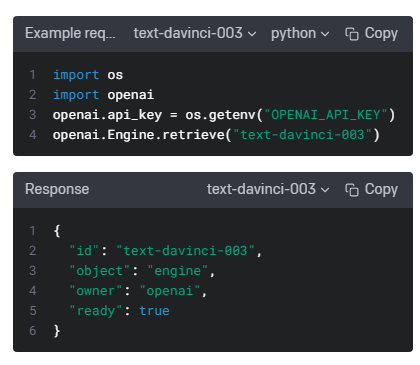
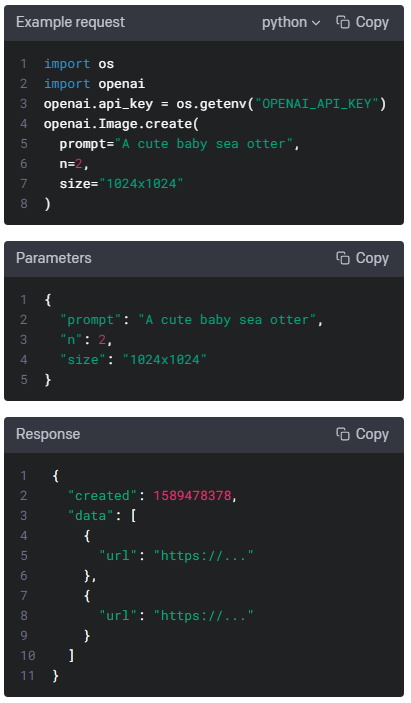
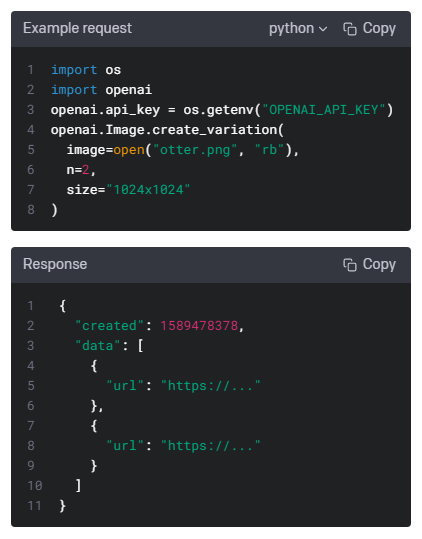
개발자로서 현장에서 일하면서 새로 접하는 기술들이나 알게된 정보 등을 정리하기 위한 블로그입니다. 운 좋게 미국에서 큰 회사들의 프로젝트에서 컬설턴트로 일하고 있어서 새로운 기술들을 접할 기회가 많이 있습니다. 미국의 IT 프로젝트에서 사용되는 툴들에 대해 많은 분들과 정보를 공유하고 싶습니다.
Classroom Session 3: Understanding technical indicators – Homework Please complete this homework prior to the next class in the course. We will review the answers and the project assigned at the beginning of the next class.
1. Which of these are trend indicators? a. Charts b. Moving Averages c. RSI d. OBV
==> b. Moving Average. 이동 평균선은 추세를 나타내는 지표이다.
==> RSI (Relative Strength Index) 는 과매도, 과매수를 알 수 있는 모멘텀 관련 지표
==> OBV (On Balance Volume)는 볼륨 관련 지표로 OBV를 통해서 상승/하락 추세가 계속 될지 멈출지 그 가능성을 봅니다.
2. Which of these is a momentum indicator? a. Charts b. Moving Averages c. RSI d. OBV
==> c. RSI
3. Which of these is a Volume Indicator? a. Charts b. Moving Averages c. RSI d. OBV
==> d. OBV
4. Which of these is a Price Indicator? a. Charts b. Moving Averages c. RSI d. OBV
==> ???
5. What are the four types of indicators a technical analyst should use?
==> Trend Indicator, Momentum Indicator, Volume Indicator, Volatility Indicator, Support and Resistance Indicator
6. Name one Volatility Indicator. (BB) *
Project: 1. Go to the technical Indicator Guide in the learning center a. Screen for each of the three indicator types and select one of each type and read the description. b. Add the three indicators to your chart c. Look up a symbol d. Determine what trend the stock is in e. Look at all three indicators in conjunction to determine if they are confirming or refuting each other f. Is there any evidence of a trend change on the chart?
Technical analysis focuses on market action — specifically, volume and price. Technical analysis is only one approach to analyzing stocks. When considering which stocks to buy or sell, you should use the approach that you're most comfortable with. As with all your investments, you must make your own determination as to whether an investment in any particular security or securities is right for you based on your investment objectives, risk tolerance, and financial situation. Past performance is no guarantee of future results.
Fidelity Brokerage Services LLC, Member NYSE, SIPC, 900 Salem Street, Smithfield, RI 02917
추세, 모멘텀, 볼륨 그리고 support 와 저항 같은 기술적 지표들의 여러가지 타입들을 구분해 보세요.
기술적 분석의 차트 패턴에 대해 알아보기
바 챠트와 캔들 챠트의 중요한 패턴들에 대한 예제들을 통해서 챠트를 이용하고 챠트 패턴들을 배우세요.
기술적 분석을 통해 리스크 관리하기
여러 확인된 방법들을 사용해서 거래 리스크를 관리하세요.
찰스 D. 커크패트릭 2세, CMT
Charles D. Kirkpatrick II, CMT는 Market Strategist 투자 뉴스레터를 발행하는 기술 분석 연구 회사인 Kirkpatrick & Company, Inc.의 사장입니다. Fort Lewis College의 경영학부 교수이자 Brandeis University International Business School의 겸임 교수인 그는 기술 분석 연구로 Market Technicians Association의 권위 있는 Charles H. Dow Award를 두 번 수상했습니다. , "기술 분석 분야에 대한 뛰어난 공헌"으로 2008년 MTA 연례 상을 수상했으며, 2012년 "학계에서 기술 분석의 장기 후원"으로 MTA 교육 재단의 Mike Epstein Award를 수상했습니다.
그는 공인 시장 기술자, Market Technicians Association 이사회의 전 회원, Journal of Technical Analysis의 전 편집자, Market Technicians Association Educational Foundation의 전 이사 및 부회장, American 전문 기술자 협회(AAPTA). 그는 Technical Analysis: The Complete Source for Financial Market Technicians, CMT 프로그램 및 기술 분석에 대한 대학 대학원 과정의 기본 교과서, Beat the Market, 가장 최근에는 Time the Markets: Using Technical Analysis to Interpret Economic Data를 공동 집필했습니다. .
그는 Phillips Exeter Academy, Harvard College(AB) 및 Wharton School(MBA)을 졸업했으며 Maine에서 아내와 함께 살고 있습니다.
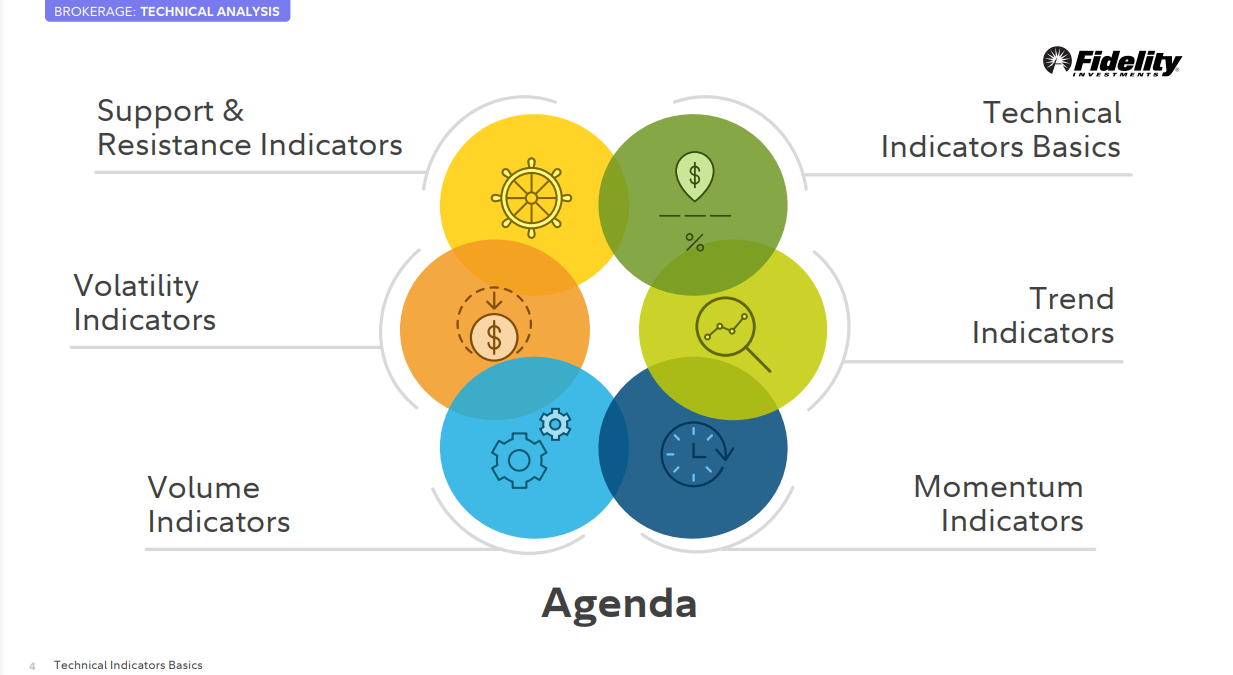
아젠다
기술적 분석 지표 기초
추세 관련 지표들
모멘텀 지표들
볼륨 지표들
변동성 지표들
저항/지지 관련 지표들
기술적 분석 관련 지표들 기초
기술 지표들이란 무엇인가?
기술관련 지표는 기존의 가격이나 볼륨들을 기초로 한 수학적 계산들이다.
추세 지표들 : Simple Moving Average (SMA), Exponential Moving Average (EMA), Moving Average Convergence/Divergence (MACD), Average Directional Movement Index (ADX)
모멘텀 지표들 : Stochastic Oscillator, Relative Strength Index (RSI)
볼륨 지표들 : On Balance Volume (OBV), Money Flow Index (MFI), Accumulation/Distribution
변동성 지표들 : Bollinger Bands®, Average True Range (ATR)
저항/지지 관련 지표 : Fibonacci Retracements
추세 관련 지표들
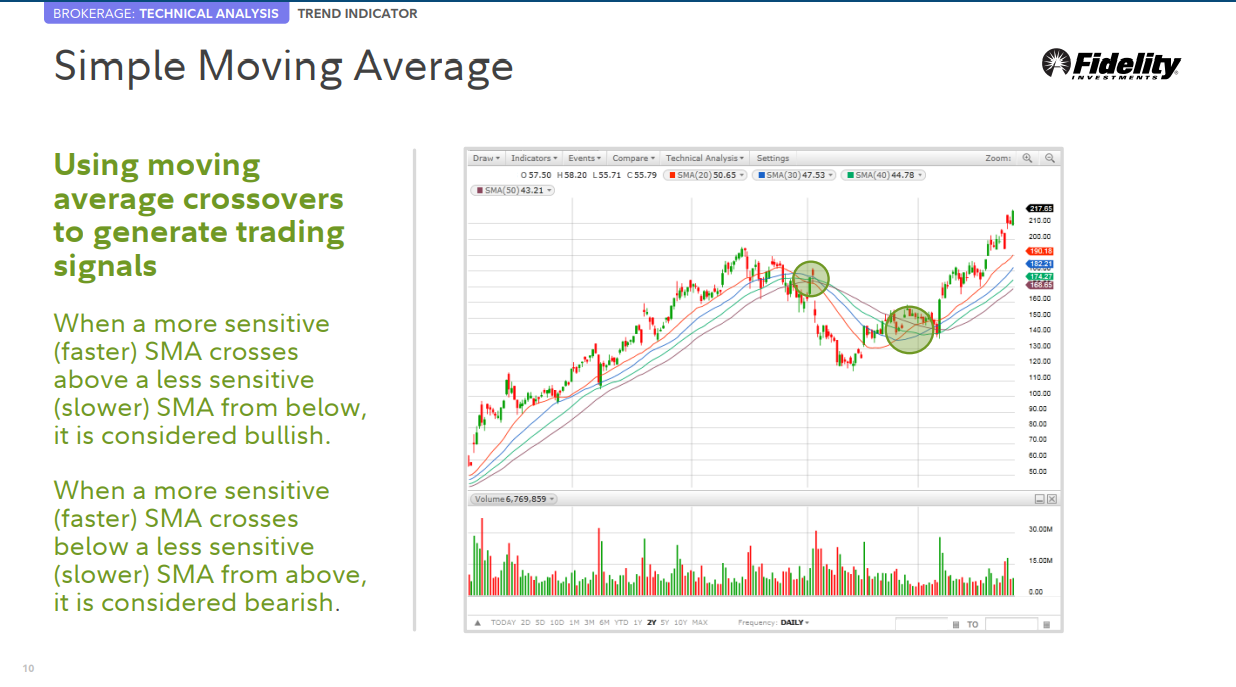
단순 이동 평균선
단순 이동 평균선(SMA) 이것은 구성하기 가장 쉬운 이동 평균입니다. 지정된 기간 동안의 평균 가격으로 계산됩니다. 평균은 막대 단위로 차트 막대에 표시되어 평균값이 변경됨에 따라 차트를 따라 이동하는 선을 형성하기 때문에 "이동"이라고 합니다.
작동 방식
추세 방향 결정 • SMA가 위로 올라가면 추세가 상승합니다. • SMA가 아래로 내려가면 추세가 하락합니다.
추세 기간 결정 • 200일선 SMA는 장기 추세에 대한 일반적인 Proxy (신호) 입니다. • 50일선 SMA는 일반적으로 중간 추세를 측정하는 데 사용됩니다. • 단기 SMA는 단기 추세를 결정하는 데 사용할 수 있습니다.
가격 교차되는 것을 보고 거래 결정 • 가격이 SMA (이동 평균선) 위로 교차하면 롱 또는 숏 커버를 원할 수 있습니다. • 가격이 SMA (이동 평균선) 아래로 교차하면 매도 또는 매수를 원할 수 있습니다.
단순 이동 평균선
이동 평균선을 교차하는 것을 보고 거래 신호 생성
더 민감한(빠른) SMA가 아래에서 덜 민감한(느린) SMA 위로 교차하면 강세로 간주됩니다.
(예 20일 선이 50일선을 교차해서 위로 향할 때 etc.)
더 민감한(빠른) SMA가 위에서 덜 민감한(느린) SMA 아래로 교차하면 약세로 간주됩니다.
(예 50일 선이 20일선을 교차해서 아래로 향할 때)
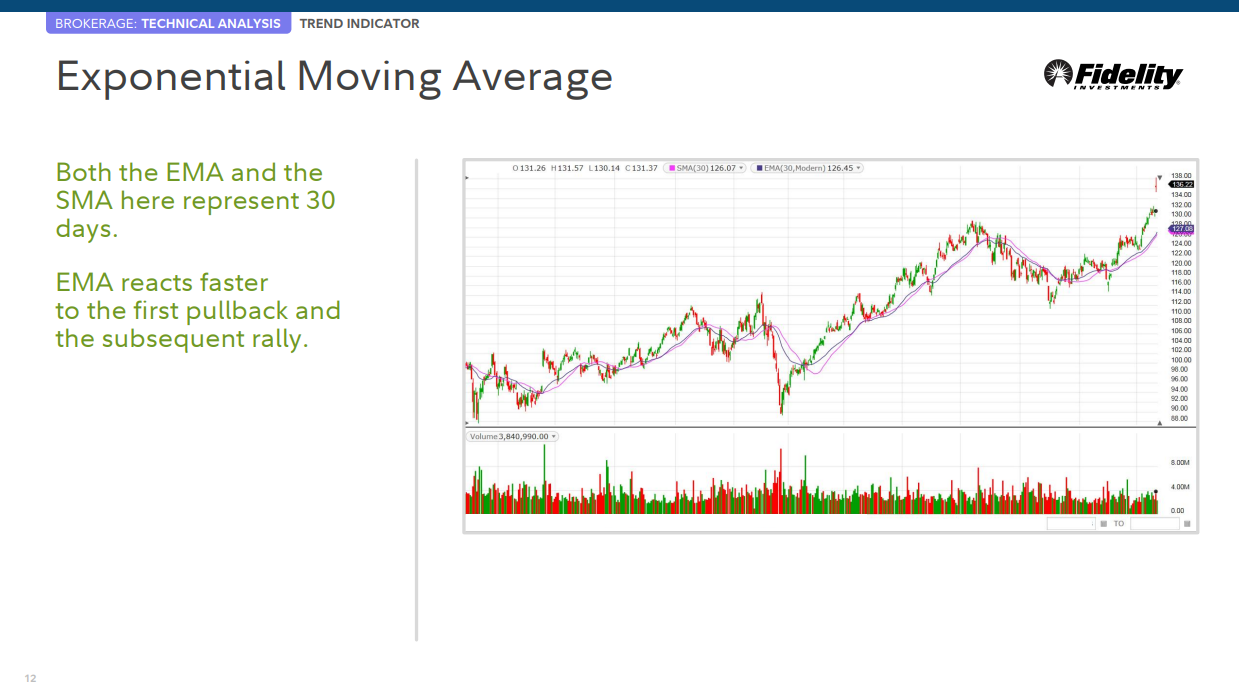
지수 이동 평균
지수 이동 평균(EMA) EMA는 일정 기간 동안 추세 방향을 측정합니다. 최신 데이터에 더 많은 가중치를 적용합니다. 고유한 계산법으로 인해 EMA는 해당 SMA보다 더 밀접하게 가격을 따를 것입니다.
작동 방식
조기에 추세 파악 • EMA를 해석할 때 SMA에 적용되는 동일한 규칙을 사용합니다. EMA는 일반적으로 단기 가격 변동에 더 민감합니다.
추세 방향 결정 • EMA가 상승할 때 가격이 EMA 근처 또는 바로 아래로 떨어질 때 매수를 고려할 수 있습니다. EMA가 하락하면 가격이 EMA를 향하거나 EMA 바로 위에서 상승할 때 매도를 고려할 수 있습니다.
지원 및 저항 영역 표시 • 상승하는 EMA는 가격 조치를 지지하는 경향이 있는 반면 하락하는 EMA는 가격 조치에 대한 저항을 제공하는 경향이 있습니다.
지수 이동 평균
여기서 EMA와 SMA는 모두 30일을 나타냅니다. EMA는 첫 번째 풀백과 후속 랠리에 더 빠르게 반응합니다.
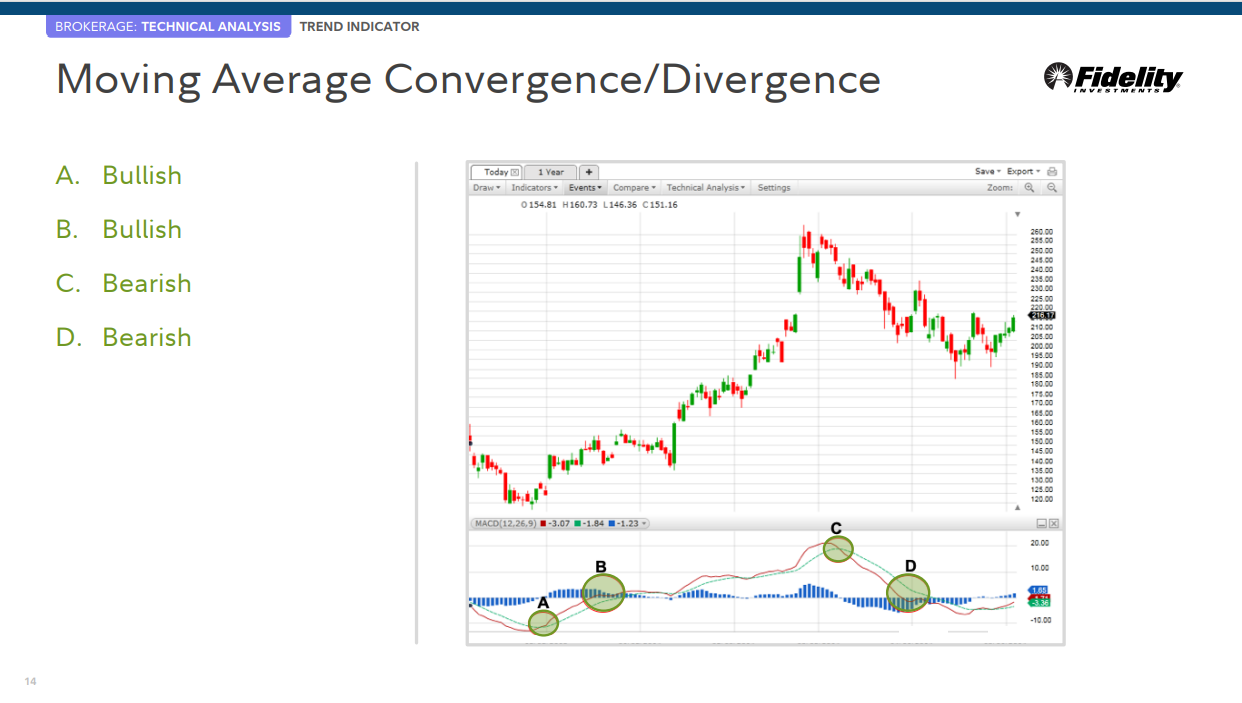
이동 평균 수렴/발산
이동 평균 수렴/발산(MACD) MACD는 추세 거래에 주로 사용되는 모멘텀 오실레이터입니다.
작동 방식
강세 또는 약세 결정 • MACD가 0선 위로 교차하는 것은 강세로 간주되고 0선 아래로 교차하는 것은 약세로 간주됩니다. MACD가 0선 아래에서 상승하면 강세로 간주됩니다. 0선 위에서 하락하면 약세로 간주됩니다.
• MACD 선이 신호선 아래에서 위로 교차하면 지표가 강세로 간주됩니다. 0선 아래에서 이 교차가 발생할수록 신호가 더 강해집니다.
• MACD 선이 신호선 위에서 아래로 교차하면 지표가 약세로 간주됩니다. 이 크로스가 0선 위에서 더 많이 발생할수록 신호가 더 강해집니다.
이동 평균 수렴/발산(MACD)
A. 상승세
B. 상승세
C. 하락세
D. 하락세
평균 방향 이동 지수
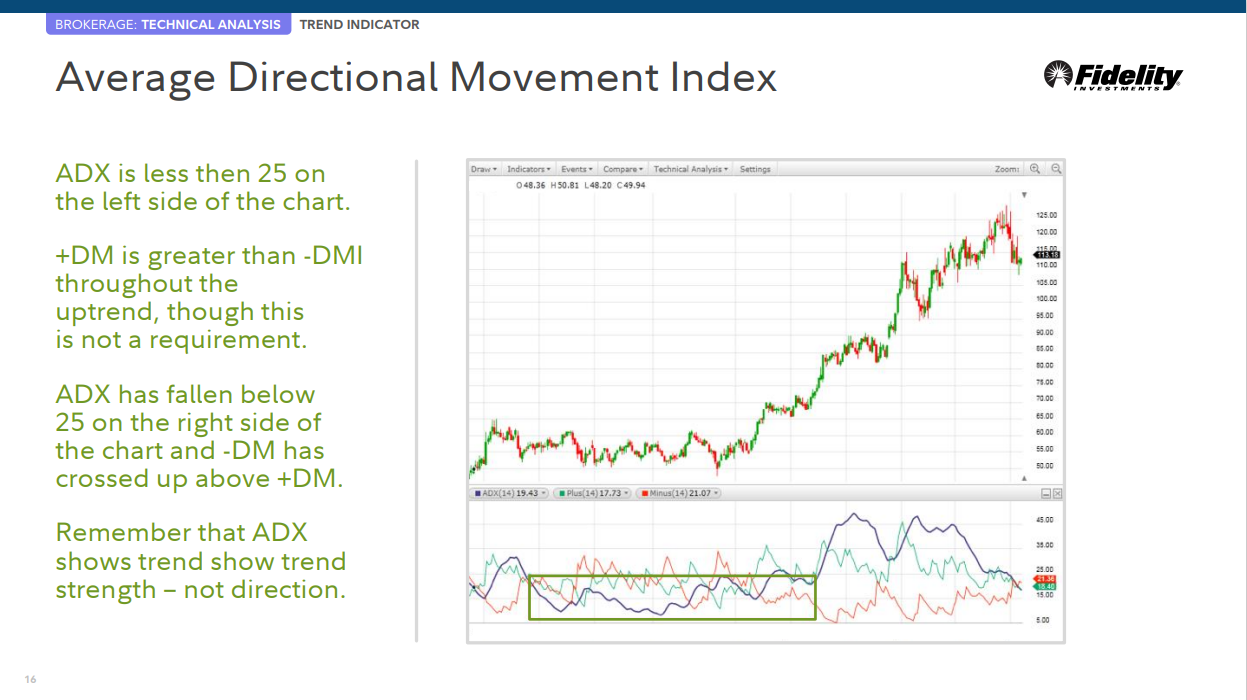
평균방향이동지수(ADX) ADX는 추세의 전반적인 강도를 측정하는 데 사용할 수 있습니다.
‐ 양의 방향성 지표(+DMI)는 오늘의 고가와 어제의 고가의 차이를 나타냅니다. 그런 다음 이러한 값을 지난 14개 기간에서 합산한 다음 플로팅합니다.
‐ 음의 방향성 지표(–DMI)는 오늘의 저가와 어제의 저가의 차이를 나타냅니다. 그런 다음 이 값을 지난 14개 기간에서 합산하여 표시합니다.
평균 방향 이동 지수
ADX는 차트의 왼쪽에서 25보다 작습니다.
+DM은 상승추세 전반에 걸쳐 -DMI보다 크지만 필수 사항은 아닙니다.
ADX는 차트 오른쪽에서 25 아래로 떨어졌고 -DM은 +DM을 넘어섰습니다.
ADX는 방향이 아닌 추세 쇼 추세 강도를 보여줍니다.
모멘텀 지표들
과매수/과매도 Oscillators
• "오실레이터"라고도 하는 제한된 표시기에는 도달할 수 있는 높이 또는 낮음에 대한 제한이 있습니다.
• 오실레이터가 최고점에 가까운 영역에 도달하면 "과매수"라고 합니다.
• 가장 낮은 범위에 근접한 영역에 도달하면 "과매도"라고 합니다.
• 이 구역의 오실레이터 값은 시장이 반전에 취약함을 나타냅니다. 오실레이터가 이러한 영역 중 하나를 벗어날 때 신호가 자주 발생합니다.
• 경우에 따라 극한 수준에 도달하면 새로운 추세가 시작되었음을 나타냅니다. 이러한 경우 오실레이터는 추세 기간 동안 영역에 남아 있으며 추세 수정에 대해 많은 잘못된 신호를 제공합니다.
• 따라서 오실레이터 과매도 및 과매수에 대한 해석은 기본 추세에 따라 달라집니다.
• 추세가 강할 때는 작동하지 않지만 거래 범위 시장에서는 탁월합니다.
확률 발진기
스토캐스틱 오실레이터는 일정 기간 동안 고저 범위에 상대적인 종가 위치를 보여주는 모멘텀 지표입니다.
지표의 범위는 0에서 100까지입니다. 스토캐스틱 오실레이터는 광범위한 거래 범위 또는 느리게 움직이는 추세에서 가장 효과적입니다.
작동 방식
출구/입구 결정
• 일반적으로 80 이상은 과매수 구간, 20 미만은 과매도 구간으로 판단됩니다.
• 오실레이터가 80을 넘어선 다음 80 아래로 다시 교차하면 매도 신호입니다. 반대로 오실레이터가 20 아래에서 다시 20 위로 교차하면 매수 신호입니다.
• 교차 신호는 두 선이 과매수 또는 과매도 영역에서 교차할 때 발생합니다.
• 새로운 고가 또는 저가가 스토캐스틱 오실레이터에 의해 확인되지 않을 때 다이버전스가 형성됩니다.
확률 발진기
이 예는 Slow Stochastic을 사용하고 있습니다. 의 효과에 주목 횡보 추세 동안의 신호.
가격과 오실레이터 간의 차이도 신호를 생성할 수 있습니다.
상대 강도 지수
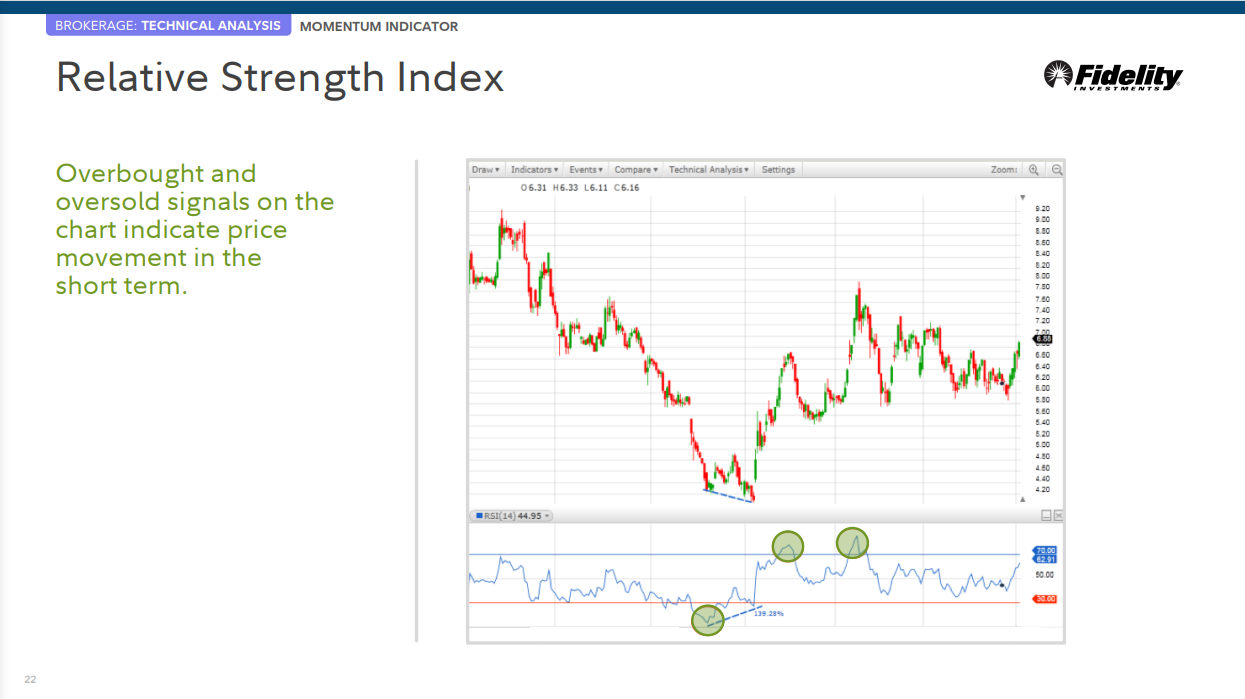
상대 강도 지수 (RSI)
RSI는 가격 움직임의 속도와 변화를 측정합니다.
작동 방식
가격의 속도와 변화를 결정
• RSI는 0과 100 사이에서 변동합니다. 전통적으로 RSI는 70 이상이면 과매수, 30 미만이면 과매도로 간주됩니다.
• 상승 추세 또는 강세장에서 RSI는 40-50 영역이 지지 역할을 하면서 40-90 범위에 머무르는 경향이 있습니다.
• 하락세 또는 약세장에서 RSI는 10-60 범위에 머물고 50-60 영역이 저항으로 작용하는 경향이 있습니다.
• 기초 가격이 RSI에서 확인되지 않은 새로운 고점 또는 저점을 기록하는 경우 이 다이버전스는 가격 반전 신호일 수 있습니다.
상대 강도 지수 (RSI)
챠트상에서 과매도 과매수 신호는 단기간에 가격 변동이 일어 날 것이란 것을 알려 준다.
볼륨에 관한 지표들
볼륨 이론의 일반적인 규칙
볼륨이 높아지면 추세 방향이 강화됩니다.
거래량 감소는 추세 방향을 감소시킵니다.
매우 높은 거래량의 가격 정점 또는 최저점은 종종 추세의 중요한 반전 지점입니다.
거래량 지표는 경고로 간주해야 하지만 추세 방향의 변화를 알리는 신호는 아닙니다.
On Balance Volume
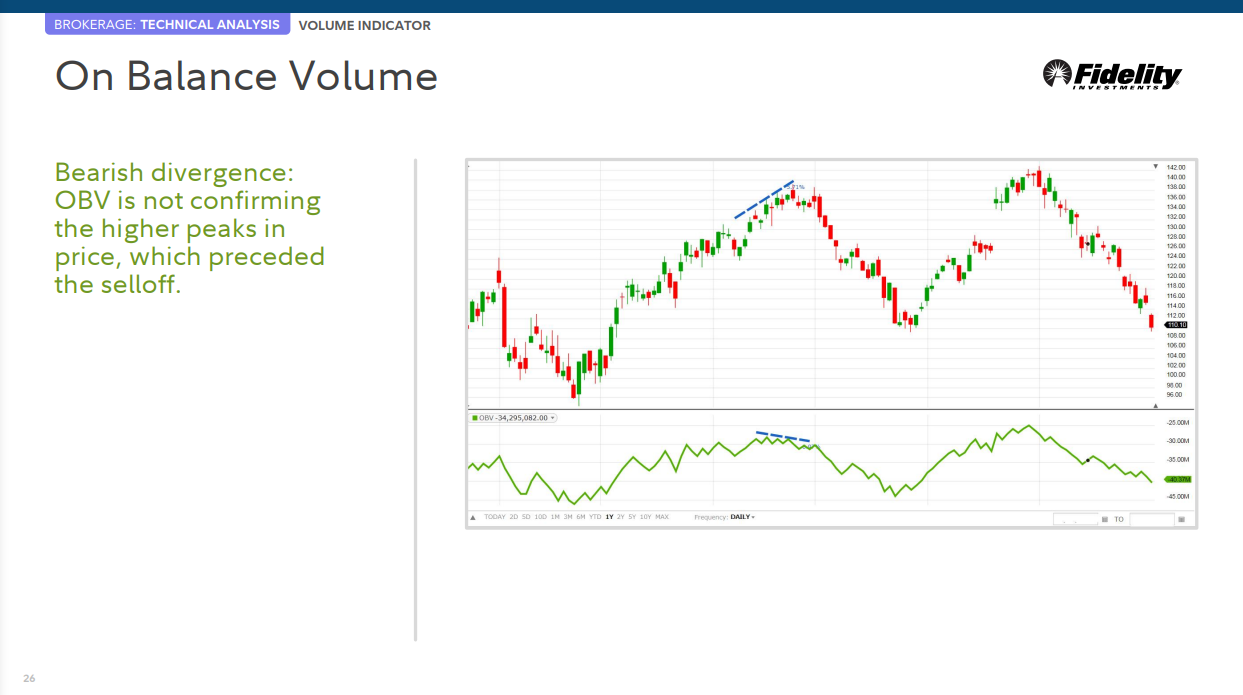
온 밸런스 볼륨(OBV)
OBV는 상승일에 거래량을 더하고 하락일에 거래량을 빼는 누적 지표로 매수 및 매도 압력을 측정합니다.
작동 방식
• OBV의 실제 값은 중요하지 않습니다. 방향에 집중하십시오.
• 가격이 계속해서 더 높은 고점을 만들고 OBV가 더 높은 고점을 만들지 못하면 상승 추세가 멈추거나 실패할 가능성이 있습니다. 이를 네거티브 다이버전스라고 합니다.
• 가격이 계속해서 저점을 낮추고 OBV가 저점을 낮추지 못하면 하락 추세가 멈추거나 실패할 가능성이 높습니다. 이를 포지티브 다이버전스라고 합니다.
On Balance Volume
약세 다이버전스: OBV는 매도 이전에 있었던 가격의 더 높은 정점을 확인하지 않고 있습니다.
Money Flow Index 자금 흐름 지수
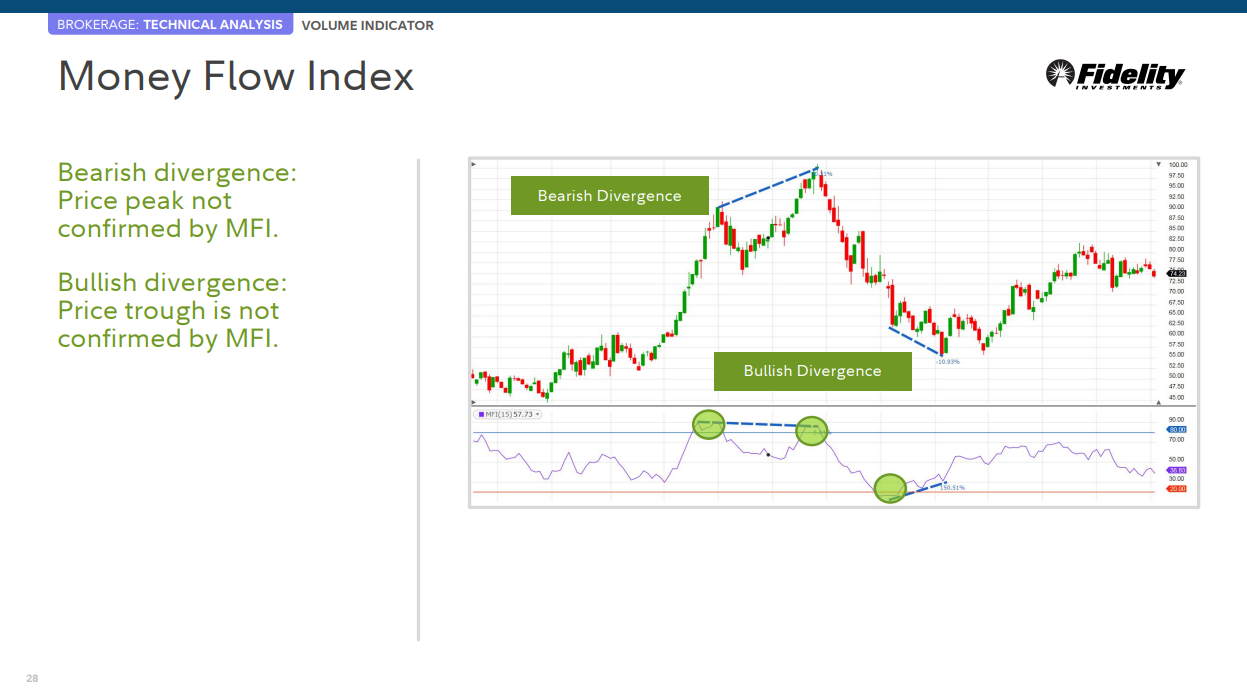
자금 흐름 지수(MFI)
MFI는 특정 기간 동안 security 안팎으로 유입되는 자금의 흐름을 측정하는 거래량 지표입니다. RSI(Relative Strength Index)와 관련이 있지만 거래량을 포함하는 반면 RSI는 가격만 고려합니다.
작동 방식
• 과매도 수준은 일반적으로 20 미만이며 과매수 수준은 일반적으로 80 이상입니다. 이러한 수준은 시장 상황에 따라 변경될 수 있습니다.
• 과매도 또는 과매수 수준은 일반적으로 매수 또는 매도할 충분한 이유가 되지 않으며 트레이더는 증권의 전환점을 확인하기 위해 추가 기술 분석 또는 연구를 고려해야 합니다.
• 기초 가격이 MFI에서 확인되지 않은 새로운 고점 또는 저점을 기록하는 경우 이 다이버전스는 가격 반전 신호가 될 수 있습니다.
Money Flow Index
약세 다이버전스: MFI가 확인하지 않은 가격 피크.
강세 다이버전스: 가격 저점은 MFI에 의해 확인되지 않습니다.
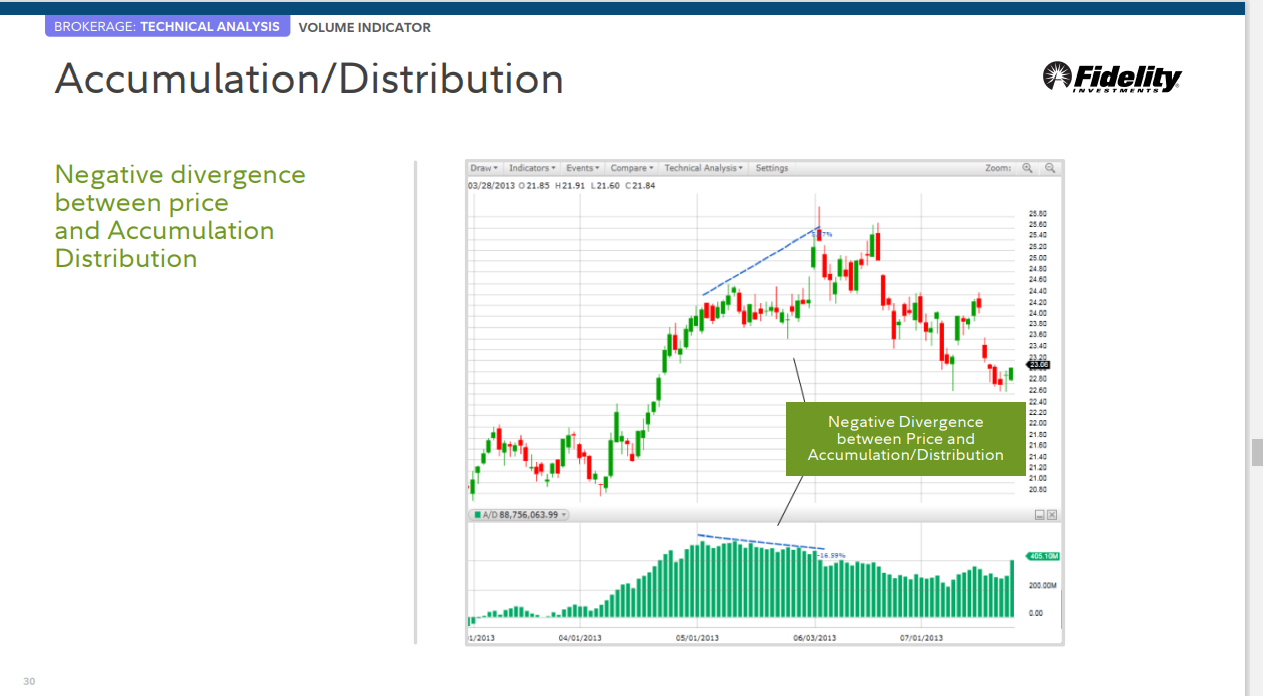
Accumulation/Distribution 축적/분배
축적/분배
축적/분배는 종가가 최고점과 최저점에 얼마나 근접해 있는지를 살펴보고 시장에서 누적 또는 분배가 발생하는지 확인합니다.
추세의 방향 결정
• 가격과 Accumulation/Distribution이 고점과 저점이 높아지면 상승세가 지속될 가능성이 높습니다.
• 가격과 Accumulation/Distribution가 고점과 저점을 낮추면 하락세가 지속될 가능성이 높습니다.
• 가격이 계속해서 고점을 형성하지만 Accumulation/Distribution가 더 높은 고점을 만들지 못하면 상승 추세가 정체되거나 실패할 가능성이 높습니다. 이것은 음의 다이버전스로 알려져 있습니다.
• 가격이 저점을 계속 낮추고 Accumulation/Distribution이 저점을 낮추지 못하면 하락세는 멈추거나 실패할 가능성이 높습니다. 이것은 포지티브 다이버전스로 알려져 있습니다.
Accumulation/Distribution
가격과 누적 분포 간의 음의 다이버전스
변동성 관련 지표들
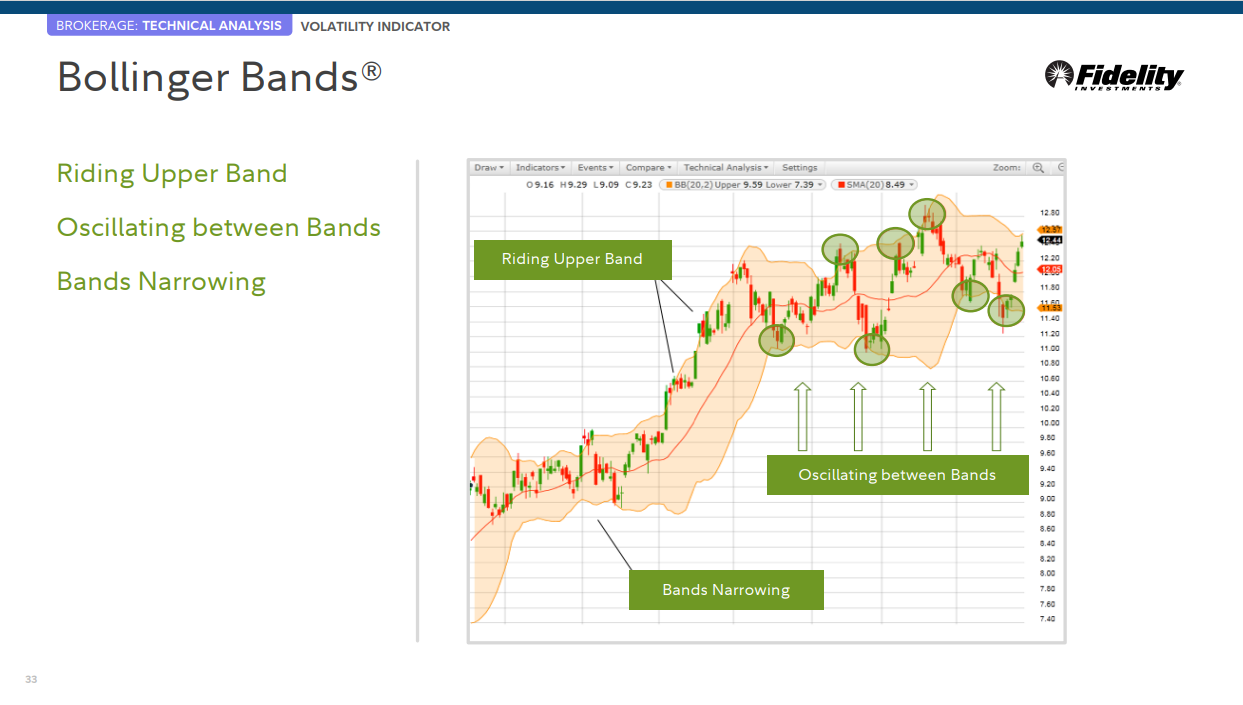
Bollinger Bands®
볼린저 밴드
Bollinger Bands는 가격의 단순 이동 평균 위와 아래의 표준 편차 수준에 표시된 가격 포락선 유형입니다. Bollinger Bands는 가격이 상대적으로 높은지 낮은지를 결정하는 데 도움이 됩니다.
작동 방식
상대적 가격 결정
• 변동성이 낮은 기간 동안 밴드가 타이트해지면 가격이 어느 방향으로든 급격하게 움직일 가능성이 높아집니다.
• 밴드가 비정상적으로 많이 분리되면 변동성이 증가하고 기존 추세가 종료될 수 있습니다.
• 잠재적인 이익 목표를 식별하는 데 도움이 되도록 밴드 엔벨로프 내에서 스윙을 사용합니다.
Bollinger Bands®
윗쪽 밴드를 타는 경우
밴드간 진동
밴드가 좁혀지는 경우
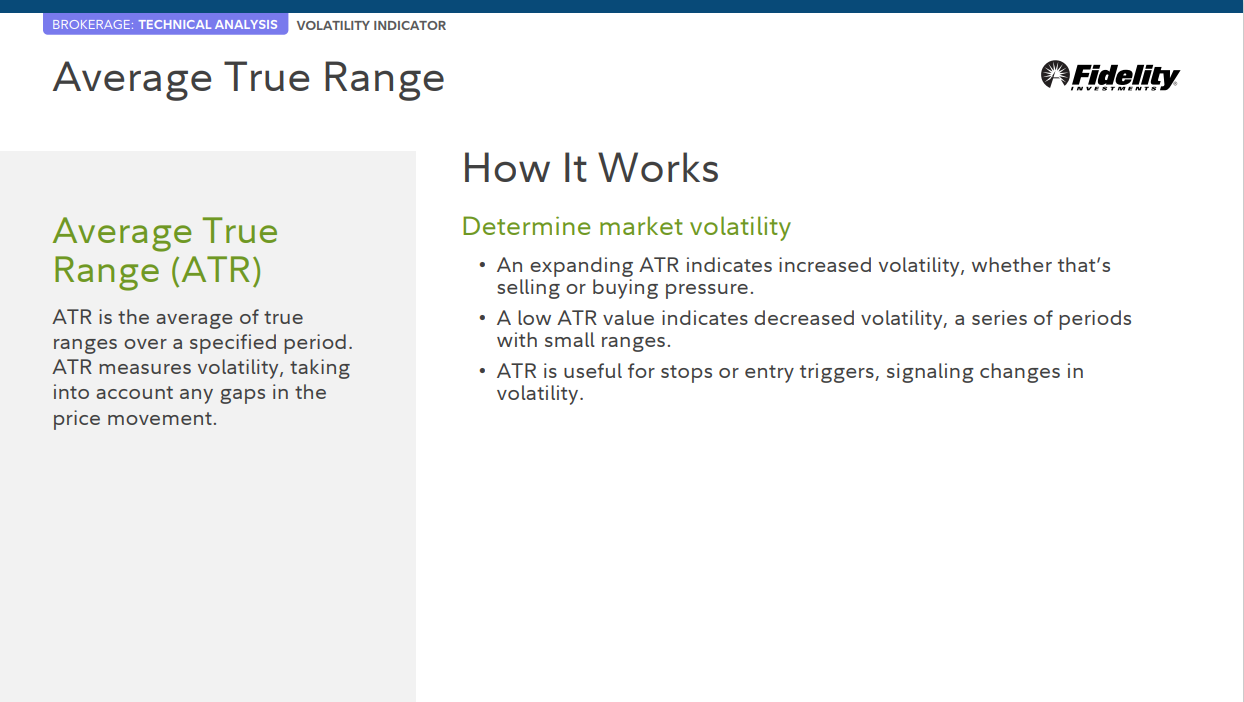
Average True Range
평균 트루 레인지(ATR)
ATR은 지정된 기간 동안 실제 범위의 평균입니다. ATR은 가격 변동의 차이를 고려하여 변동성을 측정합니다.
작동 방식
시장 변동성 결정
• 확장 ATR은 매도 압력이든 매수 압력이든 변동성이 증가했음을 나타냅니다.
• 낮은 ATR 값은 범위가 작은 일련의 기간인 변동성이 감소했음을 나타냅니다.
• ATR은 정지 또는 진입 트리거에 유용하며 변동성의 변화를 나타냅니다.
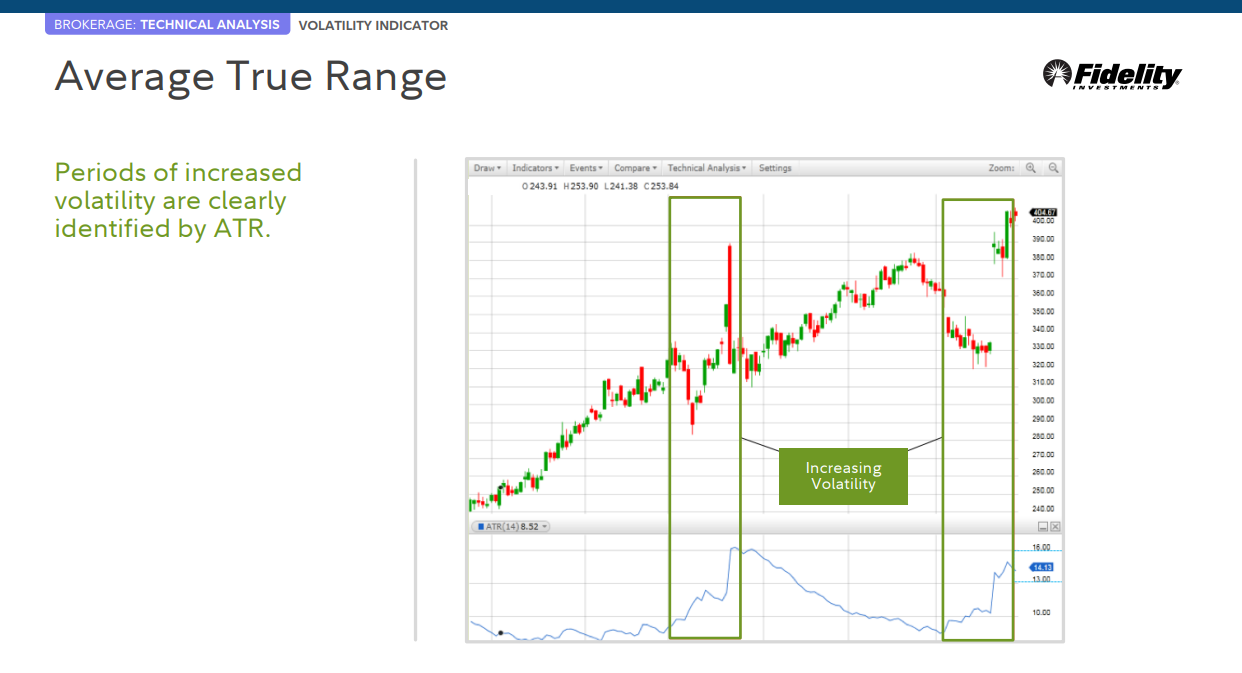
Average True Range
변동성이 증가한 기간은 ATR에 의해 명확하게 식별됩니다.
저항과 지지선 관련 지표들
Fibonacci Retracements
피보나치 되돌림
피보나치 수열 내의 수학적 관계를 기반으로 백분율 되돌림 선을 그립니다. 이러한 되돌림 수준은 가격 목표를 목표로 하는 데 사용할 수 있는 지원 및 저항 수준을 제공합니다.
작동 방식
지지 및 저항 수준 제공
• 선택한 기간의 고가와 저가 간 차이에 이 비율을 적용하면 일련의 가격 목표가 생성됩니다.
• 시장의 방향(위 또는 아래)에 따라 가격은 원래 방향으로 다시 이동하기 전에 이전 추세의 상당 부분을 되돌리는 경우가 많습니다.
• 이러한 역추세 움직임은 종종 피보나치 되돌림 수준인 특정 매개변수에 속하는 경향이 있습니다.
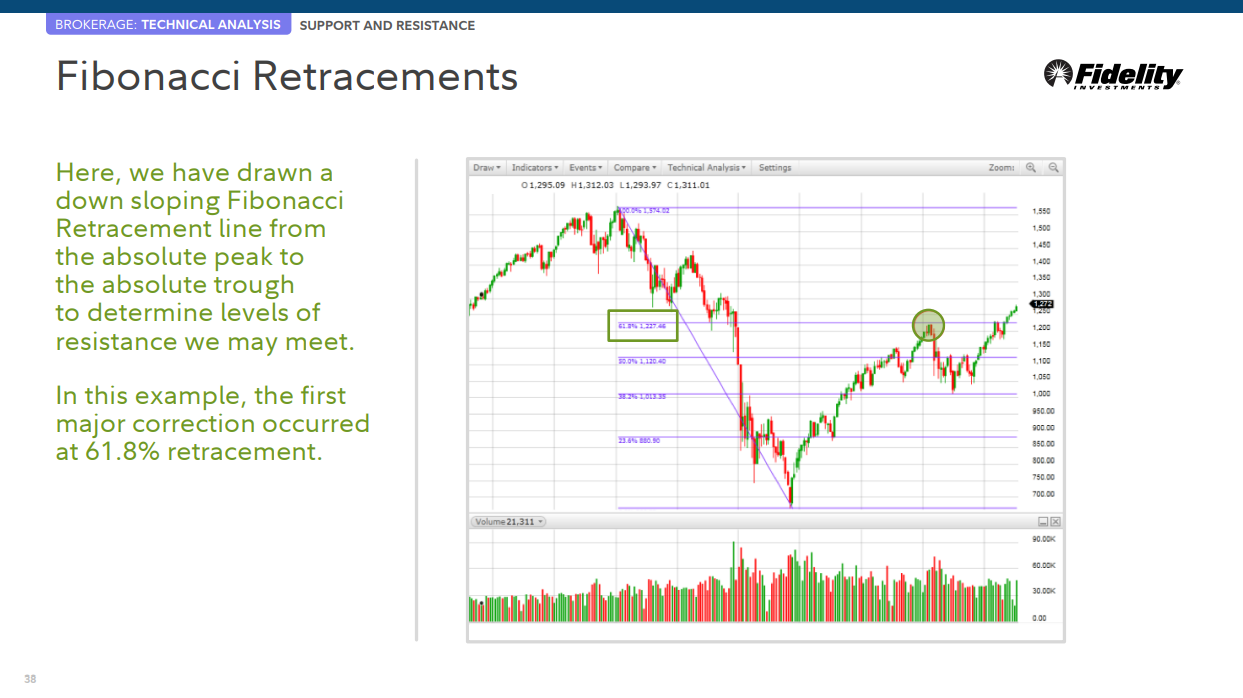
Fibonacci Retracements
여기에서 우리는 만날 수 있는 저항 수준을 결정하기 위해 절대 고점에서 절대 저점까지 내리막 피보나치 되돌림 선을 그렸습니다. 이 예에서 첫 번째 주요 조정은 61.8% 되돌림에서 발생했습니다.
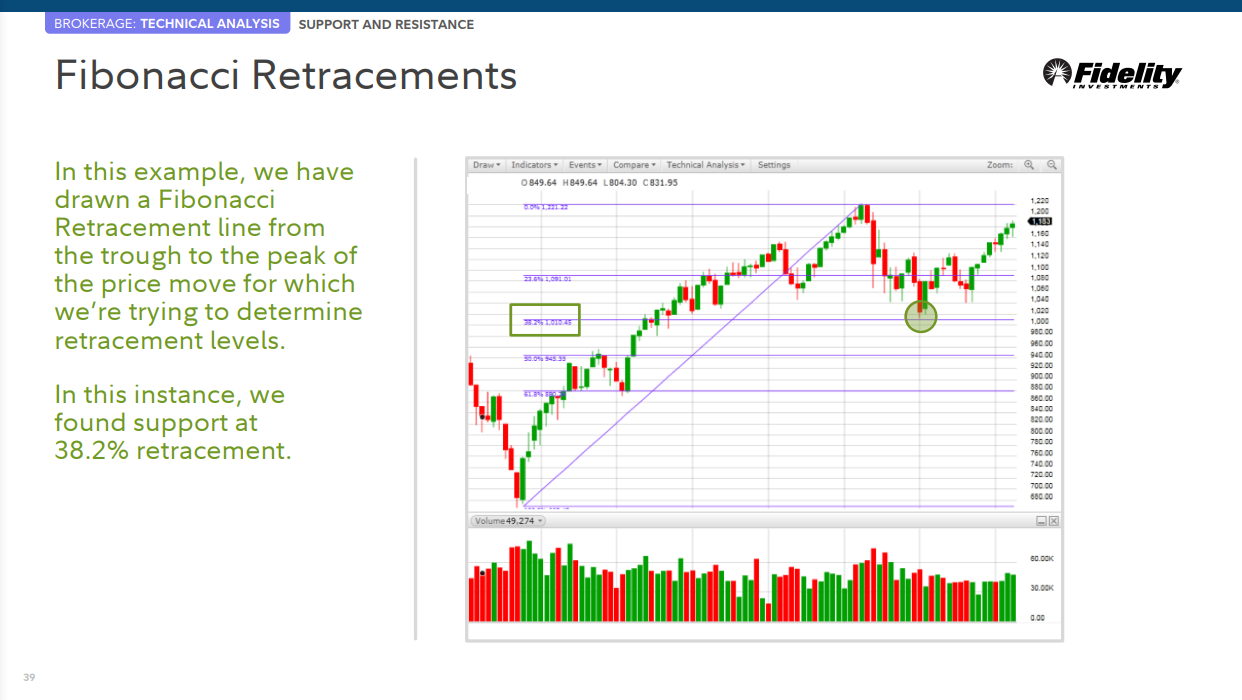
피보나치 되돌림
이 예에서는 되돌림 수준을 결정하려는 가격 움직임의 저점에서 고점까지 피보나치 되돌림 선을 그렸습니다. 이 경우 38.2% 되돌림에서 지지를 찾았습니다.
기술적 분석 시작하기
기술적 분석을 안내하는 가정에 대해 배우고 추세 거래의 기본을 이해하세요.
기술적 분석에서의 여러 지표들 이해하기
추세, 모멘텀, 볼륨 그리고 support 와 저항 같은 기술적 지표들의 여러가지 타입들을 구분해 보세요.
기술적 분석의 차트 패턴에 대해 알아보기
바 챠트와 캔들 챠트의 중요한 패턴들에 대한 예제들을 통해서 챠트를 이용하고 챠트 패턴들을 배우세요.
기술적 분석을 통해 리스크 관리하기
여러 확인된 방법들을 사용해서 거래 리스크를 관리하세요.
좀 더 자세한 사항은 Fidelity Learning Center 를 방문해 주세요.
언급된 모든 스크린샷, 차트 또는 회사 거래 기호는 설명 목적으로만 제공되며 매도 제안, 매수 제안 권유 또는 증권에 대한 권장 사항으로 간주되어서는 안 됩니다. 투자에는 손실 위험을 포함한 위험이 수반됩니다. 기술적 분석은 시장 행동, 특히 거래량과 가격에 초점을 맞춥니다. 기술적 분석은 주식을 분석하는 한 가지 방법일 뿐입니다. 매수 또는 매도할 주식을 고려할 때 가장 편한 접근 방식을 사용해야 합니다. 모든 투자와 마찬가지로 특정 증권에 대한 투자가 투자 목표, 위험 허용 범위 및 재무 상황에 따라 자신에게 적합한지 여부를 스스로 결정해야 합니다. 과거 실적이 미래 결과를 보장하지 않습니다.
Classroom Session 2: The building blocks Part 2 – Homework Please complete this homework prior to the next class in the course. We will review the answers and the project assigned at the beginning of the next class.
1. When support is broken, it becomes? a. Double Support b. Broken Arrow c. Stochastic d. Resistance
==> D. 지지선이 무너지면 이것은 다음 패턴에서는 저항선이 될 가능성이 크다.
2. True/False Support and Resistance can only be drawn horizontally?
==> False
3. Which of the following Simple Moving Average will react fastest? a. 20 Day b. 50 Day c. 100 Day d. 200 Day
==> a
4. Breakouts can occur in which direction? a. Up b. Down c. Up or Down
==> c 지지선을 뚫으면 다운, 저항선을 뚫으면 업
5. Which of the follow are used as filters for breakouts? a. Price passes close b. Multiple days above close c. Percent above close d. All of the above
==> d
6. Which of the following are required with trend trading? a. An entry strategy b. An exit strategy c. An assessment of capital risk d. All of the above
==> d
7. True or false, technical analysis attempts to predict the future.
==> False
Project: 1. Find a stock or ETF and draw support and resistance lines. a. Use Recognia Technical Analysis and add their “Support and Resistance” to the chart b. Adjust the settings to see the three time frames available c. Compare those support and resistance lines with the ones you’ve drawn
==>
2. Find a stock or ETF and identify a breakout.
Technical analysis focuses on market action — specifically, volume and price. Technical analysis is only one approach to analyzing stocks. When considering which stocks to buy or sell, you should use the approach that you're most comfortable with. As with all your investments, you must make your own determination as to whether an investment in any particular security or securities is right for you based on your investment objectives, risk tolerance, and financial situation. Past performance is no guarantee of future results.
Fidelity Brokerage Services LLC, Member NYSE, SIPC, 900 Salem Street, Smithfield, RI 02917 838888.1.0
The frequency and presence penalties found in theCompletions APIcan be used to reduce the likelihood of sampling repetitive sequences of tokens. They work by directly modifying the logits (un-normalized log-probabilities) with an additive contribution.
Completions API에 있는 빈도 및 존재 여부 패널티를 사용하여 반복적인 토큰 시퀀스를 샘플링할 가능성을 줄일 수 있습니다. 추가 기여로 로짓(정규화되지 않은 로그 확률)을 직접 수정하여 작동합니다.
c[j]is how often that token was sampled prior to the current position
c[j]는 현재 위치 이전에 해당 토큰이 샘플링된 빈도입니다.
float(c[j] > 0)is 1 ifc[j] > 0and 0 otherwise
float(c[j] > 0)은 c[j] > 0이면 1이고 그렇지 않으면 0입니다.
alpha_frequencyis the frequency penalty coefficient
alpha_frequency는 빈도 페널티 계수입니다.
alpha_presenceis the presence penalty coefficient
alpha_presence는 존재 페널티 계수입니다.
As we can see, the presence penalty is a one-off additive contribution that applies to all tokens that have been sampled at least once and the frequency penalty is a contribution that is proportional to how often a particular token has already been sampled.
보시다시피 존재 패널티는 적어도 한 번 샘플링된 모든 토큰에 적용되는 일회성 추가 기여이며 빈도 페널티는 특정 토큰이 이미 샘플링된 빈도에 비례하는 기여입니다.
Reasonable values for the penalty coefficients are around 0.1 to 1 if the aim is to just reduce repetitive samples somewhat. If the aim is to strongly suppress repetition, then one can increase the coefficients up to 2, but this can noticeably degrade the quality of samples. Negative values can be used to increase the likelihood of repetition.
페널티 계수의 합리적인 값은 반복적인 샘플을 어느 정도 줄이는 것이 목표인 경우 약 0.1에서 1 사이입니다. 반복을 강력하게 억제하는 것이 목적이라면 계수를 최대 2까지 높일 수 있지만 이렇게 하면 샘플의 품질이 눈에 띄게 저하될 수 있습니다. 음수 값을 사용하여 반복 가능성을 높일 수 있습니다.
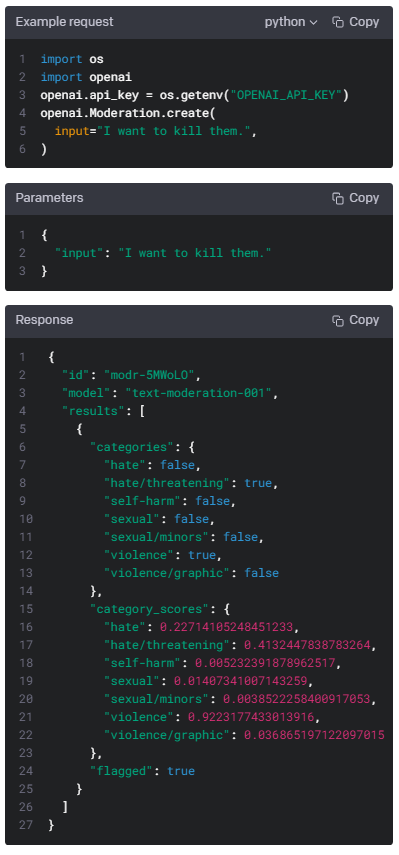
Classifies if text violates OpenAI's Content Policy
텍스트가 OpenAI의 콘텐츠 정책을 위반하는지 분류합니다.
Request body
input
string or array
Required
The input text to classify
분류할 입력 텍스트
model
string
Optional
Defaults totext-moderation-latest
기본값은 text-moderation-latest입니다.
Two content moderations models are available:text-moderation-stableandtext-moderation-latest.
두 가지 콘텐츠 조정 모델(text-moderation-stable 및 text-moderation-latest)을 사용할 수 있습니다.
The default istext-moderation-latestwhich will be automatically upgraded over time. This ensures you are always using our most accurate model. If you usetext-moderation-stable, we will provide advanced notice before updating the model. Accuracy oftext-moderation-stablemay be slightly lower than fortext-moderation-latest.
기본값은 시간이 지남에 따라 자동으로 업그레이드되는 text-moderation-latest입니다. 이렇게 하면 항상 가장 정확한 모델을 사용할 수 있습니다. text-moderation-stable을 사용할 경우 모델 업데이트 전 사전 공지를 드립니다. text-moderation-stable의 정확도는 text-moderation-latest보다 약간 낮을 수 있습니다.
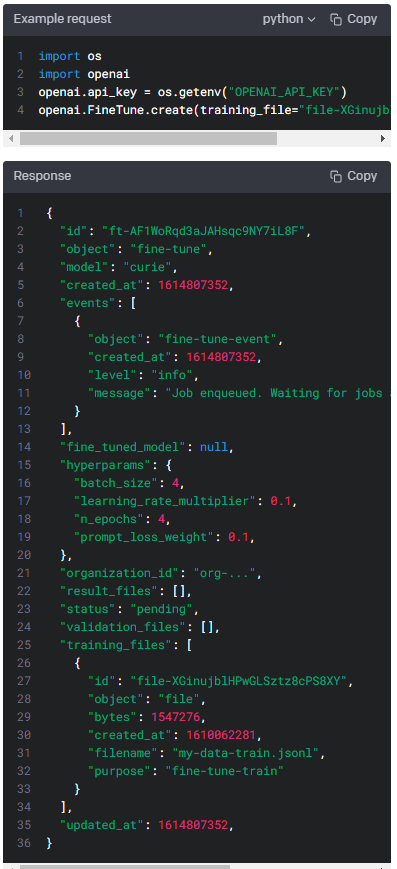
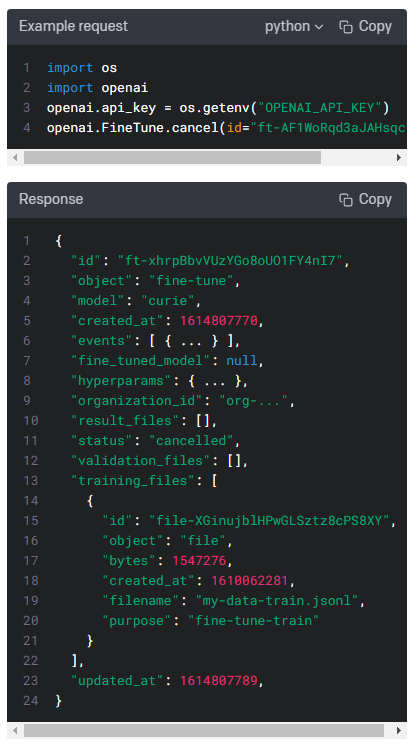
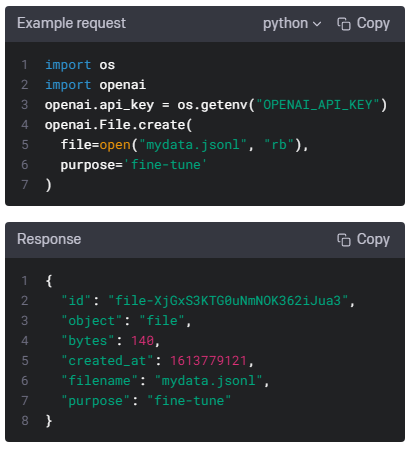
Your dataset must be formatted as a JSONL file, where each training example is a JSON object with the keys "prompt" and "completion". Additionally, you must upload your file with the purposefine-tune.
데이터 세트는 JSONL 파일로 형식화되어야 합니다. 여기서 각 교육 예제는 "prompt" 및 "completion" 키가 있는 JSON 개체입니다. 또한 미세 조정 목적으로 파일을 업로드해야 합니다.
The ID of an uploaded file that contains validation data.
유효성 검사 데이터가 포함된 업로드된 파일의 ID입니다.
If you provide this file, the data is used to generate validation metrics periodically during fine-tuning. These metrics can be viewed in thefine-tuning results file. Your train and validation data should be mutually exclusive.
이 파일을 제공하면 미세 조정 중에 정기적으로 유효성 검사 지표를 생성하는 데 데이터가 사용됩니다. 이러한 메트릭은 미세 조정 결과 파일에서 볼 수 있습니다. 학습 및 검증 데이터는 상호 배타적이어야 합니다.
Your dataset must be formatted as a JSONL file, where each validation example is a JSON object with the keys "prompt" and "completion". Additionally, you must upload your file with the purposefine-tune.
데이터 세트는 JSONL 파일로 형식화되어야 합니다. 여기서 각 검증 예제는 "prompt" 및 "completion" 키가 있는 JSON 개체입니다. 또한 미세 조정 목적으로 파일을 업로드해야 합니다.
The name of the base model to fine-tune. You can select one of "ada", "babbage", "curie", "davinci", or a fine-tuned model created after 2022-04-21. To learn more about these models, see theModelsdocumentation.
미세 조정할 기본 모델의 이름입니다. "ada", "babbage", "curie", "davinci" 또는 2022-04-21 이후 생성된 미세 조정된 모델 중 하나를 선택할 수 있습니다. 이러한 모델에 대한 자세한 내용은 모델 설명서를 참조하십시오.
n_epochs
integer
Optional
Defaults to4
The number of epochs to train the model for. An epoch refers to one full cycle through the training dataset.
모델을 훈련할 에포크 수입니다. 에포크는 교육 데이터 세트를 통한 하나의 전체 주기를 나타냅니다.
batch_size
integer
Optional
Defaults tonull
The batch size to use for training. The batch size is the number of training examples used to train a single forward and backward pass.
교육에 사용할 배치 크기입니다. 배치 크기는 단일 정방향 및 역방향 패스를 훈련하는 데 사용되는 훈련 예제의 수입니다.
By default, the batch size will be dynamically configured to be ~0.2% of the number of examples in the training set, capped at 256 - in general, we've found that larger batch sizes tend to work better for larger datasets.
기본적으로 배치 크기는 훈련 세트에 있는 예제 수의 ~0.2%로 동적으로 구성되며 최대 256개로 제한됩니다. 일반적으로 배치 크기가 클수록 데이터 세트가 더 잘 작동하는 경향이 있습니다.
learning_rate_multiplier
number
Optional
Defaults tonull
The learning rate multiplier to use for training. The fine-tuning learning rate is the original learning rate used for pretraining multiplied by this value.
훈련에 사용할 학습률 승수입니다. 미세 조정 학습률은 사전 훈련에 사용된 원래 학습률에 이 값을 곱한 것입니다.
By default, the learning rate multiplier is the 0.05, 0.1, or 0.2 depending on finalbatch_size(larger learning rates tend to perform better with larger batch sizes). We recommend experimenting with values in the range 0.02 to 0.2 to see what produces the best results.
기본적으로 학습률 승수는 최종 batch_size에 따라 0.05, 0.1 또는 0.2입니다(배치 크기가 클수록 학습률이 높을수록 더 잘 수행되는 경향이 있음). 0.02에서 0.2 범위의 값으로 실험하여 최상의 결과를 생성하는 것이 무엇인지 확인하는 것이 좋습니다.
prompt_loss_weight
number
Optional
Defaults to0.01
The weight to use for loss on the prompt tokens. This controls how much the model tries to learn to generate the prompt (as compared to the completion which always has a weight of 1.0), and can add a stabilizing effect to training when completions are short.
프롬프트 토큰에서 손실에 사용할 가중치입니다. 이것은 모델이 프롬프트를 생성하기 위해 학습을 시도하는 정도를 제어하고(항상 가중치가 1.0인 완료와 비교하여) 완료가 짧을 때 훈련에 안정화 효과를 추가할 수 있습니다.
If prompts are extremely long (relative to completions), it may make sense to reduce this weight so as to avoid over-prioritizing learning the prompt.
프롬프트가 매우 긴 경우(완료에 비해) 프롬프트 학습에 과도한 우선순위를 두지 않도록 이 가중치를 줄이는 것이 좋습니다.
compute_classification_metrics
boolean
Optional
Defaults tofalse
If set, we calculate classification-specific metrics such as accuracy and F-1 score using the validation set at the end of every epoch. These metrics can be viewed in theresults file.
설정된 경우 매 에포크가 끝날 때마다 검증 세트를 사용하여 정확도 및 F-1 점수와 같은 분류별 메트릭을 계산합니다. 이러한 메트릭은 결과 파일에서 볼 수 있습니다.
In order to compute classification metrics, you must provide avalidation_file. Additionally, you must specifyclassification_n_classesfor multiclass classification orclassification_positive_classfor binary classification.
분류 메트릭을 계산하려면 validation_file을 제공해야 합니다. 또한 다중 클래스 분류의 경우 classification_n_classes를 지정하고 이진 분류의 경우 classification_positive_class를 지정해야 합니다.
classification_n_classes
integer
Optional
Defaults tonull
The number of classes in a classification task.
분류 작업의 클래스 수입니다.
This parameter is required for multiclass classification.
이 매개변수는 다중 클래스 분류에 필요합니다.
classification_positive_class
string
Optional
Defaults tonull
The positive class in binary classification.
이진 분류의 포지티브 클래스입니다.
This parameter is needed to generate precision, recall, and F1 metrics when doing binary classification.
이 매개변수는 이진 분류를 수행할 때 정밀도, 재현율 및 F1 메트릭을 생성하는 데 필요합니다.
classification_betas
array
Optional
Defaults tonull
If this is provided, we calculate F-beta scores at the specified beta values. The F-beta score is a generalization of F-1 score. This is only used for binary classification.
이것이 제공되면 지정된 베타 값에서 F-베타 점수를 계산합니다. F-베타 점수는 F-1 점수를 일반화한 것입니다. 이진 분류에만 사용됩니다.
With a beta of 1 (i.e. the F-1 score), precision and recall are given the same weight. A larger beta score puts more weight on recall and less on precision. A smaller beta score puts more weight on precision and less on recall.
베타 1(즉, F-1 점수)에서는 정밀도와 재현율에 동일한 가중치가 부여됩니다. 베타 점수가 클수록 재현율에 더 많은 가중치를 부여하고 정밀도에는 덜 적용합니다. 베타 점수가 작을수록 정밀도에 더 많은 가중치를 부여하고 재현율에 더 적은 가중치를 둡니다.
suffix
string
Optional
Defaults tonull
A string of up to 40 characters that will be added to your fine-tuned model name.
미세 조정된 모델 이름에 추가될 최대 40자의 문자열입니다.
For example, asuffixof "custom-model-name" would produce a model name likeada:ft-your-org:custom-model-name-2022-02-15-04-21-04.
예를 들어 "custom-model-name" 접미사는 ada:ft-your-org:custom-model-name-2022-02-15-04-21-04와 같은 모델 이름을 생성합니다.
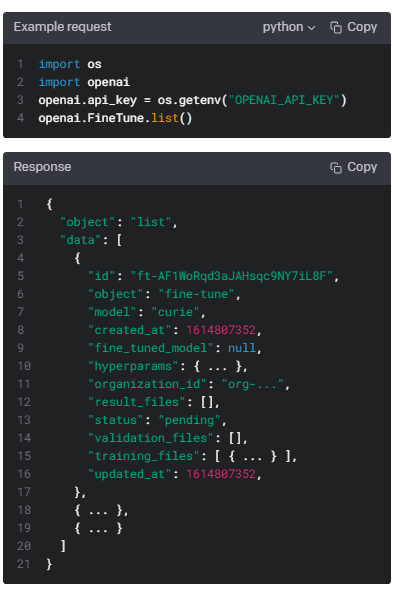
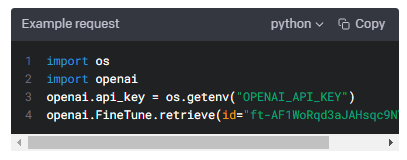
Get fine-grained status updates for a fine-tune job.
미세 조정 작업을 위해 세분화된 상태 업데이트를 받습니다.
Path parameters
fine_tune_id
string
Required
The ID of the fine-tune job to get events for.
이벤트를 가져올 미세 조정 작업의 ID입니다.
Query parameters
stream
boolean
Optional
Defaults tofalse
Whether to stream events for the fine-tune job. If set to true, events will be sent as data-onlyserver-sent eventsas they become available. The stream will terminate with adata: [DONE]message when the job is finished (succeeded, cancelled, or failed).
미세 조정 작업에 대한 이벤트를 스트리밍할지 여부입니다. true로 설정하면 이벤트가 사용 가능해지면 데이터 전용 서버 전송 이벤트로 전송됩니다. 스트림은 작업이 완료되면(성공, 취소 또는 실패) data: [DONE] 메시지와 함께 종료됩니다.
If set to false, only events generated so far will be returned.
Upload a file that contains document(s) to be used across various endpoints/features. Currently, the size of all the files uploaded by one organization can be up to 1 GB. Please contact us if you need to increase the storage limit.
다양한 엔드포인트/기능(endpoints/features)에서 사용할 문서가 포함된 파일을 업로드합니다. 현재 한 조직에서 업로드하는 모든 파일의 크기는 최대 1GB입니다. 저장 한도를 늘려야 하는 경우 당사에 문의하십시오.
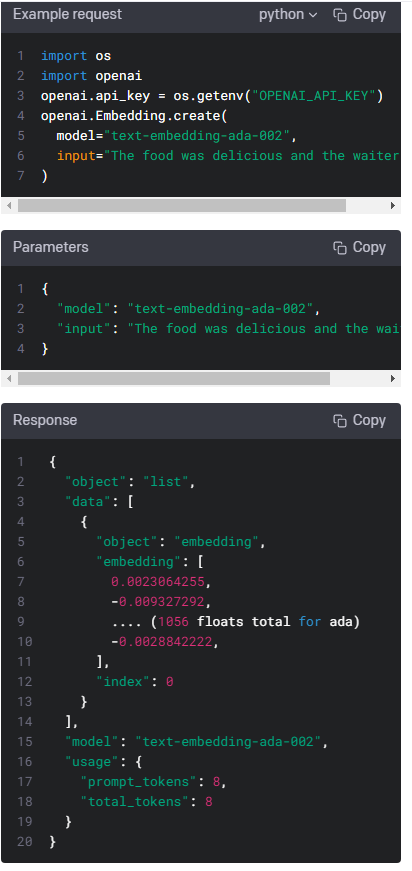
Creates an embedding vector representing the input text.
입력 텍스트를 표현하는 embedding 벡터를 만듭니다.
Request body
model
string
Required
ID of the model to use. You can use theList modelsAPI to see all of your available models, or see ourModel overviewfor descriptions of them.
사용할 모델의 ID입니다. 모델 목록 API를 사용하여 사용 가능한 모든 모델을 보거나 모델 개요에서 설명을 볼 수 있습니다.
input
string or array
Required
Input text to get embeddings for, encoded as a string or array of tokens. To get embeddings for multiple inputs in a single request, pass an array of strings or array of token arrays. Each input must not exceed 8192 tokens in length.
문자열 또는 토큰 배열로 인코딩된 임베딩을 가져올 입력 텍스트입니다. 단일 요청에서 여러 입력에 대한 임베딩을 가져오려면 문자열 배열 또는 토큰 배열 배열을 전달합니다. 각 입력은 길이가 8192 토큰을 초과할 수 없습니다.
user
string
Optional
A unique identifier representing your end-user, which can help OpenAI to monitor and detect abuse.Learn more.
OpenAI가 남용을 모니터링하고 탐지하는 데 도움이 될 수 있는 최종 사용자를 나타내는 고유 식별자입니다. 더 알아보기.
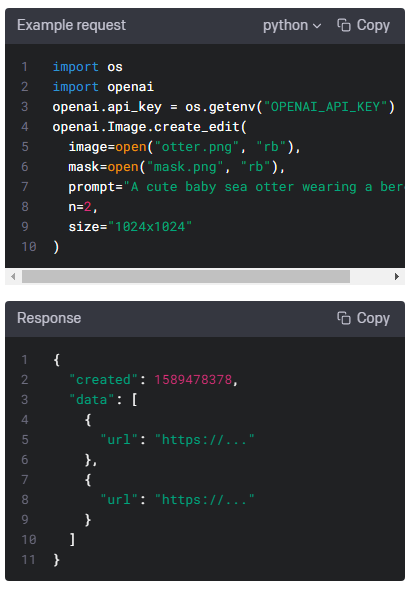
Creates an edited or extended image given an original image and a prompt.
원본 이미지와 프롬프트가 주어지면 편집되거나 확장된 이미지를 생성합니다.
Request body
image
string
Required
The image to edit. Must be a valid PNG file, less than 4MB, and square. If mask is not provided, image must have transparency, which will be used as the mask.
편집할 이미지입니다. 유효한 PNG 파일이어야 하며 4MB 미만의 정사각형이어야 합니다. 마스크를 제공하지 않으면 이미지에 투명도가 있어야 마스크로 사용됩니다.
mask
string
Optional
An additional image whose fully transparent areas (e.g. where alpha is zero) indicate whereimageshould be edited. Must be a valid PNG file, less than 4MB, and have the same dimensions asimage.
완전히 투명한 영역(예: 알파가 0인 경우)이 있는 추가 이미지는 이미지를 편집해야 하는 위치를 나타냅니다. 4MB 미만의 유효한 PNG 파일이어야 하며 이미지와 크기가 같아야 합니다.
prompt
string
Required
A text description of the desired image(s). The maximum length is 1000 characters.
원하는 이미지에 대한 텍스트 설명입니다. 최대 길이는 1000자입니다.
n
integer
Optional
Defaults to1
The number of images to generate. Must be between 1 and 10.
생성할 이미지 수입니다. 1에서 10 사이여야 합니다.
size
string
Optional
Defaults to1024x1024
The size of the generated images. Must be one of256x256,512x512, or1024x1024.
생성된 이미지의 크기입니다. 256x256, 512x512 또는 1024x1024 중 하나여야 합니다.
response_format
string
Optional
Defaults tourl
The format in which the generated images are returned. Must be one ofurlorb64_json.
생성된 이미지가 반환되는 형식입니다. url 또는 b64_json 중 하나여야 합니다.
user
string
Optional
A unique identifier representing your end-user, which can help OpenAI to monitor and detect abuse.Learn more.
OpenAI가 남용을 모니터링하고 탐지하는 데 도움이 될 수 있는 최종 사용자를 나타내는 고유 식별자입니다. 더 알아보기.