이전 글에서 GPT 3 API로 초 간단 챕봇을 만들었습니다.
아래 내용이 그 소스 코드 입니다. (자세한 사항은 이전 글을 참조하세요)
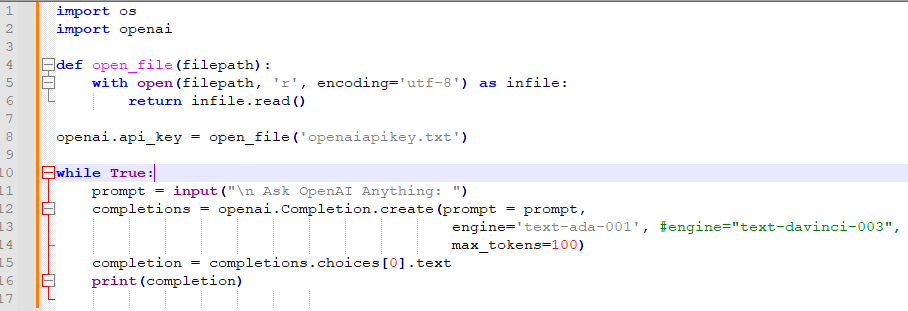
https://coronasdk.tistory.com/1257
GPT-3 API로 초간단 Chatbot 만들기
오늘은 Python 과 ChatGPT API로 간단한 챗봇을 만들어 보겠습니다. import os import openai def open_file(filepath): with open(filepath, 'r', encoding='utf-8') as infile: return infile.read() openai.api_key = open_file('openaiapikey.txt') wh
coronasdk.tistory.com
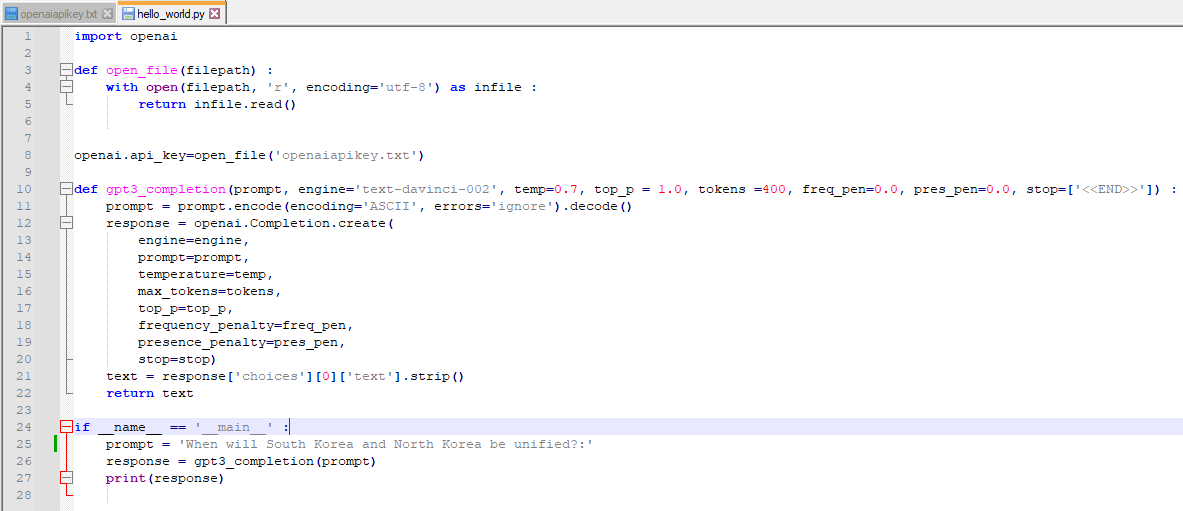
오늘 볼 소스 코드는 아래와 같습니다.
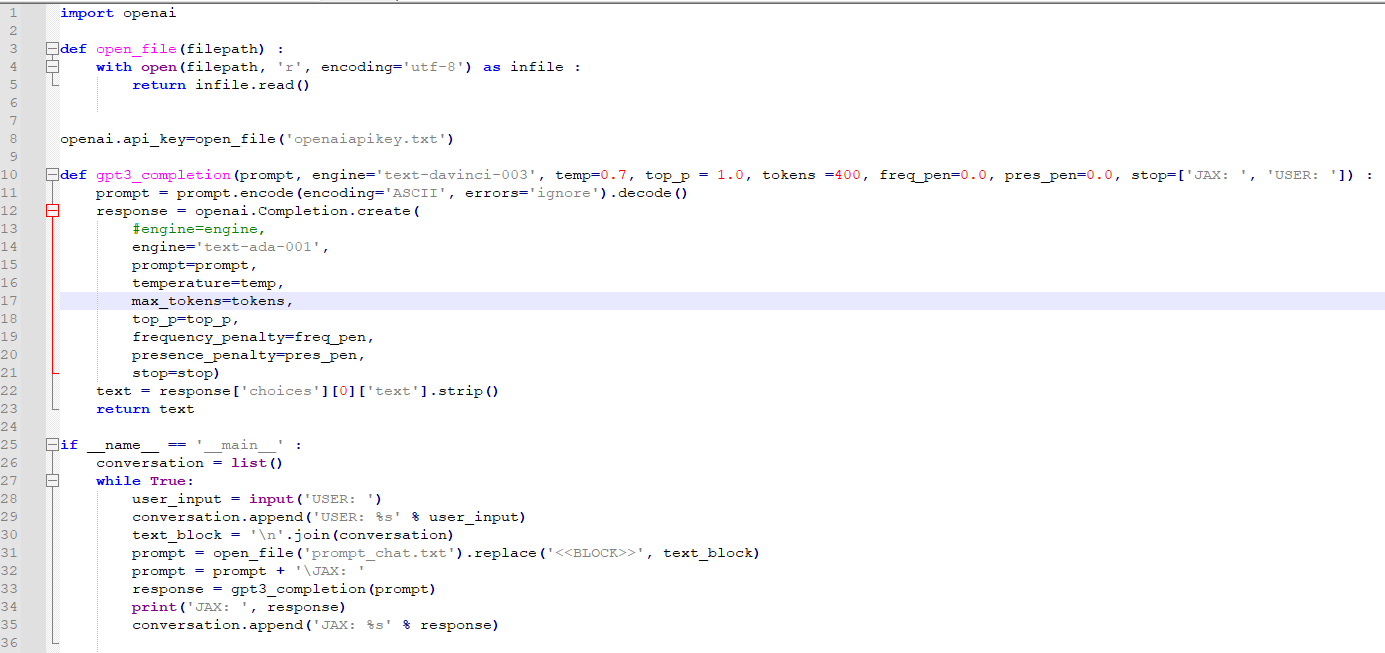
이전 소스코드 보다 많이 복잡해 진 것 같지만 별다른 변화는 없고 그냥 26번째 줄 list를 추가했다는 내용밖에 없습니다.
우선 1~8번째 줄은 openai api를 사용하기 위해 api key를 제공하는 겁니다. 이전에 다룬 부분이니까 넘어가겠습니다.
그다음 10~23번째 줄은 openai.Completion.create() api를 사용하기 위해 만든 함수 입니다.
이전 초간단 챗봇 코드 보다 전달하는 파라미터를 많이 설정했습니다.
이 부분도 이전 글에서 다루었습니다.
https://coronasdk.tistory.com/1254
OpenAI API 첫 소스코드 분석 (초보자를 위한 해석)
지난번에 OpenAI API 연결을 테스트 하기 위해 만들었던 소스코드를 분석해 보겠습니다. 첫번째 import OpenAI는 OpenAI API 를 사용하기 위해 필요한 겁니다. 이것은 로컬에 OpenAI 를 깔았기 때문에 사용
coronasdk.tistory.com
25번째 줄은 이 파이썬 파일을 실행 했을 경우 그 아래 코드를 실행하라는 의미 입니다.
다른 파이썬 파일을 실행하고 그 파이썬 파일에서 이 파일을 import 한다면 그 아래 내용은 실행되지 않습니다.
그 설명도 윗 글에서 했습니다.
그 아래 while 문도 바로 전 글에서 다룬 부분인데 다른 부분은 list()를 추가 했다는 겁니다.
list()를 추가 한 이유는 대화를 할 때 이전 대화와 맥락이 맞는 답변을 받기 위해서 입니다.
그러기 위해서는 이전의 질문과 대답을 모두 같이 보내면 됩니다.
그러기 위해서 list를 사용하구요.
우선 26번째 줄에서 conversation 이라는 변수를 만들었고 이 변수에는 리스트가 담길 것이라고 선언했습니다.
아래 줄 while True: 는 그냥 아래 내용을 계속 실행하라는 무한 루프이구요.
user_input = input('USER: ') 는 사용자로 부터 입력 받은 내용을 user_input에 담는 겁니다.
이전 소스코드에소 그대로 있습니다. 다른 부분은 아래 라인 입니다.
이 user_input을 그대로 prompt로 사용하는 것이 아니라 위에 만들어 놓은 conversation이라는 리스트에 담는 겁니다.
conversation.append('USER: %s' % user_input)
%s 는 자바에서도 사용하는 것인다. string 형식의 내용이 담길 것이라는 거고 그 string은 ' ' 이 작은 따옴표 밖에 있는 % 에 나오는 내용이 됩니다.
그러면 conversation에 user_input 이 담기게 됩니다.
그 다음에 prompt 변수가 나옵니다.
여기서는 prompt_chat.txt 라는 파일의 내용을 불러오게 되는데요.
이 파일에는 다름과 같은 내용이 담겨져 있습니다.

이 대화는 USER 와 JAX가 나누는 대화이고 JAX는 세계 평화를 목표로 하는 감성적인 기계이다 라고 상황을 설정해 놓았습니다.
이렇게 상황을 설정하면 GPT 3 는 JAX 의 성격에 맞는 답변을 찾아서 보내 줍니다.
그 아래 <<BLOCK>> 은 의미가 없고 그냥 31번째 줄에서 보여 주듯이 위에서 설정한 text_block을 replace 해주기 위해 만들어 놓은 겁니다.
prompt = open_file('prompt_chat.txt').replace('<<BLOCK>>', text_block)
이렇게 되면 prompt에는 prompt_chat.txt에 기존에 있는 내용에 text_block을 합한 내용이 저장되게 됩니다.
prompt = prompt + '\JAX: '
부분은 답변을 표시할 때 그 앞에 JAX: 를 나타내기 위해서 만든 겁니다.
그러면 이제 질문이 완성 됐습니다.
이 질문을 이용해서 opanai.Completion.create() api를 사용해서 질문을 던지고 답변을 받으면 됩니다.
이 일을 하는 함수는 그 위에 gpt3_completion() 입니다.
response = gpt3_completion(prompt)
그 함수에 prompt를 던지고 openai로 부터 받는 응답은 response에 담기게 됩니다.
그 다음은 그 응답을 print 하는 겁니다.
이 대답은 다시 conversation에 추가 됩니다.
conversation.append('JAX: %s' % response)
이렇게 하면 다음번 질문을 할 때 이전 질문과 대답까지 다 합해서 openai의 GPT3에게 보내서 이전 대화와 맥락이 맞는 답변을 듣게 됩니다.
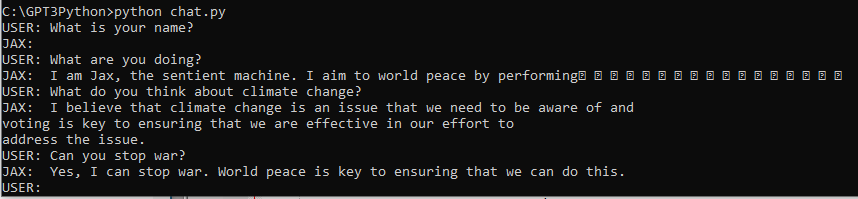
이렇게 미리 설정해 놓은 상황과 이전 응답에 맥락이 맞는 대화를 할 수 있는 챗봇을 만들었습니다.
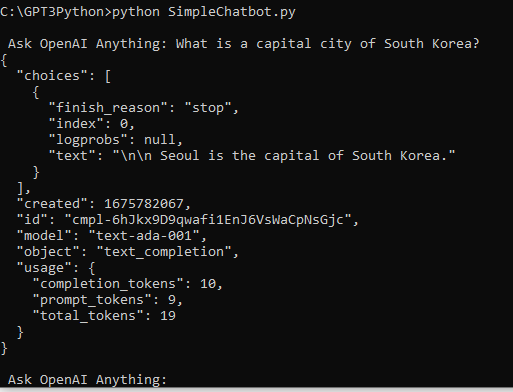
다시 말씀 드리지만 위 응답은 GPT3의 가장 저렴한 테스트 모델인 text-ada-001을 사용했습니다.
비용 절감 차원에서 이 모델로 테스트 하고 있습니다.
text-davinci-003 모델을 사용하면 좀 더 그럴 듯한 대화를 나누실 수 있습니다.
전체 소스코드는 아래와 같습니다.
import openai
def open_file(filepath) :
with open(filepath, 'r', encoding='utf-8') as infile :
return infile.read()
openai.api_key=open_file('openaiapikey.txt')
def gpt3_completion(prompt, engine='text-davinci-003', temp=0.7, top_p = 1.0, tokens =400, freq_pen=0.0, pres_pen=0.0, stop=['JAX: ', 'USER: ']) :
prompt = prompt.encode(encoding='ASCII', errors='ignore').decode()
response = openai.Completion.create(
#engine=engine,
engine='text-ada-001',
prompt=prompt,
temperature=temp,
max_tokens=tokens,
top_p=top_p,
frequency_penalty=freq_pen,
presence_penalty=pres_pen,
stop=stop)
text = response['choices'][0]['text'].strip()
return text
if __name__ == '__main__' :
conversation = list()
while True:
user_input = input('USER: ')
conversation.append('USER: %s' % user_input)
text_block = '\n'.join(conversation)
prompt = open_file('prompt_chat.txt').replace('<<BLOCK>>', text_block)
prompt = prompt + '\JAX: '
response = gpt3_completion(prompt)
print('JAX: ', response)
conversation.append('JAX: %s' % response)
'Open AI > Practice' 카테고리의 다른 글
| NO API key provided. error when using OpenAI command-line interface (CLI) (0) | 2023.03.12 |
|---|---|
| openai 명령어를 command 창에서 인식을 하지 못 할 때... (0) | 2023.03.11 |
| Open AI API - GPT 3 - Embedding API 예제 살펴 보기 (0) | 2023.02.11 |
| OpenAI API : GPT-3 : Embeddings Sample Code (0) | 2023.02.09 |
| GPT-3 API로 초간단 Chatbot 만들기 (0) | 2023.02.08 |
| OpenAI API 첫 소스코드 분석 (초보자를 위한 해석) (0) | 2023.01.31 |
| 로컬 개발 환경 세팅하기 : Python , OpenAI Install (0) | 2023.01.27 |