16.7. Natural Language Inference: Fine-Tuning BERT — Dive into Deep Learning 1.0.3 documentation
d2l.ai
16.7. Natural Language Inference: Fine-Tuning BERT
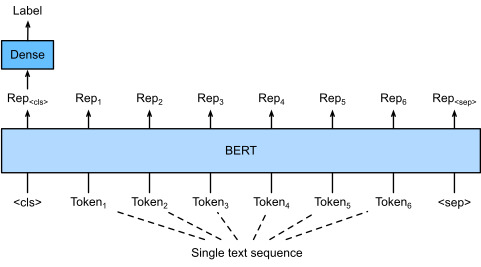
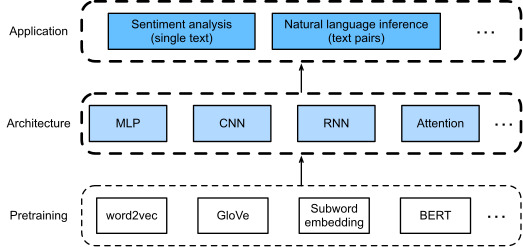
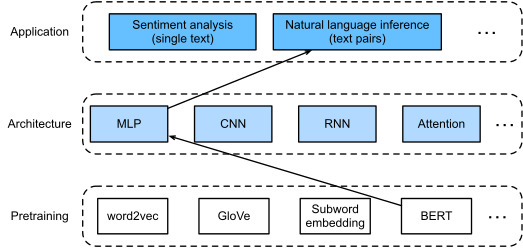
In earlier sections of this chapter, we have designed an attention-based architecture (in Section 16.5) for the natural language inference task on the SNLI dataset (as described in Section 16.4). Now we revisit this task by fine-tuning BERT. As discussed in Section 16.6, natural language inference is a sequence-level text pair classification problem, and fine-tuning BERT only requires an additional MLP-based architecture, as illustrated in Fig. 16.7.1.
이 장의 이전 섹션에서 우리는 SNLI 데이터 세트(섹션 16.4에서 설명)에 대한 자연어 추론 작업을 위한 attention-based architecture(섹션 16.5)를 설계했습니다. 이제 BERT를 미세 조정하여 이 작업을 다시 살펴보겠습니다. 섹션 16.6에서 설명한 것처럼 자연어 추론은 시퀀스 수준 텍스트 쌍 분류 문제이며 BERT를 미세 조정하려면 그림 16.7.1에 설명된 것처럼 추가적인 MLP 기반 아키텍처만 필요합니다.
In this section, we will download a pretrained small version of BERT, then fine-tune it for natural language inference on the SNLI dataset.
이 섹션에서는 사전 훈련된 BERT의 작은 버전을 다운로드한 다음 SNLI 데이터 세트에 대한 자연어 추론을 위해 미세 조정합니다.
import json
import multiprocessing
import os
import torch
from torch import nn
from d2l import torch as d2l
16.7.1. Loading Pretrained BERT
We have explained how to pretrain BERT on the WikiText-2 dataset in Section 15.9 and Section 15.10 (note that the original BERT model is pretrained on much bigger corpora). As discussed in Section 15.10, the original BERT model has hundreds of millions of parameters. In the following, we provide two versions of pretrained BERT: “bert.base” is about as big as the original BERT base model that requires a lot of computational resources to fine-tune, while “bert.small” is a small version to facilitate demonstration.
d2l.DATA_HUB['bert.base'] = (d2l.DATA_URL + 'bert.base.torch.zip',
'225d66f04cae318b841a13d32af3acc165f253ac')
d2l.DATA_HUB['bert.small'] = (d2l.DATA_URL + 'bert.small.torch.zip',
'c72329e68a732bef0452e4b96a1c341c8910f81f')이 코드는 데이터 저장소(DATA_HUB)에 두 개의 BERT(Bidirectional Encoder Representations from Transformers) 모델에 대한 정보를 추가하는 역할을 합니다. BERT는 자연어 처리 작업에 사용되는 사전 훈련된 언어 모델 중 하나로, 큰 텍스트 코퍼스에서 학습된 후 다양한 NLP 작업에 전이 학습(transfer learning)을 적용할 수 있도록 훈련된 모델입니다.
- 'bert.base': 이 키는 큰 규모의 BERT 모델에 대한 정보를 나타냅니다. 해당 모델의 체크포인트 파일은 bert.base.torch.zip로 저장되어 있으며, 해당 파일을 다운로드하여 모델을 로드할 수 있습니다. 이 모델은 큰 언어 모델이기 때문에 자연어 처리 작업에 높은 성능을 제공할 것으로 기대됩니다.
- 'bert.small': 이 키는 작은 규모의 BERT 모델에 대한 정보를 나타냅니다. 작은 모델은 더 가벼우며 계산 비용이 적게 들지만, 큰 모델보다는 성능이 낮을 수 있습니다. 이 모델은 자연어 처리 작업에 적합한 자원이 제한된 환경에서 사용될 수 있습니다.
따라서 이 코드는 데이터 저장소에서 BERT 모델의 체크포인트 파일을 다운로드하고 이를 사용하여 BERT 모델을 로드할 수 있도록 필요한 정보를 설정합니다.
Either pretrained BERT model contains a “vocab.json” file that defines the vocabulary set and a “pretrained.params” file of the pretrained parameters. We implement the following load_pretrained_model function to load pretrained BERT parameters.
사전 훈련된 BERT 모델에는 어휘 세트를 정의하는 "vocab.json" 파일과 사전 훈련된 매개변수의 "pretrained.params" 파일이 포함되어 있습니다. 사전 훈련된 BERT 매개변수를 로드하기 위해 다음 load_pretrained_model 함수를 구현합니다.
def load_pretrained_model(pretrained_model, num_hiddens, ffn_num_hiddens,
num_heads, num_blks, dropout, max_len, devices):
data_dir = d2l.download_extract(pretrained_model)
# Define an empty vocabulary to load the predefined vocabulary
vocab = d2l.Vocab()
vocab.idx_to_token = json.load(open(os.path.join(data_dir, 'vocab.json')))
vocab.token_to_idx = {token: idx for idx, token in enumerate(
vocab.idx_to_token)}
bert = d2l.BERTModel(
len(vocab), num_hiddens, ffn_num_hiddens=ffn_num_hiddens, num_heads=4,
num_blks=2, dropout=0.2, max_len=max_len)
# Load pretrained BERT parameters
bert.load_state_dict(torch.load(os.path.join(data_dir,
'pretrained.params')))
return bert, vocab이 함수는 다음과 같은 역할을 합니다:
- pretrained_model: 미리 학습된 BERT 모델의 이름 또는 경로를 나타냅니다.
- num_hiddens: BERT 모델의 은닉 상태 크기를 나타냅니다.
- ffn_num_hiddens: BERT 모델의 Feedforward 네트워크에서의 은닉 상태 크기를 나타냅니다.
- num_heads: BERT 모델의 어텐션 헤드 개수를 나타냅니다.
- num_blks: BERT 모델의 어텐션 블록 수를 나타냅니다.
- dropout: 드롭아웃 비율을 나타냅니다.
- max_len: 입력 시퀀스의 최대 길이를 나타냅니다.
- devices: 사용할 디바이스 목록입니다.
함수는 다음 단계로 수행됩니다:
- pretrained_model을 통해 지정된 미리 학습된 BERT 모델을 다운로드하고 압축을 해제합니다.
- 빈 어휘 사전(vocab)을 정의하고, 미리 정의된 어휘 파일을 로드하여 이 어휘 사전을 채웁니다.
- BERT 모델을 지정된 구성 및 어휘 사전을 사용하여 초기화합니다.
- 미리 학습된 BERT 모델의 파라미터를 로드하여 BERT 모델을 미리 학습된 상태로 설정합니다.
- 초기화된 BERT 모델과 어휘 사전을 반환합니다.
이 함수를 호출하면 미리 학습된 BERT 모델과 해당 어휘 사전이 반환됩니다. 이 모델을 사용하여 다양한 자연어 처리 작업을 수행할 수 있습니다.
To facilitate demonstration on most of machines, we will load and fine-tune the small version (“bert.small”) of the pretrained BERT in this section. In the exercise, we will show how to fine-tune the much larger “bert.base” to significantly improve the testing accuracy.
대부분의 머신에서 시연을 용이하게 하기 위해 이 섹션에서는 사전 훈련된 BERT의 작은 버전("bert.small")을 로드하고 미세 조정합니다. 이 연습에서는 훨씬 더 큰 "bert.base"를 미세 조정하여 테스트 정확도를 크게 향상시키는 방법을 보여줍니다.
devices = d2l.try_all_gpus()
bert, vocab = load_pretrained_model(
'bert.small', num_hiddens=256, ffn_num_hiddens=512, num_heads=4,
num_blks=2, dropout=0.1, max_len=512, devices=devices)위의 코드는 BERT 모델을 불러오고 설정하는 작업을 수행합니다.
- devices = d2l.try_all_gpus(): 이 코드는 가능한 모든 GPU 디바이스를 사용 가능한 경우 가져옵니다. 이것은 여러 GPU에서 BERT 모델을 병렬로 학습하거나 추론할 때 사용됩니다.
- load_pretrained_model(...): 이 함수는 앞서 정의한 load_pretrained_model 함수를 호출하여 미리 학습된 BERT 모델을 로드하고 설정합니다.
- 'bert.small': 불러올 미리 학습된 BERT 모델의 이름 또는 경로를 나타냅니다.
- num_hiddens=256: BERT 모델의 은닉 상태 크기를 설정합니다.
- ffn_num_hiddens=512: BERT 모델의 Feedforward 네트워크에서의 은닉 상태 크기를 설정합니다.
- num_heads=4: BERT 모델의 어텐션 헤드 개수를 설정합니다.
- num_blks=2: BERT 모델의 어텐션 블록 수를 설정합니다.
- dropout=0.1: 드롭아웃 비율을 설정합니다.
- max_len=512: 입력 시퀀스의 최대 길이를 설정합니다.
- devices=devices: 사용할 GPU 디바이스 목록을 전달합니다.
이 코드를 실행하면 bert 변수에는 설정된 BERT 모델이 로드되며, vocab 변수에는 어휘 사전이 로드됩니다. 이제 bert 모델을 사용하여 다양한 자연어 처리 작업을 수행할 수 있습니다.
Downloading ../data/bert.small.torch.zip from http://d2l-data.s3-accelerate.amazonaws.com/bert.small.torch.zip...
16.7.2. The Dataset for Fine-Tuning BERT
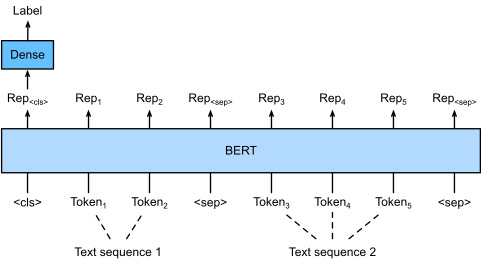
For the downstream task natural language inference on the SNLI dataset, we define a customized dataset class SNLIBERTDataset. In each example, the premise and hypothesis form a pair of text sequence and is packed into one BERT input sequence as depicted in Fig. 16.6.2. Recall Section 15.8.4 that segment IDs are used to distinguish the premise and the hypothesis in a BERT input sequence. With the predefined maximum length of a BERT input sequence (max_len), the last token of the longer of the input text pair keeps getting removed until max_len is met. To accelerate generation of the SNLI dataset for fine-tuning BERT, we use 4 worker processes to generate training or testing examples in parallel.
SNLI 데이터 세트에 대한 다운스트림 작업 자연어 추론을 위해 맞춤형 데이터 세트 클래스 SNLIBERTDataset를 정의합니다. 각 예에서 전제와 가설은 한 쌍의 텍스트 시퀀스를 형성하고 그림 16.6.2에 설명된 대로 하나의 BERT 입력 시퀀스로 압축됩니다. BERT 입력 시퀀스에서 전제와 가설을 구별하기 위해 세그먼트 ID가 사용된다는 섹션 15.8.4를 상기하세요. BERT 입력 시퀀스의 사전 정의된 최대 길이(max_len)를 사용하면 max_len이 충족될 때까지 더 긴 입력 텍스트 쌍의 마지막 토큰이 계속 제거됩니다. BERT 미세 조정을 위한 SNLI 데이터 세트 생성을 가속화하기 위해 4개의 작업자 프로세스를 사용하여 훈련 또는 테스트 예제를 병렬로 생성합니다.
class SNLIBERTDataset(torch.utils.data.Dataset):
def __init__(self, dataset, max_len, vocab=None):
all_premise_hypothesis_tokens = [[
p_tokens, h_tokens] for p_tokens, h_tokens in zip(
*[d2l.tokenize([s.lower() for s in sentences])
for sentences in dataset[:2]])]
self.labels = torch.tensor(dataset[2])
self.vocab = vocab
self.max_len = max_len
(self.all_token_ids, self.all_segments,
self.valid_lens) = self._preprocess(all_premise_hypothesis_tokens)
print('read ' + str(len(self.all_token_ids)) + ' examples')
def _preprocess(self, all_premise_hypothesis_tokens):
pool = multiprocessing.Pool(4) # Use 4 worker processes
out = pool.map(self._mp_worker, all_premise_hypothesis_tokens)
all_token_ids = [
token_ids for token_ids, segments, valid_len in out]
all_segments = [segments for token_ids, segments, valid_len in out]
valid_lens = [valid_len for token_ids, segments, valid_len in out]
return (torch.tensor(all_token_ids, dtype=torch.long),
torch.tensor(all_segments, dtype=torch.long),
torch.tensor(valid_lens))
def _mp_worker(self, premise_hypothesis_tokens):
p_tokens, h_tokens = premise_hypothesis_tokens
self._truncate_pair_of_tokens(p_tokens, h_tokens)
tokens, segments = d2l.get_tokens_and_segments(p_tokens, h_tokens)
token_ids = self.vocab[tokens] + [self.vocab['<pad>']] \
* (self.max_len - len(tokens))
segments = segments + [0] * (self.max_len - len(segments))
valid_len = len(tokens)
return token_ids, segments, valid_len
def _truncate_pair_of_tokens(self, p_tokens, h_tokens):
# Reserve slots for '<CLS>', '<SEP>', and '<SEP>' tokens for the BERT
# input
while len(p_tokens) + len(h_tokens) > self.max_len - 3:
if len(p_tokens) > len(h_tokens):
p_tokens.pop()
else:
h_tokens.pop()
def __getitem__(self, idx):
return (self.all_token_ids[idx], self.all_segments[idx],
self.valid_lens[idx]), self.labels[idx]
def __len__(self):
return len(self.all_token_ids)이 코드는 SNLI 데이터셋을 BERT 모델의 입력 형식에 맞게 전처리하는 데 사용되는 SNLIBERTDataset 클래스를 정의합니다. 이 클래스는 PyTorch의 torch.utils.data.Dataset 클래스를 상속하며, 데이터를 로드하고 전처리하는 역할을 합니다.
- __init__(self, dataset, max_len, vocab=None): 이 클래스의 생성자는 다음과 같은 매개변수를 받습니다.
- dataset: SNLI 데이터셋.
- max_len: BERT 입력 시퀀스의 최대 길이.
- vocab: 어휘 사전 (생략 가능).
- _preprocess(self, all_premise_hypothesis_tokens): 이 메서드는 데이터셋을 전처리하고 BERT 모델 입력에 맞게 변환합니다. 멀티프로세스를 사용하여 병렬로 처리하며, BERT 모델에 입력으로 들어갈 토큰 ID, 세그먼트 ID, 유효한 길이를 반환합니다.
- _mp_worker(self, premise_hypothesis_tokens): 이 메서드는 멀티프로세스 작업을 위해 호출되며, 입력으로 주어진 전제와 가설 문장의 토큰을 BERT 입력 형식에 맞게 전처리합니다.
- _truncate_pair_of_tokens(self, p_tokens, h_tokens): 이 메서드는 전제와 가설 문장의 토큰 길이가 max_len을 초과하지 않도록 자르는 역할을 합니다.
- __getitem__(self, idx): 이 메서드는 데이터셋에서 특정 인덱스 idx에 해당하는 데이터를 반환합니다. 이 데이터는 BERT 모델의 입력과 레이블을 포함합니다.
- __len__(self): 이 메서드는 데이터셋의 총 데이터 수를 반환합니다.
이 클래스를 사용하면 SNLI 데이터를 BERT 모델에 입력으로 제공하기 위한 데이터셋을 쉽게 생성할 수 있습니다.
After downloading the SNLI dataset, we generate training and testing examples by instantiating the SNLIBERTDataset class. Such examples will be read in minibatches during training and testing of natural language inference.
SNLI 데이터 세트를 다운로드한 후 SNLIBERTDataset 클래스를 인스턴스화하여 훈련 및 테스트 예제를 생성합니다. 이러한 예제는 자연어 추론을 훈련하고 테스트하는 동안 미니배치로 읽혀집니다.
# Reduce `batch_size` if there is an out of memory error. In the original BERT
# model, `max_len` = 512
batch_size, max_len, num_workers = 512, 128, d2l.get_dataloader_workers()
data_dir = d2l.download_extract('SNLI')
train_set = SNLIBERTDataset(d2l.read_snli(data_dir, True), max_len, vocab)
test_set = SNLIBERTDataset(d2l.read_snli(data_dir, False), max_len, vocab)
train_iter = torch.utils.data.DataLoader(train_set, batch_size, shuffle=True,
num_workers=num_workers)
test_iter = torch.utils.data.DataLoader(test_set, batch_size,
num_workers=num_workers)이 코드는 BERT 모델을 사용하여 SNLI 데이터셋을 학습하기 위한 데이터 로딩 및 전처리 부분을 담당합니다.
- batch_size, max_len, num_workers 설정: 이 부분에서는 배치 크기(batch_size), 최대 시퀀스 길이(max_len), 그리고 데이터 로더에 사용할 워커 수(num_workers)를 설정합니다. 원래 BERT 모델에서는 max_len을 512로 사용하나, 메모리 부족 문제가 발생할 경우 이 값을 낮출 수 있습니다.
- 데이터 다운로드 및 전처리: data_dir 변수에 SNLI 데이터셋을 다운로드하고 압축을 해제합니다. 그 후, train_set과 test_set을 각각 SNLIBERTDataset 클래스로 초기화합니다. 이 때, max_len은 지정한 값으로 설정하고, vocab은 미리 로드한 어휘 사전을 사용합니다.
- 데이터 로더 생성: train_set과 test_set을 기반으로 데이터 로더(train_iter와 test_iter)를 생성합니다. 데이터 로더는 미니배치를 생성하고 데이터를 셔플하며, 병렬로 데이터를 로드하기 위해 num_workers를 사용합니다.
이렇게 설정된 데이터 로더를 사용하여 BERT 모델을 학습하고 평가할 수 있습니다.
read 549367 examples
read 9824 examples
16.7.3. Fine-Tuning BERT
As Fig. 16.6.2 indicates, fine-tuning BERT for natural language inference requires only an extra MLP consisting of two fully connected layers (see self.hidden and self.output in the following BERTClassifier class). This MLP transforms the BERT representation of the special “<cls>” token, which encodes the information of both the premise and the hypothesis, into three outputs of natural language inference: entailment, contradiction, and neutral.
그림 16.6.2에서 알 수 있듯이 자연어 추론을 위해 BERT를 미세 조정하려면 두 개의 완전히 연결된 레이어로 구성된 추가 MLP만 필요합니다(다음 BERTClassifier 클래스의 self.hidden 및 self.output 참조). 이 MLP는 전제와 가설 모두의 정보를 인코딩하는 특수 "<cls>" 토큰의 BERT 표현을 수반, 모순 및 중립의 세 가지 자연어 추론 출력으로 변환합니다.
class BERTClassifier(nn.Module):
def __init__(self, bert):
super(BERTClassifier, self).__init__()
self.encoder = bert.encoder
self.hidden = bert.hidden
self.output = nn.LazyLinear(3)
def forward(self, inputs):
tokens_X, segments_X, valid_lens_x = inputs
encoded_X = self.encoder(tokens_X, segments_X, valid_lens_x)
return self.output(self.hidden(encoded_X[:, 0, :]))이 모델은 다음과 같은 구조를 가집니다:
- self.encoder: BERT 모델의 인코더 부분을 가져와서 저장합니다. 이는 입력 데이터에 대한 특성 추출을 담당합니다.
- self.hidden: BERT 모델의 은닉 상태 부분을 가져와서 저장합니다. 이 부분은 모델의 내부 표현을 다룹니다.
- self.output: 감정 분류를 위한 출력 레이어로, 3개의 클래스로 분류하기 위한 선형 레이어입니다.
forward 메서드에서는 다음과 같은 과정을 거칩니다:
- 입력 데이터(inputs)를 받습니다. 이 입력 데이터는 토큰, 세그먼트, 유효한 길이로 이루어져 있습니다.
- 입력 데이터를 BERT 인코더(self.encoder)를 통해 처리하여 인코딩된 데이터(encoded_X)를 얻습니다.
- 인코딩된 데이터 중 첫 번째 토큰(encoded_X[:, 0, :])의 표현을 가져와서 이를 출력 레이어(self.output)에 입력합니다.
- 출력 레이어는 입력 표현을 활용하여 감정 분류를 수행하고 결과를 반환합니다.
이렇게 정의된 BERTClassifier 모델은 BERT를 기반으로 하여 텍스트 감정 분류를 수행하는 모델입니다.
In the following, the pretrained BERT model bert is fed into the BERTClassifier instance net for the downstream application. In common implementations of BERT fine-tuning, only the parameters of the output layer of the additional MLP (net.output) will be learned from scratch. All the parameters of the pretrained BERT encoder (net.encoder) and the hidden layer of the additional MLP (net.hidden) will be fine-tuned.
다음에서는 사전 훈련된 BERT 모델 bert가 다운스트림 애플리케이션을 위한 BERTClassifier 인스턴스 net에 공급됩니다. BERT 미세 조정의 일반적인 구현에서는 추가 MLP(net.output)의 출력 레이어 매개변수만 처음부터 학습됩니다. 사전 훈련된 BERT 인코더(net.encoder)의 모든 매개변수와 추가 MLP(net.hidden)의 숨겨진 계층이 미세 조정됩니다.
net = BERTClassifier(bert)이 코드는 앞서 정의한 BERTClassifier 클래스를 사용하여 실제 BERT 모델을 텍스트 감정 분류를 위한 모델로 초기화하는 부분입니다.
여기서 net은 BERTClassifier 클래스의 인스턴스로, bert는 미리 학습된 BERT 모델을 의미합니다. 이 코드를 실행하면 net은 텍스트 감정 분류를 위한 모델로 설정되며, 이 모델은 BERT의 인코더와 은닉 상태를 활용하여 입력된 텍스트 데이터를 분류합니다.
즉, net을 사용하면 미리 학습된 BERT 모델을 감정 분류 작업에 활용할 수 있게 됩니다.
Recall that in Section 15.8 both the MaskLM class and the NextSentencePred class have parameters in their employed MLPs. These parameters are part of those in the pretrained BERT model bert, and thus part of parameters in net. However, such parameters are only for computing the masked language modeling loss and the next sentence prediction loss during pretraining. These two loss functions are irrelevant to fine-tuning downstream applications, thus the parameters of the employed MLPs in MaskLM and NextSentencePred are not updated (staled) when BERT is fine-tuned.
섹션 15.8에서 MaskLM 클래스와 NextSentencePred 클래스 모두 사용된 MLP에 매개변수를 가지고 있다는 점을 기억하세요. 이러한 매개변수는 사전 훈련된 BERT 모델 bert의 매개변수의 일부이므로 net의 매개변수의 일부입니다. 그러나 이러한 매개변수는 사전 훈련 중 마스크된 언어 모델링 손실과 다음 문장 예측 손실을 계산하는 데만 사용됩니다. 이 두 가지 손실 함수는 다운스트림 애플리케이션을 미세 조정하는 것과 관련이 없으므로 BERT가 미세 조정될 때 MaskLM 및 NextSentencePred에 사용된 MLP의 매개변수가 업데이트(정지)되지 않습니다.
To allow parameters with stale gradients, the flag ignore_stale_grad=True is set in the step function of d2l.train_batch_ch13. We use this function to train and evaluate the model net using the training set (train_iter) and the testing set (test_iter) of SNLI. Due to the limited computational resources, the training and testing accuracy can be further improved: we leave its discussions in the exercises.
오래된 그래디언트가 있는 매개변수를 허용하려면 d2l.train_batch_ch13의 단계 함수에ignore_stale_grad=True 플래그가 설정됩니다. 우리는 이 함수를 사용하여 SNLI의 훈련 세트(train_iter)와 테스트 세트(test_iter)를 사용하여 모델 네트워크를 훈련하고 평가합니다. 제한된 계산 리소스로 인해 훈련 및 테스트 정확도가 더욱 향상될 수 있습니다. 이에 대한 논의는 연습에 남겨두겠습니다.
lr, num_epochs = 1e-4, 5
trainer = torch.optim.Adam(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss(reduction='none')
net(next(iter(train_iter))[0])
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs, devices)이 코드는 BERT 모델을 텍스트 감정 분류 작업에 학습시키는 부분입니다.
- lr, num_epochs 변수는 학습률 (lr)과 학습 에포크 수 (num_epochs)를 설정합니다. lr은 0.0001로 설정되어 있으며, 학습률은 모델 가중치 업데이트에 사용되는 값입니다. num_epochs는 5로 설정되어 있으며, 데이터셋을 5번 반복하여 학습합니다.
- trainer 변수는 torch.optim.Adam 옵티마이저를 초기화합니다. 이 옵티마이저는 모델의 파라미터를 업데이트하는 데 사용됩니다.
- loss 변수는 nn.CrossEntropyLoss를 초기화합니다. 이 손실 함수는 다중 클래스 분류 작업에서 사용되며, 모델의 출력과 실제 레이블 간의 크로스 엔트로피 손실을 계산합니다. reduction='none'으로 설정되어 있으므로 손실을 각 샘플에 대한 개별 손실로 계산합니다.
- net(next(iter(train_iter))[0]) 코드는 학습 데이터의 첫 번째 미니배치를 사용하여 모델을 실행하고 출력을 확인하는 용도로 사용됩니다.
- d2l.train_ch13 함수를 호출하여 모델을 학습합니다. 이 함수는 모델, 학습 데이터 반복자, 테스트 데이터 반복자, 손실 함수, 옵티마이저, 학습 에포크 수, 그리고 디바이스를 입력으로 받아 모델을 학습하고 학습 결과를 시각화합니다. 이를 통해 BERT 모델이 텍스트 감정 분류 작업을 수행하도록 학습됩니다.
이러한 단계를 통해 BERT 모델이 주어진 데이터에 대해 감정 분류 작업을 수행하도록 학습됩니다.
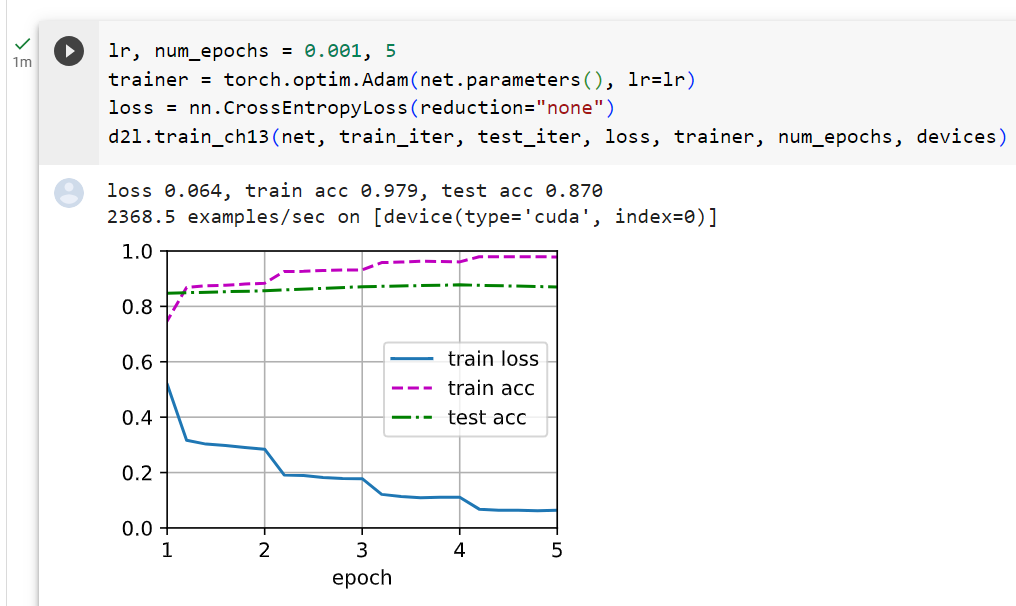
loss 0.520, train acc 0.791, test acc 0.786
10588.8 examples/sec on [device(type='cuda', index=0), device(type='cuda', index=1)]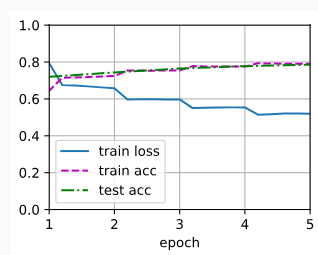
16.7.4. Summary
- We can fine-tune the pretrained BERT model for downstream applications, such as natural language inference on the SNLI dataset.
- SNLI 데이터세트에 대한 자연어 추론과 같은 다운스트림 애플리케이션을 위해 사전 훈련된 BERT 모델을 미세 조정할 수 있습니다.
- During fine-tuning, the BERT model becomes part of the model for the downstream application. Parameters that are only related to pretraining loss will not be updated during fine-tuning.
- 미세 조정 중에 BERT 모델은 다운스트림 애플리케이션을 위한 모델의 일부가 됩니다. 사전 훈련 손실에만 관련된 매개변수는 미세 조정 중에 업데이트되지 않습니다.
16.7.5. Exercises
- Fine-tune a much larger pretrained BERT model that is about as big as the original BERT base model if your computational resource allows. Set arguments in the load_pretrained_model function as: replacing ‘bert.small’ with ‘bert.base’, increasing values of num_hiddens=256, ffn_num_hiddens=512, num_heads=4, and num_blks=2 to 768, 3072, 12, and 12, respectively. By increasing fine-tuning epochs (and possibly tuning other hyperparameters), can you get a testing accuracy higher than 0.86?
- How to truncate a pair of sequences according to their ratio of length? Compare this pair truncation method and the one used in the SNLIBERTDataset class. What are their pros and cons?
'Dive into Deep Learning > D2L Natural language Processing' 카테고리의 다른 글
| D2L - 16.6. Fine-Tuning BERT for Sequence-Level and Token-Level Applications (0) | 2023.09.02 |
|---|---|
| D2L - 16.5. Natural Language Inference: Using Attention (0) | 2023.09.02 |
| D2L - 16.4. Natural Language Inference and the Dataset (0) | 2023.09.01 |
| D2L - 16.3. Sentiment Analysis: Using Convolutional Neural Networks (0) | 2023.09.01 |
| D2L - 16.2. Sentiment Analysis: Using Recurrent Neural Networks (0) | 2023.09.01 |
| D2L - 16.1. Sentiment Analysis and the Dataset (0) | 2023.09.01 |
| D2L - 16. Natural Language Processing: Applications (0) | 2023.09.01 |
| D2L - 15.10. Pretraining BERT (0) | 2023.08.30 |
| D2L - 15.9. The Dataset for Pretraining BERT (0) | 2023.08.30 |
| D2L - 15.8. Bidirectional Encoder Representations from Transformers (BERT) (0) | 2023.08.30 |