

D2L - 14.8. Region-based CNNs (R-CNNs)
2023. 8. 20. 21:58 |
import torch
import torchvision
X = torch.arange(16.).reshape(1, 1, 4, 4)
Xhttps://d2l.ai/chapter_computer-vision/rcnn.html
14.8. Region-based CNNs (R-CNNs) — Dive into Deep Learning 1.0.3 documentation
d2l.ai
14.8. Region-based CNNs (R-CNNs)
Besides single shot multibox detection described in Section 14.7, region-based CNNs or regions with CNN features (R-CNNs) are also among many pioneering approaches of applying deep learning to object detection (Girshick et al., 2014). In this section, we will introduce the R-CNN and its series of improvements: the fast R-CNN (Girshick, 2015), the faster R-CNN (Ren et al., 2015), and the mask R-CNN (He et al., 2017). Due to limited space, we will only focus on the design of these models.
섹션 14.7에서 설명한 단일 샷 멀티박스 감지 외에도 지역 기반 CNN 또는 CNN 기능이 있는 지역(R-CNN)도 객체 감지에 딥 러닝을 적용하는 많은 선구적인 접근 방식 중 하나입니다(Girshick et al., 2014). 이 섹션에서는 R-CNN과 일련의 개선 사항인 fast R-CNN(Girshick, 2015), faster R-CNN(Ren et al., 2015) 및 mask R-CNN(He 외, 2017). 제한된 공간으로 인해 이러한 모델의 디자인에만 집중할 것입니다.
14.8.1. R-CNNs
The R-CNN first extracts many (e.g., 2000) region proposals from the input image (e.g., anchor boxes can also be considered as region proposals), labeling their classes and bounding boxes (e.g., offsets). (Girshick et al., 2014)
R-CNN은 먼저 입력 이미지에서 많은(예: 2000개) region proposals을 추출하고(예: 앵커 상자도 region proposals으로 간주할 수 있음) 해당 클래스 및 경계 상자(예: 오프셋)에 레이블을 지정합니다.
Then a CNN is used to perform forward propagation on each region proposal to extract its features. Next, features of each region proposal are used for predicting the class and bounding box of this region proposal.
그런 다음 CNN을 사용하여 각 region proposal 에 대한 순방향 전파를 수행하여 해당 features을 추출합니다. 다음으로, 각 region proposal 의 features은 이 region proposal 의 클래스와 경계 상자를 예측하는 데 사용됩니다.
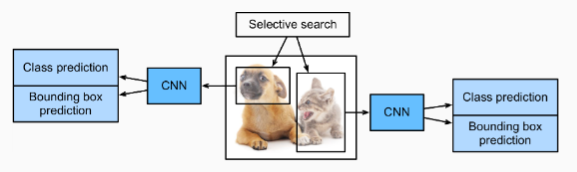
Fig. 14.8.1 shows the R-CNN model. More concretely, the R-CNN consists of the following four steps:
그림 14.8.1은 R-CNN 모델을 보여준다. 보다 구체적으로 R-CNN은 다음 네 단계로 구성됩니다.
- Perform selective search to extract multiple high-quality region proposals on the input image (Uijlings et al., 2013). These proposed regions are usually selected at multiple scales with different shapes and sizes. Each region proposal will be labeled with a class and a ground-truth bounding box.
입력 이미지에서 여러 고품질 region proposals을 추출하기 위해 선택적 검색을 수행합니다(Uijlings et al., 2013). 이러한 제안된 영역은 일반적으로 모양과 크기가 다른 여러 척도에서 선택됩니다. 각 region proposals은 클래스와 ground-truth 경계 상자로 레이블이 지정됩니다. - Choose a pretrained CNN and truncate it before the output layer. Resize each region proposal to the input size required by the network, and output the extracted features for the region proposal through forward propagation.
사전 훈련된 CNN을 선택하고 출력 계층 앞에서 자릅니다. 각 region proposal의 크기를 네트워크에서 요구하는 입력 크기로 조정하고 순방향 전파를 통해 추출된 region proposal의 -features- 특징을 출력합니다. - Take the extracted features and labeled class of each region proposal as an example. Train multiple support vector machines to classify objects, where each support vector machine individually determines whether the example contains a specific class.
각 지역 제안 region proposal 의 추출된 기능 features 과 레이블이 지정된 클래스를 예로 들어 보겠습니다. 여러 서포트 벡터 머신을 훈련시켜 개체를 분류합니다. 여기서 각 서포트 벡터 머신은 예제에 특정 클래스가 포함되어 있는지 여부를 개별적으로 결정합니다. - Take the extracted features and labeled bounding box of each region proposal as an example. Train a linear regression model to predict the ground-truth bounding box.
각 지역 제안 region proposal의 추출된 특징과 레이블이 지정된 경계 상자를 예로 들어 보겠습니다. ground-truth 경계 상자를 예측하도록 선형 회귀 모델을 훈련합니다.
Although the R-CNN model uses pretrained CNNs to effectively extract image features, it is slow. Imagine that we select thousands of region proposals from a single input image: this requires thousands of CNN forward propagations to perform object detection. This massive computing load makes it infeasible to widely use R-CNNs in real-world applications.
R-CNN 모델은 사전 훈련된 CNN을 사용하여 이미지 특징을 효과적으로 추출하지만 속도가 느립니다. 단일 입력 이미지에서 수천 개의 지역 제안 region proposals을 선택한다고 상상해보십시오. 개체 감지를 수행하려면 수천 개의 CNN 정방향 전파가 필요합니다. 이 막대한 컴퓨팅 부하로 인해 실제 응용 프로그램에서 R-CNN을 널리 사용하는 것이 불가능합니다.
Region Proposal 이란?
A "Region Proposal" refers to a process in object detection tasks where potential regions or bounding boxes containing objects of interest are proposed within an image. In object detection, the goal is to identify and localize objects within an image, often by drawing bounding boxes around them. However, directly applying object detection algorithms to all possible image regions can be computationally expensive and inefficient.
"Region Proposal(영역 제안)"은 객체 검출 작업에서 이미지 내에 관심 대상 객체가 포함될 가능성이 있는 영역 또는 경계 상자를 제안하는 과정을 의미합니다. 객체 검출에서의 목표는 이미지 내에서 객체를 식별하고 위치를 파악하는 것인데, 모든 가능한 이미지 영역에 대해 직접 객체 검출 알고리즘을 적용하는 것은 계산적으로 부담스럽고 비효율적일 수 있습니다.
To address this, region proposal methods are used to narrow down the search space for object detection. These methods aim to generate a relatively small set of potential regions or bounding boxes that are likely to contain objects. These proposals serve as the input to the subsequent object detection algorithm, significantly reducing the computational burden.
이러한 문제를 해결하기 위해 영역 제안 방법을 사용하여 객체 검출을 위한 검색 공간을 좁힙니다. 이러한 방법은 객체가 포함될 가능성이 높은 상대적으로 작은 영역이나 경계 상자 세트를 생성하는 것을 목표로 합니다. 이러한 제안은 후속 객체 검출 알고리즘의 입력으로 사용되며, 계산 부담을 크게 줄여줍니다.
There are various techniques for generating region proposals. Some common methods include:
영역 제안을 생성하는 다양한 기법이 있습니다. 일반적인 방법은 다음과 같습니다:
- Sliding Window Approach: A small window of fixed size is moved across the image at different scales and positions. Bounding boxes are generated for each window location. This approach can be computationally intensive due to the need to slide the window over the entire image.
슬라이딩 윈도우 접근법: 고정 크기의 작은 창을 이미지 상에서 다양한 스케일과 위치로 이동시키면서 각 창 위치에 대한 경계 상자를 생성합니다. 이 접근법은 전체 이미지에 대해 창을 이동시켜야 하기 때문에 계산적으로 비싼 경우가 있을 수 있습니다. - Selective Search: This method generates region proposals by grouping pixels based on their similarity in color, texture, and intensity. The algorithm combines regions of varying sizes and shapes to create a diverse set of proposals.
Selective Search(선택적 검색): 이 방법은 색상, 질감, 강도의 유사성을 기반으로 픽셀을 그룹화하여 영역 제안을 생성합니다. 알고리즘은 다양한 크기와 모양의 영역을 결합하여 다양한 제안 세트를 만듭니다. - EdgeBoxes: EdgeBoxes uses the edges in an image to generate object proposals. It identifies object-like regions by examining the number of bounding box edges that overlap with the object's edge.
EdgeBoxes: EdgeBoxes는 이미지 내의 가장자리를 활용하여 객체 제안을 생성합니다. 객체의 가장자리와 겹치는 경계 상자 가장자리의 수를 조사하여 객체와 유사한 영역을 식별합니다. - Region Proposal Networks (RPNs): RPNs are part of modern object detection frameworks like Faster R-CNN. They use convolutional neural networks to generate region proposals directly from the input image. RPNs learn to propose regions that are likely to contain objects.
Region Proposal Networks (RPNs): RPN은 Faster R-CNN과 같은 현대적인 객체 검출 프레임워크의 일부입니다. RPN은 컨볼루션 신경망을 사용하여 입력 이미지로부터 직접적으로 영역 제안을 생성합니다. RPN은 객체가 포함될 가능성이 높은 영역을 제안하도록 학습됩니다.
After generating region proposals, these proposals are typically ranked or scored based on their likelihood of containing objects. High-scoring proposals are then passed to the subsequent object classification and localization steps of the object detection pipeline.
영역 제안을 생성한 후, 이러한 제안은 일반적으로 객체 포함 가능성에 따라 순위 또는 점수를 매깁니다. 높은 점수를 받은 제안은 후속 객체 분류 및 위치 파악 단계로 전달됩니다.
In summary, "Region Proposal" refers to the process of generating potential bounding boxes or regions in an image that are likely to contain objects. This process helps reduce the search space for object detection tasks and improves the efficiency of object detection algorithms.
요약하면, "Region Proposal(영역 제안)"은 이미지 내에 있는 객체가 포함될 가능성이 높은 경계 상자나 영역을 생성하는 과정을 의미합니다. 이 과정을 통해 객체 검출 작업의 검색 공간이 축소되며, 객체 검출 알고리즘의 효율성이 향상됩니다.
14.8.2. Fast R-CNN
The main performance bottleneck of an R-CNN lies in the independent CNN forward propagation for each region proposal, without sharing computation. Since these regions usually have overlaps, independent feature extractions lead to much repeated computation. One of the major improvements of the fast R-CNN from the R-CNN is that the CNN forward propagation is only performed on the entire image (Girshick, 2015).
R-CNN의 주요 성능 병목 현상은 계산을 공유하지 않고 각 region proposal에 대한 독립적인 CNN 순방향 전파에 있습니다. 이러한 영역은 일반적으로 겹치기 때문에 독립적인 특징 추출은 많은 반복 계산으로 이어집니다. R-CNN에서 빠른 R-CNN의 주요 개선 사항 중 하나는 CNN 순방향 전파가 전체 이미지에서만 수행된다는 것입니다(Girshick, 2015).
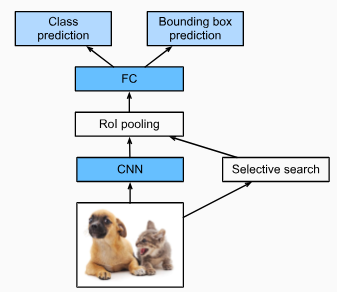
Fig. 14.8.2 describes the fast R-CNN model. Its major computations are as follows:
그림 14.8.2는 빠른 R-CNN 모델을 설명합니다. 주요 계산은 다음과 같습니다.
- Compared with the R-CNN, in the fast R-CNN the input of the CNN for feature extraction is the entire image, rather than individual region proposals. Moreover, this CNN is trainable. Given an input image, let the shape of the CNN output be 1×c×ℎ1×w1.
R-CNN과 비교할 때 빠른 R-CNN에서 특징 feature 추출을 위한 CNN의 입력은 개별 영역 제안region proposals 이 아닌 전체 이미지입니다. 게다가, 이 CNN은 학습이 가능합니다. 입력 이미지가 주어지면 CNN 출력의 모양을 1×c×ℎ1×w1이라고 합니다. - Suppose that selective search generates n region proposals. These region proposals (of different shapes) mark regions of interest (of different shapes) on the CNN output. Then these regions of interest further extract features of the same shape (say height ℎ2 and width w2 are specified) in order to be easily concatenated. To achieve this, the fast R-CNN introduces the region of interest (RoI) pooling layer: the CNN output and region proposals are input into this layer, outputting concatenated features of shape n×c×ℎ2×w2 that are further extracted for all the region proposals.
선택적 검색이 n개의 지역 제안 region proposals을 생성한다고 가정합니다. 이러한 영역 제안 region proposals(다른 모양)은 CNN 출력에서 관심 영역 regions of interest (다른 모양)을 표시합니다. 그런 다음 이러한 관심 영역은 쉽게 연결하기 위해 동일한 모양(높이 ℎ2 및 너비 w2가 지정됨)의 특징을 추가로 추출합니다. 이를 달성하기 위해 빠른 R-CNN은 관심 영역(regions of interest -RoI) 풀링 레이어를 도입합니다. CNN 출력 및 영역 제안 region proposa 이 이 레이어에 입력됩니다. 모든 영역 제안 region proposa에 대해 추가로 추출되는 shape n×c×ℎ2×w2의 연결된 특징 features 을 출력합니다. - Using a fully connected layer, transform the concatenated features into an output of shape n×d, where d depends on the model design.
완전 연결 레이어를 사용하여 연결된 피처를 모양 shape n×d의 출력으로 변환합니다. 여기서 d는 모델 디자인에 따라 다릅니다. - Predict the class and bounding box for each of the n region proposals. More concretely, in class and bounding box prediction, transform the fully connected layer output into an output of shape n×q (q is the number of classes) and an output of shape n×4, respectively. The class prediction uses softmax regression.
n개의 영역 제안 region proposals 각각에 대한 클래스 및 경계 상자를 예측합니다. 보다 구체적으로 클래스 및 경계 상자 예측에서 완전 연결 계층 출력을 각각 모양 n×q(q는 클래스 수) 및 모양 n×4의 출력으로 변환합니다. 클래스 예측은 softmax 회귀를 사용합니다.
The region of interest pooling layer proposed in the fast R-CNN is different from the pooling layer introduced in Section 7.5. In the pooling layer, we indirectly control the output shape by specifying sizes of the pooling window, padding, and stride. In contrast, we can directly specify the output shape in the region of interest pooling layer.
fast R-CNN에서 제안하는 region of interest pooling layer은 섹션 7.5에서 소개한 풀링 계층과 다릅니다. 풀링 레이어에서 풀링 창, 패딩 및 보폭의 크기를 지정하여 출력 모양을 간접적으로 제어합니다. 반대로 관심 영역 풀링 레이어에서 출력 모양을 직접 지정할 수 있습니다.
Region of Interest Pooling Layer (RoI Layer) 란?
The Region of Interest (RoI) pooling layer is a component commonly used in convolutional neural networks (CNNs) for object detection and instance segmentation tasks. Its primary purpose is to extract fixed-size feature representations from variable-sized regions of an input feature map. The RoI pooling layer plays a critical role in handling objects of different sizes and positions within an image and is crucial for enabling CNNs to perform accurate object localization and recognition.
관심 영역 풀링 레이어(Region of Interest pooling layer)는 객체 탐지 및 인스턴스 분할 작업에 널리 사용되는 컨볼루션 신경망(CNN) 구성 요소입니다. 주요 목적은 입력 특성 맵의 가변 크기 영역에서 고정 크기의 특성 표현을 추출하는 것입니다. 관심 영역 풀링 레이어는 이미지 내 다양한 크기와 위치의 객체를 처리하는 중요한 역할을 하며, 정확한 객체 지역화와 인식을 위한 CNN의 핵심 역할을 합니다.
In object detection tasks, a CNN generates a set of candidate bounding box predictions for potential objects within an image. These bounding boxes can vary in size and aspect ratio based on the object's location and scale. The RoI pooling layer is applied to these predicted bounding boxes to obtain a consistent spatial resolution of feature representations, which can then be fed into subsequent layers for classification and regression.
객체 탐지 작업에서 CNN은 이미지 내 잠재적인 객체에 대한 후보 바운딩 박스 예측 집합을 생성합니다. 이러한 바운딩 박스는 객체의 위치와 크기에 따라 크기와 종횡비가 다를 수 있습니다. 관심 영역 풀링 레이어는 이러한 예측된 바운딩 박스에 적용되어 고정된 공간 해상도(예: 7x7)의 특성 표현을 얻습니다. 이로써 후속 레이어로 분류 및 회귀 작업에 입력될 수 있습니다.
The RoI pooling layer operates as follows:
관심 영역 풀링 레이어는 다음과 같이 작동합니다:
- Input: The input consists of a feature map generated by the preceding layers of the CNN and a set of predicted bounding boxes (RoIs).
입력: 입력은 CNN의 이전 레이어에서 생성된 특성 맵과 예측된 바운딩 박스(RoIs) 집합으로 구성됩니다. - Bounding Box Adaptation: Each RoI is adapted and aligned to a fixed spatial resolution (e.g., 7x7) using RoI pooling. This involves dividing the RoI into a grid of equal cells and selecting the maximum value from each cell. This pooling operation ensures that each RoI is transformed into a consistent feature map with the same spatial dimensions.
바운딩 박스 적: 각 RoI는 관심 영역 풀링을 사용하여 고정된 공간 해상도(예: 7x7)에 맞게 조정됩니다. 이는 RoI를 동일한 크기의 셀 그리드로 나누고 각 셀에서 최대 값을 선택하는 것을 포함합니다. 이 풀링 연산을 통해 각 RoI가 동일한 공간 차원을 가진 일관된 특성 맵으로 변환됩니다. - Feature Extraction: The RoI pooling operation generates fixed-size feature maps for each RoI. These feature maps can be directly fed into fully connected layers for classification or regression tasks.
특성 추출: 관심 영역 풀링 작업은 각 RoI에 대해 고정된 크기의 특성 맵을 생성합니다. 이러한 특성 맵은 분류나 회귀 작업을 위해 직접 완전 연결 레이어에 입력될 수 있습니다.
By using the RoI pooling layer, CNNs can effectively handle objects of different sizes, enabling the network to focus on relevant object details and reducing the impact of variations in object scale and position. This layer is a key component in modern object detection architectures like Faster R-CNN and Mask R-CNN.
관심 영역 풀링 레이어를 사용함으로써 CNN은 다양한 크기의 객체를 효과적(효율)으로 처리할 수 있으며, 네트워크는 관련성 있는 객체 세부 정보에 집중하고 객체 크기와 위치의 변동을 줄일 수 있습니다. 이 레이어는 Faster R-CNN 및 Mask R-CNN과 같은 현대적인 객체 탐지 아키텍처에서 핵심 구성 요소입니다.
Overall, the RoI pooling layer plays a pivotal role in enabling CNNs to process variable-sized regions of an input feature map, thereby facilitating accurate object detection, localization, and segmentation in complex scenes.
전반적으로, 관심 영역 풀링 레이어는 입력 특성 맵의 가변 크기 영역을 처리하는 데 중요한 역할을하여 복잡한 장면에서 정확한 객체 탐지, 지역화 및 분할을 용이하게 하는 데 중요한 역할을 합니다.
For example, let’s specify the output height and width for each region as ℎ2 and w2, respectively. For any region of interest window of shape ℎ×w, this window is divided into a ℎ2×w2 grid of subwindows, where the shape of each subwindow is approximately (ℎ/ℎ2)×(w/w2). In practice, the height and width of any subwindow shall be rounded up, and the largest element shall be used as output of the subwindow. Therefore, the region of interest pooling layer can extract features of the same shape even when regions of interest have different shapes.
예를 들어 각 영역의 출력 높이와 너비를 각각 ℎ2와 w2로 지정해 보겠습니다. ℎ×w 모양의 관심 영역 창에 대해 이 창은 ℎ2×w2 그리드의 하위 창으로 나뉘며 각 하위 창의 모양은 대략 (ℎ/ℎ2)×(w/w2)입니다. 실제로 모든 하위 창의 높이와 너비는 반올림되고 가장 큰 요소가 하위 창의 출력으로 사용됩니다. 따라서 관심 영역 풀링 계층은 관심 영역의 모양이 다른 경우에도 동일한 모양의 특징을 추출할 수 있습니다.
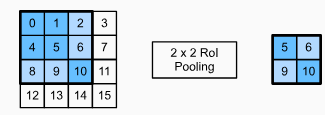
As an illustrative example, in Fig. 14.8.3, the upper-left 3×3 region of interest is selected on a 4×4 input. For this region of interest, we use a 2×2 region of interest pooling layer to obtain a 2×2 output. Note that each of the four divided subwindows contains elements 0, 1, 4, and 5 (5 is the maximum); 2 and 6 (6 is the maximum); 8 and 9 (9 is the maximum); and 10.
예를 들어, 그림 14.8.3에서 왼쪽 상단의 3×3 관심 영역이 4×4 입력에서 선택됩니다. 이 관심 영역에 대해 2×2 관심 영역 풀링 계층을 사용하여 2×2 출력을 얻습니다. 4개의 분할된 하위 창 각각에는 요소 0, 1, 4 및 5(5가 최대값)가 포함되어 있습니다. 2 및 6(6이 최대값); 8 및 9(9가 최대); 및 10.
Below we demonstrate the computation of the region of interest pooling layer. Suppose that the height and width of the CNN-extracted features X are both 4, and there is only a single channel.
아래에서는 관심 영역 풀링 계층의 계산을 보여줍니다. CNN에서 추출한 특징 X의 높이와 너비가 모두 4이고 채널이 하나만 있다고 가정합니다.
import torch
import torchvision
X = torch.arange(16.).reshape(1, 1, 4, 4)
X- import torch: 파이토치 라이브러리를 가져옵니다.
- import torchvision: 파이토치 비전 라이브러리를 가져옵니다. 이미지 관련 작업을 위한 함수와 모델을 포함하고 있습니다.
- X = torch.arange(16.).reshape(1, 1, 4, 4): 0부터 15까지의 숫자로 이루어진 배열을 생성합니다. .reshape(1, 1, 4, 4)를 사용하여 배열을 4x4 크기의 4차원 텐서로 변환합니다. 이렇게 변환하면 (batch_size, channels, height, width) 형태로 텐서를 표현하게 됩니다. 여기서 batch_size와 channels는 1로 설정되었습니다.
- X: 생성된 텐서 X를 출력합니다.
이 코드는 4x4 크기의 1채널 이미지를 표현하는 4차원 텐서 X를 생성하고 출력하는 내용을 나타냅니다.
tensor([[[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.]]]])Let’s further suppose that the height and width of the input image are both 40 pixels and that selective search generates two region proposals on this image. Each region proposal is expressed as five elements: its object class followed by the (x,y)-coordinates of its upper-left and lower-right corners.
또한 입력 이미지의 높이와 너비가 모두 40픽셀이고 선택적 검색이 이 이미지에 대해 두 개의 영역 제안region proposals을 생성한다고 가정해 보겠습니다. 각 영역 제안은 5개의 요소로 표현됩니다. 개체 클래스와 왼쪽 상단 및 오른쪽 하단 모서리의 (x,y) 좌표가 뒤따릅니다.
rois = torch.Tensor([[0, 0, 0, 20, 20], [0, 0, 10, 30, 30]])- rois: rois라는 변수에 텐서 값을 할당합니다.
- torch.Tensor: 파이토치에서 텐서를 생성하는 클래스입니다. 행렬이나 다차원 배열과 유사한 데이터 구조를 나타냅니다.
- [[0, 0, 0, 20, 20], [0, 0, 10, 30, 30]]: 2개의 리스트를 가진 리스트로 이루어진 텐서를 생성합니다. 각 리스트는 5개의 숫자로 이루어져 있으며, 각각의 리스트는 ROI(Region of Interest) 정보를 나타냅니다. 각 ROI 정보는 [batch index, class index, x1, y1, x2, y2] 형태로 표현됩니다. 여기서 batch index는 배치 내에서 몇 번째 이미지인지, class index는 객체 클래스를 의미하며, (x1, y1)은 좌상단 좌표, (x2, y2)는 우하단 좌표를 나타냅니다.
==> 요소가 5개인데 설명은 6개로 돼 있음. 교재 내용을 보면 object class,x1,y1,x2,y2 가 맞는 것 같
이 코드는 두 개의 ROI 정보를 담은 텐서 rois를 생성하는 내용을 나타냅니다.
Because the height and width of X are 1/10 of the height and width of the input image, the coordinates of the two region proposals are multiplied by 0.1 according to the specified spatial_scale argument. Then the two regions of interest are marked on X as X[:, :, 0:3, 0:3] and X[:, :, 1:4, 0:4], respectively. Finally in the 2×2 region of interest pooling, each region of interest is divided into a grid of sub-windows to further extract features of the same shape 2×2.
X의 높이와 너비는 입력 이미지의 높이와 너비의 1/10이기 때문에 두 영역 제안의 좌표는 지정된 spatial_scale 인수에 따라 0.1이 곱해집니다. 그런 다음 두 개의 관심 영역이 X에 각각 X[:, :, 0:3, 0:3] 및 X[:, :, 1:4, 0:4]로 표시됩니다. 마지막으로 2×2 관심 영역 풀링에서는 각 관심 영역을 하위 창의 그리드로 나누어 동일한 모양의 2×2 특징을 더 추출합니다.
torchvision.ops.roi_pool(X, rois, output_size=(2, 2), spatial_scale=0.1)- torchvision.ops.roi_pool: torchvision 패키지 내의 ops 모듈에서 roi_pool 함수를 호출합니다. 이 함수는 RoI (Region of Interest) Pooling 연산을 수행합니다.
- X: 입력 데이터로서, RoI Pooling 연산을 수행할 대상 텐서입니다.
- rois: RoI 정보를 담은 텐서입니다. 각 RoI 정보는 [batch index, class index, x1, y1, x2, y2] 형태로 구성되어 있습니다.
- output_size=(2, 2): RoI Pooling 연산의 출력 크기를 지정합니다. 여기서는 2x2 크기의 출력을 생성하도록 지정되었습니다.
- spatial_scale=0.1: RoI Pooling 연산에서 입력과 출력의 크기 비율을 나타내는 값입니다. 이 값은 입력 RoI의 좌표를 출력 RoI 좌표로 변환하는 데 사용됩니다.
이 코드는 입력 데이터 X와 RoI 정보를 사용하여 RoI Pooling 연산을 수행하는 내용을 나타냅니다. RoI Pooling은 주어진 RoI 영역을 정해진 크기로 출력하는 연산으로, 객체 검출과 같은 작업에서 주로 사용됩니다.
tensor([[[[ 5., 6.],
[ 9., 10.]]],
[[[ 9., 11.],
[13., 15.]]]])
14.8.3. Faster R-CNN
To be more accurate in object detection, the fast R-CNN model usually has to generate a lot of region proposals in selective search. To reduce region proposals without loss of accuracy, the faster R-CNN proposes to replace selective search with a region proposal network (Ren et al., 2015).
개체 감지에서 보다 정확하려면 fast R-CNN 모델은 일반적으로 선택적 검색에서 많은 영역 제안을 생성해야 합니다. 정확도 손실 없이 지역 제안 region proposals을 줄이기 위해 Faster R-CNN은 선택적 검색을 지역 제안 region proposals 네트워크로 대체할 것을 제안합니다(Ren et al., 2015).
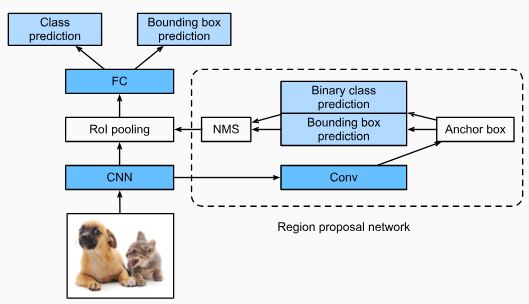
Fig. 14.8.4 shows the faster R-CNN model. Compared with the fast R-CNN, the faster R-CNN only changes the region proposal method from selective search to a region proposal network. The rest of the model remain unchanged. The region proposal network works in the following steps:
그림 14.8.4는 더 빠른 R-CNN 모델을 보여줍니다. 빠른 R-CNN과 비교할 때 더 빠른 R-CNN은 지역 제안 region proposal 방법만 선택적 검색에서 지역 제안 region proposal 네트워크로 변경합니다. 나머지 모델은 변경되지 않습니다. 지역 제안 네트워크는 다음 단계로 작동합니다.
- Use a 3×3 convolutional layer with padding of 1 to transform the CNN output to a new output with c channels. In this way, each unit along the spatial dimensions of the CNN-extracted feature maps gets a new feature vector of length c.
패딩이 1인 3×3 컨벌루션 레이어를 사용하여 CNN 출력을 c 채널이 있는 새 출력으로 변환합니다. 이러한 방식으로 CNN 추출 기능 맵의 공간 차원을 따라 각 단위는 길이가 c인 새로운 기능 벡터를 얻습니다. - Centered on each pixel of the feature maps, generate multiple anchor boxes of different scales and aspect ratios and label them.
기능 맵의 각 픽셀을 중심으로 다양한 크기와 가로 세로 비율의 여러 앵커 상자를 생성하고 레이블을 지정합니다. - Using the length-c feature vector at the center of each anchor box, predict the binary class (background or objects) and bounding box for this anchor box.
각 앵커 상자의 중심에 있는 길이-c 특징 벡터를 사용하여 이 앵커 상자의 이진 클래스(배경 또는 객체) 및 경계 상자를 예측합니다. - Consider those predicted bounding boxes whose predicted classes are objects. Remove overlapped results using non-maximum suppression. The remaining predicted bounding boxes for objects are the region proposals required by the region of interest pooling layer.
예측 클래스가 객체인 예측된 경계 상자를 고려하십시오. 최대가 아닌 억제를 사용하여 중첩된 결과를 제거합니다. 개체에 대한 나머지 예측 경계 상자는 관심 영역 풀링 레이어에 필요한 영역 제안입니다.
It is worth noting that, as part of the faster R-CNN model, the region proposal network is jointly trained with the rest of the model. In other words, the objective function of the faster R-CNN includes not only the class and bounding box prediction in object detection, but also the binary class and bounding box prediction of anchor boxes in the region proposal network. As a result of the end-to-end training, the region proposal network learns how to generate high-quality region proposals, so as to stay accurate in object detection with a reduced number of region proposals that are learned from data.
더 빠른 R-CNN 모델의 일부로 영역 제안 region proposal 네트워크가 모델의 나머지 부분과 공동으로 훈련된다는 점은 주목할 가치가 있습니다. 즉, 더 빠른 R-CNN의 목적 함수는 객체 감지에서 클래스 및 경계 상자 예측뿐만 아니라 영역 제안 region proposal 네트워크에서 앵커 상자의 이진 클래스 및 경계 상자 예측을 포함합니다. 종단 간 교육의 결과, 지역 제안 region proposal 네트워크는 고품질 지역 제안 region proposal을 생성하는 방법을 학습하여 데이터에서 학습된 지역 제안 region proposal의 수를 줄임과 동시 객체 감지에서 정확성을 유지합니다.
14.8.4. Mask R-CNN
In the training dataset, if pixel-level positions of object are also labeled on images, the mask R-CNN can effectively leverage such detailed labels to further improve the accuracy of object detection (He et al., 2017).
학습 데이터 세트에서 개체의 픽셀 수준 위치도 이미지에 레이블이 지정된 경우 마스크 R-CNN은 이러한 세부 레이블을 효과적으로 활용하여 개체 감지의 정확도를 더욱 향상시킬 수 있습니다(He et al., 2017).
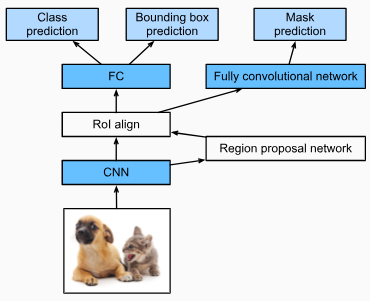
As shown in Fig. 14.8.5, the mask R-CNN is modified based on the faster R-CNN. Specifically, the mask R-CNN replaces the region of interest pooling layer with the region of interest (RoI) alignment layer. This region of interest alignment layer uses bilinear interpolation to preserve the spatial information on the feature maps, which is more suitable for pixel-level prediction. The output of this layer contains feature maps of the same shape for all the regions of interest. They are used to predict not only the class and bounding box for each region of interest, but also the pixel-level position of the object through an additional fully convolutional network. More details on using a fully convolutional network to predict pixel-level semantics of an image will be provided in subsequent sections of this chapter.
그림 14.8.5와 같이 더 빠른 R-CNN을 기반으로 마스크 R-CNN이 수정되었습니다. 특히, 마스크 R-CNN은 관심 영역 풀링 레이어를 관심 영역(RoI) 정렬 레이어로 대체합니다. 이 관심 영역 정렬 레이어는 쌍선형 보간을 사용하여 픽셀 수준 예측에 더 적합한 기능 맵의 공간 정보를 보존합니다. 이 레이어의 출력에는 모든 관심 영역에 대해 동일한 모양의 기능 맵이 포함됩니다. 각 관심 영역에 대한 클래스 및 경계 상자뿐만 아니라 추가적인 완전 컨벌루션 네트워크를 통해 개체의 픽셀 수준 위치를 예측하는 데 사용됩니다. 이미지의 픽셀 수준 의미론을 예측하기 위해 완전 컨벌루션 네트워크를 사용하는 방법에 대한 자세한 내용은 이 장의 다음 섹션에서 제공됩니다.
14.8.5. Summary
- The R-CNN extracts many region proposals from the input image, uses a CNN to perform forward propagation on each region proposal to extract its features, then uses these features to predict the class and bounding box of this region proposal.
R-CNN은 입력 이미지에서 많은 영역 제안region proposals을 추출하고, CNN을 사용하여 각 영역 제안에 대해 정방향 전파를 수행하여 해당 기능을 추출한 다음 이러한 기능을 사용하여 이 영역 제안의 클래스 및 경계 상자를 예측합니다. - One of the major improvements of the fast R-CNN from the R-CNN is that the CNN forward propagation is only performed on the entire image. It also introduces the region of interest pooling layer, so that features of the same shape can be further extracted for regions of interest that have different shapes.
R-CNN에서 빠른 R-CNN의 주요 개선 사항 중 하나는 CNN 순방향 전파가 전체 이미지에서만 수행된다는 것입니다. 또한 관심 영역 풀링 레이어를 도입하여 모양이 다른 관심 영역에 대해 동일한 모양의 특징을 추가로 추출할 수 있습니다. - The faster R-CNN replaces the selective search used in the fast R-CNN with a jointly trained region proposal network, so that the former can stay accurate in object detection with a reduced number of region proposals.
더 빠른 R-CNN은 빠른 R-CNN에서 사용되는 선택적 검색을 공동으로 훈련된 영역 제안 네트워크로 대체하므로 전자는 감소된 수의 영역 제안으로 객체 감지에서 정확성을 유지할 수 있습니다. - Based on the faster R-CNN, the mask R-CNN additionally introduces a fully convolutional network, so as to leverage pixel-level labels to further improve the accuracy of object detection.
더 빠른 R-CNN을 기반으로 하는 마스크 R-CNN은 픽셀 수준 레이블을 활용하여 개체 감지의 정확도를 더욱 향상시키기 위해 완전히 컨벌루션 네트워크를 추가로 도입합니다.
14.8.6. Exercises
- Can we frame object detection as a single regression problem, such as predicting bounding boxes and class probabilities? You may refer to the design of the YOLO model (Redmon et al., 2016).
- Compare single shot multibox detection with the methods introduced in this section. What are their major differences? You may refer to Figure 2 of Zhao et al. (2019).
'Dive into Deep Learning > D2L Computer Vision' 카테고리의 다른 글
| D2L - 14.12. Neural Style Transfer (1) | 2023.08.21 |
|---|---|
| D2L - 14.11. Fully Convolutional Networks (0) | 2023.08.21 |
| D2L - 14.10. Transposed Convolution (1) | 2023.08.21 |
| D2L - 14.9. Semantic Segmentation and the Dataset (0) | 2023.08.20 |
| D2L - 14.7. Single Shot Multibox Detection (0) | 2023.08.19 |
| D2L - 14.6. The Object Detection Dataset (0) | 2023.08.19 |
| D2L - 14.5. Multiscale Object Detection (0) | 2023.08.19 |
| D2L - 14.4. Anchor Boxes (0) | 2023.08.19 |
| D2L - 14.3. Object Detection and Bounding Boxes (0) | 2023.08.19 |
| D2L - 14.2. Fine-Tuning (0) | 2023.08.19 |