오늘 살펴 볼 쿡북 예제는 Embedding long input 입니다.
https://github.com/openai/openai-cookbook/blob/main/examples/Embedding_long_inputs.ipynb
GitHub - openai/openai-cookbook: Examples and guides for using the OpenAI API
Examples and guides for using the OpenAI API. Contribute to openai/openai-cookbook development by creating an account on GitHub.
github.com
Open AI 에서는 각 모델별로 입력값 길이의 한계가 있습니다. 입력값의 크기는 토큰을 기준으로 정해 집니다.
토큰 관련 설명은 아래 페이지를 참고하세요.
GitHub - openai/openai-cookbook: Examples and guides for using the OpenAI API
Examples and guides for using the OpenAI API. Contribute to openai/openai-cookbook development by creating an account on GitHub.
github.com
오늘 예제는 이 모델의 최대 context 길이보다 더 긴 텍스트는 어떻게 처리를 해야 하는지를 보여 줍니다.
1. Model context length
import openai
from tenacity import retry, wait_random_exponential, stop_after_attempt, retry_if_not_exception_type
EMBEDDING_MODEL = 'text-embedding-ada-002'
EMBEDDING_CTX_LENGTH = 8191
EMBEDDING_ENCODING = 'cl100k_base'
# let's make sure to not retry on an invalid request, because that is what we want to demonstrate
@retry(wait=wait_random_exponential(min=1, max=20), stop=stop_after_attempt(6), retry=retry_if_not_exception_type(openai.InvalidRequestError))
def get_embedding(text_or_tokens, model=EMBEDDING_MODEL):
return openai.Embedding.create(input=text_or_tokens, model=model)["data"][0]["embedding"]가장 먼저 openai를 import 하고 그 다음에 tenacity 모듈을 import 합니다.
tenacity는 런타임 중 오류가 발생해서 종료가 될 때 이 종료하는 것을 막고 다시 retry 하고자 할 때 사용하는 파이썬 모듈입니다.
이 모듈 중에서 retry, wait_random_exponential, Stop_after_attempt, retry_if_not_exception_type 만 import 합니다.
(이렇게 하면 @tenacity.retry 라고 하지 않고 간단하게 @retry 형식으로 사용할 수 있습니다.)
그 다음은 openai 모델을 설정하고 context length 를 8191 로 지정하고 encoding은 cl100k_base 로 합니다.
cl100k_base 는 tokenizer로 Max Input Token은 8191 로 정해져 있습니다. 2021년 9월에 발표 됐습니다.

자세한 내용은 OpenAI Guide의 Embeddings Overview 페이지를 참조하세요.
https://platform.openai.com/docs/guides/embeddings/what-are-embeddings
OpenAI API
An API for accessing new AI models developed by OpenAI
platform.openai.com
그 다음 은 @retry 구문이 나옵니다. retry 사이에 기다리는 시간은 1~20초이고 6번 까지 시도하고 exception type이 InvalidRequestError 가 아닌 경우만 retry를 시도합니다. InvalidRequest인 경우는 Retry를 해도 아무 소용 없으니까요.
그 다음은 get_embedding() 함수를 만들었습니다.
입력 파라미터로는 text_or_tokens와 모델 이름을 받습니다.
그리고 이 입력값에 대한 embedding 값을 전달받은 모델을 사용해서 openai.Embedding.create() api로 부터 받고 그 값을 return 합니다.
여기까지는 아직 아무 일을 한 것이 없습니다.
long_text = 'AGI ' * 5000
try:
get_embedding(long_text)
except openai.InvalidRequestError as e:
print(e)여기서는 long_text를 설정해 주는데 AGI 라는 글자를 5천번 반복한 값을 long_text에 넣습니다.
그리고 get_embedding()을 호출하면서 이 long_text를 전달합니다.
이 때 이 호출 부분을 try로 감싸면서 openai의 InvalidRequestError 인 경우 이 에러 메세지를 프린트 하도록 합니다.
이렇게 하면 이 InvalidRequestError 메세지가 출력 됩니다.
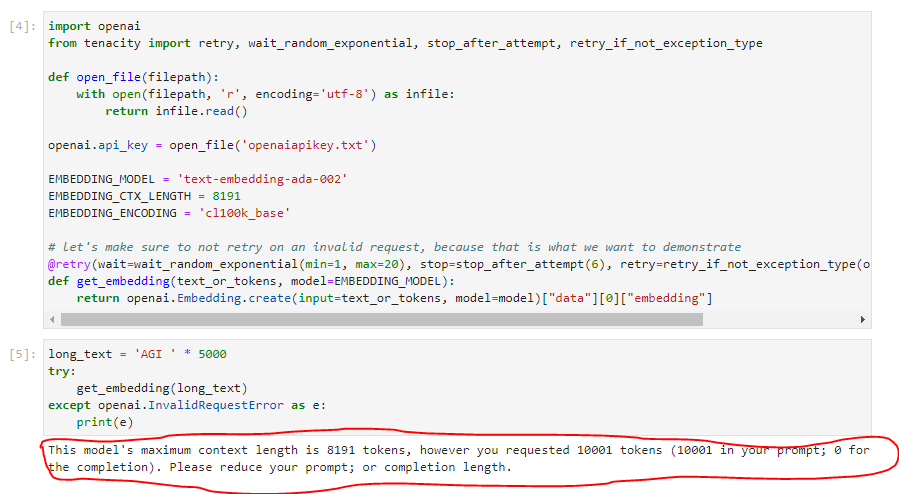
이렇게 openai의 모델이 가지고 있는 Max Input Tokens를 넘어가는 입력 텍스트를 사용해야 할 경우 어떻게 할 수 있는지 아래 예제에서 설명합니다.
첫번째 방법은 입력 텍스트를 허용되는 최대 길이로 자르거나 두분째 방법은 입력 텍스트를 chunk하고 이 chunk들을 개별적으로 포함하는 방법 입니다.
여기서 한가지 염두에 둘 것은 api 사용 가격 입니다.

text-embedding-ada-002 모델은 토큰 1 천개 당 가격이 0.0004불 입니다. 즉 0.04 센트이죠.
그럼 위에서 생성한 5000 개의 AGI 인 long_text는 몇개의 토큰이 있는지 보겠습니다.

이 long_text 입력값은 총 1만 1개의 토큰을 가지고 있습니다.
0.0004 X (10001 / 1000)을 하면 0.004 불이 나옵니다.
이 모델의 maximum 입력 값으로 요청을 해도 1센트도 안 나오네요.
참고로 저 위에 토큰 수를 계산하는 것은 아래 페이지에 가시면 볼 수 있습니다.
https://platform.openai.com/tokenizer
OpenAI API
An API for accessing new AI models developed by OpenAI
platform.openai.com
1. Truncating the input text
위에서 말한 첫번째 해결책 입니다. 모델에서 허용하는 최대 입력값 크기만큼 잘면 되죠.
여기서 크기는 토큰으로 정해지기 때문에 먼저 입력값이 몇개의 토큰으로 이루어져 있는지 알아봐야 합니다.
위 Tokenizer 페이지에서 그 작업을 했었죠. 10001 이었습니다. 그리고 위에서 사용한 모델은 8191 개의 토큰이 입력 허용 최대값이구요.
아래 방법이 이렇게 입력값을 토큰화 해서 자르는 부분입니다.
import tiktoken
def truncate_text_tokens(text, encoding_name=EMBEDDING_ENCODING, max_tokens=EMBEDDING_CTX_LENGTH):
"""Truncate a string to have `max_tokens` according to the given encoding."""
encoding = tiktoken.get_encoding(encoding_name)
return encoding.encode(text)[:max_tokens]openai의 모듈중 하나인 tiktoken 모듈을 import 합니다.
https://github.com/openai/tiktoken
GitHub - openai/tiktoken
Contribute to openai/tiktoken development by creating an account on GitHub.
github.com
그리고 truncate_text_tokens() 함수를 만들었고 입력 파라미터는 text, encoding_name, 그리고 max_tokens을 받습니다.
이 함수는 주어진 인코딩으로 max_tokens를 갖도록 문자열을 자르는 일을 합니다.
일단 encoding을 정해 줍니다. tiktoken.get_encoding() 함수를 사용하고 인코딩 이름은 위에서 정한 값을 사용합니다.
EMBEDDING_ENCODING = 'cl100k_base'
참고로 tiktoken에서는 OpenAI 모델에서 사용하는 아래 3가지 인코딩을 지원한다고 하네요.
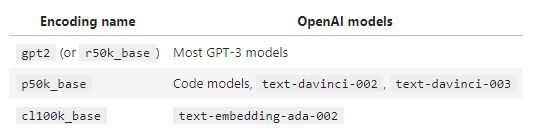
https://github.com/openai/openai-cookbook/blob/main/examples/How_to_count_tokens_with_tiktoken.ipynb
GitHub - openai/openai-cookbook: Examples and guides for using the OpenAI API
Examples and guides for using the OpenAI API. Contribute to openai/openai-cookbook development by creating an account on GitHub.
github.com
그 다음 부분이 이 인코딩을 기준으로 max_tokens 만큼 truncate 해서 return 해 주는 부분 입니다.
return encoding.encode(text)[:max_tokens]
이렇게 해서 받은 값을 출력해 보았습니다.

AGI의 반복이라서 그런지 똑같은 숫자들만 반복 되네요.
Truncate은 뒷부분을 잘라내는 겁니다.
maximum limit 까지만 남기고 나머지는 잘라내는 거죠.
예제 처럼 이 truncated 값을 get_embedding 에 보내는 length를 출력해 보았습니다.
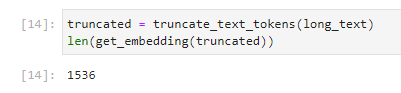
1536 이 나왔습니다. 임베딩 숫자의 차원이죠. len() 을 하지 않고 그대로 출력을 했다면 1536개의 정수를 가진 리스트가 출력 됐을 겁니다.
get_embedding() 함수가 에러 없이 작동 했다는 이야기네요.
여기까지가 입력값을 truncate 해서 제한량을 넘는 입력값을 처리하는 방법을 살펴 보았습니다.
초과 되는 부분을 잘라 내 버리는 거라서... 이게 과연 정확한 결과를 얻을 수 있을 지 의심되네요.
tiktoken의 encode()[:max_tokens] 를 사용해서 truncate 한 다음에 openai api로 request를 하면 됩니다.
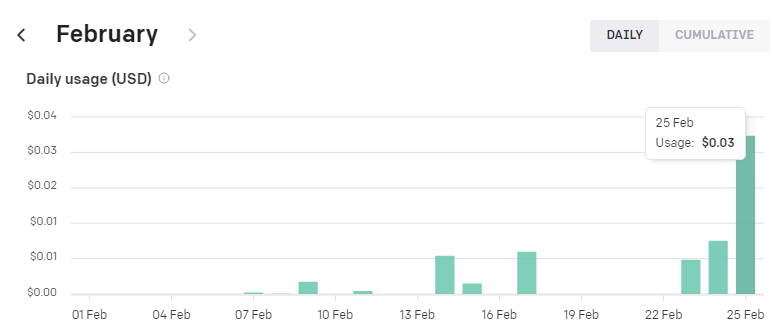
여기까지 하고 과금된 액수를 확인 했습니다.

거의 과금이 안 됐네요.
맨 마지막 막대 그래프인데 1센트도 청구가 안 됐습니다.
그 전의 가장 긴 막대 그래프가 어제 (2/24) 에 사용했던 건데 0.01달러 (1센트) 청구 된 거거든요.
2. Chunking the input text
Truncate은 작동을 하게는 할 수 있지만 잠재적으로 중요성이 있을 수도 있는 부분을 잘라내 버리는 것은 뭔가 단점이라고 할 수 있을 것 같습니다.
Truncate 이외에 할 수 있는 방법은 Chunk (뭉태기)로 나누는 겁니다.
큰 입력값을 여러 뭉태기로 나누고 그것들을 개별적으로 request해서 response를 받는 것이다.
그렇지 않으면 이 Chunk embedding들을 평균화 해서 request한 다음 response 할 수 있습니다.
이 예제에서는 큰 입력값을 chunk로 나누어 주는 모듈을 사용할 겁니다.
이 모듈은 아래 페이지에서 보실 수 있습니다.
https://docs.python.org/3/library/itertools.html#itertools-recipes
itertools — Functions creating iterators for efficient looping
This module implements a number of iterator building blocks inspired by constructs from APL, Haskell, and SML. Each has been recast in a form suitable for Python. The module standardizes a core set...
docs.python.org
방법은 아래와 같이 시작합니다.
from itertools import islice
def batched(iterable, n):
"""Batch data into tuples of length n. The last batch may be shorter."""
# batched('ABCDEFG', 3) --> ABC DEF G
if n < 1:
raise ValueError('n must be at least one')
it = iter(iterable)
while (batch := tuple(islice(it, n))):
yield batch우선 itertools 의 islice 함수를 import 합니다.
그리고 batched() 함수를 만들고 입력값으로는 iterable과 n을 받습니다.
그 다음 입력 받은 데이터를 길이가 n인 tuple로 batch 처리 합니다. 마지막 batch는 길이가 n 보다 작을 수 있습니다.
만약 길이 n이 1보다 작으면 에러를 발생 시킵니다.
raise는 에러를 발생시키는 파이썬 명령어 입니다.
이것을 사용하면 정해진 에러를 발생하고 프로그램을 멈춥니다.
https://www.w3schools.com/python/ref_keyword_raise.asp
Python raise Keyword
W3Schools offers free online tutorials, references and exercises in all the major languages of the web. Covering popular subjects like HTML, CSS, JavaScript, Python, SQL, Java, and many, many more.
www.w3schools.com
에러의 종류는 아래 페이지에서 보실 수 있습니다.
https://docs.python.org/3/library/exceptions.html#ValueError
Built-in Exceptions
In Python, all exceptions must be instances of a class that derives from BaseException. In a try statement with an except clause that mentions a particular class, that clause also handles any excep...
docs.python.org
입력값이 1보다 작지 않으면 입력받은 iterable을 iter() 로 처리합니다.
iter()은 iterator 객체를 생성하는 파이썬 함수 입니다.
https://www.w3schools.com/python/ref_func_iter.asp
Python iter() Function
W3Schools offers free online tutorials, references and exercises in all the major languages of the web. Covering popular subjects like HTML, CSS, JavaScript, Python, SQL, Java, and many, many more.
www.w3schools.com
그 다음은 while문을 돌립니다.
islice() 는 아래와 같이 작동 합니다.
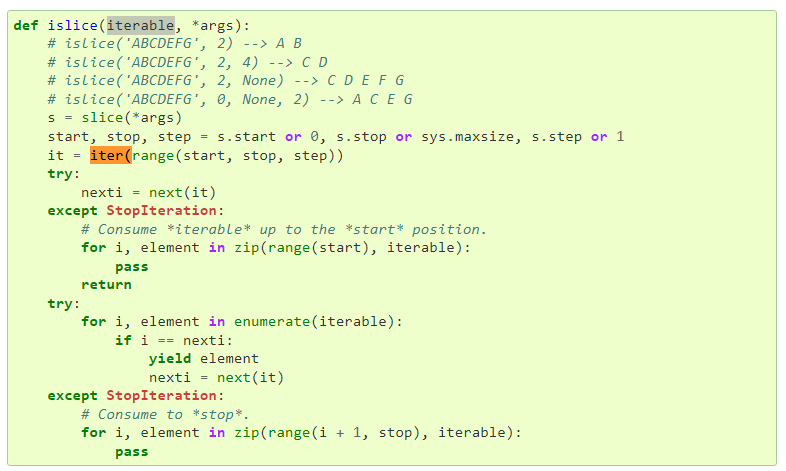
islice(it,n) 은 입력받은 it 값을 n 만큼씩 자르는 겁니다. 이 값을 tuple 형식으로 담습니다.
tuple은 아래 설명을 참조하세요. (여러 개의 아이템을 하나의 변수에 담을 때 tuple을 사용할 수 있습니다.)
https://www.w3schools.com/python/python_tuples.asp
Python Tuples
W3Schools offers free online tutorials, references and exercises in all the major languages of the web. Covering popular subjects like HTML, CSS, JavaScript, Python, SQL, Java, and many, many more.
www.w3schools.com
그리고 while문 안에 있는 := 는 2019년 10월에 새로 나온 파이썬 신택스로 좀 더 큰 expression의 일 부분으로 value를 변수에 할당하는 일을 합니다. 그리고 return까지 합니다. 별명은 바다코끼리 연산자 입니다.
https://docs.python.org/3/whatsnew/3.8.html
What’s New In Python 3.8
Editor, Raymond Hettinger,. This article explains the new features in Python 3.8, compared to 3.7. Python 3.8 was released on October 14, 2019. For full details, see the changelog. Summary – Releas...
docs.python.org
간단히 말해서 할당과 반환을 동시에 하는 연산자 입니다.
https://bio-info.tistory.com/120
[Python] 유용한 새로운 연산자! 바다코끼리 연산자 := (walrus operator)
Python 3.8부터 바다코끼리 연산자 (:=)가 도입되었습니다. 저도 최근에 알게 된, 매우 생소한 연산자입니다. 간단히 말해, 할당과 반환을 동시에 하는 연산자입니다. 개념과 목적, 예시를 알아보겠
bio-info.tistory.com
다음으로 나오는 yield 키워드는 결과 값을 return 하는 키워드 입니다.
yield는 generator를 반환합니다.
자세한 사항은 아래 글을 참조하세요.
https://www.daleseo.com/python-yield/
파이썬의 yield 키워드와 제너레이터(generator)
Engineering Blog by Dale Seo
www.daleseo.com
https://realpython.com/introduction-to-python-generators/
How to Use Generators and yield in Python – Real Python
In this step-by-step tutorial, you'll learn about generators and yielding in Python. You'll create generator functions and generator expressions using multiple Python yield statements. You'll also learn how to build data pipelines that take advantage of th
realpython.com
그래서 맨 마지막에 yield batch의 의미는 입력받은 context인 it를 입력받은 정수 n 의 크기만큼 나눈 결과 값인 batch를 반환하라는 겁니다.
즉 큰 데이터를 특정 크기 만큼의 뭉태기로 나눈 값이죠.
이제 이 값을 토큰으로 인코딩 한 다음 chunk로 나누는 일을 할 겁니다.
def chunked_tokens(text, encoding_name, chunk_length):
encoding = tiktoken.get_encoding(encoding_name)
tokens = encoding.encode(text)
chunks_iterator = batched(tokens, chunk_length)
yield from chunks_iterator이 일을 하는 함수 이름은 chunked_tokens() 이고 입력값은 3가지를 받습니다.
get_encoding() 으로 encoding을 정하고
encode()를 사용해서 tokens를 할당 합니다. (이부분은 위에서도 다룬 부분 입니다.)
그 다음에 위에 만들었던 batched() 함수를 사용해서 여러 뭉태기로 나눈 값을 받아서 chunks_iterator에 할당합니다.
그리고 이 chunks_iterator를 yield를 사용해서 반환합니다.
이제 마지막 마무리 작업을 하는 함수를 만들겠습니다.
import numpy as np
def len_safe_get_embedding(text, model=EMBEDDING_MODEL, max_tokens=EMBEDDING_CTX_LENGTH, encoding_name=EMBEDDING_ENCODING, average=True):
chunk_embeddings = []
chunk_lens = []
for chunk in chunked_tokens(text, encoding_name=encoding_name, chunk_length=max_tokens):
chunk_embeddings.append(get_embedding(chunk, model=model))
chunk_lens.append(len(chunk))
if average:
chunk_embeddings = np.average(chunk_embeddings, axis=0, weights=chunk_lens)
chunk_embeddings = chunk_embeddings / np.linalg.norm(chunk_embeddings) # normalizes length to 1
chunk_embeddings = chunk_embeddings.tolist()
return chunk_embeddingsnumpy 모듈을 import 합니다.
그리고 len_safe_get_embedding() 이라는 함수를 만듭니다.
입력값은 text와 모델, max_tokens,와 인코딩 이름 입니다.
위에서 만든 함수들에서 다 사용되는 값들입니다.
첫번째로 한 일은 chunk_embeddings와 chunk_lens라는 리스트를 초기화 합니다.
(참고로 파이썬에서 [] 는 배열-리스트-이고 () 는 튜플이고 {} 는 딕셔너리 입니다.)
https://gostart.tistory.com/58
[Python] Python 에서 (), [], {} 의 용도
Python 에서 [], (), {} 용도 배열[Array] 튜플(Tuple) 딕셔너리{Dictionary} 선언 arr = [] tup = () dic = {} 초기화 arr = [1, 2, 3, 4] tup = (1, 2, 3, 4) dic = {"january":1, "February": 2, "March":3 } 불러오기 arr[0] tup[0] dic["March"]
gostart.tistory.com
그 다음 for 루프에서는 위에 만들었던 chunked_tokens() 함수에서 return 받은 배열 수 만큼 루프를 돕니다.
그 배열(리스트)의 각 아이템별로 chunk_embeddings.append()를 해서 위에서 초기화 했던 chunk_embeddings 배열에 하나 하나 넣습니다.
그 넣는 값들이 get_embedding() 해서 openai api인 openai.Embedding.create()에서 얻은 각 아이템별 임베딩 값입니다.
이제 chunk_embeddings에는 openai로부터 받은 임베딩 값이 있습니다.
그리고 chunk_lens 배열에도 각 chunk의 length들을 배열로 넣구요.
그 다음 for 문이 끝나면 if 문이 나옵니다.
if average: 는 위에 average= true라고 정의 돼 있으므로 무조건 실행 됩니다.
if 문 안을 보면 처음에 위에서 받은 chunk_embeddings 배열의 즉 각 아이템별 임베딩 값의 average 값을 구합니다.
다른 파라미터인 axis와 weights는 아래 글을 보세요.
https://numpy.org/doc/stable/reference/generated/numpy.average.html
numpy.average — NumPy v1.24 Manual
Return the average along the specified axis. When returned is True, return a tuple with the average as the first element and the sum of the weights as the second element. sum_of_weights is of the same type as retval. The result dtype follows a genereal pat
numpy.org
이렇게 평균 낸 값을 normalize 합니다.
https://numpy.org/doc/stable/reference/generated/numpy.linalg.norm.html
numpy.linalg.norm — NumPy v1.24 Manual
[1] G. H. Golub and C. F. Van Loan, Matrix Computations, Baltimore, MD, Johns Hopkins University Press, 1985, pg. 15
numpy.org
그리고 마지막으로 이 chunk_embeddings 값을 리스트 형식으로 convert 해준 후 return 합니다.
여러개 뭉테기로 나눠서 받은 임베딩 값을 평균 내서 하나로 만들고 또 normalize 하고 이것을 리스트로 만드는 것 까지 했습니다.
average_embedding_vector = len_safe_get_embedding(long_text, average=True)
chunks_embedding_vectors = len_safe_get_embedding(long_text, average=False)
print(average_embedding_vector)
print(chunks_embedding_vektor)
자 이제 위에서 만든 long_text에 대한 임베딩 값을 chunk로 나누는 방법으로 받습니다.
average_embedding_vector는 average를 True로 해서 그 평균 값을 받습니다.
그리고 chunk_embedding_vectors는 average를 하지 않은 값을 보여 줍니다.
average_embedding_vector는 아래와 같습니다.

1536개의 정수가 있는 임베딩 값입니다.
그 다음 average를 하지 않은 chunks_embedding_vectors입니다.

똑 같은 것 같지만 이것은 평균을 내기 전의 값이기 때문에 여러개의 임베딩 값이 있습니다.
Notepad ++ 에서 , 의 숫자를 한번 검색해 봤습니다.
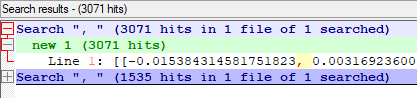
average 는 1535 개여서 총 숫자가 1536 인 1개의 임베딩 값임을 알 수 있고
두번째 average를 하지 않은 것은 콤마 숫자가 3071개여서 여기서는 2개의 chunk 가 있었다는 것을 알 수 있습니다.
예제에서 처럼 length를 출력 해 봤습니다.

방금전 살펴 본 대로 설명이 나오네요.
average=True인 경우는 한개의 1536 dimension (차원) 인 임베딩이 결과 값이고
average=False인 경우는 2개의 임베딩 벡터가 있고 그것은 chunk가 2개였기 때문이라고 되어 있습니다.
Summary
오늘 배운 내용은 입력값이 각 모델이 허용하는 입력값 크기보다 클 경우 사용할 수 있는 방법을 알아 봤습니다.
첫번째로는 허용하는 값만큼만 취하고 나머지는 truncate 해 버리는 방법입니다.
두번째는 허용하는 크기 만큼의 chunk로 나눠서 각 chunk 별로 embedding 값을 따로 받는 것입니다.
그리고 이 각각의 임베딩 값들을 numpy 의 average() 함수를 이용해서 평균을 낼 수 있습니다.
오늘은 입력값의 토큰 갯수가 많은 관계로 과금이 조금 많이 됐습니다. 3센트 (50원)
'Open AI > CookBook' 카테고리의 다른 글
| Openai cookbook : GPT-3 , Guide Techniques to improve reliability (1) | 2023.03.03 |
|---|---|
| Openai cookbook : GPT - 3 , Guide How to work with large language models (0) | 2023.03.01 |
| Openai cookbook - API usage - How to stream completions (0) | 2023.03.01 |
| Openai cookbook - API usage - How to count tokens with tiktoken (0) | 2023.03.01 |
| Openai cookbook - API usage - How to handle rate limits (0) | 2023.02.28 |
| Openai cookbook - Embeddings - Visualizing embeddings in 3D (0) | 2023.02.25 |
| Openai cookbook - Embeddings - Visualizing embeddings in 2D (1) | 2023.02.25 |
| Openai cookbook - Embeddings - Clustering embeddings (0) | 2023.02.24 |
| Openai cookbook - Embeddings - How to get embeddings (0) | 2023.02.24 |
| Openai cookbook - Embeddings - Text comparison examples - Customizing embeddings (0) | 2023.02.17 |