

https://huggingface.co/learn/nlp-course/chapter3/4?fw=pt
A full training - Hugging Face NLP Course
Now we’ll see how to achieve the same results as we did in the last section without using the Trainer class. Again, we assume you have done the data processing in section 2. Here is a short summary covering everything you will need: Before actually writi
huggingface.co
https://youtu.be/Dh9CL8fyG80?si=3CJkNCLDiNe4l80r

A full training
Now we’ll see how to achieve the same results as we did in the last section without using the Trainer class. Again, we assume you have done the data processing in section 2. Here is a short summary covering everything you will need:
이제 Trainer 클래스를 사용하지 않고 마지막 섹션에서와 동일한 결과를 얻는 방법을 살펴보겠습니다. 다시 한 번 섹션 2에서 데이터 처리를 완료했다고 가정합니다. 다음은 필요한 모든 내용을 다루는 간단한 요약입니다.
from datasets import load_dataset
from transformers import AutoTokenizer, DataCollatorWithPadding
# "glue" 데이터셋의 "mrpc" 태스크를 로드
raw_datasets = load_dataset("glue", "mrpc")
# BERT의 사전 훈련된 토크나이저를 불러오기
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
# 사용자 정의 토큰화 함수 정의
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
# 토큰화된 데이터셋 생성 (batched=True로 설정하여 배치 단위로 토큰화)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
# 데이터 콜레이터 생성 (패딩 추가)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
이 코드는 Hugging Face Transformers 라이브러리를 사용하여 데이터셋을 로드하고 토큰화하는 과정을 나타냅니다. 코드를 단계별로 설명하겠습니다.
해석:
- load_dataset("glue", "mrpc"): Hugging Face의 datasets 라이브러리를 사용하여 GLUE 벤치마크의 MRPC(Microsoft Research Paraphrase Corpus) 태스크를 로드합니다.
- AutoTokenizer.from_pretrained(checkpoint): BERT 모델의 사전 훈련된 토크나이저를 불러옵니다. 여기서는 "bert-base-uncased"를 사용합니다.
- tokenize_function(example): 사용자 정의 토큰화 함수를 정의합니다. 이 함수는 입력으로 문장1(sentence1)과 문장2(sentence2)를 받아 토큰화한 결과를 반환합니다. truncation=True는 문장이 일정 길이를 초과할 경우 자르도록 설정한 것입니다.
- raw_datasets.map(tokenize_function, batched=True): 토큰화 함수를 사용하여 데이터셋을 토큰화합니다. batched=True로 설정하여 배치 단위로 토큰화합니다.
- DataCollatorWithPadding(tokenizer=tokenizer): 데이터 콜레이터를 생성합니다. 이 객체는 배치를 처리하여 패딩을 추가하고 동일한 길이로 만들어주는 역할을 합니다. 여기서는 BERT의 토크나이저를 사용하여 패딩을 추가하도록 설정했습니다.
이렇게 토큰화된 데이터셋과 데이터 콜레이터는 모델을 훈련하거나 평가할 때 사용됩니다. 데이터셋은 토큰화된 형태로 모델에 입력되고, 데이터 콜레이터는 배치를 처리하여 패딩을 추가하여 모델이 일관된 형태로 데이터를 처리할 수 있도록 도와줍니다.

Prepare for training
Before actually writing our training loop, we will need to define a few objects. The first ones are the dataloaders we will use to iterate over batches. But before we can define those dataloaders, we need to apply a bit of postprocessing to our tokenized_datasets, to take care of some things that the Trainer did for us automatically. Specifically, we need to:
실제로 훈련 루프를 작성하기 전에 몇 가지 객체를 정의해야 합니다. 첫 번째는 배치를 반복하는 데 사용할 데이터로더입니다. 하지만 이러한 데이터로더를 정의하기 전에 Trainer가 자동으로 수행한 일부 작업을 처리하기 위해 tokenized_datasets에 약간의 후처리를 적용해야 합니다. 구체적으로 다음을 수행해야 합니다.
- Remove the columns corresponding to values the model does not expect (like the sentence1 and sentence2 columns).
- 모델이 예상하지 않는 값(예: 문장1 및 문장2 열)에 해당하는 열을 제거합니다.
- Rename the column label to labels (because the model expects the argument to be named labels).
- 열 레이블의 이름을 labels 로 바꿉니다(모델에서는 인수 이름이 labels 로 지정될 것으로 예상하기 때문입니다).
- Set the format of the datasets so they return PyTorch tensors instead of lists.
- 목록 대신 PyTorch 텐서를 반환하도록 데이터 세트의 형식을 설정합니다.
Our tokenized_datasets has one method for each of those steps:
tokenized_datasets에는 각 단계에 대해 하나의 방법이 있습니다.
tokenized_datasets = tokenized_datasets.remove_columns(["sentence1", "sentence2", "idx"])
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
tokenized_datasets.set_format("torch")
tokenized_datasets["train"].column_names
이 코드는 Hugging Face의 datasets 라이브러리에서 사용되는 데이터셋 객체의 몇 가지 조작을 수행하는 부분입니다. 코드를 단계별로 설명하겠습니다.
해석:
- tokenized_datasets.remove_columns(["sentence1", "sentence2", "idx"]): "sentence1", "sentence2", 그리고 "idx" 열을 삭제합니다. 이 열들은 토큰화 이전에 원시 데이터셋에서 가져온 열일 것으로 예상됩니다.
- tokenized_datasets.rename_column("label", "labels"): "label" 열의 이름을 "labels"로 변경합니다. 일반적으로 Hugging Face Transformers 라이브러리에서 모델 훈련을 위해 사용되는 레이블 열의 이름은 "labels"입니다.
- tokenized_datasets.set_format("torch"): 데이터셋의 형식을 "torch"로 설정합니다. 이렇게 설정하면 PyTorch 텐서 형식으로 데이터셋이 변환됩니다.
- tokenized_datasets["train"].column_names: "train" 부분의 데이터셋에 있는 열의 이름들을 반환합니다. 이를 통해 현재 데이터셋에 어떤 열들이 있는지 확인할 수 있습니다.
따라서 최종적으로 "sentence1", "sentence2", "idx" 열이 삭제되고, "label"이 "labels"로 이름이 변경되며, 데이터셋의 형식이 PyTorch 텐서로 변경된 상태의 데이터셋이 만들어집니다.
We can then check that the result only has columns that our model will accept:
그런 다음 결과에 모델이 허용하는 열만 있는지 확인할 수 있습니다.
["attention_mask", "input_ids", "labels", "token_type_ids"]

Now that this is done, we can easily define our dataloaders:
이제 이 작업이 완료되었으므로 데이터로더를 쉽게 정의할 수 있습니다.
from torch.utils.data import DataLoader
# 훈련 데이터 로더 생성
train_dataloader = DataLoader(
tokenized_datasets["train"], # 훈련 데이터셋
shuffle=True, # 에폭마다 데이터를 섞을지 여부
batch_size=8, # 배치 크기
collate_fn=data_collator # 데이터 콜레이터 함수 (패딩 추가)
)
# 검증 데이터 로더 생성
eval_dataloader = DataLoader(
tokenized_datasets["validation"], # 검증 데이터셋
batch_size=8, # 배치 크기
collate_fn=data_collator # 데이터 콜레이터 함수 (패딩 추가)
)
이 코드는 PyTorch의 DataLoader를 사용하여 훈련 및 검증 데이터셋에 대한 데이터 로더를 만드는 부분입니다. 코드를 단계별로 설명하겠습니다.
해석:
- DataLoader: PyTorch의 데이터 로더 클래스로, 데이터셋에서 샘플을 미니배치로 효율적으로 로드하는 데 사용됩니다.
- tokenized_datasets["train"] 및 tokenized_datasets["validation"]: 각각 훈련 및 검증 데이터셋을 나타냅니다.
- shuffle=True: 훈련 데이터셋을 에폭(epoch)마다 섞을지 여부를 나타내는 매개변수입니다. 훈련 데이터셋을 섞어 모델이 다양한 샘플을 학습하도록 도웁니다.
- batch_size=8: 미니배치의 크기를 나타내는 매개변수로, 각 미니배치에 포함될 샘플의 수를 결정합니다.
- collate_fn=data_collator: 데이터 콜레이터 함수를 지정합니다. 이 함수는 배치의 샘플을 처리하여 패딩을 추가하고 동일한 길이로 만들어주는 역할을 합니다. 여기서는 앞서 생성한 DataCollatorWithPadding 객체를 사용합니다.
이렇게 생성된 train_dataloader와 eval_dataloader는 각각 훈련 및 검증 단계에서 사용됩니다. 모델 훈련 시에는 train_dataloader를 이용하여 미니배치 단위로 데이터를 모델에 공급하고, 검증 시에는 eval_dataloader를 사용하여 검증 데이터셋에 대한 예측을 수행합니다.
To quickly check there is no mistake in the data processing, we can inspect a batch like this:
데이터 처리에 실수가 없는지 빠르게 확인하기 위해 다음과 같은 배치를 검사할 수 있습니다.
for batch in train_dataloader:
break
{k: v.shape for k, v in batch.items()}{'attention_mask': torch.Size([8, 65]),
'input_ids': torch.Size([8, 65]),
'labels': torch.Size([8]),
'token_type_ids': torch.Size([8, 65])}
이 코드는 train_dataloader에서 첫 번째 미니배치를 가져와서 그 구조와 크기를 출력하는 부분입니다. 코드를 단계별로 설명하겠습니다.
해석:
- for batch in train_dataloader:: train_dataloader에서 미니배치를 순회합니다.
- break: 첫 번째 미니배치를 가져오고 반복문을 종료합니다. 이 부분에서는 첫 번째 미니배치만 확인합니다.
- {k: v.shape for k, v in batch.items()}: 미니배치의 각 텐서의 크기(shape)를 딕셔너리 형태로 출력합니다. 이 딕셔너리는 각 텐서의 키와 크기를 보여줍니다.
- k는 텐서의 키를 나타내며, 여기서는 "input_ids," "attention_mask," "labels" 등이 될 수 있습니다.
- v.shape는 텐서의 크기를 나타내며, 예를 들어 (배치 크기, 최대 시퀀스 길이)와 같은 형태일 것입니다.
이 코드를 실행하면 첫 번째 미니배치의 구조와 크기를 확인할 수 있습니다. 이는 데이터 처리 및 토큰화가 올바르게 이루어졌는지 확인하는 데 도움이 됩니다.

Note that the actual shapes will probably be slightly different for you since we set shuffle=True for the training dataloader and we are padding to the maximum length inside the batch.
훈련 데이터로더에 shuffle=True를 설정하고 배치 내부의 최대 길이까지 패딩하기 때문에 실제 모양은 약간 다를 수 있습니다.
Now that we’re completely finished with data preprocessing (a satisfying yet elusive goal for any ML practitioner), let’s turn to the model. We instantiate it exactly as we did in the previous section:
이제 데이터 전처리(ML 실무자에게는 달성하기 어려운 목표이지만 그래도 만족스러)가 완전히 완료되었으므로 모델을 살펴보겠습니다. 이전 섹션에서 했던 것과 똑같이 인스턴스화합니다.
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
이 코드는 Hugging Face Transformers 라이브러리를 사용하여 시퀀스 분류 모델을 로드하는 부분입니다. 코드를 단계별로 설명하겠습니다.
해석:
- from transformers import AutoModelForSequenceClassification: 시퀀스 분류 모델을 불러오기 위해 Hugging Face Transformers 라이브러리에서 AutoModelForSequenceClassification 클래스를 가져옵니다.
- AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2): 미리 훈련된 모델을 로드합니다. checkpoint는 로드하려는 모델의 이름 또는 경로를 나타냅니다. num_labels=2는 출력 레이블의 수를 나타내며, 이 경우 이진 분류를 위해 2로 설정되었습니다.
로드된 모델은 텍스트 시퀀스를 입력으로 받아 각 클래스에 대한 로짓을 출력하는 시퀀스 분류 모델입니다. 이 모델은 이미 사전 훈련된 가중치를 가지고 있으며, 특정 작업에 맞게 조정할 수 있습니다. 이러한 모델을 훈련하거나 텍스트 분류 작업에 활용할 수 있습니다.
To make sure that everything will go smoothly during training, we pass our batch to this model:
훈련 중에 모든 것이 원활하게 진행되도록 배치를 다음 모델에 전달합니다.
outputs = model(**batch)
print(outputs.loss, outputs.logits.shape)
tensor(0.5441, grad_fn=<NllLossBackward>) torch.Size([8, 2])
이 코드는 시퀀스 분류 모델에 입력 데이터를 주입하고, 모델의 출력인 손실 값(loss)과 로짓(logits)의 형태(shape)를 출력하는 부분입니다. 코드를 단계별로 설명하겠습니다.
해석:
- model(**batch): batch에 있는 입력 데이터를 모델에 전달합니다. batch에는 토큰화된 입력 데이터가 있으며, 모델은 이를 처리하여 예측을 수행합니다.
- outputs: 모델의 출력 결과를 저장한 객체입니다. 이 객체에는 여러 속성이 포함되어 있습니다.
- outputs.loss: 모델의 출력 손실 값입니다. 이 값은 훈련 중에 사용되며, 손실을 최소화하기 위해 모델의 가중치가 업데이트됩니다.
- outputs.logits: 모델의 출력으로, 각 클래스에 대한 로짓 값입니다. 로짓은 softmax 함수를 거친 후 확률로 변환되어 예측 클래스가 결정됩니다. logits.shape는 로짓 텐서의 크기를 나타냅니다.
- print(outputs.loss, outputs.logits.shape): 모델의 출력인 손실 값과 로짓 텐서의 크기를 출력합니다.
이 코드는 모델이 입력 데이터를 처리하고 그 결과를 확인하는 데 사용됩니다. 특히, 훈련할 때는 손실 값이 중요하며, 추론 및 평가 단계에서는 로짓을 통해 예측 결과를 확인할 수 있습니다.
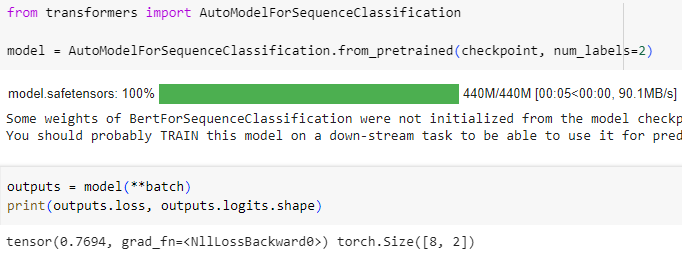
All 🤗 Transformers models will return the loss when labels are provided, and we also get the logits (two for each input in our batch, so a tensor of size 8 x 2).
모든 🤗 Transformers 모델은 레이블이 제공되면 손실을 반환하며 로지트도 얻습니다(배치의 각 입력에 대해 2개이므로 크기가 8 x 2인 텐서).
We’re almost ready to write our training loop! We’re just missing two things: an optimizer and a learning rate scheduler. Since we are trying to replicate what the Trainer was doing by hand, we will use the same defaults. The optimizer used by the Trainer is AdamW, which is the same as Adam, but with a twist for weight decay regularization (see “Decoupled Weight Decay Regularization” by Ilya Loshchilov and Frank Hutter):
훈련 루프를 작성할 준비가 거의 다 되었습니다! 우리는 최적화 프로그램과 학습률 스케줄러라는 두 가지를 놓치고 있습니다. Trainer가 직접 수행한 작업을 복제하려고 하므로 동일한 기본값을 사용하겠습니다. Trainer에서 사용하는 최적화 프로그램은 AdamW입니다. 이는 Adam과 동일하지만 체중 감소 정규화에 대한 변형이 있습니다(Ilya Loshchilov 및 Frank Hutter의 "De커플링된 체중 감소 정규화" 참조).
from transformers import AdamW
# 모델의 파라미터에 AdamW 옵티마이저를 설정
optimizer = AdamW(model.parameters(), lr=5e-5)이 코드는 Hugging Face Transformers 라이브러리에서 제공하는 AdamW 옵티마이저를 설정하는 부분입니다. 코드를 단계별로 설명하겠습니다.
해석:
- from transformers import AdamW: Hugging Face Transformers 라이브러리에서 AdamW 옵티마이저를 가져옵니다.
- optimizer = AdamW(model.parameters(), lr=5e-5): 모델의 파라미터를 가져와서 이를 AdamW 옵티마이저에 전달합니다. lr=5e-5는 학습률(learning rate)을 나타내며, 이 값은 학습 과정에서 가중치를 업데이트하는 정도를 조절합니다.
AdamW는 Adam 옵티마이저에 가중치 감쇠(weight decay)를 추가한 버전입니다. 가중치 감쇠는 모델의 가중치가 너무 커지지 않도록 제한하고, 오버피팅을 방지하는 데 도움을 줍니다.
이렇게 설정된 옵티마이저는 모델의 가중치를 업데이트할 때 사용되며, 이후에 이 옵티마이저를 통해 모델을 최적화하는 학습 과정을 진행할 수 있습니다.
Finally, the learning rate scheduler used by default is just a linear decay from the maximum value (5e-5) to 0. To properly define it, we need to know the number of training steps we will take, which is the number of epochs we want to run multiplied by the number of training batches (which is the length of our training dataloader). The Trainer uses three epochs by default, so we will follow that:
마지막으로, 기본적으로 사용되는 학습률 스케줄러는 최대값(5e-5)에서 0까지의 선형 감쇠일 뿐입니다. 이를 올바르게 정의하려면 수행할 학습 단계 수, 즉 에포크 수를 알아야 합니다. 훈련 배치 수(훈련 데이터로더의 길이)를 곱하여 실행하려고 합니다. Trainer는 기본적으로 세 가지 에포크를 사용하므로 다음을 따릅니다.
from transformers import get_scheduler
# 학습 에폭 수와 전체 학습 단계 수 설정
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
# 선형 학습률 스케줄러 설정
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)
# 전체 학습 단계 수 출력
print(num_training_steps)1377
이 코드는 Hugging Face Transformers 라이브러리에서 제공하는 학습률 스케줄러를 설정하는 부분입니다. 코드를 단계별로 설명하겠습니다.
해석:
- from transformers import get_scheduler: Hugging Face Transformers 라이브러리에서 학습률 스케줄러를 가져옵니다.
- num_epochs = 3 및 num_training_steps = num_epochs * len(train_dataloader): 전체 학습 에폭 수와 전체 학습 단계 수를 설정합니다. 이 값들은 학습률 스케줄러 설정에 사용됩니다.
- lr_scheduler = get_scheduler("linear", optimizer=optimizer, num_warmup_steps=0, num_training_steps=num_training_steps): 선형 학습률 스케줄러를 설정합니다. "linear"는 선형 스케줄러를 의미하며, 학습률이 선형으로 감소하도록 만듭니다. num_warmup_steps=0은 워머핑 단계 수를 0으로 설정하며, num_training_steps는 총 학습 단계 수입니다.
- print(num_training_steps): 전체 학습 단계 수를 출력합니다.
이렇게 설정된 선형 학습률 스케줄러는 학습률을 일정한 비율로 감소시키면서 학습을 진행합니다. 설정된 값들은 Trainer 클래스에서 사용되는 기본값을 따르도록 설정되어 있습니다.

The training loop
One last thing: we will want to use the GPU if we have access to one (on a CPU, training might take several hours instead of a couple of minutes). To do this, we define a device we will put our model and our batches on:
마지막으로, GPU에 액세스할 수 있는 경우 GPU를 사용하고 싶을 것입니다(CPU에서는 훈련에 몇 분이 아닌 몇 시간이 걸릴 수 있습니다). 이를 위해 모델과 배치를 배치할 장치를 정의합니다.
import torch
# CUDA가 사용 가능한 경우 GPU를, 그렇지 않은 경우 CPU를 선택
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
# 모델을 선택한 디바이스로 이동
model.to(device)
# 선택한 디바이스 출력
devicedevice(type='cuda')
이 코드는 PyTorch를 사용하여 모델을 GPU 또는 CPU로 이동하는 부분입니다. 코드를 단계별로 설명하겠습니다.
해석:
- import torch: PyTorch 라이브러리를 가져옵니다.
- device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu"): GPU(CUDA)가 사용 가능한 경우 GPU를 선택하고, 그렇지 않은 경우 CPU를 선택합니다. 이를 위해 torch.cuda.is_available() 함수를 사용하여 GPU 사용 가능 여부를 확인합니다.
- model.to(device): 모델을 선택한 디바이스로 이동시킵니다. 이로써 모델의 연산이 선택한 디바이스에서 수행되게 됩니다.
- device: 선택한 디바이스를 출력합니다. 이는 모델이 현재 어떤 디바이스에서 실행되고 있는지 확인할 수 있습니다.
이 코드는 모델을 GPU로 이동시키는데 사용되며, GPU가 없거나 사용이 불가능한 경우 CPU에서 모델을 실행하게 됩니다. GPU를 사용하면 모델의 연산이 병렬로 처리되어 훨씬 빠른 학습이 가능합니다.

CoLab에서는 GPU 사용은 안되고 CPU 를 사용해야 합니다.
We are now ready to train! To get some sense of when training will be finished, we add a progress bar over our number of training steps, using the tqdm library:
이제 훈련할 준비가 되었습니다! 훈련이 언제 완료되는지 알아보기 위해 tqdm 라이브러리를 사용하여 훈련 단계 수에 진행률 표시줄을 추가합니다.
from tqdm.auto import tqdm
# 훈련 단계 수만큼의 프로그레스 바 생성
progress_bar = tqdm(range(num_training_steps))
# 모델을 훈련 모드로 설정
model.train()
# 에폭 수만큼 반복
for epoch in range(num_epochs):
# 훈련 데이터로더에서 미니배치를 가져와 반복
for batch in train_dataloader:
# 미니배치의 각 요소를 선택한 디바이스로 이동
batch = {k: v.to(device) for k, v in batch.items()}
# 모델에 미니배치를 전달하여 출력을 얻음
outputs = model(**batch)
# 손실 값을 얻음
loss = outputs.loss
# 역전파 수행
loss.backward()
# 옵티마이저로 모델 파라미터 업데이트
optimizer.step()
# 학습률 스케줄러를 업데이트
lr_scheduler.step()
# 기울기를 초기화하여 다음 미니배치에 대한 역전파를 위해 준비
optimizer.zero_grad()
# 프로그레스 바 업데이트
progress_bar.update(1)
이 코드는 모델을 훈련하기 위한 학습 루프를 나타냅니다. 코드를 단계별로 설명하겠습니다.
해석:
- from tqdm.auto import tqdm: 훈련 과정에서 진행 상황을 시각적으로 확인하기 위해 tqdm 라이브러리에서 프로그레스 바를 사용합니다.
- progress_bar = tqdm(range(num_training_steps)): 전체 훈련 단계 수에 대한 프로그레스 바를 생성합니다.
- model.train(): 모델을 훈련 모드로 설정합니다. 이는 드롭아웃과 배치 정규화와 같은 학습 관련 기능을 활성화합니다.
- for epoch in range(num_epochs):: 지정된 에폭 수만큼 반복합니다.
- for batch in train_dataloader:: 훈련 데이터로더에서 미니배치를 가져와서 반복합니다.
- batch = {k: v.to(device) for k, v in batch.items()}: 미니배치의 각 요소를 선택한 디바이스로 이동시킵니다.
- outputs = model(**batch): 모델에 미니배치를 전달하여 모델의 출력을 얻습니다.
- loss = outputs.loss: 모델의 출력에서 손실 값을 얻습니다.
- loss.backward(): 역전파를 통해 기울기를 계산합니다.
- optimizer.step(): 옵티마이저를 사용하여 모델 파라미터를 업데이트합니다.
- lr_scheduler.step(): 학습률 스케줄러를 업데이트합니다.
- optimizer.zero_grad(): 모델 파라미터의 기울기를 초기화하여 다음 미니배치에 대한 역전파를 위해 준비합니다.
- progress_bar.update(1): 프로그레스 바를 업데이트하여 진행 상황을 시각적으로 확인합니다.
이렇게 훈련 루프를 통해 모델은 주어진 에폭 수에 대해 훈련되고, 손실이 감소하도록 파라미터가 업데이트됩니다.
You can see that the core of the training loop looks a lot like the one in the introduction. We didn’t ask for any reporting, so this training loop will not tell us anything about how the model fares. We need to add an evaluation loop for that.
훈련 루프의 핵심이 소개 부분과 매우 유사하다는 것을 알 수 있습니다. 우리는 보고를 요청하지 않았으므로 이 훈련 루프는 모델이 어떻게 진행되는지에 대해 아무 것도 알려주지 않습니다. 이를 위해 평가 루프를 추가해야 합니다.
The evaluation loop
As we did earlier, we will use a metric provided by the 🤗 Evaluate library. We’ve already seen the metric.compute() method, but metrics can actually accumulate batches for us as we go over the prediction loop with the method add_batch(). Once we have accumulated all the batches, we can get the final result with metric.compute(). Here’s how to implement all of this in an evaluation loop:
이전과 마찬가지로 🤗 Evaluate library 에서 제공하는 측정항목을 사용하겠습니다. 우리는 이미 metric.compute() 메소드를 보았지만 add_batch() 메소드를 사용하여 예측 루프를 진행하면서 메트릭은 실제로 배치를 누적할 수 있습니다. 모든 배치를 누적한 후에는 metric.compute()를 사용하여 최종 결과를 얻을 수 있습니다. 평가 루프에서 이 모든 것을 구현하는 방법은 다음과 같습니다.
import evaluate
# GLUE 메트릭을 로드
metric = evaluate.load("glue", "mrpc")
# 모델을 평가 모드로 설정
model.eval()
# 검증 데이터로더에서 미니배치를 가져와 반복
for batch in eval_dataloader:
# 미니배치의 각 요소를 선택한 디바이스로 이동
batch = {k: v.to(device) for k, v in batch.items()}
# 기울기를 계산하지 않도록 설정하여 평가 수행
with torch.no_grad():
outputs = model(**batch)
# 모델의 출력에서 로짓(확률 분포)을 얻음
logits = outputs.logits
# 로짓에서 예측 클래스를 결정
predictions = torch.argmax(logits, dim=-1)
# 메트릭에 현재 미니배치의 예측값과 레이블을 추가
metric.add_batch(predictions=predictions, references=batch["labels"])
# 메트릭을 통해 최종 평가 수행
metric.compute(){'accuracy': 0.8431372549019608, 'f1': 0.8907849829351535}이 코드는 모델을 사용하여 검증 데이터셋에 대한 평가를 수행하는 부분입니다. 코드를 단계별로 설명하겠습니다.
해석:
- import evaluate: 평가 관련 함수들이 정의된 evaluate 모듈을 가져옵니다.
- metric = evaluate.load("glue", "mrpc"): GLUE 벤치마크의 MRPC(Microsoft Research Paraphrase Corpus)에 대한 메트릭을 로드합니다.
- model.eval(): 모델을 평가 모드로 설정합니다. 이는 드롭아웃과 배치 정규화와 같은 학습 관련 기능을 비활성화합니다.
- for batch in eval_dataloader:: 검증 데이터로더에서 미니배치를 가져와 반복합니다.
- batch = {k: v.to(device) for k, v in batch.items()}: 미니배치의 각 요소를 선택한 디바이스로 이동시킵니다.
- with torch.no_grad():: 기울기를 계산하지 않도록 설정하여 평가 수행을 위해 모델을 실행합니다.
- outputs = model(**batch): 모델에 미니배치를 전달하여 모델의 출력을 얻습니다.
- logits = outputs.logits: 모델의 출력에서 로짓(확률 분포)을 얻습니다.
- predictions = torch.argmax(logits, dim=-1): 로짓에서 예측 클래스를 결정합니다.
- metric.add_batch(predictions=predictions, references=batch["labels"]): 메트릭에 현재 미니배치의 예측값과 레이블을 추가합니다.
- metric.compute(): 메트릭을 통해 최종 평가를 수행합니다.
이를 통해 모델이 검증 데이터에 대해 얼마나 좋은 성능을 보이는지를 측정하고, GLUE 벤치마크에서 정의된 평가 메트릭을 계산합니다.
Again, your results will be slightly different because of the randomness in the model head initialization and the data shuffling, but they should be in the same ballpark.
다시 말하지만, 모델 헤드 초기화 및 데이터 셔플링의 무작위성으로 인해 결과가 약간 다르지만 동일한 기준점에 있어야 합니다.
✏️ Try it out! Modify the previous training loop to fine-tune your model on the SST-2 dataset.
✏️ 한번 사용해 보세요! 이전 훈련 루프를 수정하여 SST-2 데이터세트에서 모델을 미세 조정하세요.
Supercharge your training loop with 🤗 Accelerate
https://youtu.be/s7dy8QRgjJ0?si=tR63TKSpr0Wj3Ebn

TPU(Tensor Processing Unit)는 구글에서 개발한 특수한 하드웨어로, 딥러닝 작업을 가속화하기 위해 설계되었습니다. TPU는 주로 텐서플로우(TensorFlow) 딥러닝 프레임워크와 함께 사용되며, 딥러닝 모델의 학습과 추론 속도를 높이는 데 중점을 둡니다.
TPU의 주요 특징은 다음과 같습니다:
- 고성능 병렬 처리: TPU는 텐서 연산에 특화된 구조로 구성되어 있어, 행렬 곱셈 및 기타 텐서 연산을 효율적으로 수행할 수 있습니다. 이는 딥러닝 모델의 대규모 연산에 적합합니다.
- 낮은 전력 소모: TPU는 높은 성능에도 불구하고 상대적으로 낮은 전력을 소비합니다. 이는 에너지 효율성 면에서 우수한 성능을 제공합니다.
- TensorFlow와의 통합: TPU는 주로 텐서플로우와 함께 사용되며, 텐서플로우에서 제공하는 TPU 지원 기능을 활용하여 모델을 효율적으로 실행할 수 있습니다.
- 대규모 딥러닝 모델 지원: TPU는 대규모 딥러닝 모델의 학습에 적합하며, 대규모 데이터셋에서의 훈련 작업에 특히 유용합니다.
TPU는 클라우드 기반의 딥러닝 작업에 많이 사용되며, 구글 클라우드(Google Cloud)와 같은 클라우드 서비스 제공업체에서 TPU를 사용할 수 있는 환경을 제공하고 있습니다. TPU는 GPU와 비교하여 특정 딥러닝 워크로드에서 높은 성능을 발휘할 수 있으며, 딥러닝 연구 및 응용 분야에서 중요한 역할을 하고 있습니다.
The training loop we defined earlier works fine on a single CPU or GPU. But using the 🤗 Accelerate library, with just a few adjustments we can enable distributed training on multiple GPUs or TPUs. Starting from the creation of the training and validation dataloaders, here is what our manual training loop looks like:
from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
# 사전 훈련된 모델과 함께 시퀀스 분류 모델을 불러옴
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
# AdamW 옵티마이저를 정의하고 모델의 파라미터를 전달
optimizer = AdamW(model.parameters(), lr=3e-5)
# 사용 가능한 GPU가 있다면 GPU로 모델을 이동
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model.to(device)
# 훈련 설정: 에폭 수 및 훈련 스텝 수 설정
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
# 러닝 레이트 스케줄러 설정
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)
# tqdm을 사용하여 훈련 진행 상황을 시각적으로 표시
progress_bar = tqdm(range(num_training_steps))
# 모델을 훈련 모드로 설정
model.train()
# 에폭 수 만큼 반복
for epoch in range(num_epochs):
# 훈련 데이터로더에서 미니배치를 가져와 반복
for batch in train_dataloader:
# 미니배치의 각 요소를 선택한 디바이스로 이동
batch = {k: v.to(device) for k, v in batch.items()}
# 모델에 미니배치를 전달하여 출력을 얻음
outputs = model(**batch)
# 손실을 얻고 역전파
loss = outputs.loss
loss.backward()
# 옵티마이저를 사용하여 모델 파라미터 업데이트
optimizer.step()
# 러닝 레이트 스케줄러를 사용하여 러닝 레이트 조절
lr_scheduler.step()
# 기울기 초기화
optimizer.zero_grad()
# tqdm 업데이트
progress_bar.update(1)
이 코드는 딥러닝 모델의 훈련을 위한 기본적인 스크립트를 나타냅니다. 코드를 단계별로 설명하겠습니다.
해석:
- 모델, 옵티마이저, 디바이스 설정: 사전 훈련된 모델을 불러오고, AdamW 옵티마이저를 정의하며, 사용 가능한 GPU가 있다면 GPU로 모델을 이동시킵니다.
- 훈련 설정: 에폭 수 및 훈련 스텝 수 설정합니다.
- 러닝 레이트 스케줄러 설정: 러닝 레이트 스케줄러를 설정하여 훈련 동안 러닝 레이트를 동적으로 조절합니다.
- tqdm을 사용한 진행 표시: tqdm은 훈련 진행 상황을 시각적으로 표시하는 도구입니다.
- 모델 훈련: 훈련 데이터로더에서 미니배치를 가져와 모델에 전달하고, 손실을 계산하여 역전파를 수행하며, 옵티마이저를 사용하여 모델 파라미터를 업데이트합니다. 러닝 레이트 스케줄러를 사용하여 러닝 레이트를 조절하고, tqdm을 업데이트하여 훈련 진행 상황을 표시합니다.
이러한 훈련 스크립트는 특정 모델과 데이터에 맞게 조정될 수 있으며, 주로 Hugging Face의 Transformers 라이브러리를 사용하여 딥러닝 모델을 훈련하는 일반적인 흐름을 나타냅니다.
And here are the changes: 변경 사항은 다음과 같습니다.
from accelerate import Accelerator
from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
# Accelerator 객체 생성
accelerator = Accelerator()
# AutoModelForSequenceClassification 모델 및 AdamW 옵티마이저 초기화
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
optimizer = AdamW(model.parameters(), lr=3e-5)
# 훈련 및 검증 데이터로더, 모델, 옵티마이저를 Accelerator로 준비
train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
train_dataloader, eval_dataloader, model, optimizer
)
# 나머지 코드는 동일하게 유지됨
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps
)
progress_bar = tqdm(range(num_training_steps))
model.train()
for epoch in range(num_epochs):
for batch in train_dataloader:
# batch = {k: v.to(device) for k, v in batch.items()} # 이 부분 삭제
outputs = model(**batch)
loss = outputs.loss
# loss.backward() # 이 부분 변경
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
이 코드는 accelerate 라이브러리를 사용하여 GPU 가속을 적용한 딥러닝 모델의 훈련 스크립트를 나타냅니다. 코드의 변경점에 대해 설명하겠습니다.
변경된 부분:
- Accelerator 사용: Accelerator 객체를 생성하고, prepare 메서드를 사용하여 훈련 데이터로더, 검증 데이터로더, 모델, 옵티마이저를 가속화합니다.
- Device 설정 제거: GPU 디바이스 설정 부분이 삭제되었습니다. Accelerator가 내부적으로 디바이스 관리를 수행합니다.
- Gradient 계산 변경: loss.backward() 대신 accelerator.backward(loss)를 사용하여 gradient 계산을 가속화합니다. Accelerator는 내부적으로 gradient 계산 및 관리를 처리합니다.
이러한 변경으로 코드는 GPU 가속을 사용하면서도 간소화되었고, 가속화 라이브러리를 통해 더욱 효율적으로 딥러닝 모델을 훈련할 수 있습니다.
The first line to add is the import line. The second line instantiates an Accelerator object that will look at the environment and initialize the proper distributed setup. 🤗 Accelerate handles the device placement for you, so you can remove the lines that put the model on the device (or, if you prefer, change them to use accelerator.device instead of device).
추가할 첫 번째 줄은 import 줄입니다. 두 번째 줄은 환경을 살펴보고 적절한 분산 설정을 초기화하는 Accelerator 개체를 인스턴스화합니다. 🤗 Accelerate가 장치 배치를 자동으로 처리하므로 장치에 모델을 배치하는 줄을 제거할 수 있습니다(또는 원하는 경우 장치 대신 accelerator.device를 사용하도록 변경).
Then the main bulk of the work is done in the line that sends the dataloaders, the model, and the optimizer to accelerator.prepare(). This will wrap those objects in the proper container to make sure your distributed training works as intended. The remaining changes to make are removing the line that puts the batch on the device (again, if you want to keep this you can just change it to use accelerator.device) and replacing loss.backward() with accelerator.backward(loss).
그런 다음 데이터로더, 모델 및 최적화 프로그램을 accelerator.prepare()로 보내는 라인에서 주요 작업이 수행됩니다. 이렇게 하면 분산 교육이 의도한 대로 작동하는지 확인하기 위해 해당 개체를 적절한 컨테이너에 래핑합니다. 나머지 변경 사항은 장치에 배치를 배치하는 줄을 제거하고(다시 말하지만 이를 유지하려면 accelerator.device를 사용하도록 변경하면 됩니다) loss.backward()를 accelerator.backward(loss)로 바꾸는 것입니다. .
If you’d like to copy and paste it to play around, here’s what the complete training loop looks like with 🤗 Accelerate:
복사하여 붙여넣고 놀고 싶다면 🤗 Accelerate를 사용한 전체 훈련 루프는 다음과 같습니다.
from accelerate import Accelerator
from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
# Accelerator 객체 생성
accelerator = Accelerator()
# AutoModelForSequenceClassification 모델 및 AdamW 옵티마이저 초기화
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
optimizer = AdamW(model.parameters(), lr=3e-5)
# 훈련 및 검증 데이터로더, 모델, 옵티마이저를 Accelerator로 준비
train_dl, eval_dl, model, optimizer = accelerator.prepare(
train_dataloader, eval_dataloader, model, optimizer
)
# 훈련 설정: 에폭 수 및 훈련 스텝 수 설정
num_epochs = 3
num_training_steps = num_epochs * len(train_dl)
# 러닝 레이트 스케줄러 설정
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)
# tqdm을 사용하여 훈련 진행 상황을 시각적으로 표시
progress_bar = tqdm(range(num_training_steps))
# 모델을 훈련 모드로 설정
model.train()
# 에폭 수 만큼 반복
for epoch in range(num_epochs):
# 훈련 데이터로더에서 미니배치를 가져와 반복
for batch in train_dl:
# 모델에 미니배치를 전달하여 출력을 얻음
outputs = model(**batch)
# 손실을 얻고 역전파
loss = outputs.loss
accelerator.backward(loss)
# 옵티마이저를 사용하여 모델 파라미터 업데이트
optimizer.step()
# 러닝 레이트 스케줄러를 사용하여 러닝 레이트 조절
lr_scheduler.step()
# 기울기 초기화
optimizer.zero_grad()
# tqdm 업데이트
progress_bar.update(1)
이 코드는 accelerate 라이브러리를 사용하여 GPU 가속을 적용한 딥러닝 모델의 훈련 스크립트를 나타냅니다.
변경된 부분:
- Accelerator 사용: Accelerator 객체를 생성하고, prepare 메서드를 사용하여 훈련 데이터로더, 검증 데이터로더, 모델, 옵티마이저를 가속화합니다.
- 변수 명칭 변경: train_dl 및 eval_dl로 변수명을 변경하여 가속화된 데이터로더를 사용합니다.
나머지 코드는 이전과 동일하게 유지되며, 가속화 라이브러리를 사용하여 GPU 가속을 적용한 효율적인 딥러닝 모델 훈련을 수행합니다.
Putting this in a train.py script will make that script runnable on any kind of distributed setup. To try it out in your distributed setup, run the command:
이것을 train.py 스크립트에 넣으면 모든 종류의 분산 설정에서 해당 스크립트를 실행할 수 있습니다. 분산 설정에서 사용해 보려면 다음 명령을 실행하세요.
accelerate config
accelerate config 명령어는 accelerate 라이브러리의 환경 설정을 확인하는 명령어입니다. 이 명령어를 사용하면 현재 가속화 환경에 대한 설정 정보를 확인할 수 있습니다. 아래는 해당 명령어에 대한 설명입니다.
위 명령어를 실행하면, 현재 사용 중인 환경에 대한 다양한 설정이 출력됩니다. 주로 다음과 같은 정보를 확인할 수 있습니다.
- accelerator 설정: 현재 사용 중인 가속화 기술, 예를 들어, cuda 또는 tpu 등이 표시됩니다.
- num_processes 및 num_gpus 설정: 병렬 처리에 사용되는 프로세스 수와 GPU 수가 표시됩니다.
- fp16 설정: 16-bit 부동 소수점 사용 여부에 대한 설정이 표시됩니다.
- fp16_backend 설정: 16-bit 부동 소수점 연산을 처리하는 백엔드(예: apex 또는 amp)가 표시됩니다.
- ddp 설정: 분산 데이터 병렬 설정이 표시됩니다.
이 명령어를 사용하면 가속화 환경에 대한 자세한 설정을 확인할 수 있어, 딥러닝 모델을 효율적으로 훈련하기 위해 가속화 라이브러리를 조정하는 데 도움이 됩니다.
which will prompt you to answer a few questions and dump your answers in a configuration file used by this command:
그러면 몇 가지 질문에 대답하고 이 명령에서 사용하는 구성 파일에 답변을 덤프하라는 메시지가 표시됩니다.
accelerate launch train.py
accelerate launch train.py 명령어는 accelerate 라이브러리를 사용하여 딥러닝 모델을 훈련하는 스크립트인 train.py를 실행하는 명령어입니다. 이 명령어를 사용하면 가속화 환경에서 훈련을 수행할 수 있습니다. 아래는 해당 명령어에 대한 설명입니다.
해당 명령어를 실행하면, train.py 스크립트가 가속화 라이브러리의 환경 설정에 맞게 실행됩니다. 이때, 여러 GPU 또는 TPU 등을 활용하여 훈련을 가속화할 수 있습니다.
이 명령어를 사용하는 주요 이점은:
- 분산 훈련 지원: accelerate는 분산 훈련을 지원하며, 여러 GPU 또는 TPU에서 모델을 효율적으로 훈련할 수 있도록 도와줍니다.
- Mixed Precision 훈련: 16-bit 부동 소수점 연산을 사용하여 모델의 훈련 속도를 향상시킵니다.
- 간편한 사용: accelerate를 사용하면 분산 훈련 및 가속화 설정에 대한 복잡한 부분을 자동으로 처리하여 간편하게 활용할 수 있습니다.
따라서, accelerate launch 명령어를 사용하면 train.py를 가속화된 환경에서 간편하게 실행할 수 있습니다.
which will launch the distributed training. 분산 교육이 시작됩니다.
If you want to try this in a Notebook (for instance, to test it with TPUs on Colab), just paste the code in a training_function() and run a last cell with:
노트북에서 이 작업을 시도하려면(예: Colab의 TPU로 테스트) training_function()에 코드를 붙여넣고 다음을 사용하여 마지막 셀을 실행하세요.
from accelerate import notebook_launcher
notebook_launcher(training_function)
from accelerate import notebook_launcher와 notebook_launcher(training_function) 코드는 Jupyter Notebook 환경에서 accelerate 라이브러리를 사용하여 모델 훈련 함수(training_function)를 가속화하여 실행하는 코드입니다. 이 코드를 사용하면 Jupyter Notebook에서 간편하게 모델 훈련을 가속화할 수 있습니다.
해당 코드를 단계별로 설명하겠습니다:
notebook_launcher 임포트:
from accelerate import notebook_launcher
accelerate 라이브러리에서 notebook_launcher 모듈을 임포트합니다. 이 모듈은 Jupyter Notebook에서 가속화된 훈련을 지원합니다.
notebook_launcher 사용:
notebook_launcher(training_function)
- notebook_launcher 함수에 모델을 훈련시키는 함수(training_function)를 전달하여 사용합니다. 이 함수는 가속화된 환경에서 모델 훈련을 시작합니다. notebook_launcher는 분산 훈련 및 Mixed Precision 훈련을 처리하는 등 가속화에 필요한 설정을 자동으로 수행합니다.
이 코드를 사용하면 Jupyter Notebook에서 간편하게 training_function을 실행할 수 있으며, accelerate 라이브러리의 기능을 활용하여 가속화된 딥러닝 모델 훈련을 수행할 수 있습니다.
You can find more examples in the 🤗 Accelerate repo.
🤗 Accelerate 저장소에서 더 많은 예시를 찾아보실 수 있습니다.
'Hugging Face > NLP Course' 카테고리의 다른 글
| HF-NLP-SHARING MODELS AND TOKENIZERS-Building a model card (0) | 2023.12.27 |
|---|---|
| HF-NLP-SHARING MODELS AND TOKENIZERS-Sharing pretrained models (0) | 2023.12.27 |
| HF-NLP-SHARING MODELS AND TOKENIZERS-Using pretrained models (0) | 2023.12.27 |
| HF-NLP-SHARING MODELS AND TOKENIZERS-The Hugging Face Hub (0) | 2023.12.26 |
| HF-NLP-FINE-TUNING A PRETRAINED MODEL-Fine-tuning, Check! (1) | 2023.12.26 |
| HF-NLP-FINE-TUNING A PRETRAINED MODEL-Fine-tuning a model with the Trainer API (1) | 2023.12.26 |
| HF-NLP-FINE-TUNING A PRETRAINED MODEL-Processing the data (1) | 2023.12.26 |
| HF-NLP-FINE-TUNING A PRETRAINED MODEL-Introduction (0) | 2023.12.26 |
| HF-NLP-USING 🤗 TRANSFORMERS : End-of-chapter quiz (0) | 2023.12.25 |
| HF-NLP-USING 🤗 TRANSFORMERS : Basic usage completed! (0) | 2023.12.25 |