

HF-NLP-SHARING MODELS AND TOKENIZERS-Using pretrained models
2023. 12. 27. 00:21 |
https://huggingface.co/learn/nlp-course/chapter4/2?fw=pt
Using pretrained models - Hugging Face NLP Course
2. Using 🤗 Transformers 3. Fine-tuning a pretrained model 4. Sharing models and tokenizers 5. The 🤗 Datasets library 6. The 🤗 Tokenizers library 9. Building and sharing demos new
huggingface.co
The Model Hub makes selecting the appropriate model simple, so that using it in any downstream library can be done in a few lines of code. Let’s take a look at how to actually use one of these models, and how to contribute back to the community.
모델 허브를 사용하면 적절한 모델을 간단하게 선택할 수 있으므로 다운스트림 라이브러리에서 몇 줄의 코드만으로 모델을 사용할 수 있습니다. 이러한 모델 중 하나를 실제로 사용하는 방법과 커뮤니티에 다시 기여하는 방법을 살펴보겠습니다.
Let’s say we’re looking for a French-based model that can perform mask filling.
마스크 채우기를 수행할 수 있는 프랑스 기반 모델을 찾고 있다고 가정해 보겠습니다.

We select the camembert-base checkpoint to try it out. The identifier camembert-base is all we need to start using it! As you’ve seen in previous chapters, we can instantiate it using the pipeline() function:
이를 시험해 보기 위해 카망베르 기반 체크포인트를 선택합니다. 식별자 camembert-base만 사용하면 됩니다! 이전 장에서 본 것처럼 파이프라인() 함수를 사용하여 인스턴스화할 수 있습니다.
from transformers import pipeline
camembert_fill_mask = pipeline("fill-mask", model="camembert-base")
results = camembert_fill_mask("Le camembert est <mask> :)")
[
{'sequence': 'Le camembert est délicieux :)', 'score': 0.49091005325317383, 'token': 7200, 'token_str': 'délicieux'},
{'sequence': 'Le camembert est excellent :)', 'score': 0.1055697426199913, 'token': 2183, 'token_str': 'excellent'},
{'sequence': 'Le camembert est succulent :)', 'score': 0.03453313186764717, 'token': 26202, 'token_str': 'succulent'},
{'sequence': 'Le camembert est meilleur :)', 'score': 0.0330314114689827, 'token': 528, 'token_str': 'meilleur'},
{'sequence': 'Le camembert est parfait :)', 'score': 0.03007650189101696, 'token': 1654, 'token_str': 'parfait'}
]
해당 코드는 Hugging Face의 Transformers 라이브러리를 사용하여 CamemBERT 모델을 활용하여 문장 내의 마스킹된 단어를 예측하는 코드입니다. 간단히 설명하면, 주어진 문장에서 <mask>로 표시된 부분을 모델이 예측하도록 하는 파이프라인을 설정하고, 그 결과를 확인하는 코드입니다.
라이브러리 임포트:
from transformers import pipeline
Transformers 라이브러리에서 pipeline 모듈을 임포트합니다.
파이프라인 설정:
camembert_fill_mask = pipeline("fill-mask", model="camembert-base")
"fill-mask" 태스크를 수행하는 파이프라인을 설정합니다. 여기서는 CamemBERT 모델을 사용하고 있습니다.
문장의 마스킹된 부분 예측:
results = camembert_fill_mask("Le camembert est <mask> :)")
설정한 파이프라인을 사용하여 주어진 문장에서 <mask>로 표시된 부분을 모델이 예측하고, 결과를 results 변수에 저장합니다.
위 코드에서는 "Le camembert est <mask> :)"라는 문장에서 <mask> 부분을 모델이 예측한 결과를 확인할 수 있습니다. 결과는 results 변수에 저장되어 있습니다.
참고: 코드는 CamemBERT 모델의 미세 조정 및 특정한 데이터셋에 따라 결과가 달라질 수 있습니다.

Some weights of the model checkpoint at camembert-base were not used when initializing CamembertForMaskedLM: ['roberta.pooler.dense.bias', 'roberta.pooler.dense.weight']
- This IS expected if you are initializing CamembertForMaskedLM from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing CamembertForMaskedLM from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
[{'score': 0.9632076025009155, 'token': 2117, 'token_str': 'capitale', 'sequence': 'Paris est la capitale de la France.'}, {'score': 0.031002620235085487, 'token': 22013, 'token_str': 'Capitale', 'sequence': 'Paris est la Capitale de la France.'}, {'score': 0.0011895311763510108, 'token': 10431, 'token_str': 'préfecture', 'sequence': 'Paris est la préfecture de la France.'}, {'score': 0.0006761185941286385, 'token': 8529, 'token_str': 'métropole', 'sequence': 'Paris est la métropole de la France.'}, {'score': 0.0005724380607716739, 'token': 285, 'token_str': 'ville', 'sequence': 'Paris est la ville de la France.'}]
https://huggingface.co/camembert-base?text=Le+camembert+est+%3Cmask%3E
camembert-base · Hugging Face
📚 anthonygaltier/text_2_price__real_estate 🏢 Artemis-IA/3-stars-sentiment-analysis
huggingface.co
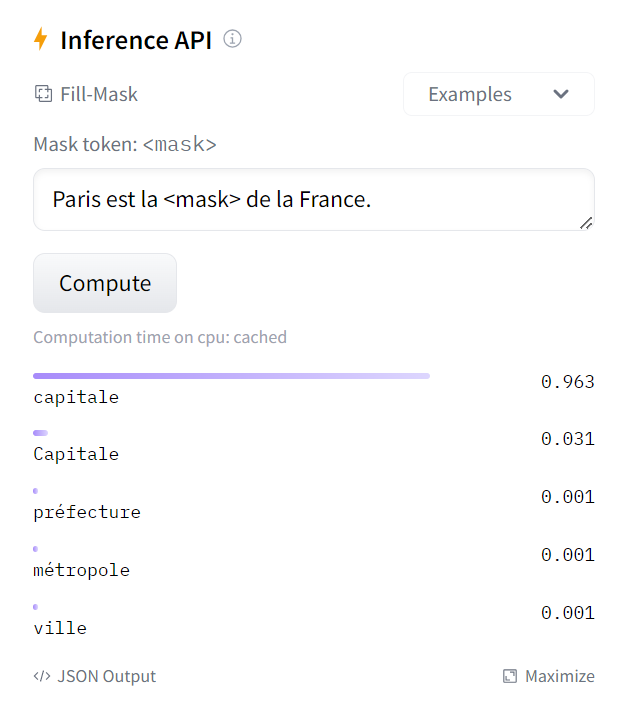
As you can see, loading a model within a pipeline is extremely simple. The only thing you need to watch out for is that the chosen checkpoint is suitable for the task it’s going to be used for. For example, here we are loading the camembert-base checkpoint in the fill-mask pipeline, which is completely fine. But if we were to load this checkpoint in the text-classification pipeline, the results would not make any sense because the head of camembert-base is not suitable for this task! We recommend using the task selector in the Hugging Face Hub interface in order to select the appropriate checkpoints:
보시다시피 파이프라인 내에서 모델을 로드하는 것은 매우 간단합니다. 주의해야 할 유일한 점은 선택한 체크포인트가 사용할 작업에 적합한지 여부입니다. 예를 들어, 여기서는 채우기 마스크 파이프라인에 카망베르 기반 체크포인트를 로드하고 있는데, 이는 전혀 문제가 없습니다. 하지만 텍스트 분류 파이프라인에 이 체크포인트를 로드하면 Camembert-base의 헤드가 이 작업에 적합하지 않기 때문에 결과가 의미가 없습니다! 적절한 체크포인트를 선택하려면 Hugging Face Hub 인터페이스의 task selector 를 사용하는 것이 좋습니다.

You can also instantiate the checkpoint using the model architecture directly:
모델 아키텍처를 직접 사용하여 체크포인트를 인스턴스화할 수도 있습니다.
from transformers import CamembertTokenizer, CamembertForMaskedLM
tokenizer = CamembertTokenizer.from_pretrained("camembert-base")
model = CamembertForMaskedLM.from_pretrained("camembert-base")
해당 코드는 Hugging Face의 Transformers 라이브러리를 사용하여 CamemBERT 모델의 토크나이저와 마스킹 언어 모델을 불러와 초기화하는 코드입니다. 간단히 설명하면, CamemBERT 모델의 토크나이저와 마스킹 언어 모델을 설정하여 활용할 수 있도록 하는 과정입니다.
라이브러리 임포트:
from transformers import CamembertTokenizer, CamembertForMaskedLM
Transformers 라이브러리에서 CamemBERT 모델의 토크나이저와 마스킹 언어 모델을 사용하기 위해 필요한 모듈을 임포트합니다.
토크나이저 및 마스킹 언어 모델 초기화:
tokenizer = CamembertTokenizer.from_pretrained("camembert-base")
model = CamembertForMaskedLM.from_pretrained("camembert-base")
from_pretrained 메서드를 사용하여 "camembert-base"라는 사전 학습된 모델을 불러오고, 이를 초기화하여 tokenizer와 model 변수에 할당합니다. CamembertTokenizer는 문장을 토큰으로 분할하는 역할을 하며, CamembertForMaskedLM은 마스킹 언어 모델의 인스턴스를 생성합니다.
이제 위의 코드를 사용하여 CamemBERT 모델의 토크나이저와 마스킹 언어 모델을 활용할 수 있습니다. 예를 들어, 문장을 토큰화하거나 마스킹된 부분을 예측하는 작업 등을 수행할 수 있습니다.
However, we recommend using the Auto* classes instead, as these are by design architecture-agnostic. While the previous code sample limits users to checkpoints loadable in the CamemBERT architecture, using the Auto* classes makes switching checkpoints simple:
그러나 Auto* 클래스는 설계상 아키텍처에 구애받지 않으므로 대신 사용하는 것이 좋습니다. 이전 코드 샘플에서는 사용자가 CamemBERT 아키텍처에서 로드할 수 있는 체크포인트로 제한했지만 Auto* 클래스를 사용하면 체크포인트 전환이 간단해졌습니다.
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("camembert-base")
model = AutoModelForMaskedLM.from_pretrained("camembert-base")
해당 코드는 Hugging Face의 Transformers 라이브러리를 사용하여 CamemBERT 모델의 토크나이저와 마스킹 언어 모델을 불러와 초기화하는 코드입니다. AutoTokenizer와 AutoModelForMaskedLM 클래스를 사용하면 모델의 종류를 명시적으로 지정하지 않고 자동으로 적절한 모델을 불러올 수 있습니다.
라이브러리 임포트:
from transformers import AutoTokenizer, AutoModelForMaskedLM
Transformers 라이브러리에서 AutoTokenizer와 AutoModelForMaskedLM 클래스를 임포트합니다.
토크나이저 및 마스킹 언어 모델 초기화:
tokenizer = AutoTokenizer.from_pretrained("camembert-base")
model = AutoModelForMaskedLM.from_pretrained("camembert-base")
from_pretrained 메서드를 사용하여 "camembert-base"라는 사전 학습된 모델을 불러오고, 이를 초기화하여 tokenizer와 model 변수에 할당합니다. AutoTokenizer는 문장을 토큰으로 분할하는 역할을 하며, AutoModelForMaskedLM은 마스킹 언어 모델의 인스턴스를 생성합니다.
이 코드는 특정 모델의 이름을 명시하지 않고도 자동으로 적절한 모델을 불러오기 때문에 편리하게 사용할 수 있습니다. 위의 코드를 사용하면 CamemBERT 모델의 토크나이저와 마스킹 언어 모델을 초기화할 수 있습니다.
When using a pretrained model, make sure to check how it was trained, on which datasets, its limits, and its biases. All of this information should be indicated on its model card.
사전 학습된 모델을 사용할 때는 모델이 어떻게 학습되었는지, 어떤 데이터세트에 대해, 한계, 편향이 있는지 확인하세요. 이 모든 정보는 모델 카드에 표시되어야 합니다.
Korean example.
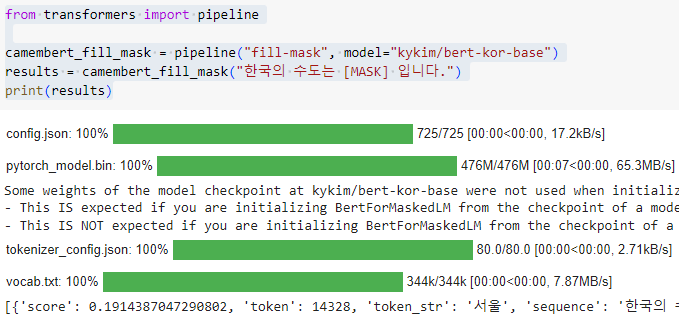
from transformers import pipeline
camembert_fill_mask = pipeline("fill-mask", model="kykim/bert-kor-base")
results = camembert_fill_mask("한국의 수도는 [MASK] 입니다.")
print(results)
[{'score': 0.1914387047290802, 'token': 14328, 'token_str': '서울', 'sequence': '한국의 수도는 서울 입니다.'},
{'score': 0.10752367973327637, 'token': 14147, 'token_str': '한국', 'sequence': '한국의 수도는 한국 입니다.'},
{'score': 0.07457706332206726, 'token': 21793, 'token_str': '로마', 'sequence': '한국의 수도는 로마 입니다.'},
{'score': 0.07277032732963562, 'token': 16809, 'token_str': '대한민국', 'sequence': '한국의 수도는 대한민국 입니다.'},
{'score': 0.022880734875798225, 'token': 25738, 'token_str': '필리핀', 'sequence': '한국의 수도는 필리핀 입니다.'}]
https://huggingface.co/kykim/bert-kor-base
kykim/bert-kor-base · Hugging Face
huggingface.co




'Hugging Face > NLP Course' 카테고리의 다른 글
| HF-NLP-SHARING MODELS AND TOKENIZERS-End-of-chapter quiz (0) | 2023.12.27 |
|---|---|
| HF-NLP-SHARING MODELS AND TOKENIZERS-Part 1 completed! (2) | 2023.12.27 |
| HF-NLP-SHARING MODELS AND TOKENIZERS-Building a model card (0) | 2023.12.27 |
| HF-NLP-SHARING MODELS AND TOKENIZERS-Sharing pretrained models (0) | 2023.12.27 |
| HF-NLP-SHARING MODELS AND TOKENIZERS-The Hugging Face Hub (0) | 2023.12.26 |
| HF-NLP-FINE-TUNING A PRETRAINED MODEL-Fine-tuning, Check! (1) | 2023.12.26 |
| HF-NLP-FINE-TUNING A PRETRAINED MODEL-A full training (1) | 2023.12.26 |
| HF-NLP-FINE-TUNING A PRETRAINED MODEL-Fine-tuning a model with the Trainer API (1) | 2023.12.26 |
| HF-NLP-FINE-TUNING A PRETRAINED MODEL-Processing the data (1) | 2023.12.26 |
| HF-NLP-FINE-TUNING A PRETRAINED MODEL-Introduction (0) | 2023.12.26 |