
https://d2l.ai/chapter_attention-mechanisms-and-transformers/large-pretraining-transformers.html
11.9. Large-Scale Pretraining with Transformers — Dive into Deep Learning 1.0.0-beta0 documentation
d2l.ai
11.9. Large-Scale Pretraining with Transformers
So far in our image classification and machine translation experiments, models were trained on datasets with input-output examples from scratch to perform specific tasks. For example, a Transformer was trained with English-French pairs (Section 11.7) so that this model can translate input English text into French. As a result, each model becomes a specific expert that is sensitive to even slight shift in data distribution (Section 4.7). For better generalized models, or even more competent generalists that can perform multiple tasks with or without adaptation, pretraining models on large data has been increasingly common.
지금까지 이미지 분류 및 기계 번역 실험에서 모델은 특정 작업을 수행하기 위해 처음부터 입력-출력 예제가 있는 데이터 세트에 대해 훈련되었습니다. 예를 들어 Transformer는 이 모델이 입력 영어 텍스트를 프랑스어로 번역할 수 있도록 영어-프랑스어 쌍(섹션 11.7)으로 훈련되었습니다. 결과적으로 각 모델은 데이터 분포의 약간의 변화에도 민감한 특정 전문가가 됩니다(섹션 4.7). 더 나은 일반화 모델 또는 적응 여부에 관계없이 여러 작업을 수행할 수 있는 더 유능한 제너럴리스트를 위해 대용량 데이터에 대한 모델 사전 훈련이 점점 보편화되었습니다.
Given larger data for pretraining, the Transformer architecture performs better with an increased model size and training compute, demonstrating superior scaling behavior. Specifically, performance of Transformer-based language models scales as a power-law with the amount of model parameters, training tokens, and training compute (Kaplan et al., 2020). The scalability of Transformers is also evidenced by the significantly boosted performance from larger vision Transformers trained on larger data (discussed in Section 11.8). More recent success stories include Gato, a generalist model that can play Atari, caption images, chat, and act as a robot (Reed et al., 2022). Gato is a single Transformer that scales well when pretrained on diverse modalities, including text, images, joint torques, and button presses. Notably, all such multi-modal data is serialized into a flat sequence of tokens, which can be processed akin to text tokens (Section 11.7) or image patches (Section 11.8) by Transformers.
사전 교육을 위한 더 큰 데이터가 주어지면 Transformer 아키텍처는 모델 크기와 교육 컴퓨팅이 증가하여 더 나은 성능을 발휘하여 우수한 확장 동작을 보여줍니다. 특히 Transformer 기반 언어 모델의 성능은 모델 매개변수, 교육 토큰 및 교육 컴퓨팅의 양에 따라 power-law으로 확장됩니다(Kaplan et al., 2020). Transformers의 확장성은 또한 더 큰 데이터에 대해 훈련된 더 큰 비전 Transformers의 성능이 크게 향상된 것으로 입증됩니다(11.8절에서 설명). 보다 최근의 성공 사례로는 Atari를 플레이하고, 이미지에 캡션을 달고, 채팅하고, 로봇 역할을 할 수 있는 일반 모델인 Gato가 있습니다(Reed et al., 2022). Gato는 텍스트, 이미지, 조인트 토크 및 버튼 누름을 비롯한 다양한 양식에 대해 사전 훈련되었을 때 잘 확장되는 단일 Transformer입니다. 특히 이러한 모든 다중 모달 데이터는 트랜스포머에 의해 텍스트 토큰(11.7절) 또는 이미지 패치(11.8절)와 유사하게 처리될 수 있는 토큰의 플랫 시퀀스로 직렬화됩니다.
Power-law 란?
The power-law, also known as a power-law distribution or scaling law, refers to a mathematical relationship between two quantities in which one quantity's value is proportional to a power of the other. In other words, a power-law distribution describes a relationship where the frequency of an event (or the occurrence of a value) decreases rapidly as the event becomes more frequent or the value becomes larger.
'Power-law', 또는 'power-law 분포' 또는 'scaling law'는 두 quantities 사이의 수학적 관계를 나타내며, 한 quantity 의 값이 다른 quantity 의 거듭제곱에 비례하는 관계를 의미합니다. 다시 말해, power-law 분포는 어떤 사건의 빈도(또는 값의 발생)가 해당 사건이 더 자주 발생하거나 값이 더 크면 빠르게 감소하는 관계를 설명합니다.
Mathematically, a power-law relationship can be expressed as:
수학적으로 power-law 관계는 다음과 같이 표현할 수 있습니다:
Here, represents the probability or frequency of the event or value , and is the exponent that determines the rate of decrease. A smaller value of leads to a slower decrease, while a larger value of leads to a faster decrease.
여기서 는 사건 또는 값 의 확률 또는 빈도를 나타내며, 는 감소율을 결정하는 지수입니다. 값이 작을수록 감소가 느리게 진행되며, 값이 클수록 빠르게 감소합니다.
Power-law distributions are common in various natural, social, and economic systems. They are characterized by a few highly frequent events or values (often referred to as "hubs" or "outliers") and many less frequent events or values. This distribution is also known as a "long-tailed" distribution because the tail of the distribution extends over a wide range of values.
Power-law 분포는 자연, 사회, 경제 시스템에서 일반적으로 나타나며, 몇 개의 높은 빈도 사건 또는 값(일반적으로 "허브" 또는 "아웃라이어"로 불림)과 많은 낮은 빈도 사건 또는 값이 특징입니다. 이 분포는 종종 "긴 꼬리" 분포로 알려져 있습니다. 분포의 꼬리 부분이 넓은 범위의 값을 포함하기 때문입니다.
Examples of phenomena that exhibit power-law distributions include the distribution of income, city sizes, word frequencies in texts, earthquake magnitudes, and the number of links in online networks like the Internet. The study of power-law distributions is essential in understanding the behavior and dynamics of complex systems and networks.
수입 분포, 도시 규모, 텍스트에서의 단어 빈도, 지진 규모, 인터넷과 같은 온라인 네트워크의 링크 수 등 다양한 자연, 사회 및 경제 현상에서 power-law 분포가 나타납니다. power-law 분포의 연구는 복잡한 시스템과 네트워크의 동작과 역학을 이해하는 데 중요합니다.
Before compelling success of pretraining Transformers for multi-modal data, Transformers were extensively pretrained with a wealth of text. Originally proposed for machine translation, the Transformer architecture in Fig. 11.7.1 consists of an encoder for representing input sequences and a decoder for generating target sequences. Primarily, Transformers can be used in three different modes: encoder-only, encoder-decoder, and decoder-only. To conclude this chapter, we will review these three modes and explain the scalability in pretraining Transformers.
multi-modal data에 대한 Transformers의 사전 교육이 성공하기 전에 Transformers는 풍부한 텍스트로 광범위하게 사전 교육을 받았습니다. 원래 기계 번역을 위해 제안된 그림 11.7.1의 Transformer 아키텍처는 입력 시퀀스를 나타내는 인코더와 대상 시퀀스를 생성하는 디코더로 구성됩니다. 기본적으로 트랜스포머는 encoder-only, encoder-decoder, and decoder-only 의 세 가지 모드로 사용할 수 있습니다. 이 장을 마무리하기 위해 이 세 가지 모드를 검토하고 Transformer를 사전 훈련할 때의 확장성을 설명합니다.
Multi Modal 이란?
'Multi-modal'은 여러 가지 다른 형태, 유형 또는 모드가 함께 존재하는 상황이나 시스템을 나타내는 용어입니다. 이 용어는 다양한 정보나 자료 소스가 혼합되어 하나의 전체를 구성하는 경우를 가리킵니다. 다른 말로 하면, 다양한 모드나 형태가 복합적으로 존재하여 상호작용하거나 조합되는 상황을 말합니다.
예를 들어, 'multi-modal data'는 여러 유형의 데이터가 함께 존재하는 경우를 의미합니다. 이러한 데이터는 텍스트, 이미지, 음성 등 다양한 형식의 정보를 포함할 수 있습니다. 머신러닝이나 딥러닝 분야에서 'multi-modal learning'은 여러 종류의 데이터로부터 모델을 학습시키는 기술을 의미합니다. 이러한 방식으로 학습된 모델은 다양한 유형의 정보를 통합하여 더 풍부한 표현을 생성하거나 복잡한 문제를 해결하는 데 사용될 수 있습니다.
또한 'multi-modal'은 감각적인 정보나 경험의 다양성을 나타낼 때도 사용될 수 있습니다. 예를 들어, 'multi-modal perception'은 시각, 청각, 후각, 촉각 등 다양한 감각 정보를 통해 환경을 인식하는 능력을 의미합니다.
BERT란?
BERT, which stands for "Bidirectional Encoder Representations from Transformers," is a revolutionary pre-trained language model developed by Google AI (Google Research) in 2018. BERT has significantly advanced the field of natural language processing (NLP) and has had a profound impact on various NLP tasks.
BERT는 "Bidirectional Encoder Representations from Transformers"의 약자로, 2018년 Google AI(구글 연구소)에서 개발한 혁신적인 사전 훈련 언어 모델입니다. BERT는 자연어 처리(NLP) 분야를 혁신하며 다양한 NLP 작업에 깊은 영향을 미쳤습니다.
Here are some key features and concepts related to BERT:
다음은 BERT에 관련한 주요 기능과 개념입니다:
- Transformer Architecture: BERT is built upon the Transformer architecture, which is a type of neural network architecture specifically designed for handling sequences of data, such as sentences or paragraphs. The Transformer architecture incorporates self-attention mechanisms that allow it to capture contextual relationships among words in a sentence.
트랜스포머 아키텍처: BERT는 트랜스포머 아키텍처를 기반으로 구축되었으며, 문장이나 단락과 같은 시퀀스 데이터를 처리하는 데 특화된 신경망 아키텍처입니다. 트랜스포머 아키텍처는 self-attention 메커니즘을 포함하며 문장 내 단어 간의 문맥 관계를 파악할 수 있습니다. - Bidirectional Context: One of the most important features of BERT is that it's bidirectional, meaning it reads text in both directions (left-to-right and right-to-left) during training. This allows the model to have a better understanding of the context in which a word appears.
양방향 문맥: BERT의 가장 중요한 특징 중 하나는 양방향입니다. 이는 모델이 학습 중에 텍스트를 양방향(왼쪽에서 오른쪽으로, 오른쪽에서 왼쪽으로)으로 읽는다는 것을 의미합니다. 이로써 모델은 단어가 문맥 내에서 어떻게 나타나는지에 대한 더 나은 이해를 갖게 됩니다. - Pre-training and Fine-tuning: BERT is pre-trained on a massive amount of text data using two unsupervised tasks: masked language modeling and next sentence prediction. In masked language modeling, random words in a sentence are masked, and the model is trained to predict those masked words. In next sentence prediction, the model learns to predict whether two sentences follow each other logically.
사전 훈련 및 세부 조정: BERT는 무언어 학습 작업 중 두 가지 비지도 작업인 마스크된 언어 모델링과 다음 문장 예측으로 대량의 텍스트 데이터에 사전 훈련됩니다. 마스크된 언어 모델링에서 문장 내의 무작위 단어가 마스크되고, 모델은 해당 마스크된 단어를 예측하도록 훈련됩니다. 다음 문장 예측에서는 두 문장이 논리적으로 이어지는지를 예측하는 방식으로 학습합니다. - Contextualized Word Representations: BERT generates contextualized word representations, which means that the representation of a word depends on its surrounding words in a sentence. This allows the model to capture various nuances and polysemy in language.
문맥화된 단어 표현: BERT는 문맥화된 단어 표현을 생성하며, 단어의 표현이 문장 내 주변 단어에 따라 다릅니다. 이를 통해 모델은 언어의 다양한 뉘앙스와 일어날 수 있는 다의성을 포착할 수 있습니다. - Transfer Learning: BERT's pre-trained model can be fine-tuned on specific downstream tasks with smaller amounts of task-specific data. This transfer learning approach has been shown to yield impressive results on a wide range of NLP tasks, such as text classification, named entity recognition, question answering, sentiment analysis, and more.
전이 학습: BERT의 사전 훈련된 모델은 작은 양의 과제 특화 데이터로 세부적인 다운스트림 작업에 대해 세밀하게 조정될 수 있습니다. 이러한 전이 학습 방식은 다양한 NLP 작업(텍스트 분류, 개체명 인식, 질문 응답, 감정 분석 등)에서 놀라운 결과를 얻을 수 있도록 해주었습니다. - Transformer Layers: BERT consists of multiple layers of Transformer encoders. Each layer processes the input sequence and passes it through self-attention mechanisms and feed-forward neural networks, enhancing the model's ability to capture complex relationships.
트랜스포머 레이어: BERT는 여러 개의 트랜스포머 인코더 레이어로 구성됩니다. 각 레이어는 입력 시퀀스를 처리하고 자기 어텐션 메커니즘과 피드포워드 신경망을 통과시켜 복잡한 관계를 포착하는 능력을 향상시킵니다. - Large Scale: BERT was initially released in two versions: BERT-base and BERT-large. The "large" version has more parameters and is capable of capturing more nuanced patterns in the text but requires more computational resources.
대규모 규모: BERT는 초기에 BERT-base와 BERT-large 두 가지 버전으로 출시되었습니다. "large" 버전은 매개변수가 더 많고 텍스트 내에서 더 미묘한 패턴을 포착할 수 있지만, 더 많은 컴퓨팅 자원이 필요합니다. - Contextualized Word Embeddings: BERT produces contextualized word embeddings, which are highly useful for downstream tasks. These embeddings capture not only syntactic information but also semantic relationships between words.
문맥화된 단어 임베딩: BERT는 문맥화된 단어 임베딩을 생성하며, 이는 하위 작업에 매우 유용합니다. 이러한 임베딩은 구문 정보 뿐만 아니라 단어 간의 의미적 관계를 포착합니다.
BERT's success has led to the development of various other transformer-based models like GPT (Generative Pre-trained Transformer), RoBERTa, XLNet, and more. These models have achieved state-of-the-art results on a wide array of NLP benchmarks and continue to drive advancements in the field.
BERT의 성공은 GPT(Generative Pre-trained Transformer), RoBERTa, XLNet 등과 같은 다양한 트랜스포머 기반 모델의 개발을 이끌었습니다. 이러한 모델은 다양한 NLP 벤치마크에서 최첨단 결과를 달성하고, 계속해서 이 분야의 발전을 주도하고 있습니다.
11.9.1. Encoder-Only
When only the Transformer encoder is used, a sequence of input tokens is converted into the same number of representations that can be further projected into output (e.g., classification). A Transformer encoder consists of self-attention layers, where all input tokens attend to each other. For example, vision Transformers depicted in Fig. 11.8.1 are encoder-only, converting a sequence of input image patches into the representation of a special “<cls>” token. Since this representation depends on all input tokens, it is further projected into classification labels. This design was inspired by an earlier encoder-only Transformer pretrained on text: BERT (Bidirectional Encoder Representations from Transformers) (Devlin et al., 2018).
Transformer encoder만 사용되는 경우 입력 토큰 시퀀스는 출력(예: 분류)으로 추가로 투영될 수 있는 동일한 수의 representations 으로 변환됩니다. Transformer 인코더는 모든 입력 토큰이 서로 attend 하는 self-attention layers으로 구성됩니다. 예를 들어 그림 11.8.1에 묘사된 비전 트랜스포머는 인코더 전용이며 일련의 입력 이미지 패치를 특수 "<cls>" 토큰의 representation 으로 변환합니다. 이 representation 은 모든 입력 토큰에 따라 달라지므로 분류 레이블에 추가로 투영됩니다. 이 디자인은 BERT(Bidirectional Encoder Representations from Transformers)(Devlin et al., 2018)라는 텍스트로 사전 훈련된 초기 인코더 전용 Transformer에서 영감을 받았습니다.
11.9.1.1. Pretraining BERT

BERT is pretrained on text sequences using masked language modeling: input text with randomly masked tokens is fed into a Transformer encoder to predict the masked tokens. As illustrated in Fig. 11.9.1, an original text sequence “I”, “love”, “this”, “red”, “car” is prepended with the “<cls>” token, and the “<mask>” token randomly replaces “love”; then the cross-entropy loss between the masked token “love” and its prediction is to be minimized during pretraining. Note that there is no constraint in the attention pattern of Transformer encoders (right of Fig. 11.9.1) so all tokens can attend to each other. Thus, prediction of “love” depends on input tokens before and after it in the sequence. This is why BERT is a “bidirectional encoder”. Without need for manual labeling, large-scale text data from books and Wikipedia can be used for pretraining BERT.
BERT는 masked language modeling을 사용하여 텍스트 시퀀스에 대해 사전 학습된 모델입니다. 임의로 마스킹된 토큰이 있는 입력 텍스트는 masked tokens을 예측하기 위해 Transformer 인코더에 공급됩니다. 그림 11.9.1과 같이 원본 텍스트 시퀀스 "I", "love", "this", "red", "car" 앞에 "<cls>" 토큰이 추가되고 "<mask>" 토큰은 무작위로 "love"을 대체합니다. 그런 다음 마스킹된 토큰 "사랑"과 그 예측 사이의 교차 엔트로피 손실은 사전 훈련 중에 최소화됩니다. Transformer 인코더(그림 11.9.1의 오른쪽)의 attention 패턴에는 제약이 없으므로 모든 토큰이 서로 attend 할 수 있습니다. 따라서 "love"의 예측은 시퀀스에서 전후의 입력 토큰에 따라 달라집니다. 이것이 BERT가 "양방향 인코더 bidirectional encoder"인 이유입니다. 수동 레이블 지정이 필요 없이 책과 Wikipedia의 대규모 텍스트 데이터를 BERT 사전 학습에 사용할 수 있습니다.
11.9.1.2. Fine-Tuning BERT
The pretrained BERT can be fine-tuned to downstream encoding tasks involving single text or text pairs. During fine-tuning, additional layers can be added to BERT with randomized parameters: these parameters and those pretrained BERT parameters will be updated to fit training data of downstream tasks.
사전 훈련된 BERT는 단일 텍스트 또는 텍스트 쌍을 포함하는 다운스트림 인코딩 작업으로 미세 조정fine-tuned 할 수 있습니다. 미세 조정 중에 무작위 매개변수를 사용하여 추가 계층을 BERT에 추가할 수 있습니다. 이러한 매개변수와 사전 훈련된 BERT 매개변수는 다운스트림 작업의 훈련 데이터에 맞게 업데이트됩니다.
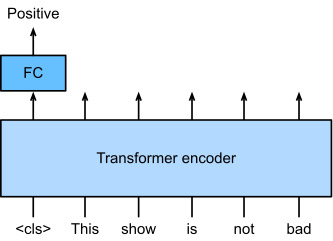
Fig. 11.9.2 illustrates fine-tuning of BERT for sentiment analysis. The Transformer encoder is a pretrained BERT, which takes a text sequence as input and feeds the “<cls>” representation (global representation of the input) into an additional fully connected layer to predict the sentiment. During fine-tuning, the cross-entropy loss between the prediction and the label on sentiment analysis data is minimized via gradient-based algorithms, where the additional layer is trained from scratch while pretrained parameters of BERT are updated. BERT does more than sentiment analysis. The general language representations learned by the 350-million-parameter BERT from 250 billion training tokens advanced the state of the art for natural language tasks such as single text classification, text pair classification or regression, text tagging, and question answering.
그림 11.9.2는 감정 분석을 위한 BERT의 미세 조정을 보여줍니다. 트랜스포머 인코더는 사전 훈련된 BERT로, 텍스트 시퀀스를 입력으로 취하고 "<cls>" 표현(입력의 전역 표현)을 완전히 연결된 추가 레이어에 공급하여 감정을 예측합니다. 미세 조정 중에 감정 분석 데이터의 예측과 레이블 간의 교차 엔트로피 손실은 그래디언트 기반 알고리즘을 통해 최소화됩니다. 여기서 추가 레이어는 처음부터 훈련되고 BERT의 사전 훈련된 매개변수는 업데이트됩니다. BERT는 감정 분석 이상의 기능을 수행합니다. 2,500억 개의 훈련 토큰에서 3억 5천만 개의 매개변수 BERT가 학습한 일반 언어 표현은 단일 텍스트 분류, 텍스트 쌍 분류 또는 회귀, 텍스트 태깅 및 질문 응답과 같은 자연어 작업을 위한 최신 기술을 발전시켰습니다.
You may note that these downstream tasks include text pair understanding. BERT pretraining has another loss for predicting whether one sentence immediately follows the other. However, this loss was later found not useful when pretraining RoBERTa, a BERT variant of the same size, on 2000 billion tokens (Liu et al., 2019). Other derivatives of BERT improved model architectures or pretraining objectives, such as ALBERT (enforcing parameter sharing) (Lan et al., 2019), SpanBERT (representing and predicting spans of text) (Joshi et al., 2020), DistilBERT (lightweight via knowledge distillation) (Sanh et al., 2019), and ELECTRA (replaced token detection) (Clark et al., 2020). Moreover, BERT inspired Transformer pretraining in computer vision, such as with vision Transformers (Dosovitskiy et al., 2021), Swin Transformers (Liu et al., 2021), and MAE (masked autoencoders) (He et al., 2022).
이러한 다운스트림 작업에는 텍스트 쌍 이해가 포함되어 있음을 알 수 있습니다. BERT 사전 훈련은 한 문장이 다른 문장 바로 뒤에 오는지 예측하는 데 또 다른 손실이 있습니다. 그러나 이 손실은 나중에 동일한 크기의 BERT 변형인 RoBERTa를 20000억 개(2조개?)의 토큰으로 사전 훈련할 때 유용하지 않은 것으로 밝혀졌습니다(Liu et al., 2019). ALBERT(매개 변수 공유 적용)(Lan et al., 2019), SpanBERT(텍스트 범위 표현 및 예측)(Joshi et al., 2020), DistilBERT(lightweight via 지식 증류)(Sanh et al., 2019) 및 ELECTRA(대체 토큰 탐지)(Clark et al., 2020). 또한 BERT는 비전 Transformers(Dosovitskiy et al., 2021), Swin Transformers(Liu et al., 2021) 및 MAE(masked autoencoders)(He et al., 2022)와 같은 컴퓨터 비전의 Transformer 사전 훈련에 영감을 주었습니다.
11.9.2. Encoder-Decoder
Since a Transformer encoder converts a sequence of input tokens into the same number of output representations, the encoder-only mode cannot generate a sequence of arbitrary length like in machine translation. As originally proposed for machine translation, the Transformer architecture can be outfitted with a decoder that autoregressively predicts the target sequence of arbitrary length, token by token, conditional on both encoder output and decoder output: (i) for conditioning on encoder output, encoder-decoder cross-attention (multi-head attention of decoder in Fig. 11.7.1) allows target tokens to attend to all input tokens; (ii) conditioning on decoder output is achieved by a so-called causal attention (this name is common in the literature but is misleading as it has little connection to the proper study of causality) pattern (masked multi-head attention of decoder in Fig. 11.7.1), where any target token can only attend to past and present tokens in the target sequence.
Transformer 인코더는 일련의 입력 토큰을 동일한 수의 출력 표현으로 변환하므로 인코더 전용 모드는 기계 번역과 같이 임의 길이의 시퀀스를 생성할 수 없습니다. 원래 기계 번역을 위해 제안된 것처럼 Transformer 아키텍처에는 인코더 출력과 디코더 출력 모두에 조건부로 토큰별로 임의 길이의 대상 시퀀스를 자동 회귀적으로 예측하는 디코더가 장착될 수 있습니다.(i) encoder-decoder cross-attention (그림 11.7.1의 디코더의 multi-head attention)는 대상 토큰이 모든 입력 토큰에 attend 하도록 허용합니다. (ii) 디코더 출력에 대한 컨디셔닝은 소위 causal attention(이 이름은 문헌에서 일반적이지만 causal 관계에 대한 적절한 연구와 거의 관련이 없기 때문에 오해의 소지가 있음) 패턴(그림에서 디코더의 마스킹된 다중 헤드 주의)에 의해 달성됩니다. . 11.7.1), 대상 토큰은 대상 시퀀스의 과거 및 현재 토큰에만 attend 할 수 있습니다.
Casual Attention이란?
"Casual Attention"은 주로 시계열 데이터와 같이 순차적인 시간 또는 순서적인 관계를 가진 데이터에서 사용되는 어텐션 메커니즘입니다. 이러한 어텐션은 현재 위치 이전의 시점들만을 참조하여 예측하거나 분석하는 데 사용됩니다.
일반적으로 어텐션 메커니즘은 현재 위치의 쿼리(Query)와 모든 위치의 키(Key) 및 값(Value)을 사용하여 가중 평균을 계산하는데, 이 때문에 시계열 데이터와 같이 순서가 중요한 데이터에서 미래의 정보가 과도하게 유출될 수 있습니다. 이러한 문제를 해결하기 위해 "Casual Attention"은 현재 시점 이후의 정보에 대한 접근을 막음으로써 미래 정보의 유출을 방지합니다.
보통 "Casual Attention"은 마스크(mask)를 사용하여 현재 시점 이후의 위치를 가리고, 오직 현재 시점 이전의 위치만을 참조하도록 제한합니다. 이로써 모델은 현재 시점까지의 정보만을 사용하여 예측하거나 분석하게 되며, 시계열 데이터와 같은 순차적인 데이터에서 더 정확한 예측을 할 수 있도록 도와줍니다.
To pretrain encoder-decoder Transformers beyond human-labeled machine translation data, BART (Lewis et al., 2019) and T5 (Raffel et al., 2020) are two concurrently proposed encoder-decoder Transformers pretrained on large-scale text corpora. Both attempt to reconstruct original text in their pretraining objectives, while the former emphasizes noising input (e.g., masking, deletion, permutation, and rotation) and the latter highlights multitask unification with comprehensive ablation studies.
사람이 라벨링한 기계 번역 데이터 이상으로 인코더-디코더 Transformer를 사전 훈련하기 위해 BART(Lewis et al., 2019) 및 T5(Raffel et al., 2020)는 대규모 텍스트 말뭉치(large-scale text corpora)에서 사전 훈련된 동시에 제안된 두 개의 인코더-디코더 Transformers입니다. 둘 다 사전 학습 목표에서 원본 텍스트를 재구성하려고 시도하는 반면, 전자는 노이즈 입력(예: 마스킹, 삭제, 순열 및 회전)을 강조하고 후자는 포괄적인 절제 연구(comprehensive ablation studies)를 통한 멀티태스크 통합을 강조합니다.
11.9.2.1. Pretraining T5
As an example of the pretrained Transformer encoder-decoder, T5 (Text-to-Text Transfer Transformer) unifies many tasks as the same text-to-text problem: for any task, the input of the encoder is a task description (e.g., “Summarize”, “:”) followed by task input (e.g., a sequence of tokens from an article), and the decoder predicts the task output (e.g., a sequence of tokens summarizing the input article). To perform as text-to-text, T5 is trained to generate some target text conditional on input text.
미리 훈련된 Transformer 인코더-디코더의 예로 T5(Text-to-Text Transfer Transformer)는 많은 작업을 동일한 text-to-text problem로 통합합니다. 모든 작업에 대해 인코더의 입력은 task description입니다(예: "Summarize", ":") 다음에 작업 입력(예: 기사의 토큰 시퀀스)이 있고 디코더는 작업 출력(예: a sequence of tokens from an article)을 예측합니다. 텍스트 대 텍스트로 수행하기 위해 T5는 입력 텍스트에 따라 일부 대상 텍스트를 생성하도록 훈련됩니다.

To obtain input and output from any original text, T5 is pretrained to predict consecutive spans. Specifically, tokens from text are randomly replaced by special tokens where each consecutive span is replaced by the same special token. Consider the example in Fig. 11.9.3, where the original text is “I”, “love”, “this”, “red”, “car”. Tokens “love”, “red”, “car” are randomly replaced by special tokens. Since “red” and “car” are a consecutive span, they are replaced by the same special token. As a result, the input sequence is “I”, “<X>”, “this”, “<Y>”, and the target sequence is “<X>”, “love”, “<Y>”, “red”, “car”, “<Z>”, where “<Z>” is another special token marking the end. As shown in Fig. 11.9.3, the decoder has a causal attention pattern to prevent itself from attending to future tokens during sequence prediction.
원본 텍스트에서 입력 및 출력을 얻기 위해 T5는 연속 범위를 예측하도록 사전 훈련됩니다. 특히 텍스트의 토큰은 각 연속 범위가 동일한 특수 토큰으로 대체되는 특수 토큰으로 무작위로 대체됩니다. 원본 텍스트가 "I", "love", "this", "red", "car"인 그림 11.9.3의 예를 고려하십시오. "love", "red", "car" 토큰은 무작위로 특수 토큰으로 대체됩니다. "red"와 "car"는 연속적인 범위이므로 동일한 특수 토큰으로 대체됩니다. 결과적으로 입력 시퀀스는 “I”, “<X>”, “this”, “<Y>”이고 타겟 시퀀스는 “<X>”, “love”, “<Y>”, “ red”, “car”, “<Z>”, 여기서 “<Z>”는 끝을 표시하는 또 다른 특수 토큰입니다. 그림 11.9.3에서 볼 수 있듯이 디코더는 시퀀스 예측 중에 미래의 토큰에 attending 하는 것을 방지하기 위해 causal attention pattern을 가지고 있습니다.
In T5, predicting consecutive span is also referred to as reconstructing corrupted text. With this objective, T5 is pretrained with 1000 billion tokens from the C4 (Colossal Clean Crawled Corpus) data, which consists of clean English text from the Web (Raffel et al., 2020).
T5에서 연속 스팬 consecutive span 예측은 손상된 텍스트 재구성이라고도 합니다. 이 목표를 통해 T5는 웹의 깨끗한 영어 텍스트로 구성된 C4(Colossal Clean Crawled Corpus) 데이터의 10000억 개의 토큰으로 사전 훈련됩니다(Raffel et al., 2020).
11.9.2.2. Fine-Tuning T5
Similar to BERT, T5 needs to be fine-tuned (updating T5 parameters) on task-specific training data to perform this task. Major differences from BERT fine-tuning include: (i) T5 input includes task descriptions; (ii) T5 can generate sequences with arbitrary length with its Transformer decoder; (iii) No additional layers are required.
BERT와 유사하게 T5는 이 작업을 수행하기 위해 작업별 교육 데이터에서 미세 조정(T5 매개변수 업데이트)해야 합니다. BERT 미세 조정과의 주요 차이점은 다음과 같습니다. (i) T5 입력에는 task descriptions이 포함됩니다. (ii) T5는 트랜스포머 디코더로 임의 길이의 시퀀스를 생성할 수 있습니다. (iii) 추가 레이어가 필요하지 않습니다.

Fig. 11.9.4 explains fine-tuning T5 using text summarization as an example. In this downstream task, the task description tokens “Summarize”, “:” followed by the article tokens are input to the encoder.
그림 11.9.4는 텍스트 요약을 예로 들어 T5 미세 조정을 설명합니다. 이 다운스트림 작업에서 작업 설명 토큰 "Summarize", ":" 뒤에 기사 토큰이 인코더에 입력됩니다.
After fine-tuning, the 11-billion-parameter T5 (T5-11B) achieved state-of-the-art results on multiple encoding (e.g., classification) and generation (e.g., summarization) benchmarks. Since released, T5 has been extensively used in later research. For example, switch Transformers are designed based off T5 to activate a subset of the parameters for better computational efficiency (Fedus et al., 2022). In a text-to-image model called Imagen, text is input to a frozen T5 encoder (T5-XXL) with 4.6 billion parameters (Saharia et al., 2022). The photorealistic text-to-image examples in Fig. 11.9.5 suggest that the T5 encoder alone may effectively represent text even without fine-tuning.
미세 조정 후 110억 매개변수 T5(T5-11B)는 다중 인코딩(예: 분류) 및 생성(예: 요약) 벤치마크에서 최첨단 결과를 달성했습니다. 출시 이후 T5는 이후 연구에서 광범위하게 사용되었습니다. 예를 들어 스위치 트랜스포머는 더 나은 계산 효율성을 위해 매개변수의 하위 집합을 활성화하기 위해 T5를 기반으로 설계되었습니다(Fedus et al., 2022). Imagen이라는 텍스트-이미지 모델에서 텍스트는 46억 개의 매개변수가 있는 고정된 T5 인코더(T5-XXL)에 입력됩니다(Saharia et al., 2022). 그림 11.9.5의 사실적인 텍스트 대 이미지 예는 미세 조정 없이도 T5 인코더만으로도 텍스트를 효과적으로 표현할 수 있음을 시사합니다.

T5란?
T5(Tap-to-Transfer Transformer) is a versatile and powerful language model developed by Google Research in 2020. T5 is based on the transformer architecture, similar to BERT, and it takes the idea of transfer learning in natural language processing to a new level. The main innovation of T5 is its unified framework that can handle a wide range of NLP tasks using a single model.
T5(Tap-to-Transfer Transformer)은 2020년에 구글 리서치에서 개발한 다재다능한 언어 모델입니다. T5는 BERT와 마찬가지로 트랜스포머 아키텍처를 기반으로 하며, 자연어 처리의 전이 학습 아이디어를 새로운 수준으로 가져갑니다. T5의 주요 혁신은 하나의 모델로 다양한 NLP 작업을 처리할 수 있는 통합된 프레임워크입니다.
Here are some key points about T5:
다음은 T5에 관한 주요 사항입니다:
- Transfer Learning for Various Tasks: T5 aims to simplify and unify the process of applying transformer models to various NLP tasks. Instead of developing separate models for different tasks like translation, text classification, question answering, and more, T5's single model can be fine-tuned for a wide array of tasks.
다양한 작업에 대한 전이 학습: T5는 트랜스포머 모델을 다양한 NLP 작업에 적용하기 위한 과정을 단순화하고 통합하려는 목표를 가지고 있습니다. 번역, 텍스트 분류, 질의 응답 등 다양한 작업을 위해 별도의 모델을 개발하는 대신 T5의 단일 모델을 다양한 작업에 미세 조정할 수 있습니다. - Unified Text-to-Text Format: T5 approaches all NLP tasks as text-to-text tasks. This means that both input and output are treated as text sequences. For example, translation can be seen as translating an input sentence to an output sentence, text classification as classifying an input text into a category, and so on.
통합된 텍스트-투-텍스트 형식: T5는 모든 NLP 작업을 텍스트-투-텍스트 작업으로 처리합니다. 이는 입력과 출력 모두를 텍스트 시퀀스로 처리하는 것을 의미합니다. 예를 들어, 번역은 입력 문장을 출력 문장으로 번역하는 작업으로 볼 수 있으며, 텍스트 분류는 입력 텍스트를 범주로 분류하는 작업과 같이 처리됩니다. - Pretraining and Fine-Tuning: T5 follows a two-step process: pretraining and fine-tuning. In the pretraining phase, the model is trained on a large corpus of text in an unsupervised manner, similar to how BERT is pretrained. In the fine-tuning phase, the pretrained model is adapted to specific tasks using labeled data.
사전 훈련과 미세 조정: T5는 사전 훈련 및 미세 조정 두 단계의 프로세스를 따릅니다. 사전 훈련 단계에서 모델은 대규모 텍스트 말뭉치에서 무지성으로 훈련되며, BERT와 유사한 방식입니다. 미세 조정 단계에서는 사전 훈련된 모델이 레이블된 데이터를 사용하여 특정 작업에 적응되는 과정입니다. - Text Generation and Compression: T5 excels in both text generation and text compression tasks. It can generate coherent and contextually relevant text, making it suitable for tasks like language translation, summarization, and story generation. Additionally, it can compress longer texts into shorter, informative versions, which is valuable for tasks like data-to-text generation.
텍스트 생성과 압축: T5는 텍스트 생성 및 텍스트 압축 작업 모두에서 뛰어난 성과를 보입니다. 일관되고 문맥에 맞는 텍스트를 생성할 수 있어 언어 번역, 요약, 이야기 생성과 같은 작업에 적합합니다. 더불어 긴 텍스트를 간결하면서도 정보를 잘 담은 형태로 압축하는 능력도 갖추고 있습니다. 이는 데이터를 텍스트로 변환하는 데이터-투-텍스트 생성 작업에 유용합니다. - Flexible Inputs and Outputs: T5 can accept various types of inputs and produce diverse outputs. For example, it can take prompts like "Translate the following English text to French: ..." and generate the translation. It can also be used for multiple-choice questions, summarization, and even image captioning by converting the task into text-to-text format.
유연한 입력과 출력: T5는 다양한 유형의 입력을 받아들이고 다양한 출력을 생성할 수 있습니다. 예를 들어 "다음 영어 텍스트를 프랑스어로 번역하세요: ..."와 같은 프롬프트를 받아들이고 번역을 생성할 수 있습니다. 선택지 문제, 요약, 심지어 이미지 캡션 작업에도 텍스트-투-텍스트 형식으로 활용될 수 있습니다. - Large-Scale Model: Similar to other transformer models, T5 comes in different sizes, such as T5-small, T5-base, T5-large, and T5-3B, with increasing model parameters and capabilities.
대규모 모델: 다른 트랜스포머 모델과 마찬가지로 T5는 T5-small, T5-base, T5-large, T5-3B 등 다양한 크기로 제공되며 모델 파라미터와 능력이 증가합니다.
T5's unified framework and its ability to handle a wide range of NLP tasks have made it a popular choice in the NLP community. It has achieved impressive results on various benchmarks and has contributed to advancing the field of natural language processing and understanding.
T5의 통합된 프레임워크와 다양한 NLP 작업을 처리하는 능력은 NLP 커뮤니티에서 인기를 얻었습니다. 다양한 벤치마크에서 놀라운 결과를 달성하며 자연어 처리와 이해 분야의 발전에 기여하였습니다.
11.9.3. Decoder-Only
We have reviewed encoder-only and encoder-decoder Transformers. Alternatively, decoder-only Transformers remove the entire encoder and the decoder sublayer with the encoder-decoder cross-attention from the original encoder-decoder architecture depicted in Fig. 11.7.1. Nowadays, decoder-only Transformers have been the de facto architecture in large-scale language modeling (Section 9.3), which leverages the world’s abundant unlabeled text corpora via self-supervised learning.
인코더 전용 및 인코더-디코더 transformer를 검토했습니다. 또는 디코더 전용 트랜스포머는 전체 인코더와 그림 11.7.1에 묘사된 원래 인코더-디코더 아키텍처에서 인코더-디코더 cross attention이 있는 디코더 하위 계층을 제거합니다. 오늘날 디코더 전용 트랜스포머는 대규모 언어 모델링(9.3절)에서 사실상의 아키텍처였으며, 이는 자기 지도 학습을 통해 전 세계의 풍부한 레이블 없는 텍스트 말뭉치를 활용합니다.
11.9.3.1. GPT and GPT-2
Using language modeling as the training objective, the GPT (generative pre-training) model chooses a Transformer decoder as its backbone (Radford et al., 2018).
학습 목표로 언어 모델링을 사용하는 GPT(Generative Pre-training) 모델은 Transformer 디코더를 백본으로 선택합니다(Radford et al., 2018).
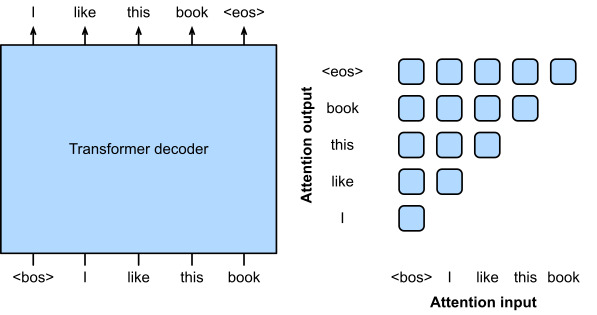
Following the autoregressive language model training as described in Section 9.3.3, Fig. 11.9.6 illustrates GPT pretraining with a Transformer encoder, where the target sequence is the input sequence shifted by one token. Note that the attention pattern in the Transformer decoder enforces that each token can only attend to its past tokens (future tokens cannot be attended to because they have not yet been chosen).
섹션 9.3.3에 설명된 autoregressive language model training에 이어 그림 11.9.6은 Transformer 인코더를 사용한 GPT 사전 교육을 보여줍니다. 여기서 대상 시퀀스는 하나의 토큰만큼 이동된 입력 시퀀스입니다. Transformer 디코더의 attention pattern은 각 토큰이 과거 토큰에만 attend할 수 있도록 합니다(미래의 토큰은 아직 선택되지 않았기 때문에 참석할 수 없음).
GPT has 100 million parameters and needs to be fine-tuned for individual downstream tasks. A much larger Transformer-decoder language model, GPT-2, was introduced one year later (Radford et al., 2019). Compared with the original Transformer decoder in GPT, pre-normalization (discussed in Section 11.8.3) and improved initialization and weight-scaling were adopted in GPT-2. Pretrained on 40 GB of text, the 1.5-billion-parameter GPT-2 obtained the state-of-the-art results on language modeling benchmarks and promising results on multiple other tasks without updating the parameters or architecture.
GPT에는 1억 개의 매개변수가 있으며 개별 다운스트림 작업에 맞게 미세 조정해야 합니다. 훨씬 더 큰 Transformer-decoder 언어 모델인 GPT-2가 1년 후에 도입되었습니다(Radford et al., 2019). GPT의 원래 Transformer 디코더와 비교하여 사전 정규화(11.8.3절에서 설명)와 향상된 초기화 및 가중치 스케일링이 GPT-2에 채택되었습니다. 40GB의 텍스트로 사전 훈련된 15억 개의 매개변수 GPT-2는 언어 모델링 벤치마크에서 최신 결과를 얻었고 매개변수나 아키텍처를 업데이트하지 않고도 여러 다른 작업에서 유망한 결과를 얻었습니다.
11.9.3.2. GPT-3
GPT-2 demonstrated potential of using the same language model for multiple tasks without updating the model. This is more computationally efficient than fine-tuning, which requires model updates via gradient computation.
GPT-2는 모델을 업데이트하지 않고 여러 작업에 동일한 언어 모델을 사용할 수 있는 가능성을 보여주었습니다. 이것은 그래디언트 계산을 통해 모델을 업데이트해야 하는 미세 조정보다 계산적으로 더 효율적입니다.
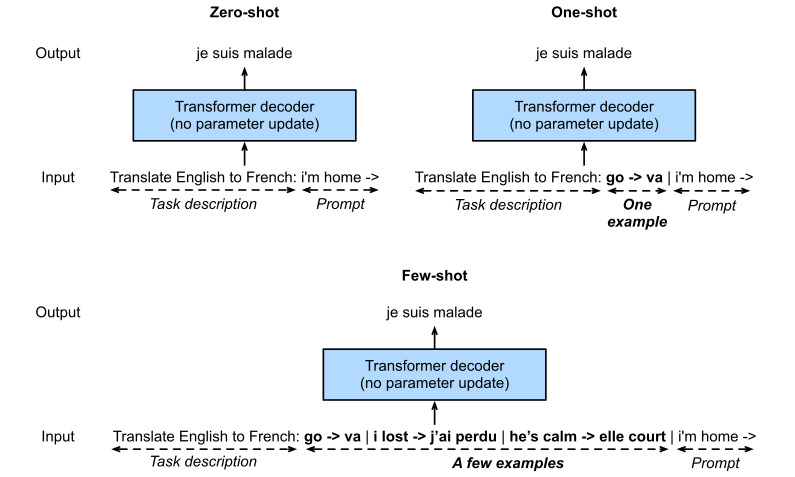
Before explaining the more computationally efficient use of language models without parameter update, recall Section 9.5 that a language model can be trained to generate a text sequence conditional on some prefix text sequence. Thus, a pretrained language model may generate the task output as a sequence without parameter update, conditional on an input sequence with the task description, task-specific input-output examples, and a prompt (task input). This learning paradigm is called in-context learning (Brown et al., 2020), which can be further categorized into zero-shot, one-shot, and few-shot, when there is no, one, and a few task-specific input-output examples, respectively (Fig. 11.9.7).
매개 변수 업데이트 없이 언어 모델을 보다 계산적으로 효율적으로 사용하는 방법을 설명하기 전에 일부 접두사 텍스트 시퀀스에 조건부 텍스트 시퀀스를 생성하도록 언어 모델을 훈련할 수 있다는 섹션 9.5를 상기하십시오. 따라서 미리 훈련된 언어 모델은 작업 설명, 작업별 입력-출력 예제 및 프롬프트(작업 입력)가 있는 입력 시퀀스에 따라 매개 변수 업데이트 없이 시퀀스로 작업 출력을 생성할 수 있습니다. 이러한 학습 패러다임을 in-context learning(Brown et al., 2020)이라고 하며, 더 나아가 제로샷(zero-shot), 원샷(one-shot), 퓨어샷(female-shot)으로 분류할 수 있다. 각각 입력-출력 예(그림 11.9.7).
in-context learning이란?
'In-context learning'은 주어진 문맥(context) 내에서 학습하는 개념을 나타냅니다. 이것은 기계 학습 또는 딥 러닝 모델이 주어진 데이터 포인트를 주변 문맥과 관련하여 학습하고 예측하는 것을 의미합니다.
예를 들어, 자연어 처리(NLP)에서 특정 단어의 의미를 이해하려면 해당 단어의 주변 문맥을 고려해야 합니다. 이를 위해 주어진 단어 주변의 단어들을 입력으로 사용하여 모델을 학습하고, 주변 문맥을 통해 해당 단어의 의미를 파악하려는 것이 'in-context learning'입니다.
'In-context learning'은 문제를 더 정확하게 이해하고 예측하기 위해 문맥 정보를 활용하는 중요한 방법 중 하나입니다. 이는 자연어 처리, 컴퓨터 비전, 음성 처리 등 다양한 분야에서 활용되며, 모델의 성능을 향상시키는 데 도움이 됩니다.
zero-shot, one-shot, few shot이란?
'Zero-shot', 'one-shot', 그리고 'few-shot'은 머신 러닝 및 딥 러닝에서 사용되는 학습 접근 방식을 나타내는 용어입니다.
- Zero-shot Learning (제로샷 학습): 제로샷 학습은 학습 데이터 없이 새로운 클래스 또는 작업에 대한 학습을 시도하는 접근 방식입니다. 모델은 이미 학습된 정보를 기반으로 새로운 데이터에 대한 예측을 수행합니다. 이를 위해 추가 정보나 외부 지식을 활용하는 경우가 많습니다.
- One-shot Learning (원샷 학습): 원샷 학습은 매우 작은 수의 학습 데이터만을 이용하여 새로운 클래스 또는 작업에 대한 학습을 시도하는 접근 방식입니다. 예를 들어, 하나의 학습 샘플만 사용하여 클래스를 구분하는 작업을 수행하는 것을 말합니다.
- Few-shot Learning (퓨샷 학습): 퓨샷 학습은 원샷 학습과 비슷하지만, 더 큰 데이터 셋에서 몇 개의 학습 샘플을 사용하여 새로운 클래스나 작업에 대한 학습을 시도하는 접근 방식입니다. 보통 5개 이하의 학습 샘플을 사용하는 경우를 말합니다.
이러한 접근 방식들은 데이터가 부족한 상황에서 새로운 클래스나 작업에 대한 모델을 구축할 때 유용하게 활용될 수 있습니다.
http://cartinoe5930.tistory.com/54
Zero-shot, One-shot, Few-shot Learning이 무엇일까?
요즘 머신러닝 논문들을 읽어보면 zero-shot, one-shot, few-shot 등을 많이 볼 수 있다. 이번 포스트에서는 이 용어들에 대해 알아보고 이 method들이 어떨 때 사용되는지 알아보았다. Overview 머신러닝에
cartinoe5930.tistory.com

These three settings were tested in GPT-3 (Brown et al., 2020), whose largest version uses data and model size about two orders of magnitude larger than those in GPT-2. GPT-3 uses the same Transformer decoder architecture in its direct predecessor GPT-2 except that attention patterns (right of Fig. 11.9.6) are sparser at alternating layers. Pretrained with 300 billion tokens, GPT-3 performs better with larger model size, where few-shot performance increases most rapidly (Fig. 11.9.8).
이 세 가지 설정은 GPT-3(Brown et al., 2020)에서 테스트되었으며, 가장 큰 버전은 GPT-2보다 약 2배 더 큰 데이터와 모델 크기를 사용합니다. GPT-3는 어텐션 패턴(그림 11.9.6의 오른쪽)이 교대 레이어에서 희박하다는 점을 제외하면 이전 GPT-2와 동일한 트랜스포머 디코더 아키텍처를 사용합니다. 3000억 개의 토큰으로 사전 훈련된 GPT-3는 더 큰 모델 크기에서 더 나은 성능을 발휘하며 여기서 퓨샷 성능이 가장 빠르게 증가합니다(그림 11.9.8).
Large language models offer an exciting prospect of formulating text input to induce models to perform desired tasks via in-context learning, which is also known as prompting. For example, chain-of-thought prompting (Wei et al., 2022), an in-context learning method with few-shot “question, intermediate reasoning steps, answer” demonstrations, elicits the complex reasoning capabilities of large language models to solve mathematical, commonsense, and symbolic reasoning tasks. Sampling multiple reasoning paths (Wang et al., 2023), diversifying few-shot demonstrations (Zhang et al., 2023), and reducing complex problems to sub-problems (Zhou et al., 2023) can all improve the reasoning accuracy. In fact, with simple prompts like “Let’s think step by step” just before each answer, large language models can even perform zero-shot chain-of-thought reasoning with decent accuracy (Kojima et al., 2022). Even for multimodal inputs consisting of both text and images, language models can perform multimodal chain-of-thought reasoning with further improved accuracy than using text input only (Zhang et al., 2023).
대규모 언어 모델은 프롬프트라고도 하는 in-context learning을 통해 모델이 원하는 작업을 수행하도록 유도하기 위해 텍스트 입력을 공식화하는 흥미로운 전망을 제공합니다. 예를 들어, 몇 번의 "질문, 중간 추론 단계, 답변" 데모가 포함된 상황 내 학습 방법인 chain-of-thought prompting(Wei et al., 2022)는 문제를 해결하기 위해 대규모 언어 모델의 복잡한 추론 기능을 이끌어냅니다. 수학, 상식 및 상징적 추론 작업. 다중 추론 경로 샘플링(Wang et al., 2023), 소수 샷 시연 다양화(Zhang et al., 2023), 복잡한 문제를 하위 문제로 줄이는 것(Zhou et al., 2023) 모두 추론 정확도를 향상시킬 수 있습니다. 사실, 각 답변 직전에 "차근차근 생각해 봅시다"와 같은 간단한 프롬프트를 통해 대규모 언어 모델은 적절한 정확도로 제로샷 연쇄 사고 추론을 수행할 수도 있습니다(Kojima et al., 2022). 텍스트와 이미지로 구성된 다중 모드 입력의 경우에도 언어 모델은 텍스트 입력만 사용하는 것보다 더 향상된 정확도로 다중 모드 사고 연쇄 추론을 수행할 수 있습니다(Zhang et al., 2023).
11.9.4. Scalability
Fig. 11.9.8 empirically demonstrates scalability of Transformers in the GPT-3 language model. For language modeling, more comprehensive empirical studies on the scalability of Transformers have led researchers to see promise in training larger Transformers with more data and compute (Kaplan et al., 2020).
그림 11.9.8은 GPT-3 언어 모델에서 Transformers의 확장성을 실증적으로 보여준다. 언어 모델링의 경우 Transformers의 확장성에 대한 보다 포괄적인 경험적 연구를 통해 연구자들은 더 많은 데이터와 컴퓨팅으로 더 큰 Transformers를 교육할 가능성을 확인했습니다(Kaplan et al., 2020).

As shown in Fig. 11.9.9, power-law scaling can be observed in the performance with respect to the model size (number of parameters, excluding embedding layers), dataset size (number of training tokens), and amount of training compute (PetaFLOP/s-days, excluding embedding layers). In general, increasing all these three factors in tandem leads to better performance. However, how to increase them in tandem still remains a matter of debate (Hoffmann et al., 2022).
그림 11.9.9에서와 같이 Model size (number of parameters, excluding embedding layers), data size (number of training tokens) 그리고 amount of training compute (PetaFLOP/s-days, excluding embedding layers) 가 늘어날 수록 성능이 좋아진다. ==> power-law scaling을 볼 수 있다. 그러나 그것들을 동시에 증가시키는 방법은 여전히 논쟁의 문제로 남아 있습니다(Hoffmann et al., 2022).
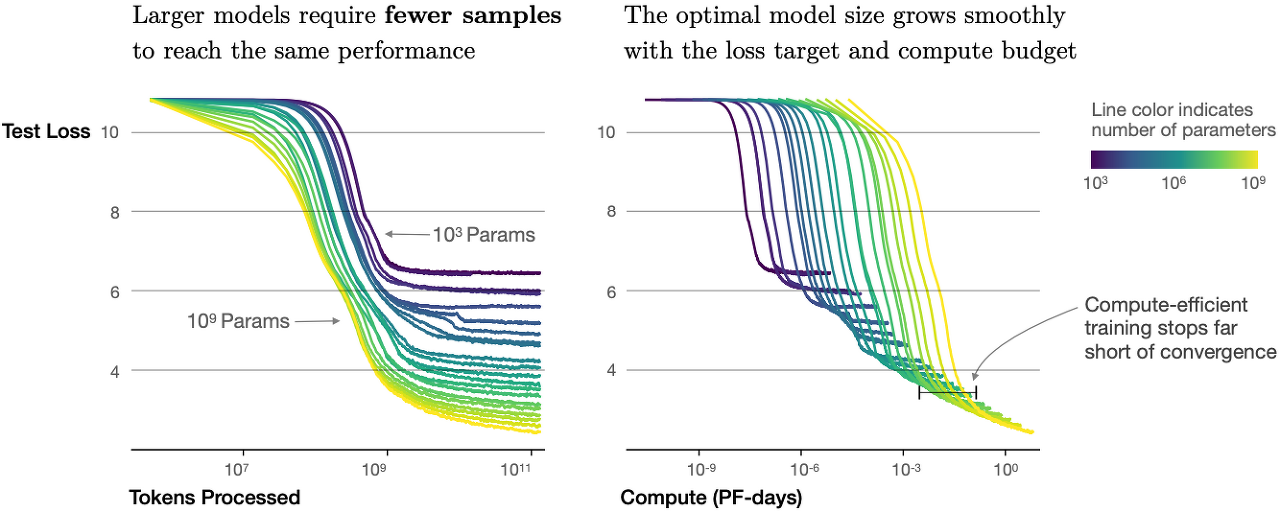
Besides increased performance, large models also enjoy better sample efficiency than small models. Fig. 11.9.10 shows that large models need fewer training samples (tokens processed) to perform at the same level achieved by small models, and performance is scaled smoothly with compute.
향상된 성능 외에도 대형 모델은 소형 모델보다 샘플 효율성이 더 좋습니다. 그림 11.9.10은 작은 모델이 달성한 것과 동일한 수준에서 수행하기 위해 더 적은 수의 교육 샘플(처리된 토큰)이 필요한 큰 모델을 보여 주며 성능은 컴퓨팅을 통해 원활하게 확장됩니다.

The empirical scaling behaviors in Kaplan et al. (2020) have been tested in subsequent large Transformer models. For example, GPT-3 supported this hypothesis with two more orders of magnitude in Fig. 11.9.11.
Kaplan et al.의 경험적 스케일링 동작. (2020) 이후의 대형 Transformer 모델에서 테스트되었습니다. 예를 들어, GPT-3는 그림 11.9.11에서 두 자릿수 이상의 크기로 이 가설을 뒷받침했습니다.
The scalability of Transformers in the GPT series has inspired subsequent Transformer language models. While the Transformer decoder in GPT-3 was largely followed in OPT (Open Pretrained Transformers) (Zhang et al., 2022) using only 1/7th the carbon footprint of the former, the GPT-2 Transformer decoder was used in training the 530-billion-parameter Megatron-Turing NLG (Smith et al., 2022) with 270 billion training tokens. Following the GPT-2 design, the 280-billion-parameter Gopher (Rae et al., 2021) pretrained with 300 billion tokens achieved state-of-the-art performance across the majority on about 150 diverse tasks. Inheriting the same architecture and using the same compute budget of Gopher, Chinchilla (Hoffmann et al., 2022) is a substantially smaller (70 billion parameters) model that trains much longer (1.4 trillion training tokens), outperforming Gopher on many tasks. To continue the scaling line of language modeling, PaLM (Pathway Language Model) (Chowdhery et al., 2022), a 540-billion-parameter Transformer decoder with modified designs pretrained on 780 billion tokens, outperformed average human performance on the BIG-Bench benchmark (Srivastava et al., 2022). Further training PaLM on 38.5 billion tokens containing scientific and mathematical content results in Minerva (Lewkowycz et al., 2022), a large language model that can answer nearly a third of undergraduate-level problems that require quantitative reasoning, such as in physics, chemistry, biology, and economics.
GPT 시리즈의 트랜스포머 확장성은 후속 트랜스포머 언어 모델에 영감을 주었습니다. GPT-3의 Transformer 디코더는 OPT(Open Pretrained Transformers)(Zhang et al., 2022)에서 전자의 탄소 발자국의 1/7만 사용하여 주로 따랐지만 GPT-2 Transformer 디코더는 530을 교육하는 데 사용되었습니다. - 2700억 개의 훈련 토큰이 있는 10억 개의 매개변수 Megatron-Turing NLG(Smith et al., 2022). GPT-2 설계에 따라 3000억 개의 토큰으로 사전 훈련된 2800억 개의 매개변수 Gopher(Rae et al., 2021)는 약 150개의 다양한 작업에서 대다수에 걸쳐 최첨단 성능을 달성했습니다. 동일한 아키텍처를 상속하고 Gopher의 동일한 컴퓨팅 예산을 사용하는 Chinchilla(Hoffmann et al., 2022)는 훨씬 더 오래(1조 4천억 개의 훈련 토큰) 훈련하는 상당히 작은(700억 매개변수) 모델로 많은 작업에서 Gopher를 능가합니다. 언어 모델링의 스케일링 라인을 계속하기 위해, 7,800억 개의 토큰으로 사전 훈련된 수정된 설계가 있는 5,400억 개의 매개변수 Transformer 디코더인 PaLM(Pathway Language Model)(Chowdhery et al., 2022)은 BIG-Bench에서 평균적인 인간 성능을 능가했습니다. 벤치마크(Srivastava et al., 2022). 과학 및 수학적 콘텐츠가 포함된 385억 개의 토큰에 대해 PaLM을 추가로 교육하면 물리학, 화학과 같이 정량적 추론이 필요한 학부 수준 문제의 거의 1/3에 답할 수 있는 대규모 언어 모델인 Minerva(Lewkowycz et al., 2022)가 생성됩니다. , 생물학 및 경제학.
Wei et al. (2022) discussed emergent abilities of large language models that are only present in larger models, but not present in smaller models. However, simply increasing model size does not inherently make models follow human instructions better. Following InstructGPT that aligns language models with human intent via fine-tuning (Ouyang et al., 2022), ChatGPT is able to follow instructions, such as code debugging and note drafting, from its conversations with humans.
Weiet al. (2022)는 더 큰 모델에만 존재하고 더 작은 모델에는 존재하지 않는 대규모 언어 모델의 창발적 능력에 대해 논의했습니다. 그러나 단순히 모델 크기를 늘리는 것이 본질적으로 모델이 사람의 지시를 더 잘 따르도록 만들지는 않습니다. 미세 조정을 통해 언어 모델을 인간의 의도에 맞추는 InstructGPT(Ouyang et al., 2022)에 이어 ChatGPT는 인간과의 대화에서 코드 디버깅 및 메모 작성과 같은 지침을 따를 수 있습니다.
GPT, GPT2, GPT3에 대하여.
GPT (Generative Pre-trained Transformer) series refers to a sequence of language models developed by OpenAI, each building upon the success and innovations of the previous version. These models are designed based on the Transformer architecture, which has proven to be highly effective for a wide range of natural language processing tasks. Here's an overview of each model:
GPT(Generative Pre-trained Transformer) 시리즈는 OpenAI에서 개발한 언어 모델 시퀀스로, 각 버전이 이전 버전의 성과와 혁신을 기반으로 발전되었습니다. 이 모델들은 Transformer 아키텍처를 기반으로 설계되어 다양한 자연어 처리 작업에 높은 효율성을 보입니다. 각 모델에 대한 개요는 아래와 같습니다:
- GPT-1 (Generative Pre-trained Transformer 1): GPT-1 was the first model in the series. It introduced the concept of pre-training a large neural network on a massive amount of text data and then fine-tuning it on specific downstream tasks. It used a decoder-only Transformer architecture and demonstrated impressive performance on various language tasks. However, it was limited by its relatively smaller size compared to later versions.
GPT-1 (Generative Pre-trained Transformer 1): GPT-1은 시리즈에서 처음 나온 모델입니다. 이 모델은 대량의 텍스트 데이터에서 큰 신경망을 사전 훈련하고 특정 하위 작업에 대해 세밀하게 튜닝하는 개념을 소개했습니다. 디코더만을 사용하는 Transformer 아키텍처를 사용하였으며, 다양한 언어 작업에서 인상적인 성능을 보였습니다. 하지만 이후 버전들과 비교하여 크기가 상대적으로 작아 제한된 성능을 보였습니다. - GPT-2 (Generative Pre-trained Transformer 2): GPT-2 was a significant leap forward in terms of size and capabilities. It gained widespread attention for its large number of parameters (up to 1.5 billion) and its ability to generate coherent and contextually relevant text. GPT-2 was so powerful that OpenAI initially chose not to release its largest versions due to concerns about potential misuse for generating fake news or deceptive content. GPT-2 showed remarkable performance across a wide range of tasks and achieved state-of-the-art results on various benchmarks.
GPT-2 (Generative Pre-trained Transformer 2): GPT-2는 크기와 성능 면에서 큰 도약을 이루었습니다. 15억 개의 파라미터를 가진 대규모 모델로, 연관성 있는 문장을 생성하는 능력으로 널리 주목받았습니다. GPT-2는 파라미터의 많은 양과 함께 크고 복잡한 텍스트를 생성할 수 있는 능력으로 유명해졌습니다. GPT-2는 다양한 작업에서 높은 성능을 보여주며 다양한 벤치마크에서 최고 수준의 결과를 달성했습니다. - GPT-3 (Generative Pre-trained Transformer 3): GPT-3 marked another substantial advancement in the series. With a staggering 175 billion parameters, GPT-3 is one of the largest language models ever created. It demonstrated the ability to generate highly coherent and contextually relevant text across a wide variety of prompts. What makes GPT-3 particularly remarkable is its "few-shot" or "zero-shot" learning capabilities. It can perform tasks with minimal examples or even no explicit training, as long as the task is described in the prompt.
- GPT-3's versatility has allowed it to excel in tasks ranging from translation and summarization to question answering and code generation. However, GPT-3 also raised concerns about biases present in its training data and the ethical implications of such powerful language models.
GPT-3 (Generative Pre-trained Transformer 3): GPT-3는 시리즈의 또 다른 큰 발전을 이루었습니다. 1750억 개의 파라미터를 가지며, 이는 역사적으로 가장 큰 언어 모델 중 하나입니다. GPT-3는 문맥상 관련성이 높은 텍스트를 다양한 프롬프트에 대해 생성할 수 있는 능력을 보였습니다. 특히 GPT-3의 놀라운 점은 "few-shot" 또는 "zero-shot" 학습 능력입니다. 몇 개의 예시나 아예 훈련이 없더라도 프롬프트에 명시된 작업을 수행할 수 있습니다.
GPT-3의 다재다능함은 번역, 요약, 질문 답변, 코드 생성과 같은 다양한 작업에서 뛰어난 성과를 거두게 했습니다. 하지만 GPT-3는 훈련 데이터의 편향성과 같은 문제, 그리고 이러한 강력한 언어 모델의 윤리적인 측면에 대한 우려를 불러일으켰습니다.
All of these models, GPT-1, GPT-2, and GPT-3, are part of the broader trend of using large-scale pre-training followed by fine-tuning for specific tasks. They have contributed significantly to advancing the field of natural language processing and understanding.
GPT-1, GPT-2 및 GPT-3는 모두 대량 사전 훈련 후 특정 작업에 대한 세부 튜닝을 통한 넓은 범위의 프레임워크를 대표합니다. 이들은 자연어 처리 및 이해 분야를 크게 발전시키는 데 기여한 중요한 모델 시리즈입니다.
11.9.5. Summary and Discussion
Transformers have been pretrained as encoder-only (e.g., BERT), encoder-decoder (e.g., T5), and decoder-only (e.g., GPT series). Pretrained models may be adapted to perform different tasks with model update (e.g., fine tuning) or not (e.g., few shot). Scalability of Transformers suggests that better performance benefits from larger models, more training data, and more training compute. Since Transformers were first designed and pretrained for text data, this section leans slightly towards natural language processing. Nonetheless, those models discussed above can be often found in more recent models across multiple modalities. For example, (i) Chinchilla (Hoffmann et al., 2022) was further extended to Flamingo (Alayrac et al., 2022), a visual language model for few-shot learning; (ii) GPT-2 (Radford et al., 2019) and the vision Transformer encode text and images in CLIP (Contrastive Language-Image Pre-training) (Radford et al., 2021), whose image and text embeddings were later adopted in the DALL-E 2 text-to-image system (Ramesh et al., 2022). Although there has been no systematic studies on Transformer scalability in multi-modal pretraining yet, a recent all-Transformer text-to-image model, Parti (Yu et al., 2022), shows potential of scalability across modalities: a larger Parti is more capable of high-fidelity image generation and content-rich text understanding (Fig. 11.9.12).
트랜스포머는 인코더 전용(예: BERT), 인코더-디코더(예: T5) 및 디코더 전용(예: GPT 시리즈)으로 사전 훈련되었습니다. 사전 훈련된 모델은 모델 업데이트(예: 미세 조정) 또는 그렇지 않은(예: 소수 샷) 다른 작업을 수행하도록 조정될 수 있습니다. Transformers의 확장성은 더 큰 모델, 더 많은 교육 데이터 및 더 많은 교육 컴퓨팅에서 더 나은 성능 이점을 제공합니다. 트랜스포머는 처음에 텍스트 데이터용으로 설계되고 사전 훈련되었기 때문에 이 섹션은 자연어 처리에 약간 기울어져 있습니다. 그럼에도 불구하고 위에서 논의한 모델은 종종 여러 양식에 걸친 최신 모델에서 찾을 수 있습니다. 예를 들어, (i) 친칠라(Hoffmann et al., 2022)는 퓨어샷 학습을 위한 시각적 언어 모델인 Flamingo(Alayrac et al., 2022)로 더욱 확장되었습니다. (ii) GPT-2(Radford et al., 2019) 및 비전 트랜스포머는 CLIP(Contrastive Language-Image Pre-training)(Radford et al., 2021)에서 텍스트와 이미지를 인코딩하며, 이미지 및 텍스트 임베딩은 나중에 채택되었습니다. DALL-E 2 텍스트-이미지 시스템에서(Ramesh et al., 2022). 다중 모달 사전 훈련에서 Transformer 확장성에 대한 체계적인 연구는 아직 없지만 최근의 모든 변환기 텍스트-이미지 모델인 Parti(Yu et al., 2022)는 양식에 걸친 확장 가능성을 보여줍니다. 더 큰 Parti는 고화질 이미지 생성 및 내용이 풍부한 텍스트 이해가 더 가능합니다(그림 11.9.12).

11.9.6. Exercises
- Is it possible to fine tune T5 using a minibatch consisting of different tasks? Why or why not? How about for GPT-2?
- Given a powerful language model, what applications can you think of?
- Say that you are asked to fine tune a language model to perform text classification by adding additional layers. Where will you add them? Why?
- Consider sequence to sequence problems (e.g., machine translation) where the input sequence is always available throughout the target sequence prediction. What could be limitations of modeling with decoder-only Transformers? Why?
'Dive into Deep Learning > D2L Attention Mechanisms and Transformer' 카테고리의 다른 글
| D2L - 11.8. Transformers for Vision (0) | 2023.08.10 |
|---|---|
| D2L - 11.7. The Transformer Architecture (0) | 2023.08.09 |
| D2L - 11.6. Self-Attention and Positional Encoding (0) | 2023.08.09 |
| D2L - 11.5. Multi-Head Attention (0) | 2023.08.08 |
| D2L - 11.4. The Bahdanau Attention Mechanism (1) | 2023.08.08 |
| D2L - 11.3. Attention Scoring Functions (0) | 2023.08.07 |
| D2L - 11.2. Attention Pooling by Similarity (0) | 2023.08.06 |
| D2L - 11.1. Queries, Keys, and Values (0) | 2023.08.05 |
| D2L - 11. Attention Mechanisms and Transformers (0) | 2023.08.03 |