generalization errorRexactly. Nobody ever tells us the precise form of the density functionp(x,y). Moreover, we cannot sample an infinite stream of data points. Thus, in practice, we mustestimatethe generalization error by applying our model to an independent test set constituted of a random selection of examplesX′and labelsy′that were withheld from our training set. This consists of applying the same formula that was used for calculating the empirical training error but to a test setX′,y′.
문제는 일반화 오류 R을 정확하게 계산할 수 없다는 점입니다. 밀도 함수 p(x,y)의 정확한 형태를 알려주는 사람은 아무도 없습니다. 게다가 무한한 데이터 포인트 스트림을 샘플링할 수도 없습니다. 따라서 실제로는 훈련 세트에서 보류된 X' 및 레이블 y'의 무작위 선택으로 구성된 독립적인 테스트 세트에 모델을 적용하여 일반화 오류를 추정해야 합니다. 이는 경험적 훈련 오류를 계산하는 데 사용된 것과 동일한 공식을 테스트 세트 X',y'에 적용하는 것으로 구성됩니다.
Crucially, when we evaluate our classifier on the test set, we are working with afixedclassifier (it does not depend on the sample of the test set), and thus estimating its error is simply the problem of mean estimation. However the same cannot be said for the training set. Note that the model we wind up with depends explicitly on the selection of the training set and thus the training error will in general be a biased estimate of the true error on the underlying population. The central question of generalization is then when should we expect our training error to be close to the population error (and thus the generalization error).
결정적으로 테스트 세트에서 분류기를 평가할 때 고정된 분류기를 사용하여 작업하므로(테스트 세트의 샘플에 의존하지 않음) 오류를 추정하는 것은 단순히 평균 추정의 문제입니다. 그러나 훈련 세트에 대해서도 마찬가지입니다. 우리가 마무리하는 모델은 훈련 세트의 선택에 명시적으로 의존하므로 훈련 오류는 일반적으로 기본 모집단의 실제 오류에 대한 편향된 추정치입니다. 일반화의 핵심 질문은 언제 훈련 오류가 모집단 오류(따라서 일반화 오류)에 가까워질 것으로 예상해야 하는가입니다.
3.6.1.1.Model Complexit
In classical theory, when we have simple models and abundant data, the training and generalization errors tend to be close. However, when we work with more complex models and/or fewer examples, we expect the training error to go down but the generalization gap to grow. This should not be surprising. Imagine a model class so expressive that for any dataset ofnexamples, we can find a set of parameters that can perfectly fit arbitrary labels, even if randomly assigned. In this case, even if we fit our training data perfectly, how can we conclude anything about the generalization error? For all we know, our generalization error might be no better than random guessing.
고전 이론에서는 단순한 모델과 풍부한 데이터가 있을 때 훈련 및 일반화 오류가 가까운 경향이 있습니다. 그러나 더 복잡한 모델 및/또는 더 적은 수의 예제를 사용하면 학습 오류는 줄어들지만 일반화 격차는 커질 것으로 예상됩니다. 이것은 놀라운 일이 아닙니다. n개의 예제로 구성된 데이터세트에 대해 무작위로 할당되더라도 임의의 레이블에 완벽하게 맞는 매개변수 집합을 찾을 수 있을 만큼 표현력이 뛰어난 모델 클래스를 상상해 보세요. 이 경우 훈련 데이터를 완벽하게 적합하더라도 일반화 오류에 대해 어떻게 결론을 내릴 수 있습니까? 우리가 아는 한, 일반화 오류는 무작위 추측보다 나을 것이 없을 수도 있습니다.
In general, absent any restriction on our model class, we cannot conclude, based on fitting the training data alone, that our model has discovered any generalizable pattern(Vapniket al., 1994). On the other hand, if our model class was not capable of fitting arbitrary labels, then it must have discovered a pattern. Learning-theoretic ideas about model complexity derived some inspiration from the ideas of Karl Popper, an influential philosopher of science, who formalized the criterion of falsifiability. According to Popper, a theory that can explain any and all observations is not a scientific theory at all! After all, what has it told us about the world if it has not ruled out any possibility? In short, what we want is a hypothesis thatcould notexplain any observations we might conceivably make and yet nevertheless happens to be compatible with those observations that wein factmake.
일반적으로 모델 클래스에 대한 제한이 없으면 훈련 데이터만 피팅하는 것만으로는 모델이 일반화 가능한 패턴을 발견했다고 결론을 내릴 수 없습니다(Vapnik et al., 1994). 반면, 모델 클래스가 임의의 레이블을 맞출 수 없다면 패턴을 발견했을 것입니다. 모델 복잡성에 대한 학습 이론적인 아이디어는 반증 가능성의 기준을 공식화한 영향력 있는 과학 철학자 칼 포퍼(Karl Popper)의 아이디어에서 영감을 얻었습니다. 포퍼에 따르면, 모든 관찰을 설명할 수 있는 이론은 전혀 과학 이론이 아닙니다! 결국, 어떤 가능성도 배제하지 않는다면 세상은 우리에게 무엇을 말해주는 것일까요? 간단히 말해서, 우리가 원하는 것은 우리가 할 수 있는 어떤 관찰도 설명할 수 없지만 그럼에도 불구하고 실제로 우리가 하는 관찰과 양립할 수 있는 가설입니다.
Now what precisely constitutes an appropriate notion of model complexity is a complex matter. Often, models with more parameters are able to fit a greater number of arbitrarily assigned labels. However, this is not necessarily true. For instance, kernel methods operate in spaces with infinite numbers of parameters, yet their complexity is controlled by other means(Schölkopf and Smola, 2002). One notion of complexity that often proves useful is the range of values that the parameters can take. Here, a model whose parameters are permitted to take arbitrary values would be more complex. We will revisit this idea in the next section, when we introduceweight decay, your first practical regularization technique. Notably, it can be difficult to compare complexity among members of substantially different model classes (say, decision trees vs. neural networks).
이제 모델 복잡성에 대한 적절한 개념을 정확히 구성하는 것은 복잡한 문제입니다. 매개변수가 더 많은 모델은 임의로 할당된 레이블을 더 많이 수용할 수 있는 경우가 많습니다. 그러나 이것이 반드시 사실은 아닙니다. 예를 들어, 커널 방법은 무한한 수의 매개변수가 있는 공간에서 작동하지만 그 복잡성은 다른 수단으로 제어됩니다(Schölkopf 및 Smola, 2002). 종종 유용하다고 입증되는 복잡성에 대한 한 가지 개념은 매개변수가 취할 수 있는 값의 범위입니다. 여기서 매개변수가 임의의 값을 취하도록 허용된 모델은 더 복잡합니다. 첫 번째 실용적인 정규화 기술인 가중치 감소를 소개하는 다음 섹션에서 이 아이디어를 다시 살펴보겠습니다. 특히, 실질적으로 다른 모델 클래스(예: 의사결정 트리와 신경망)의 구성원 간의 복잡성을 비교하는 것은 어려울 수 있습니다.
At this point, we must stress another important point that we will revisit when introducing deep neural networks. When a model is capable of fitting arbitrary labels, low training error does not necessarily imply low generalization error.However, it does not necessarily imply high generalization error either!All we can say with confidence is that low training error alone is not enough to certify low generalization error. Deep neural networks turn out to be just such models: while they generalize well in practice, they are too powerful to allow us to conclude much on the basis of training error alone. In these cases we must rely more heavily on our holdout data to certify generalization after the fact. Error on the holdout data, i.e., validation set, is called thevalidation error.
이 시점에서 우리는 심층 신경망을 도입할 때 다시 살펴볼 또 다른 중요한 점을 강조해야 합니다. 모델이 임의의 레이블을 맞출 수 있는 경우 훈련 오류가 낮다고 해서 반드시 일반화 오류가 낮다는 의미는 아닙니다. 그러나 이것이 반드시 높은 일반화 오류를 의미하는 것은 아닙니다! 우리가 자신있게 말할 수 있는 것은 낮은 훈련 오류만으로는 낮은 일반화 오류를 인증하는 데 충분하지 않다는 것입니다. 심층 신경망은 바로 그러한 모델임이 밝혀졌습니다. 실제로는 잘 일반화되지만 훈련 오류만으로 많은 결론을 내릴 수 없을 정도로 강력합니다. 이러한 경우 사실 이후 일반화를 인증하기 위해 홀드아웃 데이터에 더 많이 의존해야 합니다. 홀드아웃 데이터, 즉 검증 세트에 대한 오류를 검증 오류라고 합니다.
3.6.2.Underfitting or Overfitting?
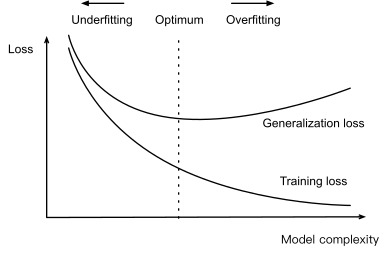
When we compare the training and validation errors, we want to be mindful of two common situations. First, we want to watch out for cases when our training error and validation error are both substantial but there is a little gap between them. If the model is unable to reduce the training error, that could mean that our model is too simple (i.e., insufficiently expressive) to capture the pattern that we are trying to model. Moreover, since thegeneralization gap(Remp−R) between our training and generalization errors is small, we have reason to believe that we could get away with a more complex model. This phenomenon is known asunderfitting.
훈련 오류와 검증 오류를 비교할 때 두 가지 일반적인 상황에 유의하고 싶습니다. 먼저, 훈련 오류와 검증 오류가 모두 상당하지만 그 사이에 약간의 차이가 있는 경우를 주의하고 싶습니다. 모델이 훈련 오류를 줄일 수 없다면 이는 모델이 너무 단순하여(즉, 표현력이 부족하여) 모델링하려는 패턴을 포착할 수 없음을 의미할 수 있습니다. 더욱이 훈련 오류와 일반화 오류 사이의 일반화 격차(Remp-R)가 작기 때문에 더 복잡한 모델을 사용하여 벗어날 수 있다고 믿을 이유가 있습니다. 이 현상을 과소적합이라고 합니다.
On the other hand, as we discussed above, we want to watch out for the cases when our training error is significantly lower than our validation error, indicating severeoverfitting. Note that overfitting is not always a bad thing. In deep learning especially, the best predictive models often perform far better on training data than on holdout data. Ultimately, we usually care about driving the generalization error lower, and only care about the gap insofar as it becomes an obstacle to that end. Note that if the training error is zero, then the generalization gap is precisely equal to the generalization error and we can make progress only by reducing the gap.
반면, 위에서 논의한 것처럼 훈련 오류가 검증 오류보다 현저히 낮아 심각한 과적합을 나타내는 경우를 주의해야 합니다. 과적합이 항상 나쁜 것은 아닙니다. 특히 딥 러닝에서는 최고의 예측 모델이 홀드아웃 데이터보다 훈련 데이터에서 훨씬 더 나은 성능을 발휘하는 경우가 많습니다. 궁극적으로 우리는 일반적으로 일반화 오류를 낮추는 데 관심을 갖고, 그 목적에 장애물이 되는 한 격차에만 관심을 갖습니다. 훈련 오류가 0이면 일반화 격차는 일반화 오류와 정확하게 동일하며 격차를 줄여야만 진전을 이룰 수 있습니다.
3.6.2.1.Polynomial Curve Fitting
To illustrate some classical intuition about overfitting and model complexity, consider the following: given training data consisting of a single feature xand a corresponding real-valued labely, we try to find the polynomial of degree d for estimating the labely.
과적합 및 모델 복잡성에 대한 몇 가지 고전적 직관을 설명하기 위해 다음을 고려하십시오. 단일 특성 x와 해당 실제 값 레이블 y로 구성된 훈련 데이터가 주어지면 레이블 y를 추정하기 위해 d차 다항식을 찾으려고 합니다.
This is just a linear regression problem where our features are given by the powers ofx, the model’s weights are given bywi, and the bias is given byw0sincex**0=1for allx. Since this is just a linear regression problem, we can use the squared error as our loss function.
이는 모든 x에 대해 x**0=1이므로 특성이 x의 거듭제곱으로 제공되고 모델의 가중치가 wi로 제공되며 편향이 w0으로 제공되는 선형 회귀 문제입니다. 이것은 선형 회귀 문제이므로 제곱 오차를 손실 함수로 사용할 수 있습니다.
A higher-order polynomial function is more complex than a lower-order polynomial function, since the higher-order polynomial has more parameters and the model function’s selection range is wider. Fixing the training dataset, higher-order polynomial functions should always achieve lower (at worst, equal) training error relative to lower-degree polynomials. In fact, whenever each data example has a distinct value ofx, a polynomial function with degree equal to the number of data examples can fit the training set perfectly. We compare the relationship between polynomial degree (model complexity) and both underfitting and overfitting inFig. 3.6.1.
고차 다항식 함수는 저차 다항식 함수보다 더 복잡합니다. 왜냐하면 고차 다항식은 더 많은 매개변수를 갖고 모델 함수의 선택 범위가 더 넓기 때문입니다. 훈련 데이터 세트를 수정하면 고차 다항식 함수는 항상 저차 다항식에 비해 더 낮은(최악의 경우 동일한) 훈련 오류를 달성해야 합니다. 실제로 각 데이터 예제에 고유한 x 값이 있을 때마다 데이터 예제 수와 동일한 차수를 갖는 다항식 함수가 훈련 세트에 완벽하게 맞을 수 있습니다. 그림 3.6.1에서 다항식 차수(모델 복잡도)와 과소적합 및 과적합 간의 관계를 비교합니다.
Fig. 3.6.1 Influence of model complexity on underfitting and overfitting.
3.6.2.2.Dataset Siz
As the above bound already indicates, another big consideration to bear in mind is dataset size. Fixing our model, the fewer samples we have in the training dataset, the more likely (and more severely) we are to encounter overfitting. As we increase the amount of training data, the generalization error typically decreases. Moreover, in general, more data never hurts. For a fixed task and data distribution, model complexity should not increase more rapidly than the amount of data. Given more data, we might attempt to fit a more complex model. Absent sufficient data, simpler models may be more difficult to beat. For many tasks, deep learning only outperforms linear models when many thousands of training examples are available. In part, the current success of deep learning owes considerably to the abundance of massive datasets arising from Internet companies, cheap storage, connected devices, and the broad digitization of the economy.
위의 한계에서 이미 알 수 있듯이 염두에 두어야 할 또 다른 큰 고려 사항은 데이터 세트 크기입니다. 모델을 수정하면 훈련 데이터 세트에 있는 샘플 수가 줄어들수록 과적합이 발생할 가능성이 더 높아집니다(심각하게도). 훈련 데이터의 양을 늘리면 일반적으로 일반화 오류가 감소합니다. 또한 일반적으로 더 많은 데이터가 해를 끼치 지 않습니다. 고정된 작업 및 데이터 분포의 경우 모델 복잡성이 데이터 양보다 더 빠르게 증가해서는 안 됩니다. 더 많은 데이터가 주어지면 더 복잡한 모델을 맞추려고 시도할 수도 있습니다. 데이터가 충분하지 않으면 단순한 모델을 이기기가 더 어려울 수 있습니다. 많은 작업에서 딥 러닝은 수천 개의 학습 예제를 사용할 수 있는 경우에만 선형 모델보다 성능이 뛰어납니다. 부분적으로 현재 딥 러닝의 성공은 인터넷 회사, 저렴한 스토리지, 연결된 장치 및 경제의 광범위한 디지털화에서 발생하는 풍부한 대규모 데이터 세트에 크게 기인합니다.
3.6.3.Model Selection
Typically, we select our final model only after evaluating multiple models that differ in various ways (different architectures, training objectives, selected features, data preprocessing, learning rates, etc.). Choosing among many models is aptly calledmodel selection.
일반적으로 우리는 다양한 방식(다양한 아키텍처, 교육 목표, 선택한 기능, 데이터 전처리, 학습 속도 등)이 다른 여러 모델을 평가한 후에만 최종 모델을 선택합니다. 여러 모델 중에서 선택하는 것을 적절하게는 모델 선택이라고 합니다.
In principle, we should not touch our test set until after we have chosen all our hyperparameters. Were we to use the test data in the model selection process, there is a risk that we might overfit the test data. Then we would be in serious trouble. If we overfit our training data, there is always the evaluation on test data to keep us honest. But if we overfit the test data, how would we ever know? SeeOnget al.(2005)for an example of how this can lead to absurd results even for models where the complexity can be tightly controlled.
원칙적으로 모든 하이퍼파라미터를 선택할 때까지 테스트 세트를 건드리면 안 됩니다. 모델 선택 과정에서 테스트 데이터를 사용한다면 테스트 데이터에 과적합될 위험이 있습니다. 그러면 우리는 심각한 문제에 빠지게 될 것입니다. 훈련 데이터를 과대적합하는 경우 정직성을 유지하기 위해 항상 테스트 데이터에 대한 평가가 있습니다. 하지만 테스트 데이터에 과대적합되면 어떻게 알 수 있을까요? Ong et al. (2005)은 복잡성이 엄격하게 제어될 수 있는 모델의 경우에도 이것이 어떻게 터무니없는 결과로 이어질 수 있는지에 대한 예를 제공합니다.
Thus, we should never rely on the test data for model selection. And yet we cannot rely solely on the training data for model selection either because we cannot estimate the generalization error on the very data that we use to train the model.
따라서 모델 선택을 위해 테스트 데이터에 의존해서는 안 됩니다. 그러나 모델을 훈련하는 데 사용하는 바로 그 데이터에 대한 일반화 오류를 추정할 수 없기 때문에 모델 선택을 위해 훈련 데이터에만 의존할 수는 없습니다.
In practical applications, the picture gets muddier. While ideally we would only touch the test data once, to assess the very best model or to compare a small number of models with each other, real-world test data is seldom discarded after just one use. We can seldom afford a new test set for each round of experiments. In fact, recycling benchmark data for decades can have a significant impact on the development of algorithms, e.g., forimage classificationandoptical character recognition.
실제 적용에서는 그림이 더 흐릿해집니다. 이상적으로는 테스트 데이터를 한 번만 만지는 반면, 최고의 모델을 평가하거나 소수의 모델을 서로 비교하기 위해 실제 테스트 데이터는 한 번만 사용한 후 거의 삭제되지 않습니다. 우리는 각 실험 라운드마다 새로운 테스트 세트를 제공할 여력이 거의 없습니다. 실제로 수십 년 동안 벤치마크 데이터를 재활용하면 이미지 분류, 광학 문자 인식 등의 알고리즘 개발에 상당한 영향을 미칠 수 있습니다.
The common practice for addressing the problem oftraining on the test setis to split our data three ways, incorporating avalidation setin addition to the training and test datasets. The result is a murky business where the boundaries between validation and test data are worryingly ambiguous. Unless explicitly stated otherwise, in the experiments in this book we are really working with what should rightly be called training data and validation data, with no true test sets. Therefore, the accuracy reported in each experiment of the book is really the validation accuracy and not a true test set accuracy.
테스트 세트에 대한 교육 문제를 해결하기 위한 일반적인 방법은 데이터를 세 가지 방식으로 분할하고 교육 및 테스트 데이터세트 외에 검증 세트를 통합하는 것입니다. 그 결과 검증 데이터와 테스트 데이터 사이의 경계가 걱정스러울 정도로 모호한 비즈니스가 불투명해졌습니다. 달리 명시적으로 언급하지 않는 한, 이 책의 실험에서 우리는 실제 테스트 세트 없이 훈련 데이터와 검증 데이터라고 해야 할 것을 실제로 사용하고 있습니다. 따라서 책의 각 실험에서 보고된 정확도는 실제 검증 정확도이지 실제 테스트 세트 정확도가 아닙니다.
3.6.3.1.Cross-Validation
When training data is scarce, we might not even be able to afford to hold out enough data to constitute a proper validation set. One popular solution to this problem is to employK-fold cross-validation. Here, the original training data is split intoKnon-overlapping subsets. Then model training and validation are executedKtimes, each time training onK−1subsets and validating on a different subset (the one not used for training in that round). Finally, the training and validation errors are estimated by averaging over the results from the Kexperiments.
훈련 데이터가 부족하면 적절한 검증 세트를 구성하기에 충분한 데이터를 보유할 여력조차 없을 수도 있습니다. 이 문제에 대한 인기 있는 해결책 중 하나는 K-겹 교차 검증을 사용하는 것입니다. 여기서는 원본 훈련 데이터가 K개의 겹치지 않는 하위 집합으로 분할됩니다. 그런 다음 모델 훈련 및 검증이 K번 실행되며, 매번 K −1 하위 집합에 대해 훈련하고 다른 하위 집합(해당 라운드에서 훈련에 사용되지 않은 것)에 대해 검증합니다. 마지막으로 훈련 및 검증 오류는 K 실험 결과를 평균하여 추정됩니다.
3.6.4.Summary
This section explored some of the underpinnings of generalization in machine learning. Some of these ideas become complicated and counterintuitive when we get to deeper models; here, models are capable of overfitting data badly, and the relevant notions of complexity can be both implicit and counterintuitive (e.g., larger architectures with more parameters generalizing better). We leave you with a few rules of thumb:
이 섹션에서는 기계 학습에서 일반화의 몇 가지 토대를 살펴보았습니다. 이러한 아이디어 중 일부는 더 심층적인 모델에 도달하면 복잡해지고 직관에 반하게 됩니다. 여기서 모델은 데이터를 잘못 과적합할 수 있으며 관련 복잡성 개념은 암시적일 수도 있고 반직관적일 수도 있습니다(예: 더 많은 매개변수를 가진 더 큰 아키텍처가 더 잘 일반화됨). 몇 가지 경험 법칙을 알려드리겠습니다.
Use validation sets (orK-fold cross-validation) for model selection; 모델 선택을 위해 검증 세트(또는 K-겹 교차 검증)를 사용합니다.
More complex models often require more data; 더 복잡한 모델에는 더 많은 데이터가 필요한 경우가 많습니다.
Relevant notions of complexity include both the number of parameters and the range of values that they are allowed to take; 복잡성과 관련된 개념에는 매개변수의 수와 허용되는 값의 범위가 모두 포함됩니다.
Keeping all else equal, more data almost always leads to better generalization; 다른 모든 것을 동일하게 유지하면 더 많은 데이터가 거의 항상 더 나은 일반화로 이어집니다.
This entire talk of generalization is all predicated on the IID assumption. If we relax this assumption, allowing for distributions to shift between the train and testing periods, then we cannot say anything about generalization absent a further (perhaps milder) assumption. 일반화에 대한 이 전체 이야기는 모두 IID 가정에 근거합니다. 이 가정을 완화하여 열차와 테스트 기간 사이에 분포가 이동하도록 허용하면 추가(아마도 더 온화한) 가정 없이 일반화에 대해 아무 말도 할 수 없습니다.
3.6.5.Exercises
When can you solve the problem of polynomial regression exactly?
Give at least five examples where dependent random variables make treating the problem as IID data inadvisable.
Can you ever expect to see zero training error? Under which circumstances would you see zero generalization error?
Why isK-fold cross-validation very expensive to compute?
Why is theK-fold cross-validation error estimate biased?
The VC dimension is defined as the maximum number of points that can be classified with arbitrary labels{±1}by a function of a class of functions. Why might this not be a good idea for measuring how complex the class of functions is? Hint: consider the magnitude of the functions.
Your manager gives you a difficult dataset on which your current algorithm does not perform so well. How would you justify to him that you need more data? Hint: you cannot increase the data but you can decrease it.
Sam Altman returns as CEO, OpenAI has a new initial board
Mira Murati as CTO, Greg Brockman returns as President. Read messages from CEO Sam Altman and board chair Bret Taylor.
Below are messages CEO Sam Altman and board chair Bret Taylor shared with the company this afternoon.
다음은 오늘 오후 CEO인 Sam Altman과 이사회 의장인 Bret Taylor가 회사와 공유한 메시지입니다.
Message from Sam to the company
Sam이 회사에 보내는 메시지
I am returning to OpenAI as CEO. Mira will return to her role as CTO. The new initial board will consist of Bret Taylor (Chair), Larry Summers, and Adam D’Angelo.
저는 OpenAI의 CEO로 복귀합니다. Mira는 CTO 역할로 복귀합니다. 새로운 초기 이사회는 Bret Taylor(의장), Larry Summers 및 Adam D'Angelo로 구성됩니다.
I have never been more excited about the future. I am extremely grateful for everyone’s hard work in an unclear and unprecedented situation, and I believe our resilience and spirit set us apart in the industry. I feel so, so good about our probability of success for achieving our mission.
나는 미래에 대해 이보다 더 흥분된 적이 없습니다. 불분명하고 전례 없는 상황 속에서도 모두의 노고에 진심으로 감사드리며, 우리의 회복력과 정신이 업계에서 우리를 돋보이게 한다고 믿습니다. 우리의 임무 달성에 대한 성공 가능성에 대해 매우 기분이 좋습니다.
Before getting to what comes next, I’d like to share some thanks.
다음 단계를 시작하기 전에 감사의 인사를 전하고 싶습니다.
I love and respect Ilya, I think he's a guiding light of the field and a gem of a human being. I harbor zero ill will towards him. While Ilya will no longer serve on the board, we hope to continue our working relationship and are discussing how he can continue his work at OpenAI.
나는 일리아를 사랑하고 존경합니다. 나는 그가 현장의 빛이자 인간의 보석이라고 생각합니다. 나는 그 사람에 대해 악의가 전혀 없습니다. Ilya는 더 이상 이사회에서 일하지 않지만, 우리는 협력 관계를 계속 유지하기를 희망하며 그가 OpenAI에서 어떻게 업무를 계속할 수 있는지 논의하고 있습니다.
I am grateful to Adam, Tasha, and Helen for working with us to come to this solution that best serves the mission. I’m excited to continue to work with Adam and am sincerely thankful to Helen and Tasha for investing a huge amount of effort in this process.
사명에 가장 적합한 솔루션을 찾기 위해 우리와 협력한 Adam, Tasha, Helen에게 감사드립니다. 저는 Adam과 계속해서 협력할 수 있게 되어 기쁘게 생각하며 이 과정에 엄청난 노력을 투자한 Helen과 Tasha에게 진심으로 감사드립니다.
Thank you also to Emmett who had a key and constructive role in helping us reach this outcome. Emmett’s dedication to AI safety and balancing stakeholders’ interests was clear.
우리가 이 결과를 달성하는 데 핵심적이고 건설적인 역할을 한 Emmett에게도 감사드립니다. AI 안전과 이해관계자의 이익 균형에 대한 Emmett의 헌신은 분명했습니다.
Mira did an amazing job throughout all of this, serving the mission, the team, and the company selflessly throughout. She is an incredible leader and OpenAI would not be OpenAI without her. Thank you.
Mira는 이 모든 과정에서 놀라운 일을 해냈고, 사심 없이 사명과 팀, 회사에 봉사했습니다. 그녀는 놀라운 리더이며 OpenAI는 그녀 없이는 OpenAI가 될 수 없습니다. 감사합니다.
Greg and I are partners in running this company. We have never quite figured out how to communicate that on the org chart, but we will. In the meantime, I just wanted to make it clear. Thank you for everything you have done since the very beginning, and for how you handled things from the moment this started and over the last week.
Greg와 나는 이 회사를 운영하는 파트너입니다. 우리는 조직도에서 이를 어떻게 전달해야 할지 아직 생각해 본 적이 없지만 그렇게 할 것입니다. 그 동안 나는 단지 분명히하고 싶었습니다. 처음부터 해주신 모든 일에 감사드리며, 이 일이 시작된 순간부터 지난 주까지 일을 처리하는 방법에 대해 감사드립니다.
The leadership team–Mira, Brad, Jason, Che, Hannah, Diane, Anna, Bob, Srinivas, Matt, Lilian, Miles, Jan, Wojciech, John, Jonathan, Pat, and many more–is clearly ready to run the company without me. They say one way to evaluate a CEO is how you pick and train your potential successors; on that metric I am doing far better than I realized. It’s clear to me that the company is in great hands, and I hope this is abundantly clear to everyone. Thank you all.
리더십 팀(Mira, Brad, Jason, Che, Hannah, Diane, Anna, Bob, Srinivas, Matt, Lilian, Miles, Jan, Wojciech, John, Jonathan, Pat 등)은 회사를 운영할 준비가 확실히 되어 있습니다. 나. CEO를 평가하는 한 가지 방법은 잠재적인 후임자를 선택하고 교육하는 방법이라고 합니다. 그 지표에서 나는 내가 깨달은 것보다 훨씬 더 잘하고 있습니다. 회사가 큰 손에 있다는 것은 나에게 분명하며, 이 사실이 모든 사람에게 충분히 명확해지기를 바랍니다. 다들 감사 해요.
Jakub, Szymon, and Aleksander are exceptional talents and I’m so happy they have rejoined to move us and our research forward. Thank you.
Jakub, Szymon 및 Aleksander는 뛰어난 재능을 갖고 있으며 그들이 다시 합류하여 우리와 우리의 연구를 발전시키게 되어 매우 기쁩니다. 감사합니다.
To all of you, our team: I am sure books are going to be written about this time period, and I hope the first thing they say is how amazing the entire team has been. Now that we’re through all of this, we didn’t lose a single employee. You stood firm for each other, this company, and our mission. One of the most important things for the team that builds AGI safely is the ability to handle stressful and uncertain situations, and maintain good judgment throughout. Top marks. Thank you all.
우리 팀 여러분께: 이 시기에 관한 책들이 쓰일 것이라고 확신합니다. 그리고 그들이 가장 먼저 말하게 될 것은 전체 팀이 얼마나 훌륭했는지였습니다. 이제 이 모든 일을 겪으면서 우리는 단 한 명의 직원도 잃지 않았습니다. 여러분은 서로, 이 회사, 그리고 우리의 사명을 굳건히 지지했습니다. AGI를 안전하게 구축하는 팀에게 가장 중요한 것 중 하나는 스트레스가 많고 불확실한 상황을 처리하고 전반적으로 올바른 판단을 유지하는 능력입니다. 좋은 점수. 다들 감사 해요.
Satya, Kevin, Amy, and Brad have been incredible partners throughout this, with exactly the right priorities all the way through. They’ve had our backs and were ready to welcome all of us if we couldn’t achieve our primary goal. We clearly made the right choice to partner with Microsoft and I’m excited that our new board will include them as a non-voting observer. Thank you.
Satya, Kevin, Amy 및 Brad는 이 과정 전반에 걸쳐 정확한 우선순위를 가지고 놀라운 파트너였습니다. 그들은 우리를 지지해 주었고 우리가 주요 목표를 달성하지 못할 경우 우리 모두를 환영할 준비가 되어 있었습니다. 우리는 Microsoft와 협력하기로 한 올바른 선택을 했으며 새 이사회에서 Microsoft를 투표권 없는 참관인으로 포함하게 되어 기쁩니다. 감사합니다.
To our partners and users, thank you for sticking with us. We really felt the outpouring of support and love, and it helped all of us get through this. The fact that we did not lose a single customer will drive us to work even harder for you, and we are all excited to get back to work.
파트너와 사용자 여러분, 우리와 함께해주셔서 감사합니다. 우리는 정말 많은 지원과 사랑을 느꼈고, 이는 우리 모두가 이 상황을 극복하는 데 도움이 되었습니다. 우리가 단 한 명의 고객도 잃지 않았다는 사실은 우리가 귀하를 위해 더욱 열심히 일하도록 이끌 것이며, 우리 모두는 다시 일을 시작하게 되어 기쁩니다.
Will Hurd, Brian Chesky, Bret Taylor and Larry Summers put their lives on hold and did an incredible amount to support the mission. I don’t know how they did it so well, but they really did. Thank you.
윌 허드(Will Hurd), 브라이언 체스키(Brian Chesky), 브렛 테일러(Bret Taylor), 래리 서머스(Larry Summers)는 목숨을 걸고 임무를 지원하기 위해 엄청난 금액을 기부했습니다. 그들이 어떻게 그렇게 잘했는지는 모르겠지만 정말 그랬습니다. 감사합니다.
Ollie also put his life on hold this entire time to just do everything he could to help out, in addition to providing his usual unconditional love and support. Thank you and I love you.
Ollie는 평소의 무조건적인 사랑과 지원을 제공하는 것 외에도 도움을 주기 위해 할 수 있는 모든 일을 하기 위해 이번 내내 자신의 삶을 보류했습니다. 감사하고 사랑합니다.
So what’s next?
We have three immediate priorities.
우리에게는 세 가지 우선순위가 있습니다.
Advancing our research plan and further investing in our full-stack safety efforts, which have always been critical to our work. Our research roadmap is clear; this was a wonderfully focusing time. I share the excitement you all feel; we will turn this crisis into an opportunity! I’ll work with Mira on this.
연구 계획을 발전시키고 항상 우리 업무에 중요한 전체 스택 안전 노력에 추가로 투자합니다. 우리의 연구 로드맵은 명확합니다. 정말 집중할 수 있는 시간이었습니다. 저는 여러분 모두가 느끼는 흥분을 공유합니다. 이 위기를 기회로 바꾸겠습니다! 이 문제에 대해서는 Mira와 협력하겠습니다.
Continuing to improve and deploy our products and serve our customers. It’s important that people get to experience the benefits and promise of AI, and have the opportunity to shape it. We continue to believe that great products are the best way to do this. I’ll work with Brad, Jason and Anna to ensure our unwavering commitment to users, customers, partners and governments around the world is clear.
지속적으로 제품을 개선하고 배포하며 고객에게 서비스를 제공합니다. 사람들이 AI의 이점과 가능성을 경험하고 AI를 형성할 기회를 갖는 것이 중요합니다. 우리는 훌륭한 제품이 이를 수행하는 가장 좋은 방법이라고 계속 믿습니다. 저는 Brad, Jason, Anna와 협력하여 전 세계 사용자, 고객, 파트너 및 정부에 대한 우리의 변함없는 약속을 확실히 할 것입니다.
Bret, Larry, and Adam will be working very hard on the extremely important task of building out a board of diverse perspectives, improving our governance structure and overseeing an independent review of recent events. I look forward to working closely with them on these crucial steps so everyone can be confident in the stability of OpenAI.
Bret, Larry 및 Adam은 다양한 관점의 이사회를 구축하고 거버넌스 구조를 개선하며 최근 사건에 대한 독립적인 검토를 감독하는 매우 중요한 작업을 수행하기 위해 열심히 노력할 것입니다. 모든 사람이 OpenAI의 안정성에 확신을 가질 수 있도록 이러한 중요한 단계에서 그들과 긴밀히 협력할 수 있기를 기대합니다.
I am so looking forward to finishing the job of building beneficial AGI with you all—best team in the world, best mission in the world.
세계 최고의 팀, 세계 최고의 미션인 유익한 AGI 구축 작업을 여러분과 함께 마무리할 수 있기를 기대합니다.
Love,Sam
Message from Bret to the company
On behalf of the OpenAI Board, I want to express our gratitude to the entire OpenAI community, especially all the OpenAI employees, who came together to help find a path forward for the company over the past week. Your efforts helped enable this incredible organization to continue to serve its mission to ensure that artificial general intelligence benefits all of humanity. We are thrilled that Sam, Mira and Greg are back together leading the company and driving it forward. We look forward to working with them and all of you.
OpenAI 이사회를 대신하여 저는 전체 OpenAI 커뮤니티, 특히 지난 주 동안 회사가 나아갈 길을 찾기 위해 함께 모인 모든 OpenAI 직원들에게 감사의 말씀을 전하고 싶습니다. 귀하의 노력은 이 놀라운 조직이 인공 일반 지능이 모든 인류에게 이익이 되도록 보장하는 임무를 계속 수행할 수 있도록 도왔습니다. Sam, Mira, Greg가 다시 함께 회사를 이끌고 발전시켜 나가게 되어 매우 기쁩니다. 우리는 그들과 여러분 모두와 함께 일할 수 있기를 기대합니다.
As a Board, we are focused on strengthening OpenAI’s corporate governance. Here’s how we plan to do it:
이사회로서 우리는 OpenAI의 기업 지배구조를 강화하는 데 중점을 두고 있습니다. 우리가 계획하는 방법은 다음과 같습니다.
We will build a qualified, diverse Board of exceptional individuals whose collective experience represents the breadth of OpenAI’s mission – from technology to safety to policy. We are pleased that this Board will include a non-voting observer for Microsoft.
우리는 기술에서 안전, 정책에 이르기까지 OpenAI의 사명을 폭넓게 대표하는 집단 경험을 갖춘 뛰어난 개인들로 구성된 자격을 갖춘 다양한 이사회를 구성할 것입니다. 이 이사회에 투표권이 없는 Microsoft 참관인이 포함되어 기쁘게 생각합니다.
We will further stabilize the OpenAI organization so that we can continue to serve our mission. This will include convening an independent committee of the Board to oversee a review of the recent events.
우리는 계속해서 사명을 수행할 수 있도록 OpenAI 조직을 더욱 안정화할 것입니다. 여기에는 최근 사건에 대한 검토를 감독하기 위해 이사회의 독립 위원회를 소집하는 것이 포함됩니다.
We will enhance the governance structure of OpenAI so that all stakeholders – users, customers, employees, partners, and community members – can trust that OpenAI will continue to thrive.
사용자, 고객, 직원, 파트너, 커뮤니티 구성원 등 모든 이해관계자가 OpenAI가 계속해서 성장할 것이라고 신뢰할 수 있도록 OpenAI의 거버넌스 구조를 강화할 것입니다.
OpenAI is a more important institution than ever before. ChatGPT has made artificial intelligence a part of daily life for hundreds of millions of people. Its popularity has made AI – its benefits and its risks – central to virtually every conversation about the future of governments, business, and society.
OpenAI는 그 어느 때보다 중요한 기관입니다. ChatGPT는 인공지능을 수억 명의 일상생활의 일부로 만들었습니다. AI의 인기로 인해 AI(AI의 이점과 위험)는 정부, 기업 및 사회의 미래에 관한 거의 모든 대화의 중심이 되었습니다.
We understand the gravity of these discussions and the central role of OpenAI in the development and safety of these awe-inspiring new technologies. Each of you plays a critical part in ensuring that we effectively meet these challenges. We are committed to listening and learning from you, and I hope to speak with you all very soon.
우리는 이러한 논의의 중요성과 경외심을 불러일으키는 신기술의 개발 및 안전에 있어 OpenAI의 중심 역할을 이해하고 있습니다. 여러분 각자는 우리가 이러한 과제를 효과적으로 해결하는 데 중요한 역할을 합니다. 우리는 여러분의 의견을 듣고 배우기 위해 최선을 다하고 있으며 곧 여러분과 이야기를 나눌 수 있기를 바랍니다.
We are grateful to be a part of OpenAI, and excited to work with all of you.
OpenAI의 일원이 된 것을 감사하게 생각하며 여러분 모두와 함께 일하게 되어 기쁩니다.
June 9, 2019, chilling at the Florida beach. Snook, the biggest fish I've snagged in my 5 years of fishing adventures. That moment holding that fish, pure joy. Gotta keep living, making more of those happy times.
Chief technology officer Mira Murati appointed interim CEO to lead OpenAI; Sam Altman departs the company.
Search process underway to identify permanent successor.
최고 기술 책임자인 Mira Murati는 OpenAI를 이끌 임시 CEO로 임명되었습니다. 영구 후임자를 찾기 위한 검색 작업이 진행 중입니다. 샘 알트먼(Sam Altman)이 회사를 떠납니다.
The board of directors of OpenAI, Inc., the 501(c)(3) that acts as the overall governing body for all OpenAI activities, today announced that Sam Altman will depart as CEO and leave the board of directors. Mira Murati, the company’s chief technology officer, will serve as interim CEO, effective immediately.
모든 OpenAI 활동의 전반적인 관리 기관 역할을 하는 OpenAI, Inc.(501(c)(3))의 이사회는 오늘 Sam Altman이 CEO직을 떠나 이사회를 떠날 것이라고 발표했습니다. 회사의 최고 기술 책임자(CTO)인 미라 무라티(Mira Murati)가 임시 CEO로 즉각 취임할 예정입니.
A member of OpenAI’s leadership team for five years, Mira has played a critical role in OpenAI’s evolution into a global AI leader. She brings a unique skill set, understanding of the company’s values, operations, and business, and already leads the company’s research, product, and safety functions. Given her long tenure and close engagement with all aspects of the company, including her experience in AI governance and policy, the board believes she is uniquely qualified for the role and anticipates a seamless transition while it conducts a formal search for a permanent CEO.
5년 동안 OpenAI 리더십 팀의 일원이었던 Mira는 OpenAI가 글로벌 AI 리더로 발전하는 데 중요한 역할을 했습니다. 그녀는 독특한 기술과 회사의 가치, 운영 및 비즈니스에 대한 이해를 바탕으로 회사의 연구, 제품 및 안전 기능을 이끌고 있습니다. 그녀의 오랜 임기와 AI 거버넌스 및 정책 경험을 포함하여 회사의 모든 측면에 대한 긴밀한 참여를 고려할 때 이사회는 그녀가 해당 역할에 대한 고유한 자격을 갖추고 있다고 믿고 영구 CEO를 공식적으로 찾는 동안 원활한 전환을 기대합니다.
Mr. Altman’s departure follows a deliberative review process by the board, which concluded that he was not consistently candid in his communications with the board, hindering its ability to exercise its responsibilities. The board no longer has confidence in his ability to continue leading OpenAI.
알트먼 씨의 사임은 이사회의 심의 검토 과정에 따른 것이며, 이사회는 그가 이사회와의 의사소통에 일관되게 솔직하지 않아 이사회의 책임 수행 능력을 방해한다는 결론을 내렸습니다. 이사회는 더 이상 OpenAI를 계속 이끌 수 있는 그의 능력에 대해 확신을 갖지 못합니다.
In a statement, the board of directors said: “OpenAI was deliberately structured to advance our mission: to ensure that artificial general intelligence benefits all humanity. The board remains fully committed to serving this mission. We are grateful for Sam’s many contributions to the founding and growth of OpenAI. At the same time, we believe new leadership is necessary as we move forward. As the leader of the company’s research, product, and safety functions, Mira is exceptionally qualified to step into the role of interim CEO. We have the utmost confidence in her ability to lead OpenAI during this transition period.”
성명서에서 이사회는 “OpenAI는 인공 일반 지능이 모든 인류에게 이익이 되도록 보장한다는 우리의 사명을 발전시키기 위해 의도적으로 구성되었습니다. 이사회는 이 사명을 수행하기 위해 최선을 다하고 있습니다. OpenAI의 창립과 성장에 대한 Sam의 많은 기여에 감사드립니다. 동시에 우리는 앞으로 나아가기 위해서는 새로운 리더십이 필요하다고 믿습니다. 회사의 연구, 제품 및 안전 기능의 리더인 Mira는 임시 CEO 역할을 맡을 수 있는 특별한 자격을 갖추고 있습니다. 우리는 이 전환 기간 동안 OpenAI를 이끌 그녀의 능력에 대해 최고의 확신을 갖고 있습니다.”
OpenAI’s board of directors consists of OpenAI chief scientist Ilya Sutskever, independent directors Quora CEO Adam D’Angelo, technology entrepreneur Tasha McCauley, and Georgetown Center for Security and Emerging Technology’s Helen Toner.
OpenAI의 이사회는 OpenAI 수석 과학자 Ilya Sutskever, 사외 이사인 Quora CEO Adam D'Angelo, 기술 기업가 Tasha McCauley, Georgetown Center for Security and Emerging Technology의 Helen Toner로 구성되어 있습니다.
As a part of this transition, Greg Brockman will be stepping down as chairman of the board and will remain in his role at the company, reporting to the CEO.
이러한 전환의 일환으로 Greg Brockman은 이사회 의장직에서 물러나며 회사에서 CEO에게 보고하는 역할을 맡게 됩니다.
OpenAI was founded as a non-profit in 2015 with the core mission of ensuring that artificial general intelligence benefits all of humanity. In 2019, OpenAI restructured to ensure that the company could raise capital in pursuit of this mission, while preserving the nonprofit's mission, governance, and oversight. The majority of the board is independent, and the independent directors do not hold equity in OpenAI. While the company has experienced dramatic growth, it remains the fundamental governance responsibility of the board to advance OpenAI’s mission and preserve the principles of its Charter.
OpenAI는 인공 일반 지능이 모든 인류에게 혜택을 제공한다는 핵심 사명을 가지고 2015년 비영리 단체로 설립되었습니다. 2019년에 OpenAI는 비영리 단체의 사명, 거버넌스 및 감독을 유지하면서 회사가 이 사명을 추구하기 위해 자본을 조달할 수 있도록 구조 조정했습니다. 이사회의 대다수는 독립적이며, 독립 이사는 OpenAI에서 지분을 보유하지 않습니다. 회사는 극적인 성장을 경험했지만 OpenAI의 사명을 발전시키고 헌장의 원칙을 보존하는 것은 이사회의 근본적인 거버넌스 책임으로 남아 있습니다.
We are introducing OpenAI Data Partnerships, where we’ll work together with organizations to produce public and private datasets for training AI models.
우리는 조직과 협력하여 AI 모델 교육을 위한 공개 및 비공개 데이터 세트를 생성하는 OpenAI 데이터 파트너십을 도입합니다.
Modern AI technology learns skills and aspects of our world — of people, our motivations, interactions, and the way we communicate — by making sense of the data on which it’s trained. To ultimately make AGI that is safe and beneficial to all of humanity, we’d like AI models to deeply understand all subject matters, industries, cultures, and languages, which requires as broad a training dataset as possible.
현대 AI 기술은 훈련된 데이터를 이해함으로써 사람, 동기, 상호 작용, 의사소통 방식 등 세상의 기술과 측면을 학습합니다. 궁극적으로 인류 모두에게 안전하고 유익한 AGI를 만들기 위해 우리는 AI 모델이 모든 주제, 산업, 문화 및 언어를 깊이 이해하기를 원하며, 이를 위해서는 가능한 한 광범위한 교육 데이터 세트가 필요합니다.
Including your content can make AI models more helpful to you by increasing their understanding of your domain. We’re already working with many partners who are eager to represent data from their country or industry. For example, we recently partnered with theIcelandic GovernmentandMiðeind ehfto improve GPT-4’s ability to speak Icelandic by integrating their curated datasets. We also partnered with non-profit organizationFree Law Project, which aims to democratize access to legal understanding by including their large collection of legal documents in AI training. We know there may be many more who also want to contribute to the future of AI research while discovering the potential of their unique data.
콘텐츠를 포함하면 도메인에 대한 이해도를 높여 AI 모델이 더욱 유용해질 수 있습니다. 우리는 이미 해당 국가나 업계의 데이터를 대표하고자 하는 많은 파트너와 협력하고 있습니다. 예를 들어, 우리는 최근 아이슬란드 정부 및 Miðeind ehf와 협력하여 선별된 데이터 세트를 통합하여 GPT-4의 아이슬란드어 말하기 능력을 향상시켰습니다. 우리는 또한 AI 교육에 대규모 법률 문서 컬렉션을 포함시켜 법적 이해에 대한 접근을 민주화하는 것을 목표로 하는 비영리 단체인 Free Law Project와 파트너십을 맺었습니다. 우리는 고유한 데이터의 잠재력을 발견하면서 AI 연구의 미래에 기여하고 싶어하는 사람들이 더 많이 있을 수 있다는 것을 알고 있습니다.
Data Partnerships are intended to enable more organizations to help steer the future of AI and benefit from models that are more useful to them, by including content they care about.
데이터 파트너십은 더 많은 조직이 관심 있는 콘텐츠를 포함하여 AI의 미래를 주도하고 더 유용한 모델의 혜택을 누릴 수 있도록 하기 위한 것입니다.
The kinds of data we’re seeking
We’re interested in large-scale datasets that reflect human society and that are not already easily accessible online to the public today. We can work with any modality, including text, images, audio, or video. We’re particularly looking for data that expresses human intention (e.g. long-form writing or conversations rather than disconnected snippets), across any language, topic, and format.
우리는 인간 사회를 반영하고 오늘날 대중이 온라인으로 쉽게 접근할 수 없는 대규모 데이터 세트에 관심이 있습니다. 텍스트, 이미지, 오디오, 비디오 등 모든 형식으로 작업할 수 있습니다. 우리는 특히 모든 언어, 주제, 형식에 걸쳐 인간의 의도를 표현하는 데이터(예: 단절된 단편이 아닌 긴 형식의 글쓰기 또는 대화)를 찾고 있습니다.
We can work with data in almost any form and can use our next-generation in-house AI technology to help you digitize and structure your data. For example, we haveworld-class optical character recognition(OCR) technology to digitize files like PDFs, andautomatic speech recognition(ASR) to transcribe spoken words. If the data needs cleaning (e.g. has lots of auto-generated artifacts or transcription errors), we can work with your team to process it into the most useful form. We are not seeking datasets with sensitive or personal information, or information that belongs to a third party; we can work with you to remove this information if you need help.
우리는 거의 모든 형태의 데이터로 작업할 수 있으며 차세대 사내 AI 기술을 사용하여 데이터를 디지털화하고 구조화할 수 있습니다. 예를 들어, 우리는 PDF와 같은 파일을 디지털화하는 세계 최고 수준의 광학 문자 인식(OCR) 기술과 음성을 텍스트로 변환하는 자동 음성 인식(ASR) 기술을 보유하고 있습니다. 데이터를 정리해야 하는 경우(예: 자동 생성된 아티팩트 또는 전사 오류가 많은 경우) 팀과 협력하여 가장 유용한 형식으로 처리할 수 있습니다. 우리는 민감한 개인정보 또는 제3자 소유의 정보가 포함된 데이터 세트를 찾고 있지 않습니다. 도움이 필요한 경우 당사는 귀하와 협력하여 이 정보를 제거할 수 있습니다.
Ways to partner with us
We currently have two ways to partner, and may expand in the future:
현재 파트너 관계를 맺는 방법에는 두 가지가 있으며 향후 확장될 수 있습니다.
Open-Source Archive: We’re seeking partners to help us create an open-source dataset for training language models. This dataset would be public for anyone to use in AI model training. We would also explore using it to safely train additional open-source models ourselves. We believe open-source plays an important role in the ecosystem.
오픈 소스 아카이브: 우리는 언어 모델 훈련을 위한 오픈 소스 데이터 세트를 만드는 데 도움을 줄 파트너를 찾고 있습니다. 이 데이터 세트는 누구나 AI 모델 교육에 사용할 수 있도록 공개됩니다. 또한 이를 사용하여 추가적인 오픈 소스 모델을 직접 안전하게 교육하는 방법도 모색할 것입니다. 우리는 오픈 소스가 생태계에서 중요한 역할을 한다고 믿습니다.
Private Datasets: We are also preparing private datasets for training proprietary AI models, including our foundation models and fine-tuned and custom models. If you have data you wish to keep private, but you would like our AI models to have a better understanding of your domain (or you’d even just like to gauge the potential of your data to do so), this is the optimal way to partner. We’ll treat your data with the level of sensitivity and access controls that you prefer.
비공개 데이터세트: 우리는 또한 기초 모델과 미세 조정 및 사용자 정의 모델을 포함하여 독점 AI 모델을 교육하기 위한 비공개 데이터세트를 준비하고 있습니다. 비공개로 유지하고 싶은 데이터가 있지만 AI 모델이 도메인을 더 잘 이해하기를 원하는 경우(또는 그렇게 할 수 있는 데이터의 잠재력을 측정하고 싶은 경우) 이것이 최적의 방법입니다. 파트너에게. 우리는 귀하가 선호하는 민감도 및 액세스 제어 수준으로 귀하의 데이터를 처리합니다.
Overall, we are seeking partners who want to help us teach AI to understand our world in order to be maximally helpful to everyone. Together, we can move towards AGI that benefits all of humanity.
전반적으로 우리는 모든 사람에게 최대한 도움이 될 수 있도록 AI가 세상을 이해하도록 가르치는 데 도움을 주고 싶은 파트너를 찾고 있습니다. 우리는 함께 인류 모두에게 이익이 되는 AGI를 향해 나아갈 수 있습니다.
You can now create custom versions of ChatGPT that combine instructions, extra knowledge, and any combination of skills.
November 6, 2023
We’re rolling out custom versions of ChatGPT that you can create for a specific purpose—called GPTs. GPTs are a new way for anyone to create a tailored version of ChatGPT to be more helpful in their daily life, at specific tasks, at work, or at home—and then share that creation with others. For example, GPTs can help youlearn the rules to any board game, help teach your kids math, or design stickers.
특정 목적을 위해 생성할 수 있는 ChatGPT의 사용자 지정 버전(GPTs)이 출시됩니다. GPTs는 누구나 일상 생활, 특정 작업, 직장 또는 집에서 더 도움이 되도록 맞춤형 버전의 ChatGPT를 만들고 해당 창작물을 다른 사람들과 공유할 수 있는 새로운 방법입니다. 예를 들어, GPTs는 보드 게임의 규칙을 배우거나, 자녀에게 수학을 가르치거나, 스티커를 디자인하는 데 도움이 될 수 있습니다.
Anyone can easily build their own GPT—no coding is required. You can make them for yourself, just for your company’s internal use, or for everyone. Creating one is as easy as starting a conversation, giving it instructions and extra knowledge, and picking what it can do, like searching the web, making images or analyzing data. Try it out atchat.openai.com/create.
누구나 쉽게 자신만의 GPT를 구축할 수 있습니다. 코딩이 필요하지 않습니다. 회사 내부용으로만 사용할 수도 있고 모든 사람을 위해 만들 수도 있습니다. 대화를 시작하고, 지침과 추가 지식을 제공하고, 웹 검색, 이미지 만들기, 데이터 분석 등 할 수 있는 작업을 선택하는 것만큼 쉽습니다. chat.openai.com/create에서 사용해 보세요.
Example GPTs are available today for ChatGPT Plus and Enterprise users to try out includingCanvaandZapier AI Actions. We plan to offer GPTs to more users soon.
ChatGPT Plus 및 Enterprise 사용자는 오늘부터 Canva 및 Zapier AI 작업을 포함한 예제 GPTs를 사용해 볼 수 있습니다. 우리는 곧 더 많은 사용자에게 GPTs를 제공할 계획입니다.
새로운 모델 및 개발자 제품에 대한 것들은 OpenAI DevDay 에서의 발표에 대해 자세히 알아보세요.
GPTs let you customize ChatGPT for a specific purpose
Since launching ChatGPT people have been asking for ways to customize ChatGPT to fit specific ways that they use it. We launched Custom Instructions in July that let you set some preferences, but requests for more control kept coming. Many power users maintain a list of carefully crafted prompts and instruction sets, manually copying them into ChatGPT. GPTs now do all of that for you.
ChatGPT를 출시한 이후 사람들은 ChatGPT를 특정 사용 방식에 맞게 사용자 정의할 수 있는 방법을 요청해 왔습니다. 우리는 몇 가지 기본 설정을 지정할 수 있는 맞춤형 지침을 7월에 출시했지만 더 많은 제어 기능에 대한 요청이 계속해서 접수되었습니다. 많은 고급 사용자는 신중하게 제작된 프롬프트 및 지침 세트 목록을 유지 관리하고 이를 수동으로 ChatGPT에 복사합니다. 이제 GPTs가 이 모든 것을 대신해 드립니다.
The best GPTs will be invented by the community
We believe the most incredible GPTs will come from builders in the community. Whether you’re an educator, coach, or just someone who loves to build helpful tools, you don’t need to know coding to make one and share your expertise.
우리는 가장 놀라운 GPTs가 커뮤니티의 빌더들로부터 나올 것이라고 믿습니다. 교육자, 코치 또는 유용한 도구를 만드는 것을 좋아하는 사람이든 관계없이 도구를 만들고 전문 지식을 공유하기 위해 코딩을 알 필요는 없습니다.
The GPT Store is rolling out later this month
Starting today, you can create GPTs and share them publicly. Later this month, we’re launching the GPT Store, featuring creations by verified builders. Once in the store, GPTs become searchable and may climb the leaderboards. We will also spotlight the most useful and delightful GPTs we come across in categories like productivity, education, and “just for fun”. In the coming months, you’ll also be able to earn money based on how many people are using your GPT.
오늘부터 GPTs를 생성하고 공개적으로 공유할 수 있습니다. 이번 달 말에는 검증된 제작자의 창작물을 선보이는 GPT 스토어를 출시할 예정입니다. 매장에 들어가면 GPTs를 검색할 수 있으며 순위표에 오를 수 있습니다. 또한 생산성, 교육, '재미를 위한' 카테고리에서 가장 유용하고 즐거운 GPTs를 집중 조명할 것입니다. 앞으로 몇 달 안에 GPT를 사용하는 사람 수에 따라 수익을 얻을 수도 있습니다.
We built GPTs with privacy and safety in mind
As always, you are in control of your data with ChatGPT. Your chats with GPTs are not shared with builders. If a GPT uses third party APIs, you choose whether data can be sent to that API. When builders customize their own GPT with actions or knowledge, the builder can choose if user chats with that GPT can be used to improve and train our models. These choices build upon the existingprivacy controlsusers have, including the option to opt your entire account out of model training.
언제나 그렇듯이 ChatGPT를 사용하여 데이터를 제어할 수 있습니다. GPTs와의 채팅은 빌더와 공유되지 않습니다. GPTs가 타사 API를 사용하는 경우 해당 API로 데이터를 전송할 수 있는지 여부를 선택합니다. 빌더가 작업이나 지식으로 자신의 GPT를 맞춤설정할 때 빌더는 해당 GPT와의 사용자 채팅을 사용하여 모델을 개선하고 교육할 수 있는지 여부를 선택할 수 있습니다. 이러한 선택은 전체 계정을 모델 교육에서 제외하는 옵션을 포함하여 사용자가 보유한 기존 개인 정보 보호 제어를 기반으로 합니다.
We’ve set up new systems to help review GPTs against ourusage policies. These systems stack on top of our existing mitigations and aim to prevent users from sharing harmful GPTs, including those that involve fraudulent activity, hateful content, or adult themes. We’ve also taken steps to build user trust by allowing builders to verify their identity. We'll continue to monitor and learn how people use GPTs and update and strengthen our safety mitigations. If you have concerns with a specific GPT, you can also use our reporting feature on the GPT shared page to notify our team.
우리는 사용 정책에 따라 GPTs를 검토하는 데 도움이 되는 새로운 시스템을 설정했습니다. 이러한 시스템은 기존 완화 조치에 더해 사용자가 사기 행위, 증오성 콘텐츠, 성인용 테마와 관련된 유해한 GPTs를 공유하는 것을 방지하는 것을 목표로 합니다. 또한 건축업자가 자신의 신원을 확인할 수 있도록 허용하여 사용자 신뢰를 구축하기 위한 조치를 취했습니다. 우리는 사람들이 GPTs를 어떻게 사용하는지 계속 모니터링하고 학습하며 안전 완화 조치를 업데이트하고 강화할 것입니다. 특정 GPT에 대해 우려사항이 있는 경우 GPTs 공유 페이지의 신고 기능을 사용하여 우리의 팀에 알릴 수도 있습니다.
GPTs will continue to get more useful and smarter, and you’ll eventually be able to let them take on real tasks in the real world. In the field of AI, these systems are often discussed as “agents”. We think it’s important to move incrementally towards this future, as it will require careful technical and safety work—and time for society to adapt. We have been thinking deeply about the societal implications and will have more analysis to share soon.
GPTs는 계속해서 더욱 유용하고 스마트해질 것이며, 결국 GPT가 현실 세계에서 실제 작업을 수행하도록 할 수 있게 될 것입니다. AI 분야에서 이러한 시스템은 종종 "에이전트"로 논의됩니다. 우리는 이 미래를 향해 점진적으로 나아가는 것이 중요하다고 생각합니다. 왜냐하면 세심한 기술 및 안전 작업과 사회가 적응할 시간이 필요하기 때문입니다. 우리는 사회적 영향에 대해 깊이 생각해 왔으며 곧 더 많은 분석을 공유할 예정입니다.
Developers can connect GPTs to the real world
In addition to using our built-in capabilities, you can also define custom actions by making one or more APIs available to the GPT. Like plugins, actions allow GPTs to integrate external data or interact with the real-world. Connect GPTs to databases, plug them into emails, or make them your shopping assistant. For example, you could integrate a travel listings database, connect a user’s email inbox, or facilitate e-commerce orders.
The design of actions builds upon insights from our plugins beta, granting developers greater control over the model and how their APIs are called. Migrating from the plugins beta is easy with the ability to use your existing plugin manifest to define actions for your GPT.
내장된 기능을 사용하는 것 외에도 GPTs에서 하나 이상의 API를 사용할 수 있도록 하여 맞춤 작업을 정의할 수도 있습니다. 플러그인과 마찬가지로 작업을 통해 GPTs는 외부 데이터를 통합하거나 실제 세계와 상호 작용할 수 있습니다. GPTs를 데이터베이스에 연결하거나, 이메일에 연결하거나, 쇼핑 도우미로 활용하세요. 예를 들어 여행 목록 데이터베이스를 통합하거나, 사용자의 이메일 받은 편지함을 연결하거나, 전자 상거래 주문을 촉진할 수 있습니다.
Enterprise customers can deploy internal-only GPTs
Since we launched ChatGPT Enterprise a few months ago, early customers have expressed the desire for even more customization that aligns with their business. GPTs answer this call by allowing you to create versions of ChatGPT for specific use cases, departments, or proprietary datasets. Early customers like Amgen, Bain, and Square are already leveraging internal GPTs to do things like craft marketing materials embodying their brand, aid support staff with answering customer questions, or help new software engineers with onboarding.
몇 달 전 ChatGPT Enterprise를 출시한 이후 초기 고객들은 자신의 비즈니스에 맞는 더 많은 사용자 정의를 원했습니다. GPTs는 특정 사용 사례, 부서 또는 독점 데이터 세트에 대한 ChatGPT 버전을 생성할 수 있도록 하여 이 요청에 응답합니다. Amgen, Bain, Square와 같은 초기 고객은 이미 내부 GPTs를 활용하여 브랜드를 구현하는 마케팅 자료 제작, 지원 직원의 고객 질문 답변 지원, 신규 소프트웨어 엔지니어의 온보딩 지원 등의 작업을 수행하고 있습니다.
Enterprises can get started with GPTs on Wednesday. You can now empower users inside your company to design internal-only GPTs without code and securely publish them to your workspace. The admin console lets you choose how GPTs are shared and whether external GPTs may be used inside your business. Like all usage on ChatGPT Enterprise, we do not use your conversations with GPTs to improve our models.
기업은 수요일부터 GPTs를 시작할 수 있습니다. 이제 회사 내부 사용자가 코드 없이 내부 전용 GPTs를 설계하고 작업공간에 안전하게 게시할 수 있는 권한을 부여할 수 있습니다. 관리 콘솔을 사용하면 GPTs 공유 방법과 외부 GPTs를 비즈니스 내에서 사용할 수 있는지 여부를 선택할 수 있습니다. ChatGPT Enterprise의 모든 사용과 마찬가지로 우리는 모델을 개선하기 위해 GPTs와의 대화를 사용하지 않습니다.
We want more people to shape how AI behaves
We designed GPTs so more people can build with us. Involving the community is critical to our mission of building safe AGI that benefits humanity. It allows everyone to see a wide and varied range of useful GPTs and get a more concrete sense of what’s ahead. And by broadening the group of people who decide 'what to build' beyond just those with access to advanced technology it's likely we'll have safer and better aligned AI. The same desire to build with people, not just for them, drove us to launch the OpenAI API and to research methods for incorporating democratic input into AI behavior, which we plan to share more about soon.
우리는 더 많은 사람들이 우리와 함께 구축할 수 있도록 GPTs를 설계했습니다. 커뮤니티의 참여는 인류에게 이익이 되는 안전한 AGI를 구축하려는 우리의 사명에 매우 중요합니다. 이를 통해 모든 사람은 광범위하고 다양한 범위의 유용한 GPTs를 확인하고 앞으로의 상황에 대해 보다 구체적인 감각을 얻을 수 있습니다. 그리고 첨단 기술에 접근할 수 있는 사람들을 넘어 '무엇을 구축할지'를 결정하는 사람들의 그룹을 확대함으로써 우리는 더 안전하고 더 나은 AI를 갖게 될 가능성이 높습니다. 사람들을 위한 것이 아니라 사람들과 함께 구축하려는 동일한 열망으로 인해 우리는 OpenAI API를 출시하고 AI 행동에 민주적 입력을 통합하는 방법을 연구하게 되었으며 이에 대해 곧 더 자세히 공유할 계획입니다.
We’ve made ChatGPT Plus fresher and simpler to use
Finally, ChatGPT Plus now includes fresh information up to April 2023. We’ve also heard your feedback about how the model picker is a pain. Starting today, no more hopping between models; everything you need is in one place. You can access DALL·E, browsing, and data analysis all without switching. You can also attach files to let ChatGPT search PDFs and other document types. Find us atchatgpt.com.
마지막으로 ChatGPT Plus에는 이제 2023년 4월까지의 최신 정보가 포함됩니다. 모델 선택기가 얼마나 어려운지에 대한 피드백도 들었습니다. 오늘부터 더 이상 모델 간에 이동하지 않아도 됩니다. 필요한 모든 것이 한 곳에 있습니다. 전환 없이 DALL·E, 브라우징, 데이터 분석에 모두 액세스할 수 있습니다. ChatGPT가 PDF 및 기타 문서 유형을 검색할 수 있도록 파일을 첨부할 수도 있습니다. chatgpt.com에서 우리를 찾아보세요.
We released the first version of GPT-4 in March and made GPT-4 generally available to all developers in July. Today we’re launching a preview of the next generation of this model,GPT-4 Turbo.
우리는 3월에 GPT-4의 첫 번째 버전을 출시했으며 7월에 모든 개발자가 GPT-4를 일반적으로 사용할 수 있도록 했습니다. 오늘 우리는 이 모델의 차세대 모델인 GPT-4 Turbo의 미리보기를 출시합니다.
GPT-4 Turbo is more capable and has knowledge of world events up to April 2023. It has a 128k context window so it can fit the equivalent of more than 300 pages of text in a single prompt. We also optimized its performance so we are able to offer GPT-4 Turbo at a3x cheaperprice for input tokens and a 2x cheaper price for output tokens compared to GPT-4.
GPT-4 Turbo는 더 많은 능력을 갖추고 2023년 4월까지의 세계 사건에 대한 지식을 보유하고 있습니다. 128k 컨텍스트 창이 있으므로 단일 프롬프트에 300페이지 이상의 텍스트에 해당하는 내용을 넣을 수 있습니다. 또한 GPT-4에 비해 입력 토큰의 경우 3배, 출력 토큰의 경우 2배 저렴한 가격으로 GPT-4 Turbo를 제공할 수 있도록 성능을 최적화했습니다.
GPT-4 Turbo is available for all paying developers to try by passinggpt-4-1106-previewin the API and we plan to release the stable production-ready model in the coming weeks.
GPT-4 Turbo는 모든 유료 개발자가 API에서 gpt-4-1106-preview를 전달하여 사용해 볼 수 있으며 앞으로 몇 주 안에 안정적인 프로덕션 준비 모델을 출시할 계획입니다.
Function calling updates
Function callinglets you describe functions of your app or external APIs to models, and have the model intelligently choose to output a JSON object containing arguments to call those functions. We’re releasing several improvements today, including the ability to call multiple functions in a single message: users can send one message requesting multiple actions, such as “open the car window and turn off the A/C”, which would previously require multiple roundtrips with the model (learn more). We are also improving function calling accuracy: GPT-4 Turbo is more likely to return the right function parameters.
함수 호출을 사용하면 앱 또는 외부 API의 기능을 모델에 설명하고 모델이 이러한 함수를 호출하기 위한 인수가 포함된 JSON 개체를 출력하도록 지능적으로 선택하도록 할 수 있습니다. 우리는 오늘 단일 메시지로 여러 기능을 호출하는 기능을 포함하여 몇 가지 개선 사항을 출시합니다. 사용자는 이전에는 여러 번 필요했던 "차 창문을 열고 에어컨을 끄세요"와 같은 여러 작업을 요청하는 하나의 메시지를 보낼 수 있습니다. 모델과의 왕복 여행(자세히 알아보기) 또한 함수 호출 정확도도 향상되었습니다. GPT-4 Turbo는 올바른 함수 매개변수를 반환할 가능성이 더 높습니다.
Improved instruction following and JSON mode
GPT-4 Turbo performs better than our previous models on tasks that require the careful following of instructions, such as generating specific formats (e.g., “always respond in XML”). It also supports our newJSON mode, which ensures the model will respond with valid JSON. The new API parameterresponse_formatenables the model to constrain its output to generate a syntactically correct JSON object. JSON mode is useful for developers generating JSON in the Chat Completions API outside of function calling.
GPT-4 Turbo는 특정 형식 생성(예: "항상 XML로 응답")과 같이 지침을 주의 깊게 따라야 하는 작업에서 이전 모델보다 더 나은 성능을 발휘합니다. 또한 모델이 유효한 JSON으로 응답하도록 보장하는 새로운 JSON 모드도 지원합니다. 새로운 API 매개변수인 response_format을 사용하면 모델이 구문적으로 올바른 JSON 개체를 생성하도록 출력을 제한할 수 있습니다. JSON 모드는 함수 호출 외부에서 Chat Completions API에서 JSON을 생성하는 개발자에게 유용합니다.
Reproducible outputs and log probabilities
The newseedparameter enablesreproducible outputsby making the model return consistent completions most of the time. This beta feature is useful for use cases such as replaying requests for debugging, writing more comprehensive unit tests, and generally having a higher degree of control over the model behavior. We at OpenAI have been using this feature internally for our own unit tests and have found it invaluable. We’re excited to see how developers will use it.Learn more.
새로운 시드 매개변수는 모델이 대부분의 경우 일관된 완료를 반환하도록 하여 재현 가능한 출력을 가능하게 합니다. 이 베타 기능은 디버깅 요청 재생, 보다 포괄적인 단위 테스트 작성, 일반적으로 모델 동작에 대한 더 높은 수준의 제어와 같은 사용 사례에 유용합니다. OpenAI에서는 자체 단위 테스트를 위해 이 기능을 내부적으로 사용해 왔으며 이 기능이 매우 중요하다는 것을 알았습니다. 개발자들이 이를 어떻게 사용할지 기대됩니다. 더 알아보기.
We’re also launching a feature to return thelog probabilitiesfor the most likely output tokens generated by GPT-4 Turbo and GPT-3.5 Turbo in the next few weeks, which will be useful for building features such as autocomplete in a search experience.
또한 앞으로 몇 주 안에 GPT-4 Turbo 및 GPT-3.5 Turbo에서 생성된 가장 가능성이 높은 출력 토큰에 대한 로그 확률을 반환하는 기능을 출시할 예정입니다. 이는 검색 환경에서 자동 완성과 같은 기능을 구축하는 데 유용할 것입니다.
Updated GPT-3.5 Turbo
In addition to GPT-4 Turbo, we are also releasing a new version of GPT-3.5 Turbo that supports a 16K context window by default. The new 3.5 Turbo supports improved instruction following, JSON mode, and parallel function calling. For instance, our internal evals show a 38% improvement on format following tasks such as generating JSON, XML and YAML. Developers can access this new model by callinggpt-3.5-turbo-1106in the API. Applications using thegpt-3.5-turboname will automatically be upgraded to the new model on December 11. Older models will continue to be accessible by passinggpt-3.5-turbo-0613in the API until June 13, 2024.Learn more.
GPT-4 Turbo 외에도 기본적으로 16K 컨텍스트 창을 지원하는 GPT-3.5 Turbo의 새 버전도 출시하고 있습니다. 새로운 3.5 Turbo는 향상된 명령 따르기, JSON 모드 및 병렬 함수 호출을 지원합니다. 예를 들어 내부 평가에서는 JSON, XML, YAML 생성과 같은 작업에 따른 형식이 38% 개선된 것으로 나타났습니다. 개발자는 API에서 gpt-3.5-turbo-1106을 호출하여 이 새로운 모델에 액세스할 수 있습니다. gpt-3.5-turbo 이름을 사용하는 애플리케이션은 12월 11일에 새 모델로 자동 업그레이드됩니다. 이전 모델은 2024년 6월 13일까지 API에서 gpt-3.5-turbo-0613을 전달하여 계속 액세스할 수 있습니다. 자세히 알아보기
Assistants API, Retrieval, and Code Interpreter
Today, we’re releasing theAssistants API, our first step towards helping developers build agent-like experiences within their own applications. An assistant is a purpose-built AI that has specific instructions, leverages extra knowledge, and can call models and tools to perform tasks. The new Assistants API provides new capabilities such as Code Interpreter and Retrieval as well as function calling to handle a lot of the heavy lifting that you previously had to do yourself and enable you to build high-quality AI apps.
오늘 우리는 개발자가 자신의 애플리케이션 내에서 에이전트와 같은 경험을 구축할 수 있도록 돕기 위한 첫 번째 단계인 Assistants API를 출시합니다. 어시스턴트는 특정 지침이 있고, 추가 지식을 활용하며, 작업을 수행하기 위해 모델과 도구를 호출할 수 있는 특수 목적의 AI입니다. 새로운 Assistants API는 코드 해석기 및 검색과 같은 새로운 기능과 함수 호출을 제공하여 이전에 직접 수행해야 했던 많은 무거운 작업을 처리하고 고품질 AI 앱을 구축할 수 있도록 해줍니다.
This API is designed for flexibility; use cases range from a natural language-based data analysis app, a coding assistant, an AI-powered vacation planner, a voice-controlled DJ, a smart visual canvas—the list goes on. The Assistants API is built on the same capabilities that enableour new GPTs product: custom instructions and tools such as Code interpreter, Retrieval, and function calling.
이 API는 유연성을 위해 설계되었습니다. 사용 사례는 자연어 기반 데이터 분석 앱, 코딩 도우미, AI 기반 휴가 플래너, 음성 제어 DJ, 스마트 시각적 캔버스에 이르기까지 다양합니다. Assistants API는 새로운 GPT 제품을 활성화하는 것과 동일한 기능, 즉 코드 해석기, 검색, 함수 호출과 같은 맞춤 지침 및 도구를 기반으로 구축되었습니다.
A key change introduced by this API ispersistent and infinitely long threads, which allow developers to hand off thread state management to OpenAI and work around context window constraints. With the Assistants API, you simply add each new message to an existingthread.
이 API에 의해 도입된 주요 변경 사항은 개발자가 스레드 상태 관리를 OpenAI에 넘겨주고 컨텍스트 창 제약 조건을 해결할 수 있도록 하는 지속적이고 무한히 긴 스레드입니다. Assistants API를 사용하면 각각의 새 메시지를 기존 스레드에 추가하기만 하면 됩니다.
Assistants also have access to call new tools as needed, including:
보조자는 필요에 따라 다음을 포함한 새로운 도구를 호출할 수도 있습니다.
Code Interpreter: writes and runs Python code in a sandboxed execution environment, and can generate graphs and charts, and process files with diverse data and formatting. It allows your assistants to run code iteratively to solve challenging code and math problems, and more.
코드 해석기: 샌드박스 실행 환경에서 Python 코드를 작성 및 실행하고, 그래프와 차트를 생성하고, 다양한 데이터와 형식이 포함된 파일을 처리할 수 있습니다. 이를 통해 어시스턴트는 코드를 반복적으로 실행하여 까다로운 코드 및 수학 문제 등을 해결할 수 있습니다.
Retrieval: augments the assistant with knowledge from outside our models, such as proprietary domain data, product information or documents provided by your users. This means you don’t need to compute and store embeddings for your documents, or implement chunking and search algorithms. The Assistants API optimizes what retrieval technique to use based on our experience building knowledge retrieval in ChatGPT.
검색: 독점 도메인 데이터, 제품 정보 또는 사용자가 제공한 문서와 같은 모델 외부의 지식으로 어시스턴트를 강화합니다. 즉, 문서에 대한 임베딩을 계산하고 저장할 필요가 없으며 청크 분할 및 검색 알고리즘을 구현할 필요가 없습니다. Assistants API는 ChatGPT에서 지식 검색을 구축한 경험을 바탕으로 사용할 검색 기술을 최적화합니다.
Function calling: enables assistants to invoke functions you define and incorporate the function response in their messages.
함수 호출: 어시스턴트가 사용자가 정의한 함수를 호출하고 메시지에 함수 응답을 통합할 수 있습니다.
As with the rest of the platform, data and files passed to the OpenAI API arenever used to train our modelsand developers can delete the data when they see fit.
플랫폼의 나머지 부분과 마찬가지로 OpenAI API에 전달된 데이터와 파일은 모델을 교육하는 데 사용되지 않으며 개발자는 적절하다고 판단되는 경우 데이터를 삭제할 수 있습니다.
You can try the Assistants API beta without writing any code by heading to theAssistants playground.
Assistants 놀이터로 이동하면 코드를 작성하지 않고도 Assistants API 베타를 사용해 볼 수 있습니다.
The Assistants API is in beta and available to all developers starting today. Please share what you build with us (@OpenAI) along with your feedback which we will incorporate as we continue building over the coming weeks. Pricing for the Assistants APIs and its tools is availableon our pricing page.
Assistants API는 베타 버전이며 오늘부터 모든 개발자가 사용할 수 있습니다. 앞으로 몇 주 동안 계속해서 구축하면서 반영할 피드백과 함께 여러분이 구축한 내용을 우리(@OpenAI)와 공유해 주세요. Assistants API 및 해당 도구의 가격은 가격 페이지에서 확인할 수 있습니다.
New modalities in the API
GPT-4 Turbo with vision
GPT-4 Turbo can accept images as inputs in the Chat Completions API, enabling use cases such as generating captions, analyzing real world images in detail, and reading documents with figures. For example, BeMyEyes uses this technology to help people who are blind or have low vision with daily tasks like identifying a product or navigating a store. Developers can access this feature by usinggpt-4-vision-previewin the API. We plan to roll out vision support to the main GPT-4 Turbo model as part of its stable release.Pricingdepends on the input image size. For instance, passing an image with 1080×1080 pixels to GPT-4 Turbo costs $0.00765. Check outour vision guide.
GPT-4 Turbo는 이미지를 Chat Completions API의 입력으로 받아들여 캡션 생성, 실제 이미지 세부 분석, 그림이 포함된 문서 읽기 등의 사용 사례를 지원합니다. 예를 들어, BeMyEyes는 이 기술을 사용하여 시각 장애가 있거나 시력이 낮은 사람들이 제품 식별이나 매장 탐색과 같은 일상 업무를 수행할 수 있도록 돕습니다. 개발자는 API에서 gpt-4-vision-preview를 사용하여 이 기능에 액세스할 수 있습니다. 우리는 안정적인 릴리스의 일부로 주요 GPT-4 Turbo 모델에 비전 지원을 출시할 계획입니다. 가격은 입력 이미지 크기에 따라 다릅니다. 예를 들어 1080×1080 픽셀의 이미지를 GPT-4 Turbo로 전달하는 데 드는 비용은 $0.00765입니다. 비전 가이드를 확인해 보세요.
DALL·E 3
Developers can integrate DALL·E 3, which werecently launchedto ChatGPT Plus and Enterprise users, directly into their apps and products through our Images API by specifyingdall-e-3as the model. Companies like Snap, Coca-Cola, and Shutterstock have used DALL·E 3 to programmatically generate images and designs for their customers and campaigns. Similar to the previous version of DALL·E, the API incorporates built-in moderation to help developers protect their applications against misuse. We offer different format and quality options, with prices starting at $0.04 per image generated. Check out ourguide to getting startedwith DALL·E 3 in the API.
개발자는 dall-e-3를 모델로 지정하여 Images API를 통해 최근 ChatGPT Plus 및 Enterprise 사용자에게 출시된 DALL·E 3를 앱과 제품에 직접 통합할 수 있습니다. Snap, Coca-Cola, Shutterstock과 같은 회사에서는 DALL·E 3를 사용하여 고객과 캠페인을 위한 이미지와 디자인을 프로그래밍 방식으로 생성했습니다. 이전 버전의 DALL·E와 마찬가지로 API에는 개발자가 응용 프로그램을 오용으로부터 보호할 수 있도록 조정 기능이 내장되어 있습니다. 우리는 생성된 이미지당 $0.04부터 시작하는 가격으로 다양한 형식과 품질 옵션을 제공합니다. API에서 DALL·E 3을 시작하는 방법에 대한 가이드를 확인하세요.
Text-to-speech (TTS)
Developers can now generate human-quality speech from text via the text-to-speech API. Our new TTS model offers six preset voices to choose from and two model variants,tts-1andtts-1-hd.ttsis optimized for real-time use cases andtts-1-hdis optimized for quality. Pricing starts at $0.015 per input 1,000 characters. Check out ourTTS guideto get started.
이제 개발자는 텍스트 음성 변환 API를 통해 텍스트에서 인간 수준의 음성을 생성할 수 있습니다. 새로운 TTS 모델은 선택할 수 있는 6개의 사전 설정 음성과 2개의 모델 변형인 tts-1 및 tts-1-hd를 제공합니다. tts는 실시간 사용 사례에 최적화되어 있고 tts-1-hd는 품질에 최적화되어 있습니다. 가격은 입력 1,000자당 $0.015부터 시작됩니다. 시작하려면 TTS 가이드를 확인하세요.
Listen to voice samples
Select text Scenic Directions Technical Recipe
As the golden sun dips below the horizon, casting long shadows across the tranquil meadow, the world seems to hush, and a sense of calmness envelops the Earth, promising a peaceful night’s rest for all living beings.
We’re creating an experimental access program forGPT-4 fine-tuning. Preliminary results indicate that GPT-4 fine-tuning requires more work to achieve meaningful improvements over the base model compared to the substantial gains realized with GPT-3.5 fine-tuning. As quality and safety for GPT-4 fine-tuning improves, developers actively using GPT-3.5 fine-tuning will be presented with an option to apply to the GPT-4 program within theirfine-tuning console.
우리는 GPT-4 미세 조정을 위한 실험적인 액세스 프로그램을 만들고 있습니다. 예비 결과에 따르면 GPT-4 미세 조정은 GPT-3.5 미세 조정을 통해 실현된 상당한 이득에 비해 기본 모델에 비해 의미 있는 개선을 달성하기 위해 더 많은 작업이 필요합니다. GPT-4 미세 조정의 품질과 안전성이 향상됨에 따라 GPT-3.5 미세 조정을 적극적으로 사용하는 개발자에게는 미세 조정 콘솔 내에서 GPT-4 프로그램에 적용할 수 있는 옵션이 제공됩니다.
Custom models
For organizations that need even more customization than fine-tuning can provide (particularly applicable to domains with extremely large proprietary datasets—billions of tokens at minimum), we’re also launching aCustom Models program, giving selected organizations an opportunity to work with a dedicated group of OpenAI researchers to train custom GPT-4 to their specific domain. This includes modifying every step of the model training process, from doing additional domain specific pre-training, to running a custom RL post-training process tailored for the specific domain. Organizations will have exclusive access to their custom models. In keeping with our existing enterprise privacy policies, custom models will not be served to or shared with other customers or used to train other models. Also, proprietary data provided to OpenAI to train custom models will not be reused in any other context. This will be a very limited (and expensive) program to start—interested orgs canapply here.
미세 조정이 제공할 수 있는 것보다 훨씬 더 많은 사용자 정의가 필요한 조직을 위해(특히 극도로 큰 독점 데이터 세트(최소 수십억 개의 토큰)가 있는 도메인에 적용 가능)를 위해 우리는 또한 사용자 정의 모델 프로그램을 출시하여 일부 조직에 특정 도메인에 맞게 맞춤형 GPT-4를 교육하는 OpenAI 연구원 전용 그룹입니다. 여기에는 추가 도메인별 사전 교육 수행부터 특정 도메인에 맞춰진 사용자 정의 RL 사후 교육 프로세스 실행까지 모델 교육 프로세스의 모든 단계를 수정하는 것이 포함됩니다. 조직은 맞춤형 모델에 독점적으로 액세스할 수 있습니다. 기존 기업 개인 정보 보호 정책에 따라 사용자 지정 모델은 다른 고객에게 제공 또는 공유되지 않으며 다른 모델을 교육하는 데 사용되지 않습니다. 또한 맞춤형 모델을 훈련하기 위해 OpenAI에 제공된 독점 데이터는 다른 어떤 맥락에서도 재사용되지 않습니다. 이는 시작하기에 매우 제한적이고 비용이 많이 드는 프로그램입니다. 관심 있는 조직은 여기에서 신청할 수 있습니다.
Lower prices and higher rate limits
Lower prices
We’redecreasing several pricesacross the platform to pass on savings to developers (all prices below are expressed per 1,000 tokens):
우리는 개발자에게 절감액을 전달하기 위해 플랫폼 전반에 걸쳐 여러 가지 가격을 인하하고 있습니다(아래의 모든 가격은 1,000개 토큰당 표시됩니다).
GPT-4 Turbo input tokens are 3x cheaper than GPT-4 at $0.01 and output tokens are 2x cheaper at $0.03.
GPT-4 Turbo 입력 토큰은 $0.01로 GPT-4보다 3배 저렴하고, 출력 토큰은 $0.03으로 2배 저렴합니다.
GPT-3.5 Turbo input tokens are 3x cheaper than the previous 16K model at $0.001 and output tokens are 2x cheaper at $0.002. Developers previously using GPT-3.5 Turbo 4K benefit from a 33% reduction on input tokens at $0.001. Those lower prices only apply to the new GPT-3.5 Turbo introduced today.
GPT-3.5 Turbo 입력 토큰은 $0.001로 이전 16K 모델보다 3배 저렴하고, 출력 토큰은 $0.002로 2배 저렴합니다. 이전에 GPT-3.5 Turbo 4K를 사용하는 개발자는 $0.001로 입력 토큰이 33% 감소되는 이점을 누릴 수 있습니다. 이러한 저렴한 가격은 오늘 출시된 새로운 GPT-3.5 Turbo에만 적용됩니다.
Fine-tuned GPT-3.5 Turbo 4K model input tokens are reduced by 4x at $0.003 and output tokens are 2.7x cheaper at $0.006. Fine-tuning also supports 16K context at the same price as 4K with the new GPT-3.5 Turbo model. These new prices also apply to fine-tunedgpt-3.5-turbo-0613models.
미세 조정된 GPT-3.5 Turbo 4K 모델 입력 토큰은 $0.003로 4배 감소하고 출력 토큰은 $0.006으로 2.7배 저렴합니다. 미세 조정은 새로운 GPT-3.5 Turbo 모델을 통해 4K와 동일한 가격으로 16K 컨텍스트도 지원합니다. 이 새로운 가격은 미세 조정된 gpt-3.5-turbo-0613 모델에도 적용됩니다.
Higher rate limits
To help you scale your applications, we’re doubling the tokens per minute limit for all our paying GPT-4 customers. You can view your new rate limits in yourrate limit page. We’ve also published ourusage tiersthat determine automatic rate limits increases, so you know what to expect in how your usage limits will automatically scale. You can now request increases to usage limits from youraccount settings.
애플리케이션 확장을 돕기 위해 모든 유료 GPT-4 고객의 분당 토큰 한도를 두 배로 늘립니다. 비율 제한 페이지에서 새로운 비율 제한을 볼 수 있습니다. 또한 자동 요금 한도 증가를 결정하는 사용량 계층을 게시했으므로 사용량 한도가 자동으로 확장되는 방식에 대해 예상할 수 있습니다. 이제 계정 설정에서 사용 한도 증가를 요청할 수 있습니다.
Copyright Shield
OpenAI is committed to protecting our customers with built-in copyright safeguards in our systems. Today, we’re going one step further and introducing Copyright Shield—we will now step in and defend our customers, and pay the costs incurred, if you face legal claims around copyright infringement. This applies to generally available features of ChatGPT Enterprise and our developer platform.
OpenAI는 시스템에 내장된 저작권 보호 장치를 통해 고객을 보호하기 위해 최선을 다하고 있습니다. 오늘 우리는 한 단계 더 나아가 저작권 보호(Copyright Shield)를 도입합니다. 이제 저작권 침해에 대한 법적 소송이 제기될 경우 우리가 개입하여 고객을 보호하고 발생한 비용을 지불할 것입니다. 이는 ChatGPT Enterprise 및 개발자 플랫폼의 일반적으로 사용 가능한 기능에 적용됩니다.
Whisper v3 and Consistency Decoder
We are releasingWhisper large-v3,the next version of our open source automatic speech recognition model (ASR) which features improved performance across languages. We also plan to support Whisper v3 in our API in the near future.
우리는 언어 전반에 걸쳐 향상된 성능을 제공하는 오픈 소스 자동 음성 인식 모델(ASR)의 다음 버전인 Whisper Large-v3를 출시합니다. 또한 가까운 시일 내에 API에서 Whisper v3를 지원할 계획입니다.
We are also open sourcing theConsistency Decoder, a drop in replacement for the Stable Diffusion VAE decoder. This decoder improves all images compatible with the by Stable Diffusion 1.0+ VAE, with significant improvements in text, faces and straight lines.
우리는 또한 Stable Diffusion VAE 디코더를 대체하는 Consistency Decoder를 오픈 소스화하고 있습니다. 이 디코더는 Stable Diffusion 1.0+ VAE와 호환되는 모든 이미지를 개선하여 텍스트, 얼굴 및 직선이 크게 향상되었습니다.