

https://d2l.ai/chapter_linear-classification/softmax-regression.html
4.1. Softmax Regression — Dive into Deep Learning 1.0.0-beta0 documentation
d2l.ai
4.1. Softmax Regression
In Section 3.1, we introduced linear regression, working through implementations from scratch in Section 3.4 and again using high-level APIs of a deep learning framework in Section 3.5 to do the heavy lifting.
섹션 3.1에서 우리는 선형 회귀를 소개했고, 섹션 3.4에서 처음부터 구현 작업을 수행하고 섹션 3.5에서 다시 딥 러닝 프레임워크의 고급 API를 사용하여 무거운 작업을 수행했습니다.
Regression is the hammer we reach for when we want to answer how much? or how many? questions. If you want to predict the number of dollars (price) at which a house will be sold, or the number of wins a baseball team might have, or the number of days that a patient will remain hospitalized before being discharged, then you are probably looking for a regression model. However, even within regression models, there are important distinctions. For instance, the price of a house will never be negative and changes might often be relative to its baseline price. As such, it might be more effective to regress on the logarithm of the price. Likewise, the number of days a patient spends in hospital is a discrete nonnegative random variable. As such, least mean squares might not be an ideal approach either. This sort of time-to-event modeling comes with a host of other complications that are dealt with in a specialized subfield called survival modeling.
회귀는 우리가 how much? 혹은 How many? 라는 질문에 대답하기 원할 때 사용할 수 있는 망치 입니다. 집이 팔릴 달러(가격), 야구팀의 승리 횟수 또는 환자가 퇴원하기 전에 입원할 일수를 예측하고 싶다면 아마도 Regression 모델을 찾을 것입니다. 그러나 회귀 모델 내에서도 중요한 차이점이 있습니다. 예를 들어, 주택 가격은 결코 음수가 되지 않으며 변경 사항은 종종 기준 가격에 상대적일 수 있습니다. 따라서 가격의 logarithm-로그-로 회귀하는 것이 더 효과적일 수 있습니다. 마찬가지로, 환자가 병원에서 보낸 일수는 discrete nonnegative random variable -음이 아닌 이산 랜덤 변수-입니다. 따라서 least mean squares -최소 평균 제곱-도 이상적인 접근 방식이 아닐 수 있습니다. 이러한 종류의 이벤트까지 걸리는 시간 모델링에는 survival modeling-생존 모델링-이라는 특수 하위 필드에서 처리되는 다른 복잡한 문제가 많이 있습니다.
The point here is not to overwhelm you but just to let you know that there is a lot more to estimation than simply minimizing squared errors. And more broadly, there’s a lot more to supervised learning than regression. In this section, we focus on classification problems where we put aside how much? questions and instead focus on which category? questions.
여기서 요점은 당신에게 기대감(뽕)을 주는 것이 아니라 단순히 squared error들을 minimize 하는 것보다 더 많은 estimation하는 방법이 있다는 것을 알려 드리기 위함입니다. 그리고 더 광범위하게 보면 supervised learning에는 regression보다 훨씬 더 많은 것이 있습니다. 이 섹션에서는 how much? 질문은 옆으로 치워 두고 classification problems에 촛점을 맞출 것입니다. 즉 어떤 category에 속하는가? 라는 질문에 초점을 맞출 것입니다.
- Does this email belong in the spam folder or the inbox?
- 이 이메일이 스팸 폴더나 받은편지함에 속해 있습니까?
- Is this customer more likely to sign up or not to sign up for a subscription service?
- 이 고객이 구독 서비스에 가입할 가능성이 더 높습니까 아니면 가입하지 않을 가능성이 더 높습니까?
- Does this image depict a donkey, a dog, a cat, or a rooster?
- 이 이미지가 당나귀, 개, 고양이 또는 수탉 중 어느 종류를 묘사하고 있습니까?
- Which movie is Aston most likely to watch next?
- Aston이 다음에 볼 가능성이 가장 높은 영화는 무엇입니까?
- Which section of the book are you going to read next?
- 다음에 읽을 책의 섹션은 무엇입니까?
Colloquially, machine learning practitioners overload the word classification to describe two subtly different problems: (i) those where we are interested only in hard assignments of examples to categories (classes); and (ii) those where we wish to make soft assignments, i.e., to assess the probability that each category applies. The distinction tends to get blurred, in part, because often, even when we only care about hard assignments, we still use models that make soft assignments.
일반적으로 기계 학습 실무자는 두 가지 미묘하게 다른 문제를 설명하기 위해 분류라는 단어를 오버로드합니다. (i) 카테고리별 혹은 클래스별로 example들을 hard assignment하는 방법 그리고 (ii) soft assignment 하는 방법 이렇게 두가지가 있습니다. 예를 들어 각 범주가 적용될 probability -확률-을 assess -평가-하기 위한 경우를 들 수 있습니다. 한편으로 그 구분이 모호해지는 경향이 있는데, 그 이유는 hard assignments에만 신경을 쓰는 경우에도 여전히 soft assignments를 만드는 모델을 사용하기 때문입니다.
Even more, there are cases where more than one label might be true. For instance, a news article might simultaneously cover the topics of entertainment, business, and space flight, but not the topics of medicine or sports. Thus, categorizing it into one of the above categories on their own would not be very useful. This problem is commonly known as multi-label classification. See Tsoumakas and Katakis (2007) for an overview and Huang et al. (2015) for an effective algorithm when tagging images.
더군다나 둘 이상의 레이블이 참일 수 있는 경우가 있습니다. 예를 들어, 한 뉴스 기사는 엔터테인먼트, 비즈니스 및 우주 비행에 대한 주제를 동시에 다루지만 의학이나 스포츠에 대한 주제는 다루지 않을 수 있습니다. 따라서 위의 범주 중 하나로 분류하는 것은 그다지 유용하지 않습니다. 이 문제는 일반적으로 multi-label classification 다중 레이블 분류 로 알려져 있습니다. 전체 개요를 보려면 Tsoumakas and Katakis(2007) 그리고 이미지에 태그를 지정할 때 효과적인 알고리즘에 대한 내용을 보려면 Huang et al. (2015) 를 참조 하세요.
4.1.1. Classification
To get our feet wet, let’s start with a simple image classification problem. Here, each input consists of a 2×2 grayscale image. We can represent each pixel value with a single scalar, giving us four features x1, x2, x3, x4. Further, let’s assume that each image belongs to one among the categories “cat”, “chicken”, and “dog”.
이해를 돕기 위해 간단한 이미지 분류 문제부터 시작하겠습니다. 여기서 각 입력은 2×2 grayscale image로 구성됩니다. 단일 스칼라로 각 픽셀 값을 나타낼 수 있으므로 x1, x2, x3, x4의 네 가지 기능을 제공합니다. 또한 각 이미지가 "고양이", "닭", "개" 범주 중 하나에 속한다고 가정해 보겠습니다.
Next, we have to choose how to represent the labels. We have two obvious choices. Perhaps the most natural impulse would be to choose y ∈ {1,2,3}, where the integers represent {dog,cat,chicken} respectively. This is a great way of storing such information on a computer. If the categories had some natural ordering among them, say if we were trying to predict {baby,toddler,adolescent,young adult,adult,geriatric}, then it might even make sense to cast this as an ordinal regression problem and keep the labels in this format. See Moon et al. (2010) for an overview of different types of ranking loss functions and Beutel et al. (2014) for a Bayesian approach that addresses responses with more than one mode.
다음으로 레이블을 표시하는 방법을 선택해야 합니다. 우리에게는 두 가지 분명한 선택이 있습니다. 아마도 가장 자연스러운 충동은 y ∈ {1,2,3}을 선택하는 것일 것입니다. 여기서 정수는 각각 {dog,cat,chicken}을 나타냅니다. 이것은 그러한 정보를 컴퓨터에 저장하는 좋은 방법입니다. 카테고리에 자연스러운 순서가 있는 경우, 예를 들어 {아기,유아,청소년,청년,성인,노인}을 예측하려는 경우 이를 ordinal regression problem-서수 회귀 문제-로 캐스팅하고 레이블을 유지하는 것이 이치에 맞을 수도 있습니다.그리고 이 format으로 레이블들을 유지합니다. 다양한 유형의 ranking loss functions에 대한 내용은 See Moon et al. (2010)을 그리고 둘 이상의 모드로 응답을 처리하는 Bayesian approach에 대한 내용은 Beutel et al. (2014)를 참조 하세요.
In general, classification problems do not come with natural orderings among the classes. Fortunately, statisticians long ago invented a simple way to represent categorical data: the one-hot encoding. A one-hot encoding is a vector with as many components as we have categories. The component corresponding to a particular instance’s category is set to 1 and all other components are set to 0. In our case, a label y would be a three-dimensional vector, with (1,0,0) corresponding to “cat”, (0,1,0) to “chicken”, and (0,0,1) to “dog”:
일반적으로 분류 문제는 클래스 간의 자연스러운 순서와 함께 발생하지 않습니다. 다행스럽게도 통계학자들은 오래 전에 범주형 데이터를 나타내는 간단한 방법인 A one-hot encoding을 발명했습니다. A one-hot encoding은 우리가 가진 범주만큼 많은 구성 요소가 있는 벡터입니다. 특정 인스턴스의 범주에 해당하는 구성 요소는 1로 설정되고 다른 모든 구성 요소는 0으로 설정됩니다. 우리의 경우 레이블 y는 "cat"에 해당하는 (1,0,0)을 갖는 3차원 벡터입니다. (0,1,0)을 "닭"으로, (0,0,1)을 "개"로 설정 합니다.:

Python - sklearn.preprocessing.OneHotEncoder 예
import pandas as pd
from sklearn.preprocessing import OneHotEncoder
# create a sample dataframe with categorical data
df = pd.DataFrame({'animal': ['cat', 'chicken', 'dog', 'cat', 'dog']})
# create an instance of the OneHotEncoder class
encoder = OneHotEncoder()
# fit the encoder to the dataframe
encoder.fit(df)
# transform the dataframe using the encoder
transformed_df = encoder.transform(df).toarray()
# create a new dataframe with the transformed data
new_df = pd.DataFrame(transformed_df, columns=encoder.get_feature_names_out(['animal']))
# print the original and transformed dataframes
print('Original dataframe:\n', df)
print('Transformed dataframe:\n', new_df)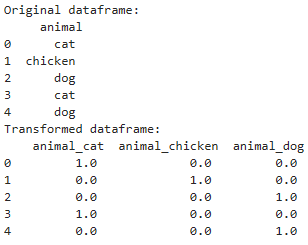
https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.OneHotEncoder.html
sklearn.preprocessing.OneHotEncoder
Examples using sklearn.preprocessing.OneHotEncoder: Release Highlights for scikit-learn 1.1 Release Highlights for scikit-learn 1.1 Release Highlights for scikit-learn 1.0 Release Highlights for sc...
scikit-learn.org
| get_feature_names_out([input_features]) | Get output feature names for transformation. |
4.1.1.1. Linear Model
In order to estimate the conditional probabilities associated with all the possible classes, we need a model with multiple outputs, one per class. To address classification with linear models, we will need as many affine functions as we have outputs. Strictly speaking, we only need one fewer, since the last category has to be the difference between 1 and the sum of the other categories but for reasons of symmetry we use a slightly redundant parametrization. Each output corresponds to its own affine function. In our case, since we have 4 features and 3 possible output categories, we need 12 scalars to represent the weights (w with subscripts), and 3 scalars to represent the biases (b with subscripts). This yields:
가능한 모든 클래스와 관련된 조건부 확률을 추정하려면 클래스당 하나씩 여러 출력이 있는 모델이 필요합니다. (Open AI의 Embeddings 참조). 선형 모델로 분류를 처리하려면 출력 만큼 affine functions가 필요합니다. (어파인 변환(affine transformation)은 평행선과 거리 비율을 보존하는 기하학적 변환). 엄밀히 말하면 마지막 범주는 1과 다른 범주의 합 사이의 차이여야 하지만 대칭의 이유로 약간 중복된 매개변수화를 사용하기 때문에 하나만 더 적게 필요합니다. 각 출력은 자체 affine 함수에 해당합니다. 우리의 경우에는 4개의 features 와 3개의 가능한 출력 범주가 있으므로 가중치를 나타내는 데 12개의 스칼라(아래 첨자가 있는 w)와 편향을 나타내는 3개의 스칼라(아래 첨자가 있는 b)가 필요합니다. 결과는 다음과 같습니다.
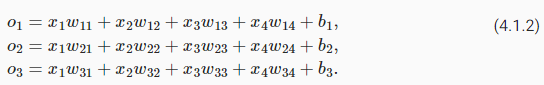
Affine function 이란?
Affine function refers to a linear function that includes a constant offset. It is a mathematical function that transforms an input vector by performing a linear transformation and adding a constant vector. The term "affine" comes from the Latin word "affinis," which means "related" or "connected."
어파인 함수(Affine function)는 상수 오프셋을 포함하는 선형 함수를 의미합니다. 이는 입력 벡터에 선형 변환을 수행하고 상수 벡터를 더하여 입력 벡터를 변환하는 수학적인 함수입니다. "어파인"이라는 용어는 라틴어인 "affinis"에서 유래하며 "관련된" 또는 "연결된"을 의미합니다.
Mathematically, an affine function can be represented as: f(x) = Ax + b
수학적으로, 어파인 함수는 다음과 같이 표현될 수 있습니다: f(x) = Ax + b
Here, x is the input vector, A is a matrix representing the linear transformation, b is the constant offset vector, and f(x) is the output vector. The matrix A scales and rotates the input vector, while the offset vector b shifts the transformed vector.
여기서 x는 입력 벡터, A는 선형 변환을 나타내는 행렬, b는 상수 오프셋 벡터, f(x)는 출력 벡터입니다. 행렬 A는 입력 벡터를 스케일링하고 회전시키며, 오프셋 벡터 b는 변환된 벡터를 이동시킵니다.
The term "affine" is often used in contrast to "linear" functions. While linear functions preserve the origin (i.e., f(0) = 0), affine functions can have a non-zero constant offset. This offset allows affine functions to shift and translate the input space.
"어파인"이라는 용어는 종종 "선형" 함수와 대조적으로 사용됩니다. 선형 함수는 원점을 보존합니다(즉, f(0) = 0), 하지만 어파인 함수는 0이 아닌 상수 오프셋을 가질 수 있습니다. 이러한 오프셋은 어파인 함수가 입력 공간을 이동하고 변환할 수 있게 합니다.
Affine functions are commonly used in various areas of mathematics, including linear algebra, geometry, and optimization. In machine learning and deep learning, affine transformations are often used as building blocks for neural networks, where they contribute to modeling complex relationships between input features and the output.
어파인 함수는 선형 대수학, 기하학, 최적화 등 다양한 수학 분야에서 널리 사용됩니다. 머신러닝과 딥러닝에서는 어파인 변환은 종종 신경망의 구성 요소로 사용되며, 입력 특성과 출력 간의 복잡한 관계를 모델링하는 데 기여합니다.
In summary, an affine function is a linear function with a constant offset. It combines a linear transformation and a constant vector to map an input vector to an output vector. Affine functions are widely used in mathematics and serve as fundamental components in machine learning and deep learning models.
요약하면, 어파인 함수는 상수 오프셋을 포함하는 선형 함수입니다. 선형 변환과 상수 벡터의 결합을 통해 입력 벡터를 출력 벡터로 매핑합니다. 어파인 함수는 수학에서 널리 사용되며, 머신러닝과 딥러닝 모델에서 기본 구성 요소로 사용됩니다.
The corresponding neural network diagram is shown in Fig. 4.1.1. Just as in linear regression, we use a single-layer neural network. And since the calculation of each output, o1, o2, and o3, depends on all inputs, x1, x2, x3, and x4, the output layer can also be described as a fully connected layer.
해당 신경망 다이어그램은 그림 4.1.1에 나와 있습니다. 선형 회귀에서와 마찬가지로 단일 계층 신경망을 사용합니다. 그리고 각 출력 o1, o2, o3의 계산은 모든 입력 x1, x2, x3, x4에 따라 달라지므로 출력 레이어는 완전 연결 레이어라고도 할 수 있습니다.

For a more concise notation we use vectors and matrices: o=Wx+b (affine function) is much better suited for mathematics and code. Note that we have gathered all of our weights into a 3×4 matrix and all biases b∈R3 in a vector.
보다 간결한 표기법을 위해 벡터와 matrices-행렬-을 사용합니다. o=Wx+b는 수학과 코드에 훨씬 더 적합합니다. 모든 가중치를 3×4 행렬로 모았고 벡터의 모든 편향 b ∈ R3을 모았습니다.
4.1.1.2. The Softmax
Assuming a suitable loss function, we could try, directly, to minimize the difference between o and the labels y. While it turns out that treating classification as a vector-valued regression problem works surprisingly well, it is nonetheless lacking in the following ways:
적절한 loss function를 가정하면 o와 레이블 y 사이의 차이를 최소화하려고 직접 시도할 수 있습니다.classification 를 벡터 값 regression problem로 처리하는 것이 놀라울 정도로 잘 작동하는 것으로 밝혀졌지만 그럼에도 불구하고 다음과 같은 면에서 부족합니다.
- There is no guarantee that the outputs oi sum up to 1 in the way we expect probabilities to behave.
- 확률이 동작할 것으로 기대하는 방식으로 출력 oi의 합이 1이 된다는 보장은 없습니다.
- There is no guarantee that the outputs oi are even nonnegative, even if their outputs sum up to 1, or that they do not exceed 1.
- 출력의 합이 1이 되거나 1을 초과하지 않더라도 출력 oi가 음수가 아니라는 보장은 없습니다.
Both aspects render the estimation problem difficult to solve and the solution very brittle to outliers. For instance, if we assume that there is a positive linear dependency between the number of bedrooms and the likelihood that someone will buy a house, the probability might exceed 1 when it comes to buying a mansion! As such, we need a mechanism to “squish” the outputs.
두 측면 모두 estimation problem를 해결하기 어렵게 만들고 솔루션은 outliers (이상치, 예외치)에 매우 취약합니다. 예를 들어 침실 수와 누군가가 집을 살 likelihood 사이에 positive linear dependency이 있다고 가정하면 맨션을 살 때 확률은 1을 초과할 수 있습니다. As such, we need a mechanism to “squish” the outputs.

이 목표를 달성할 수 있는 방법에는 여러 가지가 있습니다. 예를 들어 출력 o가 y의 손상된 버전이라고 가정할 수 있습니다. 여기서 손상은 정규 분포에서 가져온 노이즈 E를 추가하여 발생합니다. 즉 다른 말로, y=o+E이며 Ei∼N(0,a2)입니다. 이것은 Fechner(1860)가 처음 소개한 소위 probit model입니다. 매력적이지만 softmax와 비교할 때 잘 작동하지 않으며 특히 좋은 최적화 문제로 이어지지 않습니다.
The probit model is a statistical model used for binary classification problems, where the goal is to predict the probability of an event occurring or not occurring. It is a type of generalized linear model (GLM) that assumes a linear relationship between the predictor variables and the cumulative distribution function (CDF) of a standard normal distribution.
프로빗 모델은 이진 분류 문제에 사용되는 통계 모델로, 어떤 사건이 발생할 확률 또는 발생하지 않을 확률을 예측하는 것이 목표입니다. 이는 일반화 선형 모델(Generalized Linear Model, GLM)의 한 유형으로, 예측 변수와 표준 정규 분포의 누적 분포 함수(Cumulative Distribution Function, CDF) 간에 선형 관계를 가정합니다.
In the probit model, the response variable is assumed to follow a binary distribution, typically a Bernoulli distribution. The model estimates the probability of the event based on a linear combination of predictor variables, transformed through the inverse of the standard normal cumulative distribution function, known as the probit function.
프로빗 모델에서는 반응 변수가 이항 분포(일반적으로 베르누이 분포)를 따른다고 가정합니다. 모델은 예측 변수의 선형 조합을 표준 정규 분포의 누적 분포 함수의 역함수인 프로빗 함수를 통해 변환하여 사건의 확률을 추정합니다.
The probit function is defined as the inverse of the cumulative distribution function (CDF) of a standard normal distribution. It maps the linear combination of predictors to a probability between 0 and 1. The probit model assumes that the linear combination of predictors, also known as the linear predictor, follows a normal distribution.
프로빗 함수는 표준 정규 분포의 누적 분포 함수(CDF)의 역함수로 정의됩니다. 이 함수는 예측 변수의 선형 조합을 0부터 1까지의 확률로 매핑합니다. 프로빗 모델은 선형 조합의 예측 변수(선형 예측기)가 정규 분포를 따른다고 가정합니다.
The estimation of the probit model is typically performed using maximum likelihood estimation (MLE). The MLE estimates the parameters of the model that maximize the likelihood of observing the given data. The likelihood function is derived from the assumed distribution of the response variable and the predicted probabilities.
프로빗 모델의 추정은 일반적으로 최대 우도 추정(Maximum Likelihood Estimation, MLE)을 사용하여 수행됩니다. MLE는 주어진 데이터를 관측할 가능성(우도)을 최대화하는 모델의 파라미터를 추정합니다. 우도 함수는 반응 변수의 가정된 분포와 예측된 확률에 기반하여 유도됩니다.
The probit model is often used when the relationship between the predictors and the response variable is expected to be nonlinear. It allows for flexible modeling of the relationship by capturing the nonlinearity through the inverse of the standard normal CDF. However, it assumes that the errors in the model are normally distributed.
프로빗 모델은 예측 변수와 반응 변수 간의 관계가 비선형일 것으로 예상될 때 자주 사용됩니다. 표준 정규 CDF의 역함수를 통해 비선형성을 포착하여 관계를 유연하게 모델링할 수 있습니다. 그러나 모델은 오차가 정규 분포를 따른다고 가정합니다.
In summary, the probit model is a statistical model used for binary classification tasks. It assumes a linear relationship between the predictor variables and the cumulative distribution function of a standard normal distribution. The model estimates the probability of an event using the probit function, and the parameters are estimated through maximum likelihood estimation.
Another way to accomplish this goal (and to ensure nonnegativity) is to use an exponential function P(y=i) ∝ exp oi. This does indeed satisfy the requirement that the conditional class probability increases with increasing oi, it is monotonic, and all probabilities are nonnegative. We can then transform these values so that they add up to 1 by dividing each by their sum. This process is called normalization. Putting these two pieces together gives us the softmax function:
요약하면, 프로빗 모델은 이진 분류 작업에 사용되는 통계 모델입니다. 예측 변수와 표준 정규 분포의 누적 분포 함수 간에 선형 관계를 가정합니다. 모델은 프로빗 함수를 사용하여 사건의 확률을 추정하며, 파라미터는 최대 우도 추정을 통해 추정됩니다.
목표를 달성하고 음수가 아님을 보장하는 또 다른 방법은 지수 함수 P(y=i) ∝ exp oi를 사용하는 것입니다. 이것은 실제로 조건부 클래스 확률이 oi가 증가함에 따라 증가하고 단조적이며 모든 확률이 음수가 아니라는 요구 사항을 충족합니다. 그런 다음 이 값을 변환하여 각 값을 합계로 나누어 합이 1이 되도록 할 수 있습니다. 이 프로세스를 normalization 정규화라고 합니다. 이 두 조각을 합치면 softmax 함수가 됩니다.

Note that the largest coordinate of o corresponds to the most likely class according to hat y. Moreover, because the softmax operation preserves the ordering among its arguments, we do not need to compute the softmax to determine which class has been assigned the highest probability.
o의 가장 큰 좌표는 hat y에 따라 가장 가능성이 높은 클래스에 해당합니다. 또한 softmax 작업은 인수 간의 순서를 유지하기 때문에 가장 높은 확률이 할당된 클래스를 결정하기 위해 softmax를 계산할 필요가 없습니다.

The idea of a softmax dates back to Gibbs, who adapted ideas from physics (Gibbs, 1902). Dating even further back, Boltzmann, the father of modern thermodynamics, used this trick to model a distribution over energy states in gas molecules. In particular, he discovered that the prevalence of a state of energy in a thermodynamic ensemble, such as the molecules in a gas, is proportional to exp(−E/kT). Here, E is the energy of a state, T is the temperature, and k is the Boltzmann constant. When statisticians talk about increasing or decreasing the “temperature” of a statistical system, they refer to changing T in order to favor lower or higher energy states. Following Gibbs’ idea, energy equates to error. Energy-based models (Ranzato et al., 2007) use this point of view when describing problems in deep learning.
softmax 의 아이디어는 물리학의 아이디어를 채택한 Gibbs로 거슬러 올라갑니다(Gibbs, 1902). 훨씬 더 거슬러 올라가서, 현대 열역학의 아버지인 Boltzmann은 이 트릭을 사용하여 기체 분자의 에너지 상태에 대한 분포를 모델링했습니다. 특히 그는 기체 분자와 같은 열역학적 앙상블에서 에너지 상태의 보급이 exp(-E/kT)에 비례한다는 사실을 발견했습니다. 여기서 E는 상태 에너지, T는 온도, k는 볼츠만 상수입니다. 통계학자가 통계 시스템의 "temperature 온도"를 높이거나 낮추는 것에 대해 이야기할 때 그들은 더 낮거나 더 높은 에너지 상태를 선호하기 위해 T를 변경하는 것을 말합니다. Gibbs의 아이디어에 따르면 에너지는 error 오류와 같습니다. 에너지 기반 모델(Ranzato et al., 2007)은 딥 러닝의 문제를 설명할 때 이 관점을 사용합니다.
What is softmax?
Softmax is a mathematical function that is often used in machine learning and deep learning for multiclass classification problems. It is a normalization function that takes a vector of real-valued numbers as input and outputs a vector of values between 0 and 1, where the values sum up to 1.
소프트맥스(Softmax)는 다중 클래스 분류 문제에서 자주 사용되는 수학적인 함수입니다. 이 함수는 실수값 벡터를 입력으로 받아 0과 1 사이의 값으로 구성된 벡터를 출력하며, 출력값들의 합은 1이 됩니다.
The softmax function is defined as follows for a vector z of length K: softmax(z_i) = exp(z_i) / (sum(exp(z_j)) for j=1 to K)
소프트맥스 함수는 길이가 K인 벡터 z에 대해 다음과 같이 정의됩니다:
소프트맥스(z_i) = exp(z_i) / (sum(exp(z_j)) for j=1 to K)
In simpler terms, the softmax function exponentiates each element of the input vector and divides it by the sum of the exponentiated values across all elements. This ensures that the output values represent probabilities or relative weights.
간단히 말하면, 소프트맥스 함수는 입력 벡터의 각 요소를 지수 함수로 변환한 후, 모든 요소의 exponentiated values -지수 함수 값-들의 합으로 각 값을 나눠줍니다. 이렇게 함으로써 출력값들은 확률이나 상대적인 가중치를 나타냅니다.
The softmax function is commonly used to convert a vector of real-valued scores or logits into a probability distribution over multiple classes. It assigns higher probabilities to larger values in the input vector, emphasizing the most confident predictions.
소프트맥스 함수는 vector of real-valued scores나 logits 를 multiple classes-다중 클래스-에 대한 probability distribution-확률 분포-로 변환하는 데에 자주 사용됩니다. 입력 벡터의 더 큰 값에 더 높은 확률을 할당하여 most confident predictions -가장 자신있는 예측-을 emphasizing -강조-합니다.
Softmax is particularly useful in multiclass classification tasks where each instance belongs to one of several mutually exclusive classes. By converting the scores into probabilities, softmax allows us to interpret the output as the likelihood or confidence of the input belonging to each class.
소프트맥스 함수는 각 인스턴스가 상호 배타적인 여러 클래스 중 하나에 속하는 다중 클래스 분류 작업에서 특히 유용합니다. 확률로 변환함으로써 출력을 각 클래스에 대한 확률이나 신뢰도로 해석할 수 있습니다.
During the training process, softmax is often used in conjunction with a loss function such as cross-entropy loss to measure the difference between the predicted probabilities and the true class labels. The goal is to minimize the loss and train the model to produce accurate and calibrated probability distributions.
훈련 과정에서는 소프트맥스 함수를 일반적으로 크로스 엔트로피 손실과 같은 손실 함수와 함께 사용하여 예측된 확률과 실제 클래스 레이블 사이의 차이를 측정합니다. 손실을 최소화하고 정확하고 균형 잡힌 확률 분포를 출력하도록 모델을 훈련하는 것이 목표입니다.
In summary, softmax is a normalization function used in multiclass classification to convert real-valued scores into probabilities. It is widely used in machine learning and deep learning for tasks such as image classification, natural language processing, and sentiment analysis.
요약하면, 소프트맥스는 실수값 스코어를 확률로 변환하는 정규화 함수로, 다중 클래스 분류에서 널리 사용됩니다. 이미지 분류, 자연어 처리, 감성 분석과 같은 머신러닝과 딥러닝 작업에서 널리 사용되는 함수입니다.
What is logits?
Logits refer to the vector of raw, unnormalized predictions generated by a model before applying a probability distribution function such as softmax. In other words, logits are the output of the last linear layer of a neural network before going through a non-linear activation function or probability normalization.
로짓(Logits)은 확률 분포 함수(softmax 등)를 적용하기 전 모델이 생성한 원시 및 정규화되지 않은 예측값 벡터를 의미합니다. 다른 말로하면, 로짓은 신경망의 마지막 선형 레이어의 출력으로, 비선형 활성화 함수나 확률 정규화를 거치기 전의 값입니다.
Logits can be thought of as the numerical values that represent the model's confidence or belief in each possible outcome or class. They are typically used in multi-class classification problems, where each class has its corresponding logit value. The relative magnitudes of the logits indicate the model's prediction probabilities for different classes.
로짓은 각 가능한 결과 또는 클래스에 대한 모델의 신뢰도나 확신을 나타내는 수치값으로 생각할 수 있습니다. 주로 다중 클래스 분류 문제에서 사용되며, 각 클래스에 해당하는 로짓 값이 존재합니다. 로짓의 상대적인 크기는 모델이 다른 클래스에 대해 예측한 확률을 나타냅니다.
Since logits are not normalized into probabilities, they can take any real value, positive or negative. Positive logits indicate a higher likelihood of the corresponding class, while negative logits suggest a lower likelihood. The actual probabilities are obtained by applying a softmax function to the logits, which normalizes the values and produces a valid probability distribution over the classes.
로짓은 확률로 정규화되지 않아 어떤 실수 값이든 가질 수 있습니다. 양수 로짓은 해당 클래스에 대한 예측 확률이 높음을 나타내며, 음수 로짓은 예측 확률이 낮음을 시사합니다. 실제 확률은 로짓에 softmax 함수를 적용하여 얻으며, 이 과정에서 값이 정규화되고 클래스에 대한 유효한 확률 분포가 생성됩니다.
Logits play a crucial role in determining the model's predictions and are often used in conjunction with a loss function during the training process. The model's parameters are optimized to minimize the loss by adjusting the logits to better align with the ground truth labels.
로짓은 모델의 예측을 결정하는 데 중요한 역할을 합니다. 훈련 과정에서 손실 함수와 함께 사용되며, 모델의 매개변수는 로짓을 조정하여 실제 레이블과 더 잘 일치하도록 최소화하는 방향으로 최적화됩니다.
In summary, logits are the unnormalized predictions generated by a model before converting them into probabilities. They represent the model's confidence or belief in different classes and are commonly used in multi-class classification tasks. The logits are then processed through a probability distribution function such as softmax to obtain valid probabilities for each class.
요약하면, 로짓은 확률로 변환되기 전에 모델이 생성한 정규화되지 않은 예측값을 의미합니다. 로짓은 모델이 다른 클래스에 대한 신뢰도나 확신을 나타내며, 주로 다중 클래스 분류 작업에서 사용됩니다. 로짓은 softmax와 같은 확률 분포 함수를 통해 정규화된 각 클래스의 확률을 얻기 위해 처리됩니다.
What does cross-entropy loss mean?
Cross-entropy loss, also known as log loss, is a commonly used loss function in machine learning and deep learning. It measures the dissimilarity between the predicted probability distribution and the true probability distribution of the target variables.
크로스 엔트로피 손실(Cross-entropy loss) 또는 로그 손실(Log loss)은 머신러닝과 딥러닝에서 일반적으로 사용되는 손실 함수입니다. 이는 예측된 확률 분포와 실제 타겟 변수의 확률 분포 간의 불일치를 측정합니다.
In classification tasks, where the goal is to assign an input to one of several possible classes, cross-entropy loss quantifies how well the predicted probabilities align with the true labels. It compares the predicted probabilities for each class with the actual binary indicators (0 or 1) of the true class.
분류 작업에서는 입력을 여러 가능한 클래스 중 하나에 할당하는 것이 목표입니다. 크로스 엔트로피 손실은 예측된 확률과 실제 레이블 간의 정확성을 평가합니다. 예측된 확률을 각 클래스의 실제 이진 지표(0 또는 1)와 비교합니다.
The formula for cross-entropy loss is as follows: L = -∑(y * log(p) + (1 - y) * log(1 - p))
크로스 엔트로피 손실의 수식은 다음과 같습니다: L = -∑(y * log(p) + (1 - y) * log(1 - p))
Here, y represents the true label (0 or 1) for the corresponding class, and p is the predicted probability for that class. The summation is taken over all classes. The term y * log(p) represents the contribution of the true class, while (1 - y) * log(1 - p) represents the contribution of the other classes.
여기서 y는 해당 클래스에 대한 실제 레이블(0 또는 1)을 나타내고, p는 해당 클래스에 대한 예측된 확률입니다. 합은 모든 클래스에 대해 계산됩니다. y * log(p)는 실제 클래스의 기여를 나타내고, (1 - y) * log(1 - p)는 다른 클래스의 기여를 나타냅니다.
Cross-entropy loss penalizes incorrect predictions heavily, assigning a higher loss when the predicted probability deviates from the true label. It encourages the model to learn accurate and confident predictions by minimizing the loss during the training process.
크로스 엔트로피 손실은 잘못된 예측에 대해 높은 페널티를 부여하여 예측된 확률이 실제 레이블과 얼마나 다른지를 평가합니다. 이를 통해 모델은 훈련 과정에서 손실을 최소화하여 정확하고 확신할 수 있는 예측을 학습하도록 장려됩니다.
The cross-entropy loss is commonly used in combination with softmax activation for multi-class classification tasks. The softmax function converts the logits into a probability distribution over the classes, and the cross-entropy loss measures the dissimilarity between the predicted probabilities and the true labels.
크로스 엔트로피 손실은 다중 클래스 분류 작업에서 주로 소프트맥스 활성화 함수와 함께 사용됩니다. 소프트맥스 함수는 로짓을 클래스별 확률 분포로 변환하고, 크로스 엔트로피 손실은 예측된 확률과 실제 레이블 간의 불일치를 측정합니다.
In summary, cross-entropy loss is a loss function that measures the dissimilarity between the predicted probability distribution and the true probability distribution. It is commonly used in classification tasks to train models by penalizing incorrect predictions and encouraging accurate and confident probability estimates.
요약하면, 크로스 엔트로피 손실은 예측된 확률 분포와 실제 확률 분포 간의 불일치를 측정하는 손실 함수입니다. 이는 분류 작업에서 잘못된 예측에 대해 페널티를 부여하고 정확하고 확신할 수 있는 확률 추정을 장려하기 위해 사용됩니다.
4.1.1.3. Vectorization

계산 효율성을 개선하기 위해 우리는 데이터의 미니배치에서 계산을 벡터화합니다. 차원(입력 수)이 d인 n개의 예제로 구성된 미니배치 X∈Rn×d가 주어졌다고 가정합니다. 또한 출력에 q 범주가 있다고 가정합니다. 그러면 가중치는 W∈Rd×q를 만족하고 바이어스는 b∈R1×q를 만족합니다.

This accelerates the dominant operation into a matrix-matrix product XW. Moreover, since each row in X represents a data example, the softmax operation itself can be computed rowwise: for each row of O, exponentiate all entries and then normalize them by the sum. Note, though, that care must be taken to avoid exponentiating and taking logarithms of large numbers, since this can cause numerical overflow or underflow. Deep learning frameworks take care of this automatically.
이것은 매트릭스-매트릭스 제품 XW로의 지배적인 작업을 가속화합니다. 또한 X의 각 행은 데이터 예를 나타내므로 softmax 작업 자체는 행 방향으로 계산할 수 있습니다. O의 각 행에 대해 모든 항목을 지수화한 다음 합계로 정규화합니다. 그러나 큰 수의 지수화 및 대수를 취하지 않도록 주의해야 합니다. 이렇게 하면 숫자 오버플로 또는 언더플로가 발생할 수 있기 때문입니다. 딥 러닝 프레임워크는 이를 자동으로 처리합니다.
4.1.2. Loss Function
Now that we have a mapping from features x to probabilities y^, we need a way to optimize the accuracy of this mapping. We will rely on maximum likelihood estimation, the very same concept that we encountered when providing a probabilistic justification for the mean squared error loss in Section 3.1.3.
이제 특성 x에서 확률 y^로의 매핑이 있으므로 이 매핑의 정확도를 최적화하는 방법이 필요합니다. 우리는 섹션 3.1.3에서 평균 제곱 오류 손실mean squared error loss에 대한 확률적 정당성probabilistic justification을 제공할 때 접했던 것과 동일한 개념인 최대 우도 추정 likelihood estimation에 의존할 것입니다.
maximum likelihood estimation
Maximum Likelihood Estimation (MLE) is a method used to estimate the parameters of a statistical model based on observed data. It is a widely used approach in statistical inference and machine learning. The goal of MLE is to find the set of parameter values that maximize the likelihood function, which measures how likely the observed data is under the given model.
최대 우도 추정(Maximum Likelihood Estimation, MLE)은 관측된 데이터를 기반으로 통계 모델의 파라미터를 추정하는 방법입니다. 이는 통계적 추론과 머신 러닝에서 널리 사용되는 접근 방법입니다. MLE의 목표는 우도 함수(Likelihood function)를 최대화하는 파라미터 값을 찾는 것으로, 이는 주어진 모델에서 관측된 데이터가 얼마나 가능한지를 측정합니다.
To understand MLE, let's consider a simple example. Suppose we have a dataset of independent and identically distributed (i.i.d.) observations, denoted as X1, X2, ..., Xn, where each observation is generated from a probability distribution with an unknown parameter θ. Our objective is to estimate the value of θ.
MLE를 이해하기 위해 간단한 예제를 살펴보겠습니다. 알려지지 않은 파라미터 θ를 가진 확률 분포에서 독립적이고 동일하게 분포된(i.i.d.) 관측 데이터셋 X1, X2, ..., Xn이 있다고 가정해봅시다. 우리의 목적은 θ의 값을 추정하는 것입니다.
The likelihood function, denoted as L(θ), measures the probability of observing the given data for a specific value of θ. In simple terms, it represents how likely the observed data is under the assumed model. The goal of MLE is to find the value of θ that maximizes the likelihood function, i.e., the value that makes the observed data most likely.
우도 함수 L(θ)는 특정 θ 값에 대해 주어진 데이터를 관측할 확률을 측정합니다. 간단히 말해, 가정된 모델 아래에서 관측된 데이터가 얼마나 가능한지를 나타냅니다. MLE의 목표는 우도 함수를 최대화하는 θ의 값을 찾는 것이며, 즉, 관측된 데이터를 가장 가능하게 만드는 값을 찾는 것입니다.
Mathematically, MLE can be formulated as follows: θ_hat = argmax(L(θ))
수학적으로 MLE는 다음과 같이 정의될 수 있습니다: θ_hat = argmax(L(θ))
To find the value of θ that maximizes the likelihood function, we differentiate the likelihood function with respect to θ and set it equal to zero. Solving this equation gives us the maximum likelihood estimate θ_hat.
우도 함수를 최대화하는 θ의 값을 찾기 위해, 우도 함수를 θ에 대해 미분하고 그 값을 0으로 설정합니다. 이 방정식을 풀면 최대 우도 추정값 θ_hat을 얻을 수 있습니다.
In practice, it is often more convenient to work with the log-likelihood function, denoted as log(L(θ)), because it simplifies calculations and does not affect the location of the maximum. Taking the logarithm of the likelihood function, we obtain the log-likelihood function. The maximum likelihood estimate can be obtained by maximizing the log-likelihood function instead.
실제로는 계산이 더 편리하고 최댓값에 영향을 주지 않는다는 이유로 로그-우도 함수(log-likelihood function)를 사용하는 것이 흔합니다. 로그-우도 함수는 우도 함수에 로그를 취한 함수입니다. 최대 우도 추정값은 로그-우도 함수를 최대화함으로써 얻을 수 있습니다.
MLE has several desirable properties, including consistency, asymptotic efficiency, and asymptotic normality under certain conditions. It is widely used in various statistical models, such as linear regression, logistic regression, and neural networks, to estimate the model parameters based on observed data.
MLE는 일정한 조건 하에서 일관성(consistency), 점근적 효율성(asymptotic efficiency), 점근적 정규성(asymptotic normality) 등 여러 가지 우수한 특성을 가지고 있습니다. 선형 회귀, 로지스틱 회귀, 신경망과 같은 다양한 통계 모델에서 관측된 데이터를 기반으로 모델 파라미터를 추정하는 데 널리 사용됩니다.
In summary, maximum likelihood estimation is a method used to estimate the parameters of a statistical model by finding the parameter values that maximize the likelihood function or the log-likelihood function. It provides a principled approach to parameter estimation based on observed data and is widely used in statistical inference and machine learning.
요약하면, 최대 우도 추정은 우도 함수 또는 로그-우도 함수를 최대화하는 파라미터 값을 찾아 통계 모델의 파라미터를 추정하는 방법입니다. 이는 관측된 데이터를 기반으로 한 파라미터 추정에 대한 원리적인 접근 방법을 제공하며, 통계적 추론과 머신 러닝에서 널리 사용됩니다.
4.1.2.1. Log-Likelihood
The softmax function gives us a vector y^, which we can interpret as (estimated) conditional probabilities of each class, given any input x, such as y^1 = P(y=cat∣x). In the following we assume that for a dataset with features X the labels Y are represented using a one-hot encoding label vector. We can compare the estimates with reality by checking how probable the actual classes are according to our model, given the features:
softmax 함수는 y^1 = P(y=cat∣x)와 같이 입력 x가 주어지면 각 클래스의 (추정된) 조건부 확률로 해석할 수 있는 벡터 y^를 제공합니다. 다음에서는 features X가 있는 데이터 세트의 경우 레이블 Y가 one-hot encoding label vector를 사용하여 표현된다고 가정합니다. 주어진 특징에 따라 실제 클래스가 모델에 따라 얼마나 가능성이 있는지 확인하여 추정치를 현실과 비교할 수 있습니다.
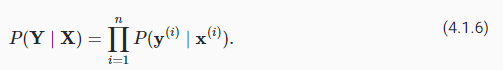
We are allowed to use the factorization since we assume that each label is drawn independently from its respective distribution P(y∣x(i)). Since maximizing the product of terms is awkward, we take the negative logarithm to obtain the equivalent problem of minimizing the negative log-likelihood:
각 레이블이 해당 분포 P(y∣x(i))와 독립적으로 그려진다고 가정하기 때문에 분해를 사용할 수 있습니다. 항의 곱을 최대화하는 것은 어색하기 때문에 음의 로그 우도를 최소화하는 동등한 문제를 얻기 위해 음의 로그를 취합니다.

where for any pair of label y and model prediction y^ over q classes, the loss function l is
여기서 q 클래스에 대한 레이블 y 및 모델 예측 y^의 쌍에 대해 손실 함수 l은 다음과 같습니다.

For reasons explained later on, the loss function in (4.1.8) is commonly called the cross-entropy loss. Since y is a one-hot vector of length q, the sum over all its coordinates j vanishes for all but one term. Note that the loss l(y,y^) is bounded from below by 0 whenever y^ is a probability vector: no single entry is larger than 1, hence their negative logarithm cannot be lower than 0; l(y,y^)=0 only if we predict the actual label with certainty. This can never happen for any finite setting of the weights because taking a softmax output towards 1 requires taking the corresponding input oi to infinity (or all other outputs oj for j≠i to negative infinity). Even if our model could assign an output probability of 0, any error made when assigning such high confidence would incur infinite loss (−log0=∞).
나중에 설명할 이유 때문에 (4.1.8)의 손실 함수는 일반적으로 cross-entropy loss 교차 엔트로피 손실이라고 합니다. y는 길이가 q인 원-핫 벡터이므로 모든 좌표 j에 대한 합은 하나를 제외한 모든 항에서 사라집니다. 손실 l(y,y^)은 y^가 확률 벡터일 때마다 아래에서 0으로 제한됩니다. 단일 항목이 1보다 크지 않으므로 음수 로그는 0보다 낮을 수 없습니다. l(y,y^)=0 실제 레이블을 확실하게 예측하는 경우에만. 1에 대한 소프트맥스 출력을 취하려면 해당 입력 oi를 무한대로(또는 j≠i에 대한 다른 모든 출력 oj를 음의 무한대로) 취해야 하기 때문에 가중치의 유한한 설정에서는 이런 일이 절대 발생할 수 없습니다. 모델이 0의 출력 확률을 할당할 수 있더라도 이러한 높은 신뢰도를 할당할 때 발생하는 모든 오류는 무한 손실(-log0=∞)을 초래할 것입니다.
Log-Likelihood (Explained by ChatGPT)
The log-likelihood is a measure used to estimate the parameters of a probabilistic model. It is closely related to Maximum Likelihood Estimation (MLE) and is obtained by taking the logarithm of the likelihood function.
로그 우도(Log-Likelihood)는 확률 모델의 파라미터를 추정하는 데 사용되는 지표입니다. 최대 우도 추정(Maximum Likelihood Estimation, MLE)과 밀접한 관련이 있으며, 우도 함수(Likelihood function)에 로그를 적용하여 얻습니다.
The likelihood function represents the probability of the observed data given the parameters of the model. The log-likelihood is derived by taking the logarithm of the likelihood function, which simplifies calculations and facilitates differentiation for optimization purposes. Moreover, since the logarithm is a monotonic function, maximizing the log-likelihood is equivalent to maximizing the original likelihood function.
우도 함수는 모델의 파라미터에 대해 관측된 데이터가 발생할 확률을 나타냅니다. 로그 우도는 우도 함수에 로그를 취한 것으로, 계산을 단순화하고 최적화를 위한 미분을 용이하게 합니다. 또한 로그는 단조 증가 함수이므로 로그 우도를 최대화하는 것은 원래의 우도 함수를 최대화하는 것과 동일합니다.
Maximizing the log-likelihood is the same as the objective of MLE, which aims to find the parameter values that maximize the likelihood of the observed data. This estimation procedure helps determine the most suitable parameter values for the model. Numerical optimization algorithms can be employed to search for the parameter values that maximize the log-likelihood.
로그 우도를 최대화하는 것은 MLE의 목표와 동일하며, 관측된 데이터의 우도를 최대화하는 파라미터 값을 찾는 것입니다. 이 추정 과정을 통해 모델에 가장 적합한 파라미터 값을 결정할 수 있습니다. 로그 우도를 최대화하는 파라미터 값을 찾기 위해서는 수치적 최적화 알고리즘을 사용하여 로그 우도 함수를 최대화하는 파라미터 값을 탐색합니다.
The log-likelihood is commonly used in parameter estimation for probabilistic models. For example, in linear regression, the log-likelihood can be maximized to estimate the parameters by assuming an error term that follows a specific probability distribution.
로그 우도는 확률 모델의 파라미터 추정에서 흔히 사용됩니다. 예를 들어, 선형 회귀에서는 특정 확률 분포를 따르는 오차 항을 가정하여 로그 우도를 최대화함으로써 파라미터를 추정할 수 있습니다.
The log-likelihood is also useful for model comparison and evaluation. By comparing the log-likelihood values of different models, one can select the model with the highest likelihood. Additionally, the log-likelihood can be used to assess the predictive performance of a model.
로그 우도는 또한 모델 비교와 평가에 유용합니다. 서로 다른 모델들의 로그 우도 값을 비교하여 가장 높은 우도를 가진 모델을 선택할 수 있습니다. 또한 로그 우도를 사용하여 모델의 예측 성능을 평가할 수 있습니다.
In summary, the log-likelihood is a metric used in parameter estimation and model evaluation for probabilistic models. It is derived by taking the logarithm of the likelihood function and plays a crucial role in maximum likelihood estimation.
요약하면, 로그 우도는 확률 모델의 파라미터 추정과 모델 평가에 사용되는 지표로, 우도 함수에 로그를 적용하여 얻습니다. 최대 우도 추정에서 중요한 역할을 하며, 로그 우도를 최대화함으로써 가장 적합한 파라미터 값을 추정할 수 있습니다.
4.1.2.2. Softmax and Cross-Entropy Loss
Since the softmax function and the corresponding cross-entropy loss are so common, it is worth understanding a bit better how they are computed. Plugging (4.1.3) into the definition of the loss in (4.1.8) and using the definition of the softmax we obtain:
4.1. Softmax Regression — Dive into Deep Learning 1.0.0-beta0 documentation
d2l.ai
softmax 함수와 이에 상응하는 cross-entropy loss 교차 엔트로피 손실은 매우 일반적이므로 계산 방법을 좀 더 잘 이해할 가치가 있습니다. (4.1.3)을 (4.1.8)의 손실 정의에 연결하고 softmax의 정의를 사용하여 다음을 얻습니다.

To understand a bit better what is going on, consider the derivative with respect to any logit oj. We get
무슨 일이 일어나고 있는지 좀 더 잘 이해하려면 모든 로짓 oj에 대한 미분을 고려하십시오. 아래 내용을 얻을 수 있습니다.

In other words, the derivative is the difference between the probability assigned by our model, as expressed by the softmax operation, and what actually happened, as expressed by elements in the one-hot label vector. In this sense, it is very similar to what we saw in regression, where the gradient was the difference between the observation y and estimate y^. This is not coincidence. In any exponential family model, the gradients of the log-likelihood are given by precisely this term. This fact makes computing gradients easy in practice.
즉, 미분은 모델이 할당한 확률(softmax 연산으로 표현)과 실제로 발생한 것(원-핫 레이블 벡터의 요소로 표현) 간의 차이입니다. 이런 의미에서 기울기는 관측치 y와 추정치 y^의 차이인 회귀에서 본 것과 매우 유사합니다. 이것은 우연이 아닙니다. 모든 exponential family 모델에서 log-likelihood 로그 우도의 기울기는 정확히 이 용어로 제공됩니다. 이 사실은 실제로 그래디언트 계산을 쉽게 만듭니다.
Now consider the case where we observe not just a single outcome but an entire distribution over outcomes. We can use the same representation as before for the label y. The only difference is that rather than a vector containing only binary entries, say (0,0,1), we now have a generic probability vector, say (0.1,0.2,0.7). The math that we used previously to define the loss l in (4.1.8) still works out fine, just that the interpretation is slightly more general. It is the expected value of the loss for a distribution over labels. This loss is called the cross-entropy loss and it is one of the most commonly used losses for classification problems. We can demystify the name by introducing just the basics of information theory. In a nutshell, it measures the number of bits to encode what we see y relative to what we predict that should happen y^. We provide a very basic explanation in the following. For further details on information theory see Cover and Thomas (1999) or MacKay and Mac Kay (2003).
이제 단일 결과뿐만 아니라 결과에 대한 전체 분포를 관찰하는 경우를 고려하십시오. 레이블 y에 대해 이전과 동일한 표현을 사용할 수 있습니다. 유일한 차이점은 이진 항목만 포함하는 벡터(예: (0,0,1)) 대신 일반 확률 벡터(예: (0.1,0.2,0.7))가 있다는 것입니다. (4.1.8)에서 손실 l을 정의하기 위해 이전에 사용한 수학은 여전히 잘 작동하지만 해석이 약간 더 일반적입니다. 레이블에 대한 분포에 대한 손실의 예상 값입니다. 이 손실을 cross-entropy loss 교차 엔트로피 손실이라고 하며 분류 문제에서 가장 일반적으로 사용되는 손실 중 하나입니다. 우리는 정보 이론의 기초를 소개함으로써 그 이름을 이해할 수 있습니다. 간단히 말해서, 그것은 우리가 y^ 발생해야한다고 예측하는 것과 관련하여 우리가 보는 것을 인코딩하는 비트 수를 측정합니다. 다음에서 매우 기본적인 설명을 제공합니다. 정보 이론에 대한 자세한 내용은 Cover와 Thomas(1999) 또는 MacKay와 Mac Kay(2003)를 참조하십시오.
4.1.3. Information Theory Basics
Many deep learning papers use intuition and terms from information theory. To make sense of them, we need some common language. This is a survival guide. Information theory deals with the problem of encoding, decoding, transmitting, and manipulating information (also known as data).
많은 딥 러닝 논문은 정보 이론의 직관과 용어를 사용합니다. 그것들을 이해하려면 공통 언어가 필요합니다. 서바이벌 가이드입니다. Information theory 정보 이론은 정보(데이터라고도 함)를 인코딩, 디코딩, 전송 및 조작하는 문제를 다룹니다.
4.1.3.1. Entropy
The central idea in information theory is to quantify the amount of information contained in data. This places a limit on our ability to compress data. For a distribution P its entropy is defined as:
정보 이론의 핵심 아이디어는 데이터에 포함된 정보의 양을 정량화하는 것입니다. 이로 인해 데이터 압축 능력이 제한됩니다. 분포 P의 경우 엔트로피는 다음과 같이 정의됩니다.

One of the fundamental theorems of information theory states that in order to encode data drawn randomly from the distribution P, we need at least H[P] “nats” to encode it (Shannon, 1948). If you wonder what a “nat” is, it is the equivalent of bit but when using a code with base e rather than one with base 2. Thus, one nat is 1log(2)≈1.44 bit.
정보 이론의 기본 정리 중 하나는 분포 P에서 무작위로 추출된 데이터를 인코딩하려면 적어도 H[P] "nats"가 인코딩되어야 한다는 것입니다(Shannon, 1948). "nat"이 무엇인지 궁금하다면, 그것은 비트와 동일하지만 밑이 2인 코드가 아닌 밑이 e인 코드를 사용할 때입니다. 따라서 하나의 nat는 1log(2)≈1.44비트입니다.
4.1.3.2. Surprisal
You might be wondering what compression has to do with prediction. Imagine that we have a stream of data that we want to compress. If it is always easy for us to predict the next token, then this data is easy to compress. Take the extreme example where every token in the stream always takes the same value. That is a very boring data stream! And not only it is boring, but it is also easy to predict. Because they are always the same, we do not have to transmit any information to communicate the contents of the stream. Easy to predict, easy to compress.
압축이 예측과 어떤 관련이 있는지 궁금할 수 있습니다. 압축하려는 데이터 스트림이 있다고 상상해보십시오. 우리가 다음 토큰을 예측하는 것이 항상 쉽다면 이 데이터는 압축하기 쉽습니다. 스트림의 모든 토큰이 항상 동일한 값을 갖는 극단적인 예를 들어보십시오. 그것은 매우 지루한 데이터 스트림입니다! 지루할 뿐만 아니라 예측하기도 쉽습니다. 그것들은 항상 동일하기 때문에 스트림의 내용을 전달하기 위해 어떤 정보도 전송할 필요가 없습니다. 예측하기 쉽고 압축하기 쉽습니다.
However if we cannot perfectly predict every event, then we might sometimes be surprised. Our surprise is greater when we assigned an event lower probability. Claude Shannon settled on log 1/P(j)=−log P(j) to quantify one’s surprisal at observing an event j having assigned it a (subjective) probability P(j). The entropy defined in (4.1.11) is then the expected surprisal when one assigned the correct probabilities that truly match the data-generating process.
그러나 모든 사건을 완벽하게 예측할 수 없다면 때때로 놀랄 수도 있습니다. 이벤트에 더 낮은 확률을 할당했을 때 우리의 놀라움은 더 커졌습니다. Claude Shannon은 log 1/P(j)=−log P(j)로 정하여 (주관적) 확률 P(j)를 할당한 이벤트 j를 관찰했을 때의 놀라움을 정량화했습니다. (4.1.11)에 정의된 엔트로피는 데이터 생성 프로세스와 정확히 일치하는 올바른 확률을 할당했을 때 예상되는 놀라움입니다.
4.1.3.3. Cross-Entropy Revisited
So if entropy is the level of surprise experienced by someone who knows the true probability, then you might be wondering, what is cross-entropy? The cross-entropy from P to Q, denoted H(P,Q), is the expected surprisal of an observer with subjective probabilities Q upon seeing data that was actually generated according to probabilities P. This is given by H(P,Q)=def ∑j−P(j)logQ(j). The lowest possible cross-entropy is achieved when P=Q. In this case, the cross-entropy from P to Q is H(P,P)=H(P).
따라서 엔트로피가 실제 확률을 아는 사람이 경험하는 놀라움의 수준이라면 교차 엔트로피가 무엇인지 궁금할 것입니다. H(P,Q)로 표시되는 P에서 Q까지의 교차 엔트로피는 확률 P에 따라 실제로 생성된 데이터를 보았을 때 주관적 확률 Q를 가진 관찰자의 예상되는 놀라움입니다. 이것은 H(P,Q)로 제공됩니다. =def ∑j-P(j)logQ(j). 가능한 가장 낮은 교차 엔트로피는 P=Q일 때 달성됩니다. 이 경우 P에서 Q까지의 교차 엔트로피는 H(P,P)=H(P)입니다.
In short, we can think of the cross-entropy classification objective in two ways: (i) as maximizing the likelihood of the observed data; and (ii) as minimizing our surprisal (and thus the number of bits) required to communicate the labels.
요컨대 교차 엔트로피 분류 목표를 두 가지 방식으로 생각할 수 있습니다. (i) 관찰된 데이터의 우도를 최대화하는 것으로 (ii) 레이블을 전달하는 데 필요한 놀라움(따라서 비트 수)을 최소화합니다.
4.1.4. Summary and Discussion
In this section, we encountered the first nontrivial loss function, allowing us to optimize over discrete output spaces. Key in its design was that we took a probabilistic approach, treating discrete categories as instances of draws from a probability distribution. As a side effect, we encountered the softmax, a convenient activation function that transforms outputs of an ordinary neural network layer into valid discrete probability distributions. We saw that the derivative of the cross entropy loss when combined with softmax behaves very similarly to the derivative of squared error, namely by taking the difference between the expected behavior and its prediction. And, while we were only able to scratch the very surface of it, we encountered exciting connections to statistical physics and information theory.
이 섹션에서 우리는 이산 출력 공간을 최적화할 수 있는 첫 번째 중요한 손실 함수를 만났습니다. 디자인의 핵심은 우리가 확률적 접근 방식을 취하여 불연속 범주를 확률 분포에서 추출한 인스턴스로 취급한다는 것입니다. 부작용으로 일반 신경망 계층의 출력을 유효한 이산 확률 분포로 변환하는 편리한 활성화 함수인 softmax를 만났습니다. 우리는 softmax와 결합될 때 교차 엔트로피 손실의 파생물이 제곱 오차의 파생물과 매우 유사하게 동작한다는 것을 보았습니다. 그리고 우리는 표면적만 긁어모을 수 있었지만 통계 물리학 및 정보 이론과의 흥미로운 연관성을 발견했습니다.
While this is enough to get you on your way, and hopefully enough to whet your appetite, we hardly dived deep here. Among other things, we skipped over computational considerations. Specifically, for any fully connected layer with d inputs and q outputs, the parameterization and computational cost is O(dq), which can be prohibitively high in practice. Fortunately, this cost of transforming d inputs into q outputs can be reduced through approximation and compression. For instance Deep Fried Convnets (Yang et al., 2015) uses a combination of permutations, Fourier transforms, and scaling to reduce the cost from quadratic to log-linear. Similar techniques work for more advanced structural matrix approximations (Sindhwani et al., 2015). Lastly, we can use Quaternion-like decompositions to reduce the cost to O(dq/n), again if we are willing to trade off a small amount of accuracy for computational and storage cost (Zhang et al., 2021) based on a compression factor n. This is an active area of research. What makes it challenging is that we do not necessarily strive for the most compact representation or the smallest number of floating point operations but rather for the solution that can be executed most efficiently on modern GPUs.
이것은 당신에게 당신의 길을 안내하기에 충분하고 당신의 식욕을 돋우기에 충분하기를 바라지만 여기서는 거의 깊이 들어가지 않았습니다. 무엇보다도 우리는 계산상의 고려 사항을 건너뛰었습니다. 구체적으로 d 입력과 q 출력이 있는 완전히 연결된 레이어의 경우 매개변수화 및 계산 비용은 O(dq)이며 실제로는 엄청나게 높을 수 있습니다. 다행히 d 입력을 q 출력으로 변환하는 비용은 근사 및 압축을 통해 줄일 수 있습니다. 예를 들어 Deep Fried Convnets(Yang et al., 2015)는 순열, 푸리에 변환 및 스케일링의 조합을 사용하여 비용을 2차에서 로그 선형으로 줄입니다. 유사한 기술이 고급 구조 행렬 근사화에 사용됩니다(Sindhwani et al., 2015). 마지막으로 쿼터니언과 같은 분해를 사용하여 비용을 O(dq/n)으로 줄일 수 있습니다. 압축 계수 n. 이것은 활발한 연구 분야입니다. 이를 어렵게 만드는 것은 우리가 반드시 가장 컴팩트한 표현이나 가장 적은 수의 부동 소수점 연산을 위해 노력하는 것이 아니라 최신 GPU에서 가장 효율적으로 실행할 수 있는 솔루션을 위해 노력한다는 것입니다.
4.1.5. Exercises


'Dive into Deep Learning > D2L Linear Neural Networks' 카테고리의 다른 글
| D2L - 4.6. Generalization in Classification (0) | 2023.06.27 |
|---|---|
| D2L - 4.5. Concise Implementation of Softmax Regression¶ (0) | 2023.06.27 |
| D2L - 4.4. Softmax Regression Implementation from Scratch (0) | 2023.06.26 |
| D2L - 4.3. The Base Classification Model (0) | 2023.06.26 |
| D2L - 4.2. The Image Classification Dataset (0) | 2023.06.26 |
| D2L - 4. Linear Neural Networks for Classification (0) | 2023.06.26 |
| D2L - Local Environment Setting (0) | 2023.06.26 |
| D2L - 3.5. Concise Implementation of Linear Regression, 이미지 분류 데이터 (Fashion-MNIST) (0) | 2023.06.22 |
| D2L - 3.4. Linear Regression Implementation from Scratch , Softmax 회귀(regression) (0) | 2023.06.22 |
| D2L - 3.3. Synthetic Regression Data (0) | 2023.06.22 |