
https://huggingface.co/learn/nlp-course/chapter2/6?fw=pt
Putting it all together
In the last few sections, we’ve been trying our best to do most of the work by hand. We’ve explored how tokenizers work and looked at tokenization, conversion to input IDs, padding, truncation, and attention masks.
지난 몇 섹션에서 우리는 대부분의 작업을 수동으로 수행하기 위해 최선을 다했습니다. 우리는 토크나이저의 작동 방식을 살펴보고 토큰화, 입력 ID로의 변환, 패딩, 잘림 및 attention masks 를 살펴보았습니다.
However, as we saw in section 2, the 🤗 Transformers API can handle all of this for us with a high-level function that we’ll dive into here. When you call your tokenizer directly on the sentence, you get back inputs that are ready to pass through your model:
그러나 섹션 2에서 본 것처럼 🤗 Transformers API는 여기서 자세히 살펴볼 고급 기능을 통해 이 모든 것을 처리할 수 있습니다. 문장에서 토크나이저를 직접 호출하면 모델을 통과할 준비가 된 입력을 다시 받게 됩니다.
from transformers import AutoTokenizer
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
sequence = "I've been waiting for a HuggingFace course my whole life."
model_inputs = tokenizer(sequence)
이 코드는 Hugging Face Transformers 라이브러리를 사용하여 사전 훈련된 감성 분류 모델을 로드하고, 주어진 텍스트 시퀀스를 토큰화하여 모델에 입력으로 전달하기 위한 입력을 생성하는 예제입니다. 코드를 이해해보겠습니다.
해석:
- AutoTokenizer.from_pretrained(checkpoint): 주어진 모델의 토크나이저를 로드합니다.
- sequence: 감성 분류를 위한 입력 텍스트 시퀀스를 정의합니다.
- tokenizer(sequence): 토크나이저를 사용하여 주어진 텍스트 시퀀스를 토큰화합니다. 이 토큰화된 입력은 모델에 바로 전달할 수 있는 형태로 구성됩니다.
이 코드를 실행하면 model_inputs에는 토큰 ID, 어텐션 마스크, 토큰 유형 ID 등이 포함된 딕셔너리가 생성됩니다. 이러한 토큰화된 입력은 모델에 직접 전달되어 감성 분류 또는 다른 NLP 작업을 수행하는 데 사용될 수 있습니다.

Here, the model_inputs variable contains everything that’s necessary for a model to operate well. For DistilBERT, that includes the input IDs as well as the attention mask. Other models that accept additional inputs will also have those output by the tokenizer object.
여기서 model_inputs 변수에는 모델이 제대로 작동하는 데 필요한 모든 것이 포함되어 있습니다. DistilBERT의 경우 여기에는 attention mask 뿐만 아니라 입력 ID도 포함됩니다. 추가 입력을 허용하는 다른 모델에도 토크나이저 개체에 의한 출력이 있습니다.
As we’ll see in some examples below, this method is very powerful. First, it can tokenize a single sequence:
아래 몇 가지 예에서 볼 수 있듯이 이 방법은 매우 강력합니다. 첫째, 단일 시퀀스를 토큰화할 수 있습니다.
sequence = "I've been waiting for a HuggingFace course my whole life."
model_inputs = tokenizer(sequence)

It also handles multiple sequences at a time, with no change in the API:
또한 API를 변경하지 않고 한 번에 여러 시퀀스를 처리합니다.
sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"]
model_inputs = tokenizer(sequences)

It can pad according to several objectives:
여러 가지 objectives 에 따라 패딩할 수 있습니다.
# Will pad the sequences up to the maximum sequence length
model_inputs = tokenizer(sequences, padding="longest")
# Will pad the sequences up to the model max length
# (512 for BERT or DistilBERT)
model_inputs = tokenizer(sequences, padding="max_length")
# Will pad the sequences up to the specified max length
model_inputs = tokenizer(sequences, padding="max_length", max_length=8)

It can also truncate sequences: 시퀀스를 자를 수도 있습니다.
sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"]
# Will truncate the sequences that are longer than the model max length
# (512 for BERT or DistilBERT)
model_inputs = tokenizer(sequences, truncation=True)
# Will truncate the sequences that are longer than the specified max length
model_inputs = tokenizer(sequences, max_length=8, truncation=True)

The tokenizer object can handle the conversion to specific framework tensors, which can then be directly sent to the model. For example, in the following code sample we are prompting the tokenizer to return tensors from the different frameworks — "pt" returns PyTorch tensors, "tf" returns TensorFlow tensors, and "np" returns NumPy arrays:
토크나이저 객체는 특정 프레임워크 텐서로의 변환을 처리한 후 모델로 직접 보낼 수 있습니다. 예를 들어, 다음 코드 샘플에서는 토크나이저에게 다양한 프레임워크의 텐서를 반환하도록 요청합니다. "pt"는 PyTorch 텐서를 반환하고 "tf"는 TensorFlow 텐서를 반환하며 "np"는 NumPy 배열을 반환합니다.
sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"]
# Returns PyTorch tensors
model_inputs = tokenizer(sequences, padding=True, return_tensors="pt")
# Returns TensorFlow tensors
model_inputs = tokenizer(sequences, padding=True, return_tensors="tf")
# Returns NumPy arrays
model_inputs = tokenizer(sequences, padding=True, return_tensors="np")

Special tokens
If we take a look at the input IDs returned by the tokenizer, we will see they are a tiny bit different from what we had earlier:
토크나이저가 반환한 입력 ID를 살펴보면 이전에 얻은 것과 약간 다른 것을 알 수 있습니다.
sequence = "I've been waiting for a HuggingFace course my whole life."
model_inputs = tokenizer(sequence)
print(model_inputs["input_ids"])
tokens = tokenizer.tokenize(sequence)
ids = tokenizer.convert_tokens_to_ids(tokens)
print(ids)
[101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012, 102]
[1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012]
One token ID was added at the beginning, and one at the end. Let’s decode the two sequences of IDs above to see what this is about:
토큰 ID는 처음에 하나, 끝에 하나가 추가되었습니다. 위의 두 ID 시퀀스를 디코딩하여 이것이 무엇인지 살펴보겠습니다.
print(tokenizer.decode(model_inputs["input_ids"]))
print(tokenizer.decode(ids))
"[CLS] i've been waiting for a huggingface course my whole life. [SEP]"
"i've been waiting for a huggingface course my whole life."
The tokenizer added the special word [CLS] at the beginning and the special word [SEP] at the end. This is because the model was pretrained with those, so to get the same results for inference we need to add them as well. Note that some models don’t add special words, or add different ones; models may also add these special words only at the beginning, or only at the end. In any case, the tokenizer knows which ones are expected and will deal with this for you.
토크나이저는 시작 부분에 특수 단어 [CLS]를 추가하고 끝에 특수 단어 [SEP]를 추가했습니다. 이는 모델이 이러한 항목으로 사전 학습되었기 때문에 동일한 추론 결과를 얻으려면 해당 항목도 추가해야 하기 때문입니다. 일부 모델은 특별한 단어를 추가하지 않거나 다른 단어를 추가하지 않습니다. 모델은 이러한 특수 단어를 시작 부분에만 추가하거나 끝 부분에만 추가할 수도 있습니다. 어떤 경우든 토크나이저는 어떤 것이 예상되는지 알고 이를 처리해 줍니다.
Wrapping up: From tokenizer to model
Now that we’ve seen all the individual steps the tokenizer object uses when applied on texts, let’s see one final time how it can handle multiple sequences (padding!), very long sequences (truncation!), and multiple types of tensors with its main API:
이제 토크나이저 객체가 텍스트에 적용될 때 사용하는 모든 개별 단계를 살펴보았으므로 마지막으로 여러 시퀀스(패딩!), 매우 긴 시퀀스(잘림!), 주요 API를 갖춘 다양한 유형의 텐서: 를 처리하는 방법을 살펴보겠습니다.
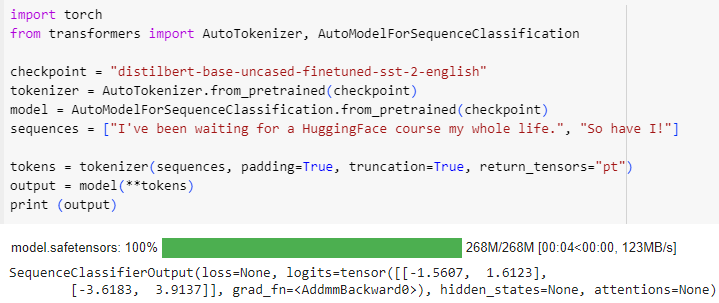
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"]
tokens = tokenizer(sequences, padding=True, truncation=True, return_tensors="pt")
output = model(**tokens)
'Hugging Face > NLP Course' 카테고리의 다른 글
| HF-NLP-FINE-TUNING A PRETRAINED MODEL-Fine-tuning a model with the Trainer API (1) | 2023.12.26 |
|---|---|
| HF-NLP-FINE-TUNING A PRETRAINED MODEL-Processing the data (1) | 2023.12.26 |
| HF-NLP-FINE-TUNING A PRETRAINED MODEL-Introduction (0) | 2023.12.26 |
| HF-NLP-USING 🤗 TRANSFORMERS : End-of-chapter quiz (0) | 2023.12.25 |
| HF-NLP-USING 🤗 TRANSFORMERS : Basic usage completed! (0) | 2023.12.25 |
| HF-NLP-USING 🤗 TRANSFORMERS : Handling multiple sequences (0) | 2023.12.25 |
| HF-NLP-USING 🤗 TRANSFORMERS : Tokenizers (1) | 2023.12.25 |
| HF-NLP-USING 🤗 TRANSFORMERS : Models (1) | 2023.12.25 |
| HF-NLP-USING 🤗 TRANSFORMERS : Behind the pipeline (0) | 2023.12.24 |
| HF-NLP-USING 🤗 TRANSFORMERS : Introduction (0) | 2023.12.24 |